ABSTRACT
RYAN SAPTA NOPA. Vector quantization based on blob image for image retrieval with hierarchy clustering. Supervised by YENI HERDIYENI.
This research proposed vector quantization using hierarchy clustering to overcome semantic problem on image retrieval. This approach considers to find templates or codebooks which arrange image in database. Images were segmented into blobs using grid segmentation. Each blob was represented by color feature using HSV-162 and texture feature using co-occurrence matrix. Output of feature extraction then clustered using hierarchy clustering to generated optimally codebook. Data experiment in this research was taken from http://www.stat.psu.edu/~jiali. The data consist of 1.000 photography image with various of theme, object, and dimension of images were 384×256 pixel. R-precision, recall, and precision were useds to evaluate the result of image retrieval. The experiment showed that segmentation using grid 12×8 have achieved best result than other grid. Based on experience, the result of R-precision showed that grid 12×8 is about 0,32. The advantage of this research that vector quantization with hierarchy clustering can be used to overcome semantic problem on image retrieval based on blob.
L t p y m y k m b m b o s b a d o c p s y d k m s D u H l s m d b y m d m o p p s g h c s P Latar Belakan Informasi tidak selalu pengukuran ke yang memilik memiliki infor yang berbeda. kemiripan citr memberikan h baik.
Manusia mendefinisikan berdasarkan p objek-objek y seperti satu beberapa kata atau arti kalim dengan baik, objek yang me cara yang serin proses segmen segmentasi cit yaitu objek has dengan perse komputasi yan Daud (200 mengenai tem semantik citra Daud (2008) untuk memper Hasil penelitian label pada tiap
Zhang et sebuah mo menggunakan dikembangkan blob atau cod yang dilakuka menggunakan dimana algo menjamin m optimal.
Kelebihan penelitian seb pada penelit segmentasi ci grid dan pem hierarchy clus clustering ma sesuai dengan PENDAHULU ng warna, bentuk dapat me emiripan citra ki kesamaan m rmasi warna, be
. Oleh karena a berbasis sem hasil temu kem
memiliki ke n semantik
engalaman ma yang menyusu kalimat yan a sehingga m mat. Citra da jika sistem m enyusun sebua ng digunakan a ntasi citra. Sa tra memiliki b
sil segmentasi epsi manusia ng lama.
08) telah mela mu kembali a. Sistem yan
menggunakan rcepat proses n ini sudah ma objek citra den t al (2000) odel berna
vektor kuanti n mampu men
debook. Pembe an oleh Zhan algoritme c ritme tersebu menghasilkan
n dan kekuran belumnya, me tian ini un itra menggun
mbentukan c stering. Pengg ampu mengor visual manusia
UAN
k, dan tekstur c emberikan h yang baik. C makna seringk entuk, dan tek a itu, penguku mantik citra da mbali yang le emampuan un sebuah c anusia mengen un sebuah ci
g disusun o memiliki seman apat didefinisi mampu mengen
ah citra. Salah s adalah melaku ayangnya, pro eberapa kesuli yang tidak ses a dan wa akukan penelit citra berba ng dikembang
segmentasi g segmentasi ci ampu memberi
ngan baik. mengembang ama keybl sasi. Model y nghasilkan kam
entukan codeb ng et al (20 clustering GL ut tidak da
codebook y ngan model p emunculkan ntuk melaku nakan segmen codebook den gunaan hierar rganisasi clus a (cai et al. 200
citra hasil Citra kali stur uran apat ebih ntuk citra nali itra, oleh ntik kan nali satu ukan oses itan suai aktu tian asis kan grid itra. kan kan lock yang mus ook 000) LA, apat yang pada ide ukan ntasi ngan rchy ster 04). Tuju P vekto meng kemb Ruan 1 2 3 Man M meni berba Cont C meru citra et al. retrie dua penem pada Segm S citra berda Krite warn S citra objek overl dikar meru pada uan Penelitian in or kuantisasi ggunakan hiera bali citra. ng Lingkup
Citra yang fotografi deng Ekstraksi ciri dan co-occurr Segmentasi g 12×8. faat Penelitian Manfaat p ngkatkan aku asiskan semant TINJAU
tent Base Imag
Content base upakan sistem
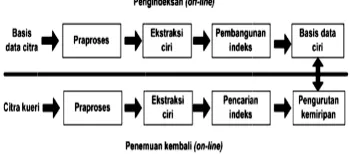
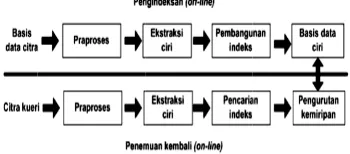
berbasiskan fi 2000). Proses eval) secara um
proses utama muan kembali
Gambar 1.
mentasi Segmentasi me
menjadi be asarkan kesam eria yang dig na, tekstur atau
Segmentasi gri menjadi beb k yang beruk lapping. Peng renakan pemba upakan cara yan
citra (Mori et Gambar 1 Sist
ni mengimp berbasiskan b archyclusterin
digunakan a gan berbagai je
i menggunaka rence matrix. grids berukura
n
penelitian i urasi temu k tik citra. UAN PUSTAK
ge Retrieval
image retrie untuk mengen tur yang digun s temu kembali mum dapat dib a yaitu pengin i citra, yang d
erupakan pros berapa blob maan kriteria y
gunakan yaitu tingkat warna id adalah pro erapa bagian kuran sama t ggunaan segm agian citra den ng paling cepa al. 1999). tem temu kemb
lementasikan blob dengan ng pada temu
adalah citra nis tema. an HSV-162 an 3×2, 6×4,
ini untuk kembali citra
KA
eval (CBIR) nali informasi nakan (Zhang i citra (image bagi menjadi ndeksan dan diilustrasikan ses membagi atau objek ang dimiliki. u kesamaan keabuan. ses membagi
matrix atau tanpa terjadi mentasi grid
L t p y m y k m b m b o s b a d o c p s y d k m s D u H l s m d b y m d m o p p s g h c s P Latar Belakan Informasi tidak selalu pengukuran ke yang memilik memiliki infor yang berbeda. kemiripan citr memberikan h baik.
Manusia mendefinisikan berdasarkan p objek-objek y seperti satu beberapa kata atau arti kalim dengan baik, objek yang me cara yang serin proses segmen segmentasi cit yaitu objek has dengan perse komputasi yan Daud (200 mengenai tem semantik citra Daud (2008) untuk memper Hasil penelitian label pada tiap
Zhang et sebuah mo menggunakan dikembangkan blob atau cod yang dilakuka menggunakan dimana algo menjamin m optimal.
Kelebihan penelitian seb pada penelit segmentasi ci grid dan pem hierarchy clus clustering ma sesuai dengan PENDAHULU ng warna, bentuk dapat me emiripan citra ki kesamaan m rmasi warna, be
. Oleh karena a berbasis sem hasil temu kem
memiliki ke n semantik
engalaman ma yang menyusu kalimat yan a sehingga m mat. Citra da jika sistem m enyusun sebua ng digunakan a ntasi citra. Sa tra memiliki b
sil segmentasi epsi manusia ng lama.
08) telah mela mu kembali a. Sistem yan
menggunakan rcepat proses n ini sudah ma objek citra den t al (2000) odel berna
vektor kuanti n mampu men
debook. Pembe an oleh Zhan algoritme c ritme tersebu menghasilkan
n dan kekuran belumnya, me tian ini un itra menggun
mbentukan c stering. Pengg ampu mengor visual manusia
UAN
k, dan tekstur c emberikan h yang baik. C makna seringk entuk, dan tek a itu, penguku mantik citra da mbali yang le emampuan un sebuah c anusia mengen un sebuah ci
g disusun o memiliki seman apat didefinisi mampu mengen
ah citra. Salah s adalah melaku ayangnya, pro eberapa kesuli yang tidak ses a dan wa akukan penelit citra berba ng dikembang
segmentasi g segmentasi ci ampu memberi
ngan baik. mengembang ama keybl sasi. Model y nghasilkan kam
entukan codeb ng et al (20 clustering GL ut tidak da
codebook y ngan model p emunculkan ntuk melaku nakan segmen codebook den gunaan hierar rganisasi clus a (cai et al. 200
citra hasil Citra kali stur uran apat ebih ntuk citra nali itra, oleh ntik kan nali satu ukan oses itan suai aktu tian asis kan grid itra. kan kan lock yang mus ook 000) LA, apat yang pada ide ukan ntasi ngan rchy ster 04). Tuju P vekto meng kemb Ruan 1 2 3 Man M meni berba Cont C meru citra et al. retrie dua penem pada Segm S citra berda Krite warn S citra objek overl dikar meru pada uan Penelitian in or kuantisasi ggunakan hiera bali citra. ng Lingkup
Citra yang fotografi deng Ekstraksi ciri dan co-occurr Segmentasi g 12×8. faat Penelitian Manfaat p ngkatkan aku asiskan semant TINJAU
tent Base Imag
Content base upakan sistem
berbasiskan fi 2000). Proses eval) secara um
proses utama muan kembali
Gambar 1.
