STRATEGI PENYELESAIAN PROGRAM STOKASTIK
TAK LINIER NON PARAMETRIK
TESIS
Oleh
EVI YANTI LUBIS 077021056/MT
SEKOLAH PASCASARJANA
UNIVERSITAS SUMATERA UTARA
STRATEGI PENYELESAIAN PROGRAM STOKASTIK
TAK LINIER NON PARAMETRIK
TESIS
Diajukan Sebagai Salah Satu Syarat
untuk Memperoleh Gelar Magister Sains dalam
Program Studi Magister Matematika pada Sekolah Pascasarjana Universitas Sumatera Utara
Oleh
EVI YANTI LUBIS 077021056/MT
SEKOLAH PASCASARJANA
UNIVERSITAS SUMATERA UTARA
Judul Tesis : STRATEGI PENYELESAIAN PROGRAM STOKASTIK TAK LINIER NON PARAMETRIK
Nama Mahasiswa : Evi Yanti Lubis Nomor Pokok : 077021056 Program Studi : Matematika
Menyetujui, Komisi Pembimbing
(Prof. Dr. Herman Mawengkang) (Dr. Sutarman, M.Sc)
Ketua Anggota
Ketua Program Studi, Direktur,
(Prof. Dr. Herman Mawengkang) (Prof. Dr. Ir. T.Chairun Nisa. B,M.Sc)
Telah diuji pada Tanggal 29 Mei 2009
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Herman Mawengkang
Anggota : 1. Dr. Sutarman, M.Sc
ABSTRAK
Program stokastik menjeleskan suatu ketidakpastian yang direpsentasikan secara clasik dengan menggunakan kelompok distribusi parameter. Kemudian parame-ter biasanya ditaksir bersama-sama dengan nilai optimal masalah. Akan tetapi, kesalahan mengatakan variabel acak utama kerap kali menghasilkan hasil yang di-dak realitis bila tidi-dak banyak diketahui tentang distribusi sebenarnya. Diajukan untuk mengatasi kesulitan ini dengan memperkenalkan pendekatan nonparamet-rik di mana mengganti penaksiran parameter distribusi dengan penaksiruan fungsi distribusi kumulatif (CDF). Tesis ini mengajukan algoritma praktis agar tujuan ini dapat tercapai dengan menggunakan representasi monoton dari invers CDF marginal dan globalisasi daerah kepercayaan berbasis proyeksi. Aplikasi algo-ritma baru ini pada teori pilihan diskrit akhirnya dibahas, baik dengan data hasil simulasi maupun dalam konteks aplikasi keuangan praktis yang terkait dengan intervensi Bank of Japan dibursa saham luar negeri.
ABSTRACT
This thesis consider a class of stochastic programming models where the uncer-tainty is classically represented using parametric distributions families. The pa-rameters are then usually estimated together with the optimal value of the problem. Howevwr, misspecification of the underlying random variabels often leads to irrea-listic results whwn little is known about their true distributions. We propose to overcome this difficulty by introducing a nonparametric approach where we replace the estimated Comulatif Distribution Function (CDF). A pratical algorithm is dis-cribed which achieves this goal by using a monotonic spline representation of the inverse marginal CDFs and a projection based trust-region globalization. Appli-cation of the new algorithm to discrete choice theory are finally discussed, both with simulated data and in the context of a practical financial application related to interventions of the bank of japan in the foreign exchange market.
KATA PENGANTAR
Segala puji bagi Allah Subhanahu wa Ta’ala, Tuhan semesta alam, yang senantiasa mencurahkan shalawat dan salam atas kekasihnya Rasulullah Muham-mad Shalallahu ’alaihi wa Sallam, beserta keluarga dan sahabatnya dan orang-orang yang mengikuti sunnahnya hingga hari kebangkitan.
Terima kasih tiada hentinya, kepada Allah Subhanahu wa Ta’ala, yang telah memberikan kesempatan sehingga penulis dapat menyelesaikan kuliah dan tesis dengan judul ”Super Efisiensi Data Envelopment Analysis dalam Kinerja Ling-kungan” tepat pada waktu yang ditentukan. Tesis ini merupakan salah satu syarat dalam menyelesaikan kuliah di Program Studi Magister Matematika Program Pasca Sarjana Universitas Sumatera Utara Medan.
Pada kesempatan ini penulis mengucapkan terimakasih dan penghargaan kepada:
Prof. dr. Chairuddin P. Lubis, DTM&H, Sp.A(K) selaku rektor Universitas Sumatera Utara.
Prof. Ir. T. Chairun Nisa, B, M.Sc, selaku Direktur Sekolah Pascasarjana Univer-sitas Sumatera Utara yang telah memberikan kesempatan kepada penulis untuk mengikuti Program Studi Magister Matematika.
Dr. Sutarman, M.Sc, selaku dosen pembimbing II, atas bimbingan dan petunjuk yang diberikan selama perkuliahan, penulisan dan perbaikan tesis ini.
Seluruh staff pengajar pada Program Studi Magister Matematika Sekolah Pascasarjana Universitas Sumatera Utara atas bimbingan dan petunjuk serta ilmu pengetahuan yang
Seluruh keluarga, khususnya kepada suami: Deri Tato. Anakku tercinta: Rivi Dzaki, M. Hamka Said yang telah memberi semangat dan doa. Aya-handa Zulkarnain Lubis, Ibunda tercinta Hayati. Adik dan kakak yang selalu memberi dukungan dan doa untuk keberhasilan penulis.
Semua teman-teman mahasiswa edukator 07 serta semua pihak yang tidak dapat disebutkan satu per satu. Tidak lupa terima kasi untuk Misiani, S.Si se-laku staff administrasi Program Studi Magister Matematika Sekolah Pascasarjana Universitas Sumatera Utara yang telah memberikan pelayanan terbaik kepada penulis.
