KLASIFIKASI FRAGMEN METAGENOM MENGGUNAKAN
PRINCIPAL COMPONENT ANALYSIS DAN K-NEAREST
NEIGHBOR
VICTORIA FEBRINA ROMAULI SIMANGUNSONG
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Fragmen Metagenom menggunakan Principal Component Analysis dan K-Nearest Neighbor adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tulisan ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2015 Victoria Febrina Romauli Simangunsong NIM G64124062
ABSTRAK
VICTORIA FEBRINA ROMAULI SIMANGUNSONG. Klasifikasi Fragmen Metagenom menggunakan Principal Component Analysis dan K-Nearest Neighbor. Dibimbing oleh WISNU ANANTA KUSUMA.
Metagenomika adalah ilmu yang mempelajari tentang analisis metagenom yang materi genetiknya diperoleh langsung dari sampel lingkungan. Ketika meng-sekuens sampel metagenom ini maka akan dihasilkan fragmen-fragmen. Pada saat fragmen-fragmen tersebut dirakit akan dihasilkan chimeric contigs atau gabungan fragmen dari berbagai organisme. Selanjutnya diperlukan proses binning yang bertujuan untuk mengklasifikasikan fragmen-fragmen tersebut ke dalam tingkat taksonomi tertentu. Pada penelitian ini peneliti melakukan klasifikasi fragmen metagenom yang diekstrasi menggunakan n-mers kemudian direduksi dimensinya menggunakan principal component analysis dan diklasifikasi menggunakan k-nearest neighbor. Nilai k yang terbaik pada KNN adalah 7. Nilai n tertinggi pada n-mers adalah 4. Akurasi pada organisme dikenal dari fold terbaik dengan menggunakan PCA 95% untuk panjang fragmen 0.5 Kbp sampai 10 Kbp berkisar antara 91.6% sampai 99,9%. Untuk organisme tidak dikenal dengan PCA 95% tingkat akurasi berkisar antara 89.64% sampai 99.32%.
Kata kunci : Fragmen metagenom,n-mers, PCA, KNN
ABSTRACT
VICTORIA FEBRINA ROMAULI SIMANGUNSONG. Fragments Metagenome Classification using Principal Component Analysis and K-Nearest Neighbor. Supervised by WISNU ANANTA KUSUMA.
Metagenomics is a study of metagenom analysis which its genetic materials is obtained directly from environmental samples. The process of metagenome sequencing produce fragments from mixture organisms. Thus, assembling fragments directly will generate chimeric contigs. Furthermore, a bining process is required to classify these fragments into a particular taxonomic level. In this study, the classification of metagenome fragment were extracted using n-mers, reduced its dimension using principal component analysis and classified using k-nearest neighbor. The experiments were conducted from in the various fragment length from 0.5 Kbp to 10 Kbp. The best results were obtained using KNN with k=7 and implementing 4-mers frequency. The accuracies of classifying known organisms obtained using PCA 95% were ranged from 91.6% to 99.9%. Moreover, the accuracies were slightly decreased when classifying unknown organisms, from 89.64% to 99.32%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI FRAGMEN METAGENOM MENGGUNAKAN
PRINCIPAL COMPONENT ANALYSIS DAN K-NEAREST
NEIGHBOR
VICTORIA FEBRINA ROMAULI SIMANGUNSONG
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
Penguji :
1 Aziz Kustiyo, SSi, MKom 2 Toto Haryanto, SKom, MSi
Judul Skripsi : Klasifikasi Fragmen Metagenom menggunakan Principal Component Analysis dan K-Nearest Neighbor
Nama : Victoria Febrina Romauli Simangunsong NIM : G64124062
Disetujui oleh
Dr. Wisnu Ananta Kusuma, ST, MT Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas segala berkat dan karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Mei 2014 ini ialah Bioinformatika, dengan judul Klasifikasi Fragmen Metagenom menggunakan Principal Component Analysis dan K-Nearest Neighbor.
Terima kasih penulis ucapkan kepada Bapak Dr. Wisnu Ananta Kusuma, ST, MT selaku pembimbing. Bapak Aziz Kustiyo SSi, MKom dan Bapak Toto Haryanto SKom, MSi selaku penguji atas saran dan masukan untuk penelitian ini. Ungkapan terima kasih juga disampaikan kepada Bapak Elman Simangunsong SH, MH, dan Ibu Dra. Sorta Mariany Sibuea, serta seluruh keluarga, dan teman-teman Alih Jenis Ilmu Komputer IPB angkatan 7 atas segala doa, dukungan semangat dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2015 Victoria Febrina Romauli Simangunsong
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN x
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Ruang Lingkup Penelitian 2
Manfaat Penelitian 3
METODE PENELITIAN 3
Data Metagenome NCBI 4
Ekstrasi Ciri 4
Normalisasi 5
Reduksi Dimensi dengan PCA 5
F-Fold Cross Validation 6
K-Nearest Neighbor 7
Pengujian dengan Organisme Tidak Dikenal 8
Analisis 8
Ruang Lingkup Sistem 8
HASIL DAN PEMBAHASAN 8
Penyiapan Data 8
Ekstrasi Ciri 9
Normalisasi 10
Reduksi Dimensi menggunakan PCA 10
F-Fold Cross Validation 10
Klasifikasi KNN 11
Akurasi 11
Pengaruh akurasi terhadap nilai n pada n-mers dan k pada KNN 12
Perbandingan akurasi menggunakan PCA dengan tanpa PCA untuk organisme
dikenal 13
Perbandingan Penelitian Terkait 15
SIMPULAN DAN SARAN 16
Simpulan 16 Saran 16 DAFTAR PUSTAKA 16 RIWAYAT HIDUP 22
DAFTAR TABEL
1 Organisme Dikenal 42 Dimensi yang diperoleh setelah direduksi dengan PCA 10 3 Akurasi organisme dikenal menggunakan k=3 pada KNN (dalam %) 11 4 Akurasi organisme dikenal menggunakan k=5 pada KNN (dalam %) 11 5 Akurasi organisme dikenal menggunakan k=7 pada KNN (dalam %) 12 6 Hasil pengujian organisme tidak dikenal dengan PCA 95 (dalam %) 13 7 Perbandingan waktu komputasi data testing (organisme tidak dikenal)
dengan PCA dan tanpa PCA pada 7-NN (satuan dalam detik) 15 8 Perbandingan Penelitian terkait organisme tidak dikenal 15 9 Perbandingan Penelitian terkait organisme dikenal 15 10 Akurasi organisme dikenal menggunakan k=3 panjang 1 Kbp & 5
Kbp (dalam%) 19
11 Akurasi organisme dikenal menggunakan k=5 panjang 1 Kbp & 5
Kbp (dalam%) 19
12 Akurasi organisme dikenal menggunakan k=7 panjang 1 Kbp & 5
Kbp (dalam%) 20
DAFTAR GAMBAR
1Metode Penelitian 3
2 Ekstrasi Ciri N-Mers 4
3 Ilustrasi proses normalisasi 5
4 Ilustrasi dimensi m x n 6
5 Ilustrasi 5-Fold Cross Validation 7
6 Hasil ekstrasi ciri n=3 panjang fragmen 0,5 Kbp 9 7 Screenshot file FASTA dibangkitkan menggunakan METASIM 9
8 Normalisasi 3-mers panjang 0,5Kbp 10
9 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 0.5 Kbp 12 10 Perbandingan akurasi dengan menggunakan PCA 95% dan tanpa PCA
11 Perbandingan akurasi dengan menggunakan PCA 95% dan tanpa PCA
untuk organisme tidak dikenal 14
12 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 1 Kbp 20 13 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 5 Kbp 20 14 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 10 Kbp 21
DAFTAR LAMPIRAN
1 Dataset organisme tidak dikenal 18
2 Jumlah Fragmen tiap organisme dikenal 18
3 Jumlah Fragmen tiap organisme tidak dikenal 19
4 Akurasi yang diperoleh untuk organisme dikenal 19 5 Pengaruh akurasi terhadap nilai n pada n-mers dan k pada KNN 20
PENDAHULUAN
Latar Belakang
Penelitian tentang analisis metagenom dalam lingkup bioinformatika terus berkembang. Secara umum, analisis materi genetik dilakukan dengan cara membudidayakannya di laboratorium, kemudian di-sequencing dan dilakukan perakitan. Proses ini dilakukan untuk menghasilkan urutan rantai DNA yang berisi informasi genetik suatu organisme. Akan tetapi, dari banyak mikroorganisme hanya 1% yang dapat dikulturkan. Sisanya harus mengambil sampel langsung dari lingkungan. Ilmu yang mempelajari tentang analisis metagenom dan materi genetiknya diperoleh langsung dari sampel lingkungan disebut metagenomika (Wu 2008). Sampel ini ketika di-sequencing akan menghasilkan fragmen-fragmen. Fragmen-fragmen yang berasal dari berbagai organisme. Pada saat dilakukan perakitan fragmen-fragmen ini, akan menghasilkan chimeric contigs gabungan fragmen yang berasal dari organisme berbeda. Untuk itu diperlukan proses binning yang bertujuan untuk mengklasifikasikan fragmen-fragmen tersebut ke dalam tingkat taksonomi tertentu.
