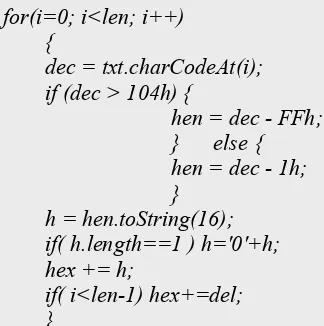PENAMBAHAN JUMLAH INFORMASI PADA
QR CODE
MENGGUNAKAN TEKNIK KOMPRESI DATA
LOSSLESS
WAHYU JULIARIANTO
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI THESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa thesis berjudul Penambahan Jumlah Informasi pada QR code Menggunakan Teknik Kompresi Data Lossless adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir thesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Oktober 2015
Wahyu Juliarianto
RINGKASAN
WAHYU JULIARIANTO. Penambahan Jumlah Informasi pada QR code
menggunakan Teknik Kompresi Data Lossless. Dibimbing oleh SUGI GURITMAN dan HERU SUKOCO.
Quick Respond (QR) code adalah barcode dua dimensi yang dirancang untuk memberikan informasi yang tersimpan dengan cepat. QR code diciptakan oleh Denso Wave untuk melakukan pengecekan terhadap suku cadang pada saat produksi. Berkat dorongan dari seorang user, QR code dikembangkan sehingga dapat digunakan untuk mengkodekan karakter alphanumerik, dan kanji. Kemampuannya untuk dibaca dari bermacam sudut dan kecepatannya dalam memberikan informasi tersimpan yang melebihi jenis barcode serupa, serta dapat menyimpan informasi hingga 2000 jenis karakter biner dan menggunakan karakter kanji menjadikan QR code sebagai sarana yang populer dalam menyampaikan informasi terutama sejak meningkatnya perkembangan pada teknologismartphone.
Seperti jenis barcode lainnya, semakin banyak informasi yang tersimpan akan membuat ukuran dari QR code semakin besar sehingga dapat membuatnya sulit untuk memberikan informasi yang tersimpan. Penelitian ini memfokuskan pada informasi yang dikompresi menggunakan kompresi datalossless. Pengujian data dilakukan menggunakan identitas pribadi berupa Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), Surat Tanda Nomor Kendaraan (STNK) dan Kartu Keluarga (KK) yang ditulis dalam bentuk teks dengan mengambil sample dari setiap data pribadi sebanyak 10 kali.
Pengujian dilakukan dengan membagi setiap sample dalam tiga jenis penulisan, yaitu menggunakan huruf besar dan kecil, seluruh penulisan menggunakan huruf besar, dan menggunakan karakter spesial sebagai pengganti huruf vokal. Informasi dikompresi menggunakan algoritme kompresi data lossles dengan karakterunicode sebagai hasil dari kompresi yang akan digunakan dalam membentuk QR code dengan jenis pengkodean unicode UTF-8. QR code yang telah dibentuk diuji terlebih dahulu dengan melakukan dekompresi untuk mendapatkan informasi asli. Bila informasi asli tidak bisa didapatkan maka perlu dilakukan modifikasi pada algoritme yang digunakan untuk mendapatkan hasil yang lebih baik. QR code yang menggunakan informasi terkompresi akan dibandingkan dengan QR code yang menggunakan informasi asli untuk mengetahui pengaruh tingkat kompresi pada informasi terhadap ukuran padaQR code.
Hasil pengujian diperoleh tingkat kompresi pada informasi yang mencapai lebih dari 25% yang dapat mengurangi ukuran dariQR codepada informasi yang sama. Tingkat kompresi dari informasi yang berada kurang dari 25% akan menambah ukuran pada QR code. Faktor lain yang mempengaruhi perubahan pada QR code adalah jenis karakter yang dapat disimpan pada QR code, karena bila ada karakter yang tidak bisa disimpan pada QR code akan menyebabkan rusaknya informasi.
SUMMARY
WAHYU JULIARIANTO. Increasing amount of information on the QR code using Lossless Data Compression Techniques. Guided by SUGI GURITMAN and HERU SUKOCO.
Quick Respond (QR) code is a two-dimensional barcode that designed to provide information stored quickly. QR code created by Denso Wave to checks on the spare parts at the time of production. Thanks to the encouragement of a user, the QR code was developed so that it can be used to encode the alphanumeric characters, and kanji. It's ability to read from a variety of angles and speed in providing stored information faster than similar types of barcodes, and can store information for up to 2000 types of binary characters and using kanji characters make a QR code as a popular tool in conveying information, especially since the increased growth in smartphone technology.
Like other types of barcodes, the more information stored will make the size of the QR code is getting bigger and make it difficult to provide the stored information. This study focuses compressed information using lossless data compression. Experiment were conducted by using a personal identity in the form of Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), Surat Tanda Nomor Kendaraan (STNK) and Kartu Keluarga (KK) that written in text form by taking a sample of any personal data 10 times.
Each sample is testing by divide into three types of writing, using upper and lower case, all the writing in big letters, and use special characters instead of vowels. Information is compressed using a data compression algorithm lossles with unicode character as a result of compression to be used in forming the QR code with unicode UTF-8 encoding. QR code that has been formed tested first by decompression to obtain original information. If the original information can not be obtained, algorithm used must modified to give a better result. QR code that uses compressed information will be compared with a QR code that uses the original information to determine the effect of compression on the information on the size of the QR code.
The test results obtained on the compression rate of the information that reaches more than 25% can reduce the size of the QR code on the same information. Compression rate of the information that was less than 25% will increase the size of the QR code. Other factors affecting the change in the QR code is a type of characters that can be stored in the QR code, because if there is a character that can not be stored in the QR code can eliminate the information stored.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Magister Ilmu Komputer
pada
Program Studi Ilmu Komputer
PENAMBAHAN JUMLAH INFORMASI PADA
QR CODE
MENGGUNAKAN TEKNIK KOMPRESI DATA
LOSSLESS
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Tesis : Penambahan Jumlah Informasi padaQR codemenggunakan Teknik Kompresi DataLossless
Nama : Wahyu Juliarianto NIM : G651110664
Disetujui oleh Komisi Pembimbing
Dr Sugi Guritman
Ketua DrEng Heru Sukoco Ssi MTAnggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
DrEng Wisnu Ananta Kusuma, ST MT
Dekan Sekolah Pascasarjana
Prof Dr Ir. Nahrowi, MSc
Tanggal Ujian Tertutup : 19 Oktober
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah S.W.T atas segala karunia-Nya sehingga sehingga karya ilmiah ini dapat diselesaikan. Tema yang dipilih pada penelitian ini adalah QR code dengan judul Peningkatan kapasitas pada QR code menggunakan Kompresi Data Lossless.
Tesis ini disusun sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada Program Ilmu Komputer, Sekolah Pascasarjana Institut Pertanian Bogor.
Pada kesempatan ini penulis menyampaikan penghargaan dan ucapan terima kasih kepada:
1. Kedua orangtuaku, Bapak Waluyo dan Ibu Sri Rahayu tercinta, yang tak kenal lelah mendukung baik secara fisik maupun do'a siang dan malam. 2. Bapak Dr Sugi Guritman selaku ketua komisi pembimbing dan Bapak
DrEng Heru Sukoco selaku anggota komisi pembimbing yang telah meluangkan waktu, tenaga dan pikiran sehingga tesis ini dapat diselesaikan.
3. Ibu Dr Ir Sri Wahjuni, MT selaku dosen penguji yang telah memberikan arahan dan masukan untuk perbaikan tesis ini.
4. Bapak DrEng Wisnu Ananta Kusuma, ST MT dan Bapak Toto Haryanto, SKom MSi yang telah banyak meluangkan waktunya dalam memberikan arahan untuk menyelesaikan tesis ini.
5. Staff Administrasi Departemen Ilmu Komputer atas kerja samanya membantu kelancaran proses administrasi hingga akhir studi.
