PERBANDINGAN METODE IMPUTASI GANDA : METODE REGRESI
VERSUS METODE PREDICTIVE MEAN MATCHING UNTUK
MENGATASI DATA HILANG PADA DATA SURVEI
Nur Malahayati
G14103005
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
NUR MALAHAYATI. Perbandingan Metode Imputasi Ganda: Metode Regresi versus Metode
Predictive Mean Matching untuk Mengatasi Data Hilang pada Data Survei. Dibimbing oleh BUDI
SUSETYO dan INDAHWATI.
Kegiatan survei dilakukan untuk mendapatkan informasi dari sebuah populasi dengan hanya mengamati sebagian unit dalam populasi itu (contoh), yang telah dipilih melalui teknik penarikan contoh tertentu. Dalam survei seringkali ditemukan adanya item nonrespon yang dapat terjadi baik karena unit contoh tidak menjawab pertanyaan maupun karena kesalahan dalam proses pemindahan data.
Adanya item nonrespon, yang selanjutnya disebut data hilang, akan mengakibatkan pendugaan parameter menjadi tidak efisien karena ukuran data yang berkurang. Selain itu juga menyebabkan metode baku untuk data lengkap tidak dapat digunakan dalam proses analisis. Sehubungan dengan permasalahan yang timbul karena data hilang dalam data survei ini, terdapat beberapa metode yang dapat digunakan untuk memprediksi data hilang tersebut, salah satunya adalah metode imputasi. Metode imputasi yang ada antara lain imputasi ganda dengan metode regresi dan dengan metode Predictive Mean Matching (PMM).
Pada penelitian ini dilakukan simulasi untuk membandingkan metode imputasi ganda regresi dan metode imputasi ganda PMM. Dari data survei contoh yang dibangkitkan, dilakukan penghilangan data dengan jumlah kehilangan yang berbeda-beda. Pembandingan yang dilakukan adalah dengan melihat rata-rata selisih nilai dugaan dari kedua metode dengan nilai aslinya. Pada pendugaan parameter populasi juga dilihat nilai Kuadrat Tengah Sisaan (KTS) data survei contoh terimputasi dari kedua metode tersebut. Hasil yang diperoleh adalah dari segi rata-rata selisih nilai dugaan dengan nilai asliya, metode regresi lebih baik daripada metode PMM, sedangkan dari segi pendugaan parameter populasi kedua metode memberikan nilai KTS yang tidak jauh berbeda.
PERBANDINGAN METODE IMPUTASI GANDA : METODE REGRESI
VERSUS METODE PREDICTIVE MEAN MATCHING UNTUK
MENGATASI DATA HILANG PADA DATA SURVEI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh:
Nur Malahayati
G 14103005
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : PERBANDINGAN METODE IMPUTASI GANDA: METODE REGRESI
VERSUS METODE PREDICTIVE MEAN MATCHING UNTUK
MENGATASI DATA HILANG PADA DATA SURVEI Nama : Nur Malahayati
NIM : G14103005
Menyetujui,
Pembimbing I Pembimbing II
Dr. Ir. Budi Susetyo, MS Ir. Indahwati, M.Si
NIP. 131 624 193 NIP. 131 909 223
Mengetahui,
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Dr. Drh. Hasim, DEA
RIWAYAT HIDUP
Penulis dilahirkan di Banjarnegara, 4 Februari 1985 sebagai anak pertama dari pasangan Edi Kusdiyanto dan Sri Kustinah.
Setelah menyelesaikan pendidikan dasar di SDN Krandegan 4 Banjarnegara pada tahun 1997, studi penulis dilanjutkan di SLTPN 1 Banjarnegara yang ditamatkan pada tahun 2000. Tahun 2003 penulis lulus dari SMUN 1 Banjarnegara dan pada tahun yang sama diterima di Departemen Statistika Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB.
Semasa menjadi mahasiswa penulis aktif di Himpunan Keprofesian Departemen Statistika Gamma Sigma Beta, sebagai staff Departemen Olahraga dan Seni periode 2003/2004 dan 2004/2005, staff Departemen Keilmuan periode 2005/2006. Praktik lapang dilakukan penulis di PT. Tempo Inti Media, Tbk pada Februari-Mei 2007.
PRAKATA
Alhamdulillahirabbil’alamin, puji syukur kepada Allah SWT atas karunia-Nya sehingga karya ilmiah ini dapat terselesaikan dengan baik. Sebagai manusia yang tak pernah sempurna, karena kesempurnaan hanya milik-Nya, penulis ingin mengucapkan terima kasih kepada seluruh pihak yang telah membantu tersusunnya karya ilmiah ini. Terima kasih kepada:
1. Bapak Dr. Ir. Budi Susetyo, MS dan Ibu Ir. Indahwati, M.Si selaku pembimbing skripsi yang selalu sabar dalam membimbing dan mengarahkan penulis selama proses pembuatan karya ilmiah ini hingga selesai.
2. Ibu dan Bapak atas segala kasih sayang, kesabaran, nasihat dan doa yang tak pernah putus.
3. Bayu Alfiansyah yang senantiasa menjadi penyemangat hidup. 4. Buper (rara) thanks for being my best friend.
5. Yudi sebagai teman yang paling mengerti perjalanan penulis dalam penyusunan karya ilmiah ini (Ganbatte kudasai!)
6. Rekan-rekanku: Ema (yang penuh keceriaan, ga ada matinya), Aang (teman setia
Offpeak), D’Re (perhatianmu membuatku terharu), Mas Icus’38 (wejangan-wejangannya
oke juga)
7. Teman-teman STK’40 atas kebersamaannya yang indah. 8. Adik-adik STK’41 (seminarku jadi rame lho!).
9. Seluruh staff Departemen Statistika.
10. Jaikers yang mengisi hari-hari penulis, you all guys, are my nice sisters.
Penulis menyadari bahwa karya ilmiah ini masih jauh dari sempurna. Untuk itu kritik dan saran sangat penulis hargai demi perbaikan karya ilmiah ini. Semoga karya ilmiah ini dapat bermanfaat bagi kita semua.
Bogor, Desember 2007
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... viii
DAFTAR TABEL... viii
DAFTAR LAMPIRAN ... ix
PENDAHULUAN... 1
Latar Belakang... 1
Tujuan... 1
TINJAUAN PUSTAKA Metode Pendugaan Item Nonrespon... 1
Imputasi Tunggal (Single Imputation) ... 2
Imputasi Ganda (Multiple Imputation) ... 2
Pola Data Hilang... 2
Mekanisme Data Hilang ... 2
Prosedur Imputasi Ganda... 3
Teori Pembuatan Nilai Imputan Ganda dengan Model Eksplisit... 3
Imputasi Ganda dengan Metode Regresi ... 3
Imputasi Ganda dengan Metode Predictive Mean Matching... 4
BAHAN DAN METODE Bahan... 4
Metode... 4
HASIL DAN PEMBAHASAN Hasil Pendugaan untuk Data Hilang 2% pada Peubah X2 dan 2% pada Peubah X3... 6
Hasil Pendugaan untuk Data Hilang 2% pada Peubah X2 dan 5% pada Peubah X3... 6
Ringkasan Hasil Seluruh Simulasi... 6
Analisis Data untuk Data yang Telah Dilengkapi Data Dugaan... 7
Contoh Kasus untuk Penerapan Imputasi Ganda... 8
KESIMPULAN Kesimpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 9
DAFTAR TABEL
Halaman
1. Metode Imputasi dalam Proc MI ... 3
2. Data Asli yang Dihilangkan pada Simulasi Ulangan 1... 6
3. Data Hasil Imputasi dengan Metode Regresi pada Ulangan 1... 6
4. Data Hasil Imputasi dengan Metode PMM pada Ulangan 1 ... 6
5. Nilai Rata-rata Selisih dan Ragam Selisih Antara Data Asli dan Data Dugaan untuk Peubah X3 ... 6
6. Nilai Rata-rata Selisih dan Ragam Selisih Antara Data Asli dan Data Dugaan untuk Peubah X3... 6
7. Penduga-penduga Koefisien Regresi ... 8
8. Statistik untuk b0... 9
DAFTAR GAMBAR
1. Ilustrasi pola data hilang monoton... 22. Ilustrasi pola data hilang nonmonoton... 2
3. Rata-rata Selisih antara Data Asli dengan Data Dugaan Peubah X3 untuk Seluruh Kelompok Beda Jumlah Data Hilang ... 7
4. Nilai KTS untuk Pendugaan Nilai Tengah Peubah X3... 7
5. Nilai Bias (xbar) untuk pendugaan Nilai Tengah Peubah X3... 7
6. Pembandingan Nilai Bias Metode Penghapusan Unit dengan Metode Imputasi Ganda pada Pendugaan Parameter X3. ... 8
7. Pembandingan Nilai KTS Metode Penghapusan Unit dengan Metode Imputasi Ganda pada Pendugaan Parameter X3. ... 8
DAFTAR LAMPIRAN
Halaman
1. Data Contoh ... 10
2. Kombinasi Jumlah (%) Data Hilang pada Peubah X2 dan X3 Data Asli yang Dihilangkan pada Simulasi 2% pada X2 dan 5% pada X3 ... 11
3. Data Asli yang dihilangkan pada Simulasi kedua... 11
4. Data Hasil Imputasi dengan Metode Regresi untuk Data Hilang 2% pada X2 dan 5% pada X3 Ulangan 1 ... 12
5. Data Hasil Imputasi dengan Metode PMM untuk Data Hilang 2% pada X2 dan 5% pada X3 Ulangan 1... 13
6. Hasil Pendugaan Nilai Tengah Peubah X3 dari Simulasi Jumlah Data Hilang 2% pada X2 dan 2% pada X3... 13
7. Output Proc MI... 14
8. Output Proc Reg ... 15
PENDAHULUAN Latar Belakang
Sensus sebuah populasi adalah usaha yang dilakukan untuk mendapatkan informasi dari setiap unit dalam populasi tersebut, sedangkan survei hanya dilakukan hanya terhadap beberapa unit populasi (contoh). Perancangan survei yang baik akan memilih contoh dengan benar agar kesimpulan terhadap populasi yang menjadi perhatian bersifat terandal dan cukup untuk menyimpulkan keadaan populasi.
