DAFTAR PUSTAKA
Bhandari, J. & Kumar,A. 2013. Analysis of Various Rules of Exact String Matching Algorithms. International Journal of Applied Research and Studies (iJARS) 2(10): 1 - 25.
Bi, C. 2009.Research and Application of SQLite Embedded Database Technology.
WSEAS Transactions on Computers 8(1): 83 - 92.
Boyer,R.S. & Moore,J.S. 1977. A Fast String Searching Algorithm. Communications
of the ACM 20(10): 762 - 772.
Cantone, D., Cristofaro, S. & Faro, S. 2010. A Space-Efficient Implementation of The Good- Suffix Heuristic. Proceedings of PSC 2010, pp. 63 - 75
Carrier, B. 2003. Defining Digital Forensic Examination and Analysis Tools Using Abstraction Layers. International Journal of Digital Evidance 1(4): 1 - 12.
Casey, E. 2011. Digital Evidence and Computer Crime: Forensic Science, Computers
and the Internet. 3rd Edition. Elsevier: Waltham.
Choudhary, R., Rasool, A. & Khare, N. 2012. Variation of Boyer-Moore String Matching Algorithm : A Comparative Analysis. International Journal of
Computer Science dan Information Security 10(2): 95 - 101.
Crochemore, M. & Lecroq, T. 1996. Pattern Matching and Text Compression Algorithms. ACM Computing Surveys (CSUR) 28(1): 39 - 41.
Effendi, D., Hartono, T. & Kurnaedi, A. 2011. Penerapan string matching menggunakan algoritma Boyer-Moore pada translator bahasa Pascal ke bahasa C. Majalah Ilmiah UNIKOM, 11(2): 262 - 275.
Hoog, A. 2011. Android Forensic: Investigation, Analysis, and Mobile Security for
Google Android. Elsevier: Waltham.
Knuth, D.E., Morris, JR.J.H. & Pratt, V.R. 1977. Fast Pattern Matching in Strings.
SIAM Journal on Computing 6(1): 323 - 350.
Lecroq, T. 1992. A variation on the Boyer-Moore algorithm. Theoritical Computer
Science 92(1): 119 - 144.
Lessard, J. & Kessler, G.C. 2010. Android Forensic: Simplifying Cell Phone Examinations. Journal of Small Scale Digital Evidance Forensics Journal 4(1): 1 - 2
Marshall, A.M. 2008. Digital Forensic, Digital Evidance in Criminal Investigation. John Wiley & Sons, Ltd.: West Sussex.
Navarro, G. 2001. A Guided Tour to Approximate String Matching. Journal of ACM
Computing Surveys (CSUR) 33(1): 31 - 88.
Patrick, A.V.H. & Geoff, R.D. 1980. Approximate String Matching. Journal ACM
Computing Surveys (CSUR) 12(4): 381 - 402
Raharjo, B. 2013. Sekilas Mengenai Forensika Digital. Jurnal Sosioteknologi 29(12): 384 - 387.
Singla, N. & Garg, D. 2012. String Matching Algorithms and their Applicability in various Applications. International Journal of Soft Computing and
Stahlberg, P., Miklau, G. & Levine, B.N. 2007. Threats to Privacy in the Forensic Analysis of Database Systems. Proceedings of the 2007 ACM SIGMOD
International Conference on Management of Data, pp. 91 - 102.
Tenlima, Y.A. 2009. Pencocokan string Pada Dokumen Teks Menggunakan Algoritma Knuth Morris Pratt. Skripsi. Universitas Kristen Duta Wacana.
Undang - undang nomor 11 tahun 2008, tentang informasi dan transaksi elektronik.
2008. Departement Komunikasi dan Informasi: Jakarta.
Yoon, H. 2012. A Study on the Performance of Android Platform. International
Journal on Computer Science and Engineering (IJCSE) 4(4): 532 - 537
Zareen, A. & Baig, S. 2010. Mobile Phone Forensics: Challenges, Analysis and Tools Classification. Proceedings of the 2010 International Workshop on Systematic
BAB 3
ANALISIS DAN PERANCANGAN
Bab ini membahas tentang analisis dan perancangan metode pencarian dengan menggunakan algortima Boyer-Moore sebagai alat bantu proses pencarian pesan SMS. Bab ini juga membahas tentang generallisasi input, perancangan fitur auto find,
filtering, dataset serta pre-processing yang dilakukan sebelum melakukan pencarian
untuk menemukan kembali pesan SMS tersebut.
3.1. Arsitektur Umum
Metode yang digunakan pada penelitian ini dapat dilihat pada Gambar 3.1 yang menunjukan arsitektur umum dari langkah-langkah yang digunakan untuk menemukan kembali pesan SMS yang telah dihapus. Langkah-langkah tersebut dibagi menjadi dua tahap yaitu: pre processing dan main process. Tahap pre processing dilakukan untuk mendapatkan file database pesan SMS pada handphone Android kemudian mengubahnya menjadi bytes heksadesimal untuk dijadikan sebagai hex
string dalam proses pencarian. Pada tahap pre processing dilakukan langkah-langkah
sebagai berikut: handphone yang ingin diperiksa dilakukan image making untuk mendapatkan copy data secara utuh dari handphone tersebut; melakukan ekstraksi file
image dari hasil image making untuk mendapatkan file database pesan SMS pada
direktori root Android; file database pesan SMS yang ditemukan dilakukan proses
generate hex values untuk diubah menjadi susunan bytes heksadesimal, output pada
pencarian. Pada tahap main process dijalankan fitur auto find sebagai proses utama dalam proses pencarian. Langkah-langkah yang dijalankan pada fitur auto find sebagai berikut: melakukan proses generalisasi input yang akan digunakan sebagai hex pattern dalam proses pencarian, input yang digunakan ialah header pesan SMS; hex string dan hex pattern yang sudah didapatkan digunakan kembali untuk melakukan prosedur
pre processing algoritma Boyer-Moore, prosedur ini dilakukan untuk menghitungan
nilai pergeseran selanjutnya pada proses pencarian dengan menggunakan fungsi
bad-character shift dan good-suffix shift; melakukan proses pencarian dengan
menggunakan algoritma Boyer-Moore; melakukan proses filtering hasil dari proses pencarian. Setelah langkah - langkah diatas dilakukan maka diharapkan fitur auto find yang dirancang dapat menemukan kembali pesan SMS yang telah dihapus. Setiap tahap dan proses yang dilakukan akan dijelaskan kembali dengan lebih terperinci pada bagian-bagian selanjutnya.
Gambar 3.1. Arsitektur Umum
3.2. Dataset
/data/data/com.android.providers.telephony/databases/ sebagaimana yang telah dijelaskan pada bagian 2.2.3, dengan berbagai kondisi yang dapat dilihat pada Tabel 3.1. Dataset utuh merupakan file database yang diketahui memiliki pesan SMS utuh sedangkan dataset terhapus merupakan file database yang diambil setelah dilakukan penghapusan pada dataset utuh, proses pengambilan dataset ini dapat dilihat pada Gambar 3.2. Sedangkan dataset test merupakan file database yang diambil secara langung dari pengguna handphone android, sehingga jumlah pesan SMS yang utuh maupun yang sudah terhapus tidak diketahui. Secara umum ketiga dataset digunakan dengan tujuan untuk melakukan pengujian terhadap metode yang sudah diterapkan, apakah mampu menampilkan hasil sesuai yang diinginkan. Sedangkan pada dataset utuh dan dataset terhapus digunakan untuk mendapatkan nilai akurasi dari hasil proses pengujian.
File mmssms1.db merupakan file database yang memiliki 10 pesan SMS utuh, begitu juga dengan file mmssms2.db dan file mmssms3.db yang masing-masing memiliki 20 dan 30 pesan SMS utuh, sedangkan untuk file mmssms4.db didapat setelah terjadi penghapusan seluruh pesan SMS pada file mmssms1.db, sehingga diketahui bahwa pada database tersebut tidak memiliki pesan SMS utuh lagi, namun belum diketahui jumlah pasti pesan SMS terhapus pada file database tersebut, begitu juga dengan file mmssms5.db dan file mmssms6.db. Untuk file database mmssms7.db, mmssms8.db, mmssms9.db dan mmssms10.db belum diketahui properti file tersebut, karena file database tersebut diambil langsung dari pengguna handphone Android.
Tabel 3.1. Properti dataset file database
File Pesan Utuh Pesan Terhapus Jenis Dataset
mmssms1.db 10 0 Utuh
mmssms2.db 20 0 Utuh
mmssms3.db 30 0 Utuh
mmssms4.db 0 Unknown Terhapus
mmssms5.db 0 Unknown Terhapus
mmssms6.db 0 Unknown Terhapus
mmssms7.db Unknown Unknown Test
mmssms8.db Unknown Unknown Test
mmssms9.db Unknown Unknown Test
mmssms10.db Unknown Unknown Test
Pada dataset utuh, terhapus dan test, hasil yang ditemukan akan ditampilkan berdasarkan dengan nomor pesan SMS tersebut, hasil proses ini bergantung pada proses yang terjadi sebelumnya pada file database tersebut seperti: proses overwriting atau vacuum procedure. File database yang sudah melakukan proses overwriting maupun vacuum procedure akan sangat sulit untuk menemukan pesan SMS yang telah dihapus karena kemungkinan sudah memiliki pola yang berbeda.
