ABSTRACT
MUHAMMAD ZAKI. Iris Recognition Using Voting Feature Interval Version 5 with 1D log-Gabor Wavelets as Feature Extraction. Under direction of Aziz Kustiyo.
Biometric recognition based on iris patterns has its own advantages because iris patterns are more stable and reliable as compared to other biometric subjects such as face and fingerprint. This research provides implementation for recognizing eye images taken from CASIA dataset based on Daugman methods for extracting features. The system uses an automatic segmentation based on threshold to localize the iris collarette and normalize the results to constant dimension using Daugman’s rubber sheet model by remaping each point within the iris region to a pair of polar coordinates. The features are extracted using 1D log-Gabor wavelets to create template which contains dimension 2 times from its normalized images. The template data are then splitted into three subsets and then alternately used for training and testing using voting feature interval version 5. The best recognition of testing data are obtained from combining vote from left and right eyes rather than using single eye sides.
1
PENDAHULUAN
Latar Belakang
Dalam beberapa tahun terakhir, identifikasi seseorang berdasarkan biometrik telah berkembang dengan pesat di kalangan akademik dan industri. Metode pengenalan identitas seseorang yang banyak digunakan di antaranya berdasarkan nomor identitas unik (kunci fisik, kartu identitas dan lainnya) atau berdasarkan ingatan terhadap sesuatu (sandi rahasia dan lainnya). Metode tersebut banyak memiliki kekurangan di antaranya adalah kartu identitas dapat hilang dan sandi dapat lupa dari ingatan seseorang. Ada dua jenis biometrik di antaranya adalah physiological (iris mata, wajah dan sidik jari) dan behavioural (suara dan tulisan tangan) (Yong et al. 2000).
Pengenalan iris mata adalah jenis biometrik berdasarkan fitur physiological. Iris memiliki tekstur yang unik dan cukup kompleks untuk digunakan dalam biometrik. Dibandingkan dengan metode biometrik lain seperti pengenalan wajah, pola iris lebih stabil dan dapat diandalkan. Iris mata seseorang juga memiliki pola yang konsisten, tidak seperti wajah yang relatif memiliki perubahan seiring dengan bertambah waktu.
Penelitian mengenai pengenalan iris mata telah dilakukan oleh Daugman (2002) yang menggunakan Gabor Wavelets dua dimensi pada ekstrasi ciri serta Hamming distances sebagai algoritme pengujian. Masek (2003) melakukan penelitian serupa dengan menggunakan data dari Chinese Academy of Science-Institute of Automation (CASIA) dan Lion’s Eye Institute (LEI). Selain itu, penelitian Abidin (2011) menggunakan jaringan syaraf tiruan sebagai algoritme pelatihan dan pengujian terhadap data CASIA dan menggunakan dekomposisi wavelet sebagai ekstraksi ciri.
Sistem pengenalan pola yang dikembangkan dalam penelitian ini terdiri atas empat tahap. Tahap pertama adalah proses segmentasi citra untuk mengambil citra iris mata saja lalu membuang bagian citra yang lainnya. Pada tahap kedua, proses normalisasi dilakukan dengan mengubah dimensi citra iris menjadi tetap seningga menghasilkan ekstraksi ciri yang lebih baik. Tahap selanjutnya adalah melakukan ekstraksi ciri terhadap citra yang sudah ternormalisasi sehingga dihasilkan template yang memiliki nilai biner dan dilanjutkan ke tahap terakhir yaitu melakukan pelatihan serta pengujian terhadap template tersebut. Pelatihan
dan pengujian template citra dilakukan pada tiga subset yang berbeda, untuk kemudian dilakukan perhitungan terhadap akurasinya menggunakan 3-fold cross validation. Penggunaan algoritme Voting Feature Intervals versi ke-5 (VFI5) pada penelitian ini diharapkan dapat memberikan pengetahuan tingkat akurasi yang diberikan untuk kemudian dapat dibandingkan dengan hasil penelitian lainnya. Tujuan
Tujuan dari penelitian ini adalah untuk mengetahui akurasi dari proses pengenalan citra iris mata menggunakan algoritme VFI5 pada citra mata kiri, kanan dan gabungan keduanya. Ruang Lingkup
Penelitian ini memiliki batasan yaitu : data yang digunakan adalah data citra mata dari sepuluh orang berbeda yang berasal dari CASIA,
bobot yang digunakan dalam pelatihan algoritme VFI5 adalah 1.
Manfaat
Manfaat dari penelitian ini diharapkan dapat memberikan informasi mengenai akurasi algoritme klasifikasi VFI5 terhadap pengenalan iris mata kiri, kanan dan gabungan vote keduanya dari individu yang berbeda.
TINJAUAN PUSTAKA
Representasi Citra Digital
Citra didefinisikan sebagai suatu fungsi dua dimensi f(x,y), dengan x dan y merupakan koordinat spasial, dan f disebut sebagai kuantitas bilangan skalar positif yang memiliki maksud secara fisik ditentukan oleh sumber citra. Suatu citra digital yang diasumsikan dengan fungsi f(x,y) direpresentasikan dalam suatu fungsi koordinat berukuran M x N. Variabel M adalah Baris dan N adalah kolom sebagaimana ditunjukkan pada Gambar 1. Setiap elemen dari array matriks disebut image element, picture element, pixel, atau pel (Gonzales dan Woods 2002).
PENDAHULUAN
Latar Belakang
Dalam beberapa tahun terakhir, identifikasi seseorang berdasarkan biometrik telah berkembang dengan pesat di kalangan akademik dan industri. Metode pengenalan identitas seseorang yang banyak digunakan di antaranya berdasarkan nomor identitas unik (kunci fisik, kartu identitas dan lainnya) atau berdasarkan ingatan terhadap sesuatu (sandi rahasia dan lainnya). Metode tersebut banyak memiliki kekurangan di antaranya adalah kartu identitas dapat hilang dan sandi dapat lupa dari ingatan seseorang. Ada dua jenis biometrik di antaranya adalah physiological (iris mata, wajah dan sidik jari) dan behavioural (suara dan tulisan tangan) (Yong et al. 2000).
Pengenalan iris mata adalah jenis biometrik berdasarkan fitur physiological. Iris memiliki tekstur yang unik dan cukup kompleks untuk digunakan dalam biometrik. Dibandingkan dengan metode biometrik lain seperti pengenalan wajah, pola iris lebih stabil dan dapat diandalkan. Iris mata seseorang juga memiliki pola yang konsisten, tidak seperti wajah yang relatif memiliki perubahan seiring dengan bertambah waktu.
Penelitian mengenai pengenalan iris mata telah dilakukan oleh Daugman (2002) yang menggunakan Gabor Wavelets dua dimensi pada ekstrasi ciri serta Hamming distances sebagai algoritme pengujian. Masek (2003) melakukan penelitian serupa dengan menggunakan data dari Chinese Academy of Science-Institute of Automation (CASIA) dan Lion’s Eye Institute (LEI). Selain itu, penelitian Abidin (2011) menggunakan jaringan syaraf tiruan sebagai algoritme pelatihan dan pengujian terhadap data CASIA dan menggunakan dekomposisi wavelet sebagai ekstraksi ciri.
Sistem pengenalan pola yang dikembangkan dalam penelitian ini terdiri atas empat tahap. Tahap pertama adalah proses segmentasi citra untuk mengambil citra iris mata saja lalu membuang bagian citra yang lainnya. Pada tahap kedua, proses normalisasi dilakukan dengan mengubah dimensi citra iris menjadi tetap seningga menghasilkan ekstraksi ciri yang lebih baik. Tahap selanjutnya adalah melakukan ekstraksi ciri terhadap citra yang sudah ternormalisasi sehingga dihasilkan template yang memiliki nilai biner dan dilanjutkan ke tahap terakhir yaitu melakukan pelatihan serta pengujian terhadap template tersebut. Pelatihan
dan pengujian template citra dilakukan pada tiga subset yang berbeda, untuk kemudian dilakukan perhitungan terhadap akurasinya menggunakan 3-fold cross validation. Penggunaan algoritme Voting Feature Intervals versi ke-5 (VFI5) pada penelitian ini diharapkan dapat memberikan pengetahuan tingkat akurasi yang diberikan untuk kemudian dapat dibandingkan dengan hasil penelitian lainnya. Tujuan
Tujuan dari penelitian ini adalah untuk mengetahui akurasi dari proses pengenalan citra iris mata menggunakan algoritme VFI5 pada citra mata kiri, kanan dan gabungan keduanya. Ruang Lingkup
Penelitian ini memiliki batasan yaitu : data yang digunakan adalah data citra mata dari sepuluh orang berbeda yang berasal dari CASIA,
bobot yang digunakan dalam pelatihan algoritme VFI5 adalah 1.
Manfaat
Manfaat dari penelitian ini diharapkan dapat memberikan informasi mengenai akurasi algoritme klasifikasi VFI5 terhadap pengenalan iris mata kiri, kanan dan gabungan vote keduanya dari individu yang berbeda.
