DENGAN ANALISIS FAKTOR
SKRIPSI
RENDRIC SETIAWAN 110823010
PROGRAM STUDI S-1 EKSTENSI MATEMATIKA DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
DENGAN ANALISIS FAKTOR
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
RENDRIC SETIAWAN 110823010
PROGRAM STUDI S-1 EKSTENSI MATEMATIKA DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
Judul : Penentuan Faktor Dominan yang Mempengaruhi Pertumbuhan Ekonomi Sumatera Utara dengan Analisis Faktor
Kategori : Skripsi
Nama : Rendric Setiawan
Nomor Induk Mahasiswa : 110823010
Program Studi : Sarjana (S1) Matematika
Departemen : Matematika
Fakultas : Matematika Dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Disetujui di Medan, Februari 2014
Komisi Pembimbing :
Pembimbing 2,Pembimbing 1,
Drs. Marihat Situmorang, M.Kom Drs. Pengarapen Bangun, M.Si NIP.19631214 198903 1 001 NIP.19560815 198503 1 005
Disetujui Oleh
Departemen Matematika FMIPA USU Ketua,
PENENTUAN FAKTOR DOMINAN YANG MEMPENGARUHI PERTUMBUHAN EKONOMI SUMATERA UTARA
DENGAN ANALISIS FAKTOR
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Februari 2015
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Kuasa atas segala rahmat dan karunia-Nya yang telah dilimpahkan, sehingga penulisan skripsi dengan judul “Penentuan Faktor Dominan yang Mempengaruhi Pertumbuhan Ekonomi Sumatera Utara dengan Analisis Faktor”dapat diselesaikan dengan baik. Pada kesempatan ini, penulis mengucapkan terima kasih yang sedalam-dalamnya kepada:
1. Bapak Drs. Pengarapen Bangun, M.Si selaku dosen dan pembimbing I yang berkenan dan rela mengorbankan waktu, tenaga dan pikiran guna memberikan petunjuk dan bimbingannya dalam penulisanskripsi ini.
2. Bapak Drs. Marihat Situmorang, M.kom selaku dosen dan pembimbing II yang juga berkenan dan rela mengorbankan waktu, tenaga dan pikiran guna memberikan petunjuk dan bimbingannya dalam penulisanskripsi ini.
3. Bapak Drs. Ujian Sinulingga, M.Si dan Drs. Partano Siagian, M.Sc selaku dosen pembanding atas masukan dan saran yang telah diberikan demi perbaikan skripsi ini.
4. Bapak Prof. Dr. Tulus, M.Si, Ph.D dan Ibu Dr. Mardiningsih, M.Si selaku ketua dan sekretaris Departemen Matematika FMIPA USU.
5. Bapak Dr. Sutarman, M.Sc selakuDekan FMIPA USU.
6. Bapak dan Ibu dosen pengajar Departemen Matematika FMIPA USU yang telah memberikan banyak ilmu pengetahuan selama masa perkuliahan.
7. Staf pegawai Departemen Matematika FMIPA USU.
8. Kedua orang tuaku (Drs. Syaiful Mar dan Yennidar Kisnawati, S.Pd), Abang (Robbi Arnandes), dan Kakak (Refika Yuli Yesa dan Rima Apri Yesa), serta Adik (Riska Novri Yesa) tercinta yang selalu memberikan kasih sayang, semangat, dorongan, dan do’a agar penulis dapat menyelesaikan skripsi ini dengan baik.
9. Sahabat-sahabat seperjuangan dan semua pihak yang telah membantu dalam penyelesaian skripsi ini yang tidak mungkin disebutkan satu persatu.
Semoga semua bimbingan, bantuan, dan doa yang diberikan menjadi amal ibadah untuk semuanya. Akhir kata penulis berharap semoga tulisan ini bermanfaat bagi setiap pembaca.
Medan, Februari 2015
Penulis
DENGAN ANALISIS FAKTOR
ABSTRAK
ABSTRACT
Halaman
PERSETUJUAN i
PERNYATAAN iii
PENGHARGAAN iv
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL ix
DAFTAR GAMBAR x
DAFTAR LAMPIRAN xi
Bab 1. PENDAHULUAN
1.1. Latar Belakang 1
1.2. Perumusan Masalah 3
1.3. Pembatasan Masalah 3
1.4. Tinjauan Pustaka 4
1.5. Tujuan Penelitian 5
1.6. Kontribusi Penelitian 6
1.7. Metodologi Penelitian 6
Bab 2. LANDASAN TEORI
2.1. Analisis Faktor 9
2.1.1. Model Analisis Faktor 10
2.1.2. Statistik yang Relevan dengan Analisis Faktor 12
2.1.3. Pelaksanaan Analsis Faktor 14
2.1.3.1. Identifikasi Data 14
2.1.3.2. Pengambilan Data 15
2.1.3.3. Bentuk Matriks Korelasi 15
2.1.3.4. Menentukan Metode Analisis Faktor 17 2.1.3.5. Penentuan Banyaknya Faktor 17
2.1.3.6. Rotasi Faktor 19
2.1.3.7. Interpretasi Faktor 20
2.1.3.8. Mengukur Ketepatan Model 20
Bab 3. HASIL DAN PEMBAHASAN
3.1. Gambaran Umum 21
3.2. Analisis Hasil Perhitungan 22
3.2.1. Uji Asumsi Kecukupan Data dan korelasi Antar
Variabel 22
3.2.2. Penentuan Banyaknya Faktor 25
3.2.3. Rotasi Faktor 26
3.2.4. Interpretasi Faktor 29
4.1. Kesimpulan 32
4.2. Saran 34
DAFTAR PUSTAKA 35
LAMPIRAN 36
DAFTAR TABEL
Nomor Tabel
Judul Halaman
2.1. 2.2. 4.1. 4.2. 4.3. 4.4. 4.5. 4.6. 4.7. 4.8. 4.9. 4.10. 4.11. 4.12. 4.13.
Matriks Korelasi Untuk Jumlah Variabel n = 3 Matriks Korelasi Untuk Jumlah Variabel n = 4
Pengujian KMO dan Bartlett’s Variabel PDRB ADHB Korelasi Variabel PDRB ADHB
Pengujian KMO dan Bartlett’s Variabel PDRB ADHK Korelasi Variabel PDRB ADHK
Eigenvalue, Variance, dan Cumulative Korelasi Matriks PDRB
Faktor Loading dan Komunalitas Variabel PDRB ADHB Sebelum dirotasi
Faktor Loading dan Komunalitas Variabel PDRB ADHK Sebelum dirotasi
Faktor Loading dan Komunalitas Variabel PDRB ADHB Setelah dirotasi
Faktor Loading dan Komunalitas Variabel PDRB ADHK Setelah dirotasi
Hasil Rotasi Faktor Varimax dari Variabel PDRB ADHB Hasil Rotasi Faktor Varimax dari Variabel PDRB ADHK Residual antara Observed Correlation dan Reproduced Correlationi Variabel PDRB ADHB
Residual antara Observed Correlation dan Reproduced Correlationi Variabel PDRB ADHK
Nomor Gambar
Judul Halaman
1.1. 15 Variabel di Reduksi Menjadi 5 Faktor 4
DAFTAR LAMPIRAN
Nomor Lamp.
Judul Halaman
1.
2.
3. 4.
Produk Domestik Regional Bruto (PDRB) Provinsi Sumatera Utara Menurut Kabupaten/Kota Atas Dasar Harga Konstan (ADHK) Tahun 2013 (Juta Rupiah)
Produk Domestik Regional Bruto (PDRB) Provinsi Sumatera Utara Menurut Kabupaten/Kota Atas Dasar Harga Berlaku (ADHB) Tahun 2013 (Juta Rupiah)
Hasil Print Out SPSS Analisis Faktor PDRB Perhitungan Analisis Faktor Dengan Menggunakan Matriks
36
38 40
PENDAHULUAN
1.1. Latar Belakang
Pembangunan ekonomi adalah suatu proses kenaikan pendapatan total dari pendapatan perkapita dengan memperhitungkan adanya pertambahan penduduk dan disertai dengan perubahan fundamental dalam struktur ekonomi suatu negara dan pemerataan pendapatan bagi penduduk suatu negara. Pembangunan ekonomi tidak dapat lepas dari pertumbuhan ekonomi. Pembangunan ekonomi mendorong pertumbuhan ekonomi, dan sebaliknya, pertumbuhan ekonomi memperlancar proses pembangunan ekonomi (id.wikipedia.org/wiki/pembangunan-ekonomi).
Menurut Badan Pusat Statistik (2014), pertumbuhan ekonomi merupakan indikator yang penting untuk mengetahui dan mengevaluasi hasil pembangunan yang dilaksanakan khusus dalam bidang ekonomi. Pertumbuhan ekonomi menunjukkan sejauh mana kinerja atau aktivitas dari berbagai sektor ekonomi dalam menghasilkan nilai tambah atau pendapatan wilayah/daerah pada periode tertentu.
Provinsi Sumatera Utara memiliki keunikan tersendiri dalam kerangka perekonomian nasional. Provinsi ini adalah daerah agraris yang menjadi pusat pengembangan perkebunan dan hortikultura di satu sisi, sekaligus merupakan salah satu pusat perkembangan industri dan pintu gerbang pariwisata Indonesia di sisi lain. Ini terjadi karena potensi sumber daya alam dan karakteristik ekosistem yang memang sangat kondusif bagi pembangunan ekonomi daerah dan nasional. Provinsi Sumatera Utara memiliki luas total sebesar 181.860,65 km2 yang terdiri dari luas daratan sebesar 71.680,68 km2 dan luas perairan sebesar 110.000,65 km2. Sebagian besar berada didaratan pulau Sumatera dan sebagian kecil berada di pulau Nias, pulau – pulau Batu, serta beberapa pulau kecil, baik diperairan bagian
barat maupun dibagian timur pulau Sumatera
Pertumbuhan ekonomi suatu daerah dapat diukur dengan melihat data PDRB (Produk Domestik Regional Bruto). PDRB merupakan salah satu indikator penting untuk mengetahui kondisi suatu daerah dalam suatu periode tertentu. Perhitungan PDRB ditampilkan dalam dua jenis yaitu, PDRB Atas Dasar Harga Berlaku (ADHB) dan PDRB Atas Dasar Harga Konstan (ADHK), yang mana dalam perhitungannya menggunakan tahun 2000 sebagai tahun dasar. PDRB pada dasarnya merupakan jumlah nilai tambah yang dihasilkan oleh seluruh unit usaha kegiatan ekonomi dalam suatu daerah/wilayah pada periode tertentu, atau merupakan jumlah nilai barang dan jasa akhir yang dihasilkan oleh seluruh unit ekonomi. PDRB atas dasar harga berlaku menggambarkan nilai tambah barang dan jasa yang dihitung menggunakan harga yang berlaku pada setiap tahun, sedangkan PDRB atas dasar harga konstan menunjukkan nilai tambah barang dan jasa tersebut yang dihitung menggunakan harga yang berlaku pada satu tahun tertentu sebagai dasar (Badan Pusat Statistik, 2014).
