7
LANDASAN TEORI
2.1 Teori
Umum
2.1.1 Pengertian Data dan informasi
Data merupakan aliran fakta yang mewakili kejadian yang terjadi dalam
organisasi atau dalam lingkungan fisik sebelum mereka diatur menjadi sebuah
form yang dapat dimengerti dan digunakan oleh pengguna (Laudon,2000,p8).
Informasi adalah data yang dikumpulkan dan dievaluasi untuk
memecahkan suatu masalah atau membuat keputusan (Inmon,2002,p388).
Informasi lebih berarti daripada data. informasi digunakan untuk membuat
keputusan. Data digunakan sebagai masukkan (input) untuk pemprosesan dan
informasi sebagai keluaran (output) dari pemprosesan tersebut.
2.1.2 Pengertian Metadata
Metadata merupakan data dari sebuah data, atau biasa disebut juga
deskripsi dari sebuah data yang dipergunakan untuk pengumpulan, penyimpanan,
pembaharuan dan mendapat kembali data bisnis dan data teknikal yang berguna
untuk organisasi (www.learndatamodeling.com), sedangkan menurut Ramon
dan Pauline (1999,p3) metadata adalah informasi mengenai database. Informasi
ini biasanya disimpan dalam sebuah kamus data (data dictionary) atau catalog.
M etadata berisi keterangan mengenai data – data yang ada didalam
database kita yang bertujuan untuk mempertahankan konsistensi penggunaan
2.1.3 Pengertian Database
M enurut Connolly dan Begg (2005,15) “Database is A shared collection
of logically related data, and a description of this data, designed to meet the
information needs of an organization ” yang dapat diartikan, Basis data
(Database) adalah sebuah koleksi dari data yang secara logikal saling berelasi,
dan deskripsi dari data tersebut, yang di desain untuk memenuhi kebutuhan
informasi pada suatu organisasi.
M enurut C. J Date (2000,p9) Database merupakan suatu kumpulan dari
data yang bersifat tahan lama (persistent), yaitu data yang berbeda satu dengan
yang lainnya, dan biasanya merupakan data yang bersifat sementara dimana
kumpulan data tersebut dapat digunakan oleh sistem – sistem aplikasi
perusahaan.
Sedangkan menurut Inmon (2002, p388), “ a database is a collection of
interrelated data stored (often with controlled, limited redudancy ) according to
a schema ” yang dapat diartikan suatu database adalah sebuah koleksi dari data
yang saling berelasi yang disimpan (sering kali dengan kontrol, dan pembatasan
terhadap redudansi) sesuai dengan skema.
Berdasarkan beberapa pengertian diatas, Database adalah kumpulan dari
data yang saling berhubungan dan terintegrasi yang mana dapat digunakan untuk
memenuhi kebutuhan informasi suatu organisasi
2.1.4 Pengertian Sistem Manajemen Database
M enurut Connolly dan Begg (2005,p16), “Database Manajemen System
control access to the database”, yang dapat diartikan Sistem M anajemen
Database adalah suatu sistem software yang memperbolehkan banyak pengguna
untuk mendefinisikan, membuat, merawat, dan mengatur akses ke database.
2.1.5 Data warehouse
M enurut Inmon (2002,p31), “Data warehouse is a subject oriented,
integrated, time variant and non volatile collection of data in support of
management’s decision making process”, yang dapat diartikan “Data warehouse
adalah kumpulan data yang berorientasi subjek, terintegrasi, berdasarkan waktu
dan tidak mengalami perubahan dalam mendukung proses pengambilan
keputusan management”.
Data warehouse merupakan tempat penyimpanan untuk ringkasan dari
data historis yang diambil dari database - database yang tersebar disuatu
organisasi. Data warehouse mengumpulkan semua data perusahaan dalam satu
tempat agar dapat diperoleh pandangan yang lebih baik dari suatu proses
bisnis/kerja dan meningkatkan kinerja organisasi. Data warehouse mendukung
proses pembuatan keputusan management.
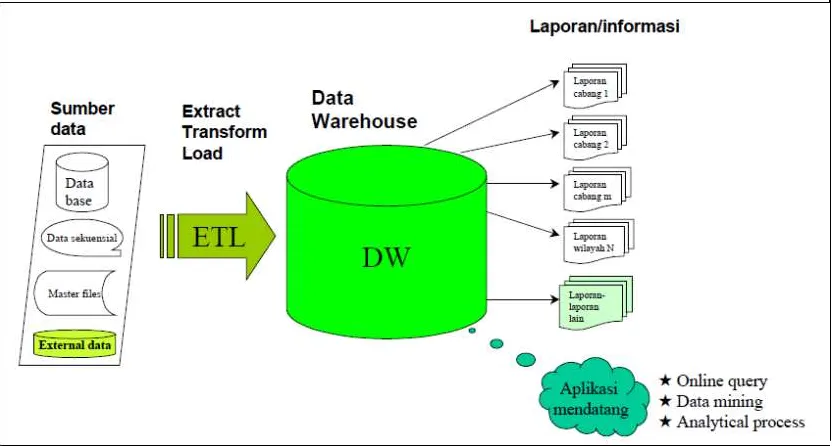
Tujuan utama dari pembuatan Data warehouse adalah untuk menyatukan
data yang beragam ke dalam sebuah tempat penyimpanan dimana pengguna
dapat dengan mudah menjalankan query (pencarian data), menghasilkan laporan,
Gambar 2.1 Proses Data Warehouse
M enurut Inmon (2002, p31 – p38) karakteristik data warehouse dapat di
jabarkan sebagai berikut :
1. Subject Oriented atau berorientasi pada subjek. Suatu data warehouse harus
berorientasi subject atau berorientasi pada subyeknya. Suatu data transaksi
(OLTP) biasanya disusun berdasarkan jenis transaksi yang ditangani oleh
aplikasi transaksi tertentu. Sebagai contoh transaksi penarikan dan
penyimpanan dana. Pada setiap transaksi teller akan memasukkan data utama
dan pendukungnya seperti nomor rekening, nilai transaksi dan tanggal.
Subject oriented (lawan dari transaction oriented) menuntut agar data – data
transaksi ini disusun dengan menyusun subyek areanya. M isalnya dalam hal
data perbankan, subjek areanya adalah nasabah, jenis transaksi, wilayah,
kantor cabang. M enyusun data menjadi subject oriented artinya memastikan
bahwa data tersebut akan dengan mudah disajikan berdasarkan subyek
2. Time – variant, artinya memiliki dimensi waktu sebagai variablenya.
Perubahan data ditelusuri dan dicatat sehingga laporan dapat dibuat dengan
menunjukkan waktu perubahannya. Sebagai contoh, apa artinya mengatakan
suatu kantor berhasil menjual 1500 items, tanpa dimensi waktu informasi
tersebut menjadi tidak berarti. Aspek time – variant dari suatu data
warehouse memberikan kemampuan dalam bentuk trend analysis sehingga
dapat melihat performance ataupun forecasting. Aspek time – variant
membuat suatu data warehouse menjadi sangat berarti untuk dianalisis.
3. Non Volatile berarti bahwa data yang telah disimpan tidak dapat berubah.
Sekali committed, data tidak pernah ditimpa/dihapus. Data akan bersifat static,
hanya dapat dibaca dan disimpan untuk kebutuhan pelaporan.
4. Integrated, artinya menggabungkan beberapa database yang mungkin berbeda
baik dari segi teknologi maupun kodifikasi suatu tabel referensinya. Untuk
menghasilkan subject oriented yang konsisten, data – data dari berbagai
sumber harus diintegrasikan yang berarti teknologi yang beragam dan kode –
kode referensi yang mungkin berbeda harus disatukan.
2.1.6 Data Mart
M enurut Connolly dan Begg (2005, p1171) , “ Data mart is a subset of a
data warehouse that supports the requirement of a particular department or
business function” yang dapat diartikan Data mart adalah suatu subset atau
bagian dari suatu data warehouse yang mendukung persyaratan atau ketentuan
membedakan data mart dengan data warehouse (Connolly dan Begg, 2005,
p1171) :
• Data mart hanya berfokus pada kebutuhan pengguna yang
berhubungan dengan satu departemen atau satu fungsi bisnis.
• Data mart biasanya tidak mengandung data operasional yang detail
seperti data warehouse.
• Karena data mart mempunyai data yang lebih sedikit dibandingkan
dengan data warehouse, data mart lebih mudah untuk dimengerti
dan dijalankan.
Terdapat beberapa alasan untuk membuat data mart (Connolly dan Begg, 2005,
p1173) :
• Untuk memberikan akses ke data yang paling sering dianalisa oleh
user.
• M enyediakan data dalam bentuk yang sesuai dengan kebutuhan
sekelompok user dalam sebuah departemen atau fungsi bisnis.
• M eningkatkan waktu respon end-user karena pengurangan jumlah
data yang akan diakses.
• M enyediakan data yang terstruktur sesuai seperti yang ada pada
ketentuan dari alat akses end-user yang mungkin membutuhkan
struktur basis data internal sendiri.
