1
Perbandingan Fuzzy C-Means Clustering dengan
Latent Class Clustering Analysis
(Studi Kasus: Pengelompokan Kabupaten/kota Di Wilayah Jawa-Bali)
Yan Yan Gustiana1, Suwanda2, dan Zulhanif3 1
ProgramMagister Statistika Terapan UNPAD, [email protected] 2
Program Studi Statistika UNISBA, [email protected] 3
Program Studi Statistika UNPAD, [email protected]
ABSTRAK
Metode pengelompokan yang saat ini berkembang memiliki ciri keanggotaan cluster yang bersifat ketidakpastian atau probabilistik. Fuzzy C-Means Clustering (FCM) adalah contoh populer dari ketidakpastian sedangkan Latent Class Clustering Analysis (LCCA) merupakan model dengan probabilistik.
Dengan bantuan program R diperoleh, perbandingan akurasi hasil pengelompokan pada tabel kontingensi antara metode FCM dan LCCA terhadap data simulasi bangkitan bivariat yang berasal dari dua populasi dengan ukuran cluster berbeda (rasio 2:1) maupun rasio sama (1:1) menunjukkan kecenderungan ketepatan FCM pada kisaran 50% dari ukuran data. Sedangkan LCCA mampu mencapai angka 89% - 99% dari ukuran data.
Adanya variasi korelasi antar variabel tidak berpengaruh pada kinerja FCM, sedangkan metode LCCA menunjukkan hubungan positif antara besarnya korelasi dengan peningkatan akurasi pengelompokan. Sehingga kinerja akurasi pengelompokan metode LCCA terbukti lebih baik dibanding metode FCM dan lebih cocok digunakan pada penelitian fenomena sosial ekonomi yang memiliki indikator saling berkaitan.
Cluster optimal pengelompokan Kabupaten/Kota berdasarkan indeks validitas cluster (Connectivity, dan Silhouette) berada pada cluster sebanyak 3. Sehingga model terbaik untuk pengelompokan capaian pembangunan dari 121 Kabupaten/Kota dengan 13 variabel indikator yang meliputi (pro growth, pro job, pro poor dan IPM) adalah LCCA 3-cluster dengan direct effect.
Mayoritas Kabupaten/Kota (ada 88) capaian pembangunannya “Kurang Baik”, 33 yang berkategori “Baik”, dan 2 termasuk “Cukup Baik”.
Kata Kunci: FCM, LCCA, Akurasi, Validitas Cluster,pro growth, pro job, pro poor, dan IPM.
1. Pendahuluan
Paradigma baru pembangunan pembangunan nasional untuk mewujudkan pembangunan berkelanjutan yang berkualitas tertuang pada empat prinsip utama yaitu: pro lapangan pekerjaan (pro-job), pro rakyat miskin (pro-poor), pro pertumbuhan (pro-growth) dan pro lingkungan (pro-environment/pro green economy).
2
Dalam hal fungsi keanggotaan, ketidakpastian (fuzzy) dalam FCM secara konseptual sama dengan term probabilitas (peluang/kemungkinan) yang digunakan pada Latent Class Clustering Analysis (LCCA) (Kaufman, dkk, 1990 dalam Vermunt, dan Magidson, 2002).
Setelah menelaah adanya kemiripan dan keunggulan pada FCM dan LCCA, dan hingga kini belum ditemukan kajian yang membandingkan antara metode FCM dengan LCCA. Maka penulis mencoba untuk menyajikannya dalam penelitian ini dengan menggunakan data simulasi hasil bangkitan dan mengimplementasikan hasilnya pada data riil sebagai studi kasus. Terutama dalam proses pengelompokan obyek, tingkat akurasi hasil pengelompokan, dan validitas cluster.
Aplikasinya dalam pengelompokan kabupaten/kota (khususnya di wilayah Jawa-Bali) berdasarkan 13 variabel indikator kontinyu yang umum digunakan dalam mengevaluasi capaian pembangunan nasional, hal ini penulis yakini sangat relevan, penting, dan menemukan momentum yang tepat untuk disajikan.
2. Tinjauan Pustaka
Pada bagian ini membahas bahan rujukan yang digunakan, meliputi:
2.1 Pengujian Distribusi Multivariat Normal
Pengujian data berdistribusi normal multivariat di uji dengan membandingkan jarak kuadrat (Johnson dan Wichern, 2007):
= ( − ) ( − ) ...(1) dimana
= sampel random ke-h, h=1,2,…,n; = vektor rata-rata kolom;
= invers matrik varians-kovarians.
Hipotesis yang digunakan adalah H0= data berasal dari distribusi normal multivariat, sedangkan H1=data tidak berdistribusi normal multivariat. H0 diterima jika sebaran data menunjukan pola tertentu (menyebar mengikuti bentuk suatu garis menurut plot antara nilai chi-square dengan jarak Mahalanobis yang telah diurutkan) atau banyaknya nilai
2 2
, j q
d lebih dari 50%.
2.2 Ukuran Kemiripan (Similarity) dan Jarak (Dissimilarity)
Beberapa pengukuran jarak yang tersedia ;
1. Euclidean Distance, diartikan sebagai straight-line distance. Euclidean Distance adalah ukuran paling umum digunakan, merupakan jarak antara dua obyek (misalnya yi ke yj) berdimensi p dirumuskan sebagai:
= (∑ − ) / ...(2) 2. Jarak Euclidean juga sering dinyatakan dalam bentuk kuadrat disebut Squared (Absolute)
Euclidean Distance.
= (∑ − ) ...(3) 3. Mahalanobis Distance (D2), generalisasi pengukuran jarak yang menghitung korelasi antara variabel dengan membagi bobot sama rata. Keberadaan interkorelasi (baik secara positif atau negatif) antara variabel pengelompokan, pengukuran yang sering dipakai menggunakan jarak Mahalanobis, yang menstandarisasi data dan hubungan antar variabel yang dinyatakan dalam matriks varians kovarians S, dirumuskan sebagai:
= − ( − ) ...(4)
3
Tabel kontigensi atau disebut juga tabel tabulasi silang atau crosstab merupakan tabel yang disusun berdasarkan tabulasi data menurut 2 atau lebih kategori yang ditampilkan karena suatu unsur dengan unsur lainnya terdapat kesesuaian atau hubungan. Dalam istilah lain dikenal sebagai confusion matrix, yaitu tata letak khusus yang memungkinkan visualisasi kinerja algoritma, biasanya supervised learning (dalam unsupervised learning biasanya disebut matriks pencocokan). Setiap kolom dari matriks merupakan contoh di kelas prediksi, sementara setiap baris mewakili contoh dalam kelas yang aktual (sebenarnya). Dimensi atau ukuran tabel kontingensi beraneka ragam, yang paling sederhana berdimensi 2, seperti contoh dibawah ini:
Tabel 2.1 Bentuk Tabel Kontingensi 2x2 Prediksi
Total
1 2
Aktual 1 a b a+b
2 c d c+d
Total a+c b+d a+b+c+d
Dimana a adalah jumlah prediksi yang benar dari kelas aktual 1 di prediksi ke kelompok 1, b adalah jumlah prediksi yang salah dari kelas aktual 1 di prediksi ke kelompok 2, sedangkan c adalah jumlah yang salah prediksi dari kelas aktual 2 di prediksi ke kelompok 1, serta d adalah jumlah prediksi yang benar dari kelas aktual 2 diprediksi ke kelompok 2.
Menurut Provost, dan Fawcett (1997) pengukuran kinerja algoritma yang dapat diukur diantaranya adalah Akurasi (AC). Adalah kebenaran keseluruhan model dan dihitung sebagai jumlah dari klasifikasi yang benar dibagi dengan jumlah total klasifikasi. Merupakan proporsi jumlah prediksi yang benar. Hal ini ditentukan dengan menggunakan persamaan dari tabel kontingensi diatas:
= ...(5)
2.4 Metode Fuzzy C-Means Clustering (FCM)
FCM merupakan model pengelompokan yang didasarkan pada teori himpunan fuzzy. Berbeda dengan K-means yang menetapkan tiap obyek menjadi anggota dari suatu cluster tertentu dengan batasan yang jelas, FCM memungkinkan keanggotaan tiap obyek terbagi pada beberapa cluster. Di sini diberlakukan kondisi = ∈[ 0; 1] sebagai fungsi keanggotaan dari himpunan fuzzy pada Y dimana ∑ = 1 untuk semua yj. Semakin besar nilai ( ) menunjukkan semakin dekat obyek tersebut dengan titik pusat cluster tertentu. Algoritma iteratif FCM memerlukan kondisi agar dapat meminimumkan fungsi obyektif JFCM seperti berikut:
= ( , , ) = ∑ ∑ − , ...(6) dimana Y adalah matriks data berukuran n x p, c adalah banyaknya cluster, p adalah dimensi
(banyaknya variabel), = ∈ adalah matriks partisi fuzzy berdimensi c x n, = [ , , …, ] adalah vektor dari c-pusat cluster berdimensi p, dan pangkat penimbang m >
1 adalah indeks ke-fuzzy-an.