mentasi Segmentasi me
menjadi be asarkan kesam eria yang dig na, tekstur atau
Segmentasi gri menjadi beb k yang beruk lapping. Peng renakan pemba upakan cara yan
citra (Mori et Gambar 1 Sist
ni mengimp berbasiskan b archyclusterin
digunakan a gan berbagai je
i menggunaka rence matrix. grids berukura
n
penelitian i urasi temu k tik citra. UAN PUSTAK
ge Retrieval
image retrie untuk mengen tur yang digun s temu kembali mum dapat dib a yaitu pengin i citra, yang d
erupakan pros berapa blob maan kriteria y
gunakan yaitu tingkat warna id adalah pro erapa bagian kuran sama t ggunaan segm agian citra den ng paling cepa al. 1999). tem temu kemb
lementasikan blob dengan ng pada temu
adalah citra nis tema. an HSV-162 an 3×2, 6×4,
ini untuk kembali citra
KA
eval (CBIR) nali informasi nakan (Zhang i citra (image bagi menjadi ndeksan dan diilustrasikan ses membagi atau objek ang dimiliki. u kesamaan keabuan. ses membagi
matrix atau tanpa terjadi mentasi grid
Representasi Warna
Histogram warna menyatakan frekuensi kemunculan atau peluang keberadaan setiap warna pada citra. Banyaknya nilai warna (bin) dapat ditetapkan sesuai kebutuhan pembuatan histogram. Histogram warna dapat dinyatakan sebagai berikut:
|
1, pixel ke-j dikuantisasi ke bin-i
0, selainnya
dengan | merupakan nilai pixel pada posisi i atau j, adalah nilai warna (bin) yang dibentuk, N adalah jumlah pixel citra. Histogram warna seperti ini disebut conventional color histogram (Han & Ma 2002).
Representasi Tekstur
Pada area pemrosesan citra tidak ada definisi yang jelas mengenai tekstur. Definisi tekstur yang ada hanya didasarkan kepada metode analisis tekstur dan fitur yang diekstrak dari citra. Tekstur dapat dianggap sebagai pola pixel yang berulang pada wilayah spasial dimana penambahan noise pada pola dan perulangan frekuensinya, dapat terlihat secara acak dan tidak terstruktur (Osadebey 2006).
Beberapa metode yang berbeda diusulkan untuk menghitung ciri tekstur. Salah satu metode yang paling sering digunakan untuk mendeskripsikan ciri tekstur adalah metode berbasis statistika dan berbasis transformasi (Osadebey 2006).
Metode berbasis statistika menganalisis distribusi spasial dari nilai keabuan dengan menghitung ciri lokal pada setiap titik citra, kemudian menurunkan beberapa perhitungan statistika dari distribusi ciri lokal tersebut. Salah satu jenis metode ini adalah co-occurrence matrix.
Co-occurrence matrix merupakan matrix pembantu yang berfungsi mencacah terjadinya sepasang pixel yang memiliki nilai intensitas dan arah tertentu. Arah yang digunakan secara umum ada 4 yaitu 0 derajat, 45 derajat, 90 derajat, dan 135 derajat yang diilustrasikan pada Gambar 2.
Gambar 2 korelasi antara sepasang pixel
dengan arah tertentu.
Gambar 3 menjelaskan bagaimana pembangunan co-occurrence matrix untuk citra A yang berukuran 4 x 4 pixel dengan 4 level keabuan, posisi operator didefinisikan dengan sudut 0 derajat dengan jarak 1 pixel.
Gambar 3 Contoh pembangunan co
-occurrence matrix arah 0 derajat. Hierarchy Clustering
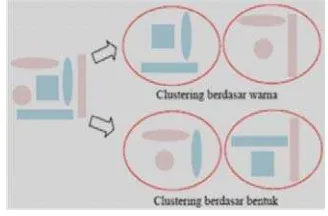
Clustering merupakan suatu cara mengelompokkan data ke dalam cluster tertentu, dimana data yang dikelompokkan memiliki kesamaan ciri dengan anggota cluster yang lainnya (Han & Kamber 2001).
Gambar 4 Ilustrasi clustering (Sumber :
Hasniawati 2007).
Algoritme hierarchy clustering membentuk denah pohon (dendrogram) dari sekumpulan objek citra yang terdapat dalam database, sehingga cluster dapat dibentuk Pi|j =
d t m t p t B ( 2 3
dengan memo tertentu. Alg memiliki karak telah dikelomp pada suatu tah tidak dapat ber Beberapa m (Hasniawati 20 1 Single linka Proses me cluster berd objek. Met pada kasus
Gambar 2 Centroid lin
Proses men cluster ber Metode memperkec serta untuk
Gambar 6 3 Complete l
Proses men cluster berd objek. Me distribusi d
Gambar 7
otong dendrog goritme Hiera kteristik yaitu pokkan ke dal apan proses, m rpindah ke clus metode hiera
007): age.
ngelompokkan dasarkan jarak tode ini sangat shape indepen
5 Ilustrasi sing nkage. ngelompokkan rdasarkan jara ini sangat cil variance d k data yang mem
6 Ilustrasi centr inkage. ngelompokkan dasarkan jarak etode ini sang data yang norm
7 Ilustrasi centr
gram pada ja archy cluster ketika suatu d lam suatu clus maka data terse
ster yang lain. rchy cluster
n objek ke su terdekat di ant cocok diguna ndent clustering
glelinkage. n objek ke su
ak centroid n cocok un di antara clus miliki pencilan
roidlinkage.
n objek ke su k terjauh di ant gat cocok un mal.
roidlinkage.
arak ring data ster ebut ring uatu tara akan g. uatu nya. ntuk ster n. uatu tara ntuk 4 A P cl an m w Vekt M sebua dan p vekto teori yang V peme yang atau himp seluru Ilustr Gamb berha optim P tahap 1 2 verage linkage roses mengelo luster berdas ntara objek. metode yang leb waktu komputas
Gambar 8 Ilus tor Kuantisasi Metode vekto ah teknik yang pengkodean cit or kuantisasi, b bagaimana u baik (Zhang e Vektor kuant etaan vektor k direpresentas centroids (Zh punan centroid uh ruang v rasi vektor ku bar 9. Proses asil jika meng mal.
Gambar 9 Ilus Proses vektor p yaitu :
Pembentukan Proses pembe teori Shanno berbagai algo al. 2000). Encoding (pen Pada tahapan blob digantik codebook yan e.
ompokkan obj arkan jarak Metode ini bih baik tetapi si yang lebih la
strasi averagel i
or kuantisasi g digunakan un
tra. Berdasarka bahwa tidak ad untuk mendesa et al. 2000).
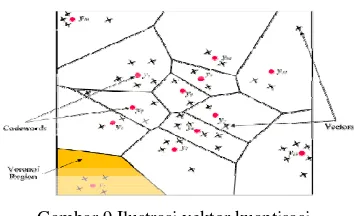
tisasi merupa ke ruang vekt sikan dengan
hang et al. 2 d yang merep ektor disebut uantisasi dapat vektor kuantis ghasilkan code
trasi vektor ku kuantisasi terd codebook. entukan codeb
on dapat m ritme clusterin ngkodean). n proses enco kan dengan no ng memiliki ja
jek ke suatu rata-rata di merupakan memerlukan ama.
linkage. merupakan ntuk kompresi an teori dasar da penjelasan ain codebook
akan proses tor (cluster), pusat vektor 2000). Suatu presentasikan
t codebook. dilihat pada asi dikatakan ebook yang
uantisasi. diri atas tiga
book menurut menggunakan ng (Zhang et
Hasil encoding setiap citra merupakan sebuah matrix.
3 Decoder.
Proses decoder digunakan untuk merekontruksi matrix menjadi citra, dengan menggantikan nomor indeks sesuai dengan codebook.
Evaluasi Sistem
Recall dan precision merupakan parameter yang digunakan untuk mengukur keefektifan model temu kembali citra. Rataan precision adalah ukuran evaluasi yang diperoleh dengan cara menghitung rataan tingkat precision pada berbagai tingkat recall (Grossman 2002).
jumlah citra relevan yang terambil jumlah citra relevan dlm basis data recall
terambil yang
citra seluruh jumlah
terambil yang
relevan citra jumlah precision
R-precision merupakan parameter yang digunakan untuk mengukur kemampuan sistem dalam menemukan kembali citra yang relevan pada R-ranking teratas, dimana R merupakan jumlah citra relevan dalam database. Sistem yang efektektif akan bernilai 1 (Pavlu 2005).
R jumlah citra yang relevanx
x = jumlah citra relevan yang terambil pada posisi teratas .
METODOLOGI
Metode penelitian ini terdiri atas lima tahapan yang dapat dilihat pada Gambar 10 yaitu :
1 Dekomposisi citra. 2 Ekstraksi ciri. 3 Vektor kuantisasi. 4 Temu kembali citra. 5 Evaluasi temu kembali.
Dekomposisi Citra
Pada tahap proses dekomposisi citra atau segmentasi, setiap citra dalam database didekomposisi menggunakan segmentasi grid. Penggunaan segmentasi grid dapat memastikan bahwa tidak ada blob yang overlapping. Ukuran grid yang digunakan pada penelitian ini yaitu 3×2, 6×4, 12×8. Ilustrasi penggunaan segmentasi grid dapat dilihat pada Gambar 11.
Gambar 11 Contoh segmentasi grid.
Gambar 10 Metodologi penelitian.
