1
ANALISIS PERTANYAAN BERBAHASA INDONESIA
PADA QUESTION ANSWERING SYSTEM (QAS)
KARTINA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2010
1
ANALISIS PERTANYAAN BERBAHASA INDONESIA
PADA QUESTION ANSWERING SYSTEM (QAS)
KARTINA
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2010
3
ABSTRACT
KARTINA. Analysis of Question in Indonesian Language in Question Answering System (QAS). Supervised by JULIO ADISANTOSO.
Question analysis is the first step in QAS. This step decides the final result of QAS process because the result of question analysis is used to retrieve relevant document and answer entity correctly. The used question query is limited to question type: WHO, WHERE, WHEN, and HOW MANY or HOW MUCH. The question word on query is used to obtain the answer candidate, while other words beside the question word are used to analyze the question. Question analysis process is started by parsing the keyword become tokens. The parsing is conducted with regarding token’s pair possibility as a phrase. This phrase formation is expected to be able to keep the semantic aspect of question sentence. The question sentence that has parsed is used to retrieve document and top passage. Top passage is obtained through heuristic scoring. The answer extraction is conducted by calculating the nearest distance between each answer candidate in top passage and each word in keyword. Answer correction is evaluated by using these criteria: right, unsupported, wrong, and null.
The evaluation result of system showed the more correct answer for the less number of documents. The result of 106 tested documents was 75.56 % for criteria right, 2.22 % for criteria unsupported, 17.78 % for criteria wrong, and 4.44 % for criteria null. The result of 200 tested documents was 73.33 % for criteria right, 22.22 % for criteria wrong, and 4.44 % for criteria null. The result of 300 tested documents was 71.11 % for criteria right, 22.22 % for criteria wrong, and 6.67 % for criteria null. This decreasing of percentage is caused by the less correct of passage scoring method that was used.
i Judul : Analisis Pertanyaan Berbahasa Indonesia pada Question Answering System (QAS) Nama : Kartina
NIM : G64063336
Menyetujui: Pembimbing,
Ir. Julio Adisantoso, M.Kom NIP. 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
ii
RIWAYAT HIDUP
Penulis dilahirkan di Wonogiri Jawa Tengah pada tanggal 18 Agustus 1988 dari ayah Partono dan ibu Kawit. Penulis merupakan putri pertama dari tiga bersaudara.
Tahun 2006 penulis lulus dari SMA Negeri 1 Wonogiri dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur Seleksi Penerimaan Mahasiswa Baru (SPMB). Tahun 2007 penulis diterima di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis menjadi asisten mata kuliah Algoritma dan Pemrograman pada tahun 2009, mata kuliah Data Mining dan Sistem Pakar pada tahun 2010. Pada tahun 2009 penulis menjadi finalis Lomba Data Mining Contest Gemastik II, Direktorat Jenderal Pendidikan Tinggi. Penulis melakukan Praktik Kerja Lapangan di Pusat Teknologi Informasi dan Komunikasi(PTIK), Badan Pengkajian dan Penerapan Teknologi (BPPT).
iii
PRAKATA
Alhamdulilahirobbil’alamin, segala puji syukur penulis panjatkan kehadirat Allah SWT atas
segala karunia-Nya sehingga tugas akhir ini berhasil diselesaikan. Topik tugas akhir yang dipilih dalam penelitian dan dilaksanakan sejak bulan Februari 2010 adalah Analisis Pertanyaan Berbahasa Indonesia pada Question Answering System (QAS).
Penulis sadar bahwa tugas akhir ini tidak akan terwujud tanpa bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada :
1. Orang tua tercinta, kedua adikku tersayang Dedi Setyawan dan Candra Tri Pamungkas, serta segenap keluarga besar, terima kasih atas doa dan dukungan yang tiada henti.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran dan dukungan dalam penyelesaian tugas akhir ini.
3. Bapak Ahmad Ridha, S.Kom, MS dan Bapak Sony Hartono Wijaya, S. Kom, M.Kom selaku dosen penguji, Dr. Sri Nurdiati, MSc selaku Kepala Departemen Ilmu Komputer serta seluruh staf Departemen Ilmu Komputer FMIPA IPB.
4. Teman-teman satu bimbingan Ekachu, Iyam, Yucan, Hendrex, Adit, Rio, Awet, dan Wildan. Terima kasih atas semangat dan kebersamaannya selama penyelesaian tugas akhir ini. 5. Sahabat-sahabatku mami Rina, Uut, Eta, Dewi, Widia, Sandi, Aadun, Windu, dan seluruh
sahabatku Ilkomerz 43. Terima kasih atas motivasi dan kebersamaannya selama ini.
6. Sahabat-sahabatku di Wisma Melati Rias, Reni, Titis, Tante Ovi, Rista, Noe, Mb Netty, Mb Irma, Mb Leng, Mb Ncha, Mb Unee, Mb Dean, Mb Selly, dan lain-lain. Terima kasih atas keceriannya selama ini.
7. Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam pelaksanaan tugas akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, Juli 2010
iv
DAFTAR ISI
Halaman DAFTAR GAMBAR ...v DAFTAR TABEL ...v DAFTAR LAMPIRAN ...v PENDAHULUAN Latar Belakang ...1 Tujuan ...1 Ruang Lingkup ...1 Manfaat ...1 TINJAUAN PUSTAKA Question Answering ...1 Analisis Pertanyaan ...1 Pembentukan Frase ...2 Retrieval Engine ...2Modul Ekstraksi Jawaban ...3
METODE PENELITIAN Pemrosesan Offline ...4
Pemrosesan Online ...5
Evaluasi Hasil Percobaan ...6
Lingkungan Pengembangan ...6
HASIL DAN PEMBAHASAN Koleksi Dokumen Pengujian ...6
Pemrosesan Dokumen...6
Pembentukan Frase ...8
Perhitungan tf-idf...9
Pemrosesan Kueri ...9
Perolehan 10 Dokumen Teratas ...9
Perolehan Top Passages dan Ekstraksi Jawaban ... 10
Hasil Percobaan ... 10
KESIMPULAN DAN SARAN Kesimpulan ... 15
Saran ... 15
DAFTAR PUSTAKA ... 16
v
DAFTAR GAMBAR
Halaman
1 Arsitektur tahap analisis pertanyaan (Schlaefer et al 2006)...2
2 Ilustrasi matriks inverted index ...3
3 Kedekatan dokumen dalam ruang vektor (Manning 2008)...3
4 Diagram alur pemrosesan offline. ...5
5 Diagram alur pemrosesan online...5
6 Struktur dokumen pengujian...6
7 Ilustrasi bagian dokumen yang digunakan untuk pemrosesan. ...7
8 Diagram alur pemrosesan dokumen ...7
9 Contoh hasil tagging dokumen. ...7
10 Histogram sebaran nilai peluang pembentukan frase ...8
DAFTAR TABEL
Halaman 1 Tabel vektor term frequency ...32 Tabel vektor df dan idf ...3
3 Contoh pasangan kata dengan nilai peluang sebesar 1 ...8
4 Daftar pasangan kata tanya dan entitas ...9
5 Persentase perolehan jawaban oleh Cidhy (2009) dan penulis ... 11
6 Persentase perolehan jawaban menggunakan jumlah dokumen yang berbeda ... 14
DAFTAR LAMPIRAN
Halaman 1 Antarmuka implementasi ... 182 Contoh dokumen XML dalam koleksi pengujian ... 19
3 Contoh pemberian entitas dokumen text dalam koleksi pengujian... 20
4 Tabel perbandingan kata tanya SIAPA menggunakan 106 dokumen... 21
5 Tabel perbandingan kata tanya BERAPA menggunakan 106 dokumen ... 22
6 Tabel perbandingan kata tanya DIMANA menggunakan 106 dokumen ... 23
7 Tabel perbandingan kata tanya KAPAN menggunakan 106 dokumen ... 24
8 Tabel perbandingan kata tanya SIAPA menggunakan 106, 200, dan 300 dokumen ... 25
9 Tabel perbandingan kata tanya BERAPA menggunakan 106, 200, dan 300 dokumen ... 27
10 Tabel perbandingan kata tanya DIMANA menggunakan 106, 200, dan 300 dokumen ... 29
11 Tabel perbandingan kata tanya KAPAN menggunakan 106, 200, dan 300 dokumen ... 31
12 Tabel perbandingan menggunakan dokumen reading comprehension... 32
1
PENDAHULUAN
Latar Belakang
Analisis pertanyaan merupakan tahap awal pada Question Answering System (QAS). Tahap ini sangat menentukan hasil akhir dari proses QAS karena hasil analisis pertanyaan akan digunakan untuk membangkitkan kueri. Oleh karena itu analisis pertanyan penting untuk dilakukan. QAS memiliki cara kerja yang lebih kompleks dibanding mesin pencari pada umumnya. Pengguna memasukkan kueri berupa pertanyaan dan sistem akan mengembalikan entitas jawaban yang tepat. Contoh mesin pencari yang telah menerapkan QAS adalah www.Ask.com dan www.answerbus.com.
