KLASIFIKASI
NAIVE BAYES
PADA DATA TIDAK
SEIMBANG UNTUK KASUS PREDIKSI RESIKO KREDIT
DEBITUR KARTU KREDIT
DEWI SRI RAHAYU
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Naive Bayes
pada Data Tidak Seimbang untuk Kasus Prediksi Resiko Kredit Debitur Kartu Kredit adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, April 2014
Dewi Sri Rahayu
ABSTRAK
DEWI SRI RAHAYU. Klasifikasi Naive Bayes pada Data Tidak Seimbang untuk Kasus Prediksi Resiko Kredit Debitur Kartu Kredit. Dibimbing oleh AZIZ KUSTIYO.
Bisnis perbankan di Indonesia masih didominasi oleh bisnis perkreditan. Sebagian besar pendapatan bank berasal dari bisnis tersebut. Namun, resiko kredit dapat menyebabkan kredit bermasalah sehingga dapat mengurangi pendapatan bank. Penelitian ini menggunakan analisis klasifikasi naive bayes pada data tidak seimbang untuk kasus prediksi resiko kredit debitur kartu kredit yang mampu mengklasifikasikan calon debitur ke dalam kategori good atau bad. Strategi
sampling digunakan untuk mengatasi permasalahan data tidak seimbang. Metode yang digunakan adalah oversampling duplikasi, oversampling acak,
undersampling acak, dan undersampling cluster. Hasil penelitian menunjukkan bahwa metode oversampling acak menunjukkan nilai terbaik setelah dilakukan strategi sampling dengan nilai f-measure sebesar 83.30%.
Kata Kunci: Data tidak seimbang, klasifikasi naive bayes, oversampling, resiko kredit, undersampling.
ABSTRACT
DEWI SRI RAHAYU. Naive Bayes Classification on the Imbalanced Data for the Predictions of Debtor’s Credit Risk. Supervised by AZIZ KUSTIYO.
Banking business in Indonesia is still dominated by the credit business field. Most of the bank's revenue comes from this business field. Unfortunately, credit risk can cause problems in loans which can reduce the bank’s revenue. This research uses a Naive Bayes classification analysis on the imbalanced data for the predictions of debtor’s credit risk that are able to classify the future debtor into the following two categories: good or bad. Sampling strategy is used to overcome the problems of imbalanced data. Duplication oversampling, random oversampling, random undersampling, and cluster undersampling are chosen as the methods. It is found that the random oversampling method shows the best value after sampling strategy is conducted with an f-measure of 83.30%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI
NAIVE BAYES
PADA DATA TIDAK
SEIMBANG UNTUK KASUS PREDIKSI RESIKO KREDIT
DEBITUR KARTU KREDIT
DEWI SRI RAHAYU
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Klasifikasi Naive Bayes pada Data Tidak Seimbang untuk Kasus Prediksi Resiko Kredit Debitur Kartu Kredit.
Nama : Dewi Sri Rahayu
NIM : G64090029
Disetujui oleh
Aziz Kustiyo, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji syukur kehadirat Allah subhanahu wa ta’ala atas segala karunia-Nya yang telah melimpahkan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan skripsi yang berjudul Klasifikasi Naive Bayes pada Data Tidak Seimbang untuk Kasus Prediksi Resiko Kredit Debitur Kartu Kredit.
Terima kasih penulis ucapkan kepada Bapak Aziz Kustiyo, SSi, MKom selaku pembimbing yang telah mencurahkan waktu dan ilmunya untuk membimbing saya. Penulis juga mengucapkan terima kasih kepada dosen penguji, Bapak Toto Haryanto, SKom, MSi dan Ibu Karlina Khiyarin Nisa, SKom, MT atas kritik dan saran. Disamping itu, penulis juga ingin menyampaikan terimakasih kepada seluruh staf Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, IPB atas semua pelayanan terbaik yang pernah penulis terima.
Selanjutnya penghormatan dan terima kasih yang sebesar-besarnya penulis berikan kepada orang tua dan keluarga tercinta yang telah mencurahkan cinta serta dukungannya baik moril maupun materil. Kepada teman-teman sebimbingan atas bantuan serta saran yang diberikan, IMTR terutama buat Zahrial Syah Alam dan teman-teman Pocut Baren atas bantuan, saran, kritik, dan dukungannya kepada penulis.
Semoga karya ilmiah ini bermanfaat.
Bogor, April 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Pengadaan Data 2
Data Tidak Seimbang 2
Praproses Data 4
Normalisasi Data 4
Strategi Sampling 4
Pembagian Data Uji dan Data Latih 5
Diskretisasi 6
Klasifikasi Naive Bayes 6
Analisis Hasil Klasifikasi 6
Penerapan Model Terbaik 8
HASIL DAN PEMBAHASAN 8
Pengadaan Data 8
Praproses Data 8
Hasil Klasifikasi 8
Perbandingan Hasil Percobaan 13
Perbandingan dengan Penelitian Sebelumnya 16
SIMPULAN DAN SARAN 18
Simpulan 18
Saran 18
DAFTAR PUSTAKA 18
DAFTAR TABEL
1 Confusion Matrix untuk data dengan dua kelas 7
2 Karakteristik atribut 8
3 Confusion matrix Data Asli 9 4 Confusion MatrixOversampling Duplikasi 10 5 Confusion Matrix Oversampling Acak 11 6 Confusion Matrix Undersampling Acak 12 7 Confusion Matrix Undersampling Cluster 12
8 Nilai akurasi setiap model data percobaan 13
9 Nilai Precision setiap model data percobaan 13
10 Nilai Recall setiap model data percobaan 14
11 Nilai F-Measure setiap model data percobaan 14
12 Hasil percobaan oversampling terbaik 15
13Perbandingan analisis hasil dengan penelitian sebelumnya 17
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Hasil percobaan data asli 9
3 Hasil percobaan oversampling duplikasi 10
4 Hasil percobaan oversampling acak 10
5 Hasil percobaan undersampling acak 11
6 Hasil percobaan undersampling cluster 12
7 Grafik f-measure terbaik 16
DAFTAR LAMPIRAN
1 Daftar atribut 20
2 Confusion matrix tiap percobaan 21
PENDAHULUAN
Latar Belakang
Bisnis perbankan di Indonesia masih didominasi oleh bisnis perkreditan. Sebagian besar pendapatan bank berasal dari bisnis perkreditan, meskipun tidak menutup mata bahwa pada akhir-akhir ini fee base income semakin meningkat akibat penjualan produk dan jasa perbankan lainnya. Selain itu, dengan menempatkan kredit (menyalurkan dana) dan menerima kembali angsuran pokok dan bunga maka sangat membantu pengelolaan likuiditas bank, bahkan bank dalam memenuhi kewajiban jangka panjangnya juga tidak lepas dari sumber-sumber dana dari pelunasan kredit. Aktivitas perkreditan yang tepat juga bisa meningkatkan rentabilitas bank (Taswan 2011). Namun kredit yang diberikan kepada para peminjam selalu ada resiko, berupa kredit tidak dapat kembali tepat pada waktunya yang dinamakan kredit bermasalah. Kredit bermasalah selalu ada dalam kegiatan perkreditan bank karena bank tidak mungkin menghindari adanya kredit bermasalah (Christianata 2008).
