BAB II
LANDASAN TEORI
Bab ini akan dibahas mengenai teori-teori pendukung pada penelitian ini. Adapun teori tersebut yaitu teori jaringan saraf tiruan dan algoritma backpropragation.
2.1. Jaringan Saraf Biologi
Jaringan saraf biologi merupakan kumpulan dari sel-sel saraf (neuron) yang memiliki tugas untuk mengolah informasi (Puspitaningrum, 2006). Komponen-komponen utama dari sebuah neuron dapat dikelompokkan menjadi 3 bagian, yaitu:
1. Dendrit yang bertugas untuk menerima informasi.
2. Badan sel (soma) yang berfungsi sebagai tempat pengolahan informasi.
3. Akson (neurit) yang bertugas mengirimkan impuls-impuls ke sel saraf lainnya.
Gambar 2.1 Sel Saraf Biologi
Pada gambar 2.1 sebuah neuron menerima impuls-impuls sinyal dari neuron yang lain melalui dendrit dan mengirimkan sinyal yang dibangkitkan oleh badan sel melalui akson. Akson dari sel saraf biologi bercabang-cabang dan berhubungan
dengan dendrit dari sel saraf lainnya dengan cara mengirimkan impuls melalui sinapsis, yaitu penghubung antara dua buah sel saraf. Sinapsis memiliki kekuatan yang dapat meningkat dan menurun tergantung seberapa besar tingkat propagasi yang diterimanya.
2.2. Jaringan Saraf Tiruan
Jaringan saraf tiruan (JST) merupakan sistem pemrosesan informasi yang mengadopsi cara kerja otak manusia (Fausset, 1994). JST memiliki kecenderungan untuk menyimpan pengetahuan yang bersifat pengalaman dan membuatnya siap untuk digunakan. Ada tiga elemen penting dalam JST (Rojas, 1996), yaitu:
1. Arsitektur jaringan beserta pola hubungan antar neuron.
2. Algoritma pembelajaran yang digunakan untuk menemukan bobot-bobot jaringan.
3. Fungsi aktivasi yang digunakan.
JST terdiri dari sejumlah besar elemen pemrosesan sederhana yang sering disebut neurons, cells atau node. Proses pengolahan informasi pada JST terjadi pada neuron – neuron. Sinyal antara neuron – neuron diteruskan melalui link – link yang saling terhubung dan memiliki bobot terisolasi. Kemudian setiap neuron menerapkan fungsi aktivasi terhadap input jaringan.
2.2.1 Arsitektur Jaringan Saraf Tiruan
Arsitektur jaringan yang sering dipakai dalam JST antara lain : 1. Jaringan layar tunggal (single layer network)
Jaringan ini hanya memiliki satu buah lapisan bobot koneksi. Jaringan lapisan tunggal terdiri dari neuron-neuron input yang menerima sinyal dari dunia luar, dan neuron-neuron output dimana kita bisa membaca respons dari jaringan saraf tiruan tersebut.
Gambar dibawah menunjukkan arsitektur jaringan dengan n neuron input (X1, X2, X3, ..., Xn) dan m buah neuron output (Y1, Y2, Y3, ..., Ym). Semua neuron input dihubungkan dengan semua neuron output, meskipun memiliki bobot yang berbeda-beda. Tidak ada neuron input yang dihubungkan dengan neuron input lainnya. Begitu juga dengan neuron output.
X1
X3 X2
Y1
Y2
Y3 W11
Wj1 Wm1
W1j Wji
Wmi
W1n Wjn
Wmn
Gambar 2.2 Single Layer Network
Besaran Wji menyatakan bobot hubungan antara ubit ke-i dalam input dengan neuron ke-j dalam output. Bobot-bobot ini saling independen. Selama proses pelatihan, bobot – bobot saling dimodifikasi untuk menigkatkankeakuratan hasil. Metode ini tepat digunakan untuk pengenalan pola karena kesederhanaannya.
2. Jaringan Layar Jamak (multi layer network)
Jaringan ini memiliki satu atau lebih lapisan tersembunyi. Jaringan layar jamak memiliki kemampuan lebih dalam memecahkan masalah dibandingkan dengan jaringan layar tunggal, namun pelatihannya lebih kompleks dan relatif lebih lama.
Gambar 2.3 Multilayer Network
Pada gambar diatas jaringan dengan n buah neuron input (X1, X2, ..., Xn), sebuah layer tersembunyi yang terdiri dari p buah neuron (Z1, Z2, .. Zp) dan m buah neuron output (Y1,Y2, ... Ym).
3. Competitive layer network
Jaringan ini mirip dengan jaringan layar tunggal ataupun ganda. Hanya saja, ada neuron output yang memberikan sinyal pada neuron input (sering disebut feedback loop). Sekumpulan neuron bersaing untuk mendapatkan hak menjadi aktif.
Al Am
Ai Aj
1 1
1 1
Gambar 2.4 Competitive layer network
2.2.2. Fungsi Aktivasi
Fungsi aktivasi pada jaringan saraf tiruan digunakan untuk memformulasikan output dari setiap neuron. Argumen fungsi aktivasi adalah net masukan (kombinasi linier masukan dan bobotnya). Jika net = XiWi, maka fungsi aktivasinya adalah 𝑓 𝑛𝑒𝑡 = 𝑓( 𝑋𝑖𝑊𝑖).
Fungsi aktivasi dalam jaringan Backpropagation memiliki beberapa karakteristik penting, yaitu fungsi aktivasi harus bersifat kontinu, terdiferensial dengan mudah dan tidak turun (Fausset, 1994). Beberapa fungsi aktivasi yang sering dipakai adalah sebagai berikut :
1. Fungsi aktivasi linier
𝑓 𝑥 = 𝑥 (1)
Fungsi aktivasi linier sering dipakai apabila keluaran jaringan yang diinginkan berupa sembarang bilangan riil (bukan hanya pada range [0,1]
atau [-1,1]. Fungsi aktivasi linier umumnya digunakan pada neuron output.
2. Fungsi aktivasi sigmoid biner
𝑓 𝑥 = 1
1+𝑒−𝑥 (2)
Fungsi aktivasi sigmoid atau logistik sering dipakai karena nilai fungsinya yang terletak antara 0 dan 1 dan dapat diturunkan dengan mudah.