Perhitungan PDRB suatu daerah dilakukan melalui tiga pendekatan, yaitu pendekatan produksi, pendekatan pendapatan, dan pendekatan pengeluaran. Berdasarkan pendekatan tersebutlah yang menunjukkan bahwa pertumbuhan ekonomi suatu daerah dipengaruhi oleh banyak variabel. Dalam penelitian kali ini dilakukan sebuah analisis berdasarkan pada perhitungan PDRB yang dipengaruhi oleh banyak variabel. Agar pertumbuhan ekonomi Sumatera Utara lebih optimal maka perlu diketahui variabel – variabel apakah yang saling berkaitan mempengaruhi pertumbuhan ekonomi yang ada di wilayah Sumatera Utara sebagai salah satu daerah yang potensi di Indonesia.
jumlah awal. Dengan adanya analisis faktor tersebut dapat diketahui variabel-variabel apakah yang saling berkaitan mempengaruhi pertumbuhan ekonomi Sumatera Utara.
Oleh sebab itu, penulis mengajukan sebuah penelitian dalam Tugas Akhir yang berjudul “Penentuan Faktor Dominan yang Mempengaruhi Pertumbuhan Ekonomi Sumatera Utara Dengan Analisis Faktor”.
1.2. RUMUSAN MASALAH
Permasalahan yang akan dibahas dalam penelitian ini adalah bagaimana menentukan faktor dominan yang mempengaruhi pertumbuhan ekonomi Sumatera Utara dengan analisis faktor.
1.3. BATASAN MASALAH
Agar permasalahan yang dikaji lebih fokus dan menjadi lebih jelas maka permasalahan dibatasi oleh :
1. Variabel-variabel ekonomi yang dibahas adalah berdasarkan perhitungan PDRB menurut lapangan usaha yang terdiri dari sektor : (1) Pertanian, (2) Pertambangan dan Penggalian, (3) Industri Pengolahan, (4) Listrik, Gas, dan Air Minum, (5) Bangunan, (6) Perdagangan, Hotel, dan Restoran, (7) Pengangkutan dan Komunikasi, (8) Keuangan, Persewaan, dan Jasa Perusahaan, dan (9) Jasa-Jasa.
2. Penelitian dilakukan berdasarkan data tahun 2013 yang dilaporkan dalam buku publikasi tahun 2014.
3. Menggunakan aplikasi SPSS. 1.4. TINJAUAN PUSTAKA
sehingga bisa dibuat satu atau beberapa kumpulan variabel yang lebih sedikit dari jumlah awal. Analisis faktor digunakan di dalam situasi sebagai berikut :
a. Mengenali atau mengidentifikasi dimensi yang mendasari (underlying dimensions) atau faktor yang menjelaskan korelasi antara suatu set variabel. b. Mengenali dan mengidentifikasi suatu set variabel baru yang tidak berkorelasi
(independent) yang lebih sedikit jumlahnya untuk menggantikan suatu set variabel asli yang saling berkorelasi di dalam analisis multivariat selanjutnya. c. Mengenali atau mengidentifikasi suatu set variabel yang penting dari suatu
set variabel yang lebih banyak jumlahnya untuk dipergunakan di dalam analisis multivariat selanjutnya.
Kalau variabel – variabel dibakukan (standardized), model analisis faktor bisa ditulis sebagai berikut :
�� = ��1�1+��2�2+��3�3+⋯+����� +⋯+����� +���� , i = 1, 2, 3, ..., p ; j = 1, 2, 3,..., p ; m = 1, 2, 3,..., p
Di mana :
��= Variabel ke-i yang dibakukan (rata – ratanya nol, standar deviasinya
satu).
��� = Koefisien regresi parsial yang dibakukan untuk variabel i pada common factor ke-j.
�� = common factor ke-j.
Faktor 1 V1 V4 V5 V8 Faktor 2 V3 V7 Faktor 3 V2 V6 V9 Faktor 4 V10 V13 V14 Faktor 5 V11 V12 V15 Variabel Awal V1 V2 V3 V4 V5 V6 V15 V7 V8
V9 V10 V11 V12 V13 V14
�� = Koefisien regresi yang dibakukan untuk variabel ke-i pada faktor
yang unik ke-i (unique factor). �� = Faktor unik variabel ke-i.
m = Banyaknya common factor.
Faktor yang unik tidak berkorelasi dengan sesama faktor yang unik dan juga tidak berkorelasi dengan common factor. Common factor sendiri bisa dinyatakan sebagai kombinasi linear dari variabel – variabel yang terlihat/terobservasi (the observed variables) hasil penelitian lapangan.
�� =��1�1+��2�2+��3�3+⋯+����� , i = 1, 2, 3, ..., p dan k = 1, 2, 3,..., p
Di mana :
�� = Perkiraan faktor ke-i (didasarkan pada nilai variabel X dengan
koefisiennya Wi
�� = Timbangan/bobot atau koefisien nilai faktor ke-i
k = banyaknya variabel 1.5. TUJUAN PENELITIAN
Berdasarkan permasalahan, maka penulisan ini bertujuan untuk mengetahui faktor dominan apakah yang mempengaruhi pertumbuhan ekonomi Sumatera Utara.
1.6. KONTRIBUSI PENELITIAN
Hasil penelitian ini diharapkan berkontribusi bagi : 1. Penulis
a. Mengetahui sektor-sektor lapangan usaha yang mempengaruhi PDRB b. Sebagai penerapan ilmu dari mata kuliah yang telah diperoleh.
2. Pemerintah Sumatera Utara
Diharapkan bisa menjadi rekomendasi sebagai bahan pertimbangan dalam melakukan perencanaan pembangunan untuk meningkatkan pertumbuhan ekonomi Sumatera Utara periode selanjutnya.
3. Departemen/Universitas
1.7. METODOLOGI PENELITIAN
Penyusunan Tugas Akhir ini menggunakan data sekunder dari Badan Pusat Statistik Sumatera Utara. Adapun metodologi dalam penelitian ini adalah sebagai berikut :
1. Identifikasi Data dan Pendefenisian Variabel
Tahap awal dalam penelitian ini yaitu, dengan melakukan identifikasi data dan menentukan data apasajakah yang akan dianalisis menggunakan metode analisis faktor. Dalam penelitian ini, data yang diamati adalah berupa data – data yang mempengaruhi pertumbuhan ekonomi suatu daerah yang ditinjau berdasarkan pendekatan perhitungan PDRB yang tersedia, yaitu pendekatan produksi, pendekatan pendapatan, dan pendekatan pengeluaran. Dengan adanya identifikasi data ini maka akan memperjelas data manakah yang bisa digunakan untuk dianalisis sehingga dapat diketahui variabel – variabel apakah yang saling berkaitan mempengaruhi pertumbuhan ekonomi terutama daerah Sumatera Utara yang bisa dikelompokkan menjadi suatu faktor yang tepat. Kemudian melakukan pendefenisian terhadap masing – masing variabel.
2. Pengambilan Data
Pada tahap ini dilakukan pengambilan data sekunder dari Badan Pusat Statistik Sumatera Utara. Data yang digunakan dalam penelitian ini adalah data PDRB dari 33 Kabupaten dan Kota Madya yang ada di Sumatera Utara Tahun 2013 yang diterbitkan pada tahun 2014 yang meliputi : (a) Sektor Pertanian, (b) Sektor Pertambangan, (c) Sektor Industri Pengolahan, (d) Sektor Listrik, Gas, dan Air Bersih, (e) Sektor Bangunan, (f) Sektor Perdagangan, Hotel, dan Restoran, (g) Sektor Pengangkutan dan Komunikasi, (h) Sektor Keuangan, Persewaan, dan Jasa Perusahaan, dan (i) Sektor Jasa – Jasa.
3. Perumusan Model Analisis Faktor
Pada tahap ini akan dirancang model analisis faktor untuk mendapatkan faktor – faktor yang merupakan representasi dari variabel – variabel yang saling berhubungan.Dalam perumusan model analisis faktor dilakukan beberapa tahapan yaitu :
Pada tahap ini akan dibentuk matriks korelasi untuk melihat korelasi antar variabel, serta mengukur homogenitas variabel sebagai indikator kesesuaian antar variabel dengan menggunakan perhitungan Kaiser-Meyer-Olkin. Hal ini bertujuan untuk mengetahui ketepatan penggunaan metode analisis faktor dalam menganalisa variabel
b. Factoring
Factoring adalah tahapan untuk mendapatkan sejumlah faktor – faktor utama yang merupakan interpretasi dari variabel – variabel yang memiliki korelasi yang tinggi. Tujuan dari factoringadalah melakukan ekstraksi faktor untuk mendapatkan nilai common factor dengan menghitung estimasi dari loading faktor dan spesifik faktor. Dengan menggunakan metode estimasi loading faktor yaitu dengan principal component.
c. Rotasi
Rotasi Merupakan tahapan yang bertujuan untuk menyederhanakan struktur dengan cara matriks faktor diubah (to be transformed) ke dalam matriks yang lebih sederhana sehingga mudah untuk diinterpretasikan. Rotasi faktor dilakukan dengan cara merotasikan loading faktor yang ada dengan menggunakan metode rotasi sehingga menghasilkan loading faktor yang baru. Metode rotasi yang digunakan adalah rotasi orthogonal dengan kriteria varimax.
4. Analisis dan Kesimpulan
LANDASAN TEORI
2.2. Analisis Faktor
Analisis faktor merupakan salah satu metode statistik multivariat yang mencoba menerangkan hubungan antara sejumlah variabel – variabel yang saling independen antara satu dengan yang lain sehingga bisa dibuat satu atau lebih kumpulan peubah yang lebih sedikit dari jumlah variabel awal. Analisis faktor digunakan untuk mereduksi data dan menginterpretasikannya sebagai suatu variabel baru yang berupa variabel bentukan. Analisis faktor juga digunakan untuk mengetahui faktor – faktor dominan dalam menjelaskan suatu masalah. Di dalam analisis varian, regresi berganda dan diskriminan, satu variabel disebut sebagai variabel tak bebas (dependent variable) atau kriterion dan variabel lainnya sebagai variabel bebas atau prediktor. Di dalam analisis faktor disebut teknik interdependensi (interdependence technique) di mana seluruh set hubungan yang independen diteliti (Supranto, 2010).
Di dalam analisis faktor, variabel tidak dikelompokkan menjadi variabel bebas dan tidak bebas, sebaliknnya penggantinya seluruh set hubungan interdependen antar-variabel diteliti. Analisis faktor dapat pula dipandang sebagai perluasan dari analisis komponen utama. Keduanya merupakan teknik analisis yang menjelaskan struktur hubungan diantara banyak variabel dalam sistem konkret.
Tujuan dari analisis faktor adalah untuk menggambarkan hubungan – hubungan kovarian antara beberapa variabel yang mendasari tetapi tidak teramati, kuantitas random yang disebut faktor (Johnson and Wichern, 2007).
