MENGGUNAKAN WEKA (WAIKATO ENVIRONMENT FOR
KNOWLADGE ANALYSIS)
SKRIPSI
Oleh :
ACHMAD ZUBAIRI MAS’UD
1034010070
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL
Nama : Achmad Zubairi Mas’ud
Dosen Pembimbing 1 : Budi Nugroho, S.Kom. M.Kom Dosen Pembimbing 2 : I Made Suartana, S.Kom. M.Kom
ABSTRAK
Dengan adanya sistem komputer berbasis jaringan yang sekarang berperan penting dalam kehidupan masyarakat modern sekarang ini, telah menjadi sasaran kejahatan dalam dunia cyber yang dilakukan oleh penyusup atau hacker, dan jumlah serangan jaringan saat ini yang terus meningkat, maka dibutuhkan Intrusion Detection System (IDS) yang mampu memantau dan mendeteksi gangguan atau intrusi pada seluruh sistem.
Agar sebuah Intrusion Detection System dapat mendeteksi jenis serangan baru, salah satu teknik yang bisa digunakan adalah dengan teknik data mining dalam IDS. Dan dalam mendeteksi suatu intrusi dibutuhkan salah satu metode dalam data mining yang mampu mengklasifikasikan sebuah serangan dengan baik yaitu decision tree.
Dan dalam tugas akhir ini dilakukan klasifikasi terhadap dataset yang dibuat dari proses data log dengan menggunakan metode decision tree dan dataset KDD CUP 1999 sebagai data training. Dan hasil dari klasifikasi pada data test menunjukkan bahwa metode decision tree cukup akurat dalam mengklasifikasikan serangan terhadap data test yang dibuat dengan rata-rata hasil keseluruhan klasifikasi pada data test sebesar 91.2% untuk class yang diprediksi dengan tepat.
ii
KATA PENGANTAR
Pertama kali ijinkanlah kami mengucapkan puja dan puji syukur ke Hadirat Tuhan Yang Maha Kuasa atas selesainya pembuatan laporan Tugas Akhir (TA) ini di Universitas Pembangunan Nasional “Veteran” Jawa Timur dengan judul
“Analisis Klasifikasi Serangan Denial of Service (DOS) Dengan Metode Decision Tree Menggunakan WEKA (Waikato Environment for Knowladge Analysis).
Penulis menyadari, Bahwa laporan Tugas Akhir ini belum sempurna dan masih banyak kekurangan. Oleh karena itu penulis sangat mengharapkan kritik dan saran dalam memperbaiki laporan ini agar menjadi lebih baik lagi.
Akhir kata penulis berharap agar Tugas Akhir ini yang telah disusun sesuai dengan kemampuan dan pengentahuan yang sangat terbatas ini dapat bermanfaat bagi pihak yang membutuhkan.
UCAPAN TERIMA KASIH
Puji syukur ke hadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya, sehingga dapat terselesaikannya Tugas Akhir ini.
Dengan selesainya tugas akhir ini tidak terlepas dari bantuan banyak pihak yang telah memberikan masukan-masukan. Untuk itu penyusun mengucapkan terima kasih sebagai perwujudan rasa syukur atas terselesaikannya tugas akhir ini dengan lancar. Ucapan terima kasih ini saya tujukan kepada :
1. Bapak Prof. Dr. Ir. Teguh Soedarto, MP selaku Rektor Universitas ini, yang telah banyak memberikan petunjuk, masukan, bimbingan, dorongan serta kritik yang bermanfaat sejak awal hingga terselesainya Tugas Akhir ini.
4. I Made Suartana, S.Kom, M.Kom selaku dosen pembimbing II yang telah banyak memberikan petunjuk, masukan serta kritik yang bermanfaat hingga terselesainya Skripsi ini.
iv
6. Terima kasih buat sahabat saya Rendy, Rizal, Agung, Bagus, Handy, Adit, Indra, Irwan yang telah berjuang bersama sampai akhir perkuliahan dan telah memberikan semangat untuk menyelesaikannya dan yang selalu ada disaat suka dan duka saat mengerjakan Tugas Akhir ini.
7. Terimakasih kepada comunitas Blacklist yang telah memberikan banyak teman selama kuliah.
8. Serta orang-orang yang tidak dapat saya sebutkan satu persatu namanya. Terimakasih atas bantuannya semoga Allah SWT yang membalas semua kebaikan dan bantuan tersebut.
Surabaya, 23 Desember 2014
DAFTAR ISI
1.6 Sistematika Penulisan ... 4
BAB II TINJAUAN PUSTAKA ... 6
2.1 Penelitian Terdahulu ... 6
2.2 Dasar Teori ... 7
2.2.1 Teori Security ... 7
2.2.1.1 Serangan Pada Keamanan Jaringan ... 7
2.2.1.2 Denial of Service (DOS) ... 9
2.2.1.3 Ping of Death (POD)... 10
2.2.1.4 Smurf... 11
2.2.2 Intrusion Detection System ... 12
2.2.3 Data Mining... 13
2.2.4 Algoritma C4.5 ... 19
2.2.5 WEKA ( Waikato Environment for Knowladge Analysis ) ... 21
BAB III METODE PENELITIAN ... 28
3.1 Rancangan Penelitian ... 28
3.1.1 Studi Literatur ... 29
vi
3.2 Perolehan Data dan Persiapan Data ... 31
3.3 Rancangan Uji Coba ... 33
3.3.1 Rancangan Uji Coba Pembentukan Model Klasifikasi ... 33
3.3.2 Rancangan Uji Coba Klasifikasi ... 34
3.4 Rancangan Analisis Klasifikasi Serangan DOS ... 35
BAB IV HASIL DAN PEMBAHASAN ... 37
4.1 Implementasi ... 37
4.1.1 Capture Paket Menggunakan TCPdump...37
4.1.2 Memproses Data Log TCPdump...38
4.1.3 Pembuatan Dataset...40
4.1.4 Pembentukan Model Klasifikasi...42
4.1.5 Klasifikasi Dataset TCPdump...45
4.2 Hasil Uji Coba dan Evalusi... 47
4.2.1 Hasil Uji Coba Pembentukan Model Klasifikasi ... 47
4.2.2 Hasil Uji Coba Klasifikasi Dataset TCPdump ... 51
4.2.3 Analisa Klasifikasi Serangan...56
BAB V KESIMPULAN DAN SARAN ... 57
5.1 Kesimpulan ... 61
5.2 Saran ... 61
BAB I
PENDAHULUAN
1.1 LATAR BELAKANG
Dengan adanya sistem komputer berbasis jaringan yang sekarang berperan penting dalam kehidupan masyarakat modern sekarang ini, telah menjadi sasaran kejahatan dalam dunia cyber yang dilakukan oleh penyusup atau hacker, dan jumlah serangan jaringan saat ini yang terus meningkat, maka dibutuhkan
Intrusion Detection System (IDS) yang mampu memantau dan mendeteksi
gangguan atau intrusi pada seluruh sistem.
Intrusion Detection System sendiri adalah sebuah aplikasi perangkat lunak
atau perangkat keras yang dapat mendeteksi aktivitas yang mencurigakan dalam sebuah sistem atau jaringan. Namun Kebanyakan IDS mendeteksi serangan dengan menganalisis informasi dari sebuah host tunggal pada banyak lokasi di seluruh jaringan. Akibatnya, komponen IDS melewatkan komunikasi antara satu sama lain. Fakta ini menghambat kemampuan untuk mendeteksi serangan terdistribusi dengan skala besar.
Untuk mengatasi masalah tersebut dibutuhkan sebuah agent dalam IDS.
agent adalah sebuah program yang dapat bergerak secara individu atau otoritas
Agar IDS dapat mendeteksi jenis serangan baru, salah satu teknik yang bisa digunakan adalah denganteknik data mining dalam IDS. Data mining merupakan teknik yang berkembang dalam dunia pengolahan data saat ini, tujuan data mining adalah mengekstrasi informasi secara otomatis dari sebuah database yang besar. Selain itu, dengan menggunakan integrasi dari kedua metodologi agent dan teknik
data mining pada IDS, dapat meningkatkan kinerja dari IDS terdistribusi,
mendeteksi serangan yang diketahui dan tidak diketahui dengan tingkat akurasi yang tinggi dalam lingkungan terdistribusi. Serta dalam teknik data mining, pola (atau tanda tangan) dari aktivitas normal dan abnormal (intrusi) dapat dibuat secara otomatis. Hal ini juga memungkinkan untuk memperkenalkan jenis serangan baru melalui proses pembelajaran tambahan. Akibatnya, semakin banyak serangan dapat dideteksi dengan benar.
