Analisis Performansi Hadoop Cluster Multi Node pada Komputasi Dokumen
Delis Permatasari1)
[email protected] Mohammad Dani, M.T. 2)
[email protected] Mia Rosmiati, S.Si., M.T. 3) [email protected]
1) 3) Program Studi Teknik Komputer Peminatan Teknik Jaringan Politeknik Telkom Bandung 2) Teknik Elektro Universitas Kebangsaan Bandung
ABSTRAK
Pengimplementasian sebuah aplikasi cluster merupakan salah satu cara dalam proses pendistribusian data, karena akan berdampak positif dalam peningkatan proses kinerja dan pengembangan sistem untuk pengolahan data tersebut. Semakin berkembangnya dunia teknologi , dimana pertumbuhan data yang sangat cepat dan semakin lama semakin besar. Hal ini memungkinkan suatu strategi khusus untuk menyiasati cara pengolahan data yang besar dengan cepat, akurat dan efisien.
Untuk mengatasi permasalahan diatas, Apache Hadoop menerapkan komputasi paralel dengan menggunakan aplikasi terdistribusi, yang dirancang secara efisien mendisitribusikan sejumlah pekerjaan besar dalam mesin cluster. Apache Hadoop menggembangkan beberapa project diantaranya Hadoop Distribution File System (HDFS) dan MapReduce framework untuk menyelesaikan pengolahan data.yang besar berbasis java dan open source.
Aplikasi Hadoop juga dapat digunakan untuk menghitung pembobotan dokumen dan menganalisis proses yang sedang berjalan di sistem tersebut. Tujuan proyek akhir ini diharapkan dengan bertambahnya jumlah node dan perubahan parameter dapat meningkatkan kinerja cluster dalam menyelesaikan suatu proses.
Kata Kunci : Hadoop, Cluster, MapReduce, HDFS, Komputasi Paralel
1. Pendahuluan 1.1 Latar Belakang
Semakin berkembangnya dunia teknologi, dimana pertumbuhan data yang sangat cepat dan semakin lama semakin besar. Hal ini memungkinkan suatu strategi khusus untuk menyiasati cara pengolahan data yang besar dengan cepat, akurat dan efisien. Pada kenyataanya data yang berkembang di dalam digital-universe. Estimate data elektronik mencapai 0,18 zettabyte pada tahun 2006 dan akan diramalkan pada tahun 2006 dan akan diramalkan tumbuh sepuluh kali lipat mencapai 1,8 zettabyte pada tahun 2011 (White,2009). Tetapi infrastuktur dari sebuah media penyimpanan memiliki kendala terutama dalam kecepatan transfer, sehingga membutuhkan waktu yang cukup lama untuk membaca keseluruhan data.
Adakalanya aplikasi yang dibuat membutuhkan ko mputer dengan sumber daya yang tinggi sebagai lingkungan yang tinggi sebagai lingkungan implementasi dan biasanya harga untuk komputer dengan sumber daya yang tinggu tidaklah murah, sedangkan untuk komputer dengan spesisfikasi yang tidak terlalu tinggi akan kurang reliable dalam
menangani data yang begitu besar (Venner,2009). Dengan demikian, teknologi dalam skala besar yang berhubungan dengan peningkatan kinerja sistem benar-benar di butuhkan.
node dapat meningkatkan kinerja cluster dalam menyelesaikan suatu proses.
1.2 Perumusan Masalah
Berdasarkan latar belakang diatas maka rumusan masalah, yaitu:
1. Bagaimana merancang hadoop cluster dengan sistem operasi ubuntu 10.04. 2. Bagaimana implementasi hadoop cluster
pada komputasi dokumen untuk meningkatkan meningkatkan kinerja cluster?
3. Bagaimana implementasi mesin cluster agar dapat dimanfaatkan dan digabungkan satu sama lain sehingga dapat bekerja sama? 4. Apakah penggunaan jumlah node dan
perubahan parameter yang bekerja pada sebuah cluster dapat berpengaruh terhadap kinerja sistem.