Basisdata Citra
Dekomposisi Citra
Ekstraksi Citra
Hierarchy Clustering
Indeks Citra
Encoding
Citra Kueri
Dekomposisi Citra
Ekstraksi Citra
Encoding
Pengukuran kemiripan
Evaluasi hasil temu kembali
Hasil encoding setiap citra merupakan sebuah matrix.
3 Decoder.
Proses decoder digunakan untuk merekontruksi matrix menjadi citra, dengan menggantikan nomor indeks sesuai dengan codebook.
Evaluasi Sistem
Recall dan precision merupakan parameter yang digunakan untuk mengukur keefektifan model temu kembali citra. Rataan precision adalah ukuran evaluasi yang diperoleh dengan cara menghitung rataan tingkat precision pada berbagai tingkat recall (Grossman 2002).
jumlah citra relevan yang terambil jumlah citra relevan dlm basis data recall
terambil yang
citra seluruh jumlah
terambil yang
relevan citra jumlah precision
R-precision merupakan parameter yang digunakan untuk mengukur kemampuan sistem dalam menemukan kembali citra yang relevan pada R-ranking teratas, dimana R merupakan jumlah citra relevan dalam database. Sistem yang efektektif akan bernilai 1 (Pavlu 2005).
R jumlah citra yang relevanx
x = jumlah citra relevan yang terambil pada posisi teratas .
METODOLOGI
Metode penelitian ini terdiri atas lima tahapan yang dapat dilihat pada Gambar 10 yaitu :
1 Dekomposisi citra. 2 Ekstraksi ciri. 3 Vektor kuantisasi. 4 Temu kembali citra. 5 Evaluasi temu kembali.
Dekomposisi Citra
Pada tahap proses dekomposisi citra atau segmentasi, setiap citra dalam database didekomposisi menggunakan segmentasi grid. Penggunaan segmentasi grid dapat memastikan bahwa tidak ada blob yang overlapping. Ukuran grid yang digunakan pada penelitian ini yaitu 3×2, 6×4, 12×8. Ilustrasi penggunaan segmentasi grid dapat dilihat pada Gambar 11.
Gambar 11 Contoh segmentasi grid.
Gambar 10 Metodologi penelitian.
Basisdata Citra
Dekomposisi Citra
Ekstraksi Citra
Hierarchy Clustering
Indeks Citra
Encoding
Citra Kueri
Dekomposisi Citra
Ekstraksi Citra
Encoding
Pengukuran kemiripan
Evaluasi hasil temu kembali
Ekstraksi Ciri
Pada penelitian ini, ekstraksi ciri dilakukan menggunakan fitur warna dan tekstur citra.
1 Ekstraksi ciri warna.
Ekstraksi ciri warna dilakukan dengan menggunakan histogram warna CCH (conventional color histogram). Setiap blob hasil dari dekomposisi citra akan dikonversi dari citra RGB (Red, Green, Blue) manjadi citra HSV (Hue, Saturation, Value). Hal ini dilakukan karena HSV (Hue, Saturation, Value) merupakan ruang warna yang komponen-komponennya berkontribusi langsung pada persepsi visual manusia. Hue digunakan untuk membedakan warna misalnya merah, hijau, dan biru serta untuk menentukan tingkat kemerahan, kehijauan, dst dari sebuah cahaya. Saturation merupakan prosentase cahaya putih yang ditambahkan ke cahaya murni. Sementara itu, value merupakan intensitas cahaya yang dirasakan (Rodrigues & Araujo 2004).
Transformasi RGB menjadi HSV diperoleh menggunakan formula:
, ,
, ,
dengan r adalah nilai red (merah) pada blob, g adalah nilai green (hijau) pada blob, dan b adalah nilai blue (biru) pada blob.
Nilai HSV yang dihasilkan akan dikuantisasi kedalam histogram-162 (HSV-162). Hue dikuantisasi menjadi 18 bin, saturation dikuantisasi menjadi 3 bin, sedangkan value dikuantisasi menjadi 3 bin, sehingga akan didapatkan kombinasi sebanyak 18×3×3 =162. Hue dikuantisasi menjadi 18 bin karena sistem visual manusia lebih sensitif terhadap hue dibandingkan saturation dan value.
Setiap citra akan direpresentasikan dengan sebuah vektor yang memiliki elemen sebanyak 162 buah. Nilai elemen vektor menyatakan jumlah pixel citra yang masuk ke dalam bin yang sesuai. Dengan kata lain, vektor citra merepresentasikan histogram warna citra tersebut. Setelah histogram citra selesai dihitung, langkah terakhir adalah melakukan normalisasi terhadap vektor masing-masing citra.
2 Ekstraksi ciri tekstur.
Ekstraksi ciri tekstur dilakukan dengan menggunakan co-occurrence matrix karena menurut Osadebey (2006) representasi co-occurrence matrix dapat digunakan untuk menghitung ciri tekstur. Langkah awal yang dilakukan untuk mendapatkan informasi tekstur sebuah citra adalah dengan menentukan co-occurrencematrix.
Peneltian ini menggunakan co-occurrence matrix dengan 16 level keabuan karena mampu meningkatkan precision temu kembali (Pebuardi 2008). Hasil co-occurrence matrix dianalisis menggunakan 6 metode statistika yang terdiri atas : energy, moment, entrophy, maximum probability, contrast, correlation, dan homogeneity. Berikut ini merupakan definisi matematis dari 6 fitur di atas :
a Energy.
Menunjukkan ukuran sifat homogenitas citra.
,
,
b Entrophy.
Menunjukkan kompleksitas tekstur citra
, ,
,
c Maximum Probability.
Menunjukkan keteraturan tekstur citra. Maximum Probability , d Contrast.
Menunjukkan kekontrasan citra. Contrast ∑ |, | ,
e Correlation.
Menunjukkan ketergantungan level ketetanggaan.
,
f Homogeneity
Menunjukkan keseragaman tekstur citra. ,
| |
,
dengan , adalah elemen baris ke-i, kolom ke-j dari co-occurance matrix.
adalah nilai rata-rata baris ke-i dan adalah nilai rata-rata kolom ke-j. adalah standar deviasi dari baris ke-i dan adalah standar deviasi dari kolom j.
Co-occurrence matrix dihitung dalam empat arah yaitu 00, 450, 900, 1350 , sehingga setiap blob menghasilkan empat nilai co-occurrence matrix. Nilai energy, entropy, maximum probability, contrast, correlation, dan homogeneity dihitung untuk setiap co-occurrence matrix, sehingga setiap fitur akan diperoleh empat nilai. Nilai dari fitur diperoleh dengan menghitung nilai rata-rata keempat nilai fitur yang bersangkutan. Hal ini dilakukan agar informasi tekstur yang diperoleh tidak peka terhadap rotasi (rotation -invariant).
Vektor Kuantisasi
Vektor kuantisasi pada temu kembali citra terdiri atas 2 tahapan proses yaitu :
a Pembentukan codebook.
Pembentukan codebook merupakan tahapan yang paling penting pada penelitian ini. Langkah awal yang dilakukan pada proses pembentukan codebook yaitu membentuk cluster tiap blob menggunakan metode complete linkage hierarchy clustering. Dibawah ini merupakan algoritme metode Complete Linkage Hierarchical :
1 Diasumsikan setiap data atau blob sebagai sebuah cluster. Kalau n = jumlah blob dan c = jumlah cluster, berarti ada c = n.
2 Menghitung jarak antar cluster, pada penelitian ini dengan Euclidean distance.
3 Mencari 2 cluster yang mempunyai jarak antar cluster yang paling maksimal / terjauh dan digabungkan kedalam cluster baru (sehingga c = c-1).
4 Kembali ke langkah 3, dan diulangi sampai terbentuk dendrogram.
Untuk mendapatkan nilai codebook dari cluster yang terbentuk, dapat dilakukan dengan menghitung rata-rata nilai blob tiap cluster.
b Encoding citra.
Setiap citra dalam database maupun citra query disegmentasi menjadi beberapa blob, sesuai dengan ukuran grid yang digunakan. Setiap blob kemudian dikodekan dengan codebook yang memiliki jarak terdekat dengan blob. Untuk menghitung jarak antara codebook dan blob, pada penelitian ini menggunakan jarak Euclidean dengan persamaan :
, | |
dengan x adalah blob citra, y adalah blob dari codebook, dan n adalah panjang vektor hasil ekstraksi citra. Hasil encoding direpresentasikan dalam bentuk vektor satu dimensi. Proses encoding citra dapat dilihat pada Gambar 8.
Gambar 12 Encoding citra (Sumber : Zhang
et al. 2000). Temu Kembali Citra
Penentuan relevansi antara query dan citra dapat dilakukan dengan menggunakan teknik dalam bidang information retrieval. Salah satunya yaitu model vector space untuk mengukur kemiripan antara query dengan dokumen. Model vektor merupakan metode pencarian citra dengan merepresentasikan kata-kata dalam dokumen dan query melalui bentuk vektor.
Pemodelan vektor pada penilitian ini terdiri dari dua tahapan, pertama adalah melakukan pengindeksan dengan mengekstraksi blob dari citra. Terakhir adalah melakukan pengurutan citra berdasarkan hasil pengukuran kemiripan (similarity measure) antar-query dan citra.
similarity antara citra query dan citra yang ada dalam database lebih besar dari 0 maka citra tesebut ditampilkan di sistem.