Pada penelitian sebelumnya yang dilakukan oleh O.Oriola ,A.B. Adeyemo & A.B.C. Robert. Mereka menggabungkan antara agent dan data mining untuk
mendeteksi intrusi yang ada dalam jaringan dan juga menggunakan hasil dari analisa dataset KDD CUP 1999 untuk membangun sebuah Distibuted Intrusion
Detection System (DIDS) (O.Oriola, A.B. Adeyemo & A.B.C. Robert,“Distributed Intrusion Detection System Using P2P Agent Mining Scheme”).
Dalam tugas akhir ini akan memproses data log yang dihasilkan oleh agent
mining yang akan digunakan sebagai dataset dalam melakukan klasifikasi
serangan dengan metode decision tree. Dalam proses klasifikasi akan menggunakan dataset KDD CUP 1999 yang merupakan kumpulan data yang digunakan untuk The Third International Knowledge Discovery and Data mining
yang disimulasikan menggunakan TCPdump sebagai data test. Dan untuk melakukan klasifikasi akan menggunakan perangkat lunak WEKA ( Waikato Environment for Knowladge Analysis ) untuk mengetahui tingkat keakuratan metode decision tree dalam mengklasifikasikan sebuah serangan .
1.2 RUMUSAN MASALAH
Adapun rumusan masalah yang akan di bahas dalam tugas akhir ini :
a. Bagaimana menangkap paket-paket data dari serangan yang dilakukan? b. Bagaimana memproses hasil data log mentah TCPdump menjadi sebuah
dataset data mining?
c. Bagaimana membuat model klasifikasi dari data training KDD CUP 1999? d. Bagaimana cara melakukan klasifikasi untuk menetukan jenis serangan pada
dataset yang dibuat?
e. Bagaimana cara menganalisa hasil klasifikasi dari dataset yang dibuat? 1.3 BATASAN MASALAH
Batasan masalah yang terdapat pada tugas akhir ini adalah sebagai berikut :
a. Serangan yang digunakan adalah serangan DOS (Denial of Service) yaitu
Ping of Death dan Smurf.
b. Dalam klasifikasi akan menggunakan beberapa atribut dari dataset KDD CUP 1999 yaitu duration, protocol_type, service, src_byte, urgent, count, srv_count dan class.
c. Melakukan klasifikasi serangan dengan metode decision tree C4.5.
d. Menggunakan algoritma j48 yang ada pada WEKA, sebagai implementasi
e. Melakukan analisa terhadap hasil klasifikasi dataset yang dibuat untuk mengetahui keakuratan decision tree dalam mengklasifikasi serangan DOS.
1.4 TUJ UAN TUGAS AKHIR
Adapun tujuan dari tugas akhir ini adalah :
a. Mengimplementasikan teknik data mining untuk mengklasifikasikan sebuah serangan DOS.
b. Mengklasifikasikan serangan DOS Ping of Death dan Smurf dengan metode
decision tree
1.5 MANFAAT TUGAS AKHIR
Manfaat yang di peroleh dari tugas akhir ini adalah :
a. Dapat melakukan klasifikasi terhadap dataset yang dibuat.
b. Dapat mengetahui tingkat akurasi dari metode decision tree dalam mengklasifikasikan serangan pada dataset yang dibuat.
1.6 SISTEMATIKA PENULISAN
Sistematika penulisan tugas akhir ini akan membantu memberikan informasi tentang tugas akhir yang dijalankan dan agar penulisan laporan ini tidak menyimpang dari batasan masalah yanga ada, sehingga susunan laporan ini sesuai dengan apa yang diharapkan. Sistematika penulisan laporan tugas akhir ini adalah sebagai berikut:
BAB I PENDAHULUAN
BAB II TINJ AUAN PUSTAKA
Tinjauan pustaka berisi tentang berbagai konsep dasar penyerangan, data mining serta analisa yang digunakan dan teori-teori yang berkaitan dengan topik masalah yang diambil dan hal-hal yang berguna dalam proses analisis permasalahan.
BAB III METODE PENELITIAN
Metode tugas akhir ini berisi tentang rancangan jaringan, rancangan serangan-serangan, rancangan klasifikasi, dan konfigurasi-konfigurasi yang digunakan dalam mendeteksi, serta metode-metode lain yang digunakan untuk menyelesaikan tugas akhir ini.
BAB IV HASIL DAN PEMBAHASAN
Dalam implementasi sistem ini berisi tentang hasil dan pembahasan tentang beberapa konfigurasi yang dilakukan pada bab sebelumnya untuk memproses data log mentah TCPdump, serta di lakukannya analisa klasifikasi dataset TCPdump sebagai data test dan menggunakan dataset KDD CUP 1999 sebagai data training menggunakan metode Decion tree dalam melakukan proses klasifikasi.
BAB V KESIMPULAN DAN SARAN
TINJ AUAN PUSTAKA
2.1 PENELITIAN TERDAHULU
Sebagai bahan acuan dalam tugas akhir ini akan dipaparkan hasil penelitian terdahulu yang pernah dibaca oleh penulis, diantaranya :
Penelitian yang dilakukan oleh O.Oriola dari Department of Computer Science
Adekunle Ajasin University dan A.B. Adeyemo & A.B.C. Robert dari Department of Computer Science University of Ibadan, dengan judul “Distributed Intrusion Detection System Using P2P Agent Mining Scheme”, dengan tujuan untuk deteksi
intrusi terdistribusi, menggunakan Distributed Data Mining (DDM) untuk menganalisis data dan operasi mining secara terdistribusi.
Pada penelitian tersebut dilakukan uji analisis dari data set KDD CUP 99 dengan menggunakan K-Means dan Expectation Maximization (EM) Algoritma
Clustering, Multilayer Perceptron Neural Networks (MLP) dan Radial Basis Function Neural Networks (RBF), Algoritma C4 Decision Tree, Algoritma Naive Bayes Tree (NBTree) dan Classification and Regression Tree (CART).
Hasil dari uji analisis tersebut adalah K-means memiliki hasil buruk dengan presentase akurasi kurang dari 60%. Dan EM dengan akurasi 63% dan untuk
Multilayer Perceptron Neural Networks (MLP) dan Radial Basis Function Neural Networks (RBF), C4.5, NBTree dan CART paling tidak memiliki tingkat akurasi
2.2 DASAR TEORI
Pada dasar terori ini akan dibahas mengenai Intrusion Detection System (IDS),Data mining, Algoritma C4.5,DOS , Smurf dan Ping of Death.
2.2.1 TEORI SECURITY
Pada teori security menjelaskan macam-macam serangan yang dapat mengganggu keamanan sistem jaringan komputer.
2.2.1.1 SERANGAN PADA KEAMANAN J ARINGAN
Untuk sistem jaringan yang mempunyai keamanan canggih dan ketat pun masih memungkinkan sistem jaringan tersebut tidak dapat aman seratus persen dari penyalahgunaan sumber daya atau serangan sistem jaringan para pencuri dunia maya. Berikut adalah macam-macam serangan pada sistem jaringan komputer :
1). Spoofing
Spoofing adalah teknik yang digunakan untuk memperoleh akses yang tidak sah
ke suatu komputer atau informasi, dimana penyerang berhubungan dengan pengguna dengan berpura-pura memalsukan bahwa mereka adalah host yang dapat dipercaya. Hal ini biasanya dilakukan oleh seorang hacker/ cracker.
2). DOS (Denial of Service)
mencegah pengguna lain untuk memperoleh akses layanan dari komputer yang diserang tersebut.
3). DNS Poisoning
DNS Poisoning merupakan sebuah cara untuk menembus pertahanan dengan cara
menyampaikan informasi IP Address yang salah mengenai sebuah host, dengan tujuan untuk mengalihkan lalu lintas paket data dari tujuan yang sebenarnya. Cara ini banyak dipakai untuk menyerang situs-situs e-commerce dan banking yang saat ini bisa dilakukan dengan cara online dengan pengamanan Token. Teknik ini dapat membuat sebuah server palsu tampil identik dengan dengan server online
banking yang asli. Oleh karena itu diperlukan digital cerficate untuk
mengamankannya, agar server palsu tidak dapat menangkap data otentifikasi dari nasabah yang mengaksesnya. Jadi dapat disimpulkan cara kerja DNS (Domain
Name System) poisoning ini adalah dengan mengacaukan DNS Server asli agar
pengguna internet terkelabui untuk mengakses web site palsu yang dibuat benar-benar menyerupai aslinya tersebut, agar data dapat masuk ke server palsu.