TINJAUAN PUSTAKA
Representasi Citra Digital
Citra didefinisikan sebagai suatu fungsi dua dimensi f(x,y), dengan x dan y merupakan koordinat spasial, dan f disebut sebagai kuantitas bilangan skalar positif yang memiliki maksud secara fisik ditentukan oleh sumber citra. Suatu citra digital yang diasumsikan dengan fungsi f(x,y) direpresentasikan dalam suatu fungsi koordinat berukuran M x N. Variabel M adalah Baris dan N adalah kolom sebagaimana ditunjukkan pada Gambar 1. Setiap elemen dari array matriks disebut image element, picture element, pixel, atau pel (Gonzales dan Woods 2002).
2 Iris Mata
Iris mata adalah salah satu organ bagian dalam mata yang terletak di belakang kornea dan di depan lensa. Fungsi yang paling penting dari iris mata adalah mengatur ukuran pupil. Iris dibagi ke dalam dua wilayah: wilayah dalam yang dekat dengan pupil dan wilayah luar yang dekat dengan sclera. Daerah yang terdekat dengan pupil disebut collarette. Collarette terdapat antara 20-30 piksel pada citra berukuran 280 x 320 piksel (Shah & Ross 2006).
Iris mata mulai terbentuk saat bulan ketiga bayi di dalam kandungan dan strukturnya mulai membentuk pola saat usia kandungan mencapai delapan bulan, walaupun perkembangan pigmen mata dapat terus berlanjut hingga usia satu tahun setelah kelahiran (Kronfeld 1962, diacu dalam Daugman 2002). Warna iris ditentukan terutama oleh kepadatan pigmen melanin pada lapisan luar dan stroma. Sebagai contoh warna iris yang biru dihasilkan oleh ketiadaan pigmen melanin sehingga cahaya yang memiliki panjang gelombang besar dapat menembus sedangkan panjang gelombang kecil diuraikan oleh stroma (Chedekel 1995, diacu dalam Daugman 2002). Gambar anatomi mata manusia dapat dilihat pada Gambar 2.
Gambar 2 Anatomi mata manusia. Segmentasi
Segmentasi adalah pembagian citra menjadi beberapa wilayah atau objek. Tingkat pembagian wilayah tergantung kepada masalah yang akan diselesaikan, yaitu ketika objek yang dicari telah berhasil dikenali dan diisolasi (Gonzales et al. 2003)
Klasifikasi
Algoritme klasifikasi terdiri atas dua komponen yaitu pelatihan dan prediksi. Pada tahap pelatihan, dilakukan proses pembentukan model suatu permasalahan yang berasal dari data kejadian sebelumnya. Model tersebut kemudian digunakan untuk memprediksi jenis
kelas suatu permasalahan yang ditemukan (Güvenir et al. 1998).
Kebutuhan yang paling penting dalam membentuk suatu sistem klasifikasi adalah akurasi prediksinya. Selain itu, lamanya waktu yang dibutuhkan selama proses pelatihan dan prediksi idealnya adalah pendek. Ketahanan sistem terhadap noise serta penanggulangan terhadap missing value juga harus diperhatikan dalam membangun sistem tersebut (Güvenir et al. 1998).
Daugman’s Rubber Sheet Model
Rubber sheet model bertujuan untuk
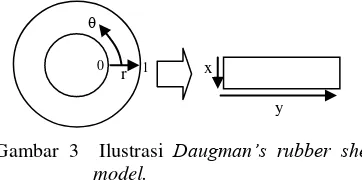
melakukan normalisasi daerah collarette iris mata. Rubber sheet model disusun oleh Daugman dengan konsep setiap titik pada koordinat wilayah collarette akan dipetakan kembali ke dalam koordinat baru dengan dimensi r × θ dimana adalah r resolusi radial dan θ adalah resolusi angular. Ilustrasi pemetaan kembali ke dalam koordinat polar dapat dilihat pada Gambar 3.
Gambar 3 Ilustrasi Daugman’s rubber sheet model.
Persaman pemetaan wilayah iris dari koordinat koordinat polar ( ) ke koordinat kartesian (x, y) adalah sebagai berikut:
(1) (2) dengan dan adalah representasi koordinat kartesian dari koordinat polar. Variabel r adalah panjang sumbu polar dan adalah sudut polar.
Rubber sheet model memperhitungkan
pelebaran pupil dan ketidakkonsistenan ukuran pupil untuk menghasilkan sebuah hasil normalisasi dengan dimensi yang konstan (Masek 2003).
Discrete Fourier Transform
Fourier transform digunakan untuk
menganalisis citra pada domain frekuensi. Dengan transformasi ini, intensitas piksel pada citra diperlakukan sebagai fungsi yang memiliki nilai amplitudo pada frekuensi tertentu. Fourier
transform memberikan freksibilitas dalam
desain dan implementasi pada banyak bidang seperti image enhancement, image restoration
dan image compression (Gonzales et al. 2003). Ketika Fourier transform digunakan pada sinyal yang diskret, maka digunakan discrete
Fourier transform. Rumus dari DFT satu
dimensi adalah:
(3) dan inverse-nya adalah:
(4) dengan adalah Fourier spectrum, adalah nilai piksel citra dan N adalah ukuran dari data yang akan ditransformasikan.
Fast Fourier transform (FFT) adalah
algoritme DFT yang memiliki kompleksitas lebih baik. DFT biasa akan memiliki kompleksitas sebesar sedangkan FFT memiliki kompleksitas sebesar . Log-Gabor Filter
Gabor filter banyak digunakan untuk
karakterisasi tekstur dari suatu citra (Mancas dan Gosselin 2006) dengan mencari representasi gabungan optimal dari sinyal pada domain spasial dan frekuensi. Dengan menggunakan Gabor filter, lokalisasi gabungan dibentuk baik pada domain spasial maupun frekuensi.
Kelemahan dari Gabor filter adalah pada even symmetric filter yang memiliki komponen DC ketika bobotnya melebihi satu oktav (Field 1987, diacu dalam Masek 2003). Komponen DC adalah nilai hasil transformasi pada domain frekuensi awal (Gonzales et al. 2003). Namun, komponen DC yang bernilai nol dapat diperoleh pada bobot berapapun jika menggunakan skala logaritmik pada Gabor filter yang disebut dengan log-Gabor filter. Respon frekuensi pada log-Gabor filter memiliki rumus:
(5)
dengan adalah nilai frekuensi, adalah pusat frekuensi dan adalah bobot filter.
K-Fold Cross Validation
Cross-validation adalah teknik komputasi menggunakan seluruh contoh sebagai data pelatihan dan data tes secara berulang kali sebanyak K kali menggunakan data tes sebanyak 1/K bagian data keseluruhan (Stone 1974, diacu dalam Bengio dan Grandvalet 2003). Untuk setiap pengulangan, digunakan kombinasi data latih dan data tes yang berbeda
dengan pengulangan sebelumnya namun dengan jumlah data yang sama.
Voting Feature Intervals versi 5
Voting Feature Intervals (VFI) adalah
algoritme klasifikasi non-incremental dan supervised yang dikembangkan oleh Demiroz dan Güvenir (1997). Algoritme tersebut digolongkan sebagai non-incremental karena semua instance pelatihan diproses secara bersama-sama. Di sisi lain, supervised digolongkan terhadap algoritme ini karena memiliki target output yang diinginkan yaitu berupa kelas-kelas. Algoritme VFI telah dikembangkan hingga versi ke-5 yang biasa disingkat menjadi VFI5.
Algoritme VFI5 memiliki dua fase, yaitu fase pelatihan dan fase tes (Güvenir et al. 1998). 1. Pelatihan
Pada fase pelatihan, dilakukan pencarian terhadap nilai EndPoints dari fitur f di setiap kelas c, yaitu berupa nilai maksimum dan minimum tiap kelas pada masing-masing fitur sehingga setiap kelas memiliki dua nilai EndPoints. Nilai EndPoints kemudian disimpan dalam bentuk array EndPoints[ f ] dan dilakukan sorting. Jika nilai fitur berupa linear, maka point intervals dibuat pada setiap nilai EndPoints sedangkan range intervals dibuat di antara nilai-nilai EndPoints dantidak termasuk nilai EndPoints itu sendiri. Di sisi lain, jika fitur berupa nilai nominal, maka cukup point intervals saja yang dibuat.
Setelah interval terbentuk, langkah selanjutnya adalah menghitung jumlah instances pelatihan i pada setiap kelas c dengan fitur f yang jatuh pada setiap interval yang bersangkutan yang direpresentasikan oleh interval_count[f, i, c]. Perhitungan terhadap setiap kelas c pada setiap interval i pada dimensi fitur f dilakukan pada prosedur count_instance. Jika interval i merupakan point interval dan nilai ef sama dengan nilai pada
batas bawah atau batas atas maka jumlah kelas instance tersebut (ef) pada interval i ditambah 1.
Jika interval i merupakan range interval dan nilai ef jatuh pada interval tersebut, maka
jumlah kelas instance ef pada interval i
ditambah 1.
