154 http://research. pps. dinus. ac. id
MODEL PREDIKSI POLA LOYALITAS PELANGGAN
TELEKOMUNIKASI MENGGUNAKAN NAIVE BAYES DENGAN
OPTIMASI PARTICLE SWARM OPTIMIZATION
Stefanus Santosa1 dan Roy Yuliantara2
1Politeknik Negeri Semarang
2Pascasarjana Teknik Informatika Universitas Dian Nuswantoro Abstrak
Tantangan yang dihadapi dalam penerapan CRM di perusahaan operator telekomunikasi seluler adalah usaha menurunkan jumlah pelanggan yang berhenti menggunakan layanan perusahaan dan kemungkinan pindah ke perusahaan kompetitor (Churn). Penelitian untuk mencari solusi atas masalah tersebut dapat dilakukan melalui data mining, Dari beberapa penelitian pada konstalasi penelitian tentang Model Prediksi Loyalitas Pelanggan Telekomunikasi menunjukkan hasil yang baik. State of The Art dari konstalasi ini adalah ditemukannya Model Prediksi Loyalitas Pelanggan Telekomunikasi menggunakan algoritma Backpropagation dengan seleksi fitur PSO dengan nilai akurasi sebesar 85,48%. Hasil akurasi yang didapatkan dirasa kurang maksimal, maka penelitian ini mencoba memperbaiki akurasi model prediksi dengan menggunakan algoritma Naïve Bayes berbasis Particle Swarm Optimization. Model Prediksi Loyalitas Pelanggan Telekomunikasi yang diusulkan dalam penelitian ini menunjukkan hasil yang baik. Diperoleh nilai akurasi yang lebih tinggi daripada penelitian sebelumnya, yakni nilai accuracy adalah 98,54 % dan nilai AUC adalah 0,99.
Keywords: Data Mining, Prediksi, Custommer Churn, Naïve Bayes, Particle Swarm Optimization 1. PENDAHULUAN
Salah satu tantangan yang dihadapi dalam penerapan CRM (Customer Relantionship Management) di perusahaan operator telekomunikasi seluler adalah usaha menurunkan jumlah pelanggan yang berhenti menggunakan layanan perusahaan dan pindah ke perusahaan kompetitor (Churn). Divisi CRM perusahaan perlu mengetahui dan memahami pola perilaku Churn pelanggannya, serta memprediksi apakah pelanggan- pelanggan aktif yang dimiliki saat ini akan Churn di masa depan. Perhatian utama dalam CRM di sebuah perusahaan telekomunikasi adalah kemudahan pelanggan yang dapat berpindah ke kompetitor perusahaan tersebut, sebuah proses perpindahan pelanggan yang disebut "churn" [1].
Telekomumikasi merupakan salah satu industri, pelanggan sangat membutuhkan perhatian khusus karena sangat berpengaruh dalam mempertahankan kestabilan pendapatan, maka dari itu manajemen di sebuah perusahaan telekomunikasi menginginkan model prediksi untuk memprediksi pelanggan yang berpotensi hilang [2].
Dalam beberapa tahun terakhir ini telah terjadi banyak perubahan di industri telekomunikasi seperti adanya pasar bebas yang membuat persaingan yang sangat ketat. Para penyedia layanan telekomunikasi telah mengeluarkan layanan serta produk baru yang menyebabkan banyaknya customer telekomunikasi yang tidak loyal sehingga membuat penyedia layanan telekomunikasi merugi
Dengan begitu banyak kompetisi, suatu perusahaan harus fokus menjaga pelanggan yang sudah ada dengan memenuhi layanan yang dibutuhkan, karena biaya menarik pelanggan baru, biasanya lebih besar daripada biaya untuk mempertahankan pelanggan saat ini [3]. Jika suatu perusahaan dapat memprediksi perilaku pelanggan sebelum menutup akun atau berhenti, perusahaan bisa melakukan cara untuk mempertahankan pelanggan tersebut [4]. Cara lain yang bisa diterapkan adalah dengan melakukan prediksi pelanggan menggunakan teknik data mining. Data mining merupakan salah satu cara yang digunakan untuk memprediksi dan mendeteksi suatu kasus, termasuk prediksi churn customer, insolvency (kepailitan) prediction, fraud (penipuan) detection [1].
http://research. pps. dinus. ac. id , 155 Algoritma data mining yang dapat digunakan untuk membantu dalam pemilihan variabel dan membangun model untuk memprediksi pelanggan yang hilang, misalnya Algoritma Genetika, Linear Regresi, ANNs, Decision Tree, Markov Model, Analisis Cluster, Naïve Bayes, dll. [5].
Pada penelitian sebelumnya dilakukan prediksi pelanggan telekomunikasi yang tidak loyal dengan mengunakan algoritma Backpropagation. Model yang dihasilkan diuji untuk mendapatkan nilai akurasi dan AUC dari setiap algoritma sehingga didapat pengujian dengan menggunakan Backpropagation nilai akurasi yang dihasilkan adalah 85.48 % dan nilai AUC adalah 0.531. Sedangkan pengujian dengan mengunakan algoritma Backpropagation berbasis Particle Swarm Optimization dilakukan seleksi atribut dan penyesuaian pada parameter didapatkan nilai akurasi 86.05% dan nilai AUC adalah 0.637. Maka dapat disimpulkan pengujian data pelanggan yang tidak loyal pada perusahaan telekomunikasi menggunakan algoritma Backpropagation dan penerapan Particle Swarm Optimization dalam pemilihan atribut tersebut menghasilkan hasil yang lebih akurat dalam prediksi loyalitas pelanggan pada perusahaan telekomunikasi dibandingkan dengan algoritma Backpropagation saja, hal itu ditandai dengan peningkatan nilai akurasi sebesar 0.57 % dan nilai AUC sebesar 0.106 [6].