3.3. Pre Processing
Sebelum pencarian dilakukan, terlebih dahulu file database harus dapat ditemukan dalam keadaan utuh, sesuai dengan yang sudah dibahas sebelumnya file database yang berisi pesan SMS yang telah dihapus dapat dilihat dalam susunan bytes heksadesimal. Sehingga perlu untuk merubah data pesan SMS yang ada pada file
database tersebut dalam bytes heksadesimal. Output pada tahap pre processing adalah
Image making dilakukan dengan tujuan untuk melakukan copy data secara
keseluruhan dan menghindari kerusakan, perubahan atau hilangnya barang bukti. Data yang di copy berupa data yang ada pada direktori root. Image making dilakukan dengan menggunakan Nandroid Backup, Nandroid Backup merupakan fasilitas yang ada pada ClockWorkMod (CWM), ClockWorkMod ini merupakan recovery mode yang sudah diatur sedemikian rupa dengan berbagai fungsi tambahan seperti
backup/restore, instalasi dan lainnya yang tidak ada di recovery mode standar pada
handphone Android.
Nandroid Backup digunakan untuk membackup sistem ponsel, internal
memori dan termasuk seluruh partisi penyimpanan dan menyimpannya ke dalam
sdcard. Hasil backup berupa folder dengan nama sesuai tgl-bln-thn-jam saat
melakukakn backup. File hasil backup dapat dilihat pada Tabel 3.2. File hasil backup tergantung pada partisi yang digunakan pada handphone Android. Output yang digunakan pada tahap selanjuntya adalah file image data.yaffs2.img yang berisi
backup partisi data.
Tabel 3.2. Properti hasil backup
Nama File Jenis Keterangan
.android_secure.vfat.tar File Tar File yang berisi backup aplikasi yang dipindahkan ke sdcard
cache.yaffs2.img File Image File yang berisi backup partisi cache data.yaffs2.img File Image File yang berisi backup partisi data
nandroid.md5 File MD5 File yang berisikan md5sum dari file image sd-ext.vfat.tar File Tar File yang berisi backup partisi sd-ext pada
sdcard
system.yaffs2.img File Image File yang berisi backup partisi file system
3.3.2. Extract Image File
Ekstraksi file image dilakukan setelah melakukan proses backup terhadap file system. Ekstraksi dilakukan dengan menggunakan tool yang bernama unyaffs. Unyaffs merupakan sebuah program yang berfungsi untuk melakukan ekstraksi file dari sebuah
dikembangkan oleh Kai.Wei.cn. Program ini cukup mudah untuk dijalankan, untuk sistem operasi linux program ini dijalankan dengan perintah: gcc -o unyaffs unyaffs.c untuk melakukan compile, sedangkan pada windows program ini dijalankan dengan perintah: unyaffs <filename>.img.
Berdasarkan hasil backup terdapat tiga file yang berjenis yaffs file system
image, yaitu: cache.yaffs2.img, data.yaffs2.img dan system.yaffs2.img, namun pada
penelitian ini file yang digunakan hanya file image data.yaffs2.img untuk dilakukan ekstarksi. Karena pada file inilah tersimpan backup file database, partisi ini yang menyimpan seluruh data-data aplikasi yang ada handphone Android, seperti call logs,
contact phone, browser history dan tentunya pesan SMS. Partisi yang dihasilkan dari
data.yaffs2.img ini merupakan partisi data yang berisi data-data yang selalu berubah-ubah. Hasil direktori yang didapatkan setelah melakukan ekstarkasi dapat dilihat pada Tabel 3.3. Output pada tahap ini adalah file database mmssms.db yang menyimpan data pesan SMS, file ini tersimpan pada direktori data.
Tabel 3.3. Hasil ekstraksi file image data.yaffs2.img
Nama Keterangan
anr Berisi stack traces (debugging) dari sistem
app Berisi file apk yang diinstal dari market atau manual app-private Tempat penyimpanan protected apps dari Android Market backup Tempat untuk mengatur dan antrian backup
crashsms Direktori yang menyimpan pesan SMS yang mengalami crash
dalvik-cache Tempat penyimpanan file dex untuk dijalankan dalvik virtual machine. data Berisi file data aplikasi system maupun user. Seperti database (sqlite). dontpanic Tempat untuk menyimpan beberapa erorr log file dari sistem
drm Berisi file pengaturan terhadap anti-consumer copy etc Berisi file pengaturan terhadap system
idd Berisi file pengaturan terhadap device
local Tempat dimana pertama kali aplikasi diinstall dicopi lost+found Direktori yang muncul di beberapa tempat di YAFFS2
File database yang sudah didapat selanjutnya akan dilakukan proses generate hex
values untuk mendapatkan nilai bytes heksadesimal. Hal ini berguna karena, pesan
SMS yang dihapus tidak bisa dilihat kembali pada handphone maupun pada SQLite
browser, pesan SMS yang telah dihapus hanya dapat dilihat melalui representasi
dalam bentuk byte heksadesimal. Berikut contoh pesan SMS pada bentuk
byte-byte heksadesimal:
09 08 00 81 03 27 08 08 08 00 00 00 00 1F 2B 36 32 38 33 31 39 34 33 37 38 34 38 37 01 41 53 E0 02 9D FF 44 69 61 6E 2E 20 42 73 61 20 73 6D 61 20 6B 74 61 20 62 72 61 6E 67 6B 74 20 6D 61 69 6E 20 66 74 73 61 6C 3F 20 41 6B 20 67 6B 20 64 61 20 6B 65 6E 64 61 72 61 61 6E 20 6E 69 2B 36 32 38 33 31 35 30 30 30 30 33 32 48 82 50 16 00 01 29 00 05 08 08 09 01 09 08 00 2B 27 08 08 08 00 00 00 00 1F 2B 36 32 38 33 31 39 34 33 37 38 34 38 37 01 41 53 DB 63 31 FF 44 69 61 6E 2E 20 4B 77 20 64 6D 61 6E 61 3F 2B 36 32 38 33 31 35 30 30 30 30 33 32 50 82 4F 16 00 01 29 00 05 08 08 09 01 09 08 00 3D 25 08 08 08 00 00
Sebagaimana yang sudah dijelaskan pada bagian 2.3.2 pesan SMS yang masih utuh maupun yang sudah dihapus membentuk sebuah pola dalam representasinya dalam bentuk byte heksadesimal. Pola tersebut dikelompokan menjadi empat bagian, yaitu : bagian pertama adalah header, nomor pesan SMS, diikuti dengan waktu pesan SMS selanjutnya isi pesan SMS tersebut. Jika dilihat 08 08 08 merupakan header dari pesan SMS tersebut kemudian diikuti bytes acak 00 00 00 00 1F, selanjutnya 2B 36 32 38 33 31 39 34 33 37 38 34 38 37 ini merupakan nomor pesan SMS yang jika diubah dalam karakter ASCII menjadi +6283194378487, kemudian diikuti dengan 01 41 53 E0 02 9D, bagian ini merepresentasikan waktu pesan SMS, namun dengan apa yang sudah dijelaskan sebelumnya, bentuk ini harus diubah terlebih dahulu dalam bentuk desimal menjadi 1380091691677, pola ini merupakan pola waktu dalam bentuk Unix
Epoch in milliseconds, jika diubah dalam pola waktu biasa maka didapatkan Rabu, 25
terhapus memiliki pola yang sama dalam representasi bytes heksadesimal. Ketika terdapat potongan ataupun bagian pesan SMS yang tidak memiliki pola yang dimaksud maka hal itu dapat diabaikan atau dihilangkan, karena mungkin saja database pesan SMS tersebut sudah melakukan prosedur vacuum. Rangkaian bytes heksadesimal inilah yang selanjutnya digunakan sebagai hex string dalam proses pencarian untuk dicocokan dengan hex pattern input generalisasi.
3.4. Main process
Setelah seluruh tahapan pre processing dilakukan maka dihasilkan hex string yang yang disimpan pada file .txt, maka file tersebut dapat digunakan dalam proses pencarian pesan SMS dengan menggunakan fitur auto find. Pada tahap main process dijalankan fitur auto find sebagai proses utama dari sistem, pada implementasinya fitur auto find menggunakan algoritma Boyer-Moore dalam sistem kerjanya. Langkah-langkah yang dilakukan seperti metode string matching dan algoritma Boyer-Moore dapat dilihat pada bagian 2.3 dan bagian 2.4. Pada tahap ini juga dilakukan generallisasi input yang digunakan serta proses filtering yang dijalankan. Langkah - langkah pada main process akan dijelasakan secara terperinci pada bagian - bagian selanjutnya.
3.4.1 Generallisasi Input
Generalisasi input disini merupakan bentuk penyeragaman pattern yang akan dicari. Generalisasi dilakukan agar sistem mendapatkan hasil sesuai dengan yang diharapkan, kemudian agar pencarian terfokus pada pola yang sudah ditentukan sehingga hasil yang ingin didapat ditampilkan secara maksimal.
SMS.
nomor_pesanSMS tanggal_pesanSMS isi_pesanSMS header
Gambar 3.3. Pola pesan SMS
3.4.2 Perancangan fitur Auto Find
Fitur auto find merupakan fitur yang dirancang untuk menemukan kembali pesan SMS secara otomatis. Fitur ini melakukan pencarian hex pattern dalam hex string secara otomatis pada bytes heksadesimal dengan menggunakan algoritma Boyer-Moore, fitur ini mencari potongan pattern input 08 08 08, sebagaimana yang sudah dijelaskan pada bagian 3.4.1.
Hasil fitur auto find ini akan menampilkan seluruh atribut pesan SMS seperti: nomor pesan SMS, tanggal pesan SMS dan isi pesan SMS yang terdapat pada
byte-byte heksadesimal hasil dari generate hex values. Pada fitur auto find dijalankan
beberapa proses yaitu: pre processing algoritma Boyer-Moore dan search process algoritma Boyer-Moore. Proses ini akan dijelaskan secara terperinci pada bagian selanjutnya.