Berdasarkan beberapa penelitian sebelumnya, bank memiliki kemungkinan menerima debitur dengan resiko kredit tinggi. Jumlah debitur kredit yang beresiko tinggi jauh lebih sedikit dibanding dengan debitur kredit yang berisiko rendah. Namun, hal ini bisa menyebabkan pengurangan pendapatan bank (Anggraini 2013). Data nasabah yang digunakan dalam pembuatan model klasifikasi ini merupakan himpunan data tidak seimbang. Data tidak seimbang merupakan suatu kondisi pada sebuah himpunan data terdapat satu kelas yang memiliki jumlah
instance yang kecil bila dibandingkan dengan kelas lainnya. Contohnya pada suatu himpunan data yang terdiri dari dua kelas, rasio jumlah instance antara dua kelas tersebut sebesar 1:100, 1:1000, dan 1:10.000. Kondisi data tidak seimbang ini dapat menyebabkan pengklasifikasian data yang tidak optimal (Barandela et al. 2002).
Salah satu penelitian dilakukan oleh Mladenic dan Grobelnik (1999) yang menggunakan metode naive bayes classifier pada selection feature yang terdiri dari 5 feature seperti: entertainment, arts, computer, education, dan references
untuk menghitung prediksi rata-rata kategori yang meliputi F-measure, precision,
dan recall. Hasil yang diperoleh dari model terbaik adalah pada feature references
dengan pengukuran f-measure, precision, dan recall sebesar 64.00%, 51.00%, dan 81.00%.
Pada penelitian ini akan dibuat suatu model untuk mengklasifikasikan nasabah dengan kategori good atau bad. Pembuatan model dilakukan dengan menggunakan klasifikasi naive bayes. Sebelumnya, penelitian dengan menggunakan data yang sama dilakukan oleh Setiawati (2011) menggunakan algoritme jaringan saraf tiruan backpropagation. Berdasarkan penelitian tersebut, diketahui bahwa perbandingan jumlah debitur pada kelas good dan bad memiliki perbedaan yang cukup besar, yaitu 5:1. Dari hasil penelitian tersebut diperoleh akurasi dari model terbaik sebesar 73.39%, serta recall dan precision kelas bad
2
Perumusan Masalah
Masalah yang dianalisis dalam penelitian ini adalah bagaimana menerapkan metode naive bayes classifier dalam mengklasifikasikan nasabah kartu kredit yang berisiko kredit good dan kredit bad serta pengaruh terhadap hasil akurasi, precision, recall, dan f-measure pada kasus data tidak seimbang.
Tujuan Penelitian
Tujuan penelitian ini adalah membangun suatu model untuk mengklasifikasikan debitur kartu kredit yang merupakan data tidak seimbang dengan menggunakan metode oversampling dan undersampling pada algoritme
naive bayesclassifier.
Manfaat Penelitian
Penelitian ini memberikan gambaran kinerja naive bayes classifier pada data tidak seimbang.
Ruang Lingkup Penelitian
Ruang lingkup dalam penelitian ini adalah set data yang digunakan pada penelitian Setiawati (2011) yaitu data sekunder nasabah kartu kredit bank X pada periode tahun 2008-2009. Metode yang digunakan pada penelitian ini adalah
oversampling dan undersampling dengan algoritme naive bayes classifier.
METODE
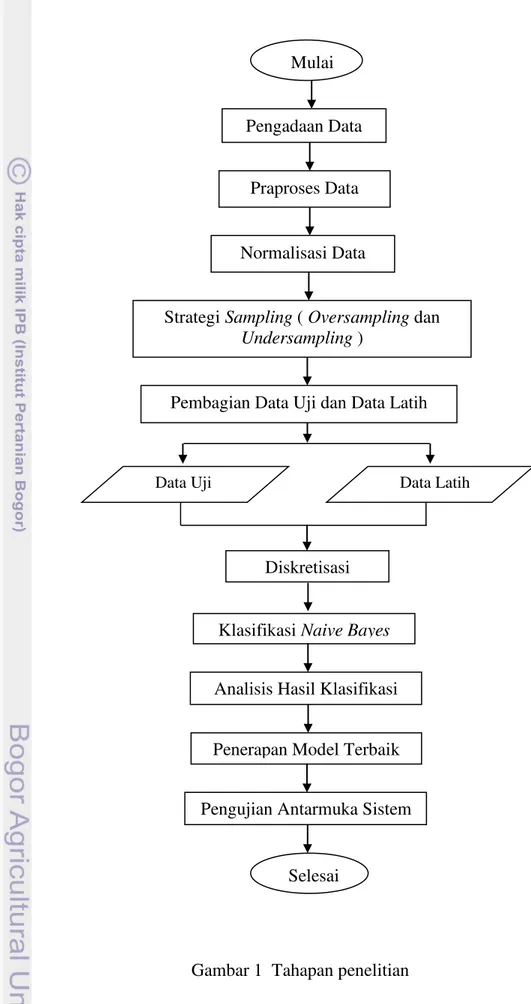
Penelitian ini dilakukan dalam beberapa tahapan. Alur tahapan metode penelitian yang dilakukan dapat dilihat pada Gambar 1.
Pengadaan Data
Pada tahap ini dilakukan pencarian data yang akan diolah dan dianalisis. Data yang dipilih adalah data sekunder nasabah kartu kredit bank X pada periode waktu 2008-2009. Data ini diperoleh dari penelitian sebelumnya yang dilakukan oleh Setiawati (2011).
Data Tidak Seimbang
3
Pengadaan Data
Praproses Data
Strategi Sampling ( Oversampling dan
Undersampling )
Pembagian Data Uji dan Data Latih
Klasifikasi Naive Bayes Analisis Hasil Klasifikasi
Penerapan Model Terbaik
Selesai Diskretisasi
Mulai
Normalisasi Data
Pengujian Antarmuka Sistem
Gambar 1 Tahapan penelitian
4
Praproses Data
Tahap ini, data yang digunakan akan diproses sesuai algoritme dan tipe data atribut itu sendiri. Data awal yang diperoleh berjumlah 4413 dengan 14 atribut, 7 atribut diantaranya termasuk ke dalam kategori atribut numerik, yaitu pendapatan, jumlah tanggungan, umur, masa kerja, lama tinggal, banyaknya kartu kredit lain, dan persentase utang kartu kredit lain, serta 6 atribut lainnya termasuk ke dalam kategori atribut nominal, yaitu jenis kelamin, status pekerjaan, jenis pekerjaan, tipe perusahaan, status rumah, dan status pernikahan, sedangkan pendidikan tergolong ke dalam atribut ordinal.
Di dunia nyata data cenderung tidak lengkap, noise, dan tidak konsisten, sehingga terdapat beberapa metode untuk pembersihan data (Han dan Kamber 2001). Pertama adalah missing value, bermula dari penghapusan data yang dilakukan terhadap beberapa atribut yang missing value, contohnya pada atribut persentase utang kartu kredit, banyaknya kartu kredit lain, dan lainnya. Untuk mengatasi missing value dilakukan penghapusan instance yang memiliki missing value sehingga terjadi pengurangan jumlah instance. Kedua adalah inconsistent data, dimana terdapat noise data yang tidak konsisten untuk beberapa atribut. Praproses data dikoreksi secara manual. Data yang mengandung nilai fitur tidak valid antara 0 atau 1 pada fitur pendapatan, dan -1 pada fitur masa kerja dan lama tinggal. Total data keseluruhan yang akan diproses dalam penelitian ini berjumlah 3895 data dengan 14 atribut independen yang terdiri dari 3259 data yang termasuk ke dalam kategori kelas good dan 636 data termasuk ke dalam kategori kelas bad.
