POLA KETERKAITAN NILAI MAHASISWA ILMU
KOMPUTER IPB ALIH JENIS DENGAN KOMPONEN EPBM
MENGGUNAKAN ALGORITME SPADE
ZICO AGUSTIAN RUSDY
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pola KeterkaitanNilai Mahasiswa Ilmu Komputer IPB Alih Jenis dengan Komponen EPBM Menggunakan Algoritme SPADEadalah benar karya saya denganarahan dari pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
ZICO AGUSTIAN RUSDY. Pola Keterkaitan Nilai Mahasiswa Ilmu Komputer IPB Alih Jenis dengan Komponen EPBM Menggunakan Algoritme SPADE. Dibimbing oleh ANNISA.
Penelitian ini bertujuan untuk mengimplementasikan algoritme SPADE untuk melihat keterkaitan antara beberapa komponen pemicu nilai akhir mata kuliah dengan berbagai kumpulan data. Algoritme Sequential Pattern Discovery using Equivalence Class (SPADE) merupakan salah satu algoritme yang digunakan untuk melakukan penemuan cepat pola sekuensial. SPADEmemiliki 3 masukan data untuk diolah agar menghasilkan pola sekuensial yaitu sid, eid, dan items.Mata kuliah menjadi masukan data untuk sid, angkatan untuk eid, dan pemicu nilai akhir mata kuliah seperti nilai mahasiswa, nilai EPBM, nilai diploma, dan status kerja sebagai items. Hasil dari penelitian ini menghasilkan kemunculan bersama maupun pola sekuensial dari pemicu nilai akhir mata kuliah mahasiswa. Dari hasil peneletian ini ditemukan bahwa angkatan 4 paling sering mengungguli angkatan-angkatan sebelumnya dengan meraih nilai baik, dan ditemukan jugasebuah hubungan erat antara cara mengajar dosen yang baik dengan nilai akhir mata kuliah dari mahasiswa yang baik.
Kata kunci: penentuan pola, sequential pattern mining, SPADE
ABSTRACT
ZICO AGUSTIAN RUSDY. Association Pattern between Course Grades and Course Evaluation Score in Computer Science Extension Program using SPADE. Supervised by ANNISA.
This study aims to implement the SPADE algorithm to see the associations between some components that trigger course grades and a variety of data collections. Sequential Pattern Discovery using Equivalence Class (SPADE) algorithm is one of the most effective algorithm to determine sequential pattern of data. SPADE has 3 input data to be processed to generate a sequential pattern, i.e., sid, eid, and items. The course becomes the input for sid, the student batch for eid, and value triggers of course grade become such as student grade, EPBM score, previous GPA, and employment status become the inputs for items. This research resulted in event atoms and sequential patterns amongs components that determine the course grade. It was found that 4th batch is the most frequent to outperform the previous batches to achieving better grades, and it has found a close connection between a good lecturers evaluation score and the good course grades.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
POLA KETERKAITAN NILAI MAHASISWA ILMU
KOMPUTER IPB ALIH JENIS DENGAN KOMPONEN EPBM
MENGGUNAKAN ALGORITME
SPADE
ZICO AGUSTIAN RUSDY
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Skripsi : Pola Keterkaitan Nilai Mahasiswa Ilmu Komputer IPB Alih Jenis Dengan Komponen EPBM Menggunakan Algoritme SPADE
Nama : Zico Agustian Rusdy
NIM : G64104051
Disetujui oleh
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen Ilmu Komputer
Tanggal Lulus:
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahuwata’alaatas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Agustus 2012 ini terkait asosiasi penentuan pola sekuensial, dengan judul Pola Keterkaitan Nilai Mahasiswa Ilmu Komputer IPB Alih Jenis dengan Komponen EPBM Menggunakan Algoritme SPADE.
Terima kasih penulis ucapkan kepada Ibu Annisa, SKom, MKom selaku pembimbing yang telah memberikan arahan, dan saran selama penelitian ini berlangsung. Ungkapan terima kasih juga disampaikan kepada orangtua, adik, serta seluruh keluarga, atas segala doa dan kasih sayangnya. Ucapan terima kasih juga penulis sampaikan kepada seluruh teman-teman mahasiswa Departemen Ilmu Komputer IPB Alih Jenis angkatan 5 dan teman-teman satu bimbingan yang telah membantu dalam penyelesaian penelitian ini.
Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan skripsi ini.Penulis berharap penelitian dan tulisan ini dapat memberikan manfaat untuk masyarakat Indonesia pada umumnya dan pihak akademik IPB pada khususnya.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Knowledge Discovery from Data (KDD) 2
Sequential Pattern Mining 3
Algoritme SPADE 3
HASIL DAN PEMBAHASAN 10
Pengumpulan Data 10
Pembersihan Data 12
Seleksi Data 12
Transformasi Data 14
Data Mining 14
SIMPULAN DAN SARAN 19
Simpulan 19
Saran 19
DAFTAR PUSTAKA 19
LAMPIRAN 20
DAFTAR TABEL
1 Sampel database vertikal (Zaki 2001) 4
2 Id-list item A (Zaki 2001) 4
3 Sampel data nilai yang telah dilakukan proses pembersihan data 12
4 Rentang nilai mata kuliah mahasiswa 15
5 Rentang nilai EPBM 15
6 Bentuk input data setelah dikonversi menjadi beberapa kode data 15 7 Hasil jumlah pola kemunculan dari hasil pengujian dengan
masing-masing minimum support 15
DAFTAR GAMBAR
1 Original input-sequence database (Zaki 2001) 5
2 Tahapan penelitian 6
3 Contoh data nilai mata kuliah 10
4 Contoh biodata mahasiswa yang diperoleh 11
5 Contoh data EPBM yang diperoleh 13
6 Contoh data yang tidak lolos seleksi dari biodata mahasiswa 13 7 Contoh nilai yang diperoleh angkatan 4 pada mata kuliah KOM322 14 8 Sampel Frequent Sequences yang terbentuk dari masukan data akademik
yang dimasukkan dengan minimum support 50% 16
9 Tampilan antarmuka aplikasi utama 16
10 Tampilan rentetan pemicu nilai akhir mata kuliah antar angkatan 17
DAFTAR LAMPIRAN
1 Tiga puluh mata kuliah yang diambil 20
2 Sampel data nilai mata kuliah 21
3 Data nilai mutu mata kuliah, EPBM, dan nilai diploma setelah
pra-proses 22
4 Sampel data nilai diploma dan status kerja 23
PENDAHULUAN
Latar Belakang
Setiap perguruan tinggi selalu melakukan evaluasi dari hasil proses perkuliahan yang telah dilakukan. Institut Pertanian Bogor menggunakan data Evaluasi Proses Belajar Mengajar (EPBM) sebagai salah satu sumber data yang digunakan untuk melakukan evaluasi. Terkait prestasi akademik mahasiswa sendiri, terdapat beberapa faktor yang mempengaruhi hasil belajar seperti karakteristik mahasiswa, konteks akademik, dan persepsi mahasiwa mengenai lingkungan belajar (Aditomo & Ayuningtyas 2008).
Dengan ketersediaan data yang melimpah tersebut, penemuan pengetahuan yang berguna dari suatu database yang besar semakin popular dan menarik perhatian (Sijabat 2011). Setiap semester terdapat data Evaluasi Proses Belajar Mengajar (EPBM). Informasi yang diperoleh dari data EPBM tiap semester adalah performa para pengajar suatu mata kuliah, belum lagi informasi lain yang diperoleh dari data mahasiswa sendiri. Dalam data EPBM dapat diketahui penilai performa pengajar dari berbagai aspek seperti apakah dosen menyiapkan materi pengajaran dengan baik, sikap mengajar, dan etika yang ditampilkan dosen saat mengajar. Penemuan pengetahuan yang berguna terkait nilai akhir mata kuliah mahasiswa tersebut dapat dilakukan menggunakan teknik data mining. Data mining merupakan proses ekstraksi informasi atau pola dalam database yang berukuran besar (Han & Kamber 2011). Salah satu teknik data mining adalah sequential pattern mining yang berguna untuk menemukan pola sekuensial yang terdapat pada database yang pertama kali diperkenalkan oleh Agrawal dan Srikant pada tahun 1995.
Sebagai contoh, mahasiswa angkatan x cenderung mendapat hasil yang bagus pada suatu mata kuliah, dikarenakan cara mengajar dosen yang baik. Kejadian seperti ini sebenarnyaterekam dalam database, hanya saja belum tergali informasi tentang hal itu. Hal ini dapat dimanfaatkan oleh para pejabat akademik perguruan tinggi sebagai bahan evaluasi dan peningkatan kualitas perkuliahan.
Oleh karena itu, algoritme SPADE dapat digunakan untuk mencari keterkaitan prestasi akademik mahasiswa Departemen Ilmu Komputer alih jenis IPB dalam suatu mata kuliahyang kaitannya dengan aspek-aspek pemicu nilai mata kuliahyang telah dibahas sebelumnya.
Tujuan Penelitian
2
kemunculan bersama maupun deretan pola sekuensial antar-pemicu prestasi dan nilai mata kuliah dari tiap angkatan.
Manfaat Penelitian
Hasil dari penelitian ini mampu memberikan informasi keterkaitan antara kumpulan komponen EPBM yang mempengaruhi nilai akhir mata kuliah mahasiswa. Pola keterkaitan yang dihasilkan dari tiap angkatan tersebut dapat digunakan sebagai bahan evaluasi untuk meningkatkan kualitas perkuliahan.
Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini adalah sebagai berikut:
1 Implementasi algoritmeSPADE dengan menggunakan data akademik mahasiswaProgram SarjanaIlmu Komputer alih jenis angkatan ke-1 sampai angkatan ke-4.
