ABSTRACT
AZIZ SANTOSO. Face Recognition with Partition using VFI5 Algorithm Based On Histogram. Under the direction by AZIZ KUSTIYO.
Research in face recognition is motivated not only by the fundamental challenges this recognition problem poses but also by numerous practical applications where human identification is needed. Face recognition, as one of the primary biometric technologies, became more important owing to rapid advances in technologies such as digital cameras, the Internet and mobile devices, and increased demands on security. Face recognition has several advantages over other biometric technologies: It is natural, non intrusive, and easy to use. There are two predominant approaches to the face recognition problem: geometric (feature based) and photometric (view based). A classification algorithm, called VFI5 (Voting Feature Intervals), is developed and applied to problem of face recognition with partition based on histogram. VFI5 represents a concept in the form of feature intervals on each feature dimension separately. Classification in the VFI5 algorithm is based on a real-valued voting. Each feature equally participates in the voting process and the class that receives the maximum amount of votes is declared to be the predicted class. The performance of the VFI5 classifier is evaluated empirically in terms of classification accuracy. Conclusion of this research indicates that VFI5 can be used for face recognition with high accuracy the level.
PENGENALAN WAJAH DENGAN PARTISI MENGGUNAKAN
ALGORITME VFI5 BERBASIS HISTOGRAM
AZIZ SANTOSO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENGENALAN WAJAH DENGAN PARTISI MENGGUNAKAN
ALGORITME VFI5 BERBASIS HISTOGRAM
AZIZ SANTOSO
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
AZIZ SANTOSO. Face Recognition with Partition using VFI5 Algorithm Based On Histogram. Under the direction by AZIZ KUSTIYO.
Research in face recognition is motivated not only by the fundamental challenges this recognition problem poses but also by numerous practical applications where human identification is needed. Face recognition, as one of the primary biometric technologies, became more important owing to rapid advances in technologies such as digital cameras, the Internet and mobile devices, and increased demands on security. Face recognition has several advantages over other biometric technologies: It is natural, non intrusive, and easy to use. There are two predominant approaches to the face recognition problem: geometric (feature based) and photometric (view based). A classification algorithm, called VFI5 (Voting Feature Intervals), is developed and applied to problem of face recognition with partition based on histogram. VFI5 represents a concept in the form of feature intervals on each feature dimension separately. Classification in the VFI5 algorithm is based on a real-valued voting. Each feature equally participates in the voting process and the class that receives the maximum amount of votes is declared to be the predicted class. The performance of the VFI5 classifier is evaluated empirically in terms of classification accuracy. Conclusion of this research indicates that VFI5 can be used for face recognition with high accuracy the level.
Judul : Pengenalan Wajah dengan Partisi Menggunakan Algoritme VFI5 Berbasis Histogram Nama : Aziz Santoso
NIM : G64052587
Menyetujui: Dosen Pembimbing,
Aziz Kustiyo, S.Si., M.Kom. NIP 19700719 199802 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
PRAKATA
Alhamdulillahi Rabbil ‘aalamiin, segala puji bagi Allah Subhanahu wa ta’ala, Tuhan semesta alam, sehingga penulis dapat menyelesaikan skripsi dengan judul Pengenalan Wajah dengan Partisi Menggunakan Algoritme VFI5 Berbasis Histogram. Shalawat dan salam semoga terlimpahkan kepada Nabi Muhammad Shallallahu ‘alaihi wasallam beserta keluarga dan para sahabatnya.
Penelitian ini dilaksanakan mulai Juni 2010 sampai dengan Februari 2011, bertempat di Departemen Ilmu Komputer. Selama pelaksanaan skripsi ini, penulis banyak mendapatkan bantuan dari berbagai pihak. Oleh karena itu, penulis mengucapkan terima kasih kepada:
1. Ibu dan Bapak, terima kasih atas semua doa dan kasih sayang yang tak ternilai.
2. Istri tercinta, Yuliya Nurtikayanti (Ilkomerz 42), terima kasih atas doa dan dukungannya di saat penulis senang maupun kesulitan.
3. Ibu dan Bapak Mertua, terima kasih atas doa, dukungan, dan ijinnya untuk menikahi Yuliya sehingga turut membantu menyelesaikan skripsi dengan lancar.
4. Mba Wiwid, Mba Dwi, Mas Ade, dan Mas Agus, terima kasih atas kuantitas pertanyaan yang sering diajukan, sehingga memicu penulis untuk lebih semangat dalam menyelesaikan skripsi. Begitu pula untuk sang keponakan, Hulwa yang membuat penulis kadang tertawa, kadang juga membuat kesal karena tidak mau digendong.
5. Bapak Aziz Kustiyo, S.Si., M.Kom. selaku pembimbing, terima kasih atas saran dan bimbingannya serta doa dan motivasinya.
6. Bapak Hari Agung Adrianto, S.Kom, M.Si. selaku penguji I dan moderator, terima kasih atas saran, kritikan dan bimbingannya kepada penulis.
7. Bapak Mushthofa, S.Kom, M.Sc. selaku penguji II, terima kasih atas saran, kritikan dan bimbingannya kepada penulis.
8. Teman-teman at-Tauhid, terima kasih telah membantu penulis dalam memberikan saran dan motivasinya.
Semoga skripsi ini dapat bermanfaat bagi siapa pun yang membacanya.
Bogor, Februari 2011
RIWAYAT HIDUP
Penulis dilahirkan di Pamekasan pada tanggal 19 Oktober 1986 dari pasangan Moh. Amin Jakfar dan Siti Hairiyah. Penulis merupakan anak pertama dari dua bersaudara. Penulis menyelesaikan pendidikan menengah atas di SMUN 3 Pamekasan pada tahun 2005.
DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA Citra Digital... 1
Pengolahan Citra (Image Processing) ... 1
Ekstraksi Fitur ... 2
Histogram... 2
Klasifikasi. ... 2
Voting Feature Intervals (VFI5) ... 2
Contoh Penerapan Algoritme VFI5 pada Data dengan Dua Fitur ... 4
Penerapan VFI5 Berbasis Histogram ... 5
Confusion Matrix ... 5
METODE PENELITIAN Data ... 6
Partisi Citra ... 6
Ekstraksi Fitur ... 6
Data Latih dan Data Uji ... 6
Algoritme VFI5 ... 7
Analisis Hasil Klasifikasi ... 7
Lingkungan Pengembangan ... 7
HASIL DAN PEMBAHASAN Data ... 7
Percobaan 1 Citra Utuh Tanpa Partisi ... 7
Percobaan 2 Citra dengan Partisi ... 9
Perbandingan Hasil Percobaan Citra Utuh Tanpa Partisi dan Percobaan Citra dengan Partisi ... 9
Citra Partisi Bagian Atas ... 10
Citra Partisi Bagian Tengah ... 11
Citra Partisi Bagian Bawah ... 12
Perbandingan Hasil Subpercobaan Ketiga Citra Partisi (Atas, Tengah, dan Bawah) ... 13
Perbandingan Hasil Seluruh Percobaan ... 14
Perbandingan dengan Penelitian Terkait ... 14
KESIMPULAN DAN SARAN Kesimpulan ... 14
Saran ... 15
DAFTAR PUSTAKA ... 15
DAFTAR TABEL
Halaman
1 Confusion matrix untuk data 2 kelas. ... 5
2 Hasil pembagian data latih dan data uji. ... 7
3 Hasil iterasi 1 percobaan citra utuh tanpa partisi ... 8
4 Hasil iterasi 2 percobaan citra utuh tanpa partisi. ... 8
5 Hasil iterasi 3 percobaan citra utuh tanpa partisi . ... 8
6 Hasil iterasi 4 percobaan citra utuh tanpa partisi. ... 8
7 Hasil iterasi 1 subpercobaan citra partisi bagian atas. ... 10
8 Hasil iterasi 2 subpercobaan citra partisi bagian atas. ... 10
9 Hasil iterasi 3 subpercobaan citra partisi bagian atas. ... 10
10 Hasil iterasi 4 subpercobaan citra partisi bagian atas. ... 10
11 Hasil iterasi 1 subpercobaan citra partisi bagian tengah. ... 11
12 Hasil iterasi 2 subpercobaan citra partisi bagian tengah ... 11
13 Hasil iterasi 3 subpercobaan citra partisi bagian tengah. ... 11
14 Hasil iterasi 4 subpercobaan citra partisi bagian tengah. ... 12
15 Hasil iterasi 1 subpercobaan citra partisi bagian bawah ... 12
16 Hasil iterasi 2 subpercobaan citra partisi bagian bawah. ... 12
17 Hasil iterasi 3 subpercobaan citra partisi bagian bawah. ... 13
18 Hasil iterasi 4 subpercobaan citra partisi bagian bawah ... 13
19 Hasil subpercobaan ketiga citra partisi. ... 13
20 Akurasi seluruh percobaan. ... 14
21 Banyaknya ekspresi yang salah diklasifikasi pada seluruh percobaan. ... 14
DAFTAR GAMBAR
Halaman 1 Dua wajah yang berbeda dan histogramnya. ... 22 Algoritme pelatihan VFI5 (Guvenir 1998). ... 3
3 Algoritme klasifikasi VFI5 (Guvenir 1998). ... 3
4 Contoh penerapan algoritme pelatihan VFI5. (a) Pencarian nilai minimum dan maksimum tiap kelas tiap fitur. (b) Pencarian keberadaan nilai instance pelatihan pada interval. (c) Tahap normalisasi pertama. (d) Tahap normalisasi kedua sebagai nilai vote pada tahap klasifikasi.. ... 4
5 Contoh penerapan algoritme klasifikasi VFI5, (a) Data uji dengan dua instance. (b) Nilai vote hasil tahap pelatihan. (c) Nilai vote data uji dan kelas hasil prediksi.. ... 5
6 Contoh citra dengan histogram asli (256 interval) dan histogram hasil pembagian menjadi 64 interval ... 5
7 Metodologi Penelitian. ... 6
8 Contoh citra wajah dengan 8 ekspresi yang berbeda. ... 6
9 Citra utuh dengan ukuran asli dan citra hasil partisinya beserta histogramnya. ... 7
10 Grafik hasil percobaan citra utuh tanpa partisi. ... 8
11 Grafik akurasi percobaan citra utuh tanpa partisi dan citra dengan partisi ... 9
12 Grafik kelas data uji benar percobaan citra utuh tanpa partisi dan citra dengan partisi. ... 9
13 Grafik hasil subpercobaan citra partisi bagian atas... 11
14 Grafik hasil subpercobaan citra partisi bagian tengah ... 12
15 Grafik hasil subpercobaan citra partisi bagian bawah... 13
16 Grafik hasil subpercobaan ketiga citra partisi. ... 13
17 Citra partisi bagian atas kelas 15 ekspresi terkejut (kiri) dan ekspresi kerling (kanan). ... 14
DAFTAR LAMPIRAN
Halaman
1 Seluruh citra yang digunakan pada penelitian beserta histogramnya ... 17
2 Tabel nilai vote percobaan citra utuh ... 25
3 Tabel nilai vote percobaan citra dengan partisi ... 27
4 Tabel nilai vote subpercobaan citra partisi bagian atas ... 29
5 Tabel nilai vote subpercobaan citra partisi bagian tengah... 31
PENDAHULUAN Latar Belakang
Penelitian mengenai pengenalan wajah termotivasi oleh banyaknya aplikasi praktis yang diperlukan dalam identifikasi wajah. Pengenalan wajah sebagai salah satu dari teknologi biometrik utama menjadi semakin penting dengan adanya kemajuan yang cepat dalam teknologi, seperti kamera digital, internet, mobile devices, dan peningkatan permintaan pada sistem keamanan. Pengenalan wajah mempunyai beberapa keuntungan di atas teknologi biometrik lainnya, yaitu alami (natural), tidak ada gangguan (non intrusive), dan mudah digunakan (Karande & Talbar 2008b).
