STUDI PERBANDINGAN METODE ORDINARY LEAST SQUARE
(OLS) DAN METODE THEIL DALAM MODEL PENENTUAN
REGRESI LINIER SEDERHANA
USWATUN HASANAH HARAHAP
090823072
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : STUDI PERBANDINGAN METODE ORDINARY
LEAST SQUARE (OLS) DAN METODE THEIL DALAM MODEL PENENTUAN REGRESI LINIER SEDERHANA.
Kategori : SKRIPSI
Nama : USWATUN HASANAH HARAHAP
Nomor Induk Mahasiswa : 090823072
Program Studi : SARJANA (S1) MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU
PENGETAHUAN ALAM
Diluluskan di
Medan,
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Henry Rani Sitepu,M.Si Drs. Pengarapen Bangun,M.Si
NIP. 195303031983031002 NIP.195608151985031005
Diketahui Oleh
Kementrian Matematika FMIPA USU
Ketua
PERNYATAAN
STUDI PERBANDINGAN METODE ORDINARY LEAST SQUARE (OLS)
DAN METODE THEIL DALAM MODEL PENENTUAN REGRESI
LINIER SEDERHANA
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing di sebutkan sumbernya.
Medan, Agustus 2011
USWATUN HASANAH HRP
PENGHARGAAN
Diawali dengan mengucap Puji dan Syukur Kehadirat Allah SWT, yang telah memberikan
penulis kekuatan dan semangat sehingga penyusunan skripsi ini dapat diselesaikan dengan baik
dan tepat waktu.
Adapun tujuan dari penulisan skripsi ini adalah merupakan salah satu syarat untuk
menyelesaikan Program S1 Statistik pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara.
Selama dalam penyusunan Skripsi ini penulis telah banyak memperoleh bantuan dan
bimbingan, untuk itu pada kesempatan ini penulis ingin mengucapkan terima kasih yang
sebesar-besarnya kepada:
1. Drs. Pengarapen Bangun, M.Si selaku pembimbing 1 pada penulis skripsi ini yang telah bersedia memberikan arahan, bimbingan dan petunjuk kepada penulis dalam penyelesaian skripsi ini.
2. Drs. Henry Rani Sitepu, M.Si selaku pembimbing 2 pada penulis skripsi ini yang telah bersedia memberikan arahan, bimbingan dan petunjuk kepada penulis dalam penyelesaian skripsi ini.
3. Drs. Marwan Harahap, M.Eng. dan Drs. Suwarno Ariswoyo, M.Si selaku dosen penguji dimana telah memberikan masukan dalam penyelesaian skripsi ini.
4. Bapak Dr. Sutarman, M.Sc selaku Dekan FMIPA USU.
5. Bapak Prof.Dr.Tulus, M.Si selaku Ketua Dapertemen Matematika FMIPA USU. 6. Bapak Drs. Pengarapen Bangun, M.Si selaku Ketua Pelaksana Jurusan Program S1 –
Statistika Ekstensi.
8. Seluruh staf pengajar di Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara Khususnya Dapertemen Matematika Jurusan Statistika Ekstensi.
9. Semua pihak terkait dalam penyelesaian skripsi ini.
Sepenuhnya penulis menyadari bahwa dalam penyusunan skripsi ini masih terdapat
kekurangan. Untuk itu penulis mengharapkan saran dan kritik yang bersifat membangun, dimana
saran dan kritik tersebut dapat dimanfaatkan untuk kemajuan ilmu pengetahuan pada saat ini dan
yang akan datang.
Semoga penulisan skripsi ini dapat memberikan manfaat dan berguna bagi pembaca dan
penulis khususnya. Akhir kata penulis mengucapkan banyak terima kasih.
Medan, Agustus 2011
ABSTRAK
Analisis regresi digunakan untuk melihat pengaruh variabel independen terhadap variabel
dependen dengan terlebih dahulu melihat pola hubungan variabel tersebut. Hal ini dapat
dilakukan dengan melalui dua pendekatan. Pendekatan yang paling umum dan sering kali
digunakan adalah pendekatan parametrik. Pendekatan parametrik mengasumsikan bentuk model
yang sudah ditentukan Apabila tidak ada informasi apapun tentang bentuk dari fungsi regresi
maka pendekatan yang digunakan adalah pendekatan nonparametrik (Hardle, 1990). Dalam hal
ini kajian analisis regresi parametrik menggunakan metode kuadrat terkecil dan regresi
nonparametrik menggunakan metode Theil. Kajian teoritis diilustrasikan dengan menggunakan
data simulasi. Dan teori ini akan menunjukkan suatu analisis bahwa untuk data yang diketahui
bentuk distribusinya, uji parametrik dengan menggunakan metode kuadrat terkecil memberikan
hasil lebih baik daripada uji nonparametrik dengan menggunakan metode Theil. Kedua metode
dikerjakan dan hasilnya dibandingkan berdasarkan parameter-parameter yang ada.
Kata kunci : regresi nonparametrik, metode kuadrat terkecil dan metode theil
ABSTRACT
Regression analysis is constructed for capturing the influences of independent variables to
dependent ones. It can be done by looking at the relationship between those variables. This task
of approximating the mean function can be done essentially in two ways. The quiet often use
parametric approach is to assume that the mean curve has some prespecified functional forms.
