i
OPTIMASI MODEL QUERY PADA SISTEM FAQ
DI SUARA WARGA UNIVERSITAS NEGERI
SEMARANG
Skripsi
diajukan sebagai salah satu persyaratan untuk memperoleh gelar Sarjana
Pendidikan Studi Pendidikan Teknik Informatika dan Komputer
Oleh
Ganang Ardiy Tama NIM.5302411232
JURUSAN TEKNIK ELEKTRO
FAKULTAS TEKNIK
UNIVERSITAS NEGERI SEMARANG
v
MOTTO
MOTTO
The only way to do great work is to love what you do
vi
PERSEMBAHAN
PERSEMBAHAN
Skripsi ini penulis persembahkan untuk :
vii
ABSTRAK
Tama, Ganang Ardiy. 2015. Optimasi Model Query pada Sistem FAQ di Suara
Warga Universitas Negeri Semarang. Skripsi, Pendidikan Teknik Informatika dan Komputer-Jurusan Teknik Elektro, Universitas Negeri Semarang. Feddy Setio Pribadi, S.Pd., M.T.
Suara Warga UNNES di Universitas Negeri Semarang (UNNES) adalah program pengaduan online permasalahan-permasalahan didalam kampus. Besarnya jumlah dan banyak terulangnya data membuat banyak pengaduan tidak ditanggapi karena pengguna lain merasa topik tersebut sudah pernah diunggah dan ditanggapi sebelumnya. Penelitian ini bertujuan untuk mengimplementasikan dan
mengetahui model query dengan kinerja terbaik pada sistem FAQ di Suara Warga
UNNES.
Sistem FAQ yang dikembangkan menggunakan metode pengembangan
perangkat lunak Waterfall model. Diujikan sebanyak 3 model query yaitu isi, isi
dengan feature selection, dan judul dengan metode perhitungan sistem tersebut
adalah pembobotan dengan Term Frequency-Inverse Document Frequency
selanjutnya dievaluasi dengan metode recall, precision, dan f-measure.
Pada penelitian ini diujikan sebanyak 25 data Suara Warga UNNES dan 45 data dari inputan 9 responden mahasiswa UNNES pada 5 topik bahasan dengan 3
model query. Hasil pengujian yang dilakukan nilai recall 0.92, precision 0.41,
f-measure 0.56dengan model query isi, nilai recall 0.86, precision 0.59, f-measure
0.70dengan model query isi dengan feature selection, nilai recall 0.88, precision
0.78, f-measure 0.82 dengan model query judul. Dari hasil tersebut model query
dari judul inputan memiliki nilai paling tinggi dari ke-3 pengujian tersebut. Saran
untuk penelitian selanjutnya adalah menerapkan feature selection pada setiap
pengujian model query dan disarankan untuk menambahkan metode untuk
mengatasi persamaan makna.
viii
KATA PENGANTAR
Alhamdulillahirabbil’alamin berkat ridho Allah SWT, semangat dan kerja
keras, serta dukungan dari orang tua, adik dan teman-teman akhirnya penulis
dapat menyelesaikan skripsi yang berjudul “Optimasi Model Query Pada Sistem Faq Di Suara Warga Universitas Negeri Semarang" ,ini dapat diselesaikan dan di ajukan untuk memenuhi syarat akhir guna persyaratan memperoleh gelar Sarjana Pendidikan pada Universitas Negeri Semarang.Untuk itu pada kesempatan ini peneliti ingin mengucapkan terima kasih kepada Yth:
1. Drs. M. Harlanu, M.Pd. selaku Dekan Fakultas Teknik Universitas Negeri
Semarang.
2. Drs. Suryono, M.T selaku Ketua Jurusan Teknik Elektro Fakultas Teknik
Universitas Negeri Semarang.
3. Feddy Setio Pribadi ,S.T,M.T, selaku Kaprodi Pendidikan Teknik
Informatika dan Komputer Jurusan Teknik Elektro Fakultas Teknik Universitas Negeri Semarang dan selaku Dosen Pembimbing yang telah meluangkan waktu, tenaga dan pikiran dalam memberikan bimbingan.
4. Bapak, Ibu, dan keluarga yang memberikan kasih sayang dan doa sehingga
skripsi ini dapat diselesaikan dengan baik.
5. Teman-teman Teknik Elektro khususnya Prodi PTIK yang telah
memberikan dukungan dalam penyusunan skripsi.
6. Pihak-pihak terkait yang telah membantu terlaksana dan tersusunnya skripsi
ini.
Akhir kata, peneliti berharap semoga penelitian ini dapat bermanfaat bagi peneliti sendiri dan pembaca. Amin.
Semarang, 1 Juni 2015
ix
DAFTAR ISI
Halaman
Halaman Judul ... i
Pernyataan Keaslian ... Error! Bookmark not defined. Pengesahan ... Error! Bookmark not defined. Motto ... v
1.8 Sistematika Penulisan ... 7
BAB II TINJAUAN PUSTAKA ... 9
x
2.1.1 Konsep Dasar Optimasi... 9
2.1.2 Konsep Dasar Sistem FAQ ... 10
2.1.2.1 Konsep Dasar Temu-kembali Informasi (Information Retrieval) 12 2.1.2.3 Konsep Dasar Pencarian dengan pembobotan TF-IDF ... 16
2.1.2.4 Pencarian Pada MYSQL Full-Text Search ... 19
2.1.3 Model Query ... 22
2.1.3.1 Feature Selection (Seleksi Fitur) Chi-Square ... 23
2.1.4 Optimasi Model Query pada Sistem FAQ ... 24
2.2 Penelitian Terdahulu ... 25
2.3 Kerangka Berfikir ... 28
BAB III METODE PENELITIAN... 29
3.1 Metodologi Pengembangan Perangkat Lunak ... 29
3.1.1 Analisis Kebutuhan Sistem ... 30
3.1.2 Desain ... 31
3.1.3 Pengkodean ... 31
3.1.4 Pengujian ... 31
3.2 Metode Pengumpulan Data ... 33
3.3 Data Penelitian ... 34
BAB IV HASIL DAN PEMBAHASAN ... 35
4.1 Hasil Penelitian ... 35
4.1.1 Analisis Sistem ... 35
4.1.1.1 Analisis Sistem yang Berjalan ... 35
4.1.1.2 Identifikasi Masalah ... 36
xi
4.1.2.1 Perancangan Alur Sistem FAQ ... 36
4.1.2.2 Perancangan Interface ... 37
4.1.3 Pengkodean ... 39
4.1.4 Pengujian ... 42
4.1.4.1 Dokumen Pengujian ... 43
4.1.4.2 Skenario Uji Coba ... 51
4.1.4.3 Hasil Uji Coba ... 51
4.2 Pembahasan ... 58
4.2.1 Perbandingan Hasil Uji Coba ... 58
4.2.2 Analisis Hasil Uji Coba ... 61
BAB V PENUTUP ... 71
5.1 Simpulan ... 71
5.2 Saran ... 72
xii
DAFTAR TABEL
Halaman
Tabel 2.1 Penghitungan TF-IDF ... 15
Tabel 2.2 Penghitungan TF-IDF Dokumen (doc n) terhadap dokumen Query .... 17
Tabel 2.3 Perankingan ... 18
Tabel 2. 4 Perhitungan MySQL Full-Text Search TF-IDF ... 20
Tabel 2.5 Perangkingan MySQL Full-Text Search TF-IDF ... 21
Tabel 2.6 Pembandingan Antara Classic Formula TF-IDF dan TF-IDF pada MySQL Full-Text Search ... 22
Tabel 4.1 Sample data Suara Warga UNNES dengan 5 topik bahasan ... 47
Tabel 4.2 Data Suara Warga UNNES Hasil Inputan Responden... 50
Tabel 4.3 Nilai Kemunculan data relevan pada setiap dokumen inputan responden ... 55
Tabel 4.4 Nilai Evaluasi Recall, Precision, dan F-measure ... 55
Tabel 4.5 Nilai Kemunculan data relevan pada setiap dokumen inputan responden ... 56
Tabel 4.6 Nilai Evaluasi Recall, Precisiom, dan F-mesure ... 56
Tabel 4.7 Nilai Kemunculan data relevan pada setiap dokumen inputan responden ... 57
Tabel 4.8 Nilai Evaluasi Recall, Precisiom, dan F-mesure ... 57
Tabel 4.9 Perbandingan nilai kemunculan data relevan ... 58
