APLIKASI MENETUKAN KEMIRIPAN SITUS WEB
PADA SISTEM TEMU BALIK INFORMASI
BERBASIS WEB MENGGUNAKAN METODE TERM
FREQUENCY INVERSE DOCUMENT FREQUENCY
(TF-IDF)
Heru Suryono (111080200160)1 , Arief Senja Fitroni S.Kom.2 1,2
Jurusan Teknik Informatika Universitas Muhammadiyah Sidoarjo. 1
[email protected], 2 [email protected].
ABSTRAK
Semakin meningkatnya kemajuan teknologi, maka banyak sekali pembuatan situs web oleh mahasiswa. Sebuah situs web dapat dapat dengan mudah dikategorikan secara manual oleh manusia, tetapi jika dilakukan secara terkomputerisasi akan membawa permasalahan tersendiri. Begitu pula dengan mencari tingkat kemiripan suatu situs web dengan situs web lainnya, manusia dapat dengan mudah menentukan apakah situs web tersebut memiliki tingkat kemiripan atau kemiripan dengan situs web lainnya atau tidak, untuk itu pada penelitian ini akan dibuat sebuah sistem temu balik informasi yang dapat menginputkan kata atau kalimat yang diinputkan pengguna ke dalam keyword dan mencari tingkat kemiripan antar situs web secara terkomputerisasi.
Dalam penelitian ini yang digunakan untuk memecahkan masalah diatas adalah dengan menggunakan algoritma TF-IDF (Term Frequency Inverse Document Frequency). TF-IDF (Term
Frequency Inverse Document Frequency) disini bertujuan untuk mencari nilai kemiripan suatu situs
web dengan situs web lainnya menggunakan kata kunci yang didapat dari hasil situs web yang sudah ditentukan.
Hasil dari penelitian ini adalah didapatkan akurasi kemiripan sistem temu balik informasi (STBI) situs web sebesar 90% dan tingkat perbedaan kemiripan sistem temu balik informasi (STBI) situs web adalah sebesar 10%. Dengan penelitian ini diharapkan proses pencarian sistem temu balik informasi (STBI) situs web secara terkomputerisasi, hasilnya dapat sesuai dengan perhitungan manual.
Kata kunci : STBI, Kemiripan, Situs Web, TF-IDF.
ABSTRACT
Heru Suryono (111080200160)1 , Arief Senja Fitroni S.Kom.2 1,2
Informatics Engineering University Of Muhammadiyah Sidoarjo. 1
[email protected], 2 [email protected].
The increasing advances in technology, then a lot of website creation by students. A website can be can be easily categorized manually by humans, but if it is done in computerized will bring its own problems. Similarity, the degree of similarity search for a website to other websites, people can easily determine whether the website has a level of similarity or likeness to any other website or not, for it was in this study will be made of a system of information retrieval that can be input word /
phrase that the user entered into the keywords and the search for the degree of similarity between the website are computerized.
In this study were used to solve the above problems is to use the algorithm TF-IDF (Term
Frequency Inverse Document Frequency). TF-IDF (Term Frequency Inverse Document Frequency)
here is to find the value of the similarity of a website with other websites using key words obtained from the website that has been determined.
Result from this study is the semblanc of accuracy obtained information retrieval system (STBI) website by 90% and the degree of similarity difference information rertieval system (STBI) website is 10%. With this research is expected search process information retrieval system (STBI) computerized website, the result can be in accordance with the manual calculation.
Keywords : STBI, Similarity, Website, TF-IDF I. PENDAHULUAN
1.1 Latar Belakang Masalah
Situs web (website) atau kita biasa menyebutnya dengan situs atau hanya web saja merupakan kumpulan dari beberapa halaman yang mempunyai topik yang saling terkait yang didalamnya terdapat unsur-unsur teks, gambar, video, atau berkas lainnya yang tersimpan dalam sebuah komputer server yang dapat diakses melalui jaringan internet. Setiap web memiliki alamat unik yang disebut dengan URL (Uniform Resource Locator). Kumpulan dari semua situs web yang dapat diakses melalui internet disebut sebagai WWW (World Wide Web). Sering kali ditemukan web yang memiliki beberapa kemiripan. Dari pengelompokkan tersebut dapat digunakan untuk membantu dalam pencarian informasi halaman-halaman web yang terkait dengan suatu topik tertentu, atau mendeteksi adanya duplikasi halaman
web (plagiarism).