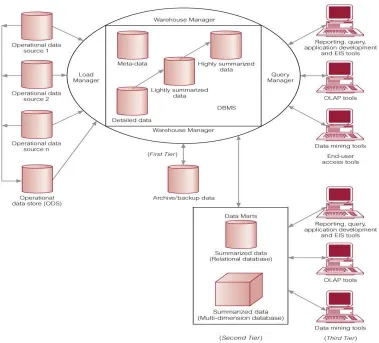
• Biaya implementasi data martbiasanya lebih murah dari biaya yang
Gambar 2.2 Arsitektur data warehouse dan data mart (Connolly dan
Begg,2005,p1172)
2.1.7 Pengertian OLTP (OnLine Transaction Processing)
OLTP adalah sistem operasional yang didasarkan pada proses dan fungsi,
seperti entry pemesanan pelanggan, order pembelian, entry stok, dan lain-lain.
Sistem operasional ini mengakses dan meng-update record dari suatu objek bisnis.
Transaksi umumnya telah didefinisikan terlebih dahulu dan memerlukan database
yang dapat diakses dengan cepat.
M enurut Connolly dan Begg (2005, p1153) Sistem OLTP adalah sistem
transaksi bersifat predictable, berulang, dan update insentive. Data dalam OLTP
diorganisasikan berdasarkan kebutuhan dari transaksi yang diasosiasikan dengan
aplikasi bisnis dan mendukung keputusan sehari-hari dari banyak user secara
bersamaan.
Database operasional pada sistem OLTP biasanya menggunakan database
yang memang khusus dirancang untuk mempercepat proses transaksi dan
manipulasi data seperti inserting, deleting, dan updating data. Oleh karena itu
model data OLTP biasanya menggunakan model relational.
2.1.8 Data mining
M enurut Connolly dan Begg (2005,p1233) data mining adalah proses
ekstraksi informasi yang valid, tidak diketahui sebelumnya, dapat dipahami, dan
actionable dari database yang besar sehingga dapat digunakan untuk pengambilan
keputusan yang krusial.
M enurut Han dan Kamber (2006,p7) data mining adalah proses menemukan
pengetahuan yang menarik dari sejumlah besar data yang tersimpan dalam
database, data warehouse, atau respositori penyimpanan data dan informasi
lainnya.
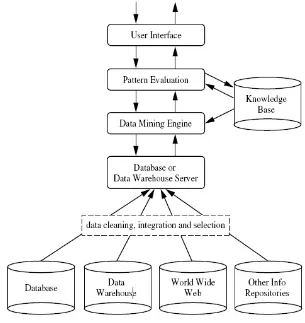
Arsitektur data mining pada umumnya meliputi hal berikut (Han dan
Kamber,2006,pp7-8):
1. Database, datawarehouse, data mart, World wide web, ataupun tempat
penyimpanan lainnya: Ini merupakan sebuah atau kumpulan dari database,
sebagai sumber data mentah untuk data mining. Teknik Data cleaning ataupun
data integration mungkin diperlukan untuk mempersiapkan data.
2. Database atau data warehouse server: Database atau data warehouse server
bertanggung jawab untuk mengambil (fetch) data yang relevan dari tempat data
disimpan berdasarkan permintaan user.
3. Knowledge base: Ini merupakan domain knowledge yang digunakan untuk
memandu pencarian atau mengevaluasi seberapa menarik hasil dari proses
mining. Pengetahuan tersebut dapat meliputi konsep hirarki, yang digunakan
untuk mengorganisasikan atribut atau nilai atribut ke dalam level abstraksi yang
berbeda. Contoh pengetahuan lain seperti konstrain, threshold, ataupun
metadata.
4. Data mining engine: Bagian ini merupakan bagian yang esensial bagi untuk
sistem data mining dan idealnya terdiri dari sekumpulan modul fungsi untuk
tugas-tugas data mining seperti karakterisasi, asosiasi dan korelasi,
classification, prediction, clustering, outlier analysis, ataupun evolution anlysis.
5. Pattern evaluation module: M odul ini berinteraksi dengan modul data mining
engine untuk memfokuskan pencarian terhadap pola yang menarik. M odul ini
dapat menggunakan interestingness threshold untuk melakukan filter terhadap
pola yang menarik. Alternatif lain pattern evaluation module dapat
diintegrasikan dengan dengan modul data mining engine.
6. User interface: M odul ini mengkomunikasikan antara user dengan sistem data
mining, mengijinkan user berinteraksi dengan sistem dengan menspesifikasikan
dan datawarehouse atau struktur data, mengevaluasi pola yang telah di mining,
dan memvisualisasikan pola dalam format yang diinginkan.
Gambar 2.3Arsitektur Sistem Data mining
2.1.8.1 Teknik Data mining
Teknik data mining berhubungan dengan penemuan dan pembelajaran
informasi dari database yang besar, pembelajaran tersebut dapat dibagi
menjadi dua metode utama, yaitu supervised dan unsupervised (Berson dan
Smith, 1997, p416):
1. Supervised
Teknik ini melibatkan tahap pelatihan dimana data lama yang telah
pada algoritma data mining. Proses ini melatih algrotima yang digunakan
untuk mengenali variabel dan nilai-nilai kunci, yang kemudian menjadi
dasar untuk membuat prediksi ketika membaca data baru.
2. Unsupervised
Teknik ini tidak melibatkan tahap pelatihan, tetapi bergantung pada
penggunaan algoritma yang mendeteksi semua bentuk asosiasi dan
rangkaian yang terjadi berdasarkan kriteria yang spesifik dalam data
masukkan. Pendekatan ini membawa ke generasi yang menghasilkan
peraturan-peraturan dalam data yang menggolongkan penemuan asosiasi,
cluster, dan segment. Peraturan ini kemudian akan melakukan
penganalisaan untuk menentukan mana yang memiliki ketertarikan secara
universal.
2.1.8.2 Fungsionalitas Data mining
Fungsionalitas data mining digunakan untuk menspesifikasikan tipe pola
(patterns) yang dapat ditemukan dalam tugas data mining. Secara umum,
tugas data mining dapat diklasifikasikan menjadi 2(Han dan
Kamber,2006,pp21):
1. Descriptive mining: mengkarakterisisasikan properti umum pada data dalam
database.
2. Predictive mining: membuat kesimpulan pada data yang telah ada dengan
tujuan untuk dapat membuat prediksi.
Berikut fungsionalitas dan tipe pola yang dapat ditemukan dengan data
1. Deskripsi konsep/kelas: Karakterisasi dan diskriminasi
Data dapat diasosiasikan dengan suatu kelas atau konsep. Contoh:
Sebuah toko elektronik dapat membuat kelas/jenis item seperti komputer,
printer, dan konsep untuk konsumen seperti bigspenders dan
budgetspenders. M erupakan hal yang bermanfaat untuk mendeskripsikan
masing-masing kelas dan konsep dalam bentuk yang ringkas tapi tepat.
Deskripsi dari kelas atau konsep tersebut disebut dengan deskripsi
kelas/konsep. Deskripsi ini dapat didapatkan melalui karakterisasi data
dengan meringkas data-data dari kelas (sering disebut target kelas) dalam
pemebelajaran seacara umum, atau data discrimintation dengan
membandingkan target kelas dengan satu atau lebih kelas lain.
Contoh Data Characterization dalam data mining adalah sistem data
mining dapat menghasilkan deskripsi yang meringkas karakteristik dari
konsumen yang membelanjakan uangnya lebih dari $1000 setiap tahun.
Hasilnya dapat berupa profil umum dari konsumen seperti, konsumen
berumur 40-50 tahun, memiliki pekerjaan, dan memiliki peringkat credit
yang baik.
2. Mining frequent pattern, asosiasi dan korelasi
Frequent Pattern sesuai namanya adalah pola yang sering muncul
dalam data. Ada beberapa tipe dari frequent patterns, seperti itemsets,
subsequences, dan substructures. Frequent itemset menunjukkan item yang
sering muncul bersamaan dalam data set. Subsequence berarti suatu
PC terlebih dahulu diikuti digital camera, kemudian kartu memori. Mining
frequent pattern dapat membawa pada penemuan asosiasi dan korelasi yang
menarik dalam data.
3. Classification and Prediction
Classification adalah proses menemukan model (atau fungsi) yang
mendeskrpisikan dan membedakan kelas dari data, dengan tujuan untuk
dapat menggunakan model untuk memprediksikan kelas dari data input
yang mana label kelasnya tidak diketahui. M odel yang didapat adalah
berdasarkan analisis dari training data dimana pada training data label kelas
telah diketahui.