Verbeke et al [7], melakukan penelitian tentang prediksi pelanggan yang tidak loyal pada sektor telekomunikasi dengan menghitung keuntungan maksimum yang dapat dihasilkan, menggunakan 21 algoritma klasifikasi yang diterapkan pada 11 dataset dari operator telekomunikasi di seluruh dunia. Percobaan yang dilakukan digunakan untuk mengevaluasi dampak dari pemilihan input, oversampling, dan teknik klasifikasi terhadap kinerja model prediksi loyalitas pelanggan. Penelitian ini menganjurkan bahwa keuntungan maksimum harus digunakan untuk mengavaluasi model prediksi pelanggan yang hilang. Pada penelitian ini algoritma yang menunjukkan kinerja yang terbaik secara keseluruhan adalah Alternating Decision Tree, mesikupun sejumlah algoritma lainnya tidak signifikan.
Idris et al [2], melakukan penelitian dibidang telekomunikasi untuk menghadapi persaingan sengit dalam mempertahankan loyalitas pelanggan, dan karena itu diperlukan model prediksi yang efisien untuk memantau pelanggan yang tidak loyal. Ukuran besar, berdimensi tinggi dan sifat seimbang dataset telekomunikasi merupakan rintangan utama dalam mencapai kinerja yang diinginkan untuk prediksi churn. Dalam penelitian ini, membahas tentang PSO berbasis metode undersampling untuk menangani ketidakseimbangan distribusi data yang bekerjasama dengan teknik pengurangan fitur yang berbeda seperti Principle Component Analysis (PCA), Rasio Fisher’s, Fscore dan Minimum Redundancy and Maximum Relevance (mRMR). Sedangkan Random Forest (RF) dan pengklasifikasi K Nearest Neighbour (KNN) digunakan untuk mengevaluasi kinerja sampel optimal dan kurangnya fitur pada dataset. Kinerja prediksi dievaluasi dengan menggunakan sensitivitas, spesifisitas dan Area under the curve (AUC) berbasis measures. Akhirnya, melalui simulasi diamati bahwa pendekatan yang diusulkan dengan menggunakan PSO, mRMR, dan RF disebut sebagai Chr-PmRF, dapat memprediksi Churners dengan cukup baik dan dapat bermanfaat bagi industri telekomunikasi yang sangat kompetitif.
B.Q. Huang, et.al [5] Penelitian ini tentang prediksi pengguna jasa telekomunikasi yang hilang menggunakan algoritma ANN, Support Vector Machine dan Decision Tree. Dataset yang digunakan 47.391 pengguna dipilih secara acak dari beberapa kantor telekomunikasi di Ireland. Di dapatkan 9999 churners dan 18.196 non churners, total keseluruhan pelanggan di training dataset sebesar 28.195. Jumlah pelanggan yang didapatkan di testing data sebesar 19.196, 1000 Churners dan 18.196 non Churners. Tingkat akurasi yang didapatkan 83.23%, berarti algoritma yang digunakan lebih efisien daripada yang sudah ada. Pemodelan yang lebih efisien tergantung pada kriteria evaluasi yang dipilih tetapi teknik pemodelan SVM tidak cocok untuk aplikasi yang digunakan.
2. LANDASAN TEORI 2.1. Naïve Bayes (NB)
Algoritma Naïve Bayes menghasilkan model probabilistik dari data yang diamati. Meskipun sederhana, Naïve Bayes telah diverifikasi untuk menjadi kompetitor dengan algoritma yang lebih kompleks seperti ANN atau Decision Tree dalam beberapa domain [8].
156 http://research. pps. dinus. ac. id Hal ini berdasarkan pada aturan kondisi probabilitas Bayes. Dengan menganalisis kontribusi masing-masing atribut independen, kondisi probabilitas ditentukan. Klasifikasi dibuat dengan menggabungkan dampak atribut yang berbeda terhadap prediksi yang akan dibuat [9].
Dengan diberikan satu contoh data training, masing- masing data direpresentasikan sebagai fitur vektor [x1, x2, ..., xd], tugas dari Naïve Bayes dapat untuk memprediksi data kelas yang paling mungkin dari contoh baru yang kelasnya tidak diketahui. Naïve Bayes menggunakan teorema Bayes untuk memperkirakan probabilitas dari kelas [9].