4 c] dinormalisasi sehingga jumlah vote dari
beberapa kelas pada setiap feature yang sama adalah 1. Normalisasi ini bertujuan agar setiap fitur memiliki kekuatan voting yang sama pada proses klasifikasi yang tidak dipengaruhi ukuranya. untuk tahap pelatihan algoritme VFI5 dapat dilihat pada Gambar 4.
train(TrainingSet); begin
for each feature f for each class c
EndPoints[f] = EndPoints [f] find_end_Points [TrainingSet, f, c];
sort(EndPoints[f])
if f is linear
for each end point p in EndPoints[f]
form a point interval from end point p form a range interval between p and the next endpoint p
else /* f is nominal */
each distinct point in EndPoints[f] forms a point interval
for each interval i on feature dimension f
for each class c
interval_count [f, i, c] = 0; count_instances(f, TrainingSet) for each interval i on feature dimension f
for each class c
interval _vote[f, I, c]=interval_count[f, i, c]/class_count[c]
normalize interval_vote[f, i, c];
end.
Gambar 4 Pseudocode pelatihan VFI5. 2. Klasifikasi
Tahap klasifikasi dimulai dengan inisiasi nilai vote setiap kelas menjadi 0. Nilai vote yaitu array yang menampung informasi nilai interval_vote tiap kelas c dari fitur f di interval i dimana nilai ef jatuh. Jika ef tidak diketahui,
maka feature tersebut tidak disertakan dalam voting (memberi nilai vote 0 untuk masing-masing kelas).
Jika nilai ef diketahui, dilakukan pencarian
untuk setiap fitur f berupa nilai interval i di mana ef jatuh. Lalu nilai setiap kelas c dari fitur
f yang direpresentasikan dengan feature_vote[f, c] dicari. Nilai tersebut didapat dengan melihat nilai dari interval_vote tempat i jatuh. Hasil dari nilai feature_vote kemudian ditambahkan untuk kemudian menjadi nilai vote untuk setiap kelas c. Nilai vote dari kelas c menunjukkan bahwa contoh e termasuk kedalam kelas c. Pseudocode dari tahap klasifikasi dapat dilihat pada Gambar 5.
classify(e); /*example to be classified */ begin
for each class c vote[c] = 0
for each feature f for each class c
feature_vote[f, c] = 0; /*vote feature f for class c */
if ef value is known i = find_interval(f, ef)
for each class c
feature_vote[f, c] = interval_vote[f, i, c] vote[c] = vote[c]+ feature_vote[f, c]*weight[f]
return the class c with highest vote[c]; end.
Gambar 5 Pseudocode klasifikasi VFI5.
METODE PENELITIAN
Penelitian ini melalui beberapa tahapan proses untuk dapat mengenali iris mata setiap individu menggunakan algoritme VFI5. Tahapan proses tersebut dapat dilihat pada Gambar 6.
Gambar 6 Tahapan pengenalan iris mata. Data
c] dinormalisasi sehingga jumlah vote dari beberapa kelas pada setiap feature yang sama adalah 1. Normalisasi ini bertujuan agar setiap fitur memiliki kekuatan voting yang sama pada proses klasifikasi yang tidak dipengaruhi ukuranya. untuk tahap pelatihan algoritme VFI5 dapat dilihat pada Gambar 4.
train(TrainingSet); begin
for each feature f for each class c
EndPoints[f] = EndPoints [f] find_end_Points [TrainingSet, f, c];
sort(EndPoints[f])
if f is linear
for each end point p in EndPoints[f]
form a point interval from end point p form a range interval between p and the next endpoint p
else /* f is nominal */
each distinct point in EndPoints[f] forms a point interval
for each interval i on feature dimension f
for each class c
interval_count [f, i, c] = 0; count_instances(f, TrainingSet) for each interval i on feature dimension f
for each class c
interval _vote[f, I, c]=interval_count[f, i, c]/class_count[c]
normalize interval_vote[f, i, c];
end.
Gambar 4 Pseudocode pelatihan VFI5. 2. Klasifikasi
Tahap klasifikasi dimulai dengan inisiasi nilai vote setiap kelas menjadi 0. Nilai vote yaitu array yang menampung informasi nilai interval_vote tiap kelas c dari fitur f di interval i dimana nilai ef jatuh. Jika ef tidak diketahui,
maka feature tersebut tidak disertakan dalam voting (memberi nilai vote 0 untuk masing-masing kelas).
Jika nilai ef diketahui, dilakukan pencarian
untuk setiap fitur f berupa nilai interval i di mana ef jatuh. Lalu nilai setiap kelas c dari fitur
f yang direpresentasikan dengan feature_vote[f, c] dicari. Nilai tersebut didapat dengan melihat nilai dari interval_vote tempat i jatuh. Hasil dari nilai feature_vote kemudian ditambahkan untuk kemudian menjadi nilai vote untuk setiap kelas c. Nilai vote dari kelas c menunjukkan bahwa contoh e termasuk kedalam kelas c. Pseudocode dari tahap klasifikasi dapat dilihat pada Gambar 5.
classify(e); /*example to be classified */ begin
for each class c vote[c] = 0
for each feature f for each class c
feature_vote[f, c] = 0; /*vote feature f for class c */
if ef value is known i = find_interval(f, ef)
for each class c
feature_vote[f, c] = interval_vote[f, i, c] vote[c] = vote[c]+ feature_vote[f, c]*weight[f]
return the class c with highest vote[c]; end.
Gambar 5 Pseudocode klasifikasi VFI5.
METODE PENELITIAN
Penelitian ini melalui beberapa tahapan proses untuk dapat mengenali iris mata setiap individu menggunakan algoritme VFI5. Tahapan proses tersebut dapat dilihat pada Gambar 6.
Gambar 6 Tahapan pengenalan iris mata. Data
5 interval dan lamp diambil di dalam ruangan
(indoor) dan bukan merupakan anak kembar. Data yang digunakan dalam penelitian ini adalah data interval karena memiliki kualitas paling baik dengan detail tekstur iris yang jelas.
Jumlah data yang digunakan adalah 180 yang berasal dari sepuluh individu yang berbeda, dimana setiap individu memiliki sembilan citra mata kiri dan kanan. Seluruh data kemudian dibagi menjadi tiga subset untuk mata kiri dan kanan yang berjumlah sama (tiga puluh buah), yaitu fold1, fold2, dan fold3 yang bertujuan untuk mencari akurasi menggunakan 3-cross-fold validation. Nama dari file dan indeksnya pada masing-masing orang dapat dilihat pada Lampiran 1.
Fold1 menggunakan data citra dengan
indeks nomer 1, 2, 3, 4, 5 dan 6 dari masing-masing orang untuk proses pelatihan dan data citra dengan indeks 7, 8 dan 9 untuk pengujian. Fold2 menggunakan data citra 4, 5, 6, 7, 8 dan 9 pada tahap pelatihan dan data citra 1, 2 dan 3 untuk tahap pengujian. Pada Fold3, digunakan data citra 1, 2, 3, 7, 8 dan 9 untuk tahap pelatihan dan data citra 4, 5 dan 6 untuk tahap pengujian. Pembagian subset dapat dilihat pada Tabel 1.
Tabel 1 Pembagian subset
Subset Data Latih
(indeks)
Data Uji (indeks) fold1 1, 2, 3, 4, 5, 6 7, 8, 9
fold2 4, 5, 6, 7, 8, 9 1, 2, 3
fold3 1, 2, 3, 7, 8, 9 4, 5, 6 .
Segmentasi
Proses segmentasi dilakukan untuk mendapatkan titik tengah lingkaran pupil beserta jari-jarinya. Abidin (2011) melakukan proses segmentasi melalui tiga tahap: thresholding, regioning dan labeling, lalu penghitungan titik tengah dan jari-hari pupil.
Pada tahap thresholding dilakukan proses untuk mendapatkan nilai piksel citra yang lebih kecil dari threshold tertentu karena pada umumnya nilai piksel pupil adalah kecil (berwarna hitam). Setelah itu, dilakukan regioning dan labeling untuk mencari luas wilayah piksel yang saling berkumpul di suatu tempat dan memberi kumpulan tersebut label. Label dengan luas terbesar kemudian akan menjadi region pupil. Proses kemudian berlanjut dengan mencari titik tengah dan jari-jari dari region pupil yang kemudian akan digunakan untuk proses normalisasi.
Normalisasi
Setelah titik tengah dan jari-jari wilayah pupil telah tersegmentasi dari citra mata, dilakukan pengambilan wilayah iris sepanjang 20 piksel ke arah luar pupil. Nilai tersebut diambil sesuai dengan hasil penelitian Masek (2003) yang menunjukkan nilai collarette yang lebih baik pada jarak 20 piksel dengan resolusi angular sebesar 240 pada dataset CASIA. Setelah ditentukan wilayah collarete dari citra mata, maka tahap selanjutnya adalah menransformasikan wilayah tersebut ke dimensi tetap menggunakan transformasi dari koordinat polar ke koordinat kartesian dengan resolusi angular sebesar 240. Transformasi ini diperlukan karena citra mata memiliki dimensi yang tidak konsisten dikarenakan pelebaran pupil akibat tingkat pencahayaan yang berbeda (Masek 2003). Hasil dari normalisasi akan memberikan ciri spasial di lokasi iris dari orang yang sama menjadi sama walaupun kondisi pencahayaan yang berbeda.