Evaluasi Temu Kembali
Pada tahap evaluasi dilakukan penilaian kinerja sistem dengan melakukan pengukuran recall dan precision untuk menentukan tingkat efektifitas proses temu kembali citra. Setiap citra dijadikan sebagai citra kueri dan citra yang relevan ditentukan secara manual dengan menghitung jumlah citra yang sekelas dengan citra kueri.
Selain menggunakan recall dan precision, evaluasi sistem ini juga dihitung dengan R-precision untuk melihat efektifitas memenukan citra relevan pada posisi teratas pada sistem. Penggunaan R-precision karena sistem mudah dievaluasi oleh pengguna.
HASIL DAN PEMBAHASAN
Penelitian ini mengimplementasikan vektor kuantisasi untuk menghasilkan codebook yang dapat merepresentasikan semantik dari suatu citra.
Data Penelitian
Data penelitian yang digunakan bersumber dari http://www.stat.psu.edu/~jiali sejumlah 1.000 citra. Pemilihan citra dilakukan secara manual dengan dimensi seragam 384×256 pixel dengan variasi objek, tema, pencahayaan yang beragam dan berformat JPEG. Contoh citra yang digunakan dapat di lihat pada Lampiran 1.
Praproses Citra
Tahapan praproses citra yang dilakukan yaitu segmentasi citra menggunakan segmentasi grid. Segmentasi citra dilakukan untuk mendapatkan blob yang menyusun citra. Citra disegmentasi menjadi beberapa region bujursangkar dengan ukuran grid yaitu: 3×2, 6×4, 12×8.
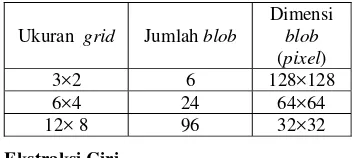
Ukuran segmentasi grid yang digunakan bervariasi, bertujuan untuk menganalisis bagaimana skala dan geometris objek mempengaruhi hasil temu kembali citra. Setiap ukuran grid yang digunakan menghasilkan jumlah dan dimensi blob yang berbeda, hal ini dilihat pada Tabel 1.
Table 1 Hasil segmentasi citra
Ukuran grid Jumlah blob
Dimensi blob (pixel)
3×2 6 128×128
6×4 24 64×64
12× 8 96 32×32
Ekstraksi Ciri
Ekstraksi ciri warna
Hasil dari ekstraksi ciri warna untuk keseluruhan blob yang ada di basis data adalah blob yang direpresentasikan dengan sebuah vektor yang memiliki elemen sebanyak 162 buah. Ekstraksi ciri warna HSV-162 yang digunakan mampu mengurangi waktu komputasi pada tahapan pembentukan codebook.
Ekstraksi ciri tekstur
Hasil dari ekstraksi ciri tekstur untuk keseluruhan blob dalam database, direpresentasikan dengan sebuah vektor yang memiliki 6 elemen yaitu energy, entropy, maximum probability, contrast, dan correlation.
Hasil ekstraksi ciri warna dan tekstur digabung menjadi satu vektor. Vektor ciri ini yang digunakan pada saat proses vector kuantisasi.
Vektor Kuantisasi
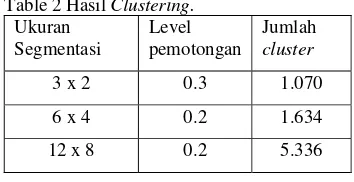
Algoritme hierarchy clustering menghasilkan dendrogram yang terbentuk dari keseluruhan blob yang ada dalam database. Hasil dendrogram yang terbentuk dipotong pada level tertentu tiap ukuran grid, bertujuan untuk mendapatkan hasil akurasi cluster yang lebih baik. Level pemotongan dendrogram dan jumlah cluster yang terbentuk dapat dilihat pada Tabel 2.
Table 2 Hasil Clustering. Ukuran
Segmentasi
Level pemotongan
Jumlah cluster
3 x 2 0.3 1.070
6 x 4 0.2 1.634
12 x 8 0.2 5.336
similarity antara citra query dan citra yang ada dalam database lebih besar dari 0 maka citra tesebut ditampilkan di sistem.
Evaluasi Temu Kembali
Pada tahap evaluasi dilakukan penilaian kinerja sistem dengan melakukan pengukuran recall dan precision untuk menentukan tingkat efektifitas proses temu kembali citra. Setiap citra dijadikan sebagai citra kueri dan citra yang relevan ditentukan secara manual dengan menghitung jumlah citra yang sekelas dengan citra kueri.
Selain menggunakan recall dan precision, evaluasi sistem ini juga dihitung dengan R-precision untuk melihat efektifitas memenukan citra relevan pada posisi teratas pada sistem. Penggunaan R-precision karena sistem mudah dievaluasi oleh pengguna.
HASIL DAN PEMBAHASAN
Penelitian ini mengimplementasikan vektor kuantisasi untuk menghasilkan codebook yang dapat merepresentasikan semantik dari suatu citra.
Data Penelitian
Data penelitian yang digunakan bersumber dari http://www.stat.psu.edu/~jiali sejumlah 1.000 citra. Pemilihan citra dilakukan secara manual dengan dimensi seragam 384×256 pixel dengan variasi objek, tema, pencahayaan yang beragam dan berformat JPEG. Contoh citra yang digunakan dapat di lihat pada Lampiran 1.
Praproses Citra
Tahapan praproses citra yang dilakukan yaitu segmentasi citra menggunakan segmentasi grid. Segmentasi citra dilakukan untuk mendapatkan blob yang menyusun citra. Citra disegmentasi menjadi beberapa region bujursangkar dengan ukuran grid yaitu: 3×2, 6×4, 12×8.
Ukuran segmentasi grid yang digunakan bervariasi, bertujuan untuk menganalisis bagaimana skala dan geometris objek mempengaruhi hasil temu kembali citra. Setiap ukuran grid yang digunakan menghasilkan jumlah dan dimensi blob yang berbeda, hal ini dilihat pada Tabel 1.
Table 1 Hasil segmentasi citra
Ukuran grid Jumlah blob
Dimensi blob (pixel)
3×2 6 128×128
6×4 24 64×64
12× 8 96 32×32
Ekstraksi Ciri
Ekstraksi ciri warna
Hasil dari ekstraksi ciri warna untuk keseluruhan blob yang ada di basis data adalah blob yang direpresentasikan dengan sebuah vektor yang memiliki elemen sebanyak 162 buah. Ekstraksi ciri warna HSV-162 yang digunakan mampu mengurangi waktu komputasi pada tahapan pembentukan codebook.
Ekstraksi ciri tekstur
Hasil dari ekstraksi ciri tekstur untuk keseluruhan blob dalam database, direpresentasikan dengan sebuah vektor yang memiliki 6 elemen yaitu energy, entropy, maximum probability, contrast, dan correlation.
Hasil ekstraksi ciri warna dan tekstur digabung menjadi satu vektor. Vektor ciri ini yang digunakan pada saat proses vector kuantisasi.
Vektor Kuantisasi
Algoritme hierarchy clustering menghasilkan dendrogram yang terbentuk dari keseluruhan blob yang ada dalam database. Hasil dendrogram yang terbentuk dipotong pada level tertentu tiap ukuran grid, bertujuan untuk mendapatkan hasil akurasi cluster yang lebih baik. Level pemotongan dendrogram dan jumlah cluster yang terbentuk dapat dilihat pada Tabel 2.
Table 2 Hasil Clustering. Ukuran
Segmentasi
Level pemotongan
Jumlah cluster
3 x 2 0.3 1.070
6 x 4 0.2 1.634
12 x 8 0.2 5.336
inilah yang akan digunakan untuk pembangunan indeks maupun query.
Penggunaan hierarchy clustering selain untuk pembentukan codebook, juga digunakan untuk mencari blob yang membentuk suatu tema citra. Contoh blob pembentuk suatu tema dapat dilihat pada Gambar 13.
Gambar 13 Objek pembentuk citra bertema bunga
Evaluasi Hasil Temu Kembali Citra
Evaluasi yang dilakukan pada penelitian ini menggunakan 2 perhitungan precision yaitu :
1. Grafik recall dan precision
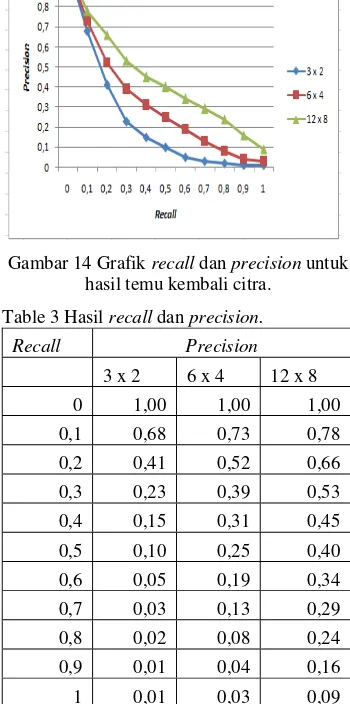
Nilai recall dan precision dihitung untuk menentukan tingkat keefektifan proses temu kembali. Evaluasi recall dan precision dengan data 1.000 citra memiliki hasil yang cukup memuaskan, dimana hasil sistem yang terbaik yaitu ukuran grid 12 x 8, hal ini dapat dilihat pada Gambar 14 dan Tabel 3. Pada Gambar 14 memperlihatkan bahwa, untuk recall 0,1 sampai recall 0,9 ukuran grid 12×8 memiliki precision dua kali lebih baik dibandingkan ukuran grid 6×4, dan 5 kali lebih baik dibandingkan ukuran grid 3×2.