...(1)
Keterangan: P (yj) adalah probabilitas sebelum kelas yang diperkirakan sebagai frekuensi kejadian dalam data training. P (yj | x1, x2, ..., xd) adalah probabilitas posterior kelas yj setelah diamati data tersebut. P (x1, x2, ..., xd | yj) menunjukkan probabilitas bersyarat mengamati sebuah contoh dengan fitur vektor [x1, x2, ..., xd], yang salah satu diantara mereka memiliki kelas yj. P (x1, x2, ..., xd) adalah probabilitas mengamati sebuah contoh dengan fitur vektor P (x1, x2, ..., xd) tanpa kelas. Karena jumlah probabilitas posterior atas semua kelas adalah salah satu, penyebut pada persamaan sisi kanan merupakan faktor normalisasi dan dapat diabaikan. Sebuah contoh akan dilabeli sebagai kelas tertentu yang memiliki probabilitas posterior tertinggi P(yj| x1,x2,…..,xd) = P(yj) P(x1,x2,…..,xd | yj)
Prosedur prediksi menggunakan Naïve Bayes [10] : a. Tentukan label class.
b. Ambil data sample secara acak.
c. Hitung nilai mean dan standart devisiasi dari label class. d. Hitung masing- masing nilai class.
e. Hitung semua nilai class. f. Hasil prediksi
2.2. Particle Swarm Optimization (PSO)
Particle Swarm Optimization (PSO) adalah teknik optimasi berbasis populasi yang dikembangkan oleh Eberhart dan Kennedy pada tahun 1995, yang terinspirasi oleh perilaku sosial kawanan burung atau ikan [11]. Particle Swarm Optimization dapat diasumsikan sebagai kelompok burung secara mencari makanan disuatu daerah. Burung tersebut tidak tahu letak makanan tersebut berada, tapi mereka tahu seberapa jauh makanan itu berada, jadi strategi terbaik untuk menemukan makanan tersebut adalah dengan mengikuti burung yang terdekat dari makanan tersebut [11]. Particle Swarm Optimization digunakan untuk memecahkan masalah optimasi. Serupa dengan algoritma genetika (GA), Particle Swarm Optimization melakukan pencarian menggunakan populasi (swarm) dari individu (partikel) yang akan diperbaharui dari iterasi. Particle Swarm Optimization memiliki beberapa parameter seperti posisi, kecepatan, kecepatan maksimum, konstanta percepatan, dan berat inersia. Particle Swarm Optimization memiliki perbandingan lebih atau bahkan pencarian kinerja lebih unggul untuk banyak masalah optimasi dengan lebih cepat dan tingkat konvergensi yang lebih stabil [11].
Untuk menemukan solusi yang optimal, masing-masing partikel bergerak ke arah posisi yang terbaik sebelumnya dan posisi terbaik secara global. Sebagai contoh, partikel ke-i dinyatakan sebagai: xi = (xi1, xi2,....xid) dalam ruang d-dimensi. Posisi terbaik sebelumnya dari partikel ke-i disimpan dan dinyatakan sebagai pbesti = (pbesti,1, pbesti,2,...pbesti,d). Indeks partikel terbaik diantara semua partikel dalam kawanan group dinyatakan sebagai gbestd. Kecepatan partikel dinyatakan sebagai: vi = (vi,1,vi,2,....vi,d). Modifikasi kecepatan dan posisi partikel dapat dihitung menggunakan kecepatan saat ini dan jarak pbesti, gbestd seperti ditunjukan persamaan berikut [11] :
vi,d = w * vi,d + c1 * R * (pbesti,d - xi,d) + c2 * R * (gbestd - xi,d) ... (2) xid = xi,d + vi ... (3) Keterangan:
http://research. pps. dinus. ac. id , 157 w = Faktor bobot inersia
c1, c2 = Konstanta akeselerasi (learning rate) R = Bilangan random (0-1)
Xi, d = Posisi saat ini dari partikel ke-i pada iterasi ke-i pbest i = Posisi terbaik sebelumnya dari partikel ke-i
gbest i = Partikel terbaik diantara semua partikel dalam satu kelompok atau populasi n = Jumlah partikel dalam kelompok
d = Dimensi
Persamaan di atas menghitung kecepatan baru untuk tiap partikel (solusi potensial) berdasarkan pada kecepatan sebelumnya (Vi,m), lokasi partikel tempat nilai fitness terbaik telah dicapai (pbest), dan lokasi populasi global (gbest untuk versi global, lbest untuk versi local) atau local neighborhood pada algoritma versi local dengan nilai fitness terbaik telah dicapai. Persamaan (1.2) memperbaharui posisi tiap partikel pada ruang solusi. Dua bilangan acak c1 dan c2 dibangkitkan sendiri. Penggunaan berat inersia w telah memberikan performa yang meningkat pada sejumlah aplikasi. Hasil dari perhitungan partikel yaitu kecepatan partikel diantara interval [0,1] [11].
Prosedur feature selection Particle Swarm Optimization [12] : a. Set parameter X
b. [FOR]: Untuk setiap
c. Evaluasi fitness dengan menggunakan posisi d. Membandingkan fitness
e.
f. Membandingkan fitness dengan global fitness terbaik sehingga: g. Jika
h. Menghitung kecepatan pada saat berikutnya menurut i.
j. Memindahkan ke posisi baru menggunakan persamaan k.
l. [ENDFOR]
m. Melanjutkan ke langkah b sampai kriteria berhenti. 2.3. Confusion Matrix
Metode ini menggunakan tabel matriks seperti pada tabel 2.2, jika Data Set hanya terdiri dari dua kelas, kelas yang satu dianggap sebagai positif dan yang lainnya negatif [13].