Proses binning dapat dilakukan dengan dua pendekatan, yaitu pendekatan dengan homologi dan komposisi. Binning berdasarkan homologi dilakukan penjajaran sekuens dengan membandingkan fragmen metagenom dengan basis data sekuens National Centre for Biotechnology Information (NCBI), kemudian hasilnya akan disimpulkan pada level taksonomi. Penelitian metode yang menggunakan pendekatan homologi adalah BLAST (Wu 2008), dan MEGAN (Huson et al. 2007). Pendekatan yang kedua adalah, binning berdasarkan komposisi. Pendekatan komposisi tidak membandingkan sekuens kueri dengan sekuens referensi sehingga pengelompokannya lebih cepat dibandingkan dengan homologi. Pendekatan ini menggunakan pasangan basa hasil ekstrasi ciri sebagai masukkan untuk pembelajaran dengan observasi (unsupervised) atau pembelajaran dengan contoh (supervised) (Kusuma dan Akiyama 2011).
Pembelajaran unsupervised digunakan ketika tidak diketahui label dari data yang harus dikelompokkan. Keluaran dari pendekatan ini adalah data yang telah dikelompokkan. Clustering termasuk ke dalam pembelajaran unsupervised. Adapun pembelajaran supervised, telah memiliki informasi mengenai label dari tiap-tiap kelompok. Klasifikasi termasuk dalam pembelajaran supervised. Penelitian metode yang menggunakan pembelajaran unsupervised yang diterapkan pada kasus metagenom adalah TETRA (Teeling et al. 2004), GSOM atau Growing Self Organizing (Hsu dan Halgamuge 2002; Overbeek 2013), SOC atau Self Organizing Clustering (Amano et al. 2007). Adapun metode pembelajaran supervised yang digunakan untuk menyelesaikan masalah metagenom adalah Naïve Bayessian Classification (Rosen et al. 2008) dan PhyloPythia (McHardy et al. 2007).
Penelitian Kusuma dan Akiyama (2011) melakukan binning fragmen metagenom berdasarkan characterization vector. Penelitian ini menggunakan dua data set yang dibangkitkan menggunakan MetaSim (Richter et al. 2008). Untuk dataset organisme yang diketahui menggunakan sepuluh spesies dari tiga genus
2
dan dataset organisme baru menggunakan sembilan spesies dari tiga genus. Metode yang digunakan sebagai ekstrasi ciri adalah n-mers. Panjang fragmen yang digunakan 0.5 Kbp, 1 kbp, 5 kbp, 10 kbp. Akurasi yang didapat dengan menggunakan data latih adalah 81% sampai 92%. Adapun untuk data uji, akurasi didapat adalah 78% sampai dengan 87%. Secara umum, kinerja metode ini menurun untuk pengklasifikasian pada data uji. Salah satu alasan kesalahan pengklasifikasian karena adanya urutan rantai yang tumpang tindih dari spesies yang berbeda, tetapi berada dalam genus yang sama. Penelitian terkait juga dilakukan oleh Ellyana (2014) dengan melakukan pengklasifikasian fragmen metagenom menggunakan fitur spaced n-mers dan k-nearest neighbor. Hasil akurasi yang diperoleh untuk dataset organisme yang diketahui adalah 88.77% sampai 99.65%.
Oleh karena itu, penelitian ini melakukan klasifikasi fragmen metagenom menggunakan n-mers sebagai ekstrasi ciri, kemudian dilakukan pereduksian dimensi menggunakan principal component analysis dan diklasifikasikan menggunakan algoritme k-nearest neighbor. Akurasi yang diperoleh akan dibandingkan dengan penelitian Ellyana (2014), dan Kusuma dan Akiyama (2011).
Perumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, masalah yang akan diteliti dapat dirumuskan sebagai berikut:
1 Bagaimana pengaruh terhadap akurasi KNN?
2 Bagaimana pengaruh nilai k pada KNN terhadap hasil akurasi?
3 Bagaimana pengaruh nilai n pada n-mers terhadap hasil akurasi KNN? 4 Bagaimana hasil akurasi yang diterapkan pada organisme tidak
dikenal?
5 Berapa lama waktu komputasi terhadap pengujian selama proses klasifikasi?
Tujuan Penelitian
Tujuan dari penelitian ini membuat model k-nearest neighbor dengan reduksi dimensi principal component analysis. Setelah itu hasilnya dibandingkan dengan penelitian sebelumnya.
Ruang Lingkup Penelitian
Ruang lingkup penelitian meliputi:
1. Data diperoleh dari NCBI yang dibangkitkan oleh perangkat lunak MetaSim. Dataset merepresentasikan organisme yang dikenal dengan organisme tidak dikenal.
2. Data yang digunakan merujuk pada penelitian Kusuma dan Akiyama (2011) & Ellyana (2014).
3 3. Panjang fragmen untuk dataset organisme yang dikenal dan organisme dikenal meliputi 0.5 kbp, 1 kbp, 5 kbp, dan 10 kbp. Dataset tersebut dipilih dari genus Agrobacterium, Bacillus, dan Staphylococcus.
4. Sekuens DNA direpresentasikan sebagai empat karakter A, T, G, dan C. Data berformat FASTA dan bebas error.
Manfaat Penelitian
Penelitian ini diharapkan dapat membantu para peneliti dalam pengklasifikasian fragmen metagenom berdasarkan tingkat genus.