3.4.2.1 Pre Processing Algoritma Boyer-Moore
2.5.2, sedangkan nilai pergeseran BmGs dihitung dengan menggunakan pseudocode yang ada pada bagian 2.5.3.
Tabel 3.4. Nilai pergeseran BmBc pada fitur auto find char BmBc[char]
0 1
8 2
0 1
8 2
0 1
8 2
* 6
Tabel 3.5. Nilai pergeseran BmGs pada fitur auto find i char[i] BmGs[i]
0 0 2
1 8 2
2 0 4
3 8 4
4 0 6
5 8 1
3.4.2.2 Searching Process
Sistem akan melakukan pencarian hex pattern pada hex string dengan menggunakan dua buah tabel pergeseran yaitu bad-character shift dan good-suffix shift, dimana ketika terjadi ketidakcocokan sistem akan memilih nilai pergeseran terbesar dari kedua tabel tersebut untuk pergeseran selanjutnya. Flowchart untuk proses pencarian algoritma Moore dapat dilihat pada Gambar 3.4. Pseudocode algoritma Boyer-Moore dalam proses pencarian ditunjukan sebagai berikut :
procedure BM(input pattern, text: array of char)
bmGs : array [0..XSIZE] of integer
bmBc : array [0..ASIZE] of integer
Algoritma
/* Preprocessing */
preBmGs(pattern, BmGs)
preBmBc(pattern, BmBc)
/* Searching */
i = 0
while (i <= text.Length - pattern.Length);
for (j = pattern.Length - 1; j >= 0 and pattern[j]=text[i+j];
--i)
if (j < 0)
arr.Add(i);
i ← i + BmGs[0];
else
i ← i + MAX(BmGs[j],BmBc[text[i+j]]-pattern.Length+1+j)
Seperti yang sudah dijelaskan sebelumnya rangkaian bytes hasil dari generate
hex values file database dapat dijadikan sebagai rangkaian string, maka pencarian
pattern generalisasi input pada string tidak lain merupakan pencocokan string. Berikut
ini contoh pencocokan pattern di dalam string dengan menggunakan algoritma Boyer-Moore:
Suatu potongan rangkaian string(R)
0 0 8 8 0 0 1 1 0 8 0 8 8 8 0 8 0 8 0 8 0 0 8 8
Akan dicocokan dengan pattern(P) 0 8 0 8 0 8
Tahapan-tahapan yang terjadi:
Tahap 1.
0 0 8 8 0 0 1 1 0 8 0 8 8 8 0 8 0 8 0 8 0 0 8 8 0 8 0 8 0 8
Pada proses pencocokan tahap 1 terjadi ketidakcocokan pattern dengan teks pada karakter 0 dan posisi 5, kemudian diambil nilai pergeseran terbesar antara BmGs[5] = 1 dan BmBc[0] = 1 maka pergeseran selanjutnya adalah 1.
BmGs[5] = BmBc[0] = 1 Shift by 1
Tahap 2.
0 0 8 8 0 0 1 1 0 8 0 8 8 8 0 8 0 8 0 8 0 0 8 8 0 8 0 8 0 8
Pada proses pencocokan tahap 2 terjadi ketidakcocokan pattern dengan teks pada karakter 1 dan posisi 5, kemudian diambil nilai pergeseran terbesar antara BmGs[5] = 1 dan BmBc[1] = 6 maka pergeseran selanjutnya adalah 6.
0 0 8 8 0 0 1 1 0 8 0 8 8 8 0 8 0 8 0 8 0 0 8 8 0 8 0 8 0 8
Pada proses pencocokan tahap 3 terjadi ketidakcocokan pattern dengan teks pada karakter 8 dan posisi 4, kemudian diambil nilai pergeseran terbesar antara BmGs[4] = 6 dan BmBc[8] = 2 maka pergeseran selanjutnya adalah 6.
BmGs[4] = 6 , BmBc[8] = 2 Shift by 6
Tahap 4.
0 0 8 8 0 0 1 1 0 8 0 8 8 8 0 8 0 8 0 8 0 0 8 8 0 8 0 8 0 8
Pada proses pencocokan tahap 4 terjadi ketidakcocokan pattern dengan teks pada karakter 0 dan posisi 5, kemudian diambil nilai pergeseran terbesar antara BmGs[5] = 1 dan BmBc[0] = 1 maka pergeseran selanjutnya adalah 1.
BmGs[5] = BmBc[0] = 1 Shift by 1
Tahap 5.
0 0 8 8 0 0 1 1 0 8 0 8 8 8 0 8 0 8 0 8 0 0 8 8
0 8 0 8 0 8
Pada proses pencocokan tahap 5 terjadi kecocokan pattern dengan teks maka sesuai algoritma yang digunakan pergeseran selanjutnya mangambil nilai dari BmGs[0] sejauh 2 pergeseran.
BmGs[0] = 2 Shift by 2
Tahap 6.
Pada proses pencocokan tahap 6 terjadi ketidakcocokan pattern dengan teks pada karakter 0 dan posisi 5, kemudian diambil nilai pergeseran terbesar antara BmGs[5] = 1 dan BmBc[0] = 1 maka pergeseran selanjutnya adalah 1.
BmGs[5] = BmBc[0] = 1 Shift by 1
Tahap 7.
0 0 8 8 0 0 1 1 0 8 0 8 8 8 0 8 0 8 0 8 0 0 8 8 0 8 0 8 0 8
Pada proses pencocokan tahap 7 terjadi ketidakcocokan pattern dengan teks pada karakter 0 dan posisi 3, kemudian diambil nilai pergeseran terbesear antara BmGs[3] = 4 dan BmBc[0] = 1 maka pergeseran selanjutnya adalah 4.
BmGs[3] = 4 , BmBc[0] = 1 Shift by 4
Ketika terjadi kecocokan sistem akan mencatat posisi di mana string ditemukan, kemudian sistem akan mengambil beberapa bytes setelahnya yang berisi pola nomor pesan SMS, tanggal pesan SMS dan isi pesan SMS begitu seterusnya. Hal ini didasari oleh setiap pesan SMS yang masih utuh maupun yang terhapus memliki bentuk pola yang sama dalam representasinya dalam bentuk bytes heksadesimal. Pola perancangan fitur auto find dapat dilihat pada Gambar 3.5.
Pada proses auto find ada kemungkinan sistem menampilkan hasil proses data pesan SMS secara berulang - ulang, oleh sebab itu diperlukan suatu proses tambahan agar hal ini tidak terjadi. Proses filtering dirancang untuk menghilangkan data ganda yang berulang pada hasil proses auto find.
Pada proses penemuan tanggal pesan SMS dibuat variabel date yang gunanya untuk menampung nilai tanggal pesan SMS, kemudian nilai variabel date dimasukan pada variabel dateCollection yang nantinya akan berisi kumpulan dari nilai tanggal pesan SMS yang sudah ditemukan sebelumnya. Variabel ada digunakan sebagai inisiasi status date pada dateCollection, secara default variabel ada bernilai 0. Kemudian dibuat perulangan untuk mengecek tanggal pesan SMS sudah ada atau belum. Jika ditemukan maka variabel ada ditambah 1. Jika tanggal sudah ada maka kemungkinan nilai variabel ada bisa lebih dari 1, jika belum ada maka variabel ada menjadi 1. Jika variabel ada bernilai 1 maka proses pencarian pesan SMS dilanjutkan. Jika tidak maka akan kembali ke proses pencarian pattern. Flowchart pada proses
filtering dapat dilihat pada Gambar 3.6.
3.4.4. Target Output
Target output pada implementasi metode ini adalah sistem diharapkan mampu
merekapitulasi dan menampilkan kembali pesan SMS serta dapat mengidentifikasi apakah pesan SMS tersebut masih utuh atau sudah terhapus. Hasil yang ditampilkan oleh sistem adalah nomor pesan SMS, tanggal pesan SMS, isi pesan SMS serta status pesan SMS tersebut, apakah masih utuh atau sudah terhapus.
Perancangan tampilan dari target ouput dapat dilhat pada Gambar 3.7. Untuk pesan SMS yang ditemukan pada sistem dan masih terdapat dalam file database maka pesan SMS tersebut masih utuh, dan sebaliknya jika pesan SMS yang ditemukan pada sistem dan sudah tidak terdapat lagi di file database maka pesan SMS tersebut sudah terhapus. Sistem menggunakan bagian tanggal pesan SMS dalam bentuk epoch time untuk dicocokan kembali pada file database untuk mendapatkan status pesan SMS tersebut.
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Bab ini membahas hasil yang didapatkan dari implementasi metode string matching untuk menemukan kembali pesan SMS yang telah dihapus dengan menggunakan algoritma Boyer-Moore berdasarkan nilai bytes heksadesimal dari file database pesan SMS sesuai dengan spesifikasi penerapan yang dibahas pada Bab 3. Bab ini akan menjabarkan hasil dari Generate hex values, fitur auto find dan hasil pengujian.
4.1. Implementasi Generate Hex Values
Pada bagian ini dijabarkan hasil implementasi dari proses generate hex values dari file
database SMS. Ada 10 file database SMS yang dilakukan proses generate yang setiap
file nya memiliki atribut atau propertinya masing-masing. Hasil proses generate ini selanjutnya akan disimpan dalam file berbentuk teks (txt) yang kemudian selanjutnya akan dijadikan sebagai dataset untuk melakukan proses pencarian. Gambar 4.1 merupakan salah satu hasil generate hex values dari dataset yang disimpan dalam bentuk file (.txt.) Sedangkan Tabel 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9 dan 4.10 menjelaskan tentang frekuensi bytes yang muncul pada pada setiap dataset tersebut.