Normalisasi Data
Normalisasi data dilakukan pada atribut data numerik yang memiliki pengaruh terhadap atribut berskala kecil dengan skala nilai antara 0.0 sampai 1.0. Normalisasi dapat mengatasi atribut yang memiliki nilai rentang yang cukup besar. Banyak metode yang digunakan untuk normalisasi data, antara lain min-max normalization yang digunakan pada penelitian ini (Han dan Kamber 2001).
Min-max normalization melakukan transformasi linear pada data asli. Untuk melakukan normalisasi data, perlu mengetahui minimum (Xmin) dan maksimum (Xmax) dari data (Mitsa 2010) :
n a n n
Dengan Xnorm adalah nilai hasil normalisasi, nilai sebelum normalisasi,
Xmin nilai minimun dari fitur, dan Xmax nilai maksimum dari fitur. Strategi Sampling
5 penerapan sampling, tingkat data tidak seimbang semakin kecil sehingga klasifikasi dapat dilakukan dengan tepat.
Strategi sampling terdiri dari oversampling dan undersampling. Pertama adalah oversampling, strategi ini dilakukan pada data kelas minoritas sehingga jumlah data mendekati jumlah data kelas mayoritas. Oversampling terdiri dari
oversampling duplikasi dan oversampling acak. Oversampling duplikasi memiliki beberapa instance yang sama sehingga tidak memiliki variasi data, sedangkan
oversampling acak dapat dilakukan dengan pembangkitan data secara acak. Kedua adalah undersampling, strategi ini dilakukan pada kelas mayoritas sehingga jumlah data kelas mayoritas sama dengan jumlah data kelas minoritas.
Undersampling terdiri dari undersampling acak dan undersampling cluster. Undersampling acak dilakukan pada kelas mayoritas sehingga jumlah data sama dengan jumlah data kelas minoritas yang diambil secara acak, sedangkan
undersampling clustering dilakukan pada software WEKA menggunakan metode
k-meansclustering.
Pembagian Data Uji dan Data Latih
Pembagian data uji dan data latih dilakukan setelah melakukan strategi
sampling, teknik yang pertama adalah metode oversampling duplikasi. Data bad
akan dibangkitkan sebanyak data good secara duplikasi, kemudian jumlah data (good dan bad) diambil 1/4 untuk data uji, dan 3/4 untuk data latih. Oversampling
acak dilakukan secara random menggunakan software Minitab, kemudian jumlah data (good dan bad) diambil 1/4 untuk data uji, dan 3/4 untuk data latih.
Metode undersampling terdiri atas undersampling acak dan
undersampling cluster. Pada undersampling acak, pembagian data uji dan data latih dilakukan dengan mengurangi jumlah data kelas terbesar yang dilakukan secara acak sehingga jumlah datanya sama dengan kelas terkecil. Jumlah data (good dan bad) diambil 1/4 untuk data uji, dan 3/4 untuk data latih.
Undersampling cluster dilakukan pada data mayoritas dengan metode clustering
menggunakan k-means yang dibagi sebanyak 10 cluster. Setelah didapat hasil
clustering, data tersebut dipisah berdasarkan cluster.
Agar data yang diambil tidak mengelompok pada suatu cluster tertentu, jumlah data yang diambil pada masing-masing cluster mengikuti fungsi berikut (Yen dan Lee 2009):
u ah data ke as a or tas u ah data clust u ah data ke as nor tas
dengan
Ci : hasil dari jumlah data setiap cluster i.
Hasil dari fungsi di atas merupakan jumlah data yang harus diambil pada setiap cluster. Jumlah data tersebut akan digunakan sebagai data uji, selebihnya menjadi data latih. Setelah melakukan pembagian data uji dan data latih pada setiap metode sampling, data tersebut diimplementasikan menggunakan software
6
Klasifikasi merupakan proses menemukan sekumpulan model atau fungsi yang menggambarkan dan membedakan konsep atau kelas-kelas data. Tujuan dari klasifikasi adalah membentuk model yang dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang label kelasnya tidak diketahui (Han dan Kamber 2001).
Diskretisasi
Algoritme klasifikasi dan clustering hanya berhubungan dengan atribut nominal dan tidak dapat menangani atribut yang diukur pada skala numerik. Pada dataset, atribut numerik harus dilakukan diskretisasi ke dalam sejumlah kecil dari rentang yang berbeda (Witten et al. 2011). Dalam penelitian ini, diskretisasi dilakukan terhadap data numerik seperti banyaknya tanggungan, pendapatan, umur, masa kerja, dan lama tinggal. Diskretisasi ini menguji beberapa rentang yang digunakan antara lain mulai dari rentang 10, 20, 30, 40, dan 50 yang diimplementasikan pada WEKA menggunakan unsupervised discretization.
Klasifikasi Naive Bayes
Naive bayes adalah metode klasifikasi yang dapat memprediksi probabilitas sebuah class, sehingga dapat menghasilkan keputusan berdasarkan data pembelajaran (Baktiar et al. 2013). Naive bayes classifier merupakan sebuah metode klasifikasi yang berakar pada teorema bayes yang memiliki asumsi bahwa atributnya independen dari nilai-nilai atribut lainnya, asumsi ini disebut probabilitas bersyarat. Berikut formula bayes yang dinyatakan dengan (Leung 2007):
| |
dengan
P(H|X) : probabilitas hipotesis H benar jika diberikan evidence X.
P(X|H) : probabilitas munculnya evidence X, jika diketahui hipotesis H benar.
P(H) : probabilitas hipotesis H (menurut hasil sebelumnya) tanpa memandang evidence apapun. P(X) : probabilitas evidence X.
Ciri utama dari naive bayes classifier adalah asumsi yang sangat kuat (naif) akan independensi dari masing-masing kondisi/kejadian (Natalius 2010). Meskipun asumsi independen ini sering diabaikan dalam praktek, naive bayes
tetap memberikan akurasi klasifikasi yang kompetitif dengan efisiensi komputasi dan banyak fitur yang diinginkan lainnya, sehingga menyebabkan naive bayes
banyak diterapkan dalam praktek.
Analisis Hasil Klasifikasi
7 dievaluasi berdasarkan data yang ada pada matriks. Tabel 1 menyajikan confusion matrix untuk data dengan dua kelas (Sun et al. 2009).
Tabel 1 Confusion Matrix untuk data dengan dua kelas
Keterangan:
TP adalah jumlah instance kelas positif yang berhasil diprediksi benar sebagai kelas positif. FN adalah jumlah instance kelas positif yang tidak berhasil diprediksi dengan benar karena masuk ke kelas negatif.
FP adalah jumlah instance kelas negatif yang tidak berhasil diprediksi benar sebagai kelas negatif karena dikelompokkan ke kelas positif.
TN adalah jumlah instance kelas negatif yang berhasil diprediksi benar sebagai kelas negatif.
Beberapa pengukuran evaluasi untuk data tidak seimbang adalah akurasi,
precision, recall, dan f-measure. Semakin tinggi tingkat akurasi, precision, recall, dan f-measure maka algoritme yang dihasilkan dengan metode tersebut semakin baik dalam melakukan klasifikasi. Berdasarkan data yang didapat akan dihitung akurasi, precision, recall, dan f-measure (Witten dan Frank 2005).