METODE PENELITIAN
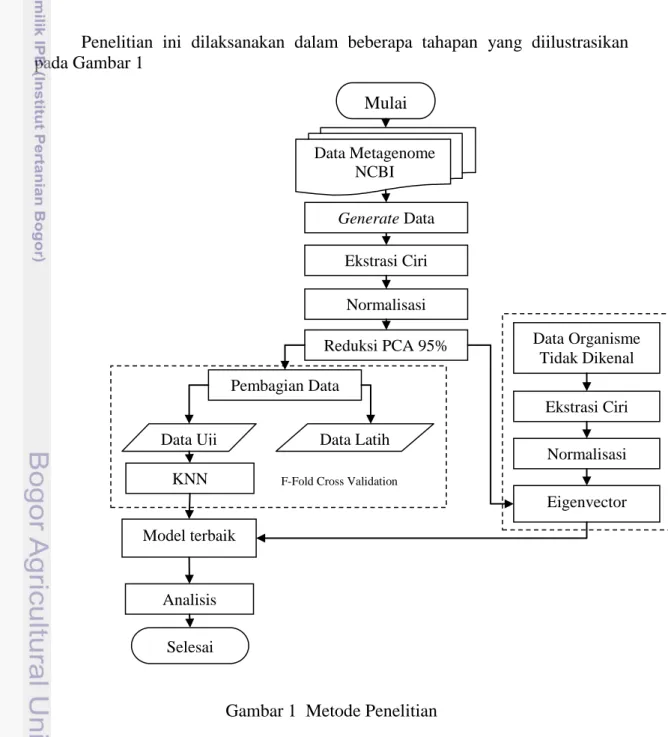
Penelitian ini dilaksanakan dalam beberapa tahapan yang diilustrasikan pada Gambar 1
Gambar 1 Metode Penelitian Mulai Data Metagenome NCBI Ekstrasi Ciri Normalisasi Reduksi PCA 95% Pembagian Data
Data Uji Data Latih
KNN F-Fold Cross Validation
Data Organisme Tidak Dikenal Ekstrasi Ciri Normalisasi Eigenvector Model terbaik Analisis Selesai Generate Data
4
Data Metagenome NCBI
Data diunduh dari situs NCBI (National Center for Biotechnology Information) pada ftp://ftp.ncbi.nlm.nih.gov/genomes/Bacteria/all.fna.tar.gz. Kemudian data metagenom dibangkitkan menggunakan MetaSim, dengan format FASTA. Dataset terdiri atas dataset organisme dikenal dan dataset organisme tidak dikenal. Dataset organisme latih terdiri atas sepuluh spesies yang dibagi menjadi data latih dan data uji dapat dilihat pada Tabel 1. Adapun dataset organisme tidak dikenal terdiri atas sembilan spesies (Lampiran 1). Panjang fragmen untuk setiap dataset terdiri atas 0.5 Kbp, 1 Kbp, 5 Kbp, dan 10 Kbp. Jumlah fragmen untuk dataset organisme dikenal adalah 10000 dan organisme tidak dikenal adalah 5000.
Tabel 1 Organisme dikenal
Species Genus
Agrobacterium radiobacter K84 chromosome 2 Agrobacterium Agrobacterium tumefaciens str. C58 chromosome
circular
Agrobacterium vitis S4 chromosome 1
Bacillus amyloliquefaciens FZB42 Bacillus Bacillus anthracis str. Ames Ancestor
Bacillus cereus 03BB102
Bacillus pseudofirmus OF4 chromosome
Staphylococcus aureus subsp. Aureus JH1 Staphylococcus Staphylococcus epidermidis ATCC 12228
Staphylococcus haemolyticus JCSC1435
Ekstrasi Ciri
Pada tahapan ekstrasi ciri dilakukan menggunakan metode n-mers. Metode ini digunakan untuk mengetahui intensitas atau banyaknya kemunculan substring tertentu pada sebuah string. Intensitas kemunculan string tersebut dapat dijadikan sebagai penciri dari suatu kelompok string. Data sekuens DNA merupakan data string, oleh karena itu ekstraksi ciri yang digunakan pada penelitian ini untuk data set DNA adalah n-mers dengan n = 3, 4, 5. Pola kemunculan dalam sekuens dihitung menggunakan empat basa utama (A, T, G, dan C) dipangkat dengan rangkaian pasangan basa yang ingin digunakan (pola kemunculan : 4n, dengan n>= 1) (Kusuma 2011). Gambar 2 merupakan ilustrasi ekstrasi ciri n-mers.
5
Normalisasi
Jumlah substring pada fragmen yang telah diekstrasi sangatlah bervariasi. Ada yang memiliki nilai yang sangat besar atau sangat kecil, dan jika dikurangkan akan menghasilkan selisih yang sangat besar. Maka dari itu perlu dilakukan normalisasi sehingga nilai yang diperoleh dapat diskalakan ke dalam batas nilai tertentu. Skala nilai berada pada rentang [0.0,1.0].
Normalisasi min-max menggunakan transformasi linear. Proses normalisasi dilakukan dengan mengurangkan nilai data asli dengan nilai minimal, lalu dibagi dengan nilai maksimal dikurangkan dengan nilai minimal. Diperoleh dengan persamaan berikut (Han et al. 2011),
v'= v-min
max-min newmax-newmin +newmin
Berikut merupakan ilustrasi dari tahapan normalisasi (Gambar 3).
Reduksi Dimensi dengan PCA
Pada tahap ini, reduksi dimensi dari fragmen metagenom dilakukan menggunakan teknik Principal Component Analysis. PCA merupakan teknik multivariate yang paling banyak digunakan pada hampir semua bidang. Teknik ini mereduksi dimensi himpunan peubah yang biasanya terdiri atas peubah yang banyak dan saling berkorelasi menjadi peubah baru yang tidak berkorelasi. Teknik ini mempertahankan sebanyak mungkin keragaman dalam himpunan data tersebut serta menghilangkan peubah-peubah asal yang mempunyai sumbangan informasi yang relatif kecil.
Hal yang pertama dilakukan adalah mendapatkan dimensi data yang ingin direduksi. Setelah itu, rata-rata dari dimensi tersebut dihitung dengan rumus sebagai berikut:
X= Xi
n i=1
n
Kemudian nilai data tiap dimensi dikurangkan dengan nilai rata-rata dimensi, dengan rumus sebagai berikut:
Data adjust = (Xi-X)
Lalu langkah selanjutnya adalah menghitung nilai matriks kovarian dari data adjust dengan rumus sebagai berikut (Smith 2002):
C= var(X) cov(X,Y) cov(Y,X) var(Y) var X = Xi-X Xi-X n i=1 (n-1) AAA AAT ... CCC 2 12 ... 5 3 1 ... 7 AAA AAT ... CCC 0,0909 1 ... 0,3636 0,1818 0 ... 0,5454 Normalisasi
6
cov X,Y = Xi-X Yi-Y
n i=1
(n-1)
Selanjutnya nilai eigenvector, eigenvalues, dan explained dihitung. Untuk menghitung eigenvalues, diperlukan matriks persegi A (k x k) dan matriks identitas kemudian dihitung dengan rumus sebagai berikut:
A-λ I = 0
Kemudian hitung determinan matriks persegi A (k x k) dan, λ menjadi eigenvalues dari A. Jika x
(k=1)adalah nonzero vector x ≠0 , sehingga A x= λ x. x
adalah eigen vector (characteristic vector) dari matriks A yang terkait dengan eigenvalue λ. Kolom dari A-λ I tergantung sehingga |A-λ I|=0. Eigenvalues sendiri menunjukan tingkat kepentingan suatu kolom dari eigenvector (Johnson RA dan Wichern DW 2007). Nilai explained dihitung dengan rumus sebagai berikut:
explained= eigenvalue
eigenvalue×100%
Tahapan terakhir yaitu kita memilih komponen eigenvector yang menyimpan data asli dan membentuk feature vector, kemudian di transpose lalu dikalikan dengan data adjust transpose, kemudian di transpose lagi dengan menggunakan rumus (Smith 2002):
Final Data=(RowFeatureVectorT ×RowDataAdjustT)T
Pada penelitian ini nilai proporsi kumulatif keragaman data asal yang dipilih adalah sebesar 95%. Berikut merupakan ilustrasi dimensi m × n, dimana nilai 𝑚 = 10000 pembacaan data, dan 𝑛 = 64 diperoleh dari frekuensi n-mers (Gambar 4).