6. Teman-teman dari kelas reguler maupun karyawan yang telah banyak membeerikan masukkan dalam menyelesaikan studi.
Penulis menyadari bahwa masih banyak kekurangan dalam penulisan tesis ini, namun demikian penulis berharap tesis ini dapat bermanfaat untuk bidang ilmu komputer, bidang pendidikan dan para bagi individu maupun kolektif (organisasi, grup, instansi, perusahaan, lembaga, konsumen) pencari informasi yang ingin mendapatkan informasi yang paling relevan sesuai dengan minat dan kebutuhannya.
Bogor, Oktober 2015
DAFTAR ISI
Struktur padaQR Code 3
Jenis karakter yang dapat dikodekan dalamQR code 4
Versi padaQR code 4
Error CorrectionpadaQR code 4
Kompresi Data 5
Proses pembuatanQR codedengan informasi terkompresi 9 Proses PengujianQR codedengan Informasi Terkompresi 11
Evaluasi Perbandingan UkuranQR Code 12
4 HASIL DAN PEMBAHASAN 13
Proses pembuatanQR codedengan informasi terkompresi 13 Proses PengujianQR codedengan informasi terkompresi 15
Evaluasi Perbandingan UkuranQR Code 16
Pengujian data pribadi menggunakan huruf besar dan kecil 19 Pengujian data pribadi menggunakan hanya huruf besar 20 Pengujian data pribadi menggunakan huruf besar dan kecil dengan karakter spesial sebagai pengganti huruf vokal 20 Pengaruh tingkat kompresi terhadap ukuran padaQR code 21
5 SIMPULAN 22
DAFTAR PUSTAKA 23
Lampiran 25
TabelError Correction CodepadaQR Code 25
DAFTAR GAMBAR
1 Struktur padaQR code 3
2 Perbandingan ukuranQR codepada versi 1 (kiri) dan versi 40
(kanan) 4
3 Prosesencodingpada Skema Pergeseran Kamus 5 4 Prosesdecodingpada Skema Pergeseran Kamus 6 5 Proses pembuatanQR codedengan informasi terkompresi 8 6 Proses pengujianQR codedengan informasi terkompresi 10 7 PerbandinganQR codemenggunakan informasi asli (gambar kiri)
denganQR codemenggunakan informasi hasil kompresi (gambar
kanan) 14
8 QR codemenggunakan informasi hasil kompresi dengan output
berupa karakterunicode 15
9 Pengaruh tingkat kompresi data dengan ukuranQR codeuntuk
penulisan informasi menggunakan huruf besar dan kecil 20 10 Pengaruh tingkat kompresi data dengan ukuranQR codeuntuk
penulisan informasi hanya menggunakan huruf besar 20 11 Pengaruh tingkat kompresi data dengan ukuranQR codeuntuk
penulisan informasi menggunakan huruf besar dan kecil dengan karakter spesial sebagai pengganti huruf vokal 21 12 Pengaruh tingkat kompresi informasi terhadap tingkat kompresi
PadaQR code 21
DAFTAR TABEL
1 Pengaruh Tingkat Kompresi dengan UkuranQR codepada Kartu
Tanda Penduduk (KTP) 19
2 Pengaruh Tingkat Kompresi dengan UkuranQR codepada Surat
Izin Mengemudi (SIM) 19
3 Pengaruh Tingkat Kompresi dengan UkuranQR codepada Surat
Tanda Nomor Kendaraan (STNK) 20
4 Pengaruh Tingkat Kompresi dengan UkuranQR codepada Kartu
1
1 PENDAHULUAN
Latar BelakangBarcode adalah representasi dari data pada objek yang dibaca oleh mesin. Pada generasi awal barcode terdiri dari garis dengan berbagai lebar dan jarak yang disebut sebagai linear atau satu dimensi (1D). Seiring dengan perkembangan jaman, garis ini berubah menjadi persegi panjang, titik, segi enam, dan berbagai pola lainnya dalam bentuk dua dimensi (2D). Meskipun menggunakan simbol yang berbeda, pola ini disebut sebagai barcode juga. Barcode sudah menjadi sarana populer yang digunakan untuk menyimpan informasi. Hampir di setiap tempat memiliki barcode yang digunakan dalam sebagai identifikasi tanda pengenal, wilayah, ataupun kode dalam bertransaksi.
QR codemerupakan jenisbarcodedua dimensi yang paling banyak dijumpai dalam kehidupan sehari-hari. QR code diciptakan oleh Denso Wave pada tahun 1994 dengan tujuan utama untuk membaca nomor dalam mengidentifikasi suku cadang selama proses produksi. Berkat dorongan dari seorang user, QR code
dikembangkan sehingga dapat digunakan untuk mengkodekan karakter alphanumerik, dan kanji. Selain itu QR code dapat menampung hingga 4000 karakter numerik dan 1800 karakter kanji. Hanya beberapa bagian dari QR code
yang memiliki data asli, termasuk Error Correction. Beberapa bagian pada QR code digunakan untuk menyimpan informasi seperti versi, posisi, letak, dan rentang waktu (Zhang 2012).
Seiring dengan bertambahnya kebutuhan akan informasi yang disimpan, QR codedikembangkan sehingga dapat menampung lebih dari dua ribu jenis karakter. Semakin banyak karakter yang disimpan, akan semakin besar ukuran dari QR code sehingga ukuran QR code akan semakin besar dan kemampuan dalam membaca informasi yang disimpan akan semakin lama. Ukuran dari QR code
yang besar akan memakan tempat yang lebih besar/banyak, sedangkan media yang dijadikan sebagai sarana penempatanQR codememiliki ruang yang terbatas sehingga ukuran dari QR code tidak boleh memakan banyak tempat. Karena keterbatasan tersebut biasanya QR code yang ditempatkan pada beberapa media hanya memiliki informasi yang terbatas untuk mengurangi ukuran agar tidak memakan banyak tempat (Goel 2014).
Beberapa penelitian telah mengidentifikasikan cara untuk mengoptimalkan data yang tersimpan pada QR code tanpa menambah ukurannya, seperti mengkonversi tipe data yang disimpan ke dalam tipe data yang berbeda sebelum dirubah dalam bentuk QR code, optimalisasi QR code (Victor 2012, Farizhah 2013, Goel 2014, Dey 2012), dan kompresi data sebelum dirubah ke dalam bentuk QR code (Parekar 2014, Arohi 2014, Porwal 2013). Ketika melakukan kompresi data, data tersebut harus dapat dikembalikan ke dalam bentuk semula agar informasi asli dapat dibaca (Parekar 2014).
karakter unicode sebagai output dari hasil kompresi untuk digunakan dalam pembentukanQR code. Ruang lingkup yang digunakan yaitu menggunakan data pribadi seperti Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), Surat Tanda Naik Kendaraan (STNK) dan Kartu Keluarga (KK) yang akan dikompresi menggunakan algoritme kompresi data lossless. Data pribadi yang akan diproses adalah data pribadi dalam format teks dengan output dari hasil kompresi berupa karakter unicode dengan pengkodean UTF-8 untuk diproses menjadi QR code. Proses encoding dan decoding menggunakan laptop dan tidak menggunakan smartphone, sehingga hanya perlu menggunakan Error Correction tingkat terendah yaitu L.
Perumusan Masalah
Permasalahan yang diangkat pada penelitian ini adalah Jumlah informasi yang berpengaruh pada besarnya ukuran dari QR code. Ukuran QR code yang terlalu besar dapat menyebabkan sulitnya membaca informasi yang tersimpan.
Tujuan Penelitian
Tujuan dari penelitian ini adalah membuat skema untuk menghasilkan ukuran QR code yang lebih kecil untuk ukuran informasi yang sama atau menghasilkan ukuran QR code yang sama dengan jumlah informasi yang lebih banyak. Skema tersebut adalah dengan melakukan kompresi pada informasi yang dimiliki menggunakan algoritme kompresi datalossless dengan karakter unicode
sebagai output dari hasil kompresi untuk digunakan dalam pembentukan QR code.
Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini yaitu menggunakan data pribadi dalam Bahasa Indonesia yang meliputi Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), Surat Tanda Naik Kendaraan (STNK) dan Kartu Keluarga (KK) yang akan dikompresi menggunakan algoritme kompresi data lossless. Data pribadi ditulis dalam format teks dan dikompresi menggunakan algoritme kompresi data lossless dengan algoritme LZMA dalam implementasinya. Karakter unicode digunakan sebagai output dari hasil kompresi untuk diproses menjadiQR code. Proses encoding dandecoding menggunakan laptop dan tidak menggunakan smartphone, sehingga hanya perlu menggunakan Error Correction
tingkat terendah yaitu L.
2 TINJAUAN PUSTAKA
QR CodeQR (Quick Respond) code adalah barcode berbentuk matriks dua dimensi yang merupakan perkembangan dari barcode satu dimensi. Berbeda dengan
barcode satu dimensi, QR code memiliki kapasitas yang tinggi dan dapat digunakan untuk mengkodekan karakter ASCII sebanyak 256 byte hingga huruf kanji. Karena itu QR code dapat digunakan untuk menyimpan nama, alamat, url
3
respon cepat sehingga dapat digunakan untuk menyampaikan informasi dan memberikan respon yang cepat pula. QR code mulai populer pada tahun 2011 ketika smartphone mulai mengambil peran penting pada tren pasar. Sebuah QR code dapat dibaca melalui perangkat kamera yang terdapat pada masing-masing smartphone. QR code telah mengalami banyak perkembangan. Saat ini QR code
telah mencapai versi 40 yang dapat menampung hingga 4000 karakter numerik dan 1800 karakter kanji(Zhang 2012).
Struktur padaQR Code
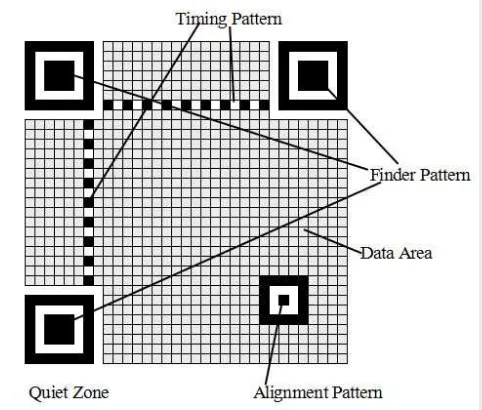
QR code adalah kumpulan modul hitam putih dalam pola persegi dengan latar belakang putihyang memiliki beberapa struktur seperti finder pattern,
alignment pattern, timing pattern, quiet zone, dan data area seperti yang ditunjukkan pada Gambar 1.
Gambar 1 Struktur padaQR code
Penjelasan :
1. Finder Pattern: Pola berupa titik hitam berukuran 3x3 yang dikelilingi oleh titik putih dan titik hitam (total 7x7) yang terletak pada tiga bagian dari empat sudut matriks. Pola ini memungkinkan QR code untuk dibaca secara 360 derajat (omni-directional) dengan kecepatan tinggi.
2. Timing Pattern: Pola ini menentukan informasi dan masking yang digunakan padaQR code.
3. Alligment Pattern: Pola berupa persegi besar dengan titik yang ukurannya lebih kecil dari finder pattern (berukuran 5x5) dan memungkinkan QRreader
untuk mengoreksi noise ketika posisi QR code melengkung. Jumlah
alligment pattern yang muncul tergantung pada seberapa banyak informasi yang dimiliki dan muncul padaQR codeversi 2 dan lebih tinggi.
4. Data Area: Berisi informasi yang disimpan dalam bentuk bilangan biner. Warna Gelap untuk nilai 1, dan warna terang untuk nilai 0.
Jenis karakter yang dapat dikodekan dalamQR code - Numerik : (0-9)
Setiap 3 karakter dikodekan dengan panjang 10 bit. - Alphanumerik : (0-9,A-Z,spasi,$,,*,+,-,.,/,:)
Setiap 2 karakter dikodekan dengan panjang 11 bit. - Byte : (karakter8-bitseperti ASCII danunicode)
Setiap 1 karakter dikodekan dengan panjang 8 bit. - Kanji : (Kanji)
Setiap 1 karakter dikodekan dengan panjang 13 bit.
Versi padaQR code
Ukuran pada QR code didefinisikan sebagai versi. Versi pada QR code
berada pada 1 sampai 40 dan akan terus meningkat. Pada versi 1 QR code
berukuran matriks 21 x 21, dan bertambah sebanyak 4 di setiap versinya. Sehingga QR code pada versi 40 memiliki ukuran matriks 177 * 177. Perbandingan ukuran padaQR codeditunjukkan pada Gambar 2.
Gambar 2 Perbandingan ukuran QR code pada versi 1 (kiri) dan versi 40 (kanan). (sumber Gambar : http://docs.telerik.com/)
Error CorrectionpadaQR code
QR code memiliki fungsi mengoreksi kesalahan dalam membaca (Error Correction) untuk setiap blok hitam-putih. Error Correction didefinisikan dalam 4 tingkat seperti berikut.
− L : Sekitar 7 kesalahan atau kurang dapat diperbaiki. − M : Sekitar 15 kesalahan atau kurang dapat diperbaiki. − Q : Sekitar 25 kesalahan atau kurang dapat diperbaiki. − H : Sekitar 30 kesalahan atau kurang dapat diperbaiki.
Semakin tinggi Error Correction yang digunakan akan meningkatkan kemampuan decoder dalam membaca pesan, tetapi mengakibatkan bertambahnya informasi yang diproses untuk menjadiQR code.
Proses PembentukanQR Code Ada 7 langkah dalam membentukQR codesebagai berikut:
1. Analisa isi data untuk menentukan jenisencodingyang akan digunakan 2. Melakukan prosesencodinguntuk data yang dimiliki
3. MembuatError Correction coding
5
5. Melakukan alokasi data pada matriks
6. Memproses data masking untuk menentukan jenis masking yang digunakan padaQR code
7. Memproses informasi format dan versiQR code
Kompresi Data
Kompresi data adalah proses untuk merekonstruksi suatu data menjadi lebih ringkas bila dibandingkan dengan bentuk sebelumnya. Kompresi sangat membantu dalam memproses, menyimpan, atau mentransfer data yang membutuhkan banyak ruang penyimpanan. Kompresi data lossless adalah bagian dari algoritme kompresi data dimana data asli yang telah dikompresi dapat dikembalikan seperti semula. Lawan dari kompresi data lossless adalah kompresi data lossy dimana data yang telah dikompresi tidak dapat dikembalikan seperti semula. Kompresi data lossless digunakan untuk mengkompresi data yang penting dimana apabila terjadi kesalahan pada saat proses kompresi akan mengakibatkan kerusakan pada data asli (tidak dapat dikembalikan). Contoh penggunaan kompresi data lossless terdapat pada program, dokumen teks, source code, beberapa file Gambar seperti PNG atau GIF, dan file audio yang digunakan dalam sebagai berkas.
Algoritme LZMA
Lempel–Ziv–Markov chain algorithm (LZMA) adalah salah satu algoritme yang digunakan untuk melakukan kompresi data lossless. LZMA merupakan salah satu pengembangan dari algoritme LZ77 yang dibuat oleh Abraham Lempel dan Jacob Ziv pada tahun 1977. LZMA merupakan variasi dari LZ77 yang menggunakan skema pergeseran kamus (dictionary compression algorithm) tetapi memiliki ukuran kamus yang sangat besar dan dukungan terhadap penggunaan kata yang berulang, dengan output yang diproses menggunakan range encoder, sehingga menghasilkan model yang sangat kompleks dalam memprediksi nilai pada setiap bit (Goel 2014). Kamus digunakan untuk menemukan kata yang sama menggunakan struktur yang dibuat pada kamus, dan menghasilkan data yang memiliki berbagai macam simbol dan pustaka yang dikodekan menggunakan range encoder. LZMA juga menggunakan delta encoding untuk mencari tingkat optimal dalam proses kompresi data.
