BAB 2
LANDASAN TEORI
Bab ini akan membahas tentang teori-teori pendukung dan penelitian sebelumnya yang berhubungan dengan polusi udara, Web Scraping, Distibuted System dan penerapan Naïve Bayes Classifier dalam melakukan klasifikasi kualitas udara.
2.1 Pencemaran Lingkungan
Lingkungan hidup merupakan ekosistem dimana benda hidup dan mati saling berhubungan satu dengan yang lain secara alamiah. Hubungan yang dimaksud adalah seperti makhluk hidup, iklim, cuaca dan sumber daya alam yang mempengaruhi cara manusia bertahan hidup (Johnson, et al, 1996). Lingkungan sering kali mengalami pencemaran baik air, tanah maupun udara. Pencemaran mempengaruhi ekosistem yang ada di area tersebut.
2.1.1 Pencemaran udara
Gambar 2. 1 Siklus pencemaran udara (Sumber : http://scienceunraveled.com/) Dikarenakan adanya faktor meteorologi, beberapa polutan akan mengalami berbagai reaksi fisika dan kimia. Faktor meteorologi yang dimaksud antara lain seperti sinar matahari, kelembaban dan temperatur. Angin juga berpengaruh dalam
pencemaran, dorongan angin akan menyebabkan polutan terdispersi (tersebar) mengikuti arah angin tersebut. Sebagian polutan dalam perjalanannya dapat terdeposisi (deposited) atau mengendap ke permukaan tanah, air, bangunan, dan tanaman. Sebagian lainnya akan tetap tersuspensi (suspended) di udara. Seluruh kejadian tersebut akan mempengaruhi konsentrasi polutan-polutan di udara ambien atau dengan kata lain, mengubah kualitas udara ambien (Kemenlh, 2007).
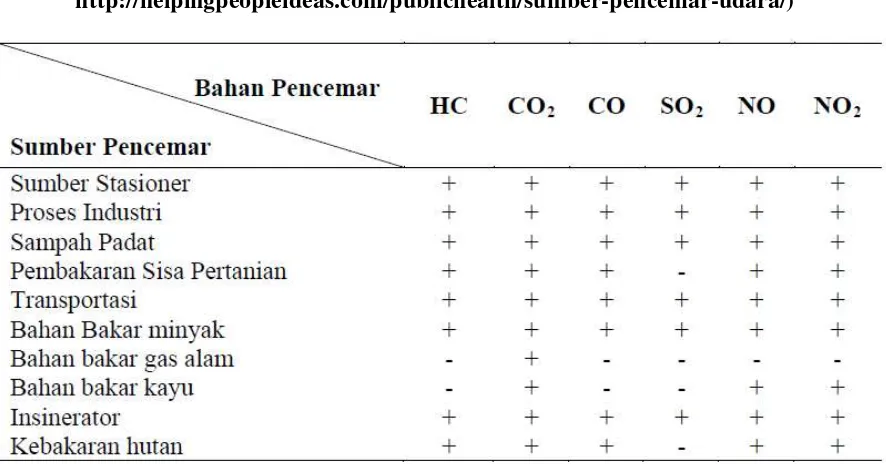
Keterangan :
+ = menghasilkan - = tidak menghasilkan
2.1.2 Kualitas udara dan kesehatan
Variasi zat-zat polutan menyebar komposisi kimianya di udara dapat menyebabkan dampak pada kesehatan manusia dan hewan. Particulate matter (PM) merupakan salah satu jenis polutan di udara, berupa campuran berbagai macam partikel kompleks pada udara untuk bernafas dengan berbagai ukuran dan komposisi dan diproduksi oleh banyak aktivitas alami dan manusia (Poschl, 2005). Sumber utama polutan partkiel adalah pabrik, pembangkit listrik, kebakaran, dan sebagainya.
Dampak pada kesehatan manusia dapat berupa mual, kesulitan bernafas, atau iritasi kulit bahkan dapat mengakibatkan kanker. Dapat juga menyebabkan cacat lahir, keterlambatan perkembangan serius pada anak-anak, dan penurunan aktivitas sistem kekebalan tubuh, serta menyebabkan sejumlah penyakit lainnya. Data Model epidemiologi dan hewan menunjukkan bahwa sistem terutama yang terkena dampak adalah kardiovaskular dan sistem pernapasan. Namun, fungsi dari beberapa organ lain dapat juga dipengaruhi (Huang and Ghio, 2006).