Feature Encoding
Pada proses feature encoding, citra iris yang telah dinormalisasi diekstraksi ciri menggunakan 1D log-Gabor wavelet dengan nilai panjang gelombang yang digunakan adalah 18 dengan sebesar 0.5 sesuai dengan penelitian Masek (2003). Setiap baris pada citra yang telah dinormalisasi, yaitu sebanyak 240 piksel pada setiap lingkaran collarette dilakukan proses FFT untuk merepresentasikan citra pada domain frekuensi. Kemudian setelah dilakukan proses FFT, nilai tersebut dikalikan dengan log-Gabor filter dan dilakukan inverse fast Fourier transform untuk mengembalikan representasi citra pada domain spasial. Hasil dari transformasi ini adalah bilangan real dan imajiner dari setiap nilai piksel.
Langkah selanjutnya adalah mengubah nilai real dan imajiner dari hasil transformasi citra menjadi bernilai biner 2 bit yang merupakan informasi ciri dari citra tersebut. Hal ini berkaitan dengan penelitian Oppenheim dan Lim (1981) yang menunjukkan bahwa phase
information lebih memberikan informasi
dibandingkan dengan amplitudo.
Untuk setiap nilai piksel pada citra yang telah ditransformasi, dicari template yang merepresentasikannya dengan kriteria sebagai berikut:
jika nilai real > 0 dan nilai imajiner < 0 template piksel adalah 10,
jika nilai real < 0 dan nilai imajiner > 0 template piksel adalah 01,
jika nilai real < 0 dan nilai imajiner < 0 nilai template adalah 00.
dengan demikian, maka didapat template bernilai biner dengan dimensi 20 x 480. Template ini kemudian digunakan untuk proses pelatian dan pengujian.
Voting Feature Interval versi 5
Setelah seluruh citra melalui tahap encode, dilakukan pelatihan dan pengujian terhadap data template citra. Data template yang berukuran 20 x 480 piksel diubah dimensinya manjadi 1 x 9600 piksel yang kemudian berlaku sebagai fitur dengan nilai biner. Karena perhitungan akurasi menggunakan 3-cross fold validation, maka banyaknya proses pelatihan dan pengujian adalah tiga kali karena subset akan saling bergantian untuk menjadi data latih dan data uji. Pengujian terhadap masing-masing subset dilakukan terhadap mata kiri, mata kanan dan gabungan mata kiri dan kanan. Pelatihan terhadap gabungan mata kiri dan kanan dilakukan terpisah pada citra mata kiri dan kanan yang diambil secara bersamaan, lalu menjumlahkan vote dari masing-masing pasangan tersebut dimana interval data uji jatuh. Nilai vote gabungan dari kelas yang memiliki jumlah terbesar dipilih sebagai kelas dari data uji. Hasil pengujian masing-masing data uji pada setiap subset kemudian disimpan untuk proses perhitungan akurasi.
Perhitungan Akurasi
Perhitungan akurasi yang diperoleh oleh algoritme VFI5 pada penelitian ini dilakukan dengan cara :
(6) Akurasi menunjukkan tingkat penglasifikasian data secara benar terhadap kelas sebenarnya. Semakin mendekati nilai 100% maka akurasi semakin baik.
Lingkungan pengembangan sistem
Proses pengerjaan penelitian ini menggunakan perangkat dan perangkat lunak dengan spesifikasi sebagai berikut:
Perangkat keras berupa Notebook:
processor intel Pentium Dual-Core
@2GHz,
RAM kapasitas 1GB,
harddisk Kapasitas 150GB,
monitor pada resolusi 1366 x 768 piksel, merek emachines model eMD725. Perangkat lunak berupa:
sistem operasi Microsoft Windows XP professional,
aplikasi pemrograman Matlab 7.1.0.246(R14) Service Pack 3.
HASIL DAN PEMBAHASAN
Segmentasi
Tujuan dari segmentasi adalah untuk mendapatkan koordinat pusat lingkaran dari pupil mata pada citra. Untuk mendapatkan koordinat tersebut, perlu dilakukan beberapa tahapan yaitu thresholding, regioning dan labeling serta pencarian nilai piksel pada pusat lingkaran yang memiliki luas region terbesar.
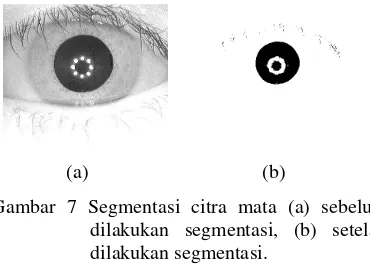
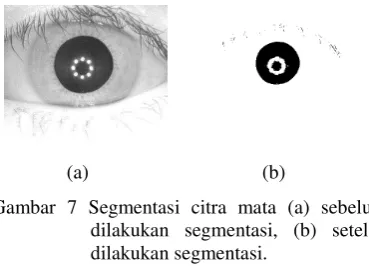
Pada tahapan thresholding, dilakukan pencarian terhadap piksel yang memiliki nilai lebih rendah dari nilai threshold tertentu. Nilai threshold didapat melalui persentase jumlah piksel yang memiliki nilai < 100 terhadap total piksel pada citra. Hal ini dikarenakan ada perbedaan intensitas pencahayaan pada pengambilan citra mata sehingga jika intensitas pencahayaan rendah, maka nilai piksel cenderung rendah. Begitu pula sebaliknya, jika intensitas pencahayaan tinggi, nilai piksel akan cenderung besar. Contoh hasil thresholding pada citra dapat dilihat pada Gambar 7.
(a) (b)
Gambar 7 Segmentasi citra mata (a) sebelum dilakukan segmentasi, (b) setelah dilakukan segmentasi.
6 jika nilai real > 0 dan nilai imajiner < 0
template piksel adalah 10,
jika nilai real < 0 dan nilai imajiner > 0 template piksel adalah 01,
jika nilai real < 0 dan nilai imajiner < 0 nilai template adalah 00.
dengan demikian, maka didapat template bernilai biner dengan dimensi 20 x 480. Template ini kemudian digunakan untuk proses pelatian dan pengujian.
Voting Feature Interval versi 5
Setelah seluruh citra melalui tahap encode, dilakukan pelatihan dan pengujian terhadap data template citra. Data template yang berukuran 20 x 480 piksel diubah dimensinya manjadi 1 x 9600 piksel yang kemudian berlaku sebagai fitur dengan nilai biner. Karena perhitungan akurasi menggunakan 3-cross fold validation, maka banyaknya proses pelatihan dan pengujian adalah tiga kali karena subset akan saling bergantian untuk menjadi data latih dan data uji. Pengujian terhadap masing-masing subset dilakukan terhadap mata kiri, mata kanan dan gabungan mata kiri dan kanan. Pelatihan terhadap gabungan mata kiri dan kanan dilakukan terpisah pada citra mata kiri dan kanan yang diambil secara bersamaan, lalu menjumlahkan vote dari masing-masing pasangan tersebut dimana interval data uji jatuh. Nilai vote gabungan dari kelas yang memiliki jumlah terbesar dipilih sebagai kelas dari data uji. Hasil pengujian masing-masing data uji pada setiap subset kemudian disimpan untuk proses perhitungan akurasi.
Perhitungan Akurasi
Perhitungan akurasi yang diperoleh oleh algoritme VFI5 pada penelitian ini dilakukan dengan cara :
(6) Akurasi menunjukkan tingkat penglasifikasian data secara benar terhadap kelas sebenarnya. Semakin mendekati nilai 100% maka akurasi semakin baik.
Lingkungan pengembangan sistem
Proses pengerjaan penelitian ini menggunakan perangkat dan perangkat lunak dengan spesifikasi sebagai berikut:
Perangkat keras berupa Notebook:
processor intel Pentium Dual-Core
@2GHz,
RAM kapasitas 1GB,
harddisk Kapasitas 150GB,
monitor pada resolusi 1366 x 768 piksel, merek emachines model eMD725. Perangkat lunak berupa:
sistem operasi Microsoft Windows XP professional,
aplikasi pemrograman Matlab 7.1.0.246(R14) Service Pack 3.
HASIL DAN PEMBAHASAN
Segmentasi
Tujuan dari segmentasi adalah untuk mendapatkan koordinat pusat lingkaran dari pupil mata pada citra. Untuk mendapatkan koordinat tersebut, perlu dilakukan beberapa tahapan yaitu thresholding, regioning dan labeling serta pencarian nilai piksel pada pusat lingkaran yang memiliki luas region terbesar.
Pada tahapan thresholding, dilakukan pencarian terhadap piksel yang memiliki nilai lebih rendah dari nilai threshold tertentu. Nilai threshold didapat melalui persentase jumlah piksel yang memiliki nilai < 100 terhadap total piksel pada citra. Hal ini dikarenakan ada perbedaan intensitas pencahayaan pada pengambilan citra mata sehingga jika intensitas pencahayaan rendah, maka nilai piksel cenderung rendah. Begitu pula sebaliknya, jika intensitas pencahayaan tinggi, nilai piksel akan cenderung besar. Contoh hasil thresholding pada citra dapat dilihat pada Gambar 7.
(a) (b)
Gambar 7 Segmentasi citra mata (a) sebelum dilakukan segmentasi, (b) setelah dilakukan segmentasi.
background dan objek ditukar, sehingga background bernilai 0 dan objek bernilai 1.