Ikhsani (2006) membangun QAS dengan metode rule-based untuk temu kembali informasi berbahasa Indonesia. Proses tokenisasi dan stemming dilakukan pada kueri pertanyaan yang telah dibuat secara subjektif oleh penulis. Selanjutnya Anggraeny (2007), mengimplementasikan QAS dengan metode
rule-based pada terjemahan Al qur’an Surat
Al-baqarah. Dilakukan parsing, stemming, dan pembuangan stopwords untuk mendapatkan kata-kata kueri. Pada tahun berikutnya, Sianturi (2008) memperbaiki rules yang digunakan dalam penelitian Ikhsani. Kueri pertanyaan yang dimasukkan ke dalam sistem dibuat sendiri oleh penulis, yang kemudian dilakukan parsing dan stemming. Cidhy (2009) telah mengimplementasikan QAS menggunakan pembobotan heuristic. Kueri pertanyaan di-parsing untuk mendapatkan kata tanya dan keyword (kata-kata selain (kata-kata tanya). Kata tanya dari kueri inilah yang mencirikan entitas kandidat jawaban yang akan dicari di dalam koleksi dokumen. Keempat penelitian di atas menggunakan kueri yang mengandung kata tanya APA, SIAPA, KAPAN, dan MENGAPA, tetapi keempatnya belum melakukan analisis semantik terhadap kueri pertanyaan.
Oleh karena itu, penelitian lebih lanjut diperlukan untuk menganalisis pertanyaan berbahasa Indonesia pada QAS agar diperoleh representasi kueri pertanyaan yang tepat. Tujuan
Tujuan dari penelitian ini adalah :
Menggunakan teknik pembentukan frase dalam tahap analisis pertanyaan untuk
mempertahankan nilai semantik dari pertanyaan berbahasa Indonesia.
Mendapatkan dokumen dan jawaban yang relevan dengan kueri.
Ruang Lingkup
Ruang lingkup penelitian yang dilakukan oleh penulis meliputi :
Koleksi dokumen terdiri atas dokumen berbahasa Indonesia.
Kueri pertanyaan yang dimasukkan dibatasi pada tipe factoid question, yaitu pertanyaan yang memiliki jawaban tunggal.
Pembentukan frase terdiri atas dua kata. Hasil dari penelitian dievaluasi
menggunakan persepsi manusia. Manfaat
Analisis pertanyaan diharapkan dapat membangkitkan kueri yang mempertahankan nilai semantik pertanyaan tersebut sehingga diperoleh dokumen yang lebih relevan.
TINJAUAN PUSTAKA
Question AnsweringQuestion Answering (QA) merupakan
aplikasi yang menggabungkan teknologi
Information Retrieval (IR) dengan Natural Language processing (NLP). Perbedaan yang
mendasar antara QA dengan IR terletak pada masukan (kueri) dan keluaran yang dihasilkan. Kueri yang dimasukkan pada IR berupa kata atau kalimat pernyataan dan keluaran yang dihasilkan adalah dokumen yang dianggap relevan oleh sistem. Sedangkan pada QA, kueri berupa kalimat tanya dan keluarannya berupa jawaban (entitas) yang dianggap sesuai oleh sistem sehingga memungkinkan sistem tidak mengembalikan jawaban apapun (Strzalkowski & Harabagiu 2008).
Kueri yang berupa kalimat tanya ini dapat dianalisis terlebih dahulu sebelum digunakan untuk memeroleh dokumen dan jawaban yang relevan dengan kueri. Tahapan untuk menganalisis kueri ini disebut sebagai tahap analisis pertanyaan.
Analisis Pertanyaan
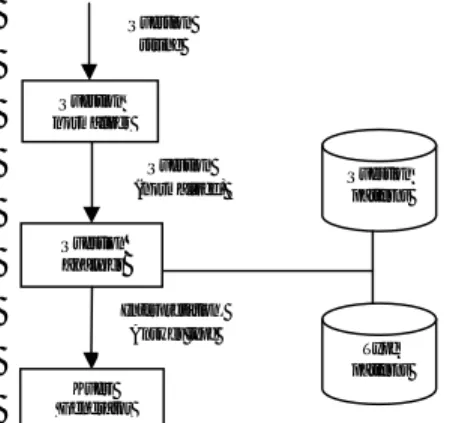
Menurut van Zaanen (2008), kualitas tahap analisis pertanyaan memberikan pengaruh yang cukup signifikan terhadap hasil QA. Sebelumnya Schlaefer et al (2006) telah melakukan tahap analisis pertanyaan pada QA
2 Question normalizer Question analyzer Question patterns Type patterns Question (normalized) Interpretation, Answer type Question string Kueri Generator
yang dibuat menggunakan framework
OpenEphyra. Gambar 1 menunjukkan arsitektur tahap analisis pertanyaan :
Gambar 1 Arsitektur tahap analisis
pertanyaan (Schlaefer et al 2006). Kueri yang berupa kalimat tanya dinormalisasi, yaitu dilakukan stemming dan pembuangan token yang tidak perlu. Keluaran dari tahap normalisasi ini menghasilkan dua representasi kalimat tanya. Representasi pertama digunakan untuk analisis pencocokan dengan pola yang sudah ada sehingga diperoleh entitas tipe jawaban yang sesuai. Representasi kedua digunakan untuk pembangkitkan kueri yang dipakai untuk memperoleh dokumen yang relevan. Perluasan kueri juga dapat dilakukan untuk mempertahankan aspek semantik dari kueri kalimat tanya, misal menggunakan WordNet atau Thesaurus (untuk Bahasa Inggris). Sedangkan untuk Bahasa Indonesia, dapat dilakukan menggunakan pembentukan frase. Pembentukan Frase
Menurut Depdiknas (2003), frase merupakan satuan bahasa yang terbentuk atas dua kata atau lebih. Frase dapat dibedakan menjadi empat macam, yaitu :
1. Frase Verbal
Frase verbal merupakan satuan bahasa yang terbentuk dari dua kata atau lebih dengan verba sebagai intinya tetapi bentuk ini tidak merupakan klausa. Contoh : sudah membaik, akan mendarat, dan tidak harus pergi.
2. Frase Nominal
Sebuah nomina dapat diperluas ke kiri atau ke kanan menjadi sebuah frase. Perluasan ke kiri dilakukan dengan meletakkan kata penggolongnya tepat di depan nomina yang didahului dengan kata numeralia, contoh : dua buah buku dan beberapa butir telur.
Perluasan ke kanan dilakukan dengan meletakkan kata penggolong dan numeralia tepat di sebelah kanan nomina, contoh : kera tiga ekor dan buku tiga buah.
3. Frase Pronominal
Frase pronominal dapat dibentuk dengan menambahkan numeralia kolektif, kata penunjuk, atau kata sendiri setelah pronominal. Contohnya : mereka berdua, mereka itu, dan saya sendiri.
4. Frase numeralia
Umumnya frase numeralia dibentuk dengan menambahkan kata penggolong. Contoh : lima orang, dua ekor sapi, dan tiga buah rumah.
Frase dapat disusun oleh dua kata atau lebih. Hasil pembentukan frase ini dapat digunakan untuk menganalisis kueri pertanyaan sebelum kueri digunakan untuk menemukembalikan dokumen yang relevan.
Retrieval Engine
IR secara otomatis pada dasarnya adalah membandingkan kata yang ada pada kueri dengan kata yang ada dalam dokumen. Pada kenyataannya, setiap dokumen dapat memiliki banyak kata yang beragam sehingga pembandingan antara kata kueri dengan dokumen menjadi sulit dilakukan. Oleh karena itu, diperlukan karakteristik yang dapat digunakan sebagai penciri suatu dokumen sehingga dokumen dapat diindeks sesuai dengan penciri yang dimiliki. Proses penentuan indeks dokumen dapat dilakukan secara manual dan otomatis. Penentuan indeks secara manual melibatkan pakar di bidang ilmu sesuai isi dokumen yang akan diolah dan tentunya memerlukan waktu yang lebih lama. Dengan kemajuan teknologi, penentuan indeks dapat dilakukan secara otomatis menggunakan model kuantitatif. Model ini meliputi model ruang vektor, model peluang, dan model Boolean.
Model ruang vektor bertujuan mengukur kesamaan antara vektor suatu dokumen dengan vektor kueri yang dimasukkan (Manning 2008). Informasi term frequency (tf), document frequency (df), dan invers
document frequency (idf) diperlukan sebagai
langkah awal untuk menghitung kesamaan antara vektor dokumen dengan vektor kueri. Nilai tf menggambarkan frekuensi kemunculan suatu kata t dalam dokumen d, yang dilambangkan dengan tft,d. Tabel 1
menunjukkan ilustrasi pembentukan vektor tf untuk kata car, auto,insurance, dan best.
3 Selanjutnya dilakukan perhitungan nilai
df yang dinotasikan dengan dft. Variabel dft
merupakan jumlah dokumen dalam koleksi yang mengandung kata t. Pembagian nilai dft
dengan total dokumen yang ada dalam koleksi menghasilkan nilai idf untuk setiap kata sebagai berikut :
idft = log
N merupakan notasi untuk jumlah dokumen yang ada dalam koleksi. Melalui idf dapat diketahui kata-kata tertentu yang merupakan penciri suatu dokumen. Nilai idf untuk masing-masing kata pada Tabel 1 diilustrasikan pada Tabel 2. Dengan demikian, dapat diperoleh bobot untuk masing-masing kata dalam dokumen, yaitu Wt,d yang
merupakan hasil perkalian antara tft,d dan idft.