2.1.3 Air Quality Index
Indeks kualitas udara (AQI) adalah nilai yang digunakan oleh instansi pemerintah untuk memberikan gambaran kepada masyarakat tentang kondisi udara atau bagaimana prediksi pencemaran yang akan terjadi. Perhitungan AQI membutuhkan nilai konsentrasi polutan pada rata rata periode tertentu yang didapatkan dari hasil monitoring udara. Polutan udara memiliki potensi yang berbeda beda dan rumus yang digunakan untuk mengubah konsentrasi polutan ke nilai AQI berbeda di setiap polutannya. Setiap rentang nilai aqi digambarkan dengan warna warna tertentu sesuai dengan ketetapan (Liao, 2014).
American Environmental Protection Agency (EPA) telah mengembangkan
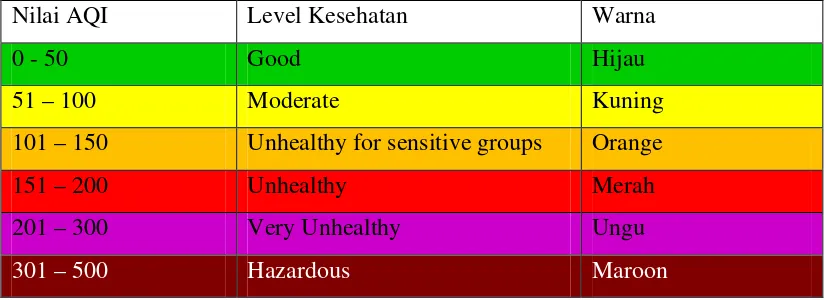
Indeks Kualitas Air yang digunakan untuk melaporkan kualitas udara. Level pencemaran menurut AQI dibagi menjadi enam kategori yang menunjukkan peningkatan bahaya dan dampaknya bagi kesehatan. Pada tabel 2.2 nilai AQI yang melebihi dari angka 300 dikategorikan sebagai kualitas udara berbahaya dan di bawah 50 kualitas udara yang baik. AQI didasarkan pada lima kriteria polutan yang diatur dalam Clean Air Act yaitu : tingkat ozon permukaan (O3), Partikel materi (PM2.5 dan
PM10), karbon monoksida (CO), sulfur dioksida (SO), dan nitrogen dioksida (NO).
Tabel 2. 2 Level Pencemaran menurut AQI
EPA telah menetapkan Standar Kualitas Udara Ambien Nasional (NAAQS) untuk masing-masing polutan ini untuk melindungi kesehatan masyarakat. Nilai AQI dari 100 umumnya sesuai dengan tingkat NAAQS untuk polutan tersebut. Clean Air
Nilai AQI Level Kesehatan Warna
0 - 50 Good Hijau
51 – 100 Moderate Kuning
101 – 150 Unhealthy for sensitive groups Orange
151 – 200 Unhealthy Merah
201 – 300 Very Unhealthy Ungu
Act membutuhkan EPA untuk meninjau Standar Kualitas Air Ambient Nasional setiap lima tahun untuk mencerminkan berkembang informasi efek kesehatan. Indeks Kualitas Udara disesuaikan secara berkala untuk mencerminkan perubahan ini. Rumus yang digunakan dalam melakukan kalkulasi nilai AQI adalah sebagai berikut :
� = �ℎ��ℎ− ����
�ℎ��ℎ− ���� (� − ����) + ���� dimana
� = ������������� U���� ,
� = Konsentrasi Polutan,
���� = ����������������≤�,
�ℎ��ℎ = ����������������≥�,
���� = �������������������������,
�ℎ��ℎ = ����������������������ℎ��ℎ,
Jika beberapa pollutan diukur pada sistem monitoring, maka nilai AQI yang paling besar atau dominan yang akan dikirimkan untuk lokasi terntentu. Data monitoring secara real time pada umumnya tersedia pada rata-rata waktu 1 jam. Namun, perhitungan AQI bagi beberapa pollutan membutuhkan nilai rata-rata dari waktu yang cukup lama. Sebagai contoh untuk melakukan perhitungan AQI ozone membutuhkan perhitungan rata-rata selama 8 jam., sementara PM2.5 membutuhkan rata-rata waktu 24 jam.