Ada dua pendekatan utama pada masalah pengenalan wajah, yaitu pendekatan geometris (feature based) dan pendekatan fotometrik (view based). Pendekatan geometris merupakan pendekatan yang mengekstraksi dan menghubungkan fitur komponen citra wajah seperti mata, hidung, dan mulut. Adapun pendekatan fotometrik merupakan pendekatan yang merepresentasikan informasi piksel citra wajah. Pada penelitian pengenalan wajah terdapat banyak metode yang diusulkan seperti
Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), dan Elastic Bunch Graph Matching (EBGM) (Karande & Talbar 2008a).
Penelitian ini menggunakan algoritme
Voting Feature Intervals (VFI5) dengan pendekatan fotometrik. Algoritme VFI5 merepresentasikan deskripsi sebuah konsep dengan sekumpulan interval fitur. Pada sekumpulan data yang sama dari ECG
recordings, algoritme VFI5 menghasilkan akurasi yang lebih tinggi, yaitu 62% dibandingkan dengan algoritme klasifikasi standar seperti Naive Bayesian (NB) yang menghasilkan akurasi 50% dan Nearest Neighbor (NN) menghasilkan yang akurasi 53% (Guvenir HA, Demiroz G, & Ilter N 1998).
Pengenalan wajah menggunakan algoritme VFI5 telah dilakukan dengan hasil akurasi yang cukup baik. Pramitasari (2009) pada penelitiannya menggunakan algoritme VFI5 dengan praproses transformasi wavelet menghasilkan akurasi mencapai 90%. Penelitian pengenalan wajah lainnya menggunakan algoritme VFI5 dilakukan oleh Purwaningrum (2009) dan menghasilkan akurasi hingga 96,3%. Penelitian Purwaningrum (2009) ini menggunakan input histogram citra yang
memiliki beberapa keunggulan dibanding menggunakan nilai piksel citra. Penggunaan algoritme VFI5 juga dilakukan pada pengenalan citra tanda tangan oleh Muttaqien (2009). Penelitian ini berbasis histogram dengan tambahan penggunaan partisi citra dan menghasilkan akurasi tertinggi hingga 95,56%.
Tujuan
Penelitian ini bertujuan melakukan pengenalan wajah dengan berbagai ekspresi menggunakan algoritme VFI5 berbasis histogram dan penggunaan partisi citra.
Ruang Lingkup
Ruang lingkup penelitian ini adalah pengenalan citra wajah dengan berbagai ekspresi berdasarkan tingkat keabuan. Data citra yang digunakan adalah data sekunder berupa citra 15 orang yang berbeda dengan masing-masing wajah memiliki delapan ekspresi yang berbeda, yaitu ekspresi memakai kacamata, tersenyum, tidak memakai kacamata, biasa, cemberut, menutup mata, kaget, dan kerling. Seluruh citra memiliki latar belakang berwarna putih yang seragam.
TINJAUAN PUSTAKA Citra Digital
Sebuah citra didefinisikan sebagai sebuah fungsi dua dimensi, f(x,y), dimana x dan y
Citra digital dibentuk oleh sejumlah elemen yang terbatas dimana setiap elemen telah memiliki lokasi dan nilai khusus. Elemen-elemen ini sering disebut sebagai picture elemen, image elemen, pels, atau pixels. dari beberapa istilah tersebut, pixels merupakan istilah yang paling sering digunakan untuk menunjukkan elemen citra digital.
Citra memiliki derajat keabuan berformat 8-bit dan 256 intensitas warna yang berkisar pada nilai 0 sampai 255. Nilai 0 menunjukkan tingkat paling hitam dan 255 menunjukkan tingkat paling putih (Gonzales & Woods 2002).
Pengolahan Citra (Image Processing)
dan pengenalan citra. Selain itu, yang dimaksud dengan pengolahan citra digital biasanya adalah pengolahan citra menggunakan komputer digital (Gonzalez & Woods 2002).
Ekstraksi Fitur
Ekstraksi fitur menghasilkan representasi baru oleh transformasi dari data asli. Pengurangan dimensi dari representasi data dengan ekstraksi fitur bisa memberikan tujuan tambahan, mencakup penghilangan redundansi, menemukan variabel tersembunyi, dan mengetahui struktur data (Dahua 2006).
Histogram
Histogram sebuah citra dengan derajat keabuan antara [0, L-1] merupakan fungsi diskret h(rk) = nk dengan rk adalah derajat keabuan ke-k dan nk adalah jumlah piksel pada
citra yang mempunyai derajat keabuan rk
dengan k = 0, 1, 2,…, L-1. Normalisasi
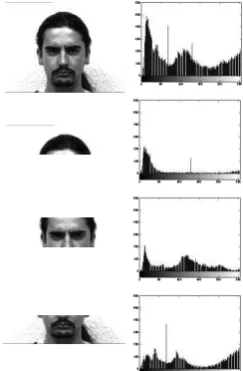
histogram dapat dilakukan dengan membagi setiap nilai dengan total jumlah piksel pada citra dengan jumlah semua komponen hasil normalisasi tersebut sama dengan 1. Histogram merupakan dasar dari berbagai teknik pemrosesan domain spasial. Histogram dapat digunakan untuk memperbaiki citra, kompresi, dan segmentasi citra (Gonzales & Woods 2002). Contoh citra dan histogramnya disajikan pada Gambar 1.
Gambar 1 Dua wajah yang berbeda dan histogramnya.
Klasifikasi
Klasifikasi merupakan serangkaian proses untuk menemukan sekumpulan model yang merepresentasikan dan membedakan kelas-kelas data. Klasifikasi ini bertujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu data yang label kelasnya tidak diketahui (Han & Kamber 2006).
Algoritme klasifikasi terdiri atas dua tahap, yaitu pelatihan dan prediksi/klasifikasi. Pada tahap pelatihan dibentuk model domain dari data pelatihan yang ada. Adapun pada tahap klasifikasi, menggunakan model tersebut untuk
memprediksi kelas dari suatu data/instance baru (Guvenir HA, Demiroz G, & Ilter N 1998).
Voting Feature Intervals (VFI5)
Algoritme VFI5 merupakan algoritme klasifikasi yang merepresentasikan deskripsi sebuah konsep dengan sekumpulan interval-interval nilai fitur. Pengklasifikasian sebuah
instance baru didasarkan pada vote klasifikasi yang dibuat oleh nilai tiap fitur secara terpisah. VFI5 bersifat supervised learning dan non-incremental sehingga semua data latih dapat diproses secara bersamaan. Tiap contoh data latih direpresentasikan sebagai nilai-nilai fitur sebuah vektor disertai sebuah label yang merepresentasikan kelas contoh data. Algoritme VFI5 membentuk interval-interval nilai fitur (interval) untuk tiap fitur dari contoh data latih (Guvenir 1998).
Interval-interval yang dibuat dapat berupa
point interval atau range interval. Point interval
terdiri atas seluruh end point secara berturut-turut, sedangkan range interval terdiri atas nilai-nilai antara dua end point yang berdekatan tetapi tidak termasuk kedua end point tersebut.
Vote tiap kelas pada interval tersebut kemudian disimpan untuk tiap intervalnya. Oleh karena itu, sebuah interval dapat merepresentasikan beberapa kelas dengan menyimpan vote tiap kelas.