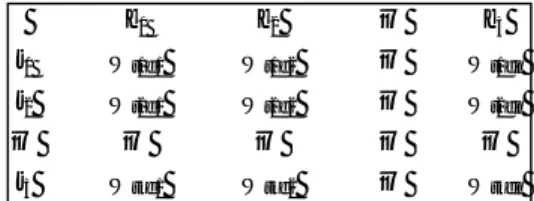
Tabel 1 Tabel vektor term frequency
Term Document d1 d2 d3 car 4 167 0 auto 232 227 0 insurance 0 10 0 best 67 0 0
Tabel 2 Tabel vektor df dan idf
Term dft idft
car 18.615 1.65
auto 6.723 2.08
insurance 19.241 1.62
best 25.235 1.5
Gambar 2 menunjukkan ilustrasi matriks
inverted index, yang berisi bobot setiap kata t
dalam suatu dokumen d.
d1 d2 … d3
t1 Wt1d1 Wt1d2 … Wt1dn
t2 Wt2d1 Wt2d2 … Wt2dn
… … … … …
t3 Wtkd1 Wtkd2 … Wtkdn
Gambar 2 Ilustrasi matriks inverted index. Ide dalam mengukur kesamaan dokumen dengan menggunakan kesamaan cosine adalah dokumen yang saling berdekatan dalam ruang vektor memiliki kecenderungan berisi informasi yang sama. Gambar 3 mengilustrasikan vektor dokumen yang terdapat dalam ruang vektor, yang diberi nilai oleh bobot kata.
Gambar 3 Kedekatan dokumen dalam ruang vektor (Manning 2008).
Berikut ini adalah formula untuk memperoleh kesamaan cosine untuk dj dan dk :
sim (dj, dk)
=
=
Berdasarkan formula kesamaan cosine, dj dan dk adalah dokumen yang terdapat dalam ruang vektor M kata, dan M merupakan vektor bobot tiap dokumen. Dalam implementasi perolehan n dokumen teratas, hal serupa dilakukan untuk mengukur kesamaan antara vektor kueri dengan dokumen. Dokumen diurutkan berdasarkan perolehan nilai cosine dengan kueri. Kemudian dipilih n dokumen teratas dengan nilai cosine tertinggi.
Modul Ekstraksi Jawaban
Setelah diperoleh n dokumen teratas, tahap yang selanjutnya adalah ekstraksi jawaban. Setiap sepuluh dokumen teratas yang diperoleh dianalisa kembali untuk mengidentifikasi kandidat jawaban dengan cara sebagai berikut (Ballesteros & Xiaoyan-Li 2007):
1. Dilakukan identifikasi entitas yang terdiri atas orang, organisasi, lokasi, ekspresi waktu, tanggal, ekspresi numerik, uang, dan persen.
2. Dokumen dibagi menjadi passages. Passage terdiri atas dua kalimat yang
berdampingan. Setiap passage memiliki satu kalimat yang overlap.
3. Dilakukan pembobotan heuristic pada setiap passage. Pertama-tama didefinisikan
count_query adalah jumlah kata yang
terdapat pada kueri (kalimat tanya),
count_match adalah jumlah hasil t1
t2 0
4 pencocokan antara kata yang terdapat pada
kueri dan passage (wordmatch), score adalah bobot dari passage, dan
wordmatch_words adalah hasil
wordmatch. Berikut proses pembobotan
yang digunakan :
a. Jika tidak ada entitas yang ditampilkan,
passage menerima nilai 0. Jika entitas
ditampilkan pada passage namun tidak memiliki tipe yang sama dengan pertanyaan, entitas diabaikan.
b. Dilakukan pencocokan kata-kata pada kueri dengan kata-kata pada passage (proses wordmatch). Jika nilai
count_match kurang dari threshold (t), score = 0. Selain itu, score = count_match. Nilai threshold (t), didefinisikan dengan cara sebagai berikut:
i. Jika count_query kurang dari 4, maka t=count_query. Dengan kata lain, passage yang tidak mengandung kata-kata yang terdapat pada kueri tidak diperhitungkan.
ii. Jika count_query antara 4 dan 8, maka t=count_query/(2.0+1.0) iii. Jika lebih besar dari 8, maka
t=count_query/(3.0+2.0)
c. Kata yang berdekatan memiliki hubungan keterkaitan informasi yang lebih tinggi. Jika seluruh kata yang cocok dengan kueri terdapat pada satu kalimat Sm=1, selain itu Sm=0. Maka,
score = score + (Sm*0.5).
d. Seperti yang diketahui urutan kata dapat mempengaruhi arti. Maka, diberikan bobot yang lebih tinggi (Ord=1) terhadap passage jika kata-kata yang cocok dengan kueri memiliki urutan yang sama seperti pada pertanyaan asli. Selain itu Ord=0. Maka, score = score + (Ord*0.5). e. Score = score + (count_match/W),
dimana W adalah jumlah kata dari
passage dengan bobot tertinggi.
4. Pembobotan terakhir yaitu menghitung total perolehan nilai yang disimpan dalam variabel heuristic_score. heuristic_score =
count_match + 0.5*Sm + 0.5*Ord + count_match/W. Dilakukan pengurutan
terhadap seluruh passage pada 10 dokumen teratas. Pengurutan dilakukan berdasarkan bobot yang dimiliki oleh setiap passage.
5. Ekstraksi kandidat jawaban dari passage peringkat teratas. Jarak antara kandidat jawaban dan posisi dari setiap kueri yang cocok dalam passage dihitung. Kandidat jawaban yang memiliki total jarak terkecil terpilih sebagai jawaban akhir.
METODE PENELITIAN
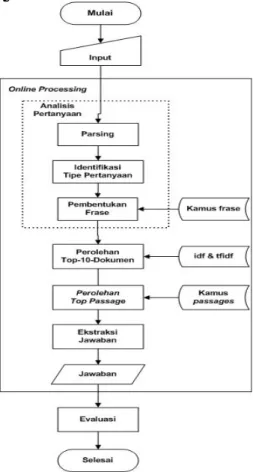
Penelitian ini dilakukan dalam tiga tahap, yaitu pemrosesan offline, pemrosesan online, dan evaluasi hasil percobaan. Diagram alur pemrosesan offline dan pemrosesan online dapat dilihat pada Gambar 4 dan 5.Pemrosesan Offline
Pemrosesan offline terdiri atas tahap praproses dokumen, pembentukan frase,
indexing dokumen, dan pembentukan
passages. Pemrosesan ini dilakukan untuk
mendapatkan kamus frase, kamus passage, dan nilai tf-idf yang akan digunakan pada pemrosesan online.
1. Praproses dokumen
Pada tahap ini, dilakukan parsing koleksi dokumen uji untuk digunakan pada tahap-tahap berikutnya. Selain itu dilakukan pembuangan kata-kata tidak penting atau
stopwords. Daftar stopwords yang digunakan
diambil dari Laboratorium Temu Kembali Informasi.
2. Pembentukan Frase
Pembentukan frase dilakukan untuk menganalisis pertanyaan yang dimasukkan oleh pengguna. Asumsi yang digunakan dalam pembentukan frase adalah jika dua kata memiliki posisi berurutan dalam suatu dokumen dan kejadian ini sering terjadi pada koleksi dokumen uji, maka dua kata tersebut dianggap sebagai sebuah frase. Berdasarkan asumsi ini maka dapat dihitung peluang munculnya kata A tepat setelah kata B yaitu :
P(A|B) =
n(A|B) = banyaknya kemunculan kata A tepat setelah B,
n(A|X) = banyaknya kemunculan kata A tepat setelah kata X, dimana X merupakan kumpulan kata unik yang ada pada koleksi dokumen,
P(A|B) = peluang munculnya kata A tepat setelah kata B.
5 Dengan menggunakan rumus peluang di atas,
akan didapat daftar kandidat frase yang disimpan dalam kamus frase.
3. Indexing Dokumen
Proses indexing yang dilakukan dalam penelitian ini menggunakan pembobotan tf-idf. Hasil indexing berupa nilai idf dan tf-idf dari seluruh dokumen. Hasil ini akan digunakan untuk menghitung ukuran kesamaan cosine antara vektor kueri dengan masing-masing vektor dokumen pada koleksi dokumen.
4. Pembentukan Passages
Sebelum dilakukan pembentukan
passages, terlebih dahulu dilakukan penamaan
entitaspada koleksi dokumen pengujian. Penamaan entitas atau tagging dilakukan dengan memanfaatkan hasil penelitian Citraningputra (2009). Entitas yang dihasilkan pada penelitian Citraningputra yaitu NAME,
ORGANIZATION, DATE, TIME,
LOCATION, NUMBER, dan CURRENCY. Selanjutnya passages dibentuk dari dua kalimat yang berurutan pada setiap dokumen. Hasil dari proses ini disimpan dalam kamus
passage.
Pemrosesan Online
Setelah pemrosesan offline selesai, tahap berikutnya adalah pemrosesan online.
Tahapan pada proses ini terdiri atas analisis pertanyaan, perolehan 10 dokumen teratas, pembobotan heuristic, dan ekstraksi jawaban. 1. Analisis Pertanyaan
Kueri pertanyaan yang dimasukkan
di-parsing terlebih dahulu. Parsing dilakukan
untuk membuang tanda baca yang ada pada kueri. Kemudian dilakukan proses case
folding yaitu pengubahan semua huruf
menjadi huruf kecil. Selanjutnya dilakukan tokenisasi untuk mendapatkan kata tanya dan
keyword (kata-kata selain kata tanya). Kata
tanya yang digunakan dibatasi pada kata : SIAPA, KAPAN, DIMANA, dan BERAPA. Berikut identifikasi tipe pertanyaan untuk setiap kata tanya :
a. SIAPA merujuk pada orang atau organisasi,
b. KAPAN merujuk pada keterangan waktu, c. DIMANA merujuk pada keterangan lokasi
suatu kejadian,
d. BERAPA merujuk pada jumlah atau satuan numerik (persen, Rupiah, dll).