𝑓′ 𝑥 = 𝑓 𝑥 (1 − 𝑓 𝑥 ) (3)
3. Fungsi aktivasi sigmoid bipolar.
𝑓 𝑥 = 2
1+𝑒−𝑥 − 1 (4)
Fungsi aktivasi ini memiliki nilai yang terletak antara -1 dan 1 dengan turunannya sebagai berikut:
𝑓′ 𝑥 = 1+𝑓 𝑥 (1−𝑓 𝑥 )
2 (5)
4. Fungsi aktivasi tangen hiperbola
Fungsi aktivasi ini juga memiliki nilai yang terletak antara -1 dan 1.
Formulanya yaitu:
𝑡𝑎𝑛 𝑥 =(𝑒𝑥−𝑒−𝑥)
(𝑒𝑥+𝑒−𝑥)= 1−𝑒−2𝑥
1+𝑒−2𝑥 (6)
dengan rumus turunannya sebagai berikut:
𝑡𝑎𝑛′ 𝑥 = 1 + tanh 𝑥 (1 − tanh 𝑥 ) (7)
2.2.3. Bias
Bias dapat ditambahkan sebagai salah satu komponen dengan nilai bobot yang selalu bernilai 1. Jika melibatkan bias, maka fungsi aktivasi menjadi:
(8) Dimana:
𝑥 = 𝑏 + 𝑥𝑖 𝑖𝑤𝑖 (9)
2.2.4. Laju Pembelajaran / learning rate (𝜼)
Penggunaan parameter learning rate memiliki pengaruh penting terhadap waktu yang dibutuhkan untuk tercapainya target yang diinginkan. Secara perlahan akan mengoptimalkan nilai perubahan bobot dan menghasilkan error yang lebih kecil (Fajri, 2011). Variabel learning rate menyatakan suatu konstanta yang bernilai antara 0.1-0.9. Nilai tersebut menunjukkan kecepatan belajar dari jaringannya.
Jika nilai learning rate yang digunakan terlalu kecil maka terlalu banyak epoch yang dibutuhkan untuk mencapai nilai target yang diinginkan, sehingga menyebabkan proses training membutuhkan waktu yang lama. Semakin besar nilai learning rate yang digunakan maka proses pelatihan jaringan akan semakin cepat, namun jika terlalu besar justru akan mengakibatkan jaringan menjadi tidak stabil dan menyebabkan nilai error berulang bolak-balik diantara nilai tertentu, sehingga mencegah error mencapai target yang diharapkan. Oleh karena itu pemilihan nilai variable learning rate harus seoptimal mungkin agar didapatkan proses training yang cepat (Hermawan, 2006).
2.3. Metode Backpropagation
Backpropagation adalah salah satu bentuk dari jaringan saraf tiruan dengan pelatihan terbimbing. Ketika menggunakan metode pelatihan terbimbing, jaringan harus menyediakan input beserta nilai output yang diinginkan. Nilai output yang diinginkan tersebut kemudian akan dibandingkan dengan hasil output aktual yang dihasilkan oleh input dalam jaringan.
Metode Backpropagation merupakan metode yang sangat baik dalam menangani masalah pengenalan pola-pola kompleks. Backpropagation melatih jaringan untuk mendapat keseimbangan antara kemampuan jaringan mengenali pola yang digunakan selama pelatihan serta kemampuan jaringan untuk memberikan respon yang benar terhadap pola masukan yang serupa dengan pola yang dipakai selama pelatihan (Siang, 2009).
Pelatihan jaringan Backpropagation meliputi tiga langkah, yaitu langkah maju (feedforward) dari pola pelatihan input, perhitungan langkah mundur (Backpropagation) dari error yang terhubung dan penyesuaian bobot-bobot (Fausset, 1994). Langkah maju dan langkah mundur dilakukan pada jaringan untuk setiap pola yang diberikan selama jaringan mengalami pelatihan.
2.3.1. Arsitektur Backpropagation
Jaringan Backpropagation memiliki beberapa neuron yang berada dalam satu atau lebih lapisan tersembunyi (hidden layer). Setiap neuron yang berada dilapisan input terhubung dengan setiap neuron yang berada di hidden layer. Begitu juga pada hidden layer, setiap neuronnya terhubung dengan setiap neuron yang ada di output layer.
Jaringan saraf tiruan Backpropagation terdiri dari banyak lapisan (multi layer), yaitu:
1. Lapisan masukan (input layer)
Input layer sebanyak 1 lapis yang terdiri dari neuron – neuron input, mulai dari neuron input pertama sampai neuron input ke-n. Input layer merupakan penghubung yang mana lingkungan luar memberikan sebuah pola kedalam jaringan saraf. Sekali sebuah pola diberikan kedalam input layer, maka output layer akan memberikan pola yang lainnya (Heaton, 2008). Pada intinya input layer akan merepresentasikan kondisi yang dilatihkan kedalam jaringan. Setiap input akan merepresentasikan beberapa variabel bebas yang memiliki pengaruh terhadap output layer.
2. Lapisan tersembunyi (hidden layer)
Hidden layer berjumlah minimal 1 lapis yang terdiri dari neuron-neuron tersembunyi mulai dari neuron tersembunyi pertama sampai neuron tersembunyi ke-p. Menentukan jumlah neuron pada hidden layer merupakan bagian yang sangat penting dalam arsitektur jaringan saraf.
Ada beberapa aturan metode berdasarkan pengalaman yang dapat digunakan untuk menentukan jumlah neuron yang akan digunakan pada hidden layer. Menurut Haykin (1999) jumlah hidden neuron 2 sampai dengan 9 sudah dapat menghasilkan
hasil yang baik dalam jaringan, namun pada dasarnya jumlah hidden neuron yang digunakan dapat berjumlah sampai dengan tak berhingga (~). Sedangkan menurut Heaton (2008), ada beberapa aturan yang dapat digunakan untuk menentukan banyaknya jumlah neuron pada hidden layer yaitu:
a. Jumlah hidden neuron harus berada diantara ukuran input layer dan output layer.
b. Jumlah hidden neuron harus 2 3 dari ukuran input layer, ditambah ukuran output layer.
c. Jumlah hidden neuron harus kurang dari dua kali jumlah input layer.