LZMA menggunakan byte dalam seluruh proses encoding (karakter yang akan dikompresi dirubah kedalam bentuk byte terlebih dahuilu) sehingga dapat mencegah adanya bit yang tercampur pada saat proses. Dikarenakan LZMA menggunakan byte dalam proses kompresinya, ukuran kamus yang digunakan menjadi lebih besar bila dibandingkan dengan algoritme kompresi yang menggunakan skema kamus klasik (menggunakan karakter yang tidak dirubah kedalam bentuk byte) dan proses ini memanfaatkan keuntungan dari jumlah RAM yang terdapat pada komputer.
Slide Dictionary algorithm
kompresi dan isi kamus akan berubah dengan sistem FIFO (First In First Out). Ukuran kamus dapat ditentukan pada saat mulai (sebelumnya harus melalui konten sumber setidaknya sekali sebelum menentukan ukuran terbaik) yang tergantung pada bagaimana programmer ingin mencapai untuk mendapatkan hasil yang lebih baik (lebih kecil ukuran hasil).
Berikut adalah proses encoding pada Slide Dictionary Algorithm: Langkah 1. Baca seluruh data untuk inisialisasi pada kamus.
Langkah 2. Baca nilai string asli dengan panjang kecocokan tertinggi.
Langkah 3. Cari nilai string yang memiliki kecocokan dengan ukuran terpanjang dalam kamus.
Langkah 4. Jika kecocokan ditemukan lebih besar dari atau sama dengan panjang kecocokan terendah:
Tulis simbol untuk pengkodean, serta offset dan panjang ukuran untuk output.
Jika tidak, tulis simbol asli dan simbol awal pada output. Langkah 5. Pergeseran salinan simbol ditulis ke output dikodekan dari string
unencoded ke dalam kamus.
Langkah 6. Baca simbol dari input asli yang sama dengan jumlah simbol ditulis pada langkah 4.
Langkah 7. Ulangi Langkah 3, sampai semua seluruh input selesai dikodekan.
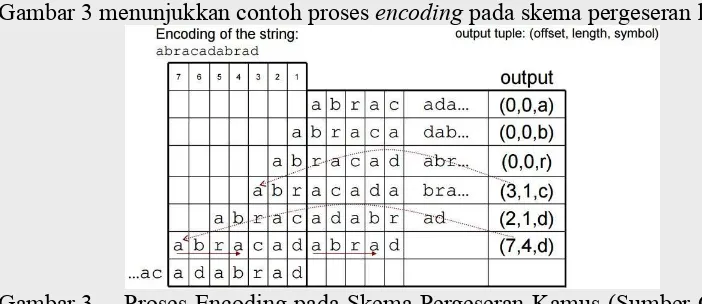
Gambar 3 menunjukkan contoh prosesencodingpada skema pergeseran kamus
Gambar 3 Proses Encoding pada Skema Pergeseran Kamus (Sumber Gambar : http://faculty.kfupm.edu.sa/)
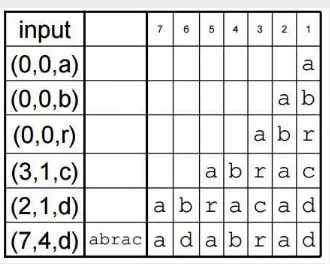
Berikut adalah proses decoding pada Slide Dictionary Algorithm: Langkah 1. Baca seluruh data untuk inisialisasi pada kamus. Langkah 2. Baca simbol yang dikodekan / tidak dikodekan. Langkah 3. Jika bendera menunjukkan string yang dikodekan:
Baca panjang dikodekan dan offset, kemudian salin jumlah tertentu simbol dari kamus ke output didekode.
Jika tidak, membaca karakter berikutnya dan tulis terjemahan pada output.
Langkah 4. Pergeseran salinan simbol ditulis ke output didekode ke dalam kamus.
Langkah 5. Ulangi langkah 2 sampai semua input selesai diterjemahkan.
7
yang digunakan pada LZMA.
Gambar 4 Proses Decoding pada Skema Pergeseran Kamus (Sumber Gambar : http://faculty.kfupm.edu.sa/)
Delta Encoding
Delta encoding adalah aliran (stream) simbol yang dikompresi sebagai perbedaan antara simbol saat ini dan simbol sebelumnya. Hal ini akan mengakibatkan kompresi untuk setiap aliran data membutuhkan lebih sedikit bit untuk mewakili perbedaan antara simbol. Penggunaan delta encoding paling sering ditemukan pada data audio atau alat pemonitor jantung karena memiliki banyak kesamaan dalam aliran datanya.
Proses Encoding
Simbol pertama dari delta stream dikodekan selalu ditulis tanpa pengkodean. Setelah itu, setiap simbol diganti dengan nilai sepanjang S bit yang mewakili nilai simbol saat ini dikurangi nilai pada simbol sebelumnya (atau sebaliknya jika Anda suka). Nilai pada S bit mewakili data yang berkisar antara -2S-1 to 2S-1-1. Menggunakan nilai S bit yang kecil dapat mempercepat proses kompresi, tetapi nilai yang terlalu kecil bisa membuat perbedaan ukuran simbol dari nilai S bit tidak muncul. Sehingga untuk mencegah ukuran delta encode yang terlalu besar karena nilai S bit, simbol escape digunakan sebagai simbol berikutnya yang tidak dikodekan dengan delta encoding sehingga simbol ast ini bisa digunakan sebagai output.
Prosesencodingpadadelta encoding dijelaskan sebagai berikut: Langkah 1. Tulis simbol pertama yang keluar tanpa pengkodean. Langkah 2. Baca simbol berikutnya dari input stream. Keluar bila EOF. Langkah 3. Hitung perbedaan antara simbol saat ini dan simbol sebelumnya. Langkah 4. Jika perbedaan dapat diwakili dalam S bit:
Tulis perbedaan pada output stream Kembali ke langkah 2
Langkah 5. Jika perbedaan tidak dapat diwakili dalam S bit: Tulis simbol escape (nilai minimum dalam S bit) Tulis simbol saat ini tanpa pengkodean
Proses Decoding
Proses decoding lebih mudah dari saat melakukan encoding. Simbol pertama dari delta stream selalu ditulis tanpa pengkodean yang dibaca kembali dan ditulis tanpa ada modifikasi. Setelah itu, baca simbol yang dikodekan sepanjang S bit. Jika simbol S bit adalah escape, maka baca simbol berikutnya dan tulis sebagai output, jika tidak, tulis simbol yang mewakili jumlah dan perbedaan dari simbol yang dikodekan sepanjang S bit sebelumnya.
Berikut adalah prosesdecodingpadadelta encoding:
Langkah 1. Salin simbol pertama pada output yang dikodekan.
Langkah 2. Baca simbol berikutnya dari input stream. Keluar bila EOF. Langkah 3. Jika delta saat ini adalah simbol escape:
Baca simbol berikutnya sebagai simbol yang tidak dikodekan Tulis simbol untuk pada output yang dikodekan
Kembali ke langkah 2
Langkah 4. Jika delta saat ini tidak simbol escape:
Hitung nilai dari simbol sebelumnya ditambah delta Tulis simbol yang dihasilkan untuk output yang dikodekan Kembali ke langkah 2
Range Coder
Fokus utama dari Range Coder adalah efisiensi pada Sliding Dictionary Algorithm, yaitu menghapus redudansi pada teks. Selain itu Range Coder mengkodekan semua simbol pesan kedalam nomor tunggal untuk mencapai rasio kompresi yang lebih besar (Arohi 2014).
Prosedur dalam range coder :
− Range encoding mengkodekan seluruh karakter dalam satu rentang
− Setiap karakter dihitung jumlah dan kemungkinan muncul
− Nilai awal dibagi sebanyak jumlah karakter, dan dibagi berdasarkan urutan munculnya karakter
− Setiap karakter dikodekan sesuai kemungkinan munculnya, dengan mengurangi kisaran saat turun ke hanya bahwa sub-range yang sesuai dengan karakter berikutnya yang akan dikodekan.