2.2 Web Scraping
Web scraping atau disebut juga dengan web harvesting atau web data extraction
adalah sebuah teknik program komputer untuk melakukan ekstraksi informasi dari sebuah halaman website. Web Scraping tidak dapat dimasukkan dalam bidang data mining karena data mining menyiratkan upaya untuk memahami pola semantik atau tren dari sejumlah besar data yang telah diperoleh. Aplikasi web scraping (juga
disebut intelligent, automated, or autonomous agents) hanya fokus pada cara memperoleh data melalui pengambilan dan ekstraksi data dengan ukuran data yang bervariasi (Josi et.al, 2014).
Data dimanipulasi dengan menggunakan query. Kegiatan untuk melakukan ekstraksi informasi terstruktur dari sebuah halaman website biasanya diimplementasikan pada program yang disebut wrapper (Arasu & Garcia-Molina, 2003). Web scraping memiliki sejumlah langkah, sebagai berikut:
1. Create Scraping Template: Pembuat program mempelajari dokumen HTML dari website yang akan diambil informasinya untuk tag HTML yang mengapit informasi yang akan diambil.
2. Explore Site Navigation: Pembuat program mempelajari teknik navigasi pada website yang akan diambil informasinya untuk ditirukan pada aplikasi web scraper yang akan dibuat.
3. Automate Navigation and Extraction: Berdasarkan informasi yang didapat pada langkat 1 dan 2 di atas, aplikasi web scraper dibuat untuk mengotomatisasi pengambilan informasi dari website yang ditentukan.
4. Extracted Data and Package History: Informasi yang didapat dari langkah 3 disimpan dalam tabel di database.
2.2.1 Struktur Semantik
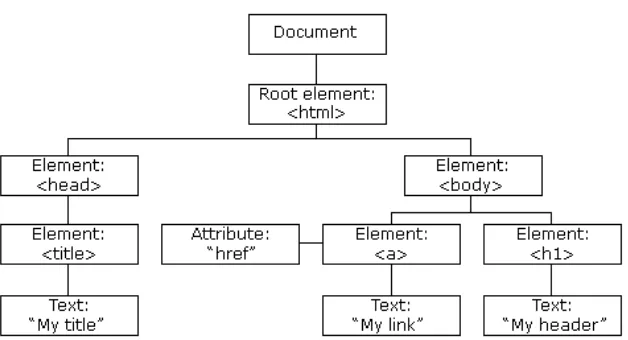
Semantic Web bertujuan untuk membangun sebuah framework yang memungkinkan data untuk dibagi dan digunakan kembali antar aplikasi, enterprise dan komunitas. Dengan menggunakan RDF (Resource Description Framework) sebagai basis model data fleksibel dan menggunakan ontologi untuk merepresentasikan data semantik. Banyak halaman website sekaran gmenggunakan model relasional dan XML tree model untuk merepresentasikan data terstruktur dan semi-terstruktur.
Gambar 2. 2 Object Tree Model (Sumber: www.w3schools.com) 2.2.2 HTML Parser
Sebuah halaman website biasanya disusun menggunakan kode-kode standar berupa tag-tag html yang memiliki karakter karakter spesial dalam penyusunan halaman website. Sebuah teknik untuk menganalisis dan membagi rangkarian string menjadi komponen-komponen dan menggambarkan aturan sintaksis disebut dengan parsing. HTML parsing dapat diartikan dengan membaca kode kode html untuk membagi karakter sintaksis yang bertujuan untuk mengambil informasi yang relevan dari sebuah halaman website.
2.2.3 Extracting and Saving Data
Untuk dapat mengetahui data apa yang akan diambil dari metode web scraping, terlebih dahulu diperlukan adanya pengenalan pola dari halaman website yang akan diambil datanya. Pengenalan pola template website dilakukan dengan memanfaatkan struktur semantik dari alaman website tersebut. Setelah diperoleh template, kemudian dilakukan ekstraksi data dengan mengubah struktur semantik menjadi objek-objek
dokumen (DOM) dan menyimpannya ke dalam struktur array.