2 Data akademik tersebut terdiri dari beberapa data antara lain data nilai mahasiswa, biodata mahasiswa, dan data EPBM Dosen.
3 Penelitian ini mencari pola kemunculan bersama dari komponen EPBM, dan data mahasiswa lainnya yang terkait dengan nilai mahasiswa pada suatu mata kuliah.
TINJAUAN PUSTAKA
Knowledge Discovery from Data (KDD)
Knowledge Discovery in Databases (KDD) adalah sebuah proses iteratif untuk ekstraksi pengetahuan dan data mining merupakan bagian dari proses KDD (Han & Kamber 2011). Data mining adalah proses penemuan pengetahuan yang menarik dari kumpulan data yang tersimpan pada database, data warehouse, dan media penyimpanan informasi lainnya.
Deskripsi mengenai tahapan proses KDD adalah sebagai berikut: 1 Pembersihan Data (Data Cleaning)
Pembersihan data dilakukan untuk membuang noise dan data yang tidak konsisten.
2 Seleksi Data (Data Selection)
Seleksi data merupakan proses pengambilan data yang relevan dengan proses analisis yang dilakukan.
3 Transformasi Data (Data Transformation)
3
4 Data Mining
Data mining merupakan proses penting yang menerapkan metode-metode cerdas untuk mengekstraksi pola-pola dalam data.
5 Evaluasi Pola (Pattern Evaluation)
Merupakan suatu proses untuk mengidentifikasi pola-pola tertentu pada data yang menarik dan merepresentasikan pengetahuan.
6 Representasi Pengetahuan (Knowledge Representation)
Penggunaan visualisasi dan teknik representasi untuk menunjukkan penemuan pengetahuan hasil proses mining kepada pengguna.
Sequential Pattern Mining
Sequential pattern mining yang berguna untuk menemukan pola sekuensial yang terdapat pada database yang pertama kali diperkenalkan oleh Agrawal dan Srikant pada tahun 1995.Sequential pattern mining ini adalah mencari pola dari sebuah data transaksi yang didalamnya terdapat sebuah pelaku transaksi, waktu transaksi dan items yang terlibat dalam transaksi. Sebuah pola sekuensial dikatakan maksimum apabila tidak mengandung pola sekuensial lainnya (Zaki 2001).Sebuah pola sekuensial dengan k-item disebut k-sequence. Sebagai contoh,
(A →BC) merupakan sebuah sequence dengan 3-sequence. Panjang sebuah pola
sekuensial adalah jumlah item yang terdapat pada pola sekuensial tersebut yang dilambangkan dengan |s|.
Sebagai contoh, (A→BC) merupakan subsequence dari (A→DE→BC) atau
(D→AB→BC) tetapi bukan subsequence dari (ABC) atau (BC→A).Misalkan α
merupakan sebuah sequence dan D merupakan sebuah database,dan diberikan sebuah user-specified thresholdσ yang disebut dengan minimum support, maka sebuah sequence dikatakan frequent jika σ (α, D) ≥ minimum support. Misalkan D merupakan sebuah database dan Ƒ merupakan kumpulan dari semua frequent sequences dalam databaseD. Sebuah frequent sequence α ∈Ƒdisebut maximal frequent sequence jika untuk masing-masing β∈Ƒ, α ≠ β, dan α bukan merupakan ⊆β.
Algoritme SPADE
4
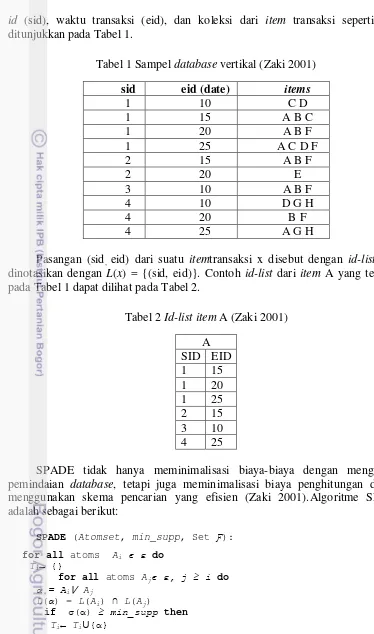
id (sid), waktu transaksi (eid), dan koleksi dari item transaksi seperti yang ditunjukkan pada Tabel 1.
Tabel 1 Sampel database vertikal (Zaki 2001) sid eid (date) items
Pasangan (sid, eid) dari suatu itemtransaksi x disebut dengan id-list yang
dinotasikan dengan L(x) = {(sid, eid)}. Contoh id-list dari item A yang terdapat pada Tabel 1 dapat dilihat pada Tabel 2.