Alternatively, nonparametric approach, i.e., without reference to a specific form, is use when
there is no information of the regression function form (Hardle,1990). In the case parametric
regression analysis theory uses Ordinary Least Square (OLS) and nonparametric regression uses
Theil method. This theory is illustrated using simulation data. And this theory will be shown an
analysis which show that for data with the type of distribution is known, parametric test using
Ordinary Least Square give better result than nonparametric with Theil method. Both of method
is done and it’s result will be compared with exiting parameters.
DAFTAR ISI
Persetujuan i
Pernyataan ii
Penghargaan iii
Abstrak v
Abstract vi
Daftar Isi vii
Daftar Tabel viii
BAB 1 PENDAHULUAN 1.1.Latar Belakang Masalah……….. 1
1.2.Perumusan Masalah………. 2
1.3.Tinjauan Pustaka………. 3
1.4.Tujuan Penelitian………. 4
1.5.Kontribusi Penelitian……… 4
1.6.Metode Penelitian……… 4
BAB 2 LANDASAN TEORI 2.1. Regresi Linier Sederhana……… 5
2.2. Metode Kuadrat Terkecil……… 6
2.3. Pengujian Hipotesis Dalam Regresi Linier Sederhana………….. 9
2.4. Interval Kepercayaan dalam Regresi Linier Sederhana…………. 11
2.5. Metode Theil untuk Pengujian Koefisien Kemiringan………….. . 13
2.6. Metode Theil untuk Pengujian Koefisien Kemiringan……… 14
2.7. Interval Kepercayaan untuk Koefisien Kemiringan……… 16
BAB 3 PEMBAHASAN 3.1. Metode Ordinary Least Square (OLS)……… 18
3.2. Metode Theil………... 19
BAB 4 KESIMPULAN DAN SARAN 4.1. Kesimpulan……….. 21
4.2. Saran……… 21
Daftar Tabel
Halaman
Tabel 1. Pengaruh Proses Produksi Pada Produk Yang Dihasilkan Dengan
Metode OLS 18
Tabel 2. Pengaruh Proses Produksi Pada Produk Yang Dihasilkan Dengan
ABSTRAK
Analisis regresi digunakan untuk melihat pengaruh variabel independen terhadap variabel
dependen dengan terlebih dahulu melihat pola hubungan variabel tersebut. Hal ini dapat
dilakukan dengan melalui dua pendekatan. Pendekatan yang paling umum dan sering kali
digunakan adalah pendekatan parametrik. Pendekatan parametrik mengasumsikan bentuk model
yang sudah ditentukan Apabila tidak ada informasi apapun tentang bentuk dari fungsi regresi
maka pendekatan yang digunakan adalah pendekatan nonparametrik (Hardle, 1990). Dalam hal
ini kajian analisis regresi parametrik menggunakan metode kuadrat terkecil dan regresi
nonparametrik menggunakan metode Theil. Kajian teoritis diilustrasikan dengan menggunakan
data simulasi. Dan teori ini akan menunjukkan suatu analisis bahwa untuk data yang diketahui
bentuk distribusinya, uji parametrik dengan menggunakan metode kuadrat terkecil memberikan
hasil lebih baik daripada uji nonparametrik dengan menggunakan metode Theil. Kedua metode
dikerjakan dan hasilnya dibandingkan berdasarkan parameter-parameter yang ada.
Kata kunci : regresi nonparametrik, metode kuadrat terkecil dan metode theil
ABSTRACT
Regression analysis is constructed for capturing the influences of independent variables to
dependent ones. It can be done by looking at the relationship between those variables. This task
of approximating the mean function can be done essentially in two ways. The quiet often use
parametric approach is to assume that the mean curve has some prespecified functional forms.
Alternatively, nonparametric approach, i.e., without reference to a specific form, is use when
there is no information of the regression function form (Hardle,1990). In the case parametric
regression analysis theory uses Ordinary Least Square (OLS) and nonparametric regression uses
Theil method. This theory is illustrated using simulation data. And this theory will be shown an
analysis which show that for data with the type of distribution is known, parametric test using
Ordinary Least Square give better result than nonparametric with Theil method. Both of method
is done and it’s result will be compared with exiting parameters.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Istilah regresi pertama kali diperkenalkan oleh Sir Francis Galton (1822-1911). Menurut Galton,
analisis regresi berkenaan dengan studi ketergantungan dari suatu variabel yang disebut tak
bebas (dependent variable) pada satu atau lebih variabel, yaitu variabel yang menerangkan
dengan tujuan untuk memperkirakan atau pun meramalkan nilai-nilai dari variabel tak bebas
(independent variable). Dalam ilmu statistik nonparametrik tidak menguji populasi ( semua
objek penelitian yang merupakan nilai yang sebenarnya ) tetapi menguji distribusi. Dan statistik
nonparametrik tidak menuntut terpenuhi banyak asumsi, misalnya data yang dianalisis tidak
harus berdistribusi normal. Oleh karena itu statistik nonparametrik sering disebut sebagai
distribusi bebas (free distribution). Statistik nonparametrik juga banyak digunakan untuk
menganalisa data nominal dan ordinal,karena itu statistik nonparametrik relatif masih kurang
banyak diketahui daripada statistik parametrik. Ada beberapa metode pendekatan regresi
nonparametrik diantaranya theil,spline, kernel, dan lain – lain.
Dalam beberapa masalah terdapat dua atau lebih variabel yang hubungannya tidak dapat
dipisahkan, dan hal tersebut biasanya diselidiki sifat hubungannya. Analisis regresi adalah
sebuah teknik statistika untuk membuat model dan menyelidiki hubungan antara dua variabel
atau lebih. Analisis regresi dapat digunakan untuk membuat sebuah model yang menggambarkan
optimalisasi atau tujuan proses kontrol. Analisis regresi telah lama dikembangkan untuk
mempelajari pola dan mengukur hubungan statistika antara dua atau lebih peubah (variabel).