Dalam sensus maupun survei, seringkali ditemukan unit-unit yang tidak merespon sejumlah pertanyaan yang diajukan (nonrespon). Kish (1965) mendefinisikan nonrespon sebagai kegagalan untuk mendapatkan nilai pengamatan dari beberapa unit yang menjadi contoh. Nonrespon, yang dalam beberapa literatur sering disebut dengan data hilang umumnya dibagi menjadi dua tipe, yaitu unit nonrespon dan item nonrespon. Unit nonrespon terjadi karena unit contoh tidak memberikan respon sama sekali dalam suatu survei. Sedangkan item nonrespon dapat terjadi karena beberapa item dalam kuesioner tidak direspon oleh responden. Secara umum, nonrespon dapat disebabkan karena responden tidak mau menjawab, tidak mampu menjawab atau tidak tahu jawabannya. Nonrespon dapat juga terjadi karena terdapat kesalahan dalam penulisan jawaban atau dalam proses input data (Longford, 2005) .
Adanya data hilang akibat nonrespon ini menimbulkan data hasil survei/sensus tidak lengkap. Data hilang tersebut tidak hanya menyebabkan pendugaan parameter menjadi tidak efisien karena ukuran data yang berkurang tetapi juga menyebabkan metode baku untuk data lengkap tidak dapat digunakan untuk menganalisis data.
Pada praktiknya, metode analisis untuk data lengkap sering digunakan untuk data-data yang mempunyai data hilang dengan cara menghapus unit-unit pengamatan yang mempunyai data hilang. Terdapat beberapa alasan logis yang memperlihatkan kenyataan bahwa prosedur tersebut tidak baik. Pertama, penghapusan unit-unit pengamatan yang mempunyai data hilang akan mengurangi ukuran contoh yang sudah ditentukan dari awal penelitian. Hal ini otomatis akan mengurangi ketepatan pendugaan populasi. Kedua, jika unit-unit pengamatan yang dihilangkan dalam analisis sangat berbeda dengan unit-unit yang tersisa, maka hasil dugaan akan menjadi berbias (Levy and Lemeshow, 1999).
Sehubungan dengan permasalahan yang ditimbulkan oleh data hilang dalam survei/sensus tersebut terdapat beberapa metode untuk mengatasinya. Dalam penelitian ini dilakukan pembandingan terhadap beberapa metode.
Tujuan
Tujuan penelitian ini adalah:
1. Memperkenalkan metode pendugaan data hilang karena adanya nonrespon pada data survei untuk kasus item nonrespon, yaitu metode imputasi
2. Mengkaji dan membandingkan beberapa metode imputasi ganda, yaitu metode regresi dan metode Predictive Mean Matching
TINJAUAN PUSTAKA Metode Pendugaan Item Nonrespon
Imputasi adalah metode yang digunakan untuk memprediksi data hilang pada kumpulan data survei karena tidak adanya respon terhadap beberapa pertanyaan. Kumpulan data dengan beberapa data hilang yang telah diprediksi akan lebih mudah untuk ditangani secara analitik (Little, 1987).
Menurut Little & Su (1989), metode imputasi dapat diklasifikasikan berdasarkan kriterianya. Klasifikasinya adalah sebagai berikut:
a. Imputasi Peubah Tunggal dan Peubah Ganda (Multivariate vs Univariate)
Misalkan adalah satu gugus peubah teramati pada unit i dan adalah gugus peubah yang hilang pada unit yang sama. Ketika terdiri lebih dari satu peubah, maka imputasi peubah tunggal akan memprediksi setiap peubah secara terpisah. Sedangkan imputasi peubah ganda akan megimputasi peubah-peubah secara simultan, dengan memperhatikan hubungan antar peubah tersebut. Imputasi peubah tunggal terlihat lebih sederhana, akan tetapi metode ini mengabaikan hubungan antar peubah.
i obs Y , i mis Y , i mis Y , i mis Y , i mis Y ,
b. Imputasi Bersyarat dan Tak Bersyarat
(Conditional vs Marginal)
Imputasi marjinal untuk unit i didasarkan pada sebaran marjinal dari , sedangkan imputasi bersyarat didasarkan pada sebaran bersyarat dengan nilai diketahui. Baik sebaran marjinal maupun sebaran bersyarat diduga dari data yang ada.
i mis Y , i mis Y , Yobs,i
c. Imputasi Stokastik vs Rata-rata (Stochastic
vs Mean)
Imputasi rata-rata memprediksi dengan rata-rata nilai data yang teramati dalam peubah yang sama, sedangkan imputasi stokastik memprediksi dengan nilai dari sebaran bersyarat atau tak bersyarat dari . Imputasi rata-rata umumnya tidak cocok untuk peubah kategorik. Jika data-data kuantitatif dilengkapi dengan metode ini, dugaan terhadap rataan data yang dihasilkan cukup memuaskan, tetapi juga akan menghasilkan dugaan yang melenceng terhadap keragaman dalam sebaran. Contohnya, jika data hilang terjadi pada peubah pendapatan diprediksi dengan menggunakan metode rata-rata, maka pendugaan terhadap persentase kemiskinan akan menjadi bias.
i mis Y , i mis Y , i mis Y ,
Imputasi Tunggal (Single Imputation)
Strategi imputasi yang mengisi nilai data hilang dengan sebuah nilai ini sering digunakan untuk mengatasi adanya item nonrespon pada praktek survei (Little, 1987). Jadi, selanjutnya pada tahap analisis data, nilai imputan/prediksi yang diperoleh dari imputasi tunggal dianggap seakan-akan seperti data yang sebenarnya.
Metode imputasi ini mempunyai kelemahan yaitu, satu nilai yang digunakan untuk menggantikan data hilang ini tidak mencerminkan keragaman penarikan contoh nilai-nilai sebenarnya saat satu model untuk nonrespon terbentuk. Kelemahan yang lain, tidak dapat mencerminkan ketidakpastian saat terdapat lebih dari satu model untuk nonrespon. Kelemahan tersebut dapat diperbaiki dengan metode imputasi ganda (Rubin, 1987).
Imputasi Ganda (Multiple Imputation)
Berbeda dengan imputasi tunggal, imputasi ini mengganti nilai data hilang dengan beberapa nilai (dua atau lebih) yang diterima sebagai representasi ketakpastian nilai-nilai data hilang (Rubin, 1987). Terdapat sejumlah m nilai untuk setiap data hilang dan akhirnya akan membentuk m buah gugus data yang telah terlengkapi. Dari masing-masing gugus data tersebut diterapkan metode analisis baku untuk data lengkap, kemudian hasil dari analisis itu dirata-ratakan.