Tabel 2 Id-list item A (Zaki 2001) A
5
(Ti,min_supp, Ƒ)
end for
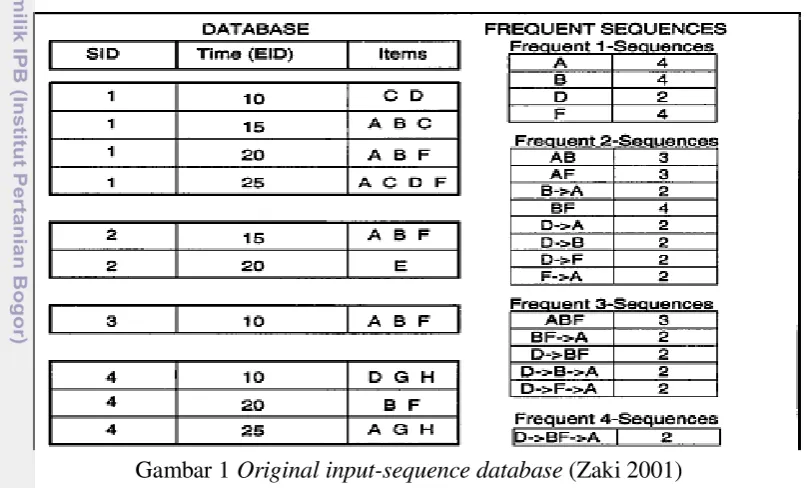
Diberikan pada database D sebuah input-sequences dan min_sup, masalah dari mining sequential patterns adalah mencari seluruh frequent sequences dalam database. F1 merupakan frequent 1-sequence yang merupakan frequent sequence
pertama yang terbentuk dari suatu item yang memenuhi minimum support, sedangkan F merupakan frequent sequences yang terbentuk dari frequent 1-sequence. Database pada Gambar 1 memiliki 8 items (A sampai H), 4 transaksi, dan 10 events. Gambar 1 juga menunjukkan seluruh frequent sequences dengan minimum support 50% (sequence harus terjadi dalam minimal 2 transkasi). Dalam contoh ini kita memiliki 2 maximal frequent sequences, ABF dan D BF A. Contoh, dari masukan pada database pada Gambar 1.
Gambar 1 Original input-sequence database (Zaki 2001)
Dalam proses pengolahan data dengan algoritme SPADE, diperlukan minimum support yang harus dicapai suatu itemset. Misalkan α merupakan sebuah sequence dan D sebuah sequence database. Support atau frequency yang
dinotasikan sebagai σ(α, D) merupakan jumlah total dari sequence di dalam
6
METODE
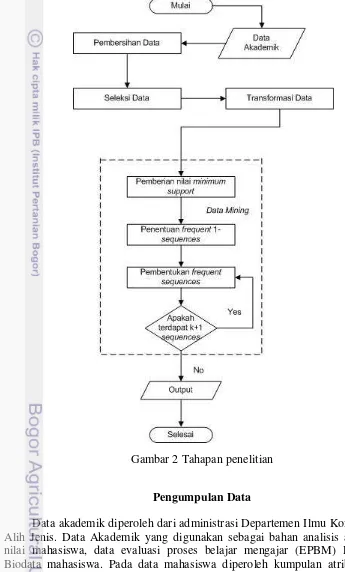
Dalam melakukan penelitian ini, terdapat tahapan proses yang dilewati untuk mencapai hasil penelititan. Skema penelitian yang akan dilakukan seperti pada Gambar 2.
Gambar 2 Tahapan penelitian
Pengumpulan Data
7
mahasiswa seperti alamat, nama orang tua, nilai IP diploma, dan status kerja. Sedangkan pada data EPBM akan diperoleh penilaian performa mengajar dosen dari berbagai segi seperti, persiapan materi yang disiapkan dosen, kemampuan dosen dalam menguraikan rencana pembelajaran, hingga sikap mengajar dosen. Data yang diperoleh adalah dalam format Microsoft Excel .xls.
PembersihanData
Pembersihan data merupakan tahap yang dilakukan untuk membuang data yang tidak konsisten. Pada tahap ini, item yang muncul pada semester yang sama tercatat lebih dari satu kali akan dianggap sebagai satu item. Selain itu, data yang tidak lengkap akan dibuang.
Setelah memperoleh data akademik yang diperlukan, selanjutnya telah dilakukan pembersihan data, seperti menghilangkan data yang null, dan salah input. Misal, jika salah satu mahasiswa datanya tidak lengkap, seperti atribut nilai mata kuliahnya kosong, maka data mahasiswa tersebut akan dibuang.
Seleksi Data
Proses seleksi data merupakan proses pengambilan data yang relevan dengan proses analisis yang dilakukan. Pada tahap ini, akan dipilih atribut yang sesuai dengan kebutuhan algoritme, yaitu sid, eid, dan items. Data masukan yang digunakan untuk sid adalah kode dari tiap mata kuliah, eid akan diisi oleh kode angkatan, dan items akan diisi oleh nilai mahasiswa, nilai dosen, nilai diploma, dan status kerja yang diperoleh dari kumpulan data yang diperoleh seperti data nilai mahasiswa, data EPBM, dan biodata mahasiswa.
