ANALISIS DAN IMPLEMENTASI ALGORITMA MINIMAX
DENGAN OPTIMASI ALPHA BETA PRUNING
PADA PERMAINAN FIVE IN ROW
SKRIPSI
NUR JANNAH
061401081
PROGRAM STUDI S1 ILMU KOMPUTER
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
ANALISIS DAN IMPLEMENTASI ALGORITMA MINIMAX DENGAN OPTIMASI ALPHA BETA PRUNING
PADA PERMAINAN FIVE IN ROW
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Komputer
NUR JANNAH 0 6 1 4 0 1 0 8 1
PROGRAM STUDI STRATA 1 ILMU KOMPUTER DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : ANALISIS DAN IMPLEMENTASI
ALGORITMA MINIMAX DENGAN OPTIMASI ALPHA BETA PRUNING
Kategori : SKRIPSI
Nama : NUR JANNAH
Nomor Induk Mahasiswa : 061401081
Program Studi : SARJANA (S1) ILMU KOMPUTER
Departemen : ILMU KOMPUTER
Fakultas : MATEMATIKA DAN ILMU
PENGETAHUAN ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 4 Desember 2010
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Syahriol Sitorus, S.Si, MIT Maya Silvi Lydia, B.Sc, M.Sc NIP 197103101997031004 NIP 197401272002122001
Diketahui/Disetujui oleh
Departemen Ilmu Komputer FMIPA USU Ketua,
PERNYATAAN
ANALISIS DAN IMPLEMENTASI ALGORITMA MINIMAX DENGAN OPTIMASI ALPHA BETA PRUNING
PADA PERMAINAN FIVE IN ROW
SKRIPSI
Saya mengakui bahwa skipsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 4 Desember 2010
PENGHARGAAN
Alhamdulillah, penulis ucapkan kepada Allah SWT yang senantiasa melimpahkan
rahmat dan karunia-Nya sehingga skripsi ini dapat diselesaikan dengan baik.
Ucapan terima kasih penulis sampaikan kepada Ibu Maya Silvi Lydia, B.Sc, M.Sc selaku dosen pembimbing I dan Bapak Syahriol Sitorus, S.Si, MIT selaku dosen pembimbing II yang telah banyak membantu memberi panduan, masukan serta saran kepada penulis selama penulisan skripsi ini. Ucapan terima kasih juga turut penulis ucapkan kepada Bapak Prof.Dr.Tulus,M.Si dan Bapak Amer Sharif, S.Si, M.Kom selaku dosen pembanding I dan II. Ucapan terima kasih juga ditujukan kepada Bapak Prof. Dr. Muhammad Zarlis, Dekan dan Pembantu Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam, serta seluruh staf pengajar di Program Studi S1 Ilmu Komputer Universitas Sumatera Utara.
Ucapan terima kasih teristimewa penulis persembahkan kepada kedua orang tua tercinta, ayahanda Muhammad Yusuf dan ibunda Nur Azizah yang tak henti-hentinya mendoakan dan memberikan semangat serta dorongan kepada penulis serta ucapan terima kasih kepada seluruh keluarga, abang dan adik-adik tersayang, Yusrizal, Liska Rahayu dan Fara Dila yang telah memberikan banyak bantuan kepada penulis selama pengerjaan skripsi ini.
ABSTRAK
Keberadaan industri game yang berkembang pesat membuktikan bahwa masyarakat menaruh minat yang besar terhadap permainan komputer. Salah satu jenis game komputer yang beredar luas antara lain game kecerdasan buatan, misalnya catur, dan
Five In Row. Five In Row merupakan game logika yang membutuhkan strategi untuk
ANALYSIS AND IMPLEMENTATION OF MINIMAX ALGORITHM WITH ALPHA BETA PRUNING OPTIMIZATION
IN FIVE IN ROW GAME
ABSTRACT
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metode Penelitian 4
1.7 Sistematika Penulisan 5
Bab 2 Landasan Teori 6
2.1. Kecerdasan Buatan 6
2.2 Five In Row 7
2.2.1 Aturan Permainan Five In Row 8
2.2.2 Jenis Five In Row 9
2.3 Agen Cerdas 9
2.3.1 Perilaku Agen 10
2.3.2 Struktur Agen Cerdas 11
2.3.2.1 Agen Refleks Sederhana 12
2.3.2.2 Agen Refleks Berbasis Model 12 2.3.2.3 Agen Berbasis Tujuan (Goal Based Agent) 13 2.3.2.4 Agen Berbasis Kegunaan (Utility Based Agent) 14 2.3.3 Lingkungan Agen dan Sifatnya 15
2.4 Algoritma Pencarian 16
2.4.1 Minimax 17
2.4.2 Alpha Beta Pruning 19
2.4.3 Fungsi Evaluasi 21
2.5 Reinforcement Learning 21
2.6 Java 22
2.7.2 Class Diagram (Diagram Kelas) 26
2.7.3 Sequence Diagram 27
2.7.4 Use Case 28
Bab 3 Analisis dan Perancangan Aplikasi 29
3.1 Analisis Kebutuhan Aplikasi 29
3.1.1 Representasi Lingkungan 29
3.1.1.1 Representasi Material 30
3.1.2 Flowchart Aplikasi 30
3.1.3 Analisis Algoritma 32
3.1.4 Nilai Formasi 41
3.1.5 Fungsi Evaluasi 42
3.1.6 Proses Evaluasi Formasi 44
3.2 Perancangan Aplikasi 48
3.2.1 Perancangan Konseptual 49
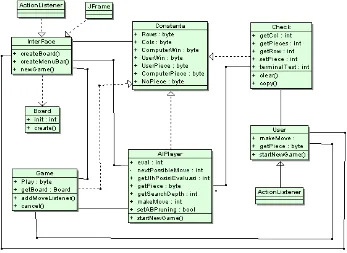
3.2.1.1 Deskripsi Class Diagram Aplikasi 49 3.2.1.2 Deskripsi Kebutuhan Fungsional Aplikasi 51 3.2.1.3 Deskripsi Proses dan Aktivitas Aplikasi 52 3.2.1.4 Deskripsi Sequence Diagram Aplikasi 57
3.2.2 Perancangan Fisik 63
3.2.2.1 Perancangan Antarmuka 63
3.2.2.2 Perancangan Piranti Masukan 67
Bab 4 Implementasi dan Pengujian 68
4.1 Implementasi Aplikasi 68
4.2 Spesifikasi Perangkat Lunak 68
4.3 Spesifikasi Perangkat Keras 68
4.4 Tampilan Aplikasi 69
4.4.1 Tampilan Utama 69
4.4.2 Tampilan Permainan 70
4.4.3 Tampilan Menu 72
4.4.4 Tampilan Game Play 72
4.5 Implementasi Algoritma 73
4.6 Pengujian Agen 76
4.6.1 Level Satu 76
4.6.2 Level Dua 77
4.6.3 Level Tiga 81
4.6.4 Level Empat 84
4.7 Pengujian Aplikasi 87
4.7.1 Pengujian Integrasi Aplikasi 88
4.7.1.1 Play 88
4.7.1.2 New Game 90
4.7.1.3 Level 91
4.7.1.4 About 92
4.7.2 Pengujian Aspek Antarmuka Aplikasi 93 4.7.3 Pengujian Aspek Penggunaan Aplikasi 95
4.7.5 Pengujian Aspek Kehandalan Aplikasi 99
Bab 5 Kesimpulan dan Saran 102
5.1. Kesimpulan 102
5.2. Saran 103
Daftar Pustaka 104
DAFTAR TABEL
Halaman
Tabel 2.1 Diagram UML 25
Tabel 3.1 Hubungan Kedalaman dan Jumlah Node 32 Tabel 3.2 Proses Pencarian Alpha Beta Pruning 38
Tabel 3.3 Nilai Formasi 41
Tabel 3.14 Proses About 56
Tabel 4.1 Pengujian Agen Level Satu 76
Tabel 4.2 Pengujian Agen Level Dua 78
Tabel 4.3 Pengujian Agen Level Tiga 81
Tebel 4.4 Perbandingan Pergerakan Max dan Min 83
Tabel 4.5 Pengujian Agen Level Empat 84
DAFTAR GAMBAR
Halaman
Gambar 2.1 Papan Permainan 8
Gambar 2.2 Ilustrasi Diagram Agen 10
Gambar 2.3 Skema Agen Refleks Sederhana 12
Gambar 2.4 Skema Agen Refleks Berbasis Model 13 Gambar 2.5 Skema Diagram Ageb Berbasis Tujuan 14 Gambar 2.6 Skema Diagram Agen Berbasis Kegunaan 15
Gambar 2.7 Pohon Minimax 19
Gambar 2.8 Pohon Alpha Beta Pruning 21
Gambar 2.9 Contoh Activity Diagram 26
Gambar 2.10 Contoh Class Diagram 27
Gambar 2.11 Contoh Sequence Diagram 28
Gambar 2.12 Contoh Use Case 28
Gambar 3.1 Papan Five In Row 29
Gambar 3.2 Representasi Material 30
Gambar 3.3 Flowchart Aplikasi Five In Row 31 Gambar 3.4 Flowchart Algoritma Minimax dengan Optimasi Alpha Beta Pruning 34 Gambar 3.5 Proses Pencarian Depth First Search 36
Gambar 3.6 Diagram Pohon Pencarian 37
Gambar 3.7 Posisi Sementara Permainan 42
Gambar 3.8 Contoh Kondisi Permainan 44
Gambar 3.9 Analisis Pohon Permainan 45
Gambar 3.10 Class Diagram 49
Gambar 3.11 Use Case Aplikasi 52
Gambar 3.12 Activity Diagram Play 54
Gambar 3.13 Activity Diagram New Game 55
Gambar 3.14 Activity Diagram Level 56
Gambar 3.15 Activity Diagram About 57
Gambar 3.16 Komponen Play 58
Gambar 3.17 Sequence Diagram Play 59
Gambar 3.18 Komponen New Game 60
Gambar 3.19 Sequence Diagram New Game 60
Gambar 3.20 Komponen Level 61
Gambar 3.21 Sequence Diagram Level 62