1.2 Perumusan Masalah
Masalah dalam penelitian ini adalah bagaimana menentukan hasil analisis antara regresi
parametrik dan regresi nonparametrik dilihat dari kedekatan nilai estimasi parameter dengan nilai
parameter dan dilihat dari nilai galatnya.
1.3 Tinjauan Pustaka
Analisis regresi merupakan salah satu teknik statistika yang digunakan secara luas dalam Ilmu
pengetahuan terapan. Yang digunakan untuk mengetahui bentuk hubungan antara peubah regresi
juga dapat dipergunakan untuk maksud peramalan. Dengan menggunakan n pengamatan suatu
model linier sederhana :
Y =
Dimana : peubah tidak bebas
: peubah bebas dengan I = 1,2,…,n;
dan : parameter-parameter yang ditentukan dan diberlakukan asumsi-asumsi model
ideal tertentu galat yaitu bahwa galat menyebar NID .
Persamaan tersebut diatas merupakan model linier sederhana dengan satu peubah bebas
metode kuadrat terkecil sedemikian rupa sehingga jumlah kuadrat kesalahan memiliki nilai
terkecil.
Menurut Daniel (1989) dalam banyak hal, pengamatan-pengamatan yang akan dikaji
tidak selalu memenuhi asumsi-asumsi yang mendasari uji-uji parametrik sehingga kerap kali
dibutuhkan teknik-teknik inferensial dengan validitas yang tidak bergantung pada asumsi-asumsi
yang kaku. Conover (1980) menjelaskan bahwa penggunaan regresi nonparametrik dilandasi
pada asumsi :
a. contoh yang diambil bersifat acak dan kontinu.
b. regresi (YIX) bersifat linier.
c. semua nilai Xi saling bebas.
Theil dalam Sprent (1991) mengusulkan koefisien kemiringan (slope) garis regresi
sebagai median kemiringan dari seluruh pasangan garis dari titik-titik dengan nilai X yang
berbeda, selanjutnya disebut dengan metode Theil. Untuk satu pasangan (X1, Y1) dan (Xj, Yj)
koefisien kemiringannya adalah :
untuk i < j dan Xi < Xj
Sehingga persamaan metode Theil, yaitu
1.4 Tujuan Penelitian
Untuk menguraikan perbandingan dan memeriksa ketepatan model regresi parametrik
Theil dilihat dari kedekatan nilai estimasi parameter dengan nilai parameter yang ditentukan dan
dari nilai galatnya.
1.5 Kontribusi Penelitian
1. Mengetahui model regresi parametrik dengan menggunakan metode kuadrat terkecil dan
metode Theil.
2. Meningkatkan pemahaman yang baik bagi penulis dalam mengetahui secara mendetail
fungsi estiamsi dengan menggunakan metode kuadrat terkecil dan metode Theil.
3. Sebagai bahan acuan untuk mempelajari permasalahan estimasi guna memudahkan dalam
pengambilan keputusan.
1.6 Metode Penelitian
1. Mengkaji estimasi dan dan dengan menggunakan metode kuadrat terkecil dan
metode Theil.
2. Melakukan pengujian hipotesis,kemudian mengambil hasil keputusan sebagai rata-rata
keputusan hipotesis.
3. Menghitung pendugaan interval kepercayaan baik untuk regresi parametrik maupun
untuk regresi nonparametrik.
4. Menarik kesimpulan dan saran.
BAB 2
LANDASAN TEORI
2.1 Regresi Linier Sederhana
Dalam beberapa masalah terdapat dua atau lebih variabel yang hubungannya tidak dapat
dipisahkan, dan hal tersebut biasanya diselidiki sifat hubungannya. Analisis regresi adalah
sebuah teknik statistika untuk membuat model dan menyelidiki hubungan antara dua variabel
atau lebih. Analisis regresi dapat digunakan untuk membuat sebuah model yang menggambarkan
hasil sebagai sebuah fungsi temperatur tertentu. Ini dapat juga digunakan untuk tujuan
optimalisasi atau tujuan proses kontrol. Analisis regresi telah lama dikembangkan untuk
mempelajari pola dan mengukur hubungan statistika antara dua atau lebih peubah (variabel).
Persamaan matematik yang memungkinkan melakukan peramalan nilai-nilai suatu
peubah tak bebas dari satu atau lebih peubah bebas disebut persamaan regresi. Istilah ini berasal
dari hasil pengamatan yang dilakukan Sir Francis Galton (1822 – 1911) yang membandingkan
tinggi badan anak laki-laki dengan tinggi badan bapaknya. Galton menyatakan bahwa tinggi
badan anak laki-laki dari badan yang tinggi pada beberapa generasi kemudian cenderung
“mundur” (regressed) mendekati rata-rata populasi.
Pada umumnya, misalkan ada sebuah variable tidak bebas tunggal atau respon y yang
berhubungan dengan k variabel bebas, katakana x1, x2,…,xk diukur dengan error yang dapat
diabaikan. {xi} disebut variabel matematik dan seringkali dikontrol oleh para pelaku percobaan.
Variabel bebas x diasumsikan sebagai sebuah variabel kontinu secara matematik, dapat
dikontrol oleh para pelaku percobaan. Misalkan hubungan sebenarnya antara y dan x sebuah
garis lurus, dan nilai observasi y pada masing-masing x adalah sebuah variabel random.