xiii
xiv
DAFTAR GAMBAR
Gambar 2.1 Kerangka Berfikir ... 28
Gambar 3.1 Tahapan model sekuensial linier ... 29
Gambar 3.2 Analisis dan kesenjangan antara rekayasa sistem dan desain perangkat lunak ... 30
Gambar 4.1 Perancangan Alur Sistem Pencarian ... 36
Gambar 4.2 Halaman Input ... 38
Gambar 4.3 Halaman Hasil FAQ ... 38
Gambar 4.4 Halaman Baca ... 39
Gambar 4.5 Perbandingan Nilai Recall ... 62
Gambar 4.6 Perbandingan Nilai Precision ... 64
xv
DAFTAR LAMPIRAN
Lampiran 1. Nilai Pembobotan TF-IDF pada Mysql Fulltext Search ... 75
Lampiran 2. Sreenshot Sistem ... 84
Lampiran 3. SK Pembimbing ... 86
1
PENDAHULUAN
1.1
Latar Belakang
Suara Warga Universitas Negeri Semarang atau sering disebut dengan
Suara Warga UNNES adalah salah satu bagian dari Sistem Akademik
Terpadu. Suara Warga UNNES digunakan sebagai media pengaduan semua
permasalahan yang berkaitan dengan kegiatan di lingkungan Universitas
Negeri Semarang. Suara Warga UNNES juga digunakan sebagai sarana bagi
civitas academica untuk berpartisipasi secara proaktif dalam mengawal program dan pelayanan yang di selengarakan oleh Universitas Negeri
Semarang. Layanan ini dapat diakses oleh seluruh civitas academica yang
terdiri dari pimpinan Universitas, pejabat Universitas, dosen, mahasiswa, dan
karyawan. Didalam Suara Warga UNNES pengguna bebas mengunggah
tulisan yang berhubungan dengan permasalahan di kampus. Fitur utama dalam
Suara Warga UNNES adalah fitur tanya-jawab. Fitur tersebut akan
mempermudah pihak terkait untuk memberikan tanggapan secara langsung
kepada pengirim terhadap tulisan yang diunggahnya.
Dewasa ini banyak sistem yang mengembangkan fitur tanya-jawab di
dalam sistem-nya seperti fitur diatas. Diantara fitur-fitur yang dikembangkan
banyak diantaranya menggunakan menggunakan fitur pencarian. Sampai saat
ini sudah banyak penelitian yang mengembangkan teknik pencarian secara
computer-based dengan berbagai pendekatan diawali sejak tahun 1940-an dimana pada saat itu sistem pencarian berbasis computer pertama dibuat. Jauh sebelum itu
pada tahun 1891-an sudah berkembang suatu ilmu yang diberi nama
temu-kembali informasi (information retrieval) yang merupakan konsep dasar dari
pencarian dokumen atau informasi. (Mark Sanderson, 2012).
FAQ (Frequently Asked Questions) menjadi salah satu bagian dari
sebuah website yang digunakan pengguna sebagai referensi awal terhadap
persoalan yang ingin pengguna ketahui sebelum menanyakan langsung ke
pihak penyedia layanan. Data dalam FAQ pada website adalah data statis yang
telah disediakan oleh penyedia layanan, pengguna tidak dapat menambahkan
data secara langsung dalam FAQ. Dengan jumlah data yang terbatas dan statis
menyebabkan pada beberapa kasus pertanyaan dan jawaban yang diinginkan
pengguna tidak tersedia pada daftar FAQ.
Terdapat lebih dari 16.000 tulisan yang telah diunggah di Suara Warga
UNNES. Banyak diantara tulisan-tulisan tersebut lambat atau bahkan tidak
ditanggapi oleh pihak terkait. Hal itu dimungkinkan karena topik bahasan dari
tulisan tersebut sudah pernah diunggah oleh pengguna lain dan sudah pernah
ditanggapi sebelumnya. Pengguna lain yang menanggapi atau membaca
tanggapan dari tulisan terdahulu merasa topik bahasan dari tulisan tersebut
sudah pernah ditanggapi sehingga tidak ditanggapi lagi. Selain itu dengan
besarnya jumlah tulisan yang diunggah dan tidak adanya FAQ membuat
pengguna lebih memilih mengungah tulisannya secara langsung tanpa
untuk mempermudah dan mempercepat pengguna mendapatkan informasi
tanggapan dengan memunculkan daftar tulisan yang sebelumnya pernah
diunggah.
Berdasarkan uraian-uraian di atas, maka peneliti tertarik untuk
melakukan penelitian terhadap sistem pencarian pada SuaraWarga UNNES
penelitian dengan judul : “OPTIMASI MODEL QUERY PADA SISTEM
FAQ DI SUARA WARGA UNIVERSITAS NEGERI SEMARANG”.
1.2
Identifikasi Masalah
Berdasarkan latar belakang yang telah dikemukakan, maka muncul
beberapa permasalahan sebagai berikut :
(1) Besarnya jumlah data dan banyak terulangnya data yang diinputkan pada
Suara Warga UNNES membuat banyak pengaduan tidak ditanggapi karena
pengguna lain merasa topik tersebut sudah pernah tanggapi sebelumnya.
(2) Tidak adanya fitur perncarian dan sistem FAQ pada Suara Warga UNNES
membuat pengguna lebih memilih mengunggah secara langsung
pengaduan tanpa mengecek terlebih dahulu apakah pengaduan dengan
topik tersebut sudah diunggah sebelumnya.
1.3
Rumusan Masalah
Berdasarkan latar belakang dan identifikasi masalah yang telah
dikemukakan, maka dirumuskan beberapa permasalahan sebagai berikut :
(2) Bagaimana kinerja sistem FAQ pada Suara Warga UNNES dengan
optimasi model query?
1.4
Tujuan Penelitian
Berdasarkan permasalahan yang telah diungkapkan di atas, maka dapat
dirumuskan tujuan dari penelitian yang akan dilakukan. Tujuan dari penelitian
ini adalah sebagai berikut :
(1) Untuk mengimplementasikan sistem FAQ pada Suara Warga UNNES.
(2) Untuk mengetahui model query dengan kinerja terbaik pada sistem FAQ di
Suara Warga UNNES.
1.5
Manfaat Penelitian
Manfaat dari penelitian ini adalah ikut berkontribusi dalam
perkembangan teknologi khususnya memberikan informasi model query yang
digunakan dalam pencarian data, sehingga perkembangan teknologi pencarian
data dapat lebih baik dengan menghasilkan hasil pencarian dengan data yang
relevan.
1.6
Batasan Masalah
Pada perencanaan optimasi model query untuk sistem FAQ pada
Suara Warga Universitas Negeri Semarang sangat kompleks, sehingga
dibutuhkan batasan masalah pada penelitian yang dilakukan yaitu;
a) Memfokuskan pada proses optimasi model query untuk sistem FAQ pada
b) Posting inputan berupa text
c) Asumsi dokumen yang diposting memiliki pola bahasa yang mengacu
pada Ejaan Yang Disempurnakan (EYD)
d) Singkatan dianggap satu kata
e) Tidak menangani kesalahan penulisan kata
f) Tidak menangani kesamaan makna pada term
1.7
Penegasan Istilah
Berikut ini dijelaskan beberapa istilah yang berkaitan dengan judul
penelitian ini. Beberapa istilah yang perlu dijelaskan adalah:
a) Optimasi
Secara umum optimasi berarti pencarian nilai terbaik (minimum atau
maksimum) dari beberapa fungsi yang diberikan pada suatu konteks.