Situs web yang digunakan adalah berdasarkan penulisan keyword yang memungkinkan untuk dilakukan identifikasi sejauh mana kemiripannya dengan halaman web yang lain, dilihat dari segi banyaknya kata atau kalimat yang dituliskan di keyword. Keyword adalah elemen atau tag html/xhtml yang diciptakan sebagai penjelas isi dari
halaman web melalui beberapa kata atau frasa /format bahasa permintaan yang di
input (dimasukan) oleh pengguna kedalam STBI.
Sistem Temu Balik Informasi (Information Retrieval) digunakan untuk menemukan kembali informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis. Salah satu aplikasi umum dari sistem temu kembali informasi adalah situs web, search-engine atau mesin pencarian yang terdapat pada jaringan internet dan lain-lain. Pengguna dapat mencari situs web yang dibutuhkannya melalui mesin pencari dan dapat mencari informasi tentang kemiripan dari beberapa web tersebut.
Disini penulis akan mencoba melakukan penelitian dengan menghitung tingkat kemiripan antar halaman web. Perbandingan dapat dilakukan dengan mengacu kepada keywords yang diinputkan oleh pengguna. Dan untuk permasalahan ini algoritma pemrograman yang dapat digunakan adalah algoritma pembobotan TF-IDF (Term Frequency
Inverse Document Frequency) untuk
perhitungannnya.
1.2 Perumusan Masalah
1. Bagaimana menerapkan algoritma TF-IDF (Term Frequency Inverse
menghitung kemiripan antar halaman
web?
2. Seberapa efektifkah algoritma TF-IDF (Term Frequency Inverse Document
Frequency) dalam menentukan kemiripan berdasarkan keywords? 3. Bagaimana cara mengembangkan
aplikasi menentukan kemiripan situs
web pada sistem temu balik informasi
berbasis web menggunakan metode TF-IDF (Term Frequency Inverse
Document Frequency)?
1.3Batasan Masalah
1. Algoritma yang digunakan TF-IDF (Term Frequency Inverse Document
Frequency) berdasarkan keywords.
2. Menggunakan metode perhitungan TF-IDF (Term Frequency Inverse Document Frequency) untuk pembobotan lalu menghitung kemiripan web selanjutnya dilakukan perangkingan.
3. Situs web yang dicari disini meliputi Mekanik dan Kendaraan, Makanan dan Minuman, Games, Internet dan Telekomunikasi, Berita dan Media, Perbelanjaan, Keolahragaan, Perjalanan, Seni dan Hiburan.
4. Pencarian situs web dapat dilakukan secara offline.
1.4 Tujuan Penelitian
Adapun tujuan yang ingin dicapai melalui penelitian ini adalah :
1. Untuk mengetahui cara untuk menerapkan algoritma Term Frequency Inverse Document Frequency (TF-IDF) agar dapat
menghitung kemiripan antar halaman web.
2. Untuk mengetahui tingkat keefektifan metode Term Frequency Inverse Document Frequency (TF-IDF) dalam
mencari kemiripan web satu dengan web yang lainnya.
3.Untuk mengetahui cara mengembangkan aplikasi menentukan kemiripan situs web pada sistem temu balik informasi berbasis web menggunakan metode Term Frequency
Inverse Document Frequency
(TF-IDF).
1.5 Manfaat
Adapun beberapa manfaat dari pengerjaanskripsi ini, antara lain :
1. Bagi Mahasiswa
a) Diharapkan penyusunan skripsi ini nantinya dapat dijadikan sebagai bahan studi perbandingan serta sebagai bahan pertimbangan untuk penelitian dan pengembangan selanjutnya.
2. Bagi Pengguna
a) Untuk mengetahui bagaimana dalam menentukan kemiripan antar halaman web, yang diinputkan pengguna ke dalam sebuah keyword yang nantinya akan didapatkan hasil dari pencarian web tersebut.
3.Bagi Universitas Muhammadiyah Sidoarjo
a) Sebagai sumbangsih dengan
kemampuan agar dapat
dipergunakan dalam rangka pengelolaan hasil belajar siswa khususnya bidang studi informatika.
II. KAJIAN PUSTAKA DAN DASAR TEORI
2.1 Pengertian Sistem temu balik informasi
Sistem Temu Balik Informasi (Information Retrieval) merupakan sebuah media pelayanan bagi pengguna yang digunakan untuk menemukan kembali informasi-informasi yang relevan
terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis. Salah satu aplikasi umum dari sistem temu kembali informasi adalah situs web,
search-engine atau mesin pencarian yang
terdapat pada jaringan internet dan lain-lain. Pengguna dapat mencari halaman-halaman web yang dibutuhkannya melalui mesin tersebut. Sedangkan pada situs web
pengguna dapat mencari informasi tentang kemiripan antar halaman web. Sistem temu-kembali informasi
memiliki tujuan untuk menemu-kembalikan semua dokumen yang relevan berdasarkan keyword yang dimasukan oleh pengguna dan menemu-kembalikan dokumen tidak relevan sedikit mungkin (Baeza-Yates dan Ribeiro-Neto, 1999). Menurut Lancaster (1968) di dalam Rijsbergen (1979): “sebuah sistem temu-kembali informasi tidak memberitahu (yakni tidak mengubah pengetahuan) pengguna mengenai masalah yang ditanyakannya. Sistem tersebut hanya memberitahukan keberadaan (atau ketidakberadaan) dan keterangan dokumen-dokumen yang berhubungan dengan permintaannya”.