Dimana intercept β0 dan slope β1 konstanta yang tidak diketahui. Diasumsikan masing-masing observasi, y, dapat digambarkan dengan model
Y = β0+ β1x + ε
Di mana ε adalah error random dengan rata-rata nol dan varians σ2. {ε} juga diasumsikan
menjadi variabel-variabel random yang tidak berhubungan. Model regresi di atas terdiri dari
sebuah variabel bebas tunggal x yang sering disebut model regresi linier sederhana.
Misalkan ada n pasangan observasi, katakana (y1, x1), (y2, x2), …. (yn, xn). Data ini dapat
digunakan untuk memperkirakan parameter β0 dan β1 yang tidak diketahui.
2.2. Metode Kuadrat Terkecil (Leat Square Method)
Untuk menentukan persamaan regresi tersebut, teknik yang paling mudah adalah dengan “jalan
kira-kira” dan langsung menarik garis lurus di sekitar titik-titiknya menurut pengamatan paling
dekat pada titik-titiknya yang berkerumunan. Kemudian dihitung besarnya konstanta dan derajat
kemiringan. Akan tetapi untuk suatu penelitian, cara ini jarang dilakukan oleh karena terlalu
kasar, juga terlalu subjektif dan sedapat mungkin harus dihindari.
Prosedur penarikan garis regresi yang banyak dikenal adalah metode kuadrat terkecil
(least square). Metode ini memilih suatu garis regresi yang membuat jumlah kuadrat jarak
vertikal dari titik-titik yang dilalui garis lurus tersebut sekecil mungkin. Dalam hal ini, akan
memperkirakan β0 dan β1 sehingga jumlah kuadrat dari deviasi atau simpangan antara observasi-observasi dan garis regresi menjadi minimum. Misalkan ada n pasangan observasi-observasi, katakan (y1,
x1), (y2, x2), …. (yn, xn). Data ini dapat digunakan untuk memperkirakan parameter β0 dan β1 sehingga jumlah kuadrat dari deviasi/simpangan antara observasi-observasi dan garis regresi
menjadi minimum.
Sehingga dapat ditulis :
Y = β0+ β1Xi+ ε i =1, …., n
(
)
[
]
∑ ∑
= = = − − − = n i n i i ii Y X X
S 1 2 1 1 0
2 β β
ε
Dengan demikian meminimumkan fungsi kuadrat terkecil S adalah mempermudah jika ditulis
kembali model tersebut, persamaan tersebut menjadi
( )
εβ
β + − +
= X X
Y 0 1
Dengan: :
∑
= n
iXi
n X (1)
X 1 0
0 β β
β = + .
Dalam persamaan diatas telah diperiksa variabel beban untuk rata-rata, dihasilkan dalam sebuah
transformasi pada intercept. Maka persamaan model regresi linier sederhana yaitu :
ε β
β + − +
= 0 1(X X) Y
Dengan menggunakan persamaan model regresi linier sederhana tersebut, maka fungsi
kuadrat terkecil adalah :
(
)
[
]
21 1 1 0
∑
= − − − = n ii X X
Y
S β β
Dengan estimator β0dan β1 yang harus memenuhi :
(
)
[
]
02 1 1 1 0 0 = − − − − = ∂∂
∑
= n ii X X
Y S β β β
(
)
[
]
(
)
02 1 1 1 0 1 = − − − − − = ∂∂
∑
= X X X X Y S i n ii β β
β
Dari dua persamaan diatas menghasilkan persamaan normal kuadrat terkecil :
(
)
(
)
∑
=n − =∑
= −i
i n
i i
i X Y X X
X
1 1
2 1
β atau 2
) ( ) ( 1 1 1
∑
∑
= = ∧ − − = n i i n i i iX X X X Y β 0 ∧
β dan β∧1adalah estimator untuk incerpt (titik potong) dan slope (kemiringan). Estimator model regresi linier sederhana adalah :
) (
1
0 X X
Y = + i − ∧ ∧ ∧
β
β
untuk menyajikan hasil-hasil dalam susunan intercept yang asli β1 maka β∧0= ' 0
∧
β - β∧1 X
sehingga perkiraan yang cocok untuk model regresi adalah
) ( 1 ' 0 X Y ∧ ∧ ∧ + =β β
Persamaan regresi linier sederhana dapat ditulis dalam bentuk lain dengan memberi
simbol khusus untuk pembilang dan penyebutnya yaitu :
SXX =
n X X X X n i i n i i 2 1 2 1 1 2 ) ( − = −
∑
∑
∑
= =SXY =
n Y X Y X X X Y n i i n i i i i n i i i − = −
∑
∑
∑
∑
= = = 1 1 1 ) ( Dengan :SXX : koreksi atau perbaikan jumlah kuadrat X dan
SXY : perbaikan jumlah silang produk X dan Y,
Sehingga estimator slope adalah :
1 ∧ β = XX XY S S
Selain estimator β0 dan β1, menurut Montgomery dan Peck (1991) estimasi σ2 juga dibutuhkan dalam uji hipotesis dan pembentukan estimasi interval yang berhubungan dengan
SSE =
∑ ∑
= = ∧ − = n i n i i i Y Y 1 1 2 21 ( )
ε
Bentuk tetap untuk SSE dapat disubstitusikan 1( ) '
0 X X
Y = + ∧ i−
∧ ∧
β
β ke dalam persamaan (8) dan dengan penyederhanaan akan menghasilkan, yaitu :
SSE = XY
n i S Y n Y ∧ = − −
∑
1 2 1 2 1 β∑
∑
− = −≡ − 2 2
1 2
1 nY (Y Y)
Y S i n i YY Dengan :
SYY = koreksi atau perbaikan jumlah kuadrat dari pengamatan.