=
/ ( )
∑ / ( ) ...(7) dan titik pusat cluster dihitung dengan:
= ∑
4
Berikut ini algoritma dari FCM (Babuska, 2009, dalam Ningrum 2012) untuk himpunan data Y dengan jumlah cluster 1 < i < c, pangkat penimbang m > 1, toleransi terminasi ε > 0 dan menentukan inisiasi matriks partisi secara random dimana ( ) ∈ atau elemen matrik
( ) ∈ [0,1], adalah sebagai berikut:
Ulangi untuk nilai l=1,2,...
1. Hitung matriks V(l) atau vektor pusat cluster ( ) berdasarkan Persamaan (8) untuk
≤ ≤ .
2. Hitung ukuran jarak , = − dimana ≤ ≤ , ≤ ≤
3. Hitung kembali matriks partisi berdasarkan Persamaan (7) untuk ≤ ≤ jika , > 0 untuk semua nilai i. Jika terdapat suatu obyek mempunyai satu atau lebih nilai , = 0 , maka untuk nilai , > 0 diberi keanggotaan nol dan sisanya gunakan batasan ∑ = 1.
4. Hentikan proses jika ( ) − ( ) < , dimana ε merupakan kriteria terminasi, biasanya dapat menggunakan nilai 0,001 atau 0,01.
2.5 Latent Class Cluster Analysis (LCCA)
LCCA merupakan suatu model yang menghubungkan sejumlah variabel indikator yang bersifat kontinyu dengan variabel laten kategorik yang dibentuknya. Kelas-kelas dari variabel laten LCCA adalah cluster. Misalkan Y1,Y2,…, Yp adalah variabel indikator yang bersifat kontinyu dan membentuk vektor acak suatu variabel laten X yang bersifat kategorik dengan c kategori.
Model LCCA merupakan turunan dari model variabel laten yang diklasifikasikan berdasarkan jenis variabel yang digunakan. Untuk variabel indikator kontinyu dengan variabel laten kategorik disebut Latent Profile Aanalysis (LPA), tetapi menurut Vermunt (2002), hanya sebagian kecil yang menggunakan istilah LPA. Nama yang lebih umum dikenal diantaranya mixture of normal components, mixture model clustering, model-based clustering, latent discriminant analysis, dan latent class clustering analysis (LCCA). Sehingga istilah LPA adalah sama dengan LCCA yang digunakan dalam penelitian ini.
Suatu individu akan memberikan respon untuk setiap variabel indikator. Misalkan yih adalah respon individu ke-h terhadap variabel indikator Yi, h = 1, 2, ..., n; i = 1, 2, ..., p. Baris vektor Y’h=(Y1h, ..., Yph) disebut sebagai pola respon dari obyek ke-h sehingga distribusi dari masing-masing variabel indikatornya mengikuti sifat ke-2 distribusi multivariat normal, dirumuskan sebagai berikut:
, = ( 2 ) / − ( − ) ...(9) di mana adalah parameter lokasi variabel kontinu Yi di kelas j dan adalah varians dari variabel ke i.
Tiap kelas memiliki vektor mean (rata-rata), yaitu:
= … , = … , = …
= rata-rata dari variabel indikator ke-i pada kelas laten ke-j, i = 1, 2, ..., n; j = 1, 2, ..., c, dan juga memiliki matriks diagonal varians-kovarians:
5
σij = varians dari variabel indikator ke-i pada kelas laten ke-j, i = 1, 2, ..., n; j = 1, 2, ..., c, nilai kovarians lainnya akan sama dengan nol.
Sehingga fungsi distribusi probabilitas bersama dari variabel yang diamati pada Persamaan (9) dapat dituliskan sebagai berikut:
( ) = ∑ ∏ ( ( 2 ) / − ( − ) ) ...(10)
Dalam LCCA, untuk masing-masing kelas j memiliki probabiltas yang bersesuaian, yang merupakan probabilitas prior untuk mengamati data Y. Distribusi probabilitas bersama dari variabel yang diamati adalah:
( ) = ∑ ( | ) ...(11) Dengan ( | )adalah fungsi distribusi dari variabel indikator.
Sementara itu, untuk mengklasifikasikan suatu objek ke dalam suatu kelas j jika diketahui y adalah probabilitas posterior yang merupakan distribusi bersyarat, ℎ( | ), dapat ditulis sebagai berikut:
ℎ( | ) = ( | ) / ( ) ...(12) Dalam hal ini, adanya variabel laten X, (yang tidak diketahui/tersembunyi atau hilang/missing) mengarahkan pilihan pada teknik analisis numerik (iteratif) yaitu Algoritma Expectation Maximization (EM).
Tiap iterasi dalam algoritma EM terdiri dari dua proses: E-Step dan M-step. Dalam tahap ekspektasi atau E-Step, dicari suatu fungsi yaitu ekspektasi dari fungsi likelihood data lengkap berdasarkan data terobservasi yang digunakan untuk mengganti keberadaan atau keanggotaan setiap individu pada setiap kelas laten (cluster) yang tidak diketahui. Selengkapnya pada Lampiran 1.
Dalam tahap M-Step, dicari nilai estimator yang dapat memaksimumkan fungsi likelihood yang telah didefinisikan pada tahap ekspektasi dibawah asumsi bahwa data hilang telah diketahui.
Kedua tahap proses E-step dan M-step ini dilakukan terus secara berulang-ulang (iteratif), hingga didapatkan estimator yang konvergen.
Estimasi probabilitas prior kelas:
̂ = ∑ ( | ) ...(13) Estimasi probabilitas bersyarat bahwa yi=1 pada kelas j adalah:
̂ = ∑ ( | ) ...(14) Dan varians pada setiap kelas:
= ∑ ∑ ( ) ( | )
∑ ∑ ( | ) ...(15)
Estimasi probabilitas posterior ℎ( | ) diperkirakan oleh: ℎ( | ) = ( | )
( ) ...(16)
Algoritma EM bekerja dimulai dengan memilih nilai awal untuk probabilitas posterior ℎ( | ), sehingga dengan menggunakan Persamaan (13) sampai dengan Persamaan (15), didapatkan sebuah pendekatan pertama untuk parameter model. Kemudian dengan menggunakan Persamaan (16) diperoleh perkiraan baru untuk
ℎ( | ). Selanjutnya digunakan kembali Persamaan (13) sampai dengan Persamaan (15) sehingga diperoleh pendekatan kedua untuk parameter model. Demikian seterusnya sampai tercapai konvergensi.
6
2.6 Validitas Cluster
Setiap cluster yang terbentuk memiliki seperangkat ukuran karakteristik. Diantaranya berupa nilai indeks validitas cluster (Brock, G. dkk, 2008). Hal ini digunakan untuk menentukan jumlah cluster optimal khususnya untuk data riil berdasarkan kemampuan kriteria indeks terpilih Pada penelitian ini penulis menggunakan 3 kriteria alternatif.
Pada paket program R library clValid dengan metode “fanny” (untuk fuzzy clustering) dan “model” (untuk mixture model atau Model-based clustring=LCCA), kriteria yang digunakan adalah indeks Connectivity, indeks Dunn dan indeks
Silhouette. Penjelasan masing-masing kriteria adalah sebagai berikut:
1. Connectivity, memiliki nilai antara 0 sampai tak hingga. Dengan kriteria terbaik adalah
yang paling minimum. Dirumuskan sebagai berikut:
( ) = ∑ ∑ ,
( ) ...(17)
Dimana ( ) adalah tetangga terdekat data ke-j dari data ke-i, jika dalam satu cluster maka , ( )bernilai 0 (nol) dan jika berbeda bernilai 1/j. N banyaknya
data observasi, L banyaknya cluster.
2. Dunn, adalah indeks yang menunjukkan rasio antara jarak terkecil data observasi di cluster
yang berbeda terhadap jarak terjauh didalam suatu cluster. Dirumuskan sebagai berikut:
( ) = , ,, , ,,∈ , ( , )
∈ ( ) ...(18)
Dimana ( ) adalah jarak maksimum antara data observasi pada cluster . Nilai indeks Dunn antara nol dan tak hingga dengan harapan semaksimal mungkin.
3. Silhouette, adalah rata-rata nilai silhouette (ukuran dari derajat keyakinan pengclusteran)
dari setiap data observasi. Untuk cluster terbaik bernilai 1 sedangkan yang terburuk -1. Dirumuskan sebagai berikut:
( ) = ( , ) ...(19)
Dimana adalah rata-rata jarak antara data i dengan seluruh data observasi lainnya dalam cluster yang sama, adalah rata-rata jarak antara data i dengan data observasi pada cluster lain yang terdekat.