Pola Data Hilang
Menurut Little (1987) terdapat dua pola data hilang, yaitu pola data hilang monoton dan pola data hilang nonmonoton.
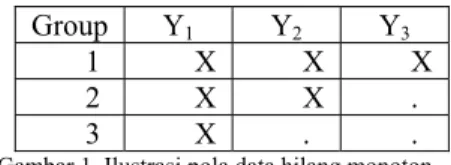
Sebuah set data dengan peubah Y1, Y2, dan Y3 dikatakan mempunyai data hilang yang berpola monoton jika kejadian hilangnya sebuah peubah Yj untuk unit tertentu
mengakibatkan semua subsequent peubah Yk, k > j hilang untuk individu unit tersebut. Jika
peubah Yj teramati untuk sebuah unit maka
semua peubah sebelumnya , Yk, k < j, juga
teramati pada unit tersebut. Ilustrasi untuk pola ini dapat dilihat pada gambar 1.
Group Y1 Y2 Y3
1 X X X 2 X X . 3 X . .
Gambar 1. Ilustrasi pola data hilang monoton.
Sedangkan pada pola nonmonoton tidak ada keteraturan letak data hilang. Ilustrasinya dapat dilihat pada gambar 2.
Group Y1 Y2 Y3
1 X X X 2 X . X 3 . X . 4 . . X
Gambar 2. Ilustrasi pola data hilang nonmonoton.
Pola data hilang sangat penting diperhatikan dalam penggunaan metode imputasi peubah ganda. Karena hal ini berkaitan dengan proses imputasi yang dilakukan. Imputasi akan dimulai untuk peubah dengan data hilang paling sedikit, dilanjutkan untuk peubah dengan data hilang tersedikit kedua, demikian seterusnya.
Mekanisme Data Hilang
Pengetahuan tentang mekanisme yang menyebabkan data hilang adalah kunci dasar dalam pemilihan analisis yang sesuai dan bagaimana menginterpretasikan hasilnya (Little, 1987).
Beberapa tipe mekanisme data hilang adalah sebagai berikut:
a. MCAR (Missing Completely at Random) Keterisian data dari peubah tertentu tidak tergantung dari besarnya nilai peubah itu maupun peubah lainnya. Contohnya, misalkan Y1 peubah pendapatan dan Y2
peubah umur. Jika peluang teramatinya peubah pendapatan sama untuk setiap unit, tidak tergantung pada nilai pendapatan itu sendiri dan pada peubah umur maka mekanisme hilangnya data pada peubah pendapatan bertipe MCAR.
b. MAR (Missing at Random)
Keterisian data dari peubah tertentu hanya tergantung pada nilai peubah itu dan tidak
tergantung pada peubah lain. Dengan mengambil contoh seperti sebelumnya, maka mekanisme hilangnya data pada peubah pendapatan bertipe MAR jika nilai pendapatan tergantung pada peubah umur. tetapi tidak tergantung pada nilai pendapatan c. Nonignorable
Keterisian data pada peubah tertentu tergantung pada nilai peubah itu dan peubah lain, sedangkan dua poin di atas, (a) dan (b) termasuk mekanisme data hilang ignorable.
Prosedur Imputasi Ganda
Terdapat beberapa metode imputasi ganda untuk menangani kasus data hilang. Beberapa metode ini, dalam penggunaannya perlu memperhatikan beberapa hal, yaitu pola data hilang (monoton atau nonmonoton), mekanisme data hilang (Missing at Random,
Missing Completely at Random, dll), jenis
peubah (kategorik atau numerik) dan sebaran data (kenormalan).
Prosedur imputasi ganda dalam SAS 9.1 mengasumsikan mekanisme data hilang
Missing at Random. Untuk sebaran data,
metode regresi, Predictive Mean Matching dan MCMC mengasumsikan sebaran normal ganda. Jenis-jenis metode imputasi ganda dapat dilihat pada tabel 1.
Sintaks untuk prosedur imputasi ganda di SAS
9.1 adalah sebagai berikut: PROC MI <pilihan-pilihan>; MONOTONE<metode
<(<peubahterimputasi< =peubah penjelas > > < /detail > ) > >;
VAR <peubah-peubah>;
Tabel 1. Metode Imputasi dalam Proc MI Pola Data
Hilang Jenis Data Metode
Monoton Kontinu 1. Regresi 2. Predictive Mean
Matching 3. Propensity Score Monoton Kategorik (Ordinal) Regresi Logistik Monoton (Nominal) Kategorik Fungsi Diskriminan Arbitrary Kontinu Markov Chain Monte Carlo (MCMC)
Pada Proc MI juga terdapat statement untuk mengatasi pola data hilang yang tidak monoton dengan mengubah pola data hilang tersebut menjadi monoton. Statement yang digunakan adalah MCMC. Metode MCMC selain digunakan untuk memprediksi data dengan pola data hilang yang tidak monoton juga dapat mengubah pola data hilang yang tidak monoton menjadi monoton. Konsep cara
kerjanya adalah dengan cara memprediksi beberapa data (bukan semua data hilang) sehingga pola datanya menjadi monoton (SAS
9.1 Help & Documentation). PROC MI <pilihan-pilihan>; MCMC impute=monotone; VAR <peubah-peubah>;
Teori Pembuatan Nilai Imputan Ganda dengan Model Eksplisit
Terdapat tiga tahapan (task) yang diperlukan untuk membuat nilai-nilai imputan yang mensimulasi sebaran posterior dengan model eksplisit Bayesian. Tiga tahapan tersebut adalah tahap pemodelan (Modelling
Task), tahap pendugaan (Estimation Task), dan
tahap imputasi (Imputation Task). Tahap pertama memilih model yang khusus untuk data. Tahap kedua membuat formula untuk sebaran posterior parameter dari model yang terpilih, dan tahap ketiga mengambil secara acak satu nilai parameter dari sebaran posterior yang didapatkan dari tahap kedua lalu mengambil secara acak nilai
Y
dari sebaran posterior bersyarat. Tahap yang ketiga jika diulang sebanyak m kali maka akan didapatkanm imputasi untuk setiap data hilang (Rubin,
1987). i mis
Y
, i mis,Imputasi Ganda dengan Metode Regresi
Dari teori tentang pembuatan nilai-nilai imputan dengan model eksplisit Bayesian, jika diterapkan pada metode regresi maka tahapannya adalah sebagai berikut:
1. Tahap Pemodelan
Tahap ini terletak pada pembentukan model, dalam hal ini model yang digunakan adalah model regresi linear normal, dengan Yi ~ N(Xiβ, σ2).
2. Tahap Pendugaan
Pada tahap ini didapatkan nilai-nilai dugaan parameter dari model.
(
)
∑
− − = obs i i X n q Y ˆ /( ) ˆ 2 1 2 1 1 β σ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ =∑
obs i i tY X V 1 ˆβ
dimana 1 −⎥
⎦
⎤
⎢
⎣
⎡
=
∑
obs i i tX
X
V
3. Tahap ImputasiDari nilai-nilai dugaan parameter yang diperoleh dari tahap kedua lalu dilanjutkan ke langkah-langkah berikut:
a. Ambil satu nilai dari peubah acak yang menyebar , misalkan g dan hitung q n1− 2
χ
g
q
n
)
/
(
ˆ
21 1 2 *=
σ
−
σ
.b. Ambil q buah peubah acak yang menyebar N(0, 1) untuk membuat q-komponen vektor Z dan hitung.
[ ]
,
ˆ
1/2 * 1 *β
σ
V
Z
β
=
+
dimana
[ ]
merupakan matriks segitiga atas pada dekomposisi Cholesky.2 / 1
V
c. Kemudian Ymis akan didapat dengan
menghitung
,
* * * iβ
iσ
iX
z
Y
=
+
dimana normal deviasi zi diambil secara
bebas dari N(0, 1).
Sebuah nilai imputan yang baru untuk
Ymis didapatkan dengan dimulai mengambil
sebuah nilai baru dari parameter . Dengan demikian, jika imputasi diulang sebanyak m kali maka ketiga langkah di atas juga diulang
m kali.