Aturan-aturan tersebut hanya berupa pertimbangan dalam menentukan arsitektur jaringan saraf tiruan. Bagaimanapun, penentuan arsitektur jaringan akan kembali pada trial and error sesuai dengan masalah yang ditangani oleh jaringan.
3. Lapisan keluaran (output layer)
Output layer berjumlah satu lapis yang terdiri dari neuron-neuron output mulai dari neuron output pertama sampai neuron output ke-m. Output layer dari jaringan saraf adalah pola yang sebenarnya diberikan oleh lingkungan luarnya (external environment). Pola yang diberikan output layer dapat secara langsung ditelusuri kembali ke input layernya. Jumlah dari neuron output tergantung dari tipe dan performa dari jaringan saraf itu sendiri.
X1
Xi
Xn
Z1
Zj
Zp
Y1
Y2
Y3
b b
V11 Vj1 Vp1 V1i V1i
Vpi
V1n Vn1 Vpn
w11 wj1 Wp1
w1j wji
wpi w1p
wp1 wpn
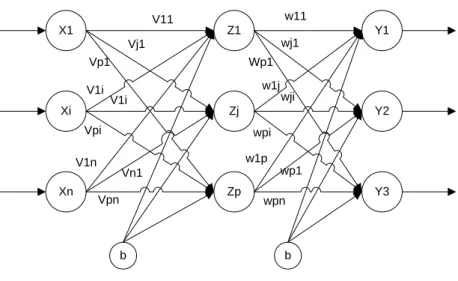
Gambar 2.5 Arsitektur Backpropagation
Gambar 2.5 adalah arsitektur Backpropagation dengan n buah masukan (ditambah dengan bias), sebuah layar tersembunyi Z1 (Vji merupakan bobot garis
yang menghubungkan bias di neuron input ke neuron layar tersembunyi Zj). Wkj merupakan bobot dari neuron layar tersembunyi Zj ke neuron keluaran Yk ( Wk0 merupakan bobot dari bias di layar tersembunyi ke neuron keluaran Yk). Pelatihan Backpropagation meliputi tiga fase, yaitu :
1. Fase I: Propagasi maju
Selama propagasi maju, sinyal masukan dipropagasikan ke hidden layer menggunakan fungsi aktivasi yang telah ditentukan hingga menghasilkan keluaran jaringan. Keluaran jaringan dibandingkan dengan target yang harus dicapai. Selisih antara target dengan keluaran merupakan kesalahan yang terjadi. Jika kesalahan lebih kecil dari batas toleransi, maka iterasi dihentikan. Akan tetapi jika kesalahan lebih besar, maka bobot setiap garis dalam jaringan akan dimodifikasi untuk mengurangi kesalahan yang terjadi.
2. Fase II: Propagasi mundur
Kesalahan yang terjadi di propagasi mundur mulai dari garis yang berhubungan langsung dengan neuron-neuron dilayar keluaran.
3. Fase III: Perubahan bobot
Pada fase ini, bobot semua garis dimodifikasi secara bersamaan. Ketiga fase tersebut diulang- ulang terus hingga kondisi penghentian dipenuhi. Kondisi penghentian yang sering dipakai adalah jumlah maksimal iterasi (epoch) atau minimal kesalahan (error).
2.3.2. Algoritma Pelatihan Backpropagation
Berikut adalah algoritma pelatihan Backpropagation dengan arsitektur satu hidden layer (Fausset, 1994):
Langkah 0 Inisialisasi bobot (set dengan bilangan acak kecil)
Langkah 1 Jika kondisi berhenti masih belum terpenuhi, lakukan langkah 2-9.
Langkah 2 Untuk setiap pasang pelatihan, lakukan langkah 3-8 Feedforwad
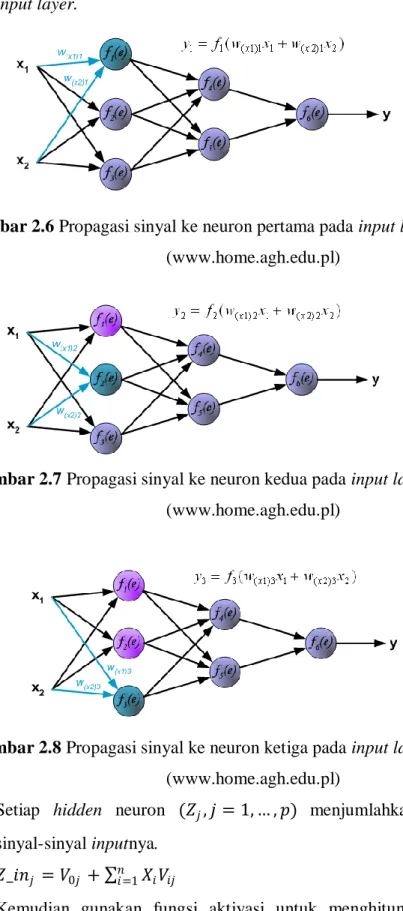
Langkah 3 Setiap neuron input (𝑋𝑖, 𝑖 = 1, … , 𝑛) menerima sinyal input 𝑋𝑖 dan meneruskan sinyal ini kesemua neuron pada lapisan di atasnya (hidden
neuron). Berikut merupakan ilustrasi bagaimana sinyal dipropagasikan keseluruh input layer. 𝑊(𝑥𝑚 )𝑛 merupakan bobot penghubung pada input layer.
Gambar 2.6 Propagasi sinyal ke neuron pertama pada input layer (www.home.agh.edu.pl)
Gambar 2.7 Propagasi sinyal ke neuron kedua pada input layer (www.home.agh.edu.pl)
Gambar 2.8 Propagasi sinyal ke neuron ketiga pada input layer (www.home.agh.edu.pl)
Langkah 4 Setiap hidden neuron (𝑍𝑗, 𝑗 = 1, … , 𝑝) menjumlahkan bobot dari sinyal-sinyal inputnya.
𝑍_𝑖𝑛𝑗 = 𝑉0𝑗 + 𝑛𝑖=1𝑋𝑖𝑉𝑖𝑗 (10)
Kemudian gunakan fungsi aktivasi untuk menghitung nilai sinyal outputnya.
𝑍𝑗 = 𝑓(𝑍_𝑖𝑛𝑗) (11) Dan kirimkan sinyal ini ke semua neuron yang berada pada lapisan diatasnya (output neuron). Gambar berikut merupakan ilustrasi bagaimana sinyal dipropagasikan keseluruh hidden layer.