Sehingga :
SSE = SYY - 1SXY ∧
β
Jumlah kuadrat residual mempunyai derajat kebebasan n-2 karena 2 derajat kebebasan
adalah gabungan dari estimasi β∧0dan β∧1yang terlihat dalam pembentukan Ŷi. Nilai ekspektasi dari SSE adalah E(SSE) = (n-2)σ2, jadi estimator tak bias dari σ2 untuk regresi parametrik adalah :
E E MS n SS = − = ∧ 2 2 σ
2.3. Pengujian Hipotesis dalam Regresi Linier Sederhana
Sebuah bagian penting dalam perkiraan yang memadai dari model regresi linier sederhana adalah
pengujian hipotesis secara statistik mengenai model parameter-parameter dan membentuk
interval keyakinan tertentu. Pengujian hipotesis dalam regresi linier sederhana adalah pengujian
intercept model regresi, juga harus dibuat asumsi tambahan bahwa komponen error εi berdistribusi normal. Maka asumsi-asumsi selengkapnya bahwa error adalah NID (0, σ2).
Selanjutnya akan dibahas bagaimana asumsi-asumsi dapat diperiksa dengan analisis
residual. Yitnosumarto (1985) menjelaskan bahwa pengujian hipotesis secara statistik hanya
dapat dilakukan apabila asumsi-asumsi yang diperlukan terpenuh. Asumsi-asumsi yang
dimaksud berdasarkan persamaan (1) adalah :
1. εi merupakan peubah acak dengan mean nol dan varian σ2atau E (εi) = 0 dan V (εi) = σ2;
2. εi dan εj dengan i ≠ j tidak berkorelasi sehingga Cov (εi, εj) = 0, i ≠ j;
3. εi tersebar secara normal atau εi≈ NID (0, σ2).
Jika pada percobaan akan dilakukan pengujian terhadap β1 yang sama dengan sebuah
konstanta misalkan β1(0) maka pada umumnya hipotesis tersebut dirumuskan sebagai berikut :
H0 : β1 = β1(0)
H1 : β1 ≠ β1(0)
Di mana akan diduga alternatifnya dua arah. Sekarang karena εi adalah NID (0, σ2) yang
mengikuti secara langsung bahwa observasi-observasi yi adalah NID (β0 + β1xi, σ2). Maka
sebagai sebuah hasil asumsi secara normal, statistiknya adalah :
xx E
S MS t0 = β −1 β1(0)
∧
Kaidah pengambilan keputusan untuk pengujian hipotesis ini adalah sebagai berikut :
H0 ditolak jika |t0| > 2 , 2n−
tα , nilai 2 , 2n−
tα dapat diperoleh dari tabel t dengan menggunakan nilai α dan derajat kebebasan (n-2) (Hines dan Montgomery, 1990). Dengan cara yang sama dapat digunakan untuk menguji intercept β0, dan hipotesisinya adalah sebagai berikut :
H0 : β0 = β00
Statistik ujinya adalah :
+ − =
∧
xx E
S X n MS t
2 00 0 0
1
β β
Dengan :
H0 ditolak jika |t0| > 2 , 2n−
tα
Hipotesis persamaan diatas dilandasi oleh pengujian dua arah, yaitu :
H0 : β1 = 0
H1 : β1 ≠ 0
Hipotesis ini dihubungkan untuk nyata regresi. Keputusan untuk menolak H0 : β1 = 0 adalah sama dengan memutuskan bahwa disana tidak ada hubungan linier antara x dan y. Perlu
dicatat bahwa ini dapat menyatakan secara tidak langsung, x berasal dari nilai yang kecil dalam
menjelaskan variasi y dan estimator y yang terbaik untuk setiap nilai x adalah ŷ = y , atau hubungan sebenarnya antara x dan y tidak linier. Secara alternatif, jika H0 : β1 = 0 ditolak, ini menyatakan bahwa x adalah nilai dalam menjelaskan variabilitas tersebut dalam y.
bagaimanapun menolak H0 : β1 = 0 dapat berarti bahwa model garis lurus, atau seringkali di sana ada sebuah pengaruh linier x.
2.4. Interval Kepercayaan dalam Regresi Linier Sederhana
Interval kepercayaan dapat digunakan sebagai taksiran suatu parameter dan dapat pula dipandang
sebagai pengujian hipotesis yaitu apakah suatu parameter yang dalam hal ini adalah β1 dan β0 sama dengan suatu nilai tertentu. Asumsi-asumsi yang digunakan dalam interval kepercayaan
normal dan bebas maka xx E S MS / ) 0 ( 1 1 −∧ β β dan + − = ∧ xx E S X n MS t 2 00 0 0 1 β
β keduanya berdistribusi t dengan
derajat kebebasan (n-2). Selanjutnya interval kepercayaan (1-α) 100% untuk parameter β1 adalah
xx E n xx E n S MS t S MS t 2 , 2 1 1 2 , 2 1 − ∧ − ∧ + ≤ ≤ − α β β α β .