Menurut Kachigan (1986), aplikasi penggunaan analisis faktor bertujuan untuk :
Salah satu penggunaan yang paling penting dari analisis faktor adalah untuk mengidentifikasi faktor yang mendasari dari sekumpulan besar variabel. Dengan mengelompokkan sejumlah besar variabel ke dalam jumlah yang lebih kecil dari kumpulan yang homogen dan membuat variabel baru yang disebut faktor yang mewakili sekumpulan variabel tersebut dalam bentuk yang lebih sederhana, maka akan lebih mudah untuk diinterpretasikan.
b. Penyaringan Variabel (Screening of variables)
Penggunaan penting dari analisis faktor selanjutnya adalah penyaringan variabel untuk disertakan dalam penelitian statistik selanjutnya, seperti analisis regresi atau analisis diskriminan.
c. Meringkas Data (Summary of Data)
Penerapan analisis faktor selanjutnya adalah untuk mengekstrak sedikit atau banyak faktor sesuai yang diinginkan dari satu set variabel.
d. Memilih Variabel (Sampling of Variables)
Penggunaan teknik analisis faktor selanjutnya adalah untuk memilih sekelompok kecil perwakilan variabel yang representatif, walaupun sebagian besar variabel berkorelasi, hal ini bertujuan untuk memecah berbagai masalah praktis.
e. Pengelompokkan Objek (Clustering of Objects)
Selain mengidentifikasi kesamaan antara variabel, analisis faktor dapat digunakan untuk mengelompokkan objek. Dalam prosedur ini, sering disebut analisis faktor sebagai inverse, sebuah sampel individu diukur pada sejumlah variabel acak, dan dikelompokkan ke dalam kelompok yang homogen berdasarkan antar-korelasinya.
2.2.1. Model Analisis Faktor
faktor yang unik untuk setiap variabel. Faktor – faktor ini tidak secara jelas terlihat (not overly observed).
Kalau variabel – variabel dibakukan (standardized), model analisis faktor bisa ditulis sebagai berikut :
�� = ��1�1+��2�2+��3�3+⋯+����� +⋯+����� +���� , i = 1, 2, 3, ..., p ; j = 1, 2, 3,..., p ; m = 1, 2, 3,..., p
Di mana :
�� = Variabel ke-i yang dibakukan (rata – ratanya nol, standar deviasinya
satu).
��� = Koefisien regresi parsial yang dibakukan untuk variabel i pada common factor ke-j.
�� = common factor ke-j.
�� = Koefisien regresi yang dibakukan untuk variabel ke-i pada faktor
yang unik ke-i (unique factor). �� = Faktor unik variabel ke-i.
m = Banyaknya common factor.
Faktor yang unik tidak berkorelasi dengan sesama faktor yang unik dan juga tidak berkorelasi dengan common factor. Common factor sendiri bisa dinyatakan sebagai kombinasi linear dari variabel – variabel yang terlihat/terobservasi (the observed variables) hasil penelitian lapangan.
�� =��1�1+��2�2+��3�3+⋯+����� , i = 1, 2, 3, ..., p dan k = 1, 2, 3,..., p
Di mana :
�� = Perkiraan faktor ke-i (didasarkan pada nilai variabel X dengan
koefisiennya Wi
�� = Timbangan/bobot atau koefisien nilai faktor ke-i
k = banyaknya variabel
syarat bahwa faktor yang kedua tidak berkorelasi (orthogonal) dengan faktor pertama. Prinsip yang sama dapat dipergunakan untuk memilih faktor selanjutnya, sebagai faktor tambahan, yaitu faktor ketiga. Jadi, faktor bisa diperkirakan/diestimasi sehingga nilai faktor yang satu tidak berkorelasi dengan faktor lainnya. Faktor yang diperoleh merupakan variabel baru yang tidak berkorelasi antara satu faktor dengan faktor lainnya, artinya tidak terjadi multi collinearity. Banyaknya faktor lebih sedikit dari banyaknya variabel asli yang dianalisis faktor, sebab analisis faktor memang mereduksi jumlah variabel yang banyak menjadi variabel baru yang jumlahnya lebih sedikit.
2.2.2. Statistik yang Relevan dengan Analisis Faktor Statistik penting yang berkaitan dengan analisis faktor adalah :
a. Bartlett’s of sphericity yaitu suatu uji statistik yang dipergunakan untuk menguji hipotesis bahwa variabel tidak saling berkorelasi (uncorrelated) dalam populasi. Dengan kata lain, matriks korelasi populasi merupakan matriks identitas (identity matrix), setiap variabel berkorelasi dengan dirinya sendiri secara sempurna dengan (r = 1) akan tetapi sama sekali tidak berkorelasi dengan lainnya (r = 0).
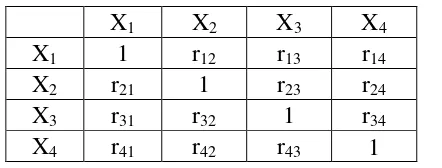
b. Correlation matrix adalah matrik segitiga bagian bawah menunjukkan korelasi sederhana r, antara semua pasangan variabel yang tercakup dalam analisis. Nilai atau angka pada diagonal utama yang semuanya sama yaitu 1 diabaikan.
Tabel 2.1. Matrik Korelasi Untuk Jumlah Variabel n = 3
X1 X2 X3
X1 1 r12 r13
X2 r21 1 r23
X3 r31 r32 1
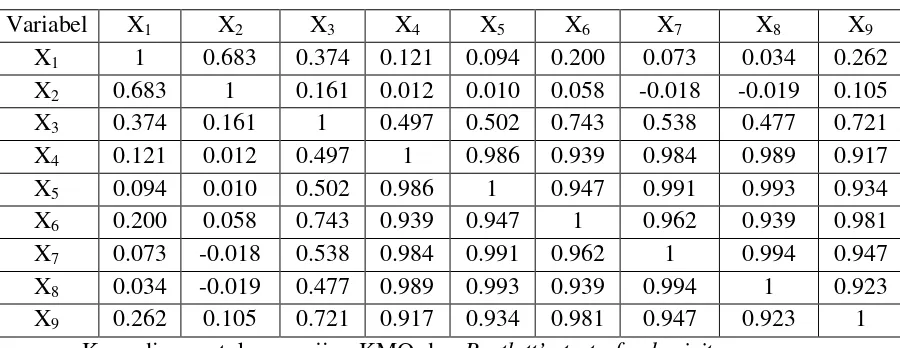
Tabel 2.2. Matriks Korelasi Untuk Jumlah Variabel n = 4
X1 X2 X3 X4
X1 1 r12 r13 r14
X2 r21 1 r23 r24
X3 r31 r32 1 r34
c. Communality adalah jumlah varian yang disumbangkan oleh suatu variabel dengan seluruh variabel lainnya dalam analisis. Bisa juga disebut proporsi atau bagian varian yang dijelaskan oleh common factor atau besarnya sumbangan suatu faktor terhadap varian seluruh variabel.
d. Eigenvalue merupakan jumlah varian yang dijelaskan oleh setiap faktor dari matriks identitas. Persamaan nilai eigen dan vektor eigen adalah :
Ax = λx (Silaban, 1984 : 279)
Dimana :
A = Matriks yang akan kita cari nilai eigen dan vektor eigennya x = Vektor eigen dalam bentuk matriks
� = Nilai eigen dalam bentuk skalar
Untuk mencari nilai eigen (nilai λ) dari sebuah matriks A yang berukuran nxn maka kita lakukan langkah berikut: Ax = λx. Agar kedua ruas berbentuk vektor, maka ruas kanan dikali dengan matriks identitas I, sehingga :
��= ���
Ax− λIx = 0
x(A− λI) = 0 sehingga det (A− λI) = 0
e. Factor loadings adalah korelasi sederhana antara variabel dengan faktor.
f. Faktor loading plot adalah suatu plot dari variabel asli dengan menggunakan
faktor loadings sebagai koordinat.
g. Factor matrix yang memuat semua faktor loading dari semua variabel pada semua factor extracted.
h. Factor score merupakan skor komposit yang diestimasi untuk setiap responden pada faktor turunan (derived factors).
i. Kaiser-Meyer-Olkin (KMO) Measure Of Sampling Adequacy (MSA), merupakan suatu indeks yang dipergunakan untuk meneliti ketepatan analisis faktor. Nilai yang tinggi antara 0,5 – 1,0 berarti analisis faktor tepat, kalau kurang dari 0,5 analisis faktor dikatakan tidak tepat.
k. Residuals merupakan perbedaan antara korelasi yang terobservasi berdasarkan input correlation matrix dan korelasi hasil reproduksi yang diperkirakan dari matrix faktor.
l. Scree Plot merupakan plot dari eigen value sebagai sumbu tegak (vertical) dan banyaknya faktor sebagai sumbu datar, untuk menentukan banyaknya faktor yang bisa ditarik (factor extraction).
2.2.3. Pelaksanaan Analisis Faktor
Langkah – langkah dalam pelaksanaan analisis faktor adalah sebagai berikut :
1. Identifikasi Data, 2. Pengambilan Data, 3. Bentuk Matriks Korelasi,
4. Menentukan Metode Analisis Faktor, 5. Penentuan Banyaknya Faktor,
6. Lakukan Rotasi, 7. Interpretasi Faktor,
8. Mengukur Ketepatan Model.
2.2.3.1. Identifikasi Data
Tahap awal dari pelaksanaan analisis faktor adalah dengan mengidentifikasi data terlebih dahulu. Hal ini bertujuan untuk menentukan data apasajakah yang akan dianalisis menggunakan metode analisis faktor. Dengan adanya indentifikasi data ini akan memperjelas data manakah yang bisa digunakan untuk dianalisis dengan menggunakan analisis faktor tersebut. Adapun data yang diamati dalam penelitian ini adalah data – data yang mempengaruhi pertumbuhan ekonomi suatu daerah ditinjau berdasarkan pendekatan perhitungan PDRB yang tersedia yaitu pendekatan produksi, pendekatan pendapatan, dan pendekatan pengeluaran.
Setelah melakukan identifikasi data, dan menentukan data apa yang akan di analisis, maka tahap selanjutnya akan dilakukan pengambilan data. Dalam Penelitian ini, data yang digunakan adalah data sekunder dari Badan Pusat Statistik Sumatera Utara. Data yang digunakan dalam penelitian ini adalah data PDRB dari 33 Kabupaten dan Kota Madya yang ada di Sumatera Utara Tahun 2013 yang diterbitkan pada tahun 2014 yang meliputi (a) Sektor Pertanian, (b) Sektor Pertambangan, (c) Sektor Industri Pengolahan, (d) Sektor Listrik, Gas, dan Air Bersih, (e) Sektor Bangunan, (f) Sektor Perdagangan, Hotel, dan Restoran, (g) Sektor Pengangkutan dan Komunikasi, (h) Sektor Keuangan, Persewaan, dan Jasa Perusahaan, dan (i) Sektor Jasa – Jasa.
