37 BAB III
METODE PENELITIAN
3.1 Populasi dan Sampel
Populasi dan sampel merupakan kumpulan dari seluruh elemen atau individu yang merupakan sumber informasi dalam sebuah penelitian.
Sampel diartikan sebagai bagian dari populasi atau bagian representative dari sebuah populasi. Populasi ini menggunakan 32 provinsi yang ada di Indonesia.
Teknik yang digunakan penulis dalam penelitian ini adalah purposive sampling yaitu teknik pengambilan sampel yang ditentukan oleh penulis sendiri dan didasarkan beberapa pertimbangam dengan kriteria tertentu yang digunakan untuk penelitian.
Teknik purposive sampling ini digunakan penulis dikarenakan
untuk mendapatkan sampel yang sesuai dan bersifat sama antar sampel
satu dan sampel lainnya. Disamping itu juga karena keterbatasan akses
data dari peneliti karena tidak semua provinsi memiliki data dengan
jumlah tahun yang sama. Provinsi yang digunakan pada penelitian ini
adalah provinsi yang berdiri di bawah tahun 2007 yang telah mempunyai
kelengkapan data dan dipublikasikan. Data PDRB, presentase penduduk
miskin, rasio gini dan angka partisipasi sekolah yang di gunakan adalah
data tahunan sesuai dengan tahun yang digunakan penulis untuk observasi.
38
Berdasarkan pertimbangan tersebut sampel yang didapat dan memenuhi kriteria yaitu provinsi yang berdiri dibawah tahun 2007, provinsi tersebut antara lain :
1. Aceh
2. Sumatera Utara 3. Sumatra Barat 4. Riau
5. Jambi
6. Sumatra Selatan 7. Bengkulu 8. Lampung 9. Banten
10. Bangka Belitung 11. DKI
12. Jawa Timur
13. Jawa Barat 14. Jawa Tengah 15. DIY
16. Nusa Tenggara Barat
17. Nusa Tenggara Timur
18. Bali
19. Kalimantan barat 20. Kalimantan Tengah 21. Kalimantan Selatan 22. Kalimantan Timur
23. Sulawesi Utara 24. Sulawesi tengah 25. Sulawesi Selatan 26. Sulawesi tenggara 27. Gorontalo
28. Sulawesi Barat 29. Maluku 30. Maluku Utara 31. Papua Barat 32. Papua
Sedangkan selebihnya provinsi di Indonesia yang tidak digunakan
dalam penelitian karena belum mempunyai data yang lengkap, disamping
itu beberapa provinsi di Indonesia belum berdiri pada tahun yang
dijadikan penelitian. Dari jumlah provinsi yang digunakan untuk observasi
sebanyak 32 provinsi dan merupakan data tahunan dari tahun 2007 hingga
tahun 2013, maka jumlah observasi yang di dapat sebanyak 224.
39 3.2 Jenis dan Cara Pengumpulan Data
Jenis data yang digunakan berupa data sekunder yang bersifat historis yaitu data PDRB menurut lapangan usaha, rasio gini, presentase penduduk miskin dan angka partisipasi sekolah yang diterbitkan oleh Badan Pusat Statistik dari tahun 2007 sampai tahun 2013. Penelitian ini menggunakan data kuatitatif yaitu data berupa angka atau besaran tertentu yang sudah dipublikasikan. Sumber penunjang lainnya berupa jurnal yang diperlukan, sumber-sumber lain guna untuk menunjang kelengkapan data yang dapat digunakan dalam penelitian ini. Berikut adalah data yang digunakan dalam penelitian ini:
1. Produk Domestik Regional Bruto (PDRB) menurut lapangan usaha 32 provinsi di Indonesia
2. Presentase jumlah penduduk miskin 32 provinsi
3. Angka Partisipasi Sekolah menurut provinsi umur 18-24 tahun 4. Rasio gini 32 provinsi
3.3 Metode pengumpulan Data
Metode yang digunakan dalam pengumpulan data adalah dengan
melakukan observasi secara langsung dan tidak langsung. Peneliti secara
langsung mendatangi Badan Pusat Statistik Provinsi DIY untuk menyalin
hard file data yang diperlukan dan secara tidak langsung melalui website
Badan Pusat Statistik peneliti mengunduh data yang diperlukan. Adapun
40
situs yang digunakan adalah http://bps.go.id/. Metode lain yang digunakan adalah studi pustaka yaitu dengan mengumpulkan informasi yang relevan melalui jurnal, artikel maupun penelitian terdahulu dari berbagai sumber guna untuk mendukung penelitian dalam memahami dan mempelajari pembahasan.