𝑊𝑚𝑛 merupakan bobot penghubung pada hidden layer.
Gambar 2.9 Propagasi sinyal ke neuron pertama pada hidden layer (www.home.agh.edu.pl)
Gambar 2.10 Propagasi sinyal ke neuron kedua pada hidden layer (www.home.agh.edu.pl)
Langkah 5 Setiap output neuron (𝑌𝑘, 𝑘 = 1, … , 𝑚) menjumlahkan bobot dari sinyal-sinyal inputnya.
𝑌_𝑖𝑛𝑘 = 𝑊0𝑘 + 𝑝𝑗 =1𝑍𝑘𝑊𝑗𝑘 (12)
Dan menerapkan fungsi aktivasinya untuk menghitung nilai sinyal outputnya.
𝑌𝑘 = 𝑓(𝑦𝑖𝑛 𝑘) (13)
Gambar 2.11 merupakan ilustrasi yang dapat menjelaskan bagaimana sinyal dipropagasikan ke output layer.
Gambar 2.11 Propagasi sinyal ke neuron output (www.home.agh.edu.pl)
Backpropagation error
Langkah 6 Setiap neuron output (𝑌𝑘, 𝑘 = 1, … , 𝑚) menerima sebuah pola target yang sesuai pada input pola pelatihan, kemudian menghitung informasi kesalahannya.
𝛿𝑘 = 𝑡𝑘− 𝑦𝑘 𝑓′(𝑦_𝑖𝑛𝑘) (14)
Hitung koreksi bobot (yang nantinya akan dipakai untuk merubah bobot 𝑊𝑗𝑘)
∆𝑊𝑗𝑘 = 𝛼𝛿𝑘𝑍𝑗 (15)
Hitung koreksi bias (yang nantinya akan digunakan untuk merubah bobot 𝑊0𝑘
∆𝑊0𝑘 = 𝛼𝛿𝑘 (16)
Dan kirim 𝛿𝑘 ke neuron pada lapisan dibawahnya. Berikut ini adalah ilustrasi dari prosesnya.
Gambar 2.12 Perbandingan sinyal keluaran dan target (www.home.agh.edu.pl) Langkah 7 Setiap hidden neuron (𝑍𝑗, 𝑗 = 1, … , 𝑝) menjumlahkan delta input (dari
neuron yang berada dilapisan bawahnya),
𝛿_𝑖𝑛𝑗 = 𝑚𝑘 =1 𝛿𝑘𝑊𝑗𝑘 (17)
Mengalikan dengan turunan dari fungsi aktivasinya untuk menghitung informasi errornya.
𝛿𝑗 = 𝛿_𝑖𝑛𝑗𝑓′(𝑍_𝑖𝑛𝑗) (18)
Hitung koreksi bobotnya (yang nantinya akan digunakan untuk mengupdate 𝑉𝑖𝑗
∆𝑉𝒊𝒋 = 𝛼𝛿𝑗𝑋𝑖 (19)
Dan hitung koreksi biasnya (yang nantinya akan digunakan untuk mengupdate 𝑉0𝑗.
∆𝑉0𝑗 = 𝛼𝛿𝑗 (20)
Prosesnya dapat dilihat dari ilustrasi gambar 2.13 dan 2.14 berikut ini:
Gambar 2.13 Propagasi sinyal error Δ Ke f4(E) (www.home.agh.edu.pl)
Gambar 2.14 Propagasi sinyal error Δ Ke f5(E) (www.home.agh.edu.plx)
Koefisien bobot Wmn digunakan untuk mempropagasikan error kembali adalah sama dengan bobot sebelumnya selama mengkomputasikan nilai keluaran. Hanya ketika arah alur data berubah
(sinyal di propagasikan dari keluaran ke masukan). Teknik ini digunakan untuk semua lapisan jaringan. Apabila propagasikan error datang dari beberapa neuron, seperti yang terlihat pada gambar 2.14 sampai 2.16 berikut:
Gambar 2.15 Propagasikan Sinyal Error Δ Ke f1(E) (www.home.agh.edu.pl)
Gambar 2.16 Propagasikan Sinyal Error Δ Ke f2(E) (www.home.agh.edu.pl)
Gambar 2.17 Propagasikan Sinyal Error Δ Ke f3(E) (Fajri, 2011)
Update weight and bias
Langkah 8 Setiap neuron output (𝑌𝑘, 𝑘 = 1, … , 𝑚) mengupdate bias dan bobot- bobotnya ( j=0, . . . ,p):
𝑊𝑗𝑘 𝑏𝑎𝑟𝑢 = 𝑊𝑗𝑘 𝑙𝑎𝑚𝑎 + ∆𝑊𝑗𝑘 (21) Setiap hidden neuron (𝑍𝑗, 𝑗 = 1, … , 𝑝) mengupdate bias dan bobot- bobotnya (i= 0, . . ., n)
𝑉𝑖𝑗 𝑏𝑎𝑟𝑢 = 𝑉𝑖𝑗 𝑙𝑎𝑚𝑎 + ∆𝑉𝑖𝑗 (22)
Gambar 2.17 sampai dengan gambar 2.22 merupakan ilustrasi dari proses pengupdate-an bobot:
Gambar 2.18 Modifikasi Bobot Δ1 (www.home.agh.edu.pl)
Gambar 2.19 Modifikasi Bobot Δ2 (www.home.agh.edu.pl)
Gambar 2.20 Modifikasi Bobot Δ3 (www.home.agh.edu.pl)
Gambar 2.21 Modifikasi Bobot Δ4 (www.home.agh.edu.pl)
Gambar 2.22 Modifikasi Bobot Δ5 (www.home.agh.edu.pl)
Gambar 2.23 Modifikasi Bobot Δ6 (www.home.agh.edu.pl)
Langkah 9 Tes kondisi berhenti dapat dilakukan ketika error yang dihasilkan oleh jaringan berada pada nilai yang lebih kecil sama dengan (≤) error target yang diharapkan atau ketika telah mencapai iterasi (epoch) maksimal yang telah ditetapkan.