Medan, Mei 2009 Penulis,
RIWAYAT HIDUP
A. Data Pribadi
Nama : Evi Yanti Lubis
Tempat/tanggal lahir : Medan/22 Maret 1981 Jenis kelamin : Perempuan
Agama : Islam
Alamat rumah : Jln. B. Zein Hamid Gg. sempurna No. 53 Medan
Riwayat Pendidikan
1989-1995 : SD Negeri 060900 1995-1997 : SMP Negeri 2 Medan 1997-1999 : SMA Negeri 13 Medan
1999-2004 : FMIPA UNIMED Medan
C. Pengalaman Kerja
DAFTAR ISI
Halaman
ABSTRAK . . . i
ABSTRACT . . . ii
KATA PENGANTAR . . . iii
RIWAYAT HIDUP . . . v
DAFTAR ISI . . . vi
DAFTAR TABEL . . . vii
BAB 1 PENDAHULUAN . . . 1
1.1 Latar Belakang . . . 1
1.2 Perumusan Masalah . . . 3
1.3 Tujuan Penelitian . . . 4
1.4 Manfaat Penelitian . . . 4
1.5 Metodologi Penelitian . . . 4
BAB 2 TINJAUAN PUSTAKA . . . 6
BAB 3 LANDASAN TEORITIS . . . 8
3.1 Pendekatan Nonparametrik . . . 12
3.2 Metode Daerah-Kepercayaan untuk Penaksiran Efisien . . . 16
3.3 Percobaan Numerik . . . 19
BAB 4 PENYELESAIAN PROGRAM STOKASTIK TAK LINIER . . 23
4.1 Aplikasi Pada Bidang Keuangan . . . 26
BAB 5 KESIMPULAN . . . 31
DAFTAR TABEL
Nomor Judul Halaman
4.1 Kalibrasi atas data hasil simulasi . . . 24
4.2 Kalibrasi data simulasi kasus 2 . . . 26
4.3 Keputusan Bank of japan 1991-2004 . . . 27
ABSTRAK
Program stokastik menjeleskan suatu ketidakpastian yang direpsentasikan secara clasik dengan menggunakan kelompok distribusi parameter. Kemudian parame-ter biasanya ditaksir bersama-sama dengan nilai optimal masalah. Akan tetapi, kesalahan mengatakan variabel acak utama kerap kali menghasilkan hasil yang di-dak realitis bila tidi-dak banyak diketahui tentang distribusi sebenarnya. Diajukan untuk mengatasi kesulitan ini dengan memperkenalkan pendekatan nonparamet-rik di mana mengganti penaksiran parameter distribusi dengan penaksiruan fungsi distribusi kumulatif (CDF). Tesis ini mengajukan algoritma praktis agar tujuan ini dapat tercapai dengan menggunakan representasi monoton dari invers CDF marginal dan globalisasi daerah kepercayaan berbasis proyeksi. Aplikasi algo-ritma baru ini pada teori pilihan diskrit akhirnya dibahas, baik dengan data hasil simulasi maupun dalam konteks aplikasi keuangan praktis yang terkait dengan intervensi Bank of Japan dibursa saham luar negeri.
ABSTRACT
This thesis consider a class of stochastic programming models where the uncer-tainty is classically represented using parametric distributions families. The pa-rameters are then usually estimated together with the optimal value of the problem. Howevwr, misspecification of the underlying random variabels often leads to irrea-listic results whwn little is known about their true distributions. We propose to overcome this difficulty by introducing a nonparametric approach where we replace the estimated Comulatif Distribution Function (CDF). A pratical algorithm is dis-cribed which achieves this goal by using a monotonic spline representation of the inverse marginal CDFs and a projection based trust-region globalization. Appli-cation of the new algorithm to discrete choice theory are finally discussed, both with simulated data and in the context of a practical financial application related to interventions of the bank of japan in the foreign exchange market.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Program stokastik mempunyai peranan penting dalam bidang matematika, dimana permasalahn tersebut dapat berupa ketidakpastian penyelesaian pada su-atu distribusi atau bahkan peranan dari susu-atu distribusi yang lebih luas. Berda-sarkan dari hasil dan ketidakpastian penyelesaian dalam suatu masalah distribusi, berbagai solusi penaksiran yang telah di kemukakan akan diurut dari nilai ke-mungkinan terkecil kenilai keke-mungkinan yang sebenarnya. Bagaimanapun, sifat dari program stokastik akan menjadi cukup sulittergantung pada berbagai pili-han pada distribusi-distribusi yang melibatkan variabel acak. Terutama untuk beberapa kelas pada permasalahan estimasi dimana terdapat satu tujuan untuk menetapkan suatu harga dari suatu penaksiran dimana hasil penaksiran tersebut berbeda-beda, Ronald at al(1990). Meskipun penaksiran tesebut mempunyai ke-mungkinan untuk mengestimasi parameter-parameter pada distribusi yang telah diketahui, distribusi-distribusi yang telah dipilih tersebut sering menjadi ham-batan, dan mungkin akan berpengaruh lebih besar dengan adanya pengelompokan asumsi-asumsi dan akan lebih mudah untuk menghitungnya dibandingkan dengan kebenaran yang ada pada permasalahan.
2
Satu dari cara yang digunakan adalah distribusi empiris, yang termasuk kedalam program stokastik, dimana sebuah penaksiran pada fungsi distribusi ku-mulatif dibentuk dari realisasi observasi untuk variabel acak, hanya jika nilai kebenaran dari distribusi tersebut tidak diketahui, Divroye(1986). Untuk pro-gram stokastik standar dimana variabel acak dispesifikasikan dengan standar dis-tribusi parametrik, ini juga diasumsikan pada permasalahan ini bahwa distrubusi dasar yang meliputi variabel acak yang dapat diestimasi selama tahap permulaan, terutama pada optimisasi. Asumsi ini muncul dan dapat digunakan berbagai ap-likasi.
Ditunjuk bentuk umum program stokastik (SP)
min
x∈X(E[f(x, ξ)])
dimana X adalah himpunan yang terdapat di Rn, ξ adalah sebuah variabel acak
pada besarm yang didefinisikan sebagai ruang probabilitas Ξ, F, P), dan g adalah sebuah fungsi dari R ke R. Untuk lebih sederhananya, bahwa X adalah diditer-ministik.
Adapun bentuk model nonparametrik Black-Holes, misalnya untuk penye-lesaian persamaan diperensial stokastik adalah
ds(t) =µs(t)dt+σs(t)dw(t)
3
Terdapat tiga penyelesaian untuk program stokastik tak linier nonparamet-rik. Salah satunya adalah dengan melakukan penaksiran nonparametrik, Ronald at al (1990) misalkan, jika terdapat m komponen pada ξ secara terpisah, pada suatu harga asumsi kebebasan diantaranya. Sebagai akibatnya, dan hanya da-pat menjelaskan dari variabel acak tak bervariasi yang dianggap lebih seder-hana dibandingkan dengan kasus dengan variabel acak bervariasi. JikaX adalah suatu variabel acak tak bervariasi yang diketahui, suatu teknik mudah digu-nakan untuk menghasilan penjelasan dari distribusi itu sendiri yang mengan-dung sampel suatu distribusi serupa di [0,1], yang kemudian didefenisikan dengan U[0.1], dan kemudian diaplikasikan kefungsi distribusi kumulatif F−1
x , sehingga
Sx ={Fx−1(U), U ∼U[0,1]}, dimana Sx adalah gambaran himpunan sampel dari
variabel acak X. Ini juga diasumsikan bahwa terdapat F−1
x, jika distribusi X
diketahui. Metode ini dikenal sebagai teknik pengembalian atau dikembalikan kepada variabel acak, Defroye(1986).
Yang kedua adalah metode trust-region, conn at al (2000) untuk estimasi efisien juga merupakan salah satu cara yang dapat digunakan untuk penyelesaian program stokastik. Jika terdapat satu koefisien nonparametrik, ζ mendefenisikan
v variabel yang dibutuhkan. Maka ζ selanjutnya disebut order-simplex. Dan ke tiga merupakan metode numerik yang juga dapat diaplikasikan dalam penyele-saian program stokastik.