Pada kalkulasi Bytes Frequency Distribution (BFD) pada tabel 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9 dan 4.10 tidak ada perbedaan jumlah frekuensi bytes yang terlalu signifikan, hal ini dikarenakan file database memiliki ukuran yang relatif sama.
BFD merupakan sebuah tabel yang menyimpan frekuensi kemunculan dari setiap
maka nilai 0 pada tabel BFD adalah 1500. Tabel BFD merepresentasikan jumlah frekuensi nilai bytes heksadesimal muncul dalam satu file database.
Gambar 4.1. Hasil Generate Hex Values
Pada file mmssms1.db ditemukan nilai bytes heksadesimal 00 berjumlah 25249 frekuensi, 01 berjumlah 993 frekuensi, 02 berjumlah 370 frekuensi, 03 berjumlah 266 frekuensi, 04 berjumlah 173 frekuensi, FD berjumlah 1 frekuensi, FE berjumlah 0 frekuensi, FF berjumlah 3 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms1.db. Tabel BFD untuk file mmssms1.db dapat dilihat pada Tabel 4.1.
Tabel 4.1. Tabel BFD untuk file mmssms1.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 25249
01 1 993
02 2 370
03 3 266
Nilai byte (heksadesimal)
Nilai byte (desimal)
Frekuensi
... ... ...
FD 253 1
FE 254 0
FF 255 3
Pada file mmssms2.db ditemukan nilai bytes heksadesimal 00 berjumlah 25292 frekuensi, 01 berjumlah 1450 frekuensi, 02 berjumlah 477 frekuensi, 03 berjumlah 340 frekuensi, 04 berjumlah 186 frekuensi, FD berjumlah 2 frekuensi, FE berjumlah 1 frekuensi, FF berjumlah 19 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms2.db. Tabel BFD untuk file mmssms2.db dapat dilihat pada Tabel 4.2.
Tabel 4.2. Tabel BFD untuk file mmssms2.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 25292
01 1 1450
02 2 477
03 3 340
04 4 186
... ... ...
FD 253 2
FE 254 1
FF 255 19
pada hasil generate hex values pada file mmssms3.db. Tabel BFD untuk file mmssms3.db dapat dilihat pada Tabel 4.3.
Tabel 4.3. Tabel BFD untuk file mmssms3.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 25262
01 1 1813
02 2 623
03 3 453
04 4 247
... ... ...
FD 253 0
FE 254 1
FF 255 30
Pada file mmssms4.db ditemukan nilai bytes heksadesimal 00 berjumlah 24949 frekuensi, 01 berjumlah 339 frekuensi, 02 berjumlah 148 frekuensi, 03 berjumlah 142 frekuensi, 04 berjumlah 79 frekuensi, FD berjumlah 1 frekuensi, FE berjumlah 0 frekuensi, FF berjumlah 13 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms4.db. Tabel BFD untuk file mmssms4.db dapat dilihat pada Tabel 4.4.
Tabel 4.4. Tabel BFD untuk file mmssms4.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 24949
01 1 339
02 2 148
03 3 142
04 4 79
Nilai byte (heksadesimal)
Nilai byte (desimal)
Frekuensi
FD 253 1
FE 254 0
FF 255 13
Pada file mmssms5.db ditemukan nilai bytes heksadesimal 00 berjumlah 23891 frekuensi, 01 berjumlah 576 frekuensi, 02 berjumlah 217 frekuensi, 03 berjumlah 210 frekuensi, 04 berjumlah 98 frekuensi, FD berjumlah 2 frekuensi, FE berjumlah 0 frekuensi, FF berjumlah 16 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms5.db. Tabel BFD untuk file mmssms5.db dapat dilihat pada Tabel 4.5.
Tabel 4.5. Tabel BFD untuk file mmssms5.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 23891
01 1 576
02 2 217
03 3 210
04 4 98
... ... ...
FD 253 2
FE 254 0
FF 255 16
frekuensi, FF berjumlah 20 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms6.db. Tabel BFD untuk file mmssms6.db dapat dilihat pada Tabel 4.6.
Tabel 4.6. Tabel BFD untuk file mmssms6.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 23486
01 1 548
02 2 282
03 3 243
04 4 111
... ... ...
FD 253 3
FE 254 1
FF 255 20
Pada file mmssms7.db ditemukan nilai bytes heksadesimal 00 berjumlah 24980 frekuensi, 01 berjumlah 1795 frekuensi, 02 berjumlah 723 frekuensi, 03 berjumlah 482 frekuensi, 04 berjumlah 237 frekuensi, FD berjumlah 0 frekuensi, FE berjumlah 1 frekuensi, FF berjumlah 31 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms7.db. Tabel BFD untuk file mmssms7.db dapat dilihat pada Tabel 4.7.
Tabel 4.7. Tabel BFD untuk file mmssms7.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 24980
01 1 1795
Nilai byte (heksadesimal)
Nilai byte (desimal)
Frekuensi
03 3 482
04 4 237
... ... ...
FD 253 0
FE 254 1
FF 255 31
Pada file mmssms8.db ditemukan nilai bytes heksadesimal 00 berjumlah 26292 frekuensi, 01 berjumlah 1889 frekuensi, 02 berjumlah 780 frekuensi, 03 berjumlah 454 frekuensi, 04 berjumlah 233 frekuensi, FD berjumlah 1 frekuensi, FE berjumlah 3 frekuensi, FF berjumlah 6 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms8.db. Tabel BFD untuk file mmssms8.db dapat dilihat pada Tabel 4.8.
Tabel 4.8. Tabel BFD untuk file mmssms8.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 26292
01 1 1889
02 2 780
03 3 454
04 4 233
... ... ...
FD 253 1
FE 254 3
Pada file mmssms9.db ditemukan nilai bytes heksadesimal 00 berjumlah 25295 frekuensi, 01 berjumlah 2141 frekuensi, 02 berjumlah 828 frekuensi, 03 berjumlah 432 frekuensi, 04 berjumlah 265 frekuensi, FD berjumlah 2 frekuensi, FE berjumlah 0 frekuensi, FF berjumlah 7 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms9.db. Tabel BFD untuk file mmssms9.db dapat dilihat pada Tabel 4.9.
Tabel 4.9. Tabel BFD untuk file mmssms9.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 25925
01 1 2141
02 2 828
03 3 432
04 4 265
... ... ...
FD 253 2
FE 254 0
FF 255 7
Pada file mmssms10.db ditemukan nilai bytes heksadesimal 00 berjumlah 25490 frekuensi, 01 berjumlah 1377 frekuensi, 02 berjumlah 550 frekuensi, 03 berjumlah 363 frekuensi, 04 berjumlah 232 frekuensi, FD berjumlah 1 frekuensi, FE berjumlah 1 frekuensi, FF berjumlah 1 frekuensi. Nilai tersebut merupakan nilai yang ditemukan pada hasil generate hex values pada file mmssms10.db. Tabel BFD untuk file mmssms10.db dapat dilihat pada Tabel 4.10.
Tabel 4.10. Tabel BFD untuk file mmssms10.db Nilai byte
(heksadesimal)
Nilai byte (desimal)
Frekuensi
00 0 25490
Nilai byte (heksadesimal)
Nilai byte (desimal)
Frekuensi
02 2 550
03 3 363
04 4 232
... ... ...
FD 253 1
FE 254 1
FF 255 3
4.2. Implementasi fitur auto find
Pada bagian ini akan dijelaskan hasil implementasi dari fitur auto find. Masing-masing file database yang sudah dilakukan proses generate hex values akan diperiksa untuk menemukan kembali pesan SMS tersebut, baik yang sudah terhapus maupun yang masih utuh. Sistem akan mencatat setiap kecocokan yang terjadi. Pada bagian ini sistem akan mendapatkan nomor pesan SMS, tanggal pesan SMS, isi pesan SMS serta status pesan SMS setelah dilakukan pencocokan dengan file database awal.
Pada proses ini sistem akan mencocokan potongan pola yang sudah ditentukan pada proses generalisasi dengan hasil proses generate hex values. Setiap kecocokan pada proses, sistem akan menampilkan properti pesan SMS tersebut sesuai dengan perancangan yang sudah ditentukan, kemudian hasil seluruh kecocokan akan ditampilkan dalam bentuk tabel seperti pada target output. Sementara parameter yang digunakan antara lain :
• Panjang pattern yang digunakan secara default pada fitur auto find berjumlah 6 bytes heksadesimal yaitu 080808, bytes ini merupakan kelompok bytes pertama sebelum kelompok bytes nomor pesan SMS.
• Panjang teks dihitung berdasarkan hasil generate hex values pada setiap file
• Jumlah kecocokan dihitung berdasarkan setiap kecocokan pattern dengan teks pada hasil generate hex values disetiap file database pesan SMS.
• Banyak nomor pesan SMS merupakan jumlah nomor pesan SMS yang ditemukan dalam teks hasil generate hex values, pesan nomor SMS secara
default berjumlah dua puluh empat bytes heksadesimal atau dua belas karakter
ASCII.
• Banyak pesan SMS utuh merupakan jumlah pesan SMS yang ditemukan dan masih tersimpan dalam file database.
• Banyak pesan SMS terhapus merupakan jumlah pesan SMS yang ditemukan dan tidak tersimpan lagi dalam file database.