Gambar 3.22 Komponen About 62
Gambar 3.23 Sequence Diagram About 63
Gambar 3.24 Interface Aplikasi 64
Gambar 3.25 Submenu Game 65
Gambar 3.26 Submenu About 65
Gambar 3.28 Message Dialog Kalah 66
Gambar 3.29 Message Dialog Menang 66
Gambar 3.30 Message Dialog Seri 66
Gambar 4.1 Papan Permainan 69
Gambar 4.2 Kondisi Akhir Permainan 70
Gambar 4.3 Message Dialog 71
Gambar 4.4 Menu Aplikasi 72
Gambar 4.5 Tampilan Game Play 73
Gambar 4.6 Diagram Hasil Evalausi Aspek Antarmuka 94 Gambar 4.7 Diagram Penilaian Aspek Antarmuka 95 Gambar 4.8 Diagram Hasil Evaluasi Aspek Penggunaan 96 Gambar 4.9 Diagram Penilaian Aspek Penggunaan Aplikasi 97 Gambar 4.10 Diagram Hasil Evaluasi Penilaian Aplikasi 98
Gambar 4.11 Diagram Penilai Aplikasi 99
ABSTRAK
Keberadaan industri game yang berkembang pesat membuktikan bahwa masyarakat menaruh minat yang besar terhadap permainan komputer. Salah satu jenis game komputer yang beredar luas antara lain game kecerdasan buatan, misalnya catur, dan
Five In Row. Five In Row merupakan game logika yang membutuhkan strategi untuk
ANALYSIS AND IMPLEMENTATION OF MINIMAX ALGORITHM WITH ALPHA BETA PRUNING OPTIMIZATION
IN FIVE IN ROW GAME
ABSTRACT
BAB I
PENDAHULUAN
1.1 Latar Belakang
Kecerdasan buatan (Artificial Intelligence) menyebabkan lahirnya berbagai teknologi
yang dapat dikatakan bersifat cerdas, misalnya permainan (game), sistem pakar
(expert system), jaringan saraf tiruan (artificial neural network) dan robotika.
Kecerdasan buatan ini dapat dimanfaatkan diberbagai bidang kebutuhan manusia,
misalnya hiburan. Dengan adanya hiburan, maka kejenuhan yang timbul akibat
kesibukan dan rutinitas yang tinggi dapat dihilangkan. Salah satu jenis hiburan adalah
game. Keberadaan industri game yang terus berkembang pesat serta semakin
maraknya peredaran perangkat keras game seperti Play Station, XBOX dan
sebagainya dapat dijadikan bukti bahwa masyarakat memang tertarik dan menaruh
minat pada bidang kecerdasan buatan yang satu ini. Bahkan dewasa ini aplikasi
permainan merupakan salah satu fitur yang harus terdapat dalam telepon selular.
Dahulu game hanyalah hiburan yang tidak terlalu diperhitungkan manfaatnya
bahkan cenderung dikatakan sia-sia. Namun kini keberadaan game dapat pula menjadi
salah satu sarana potesial guna meningkatkan kecerdasan serta melatih konsentrasi
otak, misalnya Chess, Go, Othello, Checkers, dan Five In Row yang tentunya berbasis
kecerdasan buatan, sehingga keterlibatan otak pemain sangat dibutuhkan untuk
mengatur strategi mengalahkan komputer.
Game Five In Row merupakan game logika yang membutuhkan pola pikir dalam
menyusun strategi untuk mengalahkan lawan. Five In Row telah dikenal sejak
berbeda. Jepang misalnya lebih mengenal Five In Row sebagai Gomoku, dan di
Indonesia lebih dikenal dengan nama Catur Jawa. Five In Row merupakan sebuah
permaianan berjenis board-game berukuran minimal 8 x 8 kotak yang dimainkan oleh
2 (dua) pemain. Setiap pemain harus mengisi kotak papan permainan dengan bidak
masing-masing ( hitam atau putih) sehingga membentuk sebuah garis baik vertikal,
horizontal ataupun diagonal dengan jumlah lima kepingan. Sedangkan pemain lawan
berusaha menghalangi kemenangan pemain lain sekaligus berusaha memenangkan
permainan.
Pada umumnya game komputer berjenis board-game termasuk catur, Checkers,
dan Five In Row merupakan game dua pemain (two-player) dengan
perfect-information. Dimana terdapat dua pemain yang berlawanan dan bergiliran,
masing-masing memandang kegagalan lawan sebagai kesuksesannya (Pearl, 1984). Yang
dimaksud perfect information adalah setiap pemain mengetahui persis bagaimana
posisi lawan dan pilihan langkah yang tersedia, berbeda dengan permainan kartu
dimana pemain tidak mengetahui bagaimana posisi kemenangan lawan.
Salah satu algoritma yang digunakan untuk game Five In Row adalah Minimax.
Minimax merupakan algoritma yang digunakan untuk menentukan pilihan langkah
selanjutnya agar memperkecil kemungkinan kehilangan nilai maksimal. Algoritma ini
mendeskripsikan kondisi apabila terdapat pemain yang mengalami keuntungan,
pemain lain akan mengalami kerugian senilai dengan keuntungan yang diperoleh
lawan dan sebaliknya. Algoritma Minimax adalah algoritma berupa pohon pencarian
yang akan menelusuri setiap node untuk memperoleh hasil yang maksimum, namun
jika kedalaman dan percabangan pohon terlalu besar maka algoritma Minimax akan
memerlukan waktu yang sangat lama untuk mengambil keputusan. Untuk
mempersingkat waktu pencarian sekaligus sebagai optimasi, maka digunakanlah
algoritma Alpha Beta Pruning. Alpha Beta Pruning merupakan algoritma yang akan
1.2 Rumusan Masalah
Penelitian ini memiliki beberapa perumusan masalah, yaitu:
a. Bagaimana membangun sebuah aplikasi permainan berbasis kecerdasan buatan
yang mampu mengalahkan user.
b. Bagaimana mengoptimasikan algoritma Minimax dengan Alpha Beta Pruning
yang mampu mengambil keputusan terbaik disetiap langkah.
c. Bagaimana mengolah aplikasi agar mampu bermain secara optimal dalam
waktu yang relatif singkat.
1.3 Batasan Masalah
Penelitian ini dibatasi pada:
a. Ukuran papan Five In Row adalah 10 x 10.
b. Pemain pertama adalah user.
c. Level permainan sampai dengan 6 tingkat.
d. Aplikasi ini dibangun dengan menggunakan bahasa pemrograman Java.
1.4 Tujuan Penelitian
Penelitian ini dilakukan dengan beberapa tujuan:
a. Menganalisis dan mengimplementasikan algoritma Minimax dengan optimasi
Alpha Beta Pruning pada permainan Five In Row sehingga dapat mengambil
keputusan yang cepat dan tepat.
b. Membangun aplikasi game Five In Row berbasis kecerdasan buatan.
1.5 Manfaat Penelitian
Beberapa manfaat dari penelitian ini:
a. Meningkatkan kreativitas user dalam menyusun strategi untuk mengalahkan
Five In Row berbasis kecerdasan buatan.
c. Sebagai literatur dan landasan untuk penelitian di masa yang akan datang.
1.6 Metodologi Penelitian
Langkah-langkah dalam pengerjaan Tugas Akhir ini antara lain :
1. Studi Literatur
Penulisan ini dimulai dengan studi kepustakaan yaitu mengumpulkan bahan-bahan
referensi baik dari buku, artikel, jurnal, makalah, maupun situs internet mengenai
algoritma Minimax dan Alpha Beta Pruning serta beberapa referensi lainnya untuk
menunjang pencapaian tujuan tugas akhir.
2. Analisis Sistem dan Program.
Pada tahap ini akan dilakukan analisis terhadap pemberian bobot nilai game tree
Minimax dan Alpha Beta Pruning pada pohon permainan Five In Row.
3. Perancangan Sistem.
Perancangan ini ditujukan untuk membuat desain aplikasi yang bersifat user
friendly dan mudah digunakan.
4. Pengkodean.
Pada tahap ini sistem yang telah dirancang kemudian diimplementasikan ke dalam
bahasa pemrograman Java.
5. Pengujian.
Pada tahap ini dilakukan pengujian program dan mencari kesalahan pada program
hingga program itu dapat berjalan seperti yang diharapkan. Selain itu juga akan
dilakukan pengujian aplikasi kepada user yang akan bertindak sebagai responden.
