KLASTERING VARIETAS PADI MENGGUNAKAN MODIFIKASI
METODE K-MEANS BERBASIS ORDERED WEIGHTED
AVERAGING (OWA)
Millatul Ulya, Budi Santosa, dan Nani Kurniati Jurusan Teknik Industri, FTI
Institut Teknologi Sepuluh Nopember Email: [email protected]
ABSTRAK
Metode k-means berbasis Ordered Weighted Averaging (OWA) telah dikembangkan oleh Cheng dkk (2009) untuk menyelesaikan kasus klasifikasi dengan cara mengintegrasikan k-means dan OWA. K-means sebenarnya merupakan suatu metode klastering, dan OWA adalah operator agregasi. Dengan OWA, kompleksitas data eksperimental yang akan diklasterkan dapat dikurangi dan OWA juga dapat mempertimbangkan keterkaitan antar kriteria dari data yang dianalisis. Dalam penelitian ini, modifikasi k-means berbasis OWA akan diimplementasikan dalam klastering data varietas padi, yang berisi 119 varietas padi dengan 8 atribut yang mewakili sifat fisikokimia beras yang dihasilkan.
Penelitian ini mengaplikasikan modifikasi k-means berbasis OWA pada klastering data set padi dengan tujuan untuk mengetahui jumlah klaster yang sesuai untuk data varietas padi dan mengukur performansinya serta membandingkan performansi tersebut dengan metode klastering yang lain. Ukuran performansi yang digunakan adalah silhouette value (nilai siluet) dan Sum of Squares Error (SSE). Metode pembanding yang digunakan adalah k-means (tanpa OWA) dan hierarchical clustering. Penelitian dilakukan dalam 6 eksperimen yaitu klastering data padi tersebut menjadi 3, 4, 5, 6, 7, dan 8 klaster.
Hasil penelitian ini menunjukkan bahwa data set varietas padi tersebut lebih sesuai diklasterkan menjadi 7 klaster, karena nilai siluet pada 7 klaster lebih besar dan positif dan nilai SSEnya paling kecil dibanding yang lain. Berdasarkan Nilai SSE dan nilai siluetnya, modifikasi k-means OWA (α = 0.8) lebih baik dari pada metode k-means dan hierarchical clustering dalam klastering data set padi.
Kata kunci : klastering, k-means, OWA, varietas padi.
PENDAHULUAN
Beras merupakan makanan pokok sebagian besar penduduk dunia, termasuk penduduk Indonesia. Pemerintah telah menerbitkan standar mutu (SNI) beras giling agar beras yang diperdagangkan memenuhi standar. Standar mutu atau SNI tersebut belum berlaku efektif dan kurang spesifik di Indonesia (Indrasari dkk, 2009). SNI beras giling belum efektif karena tidak semua komponen mutu yang ada di SNI digunakan sebagai dasar dalam perdagagan beras. SNI ini juga kurang spesifik, karena belum memuat semua sifat-sifat penentu mutu beras.
Menurut Damardjati dkk (1995), sifat-sifat yang menentukan mutu beras antara lain: 1) sifat fisik dan sifat giling, 2) cita rasa dan sifat tanak, dan 3) sifat gizi. SNI beras giling hanya memuat sifat fisik dan sifat fisik saja, namun belum menampung cita rasa,
konsumen tentang cita rasa, sifat tanak dan sifat gizi beras yang mereka konsumsi, sehingga sulit untuk distandarkan secara nasional. Konsumen di setiap daerah mempunyai preferensi yang berbeda-beda terhadap mutu beras. Penampilan beras dan cita rasa (Damardjati,1995) serta kepulenan nasi merupakan faktor utama pilihan konsumen berdasarkan etnis (Setyono dkk, 2008).