2.7 Indikator Capaian Pembangunan Nasional
Untuk mengevaluasi pencapaian pembangunan secara langsung cukup sulit dalam penterjemahan, oleh karena itu dapat menggunakan indikator yang secara rutin dirilis oleh BPS RI. Data riil yang digunakan merupakan data sekunder indikator kabupaten/Kota yang diperoleh dari publikasi Badan Pusat Statistik (BPS) tahun 2013. Obyek dari penelitian ini sebanyak 121 kabupaten/kota di wilayah Jawa-Bali (tidak termasuk DKI).
Indikator tersebut diantaranya jangka pendek-menengah diantaranya: angka PDRB dan turunannya (pro growth), angka ketenagakerjaan dan pengangguran (pro job), dan angka kemiskinan (pro poor). Sedangkan indikator PDRB Hijau (pro environment/green economy) belum semua daerah menyusun dan mempublikasikannya. Selain itu angka IPM dan komponen pembentuknya sebagai indikator jangka menengah-panjang juga relevan digunakan. Dalam peneilitian ini empat prinsip pembangunan dirinci menjadi 13 indikator kontinyu, meliputi:
- 4 dari aspek pro growth (meliputi pertumbuhan ekonomi, kontribusi golongan primer, sekunder dan tersier),
7
- 3 dari aspek pro poor (meliputi angka kemiskinan absolut/P0, indeks kedalaman/P1, dan indeks keparahan/P2)
- 3 dari IPM (meliputi angka harapan hidup/AHH, angka melek huruf/AMH, dan rata-rata lama sekolah/RLS).
3 Metodologi Penelitian
Metodologi yang digunakan cakupannya meliputi: langkah-langkah algoritma cluster FCM dan LCCA, desain pemilihan metode terbaik dari data simulasi, implementasi metode terpilih untuk pengelompokan data riil.
Untuk memudahkan dalam tahapan yang lebih sederhana, data simulasi yang digunakan dalam penelitian ini adalah dua populasi bivariat normal hasil bangkitan program R yang dirancang dengan ukuran cluster, nilai rata-rata, varians serta korelasi antar variabel tertentu.
Desain simulasi tipe A dengan banyaknya data 150 memiliki rasio ukuran populasi yang tidak sama (yaitu: 2:1), sedangkan tipe B banyaknya data 200 dengan rasio cluster sama (yaitu: 1:1). Masing-masing tipe (A dan B) memiliki empat (4) skenario yang mengindikasikan ukuran korelasi antar variabel. Selengkapnya desain simuasi disajikan dalam tabel berikut ini:
Tabel 3.1 Desain Data Simulasi Bangkitan
No Parameter Populasi 1 Populasi 2 Ukuran Cluster
Y1 Y2 Y1 Y2 Tipe A Tipe B
1 Mean 3 4 7 1
Selanjutnya disebut Skenario A1
Selanjutnya disebut Skenario B1
Varians 1 4 1 4
Korelasi Rho=0 Rho=0
2 Mean 3 4 7 1
Selanjutnya disebut Skenario A2
Selanjutnya disebut Skenario B2
Varians 1 4 1 4
Korelasi Rho=0.3 Rho=0.3
3 Mean 3 4 7 1
Selanjutnya disebut Skenario A3
Selanjutnya disebut Skenario B3
Varians 1 4 1 4
Korelasi Rho=0.5 Rho=0.5
4 Mean 3 4 7 1
Selanjutnya disebut Skenario A4
Selanjutnya disebut Skenario B4
Varians 1 4 1 4
Korelasi Rho=0.7 Rho=0.7
Kemudian setiap skenario data simulasi, dikelompokan menggunakkan metode FCM dan LCCA dengan pengulangan sebanyak K (yaitu: 500, 1000 dan 5000 kali).
8
4 Hasil dan Pembahasan
4.1 Pengelompoka Data Simulasi Tipe A
Dari output program R diperoleh rekap tabulasi sebagai berikut:
Tabel 4.1 Tabel Kontingensi Hasil Pengelompokan Data Simulasi Skenario A1
Pengulangan Awal Cluster Metode FCM Cluster Metode LCCA
(1) (2) (3) (4) (5) (6) (7) (8)
Dari tabel diatas pengelompokan metode FCM memberikan hasil: dari 100 data populasi pertama pada pengulangan 500 kali menunjukkan banyaknya data pengelompokan yang tepat (akurat) dari populasi 1 ke cluster 1 (FCM 1-1) sebanyak 52,07 data. Sedangkan untuk populasi kedua dari 50 data 26, 25 diantaranya tepat dikelompokan pada cluster 2 (FCM 2-2). Masing-masing sel lainnya (FCM 1-2 dan FCM 2-1) menunjukkan banyaknya data yang mengalami kesalahan pengelompokan.
Metode LCCA memperlihatkan hasil yang lebih baik dibanding metode FCM, dimana LCCA 1-1 pada pengulangan 500 kali menghasilkan ketepatan pengelompokan sebanyak 89,92 dari 100 data. Dan LCCA 2-2 sebanyak 44,34 dari 50 data.
Ketika pengulangan ditingkatkan menjadi 1000 kali dan 5000 kali, kecenderungan akurasi hasil pengelompokan FCM 1-1 maupun FCM 2-2 masing-masing hanya berkisar pada angka 50 persen, sedangkan metode LCCA 1-1 dan LCCA 2-2 akurasinya mencapai 89 persen.
Di lihat dari ukuran cluster, FCM hanya membagi dua dengan proporsi hampir sama (1:1), sedangkan metode LCCA memberikan hasil lebih mendekati proporsi populasi data awal (yaitu 2:1).
9
Tabel 4.2 Persentase Tingkat Akurasi Hasil Pengelompokan Data Simulasi Tipe A
Pengulangan Jenis Data Simulasi Metode FCM Metode LCCA
(1) (2) (3) (4)
500
A1 52 89
A2 49 97
A3 47 98
A4 51 99
1000
A1 47 89
A2 50 95
A3 50 98
A4 50 99
5000
A1 50 89
A2 50 95
A3 50 98
A4 50 99
Sumber: data diolah Lampiran 4.
Tabel 4.2 diatas, menunjukkan tingkat akurasi metode FCM (kolom 3) hampir tidak mengalami perubahan dengan adanya perbedaan tingkat korelasi antar variabel, bahkan pada pengulangan sangat banyak (diatas 1000 kali) relatif konstan pada angka 50%.
Sedangkan metode LCCA (kolom 4) menunjukkan adanya hubungan positif (searah) antara perubahan tingkat korelasi dengan peningkatan tingkat akurasi hasil pengelompokan.
4.2 Pengelompokan Data Simulasi Tipe B
Berikut ini rekapitulasi hasil tabulasi (selengkapnya disajikan pada Lampiran 3).
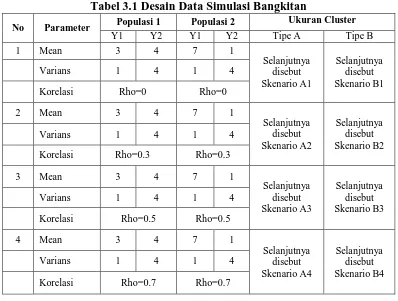
Tabel 4.3 Tabel Kontingensi Pengelompokan Data Simulasi Skenario B1
Pengulangan Awal Cluster Metode FCM Cluster Metode LCCA
(1) (2) (3) (4) (5) (6) (7) (8)
500 Pop0 1 2 Jumlah 1 2 Jumlah
1 49.48 50.52 100.00 92.43 7.57 100.00
2 50.53 49.47 100.00 7.75 92.25 100.00
Jumlah 100.01 99.99 200.00 100.18 99.82 200.00
1000 Pop0 1 2 Jumlah 1 2 Jumlah
1 49.70 50.30 100.00 91.53 8.47 100.00
2 50.16 49.84 100.00 8.54 91.30 99.84
Jumlah 99.86 100.14 200.00 100.07 99.77 199.84
5000 Pop0 1 2 Jumlah 1 2 Jumlah
1 50.93 49.07 100.00 92.08 7.92 100.00
2 49.04 50.96 100.00 7.98 91.96 99.94
Jumlah 99.96 100.04 200.00 100.06 99.88 199.94
10
Dari tabel 4.3 diatas terlihat bahwa metode FCM untuk ukuran data sama juga memberikan tingkat akurasi hasil pengelompokan yang tepat untuk FCM 1-1 maupun FCM 2-2 masing-masing sebanyak 49 data dari 100 data pada pengulangan 500 kali. Pada pengulangan 5000 kali menjadi 51 dari 100 data. Hal ini relatif sama dengan kondisi sebelumnya untuk populasi yang berukuran beda.