2.3 Sistem Terdistribusi
Sistem terdistribusi adalah kumpulan dari komputer secara independen yang terhubung dalam sebuah jaringan dimana bagi user merupakan sebuah sistem yang koheren. Tujuan utama dari sebuah sistem terdistribusi adalah agar dapat dengan mudah menghubungkan user dengan sumber daya yang didistribusikan melalui network (Tanenbaum, 2003).
Sebuah program komputer yang dijalankan pada sebuah sistem terdistibusi disebut program terdistribusi. Dan distributed programming adalah proses dalam menulis program tersebut. Komputasi terdistribusi juga merujuk pada penggunaan sistem terdistribusi untuk menyelesaikan masalah komputasi. Pada komputasi terdistribusi, sebuah masalah dibagi dalam beberapa perkerjaan, dan setiap pekerjaan yang ada diselesaikan oleh satu atau lebih komputer.
Kebanyakan sistem besar masih menggunakan sistem sentral yang berjalan pada satu mainframe dengan terminal-terminal yang terhubung kepadanya. Sistem tersebut bayak kelemahannya dimana terminal-terminal hanya sedikit kemampuan pemrosesannya dan semua tergantung pada komputer sentral.
Sampai saai ini ada tipe sistem yang utama yaitu:
• Sistem Personal yang tidak terditribusi dan dirancang untuk satu workstation
saja.
• Sistem Embedded yang bejalan pada satu processor atau pada kelompok prosessor yang terintegrasi.
• Sistem Terdistribusi dimana perangkat lunak sistem berjalan pada kelompok
processor yang bekerja sama dan terintegrasi secara longgar, dengan dihubungkan oleh jaringan. Contohnya sistem ATM bank, sistem groupware, dll
Menurut (Coulouris, et al., 2012) mengidentifikasi enam karakteristik yang penting untuk sistem terdistribusi yaitu:
• Pemakain bersama sumber daya
• Keterbukaan. Keterbukaan sistem adalah terbuka untuk banyak sistem
• Konkurensi. Sitem terdistribusi memungkinkan beberapa proses dapat
beroperasi pada saat yang sama pada berbagai computer di jaringan. Proses ini dapat (tapi tidak perlu) berkomunikasi satu dengan lainnya pada saat operasi normalnya.
• Skalabilitas. Sitem terdistribusi dapat diskala dengan meng-upgrade atau
menambahkan sumber daya baru untuk memenuhi kebutuhan sistem.
• Toleransi kesalahan. Sitem terdistribusi bersifat toleran terhadap beberapa
kegagalan perangkat keras dan lunak dan layanan terdegradasi dapat diberikan ketika terjadi kegagalan.
• Transparansi. Sitem terdistribusi adalah bersifat terbuka bagi pengguna.
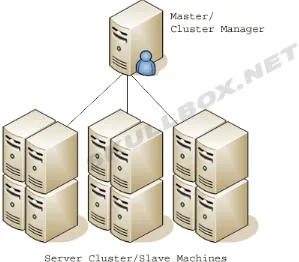
Gambar 2. 3 Arsitektur Sistem Terdistribusi (Sumber : skullbox.net)
2.3.1 Raspberry Pi
ATM. Raspberry pi banyak digunakan sebagai alat untuk menerapkan konsep Internet of Things (IoT).
Raspberry pi menjalankan sistem operasi berbasis linux sebagai sistem operasi utamanya. Distro yang digunakan berasal dari turunan debian yang dimodifikasi untuk spesifikasi raspberry pi yang dinamakan Raspbian. Pada saat sekarang, raspberry pi telah mencapai generasi ketiga dengan penambahan berbagai module nirkabel pada board-nya.
Gambar 2. 4 Raspbery Pi 2 (Sumber : raspberrypi.org ) 2.3.2 Message Passing
Message Passing menyediakan mekanisme yang mengizinkan proses saling
berkomukasi dan sinkronisasi tanpa membagi address space di dalam memory. Hal ini banyak digunakan pada komputer yang saling terkoneksi dalam sebuah jaringan. Dalam mekanisma message passing, dikenal 2 model operasi yaitu : send() dan receive(). (Silberchatz, 2013)
Untuk dapat saling berkomunikasi, setiap proses harus memenuhi beberapa persyaratan yaitu :
• Naming (Penamaan)
Setiap proses yang akan berkomunikasi harus memiliki pengenal antara satu
dan lainnya disebut dengan proses ID (PID). • Sychronization
Setiap proses yang mengirimkan pesan satu dengan yang lainnya haruslah saling sinkron. Mekanisme sinkronisasi komunikasi antar proses dapat bersifat synchronous dan asynchronous.