Penampilan beras, cita rasa, dan kepulenan nasi dapat direpresentasikan oleh sifat fisikokimia beras. Banyaknya varietas padi yang dikembangkan oleh pemerintah menghasilkan banyak pula data tentang sifat fisikokimia beras. Banyaknya data tersebut masih memungkinkan untuk diolah agar diketahui pola datanya sehingga dapat digunakan sebagai bahan pertimbangan dalam pengembangan varietas baru yang disukai konsumen. Pendekatan data mining dimungkinkan dapat digunakan untuk mengetahui pola atau hubungan dalam data tersebut. Salah satu tugas data mining adalah klastering yang bertujuan untuk mengelompokkan data/obyek yang mirip ke dalam satu klaster (Santosa, 2007). Sehingga data varietas padi dapat diklasterkan menjadi beberapa klaster yang diharapkan dapat diketahui pola tersembunyi dari data tersebut.
Metode klastering yang umum digunakan adalah k-means. Cheng dkk (2009) telah mengembangkan k-means berbasis OWA untuk kasus klasifikasi, dan metode ini dapat dimodifikasi untuk menyelesaikan kasus klastering. Yager (1988) menyatakan OWA operator dapat mengurangi kompleksitas data dengan memadukan nilai-nilai multi attribut ke nilai-nilai agregat yang berupa nilai tunggal. Masing-masing varietas padi memiliki banyak sifat fisikokimia yang mempengaruhi preferensi konsumen dalam memilih beras. Sifat-sifat fisikokimia tersebut merupakan suatu kriteria yang harus dipenuhi dalam menentukan varietas mana yang akan dipilih. Kasus ini mirip dengan kasus pengambilan keputusan multikriteria (Multicriteria Decision Making/MCDM), dimana keputusan beras dari varietas mana yang akan dipilih oleh konsumen tersebut didasarkan pada multikriteria. Menurut Yager (2004), Ordered Weighted Averaging (OWA) sangat berguna untuk proses MCDM yang sering kali memerlukan keterkaitan antar kriteria yang ada. Sehingga modifikasi metode k-means OWA ini sangat sesuai untuk digunakan dalam menyelesaikan kasus klastering data varietas padi.
Penelitian ini mengaplikasikan modifikasi k-means berbasis OWA pada klastering data set padi dengan tujuan untuk mengetahui jumlah klaster yang sesuai untuk data varietas padi dan mengukur performansinya serta membandingkan performansi tersebut dengan metode klastering yang lain. Ukuran performansi yang digunakan adalah silhouette value (nilai siluet) dan Sum of Squares Error (SSE). Metode pembanding yang digunakan adalah k-means (tanpa OWA) dan hierarchical clustering. Penelitian dilakukan dalam 6 eksperimen yaitu klastering data padi tersebut menjadi 3, 4, 5, 6, 7, dan 8 klaster.
METODE
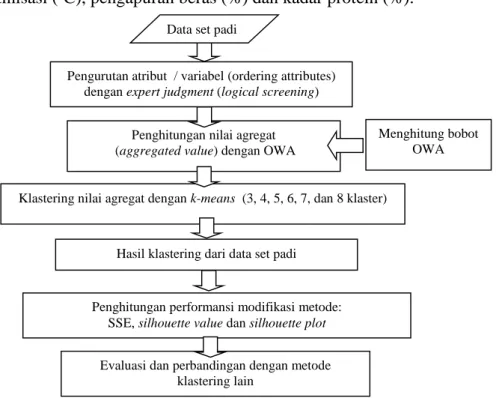
Implementasi modifikasi metode k-means OWA dilakukan pada proses klastering data set varietas padi. Modifikasi k-means berbasis OWA diharapkan dapat menyelesaikan kasus klastering padi dengan jumlah klaster yang sesuai dan bagus performansinya. Untuk mengetahui jumlah klaster yang sesuai pada data padi ini, maka dalam penelitian ini akan diimplementasikan pada 6 eksperimen (3 klaster, 4 klaster, 5 klaster, 6 klaster, 7 klaster dan 8 klaster), kemudian dihitung performansinya untuk mengetahui berapa jumlah klaster yang sesuai untuk data set padi tersebut.