Hasil pengelompokan metode LCCA menunjukkan hasil yang lebih baik dari FCM, dimana LCCA 1-1 pada pengulangan 500 maupun 5000 kali mencapai ketepatan pengelompokan sebanyak 92 dari 100 data.
Seperti analisis pada tipe A, untuk data simulasi tipe B juga diperoleh tabulasi data akurasi sebagai berikut ini:
Tabel 4.4 Persentase Tingkat Akurasi Hasil Pengelompokan Data Simulasi Tipe B
Pengulangan Jenis Data Simulasi Metode FCM Metode LCCA
(1) (2) (3) (4)
500
B1 49 92
B2 50 96
B3 51 98
B4 49 99
1000
B1 50 91
B2 48 96
B3 49 98
B4 53 99
5000
B1 51 92
B2 50 96
B3 50 98
B4 50 99
Sumber: data diolah Lampiran 3.
Dari tabel 4.4 diatas, menunjukkan tingkat akurasi hasil pengelompokan metode FCM relatif konstan pada angka 50%. Dan tidak menunjukkan adanya pengaruh korelasi antar variabel.
Sedangkan metode LCCA menunjukkan tambahan bukti adanya hubungan antara perubahan tingkat korelasi dengan peningkatan tingkat akurasi hasil pengelompokan. Hal ini berguna sebagai landasan pertimbangan dalam memilih metode clustering suatu data jika korelasi antar variabel indikator diketahui. Misalnya pada data-data di bidang sosial ekonomi, dimana umumnya antar variabel yang digunakan memiliki korelasi.
Dari tabel 4.1 dan tabel 4.3 kecenderungan pengelompokan masing-masing metode (FCM dan LCCA) tidak sensitif terhadap banyaknya pengulangan. Baik metode FCM maupun LCCA dengan pengulangan 500, 1000, dan 5000 kali menunjukkan hasil alokasi pengelompokan relatif tetap (tidak ada konvergensi). Tetapi karena adanya proses iterasi yang dimulai dengan ramdomisasi nilai inisiasi awal, maka dalam implementasi kedua metode tetap perlu dilakukan pengulangan. Meski banyaknya pengulangan bisa relatif sedikit misalnya 10 kali.
4.3 Indeks Validitas Cluster Data Simulasi
11
umum digunakan diantaranya indeks Connectivity (yang diharapkan nilai terkecil), indeks
Dunn, dan indeks Silhouette ( semakin besar nilainya semakin baik).
Dari output program R library clValid dengan pengulangan sebanyak 50, 100 dan 500 kali diperoleh rata-rata nilai indeks validitas cluster untuk setiap skenario data simulasi tipe A (dengan perbedaan rasio ukuran cluster, 2:1). Selengkapnya sebagai berikut:
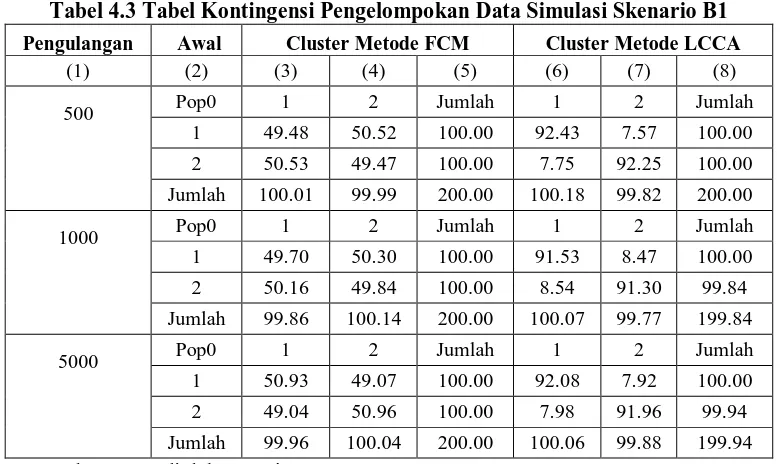
Tabel 4.5 Indeks Validitas Internal Cluster Hasil Pengelompokan Data Simulasi Tipe A
Pengulangan Jenis Data Simulasi
Metode FCM Metode LCCA Con. Dunn Silh. Con. Dunn Silh.
(1) (2) (3) (4) (5) (6) (7) (8)
50
A1 34.113 17.540 17.977 25.222 17.559 17.984
A2 31.118 17.550 17.987 21.640 17.593 17.998
A3 27.944 17.562 18.002 20.038 17.613 18.013
A4 23.072 17.594 18.020 17.895 17.678 18.027
100
A1 34.110 17.540 17.977 25.134 17.561 17.985
A2 31.458 17.548 17.986 21.854 17.589 17.998
A3 28.371 17.558 18.000 19.899 17.616 18.011
A4 23.054 17.595 18.021 17.915 17.678 18.028
500
A1 33.116 17.543 17.983 25.119 17.564 17.989
A2 30.812 17.550 17.989 21.947 17.589 18.000
A3 28.113 17.559 17.998 19.828 17.616 18.010
A4 23.494 17.595 18.019 17.962 17.677 18.026
Sumber: data diolah Lampiran 4.
Ketiga ukuran indeks validitas internal cluster yang disajikan pada tabel 4.5 menunjukkan Connectivity yaitu kolom (6) lebih kecil nilainya dibanding kolom (3), indeks
Dunn (kolom 7) lebih besar dibanding kolom (4), serta indeks Silhouette (kolom 8) lebih besar
dari kolom (5) yang berarti hasil pengelompokan metode LCCA lebih baik dibanding metode FCM.
Selain itu, dapat diketahui adanya pengaruh nilai korelasi terhadap nilai indeks validitas internal cluster. Baik metode FCM maupun metode LCCA menunjukkan hubungan positif, dimana semakin besar korelasi masing-masing nilai indeks semakin optimal (indeks Connectivity semakin kecil, sementara indeks Dunn dan Silhouette semakin besar).
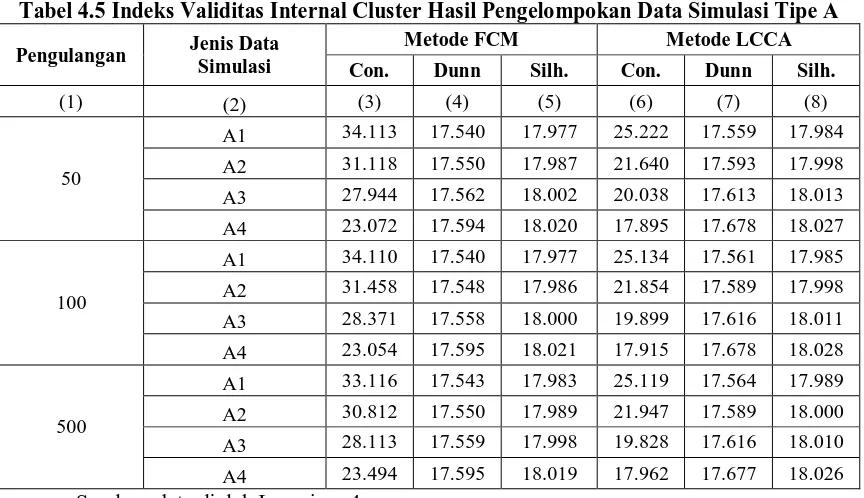
Sedangkan untuk data simulasi tipe B, menunjukan hasil yang sedikit berbeda, pada setiap banyaknya pengulangan hasil pengukuran indeks validitas internal cluster menunjukkan indeks Connectivity, dan indeks Dunn, seluruhnya merujuk metode LCCA lebih baik dibanding metode FCM.
12 Seperti pada tabel 4.6 berikut ini:
Tabel 4.6 Indeks Validitas Internal Cluster Hasil Pengelompokan Data Simulasi Tipe B
Pengulangan Jenis Data Simulasi
Metode FCM Metode LCCA Con. Dunn Silh. Con. Dunn Silh.
(1) (2) (3) (4) (5) (6) (7) (8)
50
B1 34.352 17.540 17.996 27.527 17.549 17.985
B2 30.084 17.547 18.000 22.634 17.569 17.998
B3 24.901 17.577 18.013 19.824 17.601 18.013
B4 19.927 17.630 18.027 17.797 17.662 18.027
100
B1 33.861 17.542 17.999 27.364 17.549 17.989
B2 30.235 17.545 18.001 22.755 17.569 17.999
B3 25.126 17.572 18.013 19.908 17.597 18.013
B4 19.672 17.630 18.024 17.850 17.654 18.025
500
B1 34.081 17.542 17.997 26.984 17.548 17.987
B2 30.337 17.549 18.001 23.018 17.567 17.999
B3 25.163 17.570 18.012 19.924 17.598 18.012
B4 20.046 17.629 18.027 17.885 17.657 18.027
Sumber: data diolah Lampiran 4.