• Buffer
Komunikasi secara langsung maupun tidak langsung biasanya menyisakan pesan yang terdapat pada antrian sementara di dalam memory.
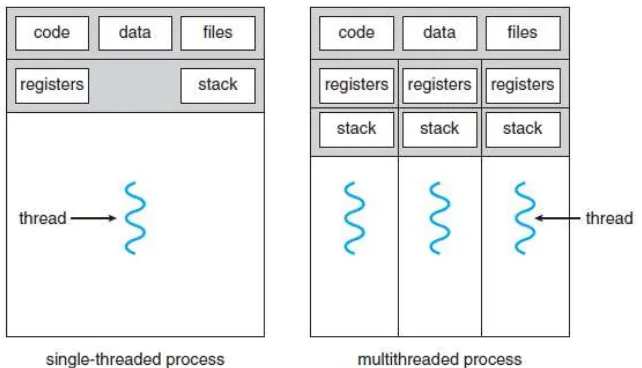
2.3.3 Multithreading
Gambar 2. 5 Single Threaded dan Multi Threaded Process (Sumber : Silberchatz, 2013)
Thread didalam sistem operasi dapat diimplementasikan dengan menggunakan library tambahan dengan sebuah API untuk membuat dan mengelola thread. Umumnya terdapat tiga library utama yang digunakan pada masa sekaran ini, yaitu : POSIX Pthreads,Windows, and Java. Seiring dengan berkembangnya bahasa pemrograman, python code mempunyai library sendiri untuk mengelola dan membuat
thread.
2.4 Naïve Bayes Classifier
Naïve Bayes merupakan sebuah teknik klasifikasi berdasarkan Teorema Bayes dengan asumsi bahwa setiap objek untuk melakukan prediksi tidak terikat atau bebas. Secara singkat, Naive Bayes classifier mengasumsikan bahwa keberadaan fitur tertentu pada sebuah kelas tidak berhubungan dengan fitur yang lain. Sebagai contoh, sebuah buah dikategorikan sebagai apel jika berwarna merah, berbentuk bundar dan mimiliki diameter 3 inchi. Bahkan jika fitur tersebut bergantung satu dengan yang lainnya, setiap properti bersifat bebas untuk saling berkontribusi dan menyatakan bahwa buah tersebut adalah apel, oleh karena itu algoritma ini disebut dengan Naïve (Koduvely, 2015).
mengaplikasikan aturan Bayes dapat kita lihat bahwa P(Y = yi|X) dapat digambarkan
dengan rumus :
�(�= ��|�= ��) = �(�= �� |�= ��)�(�= ��) ∑ ���� = ����=����(� =��)
2.5 Penelitian Terdahulu
Beberapa penelitian terkait Web Scraping dan klasifikasi telah banyak dilakukan oleh beberapa peneliti, diantara peneliti tersebut penulis menggunakan beberapa penelitian sebagai sumber referensi pada penelitian ini. Pereira pada penelitiannya menggunakan teknik web scraping untuk melakukan ekstraksi data pada media sosial.
Pada penelitian tersebut dijelaskan melalui web scraping, data yang tidak terstruktur dikonversikan menjadi data yang lebih terstruktur dan dapat disimpan serta diverifikasi pada bank data yang tersentralisasi. Tujuannya untuk mengumpulkan, menyimpan dan menganalisis data dari social media dikarenakan social media merupakan tempat data yang dibagikan secara bebas. Dengan demikian ekstraksi data web merupakan sebuah proses untuk mengubah konten yang bermanfaat pada website menjadi aset bisnis yang sangat berharga (Pereira, 2015). Sementara pada penelitian Abdillah Josi, teknik web scraping diimplementasikan pada mesin pencari artikel ilmiah seperti portal garuda, Indonesian scientific journal databases (ISJD), dan
google scholar (Josi, 2014).