2.2.3.3. Bentuk Matriks Korelasi
Proses analisis didasarkan pada suatu matriks korelasi agar variabel pendalaman yang berguna bisa diperoleh dari penelitian matriks ini. Agar analisis faktor bisa tepat dipergunakan, variabel – variabel yang akan dianalisis harus berkorelasi. Di dalam praktiknya memang demikian halnya. Apabila koefisien korelasi antar-variabel terlalu kecil, hubungan lemah, analisis faktor tidak tepat. Selain variabel asli berkorelasi dengan sesama variabel lainnya, diharapkan juga berkorelasi dengan faktor sebagai variabel baru yang disaring dari variabel – variabel asli. Banyaknya faktor lebih sedikit daripada banyaknya variabel. Untuk menghitung nilai korelasi antar-variabel secara manual digunakan rumus sebagai berikut :
r = N∑XY−(∑X)(∑Y)
�[N∑X2−(∑X)2][N∑Y2−(∑Y)2]
(Kastawan dan Harmein, 2004 : 257) Di mana :
N = Jumlah observasi Y = Skor total X = Skor total tiap – tiap observasi
diagonal pokok angkanya nol. Uji statistik untuk sphericity didasarkan pada suatu transformasi khi kuadrat dari determinan matriks korelasi. Jika diuji secara manual, maka rumus yang digunakan adalah sebagai berikut :
�2 = − �(� −1)−(2�+ 5)
6 � ��|R|
(Usman dan Sobari, 2013 : 37) Di mana :
N = Jumlah observasi
|�| = Determinan matriks korelasi
p = Jumlah variabel
Hipotesis yang dibentuk dalam pengujian ini adalah sebagai berikut : H0 : Matriks korelasi merupakan matriks identitas
H1 : Matriks korelasi bukan merupakan matriks identitas Adapun kriteria keputusannya adalah, tolak H0 jika : χ2
hitung >χ
2α, p(p−1)/2
Statistik lainnya yang berguna adalah KMO (Kaiser-Meyer-Olkin) mengukur kecukupan sampling (sampling adequacy). Indeks ini membandingkan besarnya koefisien korelasi terobservasi dengan besarnya koefisien korelasi parsial. Nilai KMO yang kecil menunjukkan bahwa korelasi antar-pasangan variabel tidak bisa diterangkan oleh variabel lainnya dan analisis faktor mungkin tidak tepat. Adapun formulasi pengujian secara matematis dituliskan dengan :
KMO = ∑ ∑ r
2 ij n j≠i n i
∑ ∑ r2
ij+∑ ∑ni nj≠ia2ij n
j≠i n i
(Usman dan Sobari, 2013 : 38) i = 1, 2, 3,..., p dan j = 1, 2, 3,..., p
Dimana,
rij2 adalah koefisien korelasi sederhana dari variabel i dan j, ���2 adalah koefisien korelasi parsial dari variabel i dan j.
2.2.3.4. Menentukan Metode Analisis Faktor
metode yang bisa dipergunakan dalam analisis faktor, khususnya untuk menghitung timbangan atau koefisien skor faktor, yaitu principal components analysis dan common factor analysis.
Di dalam principal components analysis, jumlah varian dalam data dipertimbangkan. Diagonal matriks korelasi terdiri dari angka satu dan full variance dibawa kedalam matriks faktor. Principal components analysis
direkomendasikan kalau hal yang pokok ialah menentukan bahwa banyaknya faktor harus minimum dengan memperhitungkan varian maksimum dalam data untuk dipergunakan di dalam analisis multivariate lebih lanjut. Faktor – faktor tersebut dinamakan principal components.
Di dalam common factor analysis, faktor diestimasi hanya didasarkan pada common variance, communalities dimasukkan di dalam matriks korelasi. Metode ini dianggap tepat kalau tujuan utamanya ialah mengenali/mengidentifikasi dimensi yang mendasari dan common variance yang menarik perhatian. Metode ini juga dikenal sebagai principal axis factoring.
2.2.3.5. Penentuan Banyaknya Faktor
Sebetulnya bisa diperoleh faktor sebanyak variabel yang ada, lalu tidak ada gunanya melakukan analisis faktor. Maksud melakukan analisis faktor ialah mencari variabel baru yang disebut faktor yang saling tidak berkorelasi, bebas satu sama lainnya, lebih sedikit jumlahnya daripada variabel asli, akan tetapi bisa menyerap sebagian besar informasi yang terkandung dalam variabel asli atau yang bisa memberikan sumbangan terhadap varian seluruh variabel.
Beberapa prosedur bisa disarankan, yaitu penentuan secara apriori,
eigenvalues, scree plot, percentage of variance accounted for, split-half reliability, dan significance test.
a. Penentuan Apriori
menyarikan (to extract) berhenti, setelah banyaknya faktor yang diharapkan sudah didapat, misalnya cukup 4 faktor saja. Kebanyakan program komputer memungkinkan peneliti untuk menentukan banyaknya faktor yang diinginkan. b. Penentuan Berdasarkan Eigenvalues
Di dalam pendekatan ini, hanya faktor dengan eigenvalues lebih besar dari 1 (satu) yang dipertahankan, kalau lebih kecil dari satu, faktornya tidak diikutsertakan dalam model. Suatu eigenvalues menunjukkan besarnya sumbangan dari faktor terhadap varian seluruh variabel asli. Hanya faktor dengan varian lebih besar dari satu, yang dimasukkan dalam model. Faktor dengan varian lebih kecil dari satu tidak lebih baik dari asli, sebab variabel asli telah dibakukan (standardized) yang berarti rata – ratanya nol dan variannya satu. Apabila banyaknya variabel asli kurang dari 20, pendekatan ini akan menghasilkan sejumlah faktor yang konservatif.
c. Penentuan Berdasarkan Scree Plot
Scree plot merupakan sutu plot dari eigenvalue sebagai fungsi banyaknya faktor, dalam upaya untuk ekstraksi. Bentuk scree plot dipergunakan untuk menentukan banyanknya faktor. Scree plot seperti garis yang patah – patah.
Bukti hasil eksperimen menunjukkan bahwa titik pada tempat di mana the scree
mulai terjadi, menunjukkan banyaknya faktor yang benar. Tepatnya pada saat
scree mulai merata. Kenyataan menunjukkan bahwa penentuan banyaknya faktor dengan scree plot akan mencapai satu atau lebih banyak daripada penentuan
eigenvalues.
d. Penentuan Didasarkan pada Persentase Varian
Di dalam pendekatan ini, banyaknya faktor yang diekstraksi oleh faktor mencapai suatu level tertentu yang memuaskan. Sebetulnya berapa besarnya kumulatif persentase varian sehingga dicapai suatu level yang memuaskan? Hal ini sangat tergantung pada masalahnya. Akan tetapi, sebagai pedoman/petunjuk yang disarankan adalah bahwa ekstraksi faktor dihentikan kalau kumulatif persentase varian sudah mencapai paling sedikit 60% atau 75% dari seluruh varian variabel asli.
Sampel dibagi menjadi dua, analisis faktor dilakukan pada masing – masing bagian sampel tersebut. Hanya faktor dengan faktor loading yang sesuai pada kedua sub-sampel yang dipertahankan, maksudnya faktor – faktor yang dipertahankan memang mempunyai faktor loading yang tinggi pada masing – masing bagian sampel.
f. Penentuan Berdasarkan Uji Signifikan
Dimungkinkan untuk menentukan signifikansi statistik untuk eigenvalues
yang terpisah dan pertahankan faktor – faktor yang memang berdasarkan uji statistik eigenvalue-nya signifikan pada α = 5% atau 1%. Penentuan banyaknya faktor dengan cara ini ada kelemahannya, khususnya dengan ukuran sampel yang besar, katakan diatas 200 responden, banyak faktor yang menunjukkan hasil yang signifikan, walaupun dari pandangan praktis, banyak faktor mempunyai sumbangan terhadap seluruh varian hanya kecil.
2.2.3.6. Rotasi Faktor
Rotasi faktor bertujuan untuk menyederhanakan struktur faktor, sehingga mudah untuk diinterpretasikan. Ada dua metode rotasi yang berbeda yaitu
orthogonaland obliquerotation.
Rotasi disebut : orthogonal rotation kalau sumbu dipertahankan tegak lurus sesamanya (bersudut 90 derajat). Metode rotasi yang banyak dipergunakan ialah varimax procedure. Prosedur ini merupakan metode orthogonal yang berusaha meminimumkan banyaknya variabel dengan muatan tinggi (high loading) pada satu faktor,dengan demikian memudahkan pembuatan interpretasi mengenai faktor. Rotasi orthogonal menghasilkan faktor – faktor yang tidak berkorelasi satu sama lain (uncorrelated each other).
Sebaliknya rotasi dikatakan : oblique rotation kalau sumbu tidak dipertahankan harus tegak lurus sesamanya ( bersudut 90 derajat) dan faktor – faktor tidak berkorelasi. Oblique rotation harus dipergunakan kalau faktor dalam populasi berkorelasi sangat kuat.
2.2.3.7. Interpretasi Faktor
bisa diinterpretasikan, dinyatakan dalam variabel yang mempunyai high loading
padanya. Manfaat lainnya di dalam membantu untuk membuat interpretasi ialah melalui plot variabel, dengan menggunakan factor loading sebagai koordinat.
Variabel pada ujung atau akhir suatu sumbu ialah variabel yang mempunyai high loading hanya pada faktor tertentu. Sedangkan variabel yang dekat dengan titik asal (perpotongan sumbu mempunyai muatan rendah low loading).
Variabel yang tidak dekat dengan sumbu salah satu faktor berarti berkorelasi dengan kedua faktor tersebut. Kalau suatu faktor tidak bisa dengan jelas didefenisikan dinyatakan dalam variabel aslinya, seharusnya diberi label sebagai faktor tidak terdefenisikan atau faktor umum (undefined or a general factor). Variabel – variabel yang berkorelasi kuat (nilai factor loading yang besar) dengan faktor tertentu akan memberikan inspirasi nama faktor yang bersangkutan.
2.2.3.8. Mengukur Ketepatan Model
Langkah terakhir dalam analisis faktor adalah mengukur ketepatan model (model fit). Asumsi dasar yang mendasari analisis faktor adalah bahwa korelasi terobservasi antara variabel dapat dicirikan/dikarakteristikkan (attributed) pada
common factor.