2.1.1. Komponen sistem temu balik informasi 1. Pengguna
Pengguna sistem temu balik informasi (STBI) adalah orang yang menggunakan atau memanfaatkan STBI dalam rangka kegiatan pengelolaan dan pencarian informasi. Berdasarkan perannya, pengguna STBI (sistem temu balik informasi) dibedakakan atas 2 (dua) kelompok yaitu pengguna (user) dan pengguna akhir (end user).
2. Keyword
Keyword adalah format bahasa permintaan yang di input (dimasukan) oleh pengguna kedalam STBI (sistem temu balik informasi).
3. Pembobotan Web
Perhitungan untuk pembobotan web menggunakan persamaan 3, yaitu menggunakan Algoritma TF-IDF (Term Frequency Inverse Document
Frequency).
4. Retrieved Web
Web yang telah dihitung tingkat kemiripannya, kemudian disajikan kepada pengguna dalam bentuk perankingan web.
III. METODOLOGI PENELITIAN
3.1. Lokasi Dan Waktu Penelitian
Penelitian untuk penulisan skripsi ini dilakukan dengan browsing internet, yaitu mencari sumber data dari internet. Sebagaimana, data yang diambil oleh penulis berkaitan dengan nama-nama situs web.
3.2.Bahan dan Alat Penelitian
Dalam melakukan penelitian, peneliti menggunakan bahan dan alat penelitian untuk pembuatan skripsi ini antara lain: 3.2.1. Bahan Penelitian
Bahan yang digunakan penulis untuk memperlancar penelitian yaitu berupa laporan penelitian terdahulu, serta teori-teori yang diambil dari browsing internet untuk menunjang pembuatan aplikasi menentukan kemiripan web
3.2.2. Alat penelitian
Alat yang digunakan peneliti dalam melakukan penelitian ini meliputi :
a. Seperangkat komputer dengan kecepatan 1.8 Ghz dengan RAM 2 Gb.
b. Software
1. Sistem opersai windows 8.1 (64 bit)
2. Notepade ++
3. Web browser Google Chrome
4. Xammp
5. Microsoft office visio 2007 6. Dreamweaver
3.3. Teknik Pengumpulan Data
Dalam usaha mencapai hasil yang maksimal mungkin dan sesuai dengan yang peneliti harapkan dalam pengumpulan data, sehingga peneliti dapat dengan mudah menyusun skripsi ini, maka peneliti menggunakan beberapa metode pengumpulan data antara lain :
a. Browsing Internet
Yaitu dengan mencari sumber data dari internet. Dengan maksud, penulis ingin mengetahui lebih mendalam nama-nama situs yang ada di internet yang diperkirakan
mempunyai kesamaan antar halaman webnya, agar hasil yang di dapat bisa maksimal
b. Pengamatan(Observasi)
Pengamatan dilakukan pada situs web langsung dengan maksud untuk mengambil nama situs apa saja yang nantinya bisa digunakan menjadi data, kemudian setelah itu baru dilakukan perhitungan.
IV. HASIL PENELITIAN DAN PEMBAHASAN
4.1 Hasil Dan Pembahasan Aplikasi
Untuk mencapai rancangan sistem yang baik maka terlebih dahulu dilakukan observasi dari analisa sistem temu balik informasi dalam menetukan kemripan website yang dicari pengguna/ user akan dibuatkan tabel-tabel basis data sesuai kebutuhannya, sehingga data tersebut dapat diintegrasikan program yang dibuat.
4.2. Hasil Penelitian
Implementasi merupakan tahap pengembangan rancangan menjadi sistem, Sistem ini menggunakan bahasa pemrograman PHP.