3.4 Variabel Penelitian
Variabel yang digunakan dalam penelitian ini adalah sebagai berikut :
3.4.1 Variabel Dependen
Variabel dependen disebut juga variabel terikat adalah tipe variabel yang dijelaskan atau dipengaruhi oleh variabel independen. Dalam penelitian ini variabel yang digunakan adala Rasio GINI.
3.4.2 Variabel Independen
Variabel independen adalah tipe variabel yang menjelaskan atau mempengaruhi variabel yang lain atau disebut juga variabel bebas.
Variabel-variabel independen yang akan di uji dalam penelitian ini adalah 1. PDRB Persektor (9 sektor)
2. Presentase Penduduk Miskin
3. Angka Partisipasi Sekolah (umur 18-24)
41 3.5 Definisi Operasional variabel
Definisi operasional variabel merupakan langkah dalam penelitian untuk menjelaskan setiap variabel yang dijadikan dalam observasi. Berikut adalah definisi operasional variabel yang akan digunakan dalam penelitian:
1. Rasio Gini
Rasio gini adalah ukuran ketidakmerataan atau ketimpangan agregat (secara keseluruhan) distribusi pendapatan atau kekayaan yang menunjukkan seberapa merata pendapatan dan kekayaan didistribusikan diantara populasi dalam bentuk rasio yang nilainya antara 0 dan 1. Nilai 0 menunjukkan pemerataan yang sempurna dimana setiap orang memiliki jumlah penghasilan atau kekayaan yang sama persis. Nilai 1 menunjukan ketimpangan sempurna yaitu satu orang menguasai semuanya sedangkan yang lainnya tidak memiliki apa-apa. Data yang diperlukan dalam perhitungan gini ratio:
a. Jumlah rumah tangga atau penduduk
b. Rata-rata pendapatan atau pengeluaran rumah tangga yang sudah dikelompokkan menurut kelasnya.
Rumus menghitung rasio gini:
k
i
i i
i
Q Q
G P
1
1
000 . 10
) 1 (
Dengan : P
i: presentase rumah tangga atau penduduk pada kelas ke-i
42
Q
i: presentase kumulatif total pendapatan atau pengeluaran sampai kelas ke-i
2. Produk Domestik Regional Bruto (PDRB)
Produk Domestik Regional Bruto adalah jumlah nilai tambah barang dan jasa yang dihasilkan dari seluruh kegiatan perekonomian di suatu daerah. PDRB dapat diartikan dalam tiga pengertian, yaitu :
a. Menurut pengertian produksi, PDRB adalah jumlah nilai produk barang dan jasa akhir yang dihasilkan oleh berbagai unit produksi didalam suatu wilayah dalam jangka waktu tertentu (satu tahun).
b. Menurut pengertian pendapatan, PDRB adalah jumlah balas jasa yang diterima oleh faktor-faktor produksi yang ikut serta dalam proses produksi diasuatu wilayah atau daerah dalam jangka waktu tertentu (satu tahun).
c. Menrut pengertian pengeluaran, PDRB adalah jumlah pengeluaran yang dilakukan untuk konsumsi rumah tangga dan lembaga swasra yang tidak mencari keuntungan, konsumsi pemerintah, pembentukan modal tetap bruto, perubahan stok dan ekspor neto (ekspor dikurangi impor).
Data PDRB yang digunakan dalam penelitian ini menggunakan data
PDRB atas dasar harga konstan masing-masing sektor (pertanian,
pertambangan, industry pengolahan, listrik, gas dan air bersih, konstruksi,
perdagangan, hotel dan restoran, pengangkutan dan komunikasi,
43
keuang,real estate dan jasa perusahaan, jasa-jasa). PDRB atas dasar harga konstan adalah jumlah nilai produksi atau pendapatan yang di nilai atas dasar harga tetap (harga pada tahun dasar) yang digunakan selama satu tahun.