Dalam classification ada nilai atribut yang hendak diprediksi yaitu
target atribut berupa class label. Target atribut ini merupakan atribut yang
dependen terhadap attribute vector. Dalam beberapa literarur attribute
vector disebut juga dengan feature, explanatory variables, atau atribut
Gambar 2.4 Representasi M odel Classification
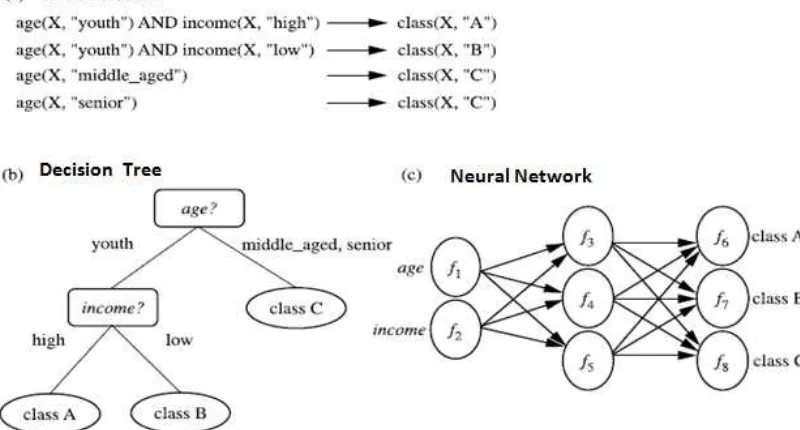
M odel yang didapat dapat direpresentasikan dalam berbagai bentuk
seperti aturan klasifikasi (IF-THEN), decision tree, formula matematik, atau
neural networks. Decision tree merupakan struktur yang menyerupai
pohon, dimana setiap node menunjukkan suatu test tertentu pada nilai
atribut, dan setiap percabangan merepresentasikan hasil dari tes, dan tree
leaves (daun) merepresentasikan kelas atau distribusi kelas. Desicion tree
dapat dengan mudah di ubah menjadi aturan klasifikasi (IF-THEN). Neural
Network, ketika digunakan untuk klasifikasi, biasanya merupakan koleksi
dari unit proses yang menyerupai neuron dengan nilai koneksi antar unit.
Ada banyak algoritma yang dapat digunakan untuk mengkonstruksi model
klasifikasi seperti Naïve Bayes, Support Vector Machine (SVM), Decision
tree.
Jika klasifiksasi memprediksikan nilai categorical (discrete, dan tidak
digunakan untuk memperikirakan nilai suatu data numerik.Regression
merupakan metodologi statistikal yang sering digunakan untuk
memperkirakan nilai numerik.
Klasifikasi dan prediksi dapat didahului dengan relevance analysis.
Relevance Analysis mengukur tingkat keterkaitan atribut-atribut yang
digunakan terhadap label kelas yang hendak diprediksi. Hasil dariRelevance
Analysis dapat digunakan untuk mengurangi atribut input dalam proses data
mining dengan menghilangkan atribut-atribut yang tidak relevan.
4. Clustering
Clustering termasuk dalam kategori unsupervised mining. Berbeda
dengan classifications dan prediction yang memerlukan pelatihan terlebih
dahulu dengan menganalisa objek data yang telah memiliki label kelas,
clustering menganalisa objek data tanpa mengetahui label kelas. Clustering
merupakan proses grouping sebuah set objek fisik atau abstrak dalam
kelas-kelas. Algoritma yang sering digunakan untuk clustering adalah k-means
dan k-medoids.
Umumnya, label kelas tidak ada dalam data training karena memang
tidak diketahui tetapi sebaliknya Clustering dapat digunakan untuk
menghasilkan label. Objek di cluster dan di masukkan dalam grup
berdasarkan prinsip “maximizing the intraclass similarity and minimizing
the interclass similarity”. Yang berarti objek cluster dibentuk sehingga
yang tinggi satu sama lain, tetapi sangat berbeda dengan objek di cluster
lain.
Clustering sering juga disebut segmentasi data karena clustering
mempartisi data set yang besar ke dalam grup sesuai dengan kesamaannya.
Clustering dapat digunakan untuk outlier detection, dimana outliers adalah
suatu nilai yang jauh dari semua cluster lain.
5. Analisis Outlier
Database dapat mengandung objek data yang tidak sesuai dengan
sifat umum atau model data.Objek data tersebut disebut sebagai outlier.
Kebanyakan metode data mining menghapus outlier karena diaggap noise
atau perkecualian.Tetapi, beberapa aplikasi seperti fraud detection, kejadian
seperti outlier tersebut dapat bermanfaat. Analisis data outlier disebut juga
outlier mining.
Outliers dapat dideteksi dengan menggunakan tes statistik yang
mengasumsikan distribusi atau probabilitas model dari data, dengan
menggunakan distance measures dimana objek yang memiliki jarak yang
jauh dari cluster-cluster lainnya dianggap outlier atau anomali.
6. Analisis evolusi
Data evolution analysis mendeskripsikan dan memodelkan tren untuk
objek yang sifatnya berubah dari waktu ke waktu. Analisis evolusi dapat
meliputi karakterisasi, dicriminasi, asosiasi dan korelasi, klasifikas i,
2.1.9 Knowle dge Discovery from Data (KDD) dan Data mining
Gambar 2.5 Proses Knowledge Discovery from Data
Banyak orang menganggap data mining merupakan sinonim untuk istilah
Knowledge Discover from Data atau KDD. Beberapa ada yang menganggap data
discovery. Proses dari KDD ditunjukkan seperti pada gambar 2.5 dan terdiri dari
proses iterative langkah-langkah berikut:
1. Data cleaning (untuk menghilangkan noise dan ketidak konsistenan dalam data)
2. Data integration (dimana beberapa sumber data dikombinasikan)
3. Data selection (ketika data yang relevan terhadap tugas diambil dari tempat
penyimpanan data)
4. Data tranformation( data ditranformasikan dan dikonsolidasikan dalam bentuk
yang sesuai untuk mining)
5. Data mining( merupakan proses utama dimana metode intelligent diaplikasikan
untuk mengekstraksi pola data)
6. Pattern evaluation (untuk mengidentifikasi pola yang benar-benar menarik
yang merepresentasikan pengetahuan berdasarkan interestingness measures)
7. Knowledge presentation (dimana visualisasi dan pengetahuan di
representasikan kepada pengguna)
Langkah 1-4 merupakan bentuk lain dari data preprocessing, dimana data
dipersiapkan untuk mining. Langkah data mining dapat berinteraksi dengan
pengguna atau knowledge base. Pola yang menarik kemudian ditampilkan pada
pengguna dan dapat disimpan sebagai pengetahuan baru dalam knowledge base.
M enurut sudut pandang ini, data mining hanyalah salah satu proses dari
keseluruhan proses yang ada. M eskipun demikian saat ini istilah data mining lebih
populer dibanding dengan KDD dan sering kali disamakan artinya dengan KDD.
2.1.10 Data Preprocessing
Database sekarang ini sangat rentan terhadap noisy, missing dan data yang
inkonsisten karena banyaknya dan beragamnya sumber data. Kualitas data yang
buruk akan mengakibatkan hasil mining yang buruk. Untuk itu diperlukan suatu
persiapan agar data dalam database dapat digunakan untuk proses data mining
(Han dan Kamber,2006,pp47-97).
2.1.10.1 Data Cleaning
Data dalam kehidupan nyata sering kali tidak lengkap, noisy, dan
inkonsisten. Data Cleaning berusaha untuk mengatasi masalah dalam data
seperti missing values, memperhalus noise serta mengidentifikasi outliers, dan
membenarkan data yang tidak konsisten.
Ada beberapa cara untuk mengatasi masalah missing value dalam data:
1. M engabaikan record: cara ini biasa dilakukan ketika class label missing
(jika mining melibatkan classfication). M etode ini tidak efektif, kecuali
record hanya mengandung beberapa atribut dengan missing value. Dengan
cara ini reocord yang tidak memiliki missing values tidak disertakan dalam
proses data mining
2. M engisi missing value secara manual: Secara umum pendekatan ini
memakan waktu dan sulit untuk dilakukan bila data set besar dan banyak
missing values.
3. M enggunakan global konstan untuk mengisi missing value: M engubah
semua missing attribute value dengan konstan yang sama, seperti contohya
salah mengartikan nilai dan dianggap membentuk konsep yang menarik,
karena mereka semua memiliki nilai yang sama. M etode ini sederhana
tetapi tidak aman.
4. M enggunakan atribut mean untuk mengisi missing value: contoh jika
rata-rata pendapatan konsumen adalah $56000. M aka nilai ini digunakan untuk
menggantikan missing value untuk pendapatan.
5. M enggunakan atribut mean untuk semua sampel yang berada dalam kelas
yang sama dengan record: Contoh jika mengklasifikasikan konsumen
berdasarkan credit_risk dan atribut pendapatan mengandung missing value,
ganti missing value dengan rata-rata pendapatan untuk konsumen yang
berada dalam kategori credit_ risk yang sama.
6. M engunakan teknik data mining untuk memprediksikan nilai yang paling
mungkin untuk mengisi missing value: Hal ini dapat dilakukan dengan
regresi, atau induksi Decision treeataupun metode data mining predictive
lainnya. Contoh: M enggunakan atribut-atribut konsumen yang ada dalam
data set, dikonstruksi sebuah model Decision treeuntuk memprediksikan
missing value untuk atribut pendapatan.
M etode 3 sampai 6 membuat prediksi terhadap data. Nilai yang diisikan belum
tentu benar. M etode 6 merupakan cara yang lebih populer bila dibandingkan
dengan metode lain, cara ini menggunakan banyak informasi yang
merepresentasikan data untuk memprediksikan nilai yang hilang.
Untuk beberapa kasus, missing value mungkin bukan menunjukkan
dapat ditanyakan mengenai nomor izin mengemudi.Kandidat yang tidak
memiliki nomor izin mengemudi dapat secara natural membuat field tidak
terisi.
Selain missing value, data dapat mengandung noise. Noise adalah
random error atau variance dalam variabel yang diukur. M etode yang dapat
digunakan untuk mengatasi masalah ini adalah:
1. Binning
M etode binning biasa digunakan untuk data numerik dengan mengurutkan
nilai data dan melihat data yang berdekatan nilainya. Nilai yang diurutkan
di distribusikan ke dalam beberapa “buckets” atau bin tergantung dari
metode binning yang digunakan.