Berikut ini adalah contoh perhitungan sederhana dari arsitektur Backpropagation yang dilakukan secara manual:
X2
X3
X4
X1
b X5
Z2
Z3
Z1
Y1
b
V11
V13 V12
V21
V22 V23 V31
V32
V33
V41V42 V43
V51 V52
V53
Z11
Z21
Z22
Gambar 2.24 Contoh Arsitektur Backpropagation
Arsitektur Backpropagation yang terdiri dari 5 buah neuron ditambah sebuah bias pada input layer dan 3 buah neuron pada hidden layer ditambah sebuah bias dan satu
buah output layer. Nilai target pada jaringan adalah 1 dan learning rate 𝛼 = 0.25.
Mula-mula bobot diberi nilai acak pada range [-1, 1]. Misal terdapat bobot seperti tabel 2.1 (bobot dari input layer ke hidden layer = 𝑉𝑖𝑗) dan tabel 2.2 (bobot dari hidden layer ke output layer =𝑊𝑘𝑗).
Tabel 2.1 Bobot dari input layer ke hidden layer
𝒁𝟏 𝒁𝟐 𝒁𝟑
𝑿𝟏= 4 -1 0.75 -0.25
𝑿𝟐= 7 0.4 0.23 0.11
𝑿𝟑= 11 0.17 0.05 -0.18
𝑿𝟒= 6 0.29 0.55 0.03
𝑿𝟓= 21 0.21 1 0.15
b = 1 0.2 -08 1
Tabel 2.2 Bobot dari hidden layer ke output layer Y
𝒁𝟏 0.1
𝒁𝟐 0.03
𝒁𝟑 0.5
b=1 0.1
Normalisasi data input kedalam range [0, 1] dengan menggunakan rumus berikut:
x′ =0.8 x − min max − min + 0.1 (Siang, 2004)
Keterangan:
x’ = x yang telah dinormalisasi x = x sebelum dinormalisasi
min = nilai minimum dari seluruh data max = nilai maksimum dari seluruh data
Maka didapatkan hasil input normalisasi dengan nilai minimum = 4 dan nilai maksimum = 21.
X1′ = 0.8 4 − 4
21 − 4 + 0.1 = 0.1
X2′ = 0.8 7 − 4
21 − 4 + 0.1 = 0.24
X3′ = 0.8 11 − 4
21 − 4 + 0.1 = 0.33
X4′ = 0.8 6 − 4
21 − 4 + 0.1 = 0.19
X5′ = 0.8 21 − 4
21 − 4 + 0.1 = 0.9
Hitung nilai output dari masing-masing hidden neuron dengan persamaan (10):
𝑍_𝑖𝑛𝑗 = 𝑉0𝑗 + 𝑛𝑖=1𝑋𝑖𝑉𝑖𝑗
𝑍𝑖𝑛 1 = 1 0.2 + 0.1 −1 + 0.24 0.4 + 0.33 0.17 + 0.19 0.29 + 0.9 0.21
= 0.2 + −0.1 + 0.096 + 0.561 + 0.551 + 0.189
= 1.48
𝑍𝑖𝑛 2 = 1 −0.8 + 0.1 0.75 + 0.24 0.23 + 0.33 0.05 + 0.19 0.55 + 0.9 1
= −0.8 + 0.75 + 0.552 + 0.165 + 0.104 + (0.9)
= 1.67
𝑍𝑖𝑛 3 = 1 1 + 0.1 −0.25 + 0.24 0.11 + 0.33 −0.18 + 0.19 0.03 + 0.9 0.15
= 1 + −0.25 + 0.026 + (−0.059) + 0.006 + 0.135
= 0.86
Kemudian terapkan fungsi aktivasi untuk masing-masing neuronnya menggunakan persamaan (11), dalam soal ini diterapkan fungsi aktivasi sigmoid biner.
𝑍𝑗 = 𝑓 𝑍_𝑖𝑛 𝑗 = 1
1+𝑒−(𝑧 𝑖𝑛𝑗)
𝑍1= 1
1+𝑒−1.48 = 1.23 𝑍2 = 1
1+𝑒−1.67 = 1.19 𝑍3 = 1
1+𝑒−0.86 = 1.42
Hitung nilai output dari neuron Y menggunakan persamaan (12) seperti berikut:
𝑌_𝑖𝑛𝑘 = 𝑊0𝑘 + 𝑝𝑗 =1𝑍𝑘𝑊𝑗𝑘
Karena jaringan hanya memiliki sebuah output Y, maka 𝑌𝑛𝑒𝑡 = 1 0.1 + 1.23 0.1 + 1.19 0.03 + 1.42(0.5)
= 0.97
𝑌 = 𝑓 𝑌𝑛𝑒𝑡 = 1
1+𝑒−(𝑌𝑛𝑒𝑡 ) = 1
1+𝑒−(0.97) = 1.38
Hitung faktor 𝛿 pada neuron output Y𝑘 sesuai dengan persamaan (14) 𝛿𝑘 = 𝑡𝑘− 𝑦𝑘 𝑓′(𝑦_𝑖𝑛𝑘) = 𝑡𝑘 − 𝑦𝑘 𝑦𝑘 (1 − 𝑦𝑘)
= 1 − 1.38 1.38 1 − 1.38
= 0.20
Suku perubahan bobot 𝑊𝑘𝑗 (dengan 𝛼 = 0.25) adalah sebagai berikut:
∆𝑊𝑗𝑘 = 𝛼𝛿𝑘𝑍𝑗 ; 𝑗 = 0,1 … 3
∆𝑊10 = 0.25 0.20 1 = 0.05
∆𝑊11 = 0.25 0.20 1.23 = 0.01
∆𝑊12 = 0.25 0.20 1.19 = 0.06
∆𝑊13 = 0.25 0.20 1.42 = 0.07
Hitung penjumlahan kesalahan di hidden neuron (= 𝛿):
𝛿_𝑛𝑒𝑡𝑗 = 𝑚𝑘 =1𝛿𝑘𝑊𝑘 karena jaringan hanya memiliki sebuah neuron output maka 𝛿_𝑛𝑒𝑡𝑗 = 𝛿𝑊1𝑗
𝛿𝑛𝑒𝑡 1 = 0.20 0.1 = 0.20 𝛿_𝑛𝑒𝑡2 = 0.20 0.03 = 0.01 𝛿_𝑛𝑒𝑡3 = 0.20 0.5 = 0.1
Faktor kesalahan 𝛿 di hidden neuron:
𝛿𝑗 = 𝛿_𝑛𝑒𝑡𝑗𝑓′(𝑍_𝑛𝑒𝑡𝑗) = 𝛿_𝑛𝑒𝑡𝑗 𝑍𝑗(1 − 𝑍𝑗) 𝛿1 = 0.20 1.23 1 − 1.23 = −0.06 𝛿2 = 0.01 1.19 1 − 1.19 = −0.002 𝛿3 = 0.1 1.42 1 − 1.42 = −0.06
Suku perubahan bobot ke hidden neuron ∆𝑉𝑗 = 𝛼𝛿𝑖𝑋𝑖 dimana 𝑗 = 1,2,3; 𝑖 = 0,1, … 5 .