Gambar 4 Ilustrasi dimensi m x n
F-Fold Cross Validation
F-fold cross-validation digunakan untuk membagi data menjadi data latih dan data uji. Metode ini melakukan perulangan sebanyak f kali untuk membagi sebuah himpunan contoh secara acak menjadi f-subset yang saling bebas. Setiap ulangan disisakan satu subset untuk pengujian, dan sisanya digunakan untuk
7 pelatihan (Fu 1994). Jumlah dataset organisme yang diketahui 10000 framen, f yang digunakan menggunakan 5-Fold. Untuk data latih digunakan 8000 fragmen, sedangkan data uji digunakan 2000 fragmen. Diilustrasikan pada Gambar 5.
Gambar 5 Ilustrasi 5-Fold Cross Validation
K-Nearest Neighbor
Metode klasifikasi yang digunakan pada penelitian ini yaitu K-Nearest Neighbor (KNN). KNN banyak diterapkan dalam pengenalan pola dan data mining untuk klasifikasi. KNN merupakan algoritme supervised dalam klasifikasi dimana hasil dari kueri instance yang baru diklasifikasikan berdasarkan mayoritas kategori pada k tetangga terdekat. KNN mengklasifikasi objek baru berdasarkan atribut dan training samples (Larose 2001).
Konsep dasar dari KNN adalah mencari jarak terdekat antara data yang akan dievaluasi dengan k tetangga terdekatnya. Nilai dari jarak antara data uji dengan data latih diurutkan dari nilai terendah. Kelas dari nilai dengan jarak terendah diperiksa. Kelas yang memiliki nilai vote tertinggi menjadi kelas dari data uji tersebut.
Jarak antara dua titik dalam ruang fitur dapat didefiniskan dengan banyak cara, salah satunya menggunakan jarak Euclid. Hasil dari perhitungan jarak Euclid digunakan untuk menentukan kemiripan antara data latih dan data uji. Kecocokan dilihat dari nilai (jarak) yang paling minimum. Jarak Euclid diperoleh dengan menggunakan persamaan berikut.
dist(p,q)= (pi-qi)2
n
i=1
dengan :dist(p,q) = jarak sampel pi = data sampel ke-i
qi = data input ke-i
n = jumlah sampel
Tahapan algoritme KNN adalah sebagai berikut (Song et al. 2007) : 1 Menentukan nilai k, dengan k merupakan jumlah tetangga terdekat.
2 Menghitung jarak data pada setiap data latih dengan menggunakan jarak Euclid.
8
Pengujian dengan Organisme Tidak Dikenal
Pengujian organisme tidak dikenal dilakukan dengan melakukan klasifikasi terlebih dahulu pada fragmen organisme dikenal. Setelah itu diperoleh akurasi tertinggi dari organisme dikenal yang kemudian dijadikan sebagai data latih. Data ujinya diperoleh dari organisme tidak dikenal. Kemudian, data uji diujikan ke data latih menggunakan algoritme KNN.
Analisis
Hasil penelitian diukur dengan menghitung tingkat akurasi dari data set uji. Persamaan untuk menghitung akurasi diperoleh sebagai berikut.
akurasi= data uji benar
data uji x 100%
Ruang Lingkup Sistem
Penelitian dilakukan dengan menggunakan perangkat keras dan perangkat lunak sebagai berikut:
1. Perangkat keras berupa komputer personal dengan spesifikasi:
Processor Intel(R) Dual Core(TM)
RAM 2 GB
160 GB 2. Perangkat lunak :
Sistem operasi Windows 8.0 32-bit
Sistem operasi Ubuntu 13.10
MetaSim
Matlab R2013a
Notepad++
Codeblocks 12.11
HASIL DAN PEMBAHASAN
Penyiapan Data
Data metagenome berupa sequens DNA yang diunduh dari situs NCBI. Sequens DNA tersebut berasal dari sepuluh organisme untuk organisme yang dikenal dan sembilan organisme tidak dikenal.Jumlah fragmen untuk organisme dikenal adalah 10000, sedangkan organisme tidak dikenal 5000.
Kemudian jumlah fragmen 10000 tersebut dibagi secara merata untuk tiga genus yang terdiri dari 10 organisme. Genus agrobacterium, jumlah fragmennya 3450. Genus bacillus, jumlah fragmennya 3400. Sedangkan genus staphylococcus, berjumlah 3150. Untuk jumlah fragmen organisme tidak dikenal sebanyak 5000. Dibagi secara merata untuk terhadap 9 organisme dari 3 genus.
9 Jumlah fragmen untuk genus agrobacterium sebesar 1700, genus bacillus jumlah fragmennya 1600, dan genus staphylococcus jumlah fragmennya 1600. Untuk pembagian selengkapnya dapat dilihat pada Lampiran 3 dan 4.
Langkah selanjutnya yang dilakukan adalah, membangkitkan sekuens
DNA setiap organisme sesuai dengan jumlahnya menggunakan MetaSim (Gambar 6). Panjang fragmen yang digunakan untuk kedua dataset adalah 0,5 Kbp, 1 Kbp, 5 Kbp, 10 Kbp.
Ekstrasi Ciri
Ekstrasi ciri pada penelitian ini menggunakan n-mers dengan nilai n=3, 4, 5. Proses ekstrasi ciri menghasilkan banyaknya pasangan trinukleotida, tetranukleotida, pentanukleotida. Untuk n = 3 pola kemunculan yang dihasilkan 43= 64 yang menghasilkan substring dari AAA sampai CCC. Untuk n = 4 pola kemunculan yang didapatkan 44= 256 yang menghasilkan substring dari AAAA sampai CCCC. Kemudian n = 5 pola kemunculan yang dihasilkan 45= 1024 dan menghasilkan substring dari AAAAA sampai CCCCC. Ekstrasi ciri menghasilkan array jumlah fragmen m x n kombinasi. Pada organisme dikenal jika n=3, maka array dimensinya 10000 x 64, selanjutnya n= 4, array dimensinya 10000 x 256, dan n= 5 array dimensinya 10000 x 1024.Hal yang sama dilakukan terhadap organisme tidak dikenal. Array dimensinya 5000 x 64 untuk n=3. Berikut merupakan screenshoot hasil ekstrasi ciri dari n=3 dengan panjang 0,5 Kbp (Gambar 7).
Gambar 7 Hasil ekstrasi ciri n=3 panjang fragmen 0,5 Kbp
10
Normalisasi
Normalisasi bertujuan untuk mengurangi hasil ekstrasi ciri yang bervariasi. Skala nilai matriks komposisi berada pada rentang 0 dan 1 yang menggunakan metode scaling. Berikut merupakan screenshot hasil normalisasi pada organisme dikenal dengan n=3, panjang fragmen 0,5 Kbp (Gambar 8).