2. Regressi
Nilai suatu data dapat diperhalus dengan memasukkan data ke dalam suatu
fungsi seperti regresi. Linear regression melibatkan penemuan garis terbaik
untuk mencocokkan dua atribut atau variabel, sehingga sebuah atribut dapat
digunakan untuk memprediksikan atribut lainnya. Multiple linear
regression merupakan ekstensi dari linear regression dimana dua atau lebih
atribut terlibat.
3. Clustering
Clustering dapat digunakan untuk mendeteksi outlier. Dengan clustering
nilai atribut yang sama atau mirip diorganisasikan ke dalam grup atau
Banyak metode untuk data smoothing juga digunakan untuk data
reduction yang melibatkan discretization.Contohnya teknik binning juga dapat
digunakan untuk mengurangi distinct value untuk setiap atribut.
2.1.10.2 Integrasi dan Transformasi Data.
Data mining sering kali membutuhkan integrasi data, menyatukan data
dari berbagai data stores. Data mungkin juga perlu untuk di transformasikan
ke dalam bentuk tertentu yang cocok untuk mining. M asalah dalam integrasi
dapat meliputi entity indetification problem ataupun data redudansi.
Dalam transformasi data. Data di ubah dan disatukan ke dalam bentuk
yang sesuai untuk mining. Data transformation dapat meliputi:
1. Smoothing, berguna untuk menghilangkan noise dari data. Hal ini dapat
dilakukan dengan binning, regression, ataupun clustering.
2. Aggregation, dimana ringkasan atau operasi agregasi dilakukan pada data.
3. Generalisasi data, dimana data primitif digantikan dengan konsep yang
lebih tinggi dengan menggunakan konsep hirarki. Contoh: atribut
categorical seperti jalan dapat di generalisasi ke dalam konsep yang lebih
tinggi seperti kota atau negara. Hal ini juga dapat dilakukan pada atribut
numerik, seperti umur, dapat di generalisasi menjadi youth, middle-age,
senior.
4. Normaliasi, atribut data di skalakan sehingga masukan ke dalam range
tertentu seperti -1.0 sampai 10.0 , atau 0.0 sampai 1.0
5. Attribute Construction, dimana atribut baru dikonstruksi dan ditambahkan
2.1.10.3 Reduksi Data
Analisis data dan mining pada data yang sangat besar dapat
membutuhkan waktu yang sangat lama, membuat proses mining sulit
dilakukan. Teknik data reduksi dapat diaplikasikan untuk mendapatkan
representasi data set yang diperkecil dalam volume, tetapi tetap menjaga
integritas dari data original. Mining pada data yang telah di reduksi lebih
efisien tetapi tetap memproduksi hasil analisis yang sama atau mendekati.
Strategi data reduksi dapat meliputi:
1. Agregasi data cube, dimana operasi agregasi diaplikasikan pada data dalam
pengkonstruksian data cube
2. Seleksi subset atribut, dimana atribut atau dimensi yang tidak relevan,
lemah, atau redundan dideteksi dan dibuang.
3. Numerosity reduction, dimana data di gantikan atau diestimasi dengan data
representasi alternatif yang lebih kecil seperti parametrics model (yang
hanya perlu menyimpan model parameter, bukan data aktual) atau metode
nonparametric seperti clustering, sampling, dan menggunakan histogram
4. Discretization dan pembuatan konsep hirarki. M erupakan metode dimana
nilai mentah dari atribut data digantikan oleh range atau level konsep yang
lebih besar. Contoh teknik untuk discretization adalah binning.
Dataset yang digunakan untuk analisis mungkin mengandung ratusan
atribut, yang mana banyak diantaranya tidak relevan untuk tugas mining
ataupun redundan. Contoh: Jika dalam kasus toko elektronik, persoalannya
dirilis, atribut seperti nomor telepon konsumen merupakan hal yang tidak
relevan, tidak seperti atribut umur ataupun selera.
Atribut subset selection mengurangi jumlah data set dengan membuang
atribut yang tidak relevan atau redundan. Tujuan dari atribut susbet selection
adalah menemukan jumlah atribut yang minimum dimana kemungkinan
distribusi hasil dari kelas data sedekat mungkin dengan original distribution
yang didapat dengan menggunakan seluruh atribut. Mining pada atribut yang
telah direduksi dapat mempercepat proses mining dan mengurangi jumlah
atribut yang muncul pada pola yang ditemukan sehingga lebih mudah
dimengerti.
Sampling data dapat digunakan sebagai teknik reduksi data karena
sampling mengijinkan dataset yang besar untuk direpresentasikan dengan
jumlah yang lebih kecil melalui subset dari keseluruhan data. Sebagai contoh
misalnya ada sebuah dataset yang besar,D, memiliki N record. Cara yang
dapat dilakukan untuk mereduksi D dengan sampling meliputi (Han, jiawei
dan Kamber, 2006, pp84-86):
1. Simple Random Sample Without Replacement (SRSWOR) dengan ukuran s:
Sampel ini dibuat dengan mengambil beberapa record s dari D (s < N),
dimana kemungkinan mengambil record sembarang dalam D adalah 1/N,
semua record memiliki peluang untuk di sampel yang sama. Data yang
sudah disampel tidak dapat disampel kembali dalam proses yang sama.
2. Simple Random Sample With Replacement (SRSWR) dengan ukuran s:
dicatat dan kemudian dikembalikan. Berarti setelah record diambil, record
diletakkan kembali di pada dataset D sehingga dapat memiliki peluang
diambil lagi.
Gambar 2.6 Simple Random Sample With/Without Replacment
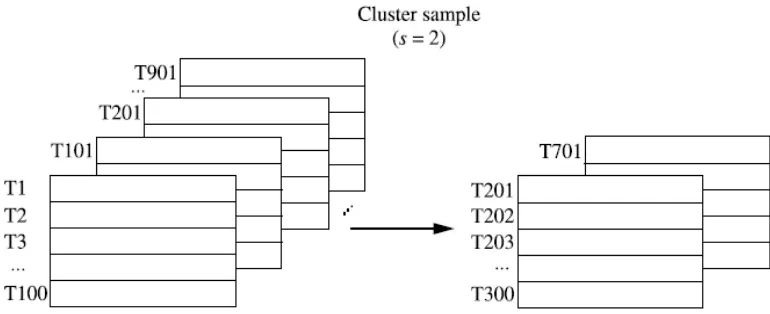
3. Cluster sample: jika record dalam D di grupkan ke dalam M cluster. M aka
SRS untuk s cluster dapat diambil dimana s < M . Contoh: record pada
databasebiasanyadi ambil per halaman setiap waktu, apabila setiap page
dianggap sebagai cluster maka representasi data yang direduksi dapat
didapat dengan misalnya menggunakan SRSWOR pada masing-masing
page untuk menghasilkan sampel cluster sejumlah s.
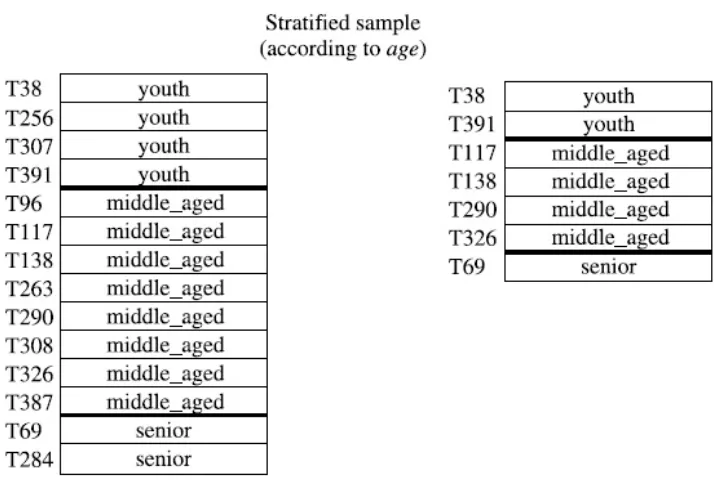
4. Stratified sample: jika D dibagi menjadi beberapa bagian yang disebut
dengan strata atau stratum, stratified sampledari D didapat dengan
menggunakan SRS untuk setiap stratum yang ada. Hal ini memastikan
adanya sampel representatif untuk setiap stratum. Contoh: stratified sample
dapat didapat dari data konsumen, dimana stratum dibuat untuk setiap
umur konsumen. Dengan cara ini stratum umur yang paling kecil sekalipun
jumlah anggotanya dapat dipastikan memiliki representasi dalam sampel.
Gambar 2.8 Stratified Sample
Binning merupakan top-down splitting technique yang didasarkan pada
jumlah bin. Binning mengelompokkan nilai yang saling berelasi dalam sebuah
bin, yang mana memperkecil jumlah nilai yang berbeda dari atributBeberapa
metode yang dapat digunakan untuk mendapatkan batasan tiap bin
1. Equal-interval binning: Biasa digunakan untuk melakukan bin pada nilai
numerik. Untuk atribut numerik dapat ditemukan nilai minimal dan
maximum. Kemudian dari range minimal dan maximum tersebut dapat
dibagi ke dalam N bin berukuran d, dimana d=(max-min)/N. Sehingga bin 1
adalah [min,min+d], bin 2 adalah [min+d,min+2d], dan bin ke N adalah
[min+(N-1)*d,max], metode ini menggunakan interval yang sama untuk
setiap bin. Equal-interval binning dapat mendistribusikan data secara tidak
merata, beberapa bin dapat mengandung banyak data sedangkan bin lainnya
kosong atau sedikit. equal-interval binningdapat menghasilkan bin yang
kosong bila ada outlier.