Gambar 4 Diagram alur pemrosesan offline.
Gambar 5 Diagram alur pemrosesan online. Dengan memanfaatkan kamus frase yang dihasilkan pada proses offline, dilakukan pembentukan frase dari kata-kata yang ada pada keyword. Hasil pembentukan frase inilah yang digunakan untuk proses perhitungan tf-idf kueri dan ukuran kesamaan cosine.
6 2. Perolehan 10 Dokumen Teratas
Sepuluh dokumen yang memiliki nilai kesamaan cosine teratas, akan dikembalikan oleh sistem.
3. Perolehan Top Passage
Kandidat top passage diperoleh dari
passages yang terletak pada sepuluh dokumen
teratas. Dengan memanfaatkan pembobotan
heuristic, diperoleh passage yang memiliki
bobot tertinggi (top passage) dari kandidat
top passage sebelumnya.
4. Ekstraksi Jawaban
Jawaban akhir diperoleh dengan menghitung jarak terdekat antara kandidat jawaban pada top passage dengan kata-kata yang merupakan hasil pencocokkan dengan
keyword.
Evaluasi Hasil Percobaan
Tahap evaluasi dilakukan oleh manusia, jawaban dinilai dari segi:
1. Pasangan jawaban dan dokumen. 2. Ketepatan untuk setiap jawaban.
Pemberian nilai dilakukan berdasarkan empat kriteria, yaitu:
1. Wrong (W): jawaban tidak benar.
2. Unsupported (U): jawaban benar tapi dokumen tidak mendukung.
3. Inexact (X): jawaban dan dokumen benar tapi terlalu panjang.
4. Right (R): jawaban dan dokumen benar. Lingkungan Pengembangan
Perangkat lunak yang digunakan untuk penelitian yaitu :
1. Windows XP Profesional SP 3 sebagai sistem operasi,
2. ActivePerl-5.10.1.1007 sebagai interpreter program Perl,
3. Apache di dalam Xampp-win32-1.7.1 sebagai web server,
4. Notepad ++ sebagai editor program. Perangkat keras yang digunakan untuk penelitian yaitu :
1. Processor Intel Celeron 1.73 GHz, 2. RAM 1 GB,
3. Harddisk kapasitas 80 GB.
HASIL DAN PEMBAHASAN
Koleksi Dokumen PengujianKoleksi dokumen pengujian yang digunakan dalam penelitian diambil dari korpus yang sudah tersedia di Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB. Sumber koleksi dokumen diambil dari media koran, majalah, dan jurnal penelitian. Semua dokumen memiliki topik bidang pertanian. Ukuran terkecil dari dokumen yaitu 1 KB dan terbesar 53 KB. Dokumen-dokumen ini berformat teks (*.txt) dengan struktur XML di dalamnya. Gambar 6 menunjukkan format strukur dokumen yang digunakan.
<DOC>
<DOCNO>suaramerdeka040104 </DOCNO>
<TITLE>Ribuan Bibit untuk Lahan
Kritis</TITLE> <AUTHOR></AUTHOR>
<DATE>Minggu,4Januari 2004</DATE> <TEXT>
NGALIYAN- Kecamatan Ngaliyan telah
mendistribusikan sekitar 30 ribu bibit
berbagai jenis tanaman. Sebelumnya,
wilayah itu telah menerima bantuan
140.250 bibit tanaman dari Departemen Pertanian. Bibit tanaman yang diberikan adalah petai, durian, rambutan, mangga, sukun, dan jati.
</TEXT> </DOC>
Gambar 6 Struktur dokumen pengujian. Pemrosesan dokumen pada tahap indexing dan pembentukan frase, hanya diambil bagian dokumen yang diapit oleh tag <TITLE> dan <TEXT>. Sedangkan untuk pembentukan
passages, hanya digunakan bagian dokumen
yang diapit oleh tag <TEXT >. Gambar 7 menunjukkan ilustrasi bagian dokumen yang diproses. <DOC> <DOCNO>suaramerdeka040104</DOCNO> <TITLE> … … … </TITLE> <AUTHOR></AUTHOR> <DATE>Minggu,4Januari 2004</DATE> <TEXT>… … … … … … …… … … …… … … … … …… … … <TEXT> </DOC>
Gambar 7 Ilustrasi bagian dokumen yang digunakan untuk pemrosesan. Pemrosesan Dokumen
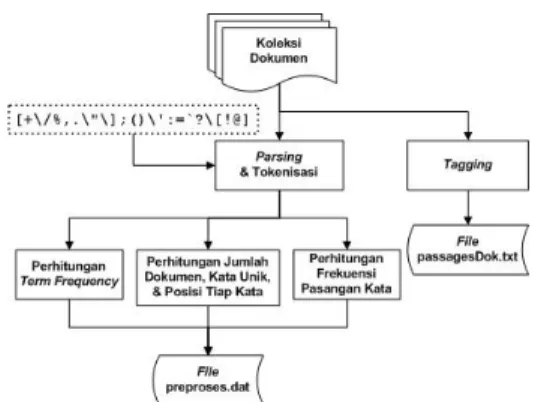
Tahap ini dilakukan untuk memudahkan proses memperoleh 10 dokumen teratas, pembentukan frase dan passages. Diagram alur pemrosesan dokumen dapat dilihat pada Gambar 8.
7 Gambar 8 Diagram alur pemrosesan
dokumen.
Langkah pertama yang dilakukan pada tahap ini adalah memasukkan satu per satu setiap bagian dokumen yang diapit tag <TEXT> ke dalam sistem name entity tagging (Citraningputra 2009). Semua dokumen hasil
tagging kemudian disimpan dalam file
passagesDok.txt. Gambar 9 menunjukkan
hasil tagging untuk dokumen suaramerdeka040104.txt.
NGALIYAN- <LOCATION>Kecamatan
Ngaliyan</LOCATION> telah mendistribusikan sekitar <NUMBER> 30</NUMBER> ribu bibit berbagai jenis tanaman. Sebelumnya, wilayah itu telah menerima bantuan
<NUMBER>140.250</NUMBER> bibit tanaman dari <ORGANIZATION>Departemen Pertanian
</ORGANIZATION>. Bibit tanaman yang diberikan adalah petai, durian, rambutan, mangga, sukun, dan jati.
Gambar 9 Contoh hasil tagging dokumen. Selanjutnya dilakukan penghapusan tanda titik (.) yang bukan akhir kalimat pada file passagesDoc.txt secara manual oleh penulis, yaitu tanda (.) yang merupakan : 1. Singkatan gelar, misal : dr. dan Prof. 2. Singkatan nama seseorang, misal : A. rifai
Badri.
3. Singkatan nama biologi suatu spesies, misal : Bambusa sp.
4. Penomoran, misal : a. Deklarasi Rio b. Program aksi agenda.
kemudian dilakukan pembentukan kalimat untuk setiap dokumen dengan menggunakan tanda pemisah antar kalimat yaitu [.?!]. Setiap
passage dibentuk dari dua kalimat yang
berurutan sehingga passage yang posisinya berdekatan saling overlap. Hasil pembentukan
passages ini disimpan dalam kamus passages.
Langkah kedua dilakukan pembacaan terhadap isi file yang berada pada folder korpus. Kemudian dilakukan pembacaan isi
file yang berada di antara tag <TITLE> dan
<TEXT>. Selanjutnya dilakukan parsing terhadap isi file dengan pemisah kata yang
terdiri atas tanda baca
[+\/%,.\"\];()\':=`?\[!@]. Tidak semua hasil parsing disimpan, karena hasil
parsing diseleksi kembali oleh stopwords
yang tersimpan dalam file stopwords.txt.
File ini terdiri atas 733 kata yang dipisahkan
dengan karakter enter, contoh kata tersebut antara lain cuma, dalam, dan, dapat, dapatkah, dari, dll.
Daftar pasangan dokumen dengan kata-kata hasil parsing dari setiap file diletakkan dalam variabel %praproses dan disimpan ke dalam file praproses.dat. Variabel %praproses memiliki struktur sebagai berikut : my %praproses=( 'N_dok' => 0, 'kata' => {}, 'tf' => {}, 'frekUrut'=> {}, 'unik' => {} );
Variabel N_dok menyimpan jumlah dokumen yang dibaca, sedangkan variabel $unik menyimpan kata unik dari seluruh dokumen. Variabel kata memiliki tiga key dengan
syntax :
$rec{'kata'}{$file}{$token}{$index Kata};
variabel $file menyimpan nama dokumen yang dibaca, $token menyimpan daftar kata pada suatu dokumen, dan $indexKata menyimpan posisi kata pada suatu dokumen. Variabel tf digunakan untuk menyimpan
term frequency, yang memiliki dua key
dengan syntax :
$rec{'tf'}{$token}{$file}
Variabel $token menyimpan daftar kata unik dan $file menyimpan nama dokumen tempat kata unik itu berada. Adapun struktur
syntax dari variabel frekUrut sebagai berikut :
$rec{'frekUrut'}{$kataA}{$kataB}
Variabel frekUrut digunakan untuk menyimpan frekuensi pasangan kata dari 1000 dokumen pengujian. Variabel $kataA digunakan untuk menyimpan kata yang muncul tepat setelah kata yang ada pada variabel $kataB.