Keunggulan algoritme VFI5 adalah algoritme ini cukup kokoh (robust) terhadap fitur yang tidak relevan tetapi mampu memberikan hasil yang baik pada real-world datasets yang ada. VFI5 mampu menghilangkan pengaruh yang kurang menguntungkan dari fitur yang tidak relevan dengan mekanisme voting -nya (Guvenir 1998). Algoritme VFI5 terdiri atas dua tahap, yaitu tahap pelatihan dan klasifikasi (Guvenir HA, Demiroz G, & Ilter N 1998). 1. Pelatihan
Langkah pertama pada tahap pelatihan adalah menemukan end points tiap kelas c pada tiap fitur f. End points kelas c yang diberikan merupakan nilai yang terkecil dan terbesar pada dimensi fitur linear (kontinu) f untuk beberapa
instance dari kelas c yang sedang diamati. Pada hal lainnya, end points pada dimensi fitur nominal (diskret) f untuk kelas c yang diberikan adalah semua nilai yang berbeda dari f pada beberapa instance kelas c yang sedang diamati.
End points dari tiap fitur f kemudian disimpan dalam array EndPoints[f]. Terdapat end points
sebanyak 2k pada tiap fitur linear dengan k
tiap end point yang berbeda dan range interval
di antaranya dibentuk. Jika fitur tersebut merupakan fitur nominal, maka tiap end point
yang berbeda merupakan sebuah point interval. Langkah selanjutnya, banyaknya instance
pelatihan pada tiap interval dihitung dan jumlah
instance kelas c pada interval i dari fitur f
direpresentasikan sebagai interval_class_ count[f,i,c]. Pada tiap instance pelatihan, dicari interval i yang merupakan nilai fitur f dari
instance pelatihan e (ef) tersebut berada. Jika
interval i adalah point interval dan ef sama
dengan batas bawah interval tersebut (yang sama dengan batas atas pada point interval), jumlah kelas instance tersebut (ef) pada interval
i ditambah 1. Jika interval i adalah range interval dan ef berada pada interval tersebut
maka jumlah kelas instance ef pada interval i
ditambah 1. Hasil proses inilah yang menjadi
vote pelatihan kelas c pada interval i. Gambar 2 Algoritme pelatihan VFI5 (Guvenir 1998).
Supaya efek perbedaan distribusi tiap kelas dapat dihilangkan, vote kelas c untuk fitur f
pada interval i dinormalisasi dengan membagi
vote tersebut dengan jumlah instance kelas c
yang direpresentasikan dengan class_count[c]. Hasil normalisasi ini dinotasikan sebagai
interval_class_vote[f,i,c]. Selanjutnya, nilai-nilai interval_class_vote[f,i,c] dinormalisasi sehingga jumlah vote beberapa kelas pada tiap fitur sama dengan 1. Tujuan normalisasi ini adalah agar tiap fitur mempunyai kekuatan
voting yang sama pada proses klasifikasi dan tidak dipengaruhi oleh ukuran fitur tersebut. Algoritme pelatihan VFI5 disajikan pada Gambar 2.
2. Klasifikasi
Tahap klasifikasi dimulai dengan inisialisasi
vote tiap kelas dengan nilai nol. Pada tiap fitur f
dicari interval i tempat nilai ef berada dengan ef
merupakan nilai fitur f dari instance uji e. Jika ef
tidak diketahui (hilang), fitur tersebut tidak diikutsertakan dalam voting dengan memberikan vote nol pada tiap kelas. Jika ef
diketahui maka interval tersebut dapat ditemukan dan dapat menyimpan instance
pelatihan beberapa kelas. Kelas-kelas dalam sebuah interval direpresentasikan oleh vote
kelas-kelas pada interval tersebut. Pada tiap kelas c, fitur f memberikan vote yang sama dengan interval_class_vote[f,i,c]. Notasi ini merepresentasikan vote fitur f yang diberikan pada kelas c.
Tiap fitur f mengumpulkan semua vote
dalam sebuah vektor (feature_vote[f,C1], …,
feature_vote[f,Cj], …, feature_vote[f,Ck]),
dengan feature_vote[f,Cj] merupakan vote fitur f
untuk kelas Cj dan k adalah jumlah kelas. Sebanyak d (jumlah fitur) vektor vote
dijumlahkan untuk memperoleh total vektor
vote (vote[C1], …, vote[Ck]). Kelas dari instance
uji e adalah kelas yang memiliki jumlah vote
terbesar. Algoritme klasifikasi VFI5 disajikan pada Gambar 3.
Contoh Penerapan Algoritme VFI5 pada Data dengan Dua Fitur
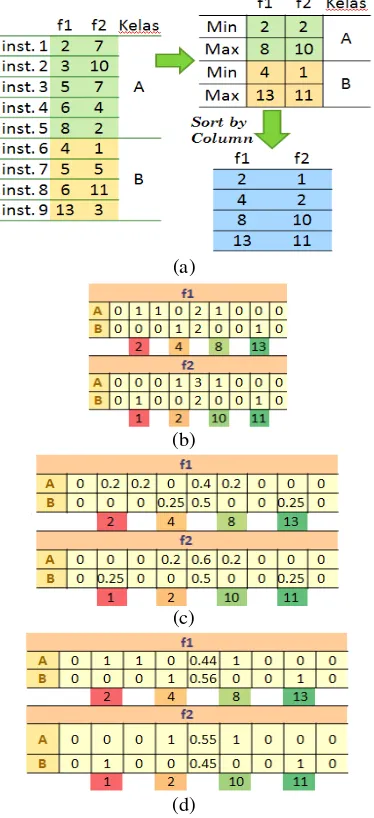
Penerapan algoritme pelatihan VFI5 dengan sembilan instance pelatihan disajikan pada Gambar 4. Pada Gambar 4(a) diketahui ada sembilan instance pelatihan dengan dua kelas yang berbeda dan masing-masing instance memiliki dua fitur (f1 dan f2). Langkah pertama dicari nilai minimum dan maksimum dari tiap fitur pada tiap kelas, kemudian semua nilai minimum dan maksimum tiap fitur tersebut diurutkan secara ascend tanpa melibatkan kelas.
Langkah selanjutnya, pada Gambar 4(b) semua nilai minimum dan maksimum yang sudah diurutkan dijadikan interval (point interval dan range interval). Setelah itu dicari pada interval mana instance pelatihan berada dan ditambah 1. Berikutnya, pada Gambar 4(c) dilakukan tahap normalisasi pertama yaitu membagi nilai-nilai tiap interval dengan jumlah
instance tiap kelas. Setelah itu, pada Gambar 4(d) dilakukan tahap normalisasi kedua yaitu membagi nilai hasil normalisasi pertama dengan jumlah nilai tiap fitur. Nilai hasil normalisasi kedua ini menjadi nilai vote yang akan digunakan pada tahap klasifikasi.
(a)
(b)
(c)
(d)
Gambar 4 Contoh penerapan algoritme pelatihan VFI5. (a) Pencarian nilai minimum
dan maksimum tiap kelas tiap fitur. (b) Pencarian keberadaan nilai instance pelatihan pada interval. (c) Tahap normalisasi pertama. (d) Tahap normalisasi kedua sebagai nilai vote
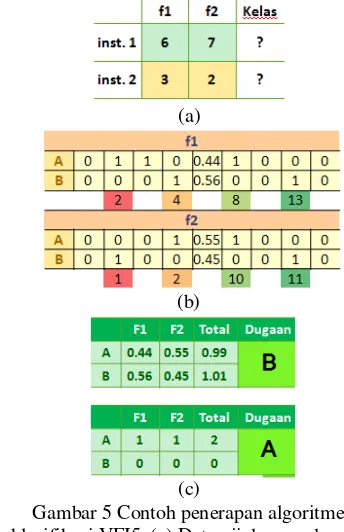
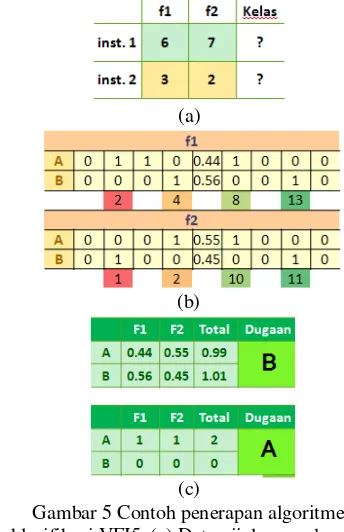
Berikut ini penerapan algoritme klasifikasi VFI5 disajikan pada Gambar 5. Pada Gambar 5(a) dapat dilihat terdapat dua instance data uji yang belum diketahui label kelasnya. Langkah pertama pada tahap klasifikasi yaitu dicari pada interval mana instance data uji berada. Setelah itu, pada Gambar 5(b) nilai vote yang diperoleh dari tahap pelatihan pada interval itu diambil untuk tiap kelasnya. Pada Gambar 5(c) dapat dilihat kelas yang memiliki nilai vote terbesar (semua nilai vote dijumlah untuk tiap kelasnya) maka diduga sebagai kelas prediksi.
(a)
(b)
(c)
Gambar 5 Contoh penerapan algoritme klasifikasi VFI5, (a) Data uji dengan dua
instance. (b) Nilai vote hasil tahap pelatihan. (c) Nilai vote data uji dan kelas hasil prediksi.
Penerapan VFI5 Berbasis Histogram
Menurut Purwaningrum (2009), penerapan VFI5 berbasis histogram adalah penggunaan nilai histogram sebagai fitur pada algoritme VFI5. Selang histogram yang memiliki nilai 0-255 (256 interval) dibagi ke dalam beberapa interval kemudian dihitung jumlah piksel yang mempunyai derajat keabuan pada interval tertentu. Nilai pada interval-interval ini yang dijadikan fitur pada algoritme VFI5.