− Ketika semua simbol telah dikodekan, hanya mengidentifikasi sub-rentang untuk mengkomunikasikan seluruh pesan
Unicode
9
seluruh dunia. Pada tahun 1988, Joe Becker dan Lee Collins memperkenalkan suatu skema baru yang dapat merepresentasikan karakter dari seluruh dunia yaitu unicode (Singh 2013).
Unicodeadalah skema untuk merepresentasikan setiap karakter dalam nomor dan kode unik yang dijadikan sebagai rujukan(Vineet 2013). Tujuan dari unicode
adalah menyatukan skema karakter dari seluruh dunia sehingga dapat digunakan dimana saja tanpa adanya ketidakcocokan dari pengkodean karakter dari setiap bagian dunia. Pengkodean unicode yang paling umum disebut sebagai sebagai UTF-n, dimana UTF adalah singkatan dari unicode Transformation Format dan n adalah angka yang menentukan jumlah bit yang digunakan dalam encoding
(Satyajeet 2014). Dua jenis pengkodean unicode yang paling sering digunakan adalah UTF-8 dan UTF-16. UTF-8 menggunakan pengkodean 1x8bit untuk karakter pada rentang 0000h 007Fh, 2x8bit untuk karakter pada rentang 0080h -07FFh, dan 3x8bit untuk karakter pada rentang 0800h - FFFFh, sedangkan UTF16 menggunakan pengkodean 1x16bit untuk karakter pada rentang 0000h -FFFFh.
3 METODE
Metode pada penelitian terdiri dari empat tahap, yaitu analisis masalah, proses pembuatan QR code, proses pengujian QR code, dan evaluasi dari penelitian yang telah dilakukan.
Analisis Masalah
Pada tahap ini dilakukan analisis terhadap jenis informasi yang akan dikompresikan menggunakan algoritme kompresi data lossless untuk diproses menjadi bentuk akhir berupa QR code. Jenis informasi yang akan diolah pada penelitian ini adalah data pribadi dalam bentuk teks. Pada data pribadi terdapat informasi berupa Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), Surat Tanda Naik Kendaraan (STNK) dan Kartu Keluarga (KK). Setiap data pribadi akan dicatat dalam bentuk teks, kemudian diuji menggunakan huruf depan besar, seluruh huruf besar, dan menggunakan karakter spesial. Selanjutnya setiap data pribadi akan dikompresi menggunakan kompresi data lossless untuk dibuat kedalam bentuk QR code. Data pribadi yang belum dikompresi akan dibuat kedalam QR code untuk membandingkan seberapa besar pengurangan ukuran yang terjadi pada QR code dengan informasi sebelum dan sesudah kompresi.
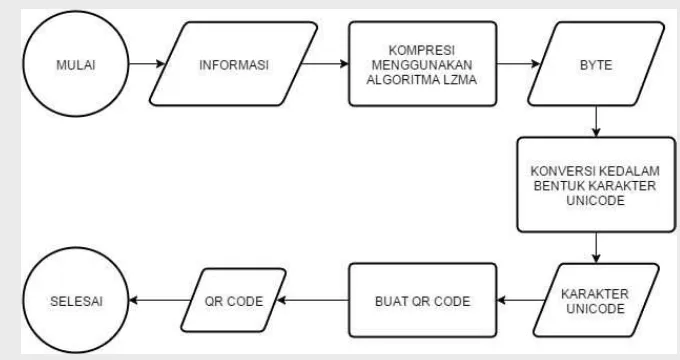
Proses pembuatanQR codedengan informasi terkompresi
Pada tahap ini akan dijelaskan bagaimana proses kompresi informasi hingga menghasilkan data yang digunakan dalam membuat QR code seperti yang dijelaskan pada Gambar 5. Langkah-langkah yang dilakukan adalah sebagai berikut :
1. Informasi berupa data pribadi dibuat dalam bentuk teks
2. Informasi dalam bentuk teks dikompresikan menggunakan algoritme kompresi datalossless
3. Hasil dari kompresi akan didapatkan nilai berupa byte
5. Didapatkan karakter unicode yang akan diproses menjadiQR code
6. BuatQR codedari karakter unicode menggunakan pengkodean UTF-8 7. QR codedengan informasi terkompresi selesai dibuat
Gambar 5 Proses pembuatanQR codedengan Informasi Terkompresi
Pada proses encoding, informasi pada Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), Surat Tanda Naik Kendaraan (STNK) dan Kartu Keluarga (KK) akan ditulis dalam bentuk teks jenis penulisan yang berbeda untuk dikompresi. Setelah ditulis dalam bentuk teks, selanjutnya adalah mengkompresikan informasi tersebut menggunakan algoritme LZMA.
Berikut adalah proses kompresi data lossless menggunakan algoritme LZMA : 1. Inisialisasi kamus untuk pengenalan nilai.
2. Baca karakter yang belum terkodekan untuk mencari nilai terpanjang. 3. Cari kecocokan karakter yang memiliki nilai terpanjang dalam kamus.
4. Jika kecocokan karakter ditemukan lebih besar dari atau sama dengan batas minimum:
a) Tulis poin untuk offset dan panjang karakter pada pengkodean output. b) Jika tidak, tulis poin dan simbol untuk melewati karakter pada
pengkodean output.
5. Geser simbol untuk melewati karakter pada bagian karakter yang tidak dikodekan dalam kamus..
6. Baca sejumlah simbol yang tidak dikodekan sebanyak jumlah simbol yang ditulis pada langkah 4.
7. Ulangi dari Langkah 3 sampai semua input selesai dikodekan.
Setelah mendapatkan output berupa byte, selanjutnya adalah mengkonversikan nilai tersebut ke dalam bentuk karakter Unicode. Proses ini perlu dilakukan karena secara tidak langsung QR code generator dan reader selalu memproses input data sebagai karakter 8-bit. Apabila tetap menggunakan byte yang didapat, maka QR code generator akan membaca setiap input sebagai karakter 8-bit sehingga ukuran dariQR codeakan membengkak.
Pada unicode ada jenis karakter yang tidak dapat dicetak pada QR code
11
Hal ini dikarenakan QR code scanner hanya membaca data mentah (raw byte) yang kemudian dikonversikan ke dalam karakter sesuai dengan jenis encoding
yang dipakai (numerik, alphanumerik, 8-bit, atau kanji). Selain itu kemampuan dari QR code generator dalam melakukan encoding dan QR code scanner juga perlu diperhatikan agar dapat membuat QR code dan membaca data pada QR code dengan baik. Setelah mendapatkan karakter mana saja yang dapat diproses oleh QR code generator, selanjutnya adalah melakukan modifikasi pada karakter
unicode sehingga seluruhnya dapat diproses pada QR code generator. Berikut adalah algoritme yang kami gunakan untuk melakukan konversi byte ke karakter
Unicode:
Setelah mengkonversikan byte ke dalam karakter Unicode, selanjutnya adalah membentukQR codedari karakterunicodeyang dimiliki.