BAB 3
HASIL DAN PEMBAHASAN
3.3. Gambaran Umum
Pertumbuhan ekonomi suatu daerah dapat diukur dengan melihat data Produk Domestik Regional Bruto (PDRB). PDRB ini adalah salah satu indikator penting untuk mengetahui kondisi suatu daerah dalam suatu periode tertentu. PDRB pada dasarnya merupakan jumlah nilai tambah yang dihasilkan oleh seluruh unit usaha kegiatan ekonomi dalam suatu daerah/wilayah pada periode tertentu, atau merupakan jumlah nilai barang dan jasa akhir yang dihasilkan oleh seluruh unit ekonomi. Perhitungan PDRB ditampilkan dalam dua jenis yaitu PDRB Atas Dasar Harga Berlaku (ADHB) dan PDRB Atas Dasar Harga Konstan (ADHK). PDRB atas dasar harga berlaku menggambarkan nilai tambah barang dan jasa yang hitung menggunakan harga yang berlaku pada setiap tahun, sedangkan PDRB atas dasar harga konstan menunjukkan nilai tambah barang dan jasa tersebut yang dihitung menggunakan harga yang berlaku pada satu tahun tertentu sebagai dasar (Badan Pusat Statistik, 2014).
Perhitungan PDRB secara konseptual menggunakan tiga macam pendekatan, salah satunya adalah pendekatan produksi. Perhitungan PDRB dengan pendekatan produksi dalam penyajiannya dikelompokkan dalam 9 lapangan usaha (sektor), yaitu :
X1 : Sektor Pertanian,
X2 : Sektor Pertambangan dan Penggalian, X3 : Sektor Industri Pengolahan,
X4 : Sektor listrik, Gas, dan Air Bersih, X5 : Sektor Bangunan,
X8 : Sektor Keuangan, Persewaan, dan Jasa Perusahaan, X9 : Sektor Jasa – Jasa.
Data yang digunakan diperoleh dari Badan Pusat Statistik Sumatera Utara dalam buku publikasi “Produk Domestik Regional Bruto Provinsi Sumatera Utara Menurut Kabupaten/Kota 2009 – 2013” yang ditunjukkan pada lampiran 1 dan lampiran 2.
3.4. Analisis Hasil Perhitungan
Proses untuk mendapatkan model umum dari analisis faktor melalui beberapa tahapan. Dalam penelitian ini menggunakan SPSS 16.0 sebagai alat bantu untuk mempermudah proses perhitungan. Setelah data diolah menggunakan SPSS 16.0 maka akan dilakukan analisis tahap demi tahap dari proses analisis faktor.
3.4.1. Uji Asumsi Kecukupan Data dan Korelasi Antar Variabel
Kaiser-Meyer-Olkin (KMO) test digunakan untuk mengukur kecukupan sampling (sampling adequacy) sedangkan Bartlett’s test of sphericity
[image:31.595.117.512.575.654.2]dipergunakan untuk menguji hipotesis bahwa variabel tak berkorelasi di dalam populasi. Pengujian KMO dan Bartlett’s test of sphericity secara manual untuk data PDRB ADHB hasilnya dapat dilihat pada lampiran 4 halaman 51 – 53. Sementara itu, untuk pengujian KMO dan Bartlett’s test of sphericity dengan menggunakan software SPSS 16 hasilnya dapat dilihat pada tabel berikut ini :
Tabel 4.1 Pengujian KMO dan Bartlett’s Variabel PDRB ADHB
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. 0.693
Bartlett's Test of Sphericity
Approx. Chi-Square 720.427
Df 36
Sig. 0.000
Kemudian untuk menguji korelasi data dengan menggunakan Bartlett”s test diperoleh hasil sig (level of significance) sebesar 0.000. Hal ini mengidentifikasikan bahwa matriks korelasi antar variabel tidak sama dengan matriks identitas atau dengan kata lain ada korelasi antar variabel. Adapun korelasi variabel PDRB ADHB jika dihitung secara manual hasilnya adalah sebagai berikut :
Dari tabel pada lampiran halaman 63 diketahui :
N = 33 ∑X12 = 4,57956E+14 (∑X2)2 = 2,41261E+13 X1 = 85247170,62 (∑X1)2 = 7,26708E+15
X2 = 4911829,61 ∑X22 = 7,34046E+12
rX1X2 = N∑X1X2−(∑X1)(∑X2)
�[N∑X12−(∑X1)2][N∑X22−(∑X2)2]
= 33(3,97479E + 13)−(85247170,62)(4911829,61)
�[33(4,57956E + 14)−(7,26708E + 15)][33(7,34046E + 12)−(2,41261E + 13)]
= 0,683
[image:32.595.115.565.475.649.2]Selanjutnya, dengan menggunakan software SPSS 16 diperoleh nilai korelasi antar-variabel secara lengkap yang hasilnya dapat dilihat pada tabel berikut ini :
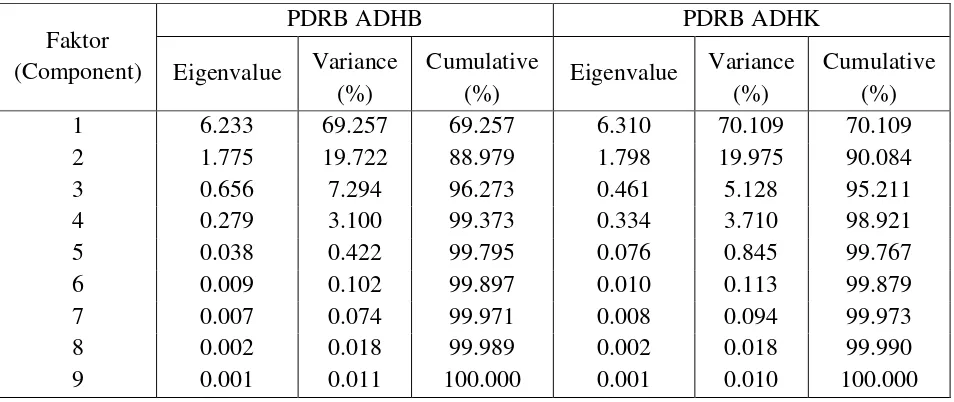
Tabel 4.2 Korelasi Variabel PDRB ADHB
Variabel X1 X2 X3 X4 X5 X6 X7 X8 X9
X1 1 0.683 0.374 0.121 0.094 0.200 0.073 0.034 0.262 X2 0.683 1 0.161 0.012 0.010 0.058 -0.018 -0.019 0.105 X3 0.374 0.161 1 0.497 0.502 0.743 0.538 0.477 0.721 X4 0.121 0.012 0.497 1 0.986 0.939 0.984 0.989 0.917 X5 0.094 0.010 0.502 0.986 1 0.947 0.991 0.993 0.934 X6 0.200 0.058 0.743 0.939 0.947 1 0.962 0.939 0.981 X7 0.073 -0.018 0.538 0.984 0.991 0.962 1 0.994 0.947 X8 0.034 -0.019 0.477 0.989 0.993 0.939 0.994 1 0.923 X9 0.262 0.105 0.721 0.917 0.934 0.981 0.947 0.923 1
Kemudian, untuk pengujian KMO dan Bartlett’s test of sphericity secara manual untuk data PDRB ADHK hasilnya dapat dilihat pada lampiran 4 halaman 54 – 56. Sementara itu, untuk pengujian KMO dan Bartlett’s test of sphericity
Tabel 4.3 Pengujian KMO dan Bartlett’s Variabel PDRB ADHK
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. 0.681 Bartlett's Test of Sphericity Approx. Chi-Square 701.252
Df 36
Sig. 0.000
Pada tabel 4.3 diperoleh nilai KMO sebesar 0.681. Hal ini menunjukkan bahwa nilai KMO yang diperoleh tersebut lebih besar dari 0.5. Dengan demikian dapat disimpulkan bahwa variabel indikator yang mempengaruhi perhitungan PDRB Sumatera Utara atas dasar harga konstan sudah memenuhi syarat yang berimplikasi data dapat dianalisis lebih lanjut menggunakan analisis faktor. Kemudian untuk menguji korelasi data dengan menggunakan Bartlett”s test diperoleh hasil sig (level of significance) sebesar 0.000. Hal ini mengidentifikasikan bahwa matriks korelasi antar variabel tidak sama dengan matriks identitas atau dengan kata lain ada korelasi antar variabel. Adapun korelasi variabel PDRB ADHK jika dihitung secara manual hasilnya adalah sebagai berikut :
Dari tabel pada lampiran halaman 64 diketahui :
N = 33 ∑X12 = 6,99568E+13 (∑X2)2 = 1,73311E+12 X1 = 33183860,17 (∑X1)2 = 1,10117E+15
X2 = 1316474,6 ∑X22 = 2,98525E+11
rX1X2 =
N∑X1X2−(∑X1)(∑X2)
�[N∑X12−(∑X1)2][N∑X22−(∑X2)2]
= 33(3,32113E + 12)−(33183860,17)(1316474,6)
�[33(6,99568E + 13)−(1,10117E + 15)][33(2,98525E + 11)−(1,73311E + 12)]
= 0,666
Selanjutnya, dengan menggunakan software SPSS 16 diperoleh nilai korelasi antar-variabel secara lengkap yang hasilnya dapat dilihat pada tabel berikut ini :
Tabel 4.4 Korelasi Variabel PDRB ADHK
X1 1 0.666 0.341 0.075 0.043 0.148 0.044 0.010 0.238 X2 0.666 1 0.280 -0.017 -0.001 0.099 0.003 -0.021 0.173 X3 0.341 0.280 1 0.601 0.571 0.736 0.627 0.568 0.748 X4 0.075 -0.017 0.601 1 0.985 0.968 0.976 0.987 0.896 X5 0.043 -0.001 0.571 0.985 1 0.970 0.987 0.994 0.915 X6 0.148 0.099 0.736 0.968 0.970 1 0.984 0.970 0.957 X7 0.044 0.003 0.627 0.976 0.987 0.984 1 0.993 0.945 X8 0.010 -0.021 0.568 0.987 0.994 0.970 0.993 1 0.914 X9 0.238 0.173 0.748 0.896 0.915 0.957 0.945 0.914 1
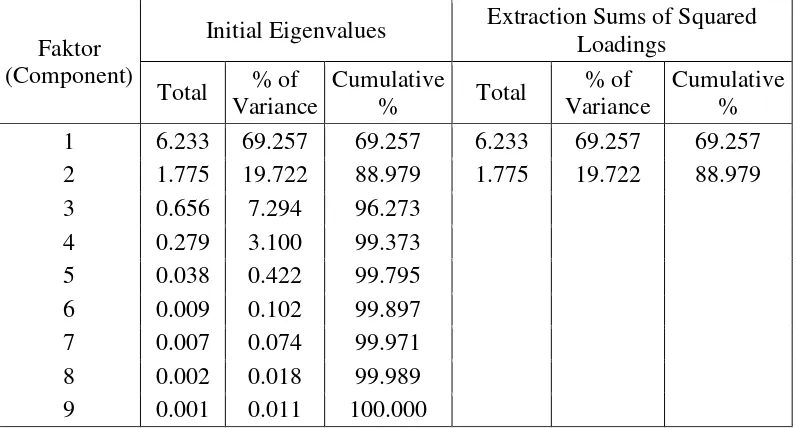
3.4.2. Penentuan Banyaknya Faktor
Dalam menentukan banyaknya faktor, digunakan metode analisis faktor yaitu analisis komponen utama (principal component analysis). Dalam analisis komponen utama, banyaknya faktor dapat ditentukan dengan melihat eigenvalue yang lebih besar atau sama dengan 1 (eigenvalue ≥ 1). Nilai eigen dan varian
[image:34.595.110.540.84.232.2]kumulatif dari PDRB ADHB dan PDRB ADHK dapat dilihat pada tabel 4.5 berikut.