8 Pembentukan Frase
Setelah tahap pemrosesan dokumen, dapat dilakukan perhitungan peluang setiap pasangan kata sebagai sebuah frase. Dengan memanfaatkan file praproses.dat, diperoleh nilai variabel frekUrut dan unik. Variabel frekUrut digunakan untuk menyimpan daftar frekuensi pasangan kata yang berurutan dari 1000 dokumen pengujian, sedangkan variabel unik berisi daftar kata unik dari 1000 dokumen yang sama. Kemudian disusun program untuk menghitung banyaknya kemunculan kata A tepat setelah kata B, yang hasilnya disimpan dalam variabel $pembilang. Selanjutnya dihitung banyaknya kemunculan kata A tepat setelah semua kata unik yang ada pada dokumen dan hasilnya disimpan dalam variabel $penyebut. Berikut ilustrasi algoritme untuk mendapatkan nilai variabel $pembilang dan $penyebut :
%frek= retrieve(‘praproses.dat’); %urut = %{$frek{‘frekUrut’}}; %unik = %{$frek{‘unik’}}; foreach $kataA of %unik{
foreach $kataB of {$unik{$kataA}}{ $pembilang{$kataA}{$kataB}= $urut{$kataA}{$kataB}; $penyebut{$kataA} += $urut{$kataA}{$kataB}; } }
Selanjutnya untuk menghitung peluang kata A setelah kata B dari semua pasangan kata unik pada koleksi dokumen, dapat dilihat pada ilustrasi algoritme di bawah :
%unik = %{$frek{‘unik’}}; foreach $kataA of %unik{
foreach $kataB of {$unik{$kataA}}{ if $kataA not equal $kataB{
$peluang{$kataA}{$kataB} = $pembilang{$kataA}{$kataB}/ $penyebut{$kataA}{$kataB}; } } }
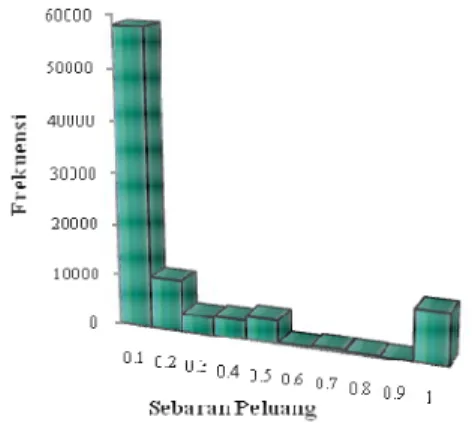
Perhitungan peluang pembentukan frase dari 1000 dokumen menghasilkan 90.901 kandidat frase dengan nilai peluang terkecil yakni 1.98 x 10-4 dan nilai terbesar adalah 1. Gambar 10 menunjukkan histogram sebaran peluang yang dihasilkan. Sumbu x histogram menunjukkan sebaran nilai peluang, sedangkan sumbu y menunjukkan frekuensi pasangan kata untuk setiap nilai peluang. Sebanyak 10.090 pasangan kata memiliki nilai peluang sebesar 1, 11.181 pasangan kata memiliki peluang
lebih dari 0.5 sampai dengan 1, 21.656 pasang kata memiliki peluang antara lebih dari 0.1 sampai kurang dari sama dengan 0.5, dan 58.064 pasang kata memiliki peluang kurang dari sama dengan 0.1. Terdapat pasangan kata dengan nilai peluang 1 yang benar dikategorikan sebagai frase. Namun ada pula pasangan kata yang sebenarnya bukan frase tapi memiliki nilai peluang sebesar 1. Contoh untuk pasangan kata “Marty Natalegawa” yang tidak termasuk frase tetapi memiliki nilai peluang sebesar 1. Hal ini disebabkan kata “Natalegawa” selalu muncul tepat setelah kata “Marty” pada koleksi dokumen. Untuk pasangan kata “mundu dipercayai” memiliki peluang sebesar 1 meskipun tidak termasuk frase. Hal ini disebabkan pasangan kata “mundu dipercayai” muncul tepat satu kali dalam koleksi dokumen. Tabel 3 menunjukkan contoh pasangan kata (kandidat frase) dengan nilai peluang sebesar 1 yang dievaluasi benar dan salah sebagai frase. Pasangan kata yang akan digunakan sebagai kandidat frase untuk proses pembentukan frase pada tahap analisis pertanyaan adalah pasangan kata yang memiliki nilai peluang lebih besar sama dengan 0.1, sehingga diperoleh 33.984 pasangan kata yang disimpan dalam kamus frase.
Gambar 10 Histogram sebaran nilai peluang pembentukan frase.
Tabel 3 Contoh pasangan kata dengan nilai peluang sebesar 1
Pasangan Kata Evaluasi
Marty Natalegawa Salah Menteri perindustrian Benar Kementrian pertahanan Benar Negeri jiran Benar Mundu dipercayai Salah
9 Perhitungan tf-idf
Dengan memanfaatkan hasil tahap pemrosesan dokumen, dapat dilakukan perhitungan document frequency (df), inverse
document frequency (idf), dan tf-idf dari
setiap token dan kandidat frase pada seluruh dokumen.
Langkah pertama yang dilakukan adalah memanfaatkan file praproses.dat untuk mendapatkan informasi term frequency pada variabel tf. Variabel ini untuk menghitung nilai df, idf, dan tf-idf setiap kata. Tujuan dari idf adalah untuk menentukan kata-kata (term) yang merupakan penciri dari suatu dokumen, oleh karena itu dalam penelitian ini hanya kata dengan nilai idf lebih besar sama dengan 0.3 yang disimpan. Hal ini bertujuan untuk menghapus kata-kata yang tidak termasuk dalam stopwords namun bukan penciri dari sebuah dokumen. Melalui idf dapat diperoleh informasi untuk menghitung nilai tf-idf yang merupakan perkalian antara nilai tf dan idf.
Langkah kedua adalah menghitung nilai df, idf, dan tf-idf setiap kandidat frase dalam setiap dokumen. Perhitungan ini dilakukan dengan memanfaatkan informasi term frequency pasangan kata pada variabel
frekUrut. Untuk pembobotan kandidat frase, diterapkan juga langkah-langkah seperti pada pembobotan kata. Selanjutnya hasil idf dan tf-idf kata dan kandidat frase digabung dan disimpan dalam satu file. Hasil idf disimpan dalam file idf.txt sedangkan hasil tf-idf disimpan dalam file tfidf.txt.
Pemrosesan Kueri
Kueri yang berupa kalimat tanya dimasukkan secara manual oleh pengguna, kueri yang digunakan harus diawali dengan kata tanya dan diakhiri dengan tanda tanya. Kata tanya yang digunakan pada penelitian ini adalah SIAPA, KAPAN, DIMANA, dan BERAPA. Analisis pertanyaan yang dilakukan meliputi parsing dan tokenisasi, identifikasi tipe pertanyaan, dan pembentukan frase.
Langkah pertama analisis pertanyaan yang dilakukan pada pemrosesan kueri adalah
parsing terhadap kalimat tanya menggunakan
tanda baca pemisah
/[\s\-+\/%,.\"\];()\':=`?\[!@>]+/.
Selanjutnya dilakukan case folding dan tokenisasi untuk mendapatkan kata-kata penyusun kueri. Hasil tokenisasi disimpan dalam array $query. Indeks pertama pada
array query[0] digunakan untuk menyimpan kata tanya dari kueri pertanyaan. Kata tanya inilah yang digunakan untuk mendapatkan kandidat jawaban yang memiliki entitas sesuai kata tanya. Tabel 4 menunjukkan daftar entitas untuk setiap tipe kata tanya.
Tabel 4 Daftar pasangan kata tanya dan entitas Kata Tanya Tag Entitas
Siapa NAME,
ORGANIZATION Kapan DATE, TIME Dimana LOCATION
Berapa NUMBER,
CURRENCY
Sementara itu $query[1] sampai $query[n] digunakan untuk menyimpan kata-kata selain kata tanya (keyword). Kemudian dilakukan pengecekan terhadap kemungkinan pasangan kata pada keyword sebagai sebuah frase. Jika pasangan kata tersebut ditemukan dalam kamus frase, maka pasangan kata tersebut dianggap sebagai sebuah frase. Hasil akhir dari analisis pertanyaan ini disimpan dalam variabel $kueriFrase. Misal untuk kueri Berapa harga pemesanan kursi Rafles?, dilakukan analisis pertanyaan sehingga diperoleh nilai $kueriFrase berikut : $kueriFrase = (
[0] = kursi rafles [1] = harga
[2] = pemesanan )
Variabel $kueriFrase inilah yang digunakan untuk mendapatkan 10 dokumen teratas. Pembentukan frase pada kueri pertanyaan ini diharapkan dapat meningkatkan relevansi dokumen yang ditemukembalikan.
Perolehan 10 dokumen teratas
Dokumen yang digunakan untuk proses perolehan jawaban adalah 10 dokumen dengan bobot kesamaan cosine tertinggi. Dengan memanfaatkan nilai idf dan tf-idf dalam file idf.txt dan tfidf.txt, dapat diperoleh norm setiap kueri dan dokumen. Nilai array $kueriFrase digunakan untuk menghitung norm kueri dan norm untuk setiap dokumen. Langkah selanjutnya adalah memasangkan nilai norm kueri dengan norm setiap dokumen untuk menghasilkan nilai dot
product dan kesamaan cosine. Dokumen yang
diambil untuk memasuki langkah selanjutnya adalah 10 dokumen dengan nilai kesamaan
10
cosine tertinggi. Selanjutnya dilakukan pemilihan passages pada kamus passage yang termasuk dalam 10 dokumen di atas. Hasil pemilihan passages ini disimpan dalam variabel $passagesDocTop untuk digunakan pada tahap perolehan top passages.