2 *
σ
Untuk kasus peubah ganda, misal data hilang Yi = (Yi1, Yi2) dengan Yi1 mempunyai n1
data teramati dan Yi2 mempunyai n2 data
teramati dan n2 ≤ n1. Maka peubah yang akan
diimputasi terlebih dahulu adalah data hilang pada peubah Yi1 (abaikan Yi2) dengan
menggunakan X (peubah dengan data lengkap) sebagai peubah penjelasnya. Kemudian untuk mengimputasi data hilang pada Yi2, model
regresi diperoleh dari unit-unit yang teramati pada peubah X, Yi1, dan Yi2. Nilai dugaan untuk
data hilang pada peubah Yi2 diperoleh dari
nilai-nilai yang sudah ada dan nilai hasil imputan pada peubah Yi1. Demikian seterusnya
untuk jumlah Yi yang lebih banyak (Rubin,
1987).
Imputasi Ganda dengan Metode Predictive
Mean Matching (PMM)
Imputasi ini konsep dasarnya seperti metode regresi. Serupa dengan langkah-langkah pada model regresi linear normal, hanya saja langkah (c) pada tahap imputasi digantikan dengan langkah-langkah sebagai berikut:
1. Hitung nilai Ymis dengan
.
*
*
X
i
mis
Y
i=
iβ
∈
2. Untuk setiap cari responden
Y
,
*
i
mis
Y
i∈
i yang nilainya paling dekat dengan ,
dan imput nilai tersebut untuk Ymis.
*
i
Y
Metode ini adalah gabungan antara metode regresi dan Hot-Deck (Rubin, 1987).Pada proc MI, untuk setiap Yi* akan
dibentuk satu set unit (sebanyak k unit) yang mempunyai nilai Yobs terdekat dengan Yi*. Default yang digunakan dalam prosedur
tersebut adalah k=5, pada option. Kemudian dari k buah nilai akan diambil secara acak satu nilai untuk memprediksi data hilang.
BAHAN DAN METODE Bahan
Penelitian ini menggunakan data hasil simulasi. Data yang dibangkitkan dibuat sedemikian rupa seperti data survei. Skenario yang digunakan adalah survei ini dilakukan untuk menduga nilai tengah lingkar pinggang pada suatu populasi perempuan di suatu kota. Diasumsikan peubah ini adalah peubah yang berpeluang besar terjadi nonrespon karena beberapa sebab dalam survei ini. Adapun peubah-peubah yang dianggap mempengaruhi lingkar pinggang tersebut adalah berat badan dan tinggi badan. Jadi dalam pembangkitan data, ketiga peubah, berat badan (X1), tinggi
badan (X2), dan lingkar pinggang (X3), tersebut
dibuat agar mempunyai korelasi yang cukup tinggi. Masing-masing peubah dibangkitkan dari sebaran normal.
Adapun data riil yang akan digunakan sebagai contoh kasus penggunaan metode imputasi ganda adalah data sekunder hasil survei yang dilakukan oleh Yayah Karliah Husaini (Musa, 2007).
Metode
1. Data populasi sebesar 1000 unit dibangkitkan. Hitung nilai tengah peubah
X3.
2. Dari data populasi diambil contoh berukuran 100 (lampiran 1), kemudian terhadap data ini dilakukan penghilangan data dengan jumlah data yang berbeda-beda.
3. Perlakuan penghilangan data hanya diberikan kepada peubah X2 dan X3,
sedangkan peubah X1 dibiarkan lengkap.
Penghilangan data dilakukan sedemikian rupa sehingga pola data hilang yang terbentuk adalah monoton.
4. Jumlah data yang dihilangkan pada peubah
X2 adalah sebanyak 2%, 5%, 10%, dan 15%. Adapun jumlah data pada peubah X3
disesuaikan dengan jumlah data hilang pada peubah X2 berdasarkan beda jumlah
data hilang yang telah ditetapkan yaitu 0, 3, 5, 10, 15, dan 20. Untuk lebih jelasnya dapat dilihat pada lampiran 2.
5. Proses penghilangan data dilakukan secara acak untuk memenuhi asumsi mekanisme kehilangan data yang acak (MAR). 6. Ulangan yang digunakan sebanyak 10 kali
pada setiap simulasi untuk memberikan peluang hilang yang sama kepada setiap data.
7. Setiap gugus data diimputasi ganda dengan m=5 (pada proc MI nimpute=5). 8. Setelah didapatkan nilai dugaan semua
data hilang, dihitung selisih antara nilai dugaan dengan nilai aslinya. Dari selisih tersebut kemudian dihitung rata-rata dan ragam dari rata-rata tersebut.
9. Dari gugus data yang telah terlengkapi dengan nilai dugaan data hilang kemudian dihitung dugaan nilai tengah peubah X3.
Karena dilakukan ulangan 10 kali maka akan didapatkan 10 gugus data contoh yang kemudian akan didapatkan pendekatan bagi nilai KTS, dengan rumus:
) ( ) ( ) (x Ragam x Bias2 x KTS = + dimana
( )
∑
[
( )
]
= − = n i i n x E x x Ragam 1 2 1 . dan( ) ( )
x = xE −μ Bias10. Metode imputasi yang baik akan menghasilkan selisih antara nilai dugaan data hilang dengan nilai aslinya yang lebih kecil dan ragam dari rata-rata yang kecil pula. Gugus data contoh yang dibentuk dari metode imputasi tersebut juga mempunyai nilai KTS yang lebih kecil dalam pendugaan parameter populasi. 11. Menerapkan metode imputasi ganda ke
dalam contoh kasus.
HASIL DAN PEMBAHASAN
Suatu penduga nilai akan dikatakan lebih baik dari penduga lainnya jika nilainya lebih mendekati nilai yang diduga. Pembandingan kedua metode imputasi ganda yang dilakukan adalah dengan membandingkan nilai penduga, dalam hal ini selisih nilai imputan dengan nilai sebenarnya.
Proses Imputasi pada Proc MI
Dengan mempertahankan urutan letak peubah X1, X2, dan X3 , maka cara kerja proc
MI pada SAS 9.1 konsep proses imputasinya
adalah dengan terlebih dahulu memprediksi data hilang pada peubah X2. Caranya adalah
dengan membentuk model regresi dari unit-unit dengan data teramati pada peubah X1 dan
X2, dengan X2 sebagai peubah respon
sedangkan X1 sebagai peubah penjelas. Dari
model regresi yang terbentuk maka akan terdapat parameter regresi dan kuadrat tengah galat (σ2) yang kemudian akan disimulasikan
sehingga terbentuk model regresi baru yang berbeda dengan model regresi awal. Pada model regresi baru terdapat tambahan unsur yang dapat dianggap sebagai galat. Data hilang pada peubah X2 pada unit ke-i akan diprediksi
melalui model regresi baru dengan memasukkan nilai peubah X1 pada unit yang
sama. Karena banyaknya imputasi yang digunakan adalah 5 (m = 5) maka proses tersebut diulang sebanyak 5 kali. Perbedaan nilai hasil imputasi berasal dari pengambilan bilangan acak dari sebaran tertentu yang berbeda-beda dalam simulasi terhadap parameter regresi dan kuadrat tengah galat.
Setelah data hilang pada peubah X2 diduga,
proses imputasi dilanjutkan ke data hilang pada peubah X3. Pada proses ini model regresi awal
dibentuk dari unit-unit dengan data teramati untuk peubah X1, X2, dan X3, dengan peubah X3
sebagai peubah respon. Selanjutnya serupa dengan proses imputasi pada peubah X2, pada
akhirnya akan diperoleh model regresi baru setelah melalui simulasi terhadap parameter-parameter regresi dan kuadrat tengah galat regresi. Data hilang pada peubah X3 pada unit
ke-i akan diprediksi melalui model regresi baru dengan memasukkan nilai peubah X1 dan X2
pada unit yang sama. Nilai hasil imputasi pada peubah X2 juga digunakan untuk menduga data
hilang pada peubah X3.
Hampir sama dengan metode regresi, metode PMM melakukan proses imputasi dimana model regresi awal yang terbentuk dari unit-unit dengan data teramati pada peubah X1
dan X2 untuk imputasi data hilang pada peubah X2 dan unit-unit dengan data teramati pada peubah X1, X2, dan X3 untuk imputasi data hilang pada peubah X3. Dari model regresi
awal, parameter-parameter regresi dan ragam dari galat disimulasikan. Selanjutnya diperoleh model regresi baru, hanya saja tidak ada penambahan unsur seperti model regresi baru pada metode regresi. Data hilang pada peubah dan unit tertentu akan diprediksi dengan nilai pada unit lain dari peubah yang sama dimana nilainya paling dekat dengan nilai respon yang dihasilkan dari model regresi baru.