Setelah citra melalui tahap thresholding seperti Gambar 7b, dilakukan labeling menggunakan fungsi bwlabel pada Matlab. Fungsi tersebut memberikan nilai 1 pada setiap piksel yang memiliki jumlah konektivitas secara vertikal atau horizontal sebanyak ≥ 4 atau ≥ 8 dengan tetangganya yang memiliki nilai yang sama. Contoh kasus penggunaan bwlabel ada pada Lampiran 2.
Hasil dari labeling adalah berupa region yang memiliki indeks 1 sampai N, dengan N adalah jumlah region yang terdeteksi oleh fungsi bwlabel. Setelah itu dilakukan perhitungan terhadap jumlah piksel yang masuk ke dalam setiap region. Region yang kemudian dipilih sebagai pupil adalah yang memiliki jumlah piksel terbanyak. Sebagai ilustrasi pada Gambar 8, region yang memiliki jumlah piksel terbanyak adalah region dengan indeks 7. Piksel yang memiliki indeks region selain 7 kemudian akan dianggap sebagai background dan diberi nilai 0 seperti terlihat pada Gambar 9.
Gambar 8 Ilustrasi labeling di setiap region pada citra mata yang telah diberi threshold.
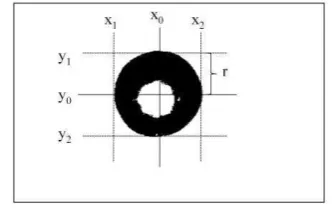
Gambar 9 Citra mata dengan region terbesar. Tahap terakhir dalam proses segmentasi adalah pencarian koordinat titik tengah pupil dari citra yang telah dicari region terbesarnya. Pencarian koordinat pupil dilakukan melalui pengecekan antara persimpangan garis vertikal
dengan garis horizontal. Pencarian akan terus berlangsung hingga menemukan kondisi ideal di daerah tengah pupil.
Ilustrasi pencarian titik tengah pupil dapat dilihat pada Gambar 10. Variabel x0 dan y0
adalah garis vertikal dan horizontal, sedangkan x1, x2, y1, dan y2 adalah batas wilayah pupil.
Persimpangan antara garis vertikal dan horizontal adalah koordinat pupil yaitu (x0, y0),
sedangkan diameter pupil didapat dari selisih antara y2 dan y1 atau x2 dan x1. Selisih yang
terpanjang dianggap sebagai diameter pupil. Jari-jari pupil didapat dari diameter pupil dibagi dua.
Gambar 10 Ilustrasi pencarian koordinat pupil Setelah koordinat titik pusat lingkaran pupil dan jari-jarinya diketahui, wilayah collarette yang kemudian digunakan untuk pengenalan adalah hingga sejauh 20 piksel dari wilayah luar lingkaran pupil. Ilustrasi wilayah iris tersebut dapat dilihat pada Gambar 11.
Gambar 11 Ilustrasi wilayah collarette. Normalisasi
8 kurang baik dan sukar untuk dilakukan
pembandingan dengan data lainnya (Masek 2003).
(a) (b)
Gambar 12 Mata kiri orang ke-1 yang diambil pada waktu berbeda (a) pengambilan pertama (b) pengambilan kedua.
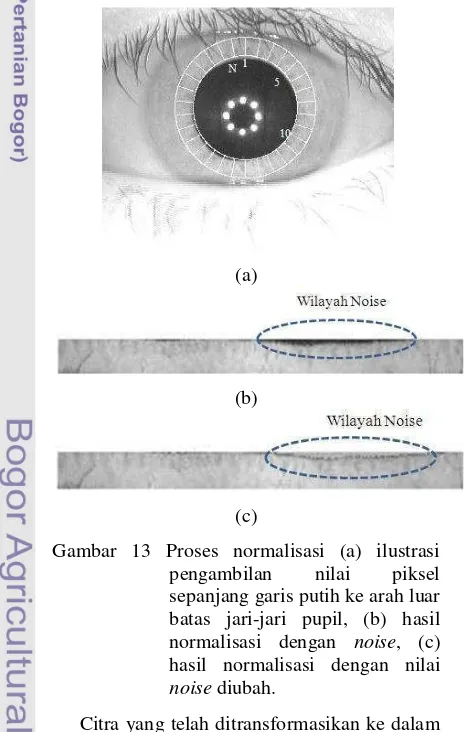
Wilayah collarette yang diambil adalah sejauh 20 piksel ke arah luar dari jari-jari pupil. Dengan pembagian sudut N sebanyak 240 sepanjang lingkaran pupil, maka akan menghasilkan array yang berukuran 20 x 240 yang memiliki nilai sepanjang garis putih ke arah luar dari batas lingkaran pupil pada seperti Gambar 13a.
(a)
(b)
(c)
Gambar 13 Proses normalisasi (a) ilustrasi pengambilan nilai piksel sepanjang garis putih ke arah luar batas jari-jari pupil, (b) hasil normalisasi dengan noise, (c) hasil normalisasi dengan nilai noise diubah.
Citra yang telah ditransformasikan ke dalam koordinat polar tampak seperti pada Gambar
13b. Agar proses ekstraksi ciri menghasilkan output yang lebih baik, maka nilai piksel yang termasuk noise seperti yang ditandai di dalam lingkaran pada Gambar 13b diubah nilainya menggunakan rumus:
(7)
dengan adalah nilai piksel setelah diubah nilainya. Hasil citra yang telah diubah nilai noise-nya akan tampak seperti Gambar 13c. Noise yang terbentuk dapat berasal dari wilayah pupil atau bulu mata yang ikut ternormalisasi. Wilayah pupil ikut ternormalisasi dikarenakan segmentasi yang kurang sempurna.
Feature Encoding
Citra yang telah dinormalisasi kemudian diekstraksi cirinya menggunakan log-Gabor filter. Karena citra yang telah dinormalisasi berdimensi 20 x 240, maka akan dihasilkan template yang memiliki dimensi 20 x 480 dengan rentang nilai biner, yaitu 0 dan 1. Dimensi template tersebut kemudian diubah menjadi ukuran 1 x 9600 yang kemudian dijadikan fitur untuk proses pelatihan dan pengujian menggunakan algoritme VFI5. Ilustrasi proses feature encoding dapat dilihat pada Lampiran 3.
Pelatihan dan Pengujian
Proses pelatihan dan pengujian dilakukan menggunakan algoritme VFI5 terhadap tiga subset yang saling lepas dari data template mata kanan, mata kiri dan gabungan keduanya sesuai dengan 3-cross fold validation. Proses tersebut dilakukan terhadap keseluruhan 9600 fitur yang masing-masing memiliki dua EndPoints yaitu 0 dan 1 dan memiliki dua interval saja karena data dari template yang terbentuk merupakan data yang berupa point interval. Kemudian dari masing-masing kelas pelatihan, dihitung vote dari setiap fitur untuk digunakan pada tahap pengujian dan dilakukan normalisasi agar rentang nilainya berkisar 0 sampai 1.
Hasil pengujian yang benar dan salah pada masing-masing subset dapat dilihat pada Tabel 2. Untuk hasil yang lebih lengkap dapat dilihat pada Lampiran 4 sedangkan untuk nilai vote keseluruhan dapat dilihat pada Lampiran 5. Peringkat kemiripan dari setiap data uji terhadap kelas yang ada dapat dilihat pada Lampiran 6.
dikarenakan nilai vote dari salah satu mata yang memberikan nilai dominan dibandingkan nilai mata yang lainnya. Sebagai contoh pada Tabel 3, saat dilakukan pengujian terhadap mata kanan pada subset fold1, terdapat kesalahan penglasifikasian kelas 2 menjadi kelas 8 (lihat pada Lampiran 4). Nilai vote untuk kelas uji dikenali sebagai kelas 2 dan kelas 8 berbeda tipis sebesar 0.0003 namun karena nilai vote untuk kelas 8 lebih besar, maka data uji akan diklasifikasikan sebagai kelas 8. Penambahan vote mata kiri memberikan nilai vote untuk kelas 2 lebih besar karena pada mata kiri, nilai
vote untuk kelas 2 jauh lebih besar
dibandingkan untuk kelas 8 dengan selisih sebesar 0.02 sehingga setelah penggabungan, nilai kelas akan diberikan pada kelas 2. Hal ini akan mengkoreksi kelas sebelumnya yang jatuh pada kelas 8.