2. Equal-frequencybinning: teknik binning ini dapat membuat bin dengan
interval yang berbeda pada setiap bin sehingga mengijinkan jumlah record
training yang sama pada masing-masing bin yang dihasilkan.
3. Top-N most frequent binning: Dapat digunakan pada data numerik ataupun
categorical. Definisi bin dihitung dari frekuensi nilai yang mucul dalam
data. Bila didefinisikan N bin, maka bin 1 adalah nilai yang paling sering
muncul, bin 2 adalah nilai yang kedua paling sering muncul, dan Bin N
adalah semua nilai sisanya.
Contoh penggunaan Binning adalah Nilai atribut dapat di discretized
dengan mengaplikasikan equal-interval ataupun metode binning lainnya, dan
kemudian menggantikan nilai setiap bin dengan mean atau median. Binning
unsupervised dicretization. Bin juga sensitif terhadap jumlah bin yang
dispesifikasikan oleh user serta keberadaan outliers.
2.1.11 Classification
Classification merupakan bentuk dari analisis data yang digunakan untuk
menghasilkan suatu model yang mendeskripsikan kelas data untuk memprediksi
kelas untuk data baru. Classification memprediksi suatu nilai categorical yaitu
nilai yang tidak memiliki urutan, dan discrete berdasarkan vector attribute.
Algoritma yang dapat digunakan untuk classification antara lain adalah naïve
Gambar 2.9 Contoh Classification
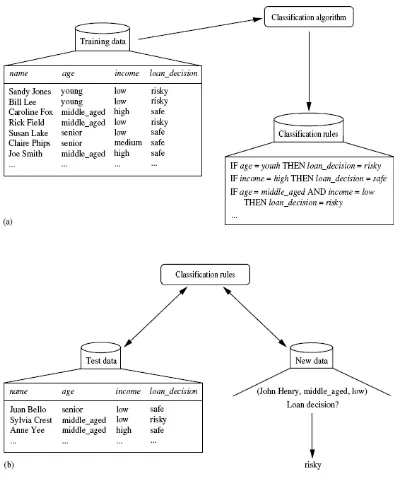
Classification terdiri dari 2 proses (Han dan Kamber,2006,pp285-288) yaitu
tahap pembelajaran (gambar 2.9a) dan classification (gambar 2.9b). Pada tahap
pertama, classifier (model prediktif yang memprediksi nilai kelas categorical)
dibuat untuk mendeskripsikan kelas data yang sebelumnya telah didefinisikan.
model prediktif dengan mempelajari training set yang terdiri dari record databas e
dan label kelas. Sebuah record X, direpresentasikan dengan n-dimensi vector
attribute, X=( , ,…, ) dimana , … merupakan nilai dari atribut
, ,..., .Setiap record, X, diasumsikan tergabung ke dalam sebuah kelas yang
telah didefinisikan sebelumnya melalui atribut database lainnya yang disebut
sebagai class label attribute. Class label attribute merupakan suatu nilai discrete
dan tidak memiliki urutan. Nilai class label attribute adalah categorical dimana
setiap nilai yang mungkin berfungsi sebagai kategori atau kelas.
Karena setiap class label pada setiap record training telah diketahui, tahap
ini disebut juga supervised learning. M aksudnya supervised adalah proses
pemebalajaran dari classifier diawasi, dikontrol (supervised) dimana classifier
diberitahu pada kelas mana sebuah record training tergabung. Hal ini berlawanan
dengan unsupervised learning dimana class label tidak diketahui, dan jumlah class
yang dipelajari tidak diketahui sebelumnya.
Tahap pertama dari proses classification dapat disebut sebagai
pembelajaran fungsi, y=f(X), yang dapat memprediksikan class label y jika
diberikan record X. Classification berusaha mempelajari fungsi atau mapping
yang memisahkan kelas data.
Tahap kedua dari proses classification adalah mengetes model dimana
model digunakan untuk classification. Tahap kedua ini bertujuan untuk mengukur
keakuratan dari classifier.Input data untuk tes ini sebaiknya tidak menggunakan
data yang sama dengan training set. Hasil tes classifier dengan menggunakan data
performa classifier. Hal ini dikarenakan classifier dibuat dengan data yang sama
pada saat tes sehingga estimasi performa yang dihasilkan adalah optimistis. Hasil
evaluasi error rate dari data training disebut juga resubstitution error. classifier
cenderung untuk overfit data tersebut karena dalam tahap learning classifier
mungkin memasukkan beberapa anomali dalam data training yang tidak ada pada
data umum secara keseluruhan. Oleh karena itu, test set yang digunakan dibentuk
dari record-record yang berbeda dari training set yang mana record tidak
digunakan untuk memebentuk classifier. (Witten dan Frank, 2005, p145)
Beberapa langkah preprocessing berikut mungkin perlu diaplikasikan pada
data untuk membantu meningkatkan akurasi, efisiensi, dan skalabilitas dari proses
classification (Han dan Kamber, 2006, pp289-290) :
1. Data Cleaning: M erujuk pada preprocessing data untuk membuang atau
mengurangi noise dan missing values. M eskipun kebanyakan algoritma
classification memiliki mekanisme untuk menangani data noise atau missing
value, langkah ini dapat membantu mengurangi kebingungan selama learning.
2. Relevance Analysis: Banyak atribut pada data yang redundan. Correlation
analysis dapat digunakan untuk mengidentifikasikan apakah atribut satu
dengan lainnya berelasi. Contoh, korelasi yang sangat kuat antara dan
dapat menunjukkan satu dari antara kedua atribut tersebut untuk di keluarkan.
Database juga sering kali mengandung atribut yang tidak relevan terhadap
kelas yang hendak diprediksi. Attribute subset selection dapat digunakan untuk
menemukan set atribut yang telah direduksi tetapi hasil probabilitas distribusi
seluruh atribut. Relevance analysis dalam bentuk correlation analysis dan
attribute subset selection dapat digunakan untuk mendeteksi atribut yang tidak
atau kurang berkontribusi pada proses classification.
3. Data transformation dan reduction: normalisasi bertujuan untuk menskalakan
semua nilai untuk atribut tertentu sehingga jatuh ke dalam rentang yang kecil
seperti -1.0 sampai 1.0 atau 0.0 sampai 1.0. Data juga dapat ditransformasikan
dengan mengeneralisasikan ke dalam level konsep yang lebih tinggi. Hirarki
konsep dapat digunakan untuk tujuan ini. Hal ini juga dapat berguna untuk
atribut dengan nilai continue. Contoh, atribut numerik untuk pendapatan dapat
digeneralisasikan kedalam nilai discrete seperti rendah, sendang, dan tinggi.
Hal yang untuk atribut categorical seperti jalan dapat diganti dengan kota.
Karena generalisasi mereduksi data training asli, operasi input/output selama
proses learning semakin sedikit. Data juga dapat direduksi dengan berbagai
metode lain seperti binning, atau clustering.
2.1.12 Classification dengan Decision treeinduction
Decision tree induction merupakan pembelajaran Decision tree dari training
set yang telah memiliki label kelas. Decision treeadalah suatu struktur pohon yang
menyerupai flowchart, dimana setiap node internal (node yang bukan daun)
menyatakan suatu tes terhadap sebuah atribut, setiap cabang merepresentasikan
hasil dari test, dan setiap node daun (atau terminal node) menyimpan label kelas.
Gambar 2.10 Contoh Decision Tree
Gambar 2.10 menunjukkan Decision tree untuk memprediksi apakah
konsumen akan membeli komputer atau tidak berdasarkan vector attributeage,
student, dan credit rating. Node internal dilambangkan dengan persegi, dan node
daun dengan oval. Beberapa algoritma Decision tree hanya dapat menghasilkan
pohon binary (setiap internal node hanya memiliki 2 cabang) sedangkan beberapa
algoritma lainnya dapat memproduksi pohon nonbinary.
Dengan decision tree, bila diberikan sebuah record X dimana class label
belum diketahui, maka atribut dari record X dites terhadap decision tree. Tes
dilakukan hingga berakhir pada node daun yang menyimpan nilai prediksi class
untuk record X.
Beberapa keunggulan dari Decision tree adalah:
1. Decision tree dapat menangani data dengan dimensi yang tinggi
2. Representasi dari pengetahuan yang didapat mudah untuk dipahami oleh
manusia
3. Proses learning dan classification dari Decision tree sederhana dan cepat
Decision tree memiliki beberapa algoritma seperti ID3, C4.5, atau CART.
Kebanyakan algoritma untuk Decision treeinduction menggunakan pendekatan
top-down, dimana proses dimulai dari record pada training set dan kelas labelnya.
Training set secara berulang akan dipartisi kedalam subset yang lebih kecil selama
tree dibangun.
Gambar 2.11 Dasar Algoritma Decision Tree
Gambar 2.11 meringkas dasar dari algoritma decision tree. Proses
1. Algoritma dipanggil dengan 3 parameter: D, attribute_list, dan
atrribute_selection_method. D merupakan partisi data. Awalanya D merupakan
keseluruhan record pada training set beserta kelas labelnya.Parameter
attribute_list merupakan list atribut yang mendeskripsikan record.