4.4 Pengujian Normalitas Multivariat Data Riil
Pemeriksaan distribusi multivariat normal dapat dilakukan dengan cara membuat q-q plot dari nilai jarak mahalanobis d2j (Johson & Wichern, 2007). Plot output program R diperoleh sebagai berikut:
Sumber: data olah lampiran 5
Gambar 4.5 Q-Q Plot Hasil Pengujian Normalitas Multivariat
Dari gambar diatas, menunjukkan sebaran data mengikuti pola tertentu berupa garis lurus, disisi lain diperoleh 62,81 persen data memiliki nilai d2j n2;0.05 sehingga dapat disimpulkan bahwa data riil yang akan digunakan telah berdistribusi multivariat normal. Selain itu dapat dikenali indikasi adanya outlier pada data kabupaten/kota tersebut.
20.000 40.000 60.000 80.000 100.000 120.000
- 5.00 10.00 15.00 20.00 25.00 30.00
13 Sumber: data olah lampiran 5
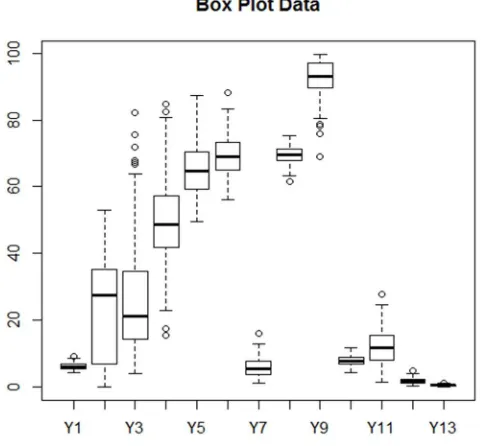
Gambar 4.6 Box Plot Data Riil
Pada gambar Box Plot diatas, dapat diketahui bahwa 11 dari 13 variabel yang digunakan memiliki data yang berada di luar batas bawah dan batas atas (whisker) yang berpotensi sebagai pencilan (outlier) yang ditandai dengan lingkaran kecil.
Dengan data riil yang telah berdistribusi multivariat normal, maka tahapan berikutnya adalah melakukan pengelompokan dengan mengunakan terpilih, yaitu LCCA. Jumlah cluster yang digunakan sebagai input adalah c=2 hingga c=6. Dengan melakukan 10 kali pengulangan, hasil selengkapnya disajikan berikut ini.
4.5 Pembentukan Cluster Optimal Data Riil
Penentuan cluster optimal dilakukan dengan menghitung indeks validitas cluster melalui bantuan program R (library clValid). Sehingga diperoleh tabulasi berikut:
Tabel 4.7 Indeks Validitas 2-6 Cluster Pengelompokan Data Riil
Metode Jenis Indeks Validitas
Banyaknya Cluster
2 3 4 5 6
(1) (2) (3) (4) (5) (6) (7)
LCCA Connectivity 54.7151 51.496 58.6079 94.7413 54.7151
Dunn 0.0478 0.0684 0.0755 0.1172 0.1075 Silhouette 0.2534 0.3505 0.2886 0.1842 0.2534
Sumber: data olah
14
bahwa model yang dihasilkan memiliki bentuk ellipsoidal, nilai varians setiap cluster sama (equal volume), bentuk setiap cluster sama (equal shape) dan arah orientasi cluster juga sama (equal orientation). Oleh karena itu, untuk melengkapi profiling metode LCCA 3 cluster dengan menggunakan Latent Gold. 4.0 harus dibangun model yang memiliki karakteristik EEE tersebut.
4.6 Output M odel LCCA
Memperhatikan tabulasi dari masing-masing parameter model cluster LCCA yang dihasilkan (Lampiran 6), maka dapat dirumuskan Persamaan model untuk masing-masing cluster tersebut ebagai berikut:
1. Cluster 1: 0,75* ∏ ( 2 ) / | | / exp − ( − ) ( − ) , dengan
adalah rata-rata variabel indikator ke-i pada cluster pertama, dan adalah matriks varians-kovarians cluster pertama.
2. Cluster 2: 0,23∗ ∏ ( 2 ) / | | / exp − ( − ) ( − ) , dengan
adalah rata-rata variabel indikator ke-i pada cluster kedua, dan adalah matriks varians-kovarians cluster kedua.
3. Cluster 3: 0,02∗ ∏ ( 2 ) / | | / exp − ( − ) ( − ) , dengan
adalah rata-rata variabel indikator ke-i pada cluster ketiga, dan adalah matriks varians-kovarians cluster ketiga.
4.7 Profiling Pengelompokan Kabupaten/ Kota
Hasil pengelompokkan kabupaten/kota tersebut adalah sebagai berikut:
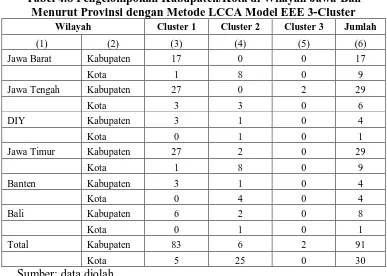
Tabel 4.8 Pengelompokan Kabupaten/Kota di Wilayah Jawa-Bali Menurut Provinsi dengan Metode LCCA Model EEE 3-Cluster
Wilayah Cluster 1 Cluster 2 Cluster 3 Jumlah
(1) (2) (3) (4) (5) (6)
Jawa Barat Kabupaten 17 0 0 17
Kota 1 8 0 9
Jawa Tengah Kabupaten 27 0 2 29
Kota 3 3 0 6
DIY Kabupaten 3 1 0 4
Kota 0 1 0 1
Jawa Timur Kabupaten 27 2 0 29
Kota 1 8 0 9
Banten Kabupaten 3 1 0 4
Kota 0 4 0 4
Bali Kabupaten 6 2 0 8
Kota 0 1 0 1
Total Kabupaten 83 6 2 91
Kota 5 25 0 30
Sumber: data diolah
15
Tingkat pencapaian pembangunan nasional pada tahun 2013 dari 121 Kabupaten/Kota se-Jawa Bali yang menjadi obyek observasi, ditinjau dari 13 indikator pada 4 aspek utama menunjukkan secara berurutan menurut peringkat, adalah sebagai berikut :
Peringkat 1 dengan kualifikasi BAIK: ada sebanyak 31 Kabupaten/Kota yang merupakan anggota Cluster 2;
Peringkat 2 dengan kualifikasi CUKUP BAIK: terdiri dari 2 Kabupaten pada Cluster 3; Peringkat 3 dengan kualifikasi KURANG BAIK: sebanyak 88 Kabupaten/Kota yang tergabung pada Cluster 1.
Dilihat dari proporsi masing-masing cluster (banyaknya kabupaten/kota) pada tahun 2013 kualitas capaian pembangunan nasional di 121 Kabupaten/kota pada wilayah Jawa-Bali 75 persen atau dominan masih kurang baik (88 dari 121). Hanya ada 25 persen yang termasuk berkualitas cukup baik dan kategori baik. Hal ini menginformasikan adanya ketimpangan pembangunan yang relatif besar di wilayah Jawa-Bali, padahal di sisi lain secara kasat mata wilayah ini diasumsikan memiliki tingkat pembangunan yang lebih baik dibandingkan wilayah lain di Indonesia.
Untuk lebih memudahkan, disajikan profiling hasil pengelompokan secara visual, berupa peta pengelompokan Kabupaten/Kota hasil metode LCCA dengan Model EEE 3-cluster disajikan pada Lampiran 7.
5. Kesimpulan dan Saran 5.1 Kesimpulan
Berdasarkan hasil dan pembahasan yang telah diuraikan sebelumnya, diperoleh kesimpulan sebagai berikut:
1. Berdasarkan hasil simulasi, diketahui persentase tingkat akurasi hasil pengelompokan metode FCM baik untuk ukuran cluster berbeda maupun sama cenderung berada pada kisaran nilai 50% dari ukuran data.
2. Hasil simulasi juga menunjukkan bahwa metode LCCA persentase tingkat akurasi hasil pengelompokannya jauh lebih baik dibanding FCM, hingga bisa mencapai 89% - 99% dari ukuran data.
3. Dari aspek validitas internal, Connectivity dan Silhouette juga menunjukkan hasil pengelompokan metode LCCA lebih baik dari FCM.
4. Korelasi antar variabel tidak berpengaruh terhadap kinerja pengelompokan FCM sedangkan pada metode LCCA menunjukkan adanya hubungan positif. Sehingga dengan LCCA semakin besar korelasi variabel data, tingkat akurasi pengelompokan yang dihasilkan semakin meningkat
5. Pengelompokan 121 Kabupaten/Kota dengan 13 variabel indikator kontinyu berdasarkan indeks validitas Connectivity dan Silhouette menunjukkan banyaknya cluster optimal pada 3 cluster.