Perolehan Top Passages dan Ekstraksi Jawaban
Passage yang disimpan variabel $passagesDocTop kemudian disaring untuk diambil passages yang memiliki TAG sesuai kata tanya kueri pertanyaan. Selanjutnya dilakukan pembobotan passages
menggunakan pembobotan heuristic. Sesuai dengan tahapan yang terdapat dalam jurnal Ballesteros & Xiaoyan-Li (2007) serta penelitian Cidhy (2009) yang digunakan sebagai acuan dalam penelitian ini, pembobotan passages terdiri atas :
1. Pembobotan passages berdasarkan hasil dari proses wordmatch sesuai threshold. Hasilnya disimpan dalam variabel count_match.
2. Pembobotan passages berdasarkan urutan nilai dari arrayWordQuestion (kata-kata selain (kata-kata tanya pada kueri) dalam
passages. Hasilnya bernilai Boolean,
disimpan dalam variabel Ord.
3. Pembobotan passages berdasarkan nilai dari arrayWordQuestion dalam
passages. Hasilnya bernilai Boolean,
disimpan dalam variabel Sm.
4. Pembobotan berdasarkan hasil dari proses
wordmatch sesuai threshold berbanding
ukuran passage (jumlah kata dalam satu
passage).
Setelah diperoleh nilai dari ke-empat variabel di atas kemudian dihitung skor heuristic setiap
passage. Berikut rumus yang digunakan :
heuristic_score = count_match +
count_match/W + Sm*0.5 + Ord*0.5.
Tahap berikutnya adalah ekstraksi jawaban dari top passages yang diperoleh. Passage yang memiliki nilai heuristic_score tertinngi menjadi top passage. Kata yang menjadi kandidat jawaban adalah kata yang memiliki entitas sesuai dengan kata tanya pada kueri pertanyaan. Yang perlu diperhatikan adalah
top passage dapat terdiri atas satu atau lebih passage dan setiap passage dapat memiliki
satu atau lebih kandidat jawaban. Jawaban akhir setiap passage diperoleh dengan cara menghitung jarak antara setiap kandidat jawaban pada setiap passage dengan masing-masing kata pada $arrayWordMatch.
$arrayWordMatch merupakan array yang menampung kumpulan kata hasil pencocokan antara keyword dengan kata-kata pada
passage. Kandidat jawaban yang memiliki
jarak terpendek dianggap sebagai jawaban yang paling tepat.
Contoh hasil percobaan menggunakan kueri pertanyaan Berapa harga pemesanan kursi Rafles ?, diperoleh 198 passage pada 10 dokumen teratas. Setelah diambil passage yang mengandung tag <NUMBER> atau <CURRENCY> diperoleh 63 passage dari 198 passage pada 10 dokumen teratas. Top passage yang diperoleh dari 63 passage :
Pada suatu saat ada seorang buyer
mendatangi pengekspor di
<LOCATION>Bekonang,
Sukoharjo</LOCATION>, memesan kursi rafles seharga <CURRENCY>Rp 275 ribu</CURRENCY>/unit. Pada pembelian berikutnya setelah membanding-bandingkan harga buyer itu mencari pengekspor lain.
Perolehan nilai untuk masing-masing jenis pembobotan yaitu 3, 0, 0, dan 0.1. Kandidat jawaban yang diperoleh hanya ada satu yaitu kata 275 ribu sehingga kata 275 ribu menjadi jawaban akhir dengan bobot jarak sebesar 3.1.
Hasil Percobaan
Hasil percobaan dievaluasi menggunakan 2 skema uji yaitu :
1. Membandingkan hasil penelitian yang dilakukan oleh penulis dengan hasil penelitian Cidhy (2009). Jumlah koleksi dokumen yang digunakan sebanyak 106 dokumen. Perbandingan dilakukan dengan melihat ketepatan dokumen, top passage, dan jawaban yang ditemukembalikan. 2. Menguji hasil penelitian penulis dengan
melakukan tiga kali percobaan menggunakan 106, 200, dan 300 dokumen. Hasil ketiga percobaan tersebut dibandingkan dari segi ketepatan passage dan jawaban yang ditemukembalikan. 3. Membandingkan hasil penelitian yang
dilakukan oleh penulis dengan hasil penelitian Cidhy (2009). Koleksi dokumen yang digunakan merupakan dokumen
reading comprehension.
Sebanyak 45 kueri digunakan untuk percobaan. Kueri tersebut diambil dari penelitian Cidhy (2009) dan dibuat sendiri
11 oleh penulis. Proses dokumentasi evaluasi
kueri dicatat dalam bentuk tabel yang terdiri atas sumber dokumen, pertanyaan (kueri), jawaban, ketepatan dokumen, ketepatan jawaban, dan koreksi. Kemudian dilakukan pencocokan antara hasil pencarian yang diperoleh terhadap pasangan dokumen dan kueri pertanyaan yang seharusnya.
Berdasarkan kesesuaian pasangan jawaban dan dokumen, penilaian dibedakan menjadi empat jenis yaitu : right, wrong, unsupported, dan null. Persentase evaluasi hasil percobaan yang dilakukan oleh Cidhy dan penulis dapat dilihat pada Tabel 5. Berikut pembahasan untuk masing-masing percobaan :
Tabel 5 Persentase perolehan jawaban oleh Cidhy (2009) dan penulis
1. Perbandingan Hasil Percobaan Untuk Kata Tanya SIAPA
Persentase ketepatan jawaban untuk kata tanya SIAPA cenderung lebih rendah dibanding kata tanya DIMANA dan KAPAN. Hal ini diakibatkan pada penulisan teks, informasi untuk jawaban SIAPA seringkali disajikan dengan cara lebih variatif. Seperti adanya penggunaan kata ganti untuk orang, misal : dia, nya, saya, mereka, dll.
Hasil penelitian yang dilakukan oleh Cidhy dan penulis, menghasilkan persentase kriteria right sebesar 75%, wrong 8.33%, dan
null sebesar 16.67%. Berdasarkan 12 kueri
pertanyaan yang diuji, diambil contoh kueri pertanyaan Siapa yang bekerja sama dengan Unibraw untuk menangani pasca panen ikan?. Hasil penelitian Cidhy mengembalikan 10 dokumen teratas berikut : [0]=>situshijau110603-01.txt [1]=>situshijau230603-03.txt [2]=>gatra180103.txt [3]=>situshijau110303-01.txt [4]=>kompas310702.txt [5]=>suarakarya000000-21.txt [6]=>indosiar300404.txt [7]=>indosiar020104.txt [8]=>kompas240103.txt [9]=>republika281202.txt
Hasil penelitian penulis mengembalikan 10 dokumen teratas sebagai berikut :
[0]=>situshijau110603-001.txt [1]=>situshijau230603-003.txt [2]=>situshijau110303-001.txt [3]=>gatra180103.txt [4]=>kompas310702.txt [5]=>suarakarya000000-021.txt [6]=>indosiar020104.txt [7]=>indosiar300404.txt [8]=>republika281202.txt [9]=>kompas240103.txt
Kedua penelitian menghasilkan 10 dokumen teratas yang berbeda, namun diperoleh dokumen teratas dan top passage yang sama. Jawaban yang diperoleh dari top passage adalah Lembaga Kimia Nasional. Berikut
top passage yang bersumber dari dokumen
situshijau110603-001.txt :
Akibatnya <ORGANIZATION>Indonesia </ORGANIZATION> belum mampu memenuhi kuota ekspor gaplek karena kualitasnya lebih rendah dibanding komoditas sejenis asal <LOCATION>Thailand</LOCATION>."
Selain itu
<ORGANIZATION>Unibraw</ORGANIZATIO N> juga menghasilkan penelitian tentang budi daya pisang dengan
kultur jaringan sekaligus
teknologi pengolahan menjadi pasta, tepung dan makanan ringan. "Dampaknya banyak pengusaha [di <LOCATION>Jatim</LOCATION>]
berbisnis pisang tapi tidak mengerti bagaimana sistem industri berbasis komoditas itu." <NAME>Sri</NAME> menambahkan <ORGANIZATION>Unibraw</ORGANIZATIO N> juga pernah bekerjasama dengan Kata Tanya Penelitian Cidhy (2009) Penelitian Oleh Penulis
Right Unsupported Wrong Null Right Unsupported Wrong Null
Siapa 75 0 8.33 16.67 75 0 8.33 16.67
Berapa 41.67 8.33 50 0 41.67 8.33 50 0
Dimana 81.82 0 18.18 0 90.91 0 9.09 0
12 <ORGANIZATION>Lembaga Kimia
Nasional</ORGANIZATION> dan instansi terkait menangani masalah penanganan pasca panen ikan mencakup peningkatan kualitas ikan asin dan ikan pindang skala UKM, tapi belum terlihat sentra industri hasil perikanan yang layak ditonjolkan.
Daftar kueri pertanyaan dan evaluasi untuk kata tanya SIAPA dapat dilihat pada Lampiran 4.