Hasil Pendugaan untuk Data Hilang 2% pada Peubah X2 dan 2% pada Peubah X3
Dari contoh berukuran 100 unit, simulasi yang pertama dilakukan adalah dengan menghilangkan data sebanyak 2% pada peubah
X2 dan 2% pada peubah X3 (selisih 0%).
Simulasi ini dilakukan dengan ulangan 10 kali, sehingga terdapat 10 posisi kehilangan data yang berbeda. Adapun data yang dihilangkan pada simulasi ini dapat dilihat di tabel 2.
Tabel 2. Data Asli yang Dihilangkan Data Asli Unit
X2 X3 89 159.6610 73.2011 90 157.4080 71.5882
Hasil pendugaan data hilang dengan menggunakan metode regresi dan PMM dapat dilihat pada tabel 3 dan 4.
Tabel 3. Data Hasil Imputasi dengan Metode Regresi pada Ulangan 1
Data Dugaan Regresi Unit Imputasi X2 X3 89 1 159.9240 73.1073 90 1 157.2100 71.8198 89 2 159.7820 73.1000 90 2 157.2380 71.7408 89 3 159.7270 73.0918 90 3 157.2260 71.6288 89 4 159.4330 73.2599 90 4 157.3670 71.6781 89 5 160.0730 73.1870 90 5 157.4490 71.8304
Tabel 4. Data Hasil Imputasi dengan Metode PMM pada Ulangan 1 Data Dugaan PMM Unit Imputasi X2 X3 89 1 159.4970 73.2354 90 1 157.5050 71.6040 89 2 159.8590 73.0111 90 2 157.0830 71.6272 89 3 159.5880 73.3183 90 3 157.4790 71.3163 89 4 159.5880 73.0111 90 4 157.5050 71.3163 89 5 159.5880 73.0707 90 5 157.1110 71.3045
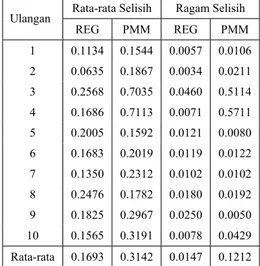
Dari hasil yang diperoleh menunjukkan bahwa metode imputasi ganda regresi lebih baik dari metode PMM. Hal ini dapat ditunjukkan oleh nilai rata-rata beda antara nilai imputan dan nilai sebenarnya, 0.16928 untuk metode regresi dan 0.314217 untuk metode PMM. Dan dari rata-rata ragam selisih pun metode regresi lebih kecil dari metode PMM (Tabel 5).
Tabel 5. Nilai Rata-rata Selisih dan Ragam Selisih Antara Data Asli dan Data Dugaan untuk Peubah X3
Rata-rata Selisih Ragam Selisih Ulangan REG PMM REG PMM 1 0.1134 0.1544 0.0057 0.0106 2 0.0635 0.1867 0.0034 0.0211 3 0.2568 0.7035 0.0460 0.5114 4 0.1686 0.7113 0.0071 0.5711 5 0.2005 0.1592 0.0121 0.0080 6 0.1683 0.2019 0.0119 0.0122 7 0.1350 0.2312 0.0102 0.0102 8 0.2476 0.1782 0.0180 0.0192 9 0.1825 0.2967 0.0250 0.0050 10 0.1565 0.3191 0.0078 0.0429 Rata-rata 0.1693 0.3142 0.0147 0.1212
Hasil Pendugaan untuk Data Hilang 2% pada Peubah X2 dan 5% pada Peubah X3
Simulasi yang dilakukan berikutnya adalah dengan menghilangkan data 2% pada peubah X2
dan 5% pada peubah X3 (selisih 3%).
Hasil dari simulasi ini menunjukkan bahwa metode regresi lebih baik daripada metode PMM, ditinjau dari nilai rata-rata selisih antara data asli dan data dugaannya juga dari nilai rata-rata ragam selisihnya. Nilai rata-rata selisih metode regresi lebih kecil daripada metode PMM, demikian juga nilai ragam selisihnya. Hasil tersebut dapat dilihat pada tabel 6.
Tabel 6. Nilai Rata-rata Selisih dan Ragam Selisih Antara Data Asli dan Data Dugaan untuk Peubah X3
Rata-rata Selisih Ragam Selisih Ulangan REG PMM REG PMM 1 0.1682 0.2161 0.0137 0.0378 2 0.1956 0.1557 0.0170 0.0316 3 0.1963 0.4949 0.0197 0.2151 4 0.2294 0.3940 0.0232 0.1972 5 0.1804 0.4163 0.0162 0.3303 6 0.1827 0.2514 0.0171 0.0392 7 0.1500 0.1290 0.0159 0.0093 8 0.2204 0.2199 0.0155 0.0350 9 0.1631 0.4485 0.0198 0.3460 10 0.1682 0.2161 0.0137 0.0378 rata-rata 0.1854 0.2942 0.0172 0.1279
Ringkasan Hasil Seluruh Simulasi
Dari semua simulasi yang dilakukan, jumlah data hilang 2%, 5%, 10%, dan 15% serta selisih jumlah data hilang 0, 3, 5, 10, 15, dan 20 didapatkan hasil bahwa metode regresi selalu lebih baik daripada metode PMM ditinjau dari nilai rata-rata selisih antara data
asli dengan data dugaan dan ragam selisih antara data asli dengan data dugaan.
Dari gambar 3 tampak bahwa nilai rata-rata selisih antara data asli dengan data dugaan dari metode regresi cenderung lebih kecil dan lebih stabil dari kondisi jumlah data hilang satu ke kondisi lainnya jika dibandingkan dengan nilai rata-rata selisih dari metode PMM.
0 0.1 0.2 0.3 0.4 0.5 1 3 5 7 9 11 13 15 17 19 21 23
Kelas Jumlah Data Hilang
R a ta -r a ta S e lis ih D a ta A sl i vs D at a D u g aan reg pmm
Gambar 3. Rata-rata Selisih antara Data Asli dengan Data Dugaan Peubah X3 untuk Seluruh Kelompok Beda Jumlah
Data Hilang
Nilai rata-rata selisih antara data asli dengan data dugaan metode PMM dari kondisi jumlah data hilang terkecil sampai terbesar cenderung mengalami kenaikan. Hal ini dapat disebabkan oleh data bangkitan yang nilainya berbeda untuk setiap unit. Sehingga semakin banyak jumlah data hilang akan membuat selisih dugaan dengan data asli semakin besar. Penjelasannya adalah berdasarkan teori imputasi ganda metode PMM, nilai imputan unit tertentu didapat dari nilai unit lain yang jaraknya paling dekat dengan nilai hasil regresi antara peubah respon dengan penjelas yang ditunjuk. Kandidat donor atau unit yang nilainya akan dipakai sebagai dugaan bagi data hilang semakin berkurang jumlahnya jika jumlah data hilang semakin banyak.
Sedangkan nilai rata-rata selisih antara data asli dengan data dugaan pada metode regresi, seiring dengan peningkatan jumlah kehilangan data, relatif stabil. Berbeda dengan metode PMM, metode regresi mendapatkan nilai dugaan untuk data hilang langsung dari model regresi baru yang terbentuk melalui simulasi koefisien regresi awal. Nilai dugaan data hilangnya bukan diambil dari unit lain (donor).
Analisis Data untuk Data yang Telah Dilengkapi Data Dugaan
Suatu gugus data yang sebelumnya mempunyai beberapa data hilang tentunya akan dianalisis lebih lanjut. Dalam pendugaan parameter, hasil analisis berdasarkan metode imputasi ganda merupakan kombinasi dari hasil analisis setiap gugus data terlengkapi. Salah satu contoh penggunaan hasil nilai
dugaan dari imputasi ganda yang dilakukan dalam penelitian ini adalah pendugaan nilai tengah populasi, dalam hal ini nilai tengah peubah lingkar pinggang X3.
Pembandingan kedua metode imputasi selanjutnya adalah dengan cara melihat nilai KTS pada saat melakukan pendugaan nilai tengah ukuran lingkar pinggang (X3) dari
sebuah populasi. Simulasi yang dilakukan adalah dengan cara menghitung rata-rata peubah lingkar pinggang dari semua gugus data contoh hasil imputasi.
