1 7 Februari, 2016
ANALISIS PEKERJAAN UTAMA BIDANG PERTANIAN PADI DAN
PALAWIJA DALAM MENGHADAPI MEA (MASYARAKAT EKONOMI
ASEAN) DI JAWA TIMUR TAHUN 2013
Rezkya Putri Septiani
Email: [email protected]
ABSTRAK
1. PENDAHULUAN
2. REGRESI LOGISTIK
Regresi logistik akan membentuk pendekatan maximum likelihood yang memaksimalkan probabiliy pengklasifikasian objek yang sedang diamati menjadi kategori yang sesuai selanjutnya mengubahnya menjadi koefisien regresi sederhana. Pada regresi linier, variabel dependen tidak dapat bersifat dikotomi dan bernilai numerik, pada regresi logistik ini, variabel dependen dapat bersifat dikotomi misalnya benar atau salah. Regresi logistik tidak seperti regresi linier biasa karena tidak mengasumsikan bahwa hubungan antara variabel dependen dan independen bersifat linier. Regresi logistik akan membentuk regresi non linier dimana model yang cocok akan mengikuti kurva linier.
Regresi logistik akan membentuk (ln P/(1-P)) berupa kombinasi linier dari variabel independen. Adapun persamaan regresi logistik ialah :
Ln[odds (T/X1, X2, ...., Xk)]=β0+β1X1+β2X2+... +βkXk
Asumsi-asumsi pada regresi logistik:
a. Variabel independen tidak harus memiliki keragaman yang sama antar kelompok variabel.
b. Tidak mengasumsikan hubungan linier antar variabel dependen dan independent c. Variabel dependen harus bersifat dikotomi (2 variabel).
d. Kategori dalam variabel independent harus terpisah satu sama lain atau bersifat eksklusif .
e. Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan hingga 50 sampel data untuk sebuah variabel prediktor (bebas).
Kecocokan Model (model fit) dan Fungsi Likelihood
Pada regresi logistik dengan nilai Y antara 0 dan 1, akan menyebabkan pendekatan linier tidak bisa digunakan sehingga pendekatan metode maximum likelihood digunakan untuk menentukan model yang tepat untuk suatu persamaan regresi.
Hipotesis dalam regresi logistik antara lain:
h0 = persamaan regresi bernilai 0 [logit(p) = 0].
h1= persamaan regresi berbeda nyata dari 0 [logit(p) ≠ 0].
Uji Wald
Uji Wald (uji parsial) yang digunakan untuk menguji pengaruh variabel independen terhadap peubah respon. Adapun hipotesis untuk uji wald ialah:
H0 : variabel independen tidak berpengaruh terhadap variabel dependen
H1 : variabel independen berpengaruh terhadap variabel dependen
Tolak H0 jika p-value < alpha (0,05)
Hosmer-Lemeshow Test
Pengujian kelayakan model dapat dilakukan dengan melihat nilai statistik Goodness of fit.Pengujian ini untuk melihat kecocokan atau kelayakan dari suatu model. Hipotesis untuk tes ini ialah :
H0 : model regresi yang dibentuk layak
H1 : model regresi yang dibentuk tidak layak
Pengujian Simultan (Omnibus Test of Model Coefficient)
Pengujian ini dilakukan untuk menguji apakah variabel-variabel independen yang terdiri dari kompetensi aparatur dan kepemimpinan secara simultan berpengaruh terhadap variabel dependen yaitu ketepatan waktu penyampaian pelaporan keuangan. Pengujian hipotesis dilakukan dengan cara membandingkan antara nilai probabilitas (sig) dengan
tingkat signifikansi (α). Untuk menentukan penerimaan atau penolakan H0 didasarkan
pada tingkat signifikansi (α) 5% dengan kriteria :
1. H0 tidak akan ditolak apabila statistik Wald hitung < Chi- square tabel, dan nilai
probabilitas (sig) > tingkat signifikansi (α). Hal ini berarti H alternatif ditolak
atau hipotesis yang menyatakan veriabel bebas berpengaruh terhadap variabel terikat ditolak.
2. H0 ditolak apabila statistik Wald hitung > Chi-square tabel, dan nilai
probabilitas (sig) < tingkat signifikansi (α). Hal ini berarti H alternatif diterima
atau hipotesis yang menyatakan variabel bebas berpengaruh terhadap variabel terikat diterima.