1.3 Tujuan
Tujuan dari Proyek Akhir ini adalah Sebagai berikut :
1. Membangun hadoop cluster dengan sistem operasi ubuntu 10.04
2. Menerapkan Mapreduce dan HDFS sebagai aplikasi terdistribusi untuk meningkatkan kinerja cluster.
3. Menganalis performansi hadoop cluster terhadap pengaruh jumlah node di dalam cluster tersebut.
4. Menguji performansi dari sistem cluster dengan menganalisis pengaruh parameter replikasi, ukuran blok, dan kapasitas task map terhadap pengujian HDFS dan waktu eksekusi mapreduce pada sistem cluster. 1.4 Batasan Masalah
Untuk memfokuskan bahasan maka penulis memberikan batasan masalah dalam Proyek Akhir ini seperti berikut:
1. Menggunakan sistem operasi 10.04.
2. Dalam implementasi menggunakan 3 buah server dan 1 buah client.
3. Dalam implementasi menggunakan suatu file berbentuk dokumen.
4. Bagian dari Hadoop Framework yang digu nakan dalam penelitian hanya MapReduce dan HDFS.
5. Parameter konfigurasi yang diuji yaitu jumlah node, nilai replikasi, ukuran blok, dan kapasitas taskmap.
6. Parameter yang diukur pada pengujian performansi yaitu waktu eksekusi untuk melihat kinerja mapreduce dan nilai throughput untuk pengujian HDFS.
7. Tidak membahas membahas web service dan database.
8. Tidak membahas sistem Security. 9. Tidak membahas Single point of Failure.
2. Dasar Teori 2.1 Cluster Computing
Cluster computing adalah suatu system perangkat keras dan perangkat lunak yang menggabungkan dan beberapa komputer dalam suatu jaringan sehingga komputer-komputer tersebut dapat bekerja sama dalam pemrosesan masalah (Rizvi et al., 2010).
Cluster computing menawarkan sejumlah manfaat lebih dari kpmputer mainframe, termasuk (Rizvi et al., 2010):
1. Mengurangi biaya yaitu menghemat sumber daya perangkat yang ada
2. Pengolahan power yaitu kekuatan pemrosesan paralel dari cluster
3. Peningkatan jaringan teknologi yaitu pengembangan cluster komputer telah kemajuan besar dalam teknologi yang berhubungan dengan jaringan.
4. Skalabilitas yaitu cluster cluster komputer dapat dengan mudah diperluas sebagai perubahan persyaratan dengan menambahkan node tambahan ke jaringan. 5. Ketersediaan yaitu ketika komputer
mainframe gagal, seluruh sistem gagal, operasinya bisa dengan sederhana ditransfer ke node lain dalam cluster ini.
2.2 Apache Hadoop
Hadoop adalah framework software berbasis java dan open source yang berfungsi untuk mengolah data yang sangat besar secara terdistribusi dan berjalan di atas cluster yang terdiri atas beberapa komputer yang saling terhubung (White, 2008). Hadoop dapat mengolah data dalam jumlah yang sangat besar hingga petabyte dan dijalankan diatas ribuan komputer. Hadoop framework mengatur segala macam proses detail sedangkan pengembang aplikasi hanya perlu fokus pada aplikasi logiknya. (White, 2009). Hadoop bersifat open source dan berada dibawah bendera Apache Software Foundation. Inti dari hadoop terdiri atas :
1. HDFS (Hadoop Distributed File System) yaitu Data yang terdistribusi.
2.2.1 Hadoop Single Node
Hadoop single node untuk sistem ini menggunakan 1 mesin. Mesin tersebut didesain menjadi master tapi tidak bekerja juga sebagai slave. Pada mesin single node semua proses dilakukan dalam 1 mesin. Hadoop terbagi dua layer yaitu layer HDFS yang menjalankan namenode dan datanode sedangkan layer MapReduce yang menjalankan Jobtracker dan Tasktracker. Pada kedua layer ini sangat penting aktif yaitu Namenode dan Jobtracker, karena apabila dua bagian ada yang tidak jalan maka kerja HDFS dan MapReduce tidak bisa dijalankan.