Pada data yang dipilih, akan terlebih dahulu dilakukan proses pengelompokan ke dalam beberapa kategori untuk diketahui nilai kualitatif dari data tersebut. Misal, pada data nilai akan dilakukan proses pengelompokan ke dalam bentuk kategori untuk mengelompokkan nilai dari suatu mata kuliah dalam kelompok nilai baik, nilai cukup, dan nilai kurang. Selain itu dari data mahasiswa juga dipilih atribut yang relevan, misal dari banyak atribut yang terdapat pada biodata mahasiswa yang tidak lolos seleksi adalah alamat, nomor telpon, nama orang tua, dan email. Sedangkan yang lolos hanya nilai diploma dan status kerja.
Transformasi Data
8
Pada tahap ini dilakukan beberapa proses transformasi data, yaitu:
1 Konversi kumpulan mata kuliah (sid) dan urutan angkatan (eid) ke dalam bentuk angka. Hal ini dilakukan untuk menyesuaikan format masukan data yang dapat diolah oleh algoritme SPADE.
2 Konversi itemske dalam bentuk alfabet.Karena lebih beragam, bentuk alfabet dipilih sebagai kode masukan data dari kumpulan items. Items yang merupakan faktor-faktor pemicu prestasi akademik diubah ke dalam bentuk alfabet dengan memberikan kode dari A hingga Y. Misal Nilai Baik dikodekan dengan A, begitu juga dengan pemicu prestasi akademik lainnya yang dikodekan ke dalam bentuk alfabet.
3 Data yang memiliki format Microsoft Excel(Nilai Angkatan.xlsx) kemudian diubah ke dalam format text (akademiknew.txt) sebagai masukan bagi algoritme SPADE.
Data Mining
Tahap ini merupakan inti dari analisisdata. Pada tahap ini diterapkan penggunaan algoritmeSPADEyang diperkenalkan oleh Mohammed J. Zaki (2001).
Tahapan-tahapan yang akan digunakan pada metode tersebut, yaitu: 1 Pemberian nilai minimum support
Pemberian nilai minimum support terhadap data merupakan syarat awal berjalannya algoritme. Nilai minimum support digunakan untuk menyaring nilai support bagi masing-masing frequent sequences setelah dilakukan proses komputasi menggunakan algoritme SPADE. Nilai support yang lebih kecil dari nilai minimum support yang diberikan tidak akan diperhitungkan.
2 Penentuan frequent 1-sequences
Penentuan frequent 1-sequences merupakan langkah pertama dalam tahapan algoritme SPADE. Pembentukanfrequent 1-sequences ditentukan berdasarkannilai minimum support σ yang diberikan terhadap data. Semua item yang memiliki support lebih besar atau sama dengan nilai minimum support merupakan frequent items yang disebut juga frequent 1-sequences. Perhitungan support dari item didasarkan pada jumlah sid yang berbeda yang terdapat pada pasangan (sid, eid) atau yang disebut juga sebagai id-list dari item tersebut.
3 Pembentukan frequent sequences
Pembentukan frequent sequences merupakan tahap akhir dari algoritme SPADE. Pada tahap ini, semua frequent sequences mulai dari frequent 2-sequences hingga frequent k-2-sequences.
9
Data mining merupakan tahap akhir dari proses KDD. Sederetan kemunculan bersama dari komponen EPBM, dan data mahasiswa yang terkait dengan nilai mahasiswa pada suatu mata kuliah akan ditampilkan.
Lingkungan Pengembangan
Lingkungan yang digunakan untuk penelitian ini memiliki spesifikasi sebagai berikut:
Perangkat Keras:
- ProcessorAMD Turion 64 X22.00 GHz - RAM kapasitas 2GB
- Harddisk kapasitas 160GB Perangkat lunak:
- Sistem Operasi Microsoft Windows 7 Ultimate Service Pack 1 32-bit - Microsoft Visual Studio 2010 sebagai IDE pembangunan sistem.
10
HASIL DAN PEMBAHASAN
Pengumpulan Data
Data akademik diperoleh dari administrasi Departemen Ilmu Komputer IPB alih jenis. Data akademik yang digunakan sebagai bahan analisis adalah data nilai mahasiswa, data EPBM Dosen, dan Biodata mahasiswa. Data yang diperoleh adalah dalam format Microsoft Excel .xls.
Gambar 3 menunjukkan tampilan data nilai yang diperoleh dari administrasi Departemen Ilmu Komputer IPB alih jenis. Terdapat 6 kolom atribut data yang dipisah oleh tanda koma. Dari data tersebut diketahui nomor baris, NRP, semester, tahun ajaran, kode mata kuliah, dan nilai mutu.