Tabel 1. Model Confusion Matrix [13] Klasifikasi
yang benar
Diklasifikasikan sebagai Positive Negative Positive True positives False positives Negative False positives True positives
Setelah data uji dimasukkan ke dalam confusion matrix, hitung nilai-nilai yang telah dimasukkan tersebut untuk dihitung jumlah sensitivity (recall), specificity, precision dan accuracy. Sensitivity digunakan untuk membandingkan jumlah TP terhadap jumlah record yang positif sedangkan specificity adalah perbandingan jumlah TN terhadap jumlah record yang negatif. Untuk menghitung digunakan persamaan di bawah ini [14].
158 http://research. pps. dinus. ac. id Keterangan:
TP = jumlah true positives TN = jumlah true negatives P = jumlah record positives N = jumlah record negatives FP = jumlah false positives 2.4. Kurva ROC
Kurva ROC menunjukkan akurasi dan membandingkan klasifikasi secara visual. ROC mengekspresikan confusion matrix. ROC adalah grafik dua dimensi dengan false positives sebagai garis horizontal dan true positives untuk mengukur perbedaan performansi metode yang digunakan. ROC curve adalah cara lain untuk menguji kinerja pengklasifikasian [15]. Sebuah grafik ROC adalah plot dengan tingkat positif salah (FP) pada sumbu X dan tingkat positif benar (TP) pada sumbu Y. Titik (0,1) adalah klasifikasi sempurna yang mengklasifikasikan semua kasus positif dan kasus negatif dengan benar, karena tingkat positif salah (FP) adalah 0 (tidak ada), dan tingkat positif benar (TP) adalah 1. Titik (0,0) merupakan sebuah klasifikasi yang memprediksi setiap kasus menjadi negatif, sedangkan titik (1,1) sesuai dengan sebuah klasifikasi yang memprediksi setiap kasus menjadi positif. Titik (1,0) adalah klasifikasi yang tidak benar untuk semua klasifikasi. Dalam banyak kasus, klasifikasi memiliki parameter yang dapat disesuaikan untuk meningkatkan TP atau penurunan FP. Setiap pengaturan parameter menyediakan pasangan FP dan TP dan serangkaian pasangan tersebut dapat digunakan untuk memetakan kurva ROC. Klasifikasi non-parametrik diwakili oleh titik ROC tunggal, sesuai dengan pasangannya. Performance keakurasian AUC dapat diklasifikasikan menjadi lima kelompok yaitu:
a. 0,90 – 1,00 = Excellent Clasification b. 0,80 – 0,90 = Good Clasification c. 0,70 – 0,80 = Fair Clasification d. 0,60 – 0,70 = Poor Clasification e. 0,50 – 0,60 = Failure
3. PREDIKSI LOYALITAS PELANGGAN TELEKOMUNIKASI MENGGUNAKAN TEKNIK KLASIFIKASI NAÏVE BAYES BERBASIS PROBABILITAS DENGAN OPTIMASI PARTICLE SWARM OPTIMIZATION
3.1. Customer Churn
Menurut Guanglie Nie. et.al [4] Customer Churn didefinisikan sebagai kecenderungan pelanggan untuk berhenti melakukan bisnis dengan sebuah perusahaan dalam periode waktu tertentu. Customer Churn adalah para pelanggan yang tidak yakin akan pelayanan perusahaan tersebut, akhirnya pelanggan membatalkan atau menghentikan kontraknya [16].
http://research. pps. dinus. ac. id , 159 berpindah layanan ke perusahaan lain. Menemukan Churners dapat membantu bank mempertahankan pelanggan mereka [17]. Pelanggan dikatakan sebagai Churners ketika pelanggan gagal untuk membayar jasa dan penyedia jasa berakhir. Indikasi lain dari Churner adalah penghentian layanan akibat pencurian, penipuan, dan pelanggan tidak memperpanjang layanan dengan sengaja [16].
Customer Churn didefinisikan sebagai pelanggan dengan kecenderungan tinggi untuk beralih ke tempat lain. Karena kehilangan pelanggan mengarah ke biaya dan kesempatan mendapatkan hasil penjualan yang tinggi [6]. Selain itu Customer Churn juga dapat didefinisikan sebagai penggambaran secara kolektif berhentinya langganan pelanggan untuk layanan. Bagi sebuah perusahaan selama setidaknya satu periode (enam bulan) sebuah Churners adalah pelanggan yang meninggalkan perusahaan untuk mendapatkan layanan yang lebih baik [5].
Dalam perusahaan telekomunikasi, retensi pelanggan adalah kegiatan utama dari CRM (Customer Relationship Management). CRM (Customer Relationship Management) didefinisikan sebagai suatu proses yang komprehensif untuk memperoleh dan mempertahankan pelanggan, dengan bantuan intelijen bisnis, untuk memaksimalkan nilai pelanggan untuk organisasi [18]. Tindakan CRM langsung berkomunikasi dengan pelanggan, misal melalui sms atau telepon langsung untuk membuat pelanggan tetap bertahan. Misal, mengirim sms seperti berikut, “mengisi ulang dengan senilai 30 maka 7 hari berikutnya anda akan mendapatkan tambahan senilai 10 untuk panggilan”.