Gambar 2.1 Hadoop Single Node
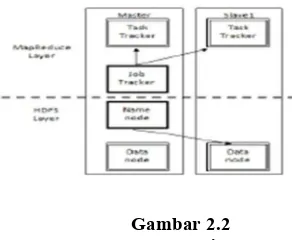
2.2.1 Hadoop Multi Node
Haddop multi node menggunakan 2 mesin, 1 untuk mesin cluster den 1 untuk mesin slave. Kedua mesin tersebut dikonfigurasi berupa mesin 2 single. Node yang akan digabung menjadi satu mesin multi node dimana satu mesin akan didesain menjadi master tapi dapat bekerja juga menjadi slave, sednagkan mesin yang lain akan menjadi slave.
Gambar 2.2 Hadoop Multi Node
2.2 MapReduce
MapReduce pertama kali dikenalkan oleh Jeffrey Dean dan Sanjay Ghemawat dari Google,Inc. MapReduce adalah model pemograman terdistribusi yang digunakan untuk melakukan pengolaha data digunakan pengolahan data besar (Ghemawat, 2004).
Model pemrograman MapReduce membagi proses menjadi dua tahapan, yaitu tahapan Map dan tahapan Reduce. Map merupakan proses yang berjalan secara parallel, sedangkan Reduce merupakan proses penggabungan hasil dari proses map.
Gambar 2.4
Proses Mapreduce pada banyak komputer
1. Proses “Map” yaitu masternode menerima input, kemudian input tersebut dipecah menjadi beberapa subproblem yang kemudian didistribusikan ke worker nodes. Worker nodes ini akan memproses subproblem yang diterimanya untuk kemudian apabila problem tersebut diselesaikan, maka akan dikembalikan ke masternode.
2. Proses “Reduce” yaitu masternode menerima jawaban dari semua subproblem dari banyak data nodes, menggabungkan jawaban-jawaban tersebut menjadi satu jawaban besar untuk mendapatkan penyelesaian dari permasalahan utama, keuntungan dari Mapreduce ini adalah proses map dan reduce dapa dijalankan secara terdistribusi.
Gambar 2.5 Arsitektur HDFS
2.5 TestDFSIO
TestDFSIO adalah Aplikasi benchmark hadoop yang berfungsi untuk menguji kinerja I / O dari HDFS. Hal ini dilakukan dengan menggunakan pekerjaan MapReduce sebagai cara yang nyaman untuk membaca atau menulis file secara paralel. Setiap file yang dibaca atau ditulis dalam tugas yang terpisah. TestDFSIO output dari map yang digunakan untuk mengumpulkan statistik yang berkaitan dengan file hanya diproses.
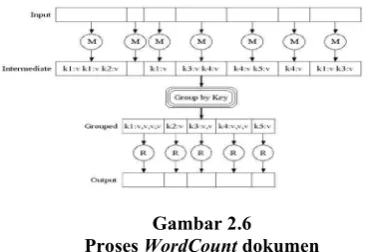
2.6 WordCount
` Wordcount adalah aplikasi benhcmark hadoop yang berfungsi untuk menghitung tingkat kemiripan dari setiap kata dalam sebuah large documents. Wordcount merupakan aplikasi penting MapReduce karena di butuhkan dalam pemetaaan file.
Gambar 2.6 Proses WordCount dokumen
Operasi wordcount berlangsung dalalm dua tahap Map dan Reduce
Pada fase pertama mapper tes ini tokenized dengan kata-kata maka kita membentuk pasangan nilai kunci dengan kata-kata di mana kunci menjadi kata itu sendiri dan nilai '1 '
Pada tahap reduce phase dikelompokkan bersama dan nilai-nilai untuk kunci yang sama ditambahkan. Reduce menghasilkan output pasangan intermediate <key, value>. Sebelum memasuki tahap reduce,
pasangan intermediate <key, value> dikelompokkan berdasarkan key, tahap ini dinamakan tahap shuffle. 2.7 Cacti
Cacti adalah salah satu software yang digunakan untuk keperluan monitoring Cacti menyimpan semua data/informasi yang diperlukan untuk membuat grafik dan mengumpulkannya dengan database MySQL. Untuk menjalankan Cacti, diperlukan software pendukung seperti MySQL, PHP, RRDTool, net-snmp, dan sebuah webserver yang support PHP seperti Apache atau IIS.