Tabel 2.3 Suku Perubahan Bobot Hidden Neuron
𝒁𝟏 𝒁𝟐 𝒁𝟑
𝑿𝟏 ∆𝑉11
= 0.25 −0.06 0.1
= −0.0015
∆𝑉21
= 0.25 −0.002 0.1
= −0.00005
∆𝑉31
= 0.25 −0.06 0.1
= −0.0015 𝑿𝟐 ∆𝑉12
= 0.25 −0.06 0.24
= −0.004
∆𝑉22
= 0.25 −0.002 0.24
= −0.0012
∆𝑉32
= 0.25 −0.06 0.24
= −0.004 𝑿𝟑 ∆𝑉13
= 0.25 −0.06 0.33
= −0.005
∆𝑉23
= 0.25 −0.002 0.33
= −0.000165
∆𝑉33
= 0.25 −0.06 0.33
= −0.005 𝑿𝟒 ∆𝑉14
= 0.25 −0.06 0.19
= −0.003
∆𝑉24
= 0.25 −0.002 0.19
= −0.000095
∆𝑉34
= 0.25 −0.06 0.19
= −0.003 𝑿𝟓 ∆𝑉15
= 0.25 −0.06 0.9
= −0.01
∆𝑉25
= 0.25 −0.002 0.9
= −0.00045
∆𝑉35
= 0.25 −0.06 0.9
= −0.01 b=1 ∆𝑉10
= 0.25 −0.06 1
= −0.02
∆𝑉20
= 0.25 −0.002 1
= −0.0005
∆𝑉30
= 0.25 −0.06 1
= −0.02
Perubahan bobot neuron output:
𝑊𝑗𝑘 𝑏𝑎𝑟𝑢 = 𝑊𝑗𝑘 𝑙𝑎𝑚𝑎 + ∆𝑊𝑗𝑘 𝑘 = 1; 𝑗 = 0, … ,3 𝑊11 𝑏𝑎𝑟𝑢 = 0.1 + 0.01 = 0.11
𝑊12 𝑏𝑎𝑟𝑢 = 0.03 + 0.06 = 0.09 𝑊13 𝑏𝑎𝑟𝑢 = 0.5 + 0.07 = 0.57 𝑊10 𝑏𝑎𝑟𝑢 = 0.1 + 0.05 = 0.15 Perubahan bobot hidden neuron:
𝑉𝑗𝑖 𝑏𝑎𝑟𝑢 = 𝑉𝑗𝑖 𝑙𝑎𝑚𝑎 + ∆𝑉𝑗𝑖 𝑘 = 1; 𝑖 = 0, … ,5
Tabel 2.4 Perubahan Bobot Hidden Neuron
𝒁𝟏 𝒁𝟐 𝒁𝟑
𝑿𝟏 ∆𝑉11 𝑏𝑎𝑟𝑢
= −1 + (−0.0015)
= −1.0015
∆𝑉21 𝑏𝑎𝑟𝑢
= 0.75 + (−0.00005)
= 0.75
∆𝑉31
= −0.25 + −0.0015
= (−0.25) 𝑿𝟐 ∆𝑉12
= 0.4 + −0.004
= 0.40
∆𝑉22
= 0.23 + −0.0012
= 0.23
∆𝑉32
= 0.11 + −0.004
= 0.11 𝑿𝟑 ∆𝑉13
= 0.17 + −0.005
= 0.17
∆𝑉23 = 0.055 + −0.000165
= 0.55165
∆𝑉33
= −0.18 + 0.005
= (−0.18) 𝑿𝟒 ∆𝑉14
= 0.29 + −0.003
= 0.29
∆𝑉24
= 0.55
+ −0.000095 = 0.55
∆𝑉34
= 0.03 + −0.003
= 0.3 𝑿𝟓 ∆𝑉15
= 0.21 + −0.01
= 0.2
∆𝑉25 = 1 + −0.00045
= 0.9995
∆𝑉35
= 0.15 + −0.01
= 0.15 b=1 ∆𝑉10 = 0.2 + −0.02
= 0.18
∆𝑉20
= −0.8 + −0.0005
= −0.8
∆𝑉30 = 1 + −0.02
= 0.98
Ulangi iterasi hingga maksimal epoch atau Error Jaringan ≤ Error target.
2.3.3. Inisialisasi Bobot Awal dan Bias
Bobot merupakan salah satu faktor penting agar jaringan dapat melakukan generalisasi dengan baik terhadap data yang dilatihkan kedalamnya (Fitrisia dan Rakhmatsyah, 2010). Pemilihan inisialisasi bobot awal akan menentukan apakah jaringan mencapai global minimum atau hanya lokal minimum dan seberapa cepat konvergensi jaringannya.
Peng-update-an antara dua buah neuron tergantung dari kedua turunan fungsi aktivasi yang digunakan pada neuron yang berada pada lapisan diatasnya dan juga fungsi aktivasi neuron yang berada pada lapisan bawahnya. Nilai untuk inisialisasi bobot awal tidak boleh terlalu besar, atau sinyal untuk setiap hidden atau output neuron kemungkinan besar akan berada pada daerah dimana turunan dari fungsi sigmoid memiliki nilai yang sangat kecil. Dengan kata lain, jika inisialisasi bobot awal terlalu kecil, input jaringan ke hidden atau output neuron akan mendekati nol, yang mana akan menyebabkan pelatihan akan menjadi sangat lambat (Fausset, 1994). Ada beberapa metode inisilisasi bobot yang dapat digunakan, yaitu:
2.3.3.1. Inisialisasi Acak
Prosedur umum yang digunakan adalah menginisialisasi bobot dan bias (baik dari input neuron ke hidden neuron maupun dari hidden neuron ke output neuron) dengan nilai acak antara -0.5 dan 0.5 atau antara -1 dan 1 (atau dengan menggunakan interval tertentu – 𝛾 dan 𝛾. Nilai bobot menggunakan nilai posotif atau negatatif karena nilai bobot akhir setelah pelatihan juga dapat bernilai keduanya.