Konsep Log Odds, Odds Ratio
3. METODE DAN TAHAPAN PENGOLAHAN DATA
Pada analisis regresi ini, akan dipilih model terbaik yang dipilih menggunakan regresi logistik untuk menganalisis bidang pekerjaan di Jawa Timur dengan pemilihan variabel berdasarkan kuesioner susenas Jawa Timur tahun 2013 sebagai berikut:
Variabel dependen : lapangan usaha/bidang pekerjaan dari tempat pekerjaan selama seminggu terakhir dengan memberikan kode 1 untuk bidang pekerjaan pertanian padi dan palawija dan kode 0 untuk bidang pekerjaan lainnya.
Variabel independen :
a. Jenjang pendidikan tertinggi yang pernah diduduki dengan membagi jenjang pendidikan menjadi dua kelompok yaitu rendah dan tinggi. Jenjang pendidikan rendah yang memiliki kode 1 ialah untuk jenjang pendidikan SD/SDLB, M.ibtidaiyah, paket A, SMP/SMPLB, M.Tsanawiyah, paket B, SMA/SMLB, M.Aliyah, SMK, dan paket C, sedangkan untuk kelompok jenjang pendidikan tinggi yang memiliki kode 0 ialah D1/D2, D3/sarjana muda, D4/S1, S2/S3. Pengambilan dan pengelompokkan variabel ini berdasarkan pertimbangan bahwa masih banyaknya para petani padi dan palawija yang berpendidikan rendah.
b. Status/kedudukan dalam pekerjaan utama selama seminggu terakhir dengan memberikan kode 1 untuk pekerja keluarga atau tidak dibayar dan kode 0 untuk lainnya. Pengambilan kode 1 untuk pekerja keluarga dengan pertimbangan bahwa masih banyak nya pekerja keluarga di bidang pertanian padi dan palawija.
Untuk memilih model yang terbaik yang digunakan dengan cara memasukkan satu per satu variabel independen ke dalam model regresi logistik dan dilihat nilai signifikansi tiap kemungkinan model dan seberapa besar variabel independen dapat menjelaskan variabel dependen. Pada regresi linier sederhana, untuk melihat kemampuan variabel independen dalam menjelaskan variabel dependen dengan menggunakan nilai R2 sedangkan dalam regresi linier logistik dapat dilihat menggunakan nilai cox & Sneel R dan Nagelkerke R Square. Semakin besar nilai kedua nya dan mendekati 100% maka semakin bagus model tersebut.
Selain itu akan digunakan Hosmer and Lemeshow Test yang merupakan uji Goodness Of Fit test (GoF) untuk menentukan apakah model yang telah dibentuk tersebut ialah model yang sudah tepat atau tidak. Suatu model dikatakan tepat apabila tidak ada perbedaan signifikan antara model dengan nilai observasinya. Omnibus test juga digunakan agar dapat dilihat pengaruh nyata dari penambahan variabel independen terhadap model. Setelah seluruh test telah dilakukan, maka akan dilakukan pendugaan parameter model regresi logistik yang dipilih.
4. ANALISIS DATA
Dari variabel-variabel yang telah ditentukan sebelumnya akan ditentukan hubungan antara variabel dependen dan independen dengan total sampel sebanyak 46923 penduduk. Analisis data menggunakan Overall Percentage, Omnibus Test, Wald Test, Hosmer And Lemeshow Test, dan Pseudo R2.