Data set padi
Data set ini terdiri dari 119 varietas padi dan memiliki 8 atribut yaitu: kadar amilosa (%), beras kepala (%), beras putih (%), panjang butir beras (mm), bentuk beras (mm), suhu gelatinisasi (ºC), pengapuran beras (%) dan kadar protein (%).
Gambar 1. Tahapan Implementasi Modifikasi Metode k-means Berbasis OWA dalam Klastering Data Set Padi
Pengurutan atribut (Ordering attributes)
Proses pengurutan atau perankingan atribut ini dilakukan berdasarkan pada expert judgment mengenai sifat-sifat fisikokimia beras yang menentukan preferensi konsumen terhadap beras yang mereka konsumsi. Penggunaan expert judgment termasuk dalam kategori logical screening untuk memilih variabel mana yang akan digunakan dalam pengelompokan atau pengklasteran (Huberty ,1994) Pendekatan ini digunakan untuk memilih variabel mana yang berhubungan secara teoritis dengan pengelompokan yang kita inginkan menurut pengetahuan spesifik yang subyektif (judgment dari ahli/praktisi). Berdasarkan sintesis beberapa expert judgment dari jurnal-jurnal penelitian sebelumnya yang meneliti tentang mutu beras, hubungan antara varietas/galur padi dengan mutu beras serta preferensi konsumen dalam memilih beras, maka urutan variabel dalam data ini adalah: kadar amilosa (%), suhu gelatinisasi (ºC), beras kepala (%), beras putih (%), panjang butir beras (mm), bentuk beras (mm), pengapuran beras (%) dan kadar protein (%).
Menghitung bobot OWA
Penentuan bobot OWA pada tahap ini menggunakan persamaan OWA yang telah dikembangkan oleh Fuller & Majleder (2001) pada persamaan (1), (2) dan (3). Jumlah variabel (n ) yang digunakan adalah 8 dan nilai α adalah > 0.5
dan , ln 1 ln 1 1 ln 1 1 1 1 n j n j n j n j w w w w n j n w n j w (1) Pengurutan atribut / variabel (ordering attributes)
dengan expert judgment (logical screening)
Penghitungan nilai agregat (aggregated value) dengan OWA
Klastering nilai agregat dengan k-means (3, 4, 5, 6, 7, dan 8 klaster)
Hasil klastering dari data set padi
Evaluasi dan perbandingan dengan metode klastering lain
Menghitung bobot OWA
Penghitungan performansi modifikasi metode: SSE, silhouette value dan silhouette plot
1 1
1
1
1 1
, 1 1 1 w n n n nw n w n n (2) Jika ), 5 . 0 ( ln ) ( 1 ... 2 1 dispW n n w w w n
, 1 1 1 1 1 1 nw n w n n wn (3) Menghitung nilai agregat dengan operator OWAJumlah atribut pada data set padi adalah n atribut. Dari langkah 2 dan 3, kita peroleh urutan atribut dan bobot OWA. Untuk menghitung nilai agregat, kita kalikan nilai-nilai urutan atribut dengan bobot OWA yang sesuai, itu dapat dinyatakan sebagai persamaan (4)
1 2 1, ,..., ) ( i i i n wb a a a f (4)di mana bi adalah elemen terbesar ke-i dalam koleksi dari agregated objects {a1,…, an}
dan wiadalah bobot variabel ke-i.
Mengklasterkan nilai agregat dengan k-means
Klastering nilai agregat dilakukan pada 6 eksperimen, yaitu diklasterkan menjadi: 3, 4, 5, 6, 7, dan 8 klaster. Hal ini dilakukan untuk mengetahui berapa jumlah klaster yang sesuai untuk data set padi tersebut berdasarkan nilai siluet dan plot siluet yang diperoleh dari hasil klastering.