1.2 Perumusan Masalah
4
1.3 Tujuan Penelitian
Adapun tujuan dalam penelitian ini adalah menentukan dan memaparkan berbagai strategi penyelesaian atau pendekatan-pendekatan yang dapat digu-nakan dalam program stokastik tak linier nonparametrik. Sehingga dalam suatu permasalahan distribusi yang tidak diketahui kepastiannya, dapat diselesaikan dengan ketiga cara yang telah disebutkan sebelumnya, yaitu penaksiran nonpara-metrik, metode trust-region untuk estimasi efisien dan metode numerik.
1.4 Manfaat Penelitian
Dengan adanya strategi penyelesaian pada program stokastik tak linier non-parametrik diharapkan dapat memberi manfaat untuk menyelesaikan suatu dis-tribusi yang tidak diketahui kepastian penyelesaiannya sehingga diperoleh suatu nilai dari permasalahan distribusi tersebut.
1.5 Metodologi Penelitian
Dalam penelitian ini akan dibahas tentang:
1. Program stokastik tak linier nonparametrik
2. Penjelasan tingkat ketiga strategi penyelesaian stokastik tak linier
3. Penaksiran non parametrik
4. Metode trust-region untuk estimasi efisien
5
BAB 2
TINJAUAN PUSTAKA
Gallant dan Tauchen (1989), dalam penulisannya menjelaskan suatu metode yang berhubungan dengan sebuah aplikasi penentuan harga, dan mengalami su-atu perbaikan harga. Estimasi menggunakan prosedur kemungkinan nilai maksi-mum pada sebuah perluasan dengan suatu model strategi pilihan yang ditentukan dengan titik kemungkinan yang ada.
pada penulisan Robinson (1983), dia menyatakan disaat data mempunyai perbedaan, deviasi terbesar dari syarat utama, diakomodasikan dan dibandingkan keestimasi kernel. Yang menggunakan metode SNP (seminonparametric), yang membentuk sebuah model parametrik sebagai penaksiran pada proses. Hussey (1989) pada penulisan disertasinya menjelaskan bahwa nilai kecocokan yang cen-derung menaik dan strategi gangguan juga berperan. Hussey menggunakan me-tode SNP dalam konjungsi dengan meme-tode kernel kemasalah struktur non linier pada suatu data industri.
Modifikasi-modifikasi bentuk yang dicapai adalah cukup kaya secara aku-rat untuk mengaproksimasikan densitas dari kelas besar yang mencakup densitas dengan lemak, ekor mirip t, densitas dengan ekor yang lebih sempit dari pada Guasian, dan densitas miring (Gallant dan Nyehkan, 1987).
7
Eksistensi terhadap adaptasi yang lebih baik untuk metode proses hetoroke-dastik kondisional yang jelas seperti data angka pertukaran telah dikembangkan oleh Gallant at al (1989).
BAB 3
LANDASAN TEORITIS
Perhatikan program stokastik (SP) umum
min
a∈X g(E[f(xξ)]) (3.1)
dimana X adalah suatu himpunan kompak dalam Rn, ξ adalah vektor random
berukuran m yang didefenisikan atas ruang pronabilitas (Ξ,F, P) dan g adalah fungsi dari RkeR. Untuk penyederhanaan, disini diasumsikan bahwa X dengan deterministik. Yang penting, tidak mengasumsikan bahwa proyeksi efesien se-cara perhitungan atas himpunan layak ini ada tersedia (contoh yang biasa adalah bilaX mendefenisikan batas sederhana atas komponen-komponenx). Asumsikan kemulusan dan regularitas diberikan dibawah ini, tetapi tidak mengharuskan kon-feksitas fungsi tujuan. Karena (1) biasanya tidak bisa diselesaiakan secara ana-litik, perhatikan proses penyelesaian yang didasarkan pada aproksimasi rata-rata sampel (SAA), yang dibentuk pengambilan sampel atas ξ.
min
dimana ˆf R(x) didefenisikan sebagai
ˆ
9
A.0 Pengambilan acak {ξq}∞q=1 terdistribusi bebas dan identik.
A.1 Untuk setiap −P ξ, fungsi f(., ξ) terdeferensialkan kontiniu untuk S.
A.2 Himpunanf(x, ξ), x∈Xdidominasi oleh fungsi terintegralkan−P K(ξ), ya-itu Ep(K) sehingga dan |f(x, ξ)| ≤ K(ξ) untuk semua x ∈ X dan setiap
−P ξ.
A.3 Masing-masing komponen gradient ∂
∂|x|lf(x, ξ)(1, . . . , n), x∈ X, didominasi oleh fungsi terintegralkan−P.
A.4 Fungsi g terdiferensialkan kontinu dua kali dalam pertanyaannya.
A.3 Memungkinkan mengaplikasikan hasil-hasil Robinstein dan Shapiro, halaman 71 menyimpulkan bahwa ekspektasi fungsi nilai E[f(x, ξ)] terdiferen-sialkan kontinu atasX, dan bahwa ekspetasi perubahan gradient bisa saling diper-tukarkan dalam rumus gradien. Amati juga bahwaA.0-A.2secara bersama-sama mengimplikasikan eksitensi hukum uniform bilangan besar (ULLN) atas S untuk aproksimasi ˆfR(x) dari f(x) : sup
x∈X
|fˆR(x)−f(x)| → 0 hampir pasti jika R → ∞,
yang pada gilirannya memungkinkan sehingga dapat menyimpulkan sifat berikut.
proposi 1 Dengan asumsi A.0-A.2, A.4 kita peroleh hukum uniform bilangan besar sup
x∈X
|gfˆR(x)−g(f(x))| → jika R→ ∞
Bukti. Misalkan ε > 0. Menurut kontinuitas g(˙), diperoleh bahwa terdapat
δ >0 sedemikian sehingga |z1−z2|< δ mengaplikasikan bahwa |g(z1)−g(z2)|<
ε. Dari ULLN atas ˆf(˙) untuk f(˙), di peroleh bahwa terdapat Rδ untuk semua
R ≥ Rδ, untuk semua x dalam X,|fˆR(x)−f(x)| < δ hampir pasti, dan karena
10
Dari A.3 dan A.4, dengan cara yang sama dapat ditetapkan ULLN an-tara derivatif parsil SAA dan tujuan yang sebenarnya. Konvergensi orde-satu (yaitu konvergensi barisan penyelesaian-penyelesaian orde-satu dari (20 ke suatu penyelesaian orde-satu (1) kemudian bisa diperoleh dari ketaksamaan variasional stokastik, sebagaimana dipresentasikan dalam Gurkan dkk. perhatikan pemetaan Φ :Rn×Ξ→Rn dan multifungsi Γ :Rn→Rn. Andaikan bahwa diperoleh fungsi yang terdefinisi dengan jelas φ(x) :=h(EP II[Φ(x, ξ)]). dapat disebut dengan
φ(x)∈Γ(x) (3.3)
sebagai persamaan tergeneralisir yang sebenarnya atau berlebihan ekspektasi dan katakan suatu titik x∗ ∈ Rm adalah penyelesaina dari (3a0 jika φ(x∗) ∈ Γ(x∗).