Attribute_selection_method menspesifikasikan prosedur heuristik yang
digunakan untuk memilih attribut yang terbaik untuk mendiskriminasikan
record berdasarkan kelas. Prosedur ini menggunakan attribute selection
measure, seperti information gain ,gini index, atau minimum descriptor length
(MDL). Apakah tree harus binary atau tidak ditentukan oleh attribute selection
measure. Beberapa attribute selection measure, seperti gini index,
mengharuskan tree yang dihasilkan binary.
2. Tree dimulai dengan node tunggal, N, merepresentasikan record dalam training
set D (langkah 1)
3. Jika record dalam D semua berada dalam class yang sama, maka node N
menjadi daun dan diberi label dengan class tersebut (langkah 2 dan 3). Langkah
4 dan 5 merupakan terminating conditions.
4. Jika record dalam D tidak semua berada dalam 1 kelas yang sama. A glortima
memanggil attribute_selection_method untuk menentukan splitting criterion.
Splitting criterion merupakan atribut yang digunakan untuk tes pada node N
dengan menentukan cara terbaik untuk memisahkan atau mempartisi record
dalam D ke kelas individual (langkah 6). Splitting criterion juga menentukan
cabang mana yang harus dibuat dari node N sesuai dari hasil output dari tes.
semurni mungkin. Partisi disebut murni bila semua record yang berada di
dalamnya berada dalam class yang sama.
5. Node N diberi label dengan splitting criterion, yang berfungsi sebagai tes pada
node tersebut (langkah 7). Cabang dibuat dari node N untuk setiap hasil dari
splitting criterion dan record D dipartisi sesuai dengan splitting tersebut
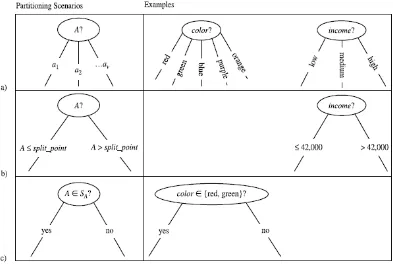
(langkah 10-11). Gambar 2.12 menunjukkan 3 skenario yang mungkin.
Gambar 2.12 Skenario hasil splitting criterion
Jika A merupakan spliiting attribute. A memiliki v nilai berbeda, { , ,…, },
berdasarkan training data:
• A merupakan nilai discrete (categorical): Dalam kasus ini, keluaran dari
test pada node N adalah nilai yang diketahui artibute A. Setiap cabang
dibuat untuk setiap nilai yang diketahui, , dari A dan diberi label dengan
memiliki label class dalam D yang memiliki nilai dari A. Karena semua
record dalam partisi yang dihasilkan memiliki nilai untuk A yang sama,
maka A tidak akan digunakan untuk dalam partisi yang akan datang.
Karena itu, atribut A dikeluarkan dari attribute_list (langkah 8 dan 9)
• A merupakan nilai continue: Dalam kasus ini, tes pada node N dapat
memiliki 2 keluaran yang mungkin yaitu konsidi A ≤ split_point dan A ≥
split_point. Dimana split_point dikembalikan oleh
attribute_selection_method sebagai bagian dari splitting criterion. Dua
cabang dibuat dari N dan diberi label (gambar 2.12(b)). Record-record
dipartisi sehingga menampung subset dari record pada D dimana A ≤
split_point, sedangkan menampung sisanya.
• A merupakan nilai discrete dan binary tree harus dibuat (gambar 2.12(c)):
Test pada node N dalam bentuk “A anggota ?”. merupakan splitting
subset dari A, yang dikembalikan oleh attribute_selection_method sebagai
bagian dari splitting criterion. merupakan subset dari nilai atribut A.
6. Algoritma menggunakan proses yang sama secara berulang untuk membentuk
Decision treeuntuk record-record pada partisi yang dihasilkan, , dari D
7. Partisi berulang ini berhenti ketika memenuhi termintating condition:
• Semua record pada partisi D (direpresentasikan pada node N) tergabung
dalam kelas yang sama (langkah 2 dan 3)
• Tidak ada atribut lagi dimana record-record dapat dipartisi lebih lanjut
label dengan nilai class yang paling banyak di D (langkah 5). Alternatif lain
distribusi class pada record di node tersebut dapat disimpan.
• Tidak ada record pada cabang yaitu ketika partisi kosong (langkah 12).
Pada kasus ini, daun dibuat dengan class yang paling banyak muncul di D
(langkah 13)
8. Hasil dari Decision tree dikembalikan (langkah 15).
(Han dan Kamber, 2006, pp291-296)
2.1.13 Support Vector Machine (SVM)
SVM dapat digunakan untuk classification baik data linear maupun
non-linear. SVM menggunakan nonlinear mapping untuk mentransformasikan data
training ke dimensi yang lebih tinggi.Dalam dimensi baru ini dicari hyperplane
(bidang) optimal sebagai pemisah. Hyperplane ini merupakan batas yang
memisahkan record dari satu kelas dengan kela lainnya. SVM menemukan
hyperplane dengan menggunakan support vector dan margin (didefinisikan oleh
support vector).
Waktu training dari SVM lebih lambat dan memakan waktu bila
dibandingkan dengan metode classification lainnya tetapi SVM memiliki tingkat
akurasi yang tinggi dan tidak rentan terhadap overfitting. SVM dapat digunakan
untuk memprediksi nilai categorical atau nilai continue.
Jika diberikan suatu masalah apakah seorang pelanggan akan membeli
komputer atau tidak, dengan label kelas yang memiliki 2 nilai dimana kelas
merupakan linearly separable dengan data set D dalam bentuk
training yang diasosiasikan dengan label kelas . Setiap dapat memiliki satu
dari dua nilai yaitu +1 (buys_computer=yes) atau -1 (buy_computer=no). Setiap
dijelaskan oleh dua atribut dan seperti ditunjukkan pada gambar 2.15
Gambar 2.13 Contoh hyperplane SVM
Dari gambar 2.13 terlihat bahwa data 2-D tersebut linearly separable karena
sebuah garis lurus dapat digambarkan untuk memisahkan semua record dari kelas
+1 dengan record dari kelas -1. Jumlah garis pemisah yang ada adalah tak terbatas
(infinite). Jika data adalah 1-D (1 atribut) yang dicari adalah titik pemisah, jika
data 3-D (memiliki 3 atribut) maka yang dicari adalah bidang (plane).
Digeneralisasikan menjadi n-dimensi maka pemisah tersebut disebut dengan
hyperplane. SVM berusaha mencari hyperplane terbaik yang memiliki error
Gambar 2.14 Contoh margin SVM
SVM mencari hyperplane terbaik dengan mencari maximum marginal
hyperplane (MM H). Gambar 2.14 menunjukkan contoh 2 hyperplane pemisah
yang mungkin dilengkapi dengan margin masing-masing. Dari gambar 2.14
terlihat bahwa kedua hyperplane dapat dengan benar memisahkan semua record
data yang diberikan. Akan tetapi, hyperplane yang memiliki margin terbesar lebih
sebelumnya. Karena itu (selama fase learning atau training), SVM mencari
hyperplane dengan margin terbesar yaitu MM H. Jarak terdekat dari hyperplane ke
salah satu sisi margin sama dengan jarak terdekat dari hyperplane tersebut ke sisi
margin lainnya. Jarak terdekat ini adalah jarak dari MMH ke record training
terdekat dari masing-masing kelas.
Record training yang berada pada sisi margin dari hyperplane disebut
dengan support vector. Support vector adalah record yang paling sulit untuk
diklasifikasikan dan memberikan informasi paling banyak mengenai classification.
Jika semua record selain support vector di keluarkan dari training data dan
training dilakukan ulang, maka akan tetap didapatkan hyperplane yang serupa.
Komplekstitisitas dari classifier lebih ditentukan oleh banyaknya support vector
dibanding dimensi data.
SVM juga dapat digunakan untuk mencari non-linear decision
boundary.Non-linear decision boundary dicari apabila kelas pada data tidak dapat
dipisahkan oleh liner hyperplane. (Han dan Kamber, 2006, pp337-344)
2.1.14 Bayesian Classification
Bayesian classifier merupakan classifier statistik yang dapat
memprediksikan probabilitas keanggotaan kelas, seperti probabilitas sebuah
record tergabung ke dalam kelas tertentu.
Bayesian Classification yang didasarkan pada teorema Bayes memilki
tingkat akurasi yang tinggi dan dapat berjalan dengan cepat dalam database yang
besar. Naïve bayesian Classifier mengasumsikan efek dari sebuah nilai atribut
pada sebuah kelas, independen terhadap nilai dari atribut lainnya. Asumsi ini
disebut juga class conditional independence. Asumsi ini dilakukan untuk
menyederhanakan proses komputasi dan karena itu dianggap “naïve”.
Jika X merupakan record data, dimana X terdiri dari n atribut. Dalam istilah
bayesian, X disebut dengan fakta. Jika H merupakan hipotesis, seperti misalnya
record X tergabung ke dalam kelas C. Untuk classification, yang ingin ditentukan
adalah P(H|X), probabilitas hipotesis H jika diberikan fakta atau record X. Dengan
kata lain yang dicari adalah probabilitas record X tergabung ke dalam kelas C, jika
diketahui deskripsi atribut dari X.