Optimasi juga dapat berarti upaya untuk meningkatkan kinerja sehingga
mempunyai kualitas yang baik dan hasil kerja yang tinggi .
b) Model Query
Model Query merupakan model penggunaan data dari sebuah struktur
dokumen yang akan digunakan sebagai query dalam sebuah pencarian
dokumen. Data yang dimaksud adalah bagian dari keseluruhan dokumen
yang ada pada data inputan. Pada Suara Warga UNNES data inputan
dibagi menjadi 2 yaitu data inputan judul dan data inputan isi. Dari kedua
c) Sistem FAQ
FAQ (Frequent Ask Question) adalah daftar pertanyaan dan jawaban yang
sudah pernah dan atau sering ditanyakan dalam beberapa konteks, dan
berkaitan dengan topik tertentu. Sedangkan sistem FAQ yang dimaksud
adalah sistem yang mampu membuat daftar pertanyaan yang sudah pernah
atau sering ditanyakan dan diajukan secara otomatis dengan cara mencari
dokumen yang relevan dengan data inputan yang di ajukan oleh user.
d) Suara Warga Univeristas Negeri Semarang
Suara Warga Universitas Negeri Semarang atau sering disebut dengan
Suara Warga UNNES adalah salah satu bagian dari Sistem Akademik
Terpadu Universitas Negeri Semarang yang digunakan untuk sebagai
media pengaduan semua permasalahan yang berkaitan dengan seluruh
kegiatan di lingkungan Universitas Negeri Semarang. Layanan ini dapat
diakses oleh seluruh civitas academica yang terdiri dari pimpinan
Universitas, pejabat Universitas, dosen, mahasiswa, dan karyawan. Di
dalam sistem Suara Warga UNNES pengguna bebas memposting apa saja
yang berhubungan dengan apa yang ada di dalam kampus namun tetap
memperhatikan aspek sopan santun dalam penyampaian laporan.
e) Data Suara Warga
Data inputan yang telah diposting pengguna ke sistem Suara Warga
1.8
Sistematika Penulisan
Secara garis besar sistematika penulisan skripsi ini terbagi menjadi
tiga bagian, yaitu: bagian awal, bagian isi, dan bagian akhir.
(1) Bagian pendahuluan, berisi Halaman Judul, Pernyataan, Pengesahan,
Motto dan Persembahan, Kata Pengantar, Abstrak, Daftar isi, Daftar Tabel,
Daftar Gambar, Daftar Lampiran.
(2) Bagian isi, terdiri dari lima bab, yaitu:
BAB I : PENDAHULUAN; pada bagian ini merupakan pengantar
terhadap perancangan optimasi model query pada sistem
FAQ di Suara Warga UNNES seperti Latar Belakang,
Rumusan Masalah, Tujuan Penelitian, Manfaat Penelitian,
Batasan Masalah, Penegasan Istilah, Metode Pengumpulan
Data dan Sistematika Penulisan.
BAB II : TINJAUAN PUSTAKA; dalam bab ini dijelaskan mengenai
Landasan Teori, menguraikan teori-teori yang mendukung
judul dan mendasari pembahasan secara detail yang terkait
dengan penelitian ini, yaitu pengertian dan konsep pencarian
dokumen menggunakan metode TF-IDF dan penelitian
terdahulu.
BAB III : METODOLOGI PENELITIAN; dalam bab ini dijelaskan
BAB IV : HASIL DAN PEMBAHASAN ; bab ini dijelaskan hasil dari
tahapan penelitian, dan hasil pengujian sistem FAQ di Suara
Warga Universitas Negeri Semarang dari data pengujian oleh
responden dengan beberapa model query.
BAB V : PENUTUP, berisi Simpulan dan Saran dari penelitian yang
berjudul Optimasi Model Query pada sistem FAQ di Suara
Warga di Suara Warga Universitas Negeri Semarang.
9
TINJAUAN PUSTAKA
Pada pembahasan ini akan dijelaskan teori-teori yang akan dipakai dalam
penelitian. Penelitian ini menggunakan konsep temu-kembali informasi (information retrieval) sebagai konsep dasar dari sistem FAQ yang dibuat. Metode perhitungan dalam sistem FAQ pada penelitian ini menggunakan metode pembobotan TF-IDF
pada Mysql Fulltext Search. Teori pengujian sistem menggunakan recall,precision,
dan f-measure yang merupakan metode evaluasi yang digunakan pada sistem temu-kembali informasi. Selain itu juga dijelaskan metode feature selection dengan chi-square yang digunakan pada salah satu model query.
2.1
Landasan Teori
2.1.1 Konsep Dasar Optimasi
Menurut Hannawati (2002) optimasi adalah pencarian nilai-nilai
variabel yang dianggap optimal, efektif dan juga efisien untuk mencapai
hasil yang diinginkan. Masalah optimasi ini beraneka ragam tergantung
dari bidangnya.
Fachrurrazi (2013) mengemukakan bahwa optimasi adalah salah
satu disiplin ilmu dalam Matematika yang fokus untuk mendapatkan nilai
minimum atau maksimum secara sistematis dari suatu fungsi, peluang,
maupun pencarian nilai lainnya dalam berbagai kasus. Optimasi sangat
efektif efisien untuk mencapai target hasil yang ingin dicapai. Tentunya
hal ini akan sangat sesuai dengan prinsip ekonomi
yang berorientasikan untuk senantiasa menekan pengeluaran untuk
menghasilkan outputan yang maksimal. Optimasi ini juga penting karena
persaingan saat ini sudah benar benar sangat ketat.
Pada bidang temu-kembali informasi terdapat beberapa hal yang
mempengaruhi hasil dari sistem yang dibuat, diantaranya adalah metode
perhitungan yang digunakan dan data yang menjadi objek perhitungan.
Bentuk optimasi pada metode perhitungan diantaranya adalah dengan
melakukan modifikasi terhadap metode perhitungan agar hasilnya lebih
optimal. Pada optimasi objek perhitungan dapat dilakukan dengan
memodifikasi data yang ada sehingga diharapkan hasil perhitungan lebih
optimal. Beberapa bentuk optimasi objek data perhitungan yang sering
digunakan dalam sistem temu kembali adalah penggunaan stopword,
stemming, dan penggunaan feature selection.
2.1.2 Konsep Dasar Sistem FAQ
Faq.org (2015), FAQ atau Frequently Asked Questions adalah
daftar pertanyaan yang sering diajukan. FAQ sendiri digunakan untuk
membantu pengguna menemukan jawaban dari pertayaan yang akan
diajukan. Pada awalnya FAQ digunakan dalam newsgroup yang pada saat
digunakan sebagai rujukan awal dan filter pengguna sebelum menggunggah pertanyaan baru.
Menurut Wikipedia (2015) Frequently asked questions (FAQ) atau
Questions and Answers (Q&A) adalah daftar pertanyaan dan jawaban yang sering diajukan dan berkaitan dengan topik tertetu. Fitur ini
digunakan pada mailinglist dan forum online yang dimana pertanyaan
umum tertentu cenderung sering diajukan kembali.
Jogiyanto (1999) didalam Muhammad Dwiky (2012) menjelaskan
bahwa suatu sistem adalah jaringan kerja prosedur-prosedur yang
saling berhubungan, berkumpul bersama-sama untuk melakukan suatu
kegiatan ataun menyelesaikan suatu sasaran tertentu.
FAQ pada sebuah website adalah berupa data statis yang dibuat
oleh penyedia layanan. Dengan jumlah data yang terbatas dan statis
menyebabkan pada beberapa kasus pertanyaan dan jawaban yang
diinginkan pengguna tidak tersedia pada daftar FAQ.