1. Akurasi (Ac)
Akurasi adalah jumlah perbandingan data yang benar dengan jumlah keseluruhan data. Perhitungan akurasi menggunakan fungsi sebagai berikut:
c 2. Precision (P)
Precision digunakan untuk mengukur seberapa besar proporsi dari kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif. Perhitungan precision menggunakan fungsi sebagai berikut:
3. Recall (R)
Recall digunakan untuk menunjukkan persentase kelas data positif yang berhasil diprediksi benar dari keseluruhan data kelas positif. Perhitungan recall
menggunakan fungsi sebagai berikut:
4. F-measure (F)
F-measure merupakan gabungan dari precision dan recall yang digunakan untuk mengukur kemampuan algoritme dalam mengklasifikasikan kelas minoritas. Perhitungan f-measure menggunakan fungsi sebagai berikut:
8
Penerapan Model Terbaik
Setelah analisis hasil klasifikasi, dilakukan penerapan model terbaik dari klasifikasi naive bayes. Antarmuka sistem mampu memprediksi risiko kredit dari kelas data baru berdasarkan model naive bayes dengan f-measure yang dihasilkan berupa nilai yang tertinggi. Model data tersebut digunakan sebagai dasar pada proses prediksi data baru.
HASIL DAN PEMBAHASAN
Pengadaan Data
Data yang dipilih adalah data sekunder nasabah kartu kredit bank X pada periode waktu 2008-2009. Data ini diperoleh dari penelitian sebelumnya yang dilakukan oleh Setiawati (2011). Total data asli yang belum mengalami praproses data berjumlah 4413 data dengan 3574 data kelas good dan 839 data kelas bad.
Praproses Data
Berdasarkan hasil analisis data yang dilakukan, tidak semua atribut
memiliki nilai yang lengkap. Data yang terdapat missing value tidak digunakan dalam
proses klasifikasi. Selain itu, data yang mengandung nilai fitur tidak valid seperti 0 atau 1 pada fitur pendapatan, -1 pada fitur masa kerja dan lama tinggal juga tidak digunakan. Kelengkapan atribut menentukan seberapa baik hasil dari klasifikasi. Setelah penghapusan data, jumlah data yang digunakan pada penelitian ini berjumlah
3895 data. Data kelas good sebanyak 3259 data dan kelas bad sebanyak 636 data.
Karakteristik dari atribut data yang diketahui dapat dilihat pada Tabel 2. Selengkapnya dapat dilihat daftar atribut pada Lampiran 1.
Tabel 2 Karakteristik atribut
Hasil Klasifikasi
Hasil klasifikasi menunjukkan nilai yang memiliki akurasi terbaik dari setiap percobaan berdasarkan rentang yang digunakan.
9 data. Akurasi terbaik percobaan data asli didapatkan pada rentang 20, dapat dilihat pada Gambar 2.
Gambar 2 Hasil percobaan data asli
Berdasarkan Gambar 2 diketahui bahwa jumlah instance uji kelas debitur
bad yang diprediksi sebagai kelas debitur good lebih besar dibanding dengan jumlah instance bad yang diprediksi benar. Pada instance uji debitur good, jumlah
instance prediksi benar lebih besar dibandingkan dengan jumlah instance yang salah prediksi, sehingga nilai recall dan precision pada kelas debitur bad sebesar 8.81%, dan 51.85%. Berikut confusion matrix data asli dapat dilihat pada Tabel 3.
Tabel 3 Confusion matrix Data Asli
Percobaan Oversampling Duplikasi
10
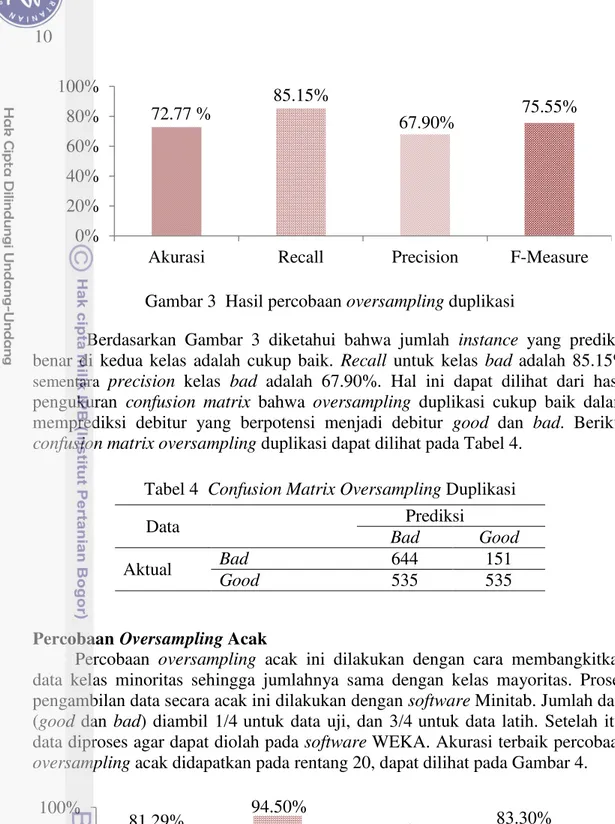
Gambar 3 Hasil percobaan oversampling duplikasi
Berdasarkan Gambar 3 diketahui bahwa jumlah instance yang prediksi benar di kedua kelas adalah cukup baik. Recall untuk kelas bad adalah 85.15% sementara precision kelas bad adalah 67.90%. Hal ini dapat dilihat dari hasil pengukuran confusion matrix bahwa oversampling duplikasi cukup baik dalam memprediksi debitur yang berpotensi menjadi debitur good dan bad. Berikut
confusion matrixoversampling duplikasi dapat dilihat pada Tabel 4. Tabel 4 Confusion MatrixOversampling Duplikasi
Percobaan Oversampling Acak
Percobaan oversampling acak ini dilakukan dengan cara membangkitkan data kelas minoritas sehingga jumlahnya sama dengan kelas mayoritas. Proses pengambilan data secara acak ini dilakukan dengan software Minitab. Jumlah data (good dan bad) diambil 1/4 untuk data uji, dan 3/4 untuk data latih. Setelah itu, data diproses agar dapat diolah pada software WEKA. Akurasi terbaik percobaan
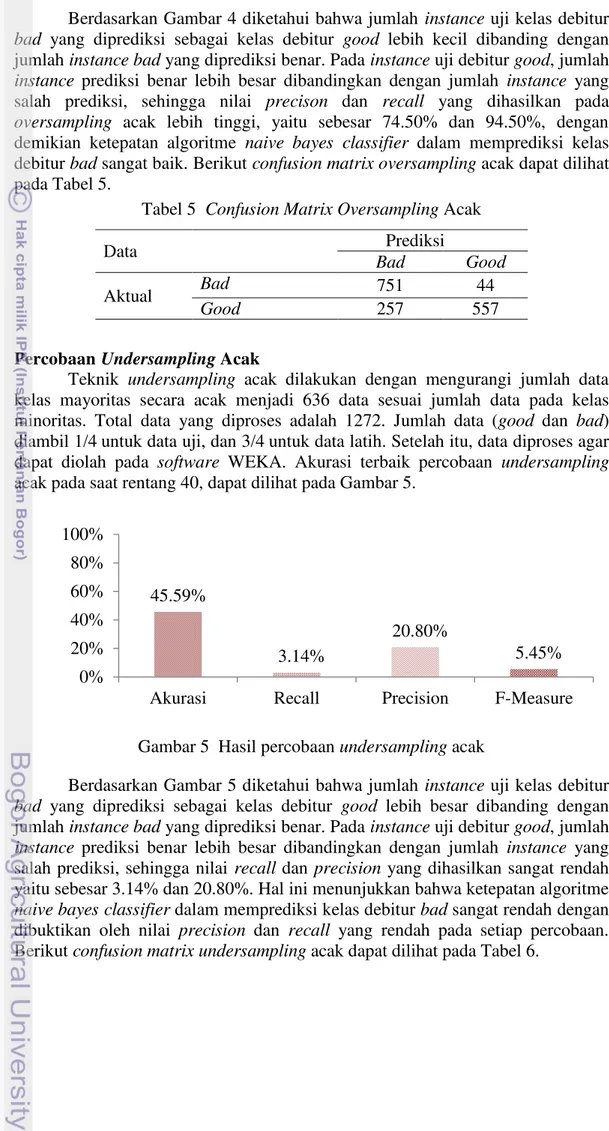
oversampling acak didapatkan pada rentang 20, dapat dilihat pada Gambar 4.