Ketika tawaran ini diterima perusahaan akan memiliki biaya tertentu terkait dengan bonus, tetapi juga laba yang dihasilkan dari mengisi ulang. Selain itu lamanya pelanggan tetap menggunakan layanan dari perusahaan akan bertambah beberapa hari, yang merupakan waktu untuk pelanggan menghabiskan bonus dari isi ulang. Tetapi tindakan ini tidak boleh ditunjukkan kepada pelanggan yang setia karena akan menghasilkan kerugian terkait bonusnya, tindakan ini harus ditunjukan kepada pelanggan yang cenderung churn, sehingga dapat mengubah pikiran mereka setelah menerima pesan tersebut. Jadi, perlu adanya prediksi customer churn agar pengiriman pesan bonus sesuai dengan kebutuhan pemasaran [19]. Faktor-faktor yang mempengaruhi customer churn [10]:
160 http://research. pps. dinus. ac. id Customer dissatisfaction diidentikan sebagai faktor utama Churn, tingkat kepuasan diukur dengan evaluasi pelanggan dari atribut layanan utama (kualitas panggilan, tingkat tarif, penagihan, layanan bernilai tambah, layanan pelanggan). Level of service usage merupakan faktor layanan yang berupa penggunaan biaya bulanan, jumlah tagihan, saldo yang belum dibayar, jumlah panggilan, dan berapa menit penggunaan. Switching costs merupakan tindakan yang biasanya memerlukan biaya misalnya, perubahan nomor telepon, dan pembelian heandset baru. Customer demographic variable mengidentifikasikan beberapa demografis pelaanggan sebagai faktor seperti, jenis kelamin, usia, metode pembayaran dan peringkat pelanggan.
Menurut analis, fitur yang signifikan untuk membedakan antara Churn dan non-Churn adalah : usia, masa kerja, jenis kelamin, jumlah tagihan, jumlah pembayaran terlambat, durasi panggilan, jumlah perubahan informasi akun [18]. Pelanggan sering memiliki kelompok sosial, dalam kelompoknya pelanggan menerima dan menyanmpaikan informasi, mempengaruhi dan dipengaruhi. Ketika sebuah kelompok tidak puas dengan operator seluler, informasi ini akan tersebar dikelompok, dan mempengaruhi tindakan anggota kelompok lain mengenai Churn. Faktor lain mendorong adalah tingginya panggilan dalam sebuah kelompok, oleh karena itu mereka lebih memilih untuk mempertahankan langgan mereka ke penyedia layanan yang sama[6].
3.2. Model Prediksi Loyalitas Pelanggan Telekomunikasi dengan Algoritma Naïve Bayes Berbasis Probabilitas menggunakan Particle Swarm Optimization
Salah satu tantangan yang dihadapi dalam penerapan CRM di perusahaan operator telekomunikasi seluler adalah usaha menurunkan jumlah pelanggan yang berhenti menggunakan layanan perusahaan dan pindah ke perusahaan kompetitor (Churn). Untuk mencegah kehilangan pelanggan maka dilakukanlah prediksi pelanggan yang akan berpindah ke kompetitor lain. Penelitian untuk mencari solusi atas masalah tersebut dapat dilakukan melalui algoritma data mining dalam memprediksi pelanggan yang hilang,
Dari beberapa penelitian pada konstalasi penelitian tentang Model Prediksi Loyalitas Pelanggan Telekomunikasi seperti yang dijelaskan pada bagian pendahuluan menunjukkan hasil yang baik. State of The Art dari konstalasi ini adalah ditemukannya Model Prediksi Loyalitas Pelanggan Telekomunikasi menggunakan algoritma Backpropagation dengan seleksi fitur PSO nilai akurasi sebesar 85,48% [6].
Dengan hasil akurasi yang didapatkan yang dirasa kurang maksimal, maka algoritma Backpropagation diganti dengan algoritma Naïve Bayes, karena algoritma Backpropagation memerlukan data training yang besar [6] sedangkan Naïve Bayes merupakan salah satu teknik prediksi berbasis klasifikasi probabilitas yang tidak memerlukan data training yang besar.
Tetapi jika metode prediksi Naïve Bayes dihadapkan dengan fitur atribut yang tidak mendapatkan label, maka secara otomatis nilai probabilitas tersebut menjadi nol. Oleh karena itu digunakan Particle Swarm Optimization untuk menyeleksi fitur atribut yang tidak mendapatkan label [20].
Particle Swarm Optimization (PSO) merupakan algoritma optimasi yang efektif yang dapat memecahkan masalah yang ada pada algoritma ANN yang pada umumnya menggunakan algoritma Backpropagation [9]. PSO memiliki perbandingan lebih untuk pemilihan fitur dan memiliki kinerja lebih unggul untuk banyak masalah optimasi dengan lebih cepat dan tingkat konvergensi yang lebih stabil [18].
Karakteristik PSO adalah interaksi sosial yang mempromosikan pembagian informasi antara partikel yang akan membantu dalam pencarian solusi yang optimal [21].
PSO memiliki beberapa parameter seperti posisi, kecepatan, kecepatan maksimum, percepatan konstanta dan berat inersia. Dalam teknik PSO terdapat beberapa cara untuk melakukan pengoptimasian diantaranya: meningkatkan bobot atribut (attribute weight) terhadap semua atribut atau variabel yang dipakai, menyeleksi atribut (attribute selection), dan seleksi fitur (feature selection). Dalam penelitian ini PSO digunakan untuk melakukan seleksi fitur.