4). Trojan Horse
Trojan horse atau Kuda Troya atau yang lebih dikenal sebagai Trojan dalam
keamanan komputer merujuk kepada sebuah bentuk perangkat lunak yang mencurigakan (malicious software/malware) yang dapat merusak sebuah sistem atau jaringan. Tujuan dari Trojan adalah memperoleh informasi dari target (password, kebiasaan user yang tercatat dalam system log, data, dan lain-lain), dan mengendalikan target (memperoleh hak akses pada target).
Injeksi SQL atau SQL Injection memiliki makna dan arti yaitu sebuah teknik yang menyalahgunakan sebuah celah keamanan yang terjadi dalam lapisan basis data sebuah aplikasi. Celah ini terjadi ketika masukan pengguna tidak disaring secara benar dari karakter-karakter pelolos bentukan string yang diimbuhkan dalam pernyataan SQL atau masukan pengguna tidak bertipe kuat dan karenanya dijalankan tidak sesuai harapan. Ini sebenarnya adalah sebuah contoh dari sebuah kategori celah keamanan yang lebih umum yang dapat terjadi setiap kali sebuah bahasa pemrograman atau skrip diimbuhkan di dalam bahasa yang lain.
2.2.1.2 DENIAL OF SERVICE (DOS)
Serangan DoS (bahasa Inggris: denial-of-service attacks') adalah jenis serangan terhadap sebuah komputer atau server di dalam jaringan internet dengan cara menghabiskan sumber (resource) yang dimiliki oleh komputer tersebut sampai komputer tersebut tidak dapat menjalankan fungsinya dengan benar sehingga secara tidak langsung mencegah pengguna lain untuk memperoleh akses layanan dari komputer yang diserang tersebut. Dalam sebuah serangan Denial of
Service, si penyerang akan mencoba untuk mencegah akses seorang pengguna
terhadap sistem atau jaringan Jenis–jenis DoS :
1). Lokal DoS : Kegiatan DoS yang dilakukan oleh cracker menggunakan interaksi langsung dengan konsole sistem operasi. Pelaku dapat berinteraksi langsung dengan konsole sistem operasi korban dan mengeksekusi perintah – perintah (script) yang dapat menghabiskan resource komputer korban tersebut.
Resource yang dimaksud adalah CPU, RAM, SWAP Space, disk, Kernel, cache
2). Remote DoS : kegiatan DoS yang dilakukan oleh cracker secara jarak jauh tanpa interaksi secara langsung dengan konsole sistem operasi korban. Pelaku melakukan kegiatan DoS dengan memanfaatkan media jaringan komputer dan internet. Pada tehnik ini, Pelaku memanfaatkan kelamahan dari protokol TCP/IP dan kelamahan lebih detail mengenai teknik remote DoS.
2.2.1.3 PING OF DEATH (POD)
Ping of Death adalah jenis serangan pada komputer yang melibatkan
pengiriman ping yang salah atau berbahaya ke komputer target. Sebuah ping biasanya berukuran 56 byte (atau 84 bytes ketika header IP dianggap). Dalam sejarahnya, banyak sistem komputer tidak bisa menangani paket ping lebih besar daripada ukuran maksimum paket IP, yaitu 65.535 byte. Mengirim ping dalam ukuran ini (65.535 byte) bisa mengakibatkan kerusakan (crash) pada komputer target. Secara tradisional, sangat mudah untuk mengeksploitasi bug ini. Secara umum, mengirimkan paket 65.536 byte ping adalah illegal menurut protokol jaringan, tetapi sebuah paket semacam ini dapat dikirim jika paket tersebut sudah terpecah-pecah, Ketika komputer target menyusun paket yg sudah terpecah-pecah tersebut, sebuah buffer overflow mungkin dapat terjadi, dan ini yang sering menyebabkan sistem crash.
Eksploitasi pada kelemahan ini telah memengaruhi berbagai sistem, termasuk Unix, Linux, Mac, Windows, printer, dan router. Namun, kebanyakan sistem sejak 1997 - 1998 telah diperbaiki, sehingga sebagian besar bug ini telah menjadi sejarah. Dalam beberapa tahun terakhir, muncul jenis serangan ping yang berbeda yang telah menyebar luas, contohya membanjiri korban dengan ping
yang mengakibatkan kegagalan normal ping mencapai sistem yg dituju (dasar serangan Denial of Service).
2.2.1.4 SMURF
Smurf attack, merupakan salah satu jenis serangan Denial of Service yang
mengeksploitasi protokol Internet Control Message Protocol (ICMP). Smurf
attack adalah sebuah serangan yang dibangun dengan menggunakan pemalsuan
terhadap paket-paket ICMP echo request, yakni sebuah jenis paket yang digunakan oleh utilitas troubleshooting jaringan, PING. Si penyerang akan memulai serangan dengan membuat paket-paket "ICMP echo request" dengan alamat IP sumber berisi alamat IP host target yang akan diserang (berarti alamat telah dipalsukan atau telah terjadi address spoofing). Paket-paket tersebut pun akan dikirimkan secara broadcast ke jaringan di mana komputer target berada, dan host-host lainnya yang menerima paket yang bersangkutan akan mengirimkan balasan dari "ICMP echo request" ("ICMP echo reply") kepada komputer target, seolah-olah komputer target merupakan komputer yang mengirimkan ICMP echo
request tersebut. Pada gambar 2.1 menunjukkan cara kerja dari serangan smurf.
Semakin banyak komputer yang terdapat di dalam jaringan yang sama dengan target, maka semakin banyak pula ICMP echo reply yang dikirimkan kepada target, sehingga akan membanjiri sumber daya komputer target, dan mengakibatkan kondisi penolakan layanan (Denial of Service) yang menjadikan para pengguna tidak dapat mengakses layanan yang terdapat di dalam komputer yang diserang. Beberapa sistem bahkan mengalami crash atau hang, dan lagi, banjir yang berisi paket-paket "ICMP echo request/reply" akan membuat kongesti (kemacetan) jaringan yang dapat memengaruhi komputer lainnya.
2.2.2 INTRUSION DETECTION SYSTEM (IDS)
Intrusion Detection System (disingkat IDS) adalah sebuah aplikasi
perangkat lunak atau perangkat keras yang dapat mendeteksi aktivitas yang mencurigakan dalam sebuah sistem atau jaringan. IDS dapat melakukan inspeksi terhadap lalu lintas inbound dan outbound dalam sebuah sistem atau jaringan, melakukan analisis dan mencari bukti dari percobaan intrusi (penyusupan).
Ada dua jenis IDS, yakni:
2). Host-based Intrusion Detection System (HIDS): Aktivitas sebuah host jaringan individual akan dipantau apakah terjadi sebuah percobaan serangan atau penyusupan ke dalamnya atau tidak. HIDS seringnya diletakkan pada
server-server kritis di jaringan, seperti halnya firewall, web server-server, atau server-server yang
terkoneksi ke Internet.
Kebanyakan produk IDS merupakan sistem yang bersifat pasif, mengingat tugasnya hanyalah mendeteksi intrusi yang terjadi dan memberikan peringatan kepada administrator jaringan bahwa mungkin ada serangan atau gangguan terhadap jaringan. Akhir-akhir ini, beberapa vendor juga mengembangkan IDS yang bersifat aktif yang dapat melakukan beberapa tugas untuk melindungi host atau jaringan dari serangan ketika terdeteksi, seperti halnya menutup beberapa
port atau memblokir beberapa alamat IP. Produk seperti ini umumnya disebut
sebagai Intrusion Prevention System (IPS). Beberapa produk IDS juga menggabungkan kemampuan yang dimiliki oleh HIDS dan NIDS, yang kemudian disebut sebagai sistem hibrid (hybrid intrusion detection system).
2.2.3 DATA MINING
Data mining adalah suatu proses yang digunakan untuk mencari informasi
dan knowledge yang berguna, dimana diperoleh dari data-data yang dimiliki. Dari buku Data Mining Technique yang dikarang oleh Berry and Linoff, proses terjadinya data mining dapat dideskripsikan sebagai virtous cycle. Didasari oleh pengembangan berkelanjutan dari proses bisnis serta didorong oleh penemuan
knowledge ditindaklanjuti dengan pengambilan tindakan dari penemuan tersebut.