Reduksi Dimensi menggunakan PCA
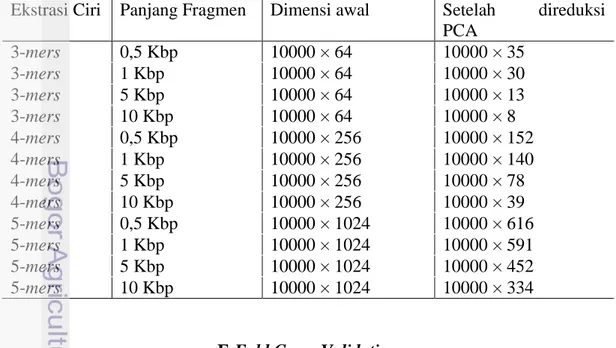
Analisis komponen utama bertujuan untuk mereduksi dimensi asal yang semula terdapat p variabel bebas menjadi q komponen utama (dimana q<p). Dimana q adalah proporsi kumulatif keragaman data dan pada penelitian ini nilai q sebesar 95%. Hasil reduksi dimensi selengkapnya dapat dilihat pada Tabel 2. Tabel 2 Dimensi yang diperoleh setelah direduksi dengan PCA
Ekstrasi Ciri Panjang Fragmen Dimensi awal Setelah direduksi PCA 3-mers 0,5 Kbp 10000 × 64 10000 × 35 3-mers 1 Kbp 10000 × 64 10000 × 30 3-mers 5 Kbp 10000 × 64 10000 × 13 3-mers 10 Kbp 10000 × 64 10000 × 8 4-mers 0,5 Kbp 10000 × 256 10000 × 152 4-mers 1 Kbp 10000 × 256 10000 × 140 4-mers 5 Kbp 10000 × 256 10000 × 78 4-mers 10 Kbp 10000 × 256 10000 × 39 5-mers 0,5 Kbp 10000 × 1024 10000 × 616 5-mers 1 Kbp 10000 × 1024 10000 × 591 5-mers 5 Kbp 10000 × 1024 10000 × 452 5-mers 10 Kbp 10000 × 1024 10000 × 334
F-Fold Cross Validation
Setelah direduksi menggunakan PCA, data set organisme dikenal tersebut dilatih dengan menggunakan f-fold cross validation untuk membagi data latih dan
11 data uji. Penelitian ini menetapkan f yang digunakan 5-fold, dimana jumlah fragmen organisme dikenal 10000. Data organisme dikenal dibagi menjadi 5 bagian, 4 untuk data latih, 1 untuk data uji. Data latih menggunakan 8000 fragmen, dan data uji menggunakan 2000 fragmen.
Klasifikasi KNN
Penelitian ini menggunakan algoritme KNN, dimana k yang digunakan = 3,5,7. Dengan menggunakan 5-fold cross validation, setiap fold-nya diujicobakan dengan panjang fragmen 0,5 Kbp, 1 Kbp, 5 Kbp, 10 Kbp.
Akurasi
Akurasi didapat setelah melakukan percobaan menggunakan algoritme KNN pada organisme yang dikenal. Berikut hasil akurasi beberapa percobaan yang telah dilakukan pada penelitian ini.
Percobaan I: dataset organisme dikenal, 3-mers, 4-mers,5-mers, PCA 95%, 5-foldcross validation, rantai terpendek (panjang fragmen 0,5 Kbp) dan rantai terpanjang (panjang fragmen 10 Kbp), 3-NN (Tabel 3).
Tabel 3 Akurasi organisme dikenal menggunakan k=3 pada KNN (dalam %)
Akurasi tertinggi untuk percobaan I pada panjang fragmen 0,5 Kbp terhadap 3-mers adalah 89,95% di fold-1, untuk 10 Kbp akurasinya 99,6% pada fold-3. Sedangkan untuk 4-mers panjang 0,5 Kbp akurasi tertinggi adalah 90,35% di fold-2, pada panjang 10 Kbp 99,9% pada fold-4. Untuk 5-mers nilai akurasi tertinggi pada panjang 0,5 Kbp adalah 88,5% di fold-1, untuk panjang 10 Kbp 99,95% pada fold-3.
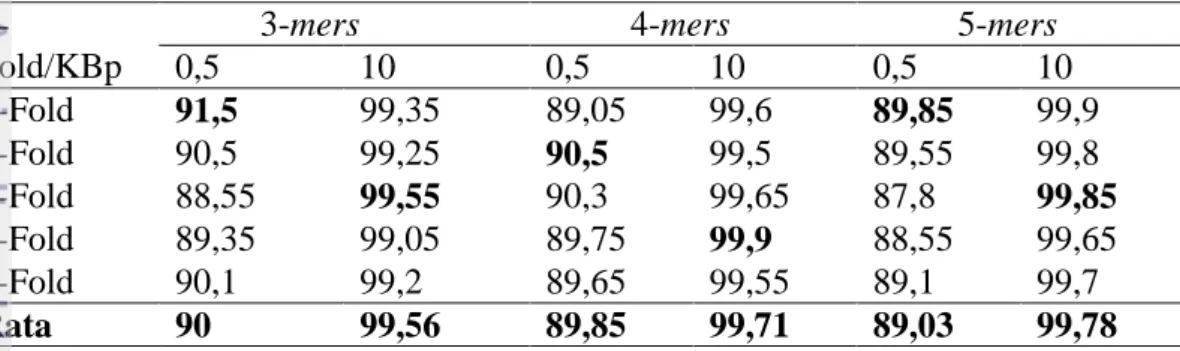
Percobaan II: dataset organisme dikenal, 3-mers, 4-mers,5-mers, PCA 95%, 5-foldcross validation, panjang fragmen 0,5 Kbp dan 10 Kbp, 5-NN (Tabel 4).
Tabel 4 Akurasi organisme dikenal menggunakan k=5 pada KNN (dalam %)
F-Fold/KBp
3-mers 4-mers 5-mers
0,5 10 0,5 10 0,5 10 1-Fold 89,95 99,3 88,75 99,6 88,5 99,9 2-Fold 89,1 99,35 90,35 99,45 88,4 99,8 3-Fold 87,5 99,6 89,35 99,75 86,95 99,95 4-Fold 88,55 99,1 89,1 99,9 87,25 99,75 5-Fold 87,95 99,3 89,25 99,55 88,3 99,65 Rata 88,61 99,33 89,36 99,66 87,88 99,81 F-Fold/KBp
3-mers 4-mers 5-mers
0,5 10 0,5 10 0,5 10 1-Fold 91,5 99,35 89,05 99,6 89,85 99,9 2-Fold 90,5 99,25 90,5 99,5 89,55 99,8 3-Fold 88,55 99,55 90,3 99,65 87,8 99,85 4-Fold 89,35 99,05 89,75 99,9 88,55 99,65 5-Fold 90,1 99,2 89,65 99,55 89,1 99,7 Rata 90 99,56 89,85 99,71 89,03 99,78
12
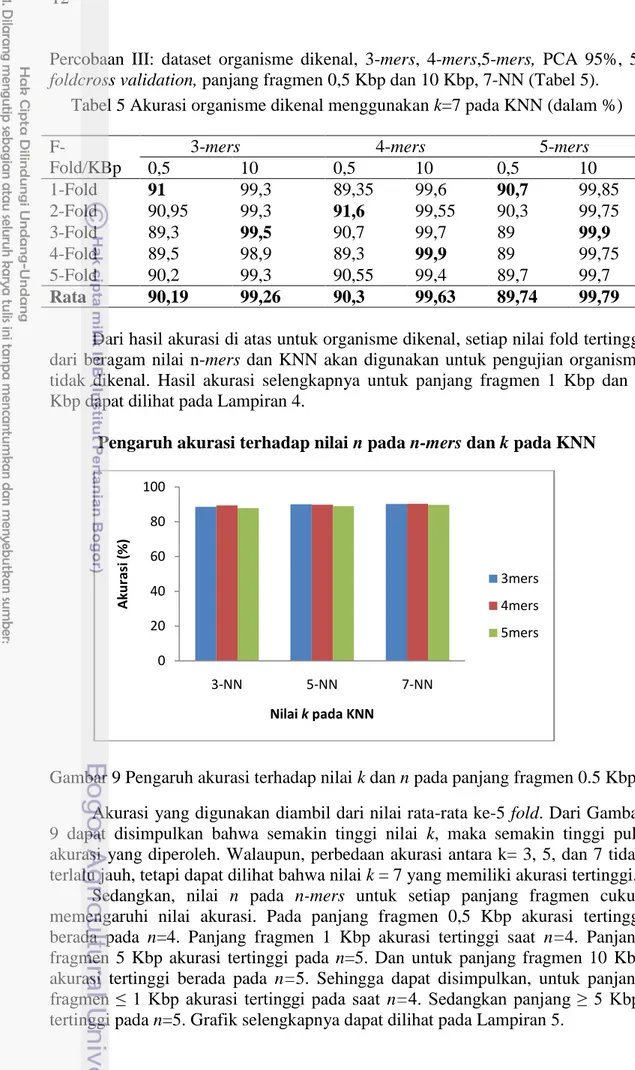
Percobaan III: dataset organisme dikenal, 3-mers, 4-mers,mers, PCA 95%, 5-foldcross validation, panjang fragmen 0,5 Kbp dan 10 Kbp, 7-NN (Tabel 5).