Berdasarkan uraian tersebut maka dapat diduga bahwa upaya optimasi prediksi Naïve Bayes dengan memanfaatkan kemampuan PSO untuk seleksi fitur akan menghasilkan akurasi yang lebih baik.
http://research. pps. dinus. ac. id , 161 4. METODE PENELITIAN
4.1. Pengumpulan Data
Sumber Data Set prediksi loyalitas pelanggan telekomunikasi diperoleh dari sebuah website yaitu : http://www.informatics.buu.ac.th/~ureerat/321641/Weka/Data%20Sets/Churn/
Jumlah data set yang digunakan sebanyak 3333 record dan atribut data tersebut dapat dilihat pada tabel di bawah ini [6] :
Tabel 2. Atribut Data Set Loyalitas Pelanggan Telekomunikasi
4.2. Eksperimen
4.2.1 Feature Selection dengan Particle Swarm Optimization
Dataset loyalitas pelanggan telekomunikasi diinisialisasi posisi populasinya secara acak dan berdasarkan kecepatan, setelah itu dilakukan evaluasi partikel fitnessnya, jika hasil partikel fitness lebih besar dari partikel best fitnessnya maka nilai best fitness diperbaharui, kemudian bandingkan lagi antara nilai partikel fitness dengan global partikel fitness, jika partikel fitness lebih besar dari nilai global fitness, maka nilai global fitness diperbaharui, setelah membandingkan nilai fitness perbaharui kecepatan partikel, perbaharui posisi. Jika memang belum memenuhi persyaratan di atas maka kembali lagi ke inisialisasi posisi populasi, apabila sudah terpenuhi syaratnya maka parameter sudah dioptimalkan dengan feature selection.
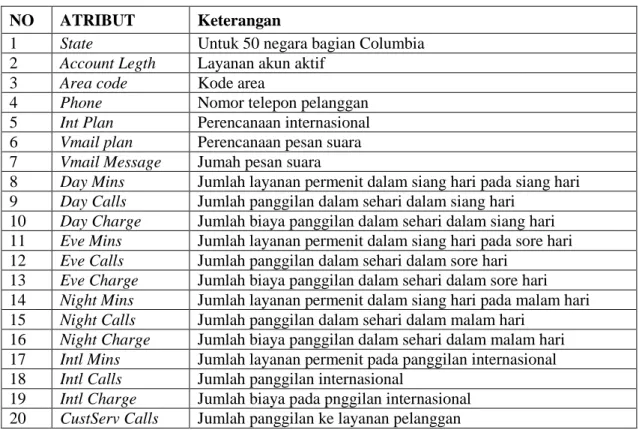
NO ATRIBUT Keterangan
1 State Untuk 50 negara bagian Columbia
2 Account Legth Layanan akun aktif
3 Area code Kode area
4 Phone Nomor telepon pelanggan
5 Int Plan Perencanaan internasional
6 Vmail plan Perencanaan pesan suara
7 Vmail Message Jumah pesan suara
8 Day Mins Jumlah layanan permenit dalam siang hari pada siang hari
9 Day Calls Jumlah panggilan dalam sehari dalam siang hari
10 Day Charge Jumlah biaya panggilan dalam sehari dalam siang hari
11 Eve Mins Jumlah layanan permenit dalam siang hari pada sore hari
12 Eve Calls Jumlah panggilan dalam sehari dalam sore hari
13 Eve Charge Jumlah biaya panggilan dalam sehari dalam sore hari
14 Night Mins Jumlah layanan permenit dalam siang hari pada malam hari
15 Night Calls Jumlah panggilan dalam sehari dalam malam hari
16 Night Charge Jumlah biaya panggilan dalam sehari dalam malam hari
17 Intl Mins Jumlah layanan permenit pada panggilan internasional
18 Intl Calls Jumlah panggilan internasional
19 Intl Charge Jumlah biaya pada pnggilan internasional
162 http://research. pps. dinus. ac. id Gambar 2. Desain Eksperimen Particle Swarm Optimization
Dalam penelitian ini digunakan tool rapidminer untuk membantu dalam proses feature selection. Untuk feature selection dengan PSO digunakan settingan nilai population size = 5, maximum number of generations = 30, inertia weight = 1. Local best weight = 1, global best weight = 1, min weight = 0 dan max weight = 1.
4.2.2 Prediksi dengan
Naïve Bayes
Dalam terminasi Naïve Bayes dataset loyalitas pelanggan telekomunikasi ditentukan terlebih dahulu label class nya, kemudian ambil data sampel dari dataset secara acak, selanjutnya hitung rata- rata dan standart devisisasi label class, kemudian hitung masing- masing class, dan yang terakhir hitung semua class, dari langkah- langkah tersebut akan didapatkan hasil akurasi. Dalam penelitian ini digunakan tool Rapidminer untuk memprediksi dengan algoritma Naïve Bayes dan guna menghitung nilai akurasi.
4.3. Evaluasi
Metode ini menggunakan tabel matriks seperti pada tabel 3, jika Data Set hanya terdiri dari dua kelas, kelas yang satu dianggap sebagai positif dan yang lainnya negatif [13].