Pengukuran Performansi
Performansi metode klastering dapat diukur dari silhouette value yaitu untuk mengetahui seberapa baik pemisahan hasil klastering yang telah dilakukan. Menurut Martinez & Martinez (2005), nilai siluet dapat mengestimasikan jumlah klaster yang sesuai pada data set. Kita notasikan ciadalah klaster yang berisi i data (obyek). aiadalah
rata-rata dissimilarity dari data ke-i ke semua anggota pada klaster yang sama atau c(i). Untuk setiap klaster yang lain, kita notasikan c, maka kita hitung d( ci, )mewakili rata-rata dissimilarity dari data ke-i ke semua obyek pada klaster c. Kita notasikan bi sebagai
minimum dari rata-rata dissimilarity d( ci, ). Maka, nilai siluet (silhouette value atau silhouette width) dapat dirumuskan sebagai berikut:
i i
i i i b a a b sw , max (5)Kita juga dapat mencari rata-rata nilai siluet dengan merata-rata nilai siKuntuk
semua observasi sebagai berikut:
n i i sw n sw 1 1 (6) Nilai siluet terletak antara -1 dan 1 (-1 < swi< 1). Nilai siluet positif yang besar dari swimenunjukkan bahwa data/obyek ke-i terklaster dengan baik. Nilai negatif yang besar dari swimenunjukkan adanya klastering yang jelek, dan jika nilai dari swimendekati nol
bahkan mungkin prosedur klastering yang digunakan tidak dapat menemukan klaster-klasternya (Izenman, 2008). Performansi metode klastering juga dapat dilihat dari nilai Sum Square Error (SSE) dari klaster yang dihasilkan. Nilai SSE merepresentasikan homegenitas intra klaster, semakin kecil nilai SSE maka semakin homogen data dalam satu klaster. Jadi metode yang terbaik akan memiliki SSE yang paling kecil. Nilai Sum of Squares Error sesuai persamaan (7).
2
) (yir cr
SSE (7)
Semua tahapan mulai menghitung bobot OWA sampai pada tahap membandingkan performansi dilakukan dengan bantuan perangkat lunak Matlab 7.01.
HASIL DAN DISKUSI
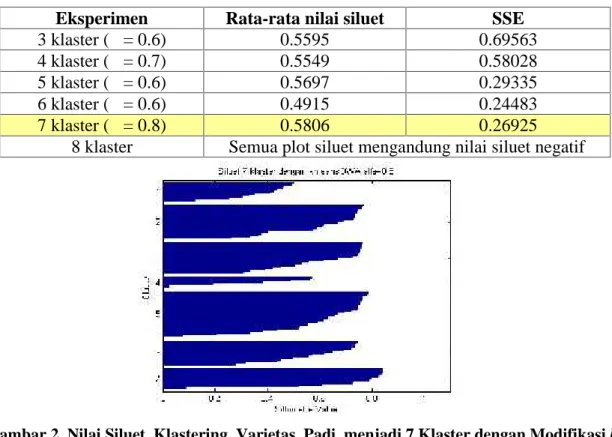
Klastering data varietas dan galur padi menggunakan modifikasi metode k-means berbasis OWA (α = 0.8) dengan jumlah klaster 7 (tujuh) adalah solusi yang terbaik pada kasus klastering ini, karena memberikan nilai Sum of Squares Error (SSE) paling kecil dan rata-rata nilai siluet paling besar dibanding metode klastering lainnya. Rekapitulasi pengukuran performansi modifikasi k-means berbasis OWA dapat dilihat Pada Tabel 1.