Tabel 5 Akurasi organisme dikenal menggunakan k=7 pada KNN (dalam %)
Dari hasil akurasi di atas untuk organisme dikenal, setiap nilai fold tertinggi dari beragam nilai n-mers dan KNN akan digunakan untuk pengujian organisme tidak dikenal. Hasil akurasi selengkapnya untuk panjang fragmen 1 Kbp dan 5 Kbp dapat dilihat pada Lampiran 4.
Pengaruh akurasi terhadap nilai n pada n-mers dan k pada KNN
Gambar 9 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 0.5 Kbp Akurasi yang digunakan diambil dari nilai rata-rata ke-5 fold. Dari Gambar 9 dapat disimpulkan bahwa semakin tinggi nilai k, maka semakin tinggi pula akurasi yang diperoleh. Walaupun, perbedaan akurasi antara k= 3, 5, dan 7 tidak terlalu jauh, tetapi dapat dilihat bahwa nilai k = 7 yang memiliki akurasi tertinggi. Sedangkan, nilai n pada n-mers untuk setiap panjang fragmen cukup memengaruhi nilai akurasi. Pada panjang fragmen 0,5 Kbp akurasi tertinggi berada pada n=4. Panjang fragmen 1 Kbp akurasi tertinggi saat n=4. Panjang fragmen 5 Kbp akurasi tertinggi pada n=5. Dan untuk panjang fragmen 10 Kbp akurasi tertinggi berada pada n=5. Sehingga dapat disimpulkan, untuk panjang fragmen ≤ 1 Kbp akurasi tertinggi pada saat n=4. Sedangkan panjang ≥ 5 Kbp, tertinggi pada n=5. Grafik selengkapnya dapat dilihat pada Lampiran 5.
0 20 40 60 80 100 3-NN 5-NN 7-NN A ku rasi (% ) Nilai k pada KNN 3mers 4mers 5mers F-Fold/KBp
3-mers 4-mers 5-mers
0,5 10 0,5 10 0,5 10 1-Fold 91 99,3 89,35 99,6 90,7 99,85 2-Fold 90,95 99,3 91,6 99,55 90,3 99,75 3-Fold 89,3 99,5 90,7 99,7 89 99,9 4-Fold 89,5 98,9 89,3 99,9 89 99,75 5-Fold 90,2 99,3 90,55 99,4 89,7 99,7 Rata 90,19 99,26 90,3 99,63 89,74 99,79
13
Pengujian pada organisme tidak dikenal
Tahapan pengujian dilakukan dengan mengambil akurasi tertinggi dari ke-5 fold pada organisme dikenal, lalu akurasi tersebut diubah menjadi data latih. Untuk data uji diambil dari organisme tidak dikenal. Kemudian data uji, diujikan ke data latih menggunakan algoritme KNN. Berikut merupakan hasil pengujian untuk organisme tidak dikenal (Tabel 4).
Tabel 6 Hasil pengujian organisme tidak dikenal dengan PCA 95 (dalam %)
Panjang Fragmen
3-mers 4-mers 5-mers
k=3 k=5 k=7
0.5 Kbp 86,14 87,2 87,5 87,9 88,72 89,64 86,84 87,94 88,36 1 Kbp 91,58 92,1 92,26 92,98 93,46 93,44 90,5 92,14 92,24 5 Kbp 96,72 96,46 96,58 98,64 98,58 98,42 96,46 96,2 96,32 10 Kbp 98,2 98,12 98,14 99,16 99,2 99,32 99,44 99,56 99,56
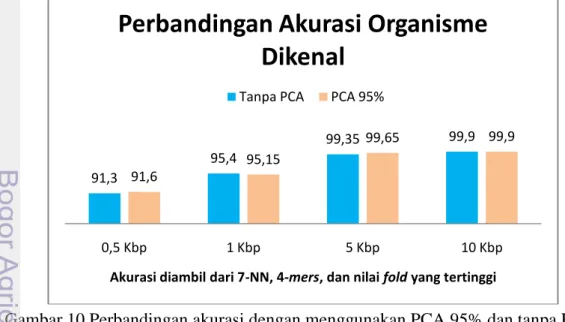
Perbandingan akurasi menggunakan PCA dengan tanpa PCA untuk organisme dikenal
Perbandingan akurasi organisme menggunakan PCA dan tanpa PCA untuk organisme dikenal dapat dilihat pada Gambar 11. Secara umum, hasil akurasi yang diperoleh menggunakan PCA dan tanpa PCA tidak jauh berbeda. Untuk panjang fragmen 0,5 Kbp dan 5 Kbp akurasi PCA lebih tinggi. Tetapi untuk panjang 1 Kbp lebih tinggi akurasi tanpa PCA. Untuk panjang 10Kbp akurasinya sama. Sehingga dapat ditarik kesimpulan, walaupun dimensi matriks sudah direduksi tetapi akurasi menggunakan PCA dan tanpa PCA tidak berbeda jauh.
Gambar 10 Perbandingan akurasi dengan menggunakan PCA 95% dan tanpa PCA untuk organisme dikenal
91,3 95,4 99,35 99,9 91,6 95,15 99,65 99,9 0,5 Kbp 1 Kbp 5 Kbp 10 Kbp
Akurasi diambil dari 7-NN, 4-mers, dan nilai fold yang tertinggi
Perbandingan Akurasi Organisme
Dikenal
14
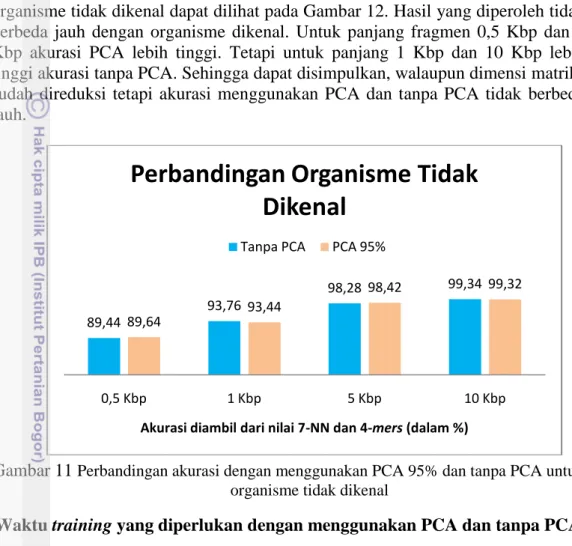
Perbandingan akurasi menggunakan PCA dengan tanpa PCA untuk organisme tidak dikenal
Perbandingan akurasi organisme menggunakan PCA dan tanpa PCA untuk organisme tidak dikenal dapat dilihat pada Gambar 12. Hasil yang diperoleh tidak berbeda jauh dengan organisme dikenal. Untuk panjang fragmen 0,5 Kbp dan 5 Kbp akurasi PCA lebih tinggi. Tetapi untuk panjang 1 Kbp dan 10 Kbp lebih tinggi akurasi tanpa PCA. Sehingga dapat disimpulkan, walaupun dimensi matriks sudah direduksi tetapi akurasi menggunakan PCA dan tanpa PCA tidak berbeda jauh.