Berikut adalah proses pembentukanQR codeyang telah disederhanakan: 1. Analisa isi data untuk menentukan jenisencodingyang akan digunakan 2. Melakukan prosesencodinguntuk data yang dimiliki
3. MembuatError Correction coding
4. Membentuk data akhir yang akan diproses padaQR code
5. Melakukan alokasi data pada matriks
6. Memproses data maskinguntuk menentukan jenis masking yang digunakan padaQR code
7. Memproses informasi format dan versiQR code
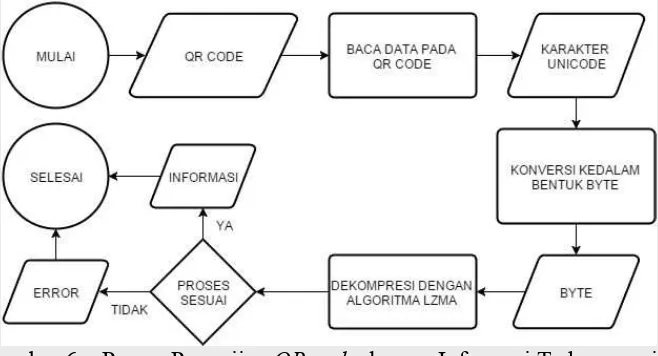
Proses PengujianQR codedengan Informasi Terkompresi
QR code yang dengan informasi terkompresi harus diuji untuk mendapatkan informasi asli. Pada tahap ini akan dijelaskan bagaimana proses membaca data yang telah dikompresi pada QR code seperti yang dijelaskan pada Gambar 6. Langkah-langkah yang dilakukan adalah sebagai berikut :
1. MembacaQR codeuntuk mendapatkan data berupa karakterUnicode. 2. Karakter unicode didapat
3. Mengkonversi karakter unicode yang didapat ke dalam bentuk byte dengan menggunakan proses terbalik dengan pada saat melakukan prosesencoding
4. byte didapat
5. Melakukan proses dekompresi menggunakan algoritme LZMA dari byte yang didapat.
Gambar 6 Proses PengujianQR codedengan Informasi Terkompresi
Prosesdecoding terlebih dahulu mendapatkan isi data dariQR codedengan cara menscanQR code tersebut. Setelah melakukan scan terhadapQR codemaka didapatkan data berupa karakter Unicode. Langkah selanjutnya adalah mengkonversi karakterunicodetersebut ke dalam bentuk bilangan byte.
Setelah mendapatkan byte, selanjutnya adalah mengembalikan informasi asli. Proses pengembalian pada algoritme LZMA lebih cepat dibanding pada saat melakukanencoding.
Berikut adalah proses dekompresi pada LZMA : 1. Inisialisasi kamus untuk nilai awal.
2. Baca poin untuk pengkodean / bukan pengkodean. 3. Jika poin menunjukkan karakter pengkodean:
a) Baca panjang karakter pengkodean dan offset, kemudian salin jumlah tertentu simbol dari kamus ke output untuk decode.
b) Jika tidak, baca karakter berikutnya dan menulis ke output diterjemahkan.
4. Pergeseran salinan simbol ditulis ke output didekode ke dalam kamus. 5. Ulangi dari Langkah 2, sampai semua seluruh input telah diterjemahkan.
Bila tidak ada kesalahan pada saat melakukan encoding / decoding, maka informasi asli akan didapatkan kembali. Tetapi bila ada kesalahan pada saat melakukan encoding / decoding, maka informasi asli akan berubah atau tidak dapat dikembalikan.
Evaluasi Perbandingan UkuranQR Code
13
Berikut adalah persamaan yang digunakan untuk menghitung ukuran QR pada code.
QR= 8 + (APxm) + (DAPxn) (1)
Keterangan :
QR = UkuranQR code
AP = Aligment Pattern(panjang= 5)
DAP = JumlahData areayang berada di antaraAligment Pattern m = Banyaknya AP pada satu garis vertikal / horizontal
n = Banyaknya DAP pada satu garis vertikal / horizontal
Sehingga
QRk=QR2 /QR1 (2)
Keterangan :
QRK = Perbandingan ukuran QR code menggunakan data setelah kompresi dan sebelum kompresi
QR1 = UkuranQR codemenggunakan data sebelum kompresi
QR2 = UkuranQR codemenggunakan data setelah kompresi
4 HASIL DAN PEMBAHASAN
Proses pembuatanQR codedengan informasi terkompresi
Informasi dari data pribadi ditulis dalam bentuk teks sebagai untuk dikompresi menggunakan algoritma kompresi datalosslesssebagai berikut.
Nama Wahyu Juliarianto
Seluruh proses pada LZMA menggunakan byte, sehingga pada proses
77 69 6E 61 6E 09 42 65 6C 75 6D 20 4B 61 77 69 6E 0A 50 65 6B 65 72 6A 61 61 6E 09 50 65 6C 61 6A 61 72 2F 4D 61 68 61 73 69 73 77 61 0A 4B 65 77 61 72 67 61 6E 65 67 61 72 61 61 6E 09 57 4E 49 0A 42 65 72 6C 61 6B 75 20 48 69 6E 67 67 61 09 39 2F 37 2F 32 30 31 38 0A
Dari proses kompresi akan diperoleh kumpulan byte seperti berikut.
5D 00 00 01 00 0C 01 00 00 00 00 00 00 00 27 18 49 A6 20 55 E7 0C 4D 60 07 98 1D 20 4A 4F 14 8F 13 5C AC 9D DF 5C 0A 76 0C E9 2C 50 5A 69 86 54 FE 8A 83 EE 8D D7 B7 44 24 3C A7 35 50 4E F8 D3 78 CB 16 DC 98 8F 22 5C D2 49 B7 73 11 24 B8 AA DC E5 68 E2 6F 3D EC EC DF 9F 7D 50 FC 71 28 67 0F 13 91 EB 70 C6 EA C8 3A 76 9C 7D C9 80 75 77 31 C9 E9 C5 A0 A9 81 EF C5 69 CB 7F 5D 79 0F 05 16 8F 1E 36 8B 51 64 D4 38 18 8F 5D 12 77 DE 98 68 6B 06 39 1D F6 B4 1D F5 4A 38 FD B0 2A BA 89 67 CF 75 7F CF BD 7E 1E 3F D4 D2 68 CB C9 05 F3 E7 B4 B7 FE 11 35 18 49 4F 70 68 D0 E5 14 3F 74 53 71 2E 2B 4E 22 C8 35 E9 DE E2 35 4D 12 AB 4F C9 CC CF 1B 0A D0 38 6F F5 66 16 73 92 01 61 B2 ED F5 1E 3F ED 5F 77 BB C0 99 2C 8E FF 0F 8F FF F7 0F AC 00
Datadari hasil kompresi digunakan untuk diproses menjadiQR code, karena
QR code generator belum memiliki pilihan untuk input jenis byte, maka data
yang dijadikan input harus dirubah menjadi karakter unicode. Bila data hasil kompresi berupa byte langsung diproses maka akan menghasilkan QR code generator akan membaca input sebagai karakter biner sehingga menghasilkan ukuranQR codeyang lebih besar dariQR codeyang menggunakan informasi asli seperti yang ditunjukkan pada Gambar 7.
Gambar 7 Perbandingan QR code menggunakan informasi asli (gambar kiri) dengan QR code menggunakan informasi hasil kompresi (output berupa byte, gambar kanan)
Untuk menghindari hal tersebut, setiap byte pada hasil kompresi dirubah menjadi karakter unicode sehingga menghasilkan nilai unicode baru seperti berikut.
]'I¦ UçM`
JO \¬ ß\
vé,PZi Tþ î ×·D$<§5PNøÓxËÜ "\ÒI·s$¸ªÜåhâo=ììß }Püq(g ëpÆêÈ:v }É uw1ÉéÅ © ïÅiË ]y - 6 QdÔ8
]wÞ hk9ö´õJ8ý°*º gÏu Ͻ~- ?ÔÒhËÉóç´·þ5IOphÐå?tSq.+N"È5éÞâ5M«OÉÌÏ
Ð8oõfs a²íõ- ?í_w»À , ÿ ÿ÷¬
Nilai unicode ini diproses menjadiQR code dengan pengkodean UTF-8 dan
15
8.
Gambar 8 QR code menggunakan informasi hasil kompresi dengan output berupa karakter unicode
Proses PengujianQR codedengan informasi terkompresi
Ketika informasi yang terdapat pada QR code diekstraksi menggunakan proses yang terbalik dengan pada saat melakukan kompresi, ternyata informasi asli tidak bisa didapatkan. Dari pengecekan didapatkan karakter unicode pada nilai 00h dan 0Ch tidak bisa diproses pada QR code sehingga karakter unicode
harus dimodifikasi agar bisa diproses seluruhnya. Berikut adalah modifikasi yang dilakukan untuk merubah nilai padaunicodesaat melakukan prosesencoding.
for(i=0; i<len; i++) {
dec = txt.charCodeAt(i); if (dec > 104h) {
hen = dec - FFh; } else { hen = dec - 1h; }
h = hen.toString(16); if( h.length==1 ) h='0'+h; hex += h;
if( i<len-1) hex+=del; }
document.calcform.hex.value = hex;
Dari modifikasi yang dilakukan, didapatkan rentang nilai baru yaitu 01h-100h + 10Bh. Nilai tersebut dirubah menjadi karakter unicode sebagai berikut.