• Unreadable Message merupakan jumlah pesan SMS yang sudah tidak bisa
dibaca karena pesan SMS tersebut tidak lagi utuh dan sudah mengalami
vacuum procedure.
Gambar 4.2. Contoh hasil fitur auto find
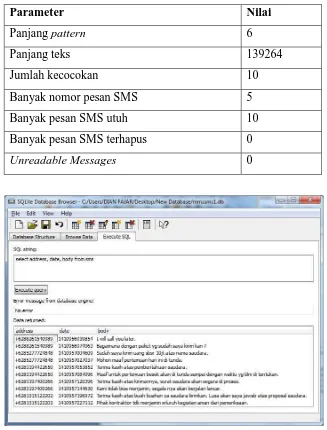
pesan SMS terhapus dan 0 pesan unreadable. Hasil auto find file database mmssms1.db dapat dilihat di Tabel 4.11 dan tabel file database mmssms1.db dapat dilihat pada Gambar 4.3.
Tabel 4.11. Hasil auto find file mmssms1.db
Parameter Nilai
Panjang pattern 6
Panjang teks 139264
Jumlah kecocokan 10
Banyak nomor pesan SMS 5
Banyak pesan SMS utuh 10
Banyak pesan SMS terhapus 0
Unreadable Messages 0
Gambar 4.3. Tabel pesan SMS file database mmssms1.db
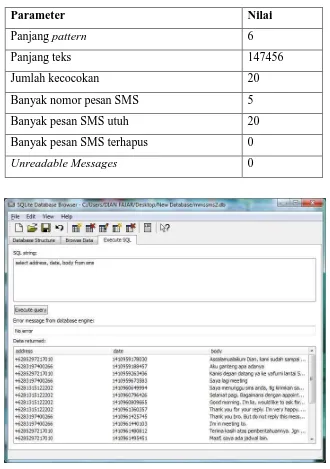
dengan teks sebanyak 20 kecocokan, sistem juga menemukan 20 pesan SMS utuh, 0 pesan SMS terhapus dan 0 pesan unreadable. Hasil auto find file database mmssms2.db dapat dilihat di Tabel 4.12 dan tabel file database mmssms1.db dapat dilihat pada Gambar 4.4.
Tabel 4.12. Hasil auto find file mmssms2.db
Parameter Nilai
Panjang pattern 6
Panjang teks 147456
Jumlah kecocokan 20
Banyak nomor pesan SMS 5
Banyak pesan SMS utuh 20
Banyak pesan SMS terhapus 0
Unreadable Messages 0
Gambar 4.4 Tabel pesan SMS file database mmssms2.db
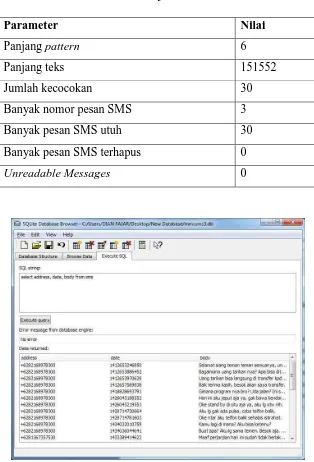
dengan teks sebanyak 30 kecocokan, sistem juga menemukan 30 pesan SMS utuh, 0 pesan SMS terhapus dan 0 pesan unreadable. Hasil auto find file database mmssms3.db dapat dilihat di Tabel 4.13 dan tabel file database mmssms3.db dapat dilihat pada Gambar 4.5.
Tabel 4.13. Hasil auto find file mmssms3.db
Parameter Nilai
Panjang pattern 6
Panjang teks 151552
Jumlah kecocokan 30
Banyak nomor pesan SMS 3
Banyak pesan SMS utuh 30
Banyak pesan SMS terhapus 0
Unreadable Messages 0
Gambar 4.5. Tabel pesan SMS file database mmssms3.db
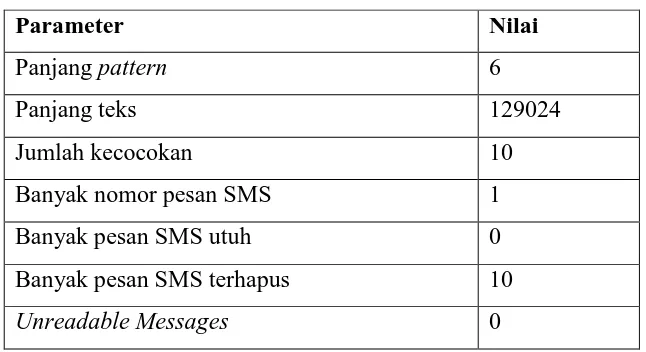
viewer file database mmsms4.db diketahui tidak memiliki pesan SMS utuh. Pada hasil
auto find dari file database mmssms4.db sistem mencatat kecocokan pattern dengan
teks sebanyak 10 kecocokan, sistem juga menemukan 0 pesan SMS utuh, 10 pesan SMS terhapus, 0 pesan unreadable dan 1 nomor pesan SMS. Hasil auto find file
[image:33.595.155.478.245.421.2]database mmssms4.db dapat dilihat di Tabel 4.14.
Tabel 4.14. Hasil auto find file mmsms4.db
Parameter Nilai
Panjang pattern 6
Panjang teks 129024
Jumlah kecocokan 10
Banyak nomor pesan SMS 1
Banyak pesan SMS utuh 0
Banyak pesan SMS terhapus 10
Unreadable Messages 0
Berdasarkan Tabel 3.1 file database mmssms5.db merupakan dataset terhapus yang diketahui memiliki riwayat penghapusan 20 pesan SMS. Jika menggunakan SQLite
viewer file database mmsms5.db diketahui tidak memiliki pesan SMS utuh. Pada hasil
auto find dari file database mmssms5.db sistem mencatat kecocokan pattern dengan
teks sebanyak 12 kecocokan, sistem juga menemukan 0 pesan SMS utuh, 12 pesan SMS terhapus, 0 pesan unreadable dan 1 nomor pesan SMS. Hasil auto find file
database mmssms5.db dapat dilihat di Tabel 4.15.
Tabel 4.15. Hasil auto find file mmsms5.db
Parameter Nilai
Panjang pattern 6
Jumlah kecocokan 12
Banyak nomor pesan SMS 1
Banyak pesan SMS utuh 0
[image:33.595.157.478.634.765.2]Tabel 4.13. Hasil auto find file mmssms5.db (lanjutan)
Parameter Nilai
Banyak pesan SMS terhapus 12
Unreadable Messages 0
Berdasarkan Tabel 3.1 file database mmssms6.db merupakan dataset terhapus yang diketahui memiliki riwayat penghapusan 30 pesan SMS. Jika menggunakan SQLite
viewer file database mmsms6.db diketahui tidak memiliki pesan SMS utuh. Pada hasil
auto find dari file database mmssms6.db sistem mencatat kecocokan pattern dengan
teks sebanyak 14 kecocokan, sistem juga menemukan 0 pesan SMS utuh, 14 pesan SMS terhapus, 0 pesan unreadable dan 1 nomor pesan SMS. Hasil auto find file
database mmssms6.db dapat dilihat di Tabel 4.16 dan tabel file database mmssms6.db
dapat dilihat pada Gambar 4.8.
Tabel 4.16. Hasil auto find file mmssms6.db
Parameter Nilai
Panjang pattern 6
Panjang teks 129905
Jumlah kecocokan 14
Banyak nomor pesan SMS 1
Banyak pesan SMS utuh 0
Banyak pesan SMS terhapus 14
Unreadable Messages 0
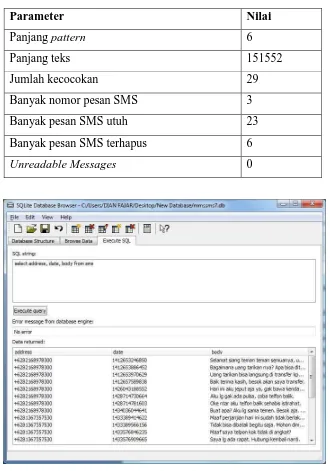
[image:34.595.155.477.427.602.2]mmssms7.db dapat dilihat di Tabel 4.17 dan tabel file database mmssms7.db dapat dilihat pada Gambar 4.6.
Tabel 4.17. Hasil auto find file mmssms7.db
Parameter Nilai
Panjang pattern 6
Panjang teks 151552
Jumlah kecocokan 29
Banyak nomor pesan SMS 3
Banyak pesan SMS utuh 23
Banyak pesan SMS terhapus 6
[image:35.595.153.483.159.630.2]Unreadable Messages 0
Gambar 4.6. Tabel pesan SMS file database mmssms7.db
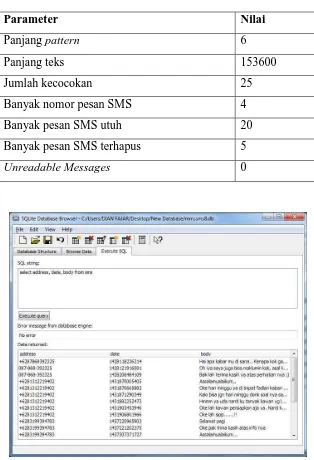
mmssms8.db dapat dilihat di Tabel 4.18 dan tabel file database mmssms8.db dapat dilihat pada Gambar 4.7.