4.3 Implementasi
Sesuai dengan rancangan sistem yang telah dibuat maka implementasi dari Website akan ditunjukkan melalui tampilan sebagai berikut :
4.3.1 Tampilan Website STBI (sistem temu balik informasi) kemiripan situs web sebagai berikut:
Berikut penjelasan dari masing-masing menu yang terdapat di halaman utama website :
1. Menu Home berisi gambar tentang situs-situs web, serta terdapat login dibawah gambar yang nantinya digunakan admin untuk masuk ke dalam aplikasi. 2. Menu Pencarian Website
digunakan untuk mengetahui kemiripan website, yang diinputkan pengguna ke dalam
keywords STBI (Sistem Temu Balik Informasi).
3. Menu Kontak kami berisi informasi tentang profil mahasiswa.
4. Master data berisikan CRUD website dan Menampilkan data website.
5. Serta menu logout untuk keluar dari aplikasi Sistem temu balik informasi website.
4.3.2 Interface utama sistem temu balik informasi kemiripan website.
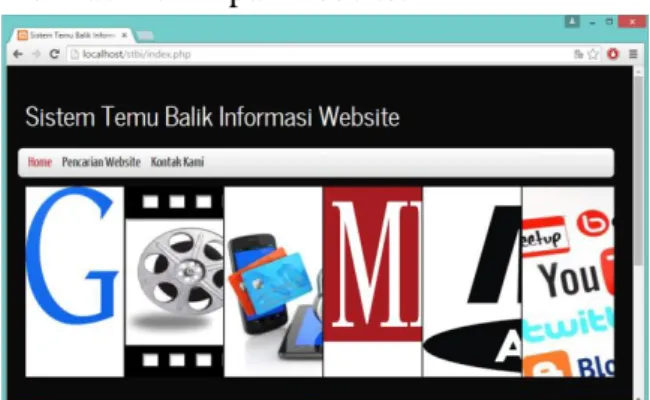
Gambar 4.1 Interface Utama STBI
Gambar di atas menunjukakan menu utama dari sistem sistem temu balik informasi. Dan merupakan interface yang pertama kali dilihat oleh user (pengguna). Dalam menu utama ini terdapat beberapa bagian diantaranya:
a. Header : judul program b. Menu utama terdiri dari:
1. Home
2. Pencarian website 3. Kontak kami 4.3.3. Menu Login
Menu ini berfungsi untuk login masuk kedalam sistem sistem temu balik informasi website. Untuk masuk kedalam proses diperlukan tahapan –tahapan , diantaranya :
1. Input Username : dipergunakan untuk memasukkan user name 2. Input passward : dipergunakan
untuk memasukkan password yang sudah proses sebelumnya.
3. Setelah proses input username dan password selesai, selnjutnya tombol OK yang merupakan proses masuk kedalam sistem temu balik informasi kemiripan website ini akan berjalan.
4.3.4 Menu Pencarian Website
Gambar 4.3. Menu Pencarian Website
Menu ini berfungsi untuk proses mengetahui kemiripan dari website yang diinputkan pengguna ke dalam STBI (sistem temu balik informasi) serta menghitung keywords website menggunakan metode TF-IDF (Term
Frequency Inverse Document Frequency).
Dalam proses ini dibutuhkan inputan dari pengguna STBI berupa keywords yang mendukung proses perhitungan kemiripan website ini.
Didalam Sub – menu Pencarian Website ini terdiri dari :
1. Header / judul utama 2. Area input, terdiri dari:
a. Keywords : digunakan unuk memasukkan kata/ kalimat yang diinputkan pengguna/ user kr dalam STBI (Sistem Temu Balik Informasi).
3. Tombol cari untuk mengetahui hasil pencarian website berupa tabel yang terdiri dari website dan nilai kemiripan.
4.3.4.1 Tampilan Hasil Perhitungan TF-IDF
Gambar 4.4 Tampilan Hasil Perhitungan TF-IDF
Di dalam tampilan ini dijelaskan bagaimana metode TF-IDF (Term
Frequency Inverse Document Frequency)
berjalan.
4.3.4.2 Tampilan Hasil Pencarian Website
Gambar 4.5 Tampilan Hasil Pencarian Website
Di dalam tampilan hasil pencarian website ini berupa tabel yang didalamnya terdapat nama website dan nilai dari kemiripan website.
4.3.5 Menu Kontak Kami
Dalam menu ini berisi keterangan tentang profil pembuat program seperti:
1. Nama mahasiswa : 2. Alamat :
3. No Tlp : 4. Email :
Menu master data merupakan menu yang memiliki data untuk menunjang proses input dan hasil dari sistem temu balik informasi website yang diinputkan admin dan menyimpannya ke dalam database. Master data terdiri dari beberapa sub-master data yang harus di update dan
delete sesuai dengan program STBI
kemiripan website yang nantinya dijalankan.