^Č(J§!VèČNa - !KP ]- à]
wČê-Q[j Uÿ ï ظE=¨6QOùÔyÌÝ #]ÓJ¸t¹«Ýæiãp>ííà ~Qýr)h ìqÇëÉ;w ~Ê vx2ÊêÆ¡ª ð
ÆjÌ ^z 7 ReÕ9 ^xß il
:- ÷µ- öK9þ±+» hÐv о @ÕÓiÌÊô赸ÿ6JPqiÑæ@uTr/,O#É6êßã6N¬PÊÍÐ
Ñ9pögt b³îö@î`x¼Á - Ā Āø
Gambar 9 QR code menggunakan informasi hasil kompresi dengan output
berupa karakterunicodehasil modifikasi
QR code diuji kembali untuk mendapatkan informasi asli. Dikarenakan informasi asli berhasil didapatkan maka untuk data algoritme yang telah dimodifikasi dapat digunakan untuk informasi berikutnya dan tidak diperlukan modifikasi lagi. Berikut adalah modifikasi yang yang digunakan pada decoding
sebelum proses dekompresi LZMA.
Evaluasi Perbandingan UkuranQR Code
Setiap informasi berupa Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), Surat Tanda Naik Kendaraan (STNK) dan Kartu Keluarga (KK) diambil sample sebanyak 10 yang diuji dengan 3 kali pengujian yang berbeda. Pada pengujian pertama informasi ditulis menggunakan huruf besar dan kecil, pengujian kedua informasi ditulis menggunakan hanya huruf besar, dan pengujian ketiga informasi ditulis menggunakan huruf besar dan kecil dengan karakter spesial sebagai pengganti huruf vokal. Setiap informasi dikompresi menggunakanlossless compression data algorithmdengan hasil kompresi berupa karakterunicode. Karakter unicodeitulah yang diproses menjadi QR code. Hasil dariQR codemenggunakan informasi terkompresi akan dibandingkan denganQR code menggunakan informasi tidak terkompresi untuk menguji apakah ukuran
QR codemenjadi lebih kecil dari sebelumnya.
17
kompresi yang baik. U.Q menunjukkan persentase pada ukuran QR code, bila nilai pada U.Q lebih kecil dari 100 maka ukuran QR code yang menggunakan informasi terkompresi lebih kecil dari ukuran QR code semula. Sebaliknya bila U.Q lebih besar dari 100 maka ukuran QR code yang menggunakan informasi terkompresi lebih besar dari ukuranQR codesemula.
Tabel 1. Pengaruh Tingkat Kompresi dengan Ukuran QR codepada Kartu Tanda Penduduk (KTP)
Informasi Pengujian 1 Pengujian 2 Pengujian 3
Data I.A Q.A I.K Q.K T.K U.Q I.A Q.A I.K Q.K T.K U.Q I.A Q.A I.K Q.K T.K U.Q
Data pribadi kedua yang digunakan adalah Surat ijin Mengemudi (SIM) yang berisi informasi nama, alamat, tempat, tgl lahir, tinggi, pekerjaan, no.sim, dan masa berlaku untuk 1 orang. Tabel 2 menunjukkan perbandingan pada informasi sebelum dan sesudah kompresi. Seperti pada pengujian menggunakan data Kartu Tanda Penduduk (KTP), ukuran data mengalami penurunan setelah kompresi pada pengujian 1 dan 2, tetapi ukuran data pada pengujian 3 justru meningkat dengan nilai minus pada T.K. Nilai pada U.Q tidak jauh berbeda dengan pengujian yang dilakukan pada SIM.
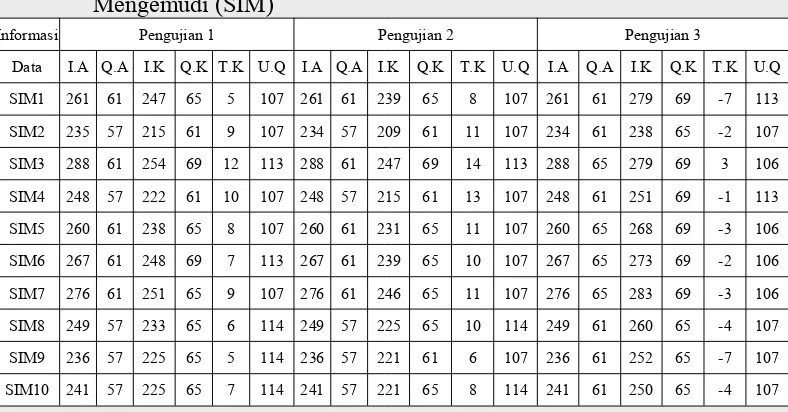
Tabel 2. Pengaruh Tingkat Kompresi dengan Ukuran QR code pada Surat Izin Mengemudi (SIM)
Informasi Pengujian 1 Pengujian 2 Pengujian 3
Data pribadi ketiga yang digunakan adalah Surat Tanda Nomor Kendaraan (STNK) berisi nomor polisi, nama pemilik, alamat, merk/type, jenis model, tahun pembuata, tahun perakitan, isi silinder, warna, nomor rangka, nomor mesin, nomor bkbp, warna tnke, bahan bakar, kode lokasi, jumlah berat yang dianjurkan, diperbolehkan, no. urut pendapt, dan masa berlaku untuk 1 jenis kendaraan. Tabel 3 menunjukkan perbandingan pada informasi sebelum dan sesudah kompresi. Nilai T.K pada STNK lebih baik bila dibandingkan dengan KTP dan SIM, hal ini bisa ditunjukkan dari informasi yang lebih banyak sehingga memungkinkan untuk lebih banyak tingkat redudansi yang dimiliki. Ketiga pengujian menunjukkan tidak ada ukuran data yang bertambah setelah mengalami proses kompresi. Nilai pada U.Q tidak mengalami penurunan meskipun memiliki tingkat kompresi hingga 22 pada pengujian 2. Keunikan terlihat pada pengujian 3 yaitu hampir tidak ada penurunan atau peningkatan ukuran pada QR code, padahal tingkat kompresi yang dimiliki lebih rendah bila dibandingkan dengan pengujian 1 dan 2. Hal ini bisa disebabkan banyaknya data yang dimiliki pada STNK bisa menutupi penggunaan karakter spesial.
Tabel 3. Pengaruh Tingkat Kompresi dengan UkuranQR codepada Surat Tanda Nomor Kendaraan (STNK)
Informasi Pengujian 1 Pengujian 2 Pengujian 3
Data I.A Q.A I.K Q.K T.K U.Q I.A Q.A I.K Q.K T.K U.Q I.A Q.A I.K Q.K T.K U.Q
19
Tabel 4. Pengaruh Tingkat Kompresi dengan Ukuran QR code pada Kartu Keluarga (KK)
Informasi Pengujian 1 Pengujian 2 Pengujian 3
Data I.A Q.A I.K Q.K T.K U.Q I.A Q.A I.K Q.K T.K U.Q I.A Q.A I.K Q.K T.K U.Q
Selanjutnya adalah membentuk data perbandingan pengujian tingkat kompresi dengan mengambil nilai pada kolom T.K dan serta ukuran QR code
dengan mengambil nilai pada kolom U.Q. Data ini dipisahkan menjadi 3 grafik sesuai dengan 3 pengujian yang dilakukan. Sebagai evaluasi 3 grafik pengujian dikumpulkan dalam 1 grafik untuk melihat pengaruh tingkat kompresi pada informasi terhadap ukuran padaQR code.