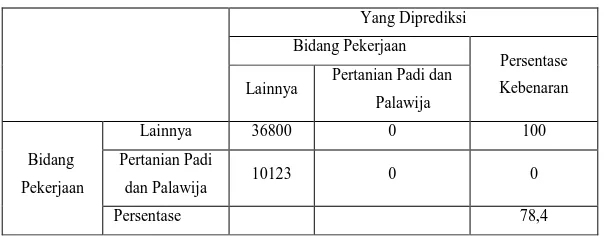
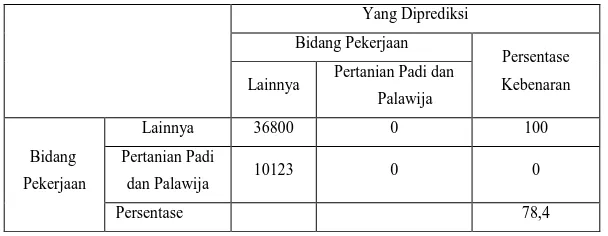
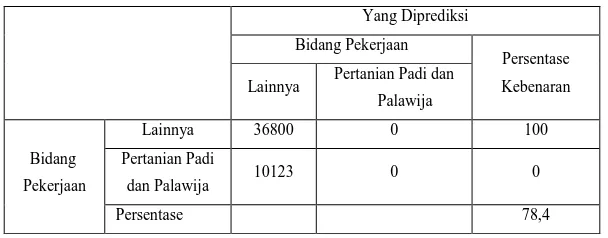
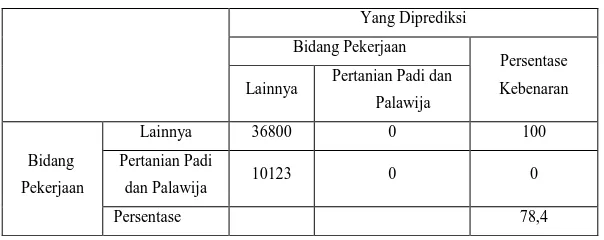
Kondisi Saat Belum Ada Variabel Independen yang Dimasukkan dalam Model
(Model Pertama)
Pada tabel diatas, nilai persentase sebelum variabel independen dimasukkan ke dalam model sebesar 78,4 % yang berarti ketepatan model penelitian ini sebesar 78,4 %.
Tabel 4.2 Variabel dalam Persamaan
B S.E Wald df Sig. Exp(B)
konstanta -1,291 0,011 13225,548 1 0 0,275
Kondisi Saat Variabel Independen Pendidikan Tertinggi Dimasukkan dalam Model
Sama seperti pada saat belum adanya variabel independen yang dimasukkan dalam model, nilai overall persentase pada keadaan yang sekarang juga menghasilkan nilai sebsar 78,4 % yang menggambarkan besarnya ketepatan model penelitian.
Tabel 4.4 Omnibus Test of Model Coeffients
Chi-square df Sig.
Step 1668,17 1 0
Block 1668,17 1 0
Model 1668,17 1 0
Tabel 4.5 Model Summary
Step -2 Log likelihood Cox&Snell R Square
Nagelkerle R Square
1 47268,622 a 0,035 0,054
Pada tabel 4.5 diketahui nilai pseudo R2 sebesar 0,035 dan 0,054 yang memberikan gambaran bagaimana variabel pendidikan tertinggi dapat menjelaskan variabel bidang pekerjaan pertanian padi dan palawija.
Tabel 4.6 Hosmer and Lemeshow Test
Step Chi-square df Sign
1 0 0 .
Untuk menguji apakah model tersebut cocok maka digunakan Hosmer and Lemeshow Test yang hasilnya dapat dilihat pada tabel 4.6, nilai chi-squarenya bernilai 0 dengan signifikansi yang tidak ada. Dari hasil tersebut maka keputusan kecocokan model tersebut tidak dapat dilakukan. Sehingga model ini disarankan untuk tidak digunakan.
Tabel 4.8 Variabel dalam Persamaan
B S.E Wald df Sig. Exp(B)
Step 1a Pendidikan
Tertinggi 2,558 0,096 711,831 1 0 12,913
Konstanta -3,724 0,095 1530,25 1 0 0,024
Kondisi Saat Variabel Independen Pendidikan Tertinggi dan Status Kedudukan
Berdasarkan hasil nilai pada tabel 4.9, nilai persentase pada saat dimasukkannya variabel independen status kedudukan dalam model ialah sebsar 78,4 % yang menggambarkan persentase kasus yang dapat diprediksi oleh model.
Tabel 4.10 Omnibus Test of Model Coeffients
Tabel 4.11 Model Summary
Step -2 Log likelihood Cox&Snel R Square
Tabel 4.12 Hosmer and Lemeshow Test
Step Chi-square df Sign
1 0,858 1 0,354
Hosmer and Lemeshow Test ini juga digunakan sebagai alat untuk menentukan kelayakan model, berdasarkan nilai pada tabel 4.12 dapat dilihat bahwa nilai chi-square yang dihasilkan sebesar 0,858 dengan signifikansi sebesar 0,354. Nilai dari signifikansi yang didapat lebih dari 0,05, sehingga hipotesis Ho untuk tes diatas diterima dan memberikan kesimpulan bahwa model yang dibentuk sudah tepat karena tidak ada perbedaan signifikan antara model dengan nilai observasinya.