Jika {ξ, . . . , ξR} adalah sampel acak, disebut
ˆ
ϕR(x)∈Γ (x) (3.4)
sebagai persamaan terbeneralisir SAA, di mana
ˆ
Di notasikanS∗ dan SR∗ masing-masing himpunan (semua)penyelesaian dari
persamaan tergeneralisir yang sebenarnya (3) dan persamaan tergeneralisir SAA (4). Di rotasikan dengand(x, A:= sup
x∈A
11
Teorema 1Misalkan S adalah himpunan bagian kompak dari Rm sedemikian se-hingga S∗⊂ S.
Asumsikan bahwa
(a.) Multifungsi Γ(x) tertutup, yaitu jika x(k) → x, y(k) ∈ Γ(xk) dan y(k) → y
maka y∈ Γ(x),
(b.) Pemetaan φ(x) kontinu atas S,
(c.) Hampir pasti ∅ 6=S∗
R ⊆S untuk R yang cukup besar dan,
(d.) ˆφR(x) konvergen keφ(x) hampir pasti sama dengan S jika R → ∞. Maka D(S∗
R, S∗ →hampir pasti jika R → ∞.
Bila X konveks, dapat kita defenisikan bahwa −∇xg(x∗) termasuk dalam
kerucut normal pada X dix∗, yang dinotasikan dengan NX(x∗). Maka teorema 1
memungkinkan bukti mudah atas konvergensi hampir pasti orde-satu. Perhatikan pilihan Γ(·) =NX(cdot);φ(∗) termasuk dalam Γ(∗) jika dan hanya jika
(φ(x∗), u−x∗)≤0,∀u∈X
Dengan mengikuti Shapiro [40], di sebut ketaksamaan varisonal sedemikian sebagai ketaksamaan varisional stokastik dan di catat bahwa asumsi (a) dari teo-rema 3.1 selalu berlaku dalam kasus ini. Misalkan S∗ dan S∗
R masing-masing
merupakan himpunan titik kritis orde-satu dari persamaan tergeneralisir yang sebenarnya (3.) dan dari persamaan tergeneralisir SAA (3.4). Maka berdasar-kan A.0-A.4, di peroleh bahwa φ(x) =−∇xg(x), dan bahwa φ(x) adalah vektor
12
sementara A.1 dan kekompakan dari X menjamin asumsi (c) dengan menetap-kanS =X. Dengan demikian Teorema 3.1 menjamin kritikalitas orde-satu dalam limitR → ∞, hampir pasti. Konvergensi orde-dua lebih sulit secara berarti un-tuk dibuktikan, namun demikian bisa disimpulkan secara deduksi berdasarkan asumsi-asumsi tambahan seperti dalam Bastian dkk.
3.1 Pendekatan Nonparametrik
Sewaktu menangani masalah (3.1) dan (3.2), kerapkali membuat perkiraan secara implisit atas distribusi vektor acakξuntuk menghasikan pengambilan yang dibutuhkan dalam membentuk SAA. Di dalam prakteknya, ini biasanya
menim-bulkan masalah, seperti yang akan di tunjukan dibawah ini. Namun jika tetap menyatakan ketidakpastian di dalam masalah yang ditangani dengan menggu-nakan variabel acak dalam model tersebut, khususnya denga menghindari spesifik atas bentuknya.
Pengamatan pertama adalah bisa memperhatikan masing-masing kem kom-ponen dari ξ secara terpisah, berupa asumsi saling ketergantungan diantaranya. Sebagai akibatnya, harus menarik dari variabel acak univariat lebih sederhana daripada menangani kasus multivariat. Jika X adalah variabel acak univariat (dikatahui), suatu teknik dikenalkan untuk menghasilakn pengambilan distribusi yang terdiri dari pengambilan sampel distribusi uniform atas [0,1], untuk selan-jutnya dinotasikan dengan U[0,1] dan mengaplikasikan invers fungsi distribusi kumulatif FX−1 untuk pengambilan ini:
13
di mana SX menyatakan himpunan sampel yang diambil dari variabel acak X.
Biasanya diasumsikan bahwaFX−1ada (atau setidaknya bisa diaproksimasi dengan baik), jika distribusi dari X dikatahui.
Metode ini dikenal sebagai teknik invers dalam literatur pembuatan bilangan acak yang juga populer dalam konteks metode reduksi variansi. Penggunaan in-vers fungsi distribusi kumulatif juga lebih diajukan sebelumnya dalam penafsiran nonparametrik standar oleh Hora dkk. Untuk menegaskan ide ini, dimasukan asumsikan bahwa A.5 komponen-komponen dari ξ adalah bebas. Ulasan di atas kemudiam mengaplikasikan bahwa bisa memperoleh pengambilan yang diperlukan dari distribusi variabel acak ξ jika dapat menaksir untuk masing-masing kompo-nen X suatu invers fungsi distribusi kumulatifFX−1 dengan sifat-sifat bahwa
a. FX−1 : [0,1]→R
b. FX−1 adalah naik monoton, jika membatasi diri pada variat kontinu,
1. FX−1 adalah kontinu.
Dengan kata lain, harus menaksiran fungsi riil kontinu yang domainnya adalah [0,1], dan mana yang baik monoton. Mungkin ada yang mengajukan bahwa pen-dekatan ini memiliki keuntungan dalam generalitas dan efesiensi, karena menaksir kepadatan sebagai penggantiFX−1hanya akan berarti fungsi daripada derivatifnya. Untuk membatasi pilihan tersebut lebih lanjut, bisa juga mengajukan asumsi tam-bahan berikut ;
14
Asumsi ini kerapkali realistis untuk kumpulan data praktis dan memiliki kelebihan dengan menghindari secara eksplisit keberadaan ekor yang kerapkali sulit untuk ditafsirkan.