Gambar 3Contoh data nilai mata kuliah
11
Gambar 4 Contoh biodata mahasiswa yang diperoleh
Gambar 5 merupakan tampilan dari beberapa atribut data EPBM yang diperoleh dari administrasi Departemen Ilmu Komputer IPB alih jenis. Terdapat 11 kolom penilaian yang diberikan oleh mahasiswa. Kriteria penilaian yang dimuat dalam data EPBM tersebut antara lain:
1 Dosen menguraikan rencana pembelajaran dengan jelas. 2 Dosen menyiapkan materi pengajaran dengan baik.
3 Dosen memberikan penekanan tentang aspek penting yang terkait dengan materi yang diberikan.
4 Dosen menyampaikan materi pengajaran yang meningkatkan minat mahasiswa terhadap mata kuliah ini.
5 Dosen memberikan ilustrasi yang mencakup keterkinian perkembangan ilmu atau aplikasi atau hasil penelitian.
6 Dosen menggunakan bahan atau alat bantu mengajar untuk membantu proses pembelajaran.
7 Dosen memberikan kesempatan kepada mahasiswa untuk bertanya atau menyampaikan pendapat.
8 Dosen memperlihatkan sikap dan penampilan yang baik.
9 Dosen menghormati dan menghargai mahasiswa sesuai dengan hak dan kewajibannya.
10 Dosen mengajar dengan meyakinkan.
12
Gambar 5 Contoh data EPBM yang diperoleh
Model pengisian pada tabel EPBM adalah dengan mengisikan kategori penilaian dari mahasiswa terhadap 11 kriteria penilaian pada halaman sebelumnya. Digunakan angka 1,2,3, dan 4 untuk menyatakan apakah tiap mahasiswa sangat tidak setuju, tidak setuju, setuju, atau sangat setuju terhadap tiap poin kriteria penilaian evaluasi proses belajar mengajar pada dosen tertentu.
Pembersihan Data
Setelah memperoleh data akademik yang diperlukan, selanjutnya telah dilakukan pembersihan data, seperti menghilangkan data yang null, dan salah input. Beberapa data yang ditemukan kosong adalah nilai, data yang terdapat kekosongan langsung dibuang. Tabel 3 menunjukkan sampel data nilai yang telah melwati proses pembersihan data.
Tabel 3 Sampel data nilai yang telah dilakukan proses pembersihan data Angkatan 1
NO NRP SEMESTER TAHUN KODE
MK
NILAI MUTU
1 G64066001 4 2007 KIM101 A
2 G64066003 4 2007 KIM101 C
3 G64066009 4 2007 KIM101 B
Seleksi Data
13
identifikasi prestasi dari tiap angkatan berdasarkan nilai diploma, dipilih rata-rata nilai dari seluruh mahasiswa pada satu angkatan. Misal, nilai diploma suatu angkatan masuk dalam kategori baik jika rata-rata nilai indeks prestasi dari satu angkatan tersebut sama dengan 3.5 atau lebih tinggi. Nilai diploma suatu angkatan dianggap baik jika sama dengan 3.1 sampai dengan 3.49. Nilai diploma suatu angkatan dianggap cukup baik jika memiliki rentang indeks prestasi mulai 2.75 sampai dengan 3.0.
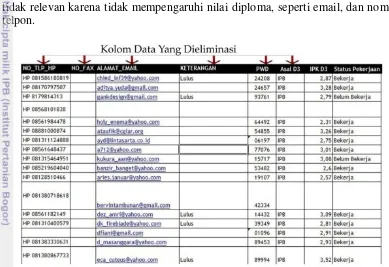
Dari Gambar 6, dapat dilihat bahwa beberapa record data yang tidak relevan dari biodata mahasiswa untuk dijadikan sebagai masukan data untuk diolah dengan algoritme SPADE dieliminasi.Record data yang dieliminasi dianggap tidak relevan karena tidak mempengaruhi nilai diploma, seperti email, dan nomor telpon.
Gambar 6 Contoh data yang tidak lolos seleksi dari biodata mahasiswa Serupa dengan nilai diploma, nilai mata kuliah mahasiswa juga diambil dari rata-rata nilai mata kuliah mahasiswa pada satu angkatan. Misal pada suatu angkatan memiliki nilai mata kuliah yang baik jika memiliki rata-rata nilai 3 sampai 4. Suatu angkatan memiliki nilai mata kuliah yang cukup jika memiliki rata-rata nilai mulai 2 sampai 2.9, terakhir suatu angkatan memiliki nilai mata kuliah yang kurang jika masuk dalam rentang nilai mulai dari 0 sampai 1.9. rentang nilai tersebut diperoleh dari hasil konversi nilai mutu ke dalam angka. Untuk nilai mutu A dikonversi menjadi 4, AB menjadi 3.5, B menjadi 3, BC menjadi 2.5, C menjadi 2, D menjadi 2, dan E menjadi 0. Sampel lengkap data nilai mata kuliah dapat dilihat pada Lampiran 2. Tabel 4 menunjukkan rentang nilai mahasiswa.