Terdapat 24 gugus data dengan karakteristik yang berbeda-beda sesuai dengan jumlah data hilang pada peubah X3 dan jumlah data hilang
pada peubah X2. Gugus- gugus data yang telah
diberi perlakuan penghilangan data kemudian dilengkapi kembali nilai-nilainya yang hilang dengan kedua metode imputasi ganda. Dari satu gugus data tak lengkap yang telah diimputasi ganda akan didapatkan 5 gugus data terlengkapi (m=5), sehingga terdapat 5 nilai statistik peubah
X2. Dari SAS (dengan Proc MI) akan secara otomatis dihasilkan satu nilai rata-rata dari kelima nilai statistik tersebut.
0.0000 0.0005 0.0010 0.0015
1 4 7 10 13 16 19 22
Kelas Jumlah Data Hilang
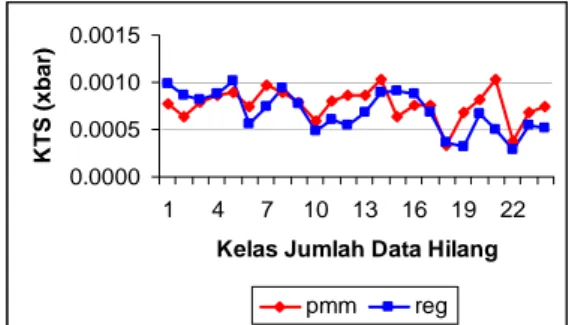
KT S ( x b a r) pmm reg
Gambar 4. Nilai KTS untuk Pendugaan Nilai Tengah Peubah X3 0.000 0.010 0.020 0.030 0.040 1 3 5 7 9 11 13 15 17 19 21 23
Kelas Jumlah Data Hilang
B ias ( x b a r) pmm reg
Gambar 5. Nilai Bias (xbar) untuk Pendugaan Nilai Tengah Peubah X3
Karena simulasi yang dilakukan dengan ulangan 10 kali maka akan didapatkan 10 nilai rata-rata untuk menduga nilai tengah X2. Dari
nilai-nilai itulah nilai KTS dihitung (nilai tengah peubah lingkar pinggang yang sebenarnya adalah 71.854).
Hasil dari simulasi dapat dilihat pada gambar 4. tidak terdapat perbedaan yang berarti antara nilai KTS yang dihasilkan dari metode imputasi regresi dan PMM.
Dilihat dari nilai biasnya juga tidak terdapat perbedaan yang berarti di antara kedua metode tersebut (gambar 5). Kedua metode menghasilkan penduga yang nilainya lebih besar dari nilai parameter yang sebenarnya (overestimate).
Pembandingan Metode Imputasi Ganda dengan Metode Baku untuk Data Lengkap
Pada praktiknya, metode baku untuk data lengkap sering digunakan dalam menganalisis data yang mengandung data hilang. Metode tersebut dilakukan dengan cara menghapus unit-unit yang mempunyai data hilang.
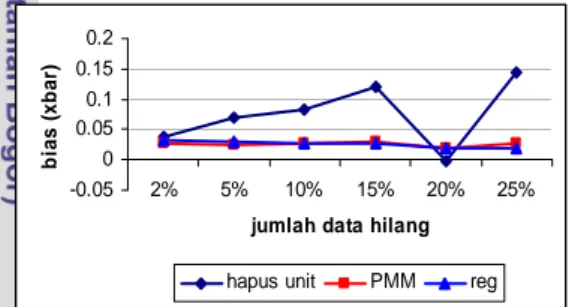
Untuk melihat akibat dari penggunaan metode penghapusan unit pada data yang mengandung data hilang dilakukan pendugaan parameter populasi dengan jumlah kehilangan data yang berbeda. Kemudian hasilnya dibandingkan dengan pendugaan parameter melalui metode imputasi ganda, baik PM maupun regresi. -0.05 0 0.05 0.1 0.15 0.2 2% 5% 10% 15% 20% 25%
jumlah data hilang
bia s ( x b a r)
hapus unit PMM reg
Gambar 6. Pembandingan Nilai Bias Metode Penghapusan Unit dengan Metode Imputasi Ganda pada Pendugaan Parameter X3. 0 0.01 0.02 0.03 0.04 2% 5% 10% 15% 20% 25%
junmlah data hilang
KT S (x b a r)
hapus unit PMM reg
Gambar 7. Pembandingan Nilai KTS Metode Penghapusan Unit dengan Metode Imputasi Ganda pada Pendugaan Parameter X3.
Pembandingan masih dilihat dari nilai bias dan nilai KTS, dengan jumlah data hilang yang dicobakan adalah 2%, 5%, 10%, 15%, 20% dan 25% baik pada peubah X2 maupun X3.
Gambar 6 dan 7 menunjukkan bahwa metode penghapusan menghasilkan nilai bias dan KTS yang jauh lebih tinggi daripada kedua metode imputasi ganda pada jumlah kehilangan data
lebih besar dan sama dengan 5%. Pada jumlah kehilangan data 2% ketiga metode tersebut memberikan nilai bias yang tidak jauh berbeda. Terlebih dengan meningkatnya jumlah data hilang, semakin banyak data hilang pada data maka nilai dugaan terhadap parameter populasi akan semakin buruk jika metode penghapusan unit dengan data hilang digunakan. Dari contoh pembandingan tersebut maka dapat ditunjukkan bahwa penggunaan metode baku untuk data lengkap kurang tepat dalam proses analisis data yang mengandung data hilang.
Contoh Kasus untuk Penerapan Imputasi Ganda
Dari data sekunder yang didapatkan peneliti hanya mengambil beberapa peubah untuk digunakan sebagai contoh penerapan metode imputasi ganda.
Peubah-peubah yang digunakan adalah Sistem Kekerabatan (X1), Jenis Kelamin Bayi
(X2), Umur Bayi (X3), Bobot Ibu (X4), dan
Bobot Bayi (X5), sedangkan peubah yang
mempunyai data hilang adalah X4 dan X5
dengan total jumlah kehilangan data sebesar 9.73% dan pola kehilangan data yang terbentuk adalah pola data hilang monoton. Keterangan tersebut dapat dilihat di lampiran 6. Untuk menduga nilai data hilang yang ada pada peubah-peubah tersebut digunakan proc MI dengan menggunakan metode PMM.
Adapun analisis lanjut yang digunakan setelah menduga data hilang adalah analsis regresi untuk menduga hubungan antara peubah respon X5 dengan peubah penjelas X1, X2, X3, dan X4. Oleh karena itu, setelah
dilakukan pendugaan data hilang dengan metode imputasi ganda dilakukan analisis regresi dengan menggunakan proc reg terhadap tiap gugus data yang telah dilengkapi datanya. Hasil analisis masing-masing gugus data yang telah dilengkapi dapat dilihat pada lampiran 7.
Tabel 7. Penduga-penduga Koefisien Regresi
Gugus b0 b1 BB2 b3 b4 1 3.047 -0.086 -0.299 0.328 0.048 2 3.298 -0.101 -0.408 0.350 0.043 3 2.540 -0.055 -0.377 0.345 0.057 4 2.836 -0.088 -0.298 0.339 0.051 5 2.889 -0.116 -0.176 0.306 0.052 Mean 2.922 -0.089 -0.312 0.333 0.050 Var 0.078 0.001 0.008 0.000 0.000
Pada tabel 7 dapat dilihat hasil akhir pendugaan koefisien regresi yang merupakan kombinasi tiap pendugaan dari gugus data yang telah dilengkapi (rata-rata penduga koefisien
hilang tidak memberikan pengaruh yang besar terhadap perubahan nilai KTS.
regresi dari tiap gugus data). Sedangkan ragam dari tiap penduga koefisien menduga keragaman nilai penduga koefisien karena dilakukan imputasi sebanyak 5 kali. Sedangkan dari tabel 8 dapat diperoleh informasi bahwa rata-rata dari nilai S2b0
sebesar 0.658, nilai ini menduga keragaman dalam b0 karena penarikan contoh (sampling).
Pada simulasi sederhana yang dilakukan dalam penelitian ini, telah ditunjukkan bahwa metode penghapusan unit yang mengandung data hilang memberikan hasil yang kurang baik, terlebih dengan jumlah kehilangan data yang cenderung besar.