Contohnya, jika dibagi ke dalam 64 interval, maka selang 0-3 menjadi 1 interval, selang 4-7 menjadi 1 interval, dan seterusnya sampai interval 64, yaitu selang 252-255. Jumlah piksel yang mempunyai derajat keabuan pada interval-interval tersebut dijadikan sebagai fitur pada algoritme VFI5. Contoh histogram hasil
pembagian menjadi 64 interval disajikan pada Gambar 6.
Gambar 6 Contoh citra dengan histogram asli (256 interval) dan histogram hasil pembagian
menjadi 64 interval. Confusion Matrix
Confusion matrix merupakan sebuah tabel yang terdiri dari banyaknya baris data uji yang diprediksi benar dan tidak benar oleh model klasifikasi. Tabel ini diperlukan untuk menentukan kinerja suatu model klasifikasi (Tan et al. 2005). Contoh confusion matrix
dapat dilihat pada Tabel 1.
Tabel 1 Confusion matrix untuk data 2 kelas Kelas Prediksi Kelas 1 Kelas 2 Kelas
Aktual
Kelas 1 K 11 K12 Kelas 2 K 21 K 22 Akurasi hasil klasifikasi dari confusion matrix dihitung dengan rumus:
Akurasi =
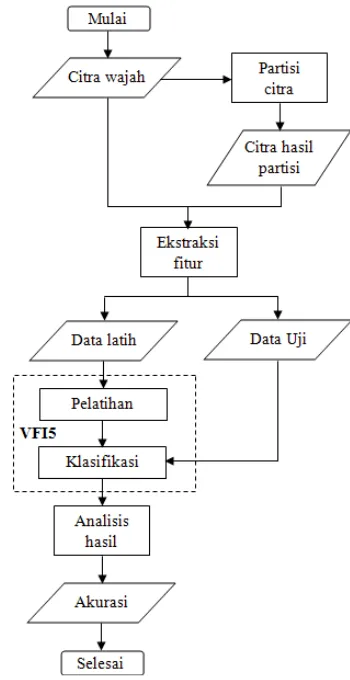
METODE PENELITIAN
Gambar 7 Metodologi Penelitian.
Data
Data yang digunakan pada penelitian ini adalah data sekunder yang diperoleh dari url ftp://plucky.cs.yale.edu/CVC/pub/images/yalefa cesA/. Data berupa 120 citra wajah yang terdiri atas 15 orang yang berbeda yang selanjutnya disebut kelas. Masing-masing kelas terdiri atas 8 ekspresi, yaitu:
Memakai kacamata (ekspresi 1) Tersenyum (ekspresi 2) Tanpa kacamata (ekspresi 3) Normal/biasa (ekspresi 4) Cemberut (ekspresi 5) Menutup mata (ekspresi 6) Terkejut (ekspresi 7) Kerling (ekspresi 8)
Seluruh citra memiliki latar belakang berwarna putih yang seragam. Data pada penelitian ini adalah data citra dengan ukuran 243 x 320 piksel. Contoh citra 8 ekspresi yang berbeda pada satu kelas disajikan pada Gambar 8 dan keseluruhan citra yang digunakan pada penelitian ini disajikan pada Lampiran 1.
ekspresi 1 ekspresi 2
ekspresi 3 ekspresi 4
ekspresi 5 ekspresi 6
ekspresi 7 ekspresi 8
Gambar 8 Contoh citra wajah dengan 8 ekspresi yang berbeda.
Partisi Citra
Data citra wajah yang digunakan pada penelitian ini terdiri atas dua macam, yaitu citra wajah utuh dengan ukuran asli seperti yang diambil dari sumbernya dan citra wajah yang dipartisi menjadi tiga bagian secara horizontal sehingga citra tiap bagian berukuran 81 x 320 piksel. Hal ini mengacu pada hasil penelitian Muttaqien (2009) yang menyebutkan bahwa pembagian secara horizontal lebih mampu meningkatkan akurasi dibandingkan pembagian secara vertikal. Begitu pula dalam kehidupan sehari-hari dapat kita lihat bahwa mata, hidung, dan bibir merupakan penciri seseorang.
Ekstraksi Fitur
Pada tahapan ini semua citra yang digunakan dihitung histogramnya, yaitu jumlah piksel pada tiap derajat keabuan. Histogram citra tersebut kemudian dibagi menjadi interval-interval. Banyaknya interval yang digunakan pada penelitian ini adalah 64 interval berdasarkan hasil penelitian Purwaningrum (2009). Nilai-nilai pada interval (fitur) inilah yang digunakan sebagai data latih dan data uji (input algoritme VFI5).
Data Latih dan Data Uji
Perbandingan antara data latih dan data uji yang digunakan adalah 3:1.
Algoritme VFI5
Algoritme VFI5 terdiri atas dua tahap, yaitu tahap pelatihan dan tahap klasifikasi. Pada tahap pelatihan yang menjadi input adalah jumlah piksel pada tiap derajat keabuan yang diperoleh dari tahap ekstraksi fitur yang telah dibagi ke dalam interval-interval. Pada tahap ini nilai vote
tiap interval dari data latih dihitung pada masing-masing kelasnya.
Adapun tahap klasifikasi dimulai dengan mencari interval yang sesuai dengan nilai tiap fitur dari data uji pada interval-interval data latih. Nilai vote pada interval tersebut kemudian dikumpulkan dan dijumlahkan untuk tiap kelasnya. Kelas yang memiliki nilai total vote
terbesar menjadi kelas prediksi bagi data uji tersebut.
Pada percobaan citra dengan partisi, tahap pelatihan dan klasifikasi dilakukan pada tiap partisinya (partisi bagian atas, tengah, dan bawah). Nilai vote yang dikumpulkan pada tahap klasifikasi tiap partisi citra dari citra yang sama dijumlahkan. Setelah itu nilai vote
dijumlahkan untuk tiap kelasnya. Kelas yang memiliki nilai total vote terbesar juga yang menjadi kelas prediksi bagi data uji tersebut.
Analisis Hasil Klasifikasi
Kinerja algoritme VFI5 pada percobaan ini dapat diketahui dari analisis hasil klasifikasi. Analisis dilakukan menggunakan tabel
confusion matrix, kemudian menghitung besaran akurasi yang berhasil dicapai, dan diambil suatu kesimpulan. Tingkat akurasi diperoleh dengan rumus:
akurasi =
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian ini ialah sistem operasi Microsoft Windows XP Professional SP2, Matlab 7.0.1, Sedangkan perangkat keras yang digunakan ialah processor Intel Pentium Dual Core 2.8 Ghz dan 2.79 Ghz, memori 512 MB DDR 2 RAM, dan hardisk 80 GB..
HASIL DAN PEMBAHASAN Data
Data pada penelitian ini terdiri atas dua macam. Data yang digunakan pada percobaan
citra utuh tanpa partisi adalah data asli berukuran 243 x 320 piksel, sedangkan pada percobaan selanjutnya adalah data hasil partisi citra asli menjadi tiga bagian dengan ukuran yang sama secara horizontal, yaitu 81 x 320 piksel. Data citra grayscale yang memiliki derajat keabuan antara 0-255 ini dihitung histogramnya kemudian dibagi menjadi 64 interval (fitur) berdasarkan penelitian Purwaningrum (2009). Contoh citra utuh dengan ukuran asli dan citra hasil partisinya menjadi tiga bagian beserta histogramnya disajikan pada Gambar 9.
Gambar 9 Citra utuh dengan ukuran asli dan citra hasil partisinya beserta histogramnya.
Data fitur dari citra kemudian dibagi menjadi data latih dan data uji dengan perbandingan 3:1 seperti yang disajikan pada Tabel 2.
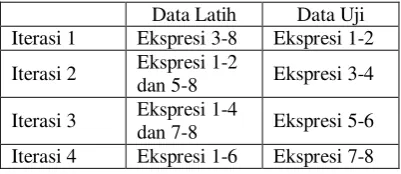
Tabel 2 Hasil pembagian data latih dan data uji Data Latih Data Uji Iterasi 1 Ekspresi 3-8 Ekspresi 1-2 Iterasi 2 Ekspresi 1-2
dan 5-8 Ekspresi 3-4 Iterasi 3 Ekspresi 1-4
dan 7-8 Ekspresi 5-6 Iterasi 4 Ekspresi 1-6 Ekspresi 7-8
Percobaan 1 Citra Utuh Tanpa Partisi
Percobaan yang pertama kali dilakukan adalah percobaan menggunakan citra utuh tanpa partisi yang berukuran 243 x 320 piksel.
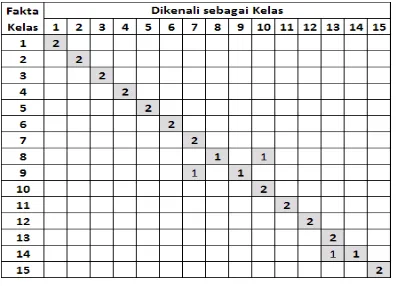
Iterasi 1
yaitu kelas 3 ekspresi 1 dikenali sebagai kelas 7 dengan selisih nilai vote0.735, kelas 7 ekspresi 1 dikenali sebagai kelas 13 dengan selisih nilai
vote9.844, kelas 14 ekspresi 2 dikenali sebagai kelas 7 dengan selisih nilai vote 0.1, dan kelas 15 ekspresi 1 dikenali sebagai kelas 8 dengan selisih nilai vote 6.547, sehingga akurasinya adalah 86.67%.
Tabel 3 Hasil iterasi 1 percobaan citra utuh tanpa partisi
Iterasi 2
Hasil iterasi 2 percobaan citra utuh tanpa partisi disajikan pada Tabel 4 dan nilai vote-nya disajikan pada Lampiran 2. Pada Tabel 4 terlihat bahwa 2 data uji salah diklasifikasi, yaitu hanya kelas 9 ekspresi 3 dan 4 saja yang salah dikenali yaitu keduanya dikenali sebagai kelas 15 dengan selisih nilai vote0.31, sehingga akurasinya adalah 93.33%.