Tabel 4 Rentang nilai mata kuliah mahasiswa
Kategori Nilai Mutu Rentang Nilai
Nilai Baik A, AB, B > 2.5
Nilai Cukup BC, C = 2.5 &> 2
14
Gambar 7 menunjukkan data nilai mata kuliah Metode Kuantitatif dengan kode KOM322 pada angkatan 3 masuk dalam kategori cukup.
Gambar 7 Contoh nilai yang diperoleh angkatan 4 pada mata kuliah KOM322 Sementara dari data EPBM rata-rata nilai dari penilaian dari mahasiswa terhadap 11 kriteria penilaian evaluasi proses belajar mengajar dari tiap dosen. Sementara itu data testimoni tidak dipilih karena tidak semua mahasiswa memberikan testimoni, dan testimoni tidak dapat diukur dalam bentuk kategorik. Penilaian EPBM pada penelitian ini terdapat 3 kategori, yaitu Dosen Baik, Dosen Cukup Baik, dan Dosen Kurang Baik. Tabel 5 menunjukkan rentang nilai EPBM yang digunakan untuk menentukan nilai dosen ke dalam bentuk kategori.
Tabel 5 Rentang nilai EPBM Kategori Rentang Nilai Dosen Baik >= 3.3
Dosen Cukup Baik = 3.0 &< 3.3 Dosen Kurang Baik < 3.0
Untuk kasus mata kuliah yang diajar oleh 2 dosen, maka nilai dari kedua dosen ditambahkan dan dibagi 2. Data nilai EPBM setelah pra-proses dapat dilihat di Lampiran 3.
Transformasi Data
15
Data akan diubah ke dalam bentuk numerik dan diurutkan secara menaik berdasarkan id mata kuliah (sid) dan angkatan (eid). Format sid dan eid akan ditransformasi ke dalam bentuk numerik sedangkan format items akan dikonversi ke dalam bentuk alfabet. Hasil transformasi dapat dilihat pada Tabel 6. Data hasil konversi terdiri atas 468 baris, 30 mata kuliah yang berbeda dan 10 itemsyang berbeda.
Tabel 6Bentuk input data setelah dikonversi menjadi beberapa kode data Kode Keterangan
Tahapan data mining diterapkan dengan menggunakan algoritme SPADE (Zaki2001). Secara garis besar, proses ini dibagi menjadi 2 bagian besar, yaitu melakukan proses komputasi untuk mendapatkan frequent 1-sequences dengan nilai support lebih besar atau sama dengan minimum support. Frequent 1-sequences yang dihasilkan akan bertindak sebagai parent class pada proses pembentukan frequent sequences. Kedua, melakukan proses pembentukan frequent sequences berukuran k yang didapatkan dari kombinasi frequent sequences berukuran k-1 dengan frequent sequencesk-1 lainnya.
16
Gambar 8 Sampel Frequent Sequences yang terbentuk dari masukan data akademik yang dimasukkan dengan minimum support 50%
Hasil keluaran dari pola sekuensial yang dihasilkan diperlukan agar pola yang ada mudah dimengerti dan diinterpretasikan. Berdasarkan hasil presentasi diharapkan dapat diperoleh pengetahuan yang berharga dari koleksi data yang telah dilakukan proses mining. Tahap representasi pengetahuan dilakukan dengan membentuk frequent sequences menggunakan algoritme SPADE. Gambar 9 menunjukkan tampilan antarmuka aplikasi yang menampilkan kumpulan frequent sequences yang terbentuk.
Gambar 9 Tampilan antarmuka aplikasi utama
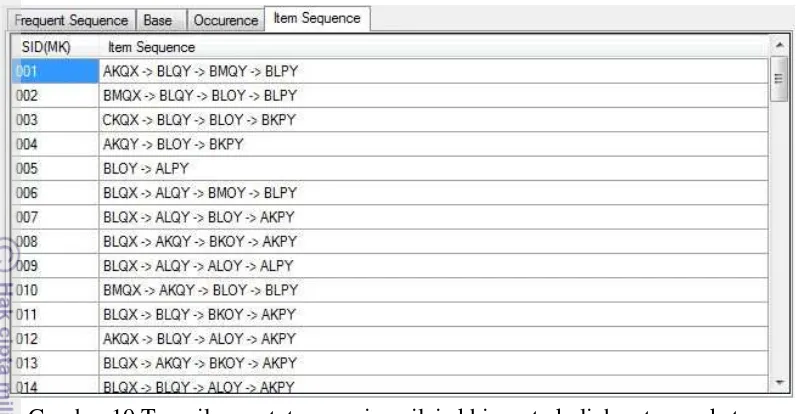
17
Gambar 10 Tampilan rentetan pemicu nilai akhir mata kuliah antar angkatan Pada bagian tab item sequence menampilkan rentetan pola kemunculan bersama nilai mata kuliah dari tiap angkatan secara sekuensial. Misal pada mata kuliah Biologi dengan kode input data 001 menunjukkan bahwa mahasiswa angkatan pertama mampu mengungguli angkatan-angkatan berikutnya dengan meraih nilai baik.