Gambar 11 Perbandingan akurasi dengan menggunakan PCA 95% dan tanpa PCA untuk organisme tidak dikenal
Waktu training yang diperlukan dengan menggunakan PCA dan tanpa PCA
Waktu komputasi pada saat testing ( pengujian organisme tidak dikenal) dapat dilihat di Tabel 7. Secara umum, waktu yang diperoleh pada tiap panjang fragmen yang telah direduksi menggunakan PCA mengalami penurunan. Tetapi, tanpa menggunakan PCA mengalami peningkatan. Untuk ekstrasi ciri 3-mers selisih waktu terkecil 5,196 detik pada panjang 1 Kbp. Selisih waktu terbesar 18,077 detik pada panjang 10 Kbp. Untuk ekstrasi ciri 4-mers selisih waktu terkecil 12,72 detik pada panjang 0.5 Kbp. Selisih waktu terbesar 36,013 detik pada panjang 10 Kbp. Untuk ekstrasi ciri 5-mers selisih waktu terkecil 39,534 detik pada panjang 0.5 Kbp. Selisih waktu terbesar 88,109 detik pada panjang 10 Kbp. 89,44 93,76 98,28 99,34 89,64 93,44 98,42 99,32 0,5 Kbp 1 Kbp 5 Kbp 10 Kbp
Akurasi diambil dari nilai 7-NN dan 4-mers (dalam %)
Perbandingan Organisme Tidak
Dikenal
15 Tabel 7 Perbandingan waktu komputasi data testing (organisme tidak dikenal) dengan
PCA dan tanpa PCA pada 7-NN (satuan dalam detik)
Panjang fragmen
PCA 95% Tanpa PCA
3-mers 4-mers 5-mers 3-mers 4-mers 5-mers 0,5 Kbp 7,001 21,711 80,362 12,416 34,431 119,896 1 Kbp 9,384 22,703 77,688 14,58 36,944 119,253 5 Kbp 6,72 12,883 62,863 14,782 37,088 127,161 10 Kbp 3,44 9,408 44,337 21,517 45,421 132,446
Perbandingan Penelitian Terkait
Berikut merupakan perbandingan terkait penelitian ini. Membandingkan penelitian Kusuma & Akiyama 2011 , Ellyana 2014, dan penelitian yang telah dilakukan (Tabel 6 dan Tabel 8). Penelitian Kusuma & Akiyama (2011) menerapkan algoritme characterization vector dalam ekstrasi fitur dan mengimplementasikan SVM sebagai classifier dan menghasilkan akurasi tertinggi sebesar 92% pada panjang fragmen. Sedangkan, Ellyana (2014) menerapkan spaced n-mers sebagai ekstrasi fitur dan KNN sebagai classifier dan mendapatkan akurasi tertinggi sebesar 99.65%. Penelitian ini menerapkan k-mers sebagai ekstrasi ciri kemudian direduksi dimensinya menggunakan principal component analysis dan KNN sebagai classifier dan menghasilkan akurasi tertinggi sebesar 99,9%. Juga dapat disimpulkan pada akurasi yang diperoleh pada penelitian ini lebih tinggi dari yang sebelumnya.
Tabel 8 Perbandingan Penelitian terkait organisme tidak dikenal
Panjang Fragmen 0,5 Kbp 1 Kbp 5 Kbp 10 Kbp
Kusuma (2011) 81.00% 85.00% 90.00% 92.00% Ellyana (2014) 88.77% 95.68% 99.17% 99.65% Penelitian ini (2015) 91.60% 95.15% 99.65% 99.90%
Tabel 9 Perbandingan Penelitian terkait organisme dikenal
Panjang Fragmen 0,5 Kbp 1 Kbp 5 Kbp 10 Kbp
Kusuma (2011) 78.00% 80.00% 86.00% 87.00% Ellyana (2014) 86.11% 91.77% 96.60% 97.96% Penelitian ini (2015) 89.64% 93.44% 98.42% 99.32%
16
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini dilakukan klasifikasi fragmen metagenom menggunakan metode K-Nearest Neighbor dan direduksi dimensi menggunakan Principal Component Analysis. Untuk nilai k yang terbaik pada KNN adalah 7-NN. Untuk nilai n tertinggi pada n-mers adalah 4-mers. Akurasi pada organisme dikenal dari fold terbaik dengan menggunakan PCA 95% untuk panjang fragmen 0.5 Kbp sampai10 Kbp berkisar antara 91.6% sampai 99,9%. Tanpa PCA diperoleh akurasi berkisar antara 91.3% sampai 99.9%. Untuk organisme tidak dikenal dengan PCA 95% akurasi yang diperoleh berkisar antara 89.64% sampai 99.32%. Sedangkan tanpa PCA akurasi yang diperoleh berkisar antara 89.44% sampai 99.34%.
Selain itu, waktu komputasi dengan menggunakan PCA mengalami penurunan walaupun panjang fragmen semakin meningkat. Selisih waktu komputasi setelah direduksi mencapai 88,109 detik pada 5-mers dengan panjang 10 Kbp. Hasil akurasi yang diperoleh seluruhnya cukup baik, baik menggunakan PCA dan tanpa PCA. PCA mampu menghasilkan akurasi yang tidak berbeda jauh dengan tanpa PCA, selain itu waktu komputasi juga dapat direduksi.
Setelah dibandingkan dengan penelitian terkait Kusuma & Akiyama 2011, Ellyana 2014, dapat dilihat bahwa akurasi yang diperoleh pada penelitian ini lebih tinggi dari penelitian sebelumnya.
Saran
Saran untuk penelitian selanjutnya:
1. Dataset dicobakan menggunakan organisme yang lebih banyak dengan kelas yang lebih banyak.
2. Menggunakan metode klasifikasi, dan reduksi dimensi yang berbeda.
DAFTAR PUSTAKA
Ellyana, F. 2014. Klasifikasi Fragmen Metagenom Menggunakan Fitur Spaced N-Mers dan K-Nearest Neighbor [skripsi]. Bogor(ID): Institut Pertanian Bogor.
Han J, Kamber M, Pei J. 2011. Data Mining Concepts and Techniques Third Edition. USA: Morgan Kaufmann. hlm 113-115.
17 Hsu AL, Halgamuge SK. 2002. Enhancement of topology preservation and hierarchical dynamic self-organizing maps for data visualisation. International Journal of Approximate Reasoning. 32(2003):259-279 Huson DH, Auch AF. Qi J, Schuster SC. 2007. MEGAN analysis of metagenomic
data. Genome Research. 17 : 1 – 11. doi : 10.1101/gr/5969107.
Johnson RA, Wichern DW. 2007 Applied Multivariate Statistical Analysis-Sixth Edition. (US): Pearson Education, Inc.