6. Penyusunan laporan dan kesimpulan akhir.
Menyusun laporan hasil analisis dan implementasi ke dalam format penulisan tugas
1.7 Sistematika Penulisan
Sistematika penulisan tugas akhir ini dibagi menjadi lima bab, yaitu sebagai berikut :
BAB 1 PENDAHULUAN
Berisi penjelasan mengenai latar belakang, rumusan masalah,
batasan masalah, tujuan penulisan, manfaat penulisan, dan
metodologi penelitian.
BAB 2 LANDASAN TEORI
Berisi pembahasan teori-teori yang mendukung pembahasan
bab selanjutnya yang diperoleh dari referensi.
BAB 3 ANALISIS DAN PERANCANGAN APLIKASI
Berisi analisis algoritma dan penerapannya pada permainan Five
In Row serta perancangan aplikasinya yang dimodelkan dengan
UML (Unified Modelling Language).
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi tentang implementasi aplikasi serta pengujiannya,
baik pengujian secara manual maupun pengujian terhadap
responden.
BAB 5 PENUTUP
Berisi rangkuman kesimpulan dan saran yang diperoleh selama
BAB 2
LANDASAN TEORI
2.1 Kecerdasan Buatan
Artificial Intelligence atau kecerdasan buatan merupakan cabang dari ilmu komputer
yang konsern dengan pengautomatisasi tingkah laku cerdas (Desiani dan Arhami,
2006).
Pengertian lain menyebutkan bahwa kecerdasan buatan adalah salah satu
bagian ilmu komputer yang membuat agar mesin (komputer) dapat melakukan
pekerjaan seperti dan sebaik yang dilakukan oleh manusia (Kusumadewi, 2003).
Sedangkan Kristanto menyatakan bahwa kecerdasan buatan adalah bagian dari
ilmu pengetahuan komputer yang khusus ditujukan dalam perancangan otomatisasi
tingkah laku cerdas dalam sistem kecerdasan komputer. Sistem memperlihatkan
sifat-sifat khas yang dihubungkan dengan kecerdasan dalam kelakuan yang sepenuhnya
bisa menirukan beberapa fungsi otak manusia, seperti pengertian bahasa, pengetahuan,
pemikiran, pemecahan masalah dan sebagainya (Kristanto, 2004).
Dari beberapa pengertian di atas, dapat ditarik kesimpulan bahwa kecerdasan
buatan merupakan bagian dari ilmu komputer yang menitikberatkan pada perancangan
otomatisasi tingkah laku cerdas. Namun, defenisi yang telah disebutkan di atas belum
cukup memadai sebab istilah ‘cerdas’ itu sendiri belum dipahami sepenuhnya.
Kecerdasan alami dalam hal ini kecerdasan manusia berbeda dengan
kecerdasan buatan. Berikut beberapa kelebihan kecerdasan buatan dan kecerdasan
1. Kecerdasan buatan lebih tahan lama dan konsisten, bahkan dapat dikatakan
permanen sejauh program dan sistemnya tidak diubah.
2. Kecerdasan buatan lebih mudah diduplikasi dan disebarluaskan, berbeda
dengan kecerdasan alami yang membutuhkan proses belajar mengajar untuk
mentransfer kecerdasan.
3. Kecerdasan buatan dapat didokumentasi.
4. Kecerdasan buatan cenderung dapat mengerjakan perkerjaan lebih baik dan
lebih cepat dibanding dengan kecerdasan alami.
Kelebihan kecerdasan alami antara lain.
1. Kecerdasan alami bersifat kreatif. Kecerdasan alami dapat berkembang dengan
mudah dan dapat menciptakan kreasi baru.
2. Kecerdasan alami memungkinkan manusia untuk menggunakan pengalaman
secara langsung. Sedangkan pada kecerdasan buatan harus bekerja dengan
input-output simbolik.
3. Manusia dapat memanfaatkan kecerdasannya secara luas, tanpa batas.
Sedangkan kecerdasan buatan memiliki batasan.
2.2 Five In Row
Five In Row merupakan permainan logika berjenis board-game yang dimainkan oleh
dua pemain dimana setiap pemain berusaha menyusun lima buah bidak sewarna dalam
satu baris baik horizontal, vertikal maupun diagonal. Ukuran papan permainan Five In
Row bervariasi, mulai dari 7 x 7 kotak, 8 x 8 kotak hingga 19 x 19 kotak. Penulis
membatasi aplikasi Five In Row ini hanya pada papan berukuran 10 x 10 kotak.
Board-game adalah permainan dengan kepingan-kepingan yang ditempatkan
di atas, dipindahkan dari atau digerakkan di atas suatu permukaan khusus, permukaan
Sakata dan Ikawa dalam Allis (1992) menuliskan sejak beberapa dekade lalu
pemain Five In Row profesional asal Jepang menyatakan bahwa pemain yang pertama
kali mendapatkan giliran akan memenangkan permainan. Oleh sebab itu, penulis
menentukan pemain yang mendapat giliran pertama adalah user sehingga mereka
dapat menyusun strategi agar menang melawan komputer.
Gambar 2.1 Papan Permainan
2.2.1 Aturan Permainan Five In Row
Berikut ini adalah beberapa ketentuan dan peraturan dalam permainan Five In Row.
a. Papan permainan dalam keadaan kosong.
b. Papan permainan Five In Row berukuran 10 x 10 kotak.
c. Dua pemain, hitam dan putih melangkah bergiliran meletakkan keping
masing-masing di kotak yang kosong pada papan.
d. Pemain hitam adalah pemain pertama, dalam hal ini user.
e. Keping-keping yang telah diletakkan pada kotak tidak dapat dipindahkan
ataupun ditangkap.
f. Pemain yang pertama kali membentuk lima keping sewarna baik secara
vertikal, horizontal maupun diagonal dinyatakan menang.
g. Jika papan permainan telah penuh namun belum ada pemain yang membentuk
2.2.2 Jenis Five In Row
Sampai saat ini, Five In Row terus dikembangkan sehingga bermunculan berbagai
jenis Five In Row. Berikut adalah beberapa jenis permainan Five In Row yang ada saat
ini, namun permainannya memiliki beberapa batasan dan peraturan berbeda .
a. Five In Row dengan papan berukuran 19 x 19 kotak. Karena board-game
lainnya yaitu Go memiliki ukuran papan serupa, maka Five In Row pun turut
diciptakan sehingga pemain dapat mengembangkan strategi.
b. Profesional Five In Row yang umumnya disebut Renju, merupakan tipe
permainan asimetris yang tidak seimbang. Langkah pemain hitam dibatasi
tidak boleh membentuk overline (lebih dari 5 keping) ataupun membentuk
doubleline, misalnya tiga-tiga atau empat-empat.
Untuk penelitian ini, hanya dibahas Five In Row standar yang aturan permainannya
telah disebutkan di atas.
2.3 Agen Cerdas
Desiani dan Arhami memuat kutipan dari Okamoto dan Takaoka (1997) menyatakan
bahwa agen dapat dipandang sebagai sebuah objek yang mempunyai tujuan dan
bersifat autonomous (memberdayakan resourcenya sendiri) untuk memecahkan suatu
permasalahan melalui interaksi, suatu kolaborasi, kompetisi, negosiasi dan
sebagainya.
Sedangkan menurut Russel dan Norvig (2004), agen adalah sesuatu yang
seolah-olah merasakan sesuatu dari lingkungannya melalui sensor dan memberikan
aksi balasan kepada lingkungannya tersebut melalui effector (actuator). Dan
kumpulan dari beberapa agen yang berada pada lingkungan kerja yang sama disebut
multi-agent.
Sebuah agen dibuat menyerupai manusia (human agent) memiliki sensor
lainnya. Berbeda dengan agen robot yang menggunakan kamera dan sinar infrared
dalam jangkauan tertentu sebagai sensor dan berbagai mesin (motor) sebagai effector.
Berikut ini adalah ilustrasi diagram agen.
Gambar 2.2 Ilustrasi Diagram Agen
(Russel dan Norvig, 2004)
2.3.1 Perilaku Agen
Rational Agent adalah suatu benda yang bisa mengerjakan hal tertentu dengan benar
(Desiani dan Arhami, 2006). Namun, pernyataan di atas harus pula dapat dibuktikan
dengan adanya penilaian atau evaluasi.
Untuk menentukan kriteria kesuksesan suatu agen, digunakanlah performance
measure. Namun sebenarnya tidak ada satu ukuran yang dapat dijadikan standar
evaluasi bagi keseluruhan agen. Walaupun demikian, performance measure harus
dapat ditentukan dengan sesuatu yang objektif yang ditentukan oleh beberapa otoritas.
Agen tidak bersifat omniscience (serba tahu). Omniscience agen berarti agen
tersebut mengetahui hasil yang sebenarnya dari aksi yang dilakukannya dan dapat
mempertimbangkannya (Desiani dan Arhami, 2006). Dengan kata lain, agen tidak
Dapat disimpulkan bahwa rational agent yang sempurna adalah untuk setiap
rangkaian persepsi suatu agen yang sempurna dapat melakukan apapun aksi yang
diharapkan akan memaksimalkan performance measure, yang diperoleh dari
fakta-fakta di lingkungan oleh persepsi dan sebagainya, yang dibangun sebagai pengetahuan
agen (Desiani dan Arhami, 2006).