Tabel 2 hasil pengujian yang benar dan salah
subset Wilayah
Mata Klasifik-asi Benar Klasifik-asi Salah fold1
Kiri 28 2
Kanan 29 1
Gabungan 30 0
fold2
Kiri 28 2
Kanan 27 3
Gabungan 30 0
fold3
Kiri 30 0
Kanan 28 2
Gabungan 30 0
Tabel 3 Nilai vote data uji kelas 2 yang salah diklasifikasi menjadi kelas 8 pada fold1
Mata Kelas
Dikenali sebagai kelas ke-(Nilai vote)
2 8
Kiri 2 0,1150 0,0950
Kanan 2 0,1046 0,1049
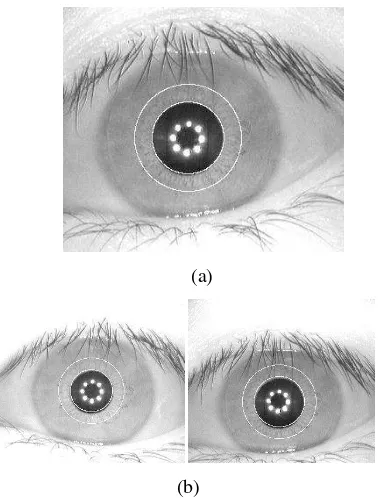
Total 0,2196 0,1999 Penyebab kesalahan klasifikasi pada data uji di antaranya dapat disebabkan oleh kesalahan pada segmentasi data latih maupun data uji itu sendiri. Gambar 14 menunjukkan ilustrasi hasil segmentasi citra mata kiri orang ke-6 yang salah diklasifikasikan menjadi kelas 10 pada subset fold1. Hasil segmentasi dari citra orang tersebut kurang sempurna karena koordinat titik tengah pupil yang didapat sedikit terlalu bawah sehingga cukup banyak wilayah pupil bagian atas yang masuk sebagai wilayah iris dan wilayah iris bagian bawah ada yang tidak terambil (Gambar 13a). Namun setelah
koordinat titik tengah pupil dinaikkan sebesar 2 piksel ke arah atas (Gambar 13b) secara manual, citra tersebut dapat dikenali dengan benar oleh sistem.
(a)
(b)
Gambar 14 Ilustrasi wilayah iris (a) sebelum modifikasi nilai titik tengah, (b) setelah modifikasi.
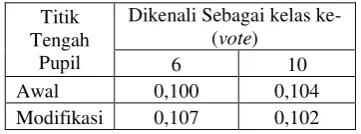
Nilai vote sebelum dan sesudah modifikasi nilai tengah pada citra mata kiri orang ke-6 tersebut dapat dilihat pada Tabel 4. Dari Tabel tersebut terlihat bahwa nilai vote data uji terhadap kelas 6 lebih kecil dibandingkan kelas 10 sebelum dilakukan modifikasi nilai titik tengah. Namun setelah dilakukan modifikasi, nilai vote untuk kelas 6 menjadi lebih besar dibandingkan dengan kelas 10 sehingga data uji dikenali dengan benar.
Tabel 4 Nilai vote kelas 6 yang salah dikenali menjadi kelas 10 pada fold1
Titik Tengah
Pupil
Dikenali Sebagai kelas ke- (vote)
6 10
Awal 0,100 0,104
Modifikasi 0,107 0,102
10 telah tersegmentasi dengan baik, namun tetap
menunjukkan kesalahan pengenalan. Hal tersebut disebabkan oleh data latih banyak yang tidak tersegmentasi dengan baik seperti terlihat pada Gambar 15b, sehingga template yang terbentuk kurang baik dalam mengekstraksi ciri dari citra tersebut.
(a)
(b)
Gambar 15 Ilustrasi wilayah iris kelas 10 yang salah diklasifikasikan pada fold1 (a) citra uji, (b) citra latih.
Akurasi
Setelah seluruh citra uji pada masing-masing subset melalui tahap pengujian, hasil kelas yang diberikan pada masing-masing data uji tersebut dicatat dan dihitung nilai akurasinya. Nilai akurasi yang dihitung adalah pada masing-masing subset dan bagian mata. Hasil akurasi yang diperoleh dapat dilihat pada Tabel 5. Tabel 5 Akurasi pengujian yang diperoleh
Subset Akurasi Bagian Mata (%)
Kiri Kanan Gabungan
fold1 93,333 96,667 100
fold2 93,333 90,000 100
fold3 100,000 93,333 100
Rata-rata 95,555 93,333 100
Perbandingan akurasi yang diperoleh pada penelitian ini dengan penelitian sebelumnya dapat dilihat pada Lampiran 7. Penelitian Masek menghasilkan akurasi sebesar 99.9% dengan menggunakan Log-Gabor Wavelet satu dimensi sebagai metode ekstraksi ciri dan
Hamming distances sebagai algoritme
pengujian. Abidin mendapatkan akurasi sebesar 92.6% menggunakan ekstraksi ciri Wavelet transform pada level dekomposisi 3 dan menggunakan jaringan syaraf tiruan propagasi balik sebagai algoritme pelatihan dan pengujian. Pada penelitian ini diperoleh akurasi sebesar 100% menggunakan ekstraksi ciri Log-Gabor Wavelet satu dimensi dan algoritme VFI5 sebagai pelatihan dan pengujian terhadap sepasang mata kanan dan kiri.
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian ini dapat diperoleh kesimpulan:
penelitian ini memberikan nilai akurasi pengenalan iris mata rata-rata sebesar 95,555% untuk mati kiri, 93,333% untuk mata kanan dan 100% untuk penggabungan vote kedua mata,
penggunaan threshold berdasarkan proporsi jumlah piksel yang bernilai < 100 memberikan hasil segmentasi yang lebih baik dibandingkan dengan penggunaan threshold yangtetap,
kesalahan pengujian diakibatkan oleh output titik pusat lingkaran pada proses segmentasi tidak terpilih dengan baik, yang mengakibatkan banyak wilayah pupil yang ikut masuk ke dalam data untuk ekstraksi ciri, sedangkan ada sejumlah wilayah iris yang tidak masuk ke dalam data tersebut.
Saran
Saran pada penelitian lebih lanjut adalah dilakukan penyempurnaan proses segmentasi dengan melakukan pergeseran titik pusat lingkaran berdasarkan arah sudut wilayah noise terhadap titik pusat awal.
DAFTAR PUSTAKA
Abidin JAZ. 2011. Pengenalan Iris Mata dengan Backpropagation Neural Network Menggunakan Praproses Transformasi
Wavelet [skripsi]. Bogor: Fakultas
Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
telah tersegmentasi dengan baik, namun tetap menunjukkan kesalahan pengenalan. Hal tersebut disebabkan oleh data latih banyak yang tidak tersegmentasi dengan baik seperti terlihat pada Gambar 15b, sehingga template yang terbentuk kurang baik dalam mengekstraksi ciri dari citra tersebut.
(a)
(b)
Gambar 15 Ilustrasi wilayah iris kelas 10 yang salah diklasifikasikan pada fold1 (a) citra uji, (b) citra latih.
Akurasi
Setelah seluruh citra uji pada masing-masing subset melalui tahap pengujian, hasil kelas yang diberikan pada masing-masing data uji tersebut dicatat dan dihitung nilai akurasinya. Nilai akurasi yang dihitung adalah pada masing-masing subset dan bagian mata. Hasil akurasi yang diperoleh dapat dilihat pada Tabel 5. Tabel 5 Akurasi pengujian yang diperoleh
Subset Akurasi Bagian Mata (%)
Kiri Kanan Gabungan
fold1 93,333 96,667 100
fold2 93,333 90,000 100
fold3 100,000 93,333 100
Rata-rata 95,555 93,333 100
Perbandingan akurasi yang diperoleh pada penelitian ini dengan penelitian sebelumnya dapat dilihat pada Lampiran 7. Penelitian Masek menghasilkan akurasi sebesar 99.9% dengan menggunakan Log-Gabor Wavelet satu dimensi sebagai metode ekstraksi ciri dan
Hamming distances sebagai algoritme
pengujian. Abidin mendapatkan akurasi sebesar 92.6% menggunakan ekstraksi ciri Wavelet transform pada level dekomposisi 3 dan menggunakan jaringan syaraf tiruan propagasi balik sebagai algoritme pelatihan dan pengujian. Pada penelitian ini diperoleh akurasi sebesar 100% menggunakan ekstraksi ciri Log-Gabor Wavelet satu dimensi dan algoritme VFI5 sebagai pelatihan dan pengujian terhadap sepasang mata kanan dan kiri.
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian ini dapat diperoleh kesimpulan:
penelitian ini memberikan nilai akurasi pengenalan iris mata rata-rata sebesar 95,555% untuk mati kiri, 93,333% untuk mata kanan dan 100% untuk penggabungan vote kedua mata,
penggunaan threshold berdasarkan proporsi jumlah piksel yang bernilai < 100 memberikan hasil segmentasi yang lebih baik dibandingkan dengan penggunaan threshold yangtetap,
kesalahan pengujian diakibatkan oleh output titik pusat lingkaran pada proses segmentasi tidak terpilih dengan baik, yang mengakibatkan banyak wilayah pupil yang ikut masuk ke dalam data untuk ekstraksi ciri, sedangkan ada sejumlah wilayah iris yang tidak masuk ke dalam data tersebut.
Saran
Saran pada penelitian lebih lanjut adalah dilakukan penyempurnaan proses segmentasi dengan melakukan pergeseran titik pusat lingkaran berdasarkan arah sudut wilayah noise terhadap titik pusat awal.
DAFTAR PUSTAKA
Abidin JAZ. 2011. Pengenalan Iris Mata dengan Backpropagation Neural Network Menggunakan Praproses Transformasi
Wavelet [skripsi]. Bogor: Fakultas
Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
vi
PENGENALAN IRIS MATA DENGAN ALGORITME
VOTING
FEATURE INTERVAL
VERSI 5 MENGGUNAKAN EKSTRAKSI
CIRI
LOG-GABOR WAVELET
MUHAMMAD ZAKI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Signal Processing, Vol. 46, hlm. 1185-1188.