Tabel 4.18. Hasil auto find file mmsms8.db
Parameter Nilai
Panjang pattern 6
Panjang teks 153600
Jumlah kecocokan 25
Banyak nomor pesan SMS 4
Banyak pesan SMS utuh 20
Banyak pesan SMS terhapus 5
Unreadable Messages 0
Gambar 4.7. Tabel pesan SMS file database mmssms8.db
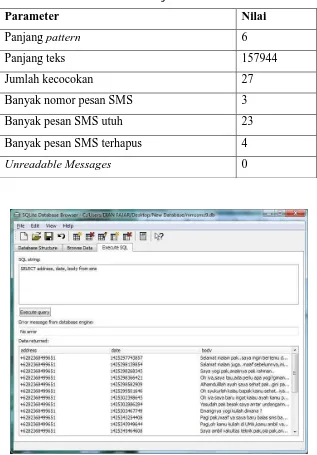
dengan teks sebanyak 27 kecocokan, sistem juga menemukan 23 pesan SMS utuh, 4 pesan SMS terhapus dan 0 pesan unreadable. Hasil auto find file database mmssms9.db dapat dilihat di Tabel 4.19 dan tabel file database mmssms9.db dapat dilihat pada Gambar 4.8.
Tabel 4.19. Hasil auto find file mmsms9.db
Parameter Nilai
Panjang pattern 6
Panjang teks 157944
Jumlah kecocokan 27
Banyak nomor pesan SMS 3
Banyak pesan SMS utuh 23
Banyak pesan SMS terhapus 4
Unreadable Messages 0
Gambar 4.8. Tabel pesan SMS file database mmssms9.db
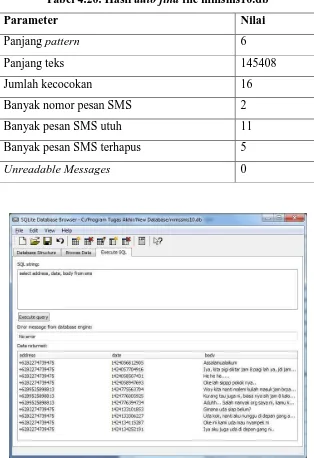
dengan teks sebanyak 16 kecocokan, sistem juga menemukan 11 pesan SMS utuh, 5 pesan SMS terhapus dan 0 pesan unreadable. Hasil auto find file database mmssms10.db dapat dilihat di Tabel 4.20 dan tabel file database mmssms10.db dapat dilihat pada Gambar 4.9.
Tabel 4.20. Hasil auto find file mmsms10.db
Parameter Nilai
Panjang pattern 6
Panjang teks 145408
Jumlah kecocokan 16
Banyak nomor pesan SMS 2
Banyak pesan SMS utuh 11
Banyak pesan SMS terhapus 5
Unreadable Messages 0
4.3. Hasil pengujian
Hasil pengujian dengan menggunakan tiga jenis dataset untuk setiap file database yang tercantum pada tabel 3.1 dapat dilihat pada tabel 4.21, tabel 4.22 dan tabel 4.23. Hasil dataset utuh dan terhapus merupakan hasil kemampuan penerapan metode yang digunakan dalam menemukan kembali pesan SMS utuh maupun terhapus pada file
database pesan SMS yang diketahui propertinya, sedangkan hasil dataset test
merupakan hasil kemampuan penerapan metode yang digunakan dalam menemukan kembali pesan SMS yang tidak diketahui propertinya terhadap file database yang diambil langsung dari pengguna handphone Android.
Hasil yang didapatkan adalah 100% untuk dataset utuh, sedangkan pada dataset terhapus sistem dapat menemukan kembali 36 pesan SMS yang terhapus atau sekitar 60%, sedangkan pada dataset test sistem dapat menemukan 87 pesan SMS utuh dan 20 pesan SMS yang terhapus. Hasil pencarian pesan SMS yang telah dihapus bergantung pada ada atau tidaknya proses yang terjadi pada file database sebelumnya. Ada beberapa kemungkinan yang mempengaruhi hasil dari proses pencarian pesan SMS yang telah dihapus, yakni:
1. Adanya kemungkinan proses overwriting pada file database tersebut.
[image:39.595.134.499.549.677.2]2. Adanya kemungkinan suatu file database telah melakukan prosedur vacuum.
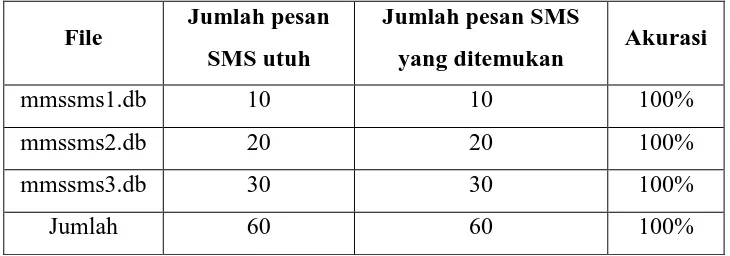
Tabel 4.20. Hasil pencarian untuk setiap dataset utuh
File Jumlah pesan SMS utuh
Jumlah pesan SMS
yang ditemukan Akurasi
mmssms1.db 10 10 100%
mmssms2.db 20 20 100%
mmssms3.db 30 30 100%
File Jumlah awal pesan SMS
Jumlah pesan SMS yang ditemukan
Jumlah pesan SMS loss
Akurasi
mmssms4.db 10 10 0 100%
mmssms5.db 20 12 8 60%
mmssms6.db 30 14 16 46,66%
[image:40.595.103.530.116.244.2]Jumlah 60 36 24 60%
Tabel 4.22. Hasil pencarian untuk setiap dataset test
File Jumlah pesan SMS utuh
Jumlah pesan
SMS terhapus Jumlah
mmssms7.db 22 6 28
mmssms8.db 20 4 24
mmssms9.db 31 5 36
mmssms10.db 14 5 19
[image:40.595.143.490.304.453.2]BAB 5
KESIMPULAN DAN SARAN
Bab ini membahas tentang kesimpulan dari metode yang diajukan dalam menemukan kembali pesan SMS yang telah dihapus pada handphone Android yang akan dibahas pada bagian 5.1, serta pada bagian 5.2 akan membahas saran-saran untuk pengembangan penelitian selanjutnya.
5.1 Kesimpulan
Berdasarkan penerapan metode yang digunakan yaitu string matching dengan menggunakan algoritma Boyer-Moore untuk menemukan kembali pesan SMS yang telah dihapus pada handphone Android berdasarkan metode tersebut, didapat beberapa kesimpulan, yaitu:
1. Penerapan metode yang digunakan mampu menampilkan kembali pesan SMS yang telah dihapus dengan menggunakan hasil generate hex values pada masing-masing file database yang digunakan, 100% pada dataset utuh dan 60% pada dataset terhapus, pada dataset test sistem dapat menemukan 87 pesan SMS utuh dan 20 pesan SMS terhapus. Sehingga dapat disimpulkan metode yang digunakan mampu menemukan kembali pesan SMS yang telah dihapus dari sebuah file database sehingga pesan SMS tersebut dapat ditampilkan.
2. Metode exact string matching yang digunakan bergantung sepenuhnya kepada isi keseluruhan file database, jika file database tersebut sudah dilakukan vacuum
sulit dilakukan, karena file database tersebut kemungkinan sudah memilki pola yang berbeda.
3. Metode yang digunakan tidak bisa mengembalikan pesan SMS yang telah dihapus secara permanen yang dihasilkan melalui proses overwriting dan vacuum
procedure.
4. Pada penelitian ini, metode pencarian dilakukan berdasarkan dengan menggunakan
pattern dari hasil generalisasi. Selanjutnya metode pencarian malakukan pencarian
dengan pola yang sudah ditentukan sebelumnya.
5. Diperlukan kemampuan untuk melakukan identifikasi pada perangkat digital tertentu yang menggunakan platform tertentu, karena banyaknya jenis perangkat digital mengakibatkan identifikasi terhadap perangkat digital sulit dilakukan walaupun memiliki platform yang sama.
5.2 Saran
Pada penelitian selanjutnya, untuk meningkatkan hasil pencarian dalam menemukan kembali pesan SMS yang telah dihapus dapat dilakukan recovery dengan metode
record recover. Dengan metode record recover diharapkan pesan SMS yang telah
dihapus secara permanen melalui proses overwriting dapat dikembalikan seperti semula, sehingga pesan SMS yang telah dihapus secara permanen dapat ditampilkan kembali. Untuk meningkatkan kepastian dari hasil yang didapatkan pada penilitian dapat dilakukan pengumpulan file database untuk setiap dataset lebih banyak dan lebih variatif. Melakukan pencarian pesan SMS yang telah dihapus dengan menggunakan potongan pola yang berbeda dapat meningkatkan akurasi serta memberikan pilihan lain dalam menemukan kembali pesan SMS yang telah dihapus. Metode penelitian ini juga dapat diaplikasikan untuk menemukan kembali call history
BAB 2
LANDASAN TEORI
Pada bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma Boyer-Moore untuk menemukan kembali pesan SMS yang telah dihapus pada handphone Android.
2.1. Mobile Forensic
Mobile forensic merupakan bagian dari ilmu yang mempelajari tentang forensik
digital namun dalam lingkup yang lebih kecil. Digital forensic mempelajari bagaimana caranya mengidentifikasi, mengumpulkan bahkan menganalisis suatu barang bukti digital untuk dijadikan sebagai alat bukti (Carrier, 2003). Terdapat empat tahapan dalam pembuktian bukti digital (Casey, 2011), sebagai berikut:
1. Identifikasi bukti digital
Identifikasi bukti digital merupakan tahapan pertama dalam proses digital
forensic. Identifikasi bukti digital bertujuan untuk mengidentifikasi bukti digital
Penyimpanan bukti digital dilakukan untuk mendapatkan bukti digital yang utuh, hal ini dilakukan untuk menghindari kerusakan, perubahan atau hilangnya barang bukti digital. Bukti digital yang utuh menentukan tingkat keberhasilan dalam melakukan digital forensic. Penyimpanan bukti digital dilakukan secara bitstream
image untuk menjaga keaslian bukti digital.