Sedangkan interval kepercayaan (1 – α) 100% untuk parameter β0 adalah :
xx E n xx E n S MS t S MS t 2 , 2 1 1 2 , 2 1 − ∧ − ∧ + ≤ ≤ − α β β α β
Menurut Montgomery dan Peck (1990) standar error dari slope β1 dirumuskan dengan
xx E
S MS se(∧β1)
Dan standar error untuk intercept β∧0adalah
+ = ∧ xx E S X n MS se 2 1 ) (β
Sedangkan standard error estimasi dapat dihitung dari persamaan :
( )
2 ) ( 2 1 2 1 0 1 2 − − − = − =∑
∑
= ∧ ∧ = n X Y n se n i i i n ii β β
ε
Dalam berbagai masalah terdapat dua atau lebih variabel yang hubungannya tidak dapat
dipisahkan, dan hal tersebut biasanya diselidiki sifat hubungannya. Analisis regresi merupakan
sebuah teknik statistik untuk membuat model dan menyelidiki hubungan antara dua variabel atau
membuat model yang menggambarkan hasil sebagai sebuah fungsi temperatur. Model ini dapat
juga digunakan untuk tujuan optimalisasi atau tujuan proses kontrol.
2.5. Metode Regresi Theil
Perkiraan slope garis regresi sebagai median slope dari seluruh pasangan garis dari titik-titik
dengan nila x yang berbeda. Untuk satu pasangan (x1, yi)dan(xj, yj), slopenya adalah :
i j
i j ij
X X
Y Y b
− −
=
Dengan: i < j dan Xi≠ Xj
Jika dinotasikan penduga median dari β dengan
,
Theil telah menyarankan perkiraan dari dengan median dari seluruh atau alternatifnya dapat dipilih=
med ( med ( ), dimana med ( ) adalah median dari seluruh pengamatan,sedangkan garis kuadrat terkecil melalui rata-ratanya.
Kenyataan bahwa menurut data-data yang ada dan yang telah ada dalam contoh
menyebabkan garis lurus yang dihasilkan akan sangat berbeda bila menggunakan metode kuadrat
terkecil, dan metode Theil tidak menyelesaikan suatu masalah.
Sprent menyarankan bahwa kuadrat terkecil yang cocok mungkin tidak sesuai dengan
datanya dan tidak mungkin mendekati garis lurus dengan kesalahannya berdistribusi normal dan
identik, tetapi mengabaikan pertanyaan yang meragukan apakah titik (6, 11, 1) kesalahannya
cukup serius, atau hubungannya tidak benar-benar linear. Pada penelitian yang serempak
mengenai pencilan yang secara efektif dijumlahkan untuk menggantikan kesalahan yang
berdistribusi normal dengan kesalahan yang berdistribusi ekor panjang. Hussain dan Sprent
(1983) berpendapat bahwa metode Theil hamper seefisien metode kuadrat terkecil bila asumsi
kenormalan sah, dan hal ini menunjukkan sebuah perbaikan nyata dalam efisien dengna
kesalahan berdistribusi ekor panjang, terutama dengan ukuran sampel kurang dari (<) 30. Ada
sebuah perbaikan yang lebih nyata pada kasus terakhir dalam memperkirakan α, meskipun ini
Hussain dan Sprent juga berpendapat bahwa penduga-penduga yang didasarkan pada
median tertimbang yang dilakukan pada keseluruhannya tidaklah lebih baik, dan kadang-kadang
kurang baik daripada penduga Theil karena ada pencilan.
2.6. Metode Theil untuk Pengujian Koefisien Kemiringan
Daniel (1989) menjelaskan bahwa pengujian koefisien kemiringan dengan menggunakan metode
Theil disusun berdasarkan statistik τ Kendall dan digunakan untuk mengetahui bentuk hubungan
peubah-peubah regresi.
Asumsi-asumsi yang melandasi pengujian pada koefisien kemiringan adalah
a. persamaan regresinya adalah Yi = β0 + β1Xi +εi, i = 1, ….,n dengan
Xi peubah bebas, βo dan β1 adalah parameter-parameter yang tidak diketahui;
b. untuk masing-masing nilai Xi terdapat nilai Yi;
c. Yi adalah nilai yang teramati dari Y yang acak dan kontinu untuk nilai Xi;
d. Semua nilai Xi saling bebas dan kita menetapkan X1 < X2 < … < Xn.
e. Nilai-nilai εi saling bebas dan berasal dari populasi yang sama.
Penduga b yang baik untuk β akan menjadi sisaan yang sesuai dengan masing-masing
pengamatan, dinotasikan dengan εidi mana εi = yi – a – bxi, akan mempunyai kemungkinan yang
sama menjadi positif atau negatif. Hal ini menyatakan asumsi bahwa εi berdistribusi secara acak dengan median nol dan bebas dari xi. Sekarang,
bij =
i j i j i j i i j j i j i j x x b x x bx a bx a X X Y Y − − + = − + + − + + = − − ( ε ) ( ε ) ε ε
Persamaan di atas menyatakan setiap bij akan lebih besar daripada b jika (xi,εi) dan (xj,εj)
sesuai dengan bahwa bij akan menjadi lebih daripada b jika ini tidak sesuai dalam pengertian
yang digunakan tau Kendall. Pemilihan terhadap med {bij} sebagai penduga b menjamin setengah
arti bahwa ini konsisten dengan korelasi nol antara x dan sisaannya. Dengan kata lain, menerima
setiap b yang tidak memberikan sejumlah pasangan yang tidak serasi (atau serasi) yang
menunjukkan tau Kendall tidak nol, yaitu tidak ingin jumlah yang tidak serasi (atau serasi)
terlalu kecil atau terlalu besar.