Sistem FAQ yang dimaksud adalah sistem yang mampu membuat
daftar pertanyaan yang sudah pernah atau sering ditanyakan dan diajukan
secara otomatis dengan cara mencari dokumen yang relevan dengan data
inputan yang di ajukan oleh user sehingga dapat memberikan saran
2.1.2.1 Konsep Dasar Temu-kembali Informasi (Information Retrieval)
Menurut Goker (2009) secara sederhana temu-kembali
informasi adalah tentang menemukan informasi. Lebih spesifik,
temu-kembali informasi adalah proses menyamakan query yang cocok
dengan objek informasi yang telah terindex. Sebuah indes adalah
struktur data yang telah dioptimasi yang dibuat diatas objek informasi,
sehingga memungkinkan untuk akses cepat pada proses pencarian.
Penguraian tersebut diantaranya menghapus kata dengan nilai semantic
yang kecil (stopword) dan menjadikannya sebagai kata dasar
(stemming).
Menurut Rijsbergen (1979) di dalam Nadirman (2006) “Sebuah
sistem temu-kembali informasi tidak memberitahu (yakni tidak
mengubah pengetahuan) pengguna mengenai masalah yang
ditanyakannya. Sistem tersebut hanya memberitahukan keberadaan
(atau ketidakberadaan) dan keterangan dokumendokumen yang
2.1.2.2 Konsep Dasar Term Frequency-Inverse Document Frequency (TF-IDF)
TF-IDF atau Term Frequency-Inverse Document Frequency
adalah angka statistic yang mendefinisikan betapa pentingnya sebuah
kata dalam kumpulan dokumen atau corpus. (Rajaraman , 2011)
Menurut Robertson (2005) metode Tf-Idf merupakan suatu cara
untuk memberikan bobot hubungan suatu kata (term) terhadap
dokumen. Metode ini menggabungkan dua konsep untuk perhitungan
bobot yaitu, frekuensi kemunculan sebuah kata didalam sebuah
dokumen tertentu dan inverse frekuensi dokumen yang mengandung
kata tersebut. Algoritma TF-IDF merupakan salah satu skema
pembobotan istilah/term dalam pencarian dokumen. Berikut tahapan
pada proses pembobotan TF-IDF, yaitu:
a) Pembobotan Lokal Term Frequency (TF).
Menurut Manning,dkk (2008) TF (Term Frequency) adalah
nilai frekuensi kemunculan sebuah term dalam sebuah dokumen.
Keakuratan sebuah pencarian sangat tergantung dengan perhitungan
TF. Dalam sebuah dokumen terdapat kata-kata yang sangat sering
muncul pada sebuah dokumen dan banyak dokumen lainnya namun
tidak penting untuk menjelaskan karakteristik atau isi dokumen. Dalam
dianggap tidak penting dalam sebuah dokumen, hal ini dimaksudkan
agar pada saat perhitungan term yang dinilai tidak penting tersebut
tidak mengganggu proses pembobotan pada dokumen. Dalam
implementasinya penghilangan term ini dapat berupa kata sambung
atau kata penghubung. Istilah untuk term yang dihilangkan ini adalah
stopword.
b) Document Frequency (DF)
Document Frequency atau Frekuensi dokumen adalah jumlah dokumen yang berisi term pada seluruh dokumen. Dengan kata lain
Document Frequency ini adalah nilai berapa banyak dokumen yang
mengandung term pada kumpulan dokumen. (Joho , 2007)
c) Pembobotan Global Invers Document Frequency (IDF)
Inverse Document Frequency (IDF) adalah bobot yang dugunakan untuk menyatakan seberapa penting sebuah term didalam
kumpulan dokumen (Ounis,2009). Nilai ini diperoleh dengan formula
berikut:
Inverse Document Frequency = log10 ( N/dft )
Keterangan:
N : jumlah dokumen
dft : jumlah dokumen yang mengandung term t
idf : log dari umlah dokumen dibagi jumlah dokumen
d) Perhitungan TF-IDF
Berikut rumus perhitungan TF-IDF:
TF-IDF = Term Frequency x Inverse Document Frequency
Atau
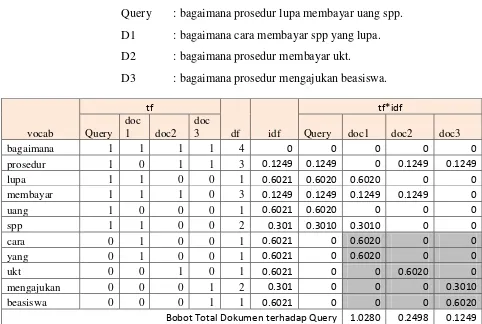
Query : bagaimana prosedur lupa membayar uang spp.
D1 : bagaimana cara membayar spp yang lupa.
D2 : bagaimana prosedur membayar ukt.
D3 : bagaimana prosedur mengajukan beasiswa.
vocab/doc
Dari tabel 2.1 dapat di lihat nilai tf-idf dari term “bagaimana”
yang muncul disemua dokumen memiliki nilai 0 atau dianggap tidak
berbobot, sedangkan nilai tf-idf dari term “uang” yang hanya muncul di
1 dokumen memiliki nilai 0.60206.
Dari tabel dan perbandingan nilai tf-idf diatas dapat disimpulkan
semakin tinggi kemunculan sebuah term di semua dokumen akan
mengurangi nilai bobot dari term tersebut, dan sebaliknya semakin
sedikit atau rendah kemunculan sebuah term di semua dokumen nilai
bobot dari term tersebut akan tinggi. Hal ini sesuai konsep dari
pembobotan dengan tf-idf dari penelitian-penilitian sebelumnya.
2.1.2.3 Konsep Dasar Pencarian dengan pembobotan TF-IDF
Dalam kumpulan dokumen yang memiliki jumlah dokumen sangat
besar, akan dibutuhkan sebuah metode yang digunakan untuk
membantu untuk menemukan sebuah informasi dari
dokumen-dokumen tersebut. Ada banyak metode yang digunakan dalam
pencarian tersebut, diantaranya mengukur bobot dokumen terhadap
query dari informasi yang dicari dan atau mengukur kesamaan (similiarity) sebuah dokumen dengan query dari
informasi yang dicari.
Tahap awal yang dilakukan dalam pencarian dengan
query pencarian dalam kumpulan dokumen. Dari pembobotan terhadap
query pencarian tersebut akan dilakukan pengurutan terhadap nilai bobot. Hasil pencarian yang ditampilkan adalah urutan ranking bobot
dari semua dokumen terhadap query pencarian.
Contoh matriks:
Query : bagaimana prosedur lupa membayar uang spp.
D1 : bagaimana cara membayar spp yang lupa.
D2 : bagaimana prosedur membayar ukt.
D3 : bagaimana prosedur mengajukan beasiswa.
Tabel 2.2 Penghitungan TF-IDF Dokumen (doc n) terhadap dokumen Query
Keterangan :
Angka 1 : Menandakan bahwa kata tersebut terdapat didalam dokumen Angka 0 : Menandakan bahwa kata tersebut tidak terdapat didalam dokumen
vocab
Dari tabel 2.2 , dapat dilihat perhitungan bobot total dokumen
terhadap dokumen query. Bobot total sebuah dokumen adalah jumlah
total bobot term yang ada di dokumen dan yang hanya ada dalam
Query. Bagian area abu-abu dari tabel adalah bagain dari term dokumen
yang tidak termasuk dalam query, bobot term yang tidak ada pada
Query tidak dihitung untuk bobot total. Bobot inilah yang nantinya akan
diranking.
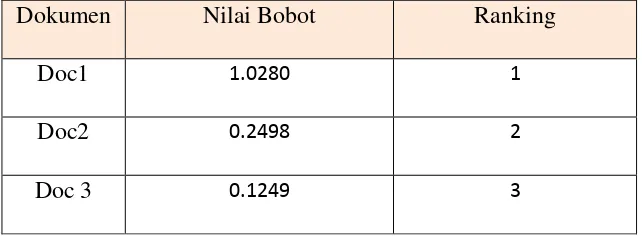
Tabel 2.3 Perankingan
Dari tabel 2.3 diatas didapatkan hasil perankingan dari
bobot total dokumen terhadap Query. Dari perankingan tersebut dapat
dapat diambil urutan untuk hasil dari pencarian. Dokumen dengan
bobot tertinggi adalah dokumen yang paling relevan menurut
perhitungan dengan TF-IDF.