6. Dengan menggunakan LCCA sebagai metode terbaik, diperoleh cluster 1 sebanyak 88 Kabupaten/Kota, kemudian cluster 2 terdiri dari 31 Kabupaten/Kota, dan cluster 3 ada sebanyak 2 Kabupaten/Kota.
7. Mayoritas Kabupaten/Kota yang ditelaah termasuk kategori “Kurang Baik”, terutama dari sisi ekonomi, IPM dan Kemiskinan.
16
5.1 Saran
1. Didalam pengelompokan wilayah Kabupaten/Kota, terutama untuk keperluan evaluasi dan perencanaan pembangunan yang menggunakan variabel indikator kontinyu dimana antar variabel saling berkorelasi sebaiknya menggunakan metode LCCA, supaya diperoleh hasil yang lebih akurat sehingga dapat mempertajam target, sasaran dari kebijakan dan atau program yang akan dilaksanakan.
2. Perlu dikaji algoritma clustering dari aspek lain misalnya: ukuran stabilitas, dan atau ukuran keberartian cluster secara biologis.
3. Selain itu perlu juga dilakukan kajian untuk data time series pada periode tertentu, misalnya untuk mengukur keberhasilan suatu era pemerintahan dibanding daerah lain.
4. Perlu dikembangkan penyempurnaan metode LCCA yang berbasis software open source, sehingga menarik lebih banyak pengguna untuk mengimplementasikan dalam berbagai penelitian.
5. Mengimplementasikan hasil-hasil penelitian yang bersifat akademis, di dalam praktek kerja keseharian secara kontinyu sehingga dapat dilakukan pengembangan dan penyempurnaan metode yang sesuai dengan realitas masalah dan kebutuhan aktual.
6. Daftar Pustaka
Badan Pusat Statistik, (2013). Data Dan Informasi Kemiskinan Kabupaten/Kota 2012, Jakarta: Badan Pusat Statistik.
Brock, G., Pihur, V., Datta, S.,(2008). “clValid: an R package for Cluster Validation”. Journal of Statictical Software, Vol. 25.Issue 4.
Collins, L.M., dan Lanza, S.T., (2010). Latent Class And Latent Transition Analysis With Applications in the Social, Behavioral, and Health Sciences. A John Wiley & Sons, Inc., Publication.
de Oliveira, J., dan Pedrycz, W. (editor). 2007. Advances in Fuzzy Clustering and its Applications. Chishester: John Wiley & Sons, Inc.
Everitt, BS., Landau, S., Leese, M., dan Stahl, D., (2011). Cluster Analysis. 5th edition. India: Wiley
Hanifah, E., (2010). Metode Latent Class Cluster untuk Variabel Indikator Bertipe Campuran Dalam Rangka Pengelompokan Desa, Tesis Universitas Padjadjaran.
Harpaz, R. Dan Haralick, R., (2006). The EM Algoritm as a Lower Bound Optimization Technique, The Graduate Centre, New York.
Johnson, R.A., dan Wichern, D.W. (2007). Applied Multivariate Statistical Analysis, Second Edition. New Jersey: Prentice-Hall, Inc.
Magidson, J., dan Vermunt, J.K. (2002). “Latent Class Models for Clustering: A Comparison with K-means”. Canadian Journal of Marketing Research Vol.20: 37-44.
Mansur, A.A., (2009). Analisis Latent Class Cluster dalam Pengklasifikasian Subjek Penerima BLT, Tesis, Universitas Padjadjaran.
Ningrum, N.I.F., (2010). Fuzzy C-Means Clustering Dengan Analisis Robust. Tesis, Universitas Padjadjaran.
17
dan Beni). Prosiding Seminar Nasional Matematika dan Pendidikan Matematika.
Provost, F. and Fawcett, T. (1997). Analysis and visualization of classifer performance: Comparison under imprecise class and cost distributions. In KDD'97: Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, hal. 43-48. AAAI Press.
Salim, E. (2013). Tinjauan “Pro Growth, Pro Job, Pro Poor, dan Pro Green Economy, Perundingan tentang Menghijaukan Rencana Pembangunan Nasional di Indonesia. Jakarta.
Vermunt, J.K., dan Magidson, J. (2002). Latent Class Cluster Analysis. Dalam Hagenaars, J.A., dan McCutcheon, A.L.,(edited), Applied Latent Class Analysis, 89-106. Cambridge University Press.
__________, (2004). “Latent Class Models”, dalam The Sage Handbook of Quantitative Methodology for the Social Sciences Chapter 10: 175-198. Thousand Oaks: Sage Publication.
__________, (2005). Technical Guide for Latent Gold 4.0: Basic and advanced. Belmont Massachusetts: Statistical Innovations Inc.
18
Lampiran-1. Algoritma EM
Prinsip dari algoritma EM dapat dijelaskan menjadi 2 bagian sebagai berikut: 1. E-Step
E-step dilakukan untuk mencari log[ ( , , ) ] , dimana:
adalah taksiran parameter pada iterasi ke-(t-1), t=1,2, ..., adalah nilai parameter pada iterasi ke-t, adalah suatu nilai taksiran awal yang diberikan (inisialisasi).
Dalam LCCA, tahapan ini untuk mencari ekspektasi dari
∏ , untuk setiap kelas-j dari variabel laten X.
log[ ( , , ) ] , =
log∏ ( ( ) , ) , ̂( ), ̂( ), ( ) (1)
Dimana , =
∏ ( )
√ . − ∑
( )
( ) dengan
( )
adalah nilai probabilitas pada iterasi ke-t, ( )adalah nilai mean pada iterasi ke-t dan ( ) adalah varians pada iterasi ke-t.
log ∏ ( ( ) , ) , ̂( ), ̂( ), ( ) =
∑ ∏ ( ( ) , ) . Pr ( | , ̂( ), ̂( ), ( )) ] (2) Dimana
∏ ( ( ) , ) = ∑ log [ ( ) , ) ]
= ∑ [ log ( ) + log , ] =
∑ log ( ) + ∑ log
⎣ ⎢ ⎢ ⎢ ⎢
⎡ ∑ ( )
( )
∏ ( )
√
⎦ ⎥ ⎥ ⎥ ⎥ ⎤
=
∑ log ( ) + ∑ −(∑
( )
( ) )− log( 2 ) −(∑
( )
) (3) Sebut Pr | , ̂( ), ̂( ), ( ) = (, ), = 1, …, ;ℎ = 1, …, maka berdasarkan Teorema Bayes:
Pr | , ̂( ), ̂( ), ( ) = Pr ( = ) . ,
∑ Pr ( = ) . ,
, ( )
=
( )
. ( ( ), ( ))
∑ ( )
. ( ( ), ( )) (4)
Substitusikan Persamaan (2.3) dan (2.4) ke dalam Persamaan (2.2), sehingga diperoleh:
log ∏ ( ( ) , ) , ̂( ), ̂( ), ( ) =
19
∑ −(∑
( )
( ) )− log( 2 ) −(∑
( )
) ) . ( (, )) ; t=1,2, .. (5)
2. M-Step
Setelah melakukan E-step, langkah selanjutnya adalah melakukan M-step, dimana akan dicari nilai taksiran untuk ( ), ( )dan ( )yang memaksimumkan
log∏ ( ( ) , ) , ̂( ), ̂( ), ( ) =
∑ ∑ log ( ) +
∑ −(∑
( )
( ) ) − log( 2 ) −(∑
( )
) ) . ( (, )) yang didapat pada E-step.
Untuk mencari nilai taksiran dari ( ), ( )dan ( ) yang memaksimumkan Persamaan (2.5) diperoleh dengan cara menurunkannya secara parsial terhadap parameter ( ), ( )dan ( )kemudian disamakan dengan nol. Karena terdapat syarat bahwa ∑ = 1, maka:
= log ( ( ) , ) , ̂( ), ̂( ), ( ) −
= ∑ ∑ log ( ) + ∑ −(∑
( )
( ) ) − log( 2 ) −
(∑ ( )) ) . ( (, )) − ∑ (6) Taksiran dari ( ) didapat dengan menurunkan I terhadap ( ), yaitu:
( ) = ( ) ,
( ) ( )
−
( 1)( ) = ( 1)( ) ,
( ) ( )
−
= ∑ ( ,
( )
)
( 1)( ) − = 0
( 1)( ) = ∑ , ( )
⋮
( )( ) = ∑ ,
( )
20
Sehingga didapat taksiran untuk ( )adalah:
̂( )
Asumsikan bahwa ( )berhingga, sehingga didapat taksiran untuk ( ) yaitu:∑ ( − ( )) (, ) = 0
Selanjutnya taksiran untuk ( ) adalah:
( ) = ( ) −
Asumsikan bahwa ( )berhingga, sehingga didapat taksiran untuk ( )
yaitu: ∑ − ( ) − ( ) (, ) = 0
− ( )
21
− ( )
. (, ) = ( ). (, )
( )
= ∑
( )
. (, )
∑ (, ) =
∑ ∑ ( ) ( | )
∑ ∑ ( | ) (9)
Proses E-step dan M-step ini dilakukan secara iteratif sampai didapatkan suatu nilai estimasi yang konvergen atau didapatkan ̂( ) − ̂( ) , ̂( ) − ̂( ) dan ( ) −
( )
, i = 1,...,p dan h =1,...,n yang cukup kecil.