Tabel 1. Rekapitulasi Nilai Rata-rata Siluet dan SSE pada Implementasi k-means Berbasis OWA pada Data Varietas Padi
Eksperimen Rata-rata nilai siluet SSE
3 klaster (α = 0.6) 0.5595 0.69563
4 klaster (α = 0.7) 0.5549 0.58028
5 klaster (α = 0.6) 0.5697 0.29335
6 klaster (α = 0.6) 0.4915 0.24483
7 klaster (α = 0.8) 0.5806 0.26925
8 klaster Semua plot siluet mengandung nilai siluet negatif
Gambar 2. Nilai Siluet Klastering Varietas Padi menjadi 7 Klaster dengan Modifikasi k-means Berbasis OWA pada α = 0.8
Berdasarkan Tabel 1 di atas, dapat dilihat kolom rata-rata nilai siluet untuk menentukan berapa jumlah klaster yang sesuai pada data set padi. Dari 6 eksperimen
yang dilakukan, maka klastering 7 klaster pada α = 0.8 memberikan rata-rata nilai siluet
Gambar 1). Nilai SSE terendah adalah pada klastering 6 klaster, namun nilai siluetnya justru paling rendah. Sehingga, jumlah klaster yang paling sesuai untuk data set padi adalah 7 klaster dengan menggunakan modifikasi k-means berbasis OWA pada orness
(α) 0.8. Namun, metode ini tetap harus dibandingkan dengan metode klastering yang
lain untuk mengetahui apakah performansinya lebih baik atau tidak dibanding metode yang lain, seperti k-means (tanpa OWA) dan hierachical clustering.
Tabel 2 membuktikan bahwa metode k-means berbasis OWA memberikan nilai Sum of Squares Error (SSE) yang paling kecil, yaitu 0.26925. Nilai SSE yang semakin kecil menunjukkan bahwa homogenitas intra klaster semakin tinggi. Sehingga metode klastering terbaik adalah yang memiliki SSE terkecil. Jika dilihat dari nilai rata-rata siluet, metode k-means berbasis OWA (pada α = 0.8) tetap memberikan nilai siluet yang paling tinggi dibanding yang lain. Dengan demikian, metode k-means berbasis OWA
(pada α = 0.8) merupakan metode klastering yang terbaik dalam klastering data padi
dari pada 4 metode klastering pembanding yang digunakan dalam penelitian ini. Tabel 2. Nilai Rata-rata Siluet dan SSE pada Masing-masing Metode Klastering dalam
Klastering Data Padi menjadi 7 Klaster
Metode Klastering Rata-rata Nilai Siluet SSE
k-means berbasis OWA pada α = 0.8 0.5806 0.26925
k-means tanpa OWA – jarak Cityblock 0.2113 36.333
k-means tanpa OWA – jarak Euclidean 0.3882 36.486
Hierarchical clusterig – Single Linkage -0.4781 538.4738
Hierarchical clusterig – Complete Linkage 0.3091 37.5231
Hasil klastering data set padi menjadi 7 klaster dapat dilihat pada Tabel 1. Sedangkan keseluruhan interpretasi hasil klastering diringkas pada Tabel 2. Pada Tabel tersebut dapat dilihat perbedaan padi dari masing-masing klaster berdasarkan delapan sifat fisikokimia berasnya. Sehingga akan mudah diketahui mana klaster yang berisi varietas padi yang lebih memenuhi preferensi konsumen beras Indonesia secara umum.
Tabel 3 Hasil klastering data varietas padi dengan k-means berbasis OWA
Klaster Jumlah
Anggota
Anggota Klaster
1 12 padi Singkarak, Cisokan, Cikapundung, IR70, IR37218-24-2-2, B6058-Mr-19-2-3-2, IR41532-18-1-8-2, B5316-20d-Mr-4-3, IR19661-150-2-2-2-2, B5332-13d-Mr-1-1, IR37218-24-2-2, B6679-Mr-23-2.
2 22 padi Tondano, PB36, Serayu, Ciherang hibrida, B6441-5-Mr5-1, B6228-Mr-47-4-3, IR39536-1-4-5-1-1-1, B5619-5g-Sm-8, B5462f-Kn-15-0-0-3, IR4432-28-5-40krad-6-Mr-9, S804b-Pn-86-1-3-4, B6256-Mr-10-p, B4169g-Ng-3-5-3, B7093-4e, BP2448-4-2, BP2268-5E-21-3, BP2280-1E-12-2, H34, H36, H43, H57, H72.