Tabel 4 Hasil iterasi 2 percobaan citra utuh tanpa partisi
Iterasi 3
Hasil iterasi 3 percobaan citra utuh tanpa partisi disajikan pada Tabel 5 dan nilai vote-nya disajikan pada Lampiran 2. Pada Tabel 5 terlihat bahwa hanya 1 data uji yang salah diklasifikasi, yaitu kelas 9 ekspresi 5 saja yang salah dikenali yaitu sebagai kelas 15 dengan selisih nilai vote 3.352, sehingga akurasinya adalah 96.67%.
Tabel 5 Hasil iterasi 3 percobaan citra utuh tanpa partisi
Iterasi 4
Hasil iterasi 4 percobaan citra utuh tanpa partisi disajikan pada Tabel 6 dan nilai vote-nya disajikan pada Lampiran 2. Pada Tabel 6 terlihat bahwa 2 data uji salah diklasifikasi, yaitu kelas 3 ekspresi 8 dikenali sebagai kelas 10 dengan selisih nilai vote 4.352 dan kelas 8 ekspresi 7 dikenali sebagai kelas 9 dengan selisih nilai vote 1.303, sehingga akurasinya adalah 93.33%.
Tabel 6 Hasil iterasi 4 percobaan citra utuh tanpa partisi
Hasil dari keempat iterasi pada percobaan citra utuh tanpa partisi memiliki rata-rata akurasi sebesar 92.50%. Jumlah data uji yang benar diklasifikasi pada keseluruhan hasil percobaan citra utuh disajikan pada Gambar 10.
Pada Gambar 10 terlihat bahwa data uji yang paling sedikit benar diklasifikasi adalah kelas 9 (K9), yaitu sebanyak 5 data uji dari total 8 data uji (tiap iterasi 2 data uji) yang digunakan pada percobaan citra utuh tanpa partisi.
Percobaan 2 Citra dengan Partisi
Percobaan selanjutnya adalah percobaan menggunakan citra hasil partisi menjadi tiga bagian secara horizontal dengan ukuran yang sama, yaitu 81 x 320 piksel. Masing-masing bagian (atas, tengah, dan bawah) diterapkan algoritme VFI5 sehingga menghasilkan nilai
vote. Ketiga nilai vote (atas, tengah, dan bawah) kemudian digabungkan/dijumlahkan dan dihitung akurasinya. Akurasi dari keempat percobaan citra dengan partisi ternyata rata-ratanya mencapai 100%. Nilai vote hasil percobaan citra dengan partisi disajikan pada Lampiran 3.
Perbandingan Hasil Percobaan Citra Utuh Tanpa Partisi dan Percobaan Citra dengan Partisi
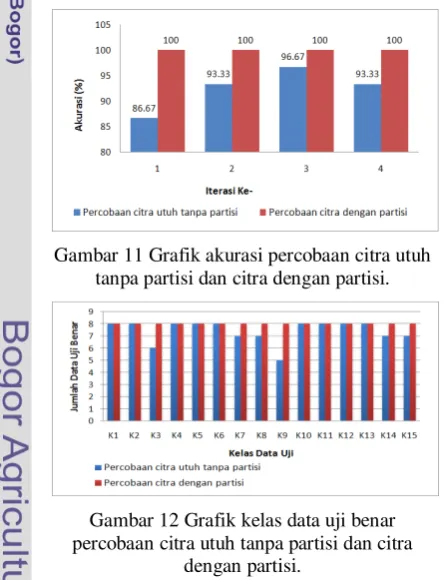
Grafik akurasi semua iterasi percobaan citra utuh tanpa partisi dan citra dengan partisi disajikan pada Gambar 11, dan grafik kelas data uji benar dari semua iterasi percobaan tersebut disajikan pada Gambar 12.
Gambar 11 Grafik akurasi percobaan citra utuh tanpa partisi dan citra dengan partisi.
Gambar 12 Grafik kelas data uji benar percobaan citra utuh tanpa partisi dan citra
dengan partisi.
Pada Gambar 11 terlihat bahwa akurasi keempat iterasi percobaan citra utuh mengalami peningkatan, yaitu iterasi 1 meningkat 13.33%,
iterasi 2 meningkat 6.67%, iterasi 3 meningkat 3.37%, dan iterasi 4 meningkat 6.67%. Pada Gambar 12 terlihat bahwa jumlah data uji yang benar diklasifikasi mengalami peningkatan pada percobaan citra dengan partisi, yaitu kelas 3 (K3), kelas 7 (K7), kelas 8 (K8), kelas 9 (K9), kelas 14 (K14), dan kelas 15 (K15). Hal ini menunjukkan bahwa terjadi peningkatan akurasi dari percobaan citra utuh ke percobaan citra dengan partisi seperti pada hasil penelitian Muttaqien (2009).
Peningkatan akurasi menjadi 100% pada percobaan citra dengan partisi disebabkan adanya penggabungan nilai vote ketiga bagian citra partisi (atas, tengah, dan bawah). Contohnya, pada iterasi 1 percobaan citra utuh, kelas 7 ekspresi 1 (nilai vote = 4.766) diklasifikasi sebagai kelas 13 (nilai vote = 14.61) dengan selisih nilai vote yang cukup besar, yaitu sebesar 9.844. Namun, pada iterasi 1 percobaan citra dengan partisi, kelas 7 ekspresi 1 benar diklasifikasi dengan nilai vote
sebesar 28.59, sedangkan nilai vote kelas 13-nya ha13-nya 4.815. Nilai vote sebesar 28.59 tersebut didapat dari penggabungan nilai vote
citra partisi bagian atas, tengah, dan bawah. Pada iterasi 1 subpercobaan citra partisi bagian atas, kelas 7 ekspresi 1 (nilai vote = 7.38) salah diklasifikasi, yaitu sebagai kelas 10 (nilai vote = 8.585) dengan selisih nilai vote
sebesar 1.205. Begitu pula pada iterasi 1 subpercobaan citra partisi bagian tengah, kelas 7 ekspresi 1 (nilai vote = 4.292) salah diklasifikasi, yaitu sebagai kelas 10 (nilai vote = 6.317) dengan selisih nilai vote sebesar 2.025. Namun, pada iterasi 1 subpercobaan citra partisi bagian bawah, kelas 7 ekspresi 1 benar diklasifikasi dengan nilai vote sebesar 16.92, sedangkan nilai vote kelas 10-nya sebesar benar diklasifikasi pada percobaan citra dengan partisi.
Citra Partisi Bagian Atas Iterasi 1
Hasil iterasi 1 subpercobaan citra partisi bagian atas disajikan pada Tabel 7 dan nilai
vote-nya disajikan pada Lampiran 4.
Tabel 7 Hasil iterasi 1 subpercobaan citra partisi bagian atas
Pada Tabel 7 terlihat bahwa 5 data uji salah diklasifikasi, yaitu kelas 4 ekspresi 1 dikenali sebagai kelas 10 dengan selisih nilai vote 0.081, kelas 7 ekspresi 1 dikenali sebagai kelas 10 dengan selisih nilai vote 1.205, kelas 7 ekspresi 2 dikenali sebagai kelas 9 dengan selisih nilai
vote 6.852, kelas 12 ekspresi 2 dikenali sebagai kelas 5 dengan selisih nilai vote 0.507, dan kelas 15 ekspresi 1 dikenali sebagai kelas 8 dengan selisih nilai vote 1.649, sehingga akurasinya adalah 83.33%.
Iterasi 2
Hasil iterasi 2 subpercobaan citra partisi bagian atas disajikan pada Tabel 8 dan nilai
vote-nya disajikan pada Lampiran 4. Pada Tabel 8 terlihat bahwa hanya 1 data uji yang salah diklasifikasi, yaitu kelas 15 ekspresi 4 dikenali sebagai kelas 9 dengan selisih nilai vote 4.788, sehingga akurasinya adalah 96.67%.
Tabel 8 Hasil iterasi 2 subpercobaan citra partisi bagian atas
Iterasi 3
Hasil iterasi 3 subpercobaan citra partisi bagian atas disajikan pada Tabel 9 dan nilai
vote-nya disajikan pada Lampiran 4.
Tabel 9 Hasil iterasi 3 subpercobaan citra partisi bagian atas
Pada Tabel 9 terlihat bahwa 3 data uji salah diklasifikasi, yaitu kelas 8 ekspresi 5 dikenali sebagai kelas 10 dengan selisih nilai vote 1.25, kelas 9 ekspresi 5 dikenali sebagai kelas 7 dengan selisih nilai vote 3.269, dan kelas 14 ekspresi 5 dikenali sebagai kelas 13 dengan selisih nilai vote 1.403, sehingga akurasinya adalah 90%.
Iterasi 4
Hasil iterasi 4 subpercobaan citra partisi bagian atas disajikan pada Tabel 10 dan nilai
vote-nya disajikan pada Lampiran 4.
Tabel 10 Hasil iterasi 4 subpercobaan citra partisi bagian atas
Pada Tabel 10 terlihat bahwa 7 data uji salah diklasifikasi, yaitu kelas 3 ekspresi 7 dikenali sebagai kelas 9 dengan selisih nilai vote 1.384, kelas 7 ekspresi 8 dikenali sebagai kelas 11 dengan selisih nilai vote 1.837, kelas 8 ekspresi 7 dikenali sebagai kelas 14 dengan selisih nilai
selisih nilai vote 0.791, kelas 15 ekspresi 7 dikenali sebagai kelas 8 dengan selisih nilai vote
0.384, dan kelas 15 ekspresi 8 dikenali sebagai kelas 3 dengan selisih nilai vote 3.809, sehingga akurasinya adalah 76.67%.