Tabel 4.13 Variabel dalam Persamaan
Kondisi Saat Variabel Independen Pendidikan Tertinggi, Status Kedudukan, Jenis
Tabel 4.14 memberikan gambaran bahwa model yang dikembangkan memiliki persentase akurasi sebesar 78,4 %. Nilai persentase tersebut memperlihatkan secara keseluruhan persentase kasus yang mampu diprediksi secara akurat oleh model.
Tabel 4.15 Omnibus Test of Model Coeffients
Chi-square df Sig.
Step 173,586 1 0
Block 173,586 1 0
Model 2887,641 3 0
Tabel 4.16 Model Summary
Step -2 Log likelihood Cox&Snel R Square
Nagelkerle R Square
1 46049,151a 0,060 0,092
Pada model ini juga memiliki nilai Cox&Snel R2 dan Nagelkerle R2 yang lebih besar dibandingkan dengan model yang lainnya, interpretasi pseudo R2 ini tidak seperti interpretasi pada regresi linier walaupun semakin tinggi pseudo R2 model semakin baik, pseudo R2 bukan satu-satunya alat ukur kelayakan model.
Tabel 4.17 Hosmer and Lemeshow Test
Step Chi-square df Sign
1 105, 192 3 0
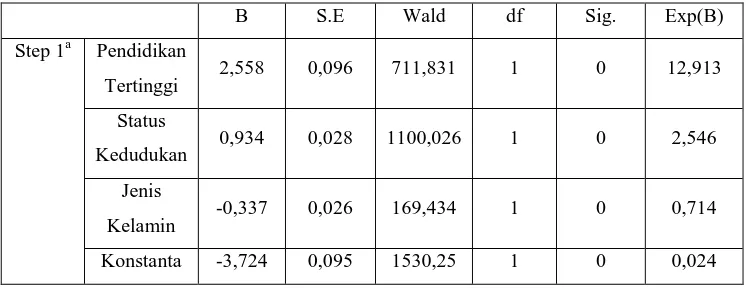
Tabel 4.18 Variabel dalam Persamaan
B S.E Wald df Sig. Exp(B)
Step 1a Pendidikan
Tertinggi 2,558 0,096 711,831 1 0 12,913
Status
Kedudukan 0,934 0,028 1100,026 1 0 2,546
Jenis
Kelamin -0,337 0,026 169,434 1 0 0,714
Konstanta -3,724 0,095 1530,25 1 0 0,024
Dengan pengaruh penambahan jenis kelamin pada model memberikan nilai parameter B sebesar -3,724 dengan nilai signifikansi kurang dari 0,05 yang berarti variabel independen tersebut signifikan pada model yang dibentuk.
Penetapan Model yang digunakan
Berdasarkan keempat kondisi diatas maka dapat diambil keputusan model yang digunakan ialah model ketiga yaitu model yang menggunakan variabel independen nya berupa pendidikan tertinggi dan status kedudukan dalam pekerjaan utama. Hal ini diputuskan dengan beberapa pertimbangan yaitu:
a. Model ketiga memiliki nilai persentase secara keseluruhan untuk kasus yang mampu diprediksi secara akurat oleh model yaitu sebesar 78,4% persen.
b. Memiliki Omnibus Tes dengan signifikansi model yang baik sehingga model ketiga ini dinyatakan model yang fit dan memiliki penambahan variabel independen yang dapat memberikan pengaruh yang sangat nyata terhadap modelnya.
c. Nilai pseudo R2 yang dilihat dengan menggunakan nilai Cox&Snel R2 dan Nagelkerle R2 pada model ini memang sedikit lebih rendah apabila dibandingkan dengan model keempat. Namun pertimbangan lainnya ialah dengan melihat hasil dari tes Hosmer and Lemeshow. Pada tes tersebut mengindikasikan bahwa model ketiga dapat diterima sedangkan model keempat tidak dapat diterima. Oleh karena itu, penggunaan model ketiga lebih memunginkan untuk dilakukan. Selain itu, Menurut Widiarta dan Wardana (2011:140), nilai Cox&Snel R2 dan Nagelkerle R2 interpretasinya tidak seperti pada regresi linier pada koefisien determinasi walaupun semakin tinggi nilai pseudo R2 berarti model tersebut semakin baik. Namun para ekonometris mengatakan di dalam regresi logistik, nilai Cox&Snel R2 dan Nagelkerle R2 bukan satu-satunya alat ukur yang digunakan untuk kelayakan model bahkan secara teoritis dan empiris nilai pseudo R2 mempunyai batas atas yang kurang dari satu, sehingga sering menganggap model tidak layak dikembangkan.