2. Perbandingan Hasil Percobaan Untuk Kata Tanya BERAPA
Persentase ketepatan jawaban untuk kata tanya BERAPA merupakan yang paling rendah dibanding kata tanya yang lain. Baik penelitian yang dilakukan oleh Cidhy (2009) maupun penulis, keduanya menghasilkan persentase kriteria right sebesar 41.67%,
unsupported 8.33%, dan wrong 50%. Hal ini
disebabkan pada penulisan teks, informasi untuk jawaban BERAPA seringkali disajikan dengan cara lebih variatif. Seperti adanya penulisan dalam bentuk rincian untuk jumlah.
Hasil penelitian yang dilakukan oleh Cidhy dan penulis mengembalikan kriteria
wrong untuk kueri pertanyaan Berapa luas wilayah yang ditanami tanaman padi di Kalimantan Timur?. Penelitian Cidhy (2009) mengembalikan jawaban 6 kecamatan dengan 10 dokumen teratas yang diperoleh sebagai berikut :
[0]=>situshijau200103-001.txt [1]=>kompas170700.txt [2]=>kompas091003.txt [3]=>kompas240302.txt [4]=>indosiar031203.txt [5]=>jurnal000000-005.txt [6]=>indosiar260504.txt [7]=>kompas240103.txt [8]=>republika290604-007.txt [9]=>bitraindonesia000000-001.txt
Top passage yang diperoleh dari dokumen
indosiar031203.txt, yaitu :
Dari catatan <ORGANIZATION>Dinas Pertanian dan Tanaman Pangan Provinsi Jambi</ORGANIZATION>, rusaknya tanaman pertanian akibat banjir yang terjadi pada tanaman padi, cabe, kacang tanah, dan jeruk. Hal itu terjadi di
<NUMBER>6 kecamatan</NUMBER> yang ada di <LOCATION>Kabupaten Kerinci</LOCATION>, seperti tanaman padi seluas <NUMBER>11,87 hektar</NUMBER> tergenang air, dan
sebanyak <NUMBER>148
hektar</NUMBER> mengalami puso.
Jawaban yang diperoleh pada penelitian kali ini yaitu 122 hektar. Jawaban ini diperoleh dari 10 dokumen teratas sebagai berikut : [0]=>indosiar031203.txt [1]=>kompas091003.txt [2]=>indosiar260504.txt [3]=>mediaindonesia050204.txt [4]=>suaramerdeka220702.txt [5]=>kompas310702.txt [6]=>suarapembaruan260703-001.txt [7]=>bitraindonesia000000-001.txt [8]=>pikiranrakyat300704-002.txt [9]=>jurnal000000-020.txt
Berikut top passage yang diperoleh dari dokumen mediaindonesia050204.txt : NUSANTARA SAMPIT--MIOL] : Tanaman padi seluas <NUMBER>122 hektar</NUMBER> pada tiga
kecamatan di kabupaten
<LOCATION>Kotawaringin Timur (Kotim)</LOCATION>
<ORGANIZATION>Kalimantan
Tengah</ORGANIZATION> mengalami fuso akibat diserang hama belalang kembara dalam sebulan terakhir. Kasubdin produksi Tanaman Pangan <ORGANIZATION>Dinas Pertanian Kotim</ORGANIZATION>
<NAME>Ir.Sefmita</NAME> di <LOCATION>Sampit</LOCATION>, <DATE>Kamis</DATE> mengatakan, serangan hama belalang kembara
yang terjadi sejak awal
<DATE>Januari 2004</DATE> menyerang lahan pertanian di <LOCATION>Kecamatan Parenggean dan Kecamatan Mentaya Hulu</LOCATION> sehingga mengakibatkan <NUMBER>122 hektar</NUMBER> tanaman padi mengalami fuso.
Setelah dievaluasi, 10 dokumen teratas yang dihasilkan pada penelitian penulis lebih relevan dibanding penelitian Cidhy (2009).
Passage yang dihasilkan pada kedua penelitian belum tepat sehingga jawaban yang dihasilkan salah. Daftar kueri pertanyaan dan
13 evaluasi untuk kata tanya BERAPA dapat
dilihat pada Lampiran 5.
4. Perbandingan Hasil Percobaan Untuk Kata Tanya DIMANA
Persentase kriteria right 90.91% dan
wrong 9.09% dihasilkan pada penelitian
penulis, sedangkan pada penelitian Cidhy (2009) diperoleh 81.82% kriteria right dan 18.18% wrong. Kriteria wrong diperoleh untuk kueri pertanyaan Dimana terjadi
penurunan produksi tanaman
tembakau?. Hasil penelitian Cidhy (2009) mengembalikan jawaban Indonesia, jawaban ini diperoleh setelah sistem mengembalikan 10 dokumen teratas berikut : [0]=>republika281202.txt [1]=>pikiranrakyat020804-001.txt [2]=>suarapembaruan150903.txt [3]=>republika130903.txt [4]=>indosiar031203.txt [5]=>situshijau210503-001.txt [6]=>situshijau110303-001.txt [7]=>suaramerdeka170602-001.txt [8]=>situshijau180803-001.txt [9]=>indobic130504-002.txt.
Berikut top passage yang diperoleh dari 10 dokumen di atas :
Mereka juga bisa menanam dan memetik tanaman sayuran serta mempelajari tanaman sayuran itu. Tanaman Asli Selain mengenal jenis-jenis tanaman sayuran yang saat ini sudah banyak beredar di pasar, pengunjung juga bisa menyaksikan jenis tanaman asli <LOCATION>Indonesia</LOCATION> (indigenous vegetabels) yang ternyata mempunyai khasiat khusus untuk kesehatan manusia.
Top passage di atas diperoleh dari dokumen
situshijau210503-001.txt. Berdasarkan hasil top passage, diperoleh satu kandidat jawaban yaitu kata Indonesia.
Dengan menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan penulis menghasilkan kriteria right yaitu Nanggroe Aceh Darussalam. Jawaban ini diperoleh setelah sistem mengembalikan 10 dokumen teratas berikut : [0]=>republika281202.txt [1]=>pikiranrakyat020804-001.txt [2]=>republika130903.txt [3]=>suarapembaruan150903.txt [4]=>suaramerdeka170602-001.txt [5]=>suarakarya000000-032.txt [6]=>mediaindonesia131203-02.txt [7]=>republika290604-007.txt [8]=>situshijau180803-001.txt [9]=>gatra180103.txt
Selanjutnya dari 10 dokumen tersebut diperoleh top passage sebagai berikut :
Penurunan justeru terjadi pada
komoditi teh. Selain itu,
penurunan lebih jelas ada pada produksi tembakau di daerah <LOCATION>Nanggro Aceh Darussalam</LOCATION>
(<LOCATION>NAD</LOCATION>) dan <LOCATION>Sumatera
Utara</LOCATION>.
Entitas Nanggro Aceh
Darussalam memiliki jarak yang lebih dekat dibanding entitas NAD dan Sumatera Utara, sehingga Nanggro Aceh Darussalam menjadi jawaban akhir. Sumber jawaban akhir diperoleh dari dokumen republika281202.txt.
Jawaban yang diperoleh pada penelitian penulis lebih tepat dibanding penelitian Cidhy (2009). Hal ini disebabkan oleh top passage dan 10 dokumen teratas yang diperoleh pada penelitian kali ini lebih relevan dibanding penelitian Cidhy (2009). Daftar kueri pertanyaan dan evaluasi untuk kata tanya DIMANA dapat dilihat pada Lampiran 6. 5. Perbandingan Hasil Percobaan Untuk
Kata Tanya KAPAN
Persentase ketepatan jawaban untuk kata tanya KAPAN merupakan yang paling tinggi dibanding kata tanya yang lain. Baik penelitian Cidhy (2009) maupun yang dilakukan penulis, menghasilkan persentase kriteria right sebesar 100% untuk 10 kueri pertanyaan yang diujikan. Semua top passage yang dihasilkan untuk setiap kueri pada kedua penelitian adalah sama. Perbedaan terjadi pada 10 dokumen yang ditemukembalikan untuk setiap kueri. Misal untuk kueri Kapan diadakan semiloka Pengembangan Kawasan Pantai sebagai alternative akselerator pembangunan daerah?, pada penelitian Cidhy (2009) diperoleh 10 dokumen teratas sebagai berikut :
[0]=>suaramerdeka230702.txt [1]=>indosiar070604.txt
14 [2]=>republika020604-002.txt [3]=>republika251002-002.txt [4]=>pembaruan110903.txt [5]=>kompas170700.txt [6]=>kompas091003.txt [7]=>kompas210502.txt [8]=>gatra230103-002.txt [9]=>republika210704-003-01.txt Hasil penelitian yang dilakukan oleh penulis, diperoleh 10 dokumen teratas yang lebih relevan dibanding penelitian Cidhy (2009). Berikut 10 dokumen yang dihasilkan : [0]=>suaramerdeka230702.txt [1]=>indosiar070604.txt [2]=>republika020604-002.txt [3]=>kompas210502.txt [4]=>pembaruan110903.txt [5]=>republika230404.txt [6]=>suaramerdeka220702.txt [7]=>kompas121099.txt [8]=>republika210704-003-01.txt [9]=>jurnal000000-005.txt
Kedua penelitian menghasilkan top passage yang sama sehingga diperoleh jawaban yang sama. Daftar kueri pertanyaan dan evaluasi untuk kata tanya KAPAN dapat dilihat pada Lampiran 7.