Aproksimasi fungsi adalah bidang matematika besar, dan berbagai teknik bisa dipertimbangkan untuk masalah penaksiranFX−1. Dalam kasus tersebut, pilih menyatakan invers fungsi distribusi kumulatif yang diinginkan sebagai kombinasi linier berhingga dari pada beberapa fungsi dasar {lq, q =, . . . , v}, yang kontinu
atas interval [0,1] untuk variabel kontinu, dimana kasus ini yakin bahwa pilihan basis yang cocok untuk tujuannya adalah pilihanB-spline. Pada umumnya, fungsi B-spline C(u) ber derajat p adalah polinomial sepotong-sepotong berderajat p, yang didefenisikan atas interval [a, b], yang bisa dinyatakan sebagai kombinasikan linier dari n+ 1 fungsi basisNi,p(u), sebagai berikut:
C(u) =
v
X
i=0
PiNi,p(u)
Koefisien-koefisien p0, p1, . . . , Pv disebut titik-titik kontrol, dan u adalah vektor
knot (u0 = 1, v1, . . . , um = b). Fungsi basis bisa dibentuk dengan perulangan
(atas derajat p) sebagai berikut:
Ni,0 =
15
tutup atau terbuka), yang berbentuk
U =
yaitu knot pertama dan terakhir mempunyai p+ 1 pergandaan. Dimungkinkan menunjukan bahwa fungsiC(u) adalahp−1 kali terdiferensialkan kontinu. Dalam tulisan ini, akan mengkaji B-spline kubik, yaitu akan tetapkan p sama dengan 3, yang memberi invers fungsi distribusi kumulatif terdiferensialkan kontinu dua kali. Tetapi sifat yang paling penting dariB-spline dalam konteks tersebut adalah bahwa, dengan pilihan basis dan knot iniC(u) naik monoton jika titik-titik kontrol memiliki sifat yang sama, yaitu jika
P0 ≤P1 ≤. . .≤Pv
Seperti yang akan dijelaskan dalam bagian berikutnya, sifat ini dijamin secara al-goritmik dalam prosedur penafsiran. Untuk penyederhanaan presentase, akan kita asumsikan bahwa semua variat acak adalah nonparametrik, sementara di dalam prakteknya (seperti dalam aplikasi riil), bisa mencampur distribusi parametrik dan distribusi nonparametrik. Kemudian masalah penaksiran nonparametrik adalah untuk menyelesaikan, untuk suatu R tetap,
16
di mana ςr adalah pengambilan dari distribusi uniform [0,1].
3.2 Metode Daerah-Kepercayaan untuk Penaksiran Efisien
Untuk menyelesaikan program (2), dengan batasan bahwa titik-titik kon-trol yang menggambarkan invers fungsi distribusi kumulatif adalah monoton, mula-mula substitusikan (8) dalam (6), yang menghasilakn fungsi tujuan (poten-sial nonkonveks)f(w)de fˆg(x, P) untuk meminimalkan terhadapwde f(x, P) atas daerah layak X×C di mana C didefinisikan oleh
C =
m
Y
i=1
{(P0j, . . . , Pvj) sedekian hingga P0j ≤P1j ≤ . . .≤Pvj} (3.9)
Untungnya, tidak sulit membuktikan bahwa C adalah himpunan konveks, sehingga hasil konsistensi, terutama Teorema 1, bisa diaplikasikan, sepanjang juga mengasumsikan bahwa iterat tetap di dalam himpunan kompak. Jika hanya ada satu koefisien nonparametrik, C memdefenisikan v variabel terurut. Kemudian cas disebut orde-simplex.
17
Karena operator proyeksi efesien padaX×Cmudah dibentuk dan kemudian bisa dieksploitasi dengan berhasil dalam penyelesaian masalah optimisasi nonlinier yang didefenisikan oleh (3.6) (denganRtetap), (3.7)dan (3.9). Ini dicapai dengan algoritma daerah-kepercayaan terspesialisasi yang efesien secara perhitungan yang sekarang dinyatakan.
Algoritma 1: Algoritma daerah-kepercayaan terproyeksikan
Tahap 0. Inisialisasi. Titik awal w0 ∈C dan jari-jari daerah-kepercayaan awal
∆0 diberikan. Konstanta η1, η2, γ1 dan γ2 juga diberikan dan memenuhi
0< η1 ≤η2 <1dan0< γ1,≤γ2 <1 (3.10)
Hitung f(w0) dan tetapkan k= 0.
Tahap 1. Defenisi model. Bentuk model mk dalam daerah-kepercayaan Bk,
yang didefinisikan sebagai
Bk ={wsedemikian hinggakw−wkk ≤∆k}
Tahap 2. Tahap perhitungan. Hitunglah tahaps(k) yang mereduksi secukup-nya model m(k) dan sedemikian hingga w(k)+s(k) ∈(X ×C)∩Bk.
Tahap 3. Penerimaan titik percobaan. Hitungf(w(k)+s(k)) dan definisikan
ρk =
f(w(k))−f(w(k)+s(k))
mk(w(k))−mk(w(k)+s(k))
(3.11)
18
Tahap 4. Update jari-jari daerah kepercayaan.
∆k+1 =
tambahkan k dengan 1 dan pergi ke Tahap 1.
Dalam uraian ini, nilai layak untuk konstanta-konstanta dari (3.10) misalnya diberikan oleh
η1 = 0,01, η2 = 0,9danγ1 =γ2 = 0,5
tetapi nilai lainnya bisa dipilih. pilih norm Euclidean dalam defenisiBk. Akhirnya
diikuti praktek yang biasa dan didefinisikan modelmk merupakan fungsi kuadratik
dengan tipe
di mana Hk adalah Hessian ∇2wwf(w(k)) atau aproksimasinya. Dalam percobaan
tersebut, digunakan aproksimasi SR1, apakah itu aproksimasi BFGS dengan ke-berhasilan serupa.
Jikaρk ≥η∇1dalam tahap 1, iterasik disebut berhasil karena titik kandidat
w(k)+s(k)diterima; dalam hal lain iterasi dinyatakan tidak berhasil dan titik baru ditolak. Jika ρk ≤ ∇η2, persesuaian antara model dan fungsi sangat baik, dan
19
Tahap s(k) dihitung dengan usaha pertama untuk mengidentifikasi batasan aktif dengan meminimalkan model sepanjang path gradient hasil proyeksi (dengan menggunakan proyeksi total pada X ×C).
3.3 Percobaan Numerik
Melakukan percobaan algoritma yang diajukan dalam konteks teori pilihan diskrit, khususnya dibidang masalah logit campuran. Ini merupakan perkem-bangan belakangan ini dalam teori dan sekarang ini digunakan dalam berbagai konteks, misalnya politik, marketing, transportasi dan keuangan, untuk men-jelaskan perilaku orang/keluarga/perusahaan yang menyatakan pilihannya
an-tara sekumpulan hingga alternatip. Dalam kerangka ini, heterogenitas cian-tarasa pada populasi ditampung dengan menggunakan model parametrik yang variabel acaknya mempunyai distribusi dengan bentuk fungsional fasefisik. Dalam seba-gian besar aplikasi yang dipublikasikan hingga saat ini, distribusi yang dipilih adalah distribusi normal. Akan tetapi, penggunaan distribusi tanpa batas(seperti distribusi normal) tampaknya tidak dapat pada sejumlah kasus, terutama bila sifat-sifat tertentu diasumsikan dinilai positip(atau negatip) oleh semua individu.