Suatu perilaku agen dapat dibangun dari dua hal, yaitu knowledge dan
autonomy. Knowledge digunakan untuk mengoperasikan agen di lingkungan tertentu
sedangkan autonomy merupakan perluasan pengetahuan agen berdasarkan
pengalaman agen saat berinteraksi dengan lingkungannya (autonomous).
2.3.2 Struktur Agen Cerdas
Kecerdasan buatan berperan penting dalam mendesain program bagi agen. Program
ini berfungsi mengimplementasikan pemetaan percepts ke agen. Program yang
dibangun harus menyatu dengan computing device yang disebut arsitektur untuk
menerima dan menjalankan agen. Arsitektur dapat berupa hardware seperti kamera
image, filtering audio input dan sebagainya.
Hubungan antara agen, arsitektur, dan program dapat disimpulkan sebagai
berikut :
Agen = arsitektur + program
Sebelum mendesain agen, harus dideskripsikan terlebih dahulu mengenai tipe
agen, percepts dan action, tujuan atau performance measure yang akan dicapai serta
lingkungan tempat agen beroperasi.
Ada 4 (empat) tipe dasar pada program agen yang mewujudkan sistem cerdas,
2.3.2.1 Agen Refleks Sederhana (Simple Reflex Agent)
Agen refleks sederhana ini merupakan tipe agen yang paling sederhana. Agen ini
memilih tindakan (action) atas dasar persepsi (percept) yang diterimanya. Tipe ini
dapat pula disebut a condition-action rule, dapat dituliskan sebagai berikut:
if … then …
Gambar 2.3 Skema Agen Refleks Sederhana
(Russel dan Norvig, 2004)
2.3.2.2 Agen Refleks Berbasis Model
Agen ini harus menjaga keadaan internal yang bergantung pada persepsi lalu untuk
merefleksikan setidaknya beberapa aspek keadaan sekarang yang tidak terobservasi.
Pembaharuan (update) informasi dari internal state terus berjalan, dengan demikian
dibutuhkan dua jenis pengetahuan yang harus dikodekan ke program. Pertama,
informasi mengenai bagaimana lingkungan mempengaruhi kebebasan agen, dan kedua
informasi mengenai bagaimana agen melakukan aksinya.
Agent
E
What the world is like now?
Gambar 2.4 Skema Agen Refleks Berbasis Model
(Russel dan Norvig, 2004)
2.3.2.3 Agen Berbasis Tujuan (Goal Based Agent)
Program agen dapat dikombinasikan dengan informasi mengenai hasil dari aksi yang
mungkin dilakukan. Tipe ini turut mempertimbangkan akibat yang diberikan serta
hasil yang dicapai atas aksi yang dilakukan. Pada dasarnya pengetahuan agen akan
keadaan lingkungannya tidak selalu cukup untuk memutuskan aksi yang akan
dilakukan. Dengan kata lain, selain keadaan sekarang, agen juga memerlukan
beberapa informasi tujuan yang menerangkan tentang tujuan kondisi yang
dikehendaki. Pencarian dan perencanaan adalah dua hal yang dilakukan untuk
mencapai tujuan agen. Meskipun tipe ini terlihat kurang efisien, namun sangat
fleksibel. Agen secara otomatis melakukan aksi yang relevan apabila terjadi
perubahan kondisi, begitu pula bila tujuannya diperbaharui maka agen akan
membangkitkan aksi yang baru pula. Agent
What the world is like now?
What action I should do now? Condition-action
state
How the world evolve?
Gambar 2.5 Skema Diagram Agen Berbasis Tujuan
(Russel dan Norvig, 2004)
2.3.2.4 Agen Berbasis Kegunaan (Utility Based Agent)
Tipe ini merupakan pengembangan dari tipe berbasis tujuan. Tujuan dianggap tidak
cukup untuk membangkitkan perilaku agen berkualitas tinggi. Utility memiliki fungsi
yang dapat memetakan suatu keadaan ke dalam bilangan riil, yang menerangkan
derajat pencapaian keberhasilan. Spesifikasi lengkap fungsi utility mengizinkan
keputusan rasional dalam dua jenis kasus dimana agen menghadapi masalah, sehingga
tujuannya tidak tercapai. Pertama, ketika terjadi konflik tujuan dimana hanya beberapa
saja yang terpenuhi, fungsi utility menspesifikasikan tukar tambah yang sesuai.
Kedua, ketika terdapat beberapa tujuan yang dapat dilakukan agen, namun tidak dapat
ditentukan mana tujuan yang berhasil dicapai, dalam hal ini fungsi utility
menyediakan kemungkinan bobot kesuksesan dari masing-masing tujuan. Agent
What the world is like now?
What action I should do now?
Goals
state
How the world evolve?
What my action do?
Agent
E
NVI
R
ONM
E
NT
sensor
actuator
percepts
action
What the world is like now?
How happy I will be in such a state?
Utility
state
How the world evolve?
What my action do?
What it will be like if I do action A?
Gambar 2.6 Skema Diagram Agen Berbasis Kegunaan
(Russel dan Norvig, 2004)
2.3.3 Lingkungan Agen dan Sifatnya
Perbedaan prinsip dari lingkungan agen berdasarkan sifatnya dipaparkan sebagai
berikut:
a. Accessible vs Inaccessible
Jika alat sensor agen memberikan akses untuk state-state lengkap dari suatu
lingkungan maka lingkungan tersebut accessible terhadap agen. Suatu
lingkungan dapat pula menjadi inaccessible akibat adanya gangguan dan
ketidakakuratan sensor atau hal lainnya.
b. Deterministic vs Nondeterministic
Apabila keadaan lingkungan selanjutnya dapat ditentukan atau terpengaruh
oleh keadaan sekarang dan tindakan yang dipilih agen, maka lingkungan
tersebut deterministic, sebaliknya disebut nondeterministic. Jika lingkungan
tersebut inaccessible maka kemungkinan lingkungan tersebut juga
nondeterministic.
Dalam lingkungan episodic, pengalaman agen dibagi ke dalam beberapa
episode. Setiap episode terdiri dari persepsi dan aksi yang dilakukan oleh agen.
Kualitas aksi yang diberikan bergantung pada episode itu sendiri karena
rangkaian episode selanjutnya tidak bergantung pada episode sebelumnya.
Lingkungan episodic lebih sederhanan sebab agen tidak harus berpikir untuk
episode selanjutnya.
d. Static vs Dynamic
Apabila lingkungan mampu berubah sementara agen sedang berpikir, maka
lingkungan tersebut disebut dynamic, sebaliknya disebut static. Tentunya
lingkungan static lebih mudah bagi agen karena tidak perlu menyimpan suatu
state untuk melakukan aksi, serta tidak perlu mencemaskan perubahan waktu.
Apabila lingkungan tidak berubah dalam suatu waktu tapi agen dapat
menentukan tingkat keberhasilannya, maka lingkungan tersebut semidynamic.
e. Discrete vs Continous
Apabila tidak terdapat batasan jelas antara persepsi dan aksi yang ada maka
lingkungan tersebut adalah descrete. Salah satu contoh lingkungan descrete
adalah catur.
f. Single Agent vs Multi-Agent
Perbedaan antara keduanya sangat sederhana. Permainan teka teki silang
misalnya memiliki single agent, sedangkan catur memiliki dua agen.
Lingkungan dua agen juga terdapat pada permainan Five In Row.
2.4 Algoritma Pencarian
Ruang keadaan dalam Five In Row dapat dipresentasikan dengan pohon pencarian
(tree search). Tiap-tiap node pada pohon berhubungan dengan keadaan yang mungkin
dalam permainan tersebut. Setiap move (gerakan) akan menyebabkan perubahan dari
keadaan sekarang (current state) ke keadaan selanjutnya (child state). Permasalahan
Beberapa cara yang digunakan untuk mengefektifkan proses pencarian adalah
(Kusumadewi, 2003):
a. Membentuk suatu prosedur sedemikian hingga hanya gerakan-gerakan yang
baik saja yang dibangkitkan.
b. Membentuk suatu prosedur pengujian sedemikian hingga path yang terbaik
yang akan di-explore pertama kali.
Pohon (tree) merupakan graph yang masing-masing node-nya (kecuali root)
hanya memiliki satu induk (parent), dengan kata lain tidak memiliki cycle. Node yang
tidak memiliki child disebut terminal node.
Pearl dalam David (2008) menyebutkan beberapa hal yang biasa dilakukan
dalam pohon pencarian adalah sebagai berikut:
a. Melihat ke depan seberapa banyak langkah yang memungkinkan.
b. Menghapus percabangan yang tidak berhubungan pada pohon pencarian
ataupun dengan metode-metode tertentu jika ada.
c. Menggunakan informasi penghitungan guna menghitung seberapa besar nilai
suatu posisi.
Metode pencarian yang umumnya digunakan pada pohon pencarian adalah
Breadth First Search (BFS) atau Depth First Search (DFS). Karena ruang pencarian
pohon permaianan Five In Row terlalu besar, maka penggunaan metode BFS dirasa
tidak tepat, sebab metode ini membutuhkan kapasitas memori yang besar. Berbeda
dengan metode DFS yang hanya membutuhkan memori relatif kecil.
2.4.1 Minimax
Minimax merupakan salah satu algoritma yang sering digunakan untuk game
kecerdasan buatan seperti catur, yang menggunakan teknik Depth First Search.