Gambar 9 menunjukkan pengaruh tingkat kompresi data dengan ukuran QR code untuk penulisan informasi menggunakan huruf besar dan kecil. Gambar 10 menunjukkan pengaruh tingkat kompresi data dengan ukuran QR code untuk penulisan informasi menggunakan huruf kecil. Gambar 11 menunjukkan pengaruh tingkat kompresi data dengan ukuran QR code untuk penulisan informasi menggunakan huruf besar dan kecil dengan karakter spesial sebagai pengganti huruf vokal. Gambar 12 menunjukkan evaluasi pada pengaruh tingkat kompresi data dengan ukuran pada QR code dengan menggabungkan seluruh hasil pengujian yang dilakukan.
Pengujian data pribadi menggunakan huruf besar dan kecil
Gambar 9 menunjukkan informasi pada KTP, SIM, dan STNK mengalami peningkatan pada ukuran QR dengan tingkat kompresi mencapai 20 sedangkan ukuran QR kompresi pada KK mengalami pengurangan ukuran QR code hingga 90 dari ukuran semula dengan tingkat kompresi mencapai lebih dari 35.
Gambar 9 Pengaruh tingkat kompresi data dengan ukuran QR code untuk penulisan informasi menggunakan huruf besar dan kecil
Pengujian data pribadi menggunakan hanya huruf besar
Gambar 10 menunjukkan tingkat kompresi pada KTP, SIM, STNK, dan KK lebih kecil bila dibandingkan dengan pengujian pertama, hal ini dikarenakan seluruh huruf yang ditulis dengan seluruh huruf besar memungkinkan untuk mengalami redudansi yang lebih banyak dibandingkan menggunakan huruf besar dan kecil seperti pada pengujian 1. Disayangkan proses ini tidak dapat menghasilkan ukuran QR kompresi yang lebih kecil dari ukuran QR asli pada KTP, SIM, dan STNK. Pada KK mengalami tingkat kompresi hingga lebih dari 40 dan berhasil mengurangi ukuran QR kompresi hingga mendekati 90 atau lebih rendah dari ukuran QR asli.
Gambar 10 Pengaruh tingkat kompresi data dengan ukuran QR code untuk penulisan informasi hanya menggunakan huruf besar
Pengujian data pribadi menggunakan huruf besar dan kecil dengan karakter spesial sebagai pengganti huruf vokal
21
Gambar 11 Pengaruh tingkat kompresi data dengan ukuran QR code untuk penulisan informasi menggunakan huruf besar dan kecil dengan karakter spesial sebagai pengganti huruf vokal
Pengaruh tingkat kompresi terhadap ukuran padaQR code
Dari ketiga pengujian didapatkan bahwa pengurangan ukuran pada QR code paling banyak terjadi pada Kartu Keluarga (KK), sedangkan pada Kartu Tanda Penduduk (KTP), Surat Izin Mengemudi (SIM), dan Surat Tanda Naik Kendaraan (STNK) ukuran dari QR code justru bertambah. Hal ini dikarenakan informasi pada Kartu Keluarga lebih banyak memiliki data untuk diproses sehingga kemungkinan adanya redudansi lebih tinggi dibandingkan dengan data pribadi lainnya.
Pengurangan ukuran pada QR code terjadi bila tingkat kompresi pada informasi mencapai minimal 25 seperti yang diperlihatkan pada Gambar 12. Hal ini dapat dijelaskan dari penggunaan karakterunicodedengan pengkodean UTF-8. Pada UTF-8, karakter unicode yang berada pada rentang dibawah 00h-7Fh dikodekan 1x8bit, sedangkan karakter unicode yang berada pada rentang 80H-7FFh dikodekan 2x8bit. Pada penelitian ini didapatkan rentang nilai 00h-FFh yang dikonversikan menjadi 00h-10Ch untuk menghindari adanya karakter unicode yang tidak dapat diproses menjadi QR code. Nilai tersebut didapatkan dari hasil percobaan untuk mencari karakterunicodemana yang tidak dapat diproses menjadiQR code.
Dari nilai tersebut didapatkan banyaknya karakter unicode dari hasil kompresi yang berada pada rentang 80h-1FFh mempengaruhi besarnya ukuran pada QR code. Sehingga dibutuhkan tingkat kompresi sebesar 70 dari ukuran semula atau lebih rendah bila jumlah karakter unicode yang berada pada rentang diatas 7Fh dari hasil kompresi sebesar 50.
Gambar 12 Pengaruh tingkat kompresi informasi terhadap tingkat kompresi pada
5 SIMPULAN
Dari penelitian dapat disimpulkan bahwa lossless data compression algorithm dapat digunakan untuk mengurangi ukuran pada QR code, tetapi ukuran pada QR code berkurang bila tingkat kompresi lebih tinggi dari 25, sedangkan hasil kompresi yang menunjukkan kurang dari 25 akan memperbesar ukuran QR code. Kemampuan QR code generator dalam mengkodekan setiap karakter unicode yang dikodekan dengan UTF-8 juga mempengaruhi dalam menghasilkan ukuran QR code, bila banyak karakter unicode yang tidak dapat diproses oleh QR code generator dapat menyulitkan dalam membuat QR code
23
DAFTAR PUSTAKA
Arohi AK, Kulkarni VS. 2014. FPGA Based Implementation of Data Compression Using Dictionary Based “LZMA” Algorithm. IRF International Conference. 15th June-2014. 978-93-84209-27-8.
Dey AS, et al. 2012. A New Technique to Hide Encrypted Data in QR codes.
International Conference on Internet Computing. 16th July 2014. 1-60132-220-8
Farizshah Mohammad, Abd Kamarulafirin. 2013. Space Saving Algorithm for Arabic Characters in QR code. Journal of Next Generation Information Technology(JNIT). Volume4, Number7, September 2013
Goel S, Singh AK. 2014.A Secure and Optimal QR code.International Journal of Computer Trends and Technology (IJCTT). Volume 1, Issue-5. September 2014. 2348-4039.
Goel S, Singh AK. 2014. Cost Minimization by QR code Compression. International Journal of Computer Trends and Technology (IJCTT). volume 15 number 4. September 2014. 157-161. 2231-5381.
Leavline EJ., et, al. 2013.Hardware Implementation of LZMA Data Compression Algorithm. International Journal of Applied Information Systems (IJAIS) – ISSN : 2249-0868. Volume 5– No.4. March 2013. 2249-0868.
Kumar A, Nigam AJ. 2015.Implementation of 2D Optimal barcode (QR code) for Images. International Journal of Computer Applications Technology and Research. Volume 4- Issue 3. 179-183. 2319-8656.
Kodituwakku SR, Amarasinge U.S. 2010. Comparison of lossless data compression for Text Data. Indian Journal of Computer Science and Engineering. 416-425. 0976-5166.
Parekar PM, Thakare SS. 2014.lossless data compression Algorithm – A Review.
International Journal of Computer Science and Information Technologies,. Vol. 5 (1). 276-278. 2347-6680.
Parekar PM, Thakare SS. 2014.Hardware Implementation of lossless LZMA Data Compression Algorithm. Progress In Science and Engineering Research Journal. Vol.02 Issue: 03/06. May- June. 201-205. 2347-6680.
Porwal S, et al. 2013. Data Compression Methodologies for Lossless Data and Comparison between Algorithms. International Journal of Engineering Science and Innovative Technology (IJESIT). Volume 2, Issue 2. March 2013. 142-147. 2319-5967.
Satyajeet R. Shinge et al. 2014. An Encryption Algorithm Based on ASCII Value of Data. International Journal of Computer Science and Information Technologies, Vol. 5 (6) , 2014, 7232-7234
Singh U, Garg U. 2013. An ASCII value based text data encryption System. International Journal of Scientific and Research Publications, Volume 3, Issue 11, November 2013. ISSN 2250-3153
Sukhliya Vt, et al. 2013. Encryption and Decryption Algorithm using ASCII values with substitution array Approach. International Journal of Advanced Research in Computer and Communication Engineering Vol. 2, Issue 8, August 2013. 2278-1021
25
Lampiran
Tabel
Error Correction Code
pada
QR Code
29