Untuk data yang telah dikumpulkan menggunakan teknik web scraping, penelitian menggunakan hybrid model proses dengan mengaplikasikan Bayessian Networks untuk menganalisis pengetahuan sehingga menghasilkan model yang dapat memberikan peramalan secara multi-class. (Welter, 2013). Berdasarkan hasil tersebut, algoritma naïve bayes dapat memberikan bentuk peramalan yang efektif dengan dikarenakan naïve bayes menggunakan teorema Bayes untuk mendapatkan tabel ramalan pada model klasifikasinya. Dengan menggabungkan literatur penelitian yang dilakukan oleh Corani, kualitas udara dapat diklasifikasikan dengan membaginya dalam beberapa class (Corani, 2016).
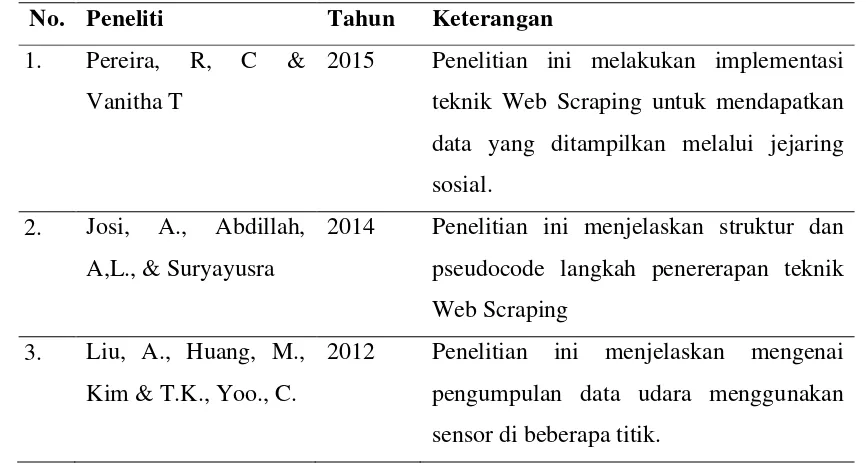
yang telah disebutkan mengenai data grabing dan klasifikasi naïve bayes yang dapat dilihat pada tabel 2.3.
Tabel 2. 3 Penelitian Terdahulu No. Peneliti Tahun Keterangan 1. Pereira, R, C &
Vanitha T
2015 Penelitian ini melakukan implementasi teknik Web Scraping untuk mendapatkan data yang ditampilkan melalui jejaring sosial.
2. Josi, A., Abdillah, A,L., & Suryayusra
2014 Penelitian ini menjelaskan struktur dan pseudocode langkah penererapan teknik Web Scraping
3. Liu, A., Huang, M., Kim & T.K., Yoo., C.
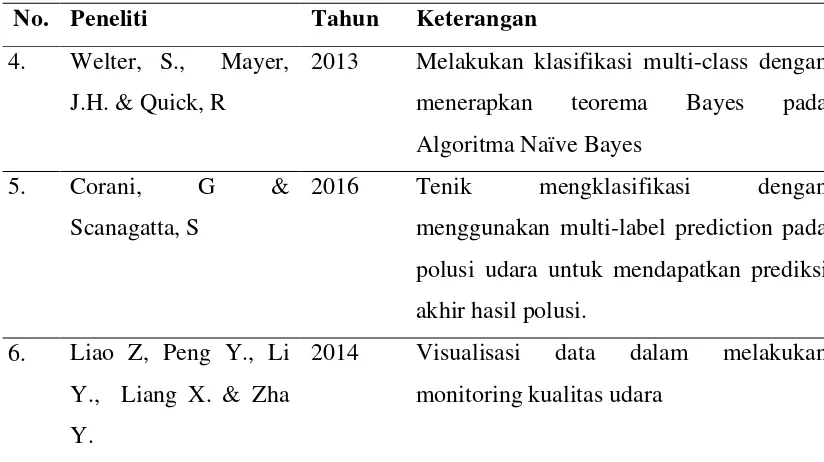
Tabel 2.3 Penelitian Terdahulu (Lanjutan)
No. Peneliti Tahun Keterangan 4. Welter, S., Mayer,
J.H. & Quick, R
2013 Melakukan klasifikasi multi-class dengan menerapkan teorema Bayes pada Algoritma Naïve Bayes
5. Corani, G &
Scanagatta, S
2016 Tenik mengklasifikasi dengan
menggunakan multi-label prediction pada polusi udara untuk mendapatkan prediksi akhir hasil polusi.
6. Liao Z, Peng Y., Li Y., Liang X. & Zha Y.