Clustering juga disebut sebagai segmentation. Metoda ini digunakan untuk
mengidentifikasi kelompok alami dari sebuah kasus yang di dasarkan pada sebuah kelompok atribut, mengelompokkan data yang memiliki kemiripan atribut.
Gambar dibawah ini menunjukkan kelompok data pelanggan sederhana yang berisi dua atribut, yaitu Age (Umur) dan Income (Pendapatan).
Gambar 2.2 Clustering (Sumber:Anonim, November 2014)
Algoritma Clustering mengelompokkan kelompok data kedalam tiga segment berdasarkan kedua atribut ini.
a) Cluster 1 berisi populasi berusia muda dengan pendapatan rendah
b) Cluster 2 berisi populasi berusia menengah dengan pendapatan yang lebih
tinggi
c) Cluster 3 berisi populasi berusia tua dengan pendapatan yang relatif rendah. Clustering adalah metode data mining yang Unsupervised, karena tidak ada
Kebanyakan Algoritma Clustering membangun sebuah model melalui serangkaian pengulangan dan berhenti ketika model tersebut telah memusat atau berkumpul (batasan dari segmentasi ini telah stabil).
2). Association
Association juga disebut sebagai Market Basket Analysis. Sebuah problem
bisnis yang khas adalah menganalisa tabel transaksi penjualan dang mengidentifikasi produk-produk yang seringkali dibeli bersamaan oleh customer, misalnya apabila orang membeli sambal, biasanya juga dia membeli kecap. Kesamaan yang ada dari data pembelian digunakan untuk mengidentifikasi kelompok kesamaan dari produk dan kebiasaan apa yang terjadi guna kepentingan cross-selling seperti gambar dibawah ini.
Gambar 2.3 Association (Sumber:Anonim, November 2014) Bisa lihat disini, beberapa hal dapat kita baca, misalnya :
a) Ketika orang membeli susu, dia biasanya membeli keju
b) Ketika orang membeli pepsi atau coke, biasanya dia membeli juice
a) Untuk mencari produk apa yang biasanya terjual bersamaan.
b) Untuk mencari tahu apa aturan yang menyebabkan kesamaan tersebut.
3). Classification
Classification adalah tindakan untuk memberikan kelompok pada setiap
keadaan. Setiap keadaan berisi sekelompok atribut, salah satunya adalah class
attribute. Metode ini butuh untuk menemukan sebuah model yang dapat
menjelaskan class attribute itu sebagai fungsi dari input attribute.
Data Mining Untuk Deteksi Intr usi
Data mining untuk deteksi intrusi disini diambil dari paper Dwi Widiastuti
Jurusan Sistem Informasi dari Universitas Gunadarma dengan judul “Analisa Perbandingan Algoritma SVM, Naive Bayes,dan Decision tree Dalam Mengklasifikasikan Serangan (Attack) Pada Sistem Pendeteksi Intrusi “. Pada penelitian tersebut dilakukan terhadap dataset yang diperoleh dari KDD 1999 sebanyak 5092 record dan dikelompokkan menjadi lima kelas. Klasifikasi dilakukan dengan menerapkan algoritma SVM (menggunakan teknik SMO),
Bayesian (menggunakan teknik NBC), dan Decision Tree (menggunakan teknik
J48) yang telah tersedia pada tools data mining yakni WEKA 3.4.13.
Berdasarkan penelitian Charles Elkan (2000), data log file sebelum menjadi
data set dieksrak sedemikian rupa dengan menggunakan 41 variable/atribut yang
dianggap berpengaruh pada sistem pendeteksi intrusi dan merupakan variable yang cukup efektif untuk menghitung performa algoritma.
multihop, neptune, nmap, normal,perl, phf, pod, portsweep, rootkit, satan, smurf, spy, teardrop, warezclient, warezmaster. Dataset penelitian ini (5092 record) serangan-serangan tersebut diklasifikasikan berdasarkan sasaran dan tujuan serangan menjadi lima kelas kategori, yakni : DoS, Probe, U2R, dan U2L, dan Normal (Mrutyunjaya Panda dan Mana R. Patra, 2007).
Dari data yang tersedia, diolah menggunakan Microsoft Excel di konversi menjadi format csv yang kemudian diubah menjadi format file yang dikenali oleh WEKA yaitu arff. Hasil pemrosesan data diringkas dalam bentuk tabel sebagai berikut :
Tabel 2.1 Perbandingan SVM, Naïve Bayes, dan Decision Tree Pada Data Numerik
SVM
Use Training Set Cross Validation Percentage Split Correctly Classified 96.6614 % 96.6418 % 96.7277 %
Incorrectly Classified 3.3386 % 3.3582 % 3.2723 %
Kappa Statistic 0.9394 0.939 0.9397
Mean Absolute Error 0.2417 0.2418 0.2419
Naive Bayes
Use Training Set Cross Validation Percentage Split Correctly Classified 94.0691 % 93.5192 % 94.3717 % Incorrectly Classified 5.9309 % 6.4808 % 5.6283 %
Kappa Statistic 0.8919 0.8824 0.8952
Mean Absolute Error 0.0246 0.0266 0.0233
Root Mean Squared
Use Training Set Cross Validation Percentage Split Correctly Classified 98.0558 % 97.7612 % 97.7094 % Incorrectly Classified 1.9442 % 2.2388 % 2.2906 %
Kappa Statistic 0.9648 0.9594 0.9582
Mean Absolute Error 0.0258 0.0269 0.0304
Root Mean Squared
dibutuhkan untuk membangun sebuah model), terlihat dari perbandingan tabel 2.2.
Tabel 2.2 Hasil Perbandingan Waktu Komputasi Algoritma (Satuan : second )
SVM (SMO) Bayesian digunakan untuk melakukan klasifikasi atau segmentasi atau pengelompokan dan bersifat prediktif. Dasar algoritma C4.5 adalah pembentukan pohon keputusan (decision tree). Dengan algoritma ini, mesin (komputer) akan diberikan sekelompok data untuk dipelajari yang disebut learning dataset. Kemudian hasil dari pembelajaran selanjutnya akan digunakan untuk mengolah data-data yang baru yang disebut test dataset. Karena algoritma C4.5 digunakan untuk melakukan klasifikasi, jadi hasil dari pengolahan test dataset berupa pengelompokkan data ke dalam kelas-kelasnya.
Dalam pembentukan decision tree C4.5 digunakan rumus menghitung entropy dan
Rumus hitung entropy :
pi : Proporsi dari Si terhadap S Rumus hitung information gain :
n : Jumlah partisi atribut A
|Si| : Jumlah kasus pada partisi ke i
|S| : Jumlah kasus dalam S
2.2.5 WEKA ( Waikato Environment for Knowladge Analysis )
menjadi bagian dari Pentaho. Weka terdiri dari koleksi algoritma machine learning yang dapat digunakan untuk melakukan generalisasi / formulasi dari sekumpulan data sampling. Walaupun kekuatan Weka terletak pada algoritma yang makin lengkap dan canggih, kesuksesan data mining tetap terletak pada faktor pengetahuan manusia implementornya. Tugas pengumpulan data yang berkualitas tinggi dan pengetahuan pemodelan dan penggunaan algoritma yang tepat diperlukan untuk menjamin keakuratan formulasi yang diharapkan.