Dokumen Nilai Bobot Ranking
Doc1 1.0280 1
Doc2 0.2498 2
2.1.2.4 Pencarian Pada MYSQL Full-Text Search
MySQL adalah sebuah implementasi dari sistem manajemen
basisdata relasional (RDBMS) yang didistribusikan secara gratis
dibawah lisensi GPL (General Public License). Setiap pengguna dapat
secara bebas menggunakan MySQL, namun dengan batasan perangkat
lunak tersebut tidak boleh dijadikan produk turunan yang bersifat
komersial. MySQL sebenarnya merupakan turunan salah satu konsep
utama dalam basisdata yang telah ada sebelumnya; SQL (Structured
Query Language). SQL adalah sebuah konsep pengoperasian
basisdata, terutama untuk pemilihan atau seleksi dan pemasukan data,
yang memungkinkan pengoperasian data dikerjakan dengan mudah
secara otomatis. (Wikipedia,2015)
MySQL Full-Text Search adalah salah satu fungsi dalam
pencarian yang ada dalam MySQL. Di MySQL Full-Text Search
metode yang digunakan dalam pencariannya adalah perangkingan
bobot TF-IDF. MySQL Full-Text Search menggunakan modifikasi dari
formula pembobotan “term frequency-inverse document
frequency” (TF-IDF) untuk merangking tingkat relevansi dokumen
dari query yang diberikan. Pembobotan TF-IDF dihitung dari seberapa
banyak frekuensi term muncul dalam sebuah dokumen dan seberapa
yang digunakan dalam MySQL Full-Text Search adalah sebagai berikut,
TF-IDF = Term Frequency x Inverse Document Frequency
Atau
DF : Jumlah kemunculan kata dalam kalimat (df) IDF : Bobot Inverse Document Frequency
N : Jumlah Total Semua Dokumen.
Wt,d : bobot dokumen d terhadap term t
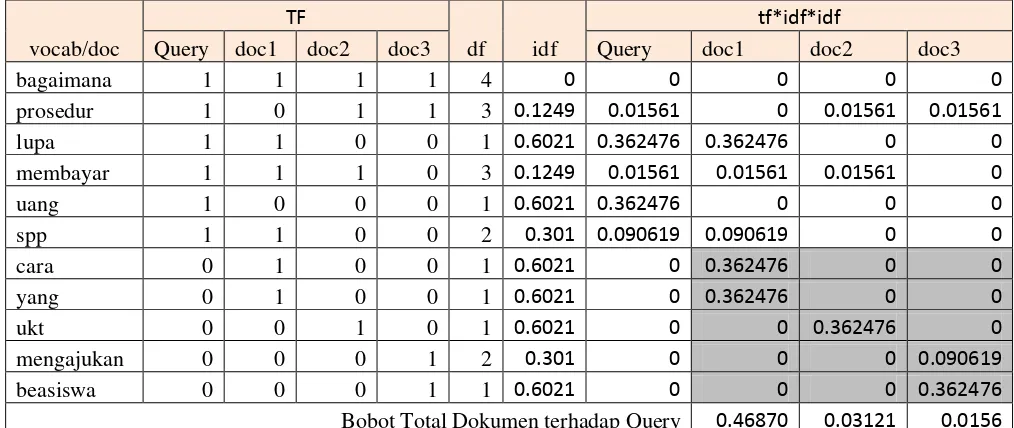
Berikut adalah contoh perbandingan Classic Formulas TF-IDF
dan MySQL Full-Text Search TF-IDF,
vocab/doc
Dari tabel 2.4 , dapat dilihat perhitungan bobot total dokumen
terhadap dokumen query dengan TF-IDF pada MySQL Full-Text
Search. Bobot total sebuah dokumen adalah jumlah total bobot term yang ada di dokumen dan yang hanya ada dalam Query. Bagian area
abu-abu dari tabel adalah bagain dari term dokumen yang tidak
termasuk dalam query, bobot term yang tidak ada pada Query tidak
dihitung untuk bobot total. Bobot inilah yang nantinya akan
diranking.
Dokumen Nilai Bobot Ranking
Doc1 0.46870 1
Doc2 0.03121 2
Doc 3 0.0156 3
Tabel 2.5 Perangkingan MySQL Full-Text Search TF-IDF
Dari tabel 2.5 diatas adalah hasil perankingan dari bobot total
dokumen terhadap Query dengan TF-IDF pada MySQL Full-Text
Search . Dari perankingan tersebut dapat dapat diambil urutan untuk hasil dari pencarian. Dokumen dengan bobot tertinggi adalah dokumen
yang paling relevan menurut perhitungan dengan TF-IDF.
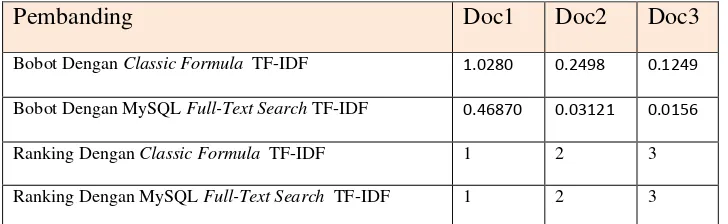
Dari perhitungan diatas, untuk melihat perbedaan Classic
Formula TF-IDF dan TF-IDF pada MySQL Full-Text Search maka dilakukanlah pembandingan. Pembandingan dapat dilihat pada table
Tabel 2.6 Pembandingan Antara Classic Formula TF-IDF dan TF-IDF pada MySQL
Full-Text Search
Tabel 2.6 diatas adalah hasil pembandingan antara Classic
Formula TF-IDF dan TF-IDF pada MySQL Full-Text Search . Dari pembadingan tersebut dapat disimpulkan bahwa modifikasi yang
dilakukan oleh MySQL Full-Text Search pada formula TF-IDF tidak
mengubah nilai urutan/ranking dokumen. Perubahan terjadi pada nilai
bobot dokumen. Secara konsep perankingan modifikasi yang
dilakukan MySQL Full-Text Search tidak menggubah nilai
urutan/ranking.
2.1.3 Model Query
Menurut Hasugian (2006) query adalah format bahasa perintah.
Format Bahasa tersebut di input (dimasukan) oleh pengguna kedalam
Sistem temu kembali informasi. Dalam interface (antar muka) Sistem
temu kembali informasi selalu disediakan kolom/ruas sebagai tempat bagi
pengguna untuk mengetikkan (menuliskan) query nya. Dalam
perpustakaan OPAC (Online Public Acces Catalog) disebut “Search
expression”. Pada kolom itulah pengguna mengetik/ menuliskan bahasa
Pembanding Doc1 Doc2 Doc3
Bobot Dengan Classic Formula TF-IDF 1.0280 0.2498 0.1249
Bobot Dengan MySQL Full-Text Search TF-IDF 0.46870 0.03121 0.0156
Ranking Dengan Classic Formula TF-IDF 1 2 3
permintaanya (query), dan setelah query itu dimasukkan selanjutnya mesin akan melakukan proses pemanggilan terhadap dokumen yang diinginkan
dari database.
Model query merupakan bentuk query yang diambil dari sebuah
struktur dokumen. Bentuk query yang diambil dari bagian dari struktur
dokumen dapat berupa sebuah term atan terdiri dari banyak term. Ogilvie
(2013) membuat contoh aturan bahwa permodelan dokumen terstruktur
terdiri dari tittle, abstract, dan body. Ketiga bagian tersebut merupakan
bagian utama dari struktur dokumen. Penggunaan model query dalam
sistem temu kembali dimaksudkan untuk mengefektifkan penggunaan
query yang sesuai dengan sistem yang dibuat.