Recall 0 memperlihatkan bahwa semua grid memiliki nilai yang sama yaitu 1, yang menunjukkan ketiga grid memiliki efektifitas yang sama. Recall 1 memperlihatkan bahwa ketiga grid kurang efektif temu kembali citra.
Gambar 14 Grafik recall dan precision untuk
hasil temu kembali citra. Table 3 Hasil recall dan precision.
Recall Precision
3 x 2 6 x 4 12 x 8
0 1,00 1,00 1,00 0,1 0,68 0,73 0,78 0,2 0,41 0,52 0,66 0,3 0,23 0,39 0,53 0,4 0,15 0,31 0,45 0,5 0,10 0,25 0,40 0,6 0,05 0,19 0,34
0,7 0,03 0,13 0,29
0,8 0,02 0,08 0,24 0,9 0,01 0,04 0,16 1 0,01 0,03 0,09 Contoh aplikasi hasil temu kembali citra dengan segmentasi grid 3×2 dapat dilihat pada Gambar di bawah ini. Contoh hasil temu kembali grid 6×4 dan 12×8 dapat di lihat pada Lampiran 2.
Gambar 15 Aplikasi temu kembali segmentasi grid 3×2.
Bunga
Daun Kelopak
Bunga
Kunin
Ungu Biru
Merah
2. R-precision
Evaluasi R-precision pada penelitian ini menggunakan data citra tiap kelas yang dipilih secara acak dalam database. Hasil R-precision menunjukkanbahwa ukuran grid 12 x 8 mampu menemukan sebanyak 32% citra pada posisi teratas. Hasil pengukuran dapat dilihat pada Tabel 4, sedangkan grafik pengujian R-precision dapat dilihat pada Gambar 16.
Table 4 Hasil rataan R-Precision.
Ukuran grid 3 x 2 6 x 4 12 x 8 R-precision 0,18 0,28 0,32
Gambar 16 Grafik pengujian R-Precision. Hasil evaluasi menggunakan R-precision menunjukkan bahwa untuk kelas kembang api, sistem mampu menemukan hampir 60% citra pada posisi teratas untuk ukuran grid 12 x 8 dan 6 x 4.
Hasil R-precision pada sistem ini dipengaruhi oleh hasil penentuan kelas pada citra query, jika citra query tepat di-cluster pada kelasnya, maka nilai evaluasi R-precision akan meningkat. Hasil penentuan kelas dapat di lihat pada Lampiran 4.
Selain indikator ketepatan sistem untuk menemukan citra yang relevan dalam database, penelitian ini juga melakukan evaluasi kinerja waktu sistem untuk menemukan citra yang relevan dalam database. Hasil pengukuran menunjukkan bahwa ukuran grid 3×2 mampu dua kali lebih cepat melakukan pencarian citra relevan dalam database. Hal ini karena jumlah blob dan codebook yang terbentuk untuk ukuran grid 3×2 yang lebih sedikit dibandingkan
dengan ukuran grid yang lainnya. Hasil pengukuran dapat dilihat pada Tabel 5.
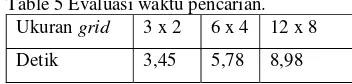
Table 5 Evaluasi waktu pencarian. Ukuran grid 3 x 2 6 x 4 12 x 8
Detik 3,45 5,78 8,98
Sistem temu kembali citra dengan vektor kuantisasi sangat cocok untuk citra yang memiliki latar belakang yang lebih kompleks seperti pemandangan alam, kembang api dan lain-lain. Ini dapat dilihat hasil perbandingan recall dan precision antara kelas kembang api dan bangunan pada Lampiran 5.
Gambar 17 Contoh gambar kelas kembang api dan bangunan.
Hasil rataan recall dan precision untuk kelas kembang api lebih baik daripada kelas bangunan untuk segmentasi grid berukuran 6 x 4 dan 12 x 8, sedangkan untuk ukuran grid 3 x 2 vektor kuantisasi belum mampu menghasilkan codebook yang baik untuk gambar yang memiliki latar belakang atau tekstur yang kompleks.
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini mengimplementasikan vektor kuantisasi dengan menggunakan algoritme hierarchy clustering. Pembentukan codebook dengan menggunakan algoritme hierarchy clustering dapat menghasilkan codebook yang lebih optimal.
Penggunaan vektor kuantisasi sangat bagus digunakan untuk citra yang memiliki objek yang banyak atau citra dengan tekstur yang kompleks. Hasil pengukuran evaluasi menunjukkan bahwa ukuran segmentasi yang lebih besar tidak begitu berpengaruh terhadap perubahan geometris.
2. R-precision
Evaluasi R-precision pada penelitian ini menggunakan data citra tiap kelas yang dipilih secara acak dalam database. Hasil R-precision menunjukkanbahwa ukuran grid 12 x 8 mampu menemukan sebanyak 32% citra pada posisi teratas. Hasil pengukuran dapat dilihat pada Tabel 4, sedangkan grafik pengujian R-precision dapat dilihat pada Gambar 16.
Table 4 Hasil rataan R-Precision.
Ukuran grid 3 x 2 6 x 4 12 x 8 R-precision 0,18 0,28 0,32
Gambar 16 Grafik pengujian R-Precision. Hasil evaluasi menggunakan R-precision menunjukkan bahwa untuk kelas kembang api, sistem mampu menemukan hampir 60% citra pada posisi teratas untuk ukuran grid 12 x 8 dan 6 x 4.
Hasil R-precision pada sistem ini dipengaruhi oleh hasil penentuan kelas pada citra query, jika citra query tepat di-cluster pada kelasnya, maka nilai evaluasi R-precision akan meningkat. Hasil penentuan kelas dapat di lihat pada Lampiran 4.
Selain indikator ketepatan sistem untuk menemukan citra yang relevan dalam database, penelitian ini juga melakukan evaluasi kinerja waktu sistem untuk menemukan citra yang relevan dalam database. Hasil pengukuran menunjukkan bahwa ukuran grid 3×2 mampu dua kali lebih cepat melakukan pencarian citra relevan dalam database. Hal ini karena jumlah blob dan codebook yang terbentuk untuk ukuran grid 3×2 yang lebih sedikit dibandingkan
dengan ukuran grid yang lainnya. Hasil pengukuran dapat dilihat pada Tabel 5.
Table 5 Evaluasi waktu pencarian. Ukuran grid 3 x 2 6 x 4 12 x 8
Detik 3,45 5,78 8,98
Sistem temu kembali citra dengan vektor kuantisasi sangat cocok untuk citra yang memiliki latar belakang yang lebih kompleks seperti pemandangan alam, kembang api dan lain-lain. Ini dapat dilihat hasil perbandingan recall dan precision antara kelas kembang api dan bangunan pada Lampiran 5.
Gambar 17 Contoh gambar kelas kembang api dan bangunan.
Hasil rataan recall dan precision untuk kelas kembang api lebih baik daripada kelas bangunan untuk segmentasi grid berukuran 6 x 4 dan 12 x 8, sedangkan untuk ukuran grid 3 x 2 vektor kuantisasi belum mampu menghasilkan codebook yang baik untuk gambar yang memiliki latar belakang atau tekstur yang kompleks.
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini mengimplementasikan vektor kuantisasi dengan menggunakan algoritme hierarchy clustering. Pembentukan codebook dengan menggunakan algoritme hierarchy clustering dapat menghasilkan codebook yang lebih optimal.
Penggunaan vektor kuantisasi sangat bagus digunakan untuk citra yang memiliki objek yang banyak atau citra dengan tekstur yang kompleks. Hasil pengukuran evaluasi menunjukkan bahwa ukuran segmentasi yang lebih besar tidak begitu berpengaruh terhadap perubahan geometris.
Saran
Berikut ini adalah penelitian lanjutan yang dapat dilakukan :
1. Melakukan segmentasi objek menggunakan adaptive perceptual color-texture image segmentation (Chen et al. 2005)
2. Perhitungan cosine similarity dengan memberikan bobot tertentu tiap blob.
DAFTAR PUSTAKA
Cai D et al. 2004. Hierarchical clustering of WWW image search results using visual, textual and link information. New York, USA.
Chen J et al. 2005. Adaptive Perceptual Color-Texture Image Segmentation. IEEE Transactions On Image Processing, Vol. 14, No. 10.
Daud Imam Abu, 2008. Anotasi Automatis Citra menggunakan Statiscal MachineTranslation untuk Temu Kembali Citra [skripsi]. Bogor : Institut Pertanian Bogor.
Grossman D. IR Book. http://www.ir.iit.edu/~dagr/cs529/ir_book .html [Akses : 4 januari 2011].
Han J & Kai-Kuang Ma. 2002. Fuzzy Color Histogram and Its Use in Color Image Retrieval. IEEE Transaction on Image Processing, vol. 11, no. 8.