2.8 Ubuntu
Ubuntu adalah sistem operasi turunan dari distro Linux jenis Debian unstable (sid), Ubuntu merupakan project untuk komunitas, yang bertujuan untuk menciptakan sebuah sistem operasi beserta dengan paket aplikasinya yang bersifat free dan open source, karena Ubuntu mempunyai prinsip untuk selamanya bersifat gratis (free of charge) dan tidak ada tambahan untuk versi enterprise edition.
3 Analisis Kebutuhan Dan Perancangan 3.1 Identifikasi Kebutuhan
Adapun alur perngerjaan sebagai berikut:
Start
Perancangan dan Impelementasi
Pengambilan data
Analisis
Kesimpulan End Instalasi Server
Pengumpulan
Dokumentasi Perumusan Masalah
Konfigurasi Sistem
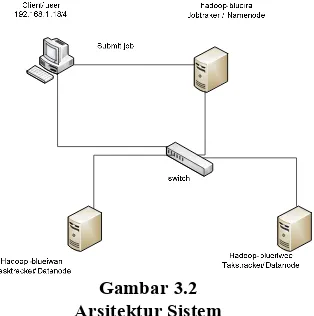
3.2 Perancangan Sistem 3.2.1 Arsitektur Sistem
Adapun arsitektur sistem yang direncanakan dalam proyek akhir ini adalah sebagai berikut:
Gambar 3.2 Arsitektur Sistem
3.2.2 Skenario Pengujian MapReduce
Berikut adalah skema dari arsitektur sistem yang telah dirancang dalam Proyek Akhir ini:
Gambar 3.3 Proses kinerja MapReduce
3.2.2 Skenario Pengujian HDFS
Skenario Pengujian HDFS ini bertujuan untuk meli hat performansi nilai throughput pada Hadoop Distrubuted File System (HDFS) dari sistem cluster.
Gambar 3.4
Proses kinerja Write pada HDFS
Gambar 3.5
Proses kinerja Read pada HDFS
3.2.2 Skenario Pengujian Multi node Cluster
Gambar 3.6
4 Implementasi dan Pengujian 4.1 Implementasi
1. Pertama melakukan instalasi java pada tiap server dengan perintah:
#apt-get install jdk sun-java6-plugin
2. Melakukan instalasi ssh dan rsync sebaagai aplikasi remote server.
$apt-get openssh-server $apt-get rsync
3. Menambah alamat ip pada konfigurasi jaringan pada tiap host dengan perintah $nano /etc/hosts
4. Sebelum melakukan instalasi, download hadoop terlebih dahulu kemudain dapat melakukan Instalasi Hadoop-02.02 perintah dengan perintah :
$ cd /usr/local/
$sudo tar –xvf hadoop-0.20.2 tar.gz
$sudo chown -R padlis:hadoop hadoop-0.20.2 5. Karena hadoop berplatform aplikasi java
maka penulis menambahkan konfigurasi pada aplikasi hadoop :
$cd /usr/local/hadoop-0.20.2/conf $nano /hadoop-env.sh
# The java implementation to use. Required. export JAVA_HOME=/usr/lib/jvm/java-6-sun
6. Kemudian penulis melakukan konfigurasi hadoop untuk merubah parameter dalam memproses dokumen.
$ cd /usr/local/hadoop-0.20.2/conf $ nano /core-site.xml
$ nano /mapred-site.xml $ nano /hdfs-site.xml
7. Kemudian format node dari file system $cd /usr/local/hadoop-0.20.2
$bin/hadoop namenode -format 8. Menjalankan java proses server hadoop
$ cd /usr/local/hadoop-0.20.2 $ bin/start-dfs.sh
$ bin/mapred-dfs.sh
9. Menjalankan aplikasi Mapreduce $ bin/hadoop dfs –ls
$ bin/hadoop dfs –copyFromLocal
/home/padlis/wt/256Mb /usr/padlis/128 MB/ 10.Kemudian penulis menjalankan wordcount
$ bin/hadoop jar hadoop-*-examples.jar wordcount/usr/padlis/256mb
/usr/test/wtcount/256r3-output 11.Menjalankan aplikasi TestDFSIO
$ hadoop jar $HADOOP_INSTALL/hadoop*test.jar TestDFSIO write nrFiles 1 -fileSize 128
$ hadoop jar $HADOOP_INSTALL/hadoop*test.jar TestDFSIO read nrFiles 1 -fileSize 128
12. Melakukan instalasi apache2 untuk menggunakan aplikasi monitoring cacti. $apt-get install apache2
$apt-get install cacti
13. Tampilan web interface hadoop 14. t
15.