3. Analisa bukti digital
Analisa bukti digital merupakan hal yang utama dalam digital forensic. Hal ini dilakukan untuk mencari atau menganalisis keberadaan bukti digital yang mungkin ditemukan.
4. Presentasi bukti digital
Bukti digital yang sudah ditemukan akan ditampilkan untuk dijadikan barang bukti digital yang sah menurut hukum.
Proses forensik digital bergantung pada sistem operasi yang digunakan. Sebagai contoh, kebanyakan pengguna komputer dekstop menggunakan sistem operasi Microsoft Windows, atau pengguna smartphone yang lebih banyak menggunakan sistem operasi Android. Oleh karena itu, diperlukan kemampuan untuk melakukan identifikasi pada perangkat digital tertentu yang menggunakan sistem operasi tertentu, karena banyaknya jenis perangkat digital mengakibatkan identifikasi terhadap perangkat digital sulit dilakukan (Raharjo, 2013).
Mobile forensic memeberikan pemahaman tentang bagaimana barang bukti
digital diperoleh dari mobile phone. Di dalam mobile phone ada banyak layanan atau fitur yang dapat dijadikan sebagai bukti digital seperti Subscriber Identity Module (SIM), internal memory, memory card dan network service providers (Zareen & Baig 2010). Adapun beberapa bukti digital yang kemungkinan besar dapat didapatkan pada
Tabel 2.1. Daftar bukti digital yang dapat ditemukan (Zareen & Baig, 2010)
No. Bukti Digital Sumber
1 Name of Service Provider Dicetak dibelakang SIM Card 2 Unique Id Number Dicetak dibelakang SIM Card 3 Location Area Identity (LAI) Disimpan pada SIM Card 4 International Mobile Equipment
Identity (IMEI)
Disimpan dan dicetak pada mobile phone
5 Text Message Data (SMS) Disimpan pada SIM Card atau memory 6 Contact Disimpan pada SIM Card atau memory 7 Call Logs Disimpan pada SIM Card atau memory 8 Images/Sound/Videos Disimpan pada memory
2.2. Android
Android merupakan sistem operasi yang di kembangkan oleh Open Handset Alliance (OHA). Gabungan ini berisikan lebih dari 50 perusahaan mobile technology, mulai dari handset manufactures dan service provider sampai semiconductor manufacture dan software developers, seperti Acer, ARM, Google, eBay, HTC, Intel, LG Electronics, Qualcomm, Sprint and T-Mobile. Tujuan utama OHA adalah mempercepat innovasi terhadap perkembangan perangkat mobile dengan memberikan susuatu yang lebih murah namun memiliki kemampuan yang lebh baik (Lessard et al, 2010).
Tahun Jumlah(milliar) Populasi(%)
2012 4,08 58,2
2013 4,33 61,1
2014 4,55 63,5
2015 4,77 65,8
2016 4,95 67,7
[image:46.595.201.433.117.267.2]2017 5,13 69,4
Tabel 2.3. Data market share OS smartphone di dunia tahun 2014 (IDC, Aug 2015)
Operating System Market Share
Android 84,8%
iOS 11,6%
Windows Phone 2,5%
BlackBerry OS 0,5%
Others 0,7%
2.2.1. Architecture
Sangat penting untuk mengenal lebih jauh lagi mengenai sistem operasi Android khusunya bagaimana arsitektur sistem operasi tersebut bekerja, hal ini dapat berguna untuk melakukan prosedur keamanan maupun dalam melakukan analisis forensik (Hoog, 2010). Secara umum arsitektur Android dibedakan menjadi lima bagian atau lapisan yaitu (Yoon, 2012) :
1. Linux Kernel
[image:46.595.211.423.346.478.2]driver layar, kamera, keypad, WiFi, flash memory, audio dan IPC untuk
menyediakan proses pada sumber daya aplikasi.
2. Libraries
Libraries merupakan sebuah paket pustaka yang berisi fitur - fitur yang digunakan untuk menjalankan aplikasi. Pustaka hanya dapat digunakan oleh program yang berada di level atasnya. Beberapa library yang terdapat adalah libraries media untuk memutar video atau audio, libraries SQLite untuk menggunakan database pada perangkat Android.
3. Android Runtime
Android runtime merupakan layer di mana aplikasi Android dijalankan. Core
libraries merupakan sabuah paket inti yang berfungsi sebagai penerjemah
bahasa C atau Java, sedangkan Dalvik Virtual Machine merupakan mesin
virtual berbasis register yang digunakan untuk pengoptimalan dalam
menjalankan fungsi - fungsi Android secara efisien.
4. Application Framework
Dalam membangun aplikasi, Android menggunakan kerangka aplikasi yang menyediakan kelas - kelas tersendiri. Selain itu, juga menyediakan abstraksi generik untuk mengakses, serta mengatur tampilan user interface dan sumber daya aplikasi.
5. Applications Layer
Top-level dari arsitektur Android adalah lapisan aplikasi. Lapisan ini yang pertama kali tampak ketika pengguna mengoperasikan perangkat Android, tanpa mengetahui proses apa saja yang sedang berlangsung di balik lapisan ini. Program berjalan dalam Android runtime dengan menggunakan kelas dan
Bagian - bagian tersebut bekerja secara bersamaan dan saling bergantung dengan yang lain. Rangkuman bagian arsitektur Android dapat dilihat pada Gambar 2.1.
Gambar 2.1. Arsitektur sistem operasi Android (Yoon, 2012)
2.2.2. Library Layer
Bagian terpenting dalam melakukan analisis forensik adalah tempat di mana data tersebut disimpan. Bagian ini berada pada lapisan libraries. Pada perangkat Android semua data disimpan dalam database file berjenis SQLite. Beberapa data seperti pesan
APPLICATIONS
Home Contact Phone Browser ...
APPLICATION FRAMEWORK Activity Manager Window Manager Content
Provider View System
Telephony Manager Resource Manager Location Manager Notification Manager Package Manager
LIBRARIES ANDROID RUNTIME
Core Libraries
Dalvik Virtual Machine Surface
Manager
OpenGL | ES
SMS, call history, browser history, password dan lainnya disimpan dalam sebuah file
database SQLite. SQLite yang memiliki sifat removable sangat membantu dalam
melakukan analisis forensik.
SQLite merupakan sebuah embedded database yang bersifat open source, yang dibuat dengan menggunakan bahasa C oleh D. Richard Hipp, jika dibandingkan dengan database lainnya seperti SQL Server, Oracle, MySQL dan lainnya, SQLite merupakan database yang ringan digunakan dalam prosesnya, selain itu SQLite menjadi embedded database yang mempunyai engine yang lengkap sehingga tidak membutuhkan komponen yang lain, ada delapan keunggulan yang dimiliki SQLite antara lain (Bi, 2009) :
1. Open Source Embedded Database
SQLite merupakan embedded database yang bersifat open source. Terdiri kurang dari 30.000 baris ANSI C, yang mana ini dapat digunakan secara bebas untuk tujuan tertentu.
2. Practical Database
SQLite tidak memerlukan proses instalasi dan konfigurasi, tidak memerlukan proses start dan stop, dan tidak membutuhkan wewenang seorang administrator. Seperti pada kasus system collapse atau lose of power, SQLite dapat mengembalikan keadaan seperti semula secara otomatis.
3. Easily Database
File database SQLite dapat dibaca dan ditulis pada media penyimpanan secara
Perbedaan yang mencolok pada SQLite terletak pada tidak ada tipe datanya. SQLite dapat memasukan data apapun ke tabel apapun, tanpa mengetahui atribut data tersebut.
5. Many Support
SQLite mendukung ACID dan SQL92 serta multiple tables dan indexes,
transactions, views, triggers seperti database umumnya.
6. Multi Platform
SQLite memiliki kinerja yang cepat, efisien dan terukur, yang tidak bergantung pada sistem operasi yang sedang digunakan. SQLite dapat digunakan pada sistem operasi yang beragam.
7. Supports API
SQLite menyediakan banyak dukungan untuk terhadap API, dan mendukung bahasa pemrograman yang umum seperti C/C++, PHP, Perl dan lainnya. API berguna sebagai penghubung antara programming language dengan database
file.
8. Good reliability
SQLite memiliki ketahanan yang bagus dalam melakukan sebuah proses data. Dan telah memenuhi dari 90% cakupan uji.
2.2.3. Database Architecture
penyimpanan (Hoog, 2010). Secara umum file database yang digunakan pada
smartphone Android berada pada direktori data/data/<packagaName>/databases
[image:51.595.135.498.189.307.2]seperti pada Tabel 2.4 .
Tabel 2.4. Subdirektori /data/data/<packageName> (Hoog, 2010)
shared_prefs Directory Storing
lib Custom library files an application requires
files Files the developer saves to internal storage
cache Files cached by the application
databases SQLite database and journal files
File database yang menyimpan data pesan SMS berada pada direktori
/data/data/com.android.providers.telephony/databases/mmssms.db. File mmssms.db memliki beberapa tabel seperti pada Gambar 2.2. Pesan SMS tersimpan dalam tabel sms pada database tersebut. Adapun arsitektur tabel sms seperti pada Tabel 2.5.