Hasniawaty H. 2007. Image Clustering berdasarkan warna untuk identifikasi buah dengan metode valley tracing [skripsi]. Surabaya: Institut Teknologi Surabaya.
Jia L. Photography image database for retrieval and automatic annotation. Pennsylvania State University. http://www.stat.psu.edu/~jiali [29 November 2010].
Han J, Kamber M. 2006. Data Mining: Concepts and Techniques. San Fransisco : Morgan Kaufmann Publisher.
Lu G, Teng S. 1999. A novel image retrieval Technique based on vector quantization. Vienna, Austria
Mori Y, Takahashi H, Oka T. 1999. Image-to-word transformation based on dividing and vector quantizing images with words. In First International Workshop on
Multimedia Intelligent Storage and Retrieval Management. Orlando, Florida. Osadebey ME. 2006. Integrated
Content-Based Image Retrieval Using Texture, Shape and Spatial Information [thesis]. Umea : Department of Applied Physics and Electronics, Umea University.
Pavlu V. 2005. A Geometric Interpretation of Rprecision and Its Correlation with Average Precision. Boston, USA.
Pebuardi R. 2008. Pengukuran kemiripan citra berbasis warna, bentuk, dan tekstur menggunakan bayessian network [skripsi]. Bogor: Institut Pertanian Bogor
Rodrigues PS & Arnaldo de Albuquerque Araujo. 2004. A Bayesian Network Model Combining Color, Shape and Texture Information to Improve Content Based Image Retrieval Systems. LNCC, Petropolis, Brazil.
VEKTOR KUANTISASI BERBASIS
BLOB
CITRA UNTUK
TEMU KEMBALI CITRA DENGAN
HIERARCHY CLUSTERING
RYAN SAPTA NOPA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
INSTITUT PERTANIAN BOGOR
Saran
Berikut ini adalah penelitian lanjutan yang dapat dilakukan :
1. Melakukan segmentasi objek menggunakan adaptive perceptual color-texture image segmentation (Chen et al. 2005)
2. Perhitungan cosine similarity dengan memberikan bobot tertentu tiap blob.
DAFTAR PUSTAKA
Cai D et al. 2004. Hierarchical clustering of WWW image search results using visual, textual and link information. New York, USA.
Chen J et al. 2005. Adaptive Perceptual Color-Texture Image Segmentation. IEEE Transactions On Image Processing, Vol. 14, No. 10.
Daud Imam Abu, 2008. Anotasi Automatis Citra menggunakan Statiscal MachineTranslation untuk Temu Kembali Citra [skripsi]. Bogor : Institut Pertanian Bogor.
Grossman D. IR Book. http://www.ir.iit.edu/~dagr/cs529/ir_book .html [Akses : 4 januari 2011].
Han J & Kai-Kuang Ma. 2002. Fuzzy Color Histogram and Its Use in Color Image Retrieval. IEEE Transaction on Image Processing, vol. 11, no. 8.
Hasniawaty H. 2007. Image Clustering berdasarkan warna untuk identifikasi buah dengan metode valley tracing [skripsi]. Surabaya: Institut Teknologi Surabaya.
Jia L. Photography image database for retrieval and automatic annotation. Pennsylvania State University. http://www.stat.psu.edu/~jiali [29 November 2010].
Han J, Kamber M. 2006. Data Mining: Concepts and Techniques. San Fransisco : Morgan Kaufmann Publisher.
Lu G, Teng S. 1999. A novel image retrieval Technique based on vector quantization. Vienna, Austria
Mori Y, Takahashi H, Oka T. 1999. Image-to-word transformation based on dividing and vector quantizing images with words. In First International Workshop on
Multimedia Intelligent Storage and Retrieval Management. Orlando, Florida. Osadebey ME. 2006. Integrated
Content-Based Image Retrieval Using Texture, Shape and Spatial Information [thesis]. Umea : Department of Applied Physics and Electronics, Umea University.
Pavlu V. 2005. A Geometric Interpretation of Rprecision and Its Correlation with Average Precision. Boston, USA.
Pebuardi R. 2008. Pengukuran kemiripan citra berbasis warna, bentuk, dan tekstur menggunakan bayessian network [skripsi]. Bogor: Institut Pertanian Bogor
Rodrigues PS & Arnaldo de Albuquerque Araujo. 2004. A Bayesian Network Model Combining Color, Shape and Texture Information to Improve Content Based Image Retrieval Systems. LNCC, Petropolis, Brazil.
VEKTOR KUANTISASI BERBASIS
BLOB
CITRA UNTUK
TEMU KEMBALI CITRA DENGAN
HIERARCHY CLUSTERING
RYAN SAPTA NOPA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
INSTITUT PERTANIAN BOGOR
ABSTRACT
RYAN SAPTA NOPA. Vector quantization based on blob image for image retrieval with hierarchy clustering. Supervised by YENI HERDIYENI.
This research proposed vector quantization using hierarchy clustering to overcome semantic problem on image retrieval. This approach considers to find templates or codebooks which arrange image in database. Images were segmented into blobs using grid segmentation. Each blob was represented by color feature using HSV-162 and texture feature using co-occurrence matrix. Output of feature extraction then clustered using hierarchy clustering to generated optimally codebook. Data experiment in this research was taken from http://www.stat.psu.edu/~jiali. The data consist of 1.000 photography image with various of theme, object, and dimension of images were 384×256 pixel. R-precision, recall, and precision were useds to evaluate the result of image retrieval. The experiment showed that segmentation using grid 12×8 have achieved best result than other grid. Based on experience, the result of R-precision showed that grid 12×8 is about 0,32. The advantage of this research that vector quantization with hierarchy clustering can be used to overcome semantic problem on image retrieval based on blob.
VEKTOR KUANTISASI BERBASIS
BLOB
CITRA UNTUK
TEMU KEMBALI CITRA DENGAN
HIERARCHY CLUSTERING
RYAN SAPTA NOPA
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
Pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
INSTITUT PERTANIAN BOGOR
Judul : Vektor Kuantisasi berbasis Blob Citra untuk Temu Kembali Citra dengan Hierarchy Clustering
Nama : Ryan Sapta Nopa NIM : G64086056
Menyetujui : Pembimbing
Dr. Yeni Herdiyeni, S.Si, M.Kom. NIP 19750923 200012 2 001
Mengetahui :
Ketua Departemen Ilmu Komputer Institut Pertanian Bogor
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
RIWAYAT HIDUP
PRAKATA
Alhamdulillahi Rabbil’ Alamin, puji, dan syukur penulis ucapkan kehadirat Allah Subhanahu wa Ta’ala atas segala limpahan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul Temu Kembali Citra Dengan Vektor Kuantisasi Menggunakan Hierarchy Clustering. Dalam menyelesaikan tugas akhir ini , penulis banyak sekali mendapat bantuan dan motivasi dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada semua pihak antara lain :
1 Kedua orang tua tercinta, yang telah memberikan kasih sayang serta doa sehingga penulis dapat menyelesaikan studi di departemen Ilmu Komputer IPB.
2 Ibu Dr. Yeni Herdiyeni S.Si, M.Kom selaku dosen pembimbing atas bimbingan dan arahan selama pengerjaan tugas akhir ini.
3 Bapak Ir. Julio Adisantoso M.Kom dan Mushthofa S.kom, M.Sc selaku dosen penguji. 4 Teman-teman satu bimbingan atas kerjasamanya selama penelitian.
5 Teman-teman seperjuangan ekstensi Ilmu Komputer angkatan 3.
Semoga penelitian yang dikerjakan dapat memberikan manfaat bagi perkembangan ilmu pengetahuan.
Bogor, Juli 2011
DAFTAR ISI
Halaman
DAFTAR TABEL
Halaman
1 Hasil segmentasi citra ... 7 2 Hasil clustering. ... 7 3 Hasil recall dan precision. ... 8 4 Hasil rataan R-Precision. ... 9 5 Evaluasi waktu pencarian. ... 9
DAFTAR GAMBAR
Halaman
1 Sistem temu kembali citra. ... 1 2 Korelasi antara sepasang pixel dengan arah tertentu. ... 2 3 Contoh pembangunan co-occurrence matrix arah 0 derajat. ... 2 4 Ilustrasi clustering. ... 2 5 Ilustrasi singlelinkage. ... 3 6 Ilustrasi centroidlinkage. ... 3 7 Ilustrasi centroidlinkage. ... 3 8 Ilustrasi averagelinkage. ... 3 9 Ilustrasi vektor kuantisasi. ... 3 11 Contoh segmentasi grid. ... 4 10 Metodologi penelitian. ... 4 12 Encoding citra. ... 6 13 Objek pembentuk citra bertema bunga ... 8 14 Grafik recall dan precision untuk hasil temu kembali citra. ... 8 15 Aplikasi temu kembali segmentasi grid 3×2. ... 8 16 Grafik pengujian R-Precision. ... 9 17 Contoh gambar kelas kembang api dan bangunan. ... 9
DAFTAR LAMPIRAN
L t p y m y k m b m b o s b a d o c p s y d k m s D u H l s m d b y m d m o p p s g h c s P Latar Belakan Informasi tidak selalu pengukuran ke yang memilik memiliki infor yang berbeda. kemiripan citr memberikan h baik.