Gambar 2.4 Tampilan WEKA (Sumber:Erdi Susanto, November 2014) Empat tombol diatas dapat digunakan untuk menjalanankan Aplikasi :
1) Explorer digunkan untuk menggali lebih jauh data dengan aplikasi WEKA 2) Experimenter digunakan untuk melakukan percobaan dengan pengujian
statistic skema belajar
3) Knowledge Flow digunakan untuk pengetahuan pendukung
Gambar 2.5 Tampilan explorer WEKA (Sumber:Erdi Susanto, November 2014) Pada bagian atas window, tepatnya pada bawah judul bar. Terdapat deretan data, seperti Prepocess, Classify, Cluster, Associate, Select Attributes Visualize. Namun yang aktif hanya Prepocess ini dikarenakan sebelum menggunakan algoritma diatas pastikan sudah melakukan set file yang akan dieksekusi Berikut langkah-langkahnya :
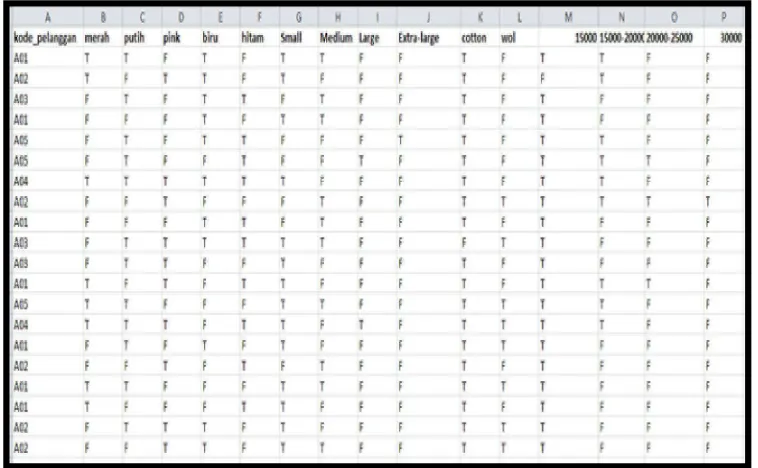
Buka file yang akan dieksekusi oleh Weka, pergunakan extensi file .csv (Command Separated Values). Perlu diingat bahwa sebelumnya kita sudah harus menyediakan data-data pada file tersebut. Disini menggunakan contoh Transaksi.csv sebagai berikut
Gambar 2.7 Tampilan data transaksi (Sumber:Erdi Susanto, November2014) Kemudian pilih algoritma yang akan digunakan seperti tampilan berikut ini :
Algoritma yang akan digunakan adalah J48. Perbedaan ID3, C4.5 dan J48 sebagai berikut ini:
ID3 merupakan algoritma yang dipergunakan untuk membangun sebuah decision tree atau pohon keputusan. Algoritma ini ditemukan oleh J. Ross Quinlan, dengan memanfaatkan Teori Informasi atau Information Theory milik Shanon. ID3 sendiri merupakan singkatan dari Iterative Dichotomiser 3. Idenya, adalah membuat pohon dengan percabangan awal adalah atribut yang paling signifikan. Maksudnya signifikan adalah yang paling bisa mempartisi antara iya dan tidak. Bisa dilihat, bahwa atribut “patron” membagi 3, dimana hasil pembagiannya cukup ideal. Maksudnya ideal adalah setiap cabang terdiri dari hijau saja atau merah saja. Memang, untuk cabang “full” tidak satu warna (hijau saja atau merah saja). Tapi, pemilihan atribut patron jelas lebih baik daripada atribut type.
Untuk menentukan atribut mana yang lebih dahulu dipergunakan untuk membuat cabang pohon, digunakanlah teori informasi. Pada WEKA, ada pilihan untuk menggunakan ID3 ini, dengan nama yang sama. Namun, jelas semua atribut harus bertipe nominal, dan tidak boleh ada yang kosong
Sedangkan, C4.5 merupakan pengembangan dari ID3. Beberapa perbedaannya antara lain :
1). Mampu menangani atribut dengan tipe diskrit atau kontinu. 2). Mampu menangani atribut yang kosong (missing value) 3). Bisa memangkas cabang.
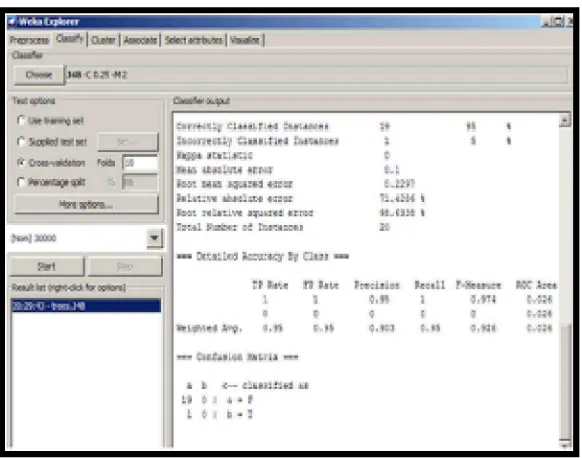
Gambar 2.9 Contoh hasil klasifikasi (Sumber:Erdi Susanto, November 2014)
Jadi, ketika ingin melakukan klasifikasi dengan menggunakan WEKA, akan ada 4 (empat) buah pilihan, yang disebut dengan test options. Test options ini digunakan untuk mengetes hasil dari klasifikasi yang telah dilakukan. Berikut penjelasan mengenai masing-masing option.
1). Use training set
Pengetesan dilakukan dengan menggunakan data training itu sendiri. 2). Supplied test set
Pengetesan dilakukan dengan menggunakan data lain. Dengan menggunakan option inilah, kita bisa melakukan prediksi terhadap data test.
3). Cross-validation
Pada cross-validation, akan ada pilihan berapa fold yang akan digunakan. Nilai
Data training dibagi menjadi k buah subset (subhimpunan). Dimana k adalah nilai
dari fold. Selanjutnya, untuk tiap dari subset, akan dijadikan data tes dari hasil klasifikasi yang dihasilkan dari k-1 subset lainnya. Jadi, akan ada 10 kali tes. Dimana, setiap datum akan menjadi data tes sebanyak 1 kali, dan menjadi data training sebanyak k-1 kali. Kemudian, error dari k tes tersebut akan dihitung rata-ratanya.
4. Percentage split
Hasil klasifikasi akan dites dengan menggunakan k% dari data tersebut. k merupakan masukan dari user. Untuk melihat decision tree-nya liat tampilan sebagai berikut ini :
METODE PENELITIAN
3.1 RANCANGAN PENELITIAN
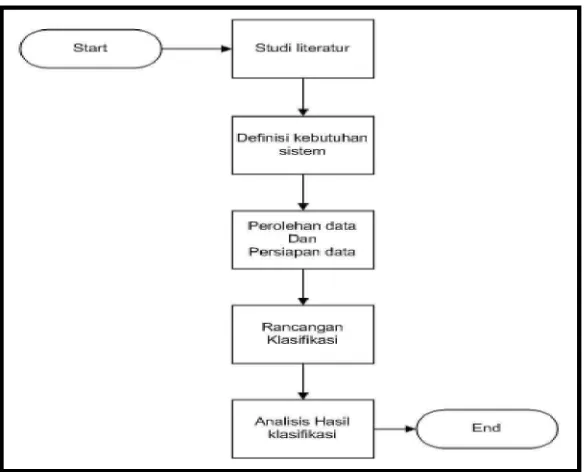
Dalam bab ini akan membahas tentang penyelesaian masalah yang sudah dipaparkan dalam rumusan masalah. Untuk sistem yang dibutuhkan akan dibedakan berdasarkan hardware dan software, dimana hardware yang digunakan harus dapat menjalankan software-software seperti Windows 7, WEKA( Waikato Environment for Knowladge Analysis ), Wireshark, Microsoft office excel dan TCPdump. Windows 7 sebagai sistem operasi utama yang digunakan untuk menjalankan WEKA. TCPdump adalah aplikasi Network Tools untuk melakukan tes sniffer dalam networking, Microsoft office excel digunakan sebagai penyimpan data. Berikut adalah diagram alur untuk rancangan penelitian :
Untuk melakukan serangan DoS akan menggunakan Backtrack 5 R3 sebagai virtual OS, dan dalam melakukan serangan di butuhkan 2 buah virtual OS Backtrack 5 R3 yang masing-masing berguna sebagai penyerang dan target yang di serang, kemudian setelah serangan dilakukan, digunakan TCPdump untuk menangkap paket-paket serangan tersebut.
3.1.1 STUDI LITERATUR
Tahap ini dilakukan studi literatur terhadap konsep dan metode yang digunakan, serta pengumpulan data-data mengenai yang dibutuhkan seperti jurnal maupun makalah, implementasi, serta artikel ilmiah dan buku.
3.1.2 DEFINISI KEBUTUHAN SISTEM
Pada tahap ini dilakukan pendefinisian terhadap apa saja yang di butuhkan untuk membangun tugas akhir ini, antara lain :
1) Kebutuhan Hardware
Dalam pengerjaan tugas akhir ini menggunakan sebuah notebook dengan spesifikasi sebagai berikut: Aspire 4732z, Intel Dual Core 2.10Ghz, Memory RAM 2GB, HDD 320GB.