Algoritma Minimax akan melakukan pengecekan pada seluruh kemungkinan yang
tersebut. Keuntungan penggunaan algoritma Minimax adalah mampu menganalisis
semua kemungkinan posisi permainan untuk menghasilkan keputusan terbaik dengan
mencari langkah yang akan membuat lawan mengalami kerugian. Fungsi evaluasi
yang digunakan adalah fungsi evaluasi statis dengan asumsi lawan akan melakukan
langkah terbaik yang mungkin. Pada Minimax dikenal adanya istilah ply yaitu gerakan
pemain max dan lawan min.
Berikut adalah pseudocode Minimax.
MinMax (GamePosition game) { return MaxMove (game);
}
MaxMove (GamePosition game) { if (GameEnded(game)) {
return EvalGameState(game); }
else {
best_move < - {};
moves <- GenerateMoves(game); ForEach moves {
MinMove (GamePosition game) { best_move <- {};
moves <- GenerateMoves(game); ForEach moves {
return best_move; }
Algoritma Minimax memiliki kelemahan yang dirasa cukup menyulitkan.
Algoritma ini menelusuri seluruh node yang ada pada pohon pencarian mulai dari
kedalaman awal hingga kedalaman akhir, sehingga waktu yang dibutuhkan relatif
lama. Jika ada d kedalaman maksimum (depth) dan ada b langkah (branch) yang dapat
Gambar 2.7 Pohon Minimax
2.4.2 Alpha Beta Pruning
Untuk menyiasati banyaknya node yang ditelusuri oleh Minimax, perlu dibuat sebuah
optimasi yang dapat mereduksi kemungkinan yang akan dianalisis. Alpha beta
pruning merupakan optimasi dari algoritma Minimax yang akan mengurangi jumlah
node yang dievaluasi oleh pohon pencarian. Algoritma ini akan berhenti mengevaluasi
langkah ketika terdapat minimal satu langkah yang lebih buruk daripada langkah yang
dievaluasi sebelumnya. Sehingga langkah berikutnya tidak perlu dievaluasi lebih jauh.
Dengan algoritma ini hasil optimasi dari algoritma Minimax tidak akan berubah.
Variabel alpha (α) digunakan sebagai batas bawah node max, sedangkan variabel beta (β) digunakan sebagai batas atas node min. Pada node min, evaluasi akan dihentikan apabila telah didapat node anak yang memiliki nilai lebih kecil dibanding
dengan nilai batas bawah (α), sebaliknya pada node max evaluasi akan dihentikan
apabila telah didapat node anak yang memiliki nilai lebih besar dibanding dengan nilai
batas atas (β).
MAX
MIN
MAX
Pada root pohon pencarian, nilai α ditetapkan sama dengan -∞ sedangkan nilai
β diset sama dengan +∞. Node yang melakukan maksimasi akan memperbaiki nilai α
dari nilai anak-anaknya, sedangkan node yang melakukan minimasi akan
memperbaiki nilai β dari nilai anak-anaknya. Jika α > β, maka evaluasi dihentikan (Kusumadewi, 2003).
Jika tiap kedalaman (depth) berada dalam best case (langkah terbaik selalu
langsung didapat) maka time complexity algoritma adalah O(bd/2) dengan b = faktor
percabangan tiap node dan d = kedalaman (depth) maksimum (Russell dan Norvig,
2003). Sedangkan time complexity Minimax yang O(bd), dengan demikian
penggunaan Alpha Beta Pruning dapat menghemat banyak waktu.
Berikut adalah pseudocode Alpha Beta Pruning.
int AlphaBeta (pos, depth, alpha, beta)
{
if (depth == 0) return Evaluate(pos);
best = -∞;
succ = Successors(pos);
while (not Empty(succ) && best < beta)
{
pos = RemoveOne(succ);
if (best > alpha) alpha = best;
value = -AlphaBeta(pos, depth-1, -beta, -alpha);
if (value > best) best = value;
}
return best;
Gambar 2.8 Pohon Alpha Beta Pruning
2.4.3 Fungsi Evaluasi
Performa aplikasi permainan bergantung pada kualitas fungsi evaluasinya. Fungsi
evaluasi yang tidak akurat akan membuat agen mengambil keputusan yang salah
sehingga mengalami kekalahan. Fungsi evaluasi merupakan fungsi yang dikhususkan
untuk mengevaluasi nilai atau kelebihan posisi keping pemain pada papan, dimana
fungsi ini mengembalikan estimasi nilai yang dikehendaki dari sebuah posisi.
2.5 Reinforcement Learning
Reinforcement learning adalah pembelajaran terhadap apa yang akan dilakukan,
bagaimana memaparkan situasi ke dalam tindakan (Russel dan Norvig, 2004).
Reinforcement learning dapat digunakan untuk memecahkan masalah pengambilan
keputusan pada agen. Dasar dari reinforcement learning ini adalah pemanfaatan
pengalaman untuk mempelajari suatu tindakan yang akan dilakukan beserta akibatnya
berdasarkan nilai yang dihasilkan oleh value function. Value function merupakan MAX
MIN
MAX
fungsi yang dapat memberikan hasil terbaik yang dapat diperoleh agen jika melakukan
tindakan tertentu pada masa tertentu. Hasil pembelajaran akan diterjemahkan menjadi
policy agen, yang merupakan pemetaan antara keadaan dan tindakan. Secara lebih
jelas, policy dapat pula dikatakan sebagai aturan untuk memutuskan suatu tindakan
yang akan dilakukan pada keadaan tertentu.
Agen mempelajari policy yang paling optimal secara bertahap dengan
melakukan berbagai macam tindakan yang mungkin dilakukan pada suatu keadaan
tertentu. Policy agen diharapkan semakin meningkat seiring dengan bertambahnya
pengalaman agen terhadap kondisi lingkungannya. Agen mencoba memilih tindakan
yang paling sesuai dengan kondisi yang dihadapi, sehingga agen mendapatkan nilai
optimal ketika mencapai tujuan.
Untuk mencapai tujuan tersebut, agen tentunya harus pula mengoptimalkan
penggunaan sensor yang dimilikinya sehingga mampu melihat kondisi lingkungan dan
tindakan yang mungkin.
2.6 Java
Java adalah bahasa pemrograman yang berorientasi objek (OOP) dan dapat dijalankan
pada berbagai platform sistem operasi. Perkembangan Java tidak hanya terfokus pada
satu sistem operasi, namun dikembangkan untuk berbagai sistem operasi dan bersifat
open source. Berikut adalah beberapa karakteristik Java:
1. Sederhana (Simple),
Memiliki sintaks yang hampir sama dengan C++ namun sintaks Java telah
banyak mengalami perkembangan terutama menghilangkan penggunaan
pointer yang rumit dan multiple inheritance.
2. Berorientasi objek (Object Oriented)
Java menggunakan pemrograman berorientasi objek yang membuat program
3. Terdistribusi (Distributed)
Java dibuat untuk membangun aplikasi terdistribusi secara mudah dengan
adanya libraries networking yang terintegrasi pada Java.
4. Interpreted
Dijalankan dengan interpreter Java Virtual Machine (JVM). Hal ini
menyebabkan source code Java dapat dijalankan pada platform berbeda-beda.
5. Robust
Java memiliki reliabilitas yang tinggi. Compiler pada Java memiliki
kemampuan mendeteksi error lebih teliti dibandingkan dengan bahasa
pemrograman lain.
6. Secure
Java juga digunakan untuk aplikasi internet, sehingga Java memiliki beberapa
mekanisme keamanan untuk menjaga aplikasi tidak digunakan untuk merusak
sistem komputer yang menjalankan aplikasi tersebut.
7. Architecture Neutral
Program Java merupakan platform independent. Dengan kata lain, program
cukup mempunyai satu buah versi yang dapat dijalankan diberbagai platform
dengan JVM.
8. Portable
Souce code maupun program Java dapat dengan mudah dipindahkan ke platform lain tanpa harus dikompilasi ulang.
9. Performance
Performance Java memang dirasa kurang tinggi, namun dapat ditingkatkan
dengan menggunakan Java lain seperti buatan Inprise, Microsoft maupun
10. Multithread
Java memiliki kemampuan untuk membuat suatu program yang dapat
melakukan beberapa pekerjaan sekaligus secara simultan.
11. Dynamic
Java didesain untuk dijalankan pada lingkungan yang dinamis. Perubahan pada
suatu class dapat dilakukan tanpa menganggu program yang menggunakan
class tersebut.
2.7 UML (Unified Modelling Language)
UML (Unified Modelling Language) adalah keluarga notasi grafis yang didukung oleh
meta-model tunggal, yang membantu pendeskripsian dan desain sistem perangkat
lunak, khususnya sistem yang dibangun menggunakan pemrograman berorientasi
objek (Fowler, 2005). Notasi merupakan grafik-grafik yang terlihat dalam model,
misalnya notasi class diagram, activity diagram dan sebagainya. Sedangkan
meta-model adalah metode yang mendefinisikan hubungan antara notasi pada meta-model.
UML bukanlah bahasa pemrograman visual, melainkan bahasa permodelan
visual yang berisikan notasi yang digunakan di model dan aturan-aturan yang
menuntun bagaimana menggunakannya.