22
Lampiran-2. Syntax dan Output Data Simulasi Tipe A (Rasio Cluster 2:1)
> #Memanggil library yang digunakan > library(mclust)
Package 'mclust' version 4.3 > library(e1071)
> library(gmodels) > library(mvtnorm)
> #Merumuskan Fungsi Simulasi Cluster
> simclust<-function( m1=c(miu11, miu21),m2=c(miu12,
miu22),var1=c(var11,var21),var2=c(var12,var22),p1,p2,rho,m_fcm,K) + {
+ #Menyiapkan tempat untuk output + fcm11=vector(,K)
23
> #Menentukan Nilai Parameter Rata-rata dan Varians data Bangkitan dari Distribusi Normal Bivariat > m1<-c(3,4)
> m2<-c(7,1) > var1<-c(1,4) > var2<-c(1,4) >
> #Menjalankan Fungsi Simulasi Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe A, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=500 > SimA1<-simclust(m1,m2,var1,var2,100,50,0,2,500) #Simulasi Tipe A skenario 1 > attach(SimA1) #untuk memisahkan fcm dan model
...
{data hasil direkap ke dalam tabel dibawah ini, kemudian proses pengulangan dilakukan lagi untuk K=1000 dan 5000 kali.}
Rekap Output Data Simulasi Skenar io A1
24
Kemudian dengan menjalankan syntax fungsi simulasi sebagai berikut:
> SimA2<-simclust(m1,m2,var1,var2,100,50,0.3,2,500) #Simulasi Tipe A skenario 2 > attach(SimA2) #untuk memisahkan fcm dan model
...
Rekap Output Data Simulasi Skenar io A2
500 1000 5000
Kemudian dengan menjalankan syntax fungsi simulasi sebagai berikut:
> SimA3<-simclust(m1,m2,var1,var2,100,50,0.5,2,500) #Simulasi Tipe A skenario 3 > attach(SimA3) #untuk memisahkan fcm dan model
...
Rekap Output Data Simulasi Skenar io A3
25
Kemudian dengan menjalankan syntax fungsi simulasi sebagai berikut:
> SimA4<-simclust(m1,m2,var1,var2,100,50,0.7,2,500) #Simulasi Tipe A skenario 4 > attach(SimA4) #untuk memisahkan fcm dan model
...
Rekap Output Data Simulasi Skenar io A4
500 1000 5000
> #Output FCM > mean(fcm11) [1] 48.724 > mean(fcm12) [1] 51.276 > mean(fcm21) [1] 25.714 > mean(fcm22) [1] 24.286
> #Output MODEL > mean(model11) [1] 99.392
> mean(model12) [1] 0.608
> mean(model21) [1] 0.312
> mean(model22) [1] 49.688
> #Output FCM > mean(fcm11) [1] 50.056 > mean(fcm12) [1] 49.944 > mean(fcm21) [1] 25.011 > mean(fcm22) [1] 24.989
> #Output MODEL > mean(model11) [1] 99.164
> mean(model12) [1] 0.836
> mean(model21) [1] 0.262
> mean(model22) [1] 49.339
> #Output FCM > mean(fcm11) [1] 49.7602 > mean(fcm12) [1] 50.2398 > mean(fcm21) [1] 25.1436 > mean(fcm22) [1] 24.8564 > #Output MODEL > mean(model11) [1] 99.3
> mean(model12) [1] 0.6956
> mean(model21) [1] 0.2714
26
Lampiran-3 Syntax dan Output Data Simulasi Tipe B (Rasio Cluster 1:1)
> #Memanggil library yang digunakan > library(mclust)
Package 'mclust' version 4.3 > library(e1071)
> library(gmodels) > library(mvtnorm)
> #Merumuskan Fungsi Simulasi Cluster
> simclust<-function( m1=c(miu11, miu21),m2=c(miu12,
miu22),var1=c(var11,var21),var2=c(var12,var22),p1,p2,rho,m_fcm,K) + {
+ #Menyiapkan tempat untuk output + fcm11=vector(,K)
27
> #Menentukan Nilai Parameter Rata-rata dan Varians data Bangkitan dari Distribusi Normal Bivariat > m1<-c(3,4)
> m2<-c(7,1) > var1<-c(1,4) > var2<-c(1,4) >
> #Menjalankan Fungsi Simulasi Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe B, Ukuran Cluster Sama untuk Pengulangan sebanyak K=500 > SimB1<-simclust(m1,m2,var1,var2,100,100,0,2,500) #Simulasi Tipe B skenario 1 > attach(SimB1) #untuk memisahkan fcm dan model
...
{data hasil direkap ke dalam tabel dibawah ini, kemudian proses pengulangan dilakukan lagi untuk K=1000 dan 5000 kali.}
Rekap Output Data Simulasi Skenario B1
28
Kemudian dengan menjalankan syntax fungsi simulasi sebagai berikut:
> SimB2<-simclust(m1,m2,var1,var2,100,100,0.3,2,500) #Simulasi Tipe B skenario 2 > attach(SimB2) #untuk memisahkan fcm dan model
...
Rekap Output Data Simulasi Skenario B2
500 1000 5000
Kemudian dengan menjalankan syntax fungsi simulasi sebagai berikut:
> SimB3<-simclust(m1,m2,var1,var2,100,100,0.5,2,500) #Simulasi Tipe B skenario 3 > attach(SimB3) #untuk memisahkan fcm dan model
...
Rekap Output Data Simulasi Skenario B3
29
Kemudian dengan menjalankan syntax fungsi simulasi sebagai berikut:
> SimB4<-simclust(m1,m2,var1,var2,100,100,0.7,2,500) #Simulasi Tipe B skenario 4 > attach(SimB4) #untuk memisahkan fcm dan model
...
Rekap Output Data Simulasi Skenario B4
500 1000 5000
> #Output FCM > mean(fcm11) [1] 49.168 > mean(fcm12) [1] 50.832 > mean(fcm21) [1] 50.772 > mean(fcm22) [1] 49.228
> #Output MODEL > mean(model11) [1] 99.504
> mean(model12) [1] 0.496
> mean(model21) [1] 0.412
> mean(model22) [1] 99.388
> #Output FCM > mean(fcm11) [1] 52.943 > mean(fcm12) [1] 47.057 > mean(fcm21) [1] 47.067 > mean(fcm22) [1] 52.933
> #Output MODEL > mean(model11) [1] 99.385
> mean(model12) [1] 0.615
> mean(model21) [1] 0.515
> mean(model22) [1] 99.186
> #Output FCM > mean(fcm11) [1] 50.0898 > mean(fcm12) [1] 49.9102 > mean(fcm21) [1] 49.9082 > mean(fcm22) [1] 50.0918 > #Output MODEL > mean(model11) [1] 99.475
> mean(model12) [1] 0.525
> mean(model21) [1] 0.5186
30
Lampiran-4 Syntax dan Output Validitas Cluster untuk Data Simulasi
>#Memanggil library yang digunakan > library(mclust)
> library(e1071) > library(gmodels) > library(mvtnorm) > library(clValid)
> #Merumuskan Fungsi Simulasi Validitas Cluster
> simclust.int<-function( m1=c(miu11, miu21),m2=c(miu12,
miu22),var1=c(var11,var21),var2=c(var12,var22),N1,N2,rho,m_fcm,K){ + for(i in 1:K)
+ {
+ #Membangkitkan data + #Populasi 1
+ cov1 <- rho*sqrt(var1[1]*var1[2])
+ sig1 <- matrix(c(var1[1], cov1, cov1, var1[2]), nrow=2)#covariance matrix + data1 <-rmvnorm(N1, mean=m1, sigma=sig1)
+ pop0<-rep(1,N1)#inisial populasi 1 + data11<-cbind(data1,pop0)#Gabung kolom +
+ #Populasi 2
+ cov2 <- rho*sqrt(var2[1]*var2[2])
+ sig2 <- matrix(c(var2[1], cov2, cov2, var2[2]), nrow=2) #covariance matrix + data2 <-rmvnorm(N2, mean=m2, sigma=sig2)
+ pop0<-rep(2,N2)#inisial populasi 2 + data22<-cbind(data2,pop0)#Gabung kolom +
+ A<-rbind(data11,data22)#Gabung baris +
+ B<-A[,-3] +
+ #Validitas Internal Cluster
+ intern <- clValid(B, 2, clMethods = c("fanny", "model"), validation = "internal") + summary(intern)
+ } + + }
> #Menentukan Nilai Parameter Rata-rata dan Varians data Bangkitan dari Distribusi Normal Bivariat > m1<-c(3,4)
> m2<-c(7,1) > var1<-c(1,4) > var2<-c(1,4) >
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe A, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50
>
> VClust_A1<-simclust.int(m1,m2,var1,var2,100,50,0,2,50) #Validitas Cluster Tipe A skenario 1
Clustering Methods: fanny model
Cluster sizes: 2
Validation Measures:
31
Optimal Scores:
Score Method Clusters Connectivity 9.4524 model 2
Dunn 0.0667 model 2 Silhouette 0.5010 model 2
. . .