3. Presentase Penduduk Miskin
Presentase penduduk miskin adalah jumlah penduduk miskin disuatu wilayah untuk mempermudah membandingkan suatu wilayah dengan wilayah lainnya. Tingkatan status kemiskinan tersebut bias menjadi alat ukur yang berfungsi sebagai patokan dasar perencanaan jika dibandingkan antar waktu untuk memberikan gambaran kemajuan setelah suatu periode atau perbandingan antar wilayah untuk memberikan gambaran tentang tingkat kemajuan suatu wilayah relative terhadap wilayah lain.
Nilai presentase penduduk miskin berkisar antara 0-100. Semakin tinggi presentase menunjukkan tingkat jumlah penduduk miskin disuatu wilayah semakin tinggi. Cara menghitung presentase penduduk miskin sebagai berikut :
P
o= banyaknya penduduk miskin / jumlah penduduk × 100%
4. Angka Partisipasi Sekolah (APS)
Angka partisipasi sekolah merupakan ukuran daya serap lembaga
pendidikan terhadap penduduk usia sekolah. APS merupakan indikator
dasar yang digunakan untuk melihat akses penduduk pada fasilitas
pendidikan khususnya bagi penduduk usia sekolah di suatu
44
wilayah/daerah. Semakin tinggi angka partisipasi sekolah semakin besar jumlah penduduk yang berkesempatan mengenyam pendidikan. Namun demikian meningkatnya APS tidak selalu dapat diartikan sebagai meningkatnya pemerataan kesempatan masyarakat untuk mengenyam pendidikan. APS yang tinggi menunjukkan terbukanya peluang yang lebih besar dalam mengakses pendidikan secara umum. Pada kelompok umur mana peluang tersebut terjadi dapat dilihat dari besarnya APS pada setiap kelompok umur.
Table 3.1 Ringkasan Data
No Variabel Satuan Periode Sumber Data
1 PDRB Sektor Pertanian, Perkebunan, Peternakan &
kehutanan
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
2 PDRB Sektor Pertambangan dan penggalian
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
3 PDRB Sektor Industri Pengolahan
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
4 PDRB Sektor Listrik, Gas dan Air Bersih
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
5 PDRB Sektor Konstruksi
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
6 PDRB Sektor Perdagangan, Hotel
& Restoran
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
7 PDRB Sektor Pengankutan &
komunikasi
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
8 PDRB Sektor Keuangan, Real
Dalam Milyar Mulai dari tahun 2007 –
Badan Pusat
Statistik Provinsi
45 Estat & Jasa
Perusahaan
Rupiah tahun 2013 DIY
9 PDRB Sektor Jasa-Jasa
Dalam Milyar Rupiah
Mulai dari tahun 2007 – tahun 2013
Badan Pusat Statistik Provinsi DIY
10 Presentase penduduk Miskin
Dalam Persen (%)
Mulai dari tahun 2007 – tahun 2013
Website Badan Pusat Statistik Indonesia 11 Angka Partisipasi
Sekolah
Dalam persen (%)
Mulai dari tahun 2007 – tahun 2013
Website Badan Pusat Statistik Indonesia
3.6 Metode Analisis Data
Penelitian ini bersifat deskriptif sehingga digunakan data kuantitatif yaitu analisis dengan mengolah data dari hasil yang dinyatakan dalam angka untuk dianalisis dengan perhitungan statistik terhadap objek yang diteliti.
3.6.1 Statistik Deskriptif
Statistika deskriptif adalah metode-metode yang berkaitan dengan pengupulan dan penyajian suatu gugus data sehingga memberikan informasi yang berguna. Dengan statistika deskriptif, kumpulan data yang diperoleh akan tersaji dengan ringkas dan rapih serta dapat memberikan informasi inti dari kumpulan data yang ada. Informasi yang dapat diperoleh dari statistika deskriptif ini antara lain :
a. Ukuran pemusatan data (Measure of central tendency), ukuran
pemusatan data yang sering digunakan adalah distribusi
frekuensi.
46
b. ukuran penyebaran data, (Measure of spread, ukuran penyebaran data yang sering digunakan standar deviasi ukuran ini cocok digunakan untuk numerik atau continuos.
Sementara informasi yang didapat dari statistic deskriptif diantaranya :
a. mean atau rata-rata merupakan nilai yang memberi informasi tentang besaran rata-rata yang ada pada data.
b. Median merupakan nilai tengah dari rangkaian data yang telah disusun secara berurut.
c. Standar deviasi adalah nilai statistic yang digunakan untuk menentukan bagaimana sebaran data dalam sampel, dan seberapa dekat titik data individu ke mean – atau rata-rata – nilai sampel.
d. Nilai maksimum adalah nilai yang terbesar dalam rangkaian data sampel
e. Nilai minimum adalah terkecil dalam rangkaian data sampel.