Daugman J. 2002. How iris Recognition Works. IEEE International Conference on Image Processing, Vol. 1, hlm: I -33-I-36.
Demiröz G. 1997. Non-Incremental Classification Learning Algorihms Based on Voting Feature Intervals [Tesis]. Ankara: Department of Computer Engineering and Information Science, Institute of Engineering and Science, Bilkent University.
Demiröz G, Güvenir HA. 1997. Classification by Voting Feature Intervals. Proceedings of the 9th European Conference on Machine Learning, Vol 1224, hlm: 85-92.
Demiröz G, Güvenir HA, Ilter N. 1998. Learning Differential Diagnosis of Erythemato Squamous Diseases using Voting Feature Intervals. Artificial Intelligence in Medicine, Vol.13, hlm: 147-165.
Gonzales RC, Woods RE, Eddins SL. 2003. Digital Image Processing Using MATLAB. Prentice Hall : Upper Saddle River, NJ. Jain AK, Ross A, Prabhakar S. 2004. An
Introduction to Biometric Recognition. IEEE Transactions on Circuits and Systems for Video Technology, Vol. 14, hlm: 4-20.
Kohavi R. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. Proceedings of the 14th International Joint Conference on Artificial Intelligence; Quebec, 20-25 Agu 1995, hlm 1137-1143.
Masek L. 2003. Recognition Iris Patterns for
Biometric Identification [Skripsi].
Australia: The School Computer Science and Software Engineering, The University of Western Australia.
Oppenheim A, Lim J. 1981. The importance of phase in signals. Proceedings of the IEEE, Vol.69, hlm 529-541.
Shah S, Ros A. 2006. Generating Synthetic Irises By Feature Agglomeration. IEEE
International Conference on Image
Processing; Atlanta, 8-11 Okt 2006, hlm 317-320.
Yong Z, Tieniu T, Yunghong W. 2008. Biometric Personal Identification
Based on Iris Patterns. 15t h International Conference on Pattern
vi
PENGENALAN IRIS MATA DENGAN ALGORITME
VOTING
FEATURE INTERVAL
VERSI 5 MENGGUNAKAN EKSTRAKSI
CIRI
LOG-GABOR WAVELET
MUHAMMAD ZAKI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENGENALAN IRIS MATA DENGAN ALGORITME
VOTING
FEATURE INTERVAL
VERSI 5 MENGGUNAKAN EKSTRAKSI
CIRI
LOG-GABOR WAVELET
MUHAMMAD ZAKI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
v ABSTRACT
MUHAMMAD ZAKI. Iris Recognition Using Voting Feature Interval Version 5 with 1D log-Gabor Wavelets as Feature Extraction. Under direction of Aziz Kustiyo.
Biometric recognition based on iris patterns has its own advantages because iris patterns are more stable and reliable as compared to other biometric subjects such as face and fingerprint. This research provides implementation for recognizing eye images taken from CASIA dataset based on Daugman methods for extracting features. The system uses an automatic segmentation based on threshold to localize the iris collarette and normalize the results to constant dimension using Daugman’s rubber sheet model by remaping each point within the iris region to a pair of polar coordinates. The features are extracted using 1D log-Gabor wavelets to create template which contains dimension 2 times from its normalized images. The template data are then splitted into three subsets and then alternately used for training and testing using voting feature interval version 5. The best recognition of testing data are obtained from combining vote from left and right eyes rather than using single eye sides.
Penguji:
v Judul : Pengenalan Iris Mata dengan Algoritme Voting Feature Interval Versi 5 Menggunakan
Ekstraksi Ciri Log-Gabor Wavelet. Nama : Muhammad Zaki
NIM : G64063191
Menyetujui:
Pembimbing
Aziz Kustiyo, S.Si., M.Kom NIP 19700719 199802 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu wa Ta’ala atas limpahan rahmat dan hidayah-Nya sehingga tugas akhir dengan judul Pengenalan Iris Mata dengan Algoritme Voting Feature Interval Versi 5 Menggunakan Ekstraksi Ciri Log-Gabor Wavelet dapat diselesaikan.
Terima kasih penulis ucapkan kepada ibu dan ayah yang selalu mencurahkan kasih sayang dan doanya. Juga kepada Novel, kakak sulung yang berkerja keras membiayai kuliah penulis, lalu Nurlaila dan Nazah sebagai kakak perempuan yang selalu mendukung dan memotivasi penulis. Ucapan terima kasih juga penulis sampaikan untuk Bapak Aziz Kustiyo, S.Si, M.Kom selaku dosen pembimbing atas bimbingan dan arahannya selama pengerjaan tugas akhir ini, serta Bapak Dr. Ir. Agus Buono, M.Si, M.Kom selaku penguji pertama dan Bapak Mushtofa, S.Kom, M.Sc selaku penguji kedua tugas akhir ini. Penulis juga menyampaikan terima kasih kepada Ja’far, sahabat penulis yang banyak bertukar pikiran dan ide dalam pengerjaan tugas akhir ini. Semoga karya ilmiah ini bermanfaat.
Bogor, 04 Mei 2011
v RIWAYAT HIDUP
DAFTAR ISI
Halaman DAFTAR TABEL ... vi DAFTAR GAMBAR ... vi DAFTAR LAMPIRAN ... vi PENDAHULUAN ... 1 Latar Belakang ... 1 Tujuan ... 1 Ruang Lingkup ... 1 Manfaat ... 1 TINJAUAN PUSTAKA ... 1
vi DAFTAR TABEL
Halaman 1 Pembagian subset ... 5 2 Hasil pengujian yang benar dan salah ... 9 3 Nilai vote data uji kelas 2 yang salah diklasifikasi menjadi kelas 8 pada fold1 ... 9 4 Nilai vote kelas 6 yang salah dikenali menjadi kelas 10 pada fold1 ... 9 5 Akurasi pengujian yang diperoleh ... 10
DAFTAR GAMBAR
Halaman 1 Fungsi koordinat sebagai representasi citra digital. ... 1 2 Anatomi mata manusia ... 2 3 Ilustrasi Daugman’s rubber sheet model. ... 2 4 Pseudocode pelatihan VFI5. ... 4 5 Pseudocode klasifikasi VFI5. ... 4 6 Tahapan pengenalan iris mata. ... 4 7 Segmentasi citra mata . ... 6 8 Ilustrasi labeling di setiap region pada citra mata ... 7 9 Citra mata dengan region terbesar. ... 7 10 Ilustrasi pencarian koordinat pupil. ... 7 11 Ilustrasi wilayah collarette. ... 7 12 Mata kiri orang ke-1 yang diambil pada waktu berbeda. ... 8 13 Proses normalisasi... 8 14 Ilustrasi wilayah iris sebelum dan setelah modifikasi. ... 9 15 Ilustrasi wilayah iris kelas 10 yang salah diklasifikasikan pada fold1. ... 10
DAFTAR LAMPIRAN
PENDAHULUAN
Latar Belakang
Dalam beberapa tahun terakhir, identifikasi seseorang berdasarkan biometrik telah berkembang dengan pesat di kalangan akademik dan industri. Metode pengenalan identitas seseorang yang banyak digunakan di antaranya berdasarkan nomor identitas unik (kunci fisik, kartu identitas dan lainnya) atau berdasarkan ingatan terhadap sesuatu (sandi rahasia dan lainnya). Metode tersebut banyak memiliki kekurangan di antaranya adalah kartu identitas dapat hilang dan sandi dapat lupa dari ingatan seseorang. Ada dua jenis biometrik di antaranya adalah physiological (iris mata, wajah dan sidik jari) dan behavioural (suara dan tulisan tangan) (Yong et al. 2000).
Pengenalan iris mata adalah jenis biometrik berdasarkan fitur physiological. Iris memiliki tekstur yang unik dan cukup kompleks untuk digunakan dalam biometrik. Dibandingkan dengan metode biometrik lain seperti pengenalan wajah, pola iris lebih stabil dan dapat diandalkan. Iris mata seseorang juga memiliki pola yang konsisten, tidak seperti wajah yang relatif memiliki perubahan seiring dengan bertambah waktu.
Penelitian mengenai pengenalan iris mata telah dilakukan oleh Daugman (2002) yang menggunakan Gabor Wavelets dua dimensi pada ekstrasi ciri serta Hamming distances sebagai algoritme pengujian. Masek (2003) melakukan penelitian serupa dengan menggunakan data dari Chinese Academy of Science-Institute of Automation (CASIA) dan Lion’s Eye Institute (LEI). Selain itu, penelitian Abidin (2011) menggunakan jaringan syaraf tiruan sebagai algoritme pelatihan dan pengujian terhadap data CASIA dan menggunakan dekomposisi wavelet sebagai ekstraksi ciri.