3 20 padi Bogolestari, Cisadane, Barito, IR20, 627/10krad-3-20-537-7, B4354g-Pn-3, B4180f-30-Ng-4-2, B4127f-Kn-41, B6136-3-Tb-0-1-5, S487b-75, B5975-Mr-6-3-2-3, Pn-1f-18, B5986-Pn-7-4-2, B7093-4e,BP1356-1G-KN-4, BP2276-2E-28-2, IR73012-15-2-2-1, S4527E-PN-2-3-KN-0, IR73005-69-1-1-2, H30.
4. 7 padi Bengawan Solo, Batang Pane, B5411e-7b-31-0-3, B4632h-Kp-1, B4363h-Sm-8-3-3-2, B7004d-Mr-10-1, H63.
5. 29 padi Fatmawati, Kalimutu, IR64, Jatiluhur, Arias, Ciapus, IR31892-100-3-3-3-3, B6441-2-Mr-5-4, B6058-Mr-19-2-1-2, IR28224-3-2-3-2, B6717-Mr-5-2, IR32896-6-3-3-2, B6350-Mr-6-1, IR39536-1-3-4-2-2, IR33658-1-6-1-2-1-2, IR35667-30-1-2-2-2, IR24705-116-2-3, IR33463-55-2-1-2-2-2-1, B6555-Mr-192-1-36, B6058-Mr-19-2-3-2, B5689f-Sm-33-3, B4460h-Mr-6, B5540e-Tb-16, B6780-Mr-36-3, IR33450-25-2-1-2-2-2-1, B5313g-Sm-57-1, B6350-Mr-6-1-2, IR19661-150-2-2-2-2, RUTT5669B-15-1-2-2-2.
6. 16 padi Cimandiri, Batang Agam, Kapuas, Progo, Rojolele, Cendrawati, Hawarabatu, Mekongga, Maros, Gadis Jambe, Citarum, Ciherang, Memberamo, Cigeulis,
B5446g-7. 13 padi Ciujung, Semeru, Cipunegara, Sadang, PB56, PB50, Rendah Padang, Way Apo Buru, Cilosari, S499b-28, B6440-5-Mr-2-3, B5440e-Tb-16, H27.
Tabel 4 Rekapitulasi Hasil Klastering Data Varietas Padi
Sifat fisikokimia Klaster
1 2 3 4 5 6 7
Kadar amilosa*) Tinggi Sedang –
tinggi Sedang Rendah – sedang Sedang – tinggi Rendah – sedang Rendah – sedang Suhu gelatinisasi**) Sedang –
tinggi Rendah – tinggi Rendah – sedang Rendah – sedang Rendah – tinggi Rendah – sedang Rendah – sedang Beras kepala***) Mutu III Mutu III
dan IV
Mutu IV Mutu V Mutu II dan III
Mutu V Mutu III, IV, dan V Beras putih (%) 63–74 65.0–73.3 66–72.2 67–71.9 65–74 66 – 73 68 – 73% Panjang beras****) Sedang –
panjang Sedang – panjang Sedang – panjang Panjang Sedang – panjang Sedang – panjang Sedang – panjang Bentuk beras****) Medium –
ramping
Medium – ramping
Medium – ramping
Medium Medium Medium – ramping
Medium – ramping Pengapuran beras*****) Sedang Sedang Sedang Sedang Sedang Sedang Sedang
Kadar protein (%) 7.1–10.8 6.3–10 7.2–10.4 7.5–11.3 6.4–9.4 5.0–11.6 6.1 – 10.2 Keterangan:
*) Kategori kadar amilosa menurut Khush dkk (1979) dalam Arief dan Asnawi (1999) **) Kategori suhu gelatinisasi menurut Suismono dkk (2003)
***) Kategori mutu beras menurut SNI beras giling (Badan Standarisasi Nasional, 1999) ****) Kategori panjang dan bentuk beras menurut Juliano (1993)
*****) Kategori persen pengapuran beras menurut Allidawati dan Bambang (1993)
Berdasarkan tabel di atas, terlihat bahwa klaster 4, 5 dan 7 memiliki karakteristik beras yang relatif sama, hanya berbeda pada persen beras kepala. Ketiga klaster ini berisi varietas