Dari analisis regresi yang dihasilkan dari
proc MIAnalyze dapat disimpulkan bahwa
peubah Sistem Kekerabatan dan Jenis Kelamin Bayi tidak berpengaruh nyata terhadap peubah Bobot Bayi. Hasil tersebut dapat dilihat pada pengujian parsial terhadap tiap penduga koefisien regresi dalam output proc MIAnalyze (lampiran 8).
Saran
Maka para analis data hendaknya lebih berhati-hati dalam penanganan data yang mengandung data hilang, sehubungan dengan metode analisis baku untuk data lengkap atau metode penghapusan unit yang sering diterapkan pada kasus dengan data hilang.
Sebagai saran untuk penelitian selanjutnya yaitu perlu dilakukan simulasi serupa tapi dengan data yang tidak semua unitnya mempunyai nilai yang berbeda (terdapat beberapa unit yang mempunyai nilai sama). Hal ini dimungkinkan akan memberikan hasil yang berbeda khususnya untuk metode PMM.
Tabel 8. Statistik untuk b0
Gugus b0 SEb0 S2b0 1 3.047 0.803 0.644 2 3.298 0.816 0.665 3 2.540 0.834 0.695 4 2.836 0.828 0.685 5 2.889 0.776 0.602 Mean 2.922 0.658 Var 0.078
Masih terdapat faktor-faktor yang dapat dan perlu dilihat untuk membandingkan metode imputasi ganda regresi dan PMM selain dari yang sudah diteliti dalam penelitian ini.
KESIMPULAN & SARAN DAFTAR PUSTAKA
Kesimpulan Cochran, W. G. 1977. Sampling Technique.
New York: Wiley. Dalam hal pendugaan terhadap data hilang
dalam data contoh metode imputasi ganda regresi lebih baik daripada metode PMM, karena nilai dugaan yang dihasilkan lebih dekat dengan nilai sebenarnya. Dengan jumlah kehilangan data yang semakin meningkat, selisih nilai dugaan dengan nilai aslinya juga akan meningkat pada metode PMM. Sedangkan pada metode regresi, peningkatan jumlah kehilangan data tersebut tidak mempengaruhi selisih nilai dugaan dengan nilai aslinya (cenderung stabil). Dengan kata lain, keragaman selisih nilai dugaan dengan nilai asli pada metode regresi lebih kecil daripada keragaman yang diperoleh pada metode PMM.
Kish, Leslie. 1965. Survey Sampling. New York: Wiley.
Levy, P. S. and Lemeshow, S. 1999. Sampling
of Populations: Methods & Applications 3rd ed. New York: Willey.
Little, R. J. A. and Rubin, D. B. 1987.
Statistical Analysis with Missing Data.
New York: Wiley.
Longford, N. T. 2005. Missing Data and
Small-Area Estimation. New York: Springer.
Rubin, D. B. 1987. Multiple Imputation for
Nonresponse in Sample Surveys. New
York: Willey
Lepkowski, J. M. 1989. Treatment of Wave
Nonresponse in Panel Surveys dalam Panel Surveys. New York: John Willey & Sons.
Sedangkan dari segi pendugaan parameter populasi melalui data contoh yang telah dilengkapi dengan data imputan, kedua metode imputasi ganda tersebut tidak memiliki perbedaan yang nyata. Hal ini bisa dilihat dari nilai KTS untuk pendugaan parameter populasi yang dihasilkan. Meningkatnya jumlah data
Little, R. J. A. & Su, Hong Lin. 1989. Item
Nonresponse in Panel Surveys dalam Panel Surveys. New York: John Willey & Sons.
Musa, Sjarkani. 2007. Metodologi Penelitian dengan Statistika. Departemen Statistika IPB. Bogor: inpress.
Lampiran 1. Tabel Data Contoh Unit BB TB LP Unit BB TB LP 1 49.4324 149.511 66.7163 51 61.7837 161.582 74.5994 2 56.899 156.787 71.045 52 53.5326 153.563 68.9106 3 60.8716 160.507 73.8709 53 55.5621 155.583 70.1455 4 57.0462 156.94 71.1986 54 63.8222 163.527 75.8575 5 61.9272 161.766 74.6957 55 57.8411 157.695 71.7531 6 60.6801 160.344 73.7195 56 70.6627 171.177 80.3865 7 66.6718 166.669 77.273 57 59.297 159.123 72.7088 8 45.826 145.309 64.4776 58 58.2188 157.928 71.9686 9 50.9437 151.015 67.4766 59 55.0428 155.177 69.8403 10 61.7919 161.646 74.6008 60 60.1597 159.77 73.2873 11 49.8609 149.954 66.9404 61 53.9314 153.995 69.152 12 57.1347 157.036 71.2669 62 44.7839 144.006 63.7782 13 59.4109 159.261 72.7755 63 65.3905 165.282 76.6412 14 60.2089 159.859 73.3183 64 59.7752 159.497 73.0111 15 54.5868 154.747 69.5767 65 58.3445 158.128 72.0501 16 56.7198 156.733 70.9461 66 57.133 157.035 71.2655 17 58.7177 158.628 72.3472 67 58.557 158.525 72.2457 18 69.7591 169.965 79.0619 68 68.223 167.947 78.1382 19 45.7562 145.185 64.4586 69 47.3786 147.447 65.5552 20 50.8761 150.763 67.3748 70 64.1827 163.982 75.9467 21 54.0898 154.264 69.3025 71 59.7585 159.462 72.9709 22 54.1971 154.337 69.3967 72 62.2208 161.971 74.8943 23 59.6469 159.39 72.8951 73 64.5753 164.549 76.1953 24 57.1945 157.083 71.3045 74 51.687 151.628 67.8628 25 56.5225 156.524 70.7828 75 57.5698 157.479 71.604 26 58.3562 158.149 72.1079 76 63.4873 163.28 75.6435 27 53.5118 153.548 68.9023 77 62.8994 162.668 75.4704 28 55.9135 155.858 70.3363 78 61.3592 161.048 74.1686 29 59.6908 159.427 72.9341 79 54.6803 154.8 69.6147 30 56.9406 156.844 71.0917 80 63.4925 163.299 75.6624 31 59.6787 159.405 72.9249 81 57.5752 157.505 71.6272 32 61.2508 160.982 74.1383 82 65.5858 165.5 76.6875 33 52.2551 152.265 68.1591 83 53.1723 153.29 68.7722 34 56.4417 156.359 70.7002 84 62.3156 162.049 74.9539 35 69.1813 169.032 78.974 85 64.2358 164.052 75.9784 36 47.4949 147.739 65.6055 86 53.8233 153.89 69.0765 37 59.6207 159.367 72.8934 87 64.5114 164.428 76.1693 38 61.7111 161.439 74.5172 88 59.1763 159.039 72.5925 39 60.1028 159.685 73.2354 89 60.022 159.661 73.2011 40 57.2394 157.111 71.3163 90 57.5408 157.408 71.5882 41 64.9534 164.735 76.5012 91 58.9646 158.831 72.4349 42 49.4265 149.481 66.7145 92 59.9014 159.588 73.0707 43 59.5014 159.276 72.7985 93 59.3503 159.167 72.724 44 61.4507 161.101 74.2566 94 57.0478 156.984 71.2074 45 55.2888 155.37 69.9708 95 57.0597 156.99 71.2202 46 54.4116 154.608 69.4961 96 49.9278 150.039 66.9526 47 48.8691 148.659 66.253 97 56.5483 156.583 70.8065 48 61.0478 160.741 73.9923 98 55.6151 155.624 70.1673 49 56.6587 156.659 70.8927 99 55.861 155.847 70.3211 50 46.8773 146.405 65.298 100 65.0771 164.868 76.5546
10
Lampiran 2. Kombinasi (kelas) Jumlah (%) Data Hilang pada Peubah X2 dan X3 Kelas X2 X3 1. 2 2 2. 2 5 3. 2 7 4. 2 12 5. 2 17 6. 2 22 7. 5 5 8. 5 8 9. 5 10 10. 5 15 11. 5 25 12. 5 30 13. 10 10 14. 10 13 15. 10 15 16. 10 20 17. 10 25 18. 10 30 19. 15 15 20. 15 18 21. 15 20 22. 15 25 23. 15 30 24. 15 35