Android_metadata
locale
pdu canonical_addresses
sqlite_sequences Pending_msgs threads
Words_contentc Words_segment Words_segdir
Pdu_recipient_threads Semc_threads addr
Semc_metadata part rate drm
sms raw attachment Sr_pending
[image:51.595.197.436.428.720.2]Name Type
_id INTEGER PRIMARY KEY
thread_id INTEGER
address TEXT
person INTEGER
date INTEGER
date_sent INTEGER
protocol INTEGER
read INTEGER
status INTEGER
type INTEGER
reply_path_present INTEGER
subject TEXT
body TEXT
service_center TEXT
locked INTEGER
error_code INTEGER
seen INTEGER
semc_message_priority INTEGER
parent_id INTEGER
delivery_status INTEGER
star_status INTEGER
2.3. Short Message Service
Short Message Service (SMS) merupakan layanan yang berbentuk Instant Messaging
(IM) yang memungkinkan user untuk bertukar pesan singkat kapanpun dan dimanapun. Pesan SMS dikirim menggunakan jaringan GSM (Global System for
[image:52.595.174.461.116.586.2]kata lain sebuah pesan bisa memuat 140 karakter 8-bit, 160 karakter 7-bit atau 70 karakter 16-bit.
[image:53.595.162.471.321.515.2]Dengan perkembangan teknologi yang semakin pesat, layanan text messages sudah sesuatu yang tidak asing lagi bagi user. Konsep yang user friendly memberikan kemudahan bagi pengguna sehingga layanan ini menjadi sangat disukai. Menurut data yang dikeluarkan oleh Pew Research Center pada tahun 2012 pengguna smartphone sangat aktif menggunakan layanan text messages sebesar 61% per hari dan 80% per minggu, hal ini membuat layanan text messages menjadi layanan favorit pada pengguna smartphone, sebagaimana terlihat pada Tabel 2.6.
Tabel 2.6. Aktivitas pengguna smartphone (Pew Research Center, Oct 2012)
Activity Weekly (%) Daily (%)
Text Messages 80 61
Internet Browsing 62 36
Played Games 54 31
Social Networking Site 62 46
Music/Videos 31 8
Read books 15 7
Shop 24 5
Read magazines 11 4
2.3.1. Deleted Message
Delete message merupakan salah satu pilihan untuk menghapus satu item
pesan SMS yang dikirim atau yang diterima.
2. Delete Conversation
Delete conversation merupakan pilihan untuk menghapus seluruh percakapan
pesan SMS berdasarkan satu nomor pengirim.
3. Delete Several
Delete several memiliki fungsi yang sama dengan delete conversation, namun
memiliki pilihan item nomor pengirim lebih dari satu.
4. Delete All
Delete all memeiliki fungsi menghapus seluruh percakapan pesan SMS yang
ada pada smartphone Android tersebut, baik itu pesan SMS keluar atau masuk.
Pesan SMS tersimpan dalam sebuah file database berjenis SQLite, pesan SMS yang dihapus kemungkinan tidak dihapus secara permanen atau ditimpa dengan pesan SMS yang lain, pesan SMS yang sudah dihapus tersebut masih disimpan dalam file
database. Pesan SMS yang telah dihapus masih mungkin untuk ditemukan selama
pesan SMS tersebut belum ditimpa oleh pesan SMS yang baru. Pesan SMS yang telah dihapus tersebut bisa dilihat dalam bentuk hexadecimal dengan pola yang mudah dipahami (Hoog, 2010). Pada banyak kasus, penghapusan pesan SMS dalam file
database SQLite tidak disempurnakan dengan penghapusan bit nya, sehingga pesan
SMS tersebut tidak benar - benar terhapus secara bersih, kondisi ini dapat digunakan untuk menemukan kembali pesan SMS yang telah dihapus (Stahlberg at al, 2007).
Record pesan SMS yang dihapus akan dipindahkan ke ruang yang tidak terisi
yang baru, dengan mempertimbangkan dua faktor: apakah record yang baru akan cocok dengan ruang yang diberikan dan apakah record yang baru memenuhi tata aturan pada tabel tersebut. Proses penghapusan dan pemasukan record dapat dilihat pada Gambar 2.3. Proses ini dibagi menjadi empat tahapan, yaitu :
1. Tahap pertama terdapat enam record yang aktif, yang menempati sebagian ruang yang sudah dialokasikan untuk table storage.
2. Tahap kedua, setelah penghapusan record t3 dan t5, ruang yang ditempati akan dibebaskan, tetapi data tersebut masih dapat dipulihkan.
3. Selanjutnya pada tahap ketiga, record t7 dimasukan, menggunakan ruang bebas yang ada sehingga menimpa record t3. Dilain sisi terdapat proses penghapusan record t1 dan t4.
4. Pada tahap selanjutnya prosedur vacuum dijalankan, untuk mengatur kembali
active records (t2,t7,t6), dan mengurangi ruang yang dialokasikan pada
database file. Record t5 akan dibuang dan menduplikat record t6 pada ruang
[image:55.595.118.522.444.604.2]yang tidak terisi di file system.
Gambar 2.3. Ilustrasi insert dan delete record (Stahlberg at al, 2007)
2.3.2. Message Pattern
empat bagian seperti pada Gambar 2.5 dan Gambar 2.6, yaitu :
1. File Info
Pada bagian ini terdapat informasi tentang identifikasi jenis file. Pada 16 bytes pertama maka akan ditemukan pola hexadecimal 53 51 4C 69 74 65 20 66 6F 72 6D 61 74 20 33 00 , jika diubah ke dalam bentuk ASCII menjadi “SQLite format 3.”, ini menunjukan file tersebut berjenis database SQLite.
2. Struktur Tabel Database
Selanjutnya setelah bagian file info, terdapat bagian struktur tabel database. Pada bagian ini seluruh tabel dan strukturnya yang ada pada database akan direpresentasikan dalam hexadecimal. Setiap tabel yang ada akan ditandai dengan pola 43 52 45 41 54 45 20 54 41 42 4C 45 jika diubah ke dalam karakter ASCII menjadi “CREATE TABLE”.
3. Pesan SMS
Pola pesan SMS baik itu yang masih tersimpan atau yang sudah dihapus selalu diawali oleh header pesan SMS tersebut, kemudian nomor pesan sms, tanggal dan isi pesan SMS. Selengkapnya dapat dilihat pada Gambar 2.4.
Gambar 2.4. Pola pesan SMS (Hoog, 2010)
dikirim atau diterima. Untuk mengetahui waktu pesan SMS tersebut 6 bytes pola akan diubah terlebih dahulu dalam bentuk decimal, kemudian didapatkan pola waktu berdasarkan Unix Epoch in milliseconds (Hoog, 2010). Contoh : 01 41 30 74 FF DA diubah kedalam desimal menghasilkan 13799497476058 ini merupakan bentuk waktu dalam bentuk Unix Epoch dan ketika diubah kedalam bentuk waktu biasa maka akan didapatkan Rabu, 18 September 2013 09:44:36.
4. Trigger Database
Kemudian pada bagian terakhir terdapat kumpulan trigger yang digunakan pada file database tersebut. Seperti trigger insert, trigger update atau trigger
[image:57.595.110.526.393.582.2]delete.
Gambar 2.6. Struktur file database yang berisi pesan SMS (Hoog, 2010)
2.4. String Matching
String matching atau pencocokan string merupakan sebuah metode pencarian sebuah
pattern P [1...m] pada teks T [1...n] dimana m<=n (Lecroq, 1992). Terdapat dua
teknik yang biasa digunakan pada string matching, yang pertama adalah exact
matching, teknik ini digunakan pada algoritma Needleman Wunsch, Smith Waterman,
Knuth–Morris–Pratt, Dynamic Programming, maupun Boyer-Moor, selain exact
matching terdapat teknik lainnya yaitu approximate matching, teknik ini digunakan
pada algoritma fuzzy string, Rabin Karp, Brute Force (Singla et al, 2012).
2.4.1. Exact String Matching
Exact string matching merupakan pencocokan string secara tepat dengan susunan
Teks T = t1, t2, t3 ... tn dimana n adalah panjang teks sedangkan pattern P =
p1, p2, p3 ... pm m adalah panjang pattern. Exact string matching membandingkan
karakter yang ada teks T dengan karakter yang pada pattern P dengan berdasarkan kecocokan karakter (Bhandari et al, 2013). Sebagai contoh : algorithm dengan
alggrithm, memiliki jumlah karakter yang sama namun ada satu karakter yang berbeda
maka dianggap tidak cocok.
2.4.2 Approximate String Matching
Approximate string matching merupakan pencocokan string berdasarkan kemiripan
karakter dari segi penulisannya yang ada pada pattern P dan teks T (Patrick et al, 1980). Tingkat kemiripan ditentukan oleh jumlah karakter dan susunan karakter, serta kemiripan antara dua buah string yang dibandingkan. Contoh : a goritna dengan
algoritma, memilki jumlah karakter yang sama namun terdapat dua karakter yang
berbeda. Jika perbedaan ini dianggap sebagai kesalahan dalam penulisan, maka dua
string tersebut dapat dikatakan cocok.
Approximate string matching secara umum dapat diasumsikan dengan T1...n
dimana T adalah teks dan n panjang teks, kemudian P1...m dimana P adalah pattern dan m panjang pattern yang relatif lebih singkat dari n. Kemiripan atau kecocokan ditentukan oleh jumlah karakter alfabet ∑ dan urutan alfabet σ . Dan k yang
menyatakan ketidakcocokan diantara dua buah string (Navarro, 2001).
2.4.3. Window Sliding
Window sliding merupakan teknik yang diterapkan pada exact matching