Untuk mencegah kesulitan ini, model-model belakangan ini menggunakan distribusi dengan batas, yang kerapkali diperoleh sebagai transformasi normal sederhana. Train dan Sonnier menetapkan model logit campuran dengan dis-tribusi lognormal, disdis-tribusi normal dihapus dan disdis-tribusi Johnson Sb yang
20
itu, asumsi pendukung A.6dengan batasan bisa dianggap tepat, karena perilaku ekstrim, yang bersesuaian dengan nilai (absolut) X yang sangat besar, biasanya kurang mendapat sambutan Juga perlu dicatat bahwa jika penggunaan distribusi normal diketahui mempermudah proses penaksiran, namun kegagalan dalam kon-vergensi ada dilaporkan untuk distribusi tanpa batas atau distribusi nonpara-metrik, dan juga kesulitan yang ditimbulkan keberadaan yang banyak maksimum lokal. Dalam aplikasi berikutnya, kumpulan i individu, dimana setiap individu
i harus memilih satu alternatif di dalam himpunan berhingga Ai. Asosiasikan
utilitasUij pada setiap alternatip Aj dariAi, sebagai dipersepsikan oleh individu
i. Sejalan dengan teori ekonometrik yang diterima, juga diasumsikan bahwa
indi-vidu yang bertujuan memaksimalkan utilitasnya, tetapi utilitas ini tidak diamati sepenuhnya.
Kemudian teknik standar adalah mendekomposisikan utilitasUij dalam
jum-lah bagian terukur deterministik Vij(β), dimana β adalah vektor yang akan
di-taksir dan bagian acak yang tidak diamatiεij. Maka Probabilitas bahwa individu
i memilih alternatipj diberikan oleh:
Pij(β) =P[Vij(β) +εij ≥Vik(β) +εik,∀Ak ∈Ai]
Rumusan probabilitas tentu saja tergantung pada pilihan distribusi untuk
εij. Bila εij diasumsikan tidak tergantung dan berdistribusi Gumbel indentik
antara individu-individu dan alternatip-alternatip, diperoleh rumus probabilitas logit tradisional
Pij =
eVij(β)
PAi
21
Dalam kerangka logit campuran, diasumsikan bahwa β adalah vektor kon-stanta, tetapi menganggapnya sebagai vektor acak dengan fungsi distribusi ku-mulatifFB(β) sehingga probabilitas pada ruas kiri dari (3.12) sekarang bersyarat
atas realisasi β, dan probabilitas tak bersyarat menjadi
Pij =EB[Lij(β)] =
Z Z
Lij(β)dPB(β) (3.13)
Karena biasanya tidak bisa menaksir β secara langsung, diasumsikan bahwa ini dapat dinyatakan sebagai B =b(Γ, θ), di mana Γ adalah suatu vektor acak danθ suatu vektor parameter-parameter konstan, yang lagi-lagi akan ditaksir.
Dalam bentuk lain, di asumsikan famili distribusi untuk B yang dipara-meterisasikan oleh θ. Jika secara tradisi vektor β kontinu, dapat ditulus (3.13) sebagai
Pij(θ) =
Z
Lij(γ, θ)φ(γ, θ)dγ
di mana π(γ, θ) adalah kepadatan B dengan vektor parameter θ.
Dalam kasus bila individu yang sama bisa menyatakan beberapa pilihan, maka untuk setiap individu di amati barisan pilihan yi = (ji1, . . . , jiT i), yang
dapat diasumsikan berkorelasi. (Kasus sedemikian disebut sebagai ”data panel”).
Cara mudah mengakomodir situasi ini Adalah mengasumsikan heterogenitas hanya ada pada tingkat populasi, tetapi tidak ada pada tingkat individu. Maka
22
Kemudian vektor dari parameter-parameter yang tidak diketahuiθ ditaksir dengan memaksimalkan fungsi log-likelihood, yaitu dengan menyelesaikan masalah
max
di mana yi adalah vektor pilihan-pilihan alternatif yang diambil oleh individui.
Seperti yang ditegaskan dalam Bastin et al. [6],(3.14) bisa dipandang sebagai perluasan dari (3.1), dan SAA yang bersesuaian adalah
max
dan R adalah jumlah pengambilan acak γr1. Program SAA (3.15) dapat
BAB 4
PENYELESAIAN PROGRAM STOKASTIK TAK LINIER
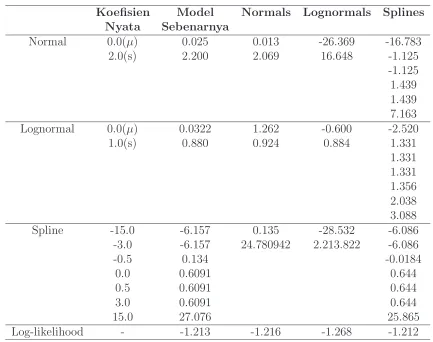
Pertama disahkan prosedur penaksiran atas data hasil simulasi. Berharap untuk memperbaikinya dan menemukan distribusi utama, dan membandingkan-nya dengan penaksiran parametrik awal. Dalam percobaan simulasi tersebut, diambil populasi sintetik yang terdiri dari 2000 individu, yang masing-masing memberikan satu pengamatan. Rancangan tersebut berisi empat alternatif, yang berdistribusi normal dengan parameter-parameterN(0,5; 1) dan tiga variabel be-bas, satu normal, satu lognormal dan satu spline. Parameter-parameter yang di-gunakan untuk distribusi ini diberikan dalam tabel 4.1. Kemudian ditaksir empat
model, satu dengan menggunakan kelompok distribusi yang tepat, satu diben-tuk hanya dengan normal, satu dibendiben-tuk hanya dengan lognormal, satu hanya menggunakan spline.
Dalam prosedur penaksiran, X =Rn, agar sesuai dengan teori yang
dikem-bangkan, di asumsikan bahwa vektor lengkap iterate-iterate tetap didalam satu himpunan. Di pilih 5 titik knot berjarak sama per aproksimasi spline, yaitu dengan memperhitungkan pengulangan dalam bentuk (3.5), dipilih
U ={0,0,0,0,0,25,0,5,75,1,1,1,1}
se-24
lainnya, terutama dalam Train dan Weeks. Speksifikasi model yang hanya diben-tuk atas spline mengungguli semua model lainnya dalam bendiben-tuk nilai optimal log-likelihood dan telah mendekati hasil yang diperoleh dengan spesifikasi yang tepat. Akan tetapi, perbedaannya adalah pada akurasi pengambilan sampel, jadi tidak ada kesimpulan kuat yang bisa dicapai, tetapi tidak bisa mengesampingkan kesesuaian atas data sampel. Konvergensi numerik dengan hanya-spline lebih lambat jika yang diinginkan hanya speksifikasi. Tetapi, hal ini juga tidak karena kedua parameter pertama melannggar AsumsiA.6
Tabel 4.1 Kalibrasi atas data hasil simulasi
Koefisien Model Normals Lognormals Splines Nyata Sebenarnya
Normal 0.0(µ) 0.025 0.013 -26.369 -16.783
2.0(s) 2.200 2.069 16.648 -1.125
-1.125 1.439 1.439 7.163
Lognormal 0.0(µ) 0.0322 1.262 -0.600 -2.520
1.0(s) 0.880 0.924 0.884 1.331
1.331 1.331 1.356 2.038 3.088
Spline -15.0 -6.157 0.135 -28.532 -6.086
-3.0 -6.157 24.780942 2.213.822 -6.086
-0.5 0.134 -0.0184
0.0 0.6091 0.644
0.5 0.6091 0.644
3.0 0.6091 0.644
15.0 27.076 25.865
Log-likelihood - -1.213 -1.216 -1.268 -1.212
25
kedua, sementara model terbaik, seperti yang diperkirakan, adalah model yang dispesifikasi dengan tepat, yang biasanya tidak ada dalam percobaan. model normal semua mencapai persesuaian yang baik, kecuali atas variabel terakhir.