Hasil dari keempat iterasi pada subpercobaan citra partisi bagian atas memiliki rata-rata akurasi sebesar 86.67%. Jumlah data uji yang benar diklasifikasi pada keseluruhan hasil subpercobaan citra partisi bagian atas disajikan pada Gambar 13. Pada Gambar 13 terlihat bahwa data uji yang paling sedikit benar diklasifikasi adalah kelas 15 (K15), yaitu sebanyak 4 data uji dari total 8 data uji (tiap iterasi 2 data uji) yang digunakan pada subpercobaan citra partisi bagian atas.
Gambar 13 Grafik hasil subpercobaan citra partisi bagian atas.
Citra Partisi Bagian Tengah Iterasi 1
Hasil iterasi 1 subpercobaan citra partisi bagian tengah disajikan pada Tabel 11 dan nilai
vote-nya disajikan pada Lampiran 5.
Tabel 11 Hasil iterasi 1 subpercobaan citra partisi bagian tengah
Pada Tabel 11 terlihat bahwa 7 data uji salah diklasifikasi, yaitu kelas 3 ekspresi 1 dikenali sebagai kelas 11 dengan selisih nilai vote 9.242, kelas 7 ekspresi 1 dikenali sebagai kelas 10 dengan selisih nilai vote 2.025, kelas 7 ekspresi 2 dikenali sebagai kelas 10 dengan selisih nilai
vote 1.089, kelas 8 ekspresi 2 dikenali sebagai kelas 7 dengan selisih nilai vote 0.963, kelas 9
ekspresi 1 dikenali sebagai kelas 2 dengan selisih nilai vote 1.913, kelas 9 ekspresi 2 dikenali sebagai kelas 10 dengan selisih nilai
vote 1.574, dan kelas 15 ekspresi 1 dikenali sebagai kelas 2 dengan selisih nilai vote 4,863, sehingga akurasinya adalah 76.67%.
Iterasi 2
Hasil iterasi 2 subpercobaan citra partisi bagian tengah disajikan pada Tabel 12 dan nilai
vote-nya disajikan pada Lampiran 5. Pada Tabel 12 terlihat bahwa 2 data uji salah diklasifikasi, yaitu hanya kelas 12 ekspresi 3 dan 4 saja yang salah dikenali yaitu keduanya dikenali sebagai kelas 2 dengan selisih nilai vote0.402, sehingga akurasinya adalah 93.33%.
Tabel 12 Hasil iterasi 2 subpercobaan citra partisi bagian tengah
Iterasi 3
Hasil iterasi 3 subpercobaan citra partisi bagian tengah disajikan pada Tabel 13 dan nilai
vote-nya disajikan pada Lampiran 5.
Tabel 13 Hasil iterasi 3 subpercobaan citra partisi bagian tengah
vote 1.572, dan kelas 12 ekspresi 6 dikenali sebagai kelas 15 dengan selisih nilai vote0.996, sehingga akurasinya adalah 86.67%.
Iterasi 4
Hasil iterasi 4 subpercobaan citra partisi bagian tengah disajikan pada Tabel 14 dan nilai
vote-nya disajikan pada Lampiran 5. Pada Tabel 14 terlihat bahwa 8 data uji salah diklasifikasi, yaitu kelas 2 ekspresi 7 dikenali sebagai kelas 15 dengan selisih nilai vote 3.6, kelas 3 ekspresi 7 dikenali sebagai kelas 9 dengan selisih nilai
vote 2.561, kelas 7 ekspresi 8 dikenali sebagai kelas 13 dengan selisih nilai vote 3.376, kelas 8 ekspresi 7 dikenali sebagai kelas 4 dengan selisih nilai vote 0.097, kelas 10 ekspresi 7 dikenali sebagai kelas 14 dengan selisih nilai
vote 0.276, kelas 11 ekspresi 7 dikenali sebagai kelas 3 dengan selisih nilai vote 4.406, kelas 12 ekspresi 7 dikenali sebagai kelas 6 dengan selisih nilai vote 0.162, dan kelas 15 ekspresi 8 dikenali sebagai kelas 1 dengan selisih nilai vote
0.266. sehingga akurasinya adalah 73.33%. Tabel 14 Hasil iterasi 4 subpercobaan citra partisi bagian tengah
Hasil dari keempat iterasi pada subpercobaan citra partisi bagian tengah memiliki rata-rata akurasi sebesar 82.50%. Jumlah data uji yang benar diklasifikasi pada keseluruhan hasil subpercobaan citra partisi bagian tengah disajikan pada Gambar 14.
Gambar 14 Grafik hasil subpercobaan citra partisi bagian tengah.
Pada Gambar 14 terlihat bahwa data uji yang paling sedikit benar diklasifikasi adalah kelas 8 (K8) dan kelas 12 (K12), yaitu sebanyak 4 data uji dari total 8 data uji (tiap iterasi 2 data uji) yang digunakan pada subpercobaan citra partisi bagian tengah.
Citra Partisi Bagian Bawah Iterasi 1
Hasil iterasi 1 subpercobaan 1 citra partisi bagian bawah disajikan pada Tabel 15 dan nilai
vote-nya disajikan pada Lampiran 6. Pada Tabel 15 terlihat bahwa hanya 1 data uji yang salah diklasifikasi, yaitu kelas 9 ekspresi 1 dikenali sebagai kelas 8 dengan selisih nilai vote 1.609, sehingga akurasinya adalah 96.67%.
Tabel 15 Hasil iterasi 1 subpercobaan citra partisi bagian bawah
Iterasi 2
Hasil iterasi 2 subpercobaan citra partisi bagian bawah disajikan pada Tabel 16 dan nilai
Iterasi 3
Hasil iterasi 3 subpercobaan citra partisi bagian bawah disajikan pada Tabel 17 dan nilai
vote-nya disajikan pada Lampiran 6. Pada Tabel 17 terlihat bahwa hanya 1 data uji yang salah diklasifikasi, yaitu kelas 8 ekspresi 6 dikenali sebagai kelas 15 dengan selisih nilai vote 1.392, sehingga akurasinya adalah 96.67%.
Tabel 17 Hasil iterasi 3 subpercobaan citra partisi bagian bawah
Iterasi 4
Hasil iterasi 4 subpercobaan citra partisi bagian bawah disajikan pada Tabel 18 dan nilai
vote-nya disajikan pada Lampiran 6. Pada Tabel 18 terlihat bahwa 3 data uji salah diklasifikasi, yaitu kelas 4 ekspresi 7 dikenali sebagai kelas 9 dengan selisih nilai vote 0.676, kelas 8 ekspresi 7 dikenali sebagai kelas 12 dengan selisih nilai
vote 2.306, dan kelas 10 ekspresi 7 dikenali sebagai kelas 5 dengan selisih nilai vote 1.089, sehingga akurasinya adalah 90%.
Tabel 18 Hasil iterasi 4 subpercobaan citra partisi bagian bawah
Hasil dari keempat iterasi pada subpercobaan citra partisi bagian bawah memiliki rata-rata akurasi sebesar 95.84%. Jumlah data uji yang benar diklasifikasi pada keseluruhan hasil subpercobaan citra partisi bagian bawah disajikan pada Gambar 15. Pada Gambar 15 terlihat bahwa data uji yang paling
sedikit benar diklasifikasi adalah kelas 8 (K8), yaitu sebanyak 6 data uji dari total 8 data uji (tiap iterasi 2 data uji) yang digunakan pada subpercobaan citra partisi bagian bawah.
Gambar 15 Grafik hasil subpercobaan citra partisi bagian bawah.
Perbandingan Hasil Subpercobaan Ketiga Citra Partisi (Atas, Tengah, dan Bawah)
Grafik hasil subpercobaan ketiga citra partisi disajikan pada Gambar 16. Adapun nilai akurasi dari ketiga subpercobaan citra partisi disajikan pada Tabel 19.
Gambar 16 Grafik hasil subpercobaan ketiga citra partisi.
Tabel 19 Hasil subpercobaan ketiga citra partisi
Iterasi Ke-
Akurasi Subpercobaan Citra Partisi Bagian (%)
Atas Tengah Bawah
1 83.33 76.67 96.67
2 96.67 93.33 100
3 90 86.67 96.67
4 76.67 73.33 90
Rata-Rata 86.67 82.50 95.84
Akurasi subpercobaan citra partisi bagian atas seharusnya dapat menjadi akurasi tertinggi dibanding akurasi subpercobaan citra partisi bagian tengah dan bawah. Hal ini disebabkan potongan citra bagian atas di satu kelas pada delapan ekspresinya sama karena tidak terpengaruh oleh perbedaan ekspresi yang umumnya pada bagian tengah dan bawah wajah. Namun tidak demikian, penyebabnya adalah posisi objek/orang pada citra tidak semuanya sama, sehingga objek/orang pada citra partisi bagian atas, tengah, dan bawah yang terpotong juga tidak sama. Contoh hasil pemotongan citra partisi bagian atas yang tidak sama disajikan pada Gambar 17.
Gambar 17 Citra partisi bagian atas kelas 15 ekspresi terkejut (kiri) dan ekspresi kerling
(kanan).
Perbandingan Hasil Seluruh Percobaan
Setelah seluruh percobaan dilakukan dapat diketahui akurasi terbaik pada penelitian ini serta kelas dan ekspresi citra yang mudah dan sulit dikenali. Akurasi seluruh percobaan disajikan pada Tabel 20, jumlah data uji yang benar diklasifikasi dari tiap kelas pada seluruh percobaan disajikan pada Gambar 18, dan banyaknya ekspresi yang salah diklasifikasi pada seluruh percobaan disajikan pada Tabel 21.