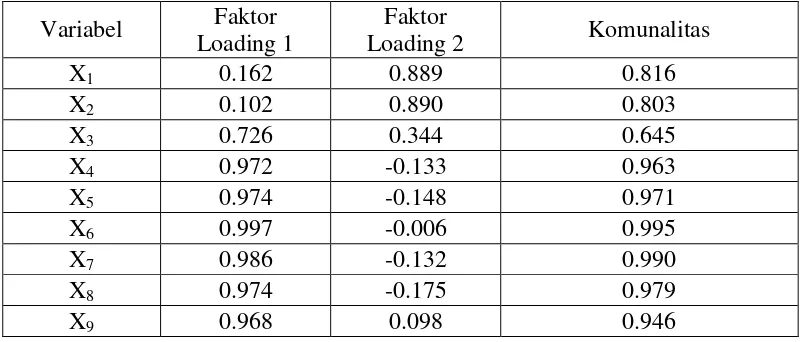
Tabel 4.5 Eigenvalue, Variance, dan Cumulative Korelasi Matriks PDRB
Faktor (Component)
PDRB ADHB PDRB ADHK
Eigenvalue Variance (%)
Cumulative
(%) Eigenvalue
Variance (%)
Cumulative (%)
1 6.233 69.257 69.257 6.310 70.109 70.109
2 1.775 19.722 88.979 1.798 19.975 90.084
3 0.656 7.294 96.273 0.461 5.128 95.211
4 0.279 3.100 99.373 0.334 3.710 98.921
5 0.038 0.422 99.795 0.076 0.845 99.767
6 0.009 0.102 99.897 0.010 0.113 99.879
7 0.007 0.074 99.971 0.008 0.094 99.973
8 0.002 0.018 99.989 0.002 0.018 99.990
9 0.001 0.011 100.000 0.001 0.010 100.000
Tabel 4.5 menunjukkan banyaknya faktor yang mempunyai nilai
[image:34.595.113.590.414.615.2]kesembilan variabel yang mempengaruhi perhitungan PDRB Sumatera Utara berdasarkan ADHB maupun ADHK tersebut dapat diwakili oleh dua faktor yang masing – masing faktor merupakan representasi dari sembilan variabel yang ada.
3.4.3. Rotasi Faktor
Rotasi faktor bertujuan untuk menyederhanakan struktur faktor, sehingga mudah untuk diinterpretasikan. Hasil ektraksi faktor awal diketahui bahwa terdapat 2 faktor baik itu berdasarkan PDRB ADHB maupun PDRB ADHK yang selanjutnya dapat diolah dengan nilai variance cumulative masing – masing yaitu 88.979% dan 90.084%. Ada 9 variabel yang tersebar kedalam 2 faktor tersebut yang merupakan faktor – faktor yang mempengaruhi pertumbuhan ekonomi Sumatera Utara. Kemudian kedua faktor tersebut diberi nama baru sesuai dengan variabel terukur yang berkelompok pada faktor tersebut.
[image:35.595.108.515.684.753.2]Dalam menentukan variabel mana yang akan masuk ke dalam faktor satu maupun faktor dua, maka dapat ditentukan berdasarkan nilai mutlak faktor loading (yang telah dirotasi) dari setiap variabel. Nilai mutlak faktor loading terbesar menunjukkan bahwa variabel tersebut masuk kategori faktor yang sesuai dengan besaran nilai tersebut. Dari tabel 4.8 dan tabel 4.9 masing – masing merupakan variabel PDRB ADHB dan PDRB ADHK, dapat ditentukan variabel – variabel mana yang akan masuk ke dalam faktor satu atau faktor dua. Tabel 4.6 dan tabel 4.7 menunjukkan nilai faktor loading beserta komunalitasnya untuk yang belum dirotasi untuk Variabel PDRB ADHB dan PDRB ADHK. Sedangkan tabel 4.8 dan tabel 4.9 menunjukkan nilai faktor loading beserta komunalitasnya untuk yang telah dirotasi untuk PDRB ADHB dan PDRB ADHK.
Tabel 4.6 Faktor Loading dan Komunalitas Variabel PDRB ADHB Sebelum dirotasi
Variabel Faktor Loading 1
Faktor
Loading 2 Komunalitas
X1 0.204 0.902 0.855
X3 0.668 0.327 0.553
X4 0.970 -0.113 0.953
X5 0.975 -0.127 0.967
X6 0.992 0.011 0.984
X7 0.982 -0.145 0.985
X8 0.968 -0.178 0.968
[image:36.595.112.513.84.195.2]X9 0.982 0.068 0.969
Tabel 4.7 Faktor Loading dan Komunalitas Variabel PDRB ADHK Sebelum dirotasi
Variabel Faktor Loading 1
Faktor
Loading 2 Komunalitas
X1 0.162 0.889 0.816
X2 0.102 0.890 0.803
X3 0.726 0.344 0.645
X4 0.972 -0.133 0.963
X5 0.974 -0.148 0.971
X6 0.997 -0.006 0.995
X7 0.986 -0.132 0.990
X8 0.974 -0.175 0.979
[image:36.595.111.513.255.426.2]X9 0.968 0.098 0.946
Tabel 4.8 Faktor Loading dan Komunalitas Variabel PDRB ADHB Setelah dirotasi
Variabel Faktor Loading 1
Faktor
Loading 2 Komunalitas
X1 0.089 0.920 0.854
X2 -0.036 0.879 0.774
X3 0.621 0.409 0.553
X4 0.976 0.011 0.953
X5 0.983 -0.003 0.966
X6 0.983 0.137 0.985
X7 0.992 -0.019 0.984
X8 0.982 -0.054 0.967
X9 0.966 0.192 0.970
Tabel 4.9 Faktor Loading dan Komunalitas Variabel PDRB ADHK Setelah dirotasi
Variabel Faktor Loading 1
Faktor
Loading 2 Komunalitas
[image:36.595.110.513.464.750.2]X2 -0.008 0.896 0.803
X3 0.678 0.431 0.645
X4 0.981 -0.013 0.963
X5 0.985 -0.027 0.971
X6 0.990 0.117 0.994
X7 0.995 -0.010 0.990
X8 0.988 -0.054 0.979
X9 0.948 0.216 0.945
[image:37.595.113.513.85.215.2]Dari tabel 4.8 dan tabel 4.9 dapat ditentukan nilai mutlak faktor loading terbesar. Dengan demikian, dapat dikelompokkan variabel – variabel yang akan masuk pada faktor satu atau faktor dua. Pengelompokkan variabel – variabel ke dalam faktor Hasil dari rotasi faktor loading dari variabel PDRB ADHB dan PDRB ADHK dapat dilihat pada tabel 4.10 dan tabel 4.11 berikut.
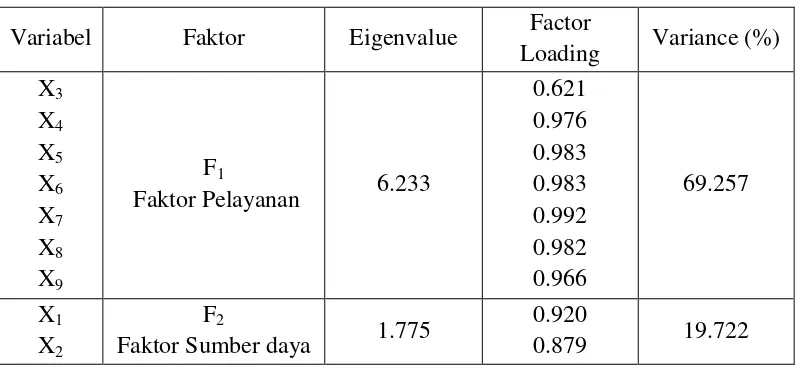
Tabel 4.10 Hasil Rotasi Faktor Varimax dari Variabel PDRB ADHB Variabel Faktor Eigenvalue Factor
Loading Variance (%) X3
X4 X5 X6 X7 X8 X9
F1
Faktor Pelayanan 6.233
0.621 0.976 0.983 0.983 0.992 0.982 0.966
69.257
X1 X2
F2
Faktor Sumber daya 1.775
0.920
0.879 19.722
Tabel 4.11 Hasil Rotasi Faktor Varimax dari Variabel PDRB ADHK Variabel Faktor Eigenvalue Factor
[image:37.595.113.515.378.564.2]X3 X4 X5 X6 X7 X8 X9 F1
Faktor Pelayanan 6.310
0.678 0.981 0.985 0.990 0.995 0.988 0.948 70.109 X1 X2 F2
Faktor Sumber daya 1.798
0.902
0.896 19.975
3.4.4. Interpretasi Faktor
Berdasarkan analisis sebelumnya maka interpretasi hasil berdasarkan eigenvalue dari setiap faktor dapat dijelaskan sebagai berikut :
1. PDRB ADHB
a. Faktor 1 : Faktor Pelayanan
Faktor ini merupakan faktor yang paling dominan yang mempengaruhi pertumbuhan ekonomi Sumatera Utara. Faktor ini mempunyai eigenvalue sebesar 6.233 dan mampu menjelaskan keragaman total sebesar 69.257%. Variabel – variabel yang termasuk kedalam faktor ini adalah Industri Pengolahan (faktor loading = 0.621), Listrik, gas, dan air bersih (faktor loading = 0.976), Bangunan (faktor loading = 0.983), perdagangan, hotel, dan restoran (faktor loading = 0.983), pengangkutan dan komunikasi (faktor loading = 0.992), keuangan, persewaan, dan jasa perusahaan (faktor loading = 0.982), dan jasa – jasa (faktor loading = 0.966). b. Faktor 2 : Faktor Sumber Daya
Faktor ini merupakan faktor pendukung yang mempengaruhi pertumbuhan ekonomi Sumatera Utara. Faktor ini mempunyai eigenvalue sebesar 1.775 dan mampu menjelaskan keragaman total sebesar 19.722%. Variabel – variabel yang termasuk kedalam faktor ini adalah Pertanian (faktor loading = 0.920), serta pertambangan dan penggalian (faktor loading = 0.879).
2. PDRB ADHK
a. Faktor 1 : Faktor Pelayanan
variabel yang termasuk kedalam faktor ini adalah Industri Pengolahan (faktor loading = 0.678), Listrik, gas, dan air bersih (faktor loading = 0.981), Bangunan (faktor loading = 0.985), perdagangan, hotel, dan restoran (faktor loading = 0.990), pengangkutan dan komunikasi (faktor loading = 0.995), keuangan, persewaan, dan jasa perusahaan (faktor loading = 0.988), dan jasa – jasa (faktor loading = 0.948). b. Faktor 2 : Faktor Sumber Daya
Faktor ini merupakan faktor pendukung yang mempengaruhi pertumbuhan ekonomi Sumatera Utara. faktor ini mempunyai eigenvalue sebesar 1.798 dan mampu menjelaskan keragaman total sebesar 19.975%.Variabel – variabel yang termasuk kedalam faktor ini adalah Pertanian (faktor loading = 0.902), serta pertambangan dan penggalian (faktor loading = 0.896).