Persesuaian untuk parameter berdistribusi lognormal lebih baik daripada yang diperkirakan, adalah model yang dispesifikasi denga tepat, yang biasanya tidak adadalam percobaan. Model normal semua mencapai persesuai yang baik, kecuali atas variabel terakhir.
Persesuaian untuk parameter berdistribusi lognormal lebih baik daripada yang diperkirakan, satu-satunya masalah adalah tidak terbatasnya jumlah mata uang dalam bentuk negatif, walaupun spesifikasi spline yang sebenarnya dibatasi. Model spline semuanya bisa dipandang sebagai kesepakatan bila tidak mempunyai informasi tentang distribusi yan sebenarnya. Persesuaian dengan parameter per-tama dan ketiga sangat baik, sementara model memuat esensiparameter kedua, dengan cara yang lebih baik dari pada dengan model lognormal.
Akan tetapi, temuan-temuan ini harus diteliti lebih lanjut, karena denga konstruksi dua hari parameter adalah simetris, seperti halnya distribusi normal. Kondisi swdemikian mendukung distribusi normal, tetapi diharapkan sebaliknya terjadi bila distribusi sangat asimetrik.
26
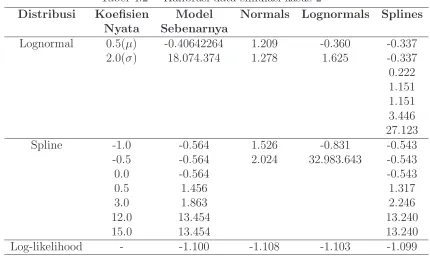
Tabel 4.2 Kalibrasi data simulasi kasus 2
Distribusi Koefisien Model Normals Lognormals Splines Nyata Sebenarnya
Lognormal 0.5(µ) -0.40642264 1.209 -0.360 -0.337
2.0(σ) 18.074.374 1.278 1.625 -0.337
0.222 1.151 1.151 3.446 27.123
Spline -1.0 -0.564 1.526 -0.831 -0.543
-0.5 -0.564 2.024 32.983.643 -0.543
0.0 -0.564 -0.543
0.5 1.456 1.317
3.0 1.863 2.246
12.0 13.454 13.240
15.0 13.454 13.240
Log-likelihood - -1.100 -1.108 -1.103 -1.099
Kedua kasus ini menunjukan bahwa sebuah contoh parameter dapat mem-beri penjelasan yang baik tentang taksiran-taksiran yang ada, tetapi juga dapat sebuah kesalahan dari ketelitian yang memberikan hasil yang sangat buruk, suatu parameter tidak dapat mewakili keseluruhan dari hasil yang diharapkan kare-nadalam setiap percobaan selalu terdapat kekurangan yakni ketidakjelasan data.
4.1 Aplikasi Pada Bidang Keuangan
Algoritma yang dikembangkan diaplikasikan pada masalah keuangan ten-tang intervensi bank pusat dan dinamika di pasar devisa (FX). Mengintervensi pasar FX merupakan proses yang kompleks. Baru-baru ini, beberapa tulisan penelitian mengkaji faktor-faktor yang menentukan intervensi.
27
Eksistensi non-intervensi juga telah dipaparkan, yang menunjukan bahwa Bank of Japan (BoJ), yang melakukan intervensi atas pasar FX lebih dari 300 kali se-jak awal tahun 1990-an, dan memegang peranan utama dalam melakukan operasi berskala sangat besar.
Data yang digunakan untuk analisa dikumpulkan dari website Kementerian Keuangan Jepang (di mana data tersebut tersedia untuk publik) Periode april 1991 hingga September 2004. Untuk setiap intervensi, tanggal yang tepat, jum-lah mata uang yang terlihat diketahui; database memuat data untuk total 3497 hari dagang resmi. Dalam situasi tertentu di mana intervensi dimungkinkan, ada empat hasil yang mungkin dari keputusan bank sentral: tidak ada intervensi-nitervensi publik, intervensi rahasia yang terdeteksi pasar (lihat tabel 4.3 sebagai rincian tentang keputusan BoJ adalah periode 1991-2004).
Tabel 4.3 Keputusan Bank of japan 1991-2004
Hari dagang Intervensi Publik Tidak terdekteksi Terdeteksi
3497 342 212 74 56
Kembali diperolehX =Rndalam kasus ini. Seperti halnya untuk data hasil
simulasi, pilih 5 titik knot berjarak sama per aproksimasi spline.
Model pilihan diskrit digunakan untuk menganalisa keputusan BoJ, untuk menentukan faktor-faktor yang mempengaruhi intervensi atas pasar FX dan jenis-jenisnya. keempat hasil yang dinyatakan membentuk himpunan alternatip yang tersedia untuk BoJ. Variabel didaftarkan dalam tabel 4.4. Koefisien relatif ditaksir sebagai sepesifikasi pada suatu alternatif. Untuk deskripsi prosedur yang lengkap untuk menghitung variabel ini, lebih lengkap dipaparkan dalam Beine dkk.
dila-28
porkan untuk (a) model logit, (b) model logit campuran dengan komponen ke-salahan dan parameter acak atas variabel ”jumlah” (diasumsikan berdistribusi normal), (c) logit campuran dengan komponen kesalahan dan parameter acak atas ”jumlah”dengan distribusi nonparametrik (B-Spline).
Komponen kesalahan dispesifikasi di sini untuk menjelaskan korelasi antar alternatif yang berbagai rahasia dalam intervensi bank sentral. Kesesuaian model meningkat secara signifikan dari formulasi logit ke formulasi logit campuran: peng-gunaan B-spline juga menghasilkan peningkatan nilai hasil log-likelihood. Dinya-takan bahwa variabel yang signifikan tetap mempunyai tanda yang sama atas ketiga spesifikasi yang berbeda dan bahwa variabel tersebut sesuai dengan perki-raan para analisa keuangan. Komponen kesalahan dilaporkan signifikan, yang menegaskan hipotesa korelasi antara alternatip-alternatip yang berbagi kompo-nen kesalahan ini. Penafsiran ekonomis rinci atas hasil-hasil yang diperoleh jelas dipaparkan dalam Beine dkk, kemudian difokuskan perhatian pada apa yang ter-jadi pada variabel ”jumlah”.
Khususnya, bankir pusat memaparkan bahwa intervensi besar jauh lebih besar kemungkinannya terdeteksi. Koefisien variabel jumlah yang memegang pe-ranan yang signifikan dalam setiap keputusan intervensi ditemukan positip dalam formulasi logit (seperti yang diperkirakan).