Kusuma WA, Akiyama Y. 2011. Metagenome fragment binning based on characterization vector. International Conference on Bioinformatics and Biomedical Technology (ICBBT 2011); 2011 Mar 25–27; Sanya, China. Larose DT. 2005. DiscoveringKnowledge in Data:An Introduction to Data
Mining.New Jersey (US): Wiley.
McHardy AC, Martín HG, Tsirigos A, Hugenholtz P, Rigoutsos I. 2007. Accurate phylogonetic classification of variabel-length DNA fragments. Nature Methods. 4(1):63–72. doi: 10.1038/nmeth976.
Overbeek, MV. 2013. Pengelompokan Fragmen Metagenom Dengan Metode Growing Self Organizing Map [tesis]. Bogor (ID): Institut Pertanian Bogor.
Richter DC, Ott F, Auch AF, Schmid R, Huson DH. 2008. MetaSim-A Sequencing Simulator for Genomics and Metagenomics. PLoS ONE 3(10): e3373.doi:10.1371/journal.pone.0003373.
Smith LI. 2002. A tutorial on Principal Component Analysis. [26 Februari 2002] Song Y, Huang J, Zhou D, Zha H, Giles CL. 2007. IKNN: Informative k-nearest
neighborpattern classification.Knowledge Discovery in Databases: PKDD 2007. hlm 248-264.
Teeling H, Waldmann J, Lombardot T, Bauer M, Glockner FO. 2004. TETRA : a web service and stand-alone program for the analysis and comparison of tetranucleotide usage pattern in sequence DNAs. BMC Informatics. 5(163). doi:10.1186/1471-2105-5-163.
Wu H. 2008. PCA-Based Linear Combinations Of Oligonucleotide Frequencies For Metagenomic Dna Fragment Binning.Computational Intelligence in Bioinformatics and Computational Biology 2008. hlm 46-53.
18
Lampiran 1 Dataset organisme tidak dikenal
Species Genus
Agrobacterium radiobacter K84 chromosome 1 Agrobacterium Agrobacterium tumefaciens str. C58 chromosome
linear
Agrobacterium vitis S4 chromosome 2
Bacillus thuringiensis str Al Hakam Bacillus Bacillus subtilis subsp. Subtilis str 168
Bacillus pumilus SAFR-032
Staphylococcus carnosus subsp. Carnosus Staphylococcus Staphylococcus saprophyticus subsp. Saprophyticus
ATCC 15305
Staphylococcus Lugdunensis HKU09-01
Lampiran 2 Jumlah Fragmen tiap organisme dikenal
Genus Nama Organisme Jumlah Fragmen
Agrobacterium
Agrobacterium radiobacter K84 chromose 2
Agrobacterium tumefaciens str. C58 chromosome circular
Agrobacterium vitis S4 chromosome 1
1150 1150 1150
Bacillus
Bacillus amyloliquefaciens FZB42 Bacillus anthracis str. Ames Ancestor Bacillus cereus 03BB102
Bacillus pseudofirmus OF4 chromosome 850 850 850 850 Staphylococcus
Staphylococcus aureus subsp. Aureus JH1
Staphylococcus epidermidis ATCC 12228 Staphylococcus haemolyticus JCSC1435 1050 1050 1050
19 Lampiran 3 Jumlah Fragmen tiap organisme tidak dikenal
Genus Nama Organisme Jumlah Fragmen
Agrobacterium Agrobacterium radiobacter K84 chromosome 1 600 Agrobacterium tumefaciens str. C58 chromosome linear 550 Agrobacterium vitis S4 chromosome 2 550
Bacillus
Bacillus thuringiensis str Al Hakam 550 Bacillus subtilis subsp. Subtilis str 168
550 Bacillus pumilus SAFR-032 550
Staphylococcus
Staphylococcus carnosus subsp. Carnosus
550 Staphylococcus saprophyticus subsp. Saprophyticus ATCC 15305
550 Staphylococcus Lugdunensis HKU09-01
550
Lampiran 4 Akurasi yang diperoleh untuk organisme dikenal
Tabel 10 Akurasi organisme dikenal menggunakan k=3 panjang 1 Kbp & 5 Kbp (dalam%)
Tabel 11 Akurasi organisme dikenal menggunakan k=5 panjang 1 Kbp & 5 Kbp (dalam%)
F-Fold/KBp
3-mers 4-mers 5-mers
1 5 1 5 1 5 1-Fold 93,2 98,55 94,1 94,1 94,1 99,5 2-Fold 94,55 98,55 94 94 94 99,05 3-Fold 93,95 98,9 94,8 94,65 94,65 99,5 4-Fold 93,7 99 95,05 94,05 94,05 99,55 5-Fold 93,7 98,85 95,2 94,35 95,2 99,75 Rata 93,82 98,77 94,63 94,23 94,63 99,47 F-Fold/KBp
3-mers 4-mers 5-mers
1 5 1 5 1 5 1-Fold 93,9 98,45 94,7 99,55 95 99,45 2-Fold 94,3 98,35 93,8 99,25 94,25 99,15 3-Fold 94,6 98,8 94,9 99 94,6 99,45 4-Fold 93,95 99,05 95,1 98,7 94,4 99,45 5-Fold 94,2 98,7 95,55 99,2 94,85 99,45 Rata 94,19 98,67 94,81 99,14 94,62 99,39
20
Tabel 12 Akurasi organisme dikenal menggunakan k=7 panjang 1 Kbp & 5 Kbp (dalam%)
Lampiran 5 Pengaruh akurasi terhadap nilai n pada n-mers dan k pada KNN
Gambar 12 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 1 Kbp
Gambar 13 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 5 Kbp 0 20 40 60 80 100 3-NN 5-NN 7-NN A ku rasi (% ) Nilai k pada KNN 3mers 4mers 5mers 0 20 40 60 80 100 3-NN 5-NN 7-NN A ku rasi (% ) Nilai k pada KNN 3mers 4mers 5mers F-Fold/KBp
3-mers 4-mers 5-mers
1 5 1 5 1 5 1-Fold 93,2 98,55 94,75 99,65 95,45 99,4 2-Fold 94,65 98,3 94,2 99,2 94,6 99,15 3-Fold 94,1 98,8 95,15 99,05 94,6 99,5 4-Fold 93,9 98,75 95,15 98,9 94,65 99,05 5-Fold 93,95 98,4 95,05 99,2 94,8 99,3 Rata 93,96 98,56 94,86 99,2 94,82 99,28
21
Gambar 14 Pengaruh akurasi terhadap nilai k dan n pada panjang fragmen 10 Kbp 0 20 40 60 80 100 3-NN 5-NN 7-NN A ku rasi (% ) Nilai k pada KNN 3mers 4mers 5mers
22
RIWAYAT HIDUP
Penulis dilahirkan di Medan, Sumatera Utara pada tanggal 12 Februari 1992 dari Bapak Elman Simangunsong, SH, MH dan Ibu Dra Sorta Mariany Sibuea. Penulis merupakan putri bungsu dari 5 bersaudara. Penulis menyelesaikan pendidikan menengah atas di SMA Negeri 3 Medan pada tahun 2009 dan melanjutkan pendidikan diploma 3 di Institut Pertanian Bogor melalui jalur undangan Jurusan Manajemen Informatika dan menyelesaikannya pada tahun 2012. Kemudian pada tahun yang sama, penulis terdaftar sebagai mahasiswa Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Institut Pertanian Bogor dan bekerja sebagai guru komputer (Oktober 2012 - Juni 2014) di SD Katolik Mardi Yuana Bogor. Penulis merupakan pengurus aktif di Komunitas Mahasiswa Kristen Alih Jenis IPB periode 2013-2014.