2.1.3.1 Feature Selection (Seleksi Fitur) Chi-Square
Menurut C.Sun (2009) didalam Supriyanto (2011) seleksi fitur
adalah proses menghilangkan beberapa fitur atau term yang kurang
relevan untuk penentuan topik suatu dokumen. Chi-square adalah salah
satu seleksi fitur yang mampu mengilangkan banyak fitur tanpa
mengurangi tingkat akurasi.
Keterangan:
2.1.4 Optimasi Model Query pada Sistem FAQ
Data yang dihasilkan oleh sistem FAQ yang mengimplementasikan
sistem temu-kembali informasi menjadi tolakukur dalam menentukan
efektifitas sebuah sistem FAQ itu sendiri. Tidak hanya menampilkan
jumlah data yang relevan sebanyak-banyaknya, dalam sistem
temu-kembali juga diharapkan mampu menangani jumlah tidak relevan dari data
yang berhasil ditampilkan sistem. Hal tersebutlah yang mendasari untuk
dilakukan optimasi dalam sebuah sistem FAQ.
Perbedaan pola data yang ada dilapangan menyebabkan perbedaan
bentuk optimasi dari tiap-tiap kasus sistem temu-kembali. Bentuk optimasi
dari sebuah sistem temu-kembali diantaranya adalah memodifikasi
objek-objek yang berpengaruh dalam sistem temu-kembali itu sendiri untuk
menghasilkan hasil yang akurat. Pada bidang temu-kembali informasi
terdapat beberapa hal yang mempengaruhi hasil dari sistem yang dibuat,
diantaranya adalah metode perhitungan yang digunakan dan data yang
menjadi objek perhitungan.
Bentuk optimasi pada metode perhitungan diantaranya adalah
dengan melakukan modifikasi terhadap metode perhitungan agar hasilnya
lebih optimal. Bentuk optimasi ini bisa dilakukan dengan mencari metode
perhitungan terbaik dengan cara mengujikan beberapa metode perhitungan
Pada optimasi objek perhitungan dapat dilakukan dengan
memodifikasi data yang ada sehingga diharapkan hasil perhitungan lebih
optimal. Beberapa bentuk modifikasi objek data perhitungan yang sering
digunakan dalam sistem temu kembali adalah penggunaan stopword,
stemming, dan penggunaan feature selection. Hasil dari modifikasi data
perhitungan tersebut akan dijadikan sebuah query yang nanti akan dihitung
pada sistem temu-kembali yang telah dibuat. Bentuk optimasi yang dapat
dilakukan adalah dengan mengujikan model-model query yang ada untuk
diambil model query terbaik yang memiliki nilai akurasi yang tertinggi.
2.2 Penelitian Terdahulu
Penelitian terdahulu yang berkaitan dengan pencarian dokumen sangat
diperlukan sebagai bahan acuan dalam penulisan. Adapun beberapa penelitian
terdahulu mengenai pencarian dokumen teks, antara lain dilakukan oleh
Harjanto (2012) dari Universitas Diponegoro yang berjudul "Sistem Temu
Kembali Informasi pada Dokumen Teks Menggunakan Metode Term
Frequency Inverse Document Frequency (TF-IDF)." hasil penelitiannya
menyatakan bahwa metode pembobotan dokumen TF-IDF dapat me-retrieve
dokumen sesuai dengan query pengguna. Hasil recall rata-rata dari 20
dokumen dan 5 query memberikan nilai 97,2%. Penelitian serupa dilakukan
oleh Fitri (2013) dari Universitas Tanjungpura dalam penelitiannya yang
berudul “Perancangan Sistem Temu Balik Informasi Dengan Metode
Indonesia”, menyatakan bahwa dengan kombinasi TF-IDF dapat menyajikan
data relevan pada pencariannya. Nilai presisi dan recall menunjukan dari hasil
pengujuan yang dilakukan pada 5 kata kunci menghasilkan nilai recall 1 yang
menunjukan bahwa semua dokumen yang relevan dapat ditemu-kembalikan
oleh sistem, dan nilai precision antara 0.1316 dan 1 yang menunjukan terdapat
dokumen lain selain dokumen relevan yang ditemu-kembalikan oleh sistem.
Pada kedua penelitian diatas membahas sistem-temu kembali dengan
metode pembobotan TF-IDF. Pembobotan dilakukan dengan menghitung
bobot tiap term yang ada pada query dengan dokumen yang ada. Query yang
digunakan diambil dari satu field atau dengan satu model query. Penelitian
lain yang membahas sistem-temu kembali dengan mempergunakan lebih dari
satu field atau lebih dengan satu model antara lain dilakukan oleh Saptari
(2006) dari Universitas Gajah Mada dengan penelitiannya yang berjudul
“Temu Kembali Informasi Bibliografi Dengan Bahasaalami Pada field Judul
dan Sufjek (Studi Efektivitas Katalog Induk Terpasang Perpustakaan UGM)”.
Dalam penelitiannya dibahas sistem temu kembali dengan penggunaan lebih
dari satu field atau lebih dari satu model query. Dari penggunaan lebih dari
satu model query tersebut dilakukan pembandingan. Hasil penelitian tersebut
didapatkan nilai efektifitas 66.66% dengan penggunaan query dari field judul
dan nilai efektifitas 58.3% dengan penggunaan query dari field subjek.
Penelitian serupa dilakukan oleh Kusumawardani (2013) dari
Universitas Airlangga dengan judul penelitiannya “Temu Kembali Informasi
dengan controlled vocabulary pada field judul, subyek, dan pengarang di
Perpustakaan Universitas Airlangga)”. Pada penelitian tersebut dibahas sistem
temu kembali dengan 3 field atau model query yang masing-masing dari field
tersebut dibandingkan hasilnya. Dari hasil pengujian terhadap 100 judul
dokumen didapatkan sebanyak 98 dokumen berhasil ter-retrive dengan
penggunaan query judul. Pengujian yang sama dilakukan terhadap 119 nama
pengarang dari dokumen didapatkan sebanyak 100 dokumen berhasil
ter-retrive dengan query yang diambil dari field pengarang. Sedangkan pengujian
dengan dengan query yang diambil dari subjek didapatkan hanya sebesar 19
2.3 Kerangka Berfikir
29
METODE PENELITIAN
3.1
Metodologi Pengembangan Perangkat Lunak
Metode pengembangan perangkat lunak yang digunakan yaitu linier
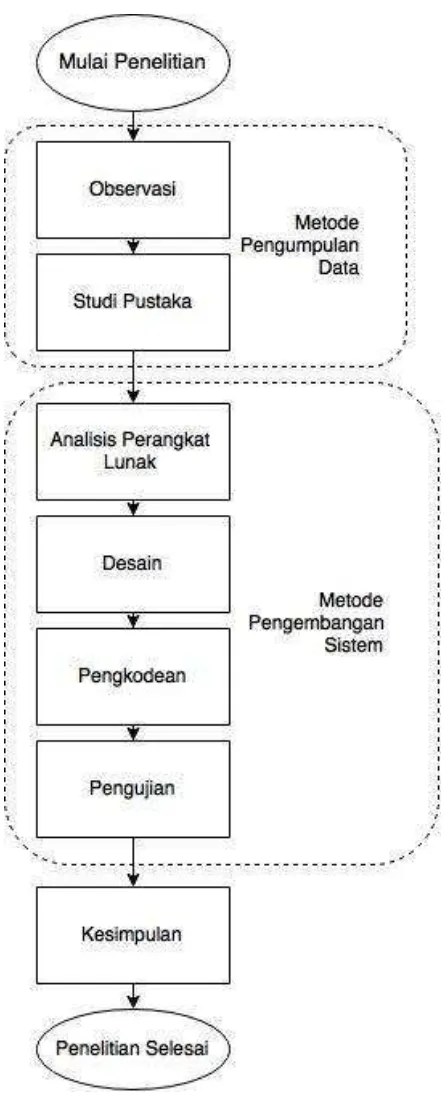
sequential model atau yang biasa disebut dengan waterfall model. Linier sequential model merupakan metode pengembangan perangkat lunak yang diawali dari proses analisis, kemudian desain, koding dan testing (Fowler, 2005).