11 Berdasarkan Gambar 4 diketahui bahwa jumlah instance uji kelas debitur
bad yang diprediksi sebagai kelas debitur good lebih kecil dibanding dengan jumlah instance bad yang diprediksi benar. Pada instance uji debitur good, jumlah
instance prediksi benar lebih besar dibandingkan dengan jumlah instance yang salah prediksi, sehingga nilai precison dan recall yang dihasilkan pada
oversampling acak lebih tinggi, yaitu sebesar 74.50% dan 94.50%, dengan demikian ketepatan algoritme naive bayes classifier dalam memprediksi kelas debitur bad sangat baik. Berikut confusion matrix oversampling acak dapat dilihat pada Tabel 5.
Tabel 5 Confusion Matrix Oversampling Acak
Percobaan Undersampling Acak
Teknik undersampling acak dilakukan dengan mengurangi jumlah data kelas mayoritas secara acak menjadi 636 data sesuai jumlah data pada kelas minoritas. Total data yang diproses adalah 1272. Jumlah data (good dan bad) diambil 1/4 untuk data uji, dan 3/4 untuk data latih. Setelah itu, data diproses agar dapat diolah pada software WEKA. Akurasi terbaik percobaan undersampling
acak pada saat rentang 40, dapat dilihat pada Gambar 5.
Gambar 5 Hasil percobaan undersampling acak
Berdasarkan Gambar 5 diketahui bahwa jumlah instance uji kelas debitur
bad yang diprediksi sebagai kelas debitur good lebih besar dibanding dengan jumlah instance bad yang diprediksi benar. Pada instance uji debitur good, jumlah
instance prediksi benar lebih besar dibandingkan dengan jumlah instance yang salah prediksi, sehingga nilai recall dan precision yang dihasilkan sangat rendah yaitu sebesar 3.14% dan 20.80%. Hal ini menunjukkan bahwa ketepatan algoritme
naive bayes classifier dalam memprediksi kelas debitur bad sangat rendah dengan dibuktikan oleh nilai precision dan recall yang rendah pada setiap percobaan. Berikut confusion matrix undersampling acak dapat dilihat pada Tabel 6.
12
Tabel 6 Confusion Matrix Undersampling Acak
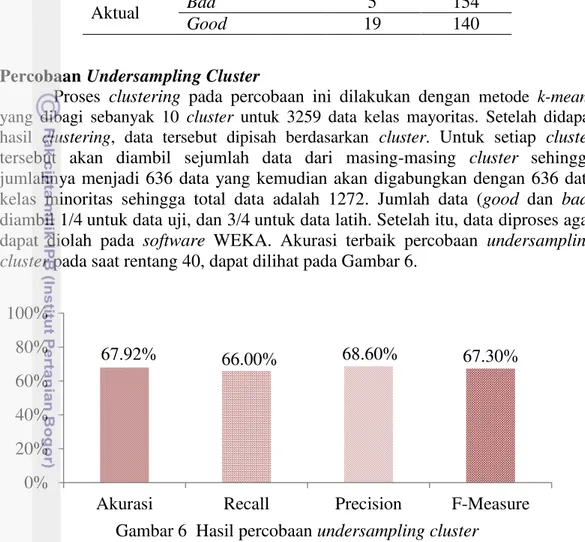
Percobaan Undersampling Cluster
Proses clustering pada percobaan ini dilakukan dengan metode k-means
yang dibagi sebanyak 10 cluster untuk 3259 data kelas mayoritas. Setelah didapat
hasil clustering, data tersebut dipisah berdasarkan cluster. Untuk setiap cluster
tersebut akan diambil sejumlah data dari masing-masing cluster sehingga jumlahnya menjadi 636 data yang kemudian akan digabungkan dengan 636 data kelas minoritas sehingga total data adalah 1272. Jumlah data (good dan bad) diambil 1/4 untuk data uji, dan 3/4 untuk data latih. Setelah itu, data diproses agar dapat diolah pada software WEKA. Akurasi terbaik percobaan undersampling cluster pada saat rentang 40, dapat dilihat pada Gambar 6.
Gambar 6 Hasil percobaan undersampling cluster
Berdasarkan Gambar 6 diketahui bahwa bahwa jumlah instance uji kelas debitur bad yang diprediksi sebagai kelas debitur good lebih kecil dibanding dengan jumlah instance bad yang diprediksi benar. Pada instance uji debitur good, jumlah instance prediksi benar lebih besar dibandingkan dengan jumlah instance
yang salah prediksi. Recall untuk kelas bad adalah 66.03%, sedangkan precision
untuk kelas bad adalah 68.62%. Hasil pengukuran confusion matrix ini dapat dikatakan bahwa undersampling cluster cukup baik dalam memprediksi debitur yang berpotensi menjadi debitur good dan bad. Berikut confusion matrix undersampling cluster dapat dilihat pada Tabel 7.
Tabel 7 Confusion Matrix Undersampling Cluster
13 Perbandingan Hasil Percobaan
Berdasarkan hasil klasifikasi, diperoleh nilai akurasi, precision, recall, dan
f-measure percobaan pada data asli, oversampling duplikasi, oversampling acak,
undersampling acak, dan undersampling cluster yang diperlihatkan pada Tabel 8, Tabel 9, Tabel 10, dan Tabel 11.