UML lahir dari penggabungan banyak bahasa permodelan grafis berorientasi
objek yang berkembang pesat pada akhir 1980-an dan awal tahun 1990-an serta
merupakan standar yang relatif terbuka yang dikontrol oleh Object Management
Group (OMG), sebuah konsorsium terbuka yang terdiri dari banyak perusahaan.
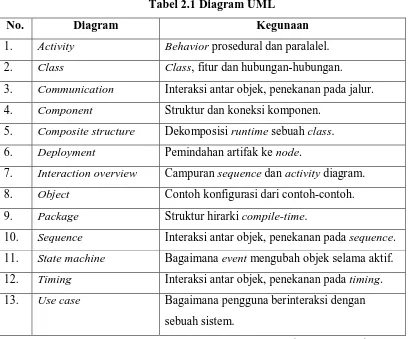
UML 2 terdiri dari 13 diagram resmi seperti yang terlihat pada tabel di bawah
Tabel 2.1 Diagram UML
No. Diagram Kegunaan
1. Activity Behavior prosedural dan paralalel.
2. Class Class, fitur dan hubungan-hubungan.
3. Communication Interaksi antar objek, penekanan pada jalur. 4. Component Struktur dan koneksi komponen.
5. Composite structure Dekomposisi runtime sebuah class.
6. Deployment Pemindahan artifak ke node.
7. Interaction overview Campuran sequence dan activity diagram.
8. Object Contoh konfigurasi dari contoh-contoh.
9. Package Struktur hirarki compile-time.
10. Sequence Interaksi antar objek, penekanan pada sequence.
11. State machine Bagaimana event mengubah objek selama aktif.
12. Timing Interaksi antar objek, penekanan pada timing.
13. Use case Bagaimana pengguna berinteraksi dengan sebuah sistem.
(Fowler, 2005)
Beberapa diagram dari tabel di atas akan dipaparkan sebagai berikut.
2.7.1 Activity Diagram (Diagram Aktivitas)
Diagram ini digunakan untuk menunjukkan aliran aktivitas di sistem sekaligus sebagai
pandangan dinamis terhadap sistem. Diagram ini penting untuk memodelkan fungsi
Gambar 2.9 Contoh Activity Diagram
(Fowler, 2005)
Diagram ini dapat dikatakan mirip seperti diagram alir namun diperluas
dengan menunjukkan aliran kendali suatu aktivitas ke aktivitas lain serta mendukung
behavior paralel. Diagram aktivitas berupa operasi-operasi dan aktivitas-aktivitas use
case.
2.7.2 Class Diagram (Diagram Kelas)
Diagram kelas merupakan diagram yang paling sering digunakan pada permodelan
berorientasi objek. Diagram kelas menunjukkan aspek statik sistem terutama untuk
mendukung kebutuhan fungsional sistem, misalnya kebutuhan pengguna. Class pada
diagram kelas dapat secara langsung diimplementasikan di bahasa pemrograman
Gambar 2.10 Contoh Class Digram
(Fowler,2005)
2.7.3 Sequence Diagram
Sebuah sequence diagram menjabarkan behavior sebuah skenario tunggal. Skenario
adalah rangkaian langkah-langkah yang menjabarkan sebuah interaksi antara seorang
pengguna dengan sebuah sistem. Diagram tersebut menunjukkan sejumlah objek
Gambar 2.11 Contoh Sequence Diagram
(Fowler, 2005)
2.7.4 Use Case
Use case adalah teknik untuk merekam persyaratan fungsional sebuah sistem (Fowler,
2005). Use case mendeskripsikan tipe interaksi antara pengguna dengan sistem
dengan menyajikan narasi bagaimana sistem tersebut digunakan.
Gambar 2.12 Contoh Use Case
BAB 3
ANALISIS DAN PERANCANGAN APLIKASI
3.1 Analisis Kebutuhan Aplikasi
Analisis sistem adalah proses menentukan kebutuhan sistem, apa yang harus
dilakukan sistem untuk memenuhi kebutuhan klien (user) (Sutopo, 2001). Tahapan
analisis kebutuhan merupakan tahap awal untuk membangun sebuah sistem atau
aplikasi. Dengan adanya analisis ini diharapkan agar nantinya dihasilkan aplikasi yang
baik dan sesuai dengan kebutuhan.
3.1.1 Representasi Lingkungan
Lingkungan merupakan tempat agen melakukan interaksi. Lingkungan permainan
Five in Row berupa papan (board) yang direpresentasikan sebagai berikut.
10
9
8
7
6
5
4
3
2
1 2 3 4 5 6 7 8 9 10
3.1.1 Representasi Material
Material permainan Five in Row yang berupa kepingan (piece) direpresentasikan
sebagai berikut: No piece = 0, User piece = 1, dan Computer piece = 2. Kepingan
pemain (user piece) akan berwarna hitam, sedangkan kepingan komputer (computer
piece) akan berwarna putih.
0 0 0 0 0 0 0
Gambar 3.2 Representasi Material
3.1.2 Flowchart Aplikasi
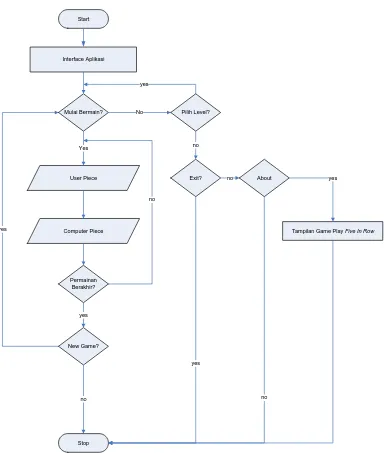
Flowchart (diagram alir) merupakan diagram yang memperlihatkan aliran kontrol
seluruh sistem termasuk program, input, output, dan database (Whitten, 1998).
Dengan adanya flowchart, maka runtutan proses berjalannya suatu aplikasi dapat
Start
Tampilan Game Play Five In Row Yes
Gambar 3.3 Flowchart Aplikasi Five in Row
Untuk lebih jelasnya, proses aplikasi Five in Row akan dipaparkan sebagai berikut.
1. User menjalankan aplikasi permainan, kemudian komputer akan membangkitkan interface papan permainan sekaligus level default, yaitu 2.
2. Jika user langsung ingin bermain melawan komputer maka silakan meletakkan
keping (piece) pada kotak yang diinginkan. Setelah itu komputer akan
membangkitkan gerakan kemudian menampilkan posisi computer piece yang
akan membendung gerakan user.
3. Selama permainan berlangsung komputer akan membangkitkan fungsi
Apabila belum permainan akan terus berlanjut. Jika permainan telah berakhir
maka user boleh memilih untuk memulai permainan baru ataupun tidak.
4. Level default adalah level 2, namun user boleh memilih level permainan sesuai
keinginan. Level dua dijadikan default sebab level satu dirasa terlalu mudah
untuk dikalahkan.
5. Jika user ingin mengetahui informasi mengenai Five in Row, user dapat
memilih menu about.
3.1.3 Analisis Algoritma
Seperti yang telah dipaparkan pada bab sebelumnya, algoritma yang digunakan untuk
membangun aplikasi ini adalah Minimax dan Alpha Beta Pruning. Algoritma
Minimax tidak digunakan secara tunggal sebab algoritma tersebut dirasa kurang
efisien. Minimax akan mengevaluasi seluruh node yang ada pada pohon pencarian
satu persatu hingga selesai, sedangkan jumlah node yang akan dievaluasi tidaklah
sedikit. Berikut adalah tabel jumlah node yang akan dievaluasi menurut tingkat
kedalamannya, dimana branching factor b adalah jumlah pergerakan maksimum
masing-masing node dan depth d adalah kedalaman pohon pencarian.
Tabel 3.1 Hubungan Kedalaman dan Jumlah Node
Kedalaman Jumlah node O(bd)
Ukuran papan permainan Five in Row adalah 10 x 10 yang berarti berjumlah
100 kotak. Dengan demikian jumlah pergerakan maksimum yang dimiliki
masing-masing node adalah 100, sebab Five in Row tidak memiliki illegal move seperti halnya
permainan catur ataupun Othello. Yang dimaksud dengan illegal move adalah gerakan
dengan huruf L pada catur. Jumlah pergerakan maksimum ini akan dijadikan
percabangan pada pohon pencarian.
Dengan adanya Alpha Beta Pruning diharapkan waktu pencarian akan jauh
lebih singkat karena tujuan utama dari algoritma ini adalah mengabaikan subtree atau
percabangan yang tidak mempengaruhi hasil akhir. Berikut beberapa ketentuan dalam
algoritma Alpha Beta Pruning.
1. Alpha (α) merupakan nilai batas bawah maksimum atau nilai terbaik
sementara pada max. Alpha digunakan pada node min dan diset pada node
max.
2. Beta (β) merupakan nilai batas atas minimum atau nilai terbaik sementara pada
min. Beta digunakan pada node max dan diset pada node min.
3. Max bertujuan untuk memaksimalkan nilai dengan cara memilih node anak
dengan nilai paling besar. Nilai awal max adalah –∞ dan akan bertambah
seiring dengan pencarian.
4. Min bertujuan untuk meminimalkan nilai dengan cara memilih node anak
dengan nilai paling kecil. Nilai awal min adalah +∞ dan akan berkurang
seiring dengan berjalannya pencarian.
5. Max adalah agen yang mewakili komputer, sedangkan min adalah agen yang
mewakili gerakan lawan dalam hal ini user.