dan galur padi yang sangat disukai konsumen indonesia secara umum karena menghasilkan beras yang pulen, butir beras panjang dan berbentuk ramping serta rasa nasi enak. Perbedaan terdapat pada persen beras kepala saja. Perbedaan ini tidak murni disebabkan karena faktor genetik saja, namun juga sangat dipengaruhi proses pengeringan dan penggilingan padi. Beras dari varietas pada klaster 4 yang saat ini masih ditanam oleh petani adalah beras Bengawan Solo dan Batang Pane. Sedangkan pada klaster 6, berisi beras yang saat ini banyak sekali ditanam oleh petani Jawa Timur, Jawa Barat dan Jawa Tengah yaitu Ciherang, Memberamo, Cigeulis, Rojolele, Mekongga dan Maros (Ruskandar, 2009). Sebaliknya pada klaster 7, meskipun termasuk dalam beras yang sesuai preferensi konsumen secara umum, namun beras dari klaster ini sudah tidak ditanam lagi, kecuali varietas Way Apo Buru yang tahun 2008 masih ditanam sekitar 4.37% dari sentra produksi padi di Jawa Timur (Ruskandar, 2009). Klaster 3 juga memiliki karakteristik beras yang hampir sama dengan klaster 4, 6 dan 7. Namun pada klaster ini, kadar amilosa dan persen beras kepala lebih homogen dari pada ketiga klaster tersebut. Jadi dapat dikatakan bahwa semua beras pada klaster 3 memiliki sifat yang sama yaitu berasnya pulen, panjang dan ramping serta rasanya enak. Meski secara umum beras klaster 3 sesuai dengan preferensi konsumen indonesia, beras ini tidak dapat ditemui lagi karena sudah jarang ditanam oleh petani.
Klaster 1 merupakan klaster yag berisi beras pera, butir beras panjang dan ramping serta rasanya enak (bagi konsumen yang menyukai beras pera). Beras dari klaster ini merupakan beras yang juga disukai oleh sebagian etnis di Indonesia. Secara umum, masyarakat Indonesia lebih menyukai beras yang pulen dari pada beras pera. Namun, ada juga etnis atau konsumen di daerah tertentu yang justru menyukai beras pera seperti konsumen beras di Sumatera Barat dan Aceh. Sedangkan konsumen di pulau Jawa dan Sulawesi umumnya menyukai beras yang pulen (Allidawati dan Bambang, 1993).
Klaster 5 dengan anggota 29 macam padi merupakan klaster yang berisi varietas beras yang pulen dan pera, butir beras sedang sampai panjang dan bentuknya medium,
Allidawati dan Bambang (1993), sebagian besar galur padi pada klaster 5 tersebut kurang disukai oleh konsumen, kecuali 9 padi yaitu: Fatmawati, Kalimutu, IR64, Jatiluhur, Arias, Ciapus, B6350-Mr-6-1, IR39536-1-3-4-2-2, RUTT5669B-15-1-2-2-2 yang memiliki rasa enak. Sembilan padi yang memiliki rasa nasi enak tersebut termasuk satu klaster dengan varietas padi yang yang kurang enak karena memiliki kemiripan pada bentuk berasnya yang sama-sama medium.