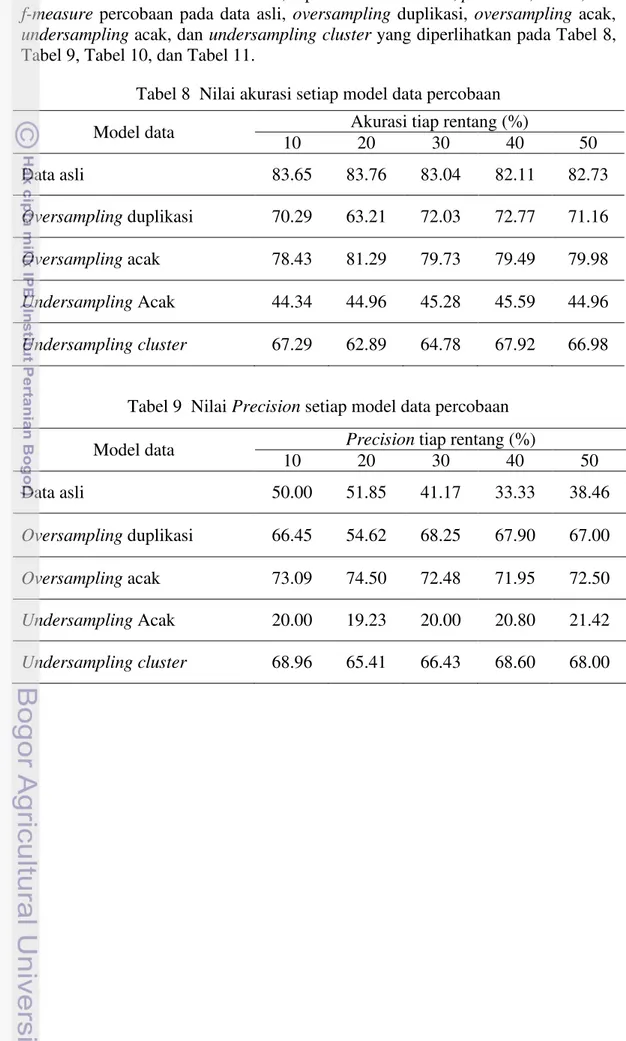
Tabel 8 Nilai akurasi setiap model data percobaan
Tabel 9 Nilai Precision setiap model data percobaan
Model data Akurasi tiap rentang (%)
10 20 30 40 50
Data asli 83.65 83.76 83.04 82.11 82.73
Oversampling duplikasi 70.29 63.21 72.03 72.77 71.16
Oversampling acak 78.43 81.29 79.73 79.49 79.98
Undersampling Acak 44.34 44.96 45.28 45.59 44.96
Undersampling cluster 67.29 62.89 64.78 67.92 66.98
Model data Precision tiap rentang (%)
10 20 30 40 50
Data asli 50.00 51.85 41.17 33.33 38.46
Oversampling duplikasi 66.45 54.62 68.25 67.90 67.00
Oversampling acak 73.09 74.50 72.48 71.95 72.50
Undersampling Acak 20.00 19.23 20.00 20.80 21.42
14
Tabel 10 Nilai Recall setiap model data percobaan
Tabel 11 Nilai F-Measure setiap model data percobaan
Berdasarkan nilai akurasi yang diperoleh pada Tabel 8 terlihat bahwa akurasi antara data asli dengan data yang sudah dilakukan strategi sampling
memiliki perbedaan yang signifikan. Metode klasifikasi naive bayes pada data asli menghasilkan akurasi lebih tinggi dibandingkan dengan akurasi yang dihasilkan setelah dilakukan strategi sampling, yaitu sebesar 83.76%. Berdasarkan confusion matrix yang dihasilkan pada percobaan data asli, jumlah instance kelas debitur
good yang diprediksi dengan benar lebih besar dibandingkan dengan jumlah
instance yang salah diprediksi. Hal ini dapat dilihat dari hasil confusion matrix
tiap percobaan pada Lampiran 2.
Pada metode oversampling duplikasi, oversampling acak, dan
undersamplingcluster, akurasi yang dihasilkan lebih kecil dari percobaan data asli, namun jumlah instance kelas debitur bad yang diprediksi dengan benar cukup tinggi, sedangkan undersampling acak, jumlah instance kelas bad yang salah diprediksi lebih besar dibandingkan dengan jumlah instance kelas bad yang diprediksi dengan benar, sehingga akurasi yang dihasilkan undersampling acak sangat rendah.
Model data Recall tiap rentang (%)
10 20 30 40 50
Data asli 6.28 8.81 8.81 9.43 9.43
Oversampling duplikasi 80.50 81.00 81.13 85.15 82.01
Oversampling acak 89.18 94.50 95.09 95.84 95.84
Undersampling Acak 3.77 3.14 3.14 3.14 3.77
Undersampling cluster 62.89 54.71 59.74 66.00 64.15
Model data F-Measure tiap rentang (%)
10 20 30 40 50
Data asli 11.15 15.04 14.50 14.70 15.15
Oversampling duplikasi 72.80 65.24 74.13 75.55 73.75
Oversampling acak 80.33 83.30 82.25 82.19 82.57
Undersampling Acak 6.34 5.40 5.43 5.45 6.41
15 Nilai Precision dan recall yang diperoleh pada Tabel 9 dan Tabel 10 menunjukkan bahwa precision dan recall yang dihasilkan pada metode
oversampling duplikasi, oversampling acak, dan undersampling cluster lebih tinggi dibandingkan dengan percobaan pada data asli dan metode undersampling
acak. Berdasarkan confusion matrix yang dihasilkan pada oversampling duplikasi,
oversampling acak, dan undersampling cluster, jumlah instance kelas bad yang diprediksi dengan benar lebih besar dibandingkan dengan jumlah instance kelas
bad yang salah diprediksi, sedangkan jumlah instance kelas bad yang diprediksi dengan benar lebih besar dibanding dengan jumlah instance kelas good yang salah diprediksi. Hal ini dapat dilihat dari hasil confusion matrix tiap percobaan pada Lampiran 2.
Pada percobaan data asli dan metode undersampling acak menunjukkan bahwa jumlah instance kelas bad yang diprediksi dengan benar lebih kecil dibanding jumlah instance kelas bad yang salah diprediksi, sedangkan jumlah
instance kelas bad yang diprediksi dengan benar lebih besar dibandingkan dengan jumlah instance kelas good yang salah diprediksi, sehingga menyebabkan
precision dan recall yang dihasilkan pada percobaan data asli dan metode
undersampling acak sangat rendah.
Nilai f-measure dapat dilihat pada Tabel 11. Perhitungan f-measure
menggunakan nilai precision dan recall. Nilai f-measure tinggi merepresentasikan bahwa nilai precision dan recall juga tinggi. Nilai f-measure tertinggi menggunakan algoritme naive bayes diperoleh pada metode oversampling acak, yaitu sebesar 83.30%. Sedangkan pada undersampling acak diperoleh nilai f-measure sebesar 6.41% yang merupakan f-measure terkecil. Berikut hasil percobaan metode oversampling terbaik dapat dilihat pada Tabel 12.
Tabel 12 Hasil percobaan oversampling terbaik
Berdasarkan hasil percobaan yang diperoleh pada Tabel 12 menunjukkan bahwa metode oversampling acak memiliki nilai yang lebih tinggi dibandingkan dengan metode oversampling duplikasi, dengan f-measure yang dihasilkan oleh metode oversampling acak adalah sebesar 83.30%. Hal ini dapat dilihat dari
confusion matrix yang dihasilkan kedua percobaan ini pada Lampiran 2. Berdasarkan hasil yang diperoleh dari confusion matrix menunjukkan bahwa
oversampling acak memiliki kinerja yang lebih baik dalam memprediksi kelas debitur bad dibandingkan dengan oversampling duplikasi.
Secara global, nilai akurasi tertinggi diperoleh pada data asli yaitu sebesar 83.76%, sedangkan precision, recall, dan f-measure tertinggi diperoleh pada saat dilakukan metode oversampling acak yaitu sebesar 74.50%, 95.84%, dan 83.30%. Nilai akurasi, precision, recall, dan f-measure yang dilakukan pada strategi
sampling khususnya metode oversampling menunjukkan hasil yang cukup tinggi Model Data Akurasi Precision Recall F-measure Oversampling duplikasi 72.77 68.25 85.15 75.55
16
dibandingkan dengan metode undersampling yang memiliki perbedaan yang cukup signifikan antar kedua percobaan, yang mengakibatkan metode
oversampling ini dapat meningkatkan performansi dalam mengklasifikasikan data tidak seimbang pada kasus prediksi risiko kredit. Berikut hasil klasifikasi terbaik setiap percobaan berdasarkan f-measure tertinggi dapat dilihat pada Gambar 7.