Gambar 4.1
Web InterfaceNamenode
Gambar 4.2
Web Interface JobTracker
Gambar 4.3
Web Interface Tasktracker
4.2 Hasil Pengujian
4.2.1 Pengujian pada Aplikasi WordCount
Tabel 4.1 Hasil Pengujian Wordcount
Ukuran data 128 Mb 256 Mb
Pengujian 1 676 1431
Pengujian 2 673 1428
Pengujian 3 679 2155
Pengujian 4 1043 2161
Gambar 4.4
Grafik hasil Pengujian Wordcount
Dari hasil pengujian secara keseluruhan, bahwa ada perbedaan waktu komputasi pada pengujian 1 sampai pengujian 4. Selisih waktu antara jumlah file 128 MB dan 256 MB menggunakan MapReduce mencapai 3865 detik sehingga kecepatan komputasi dengan jumlah file yang sangat kecil yang dibutuhkan semakin cepat.
4.2.2 Pengujian Aplikasi TestDFSIO
Tujuan Pengujian untuk menguji perfomansi dari sistem cluster dengan mengubah parameter berdasarkan skenario pengujian. Pengujian mengambil sampel data nilai throughput pada output TestDFSIO.
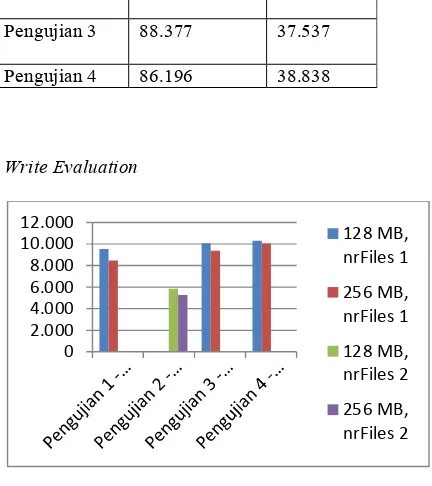
Tabel 4.2 Tabel Pengujian TestDFSIO Write
Ukuran data 128 MB 256 MB Pengujian 1 9.537 8.490 Pengujian 2 5.855 5.293 Pengujian 3 10.089 9.380 Pengujian 4 10.309 10.069
Tabel 4.3
Tabel Pengujian TestDFSIO Read
Ukuran data 128 Mb 256 MB Pengujian 1 113.565 108.253 Pengujian 2 118.177 109.720 Pengujian 3 88.377 37.537 Pengujian 4 86.196 38.838
Write Evaluation
Gambar 4.5
Grafik hasil Pengujian proses write pada HDFS
Secara keseluruhan Performansi write pada pengujian 1 sampai dengan pengujian 4 dengan ukuran file 128 MB dan 256 MB terlihat mirip satu sama lain. Semakin kecil ukuran file di proses pada skala fisik mendekati kecenderungan yang sama. Semakin kecil data yang akan diproses,semakin besar nilai throughput yang diberikan. Proses write
dengan file direplikasi secara logis menghasilkan kinerja lebih lambat. Hal itu disebabkan kenaikan jumlah nilai throughput ketika melakukan proses
write dipengaruhi nilai replikasi yang diperkecil.
0 1000 2000 3000
128 MB 256 MB
0 2.000 4.000 6.000 8.000 10.000
12.000 128 MB,
Read evaluation
Gambar 4.6 Grafik hasil pengujian proses read pada HDFS
Pada pengujian 1 sampai pengujian 4 dengan kedua ukuran file 128 MB dan 256 MB terlihat mirip satu sama lain dan proses read lebih cepat daripada proses write. Performansi read file kecil (128 MB) lebih cepat dibandingkan dengan kumpulan data besar (256 MB). Semakin kecil data yang akan diproses, semakin besar nilai throughput yang diberikan. Proses Read dengan file direplikasi menghasilkan kinerja yang lebih cepat. Pada proses read walaupun nilai replikasi 3 membuat jumlah blok lebih banyak namun tidak terjadi perubahan. Hal ini dikarenakan Namenode tidak membutuhkan waktu ekstra untuk memberikan waktiu pada Datanode.