Adapun Sub-master data ini terdiri dari :
1. CRUD (Create, Update, Delete) Website
2. Tampilkan Website
4.3.6 Menu tambah website
Gambar 4.7 Menu Tambah Website
Menu tambah website ini, merupakan tampilan untuk menambah data website yang nantinya akan disimpan ke dalam database.
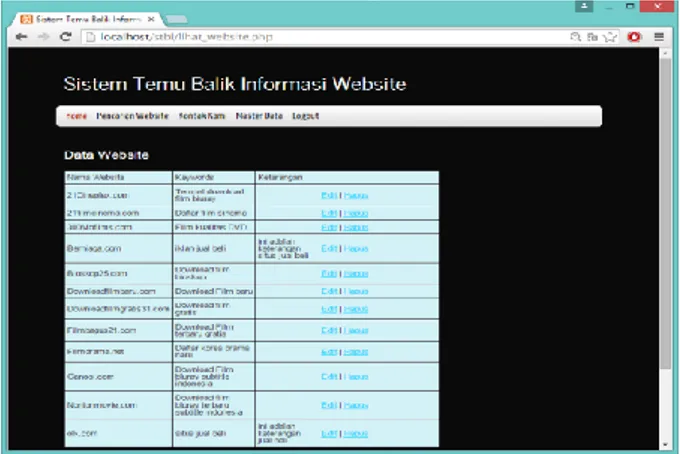
4.3.7 Menu Tampilan Data Website
Gambar 4.8 Menu tampilan data website
Menu Ini berfungsi untuk menampilkan hasil yang ditambahkan oleh admin, serta terdapat edit dan hapus yang ada pada table.
V. Kesimpulan
Kesimpulan yang diperoleh dengan adanya Aplikasi Menetukan Kemiripan Situs Web Pada Sistem Temu Balik Informasi Berbasis Web Menggunakan Metode TF-IDF (Term Frequency Inverse
Document Frequency) diharapkan dapat
mempermudah dan mempercepat pengguna/ user dalam mengetahui kemiripan website yang dicari dengan menggunakan aplikasi sistem temu balik informasi website.
1. Pengetahuan yang dimiliki pengguna mengenai sistem temu balik informasi website yang digunakan pada aplikasi ini.
2. Dalam Aplikasi ini menggunakan metode TF-IDF (Term Frequency Inverse Document Frequency).
3. Aplikasi ini dapat membantu pengguna untuk mengetahui kemiripan website satu dengan website yang lainnya.
4. Aplikasi yang digunakan berbasis web.
DAFTAR PUSTAKA
Referensi Buku dan Jurnal :
[1] Andi, 2011 Kupas Tuntas Adobe
Dreamweaver CS5 Dengan Pemrograman PHP & MYSQL.
[2] Abdul Kadir, 2003, Pemrograman WEB Mencakup: HTML, CSS, JavaScript & PHP, Penerbit
Andi, Yogyakarta.
[3] Adhit Herwansyah, Aplikasi Pengkategorian Dokumen Dan Pengukuran Tingkat Similaritas Dokumen Menggunakan Kata
Kunci Pada Dokumen
Penulisan Ilmiah Universitas Gunadarma, Universitas Gunadarma.
[4] Ari Wibowo, Pengujian Kerelevanan
Sistem Temu Kembali
Informasi, Universitas Politeknik Negeri Batam.
[5] Baeza-Yates & Ribeiro-Neto, 1999,
Modern Information Retrieval,
Harlow, Addison-Wesley.
[6] Edhy Sunanta, Edisi pertama 2004, Sistem Basis Data, Penerbit Graha Ilmu, Yogjakarta.
[7] Fatkhul Amin, 2011 Implementasi Search
Engine (Mesin Pencari) Menggunakan Metode Vector
Space Model, Universitas Stikubank Semarang.
[8] Firnas Nadirman, 2006 Sistem Temu Kembali Informasi Metode
Vector Space Model Pada
Pencarian File Dokumen Berbasis Teks, Universitas Gadjah Mada.
[9] Giat Karyono 2012, Temu Balik Informasi Dokumen Teks Berbahasa Indonesia Dengan Metode
Vector Space Retrieval Model, Universitas STMIK AMIKOM Purwokerto.
[10] Jonner Hasugian, 2006 Penggunaan Bahasa Alamiah dan Kosa Kata Terkendali Dalam Sistem Temu Balik Informasi Berbasis Teks, Universitas Sumatera Utara.
[11] Ardhina Pratiwi, 2013 Temu Kembali Informasi Pada Opac Di Unit Perpustakaan Fakultas Kedokteran Universitas Gadjah Mada Berbasis Intranet, Universitas Islam Negeri Sunan Kalijaga Yogyakarta.