Karena nc+ nd = N sama dengan jumlah bij yang ditimbulkan dari n pengamatan dengan xi
yang berbeda, maka menolak τ = 0 dalam pengujian dua arah pada tingkat 5 % misalnya.
Hipotesis-hipotesis yang melandasi pengujian ini adalah
a. dua arah : Ho : β1 = β1(0) H1 : β1 ≠ β1(0) ;
b. satu arah : Ho: β1≤ β1(0) H1: β1> β1(0)
c. satu arah : H0: β1≥ β1(0) ; H1: β1< β1(0)
Seperti yang telah dijelaskan, prosedur yang diuraikan disusun berlandaskan statistik τ
Kendall, sehingga statistik ujianya adalah
n Q P− = ∧ τ Dengan ∧
τ = statistik uji τ Kendall
P = banyaknya pasangan berurutan wajar
Q = banyaknya pasangan berurutan terbalik
n = banyaknya pasangna yang diamati
Kaidah pengambilan keputusan untuk ketiga pasangan hipotesis di atas adalah sebagai
berikut :
a. dua arah :
≤ > ∧ 0 * 0 * , 2 , ( , 2 , ( H terima n H tolak n α τ α τ τ
b. satu arah :
c. satu arah : ≥ < ∧ 0 * 0 * ), 2 , ( ), 2 , ( H terima n H tolak n α τ α τ τ τ*
adalah harga-harga kritis dalam table statistik uji τ Kendall. Pengujian koefisien kemiringan
ini dengan membuat tataan dan membandingkan semua hasil pengamatan menurut nilai-nilai X
(Daniel, 1989).
2.7. Interval Kepercayaan untuk Koefisien Kemiringan
Metode pembentukan interval kepercayaan terhadap koefisien kemiringan ini dilandaskan pada
prosedur pengujian hipotesis Theil untuk β1, sedangkan asumsi-asumsi yang mendasari prosedur pengujian hipotesis ini juga berlaku pada pembentukan interval kepercayaan (1-α) bagi
≤ > ∧ 0 * 0 * , 2 , ( , 2 , ( H terima n H tolak n α τ α τ τ
Lebih lanjut Daniel (1989) menjelaskan bahwa konstanta untuk interval kepercayaan
adalah k = 2 2 ) 2 , (
2− nα −
nC S
Dengan :
k = konstanta untuk interval kepercayaan
2 C
n = banyaknya nilai bij yang mungkin dari n pasangan pengamatan
S(n,α/2) = titik kritis τ Kendall untuk n pasangan pengamatan pada taraf α
Berdasarkan nilai konstanta tersebut akan diperoleh β∧Lsebagai batas bawah interval kepercayaan untuk β1 dan β∧U sebagai batas interval kepercayaan untuk β1, β∧Ladalah nilai bij ke-k yang dihitung dari nilai paling ke-kecil dalam statistike-k tataan bagi nilai bij.
∧ U
Interval kepercayaan untuk β1 dengan suatu koefisien kepercayaan (1-α) adalah
C (β∧L< β1 < β∧U) = 1 – α
dengan C adalah kependekan dari confidence (kepercayaan) dan menunjukkan bahwa ekspresi
ini lebih merupakan suatu pernyataan kepercayaan daripada suatu pernyataan probabilitas
BAB 3
PEMBAHASAN
3.1 Metode Ordinary Least Square (OLS)
Contoh kasus diambil dari seorang insinyur kimia menyelidiki pengaruh proses produksi pada
produk yang dihasilkan. Hasil penyelidikan tersebut menghasilkan data sebagai berikut (Hines
[image:29.612.66.525.351.635.2]dan Montgomery, halaman (412).
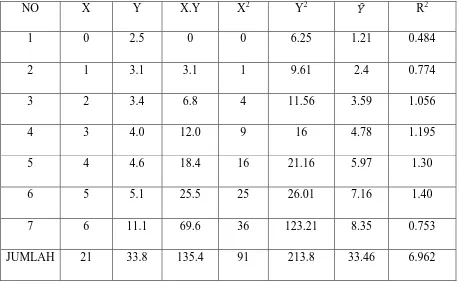
Tabel 1. Pengaruh Proses Produksi Pada Produk Yang Dihasilkan Dengan Metode OLS
NO X Y X.Y X2 Y2 R2
1 0 2.5 0 0 6.25 1.21 0.484
2 1 3.1 3.1 1 9.61 2.4 0.774
3 2 3.4 6.8 4 11.56 3.59 1.056
4 3 4.0 12.0 9 16 4.78 1.195
5 4 4.6 18.4 16 21.16 5.97 1.30
6 5 5.1 25.5 25 26.01 7.16 1.40
7 6 11.1 69.6 36 123.21 8.35 0.753
= 1.19x + 1.21
y y R
∧
=
2
Dimana jumlah rata- rata R2 memiliki nilai diantara -1 < R2 < 1, maka rata-rata jumlah R2 dari
Metode OLS adalah 0.99.
[image:30.612.66.485.380.709.2]3.2 Metode Theil
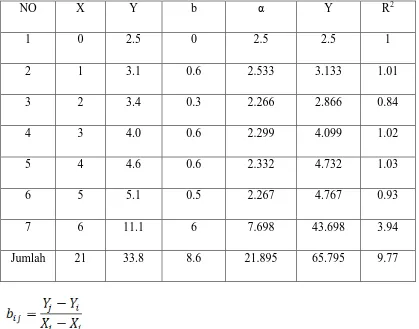
Tabel 2. Pengaruh Proses Produksi Pada Produk Yang Dihasilkan Dengan Metode Theil.