6. Perbandingan Hasil Percobaan Menggunakan 106, 200, dan 300 Dokumen
Percobaan dilakukan untuk membandingkan ketepatan passage dan jawaban yang ditemukembalikan dengan menggunakan jumlah koleksi dokumen yang berbeda. Percobaan 1 dilakukan dengan menggunakan 106 dokumen, percobaan 2 menggunakan 200 dokumen, dan percobaan 3 menggunakan 300 dokumen. Persentase ketepatan jawaban yang ditemukembalikan dari hasil percobaan dapat dilihat pada Tabel 6 dan Gambar 11.
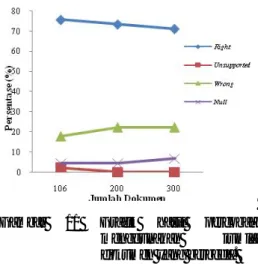
Tabel 6 Persentase perolehan jawaban menggunakan jumlah dokumen yang berbeda
Jumlah
Dokumen Right Unsupported Wrong Null 106 75.56 2.22 17.78 4.44
200 73.33 0 22.22 4.44
300 71.11 0 22.22 6.67
Gambar 11 Grafik hasil percobaan menggunakan jumlah dokumen yang berbeda. Berdasarkan Gambar 11 dapat dilihat bahwa persentase kriteria right yang dihasilkan menurun dengan menaiknya jumlah koleksi dokumen yang digunakan. Persentase untuk kriteria right pada percobaan 1 sebesar 75.6%, sedangkan pada percobaan 2 menurun menjadi 73.33% dan percobaan 3 menurun menjadi 71.11%. Penurunan ini terjadi karena pada percobaan 2 dan 3, diperoleh jawaban yang salah untuk pertanyaan Kapan Bungaran Saragih menyatakan kelangkaan pupuk diakibatkan adanya penyebaran yang terjadi secara sporadic?. Meskipun dokumen teratas yang ditemukembalikan sudah sama yaitu indosiar260504.txt, namun ketiga percobaan mengembalikan top passage yang berbeda. Setelah diamati ternyata passage yang diperoleh pada percobaan 1 sudah tepat sehingga jawaban yang dihasilkan benar (right). Sedangkan pada percobaan 2 dan 3,
passage yang diperoleh tidak tepat sehingga
jawaban yang dihasilkan salah (wrong). Kriteria unsupported hanya diperoleh pada percobaan 1, untuk pertanyaan Berapa harga beras dalam negri antara bulan Juni-Juli?. Meskipun jawaban dan
passage yang dihasilkan sudah tepat yaitu
Rp4.000, namun dokumen
kompas180504.txt yang
ditemukembalikan masih belum tepat. Sedangkan pada percobaan 2 dan 3, dokumen yang ditemukembalikan sama dengan percobaan 1 tetapi top passage belum tepat sehingga diperoleh tipe jawaban wrong untuk pertanyaan ini.
Persentase kriteria wrong pada percobaan 1 sebesar 17.78 %, namun pada percobaan 2 dan 3 meningkat menjadi 22.2 %. Peningkatan ini terjadi karena pada percobaan 2 dan 3,
15 diperoleh jawaban yang salah untuk
pertanyaan Berapa harga pemesanan kursi Rafles?. Meskipun ketiga percobaan
menemukembalikan dokumen
suaramerdeka030403.txt sebagai dokumen teratas, namun top passage yang diperoleh pada percobaan 2 dan 3 belum tepat sehingga jawaban yang dihasilkan salah. Sedangkan top passage yang diperoleh pada percobaan 1 sudah tepat sehingga diperoleh jawaban yang benar. Setelah diamati untuk pertanyaan Berapa usia panen pertama kali lengkeng?, ketiga percobaan menemukembalikan dokumen teratas yang sama yaitu trubus000104.txt, namun top
passage yang dihasilkan berbeda-beda. Ketiga top passage yang dihasilkan masih belum
tepat sehingga jawaban yang dihasilkan masih salah (wrong).
Persentase kriteria null pada percobaan 1 dan 2 sebesar 4.44 %, sedangkan pada percobaan 3 meningkat menjadi 6.67 %. Kriteria null atau tidak mengembalikan jawaban apapun dikarenakan tidak ditemukan entitas yang sesuai pada top passage. Contoh untuk pertanyaan Siapa Bungaran Saragih?, percobaan 1, 2, dan 3 tidak mengembalikan jawaban. Hal ini terjadi karena top passage yang dikembalikan oleh ketiga percobaan adalah sebagai berikut : Menurut <NAME>Bungaran Saragih</NAME>, hal tersebut wajar dengan keadaan setiap penyalur pupuk, dimana mereka memerlukan waktu dalam proses pengepakan kembali. Mengenai kelangkaan pupuk di <LOCATION>Cirebon</LOCATION> yang hanya terjadi di beberapa kecamatan, <NAME>Bungaran Saragih</NAME> menegaskan bahwa produsen pupuk setempat telah menutupi kelangkaan tersebut dengan pengiriman pupuk dari luar wilayah
<LOCATION>Cirebon</LOCATION>.
Entitas yang sesuai untuk kueri pertanyaan
sebelumnya adalah NAME dan
ORGANIZATION. Sedangkan pada top
passage di atas hanya terdapat entitas NAME.
Namun karena kata yang diapit tag NAME merupakan kata pada keyword, maka kata tersebut tidak dianggap sebagai kandidat jawaban. Sehingga tidak ditemukan jawaban dari top passage tersebut.
Hasil ketiga percobaan menunjukkan
ketepatan top passage yang diperoleh sangat mempengaruhi jawaban yang dihasilkan. Oleh
karena itu, semakin baik metode untuk melakukan pembobotan passage maka semakin tepat jawaban yang diperoleh. Hasil lengkap percobaan ini dapat dilihat pada Lampiran 8, 9, 10, dan 11.
7. Perbandingan Hasil Percobaan Menggunakan Dokumen Reading Comprehension
Dokumen yang digunakan pada percobaan merupakan dokumen reading comprehension, dokumen ini memiliki struktur bahasa Indonesia yang baku. Jumlah dokumen yang digunakan sebanyak 9 buah dan diambil dari depdiknas serta situs http://duniabelajar.com. Sepuluh kueri diambil dari dokumen ini untuk diuji ke dalam penelitian Cidhy (2009) dan penulis. Kueri yang digunakan memiliki tipe pertanyaan SIAPA, DIMANA, BERAPA, dan KAPAN. Baik penelitian Cidhy (2009) maupun penulis, menghasilkan persentase kriteria right sebesar 100 %. Persentase yang tinggi ini menunjukkan bahwa kedua penelitian dapat mengembalikan jawaban yang tepat untuk dokumen dan kueri yang formatnya sudah baku. Hasil lengkap percobaan ini dapat dilihat pada Lampiran 12.
KESIMPULAN DAN SARAN
KesimpulanHasil penelitian menunjukkan :
1. Pembentukan frase pada tahap analisis pertanyaan dapat meningkatkan relevansi dokumen yang ditemukembalikan. 2. Hasil pembentukan frase menggunakan
konsep peluang masih kurang bagus karena frase dibatasi pada dua kata saja. 3. Semakin tepat top passage yang diperoleh,
maka semakin tepat jawaban yang dikembalikan oleh sistem QA. Oleh karena itu meskipun diperoleh dokumen yang relevan tetapi metode pembobotan passage belum tepat, maka jawaban yang diperoleh juga belum tepat.
4. Sistem yang dibangun sudah benar untuk memproses dokumen reading comprehension.
Saran
Perlu dilakukan perbaikan dalam formula untuk mendapatkan kandidat frase, misal menggunakan kamus yang diambil dari KBBI sehingga dapat meningkatkan relevansi
16 dokumen yang ditemukembalikan. Selain itu,
permasalahan utama pada QAS adalah bagaimana mendapatkan top passage yang sesuai. Oleh karena itu, perlu dilakukan perbaikan metode untuk pembobotan passage pada penelitian-penelitian selanjutnya.
DAFTAR PUSTAKA
Anggraeni M. 2007. Implementasi Question
Answering System dengan Metode Rule-Based pada Terjemahan l-Qur’an Surat
Al-baqarah [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Ballesteros, L. A dan Xiaoyan-Li. 2007.
Heuristic and Syntactic for Cross-language Question Answering. Di dalam: Proceedings of NTCIR-6 Workshop Meeting. Tokyo, 15-18 Mei 2007. hlm
230-233.
Cidhy D A T K. 2009. Implementasi Question
Answering System dengan Pembobotan Heuristic [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Citraningputra P. 2009. Entitas Tagging untuk Dokumen Berbahasa Indonesia Menggunakan Metode Berbasis Aturan [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
[Depdiknas] Departemen Pendidikan Nasional, Pusat Bahasa. 2003. Tata Bahasa Baku Bahasa Indonesia. Ed ke-3. Jakarta: Balai Pustaka.
Ikhsani N. 2006. Implementasi Question
Answering System dengan Metode Rule-Based untuk Temu Kembali Informasi
Berbahasa Indonesia [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Manning C D, Raghavan P, Schütze H. 2008.
Introduction to Information Retrieval.
Cambridge: Cambridge University Press. Sianturi R. 2008. Implementasi Question
Answering System dengan Metode Rule-Based pada Banyak Dokumen Berbahasa
Indonesia [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Schlaefer N, P. Gieselmann, and G. Sautter. 2006. The Ephyra QA System at TREC. Strzalkowski T, Harabagiu S. 2008. Advances
in Open Domain Question Answering.
Dordrecht: Springer.
van Zaanen M. 2008. Multi-lingual Question
Answering Using OpenEphyra at
17
LAMPIRAN
18 Lampiran 1 Antarmuka implementasi