3.4.5. Ketepatan Model (Model Fit)
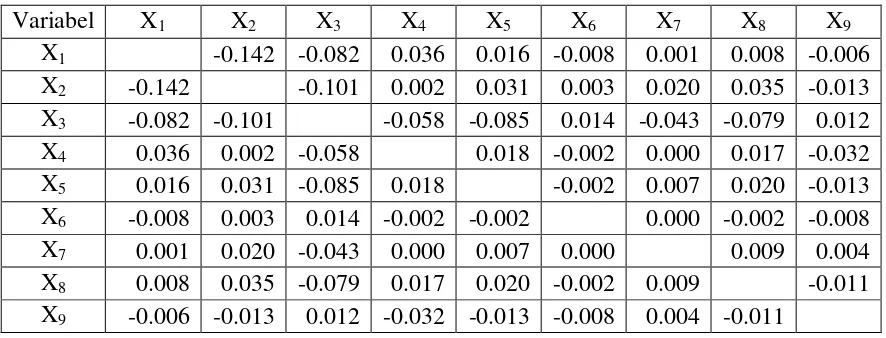
Perbedaan antara korelasi yang terobservasi dan korelasi yang direproduksi dapat dikaji untuk menentukan ketepatan model (model fit). Perbedaan ini disebut sisa atau residual. Berdasarkan hasil perhitungan atas dasar nilai mutlak/absolut yang besar dari 0.05 maka diperoleh nilai residual dari analisis ini yang lebih kecil dari 50%, yaitu 25% atau sebanyak 9 residual untuk variabel PRDB ADHB. Sementara itu, untuk variabel PDRB ADHK diperoleh nilai residual yang lebih kecil dari 50%, yaitu 16% atau sebanyak 6 residual.
Hal ini menginformasikan bahwa model faktor – faktor yang mempengaruhi pertumbuhan ekonomi Suamtera Utara memiliki ketepatan sebesar 75% pada tingkat penyimpangan 5% untuk variabel PDRB ADHB. Kemudian untuk PDRB ADHK, memiliki ketepatan sebesar 84% untuk penyimpangan 5%. Dengan demikian dapat disimpulkan bahwa, model faktor – faktor yang mempengaruhi pertumbuhan ekonomi Sumatera Utara berdasarkan variabel PDRB ADHB maupun PDRB ADHK dapat diterima.
Tabel 4.12 Residual antara Observed Correlation dan Reproduced Correlationi Variabel PDRB ADHB
Variabel X1 X2 X3 X4 X5 X6 X7 X8 X9
X3 -0.058 -0.176 -0.114 -0.107 0.077 -0.071 -0.111 0.043 X4 0.024 0.038 -0.114 0.026 -0.021 0.015 0.031 -0.028 X5 0.009 0.048 -0.107 0.026 -0.018 0.015 0.026 -0.014 X6 -0.013 -0.027 0.077 -0.021 -0.018 -0.011 -0.019 0.006 X7 0.002 0.035 -0.071 0.015 0.015 -0.011 0.018 -0.007 X8 -0.004 0.064 -0.111 0.031 0.026 -0.019 0.018 -0.015 X9 0.000 -0.028 0.043 -0.028 -0.014 0.006 -0.007 -0.015
Tabel 4.13 Residual antara Observed Correlation dan Reproduced Correlationi Variabel PDRB ADHK
Variabel X1 X2 X3 X4 X5 X6 X7 X8 X9
KESIMPULAN DAN SARAN
4.1. Kesimpulan
Dari hasil analisis dan pembahasan yang telah dilakukan pada bab sebelumnya maka dapat diambil kesimpulan, yaitu :
1. Setelah dilakukan analisis faktor terhadap sembilan variabel yang diteliti maka terdapat 2 faktor yang merupakan faktor – faktor yang mempengaruhi pertumbuhan ekonomi Sumatera Utara untuk PDRB tahun 2013 berdasarkan atas dasar harga berlaku (ADHB) maupun berdasarkan atas dasar harga konstan (ADHK). Faktor – faktor tersebut antara lain :
a. Faktor Pelayanan
Untuk PDRB ADHB, faktor ini merupakan faktor yang paling dominan yang mempengaruhi pertumbuhan ekonomi Sumatera Utara. Faktor ini mempunyai eigenvalue sebesar 6.233 dan mampu menjelaskan keragaman total sebesar 69.257%. Variabel – variabel yang termasuk kedalam faktor ini adalah Industri Pengolahan (faktor loading = 0.621), Listrik, gas, dan air bersih (faktor loading = 0.976), Bangunan (faktor loading = 0.983), perdagangan, hotel, dan restoran (faktor loading = 0.983), pengangkutan dan komunikasi (faktor loading = 0.992), keuangan, persewaan, dan jasa perusahaan (faktor loading = 0.982), dan jasa – jasa (faktor loading = 0.966). Sementara itu, untuk PDRB ADHK, faktor ini juga merupakan faktor yang paling dominan yang mempengaruhi pertumbuhan ekonomi Sumatera Utara. Faktor ini mempunyai eigenvalue sebesar 6.310 dan mampu menjelaskan keragaman total sebesar 70.109%. Variabel – variabel yang termasuk kedalam faktor ini adalah Industri Pengolahan (faktor loading = 0.678), Listrik, gas, dan air bersih (faktor loading = 0.981), Bangunan (faktor loading = 0.985), perdagangan, hotel, dan restoran (faktor loading = 0.990), pengangkutan dan komunikasi (faktor loading = 0.995), keuangan, persewaan, dan jasa perusahaan (faktor loading = 0.988), dan jasa – jasa (faktor loading = 0.948).
b. Faktor Sumber Daya
19.722%. Variabel – variabel yang termasuk kedalam faktor ini adalah Pertanian (faktor loading = 0.920), serta pertambangan dan penggalian (faktor loading = 0.879). Sementara itu, untuk PDRB ADHK, faktor ini merupakan faktor pendukung yang mempengaruhi pertumbuhan ekonomi Sumatera Utara. faktor ini mempunyai eigenvalue sebesar 1.798 dan mampu menjelaskan keragaman total sebesar 19.975%.Variabel – variabel yang termasuk kedalam faktor ini adalah Pertanian (faktor loading = 0.902), serta pertambangan dan penggalian (faktor loading = 0.896).
2. Berdasarkan hasil perhitungan atas dasar nilai mutlak/absolut yang besar dari 0.05 maka diperoleh nilai residual dari analisis ini yang lebih kecil dari 50%, yaitu 25% atau sebanyak 9 residual untuk variabel PRDB ADHB. Sementara itu, untuk variabel PDRB ADHK diperoleh nilai residual yang lebih kecil dari 50%, yaitu 16% atau sebanyak 6 residual. Hal ini menginformasikan bahwa model faktor – faktor yang mempengaruhi pertumbuhan ekonomi Suamtera Utara memiliki ketepatan sebesar 75% pada tingkat penyimpangan 5% untuk variabel PDRB ADHB, kemudian untuk PDRB ADHK, memiliki ketepatan sebesar 84% untuk penyimpangan 5% dan dapat diterima.
4.2. Saran
Berdasarkan hasil analisis dan pembahasan yang didapatkan maka saran yang dapat diberikan, yaitu :
1. Hasil dari penelitian ini dapat dikembangkan dengan penelitian selanjutnya dengan menggunakan metode analisis cluster untuk mengetahui pengelompokkan berdasarkan daerahnya.
DAFTAR PUSTAKA
Badan Pusat Statistik Sumatera Utara. 2014. Produk Domestik Regional Bruto
Provinsi Sumatera Utara Kabupaten/Kota Se-Sumatera Utara 2009 – 2013.
Badan Pusat Statistik. 2014. Provinsi Sumatera Utara Dalam Angka 2014.
Silaban, Pantur. 1984. Aljabar Linier Elementer. Jakarta : PT. Gelora Aksara Pratama.
Johnson, Richard, A and Winchern, D. W. 2007. Applied Multivariate Statistical Analysis, Sixth Edition . Prentice – Hall, Pearson Education Inc.
Usman, Hardius dan Sobari, Nurdin. 2013. Aplikasi Teknik Miltivariate Untuk Riset Pemasaran. Jakarta : PT. Rajagrafindo Persada.
Supranto, J. M.A, APU, prof. 2010. Analisis Multivariat : Arti dan Interpretasi, cetakan kedua, Jakarta. PT. Asdi Mahasatya.
Kastawan, Wiwit dan Harmein, Irzam. 2004. Schaum’s Outlines Teori dan Soal – Soal Statistik. Jakarta. PT. Gelora Aksara Pratama.