P(H|X) merupakan posterior probability, H dikondisikan pada X. Contoh,
jika data pelanggan sebuah toko komputer dideskripsikan dengan atribut umur dan
pendapatan. X adalah pelanggan berumur 35 tahun dengan pendapatan Rp
10.000.000,00. M isalkan ingin diketahui apakah pelanggan X akan membeli
P(H) adalah prior probability. Dalam contoh diatas berarti adalah
probabilitas pelanggan akan membeli komputer tanpa melihat umur dan
pendapatan atapun informasi atribut lainnya.
P(X|H) adalah posterior probability dimana X dikondisikan pada H. Sesuai
contoh berarti probabilitas pelanggan , X, berumur 35 tahun dengan pendapatan
Rp. 10.000.000,00 jika diketahui pelanggan membeli komputer.
P(X) merupakan prior probability dari X. M enggunakan contoh berarti
probabilitas seseorang dari database pelanggan yang mana berumum 35 tahun dan
memiliki pendapatan Rp. 10.000.000,00.
P(H), P(X|H), dan P(X) dapat dicari dari training set dimana train set telah
memiliki label class. Teorema Bayes berguna untuk untuk menghitung posterior
probability P(H|X) dari P(H), P(X|H), dan P(X) dengan rumusan sebagai berikut
P(H|X)=
Proses kerja Bayesian Classifier adalah sebagai berikut:
1. Jika D adalah training set yang terdiri dari record dan label kelasnya
masing-masing. Setiap record direpresentasikan dengan n-dimensi attribute vector,
X=( , ,…, ). Dan memiliki n atribut , ,…, .
2. Jika terdapat m kelas, , ,…, . Apabila diberikan record, X, classifier akan
memprediksikan X tergabung ke dalam kelas yang memiliki nilai posterior
probability tertinggi, dikondisikan pada X. Naïve bayesclassifier
memprediksikan record X tergabung dalam class jika dan hanya jika
M aka nilai P( |X) merupakan nilai probabilitas tertinggi. Nilai kelas
dimana P( |X) dimaksimalkan disebut dengan maximum posteriori hypothesis.
P( |X)=
3. Karena nilai P(X) konstan untuk semua kelas, maka hanya yang
perlu dimaksimalkan. Jika prior probability dari kelas tidak diketahui, maka
biasanya diasumsikan bahwa setiap kelas adalah sama yang mana
P( )= )=…= , dan yang perlu dimaksimalkan hanya nilai .
Selain itu, nilai harus dimaksimalkan. Nilai prior probabilitas
kelas dapat diestimasikan dengan =| |/|D|, dimana | | adalah jumlah
record dalam D yang memiliki label kelas .
4. Bila diberikan dataset dengan banyak atribut, maka akan sangat sulit dan mahal
biaya untuk menghitung nilai . Untuk mengurangi proses komputasi
dalam mengevaluasi , asumsi naïve class conditional independence
dibuat. Asumsi tersebut menganggap nilai dari sebuah atribut independen
terhadap satu sama lain. M aka
=
…
Probabilitas , ,…, dapat dicari dari data training.
menunjukkan nilai dari atribut untuk record X. Untuk setiap atribut akan
dilihat apakah atribut adalah categorical atau berupa nilai continue. Contoh,
• Jika adalah categorical, maka adalah jumlah record yang
memiliki label kelas dalam D dan memiliki nilai untuk atribut
dibagi dengan | | yang merupakan jumlah record dengan label kelas
pada D
• Jika adalah nilai continue, maka perlu dilakukan kalkulasi tambahan.
Atribut dengan nilai continue diasumsikan memiliki Gaussian distribution
dengan mean dan standard deviasion , yang didefinisikan sebagai
g(x, , ) =
sehingga
P( | ) = g( , , )
Yang perlu dihitung adalah (mean) dan (standard deviation) dari
nilai atribut untuk record dengan kelas . Sebagai contoh, jika X=(35,
Rp. 10.000.000), dimana adalah atribut umur dan pendapatan. Label
kelas adalah atribut buys_computer. Nilai label kelas untuk X adalah yes.
M isalkan atribut umur tidak di discretisized dan tetap sebagai atribut
dengan nilai continue. M isalkan dari training set, ditemukan bahwa
pelanggan dalam D yang membeli komputer berumur 38 12. Dengan kata
lain untuk atribut umum pada kelas ini memiliki nilai dan =12.
Nilai dan =12 digunakan untuk mengesitmasikan
5. Untuk memprediksi label kelas X maka P( ) dievaluasi untuk setiap
kelas . Classifier memprediksi label kelas dari record X adalah kelas jika
dan hanya jika
P(X ) P( > P(X ) P( untuk 1 j m, j i
Dengan kata lain, nilai prediksi kelas untuk record X adalah kelas dimana
P(X )P( adalah maksimum.(Han dan Kamber, 2006, pp310-313)
2.1.15 Pengukuran Error dan Akurasi Model Pre diktif
2.1.15.1 Pengukuran akurasi classifiers
Akurasi dari dari sebuah classifier, model prediktif yang memprediksi
nilai categorical, untuk sebuah kumpulan data tes adalah persentase dari
record data tes yang dengan benar diklasifikasikan oleh classifier. Dalam
literatur pattern recognition, ini disebut juga sebagai overall recognition rate
dari classifier, yang mana merefleksikan seberapa baik classifier mengenali
record dari kelas-kelas yang berbeda.
Error rate atau misclassification rate untuk classifier, M , didefinisikan
sebagai 1 - Acc(M ), dimana Acc(M ) merupakan akurasi dari M . Jika kita
hendak menggunakan training set untuk mengestimasi error rate dari model,
nilai ini dikenal dengan resubstituion error. Perhitungan error ini optimistis
pada true error rate karena model tidak di tes pada data sampel yang belum
pernah dilihat sebelumnya.
Confusion matrix merupakan alat pengukuran yang dapat digunakan
kelas-kelas yang berbeda. Jika diberikan m kelas-kelas, confusion matrix adalah sebuah
tabel yang minimal berukuran m kali m. Sebuah nilai, , di baris pertama
mdan kolom m mengindikasikan jumlah record pada class I yang diberi label
oleh classifier sebagai class j. Jika classifier memiliki akurasi yang baik,
idealnya semua record akan direpresentasikan sepanjang garis diagonal
confusion matrix, dari , sampai , dimana nilai pada kolom lainnya
bernilai nol. Confusion matrix dapat memiliki baris atau kolom tambahan
untuk menyedikiakan informasi nilai total atau recognition rate untuk setiap
class. Gambar 2.15 menunjukkan struktur confusion matrix untuk 2 nilai class
positive dan negatif.
Gambar 2.16 Struktur Confusion Matrix untuk 2 nilai class
Jika classifier memprediksi 2 nilai class, yaitu positive dan negatif. M aka
true positive menunjukkan jumlah record positive yang dengan benar diberi
label oleh classifier, sedangkan true negative adalah record negative yang
dengan benar diberi label oleh classifier. False positive adalah record dimana
label kelas diprediksi diprediksi positive dimana sebenarnya negative. False
negative adalah record dimana label kelas diprediksi diprediksi negative
dimana sebenarnya positive. Contoh confusion matrix untuk 2 nilai kelas
ditunjukkan seperti pada tabel 2.1. (Han dan Kamber,2006,pp360-362; Witten
Tabel 2.1 Contoh Confusion M atrix
Classes buys=yes buys=no total Recognition(%)
Buys=yes
2.1.15.2 Pengukuran ErrorPredictor
Untuk predictor, model prediktif yang memprediksi suatu nilai continue,
biasa yang diukur adalah tingat error dari predictor. Jika adalah kumpulan
data tes dalam bentuk ( , ),( , ),…,( , ), dimana adalah kumpulan
record dengan n dimensi dengan nilai class label yang telah diketahui, , dan
d adalah jumlah record dalam . Karena predictor mengembalikan nilai
continue, sulit untuk menentukan secara tepat apakah nilai yang diprediksi, ,
untuk tepat atau tidak. Daripada berfokus pada apakah nilai merupakan
nilai yang benar-benar sama dengan , pengukuran dilakukan dengan melihat
seberapa jauh nilai yang diprediksi dari nilai yang sebenarnya. Loss function
mengukur error antara dan nilai yang diprediksi .Loss function yang
banyak digunakan adalah:
Absolute Error : | - |
Squared Error : (
-Berdasarkan rumus di atas, error rate, atau generalisasi error, adalah
Mean absolute error :
Mean square error :
Jika diambil akar dari square root, hasilnya disebut juga dengan root mean
square error (RSM E). RSM E berguna untuk mengukur error dalam ukuran
yang sama dengan nilai yang sedang diprediksi. (Han dan Kamber, 2006,
pp362-363)
2.1.16 Siklus Hidup Proyek Data mining
Siklus hidup pengembangan proyek data mining teridri dari 6 fase. Urutan
untuk fase tidaklah harus sama. Garis lingkaran luar melambangkan sifat cyclic
dari data mining. Sebuah proses data mining terus berlanjut setelah solusi telah
diaplikasikan. Pembelajaran yang dipelajari selama proses dapat menimbulkan
pertanyaan bisnis yang baru dan lebih terfokus. Berikut deskripsi dari setiap fase
(Chapman, 2000, pp13-14):
1. Business Understanding
Fase awal berfokus pada mempelajari tujuan dari proyek dan kebutuhan dari
sudut pandang bisnis, dan mengubah pengetahuan ini menjadi masalah dalam
data mining, dan rencana awal didesain untuk mencapai tujuan.