Berikut adalah pseudocode algoritma Minimax dengan optimasi Alpha Beta
Pruning.
int alphaBetaMax( int alpha, int beta, int depthleft ) { if ( depthleft == 0 ) return evaluate();
int alphaBetaMin( int alpha, int beta, int depthleft ) { if ( depthleft == 0 ) return -evaluate();
for ( all moves) {
return alpha; // alpha-cutoff
Berikut adalah flowchart algoritma Minimax dengan optimasi Alpha Beta
Pruning.
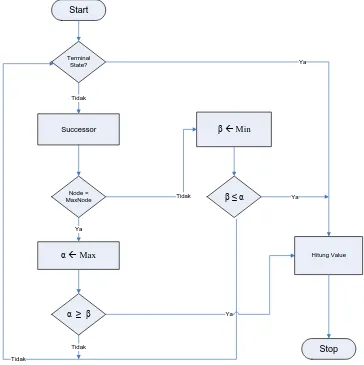
Gambar 3.4 Flowchart Algoritma Minimax dengan Optimasi Alpha Beta
Pruning
Flowchart di atas memperlihatkan bagaimana algoritma Minimax dan Alpha
Beta Pruning mengevaluasi setiap node pada pohon permainan.
Pada awal permainan akan diperiksa terlebih dahulu apakah node yang
mengevaluasi nilai yang diperoleh dan menghentikan pencarian. Sebaliknya jika tidak
maka successor akan dibangkitkan untuk mengevaluasi node anak yang ada pada
kedalaman selanjutnya.
Jika yang dievaluasi adalah node max maka nilai node tersebut akan diperiksa.
Jika nilainya maksimal maka akan ditetapkan menjadi α. Apabila nilai α lebih besar atau sama dengan β, maka evaluasi dihentikan. Dengan demikian node di bawahnya tidak perlu dievaluasi.
Sebaliknya jika yang dievaluasi adalah node min maka akan terus diperiksa
selama nilai β tidak lebih kecil atau sama dengan α. Apabila nilai β ditemukan bernilai lebih kecil atau sama dengan nilai α maka evaluasi dihentikan.
Berikut ini akan dipaparkan tahapan optimasi Alpha Beta Pruning secara
singkat.
1. Dapatkan nilai Alpha dan Beta. Alpha adalah nilai maksimum yang
ditemukan. Beta adalah nilai minimum yang ditemukan.
2. Pada node max, sebelum mengevaluasi node anak, bandingkan terlebih dahulu
nilai yang didapatkan dengan nilai Beta. Jika nilainya lebih besar, batalkan
pencarian untuk node tersebut.
3. Pada node min, sebelum mengevaluasi node anak bandingkan terlebih dahulu
nilai yang didapatkan dengan nilai Alpha. Jika nilainya lebih kecil, batalkan
pencarian untuk node tersebut.
Algoritma Minimax ini bersifat depth first search, yang berarti proses
pengecekan akan dilakukan hingga ke kedalaman tertentu sesuai level permainan
kemudian beralih ke tingkat atas. Untuk lebih jelasnya proses depth first search akan
-10
Gambar 3.5 Proses Pencarian Depth First Search
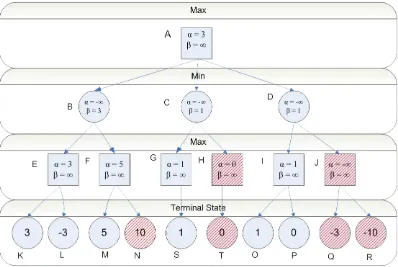
Awal pencarian akan dimulai dari node root yaitu node A, dimana node ini
memiliki tiga anak yaitu node B, node C dan node D. Yang pertama diperiksa adalah
node B beserta turunannya yaitu node E dan node F, namun node E yang memiliki
anak node K dan L harus dievaluasi terlebih dahulu kemudian nilai dikembalikan ke
node E, lalu node E mengembalikan nilai pada node induknya yaitu node B. Karena node B masih memiliki node anak yang belum diperiksa maka proses evaluasi terus
berlangsung terhadap node F beserta turunannya. Setelah seluruh cabang pada node B
selesai diperiksa maka nilai akan dikembalikan kepada node A. Demikian seterusnya
hingga proses pencarian seluruh pohon selesai dijalankan. Proses evaluasi pohon
Gambar 3.6 Diagram Pohon Pencarian
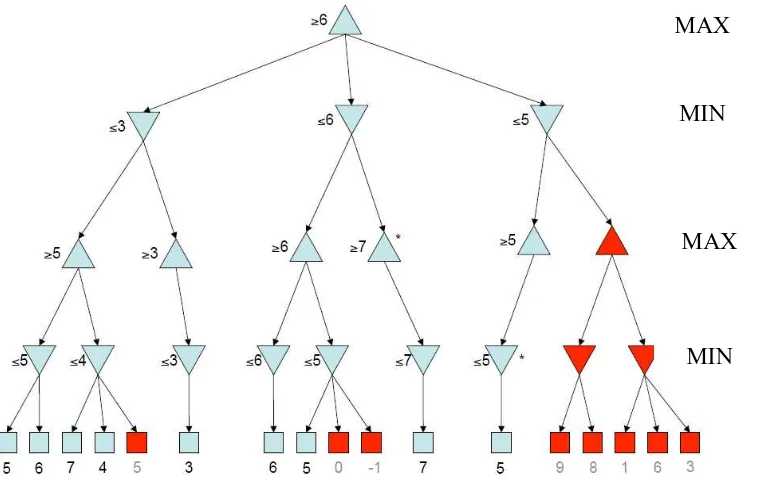
Diagram di atas memperlihatkan bahwa pada baris max nilai alpha (α) selulu
-∞, sedangkan pada baris min nilai beta (β) selalu +∞. Sebenarnya nilai α dan β yang
terdapat pada diagram di atas bukanlah nilai alpha dan beta selama proses
berlangsung. Nilai di atas hanya memperlihatkan bahwa pada node max fungsi
evaluasi hanya boleh mengubah nilai alpha dan sebaliknya pada node min fungsi
evaluasi hanya boleh mengubah nilai beta.
Untuk lebih jelasnya mengenai proses evaluasi pada pohon tersebut, akan
Tabel 3.2 Proses Pencarian Alpha Beta Pruning
No Node
Yang
dievaluasi
Node yang
dipanggil
Nilai α Nilai β Nilai
Node
Fungsi Keterangan
1. A B -∞ +∞ - Node A (B, -∞, +∞) Pada awal permainan nilai α = -∞ sedangkan
nilai β = +∞.
2. B E -∞ +∞ - Node B (E, -∞, +∞)
3. E K -∞ +∞ 3 Node E (K, -∞, +∞) Nilai 3 ditetapkan menjadi nilai α
4. E L 3 +∞ 3 Node E (L, 3, +∞) Nilai node L < node K, dengan demikian node E (max) tetap akan memiliki nilai 3.
5. E Selesai α = 3 β = +∞ E = 3 Node E telah selesai dievaluasi, dengan
demikian proses akan beralih ke tingkat atas
yaitu node B.
6. B F -∞ 3 3 Node B (F, -∞, 3) Nilai 3 yang diperoleh dari node E diset menjadi
nilai β, sedangkan nilai α kembali menjadi -∞.
Tulang
No. Node
yang di
evaluasi
Node yang
dipanggil
Nilai α Nilai β Nilai
Node
Fungsi Keterangan
7. F M -∞ 3 5 Node F (M, -∞, 3) Nilai 5 berasal dari node M yang kemudian
ditetapkan menjadi nilai α.
8. F Selesai α = 5 β = 3 F = 5 Node N tidak perlu diperiksa sebab nilai α ≥ β. (α = 5 sedangkan β = 3).
9. B Selesai -∞ β = 3 B = 3 Nilai 3 diperoleh dari node E yang bernilai lebih
kecil dari node F.
10. A C 3 +∞ Node A (C, 3, +∞) Nilai node A sementara adalah 3.
11. C G 3 +∞ G = 1 Node C (G, 3, +∞) Node G bernilai 1.
12. C Selesai α = 3 β = 1 C = 1 Node H tidak perlu diperiksa karena didapati
bahwa node C < node B.
13. A D 3 +∞ A = 3
D = -
Node A (D, 3, +∞) Node A masih bernilai 3 karena node C < node
B, sehingga tidak mempengaruhi nilai awal.
14. D I 3 +∞ D = - Node D (I, 3, +∞)
No. Node
yang di
evaluasi
Node yang
dipanggil
Nilai α Nilai β Nilai
Node
Fungsi Keterangan
15. I O 3 +∞ I = 1 Node I (O, 3, +∞) Nilai 1 diperoleh dari node O, kemudian
ditetapkan menjadi nilai α.
16. I P 3 +∞ I = 1 Node I (P, 3, +∞) Nilai node I tetap 1.
17. I Selesai α = 1 +∞ I = 1
18. D Selesai β = 1 D = 1 Node J tidak perlu diperiksa karena node D <
node B
19. A Selesai α = 3 β = +∞ 3 Jadi, fungsi evaluasi mendapatkan nilai 3 untuk
node A.
3.1.4 Nilai Formasi
Nilai formasi mutlak diperlukan sebagai bobot dari pohon pencarian yang akan
dibangkitkan. Nilai formasi merupakan nilai yang diperoleh berdasarkan jumlah
keping yang ada dalam satu baris, kolom ataupun diagonal pada papan permainan.