id.wikipedia.org/wiki/pembangunan-ekonomi. Diakses tanggal 13 November 2014
Tahun 2013 (Juta Rupiah)
No. Kabupaten/Kota Pertanian Pertambangan dan Penggalian
Industri Pengolahan
Listrik, Gas, dan
Air Bersih
Bangunan
Perdagangan, Hotel, dan
Restoran
Pengangkutan dan Komunikasi
Keuangan, Persewaan, dan Jasa Perusahaan
Jasa-Jasa
No. Kabupaten/Kota Pertanian Pertambangan dan Penggalian
Industri Pengolahan
Listrik, Gas, dan Air Bersih
Bangunan
Perdagangan, Hotel, dan
Restoran
Pengangkutan dan Komunikasi
Keuangan, Persewaan, dan Jasa Perusahaan
Jasa-Jasa
Tahun 2013 (Juta Rupiah)
No. Kabupaten/Kota Pertanian Pertambangan dan Penggalian
Industri Pengolahan
Listrik, Gas, dan
Air Bersih
Bangunan
Perdagangan, Hotel, dan
Restoran
Pengangkutan dan Komunikasi
Keuangan, Persewaan, dan Jasa Perusahaan
Jasa-Jasa
1 Nias 924102.51 60944.85 16462.67 2962.97 116595.98 68539.27 49683.36 66811.15 332731.09 2 Mandailing Natal 2546697.65 69061.38 196319.52 22203.19 502538.12 1025824.54 310599.73 111752.88 788136.48 3 Tapanuli Selatan 2114841.87 15409.66 1106633.54 3885.85 150833.33 561520.50 119087.85 23147.29 390573.17 4 Tapanuli Tengah 1283302.62 20604.03 469681.07 30375.71 195538.97 403618.03 82510.04 116150.10 702500.73 5 Tapanuli Utara 2587168.99 7549.70 83058.98 46600.60 373573.54 814160.30 213788.90 183614.68 811587.82
6 Toba Samosir 1128935 22269 2196922 50380 388736 514416 147873 138852 422603
No. Kabupaten/Kota Pertanian Pertambangan dan Penggalian
Industri Pengolahan
Listrik, Gas, dan Air Bersih
Bangunan
Perdagangan, Hotel, dan
Restoran
Pengangkutan dan Komunikasi
Keuangan, Persewaan, dan Jasa Perusahaan
Jasa-Jasa
Lampiran 3. Hasil Print Out SPSSAnalisis Faktor PDRB
1. Uji Kecukupan Data dan Korelasi Antar Variabel
a. PDRB ADHB
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .693 Bartlett's Test of Sphericity Approx. Chi-Square 720.427
df 36
Sig. .000
b. PDRB ADHK
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .681 Bartlett's Test of Sphericity Approx. Chi-Square 701.252
df 36
c. Korelasi Antar Variabel PDRB ADHB
Correlation Matrixa
X1 X2 X3 X4 X5 X6 X7 X8 X9
Correlation X1 1.000 0.683 0.374 0.121 0.094 0.200 0.073 0.034 0.262
X2 0.683 1.000 0.161 0.012 0.010 0.058 -0.018 -0.019 0.105 X3 0.374 0.161 1.000 0.497 0.502 0.743 0.538 0.477 0.721 X4 0.121 0.012 0.497 1.000 0.986 0.939 0.984 0.989 0.917 X5 0.094 0.010 0.502 0.986 1.000 0.947 0.991 0.993 0.934 X6 0.200 0.058 0.743 0.939 0.947 1.000 0.962 0.939 0.981 X7 0.073 -0.018 0.538 0.984 0.991 0.962 1.000 0.994 0.947 X8 0.034 -0.019 0.477 0.989 0.993 0.939 0.994 1.000 0.923 X9 0.262 0.105 0.721 0.917 0.934 0.981 0.947 0.923 1.000
Sig. (1-tailed) X1 0.000 0.016 0.252 0.302 0.133 0.344 0.426 0.070
X2 0.000 0.185 0.473 0.479 0.374 0.461 0.459 0.280
X3 0.016 0.185 0.002 0.001 0.000 0.001 0.003 0.000
X4 0.252 0.473 0.002 0.000 0.000 0.000 0.000 0.000
X5 0.302 0.479 0.001 0.000 0.000 0.000 0.000 0.000
X6 0.133 0.374 0.000 0.000 0.000 0.000 0.000 0.000
X7 0.344 0.461 0.001 0.000 0.000 0.000 0.000 0.000
X8 0.426 0.459 0.003 0.000 0.000 0.000 0.000 0.000
d. Korelasi Antar Variabel PDRB ADHK
Correlation Matrixa
X1 X2 X3 X4 X5 X6 X7 X8 X9
Correlation X1 1.000 0.666 0.341 0.075 0.043 0.148 0.044 0.010 0.238
X2 0.666 1.000 0.280 -0.017 -0.001 0.099 0.003 -0.021 0.173
X3 0.341 0.280 1.000 0.601 0.571 0.736 0.627 0.568 0.748
X4 0.075 -0.017 0.601 1.000 0.985 0.968 0.976 0.987 0.896 X5 0.043 -0.001 0.571 0.985 1.000 0.970 0.987 0.994 0.915
X6 0.148 0.099 0.736 0.968 0.970 1.000 0.984 0.970 0.957
X7 0.044 0.003 0.627 0.976 0.987 0.984 1.000 0.993 0.945
X8 0.010 -0.021 0.568 0.987 0.994 0.970 0.993 1.000 0.914
X9 0.238 0.173 0.748 0.896 0.915 0.957 0.945 0.914 1.000
Sig. (1-tailed) X1 0.000 0.026 0.339 0.407 0.205 0.405 0.478 0.092
X2 0.000 0.058 0.462 0.498 0.291 0.494 0.453 0.167
X3 0.026 0.058 0.000 0.000 0.000 0.000 0.000 0.000
X4 0.339 0.462 0.000 0.000 0.000 0.000 0.000 0.000
X5 0.407 0.498 0.000 0.000 0.000 0.000 0.000 0.000
X6 0.205 0.291 0.000 0.000 0.000 0.000 0.000 0.000
X7 0.405 0.494 0.000 0.000 0.000 0.000 0.000 0.000
X8 0.478 0.453 0.000 0.000 0.000 0.000 0.000 0.000
X9 0.092 0.167 0.000 0.000 0.000 0.000 0.000 0.000
Lanjutan Lampiran 3.
Tabel Eigenvalue, Variance, Cumulative, PDRB ADHB
Faktor (Component)
Initial Eigenvalues Extraction Sums of Squared Loadings
Total % of Variance
Cumulative
% Total
% of Variance
Cumulative % 1 6.233 69.257 69.257 6.233 69.257 69.257 2 1.775 19.722 88.979 1.775 19.722 88.979 3 0.656 7.294 96.273
4 0.279 3.100 99.373 5 0.038 0.422 99.795 6 0.009 0.102 99.897 7 0.007 0.074 99.971 8 0.002 0.018 99.989 9 0.001 0.011 100.000
Extraction Method: Principal Component Analysis.
Tabel Eigenvalue, Variance, Cumulative, PDRB ADHK
Faktor (Component)
Initial Eigenvalues Extraction Sums of Squared Loadings
Total % of Variance
Cumulative
% Total
% of Variance
Cumulative % 1 6.310 70.109 70.109 6.310 70.109 70.109 2 1.798 19.975 90.084 1.798 19.975 90.084 3 0.461 5.128 95.211
Lanjutan Lampiran 3.
Tabel Faktor Loading Variabel PDRB ADHB Sebelum dirotasi
Variabel Faktor (Component)
1 2
X1 0.204 0.902
X2 0.075 0.877
X3 0.668 0.327
X4 0.970 -0.113
X5 0.975 -0.127
X6 0.992 0.011
X7 0.982 -0.145
X8 0.968 -0.178
X9 0.982 0.068
Extraction Method: Principal Component Analysis. a. 2 components extracted.
Tabel Faktor Loading Variabel PDRB ADHB Setelah dirotasi
Variabel Faktor (Component)
1 2
X1 0.089 0.920
X2 -0.036 0.879
X3 0.621 0.409
X4 0.976 0.011
X5 0.983 -0.003
X6 0.983 0.137
X7 0.992 -0.019
X8 0.982 -0.054
X9 0.966 0.192
Lanjutan Lampiran 3.
Tabel Faktor Loading Variabel PDRB ADHK Sebelum dirotasi
Variabel Faktor (Component)
1 2
X1 0.162 0.889
X2 0.102 0.890
X3 0.726 0.344
X4 0.972 -0.133
X5 0.974 -0.148
X6 0.997 -0.006
X7 0.986 -0.132
X8 0.974 -0.175
X9 0.968 0.098
Extraction Method: Principal Component Analysis. a. 2 components extracted.
Tabel Faktor Loading Variabel PDRB ADHK Setelah dirotasi
Variabel Faktor (Component)
1 2
X1 0.052 0.902
X2 -0.008 0.896
X3 0.678 0.431
X4 0.981 -0.013
X5 0.985 -0.027
X6 0.990 0.117
X7 0.995 -0.010
X8 0.988 -0.054
X9 0.948 0.216
Tabel Residual antara Observed Correlation dan Reproduced Correlationi Variabel PDRB ADHB Reproduced Correlations
X1 X2 X3 X4 X5 X6 X7 X8 X9
Reproduced Correlation
X1 0.855a 0.806 0.432 0.096 0.084 0.213 0.070 0.038 0.262
X2 0.806 0.774a 0.337 -0.026 -0.038 0.085 -0.053 -0.083 0.134
X3 0.432 0.337 0.553a 0.610 0.609 0.666 0.608 0.588 0.678
X4 0.096 -0.026 0.610 0.953a 0.960 0.961 0.968 0.958 0.945
X5 0.084 -0.038 0.609 0.960 0.967a 0.966 0.976 0.966 0.949
X6 0.213 0.085 0.666 0.961 0.966 0.984a 0.972 0.958 0.975
X7 0.070 -0.053 0.608 0.968 0.976 0.972 0.985a 0.976 0.954
X8 0.038 -0.083 0.588 0.958 0.966 0.958 0.976 0.968a 0.938
X9 0.262 0.134 0.678 0.945 0.949 0.975 0.954 0.938 0.969a
Residualb X1 -0.123 -0.058 0.024 0.009 -0.013 0.002 -0.004 0.000
X2 -0.123 -0.176 0.038 0.048 -0.027 0.035 0.064 -0.028
X3 -0.058 -0.176 -0.114 -0.107 0.077 -0.071 -0.111 0.043
X4 0.024 0.038 -0.114 0.026 -0.021 0.015 0.031 -0.028
X5 0.009 0.048 -0.107 0.026 -0.018 0.015 0.026 -0.014
X6 -0.013 -0.027 0.077 -0.021 -0.018 -0.011 -0.019 0.006
X7 0.002 0.035 -0.071 0.015 0.015 -0.011 0.018 -0.007
X8 -0.004 0.064 -0.111 0.031 0.026 -0.019 0.018 -0.015
X9 0.000 -0.028 0.043 -0.028 -0.014 0.006 -0.007 -0.015
Extraction Method: Principal Component Analysis. a. Reproduced communalities
Tabel Residual antara Observed Correlation dan Reproduced Correlationi Variabel PDRB ADHK Reproduced Correlations
X1 X2 X3 X4 X5 X6 X7 X8 X9
Reproduced Correlation
X1 0.816a 0.807 0.424 0.039 0.027 0.157 0.043 0.002 0.244
X2 0.807 0.803a 0.381 -0.019 -0.032 0.097 -0.017 -0.057 0.186
X3 0.424 0.381 0.645a 0.660 0.656 0.722 0.670 0.646 0.736
X4 0.039 -0.019 0.660 0.963a 0.967 0.970 0.976 0.970 0.928
X5 0.027 -0.032 0.656 0.967 0.971a 0.973 0.980 0.975 0.928
X6 0.157 0.097 0.722 0.970 0.973 0.995a 0.984 0.972 0.964
X7 0.043 -0.017 0.670 0.976 0.980 0.984 0.990a 0.983 0.941
X8 0.002 -0.057 0.646 0.970 0.975 0.972 0.983 0.979a 0.925
X9 0.244 0.186 0.736 0.928 0.928 0.964 0.941 0.925 0.946a
Residualb X1 -0.142 -0.082 0.036 0.016 -0.008 0.001 0.008 -0.006
X2 -0.142 -0.101 0.002 0.031 0.003 0.020 0.035 -0.013
X3 -0.082 -0.101 -0.058 -0.085 0.014 -0.043 -0.079 0.012
X4 0.036 0.002 -0.058 0.018 -0.002 0.000 0.017 -0.032
X5 0.016 0.031 -0.085 0.018 -0.002 0.007 0.020 -0.013
X6 -0.008 0.003 0.014 -0.002 -0.002 0.000 -0.002 -0.008