Bila koefisien yang sama diandaikan berdistribusi normal sebagian besar (53%) keputusan intervensi dicirikan oleh nilai negatip dari parameter ”jumlah”. Untuk mengatasi masalah ini diadopsilah distribusi nonparametrik, yang meng-hasilkan koefisien berbatas positip dalam interval [0,01, 1,88].
29
jukan model logit sebelumnya, walaupun faktor ini lebih penting pada sepertiga waktu. Dari sudut pandang parameter ”jumlah” rendah ini, layak kiranya berpikir apakah model logit campuran berkinerja baik hanya karena komponen kesalahan.
Tabel 4.4 Variabel bebas koefisien relatif W (tidak ada keputusan intervensi)
Jangka pendek Tingkat absolut penyimpangan nilai tukar jangka pen-dek (%)
Jangka menengah Tingkat absolut i penyimpangan nilai tukar jangka menengah (%)
Tak bersesuaian Tingkat absolut ketaksesuaian nilai tukar (%)
Pernyataan 1 jika otoritas mengeluarkan pernyataan yang meny-atakan ketidak nyamanan dengan nilai tukar atau mene-gaskan/membahas intervensi pada hari operasi
Intervensit−1 1 jika ada intervensi resmi sehari sebelumnya
RVt−1 Nilai tukar merealisasikan perubahan hari sebelumnya,
ditaksir di akhir hari kerja. Z(proses publik)
Kecondongan 1 jika intervensi berusaha membalikkan trend nilai tukar belakangan ini
Laporan sebelumnya 1 jika intervensi yang dideteksi berakhir berhasil
Inkonsistensi 1 jika arah intervensi tidak sesuai dengan penurunan nilai tukar
Jumlah pernyataan Jumlah intervensi verbal dari otoritas yang mengisyaratkan ketidak-nyamanan denga nilai tukar dalam 5 hari sebelum intervensi
X(proses deteksi)
Jumlah Jumlah yang diinvesatasikan dalam intervensi setiap hari
Persetujuan 1 jika intervensi disetujui
Berhasil 1 jika intervensi menggerakkan nilai tukar dalam arah yang diinginkan
Mengumpul 1 jika setidaknya ada satu intervensi terdeteksi dalam 5 hari terakhir sebelumnya
parame-30
BAB 5
KESIMPULAN
Mengkaji masalah program stokastik, di mana sebagian parameter distribusi probabilitas ditaksir bersama-sama dengan optimisasi, dan penentuan distribusi yang sebenarnya atau distribusi empiris sebelum optimisasi akan sulit dilakukan.
Untuk meringankan kesulitan ini, diajukan pendekatan nonparametrik baru yang didasarkan pada aproksimasi invers fungsi distribusi kumulatif, khusunya dengan menggunakan B-spline kubik. Diberikan metodologi yang diajukan dalam konteks pemodelan pilihan disktit. Atas data hasil simulasi, disimpulkan bahwa kesalahan spesifikasi variabel acak utama sering kali memberikan hasil yang tidak realitis. Sementara pendekatan nonparametrik memungkinkan dapat memuat keacakan dalam populasi juga menawarkan metode atas model keuangan, yang mengatasi intervensi bank dipasr FX dan memperoleh hasil yang baik sesuai yang diharapkan.
Akan tetapi, tetap ada berbagai pertanyaan terbuka. Mungkin pada awalnya berpikir tentang bagaimana memilih jumlah knot dan posisinya untuk meningkat-kan efesiensi dan kualitas taksiran, karena terlalu banyak knot ameningkat-kan menghasilmeningkat-kan kesesuaian yang berlebihan, sedikit kemungkinan dapat menghasilkan aproksimasi buruk.
32
Bermacam pertanyaan muncul dari pengamatan bahwa sebagian besar me-tode untuk menghasilkan distribusi multivariat didasarkan pada fungsi marginal dan perlakuan atas ketergantungan antara marginal-marginal ini. Metode ini biasanya mengeksploitasi teknik infersi untuk menghasilkan marginal, dan per-luasan alami dari metode yang diajukan terfokus pada aplikasinya dalam teknik pembentukan vektor acak multivariat.
DAFTAR PUSTAKA
Avramidis A.N & J.R, Wilson. (1994). A flexible Method For Estimating Inverse Distribution Fuction In Simulation Experiments. 342-355
Barros C.P, C. Ferreira, and J.Williams (2007). Analysing The Determinants Of Perfomance Of Best And Worst European Banks: A mixed logit approach.
Journal of Banking and Finance’ 31(7):2189-2203,Compenhagen, Denmark Bastin F, Cirillo C and Ph.L.Toint(2006). Convergence Theory For Nonconvex
Stochastic Programming With An Application To Mixed Logit.Mathematical Programming, 108(2-3):207-234
Beine M, Bernal O, Gnabo J.Y, and Lecourt C. Intervention Policy of the BoJ:aunified approach. Jornal of Banking and Finance, Submitted
Conn A.R, Gould N. I. M., and Ph.L Toint (2000) Trist-Region Methods. SIAM, Philadelpia, USA
Devyore L. (1996). Non-uniform Random Variate Generation. Springer Verlag, New York, USA
Dong M.X and. Wets R.J.B (2000). Estimating density functions: A constrained maximum likelihood function.Jurnal of Nonparametric Statistics, 12(4):549-595 Mathematical Programming. 313-333
Gurkan G, Ozge A, and Robinson S.M (1999). Sample-Path Sokution Of Stochastic Variational Inequalities. Mathematical Programming, 84(2):313-333.
Hora S.C(1983). Estimation of The Inverse Fuction For Random Number Genara-tion. Comunnication of theACD, 26:590-594.
Hussey. (2007).Competing Methods for Representing Random Taste Heterogeneity Time Series Analysis: Estimation an Simulation in Discrete Choice Models. Working paper, Danish Transport Research Institute, USA
Neely C.J. (2006). Authoritiesbeliefs about foreign exchange intervention: Getting back to the hood. Technical report2006-045A, Federal Reseve Bank of Saint Louis.
Nocedal J and S.J Wright (1999). Numerical Optimization. Springer, New York, USA
Pflug G. C. (2003) Stochastic optimization and statistical inference. In A. Shapiro and A. A. Ruszcsynski, editors, Stochastic Programming , volume 10 of Handsbooks in Operation Research and Management Science, Pages 353-425. Elsevier
Robinson. (1999). Sample Path Solution Of Stochastic Variational Inequalities,
Mathematical Programming 313-333
34
Rubinstein R.Y and Shapiro A. (1993) Discrete Event Systems. Jhon Wiley & Sons, Chicester England
Shapiro A. (2003). Stochastic Programming Monte Carlo Sampling Methods. In A. Shapiro and A. Ruszczynski, editors, volume 10 Handsbooks in Operation Research and Management Science, pages 353-425. Elsevier