2) Kebutuhan Software
Software atau perangkar lunak yang digunakan dalam tugas akhir ini
sebagai berikut: a. Windows 7 Ultimate
b. Microsoft office excel
Adalah perangkat lunak yang di gunakan untuk menyimpan data.
c. VMware
Merupakan software yang digunakan untuk virtual machine (mesin virtual) fungsinya adalah untuk menjalankan banyak operating sistem dalam satu perangkat keras (tentu saja perlu di perhatikan spesifikasi komputer yang digunakan) dan untuk menjalankan aplikasi yang ditunjuk untuk sistem operasi lainnya.
d. Backtr ack 5 R3
Adalah sebuah sistem operasi yang berjalan pada virtual machine.
e. TCPdump
adalah sebuah tool yang berfungsi untuk melihat paket data yang berjalan di jaringan.
f. Wireshar k
adalah tools yang digunakan untuk menganalisis paket ditangkap oleh TCPdump.
3.2 PEROLEHAN DATA DAN PERSIAPAN DATA
Dalam klasifikasi, dataset dibagi menjadi 2 yaitu data training dan data
test. Data training adalah data yang digunakan untuk pembelajaran dan
membentuk sebuah model klasifikasi, sedangkan data test adalah data yang digunakan untuk menguji seberapa akurat model tersebut mengklasifikasi dengan tepat. Dan dalam melakukan percobaan klasifikasi, dataset dari KDD CUP 1999 yang hanya berisi Ping of Death dan Smurf akan digunakan sebagai data training dengan total sebanyak 500 record. Sedangkan untuk data test akan menggunakan
dataset yang dibuat dari pengolahan data log mentah TCPdump yang berisi
paket-paket Ping of Death dan Smurf, data test akan di bagi menjadi 30 data test yaitu 15 data test Smurf dan 15 data test Ping of Death yang akan diuji coba dalam dua kesempatan, dan masing-masing data test berisi sebanyak 100 record.
Pada percobaaan ini akan menggunakan 8 atribut yang terdapat pada dataset KDD CUP 1999, 8 atribut tersebut dipilih karena berpengaruh besar dalam menentukan serangan DOS Smurf dan Ping of Death, berikut adalah atribut yang digunakan :
1) atribut duration (durasi) numeric
2) atribut protocol_type (tipe protokol) {icmp} 3) atribut service (layanan) {ecr_i,tim_i,vmnet} 4) atribut src_bytes (bytes yang terkirim) numeric 5) atribut urgent (paket urgent) numeric
6) atribut count (jumlah) numeric
Adapun penjelasan mengenai ke 8 atribut , yaitu : 1) duration : durasi dari koneksi.
2) protocol_type : tipe koneksi protokol yang digunakan seperti TCP, UDP dan ICMP.
3) service : vmnet,http, ftp, smtp, telnet... dan lain-lain. 4) src_bytes : bytes yang terkirim dalam satu koneksi. 5) urgent : jumlah paket urgent didalam sebuah koneksi.
6) count : jumlah dari koneksi dengan host yang sama dalam dua detik terakhir.
7) srv_count : jumlah dari koneksi dengan service yang sama dalam dua detik terakhir.
3.3 RANCANGAN UJ I COBA
Pada rancangan uji coba terdapat 2 rancangan yaitu rancangan pembuatan model klasifikasi dan rancangan klasifikasi, berikut adalah rancangannya:
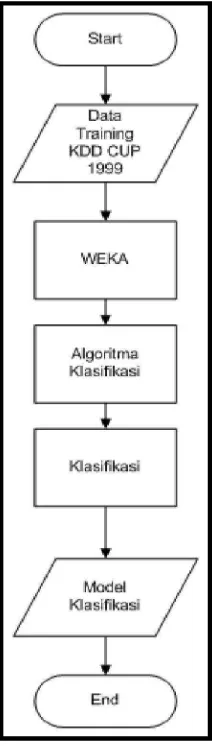
3.3.1 Rancangan Uji Coba Pembentukan Model Klasifikasi
Dalam rancangan uji coba pembentukan model klasifikasi. data training KDD CUP 1999 digunakan untuk membentuk model klasifikasi, berikut adalah rancangannya :
Gambar 3.2 Rancangan Uji Coba Pembentukan Model Klasifikasi
Pada rancangan tersebut, dataset KDD CUP 1999 digunakan sebagai data
di klasifikasi dengan menggunakan WEKA. Dalam proses klasifikasi nantinya akan menggunakan salah satu algoritma klasifikasi yang terdapat pada WEKA yaitu algoritma j48. Dan setelah algoritma sudah ditentukan maka dijalankan proses klasifikasi terhadap data training KDD CUP 1999 dan hasil dari klasifikasi
data training tersebut akan membentuk sebuah model klasifikasi yang akan
digunakan dalam mengklasifikasi data test. 3.3.2 Rancangan Uji Coba Klasifikasi
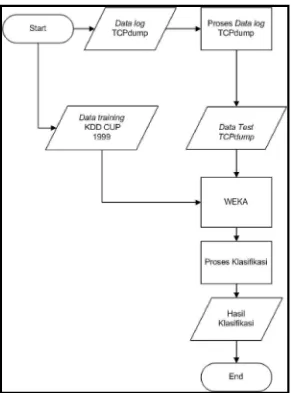
Dalam rancangan uji coba ini akan dilakukan klasifikasi terhadap data test TCPdump. berikut adalah rancangannya :
Pada rancangan uji coba, data log mentah TCPdump yang berisi paket-paket serangan Smurf dan Ping of death akan diolah menggunakan wireshark untuk mendapatkan nilai dari atribut yang telah ditentukan, setelah itu data yang diperoleh dari pengolahan data log TCPdump akan disimpan di dalam database microsoft excel yang kemudian data tersebut akan di konversi menjadi sebuah
dataset yang akan digunakan untuk klasifikasi serangan.
Dan dalam proses klasifikasi, dataset KDD CUP 1999 akan digunakan sebagai data training untuk membentuk sebuah model klasifikasi. Dan setelah model klasifikasi terbentuk maka dilakukan pengujian terhadap model tersebut menggunakan data test serangan Smurf dan Ping of death dengan menggunakan perangkat lunak WEKA untuk mengetahui hasil klasifikasi serangan terhadap
dataset yang dibuat. Dan setelah itu akan dilakukan analisa terhadap hasil
klasifikasi untuk mengetahui tingkat keakuratan metode decision tree dalam mengklasifikasikan sebuah serangan DoS Ping of Death dan Smurf.
3.4 RANCANGAN ANALISIS KLASIFIKASI SERANGAN DOS
Pada rancangan analisis akan menjelaskan bagaimana cara mengetahui keakuratan metode decision tree dalam mengklasifikasikan serangan DOS. Adapun parameter-parameter yang digunakan untuk mengetahui tingkat keakuratan tersebut, adalah :
1). Correctly Classified
Correctly Classified adalah jumlah data yang di klasifikasikan dengan tepat
2).Incorrectly Classified
Incorrectly Classified adalah jumlah data yang di klasifikasikan dengan
tidak tepat.
3). Total Number of Instances
Total jumlah data contoh yang ada pada dataset.
Dan untuk setiap dataset yang dibuat akan dilakukan pengukuran dengan menggunakan parameter-parameter tersebut untuk mengetahui tingkat keakuratan metode decision tree dalam mengklasifikasikan serangan DOS Smurf dan Ping of
BAB IV
HASIL DAN PEMBAHASAN
4.1 IMPLEMENTASI
Implementasi yang dilakukan pada bab ini didasari pada rancangan penelitian pada bab 3. Berikut adalah hasil implementasinya:
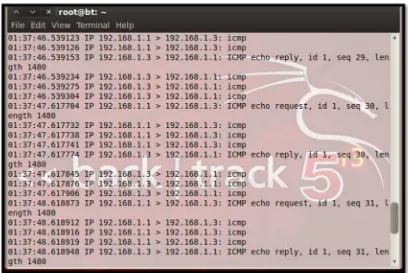
4.1.1 Capture Paket Menggunakan TCPdump
Pada gambar 4.1 merupakan hasil capture paket-paket dari DOS serangan
Ping of Death yang dilakukan menggunakan perangkat lunak TCPdump.
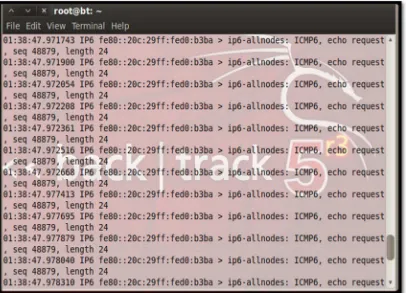
Gambar 4.2 Capture Serangan Smurf
Pada gambar 4.2 merupakan hasil capture dari paket-paket serangan DOS
Smurf. Proses capture menggunakan TCPdump sendiri dilakukan sampai
mendapat 30 data log mentah terdiri dari 15 data log serangan Smurf dan 15 data
log serangan Ping of Death.