2.3.3.2. Inisialisasi Nguyen-Widrow
Inisialisasi Nguyen-Widrow merupakan modifikasi bobot acak yang membuat inisialisasi bobot dan bias ke hidden neuron sehingga menghasilkan iterasi lebih cepat.
Bobot-bobot dari hidden neuron ke output neuron (dan bias pada output neuron) diinisialisasikan dengan nilai acak antara -0.5 dan 0.5.
Inisialisasi bobot-bobot dari input neuron ke hidden neuron didesain untuk meningkatkan kemampuan hidden neuron untuk belajar. Inisialisasi bobot dan bias secara acak hanya dipakai dari input neuron ke hidden neuron saja, sedangkan untuk bobot dan bias dari hidden neuron ke output neuron digunakan bobot dan bias diskala khusus agar jatuh pada range tertentu. Faktor skala Nguyen-Widrow didefinisikan sebagai berikut:
𝛽 = 0.7(𝑝)1𝑛 (23)
Keterangan:
n : Banyak input neuron p : Banyak hidden neuron β : Faktor skala
Prosedur Inisialisasi Nguyen-Widrow terdiri dari langkah-langkah sederhana sebagai berikut:
Untuk setiap hidden neuron ( j = 1, ..., p):
𝑉𝑖𝑗 𝑙𝑎𝑚𝑎 = 𝑏𝑖𝑙𝑎𝑛𝑔𝑎𝑛 𝑎𝑐𝑎𝑘 𝑎𝑛𝑡𝑎𝑟𝑎 − 0.5 𝑑𝑎𝑛 0.5 (𝑎𝑡𝑎𝑢 𝑎𝑛𝑡𝑎𝑟𝑎 − 𝛾 𝑑𝑎𝑛 𝛾) Hitung 𝑉𝑗𝑖 𝑙𝑎𝑚𝑎 = 𝑉1𝑗(𝑙𝑎𝑚𝑎)2 + 𝑉2𝑗(𝑙𝑎𝑚𝑎)2+ … + 𝑉𝑛𝑗(𝑙𝑎𝑚𝑎)2 (24)
Bobot yang dipakai sebagai inisialisasi:
𝑉𝑖𝑗 = 𝛽 𝑉𝑖𝑗 (𝑙𝑎𝑚𝑎 )
| 𝑉𝑖𝑗 | (25)
Bias yang dipakai sebagai inisialisasi:
𝑉0𝑗 = 𝑏𝑖𝑙𝑎𝑛𝑔𝑎𝑛 𝑎𝑐𝑎𝑘 𝑎𝑛𝑡𝑎𝑟𝑎 − 𝛽 𝑑𝑎𝑛 𝛽
2.3.4. Momentum (𝜶)
Pada standard Backpropagation, perubahan bobot didasarkan atas gradient yang terjadi untuk pola yang dimasukkan pada saat itu. Modifikasi yang dapat dilakukan adalah dengan menggunakan momentum yaitu dengan melakukan perubahan bobot yang didasarkan atas arah gradient pola terakhir dan pola sebelumnya yang dimasukkan. Penambahan momentum dimaksudkan untuk menghindari perubahan bobot yang mencolok yang diakibatkan oleh adanya data yang sangat berbeda dengan yang lain. Variabel momentum dapat meningkatkan waktu pelatihan dan stabilitas dari proses pelatihan (Al-Allaf, 2010). Berikut merupakan rumus dari Backpropagation:
∆𝑊 = 𝜂 ∗ 𝛿 ∗ 𝑛𝑖 (26)
Keterangan:
η
: learning rate. Nilainya 0.25 atau 0.5 𝑛𝑖 : nilai dari neuron ke i
Perubahan bobot dilakukan dengan cara menambahkan bobot yang lama dengan
∆
w. Akan tetapi, bobot pada iterasi sebelumnya memberikan pengaruh besar terhadap performa jaringan saraf. Oleh karena itu, perlu ditambahkan dengan bobot yang lama dikalikan momentum, menjadi :∆𝑊 = 𝜂 ∗ 𝛿 ∗ 𝑛𝑖+ 𝛼 ∗ Δ𝑊′ (27)
Keterangan :
α
: momentum faktor, nilainya antara 0 dan 1.
∆w’ : bobot pada iterasi sebelumnya.
Teknik momentum tidak menutup kemungkinan dari konvergensi pada lokal minimum, akan tetapi penggunaan teknik ini dapat membantu untuk keluar dari lokal minima (Li et al, 2009).
2.3.5. Perhitungan Error
Perhitungan error bertujuan untuk pengukuran keakurasian jaringan dalam mengenali pola yang diberikan. Ada tiga macam perhitungan error yang sering digunakan, yaitu Mean Square Error (MSE), Mean Absolute Error (MAE) dan Mean Absolute Percentage Error (MAPE).