Tabel 3. Model Confusion Matrix [13] Klasifikasi
yang benar
Diklasifikasikan sebagai Positive Negative Positive True positives False positives Negative False positives True positives
Setelah data uji dimasukkan ke dalam confusion matrix, dihitung nilai-nilai yang telah dimasukkan tersebut untuk memperoleh jumlah sensitivity (recall), specificity, precision dan accuracy. Sensitivity digunakan untuk membandingkan jumlah TP terhadap jumlah record yang positif sedangkan specificity adalah perbandingan jumlah TN terhadap jumlah record yang negatif.
Kurva ROC menunjukkan akurasi dan membandingkan klasifikasi secara visual. ROC Jika partikel fitness > partikel best
fitness => Perbarui best partikel
Perbarui partikel kecepatan Perbarui posisi partikel
Jika partikel fitness > global best fitness Perbarui global best
Mengevaluasi partikel fitness Inisialisasi posisi populasi secara
acak dan kecepatan
Parameter dioptimalkan dengan feature subset
http://research. pps. dinus. ac. id , 163 mengekspresikkan confusion matrix. ROC adalah grafik dua dimensi dengan false positives sebagai garis horizontal dan true positives untuk mengukur perbedaan performansi metode yang digunakan. ROC curve adalah cara lain untuk menguji kinerja pengklasifikasian [15]. Sebuah grafik ROC adalah plot dengan tingkat positif salah (FP) pada sumbu X dan tingkat positif benar (TP) pada sumbu Y. Titik (0,1) adalah klasifikasi sempurna yang mengklasifikasikan semua kasus positif dan kasus negatif dengan benar, karena tingkat positif salah (FP) adalah 0 (tidak ada), dan tingkat positif benar (TP) adalah 1. Titik (0,0) merupakan sebuah klasifikasi yang memprediksi setiap kasus menjadi negatif, sedangkan titik (1,1) sesuai dengan sebuah klasifikasi yang memprediksi setiap kasus menjadi positif. Titik (1,0) adalah klasifikasi yang tidak benar untuk semua klasifikasi. Dalam banyak kasus, klasifikasi memiliki parameter yang dapat disesuaikan untuk meningkatkan TP atau penurunan FP. Setiap pengaturan parameter menyediakan pasangan FP dan TP dan serangkaian pasangan tersebut dapat digunakan untuk memetakan kurva ROC. Klasifikasi non-parametrik diwakili oleh titik ROC tunggal, sesuai dengan pasangannya. Performance keakurasian AUC dapat diklasifikasikan menjadi lima kelompok yaitu:
a. 0,90 – 1,00 = Excellent Clasification b. 0,80 – 0,90 = Good Clasification c. 0,70 – 0,80 = Fair Clasification d. 0,60 – 0,70 = Poor Clasification e. 0,50 – 0,60 = Failure
5. HASIL DAN PEMBAHASAN 5.1. Hasil Eksperimen dan Pengujian
Dengan menggunakan Particle Swarm Optimization, data yang diolah diberikan bobot untuk pemilihan fitur. Particle Swarm Optimization pada tahap seleksi pemilihan atribut akan diproses sehingga menghasilkan tingkat akurasi yang lebih baik. Pengujian pada keseluruhan data akan dilakukan dengan menggunakan tool Rapidminer, pengukuran akurasi dan nilai AUC yang terbentuk akan didasarkan dengan menggunakan Confusion Matrix dan ROC Curve.
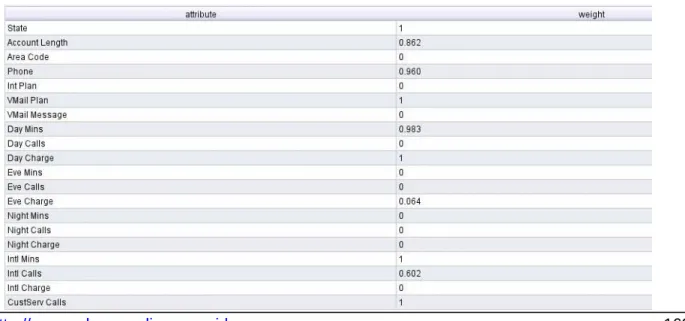
Langkah selanjutnya adalah menyeleksi atribut yang digunakan yaitu State,Account Length, Area Code, Phone, Int Plan, Vmail Plan, Vmail Message, Day Mins, Day Calls, Day Charge, Eve Mins, Eve Calls, Eve Charge, Night Mins, Night Calls, Night Charge, Intl Mins, Intl Calls, Intl Charge, CustServ Calls, dan 1 (satu) atribut sebagai label yaitu Churn. Dari hasil eksperimen untuk meningkatkan akurasi dengan menggunakan algoritma Naïve Bayes dengan fitur seleksi Particle Swarm Optimization diperoleh hasil seperti dalam tabel di bawah ini.
164 http://research. pps. dinus. ac. id Dari 20 variabel dilakukan seleksi atribut sehingga dihasilkan 10 atribut yang digunakan yaitu : State, Account Length, Phone, VMail Plan, Day Mins, Day Charge, Eve Charge, Intl Mins, Int Calls, CustServ Calls. Sedangkan atribut lainnya seperti Area Code, Int Plan, VMail Message, Day Calls, Eve Mins, Eve Calls, Night Mins, Night Calls, Night Charge, Intl Charge tidak terpengaruh terhadap bobot atribut, karena bobot atribut tersebut 0, maka dari itu bobot atribut yang dipakai adalah 1 (satu).