4.1.2 Memproses Data Log TCPdump
Gambar 4.3 Hasil Filter Data Log Ping of Death
Pada gambar 4.3 merupakan hasil dari data log mentah dari serangan Ping
of Death yang telah di filter menggunakan Wireshark.
Gambar 4.4 Hasil Filter Data Log Smurf
4.1.3 Pembuatan Dataset
Setelah melakukan pengolahan pada data log TCPdump dan mendapat nilai dari masing-masing atribut, maka data tersebut disimpan ke database menggunakan Microsoft Office Excel dengan format *Csv.
Gambar 4.5 Database Serangan Ping of Death
Pada gambar 4.5 menampilkan database dari serangan Ping of Death yang sudah memiliki atribut beserta nilai dari atribut tersebut. Dan masing-masing
Gambar 4.6 Database Serangan Smurf
Gambar 4.7 Dataset Dengan Format *Arff
Pada gambar 4.7 menampilkan dataset dengan format *Arff yang akan digunakan dalam percobaan klasifikasi serangan DOS dengan menggunakan metode decision tree.
4.1.4 Pembentukan Model Klasifikasi
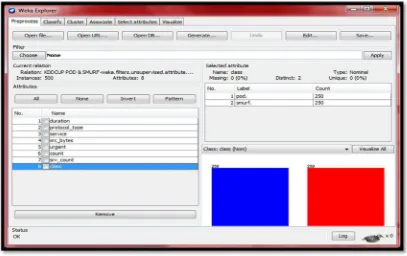
Gambar 4.8 Dataset KDD CUP 1999
Pada Gambar 4.8 menampilkan dataset KDD CUP 1999 yang telah di open menggunakan WEKA, Setelah dataset KDD CUP 1999 dibuka, maka dipilih tab
classify yang terdapat pada WEKA untuk melakukan klasifikasi.
Pada gambar 4.9 menampilkan menu yang terdapat pada tab classify WEKA. Pada menu test option dipilih use training set untuk melakukan pengujian terhadap dataset KDD CUP 1999 sebagai data training itu sendiri.
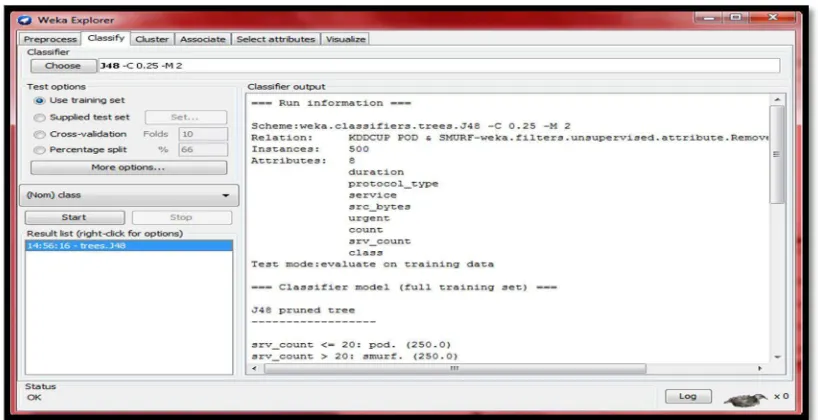
Gambar 4.10 Tampilan Menu Algoritma Klasifikasi WEKA
Pada gambar 4.10 menampilkan algoritma klasifikasi yang terdapat pada WEKA. Pada implementasi ini algoritma yang digunakan untuk mengklasifikasi adalah algoritma j48. Dan setelah algoritma sudah dipilih maka proses pembuatan model pada data training dapat dijalankan dengan menekan tombol start.
Pada gambar 4.11 menampilkan hasil data training KDD CUP 1999 yang telah di klasifikasi. Dan dari hasil data training tersebut akan menjadi sebuah model yang akan digunakan dalam mengklasifikasikan dataset yang telah dibuat. Model tersebut juga dapat disimpan dengan klik kanan pada result list kemudian
save model.
4.1.5 Klasifikasi Dataset TCPdump
Pada gambar 4.12 menampilkan pemilihan opsi supplied test set pada test
option untuk melakukan klasifikasi menggunakan data test. Setelah itu klik
tombol set untuk memilih dataset yang akan digunakan sebagai data test.
Gambar 4.13 Pemilihan Data Test
Pada gambar 4.13 menampilkan pemilihan data test yang akan digunakan, dan dataset ping of death 1 adalah dataset yang dipilih untuk digunakan sebagai
data test. Dan setelah memilih data test maka proses klasifikasi dapat dijalankan
dengan menekan tombol start.
Pada gambar 4.14 menampilkan hasil klasifikasi dari data test ping of death 1. Dan dari hasil tersebut dapat dilihat apakah data test dapat di klasifikasikan dengan tepat dan benar.
4.2 HASIL UJ I COBA DAN EVALUASI
Pada bagian ini akan menjelaskan tentang hasil uji coba dan hasil analisa yang di lakukan. Berikut adalah hasil dari uji coba yang dilakukan :
4.2.1 Hasil Uji Coba Pembentukan Model Klasifikasi
Pada hasil uji coba model klasifikasi, akan menggunakan dataset dari KDD CUP 1999 yang akan digunakan sebagai data training dan hasil dari klasifikasi
data training tersebut yang akan digunakan sebagai model klasifikasi. Dan untuk
menguji model klasifikasi KDD CUP 1999 yang telah dibuat, maka akan digunakan 30 kali percobaan dengan menggunakan 30 data test yang berbeda yang terdiri dari 15 dataset serangan Smurf dan 15 dataset serangan Ping of
Death. Pada awal uji coba pembuatan terhadap data training KDD CUP 1999
akan menggunakan 8 atribut duration, protocol_type, service, src_bytes, urgent, count, srv_count dan class dalam pembuatan sebuah model classifier. Berikut adalah hasil pembuatan model dari klasifikasi dataset KDD CUP 1999 sebagai
Gambar 4.15 Hasil Run information KDD CUP 1999
Pada gambar 4.15 menampilkan informasi dari data training KDD CUP 1999 yang telah diklasifikasi dengan jumlah 500 record dan 8 atribut yang digunakan yaitu atribut duration, protocol_type, service, src_bytes, urgent, count, srv_count dan class dengan test mode sebagai data training.
Pada gambar 4.16 menampilkan hasil detail akurasi berdasarkan class pada klasifikasi data training KDD CUP 1999. Dan pada detail akurasi tersebut menampilkan True Positive (TP) Rate, False Positive (FP) Rate, Precision,
Recall, F-Measure, ROC Area dari setiap class. True Positive (TP) Rate adalah
proporsi contoh yang diklasifikasikan sebagai kelas x , di antara semua contoh yang benar-benar memiliki kelas x , yaitu berapa banyak bagian dari kelas itu ditangkap. False Positive (FP) Rate adalah proporsi contoh yang diklasifikasikan sebagai kelas x , tetapi termasuk ke dalam kelas yang berbeda , di antara semua contoh yang bukan dari kelas x. Precision adalah proporsi contoh yang benar-benar memiliki kelas x di antara semua yang diklasifikasikan sebagai kelas x.
F-Measure adalah gabungan antara Precision dan Recall dengan rumus
2*Precision*Recall/Precision+Recall. Dan Receiver operating characteristic (ROC) Area adalah plot dari True Positive (TP) Rate dengan False Positive (FP)
Rate.
Pada gambar 4.17 menampilkan evaluasi dari training set yang berisikan
Correctly Classified Instances 100%, Incorrectly Classified Instances 0%, Kappa statistic 1, Mean absolute error 0, Root mean squared error 0, Relative absolute error 0%, Root relative squared error 0% dan Total number of Instances 500. Correctly Classified adalah jumlah data yang di klasifikasikan dengan tepat dan
benar. Incorrectly Classified adalah jumlah data yang di klasifikasikan dengan tidak tepat. Kappa Statistic adalah ukuran kesepakatan dari prediksi dengan class yang sebenarnya. Mean Absolute Error adalah salah satu dari sejumlah cara membandingkan perkiraan dengan hasil akhirnya mereka. Root mean squared error adalah aturan skoring kuadrat yang mengukur besarnya rata-rata kesalahan. Relative absolute error adalah total dari absolute error dengan jenis normalisasi
yang sama. Root relative squared error adalah rata-rata dari nilai yang sebenarnya dari data training. Total number of Instances merupakan total dari data contoh.