3.6.2 Data Panel
Metode yang digunakan dalam penelitian ini adalah melakukan
analisis regresi data panel dengan menggunakan bantuan program E-views
7. Data panel merupakan gabungan antara data silang (cross-section)
dengan data runtut waktu (time series). Penggunaan data panel dapat
menjelaskan dua macam informasi yaitu informasi antar unit (cross-
section) pada perbedaan antar subjek, dan informasi antar waktu (time
47
series) yang merefleksikan perubahan pada subjek waktu. Dalam regresi data panel ada tiga cara pendekatan yaitu common effect, fixed effect, dan random effect.
a. Pendekatan Koefisien Tetap Antar Waktu dan Individu (Common Effect)
Teknik yang paling sederhana yaitu dengan menggabungkan data time series dan data cross section disebut metode common effect atau metode OLS (ordinary Least Square). Metode ini tidak memperhatikan perbedaan baik antar waktu maupun antar individu sehingga hasil analisis regresi diasumsikan sama pada individu atau objek dalam berbagai periode waktu
b. Pendekatan Slope Konstan tetapi Intersep Berbeda Antar Individu (Fixed effect)
Pada pembahasan sebelumnya kita mengasumsikan bahwa intersep maumupun slope adalah sama baik antar waktu maupun antar perusahaan.
Namun, asumsi ini jelas sangat jauh dari kenyataan sebenarnya. Adanya variabel-variabel yang tidak semuanya masuk dalam persamaan model memungkinkan adanya intersep yang tidak konstan atau dengan kata lain, intersep ini mungkin berubah untuk setiap individu dan waktu. Pemikiran inilah yang menjadi dasar pemikiran pembentukan model tersebut.
Model fixed effect merupakan teknik mengestimasi data panel
dengan menggunakan variabel dummy untuk menangkap adanya intersep
48
(Widardjono, 2009:232). Metode ini disebut juga metode LSDV (Least Square Dummy Variables)
c. Pendekatan Efek Acak (Random Effect)
Pada model efek tetap, perbedaan antar-individu dana tau waktu dicerminkan lewat intercept, maka pada model efek acak, perbedaan tersebut diakomodasikan lewat error. Teknik ini juga memperhitungkan bahwa error mungkin berkolerasi sepanjang time series dan cross section.
3.6.3 Pemilihan Model Data Panel
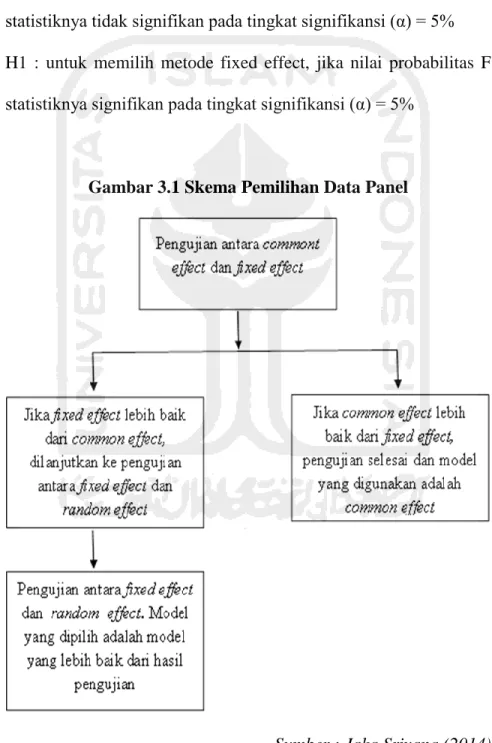
Seperti diketahui terdapat tiga jenis teknik estimasi model regresi data panel, yaitu model dengan metode OLS (common), model Fixed Effect dan model Random Effect. Pemilihan model terbaik dapat dilakukan dengan du acara pertama, dengan membandingkan antara uji fixed effect dan random effect yang dikenal dengan uji Hausman. Kedua, dengan membandingkan antara common dan fixed effect.