Sistem pengenalan pola yang dikembangkan dalam penelitian ini terdiri atas empat tahap. Tahap pertama adalah proses segmentasi citra untuk mengambil citra iris mata saja lalu membuang bagian citra yang lainnya. Pada tahap kedua, proses normalisasi dilakukan dengan mengubah dimensi citra iris menjadi tetap seningga menghasilkan ekstraksi ciri yang lebih baik. Tahap selanjutnya adalah melakukan ekstraksi ciri terhadap citra yang sudah ternormalisasi sehingga dihasilkan template yang memiliki nilai biner dan dilanjutkan ke tahap terakhir yaitu melakukan pelatihan serta pengujian terhadap template tersebut. Pelatihan
dan pengujian template citra dilakukan pada tiga subset yang berbeda, untuk kemudian dilakukan perhitungan terhadap akurasinya menggunakan 3-fold cross validation. Penggunaan algoritme Voting Feature Intervals versi ke-5 (VFI5) pada penelitian ini diharapkan dapat memberikan pengetahuan tingkat akurasi yang diberikan untuk kemudian dapat dibandingkan dengan hasil penelitian lainnya. Tujuan
Tujuan dari penelitian ini adalah untuk mengetahui akurasi dari proses pengenalan citra iris mata menggunakan algoritme VFI5 pada citra mata kiri, kanan dan gabungan keduanya. Ruang Lingkup
Penelitian ini memiliki batasan yaitu : data yang digunakan adalah data citra mata dari sepuluh orang berbeda yang berasal dari CASIA,
bobot yang digunakan dalam pelatihan algoritme VFI5 adalah 1.
Manfaat
Manfaat dari penelitian ini diharapkan dapat memberikan informasi mengenai akurasi algoritme klasifikasi VFI5 terhadap pengenalan iris mata kiri, kanan dan gabungan vote keduanya dari individu yang berbeda.
TINJAUAN PUSTAKA
Representasi Citra Digital
Citra didefinisikan sebagai suatu fungsi dua dimensi f(x,y), dengan x dan y merupakan koordinat spasial, dan f disebut sebagai kuantitas bilangan skalar positif yang memiliki maksud secara fisik ditentukan oleh sumber citra. Suatu citra digital yang diasumsikan dengan fungsi f(x,y) direpresentasikan dalam suatu fungsi koordinat berukuran M x N. Variabel M adalah Baris dan N adalah kolom sebagaimana ditunjukkan pada Gambar 1. Setiap elemen dari array matriks disebut image element, picture element, pixel, atau pel (Gonzales dan Woods 2002).
2 Iris Mata
Iris mata adalah salah satu organ bagian dalam mata yang terletak di belakang kornea dan di depan lensa. Fungsi yang paling penting dari iris mata adalah mengatur ukuran pupil. Iris dibagi ke dalam dua wilayah: wilayah dalam yang dekat dengan pupil dan wilayah luar yang dekat dengan sclera. Daerah yang terdekat dengan pupil disebut collarette. Collarette terdapat antara 20-30 piksel pada citra berukuran 280 x 320 piksel (Shah & Ross 2006).
Iris mata mulai terbentuk saat bulan ketiga bayi di dalam kandungan dan strukturnya mulai membentuk pola saat usia kandungan mencapai delapan bulan, walaupun perkembangan pigmen mata dapat terus berlanjut hingga usia satu tahun setelah kelahiran (Kronfeld 1962, diacu dalam Daugman 2002). Warna iris ditentukan terutama oleh kepadatan pigmen melanin pada lapisan luar dan stroma. Sebagai contoh warna iris yang biru dihasilkan oleh ketiadaan pigmen melanin sehingga cahaya yang memiliki panjang gelombang besar dapat menembus sedangkan panjang gelombang kecil diuraikan oleh stroma (Chedekel 1995, diacu dalam Daugman 2002). Gambar anatomi mata manusia dapat dilihat pada Gambar 2.
Gambar 2 Anatomi mata manusia. Segmentasi
Segmentasi adalah pembagian citra menjadi beberapa wilayah atau objek. Tingkat pembagian wilayah tergantung kepada masalah yang akan diselesaikan, yaitu ketika objek yang dicari telah berhasil dikenali dan diisolasi (Gonzales et al. 2003)
Klasifikasi
Algoritme klasifikasi terdiri atas dua komponen yaitu pelatihan dan prediksi. Pada tahap pelatihan, dilakukan proses pembentukan model suatu permasalahan yang berasal dari data kejadian sebelumnya. Model tersebut kemudian digunakan untuk memprediksi jenis
kelas suatu permasalahan yang ditemukan (Güvenir et al. 1998).
Kebutuhan yang paling penting dalam membentuk suatu sistem klasifikasi adalah akurasi prediksinya. Selain itu, lamanya waktu yang dibutuhkan selama proses pelatihan dan prediksi idealnya adalah pendek. Ketahanan sistem terhadap noise serta penanggulangan terhadap missing value juga harus diperhatikan dalam membangun sistem tersebut (Güvenir et al. 1998).
Daugman’s Rubber Sheet Model
Rubber sheet model bertujuan untuk
melakukan normalisasi daerah collarette iris mata. Rubber sheet model disusun oleh Daugman dengan konsep setiap titik pada koordinat wilayah collarette akan dipetakan kembali ke dalam koordinat baru dengan dimensi r × θ dimana adalah r resolusi radial dan θ adalah resolusi angular. Ilustrasi pemetaan kembali ke dalam koordinat polar dapat dilihat pada Gambar 3.
Gambar 3 Ilustrasi Daugman’s rubber sheet model.
Persaman pemetaan wilayah iris dari koordinat koordinat polar ( ) ke koordinat kartesian (x, y) adalah sebagai berikut:
(1) (2) dengan dan adalah representasi koordinat kartesian dari koordinat polar. Variabel r adalah panjang sumbu polar dan adalah sudut polar.
Rubber sheet model memperhitungkan
pelebaran pupil dan ketidakkonsistenan ukuran pupil untuk menghasilkan sebuah hasil normalisasi dengan dimensi yang konstan (Masek 2003).
Discrete Fourier Transform
Fourier transform digunakan untuk
menganalisis citra pada domain frekuensi. Dengan transformasi ini, intensitas piksel pada citra diperlakukan sebagai fungsi yang memiliki nilai amplitudo pada frekuensi tertentu. Fourier
transform memberikan freksibilitas dalam
desain dan implementasi pada banyak bidang seperti image enhancement, image restoration
dan image compression (Gonzales et al. 2003). Ketika Fourier transform digunakan pada sinyal yang diskret, maka digunakan discrete
Fourier transform. Rumus dari DFT satu
dimensi adalah:
(3) dan inverse-nya adalah:
(4) dengan adalah Fourier spectrum, adalah nilai piksel citra dan N adalah ukuran dari data yang akan ditransformasikan.
Fast Fourier transform (FFT) adalah
algoritme DFT yang memiliki kompleksitas lebih baik. DFT biasa akan memiliki kompleksitas sebesar sedangkan FFT memiliki kompleksitas sebesar . Log-Gabor Filter
Gabor filter banyak digunakan untuk
karakterisasi tekstur dari suatu citra (Mancas dan Gosselin 2006) dengan mencari representasi gabungan optimal dari sinyal pada domain spasial dan frekuensi. Dengan menggunakan Gabor filter, lokalisasi gabungan dibentuk baik pada domain spasial maupun frekuensi.
Kelemahan dari Gabor filter adalah pada even symmetric filter yang memiliki komponen DC ketika bobotnya melebihi satu oktav (Field 1987, diacu dalam Masek 2003). Komponen DC adalah nilai hasil transformasi pada domain frekuensi awal (Gonzales et al. 2003). Namun, komponen DC yang bernilai nol dapat diperoleh pada bobot berapapun jika menggunakan skala logaritmik pada Gabor filter yang disebut dengan log-Gabor filter. Respon frekuensi pada log-Gabor filter memiliki rumus:
(5)
dengan adalah nilai frekuensi, adalah pusat frekuensi dan adalah bobot filter.
K-Fold Cross Validation
Cross-validation adalah teknik komputasi menggunakan seluruh contoh sebagai data pelatihan dan data tes secara berulang kali sebanyak K kali menggunakan data tes sebanyak 1/K bagian data keseluruhan (Stone 1974, diacu dalam Bengio dan Grandvalet 2003). Untuk setiap pengulangan, digunakan kombinasi data latih dan data tes yang berbeda
dengan pengulangan sebelumnya namun dengan jumlah data yang sama.
Voting Feature Intervals versi 5
Voting Feature Intervals (VFI) adalah
algoritme klasifikasi non-incremental dan supervised yang dikembangkan oleh Demiroz dan Güvenir (1997). Algoritme tersebut digolongkan sebagai non-incremental karena semua instance pelatihan diproses secara bersama-sama. Di sisi lain, supervised digolongkan terhadap algoritme ini karena memiliki target output yang diinginkan yaitu berupa kelas-kelas. Algoritme VFI telah dikembangkan hingga versi ke-5 yang biasa disingkat menjadi VFI5.
Algoritme VFI5 memiliki dua fase, yaitu fase pelatihan dan fase tes (Güvenir et al. 1998). 1. Pelatihan
Pada fase pelatihan, dilakukan pencarian terhadap nilai EndPoints dari fitur f di setiap kelas c, yaitu berupa nilai maksimum dan minimum tiap kelas pada masing-masing fitur sehingga setiap kelas memiliki dua nilai EndPoints. Nilai EndPoints kemudian disimpan dalam bentuk array EndPoints[ f ] dan dilakukan sorting. Jika nilai fitur berupa linear, maka point interva