Dilakukan beberapa percobaan terhadap masukan data untuk algoritme SPADE dengan menentukan beberapa variasi angka minimum support, diantaranya 50%, 60%, dan 70% minimum support. Jumlah pola kemunculan dari hasil percobaan ditampilkan pada Tabel 7.
Tabel 7 Hasil jumlah pola kemunculan dari hasil pengujian dengan masing-masing minimum support
Dengan support 50%, pola kemunculan bersama 3 itemset didominasi oleh nilai baik yang muncul 6 kali, 3 di antaranya selalu muncul bersama dosen baik. Misal pola yang muncul dengan support terbesar untuk 2 itemset adalah A,K dengan support 70%, sedangkan untuk 3 itemsetadalah A,K,Y dengan support 63.33% yang berarti nilai baik muncul bersama dosen baik dan juga status tidak bekerja.
18
19
SIMPULAN DAN SARAN
Simpulan
Dari penelitian yang telah dilakukan dalam penentuan pola sekuensial prestasi akademik mahasiswa jurusan ilmu komputer alih jenis IPB ini dapat diambil beberapa kesimpulan sebagai berikut:
1 Algoritme SPADE mampu menampilkan keterkaitan pemicu-pemicu nilai akhir mata kuliah mahasiswa secara sekuensial.
2 Angkatan 4 mahasiswa departemen ilmu komputer program alih jenis paling sering mengungguli nilai mata kuliah angkatan-angkatan sebelumnya dengan meraih nilai baik.
3 Nilai yang baik sangat erat kaitannya dengan performa mengajar dosen yang baik.
Saran
Beberapa hal yang perlu dikembangkan lebih lanjut dari penelitian ini antara lain sebagai berikut:
1 Menambah pemicu-pemicu yang memungkinkan dalam penentuan pola sekuensial prestasi akademik.
2 Membandingkan efektifitas Algoritme SPADE dalam hal penentuan pola sekuensial prestasi akademik dengan algoritme pencari pola sekuensial lain.
DAFTAR PUSTAKA
Aditomo A, Ayuningtyas A. 2008. Apakah Hubungan antara Orientasi Belajar dan Prestasi Akademik Tergantung pada Konteks ?. Anima. Indonesian Psychological Journal.
Agrawal R, Srikant R.1995. Mining Sequential Patterns. In Proc. Eleventh International Conference on (hal 3-14).IEEE.
Han J, Kamber M, Pei J. 2011. Data Mining Concepts and Techniques. 3rd Edition. USA.Morgan Kaufmann Publishers.
Sijabat R. 2011. Penentuan Pola Sekuensial Data Transaksi Pembelian Menggunakan Algoritme SPADE [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
20
Lampiran 1 Tiga puluh mata kuliah yang diambil SID Kode Mata
Kuliah
Nama Mata Kuliah
001 BIO100 Biologi
002 KIM101 Kimia
003 KOM204 Bahasa Pemrograman
004 KOM206 Organisasi Komputer
005 KOM207 Struktur Data
006 KOM208 Teori Bahasa dan Otomata
007 KOM301 Komputer Grafik
008 KOM311 Sistem Operasi
009 KOM312 Komunikasi Data dan Jaringan Komputer
010 KOM321 Kecerdasan Buatan
011 KOM322 Metode Kuantitatif
012 KOM323 Sistem Pakar
013 KOM331 Rekayasa Perangkat Lunak
014 KOM332 Data Mining
015 KOM333 Interaksi Manusia dan Komputer
016 KOM334 Pengembangan Sistem Berorientasi Objek
017 KOM335 Sistem Informasi
018 KOM398 Metode Penelitian dan Telaah Pustaka
019 KOM401 Analisis Algoritme
020 KOM412 Pengantar Kriptografi
021 KOM421 Pengantar Pengolahan Citra Digital 022 KOM422 Pengantar Pemrosesan Bahasa Alami
023 KOM431 Temu Kembali Informasi
024 KOM497 Kolokium
025 KOM498 Seminar
026 KOM499 Tugas Akhir
027 MAT215 Aljabar Linear
028 MAT217 Kalkulus Lanjut
029 STK202 Pengantar Hitung Peluang
21
22
Lampiran 3 Data nilai mutu mata kuliah, EPBM, dan nilai diploma setelah pra-proses
23
24
Lampiran 5 Data input program algoritme SPADE
27
RIWAYAT HIDUP
Penulis dilahirkan di kota Bogor, pada tanggal 28 Agustus 1990 sebagai anak pertama dari pasangan Rusdy Johan dan Erna Fahmi. Penulis merupakan lulusan MAS Al Zaytun Indramayu (2004-2007), MTS Al Zaytun Indramayu (2001-2004), dan SDN 18 Muara Enim (2000-2001).