Pada gambar 4.18 menampilkan confusion matrix dari model klasifikasi KDD CUP 1999, pada confusion matrix setiap kolom menunjukkan contoh class yang diprediksi dan setiap baris menunjukkan contoh class sebenarnya. Dan hasil
confusion matrix dari KDD CUP 1999 menunjukkan dari 500 record, sebanyak
250 record diklasifikasikan sebagai class pod. Dan 250 record diklasifikasikan sebagai class smurf.
4.2.2 Hasil Uji Coba Klasifikasi Dataset TCPdump
Pada hasil uji coba klasifikasi dataset TCPdump, akan menggunakan 10
dataset yang dibuat dari data log TCPdump yang akan digunakan sebagai data
uji/data test. Pada 30 dataset yang akan digunakan sebagai data test akan ada 15
dataset serangan Smurf dan 15 dataset serangan Ping of Death. Dan
masing-masing dataset akan dilakukan 1 kali percobaan sebagai data test/data uji untuk menguji model klasifikasi KDD CUP 1999. Berikut adalah hasil uji coba klasifikasi dari dataset TCPdump :
Pada gambar 4.19 menunjukkan hasil evaluasi pada salah satu data test serangan Ping of Death yang digunakan yaitu data test Ping of Death 1. Dan waktu yang diperlukan dalam melakukan klasifikasi adalah 0 second. Dan pada hasil evalusi tersebut menunjukkan Correctly Classified Instances sebesar 100%,
Incorrectly Classified Instances 0%, Kappa statistic 1, Mean absolute error 0, Root mean squared error 0, Relative absolute error 0% dan Root relative squared error 0% dari Total Number of Instances sebanyak 100 record.
Gambar 4.20 Hasil Detail Akurasi Berdasar Class Data Test Ping of Death 1
Pada gambar 4.20 menunjukkan hasil detail akurasi berdasarkan class pada
data test serangan Ping of Death 1. Hasil tersebut menunjukkan TP Rate sebanyak
Gambar 4.21 Hasil Confusion Matrix Data Test Ping of Death 1
Pada gambar 4.22 menunjukkan hasil evaluasi pada salah satu data test serangan Smurf yang digunakan yaitu data test Smurf 1. Dan waktu yang diperlukan dalam melakukan klasifikasi adalah 0.03 second. Dan pada hasil evalusi tersebut menunjukkan Correctly Classified Instances sebesar 100%,
Incorrectly Classified Instances 0%, Kappa statistic 1, Mean absolute error 0, Root mean squared error 0, Relative absolute error 0% dan Root relative squared error 0% dari Total Number of Instances sebanyak 100 record.
Gambar 4.23 Hasil Detail Akurasi Berdasar Class Data Test Smurf 1
Pada gambar 4.23 menunjukkan hasil detail akurasi berdasarkan class pada
Gambar 4.24 Hasil Confusion Matrix Data Test Smurf 1
4.2.3 Analisis Klasifikasi Serangan
Pada bagian ini akan dilakukan analisis terhadap hasil klasifikasi serangan terhadap 30 data test dalam dua kesempatan percobaan dengan masing-masing
data test berisi 100 record.
Tabel 4.1 Analisis Klasifikasi Lima Belas Data Test Pada Kesempatan Pertama
Pada tabel 4.1 menampilkan hasil dari lima belas kali percobaan klasifikasi serangan Ping of Death dan Smurf terhadap lima belas data test pada kesempatan pertama.
Tabel 4.2 Analisis Klasifikasi Lima Belas Data Test Pada Kesempatan Kedua
Data Test Cor r ectly
data test terdapat correctly classified untuk mengetahui berapa persen data yang
diklasifikasikan secara tepat, sedangkan incorrectly classified berguna untuk mengetahui berapa persen data yang diklasifikasikan dengan tidak tepat dan total
number of instances untuk mengetahui jumlah record yang terdapat pada data test
Dalam menganalisis klasifikasi serangan tidak hanya mengetahui berapa persen correctly classified dan incorrectly classified, nantinya akan dilakukan analisis kappa. Dari hasil analisis kappa tersebut akan di ketahui apakah metode
decision tree dapat mengklasifikasikan serangan pada data test yang dibuat. Dan
Pada tabel 4.3 terdapat K1 dan K2, K1 adalah percobaan pada kesempatan pertama, sedangkan K2 adalah percobaan pada kesempatan kedua. Dan untuk setiap data test yang diklasifikasikan dengan correctly classified sebesar 100%=1
dan data test yang diklasifikasikan dengan correctly classified sebesar <100%=0.
Untuk melakukan perhitungan kappa akan menggunakan software SPSS (Statistical Product and Service Solutions). Dan berikut adalah hasil perhitungan kappa menggunakan SPPS :
Pada gambar 4.25 menampilkan hasil analisis kappa menggunakan SPSS. Dan untuk nilai kappa dikelompokkan sebagai berikut :
• Kappa > 0,80 : Sangat Baik
• Kappa 0,61-0,80 : Baik
• Kappa 0,41-0,60 : Cukup Baik
• Kappa 0,21-0,40 : Cukup
• Kappa < 0,21 : Buruk
Dalam penelitian ini hasil kappa yang diperoleh dari perhitungan menggunakan SPSS adalah 0,423. Dan hasil tersebut menunjukkan bahwa metode
decision tree cukup baik dalam mengklasifikasikan data test yang dibuat
BAB V
KESIMPULAN DAN SARAN
5.1 KESIMPULAN
Kesimpulan yang diperoleh dari hasil uji coba dan analisis yang telah dilakukan untuk Tugas Akhir ini adalah sebagai berikut :
1) Metode decision tree menghasilkan tingkat keakuratan yang cukup tinggi dalam mengklasifikasikan serangan Ping of Death dengan rata-rata class yang diprediksi dengan tepat di atas 60%.
2) Metode decision tree juga menghasilkan tingkat keakuratan yang sangat tinggi dalam mengklasifikasikan serangan Smurf dengan rata-rata class yang diprediksi dengan tepat sebesar 100%.
3) Secara keseluruhan metode decision tree terbukti cukup akurat dalam mengklasifikasikan serangan Denial of Service (DOS) yaitu Ping of Death dan Smurf dengan rata-rata keseluruhan hasil dari klasifikasi semua data test yang dibuat sebesar 91.2% untuk class yang di prediksi dengan tepat dan nilai kappa sebesar 0,423 yang dinilai cukup baik dalam penelitian ini.
5.2 SARAN
Saran yang dapat diberikan untuk pengembangan lebih lanjut dari Tugas Akhir ini adalah sebagai berikut :
1) Mencoba menambahkan atribut lain untuk mendapatkan tingkat keakuratan yang lebih tinggi dalam melakukan klasifikasi serangan dengan metode
2) Mencoba melakukan pengujian model KDD CUP 1999 dengan dataset serangan yang lain, untuk mengetahui keakuratan metode decision tree dalam mengklasifikasi berbagai macam serangan, selain serangan Ping of Death dan
DAFTAR PUSTAKA
Anonim, Denial of Service, dari http://id.wikipedia.org/wiki/Denial_Of_Service ,15 November 2014.
Anonim, Ping Kematian dari http://id.wikipedia.org/wiki/Ping_ Kematian, 15 November 2014.
Anonim, Sistem Deteksi Intrusi dari http://id.wikipedia.org/wiki/Sistem_deteksi intrusi, 15 November 2014.
Anonim, Serangan Smurf, dari http://id.wikipedia.org/wiki/Serangan_Smurf 15 November 2014.
Brahmi, I., Yahia, B. S., & Poncelet, P. (2010). MAD-IDS: Novel Intrusion Detection System using. 12.
O. Oriola., A.B. Adeyemo., & A.B.C. Robert. (2012). Distributed Intrusion Detection System Using P2P Agent Mining Scheme.
Susanto E. , Data Mining Menggunakan WEKA dari
http://www.erdisusanto.com/2012/06/data-mining-menggunakan-weka.html, 15 November 2014.
Widiastuti, D. (2012). Analisa Perbandingan Algoritma SVM, Naive Bayes, dan Decision Tree Dalam Mengklasifikasikan Serangan (Attack). 8.
Yusroni, M. A.,Macam-Macam Serangan Pada Sistem dari