Manusia mendefinisikan berdasarkan p objek-objek y seperti satu beberapa kata atau arti kalim dengan baik, objek yang me cara yang serin proses segmen segmentasi cit yaitu objek has dengan perse komputasi yan Daud (200 mengenai tem semantik citra Daud (2008) untuk memper Hasil penelitian label pada tiap
Zhang et sebuah mo menggunakan dikembangkan blob atau cod yang dilakuka menggunakan dimana algo menjamin m optimal.
Kelebihan penelitian seb pada penelit segmentasi ci grid dan pem hierarchy clus clustering ma sesuai dengan PENDAHULU ng warna, bentuk dapat me emiripan citra ki kesamaan m rmasi warna, be
. Oleh karena a berbasis sem hasil temu kem
memiliki ke n semantik
engalaman ma yang menyusu kalimat yan a sehingga m mat. Citra da jika sistem m enyusun sebua ng digunakan a ntasi citra. Sa tra memiliki b
sil segmentasi epsi manusia ng lama.
08) telah mela mu kembali a. Sistem yan
menggunakan rcepat proses n ini sudah ma objek citra den t al (2000) odel berna
vektor kuanti n mampu men
debook. Pembe an oleh Zhan algoritme c ritme tersebu menghasilkan
n dan kekuran belumnya, me tian ini un itra menggun
mbentukan c stering. Pengg ampu mengor visual manusia
UAN
k, dan tekstur c emberikan h yang baik. C makna seringk entuk, dan tek a itu, penguku mantik citra da mbali yang le emampuan un sebuah c anusia mengen un sebuah ci
g disusun o memiliki seman apat didefinisi mampu mengen
ah citra. Salah s adalah melaku ayangnya, pro eberapa kesuli yang tidak ses a dan wa akukan penelit citra berba ng dikembang
segmentasi g segmentasi ci ampu memberi
ngan baik. mengembang ama keybl sasi. Model y nghasilkan kam
entukan codeb ng et al (20 clustering GL ut tidak da
codebook y ngan model p emunculkan ntuk melaku nakan segmen codebook den gunaan hierar rganisasi clus a (cai et al. 200
citra hasil Citra kali stur uran apat ebih ntuk citra nali itra, oleh ntik kan nali satu ukan oses itan suai aktu tian asis kan grid itra. kan kan lock yang mus ook 000) LA, apat yang pada ide ukan ntasi ngan rchy ster 04). Tuju P vekto meng kemb Ruan 1 2 3 Man M meni berba Cont C meru citra et al. retrie dua penem pada Segm S citra berda Krite warn S citra objek overl dikar meru pada uan Penelitian in or kuantisasi ggunakan hiera bali citra. ng Lingkup
Citra yang fotografi deng Ekstraksi ciri dan co-occurr Segmentasi g 12×8. faat Penelitian Manfaat p ngkatkan aku asiskan semant TINJAU
tent Base Imag
Content base upakan sistem
berbasiskan fi 2000). Proses eval) secara um
proses utama muan kembali
Gambar 1.
mentasi Segmentasi me
menjadi be asarkan kesam eria yang dig na, tekstur atau
Segmentasi gri menjadi beb k yang beruk lapping. Peng renakan pemba upakan cara yan
citra (Mori et Gambar 1 Sist
ni mengimp berbasiskan b archyclusterin
digunakan a gan berbagai je
i menggunaka rence matrix. grids berukura
n
penelitian i urasi temu k tik citra. UAN PUSTAK
ge Retrieval
image retrie untuk mengen tur yang digun s temu kembali mum dapat dib a yaitu pengin i citra, yang d
erupakan pros berapa blob maan kriteria y
gunakan yaitu tingkat warna id adalah pro erapa bagian kuran sama t ggunaan segm agian citra den ng paling cepa al. 1999). tem temu kemb
lementasikan blob dengan ng pada temu
adalah citra nis tema. an HSV-162 an 3×2, 6×4,
ini untuk kembali citra
KA
eval (CBIR) nali informasi nakan (Zhang i citra (image bagi menjadi ndeksan dan diilustrasikan ses membagi atau objek ang dimiliki. u kesamaan keabuan. ses membagi
matrix atau tanpa terjadi mentasi grid
Representasi Warna
Histogram warna menyatakan frekuensi kemunculan atau peluang keberadaan setiap warna pada citra. Banyaknya nilai warna (bin) dapat ditetapkan sesuai kebutuhan pembuatan histogram. Histogram warna dapat dinyatakan sebagai berikut:
|
1, pixel ke-j dikuantisasi ke bin-i
0, selainnya
dengan | merupakan nilai pixel pada posisi i atau j, adalah nilai warna (bin) yang dibentuk, N adalah jumlah pixel citra. Histogram warna seperti ini disebut conventional color histogram (Han & Ma 2002).
Representasi Tekstur
Pada area pemrosesan citra tidak ada definisi yang jelas mengenai tekstur. Definisi tekstur yang ada hanya didasarkan kepada metode analisis tekstur dan fitur yang diekstrak dari citra. Tekstur dapat dianggap sebagai pola pixel yang berulang pada wilayah spasial dimana penambahan noise pada pola dan perulangan frekuensinya, dapat terlihat secara acak dan tidak terstruktur (Osadebey 2006).
Beberapa metode yang berbeda diusulkan untuk menghitung ciri tekstur. Salah satu metode yang paling sering digunakan untuk mendeskripsikan ciri tekstur adalah metode berbasis statistika dan berbasis transformasi (Osadebey 2006).
Metode berbasis statistika menganalisis distribusi spasial dari nilai keabuan dengan menghitung ciri lokal pada setiap titik citra, kemudian menurunkan beberapa perhitungan statistika dari distribusi ciri lokal tersebut. Salah satu jenis metode ini adalah co-occurrence matrix.
Co-occurrence matrix merupakan matrix pembantu yang berfungsi mencacah terjadinya sepasang pixel yang memiliki nilai intensitas dan arah tertentu. Arah yang digunakan secara umum ada 4 yaitu 0 derajat, 45 derajat, 90 derajat, dan 135 derajat yang diilustrasikan pada Gambar 2.
Gambar 2 korelasi antara sepasang pixel
dengan arah tertentu.
Gambar 3 menjelaskan bagaimana pembangunan co-occurrence matrix untuk citra A yang berukuran 4 x 4 pixel dengan 4 level keabuan, posisi operator didefinisikan dengan sudut 0 derajat dengan jarak 1 pixel.
Gambar 3 Contoh pembangunan co
-occurrence matrix arah 0 derajat. Hierarchy Clustering
Clustering merupakan suatu cara mengelompokkan data ke dalam cluster tertentu, dimana data yang dikelompokkan memiliki kesamaan ciri dengan anggota cluster yang lainnya (Han & Kamber 2001).
Gambar 4 Ilustrasi clustering (Sumber :
Hasniawati 2007).
Algoritme hierarchy clustering membentuk denah pohon (dendrogram) dari sekumpulan objek citra yang terdapat dalam database, sehingga cluster dapat dibentuk Pi|j =
d t m t p t B ( 2 3
dengan memo tertentu. Alg memiliki karak telah dikelomp pada suatu tah tidak dapat ber Beberapa m (Hasniawati 20 1 Single linka Proses me cluster berd objek. Met pada kasus
Gambar 2 Centroid lin
Proses men cluster ber Metode memperkec serta untuk
Gambar 6 3 Complete l
Proses men cluster berd objek. Me distribusi d
Gambar 7
otong dendrog goritme Hiera kteristik yaitu pokkan ke dal apan proses, m rpindah ke clus metode hiera
007): age.
ngelompokkan dasarkan jarak tode ini sangat shape indepen
5 Ilustrasi sing nkage. ngelompokkan rdasarkan jara ini sangat cil variance d k data yang mem
6 Ilustrasi centr inkage. ngelompokkan dasarkan jarak etode ini sang data yang norm
7 Ilustrasi centr
gram pada ja archy cluster ketika suatu d lam suatu clus maka data terse
ster yang lain. rchy cluster
n objek ke su terdekat di ant cocok diguna ndent clustering
glelinkage. n objek ke su
ak centroid n cocok un di antara clus miliki pencilan
roidlinkage.
n objek ke su k terjauh di ant gat cocok un mal.
roidlinkage.
arak ring data ster ebut ring uatu tara akan g. uatu nya. ntuk ster n. uatu tara ntuk 4 A P cl an m w Vekt M sebua dan p vekto teori yang V peme yang atau himp seluru Ilustr Gamb berha optim P tahap 1 2 verage linkage roses mengelo luster berdas ntara objek. metode yang leb waktu komputas
Gambar 8 Ilus tor Kuantisasi Metode vekto ah teknik yang pengkodean cit or kuantisasi, b bagaimana u baik (Zhang e Vektor kuant etaan vektor k direpresentas centroids (Zh punan centroid uh ruang v rasi vektor ku bar 9. Proses asil jika meng mal.