Clustering Methods: fanny model
Cluster sizes: 2
Validation Measures:
2 fanny Connectivity 12.0310 Dunn 0.0276 Silhouette 0.5292 model Connectivity 0.7472 Dunn 0.1530 Silhouette 0.5418
Optimal Scores:
Score Method Clusters Connectivity 0.7472 model 2
Dunn 0.1530 model 2 Silhouette 0.5418 model 2
...
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe A, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50
>
> VClust_A2<-simclust.int(m1,m2,var1,var2,100,50,0.3,2,50) #Validitas Cluster Tipe A skenario 2 ...
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe A, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50
>
> VClust_A3<-simclust.int(m1,m2,var1,var2,100,50,0.5,2,50) #Validitas Cluster Tipe A skenario 3 ...
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe A, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50
>
> VClust_A4<-simclust.int(m1,m2,var1,var2,100,50,0.7,2,50) #Validitas Cluster Tipe A skenario 4
...
32
Validitas Internal Cluster Hasil Pengelompokan pada Data Simulasi Tipe A
Pengulangan Jenis Data Simulasi
Metode FCM Metode LCCA
Con. Dunn Silh. Con. Dunn Silh.
(1) (2) (3) (4) (5) (6) (7) (8)
50
A1 34.113 17.540 17.977 25.222 17.559 17.984
A2 31.118 17.550 17.987 21.640 17.593 17.998
A3 27.944 17.562 18.002 20.038 17.613 18.013
A4 23.072 17.594 18.020 17.895 17.678 18.027
100
A1 34.110 17.540 17.977 25.134 17.561 17.985
A2 31.458 17.548 17.986 21.854 17.589 17.998
A3 28.371 17.558 18.000 19.899 17.616 18.011
A4 23.054 17.595 18.021 17.915 17.678 18.028
500
A1 33.116 17.543 17.983 25.119 17.564 17.989
A2 30.812 17.550 17.989 21.947 17.589 18.000
A3 28.113 17.559 17.998 19.828 17.616 18.010
A4 23.494 17.595 18.019 17.962 17.677 18.026
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster
> #Simulasi Tipe B, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50 >
> VClust_B1<-simclust.int(m1,m2,var1,var2,100,100,0,2,50) #Validitas Cluster Tipe B skenario 1
...
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe B, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50
>
> VClust_B2<-simclust.int(m1,m2,var1,var2,100,100,0.3,2,50) #Validitas Cluster Tipe B skenario 2 ...
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe B, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50
>
> VClust_B3<-simclust.int(m1,m2,var1,var2,100,100,0.5,2,50) #Validitas Cluster Tipe B skenario 3 ...
> #Menjalankan Fungsi Simulasi Validitas Internal Cluster Sesuai Jenis Skenario Parameter > #Simulasi Tipe B, Ukuran Cluster Berbeda untuk Pengulangan sebanyak K=50
>
> VClust_B4<-simclust.int(m1,m2,var1,var2,100,100,0.7,2,50) #Validitas Cluster Tipe B skenario 4
...
33
Validitas Internal Cluster Hasil Pengelompokan pada Data Simulasi Tipe B
Pengulangan Jenis Data Simulasi
Metode FCM Metode LCCA Con. Dunn Silh. Con. Dunn Silh.
(1) (2) (3) (4) (5) (6) (7) (8)
50
B1 34.352 17.540 17.996 27.527 17.549 17.985
B2 30.084 17.547 18.000 22.634 17.569 17.998
B3 24.901 17.577 18.013 19.824 17.601 18.013
B4 19.927 17.630 18.027 17.797 17.662 18.027
100
B1 33.861 17.542 17.999 27.364 17.549 17.989
B2 30.235 17.545 18.001 22.755 17.569 17.999
B3 25.126 17.572 18.013 19.908 17.597 18.013
B4 19.672 17.630 18.024 17.850 17.654 18.025
500
B1 34.081 17.542 17.997 26.984 17.548 17.987
B2 30.337 17.549 18.001 23.018 17.567 17.999
B3 25.163 17.570 18.012 19.924 17.598 18.012
34
Lampiran-5 Pengujian Normalitas Multivariat
50.000 100.000 150.000
- 0.200 0.400 0.600 0.800 1.000 1.200
chisquare plot
20.000 40.000 60.000 80.000 100.000 120.000
- 5.00 10.00 15.00 20.00 25.00 30.00
35
Lampiran-6 Tabel Nilai Rata-rata Indikator Metode LCCA Model EEE 3-Cluster dengan Direct Effect Hasil 10 kali Pengulangan
Cluster Size 0.75 0.23 0.02
Rata-rata Indikator Cluster1 Cluster2 Cluster3
Y1 5.94 6.75 4.58
Y2 29.07 7.48 23.43
Y3 23.92 32.30 38.95
Y4 47.01 60.23 37.61
Y5 66.63 62.10 63.85
Y6 70.38 66.49 72.40
Y7 5.48 6.76 7.31
Y8 69.03 69.80 70.86
Y9 90.85 95.72 93.17
Y10 7.31 9.60 8.05
Y11 13.41 7.98 12.92
Y12 1.94 1.17 1.90
Y13 0.44 0.27 0.79
Tabel Rata-rata Error Varians Indikator Metode LCCA Model EEE 3-Cluster dengan Direct Effect Hasil 10 kali Pengulangan Error Varians Indikator Cluster1 Cluster2 Cluster3
Y1 0.77 0.77 0.77
Y2 127.75 127.75 127.75
Y3 265.65 265.65 265.65
Y4 154.92 154.92 154.92
Y5 49.01 49.01 49.01
Y6 32.47 32.47 32.47
Y7 8.56 8.56 8.56
Y8 6.69 6.69 6.69
Y9 23.17 23.17 23.17
Y10 0.59 0.59 0.59
Y11 21.25 21.25 21.25
Y12 0.67 0.67 0.67
36
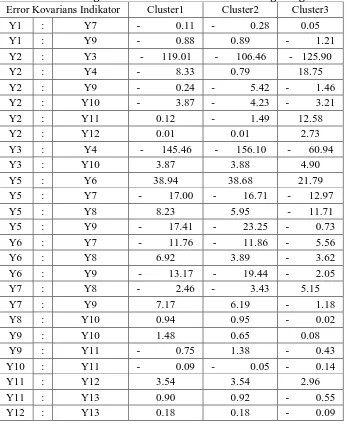
Tabel Rata-rata Error Kovarians Indikator Metode LCCA Model EEE 3-Cluster dengan Direct Effect Hasil 10 kali Pengulangan
Error Kovarians Indikator Cluster1 Cluster2 Cluster3 Y1 : Y7 - 0.11 - 0.28 0.05 Y1 : Y9 - 0.88 0.89 - 1.21 Y2 : Y3 - 119.01 - 106.46 - 125.90
Y2 : Y4 - 8.33 0.79 18.75
Y2 : Y9 - 0.24 - 5.42 - 1.46 Y2 : Y10 - 3.87 - 4.23 - 3.21
Y2 : Y11 0.12 - 1.49 12.58
Y2 : Y12 0.01 0.01 2.73
Y3 : Y4 - 145.46 - 156.10 - 60.94
Y3 : Y10 3.87 3.88 4.90
Y5 : Y6 38.94 38.68 21.79
Y5 : Y7 - 17.00 - 16.71 - 12.97
Y5 : Y8 8.23 5.95 - 11.71
Y5 : Y9 - 17.41 - 23.25 - 0.73 Y6 : Y7 - 11.76 - 11.86 - 5.56
Y6 : Y8 6.92 3.89 - 3.62
Y6 : Y9 - 13.17 - 19.44 - 2.05 Y7 : Y8 - 2.46 - 3.43 5.15
Y7 : Y9 7.17 6.19 - 1.18
Y8 : Y10 0.94 0.95 - 0.02
Y9 : Y10 1.48 0.65 0.08
Y9 : Y11 - 0.75 1.38 - 0.43 Y10 : Y11 - 0.09 - 0.05 - 0.14
Y11 : Y12 3.54 3.54 2.96
Y11 : Y13 0.90 0.92 - 0.55
37