Gambar 7 Grafik f-measure terbaik
Berdasarkan Gambar 7 menunjukkan bahwa strategi sampling mampu meningkatkan nilai f-measure. Pada saat metode oversampling duplikasi,
oversampling acak, dan undersampling cluster, f-measure yang dihasilkan lebih tinggi yaitu sebesar 75.55% (rentang 40), 83.30% (rentang 20), dan 67.30% (rentang 40) dibandingkan dengan f-measure yang dihasilkan pada data asli dan
undersampling acak. Perhitungan f-measure menggunakan nilai precision dan
recall, sehingga nilai f-measure yang dihasilkan bergantung pada hasil yang diperoleh dari precision dan recall.
Berdasarkan hasil analisis yang dilakukan terhadap akurasi, precision,
recall, dan f-measure, didapatkan model terbaik yang dihasilkan pada strategi
oversampling acak karena menghasilkan akurasi, precision, recall, dan f-measure
yang tinggi. F-measure terbaik dihasilkan pada nilai rentang 20. Antarmuka sistem akan dibuat menggunakan klasifikasi naive bayes yang mampu memprediksi risiko kredit pada kelas data baru. Antarmuka sistem ini akan bermanfaat untuk melakukan prediksi ketika sistem dimasukkan data baru, sehingga sistem mampu menampilkan hasil kelas prediksi yaitu kelas good atau kelas bad pada data baru.
Perbandingan dengan Penelitian Sebelumnya
Setiawati (2011), Wijayanti (2013), Anggraini (2013), dan Ulya (2013) melakukan penelitian menggunakan data yang sama dengan penelitian ini. Pada penelitian yang dilakukan Setiawati (2011), merupakan classifier jaringan saraf tiruan pada propagasi balik. Pengambilan sampel sebanyak 50 kali dilakukan untuk mengatasi data yang tidak seimbang. Model terbaik dari penelitian ini menghasilkan akurasi sebesar 73.39% dan f-measure sebesar 44.57%. Pada penelitian Wijayanti (2013), melakukan perubahan pada algoritme dan juga
resampling untuk mengatasi data yang tidak seimbang. Algoritme yang digunakan
17 sebesar 92.54%. Pada penelitian Anggraini (2013), melakukan pengambilan sampel pada tiap kelas dan strategi sampling untuk mengatasi data yang tidak seimbang. Algoritme yang digunakan C4.5 dan CART dengan hasil akurasi sebesar 88.65% dan f-measure sebesar 89.60%. Pada penelitian Ulya (2013), melakukan strategi sampling menggunakan algoritme k-nearest neighbor dengan hasil akurasi sebesar 96.24% dan f-measure sebesar 96.30%. Perbandingan akurasi, precision, recall, dan f-measure pada penelitian ini terhadap penelitian yang sudah dilakukan sebelumnya dapat dilihat pada Tabel 13.
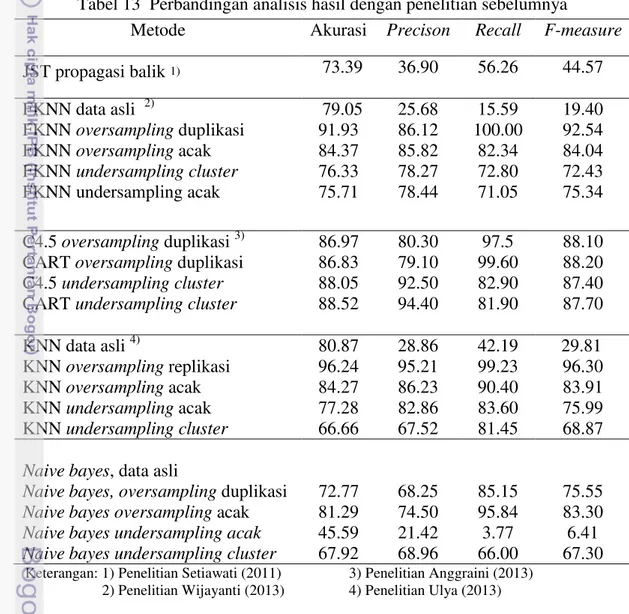
Tabel 13 Perbandingan analisis hasil dengan penelitian sebelumnya
Metode Akurasi Precison Recall F-measure
JST propagasi balik 1) 73.39 36.90 56.26 44.57 C4.5 undersampling cluster 88.05 92.50 82.90 87.40 CART undersampling cluster 88.52 94.40 81.90 87.70
KNN data asli 4) 80.87 28.86 42.19 29.81
KNN oversampling replikasi 96.24 95.21 99.23 96.30 KNN oversampling acak 84.27 86.23 90.40 83.91 KNN undersampling acak 77.28 82.86 83.60 75.99 KNN undersampling cluster 66.66 67.52 81.45 68.87
Naive bayes, data asli
Naive bayes, oversampling duplikasi 72.77 68.25 85.15 75.55
Naive bayes oversampling acak 81.29 74.50 95.84 83.30
Naive bayesundersampling acak 45.59 21.42 3.77 6.41
Naive bayesundersampling cluster 67.92 68.96 66.00 67.30 Keterangan: 1) Penelitian Setiawati (2011) 3) Penelitian Anggraini (2013)
2) Penelitian Wijayanti (2013) 4) Penelitian Ulya (2013)
Berdasarkan Tabel 13 terlihat bahwa secara global, nilai f-measure yang dihasilkan pada penelitian sebelumnya Ulya (2013) lebih tinggi yaitu sebesar 96.30% pada algoritme k-nearest neighbor dibandingkan pada penelitian ini yang menggunakan algoritme naive bayes classifier yaitu sebesar 83.30%. Kinerja
naive bayes classifier dalam memprediksi risiko kredit masih sangat rendah. Hal ini dibuktikan dari hasil f-measure yang diperoleh pada algoritme naive bayes
18
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menerapkan naive bayes dalam mengklasifikasikan calon debitur kartu kredit kedalam kategori good atau bad dengan menggunakan metode
oversampling dan undersampling. Berdasarkan penelitian yang telah dilakukan, disimpulkan bahwa model naive bayes yang menggunakan metode oversampling
duplikasi, oversampling acak, dan undersampling cluster lebih baik dibandingkan pada percobaan data asli dan undersampling acak. Hal ini dibuktikan pada hasil
confusion matrix yang menggambarkan kinerja dari setiap percobaan.
F-measure yang dihasilkan pada metode oversampling acak merupakan hasil tertinggi dari metode yang lain, dengan nilai f-measure sebesar 83.30% pada saat rentang 20. Metode oversampling acak adalah hasil terbaik pada penelitian ini, karena metode oversampling acak dapat meningkatkan performansi dalam mengklasifikasikan data tidak seimbang pada kasus prediksi risiko kredit.
Perbandingan dengan penelitian sebelumnya menunjukkan bahwa akurasi,
precision, recall, dan f-measure yang dihasilkan menggunakan oversampling dan
undersampling dengan algoritme naive bayes classifier masih kurang baik. Hal ini dikarenakan akurasi, precision, recall, dan f-measure yang dihasilkan lebih rendah dibandingkan penelitian yang dilakukan menggunakan algoritme fuzzy k-nearest neighbor, C4.5 dan CART, dan k-nearest neighbor dalam menggunakan data yang sama.