Gambar 9 Ilus Proses vektor p yaitu :
Pembentukan Proses pembe teori Shanno berbagai algo al. 2000). Encoding (pen Pada tahapan blob digantik codebook yan e.
ompokkan obj arkan jarak Metode ini bih baik tetapi si yang lebih la
strasi averagel i
or kuantisasi g digunakan un
tra. Berdasarka bahwa tidak ad untuk mendesa et al. 2000).
tisasi merupa ke ruang vekt sikan dengan
hang et al. 2 d yang merep ektor disebut uantisasi dapat vektor kuantis ghasilkan code
trasi vektor ku kuantisasi terd codebook. entukan codeb
on dapat m ritme clusterin ngkodean). n proses enco kan dengan no ng memiliki ja
jek ke suatu rata-rata di merupakan memerlukan ama.
linkage. merupakan ntuk kompresi an teori dasar da penjelasan ain codebook
akan proses tor (cluster), pusat vektor 2000). Suatu presentasikan
t codebook. dilihat pada asi dikatakan ebook yang
uantisasi. diri atas tiga
book menurut menggunakan ng (Zhang et
Hasil encoding setiap citra merupakan sebuah matrix.
3 Decoder.
Proses decoder digunakan untuk merekontruksi matrix menjadi citra, dengan menggantikan nomor indeks sesuai dengan codebook.
Evaluasi Sistem
Recall dan precision merupakan parameter yang digunakan untuk mengukur keefektifan model temu kembali citra. Rataan precision adalah ukuran evaluasi yang diperoleh dengan cara menghitung rataan tingkat precision pada berbagai tingkat recall (Grossman 2002).
jumlah citra relevan yang terambil jumlah citra relevan dlm basis data recall
terambil yang
citra seluruh jumlah
terambil yang
relevan citra jumlah precision
R-precision merupakan parameter yang digunakan untuk mengukur kemampuan sistem dalam menemukan kembali citra yang relevan pada R-ranking teratas, dimana R merupakan jumlah citra relevan dalam database. Sistem yang efektektif akan bernilai 1 (Pavlu 2005).
R jumlah citra yang relevanx
x = jumlah citra relevan yang terambil pada posisi teratas .
METODOLOGI
Metode penelitian ini terdiri atas lima tahapan yang dapat dilihat pada Gambar 10 yaitu :
1 Dekomposisi citra. 2 Ekstraksi ciri. 3 Vektor kuantisasi. 4 Temu kembali citra. 5 Evaluasi temu kembali.
Dekomposisi Citra
Pada tahap proses dekomposisi citra atau segmentasi, setiap citra dalam database didekomposisi menggunakan segmentasi grid. Penggunaan segmentasi grid dapat memastikan bahwa tidak ada blob yang overlapping. Ukuran grid yang digunakan pada penelitian ini yaitu 3×2, 6×4, 12×8. Ilustrasi penggunaan segmentasi grid dapat dilihat pada Gambar 11.
Gambar 11 Contoh segmentasi grid.
Gambar 10 Metodologi penelitian.
Basisdata Citra
Dekomposisi Citra
Ekstraksi Citra
Hierarchy Clustering
Indeks Citra
Encoding
Citra Kueri
Dekomposisi Citra
Ekstraksi Citra
Encoding
Pengukuran kemiripan
Evaluasi hasil temu kembali
Ekstraksi Ciri
Pada penelitian ini, ekstraksi ciri dilakukan menggunakan fitur warna dan tekstur citra.
1 Ekstraksi ciri warna.
Ekstraksi ciri warna dilakukan dengan menggunakan histogram warna CCH (conventional color histogram). Setiap blob hasil dari dekomposisi citra akan dikonversi dari citra RGB (Red, Green, Blue) manjadi citra HSV (Hue, Saturation, Value). Hal ini dilakukan karena HSV (Hue, Saturation, Value) merupakan ruang warna yang komponen-komponennya berkontribusi langsung pada persepsi visual manusia. Hue digunakan untuk membedakan warna misalnya merah, hijau, dan biru serta untuk menentukan tingkat kemerahan, kehijauan, dst dari sebuah cahaya. Saturation merupakan prosentase cahaya putih yang ditambahkan ke cahaya murni. Sementara itu, value merupakan intensitas cahaya yang dirasakan (Rodrigues & Araujo 2004).
Transformasi RGB menjadi HSV diperoleh menggunakan formula:
, ,
, ,
dengan r adalah nilai red (merah) pada blob, g adalah nilai green (hijau) pada blob, dan b adalah nilai blue (biru) pada blob.
Nilai HSV yang dihasilkan akan dikuantisasi kedalam histogram-162 (HSV-162). Hue dikuantisasi menjadi 18 bin, saturation dikuantisasi menjadi 3 bin, sedangkan value dikuantisasi menjadi 3 bin, sehingga akan didapatkan kombinasi sebanyak 18×3×3 =162. Hue dikuantisasi menjadi 18 bin karena sistem visual manusia lebih sensitif terhadap hue dibandingkan saturation dan value.
Setiap citra akan direpresentasikan dengan sebuah vektor yang memiliki elemen sebanyak 162 buah. Nilai elemen vektor menyatakan jumlah pixel citra yang masuk ke dalam bin yang sesuai. Dengan kata lain, vektor citra merepresentasikan histogram warna citra tersebut. Setelah histogram citra selesai dihitung, langkah terakhir adalah melakukan normalisasi terhadap vektor masing-masing citra.
2 Ekstraksi ciri tekstur.
Ekstraksi ciri tekstur dilakukan dengan menggunakan co-occurrence matrix karena menurut Osadebey (2006) representasi co-occurrence matrix dapat digunakan untuk menghitung ciri tekstur. Langkah awal yang dilakukan untuk mendapatkan informasi tekstur sebuah citra adalah dengan menentukan co-occurrencematrix.
Peneltian ini menggunakan co-occurrence matrix dengan 16 level keabuan karena mampu meningkatkan precision temu kembali (Pebuardi 2008). Hasil co-occurrence matrix dianalisis menggunakan 6 metode statistika yang terdiri atas : energy, moment, entrophy, maximum probability, contrast, correlation, dan homogeneity. Berikut ini merupakan definisi matematis dari 6 fitur di atas :
a Energy.
Menunjukkan ukuran sifat homogenitas citra.
,
,
b Entrophy.
Menunjukkan kompleksitas tekstur citra
, ,
,
c Maximum Probability.
Menunjukkan keteraturan tekstur citra. Maximum Probability , d Contrast.
Menunjukkan kekontrasan citra. Contrast ∑ |, | ,
e Correlation.
Menunjukkan ketergantungan level ketetanggaan.
,
f Homogeneity
Menunjukkan keseragaman tekstur citra. ,
| |
,
dengan , adalah elemen baris ke-i, kolom ke-j dari co-occurance matrix.
adalah nilai rata-rata baris ke-i dan adalah nilai rata-rata kolom ke-j. adalah standar deviasi dari baris ke-i dan adalah standar deviasi dari kolom j.
Co-occurrence matrix dihitung dalam empat arah yaitu 00, 450, 900, 1350 , sehingga setiap blob menghasilkan empat nilai co-occurrence matrix. Nilai energy, entropy, maximum probability, contrast, correlation, dan homogeneity dihitung untuk setiap co-occurrence matrix, sehingga setiap fitur akan diperoleh empat nilai. Nilai dari fitur diperoleh dengan menghitung nilai rata-rata keempat nilai fitur yang bersangkutan. Hal ini dilakukan agar informasi tekstur yang diperoleh tidak peka terhadap rotasi (rotation -invariant).
Vektor Kuantisasi
Vektor kuantisasi pada temu kembali citra terdiri atas 2 tahapan proses yaitu :
a Pembentukan codebook.
Pembentukan codebook merupakan tahapan yang paling penting pada penelitian ini. Langkah awal yang dilakukan pada proses pembentukan codebook yaitu membentuk cluster tiap blob menggunakan metode complete linkage hierarchy clustering. Dibawah ini merupakan algoritme metode Complete Linkage Hierarchical :
1 Diasumsikan setiap data atau blob sebagai sebuah cluster. Kalau n = jumlah blob dan c = jumlah cluster, berarti ada c = n.
2 Menghitung jarak antar cluster, pada penelitian ini dengan Euclidean distance.
3 Mencari 2 cluster yang mempunyai jarak antar cluster yang paling maksimal / terjauh dan digabungkan kedalam cluster baru (sehingga c = c-1).
4 Kembali ke langkah 3, dan diulangi sampai terbentuk dendrogram.
Untuk mendapatkan nilai codebook dari cluster yang terbentuk, dapat dilakukan dengan menghitung rata-rata nilai blob tiap cluster.
b Encoding citra.
Setiap citra dalam database maupun citra query disegmentasi menjadi beberapa blob, sesuai dengan ukuran grid yang digunakan. Setiap blob kemudian dikodekan dengan codebook yang memiliki jarak terdekat dengan blob. Untuk menghitung jarak antara codebook dan blob, pada penelitian ini menggunakan jarak Euclidean dengan persamaan :
, | |
dengan x adalah blob citra, y adalah blob dari codebook, dan n adalah panjang vektor hasil ekstraksi citra. Hasil encoding direpresentasikan dalam bentuk vektor satu dimensi. Proses encoding citra dapat dilihat pada Gambar 8.
[image:31.612.335.505.305.405.2]Gambar 12 Encoding citra (Sumber : Zhang
et al. 2000). Temu Kembali Citra
Penentuan relevansi antara query dan citra dapat dilakukan dengan menggunakan teknik dalam bidang i