Tabel 20 Akurasi seluruh percobaan
Iterasi
Citra Partisi Bagian
Atas Tengah Bawah
Gambar 18 Grafik jumlah data uji yang benar diklasifikasi pada seluruh percobaan.
Tabel 21 Banyaknya ekspresi yang salah diklasifikasi pada seluruh percobaan
Pada Tabel 20 terlihat bahwa akurasi tertinggi diperoleh pada percobaan citra dengan partisi yaitu dengan rata-rata akurasi sebesar 100%, sedangkan akurasi terendah diperoleh pada subpercobaan citra partisi bagian tengah dengan rata-rata akurasi sebesar 82.50%. Pada Gambar 18 terlihat bahwa kelas yang data ujinya semua benar diklasifikasi pada seluruh percobaan adalah K1, K5, K6, dan K13, sedangkan kelas yang pada seluruh percobaan (kecuali percobaan dengan citra partisi) terdapat data uji yang salah diklasifikasi adalah K8 dan K9. Adapun pada Tabel 21 terlihat bahwa secara keseluruhan ekspresi yang paling mudah dikenali adalah ekspresi 3 (E-3) dan ekpsresi yang paling sulit dikenali adalah ekspresi 7 (E-7).
Perbandingan dengan Penelitian Terkait
Pada penelitian Muttaqien (2009), akurasi tertinggi pada pengenalan tanda tangan dengan partisi mencapai 95.56%, sedangkan pada penelitian ini akurasi tertinggi mencapai 100%. Pada penelitian Purwaningrum (2009), akurasi tertinggi pada pengenalan wajah menggunakan data latih tunggal mencapai 96.3%, sedangkan pada penelitian ini akurasi tertinggi mencapai 96.67% (percobaan citra utuh tanpa partisi).
KESIMPULAN DAN SARAN Kesimpulan
Pada penelitian ini dapat disimpulkan: 1. Akurasi pada percobaan citra utuh memiliki
rata-rata sebesar 92.50% dan mencapai 100% pada percobaan citra dengan partisi. 2. Adanya partisi citra dapat meningkatkan
3. Akurasi tertinggi hasil percobaan ketiga partisi citra bagian dicapai pada percobaan citra partisi bagian bawah dengan rata-rata sebesar 95.84%.
Saran
Penelitian lebih lanjut dapat dilakukan yaitu dengan menggunakan teknik penambahan noise
pada citra untuk mengetahui pengaruh noise
terutama terhadap percobaan citra dengan partisi yang menghasilkan akurasi 100%.
DAFTAR PUSTAKA
Dahua L. 2006. Discriminant Feature Persuit: from Statistical Learning to Informative Learning. Hong Kong: The Chinese University.
Gonzalez RC & Woods RE. 2002. Digital Image Processing. New Jersey: Prentice Hall.
Guvenir HA. 1998. A Classification Learning Algorithm Robust to Irrelevant Features. Di Dalam: Giunchiglia F, editor. Artificial Intelligence: Methodology, System
Applications. Proceeding of AIMSA ’98;
Sozopol, 21-23 September 1998. Sozopol: Springer-Verlag. hlm 281-290.
Guvenir HA, Demiroz G, & Ilter N. 1998. Learning differential diagnosis of erythemato-squamous diseases using voting feature intervals. Artificial Intelligence in Medicine 13:147-165.
Han J, Kamber M. 2006. Data Mining Concepts And Techniques. Ed ke-2. San Fransisco: Elsevier Inc.
Karande KJ & Talbar SN. 2008a. Face Recognition under Variation of Pose and Illumination using Independent Component Analysis. ICGST-GVIP, Vol. 8.
Karande KJ & Talbar SN. 2008b. Independent Component Analysis of Edge Information for Face Recognition. International Journal of Image Processing, Vol. 3.
Muttaqien F. 2009. Pengenalan Tanda Tangan dengan Citra Pelatihan Tunggal Menggunakan Algoritme VFI5 Berbasis Histogram [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Pramitasari N. 2009. Pengenalan Citra Wajah Menggunakan Algoritme VFI5 dengan Praproses Transormasi Wavelet [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Purwaningrum EA. 2009. Pengenalan Wajah dengan Citra Pelatihan Tunggal Menggunakan Algoritme VFI5 Berbasis Histogram [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Lampiran 1(lanjutan) Kelas 15
0 50 100 150 200 250 0
100 200 300 400 500 600
0 50 100 150 200 250 0
100 200 300 400 500 600
0 50 100 150 200 250 0
100 200 300 400 500 600
0 50 100 150 200 250 0
100 200 300 400 500 600
0 50 100 150 200 250 0
100 200 300 400 500 600
0 50 100 150 200 250 0
100 200 300 400 500 600
0 50 100 150 200 250 0
100 200 300 400 500 600
0 50 100 150 200 250 0
Lampiran 2 Tabel nilai vote percobaan citra utuh tanpa partisi Nilai vote iterasi 1 percobaan citra utuh tanpa partisi
Lampiran 2 (lanjutan)
Nilai vote iterasi 3 percobaan citra utuh tanpa partisi
Lampiran 3 Tabel nilai vote percobaan citra dengan partisi Nilai vote iterasi 1 percobaan citra dengan partisi
Lampiran 3 (lanjutan)
Nilai vote iterasi 3 percobaan citra dengan partisi
Lampiran 4 Tabel nilai vote subpercobaan citra partisi bagian atas Nilai vote iterasi 1 subpercobaan citra partisi bagian atas
Lampiran 4 (lanjutan)
Nilai vote iterasi 3 subpercobaan citra partisi bagian atas
Lampiran 5 Tabel nilai vote subpercobaan citra partisi bagian tengah Nilai vote iterasi 1 subpercobaan citra partisi bagian tengah
Lampiran 5 (lanjutan)
Nilai vote iterasi 3 subpercobaan citra partisi bagian tengah
Lampiran 6 Tabel nilai vote subpercobaan citra partisi bagian bawah Nilai vote iterasi 1 subpercobaan citra partisi bagian bawah
Lampiran 6 (lanjutan)
Nilai vote iterasi 3 subpercobaan citra partisi bagian bawah
PENDAHULUAN Latar Belakang
Penelitian mengenai pengenalan wajah termotivasi oleh banyaknya aplikasi praktis yang diperlukan dalam identifikasi wajah. Pengenalan wajah sebagai salah satu dari teknologi biometrik utama menjadi semakin penting dengan adanya kemajuan yang cepat dalam teknologi, seperti kamera digital, internet, mobile devices, dan peningkatan permintaan pada sistem keamanan. Pengenalan wajah mempunyai beberapa keuntungan di atas teknologi biometrik lainnya, yaitu alami (natural), tidak ada gangguan (non intrusive), dan mudah digunakan (Karande & Talbar 2008b).
Ada dua pendekatan utama pada masalah pengenalan wajah, yaitu pendekatan geometris (feature based) dan pendekatan fotometrik (view based). Pendekatan geometris merupakan pendekatan yang mengekstraksi dan menghubungkan fitur komponen citra wajah seperti mata, hidung, dan mulut. Adapun pendekatan fotometrik merupakan pendekatan yang merepresentasikan informasi piksel citra wajah. Pada penelitian pengenalan wajah terdapat banyak metode yang diusulkan seperti
Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), dan Elastic Bunch Graph Matching (EBGM) (Karande & Talbar 2008a).
Penelitian ini menggunakan algoritme
Voting Feature Intervals (VFI5) dengan pendekatan fotometrik. Algoritme VFI5 merepresentasikan deskripsi sebuah konsep dengan sekumpulan interval fitur. Pada sekumpulan data yang sama dari ECG
recordings, algoritme VFI5 menghasilkan akurasi yang lebih tinggi, yaitu 62% dibandingkan dengan algoritme klasifikasi standar seperti Naive Bayesian (NB) yang menghasilkan akurasi 50% dan Nearest Neighbor (NN) menghasilkan yang akurasi 53% (Guvenir HA, Demiroz G, & Ilter N 1998).
Pengenalan wajah menggunakan algoritme VFI5 telah dilakukan dengan hasil akurasi yang cukup baik. Pramitasari (2009) pada penelitiannya menggunakan algoritme VFI5 dengan praproses transformasi wavelet menghasilkan akurasi mencapai 90%. Penelitian pengenalan wajah lainnya menggunakan algoritme VFI5 dilakukan oleh Purwaningrum (2009) dan menghasilkan akurasi hingga 96,3%. Penelitian Purwaningrum (2009) ini menggunakan input histogram citra yang
memiliki beberapa keunggulan dibanding menggunakan nilai piksel citra. Penggunaan algoritme VFI5 juga dilakukan pada pengenalan citra tanda tangan oleh Muttaqien (2009). Penelitian ini berbasis histogram dengan tambahan penggunaan partisi citra dan menghasilkan akurasi tertinggi hingga 95,56%.
Tujuan
Penelitian ini bertujuan melakukan pengenalan wajah dengan berbagai ekspresi menggunakan algoritme VFI5 berbasis histogram dan penggunaan partisi citra.
Ruang Lingkup
Ruang lingkup penelitian ini adalah pengenalan citra wajah dengan berbagai ekspresi berdasarkan tingkat keabuan. Data citra yang digunakan adalah data sekunder berupa citra 15 orang yang berbeda dengan masing-masing wajah memiliki delapan ekspresi yang berbeda, yaitu ekspresi memakai kacamata, tersenyum, tidak memakai kacamata, biasa, cemberut, menutup mata, kaget, dan kerling. Seluruh citra memiliki latar belakang berwarna putih yang seragam.