Dari model ketiga, persamaan regresi logistiknya ialah sebagai berikut:
Log odds(bidang pekerjaan) = B0 + B1*pendidikan tertinggi + B2*status kedudukan
Interpretasi dari Persamaan Model Regresi Logistik
Dengan mengacu pada tabel 4.13, untuk setiap kenaikan nilai pada variabel pendidikan tertinggi(kode 1 untuk pendidikan tertinggi yang rendah) akan meningkatkan log bidang pekerjaan sebesar 2,463. Tingkat pendidikan memiliki hubungan positif dengan bidang pekerjaan yang dilihat dari nilai log bidang pekerjaan yang positif. Besarnya pengaruh ditunjukkan pada nilai EXP(B) yang sering disebut dengan nilai odds ratio. Variabel pendidikan tertinggi ini memiliki nilai odds ratio sebesar 11,743 yang mengindikasikan bahwa penduduk yang memiliki pendidikan tertinggi yang rendah beresiko 11,743 kali lipat untuk memiliki jenis pekerjaan bidang pertanian padi dan palawija dibandingkan dengan penduduk yang memiliki pendidikan yang tinggi.
Selain itu, setiap kenaikan pada variabel status kedudukan (kode 1 untuk status kedudukan di pekerjaan utama ialah pekerja keluarga atau tidak dibayar) akan meningkatkan nilai log bidang pekerjaan sebesar 0,934. Status kedudukan memiliki hubungan yang positif terhadap bidang pekerjaan. Variabel ini memiliki nilai odds ratio sebesar 2,546 maka orang yang memiliki status kedudukan pekerja keluarga/tidak dibayar cenderung 2,546 kali bekerja di bidang pekerjaan pertanian padi dan palawija. Jika pendidikan tertinggi dan status kedudukan bernilai 1(berdasarkan pemberian kode di pembahasan sebelumnya) maka persamaan regresi logistik menjadi :
Log odds(bidang pekerjaan) = -3,804 + 2,463 + 0,934 odds(bidang pekerjaan) = e-3,804 + 2,463 + 0,934
probabilitas = e-3,804 + 2,463 + 0,934 probabilitas = 0,6656
5. KESIMPULAN DAN SARAN
Jawa Timur memiliki PDRB tertinggi ketiga untuk lapangan usaha pertanian pada tahun 2013. Indonesia yang memiliki sumberdaya alam yang banyak harus dapat dimanfaatkan agar penduduk Indonesia dapat bersaing dengan negara lain yang didukung dengan adanya MEA (Masyarakat Ekonomi ASEAN). Berdasarkan hasil analisis saya, bidang pekerjaan pertanian padi dan palawija di Jawa Timur belum memiliki sumber daya manusia yang mempunyai tingkat pendidikan dan status kedudukan pekerjaan yang tinggi. Hal ini dibuktikan dengan kecenderungan penduduk yang bekerja di bidang pertanian ialah penduduk yang tingkat pendidikannya rendah (di bawah SMA sederajat) dengan status kedudukan mereka dalam bidang pertanian tersebut ialah pekerja keluarga/tidak digaji.
DAFTAR PUSTAKA
1. Widiarta, I.B.P. dan Wardana, I.G.N. (2011) .“Analisis Pemilihan Moda dengan
Regresi Logistik pada Rencana Koridor Trayek Trans Sarbagita”. Jurnal Ilmiah
Teknik Sipil. 15(2).
2. Netter, John, William Wasserman, and Michael Kutner. 1989. Applied Linier Statistical Models. Richard D Irwin, Inc, Illinois.Boston.
3. Al-Ghamdi, A.S. 2002. Using Logistic Regression To Estimate The Influence of Accident Factors on Accident Severity, Accident Analysis and Prevention 34, pp.729-741.
4. Badan Pusat Statistik Provinsi Jawa Timur. 2010. Produk Domestik Regional Bruto Provinsi Jawa Timur Menurut Lapangan Usaha. Jawa Timur.
5. Ghozali, Imam. 2011. Aplikasi Analisis Multivariate dengan Program IBM SPSS 19 (edisi kelima ).Semarang : Universitas Diponegoro.