MSE merupakan error rata–rata kuadrat dari selisih antara output jaringan dengan output target. Tujuan utama adalah memperoleh nilai errorsekecil-kecilnya dengan secara iterative mengganti nilai bobot yang terhubung pada semua neuron pada jaringan. Untuk mengetahui seberapa banyak bobot yang diganti, setiap iterasi memerlukan perhitungan error yang berasosiasi dengan setiap neuron pada output dan hidden layer. Rumus perhitungan MSE adalah sebagai berikut (Bayata et al, 2011):
𝑀𝑆𝐸 = 1
𝑁 𝑁𝑖=1(𝑡𝑘− 𝑦𝑘)2 (28)
Keterangan:
𝑡𝑘 = nilai output target 𝑦𝑘 = nilai output jaringan N = jumlah output dari neuron
MAE merupakan perhitungan error hasil absolute dari selisih antara nilai hasil system dengan nilai aktual. Rumus perhitungan MAE adalah sebagai berikut:
𝑀𝐴𝐸 = 1
𝑁 𝑁𝑖 =1|𝑡𝑘 − 𝑦𝑘| (29)
MAPE hampir sama dengan MAE, hanya hasilnya dinyatakan dalam persentase. Rumus perhitungan MAPE adalah sebagai berikut:
𝑀𝐴𝑃𝐸 = 1
𝑁 𝑁𝑖 =1|𝑡𝑘 − 𝑦𝑘| x 100% (30)
2.3.6. Penggantian bobot
Penggantian bobot jaringan dilakukan jika error yang dihasilkan oleh jaringan tidak lebih kecil sama dengan (≤) nilai error yang telah ditetapkan. Bobot baru didapat
dengan menjumlahkan bobot yang lama dengan ∆𝑤. Rumus untuk mengganti bobot adalah sebagai berikut:
∆𝑤 = η ∗ δi∗ 𝑛𝑖 (31)
Keterangan:
η = learning rate
δi = error yang berasosiasi dengan neuron yang dihitung 𝑛𝑖 = nilai error dari neuron yang dihitung
Berikut adalah rumus penggantian bobot tanpa momentum:
𝑤𝑗𝑘 𝑡 + 1 = 𝑤𝑗𝑘 𝑡 + ∆𝑤𝑗𝑘 (32)
∆𝑤𝑗𝑘 = −𝛼 𝜕𝐸 (𝑤𝑗𝑘)
𝜕 𝑤𝑗𝑘 (33)
𝑣𝑖𝑗 𝑡 + 1 = 𝑣𝑖𝑗 𝑡 + ∆𝑣𝑖𝑗 (34)
∆𝑣𝑖𝑗 = −𝛼 𝜕𝐸 (𝑣𝑖𝑗)
𝜕 𝑣𝑖𝑗 (35)
Rumus penggantian bobot menggunakan momentum:
𝑤𝑗𝑘 𝑡 + 1 = 𝑤𝑗𝑘 𝑡 + ∆𝑤𝑗𝑘 + η ∆wjk (𝑡 − 1) (36)
∆𝑤𝑗𝑘 = −𝛼 𝜕𝐸 (𝑤𝑗𝑘)
𝜕 𝑤𝑗𝑘 (37)
𝑣𝑖𝑗 𝑡 + 1 = 𝑣𝑖𝑗 𝑡 + ∆𝑣𝑖𝑗 + η ∆vij (𝑡 − 1) (38)
∆𝑣𝑖𝑗 = −𝛼 𝜕𝐸 (𝑣𝑖𝑗)
𝜕 𝑣𝑖𝑗 (39)
2.3.7. Testing
Pada proses testing JST hanya akan diterapkan tahap propagasi maju. Setelah training selesai dilakukan, maka bobot-bobot yang terpilih akan digunakan untuk menginisialisasi bobot pada proses testing JST. Adapun tahapannya adalah sebagai berikut:
1. Masukkan nilai input dari data testing.
2. Lakukan perhitungan neuron-neuron pada hidden layer dengan rumus:
𝑍𝑖𝑛𝑗 = 𝑉0𝑗 + 𝑛𝑖=1𝑋𝑖. 𝑉𝑖𝑗 (40)
3. Hitung hasil output dari masing-masing hidden layer dengan menerapkan kembali fungsi aktivasi.
𝑍𝑗 = 𝑓(𝑍𝑖𝑛𝑗) (41)
= 1
1+𝑒−𝑍 _𝑖𝑛𝑗 (42)
Sinyal tersebut kemudian akan diteruskan kesemua neuron pada lapisan berikutnya yaitu output layer.
4. Setiap neuron pada output layer (Yk, k=1,..,5) menjumlahkan sinyal-sinyal output beserta bobotnya:
𝑌𝑖𝑛𝑘 = 𝑊0𝑘 + 𝑛𝑖 =1𝑍𝑗. 𝑊𝑗𝑘 (43)
5. Menerapkan kembali fungsi aktivasi untuk menghitung sinyal output
𝑌𝑘 = 𝑓(𝑌_𝑖𝑛𝑘) (44)
= 1
1+𝑒−𝑌_𝑖𝑛𝑘 (45)
2.3.8. Metode Resilient Backpropagation
Resilient backpropagation (Rprop) dikembangkan oleh Martin Riedmiller dan Heinrich Braun pada tahun 1992. Metode ini adalah salah satu modifikasi dari proses standard Backpropagation yang digunakan untuk mempercapat laju pembelajaran pada pelatihan jaringan syaraf tiruan Backpropagation. Rprop dikembangkan untuk menghindari perubahan gradien yang terlalu kecil selama proses update dengan fungsi aktivasi sigmoid, yang menyebabkan pembentukan jaringan menjadi lambat. Dalam proses update weight, Rprop memiliki faktor delta, dimana nilai delta akan mengikuti arah perubahan weight. Jika perubahan weight kecil, nilai delta akan membesar, sebaliknya, ketika perubahan weight aktif, nilai delta akan mengecil.
Rprop melaksanakan dua tahap pembelajaran yaitu tahap maju (forward) untuk mendapatkan error output dan tahap mundur (backward) untuk mengubah nilai bobot-bobot. Proses pembelajaran pada algoritma RPROP diawalai dengan definisi masalah, yaitu menentukan matriks masukan (P) dan matriks target (T). kemudian dilakukan proses inisialisasi yaitu menentukan bentuk jaringan, MaxEpoch, Target_Error, delta_dec, delta_inc, delta0, deltamax, dan menetapkan nilai-nilai bobot sinaptik vij dan wjk secara acak.
Besarnya perubahan setiap bobot ditentukan oleh suatu faktor yang diatur pada parameter yang disebut delt_inc dan delt_dec. Apabila gradien fungsi error berubah tanda dari satu iterasi ke iterasi berikutnya, maka bobot akan berkurang sebesar delt_dec. Sebaliknya apabila gradien error tidak berubah tanda dari satu iterasi ke iterasi berikutnya, maka bobot akan berkurang sebesar delt_inc. Apabila gradien error sama dengan 0 maka perubahan sama dengan perubahan bobot sebelumnya. Pada awal iterasi, besarnya perubahan bobot diinisalisasikan dengan parameter delta0.
Besarnya perubahan tidak boleh melebihi batas maksimum yang terdapat pada parameter deltamax, apabila perubahan bobot melebihi batas maksimum perubahan bobot, maka perubahan bobot akan ditentukan sama dengan maksimum perubahan bobot.