Saran
Pada penelitian selanjutnya diharapkan dapat melakukan klasifikasi naive bayes tanpa melakukan proses diskretisasi, melainkan menggunakan sebaran peluang untuk mendapatkan nilai peluang, dan melakukan klasifikasi naive bayes
dengan strategi sampling lain, seperti: synthetic minority oversampling technique
(SMOTE).
DAFTAR PUSTAKA
Anggraini D. 2013. Perbandingan algoritme C4.5 dan CART pada data tidak seimbang untuk kasus prediksi risiko kredit debitur kartu kredit [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Barandela R, Sanchez JS, Garcia V, Rangel E. 2002. Strategies for Learning in class imbalance problems. Pattern Recognition; 36(3):849-850.
Baktiar YA, Hidayat N, Regasari R. 2013. Implementasi metode Naive Bayes untuk klasifikasi kenaikan Grade Karyawan pada Fuzzyfikasi Data Kinerja Karyawan (Studi Kasus PT PJB UP Brantas) [Internet]. ;[diunduh 2013 November 5]. Tersedia pada: http://ptiik.ub.ac.id/doro/archives/detail/DR00053201312.
19
Leung MK. 2007. Naive Bayesian Classifier. Polytechnic University Department of Computer Science [internet]. ;[diunduh 2014 Maret 31]. Tersedia pada: http://cis.poly.edu/~mleung/FRE7851/f07/naiveBayesianClassifier.pdf
Mitsa, T. 2010. Data Mining and Knowledge Discovery Series. Minneapolis (US): Chapman & Hall/CRC.
Mladenic D, Grobelnik M. 1999. Feature Selection For Unbalanced Class Distribution and Naive Bayes. Slovenia (SI) : J.Stefan Institute.
Natalius S. 2010. Metoda Naive Bayes Classifier dan penggunaannya pada klasifikasi dokumen [skripsi]. Bandung (ID): Institut Teknologi Bandung. Sastrawan, Baizal, Bijaksana. 2010. Analisis Pengaruh Metode Combine
Sampling dalam Churn Prediction untuk Perusahaan Telekomunikasi.
Seminar Nasional Informatika U N ”V t an”; 2010 Mei 22; Yogyakarta, Indonesia. Yogyakarta (ID): Institut Teknologi Telkom.
Setiawati AP. 2011. Penelusuran banyaknya unit dan lapisan tersembunyi jaringan saraf tiruan pada data tidak seimbang (Studi kasus debitur kartu kredit Bank Mandiri tahun 2008-2009) [skripsi].Bogor (ID): Institut Pertanian Bogor. Sun Y, Wong AKC, Kamel MS. 2009. Classification of imbalanced data:
Internation J Pattern Recognition Artific Intelligen; 23(4):687-719.
Taswan. 2011. Konsekuensi Informasi Asimetris Dalam Perkreditan Dan Penanggananya Pada Lembaga Perbankan "Consequensi of Credit Asymetric Informasi and It's Treatment in Banking Institutions". Fokus Ekonomi. 10(3): 226-234. Semarang (ID): Universitas Stikubank.
Ulya. 2013. Klasifikasi debitur kartu kredit menggunakan algoritme K-Nearest Neighbor untuk kasus imbalanced data [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Witten IH, Frank E. 2005. Data Mining: Practical Machine Learning Tools and Techniques. San Fransisco (US) : Morgan Kauffman.
Witten IH, Frank E, Hall MA. 2011. Practical Machine Learning Tools and Techniques. San Fransisco (US) : Morgan Kauffman.
20
LAMPIRAN
Lampiran 1 Daftar atribut
Atribut Keterangan
Pendidikan 1 = SMP/SMA
2 = Akademi 3 = S1/S2
Jenis Kelamin 1 = Pria
2 = Wanita Status Pernikahan 1 = Lajang 2 = Menikah 3 = Bercerai
Tipe Perusahaan 1 = Kontraktor
2 = Conversion 3 = Industri Berat 4 = Pertambangan 5 = Jasa
6 = Transportasi
Status Pekerjaan 1 = Permanen
2 = Kontrak
Pekerjaan 1 = Conversion
2 = PNS
3 = Professional 4 = Wiraswasta
5 = Perusahaan Swasta
Masa Kerja Dalam bulan
Lama Tinggal Dalam bulan
Status Pemilikan Rumah 0 = Bukan Milik Sendiri 1 = Milik Sendiri
Banyaknya Tanggungan
Pendapatan Rupiah
Banyaknya Kartu Kredit Lain Persentase Utang Kartu Kredit
Umur Dalam tahun
Kelas 1 = Debitur bad
21
Lampiran 2 Confusion matrix tiap percobaan
Percobaan data asli Percobaan oversampling duplikasi
Rentang 20 Rentang 20
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 14 145 Aktual Bad 44 151
Good 13 801 Good 79 535
Rentang 30 Rentang 30
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 14 145 Aktual Bad 45 150
Good 20 794 Good 300 514
Rentang 40 Rentang 40
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 15 144 Aktual Bad 77 118
Good 30 784 Good 20 494
Rentang 50 Rentang 50
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 15 144 Aktual Bad 52 143
Good 24 790 Good 21 493
Rentang 10 Rentang 10
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 10 149 Aktual Bad 40 155
22
Lampiran 2 Lanjutan
Percobaan oversampling acak Percobaan undersampling acak
Rentang 10 Rentang 10
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 709 86 Aktual Bad 6 153
Good 261 553 Good 24 135
Rentang 20 Rentang 20
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 751 44 Aktual Bad 5 154
Good 257 557 Good 21 138
Rentang 30 Rentang 30
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 756 39 Aktual Bad 5 154
Good 287 527 Good 20 139
Rentang 40 Rentang 40
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 762 33 Aktual Bad 5 154
Good 297 517 Good 19 140
Rentang 50 Rentang 50
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 762 33 Aktual Bad 6 153
23
Lampiran 2 Lanjutan
Percobaan Undersampling cluster
Rentang 10 Rentang 20
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 100 59 Aktual Bad 87 72
Good 45 114 Good 46 113
Rentang 30 Rentang 40
Data Prediksi Data Prediksi
Bad Good Bad Good
Aktual Bad 95 64 Aktual Bad 105 54
Good 48 111 Good 48 111
Rentang 50
Data Prediksi
Bad Good
Aktual Bad 102 57
Good 48 111
24
RIWAYAT HIDUP
Penulis merupakan putri keenam dari enam bersaudara dari pasangan Bapak Sulaiman dan Ibu Ratna, Spd. Penulis dilahirkan di kota Banda Aceh pada tanggal 24 September 1991. Tahun 2009 penulis lulus dari SMA Negeri 3 Banda Aceh dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI) pada Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama di bangku kuliah penulis aktif diberbagai kegiatan. Pada Tahun pertama (TPB) penulis mengikuti kegiatan Seni Budaya Gentra Kaheman. Tahun 2011 penulis merupakan Panitia IT TODAY di Departemen Ilmu Komputer. Tahun 2012 penulis mengikuti kegiatan Wirausaha Muda yang mampu meningkatkan kreativitas. Pada tanggal 26 Juni 2013 sampai dengan 23 Agustus 2013 penulis menjalankan praktik kerja lapangan di MULTIMEDIA NUSANTARA (METRASAT) Bogor. Penulis juga anggota dari Organisasi Mahasiswa Daerah (OMDA) Aceh periode 2009-2010. Penulis aktif sebagai pengurus Ikatan Mahasiswa Tanah Rencong sebagai Sekretaris Umum di OMDA Aceh periode 2011-2012.