2. Data Understanding
Data understanding dimulai dengan mengkoleksi data awal dan dilanjutkan
dengan aktivitas dengan tujuan untuk lebih memahami data, mengidentifikasi
kualitas data, dan menemukan pengetahuan, atau mendeteksi subset yang
menarik untuk membentuk hipotesis untuk informasi yang tersembunyi.
3. Data Preparation
Fase preparasi data meliputi semua aktivitas untuk mengkonstruksi dataset
akhir dari data mentah untuk dimasukkan dalam program data mining. Data
preparation biasanya dilakukan beberapa kali. Tugas ini meliputi transformasi
dan membersihkan tabel, record, atau seleksi atribut.
4. Modeling
Dalam fase ini, beberapa teknik modeling data mining di seleks i dan
Biasanya ada beberapa teknik untuk tipe permasalahan data mining yang sama.
Beberapa teknik memiliki persyaratan yang spesifik untuk data, karena itu
bergerak mundur ke data preparation sering kali dibutuhkan.
5. Evaluation
Pada tahap proyek ini, model yang memiliki kualitas yang baik dari sudut
pandang data anlisis telah dibuat. Sebelum melanjutkan ke tahap akhir
implementasi, penting untuk melakukan evaluasi dari model, dan mereview
langkah-langkah yang dieksekusi untuk mengkonstruksi model, untuk
memastikan tujuan bisnis sudah tercapai. Tujuan utama tahapan ini adalah
menentukan apakah ada permasalahan bisnis penting yang belum dapat
dipenuhi. Pada akhir dari fase ini, dibuat keputusan apakah akan menggunakan
data mining yang telah dibuat.
6. Deployment
Pembuatan dari model umumnya bukan akhir dari proyek. Walupun tujuan dari
model adalah meningkatkan pengetahuan akan data, pengetahuan yang telah
dikumpulkan perlu untuk diorganisasikan dan direpresentasikan dalam bentuk
yang dapat digunakan oleh konsumen. Tergantung dari persyaratan, fase
deployment dapat sesederhana seperti menghasilkan laporan atau kompleks
seperti mengimplementasikan proses data mining yang berulang. Pada tahap ini
penting untuk memastikan bahwa pengguna mengerti apa yang harus dilakukan
2.2 Teori Khusus
2.2.1 Airline
Airline memberikan jasa transportasi udara untuk penumpang ataupun
barang muatan, biasanya dengan lisensi dan sertifikat operasi.Airline dapat
meminjam ataupun memiliki pesawatnya sendiri untuk memberikan jasa tersebut,
dan mungkin membentuk hubungan kerjasama atau aliansi dengan airline lain
(http://en.wikipedia.org/wiki/airline)
2.2.2 Computer Reservation System (CRS)
Computer Reservation System (CRS) merupakan sistem terkomputerisasi
yang digunakan untuk menyimpan dan menerima, mengambil informasi dan
melakukan transaksi yang berkaitan dengan air travel. Awalnya CRS di gunakan
dan dioperasikan untuk airline, saat ini CRS juga digunakan untuk travel agent.
CRS yang membuat reservasi dan menjual tiket untuk beberapa airline disebut
juga Global Distribution Systems (GDS). GDS membuat sistem dari airline dapat
diakses oleh konsumen melalui internet gateways. Penerapan GDS saat ini selain
untuk tiket airline juga dapat digunakan untuk memesan kamar hotel atau mobil.
Contoh sistem GDS yang banyak digunakan adalah: SABRE, Galileo, Wolrdspan,
Abacus.
Airline yang menggunakan sistem GDS dikenakan distribution feeoleh
penyedia jasa GDS untuk setiap penerbangannya. Semakin meluasnya dan
terjangkaunya server hardware dan diperkenalkannya automated pricing,
sebagian besar volume pembelian mereka ke website CRS mereka sendiri
dan menghindari distribution fee yang dikenakan oleh penyedia jasa GDS.
(http://en.wikipedia.org/wiki/computer_reservation_system)
2.2.3 Passenger Name Record (PNR)
Dalam industri travel, Passenger Name Record adalah sebuah record dalam
database CRS yang mengandung record perjalanan untuk seorang penumpang,
atau grup penumpang yang melakukan perjalanan bersama. Konsep PNR pertama
kali diperkenalkan oleh airline yang perlu untuk bertukar informasi reservas i
dalam kasus penumpang memerlukan penerbangan dari beberapa airline untuk
mencapai tujuan (interlining). Untuk tujuan ini International Air Transport
Association (IATA) mendefinisikan standard layout dan isi dari PNR.
Ketika penumpang melakukan booking sebuah perjalanan, travel agentakan
menciptakan PNR dalam CRS yang digunakannya. Hal ini biasanya dilakukan
melalui GDS, seperti SABRE, Amadeus, atau Galileo, tetapi bila booking dibuat
secara langsung oleh airline maka PNR dapat berada dalam database CRS
milikairline tersebut. PNR ini disebut juga master PNR untuk penumpang dan
perjalanan yang bersangkutan. PNR diidentifikasi dalam database dengan record
locator. Walaupun PNR awalnya diperkenalkan oleh air travel, sekarang PNR
juga digunakan untuk booking hotel, mobil, kereta, dan lain-lain.
Dari sudut pandang teknikal minimal ada 5 bagian utama dari PNR sebelum
booking dapat dilakukan. Hal tersebut adalah:
2. Contact Detail untuk travel agent atau airline
3. Ticketing detail, seperti nomor tiket atau time limit untuk ticketing
4. Perjalanan paling tidak 1 segmen, yang mana harus sama untuk semua
penumpang yang tercantum
5. Nama orang yang melakukan booking
Setelah booking diselesaikan sampai level tersebut, maka sistem CRS akan
menerbitkan recordlocator yang bersifat unik. Record locatorakan tetap sama
walaupun terjadi perubahan kecuali jika terjadi split PNR.
(http://en.wikipedia.org/wiki/PNR)
2.2.4 Record Locator
Record locator merupakan nomor referensi alpha-numerik yang digunakan
oleh airline dan travel agent untuk mengidentifikasikan booking. Biasanya terdiri
antara 5-7 karakter. Sistem Airline hanya menggunakan huruf besar dan beberapa
cenderung menghindari penggunaan huruf I dan O karenea kemiripannya dengan
angka 1 dan 0.
Setiap airlineakan mengalokasikan record locator nya masing-masing, dan
jika penerbangan dipesan oleh sistem travel agent, maka travel agent akan
memiliki record locator yang berbeda. Contoh: Penumpang X pergi dari Paris
dengan airline A dan kembali dengan airlineB, dan melakukan booking melalui
sistem GDS C. M aka booking penumpang X akan memiliki 3 record locator, 1
utnuk A, satu untuk B, dan 1 untuk C.
Dalam 1 record locator dapat terdiri dari lebih 1 penumpang, yang mana
sama. Biasanya 1 locator dapat menampung hingga 9 penumpang tergantung dari
kebijaksanaan airline masing-masing.
Sebuah record locator merupakan pointer pada PNR (Passenger Name
Record). M eskipun demikian, istilah PNR seringkali digunakan baik untuk record
locator maupun keseluruhan booking dan detailnya.
(http://en.wikipedia.org/wiki/record_locator)
2.2.5 Overbooking
Overbooking merupakan istilah yang digunakan untuk mendeskripsikan
penjualan akses suatu servis yang melebihi kapasitas servis itu sendiri.
Overbooking sering dilakukan oleh perusahaan yang bergerak di bidang
telekomunikasi, airline, kereta, kapal ataupun hotel.
Dalam Industri telekomunikasi overbooking berarti service provider
ataupun telephone company menjual access ke terlalu banyak konsumen yang
mengakibatkan ketidakmampuan konsumen untuk menggunakan sesuai dengan
yang mereka beli. Overbooking dalam industri telekomunikasi sering dilakukan
Gambar 2.18 Grafik Proses OverbookingAirline
Perusahaan seperti airline, kereta ataupun kapal dapat mengijinkan booking
oleh konsumen melebihi kapasitas yang sebenarnya dapat ditampung oleh pesawat,
kereta, ataupun kapal. Hal ini mengijinkan mereka untuk dapat menjual hampir
keseluruhan tempat walaupun beberapa konsumen ada yang ketinggalan
perjalanan ataupun tidak muncul (no-show) yang mana biasanya tiket dapat di
rebookulang setelahnya. Penumpang bisnis ada kalanya membatalkan pada
saat-saat terkakhir contohnya ketika meeting melebihi waktu yang diperkirakan. Jika
semua penumpang muncul, overbooking akan mengakibatkan oversale. Dalam
kasus seperti ini, untuk airline dapat terjadi penolakan boarding pada penumpang
tertentu (involuntary denied boarding), dengan penukaran berupa kompensasi
yang dapat berupa tiket gratis tambahan atau upgrade class pada penerbangan
berikutnya. Overbooking dapat dilakukan dan menghasilkan lebih banyak
kapasitas pesawat dan membiarkan pesawat take-off dengan kursi kosong.
(http://en.wikipedia.org/wiki/overbooking)