4.2.3 Perbandingan Single node dan Multi node Berikut adalah hasil perbandingan antara Single node dengan multi node dalam proses eksekusi data. Table ini menunjukan bahwa ada perbandingan antara single node dengan multi node.
:
Tabel 4.4 Perbandingan Single node dan Multi node
Ukuran data
Blok 64 MB Blok 128 mb 128 MB 256
MB 128 MB 256 MB Single
Node 1969 detik 4178 detik 1355 detik 4192 detik Multi
node 676 detik 1431 detik 673 detik 1428 detik
Gambar 4.7
Grafik hasil Perbandingan single node dan multi node
Secara Keseluruhan perbedaan waktu komputasi wordcount pada mode single node dan mode distribusi multi node menggunakan MapReduce sangat terlihat karena jumlah inputan yang sangat besar. Performansi multi node lebih cepat di bandingkan dengan single node. Selisih waktu antara mode single node dan mode multi node menggunakan MapReduce mencapai 1.521 detik sehingga kecepatan komputasi pada mode multi node yang dibutuhkan semakin cepat.
4.2.4 Pengujian Monitoring menggunakan Cacti
Gambar 4.8
Monitoring dengan cacti
Gambar 4.9 Monitoring dengan cacti
0 20.000 40.000 60.000 80.000 100.000 120.000
128 MB, nrFiles 1 256 MB, nrFiles 1 128 MB, nrFiles 2 256 MB, nrFiles 2
0 1000 2000 3000 4000 5000
Kenaikan jumlah node membuat rata2 utilitas CPU meningkat. Peningkatan konsumsi CPU disebabkan oleh beban proses yang dikerjakan CPU. Hal tersebut dikarenakan ketika proses MapReduce belangsung ada CPU mengalokasikan waktu untuk menunggu blok data yang di proses. Karena semakin banyaknya jumlah blok yang saling bertukar antar node sampainya data menjadi lebih lama,
BAB 5 KESIMPULAN DAN SARAN 5.1 Kesimpulan
Berikut adalah kesimpulan dari hasil pengujian sistem yang dibuat pada proyek akhir ini dapat :
1. Dari hasil pengujian single node dan multi node disimpulkan adanya perubahan yang cukup signifikan antara single node dan multi node menggunakan MapReduce mencapai 1.521 detik sehingga kecepatan komputasi multi node lebih cepat dibandingkan dengan komputasi single node.
2.
Faktor yang berpengaruh terhadap
kinerja i/o hdfs adalah
file size dan
block size.
5.2 Saran
Berikut adalah saran yang dapat dilakukan dalam pengembangan selanjutnya yaitu melakukan query pencarian dokumen dengan jumlah data yang sangat besar dan Klusterisasi dokumen yang biasanya memerlukan jumlah sampel data yang sangat banyak Referensi
[1] Abdurachman, Zaky. (2011). Single Node Cluster dengan Hadoop. Jakarta Pusat: InfoLinux Media Utama.
[2] Apache Hadoop. (2011). Retrieved Februari 10, 2012, from Apache Software Foundation.: http://hadoop.apache.org/
[2] Fisher, M. (2003). JDBC(TM), API Tutorial and Reference. California: Sun Microsystem. Inc. Addison Weys.
[3] Ghemawat., J. D. (2004). MapReduce: Simplified Data. California: Google, Inc.
[4] Komputer., W. (2011). Administrasi Jaringan dengan Linux Ubuntu 11.4. Yogyakarta: Andi. [5] Rizvi et al. (2010). Distributed Media Player. New Delhi.
[5] S.Tanenbaum, A. &. (1995). Distributed Systems Principles and Paradigms. New Jersey: Prentice Hall.
[7] Venner, Jason. (2012). Pro Hadoop. United States of America: Apress.
[8] White, Tom. (2009). Hadoop: The Definitive Guide. California: 0'Reilly Media, Inc.