Berikut merupakan ilustrasi dari proses tersebut.
Gambar 3.1 Tahapan model sekuensial linier (Fowler, 2005)
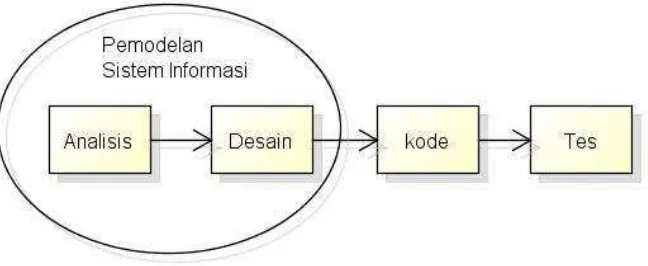
Menurut Pressman (2002) Sequential linier model atau metode waterfall
merupakan sebuah pendekatan perangkat lunak yang dimulai pada proses analisis
perangkat lunak, dilanjutkan desain perangkat lunak kemudian kode/ pembuatan
perangkat lunak dan diakhiri dengan pengujian perangkat lunak.
Kelebihan dan kekurangan model Waterfall adalah, beberapa prinsip utama
yaitu project dibagi-bagi dalam beberapa fase yang saling berurutan, penekanan
keseluruhan sistem sekaligus, sekaligus kontrol yang ketat dalam siklus
hidup project dengan menggunakan bantuan dokumentasi tertulis. Kelebihan dari
metode waterfall mempunyai kemudahan untuk dimengerti, mudah digunakan,
requirement dari sistem bersifat stabil, baik dalam manajemen kontrol, serta
bekerja dengan baik ketika kualitas lebih diutamakan dibandingkan dengan
biaya dan jadwal atau deadline.
3.1.1 Analisis Kebutuhan Sistem
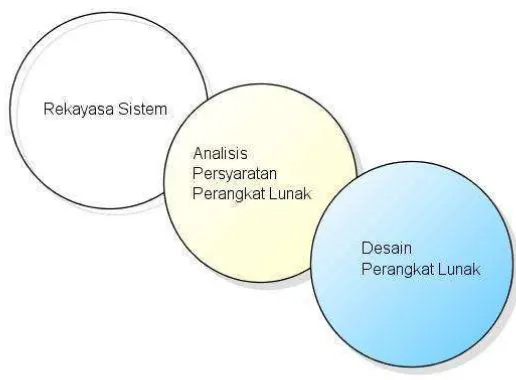
Analisis kebutuhan adalah tugas rekayasa perangkat lunak yang
menjembatani jurang antara alokasi perangkat lunak tingkat sistem dan
perancangan perangkat lunak. Analisis kebutuhan sistem akan memberikan
model-model yang akan diterjemahkan kedalam data, arsitektur, interface,
dan desain prosedural kepada perancang perangkat lunak (Pressman,
2002).
Gambar 2.2 Analisis dan kesenjangan antara rekayasa sistem dan desain perangkat lunak
3.1.2 Desain
Pada tahap ini alur dari sistem dibuat. Alur tersebut adalah skenario
bagaimana sistem itu berjalan, Selain itu pada tahap ini dilakukan
perancangan terhadap tampilan antar-muka atau interface dari sister yang
akan dibuat. Pada penelitian ini kedua tahap tersebut akan mengacu pada
sistem Suara Warga UNNES yang sudah berjalan, pada perancangan hanya
ditambahkan alur bagaimana proses sistem FAQ berjalan dan pada bagian
antar-muka ditambahkan halaman ditampilkannya hasil FAQ pada sistem
yang dijadikan simulasi Suara Warga UNNES yang akan dibuat.
3.1.3 Pengkodean
Setelah tahap analisis dan desain selanjutnya adalah tahap
pengkodean atau koding. Pada tahap ini mengimplementasikan apa yang
sudah dianalisis dan dirancang kedalam bahasa pemrograman website
seperti PHP, HTML, CSS dan lain-lain sehingga semua fungsi dapat
dijalankan dengan baik oleh pengguna. Proses pengkodean dalam penelitian
ini menggunakan framework PHP yaitu Codeigniter.
3.1.4 Pengujian
Pengujian adalah sebuah proses terhadap aplikasi atau program
untuk menemukan segala kesalahan dan segala kemungkinan yang akan
menimbulkan kesalahan sesuai spesifikasi perangkat lunak yang telah
yang diuji adalah efektifitas penggunaan model query terhadap sistem pencarian atau sistem temu-kembali di Sistem FAQ.
Untuk mengevaluasi kinerja sebuah sistem pencarian atau sistem
temu kembali dibutuhkan sebuah metode yang dapat mengukur
keefektifan dan keakuratan sebuah algoritma dari sebuah sistem temu
kembali. Recall dan Precision adalah langkah dasar yang digunakan dalam
mengevaluasi model pencarian (Hardi, 2006).
Recall adalah rasio dari jumlah dokumen relevan yang berhasil diambil atau ditemukembalikan dari seluruh dokumen relevan yang ada
pada sistem (Nadirman , 2006). Berikut persamaan dari Recall :
Dari formula diatas diketahui bahwa jumlah data relevan
yang ter-retrive adalah jumlah data yang berhasil ditemu-kembalikan oleh
sistem dan relevan dengan query pencarian, sedangkan jumlah
keseluruhan data relevan adalah jumlah keseluruhan data yang relevan
yang ada didalam sistem. Hasil recall adalah hasil pembagian dari kedua
variabel tersebut.
Precission adalah rasio dokumen relevan yang rasio dari jumlah dokumen relevan yang berhasil diambil atau ditemukembalikan dari
seluruh dokumen yang berhasil diambil atau ditemukembalikan
Dari formula diatas diketahui bahwa jumlah data relevan yang
ter-retrive adalah jumlah data yang berhasil ditemu-kembalikan oleh sistem
dan relevan dengan query pencarian, sedangkan jumlah keseluruhan data
yang teretrive adalah jumlah keseluruhan data berhasil ditemu-kembalikan
oleh sistem baik data relevan maupun data yang tidakv relevan. Hasil
precision adalah hasil pembagian dari kedua variabel tersebut.
F-measure merupakan nilai hubungan yang mengkombinasikan
antara hasil perhitungan recall dan precision yang mempresentasikan
akurasi sistem (Zhang , 2009) . Persamaan F-measure seperti berikut :
3.2
Metode Pengumpulan Data
Metode pengumpulan data yang diterapkan dalam memperoleh data yang
dibutuhkan yaitu observasi. Observasi atau pengamatan dilakukan pada Suara
Warga UNNES yang diakses pada Sistem Akademik Terpadu (SIKADU) melalui
http://akademik.unnes.ac.id. Berdasarkan pengamatan yang dilakukan di Suara
Warga UNNES diperoleh bahwasannya, masih terjadi banyak perulangan
pertanyaan yang sama yang telah diajukan, walaupun pertanyaan dengan topik
yang sama sudah pernah ditanggapi sebelumnya oleh pengguna lain. Tidak
secara langsung pertanyaan tanpa mengecek terlebih dahulu apakah pertanyaan
tersebut sudah pernah diajukan.
3.3
Data Penelitian
Data penelitian diperoleh dengan menggunakan 25 data unggahan pengguna
Suara Warga UNNES yang diambil secara acak dan dikelompokan menjadi 5
topik bahasan, sehingga setiap topik bahasan memiliki 5 data unggahan pengguna
dari Suara Warga UNNES. Data tersebut dimasukan pada database simulasi
sistem FAQ Suara Warga UNNES yang telah dibuat.