Apabila dalam uji yang pertama mendapatkan hasil bahwa model common effect adalah metode terbaik, maka pengujian cukup sampai tahan pertama yakni metode analisis yang digunakan adalah metode common effect. Namun apabila dalam uji pertama mendapatkan hasil bahwa model fixed effect adalah yang terbaik, maka pengujian dilanjutkan pada metode yang kedua yaitu melakukan uji Hausman yaitu dengan membandingkan metode fixed effect dan random effect.
1. Uji Signifikansi Common Effect dan Fixed Effect
49
Setelah melakukan regresi dua model dengan asusmsi bahwa slope dan intersep sama dan model dengan asumsi bahwa slope sama tetapi intersep berbeda. Keputusan untuk menambahkan variabel dummy guna untuk mengetahui bahwa intersep berbeda (Widardjono, 2009)
Uji ini digunakan untuk memilih antara model common effect dan fixed effect. Pemilihannya dengan cara melihat nilai probabilitas F statistikanya.
H0 : untuk memilij metode Common Effect, jika nilai probabilitas F statistiknya tidak signifikan pada tingkat signifikansi (α) = 5%
H1 : untuk memilih metode Fixed Effect, jika nilai probabilitas F statistiknya signifikan pada tingkat signifikansi (α) = 5%
2. Uji Signifikansi Fixed Effect dan Random Effect
Ada dua hal untuk mempertimbangkan pemilihan model antara fixed effect dan random effect. Pertama, tentang ada tidaknya korelasi antara error term eit dengan variabel bebas. Jika diasumsikan terjadi korelasi antara eit dengan variabel bebas maka model random effect lebih tepat. Kedua, berkaitan dengan jumlah sampel penelitian, jika sampel yang diambil adalah hanya sebagian kecil dari populasi maka kita akan mendapatkan error term eit yang bersifat random sehingga model random effect lebih tepat.
Hausnan mengembangkan suatu uji statistik untuk memilih
model antara fixed effect dan random effect yang didasarkan pada
LSDV di dalam metode fixed effect dan GLS tidak efisien, namun
50
di lain sisi metode OLS efisien dan GLS tidak efisien, karena itu uji hipotesis nolnya adalah hasil estimasi keduanya tidak berbeda sehingga uji Hausman bisa dilakukan berdasarkan perbedaan estimasi tersebut.
H0 = memilih metode random effect, jika nilai probabilitas F statistiknya tidak signifikan pada tingkat signifikansi (α) = 5%
H1 : untuk memilih metode fixed effect, jika nilai probabilitas F statistiknya signifikan pada tingkat signifikansi (α) = 5%
Gambar 3.1 Skema Pemilihan Data Panel
Sumber : Jaka Sriyana (2014)
51 3.6.4 Pengujian Hipotesis
Untuk melakukan pengujian terhadap hipotesis-hipotesis yang diajukan, perlu dilakukan adanya model regresi berganda dan menggunakan model analisis Uji t dan Uji F.
Uji t digunakan untuk menguji secara parsial masing-masing variabel. Hasil uji t dapat dilihat pada table coefficients pada kolom sig (significance) jika probabilitas nilai t atau signifikansi < 0,05 maka dapat dikatakan bahwa terdapat pengaruh antara variabel bebas terhadap variabel terikat secara parsial. Jika probabilitas t atau signifikansi > 0,05 maka dapat dikatakan bahwa tidak terdapat pengaruh yang signifikan antara masing-masing variabel bebas terhadap variabel terikat.
Uji F digunakan untuk mengetahui pengaruh variabel bebas secara bersama-sama (simultan0 terhadap variabel terikat. Signifikan berarti hubungan yang terjadi dapat berlaku untuk populasi. Hasil uji F dapat dilihat pada table ANOVA dalam kolom sig. penggunaan tingkat signifikansi beragam, tegantung keinginan peneliti yaitu 0,01 (1%), 0,05 (5%) dan 0,10 (10%).
1. Model Regresi Data Panel
Pada tahap ini penulis akan membuat model regresi yang
menggambarkan hubungan antara PDRB 9 sektor, Presentase Penduduk
Miskin, dan Angka Partisipasi Sekolah terhadap variabel dependen Rasio
Gini. Adapun modelnya dituliskan sebagai berikut :
52
GINIDit = β0 + β1(ppk)it + β2(pp)it + β3(ip)it + β4(LGA)it + β5(K)it + β6(PHR)it + β7(PK)it + β8(KRJP)it +
β9(jasa)it + β10(PPM)it + β11(APS)it + eit