Lampiran 3. Data Asli yang Dihilangkan pada Simulasi kedua
Data Asli Unit X2 X3 89 150.763 67.3748 90 154.264 69.3025 91 69.3967 92 72.8951 93 71.3045
Lampiran 4. Data Hasil Imputasi dengan Metode Regresi untuk Data Hilang 2% pada X2 dan 5%
pada X3 Ulangan 1
Data Dugaan Regresi Unit Imputasi X2 X3 89 1 159.924 73.2021 90 1 157.21 71.5003 91 1 72.4482 92 1 73.3175 93 1 72.9321 89 2 159.25 73.2377 90 2 157.727 71.5851 91 2 72.5248 92 2 73.0719 93 2 72.6306 89 3 159.764 73.1301 90 3 157.288 71.6848 91 3 72.4849 92 3 73.3848 93 3 72.7983 89 4 160.034 73.2287 90 4 157.623 71.8264 91 4 72.4809 92 4 73.2734 93 4 72.9567 89 5 160.394 72.7657 90 5 157.386 71.6861 91 5 72.8995 92 5 72.8837 93 5 72.8114
12
Lampiran 5. Data Hasil Imputasi dengan Metode PMM untuk Data Hilang 2% pada X2 dan 5% pada X3 Ulangan 1 Data Dugaan PMM Unit Imputasi X2 X3 1 159.497 73.0111 1 157.505 71.3045 1 72.5925 1 72.9709 1 72.5925 2 159.588 73.3183 2 157.695 71.6272 2 72.7088 2 73.0111 2 72.8934 3 159.685 73.3183 3 157.505 71.6272 3 72.7088 3 73.0111 3 72.7985 4 159.588 72.9709 4 157.111 71.6272 4 72.3472 4 73.0111 4 72.7755 5 159.497 73.2873 5 157.111 71.7531 5 72.7755 5 72.9249 5 72.5925
Lampiran 6. Hasil Pendugaan Nilai Tengah Peubah X3 dari Simulasi Jumlah Data Hilang 2% pada X2 dan 2% pada X3 Nilai Rata-rata X3 Ulangan PMM REG 1 71.88041 71.88366 2 71.88158 71.88273 3 71.87488 71.88695 4 71.88295 71.88604 5 71.88292 71.88668 6 71.88182 71.88603 7 71.88277 71.88463 8 71.88450 71.88762 9 71.88299 71.88622 10 71.88208 71.88380 Var(xbar) 0.00001 0.00000 B (xbar) 0.02769 0.03144 MSE(xbar) 0.00077 0.00099
Lampiran 7. Output Proc MI
The MI Procedure Model Information
Data Set WORK.SURVEI2 Method Monotone Number of Imputations 5
Seed for random number generator 51343672 Monotone Model Specification
Method Imputed Variables Regression-PMM( K= 5) JkBy UmBy Bibu BBy
Missing Data Patterns Jk Um
Group Ker By By Bibu BBy Freq Percent 1 X X X X X 102 90.27 2 X X X X . 3 2.65 3 X X X . . 8 7.08
Missing Data Patterns
---Group Means--- Group Ker JkBy UmBy Bibu BBy
1 1.980392 1.500000 5.823529 46.901961 6.618627 2 2.000000 1.666667 3.000000 43.666667 . 3 1.875000 1.250000 6.125000 . .
Multiple Imputation Variance Information ---Variance---
Variable Between Within Total DF Bibu 0.052054 0.475438 0.537903 73.251 BBy 0.000830 0.017866 0.018863 97.172
Multiple Imputation Variance Information
Relative Fraction
Increase Missing Relative Variable in Variance Information Efficiency Bibu 0.131383 0.122026 0.976176 BBy 0.055772 0.054144 0.989287
Multiple Imputation Parameter Estimates
Variable Mean Std Error 95% Confidence Limits DF Bibu 46.921239 0.733418 45.45962 48.38286 73.251 BBy 6.562301 0.137342 6.28972 6.83488 97.172
Lampiran 8. Output Proc Reg
REG Model Coefficients and Covariance matrices
Obs _Imput_ _TYPE_ _NAME_ Intercept Ker JkBy UmBy Bibu
1 1 PARMS 3.04689 -0.0856 -0.29924 0.32821 0.04841 2 1 COV Intrcept 0.64405 -0.04002 -0.04835 -0.00903 -0.00926 3 1 COV Ker -0.04002 0.01297 0.00107 0.00024 0.000245 4 1 COV JkBy -0.04835 0.00107 0.03356 -0.00087 0.000029 5 1 COV UmBy -0.00903 0.00024 -0.00087 0.00086 0.000104 6 1 COV Bibu -0.00926 0.00024 0.00003 0.0001 0.000174 7 2 PARMS 3.29778 -0.10138 -0.40802 0.34966 0.04321 8 2 COV Intercept 0.66523 -0.04164 -0.05005 -0.01021 -0.00939 9 2 COV Ker -0.04164 0.01408 0.0011 0.00026 0.000228
10 2 COV JkBy -0.05005 0.0011 0.03666 -0.00098 -2.1E-05 11 2 COV UmBy -0.01021 0.00026 -0.00098 0.00095 0.000121 12 2 COV Bibu -0.00939 0.00023 -0.00002 0.00012 0.000176 13 3 PARMS 2.54041 -0.05504 -0.3765 0.34464 0.057157 14 3 COV Intercept 0.69501 -0.04352 -0.05064 -0.00993 -0.01003 15 3 COV Ker -0.04352 0.01372 0.00112 0.00028 0.000282 16 3 COV JkBy -0.05064 0.00112 0.03534 -0.00092 0.000025 17 3 COV UmBy -0.00993 0.00028 -0.00092 0.00091 0.000117 18 3 COV Bibu -0.01003 0.00028 0.00003 0.00012 0.000188 19 4 PARMS 2.83628 -0.08776 -0.29849 0.33851 0.050708 20 4 COV Intercept 0.6852 -0.04529 -0.05308 -0.00869 -0.0097 21 4 COV Ker -0.04529 0.01392 0.0012 0.00026 0.000307 22 4 COV JkBy -0.05308 0.0012 0.03564 -0.00091 0.000063 23 4 COV UmBy -0.00869 0.00026 -0.00091 0.00089 0.000092 24 4 COV Bibu -0.00969 0.00031 0.00006 0.00009 0.000179 25 5 PARMS 2.88923 -0.11569 -0.17637 0.30641 0.051529 26 5 COV Intercept 0.60195 -0.042 -0.03851 -0.00864 -0.0086 27 5 COV Ker -0.042 0.01307 0.00075 0.00027 0.000288 28 5 COV JkBy -0.03851 0.00075 0.03355 -0.00097 -0.00015 29 5 COV UmBy -0.00864 0.00027 -0.00097 0.00085 0.000099 30 5 COV Bibu -0.0086 0.00029 -0.00015 0.0001 0.00016
Lampiran 9. Output Proc MIAnalyze
The MIANALYZE Procedure Model Information
Data Set WORK.OUTREG Number of Imputations 5
Multiple Imputation Variance Information ---Variance---
Parameter Between Within Total DF Intercept 0.077709 0.658287 0.751538 68.428 Ker 0.000508 0.013553 0.014163 96.934 JkBy 0.008030 0.034951 0.044587 42.182 UmBy 0.000293 0.000894 0.001245 30.241 Bibu 0.000025620 0.000176 0.000207 60.249
Multiple Imputation Variance Information Relative Fraction
Increase Missing Relative Parameter in Variance Information Efficiency Intercept 0.141657 0.130746 0.974517 Ker 0.044974 0.043924 0.991292 JkBy 0.275716 0.233815 0.955326 UmBy 0.393424 0.309334 0.941738 Bibu 0.174576 0.157879 0.969391
Multiple Imputation Parameter Estimates
Parameter Estimate Std Error 95% Confidence Limits DF Intercept 2.922117 0.866913 1.19242 4.651819 68.428 Ker -0.089095 0.119008 -0.32530 0.147105 96.934 JkBy -0.311724 0.211157 -0.73780 0.114353 42.182
UmBy 0.333486 0.035286 0.26145 0.405526 30.241 Bibu 0.050203 0.014382 0.02144 0.078969 60.249
Multiple Imputation Parameter Estimates
t for H0:
Parameter Minimum Maximum Theta0 Parameter=Theta0 Pr > |t| Intercept 2.540413 3.297777 0 3.37 0.0012 Ker -0.115693 -0.055044 0 -0.75 0.4559 JkBy -0.408024 -0.176367 0 -1.48 0.1473 UmBy 0.306414 0.349659 0 9.45 <.0001 Bibu 0.043210 0.057157 0 3.49 0.0009