Data dari Suara Warga UNNES memiliki 2 field inputan yaitu judul dan isi.
Karakteristik dari data tersebut adalah singkat dan pada kasus tertentu banyak
terjadi kesalahan pengetikan. Selain itu struktur kalimat pada sebagian besar data
mempergunakan salam pembuka sehingga pada tahap preprocessing dilakukan
penghilangan stopword.
Sebagai data penguji dilakukan pengambilan data dari 9 responden yang
terdiri dari mahasiswa Universitas Negeri Semarang secara acak yang
masing-masing responden mengisi form simulasi Suara Warga UNNES sesuai skenario
yang telah dibuat. Skenario tersebut mewakili permasalahan yang ada pada data 5
topik bahasan yang sebelumnya telah diambil dari sistem Suara Warga UNNES.
Dari 9 responden dan 5 topik bahasan diperoleh 45 data yang digunakan sebagai
71
BAB V
PENUTUP
5.1
Simpulan
Sistem FAQ di Suara Warga UNNES sudah diimplementasikan
dan dilakukan uji coba untuk selanjutnya dilakukan optimasi. Optimasi
model query dilakukan dengan pengujian beberapa model query untuk
mengetahui model query apa yang terbaik untuk sistem FAQ di Suara
Warga Universitas Negeri Semarang .
Hasil pengujian dari sebanyak 25 data Suara Warga dan 45 data
pengujian dari 9 responden didapatkan nilai F-measure yang mewakili
kinerja dari ketiga model query tersebut yaitu uji coba 1 dengan model
query data isi sebesar 0.56, uji coba 2 dengan model query data isi dengan
feature selection sebesar 0.70, dan uji coba 3 dengan model query data
judul sebesar 0.82. Dari hasil pengujian tersebut didapatkan model query
dari data judul adalah model query yang memiliki nilai tertinggi pada kasus
Saran untuk penelitian optimasi model query untuk sistem FAQ
adalah menambahkan feature selection pada semua model query sehingga
dapat menangani term-term yang dianggap mengganggu dari proses
pencarian. Disarankan juga untuk menambahkan motode untuk mengatasi
persamaan makna pada masing-masing term yang dipakai pada sehingga
73
DAFTAR PUSTAKA
Fachrurrazi, S. 2013. “Penerapan Algoritma Genetika Dalam Optimasi
Pendistribusian Pupuk Di PT Pupuk Iskandar Muda Aceh Utara” . Aceh :
Universitas Malikussaleh Reuleut.
Faq.Org. 1997. “FAQs about FAQs”. http://www.faqs.org/faqs/faqs/about-faqs/.
(24 Juni 2015).
Fitri, Meisya. 2013. Perancangan Sistem Temu Balik Informasi Dengan Metode Pembobotan Kombinasi Tf-Idf Untuk Pencarian Dokumen Berbahasa Indonesia. Universitas Tanjungpura : Semarang
Fowler, Martin. 2004. “UML distilled: a brief guide to the standard object
modeling language”. Addison-Wesley Professional,.
Goker, Ayse, and John Davies, eds. 2009. “Information retrieval: Searching in the
21st century”. John Wiley & Sons,.
Harjanto, dkk. 2012. Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF).. Universitas Diponegoro : Semarang
Hasugian, Jonner. "Penelusuran informasi ilmiah secara online: perlakuan terhadap seorang pencari informasi sebagai real user." Pustaha 2.1 (2006): 1-13.
Hannawati, Anies. Thiang, Eleaza.r. 2002.“Pencarian Rute Optimum
Menggunakan Algoritma Genetika”. Universitas Kristen Petra :
Surabaya.
Hardi, Wisnu . 2006 . “Mengukur Kinerja Search Engine: Sebuah Eksperimentasi
Penilaian Precision And Recall Untuk Informasi Ilmiah Bidang Ilmu
Perpustakaan Dan Informasi”. UNSYIAH : ACEH.
Joho, H. and Sanderson, M. 2007 . “Document frequency and term specificity “.
In:Proceedings of the Recherche d'Information Assistée par Ordinateur
Conference (RIAO). RIAO 2007 - 8th Conference, 30th May - 1st June
2007, Pittsburgh, PA
Manning, Christopher D., Prabhakar Raghavan, and Hinrich Schütze. 2008.
“Introduction to information retrieval. Vol. 1”. Cambridge: Cambridge
Muhammad Dwiky, Khalifardhi. 2012. “Sistem Informasi Evaluasi Nilai Hasil Belajar Siswa Menggunakan Visual Basic 6.0 dan Microsoft Access di
Sma Negeri 1 Gamping”. Yogyakarta: Universitas Negeri Yogyakarta.
Nadirman, Firnas . 2006 . “Sistem Temu-Kembali Informasi Dengan Metode
Vector Space Model Pada Pencarian File Dokumen Berbasis Teks
“.Yogjakarta: UGM.
Ogilvie, P., & Callan, J. 2003. “Language models and structured document
retrieval”. Fuhr et al.[126], 18-23.
Ounis , Iadh . 2009. “Inverse Document Frequency”. Springer US : Springer US.
Sanderson, Mark, and W. Bruce Croft. "The history of information retrieval research." Proceedings of the IEEE 100.Special Centennial Issue (2012): 1444-1451.
Rajaraman, A., & Ullman, J. D. 2012. “Mining of massive datasets (Vol. 77)”. Cambridge: Cambridge University Press.
Robertson, S., 2004. “Understanding Inverse Document Frequency: On theoretical
arguments for IDF”, Journal of Documentation, Vol.60, no.5, pp. 503
-520
Pressman, R. S. (2002). “Rekayasa Perangkat Lunak Pendekatan Praktisi (buku
satu)”. Yogyakarta : Andi Yogyakarta.
Saptari, Janu. 2006. “Temu Kembali Informasi Bibliografi Dengan Bahasaalami
Padafield Judul Dan Sufjek (Studi Efektivitas Katalog Induk Terpasang
Perpustakaan Ugm)”. Universitas Gajah Mada : Yogyakarta
Supriyanto, C., & Affandy, A. A. (2011).”Kombinasi Teknik Chi Square Dan
Singular Value Decomposition Untuk Reduksi Fitur Pada
Pengelompokan Dokumen”. Semantik, 1(2011).
Sugiyono, D. (2000). Metode Penelitian. Bandung: CV Alvabeta.
Wikipedia. 2015. “MYSQL”. https://id.wikipedia.org/wiki/MySQL. (24 Juni 2015).
---. 2015. “FAQ”. https://en.wikipedia.org/?title=FAQ. (24 Juni 2015).
Zhang, Ethan . Yi Zhang. 2009. “Encyclopedia of Database Systems : F-Measure
75
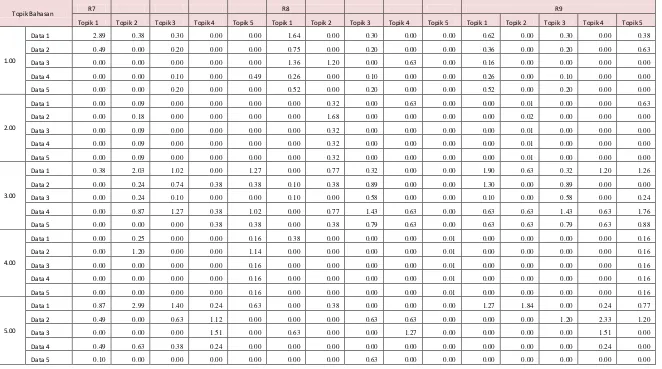
Lampiran 1. Data Perhitungan Nilai Pembobotan TF-IDF pada Mysql Fulltext Search
Topik Bahasan R7 R8 R9
Topik Bahasan R7 R8 R9
Topik Bahasan R7 R8 R9
84
Gambar 1. Halaman Tulis Suara Warga
85