Dua atau tiga buah kepingan yang berada pada satu baris ataupun kolom tentunya
berbeda nilainya dengan keping tunggal, begitu pula halnya dengan sederetan
kepingan yang tidak terbendung lawan tentunya memiliki nilai lebih unggul
dibandingkan dengan yang terbendung. Berikut adalah tabel nilai formasi pada
permainan Five in Row dengan ‘X’ adalah user piece dan ‘O’ adalah computer
piece.
Tabel 3.3 Nilai Formasi
Nama Formasi Nilai Bentuk Formasi
Comp_capped2 5 _OOX_
User_capped2 5 _XXO_
Comp_uncapped2 10 _OO_
User_uncapped2 10 _XX_
Comp_capped3 20 _OOOX
User_capped3 30 _XXXO
Comp_uncapped3 100 _OOO_
User_uncapped3 120 _XXX_
Comp_capped4 500 _OOOOX
User_capped4 500 _XXXXO
Nilai formasi tersebut diperoleh dengan mempertimbangkan prioritas
formasi yang akan dipilih oleh agen, misalnya apabila ditemukan formasi
comp_uncapped3 dan user_uncapped3 tentunya harus diprioritaskan penutupan
pada formasi user_uncapped3 sebab dikhawatirkan user dapat memenangkan
3.1.5 Fungsi Evaluasi
Fungsi evaluasi berfungsi sebagai penghitung nilai dari setiap node yang terdapat
pada pohon permainan. Nilai yang telah didapat akan dijadikan acuan pergerakan
selanjutnya. Formasi yang dibentuk oleh keping permainan akan menghasilkan
nilai yang akan dijadikan bobot nilai pohon.
Secara matematik, fungsi evaluasi diekspresikan sebagai berikut:
����(�) = �1�1(�) + �2�2(�) + … + ����(�) = � ����(�) �
�=1
Dalam catur, w adalah bobot tiap buah catur dan f adalah jumlah buah catur
tersebut pada papan catur. Sedangkan dalam Five in Row, w adalah bobot formasi
dan f adalah jumlah formasi yang terbentuk.
����� =��2.��2 + ���2.���2 + ��3.��3 + ���3.���3+ ��4.��4
adalah capped4. Berikut adalah contoh perhitungan
fungsi evaluasi pada aplikasi ini.
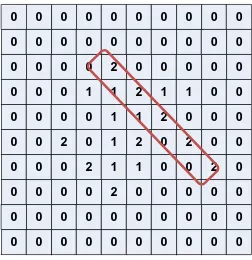
Yang pertama kali dilakukan adalah pemeriksaan formasi keping putih
(computer piece). Pada baris B terdapat 3 keping putih, namun ini tidak bisa
dihitung sebagai solusi sebab telah terbendung oleh keping hitam. Begitu pula
dengan diagonal yang diisi pada kotak F5, G6, H7 dan I8 yang tidak bisa
dianggap solusi.
1. Pada baris F terdapat uncapped2 yaitu F3 dan F5. Nilainya = 5.
2. Pada kolom 3 terdapat capped2 yaitu F3 dan C3. Nilainya = 5.
3. Pada kolom 5 terdapat capped2 yaitu E5 dan F5. Nilainya = 5.
4. Pada kolom 7 terdapat capped4 yaitu F7, D7, C7, B7. Nilainya = 500.
5. Pada diagonal terdapat uncapped2 yaitu G6 dan F7. Nilainya = 5.
6. Diagonal lain terdapat capped2 yaitu E5 dan C3. Nilainya = 5.
7. Keping B6 dan C7 juga membentuk capped2. Nilainya = 5.
Dengan demikian jumlah uncapped2 ada 2 formasi, capped2 ada 4 formasi dan
capped4 1 formasi. Maka jumlah valuenya adalah:
Value Max = 2*5 + 4*5+ 500 = 530.
Sekarang akan dicari value dari keping hitam atau user piece. Seperti langkah di
atas, pertama kali harus dilakukan evaluasi posisi.
1. Pada baris D terdapat capped2 yaitu D5 dan D6. Nilainya = 5.
2. Pada kolom 4 terdapat uncapped2 yaitu C4 dan E4. Nilainya = 5.
3. Pada diagonal terdapat capped2 yaitu F6 dan G7. Nilainya = 5.
4. Pada diagonal lain terdapat uncapped2 yaitu C5 dan D6. Nilainya = 5.
Maka jumlah formasi capped2 ada 2, begitu pula dengan formasi uncapped2.
Sehingga jumlah valuenya adalah:
Sehingga value total:
Value Total = 530 – 20 = 490
Yang artinya posisi di atas sangat menguntungkan bagi pemain putih (computer).
Jika giliran putih bermain, maka tidak diragukan lagi formasi capped4 akan
segera dijadikan formasi kemenangan. Sebaliknya apabila giliran hitam maka user
akan segera mengambil tindakan dengan menutup kotak E7 dengan keping hitam
sehingga jalan kemenangan putih tertutup.
3.1.6 Proses Evaluasi Formasi
Proses untuk mendapat bobot nilai pada pohon permainan tidaklah singkat.
Mulanya komputer akan menelusuri kemungkinan pergerakan langkah yang akan
dilakukan dan asumsi pergerakan lawan. Kemudian hasil dari formasi yang
terbentuk dari masing-masing kemungkinan akan dihitung sesuai dengan fungsi
evaluasi. Berikut akan dibahas sebuah contoh kasus proses evaluasi formasi yang
terdapat pada pohon permainan Five in Row.
Gambar 3.8 Contoh Kondisi Permainan
Gambar di atas adalah sebuah keadaan yang terjadi pada pertengahan
permainan yang akan dibahas proses evaluasinya. Posisi seperti gambar di atas
akan dijadikan root pada pohon permainan yang selanjutnya akan ditelusuri
Gambar di atas memperlihatkan pohon permainan dimana posisi teratas
merupakan root atau posisi awal yang akan dievaluasi, sedangkan kedalaman
pertama adalah beberapa asumsi gerakan user (min) yang dievaluasi oleh
komputer dan kedalam kedua adalah langkah-langkah yang diambil oleh
komputer (max).
Gambar bintang berwarna hitam merupakan kemungkinan pergerakan
langkah yang dilakukan oleh lawan (user), dan gambar bintang berwarna merah
merupakan kemungkinan langkah yang diambil oleh komputer. Tentu saja jumlah
node yang diperiksa sebenarnya lebih banyak, namun pada gambar di atas hanya
ditampilkan beberapa node sebagai contoh.
Berikutnya, masing-masing kondisi pada kedalaman kedua dihitung
nilainya (value) berdasarkan fungsi evaluasi yang ada, dengan memperhatikan
seluruh formasi yang terbentuk seperti yang terlihat pada tabel 3.3. Pada contoh di
atas, kedalaman kedua merupakan terminal state yang ada pada permainan level
dua. Apabila user memilih level tiga, berarti terminal state-nya adalah kedalaman
ketiga dan seterusnya. Berikut adalah hasil penghitungan value dari
masing-masing kondisi.
Tabel. 3.4 Value Tiap Node
No. Node yang Dievaluasi Value
1.
-570
2.
Tabel. 3.4 Value Tiap Node (Sambungan)
No. Node yang Dievaluasi Value
3.
-95
4.
-165
5.
-145
6.
-170
7.
-190
Apabila dilihat dari hasil perhitungan value di atas, maka peluang
komputer menang relatif kecil bila dibandingkan dengan peluang kemenangan
user dengan asumsi user bermain secara maksimal.
Nilai-nilai yang telah didapat di atas kemudian dijadikan sebagai bobot
dari masing-masing node pada pohon pencarian tersebut. Dengan adanya bobot
dilakukan, disinilah letak tugas dari algoritma Minimax dan Alpha Beta Pruning.
Minimax dan Alpha Beta Pruning akan menelusuri node-node tersebut hingga
diperoleh hasil maksimal yang terdapat pada pohon permainan.
Namun ada kalanya terdapat beberapa kondisi yang perlu dilakukan
beberapa pengecualian, misalnya ada kondisi permainan yang memiliki value total
yang sama, sehingga agen harus mengambil keputusan yang tepat dengan
melakukan memilih prioritas. Berikut adalah beberapa parameter yang perlu
diterapkan untuk kondisi khusus.
1. Apabila ada dua value yang sama, dan keduanya merupakan nilai terbaik
maka agen akan memilih node yang terlebih dahulu didapatkan atau
ditelusuri.
2. Jika agen menemukan formasi empat, misalnya comp_capped4 atau
comp_uncapped4, maka tidak perlu lagi dilakukan penghitungan value.
Agen akan langsung membentuk Five In Row.
3.2 Perancangan Aplikasi
Menurut John Burch dan Gary Grudnitski dalam Yatini (2007) menyebutkan
bahwa perancangan dapat didefinisikan sebagai penggambaran, perencanaan dan
pembuatan sketsa atau pengaturan dari beberapa elemen yang terpisah ke dalam
suatu kesatuan yang utuh dan berfungsi.
Perancangan sistem dapat dibagi menjadi dua tahap yaitu perancangan
konseptual dan perancangan fisik yang tujuan utamanya adalah menghasilkan