NO X Y b α Y R2
1 0 2.5 0 2.5 2.5 1
2 1 3.1 0.6 2.533 3.133 1.01
3 2 3.4 0.3 2.266 2.866 0.84
4 3 4.0 0.6 2.299 4.099 1.02
5 4 4.6 0.6 2.332 4.732 1.03
6 5 5.1 0.5 2.267 4.767 0.93
7 6 11.1 6 7.698 43.698 3.94
Untuk i < j dan Xi < Xj
y y R
∧
=
2
Dimana jumlah rata- rata R2 memiliki nilai diantara -1 < R2 < 1, maka rata-rata jumlah R2 dari
Metode Theil adalah 1.40. Garis yang cocok adalah y = 0.567x + 2,332. Dan untuk data di atas,
akan ditentukan sebuah selang kepercayaan 95 % untuk β. Maka yang digunakan adalah metode yang didasarkan pada tau Kendall.
Untuk pengujian dua arah pada tingkat 5 %, nilai kritis untuk nc−nd adalah 15. Sekarang N (jumlah dari bij) adalah 21 maka r = ½ (21-15) = 3, sehingga menolak 3 bij terbesar
dan terkecil berikutnya memberikan batas-batas kepercayaan, sehingga selang kepercayaan 95 %
untuk β adalah selang {(bij(4), bij(18)} di mana bij (4) dan bij (18) adalah urutan ke-4 dan ke-18 dari bij. Dan nilai yang diperoleh dalam contoh tersebut dengan mudah melihat bij (4) = 0,450
dan bij (18) = 1,900. Dengan sebuah selang kepercayaan 95 % untuk β adalah (0,450, 1,900). Hasil estimasi parameter untuk data berdistribusi normal dari kedua metode diperoleh
hasil yang tidak terlalu jauh berbeda. Hal ini menunjukkan bahwa metode Theil hampir seefisien
metode kuadrat terkecil untuk data yang asumsi kenormalannya valid. Apabila dilihat dari nilai
galat masih lebih baik regresi parametrik dengan menggunakan metode kuadrat terkecil dari pada
regresi nonparametrik dengan menggunakn metode Theil karena nilai galatnya lebih kecil
sehingga masih tetap lebih baik regresi parametrik sesuai dengan jenis data yaitu data yang
berdistribusi normal.
Regresi linier sederhana parametrik dengan menggunakan metode kuadrat terkecil untuk
data yang berdistribusi uniform maupun regresi linier sederhana nonparametrik dengan
menggunakan metode Theil tidak bisa mewakili suatu regresi yang baik. Hal ini ditunjukkan oleh
Hasil analisis untuk data simulasi berdistribusi gamma menunjukkan bahwa metode
kuadrat terkecil untuk regresi parametrik memberikan hasil yang lebih baik dari pada metode
Theil untuk regresi nonparametrik. Hal ini ditunjukkan oleh nilai estimator yang lebih mendekati
nilai parameter yang telah ditentukan, interval kepercayaan yang lebih pendek dan memuat nilai
parameter serta nilai standart error yang lebih kecil pada regresi parametrik.
BAB 4
KESIMPULAN DAN SARAN
4.1. Kesimpulan
Dari hasil analisis dapat disimpulkan bahwa dalam penelitian ini khususnya untuk analisis
regresi linier sederhana, metode kuadrat terkecil untuk regresi parametrik memberikan hasil
estimator yang lebih baik dari pada metode Theil pada regresi nonparametrik. Perbandingan
antara Metode OLS dengan Metode Theil dapat diketahui dengan menggunakan koefisien
determinasi R2. Nilai yang dihasilkan dari R2 dengan metode OLS, yaitu 0.99 sedangkan nilai
dari R2 dengan metode Theil, yaitu 1.40. Maka metode kuadrat terkecil dikatakan lebih baik jika
-1 < R2 < 1.
4.2. Saran
Penelitian ini bisa dikembangkan lebih lanjut dengan menggunakan sampel yang banyak atau
sampel yang berbeda, sehingga dapat diketahui pengaruhnya terhadap perbandingan antara
DAFTAR PUSTAKA
Conover, W.J. (1980), Practical NonParametrik Statistics (2-nd edn) John Wiley and Sons. New York.
Daniel, W.W. (1982). Statistika Nonparametrik Terapan. Jakarta : John Gramedia.
Draper, N dan Smith, H. (1992). Analisis Regresi Terapan. Jakarta : Gramedia Pustaka Umum.
E, A. Mena, N. Kossovsky, C. Chu, C. Hu. (1995). Journal of Investigative Surgery : 31-42
F. J. Anscomba. (1973). Graphsin Statistical Analisis, “The American Statistician,” 27 : 17-21. Faraway, Julian. (2002). Practical Regression and Anova Using R. Dapat diakses di
Hines, W.W dan Montgomery, D. C. (1990). Probabilita dan Statistik dalam Ilmu Rekayasa dan Manajemen. Jakarta : Universitas Indonesia.
Sparks, A.H., P.D. Esker, M. Bates, W. Dall’ Acqua, Z. Guo, V. Segovia, S.D. Silwal, S. Tolos, and K.A. Garrett. (2008). Ecology and Epidemiology in R : Disease Progress over Time. The Plant Health Instructor. DOI:10.1094/PHI-A-2008-0129-02.
Sprent, P. (1991). Metode Statistika Nonparametrik Terapan. Jakarta : Universitas Indonesia.
Whipple, W, Neely. (2008). CDE Tutorial on R : Linier Regression. Dapat diakses di