TINJAUAN PUSTAKA Citra Digital
Sebuah citra didefinisikan sebagai sebuah fungsi dua dimensi, f(x,y), dimana x dan y
Citra digital dibentuk oleh sejumlah elemen yang terbatas dimana setiap elemen telah memiliki lokasi dan nilai khusus. Elemen-elemen ini sering disebut sebagai picture elemen, image elemen, pels, atau pixels. dari beberapa istilah tersebut, pixels merupakan istilah yang paling sering digunakan untuk menunjukkan elemen citra digital.
Citra memiliki derajat keabuan berformat 8-bit dan 256 intensitas warna yang berkisar pada nilai 0 sampai 255. Nilai 0 menunjukkan tingkat paling hitam dan 255 menunjukkan tingkat paling putih (Gonzales & Woods 2002).
Pengolahan Citra (Image Processing)
PENDAHULUAN Latar Belakang
Penelitian mengenai pengenalan wajah termotivasi oleh banyaknya aplikasi praktis yang diperlukan dalam identifikasi wajah. Pengenalan wajah sebagai salah satu dari teknologi biometrik utama menjadi semakin penting dengan adanya kemajuan yang cepat dalam teknologi, seperti kamera digital, internet, mobile devices, dan peningkatan permintaan pada sistem keamanan. Pengenalan wajah mempunyai beberapa keuntungan di atas teknologi biometrik lainnya, yaitu alami (natural), tidak ada gangguan (non intrusive), dan mudah digunakan (Karande & Talbar 2008b).
Ada dua pendekatan utama pada masalah pengenalan wajah, yaitu pendekatan geometris (feature based) dan pendekatan fotometrik (view based). Pendekatan geometris merupakan pendekatan yang mengekstraksi dan menghubungkan fitur komponen citra wajah seperti mata, hidung, dan mulut. Adapun pendekatan fotometrik merupakan pendekatan yang merepresentasikan informasi piksel citra wajah. Pada penelitian pengenalan wajah terdapat banyak metode yang diusulkan seperti
Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), dan Elastic Bunch Graph Matching (EBGM) (Karande & Talbar 2008a).
Penelitian ini menggunakan algoritme
Voting Feature Intervals (VFI5) dengan pendekatan fotometrik. Algoritme VFI5 merepresentasikan deskripsi sebuah konsep dengan sekumpulan interval fitur. Pada sekumpulan data yang sama dari ECG
recordings, algoritme VFI5 menghasilkan akurasi yang lebih tinggi, yaitu 62% dibandingkan dengan algoritme klasifikasi standar seperti Naive Bayesian (NB) yang menghasilkan akurasi 50% dan Nearest Neighbor (NN) menghasilkan yang akurasi 53% (Guvenir HA, Demiroz G, & Ilter N 1998).
Pengenalan wajah menggunakan algoritme VFI5 telah dilakukan dengan hasil akurasi yang cukup baik. Pramitasari (2009) pada penelitiannya menggunakan algoritme VFI5 dengan praproses transformasi wavelet menghasilkan akurasi mencapai 90%. Penelitian pengenalan wajah lainnya menggunakan algoritme VFI5 dilakukan oleh Purwaningrum (2009) dan menghasilkan akurasi hingga 96,3%. Penelitian Purwaningrum (2009) ini menggunakan input histogram citra yang
memiliki beberapa keunggulan dibanding menggunakan nilai piksel citra. Penggunaan algoritme VFI5 juga dilakukan pada pengenalan citra tanda tangan oleh Muttaqien (2009). Penelitian ini berbasis histogram dengan tambahan penggunaan partisi citra dan menghasilkan akurasi tertinggi hingga 95,56%.
Tujuan
Penelitian ini bertujuan melakukan pengenalan wajah dengan berbagai ekspresi menggunakan algoritme VFI5 berbasis histogram dan penggunaan partisi citra.
Ruang Lingkup
Ruang lingkup penelitian ini adalah pengenalan citra wajah dengan berbagai ekspresi berdasarkan tingkat keabuan. Data citra yang digunakan adalah data sekunder berupa citra 15 orang yang berbeda dengan masing-masing wajah memiliki delapan ekspresi yang berbeda, yaitu ekspresi memakai kacamata, tersenyum, tidak memakai kacamata, biasa, cemberut, menutup mata, kaget, dan kerling. Seluruh citra memiliki latar belakang berwarna putih yang seragam.
TINJAUAN PUSTAKA Citra Digital
Sebuah citra didefinisikan sebagai sebuah fungsi dua dimensi, f(x,y), dimana x dan y
Citra digital dibentuk oleh sejumlah elemen yang terbatas dimana setiap elemen telah memiliki lokasi dan nilai khusus. Elemen-elemen ini sering disebut sebagai picture elemen, image elemen, pels, atau pixels. dari beberapa istilah tersebut, pixels merupakan istilah yang paling sering digunakan untuk menunjukkan elemen citra digital.
Citra memiliki derajat keabuan berformat 8-bit dan 256 intensitas warna yang berkisar pada nilai 0 sampai 255. Nilai 0 menunjukkan tingkat paling hitam dan 255 menunjukkan tingkat paling putih (Gonzales & Woods 2002).
Pengolahan Citra (Image Processing)
dan pengenalan citra. Selain itu, yang dimaksud dengan pengolahan citra digital biasanya adalah pengolahan citra menggunakan komputer digital (Gonzalez & Woods 2002).
Ekstraksi Fitur
Ekstraksi fitur menghasilkan representasi baru oleh transformasi dari data asli. Pengurangan dimensi dari representasi data dengan ekstraksi fitur bisa memberikan tujuan tambahan, mencakup penghilangan redundansi, menemukan variabel tersembunyi, dan mengetahui struktur data (Dahua 2006).
Histogram
Histogram sebuah citra dengan derajat keabuan antara [0, L-1] merupakan fungsi diskret h(rk) = nk dengan rk adalah derajat keabuan ke-k dan nk adalah jumlah piksel pada
citra yang mempunyai derajat keabuan rk
dengan k = 0, 1, 2,…, L-1. Normalisasi
histogram dapat dilakukan dengan membagi setiap nilai dengan total jumlah piksel pada citra dengan jumlah semua komponen hasil normalisasi tersebut sama dengan 1. Histogram merupakan dasar dari berbagai teknik pemrosesan domain spasial. Histogram dapat digunakan untuk memperbaiki citra, kompresi, dan segmentasi citra (Gonzales & Woods 2002). Contoh citra dan histogramnya disajikan pada Gambar 1.
Gambar 1 Dua wajah yang berbeda dan histogramnya.
Klasifikasi
Klasifikasi merupakan serangkaian proses untuk menemukan sekumpulan model yang merepresentasikan dan membedakan kelas-kelas data. Klasifikasi ini bertujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu data yang label kelasnya tidak diketahui (Han & Kamber 2006).
Algoritme klasifikasi terdiri atas dua tahap, yaitu pelatihan dan prediksi/klasifikasi. Pada tahap pelatihan dibentuk model domain dari data pelatihan yang ada. Adapun pada tahap klasifikasi, menggunakan model tersebut untuk
memprediksi kelas dari suatu data/instance baru (Guvenir HA, Demiroz G, & Ilter N 1998).
Voting Feature Intervals (VFI5)
Algoritme VFI5 merupakan algoritme klasifikasi yang merepresentasikan deskripsi sebuah konsep dengan sekumpulan interval-interval nilai fitur. Pengklasifikasian sebuah
instance baru didasarkan pada vote klasifikasi yang dibuat oleh nilai tiap fitur secara terpisah. VFI5 bersifat supervised learning dan non-incremental sehingga semua data latih dapat diproses secara bersamaan. Tiap contoh data latih direpresentasikan sebagai nilai-nilai fitur sebuah vektor disertai sebuah label yang merepresentasikan kelas contoh data. Algoritme VFI5 membentuk interval-interval nilai fitur (interval) untuk tiap fitur dari contoh data latih (Guvenir 1998).
Interval-interval yang dibuat dapat berupa
point interval atau range interval. Point interval
terdiri atas seluruh end point secara berturut-turut, sedangkan range interval terdiri atas nilai-nilai antara dua end point yang berdekatan tetapi tidak termasuk kedua end point tersebut.
Vote tiap kelas pada interval tersebut kemudian disimpan untuk tiap intervalnya. Oleh karena itu, sebuah interval dapat merepresentasikan beberapa kelas dengan menyimpan vote tiap kelas.
Keunggulan algoritme VFI5 adalah algoritme ini cukup kokoh (robust) terhadap fitur yang tidak relevan tetapi mampu memberikan hasil yang baik pada real-world datasets yang ada. VFI5 mampu menghilangkan pengaruh yang kurang menguntungkan dari fitur yang tidak relevan dengan mekanisme voting -nya (Guvenir 1998). Algoritme VFI5 terdiri atas dua tahap, yaitu tahap pelatihan dan klasifikasi (Guvenir HA, Demiroz G, & Ilter N 1998). 1. Pelatihan
Langkah pertama pada tahap pelatihan adalah menemukan end points tiap kelas c pada tiap fitur f. End points kelas c yang diberikan merupakan nilai yang terkecil dan terbesar pada dimensi fitur linear (kontinu) f untuk beberapa
instance dari kelas c yang sedang diamati. Pada hal lainnya, end points pada dimensi fitur nominal (diskret) f untuk kelas c yang diberikan adalah semua nilai yang berbeda dari f pada beberapa instance kelas c yang sedang diamati.
End points dari tiap fitur f kemudian disimpan dalam array EndPoints[f]. Terdapat end points
sebanyak 2k pada tiap fitur linear dengan k