KESIMPULAN
Klastering data set padi menghasilkan 7 klaster. Klaster yang berisi padi dengan beras yang pulen, panjang, ramping, dan rasanya enak serta saat ini masih ditanam oleh para petani adalah klaster 4 dan 6. Sedangkan klaster yang berisi padi dengan beras yang pera, panjang, ramping, dan rasanya enak adalah klaster 1. Modifikasi metode k-means berbasis OWA memberikan silhouette value yang terbaik yaitu pada α = 0.8 dengan nilai rata-rata siluet 0.5806 dan sum of squares error yang terkecil yaitu 0.26925 dibandingkan metode klastering yang lain dalam mengklasterkan data set padi. DAFTAR PUSTAKA
Allidawati dan Bambang, K. (1993), Metode Uji Mutu Beras dalam Program Pemuliaan Padi, dalam Padi: Buku 2, Eds: Ismunadji dkk., Balitbang Pertanian, Pusat Penelitian dan Pengembangan Tanaman Pangan, Bogor.
Badan Standarisasi Nasional (1999), Standar Nasional Beras Giling No, 01-6128-1999. Badan Standarisasi Nasional, Jakarta.
Cheng, C.H., Wang, J.W. dan Wu, M.C. (2009), OWA-Weighted Based Clustering Method for Classification Problem, Expert Systems with Application 26, 4988-4995.
Damardjati, D.S. (1995), Karakterisasi Sifat dan Standarisasi Mutu Beras sebagai Landasan Pengembangan Agribisnis dan Agroindustri Padi di Indonesia, Badan Litbang Pertanian.
Fuller, R. dan Majlender, P. (2001), An Analytic Approach for Obtaining Maximal Entropy OWA Operator Weights, Fuzzy Sets and Systems, 124, 53–57.
Huberty (1994), Applied Discriminant Analysis. Wiley Interscience. New York.
Indrasari, S.D., Purwani, E.Y., Widowati, S. dan Damardjati, D.S. (2009), “Peningkatan Mutu Nilai Tambah Beras Melalui Mutu Fisik, Cita Rasa, dan Gizi”, dalam Padi Inovasi dan Teknologi Buku 2, Eds: Daradjat dkk, Balai Besar Penelitian Tanaman Padi, Subang
Izenman, A.J. (2008), Modern Multivariate Statistical Techniques, Regression, Classification, and Manifold Learning, Springer Science&Business Media, USA.
Juliano, B.O. (1993), Rice in Human Nutrition, Collaboration IRRI dan FAO, Roma
Khush dkk (1979), ”Rice Grain Quality Evaluation and Improvement at IRRI”, dalam
Sains dan Teknologi, Vol,5 Nomor 1, Fakultas MIPA Universitas Lampung. Martinez, A.L. dan Martinez, A.R. (2005), Exploratory Data Analysis with MATLAB,
CRC Press Company, USA.
Ruskandar, A. (2009), Varietas Ciherang Makin Mendominasi, Warta Penelitian dan Pengembangan Pertanian, Vol.31, No.6.
Santosa, B. (2007), Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis, Graha Ilmu, Jakarta.
Setyono, A., Bram, K., Jumali dan Prihadi W. (2008), “Evaluasi Mutu Beras di Beberapa Wilayah Sentra Produksi Padi”, dalam Prosiding Seminar Nasional Padi 2008, Eds: Setyono dkk, Balai Besar Penelitian Tanaman Padi, Subang. Suismono, A.S., Indrasari, S.D., Wibowo, P. dan Las (2003), Evaluasi Mutu beras
Berbagai Varietas Padi di Indonesia, Balai Penelitian Tanaman Padi, Sukamandi.
Yager, R.R. (1988), On Ordered Weighted Averaging Aggregation Operators in Multicriteria Decision Making, IEEE Transactions on SMC, 18, 183–190.
Yager, R.R. (2004), Modeling prioritized multi criteria decision making, IEEE Transactions on System, Man, and Cybernetics – Part B: Cybernetics, 23(6), 2396–2403.