5.2. Evaluasi
Untuk melihat peningkatan akurasi, dataset akan diolah dengan algoritma Naïve Bayes dan untuk memaksimalkan akurasi yang dicapai maka digunakan Particle Swarm Optimization untuk feature selection. Algoritma Naïve Bayes dan pemilihan fitur Particle Swarm Optimization mampu menghasilkan tingkat akurasi yang tinggi dan nilai AUC yang lebih baik.
a. Confusion Matrix
Tabel di bawah ini menunjukkan hasil confusion matrix dari algoritma Naïve Bayes dan feature selection Particle Swarm Optimization yaitu:
Tabel 5. Nilai Akurasi Menggunakan Algoritma Naïve Bayes dan PSO
Tabel 6. Nilai Precision Rate Menggunakan Algoritma Naïve Bayes dan PSO
http://research. pps. dinus. ac. id , 165 Nilai akurasi dengan Naïve Bayes dan PSO jumlah True Positive (tp) adalah 2837 record diklasifikasikan sebagai No Churn dan False Negative (fn) sebanyak 42 record diklasifikasikan sebagai No Churn tetapi True Churn. Berikutnya 441 record untuk True Negative (tn) diklasifikasikan sebagai Churn, dan 13 record False Positive (fp) diklasifikasin sebagai Churn ternyata No Churn. Berdasarkan gambar di atas menunjukan bahwa, tingkat akurasi dengan menggunakan algoritma Naïve Bayes berbasis PSO adalah sebesar 98.54 %, dan dapat dihitung untuk mencari nilai accuracy, sensitivity, specificity, PPV, dan NPV hasilnya pada persamaan di bawah ini:
Hasil dari perhitungan di atas adalah sebagai berikut:
Accuracy = 0,9854
Sensitifity = 0,9855
Specificity = 0,9714
PPV = 0,9954
NPV = 0,9130
Tabel 8. Nilai Accuracy, Sensitivity, Specificity, PPV dan NPV Menggunakan Algoritma Naïve Bayes dan Particle Swarm Optimization dalam Bentuk Prosentase
Tabel 9.
b. Kurva ROC
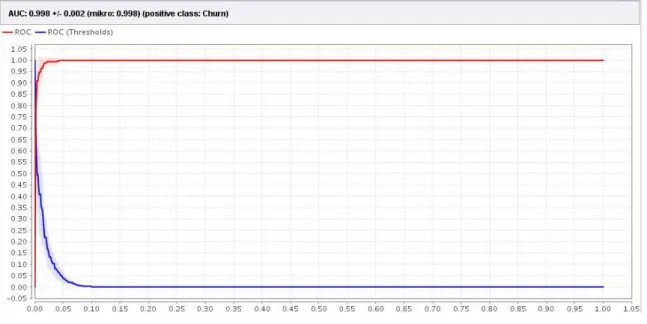
Hasil perhitungan divisualisasikan dengan kurva ROC. Perbandingan kedua class bisa dilihat pada gambar 3 yang merupakan kurva ROC untuk algoritma Naïve Bayes dan Particle Swarm Optimization. Kurva ROC pada gambar 3 mengekspresikan confusion matrix dari tabel 8. Garis horizontal adalah false positives dan garis vertikal true positives. Menghasilkan nilai AUC (Area Under Curve) sebesar 0,998.
Accuracy
98,54 %
Sensitivity
98,55 %
Specificity
97,14 %
PPV
99,54 %
166 http://research. pps. dinus. ac. id Gambar 3. Kurva ROC
Gambar di atas menunjukkan hasil dari Kurva ROC dengan Algoritma Naïve Bayes dan Particle Swarm Optimization dengan nilai AUC yaitu : 0.99. Hasil pengujian model berupa pengukuran tingkat akurasi dan AUC (Area Under Curve) dari penentuan tidak loyal atau hilangnya pelanggan telekomunikasi. Hasil akurasi yang diperoleh dengan menggunakan algoritma Naïve Bayes dan pemilihan fitur Particle Swarm Optimization sebesar 98,54 % dan AUC 0,99.
5.3. Pembahasan Hasil
Hasil yang diusulkan dari penelitian ini berupa Model Prediksi Loyalitas Pelanggan Telekomunikasi Menggunakan Algoritma Naïve Bayes dan Pemilihan Fitur Particle Swarm Optimization. Model komputasi loyalitas pelanggan mempunyai peranan yang penting dalam mempertahankan pelanggan. Hasil penelitian ini memiliki tujuan bagi pembuat keputusan, khusunya di industri telekomunikasi agar dapat menentukan kemungkinan adanya pelanggan yang meninggalkan layanan dan perhatian terhadap informasi dan pelayanan kepada pelanggan.
Pada penelitian ini digunakan Data Set sejumlah 3333 record dari sumber dataset prediksi pelanggan
telekomunikasi yang hilang diperoleh dari sebuah website
http://www.informatics.buu.ac.th/~ureerat/321641/Weka/Data%20Sets/Churn/. Dibandingkan penelitian sebelumnya untuk memperoleh tingkat akurasi dan AUC dari loyalitas pelanggan telekomunikasi digunakan algoritma Naïve Bayes dengan pemilihan fitur Particle Swarm Optimization sehingga diperoleh akurasi yang lebih baik.
Pada penelitian Muzakir Irvan [6], hasil prediksi loyalitas pelanggan telekomunikasi dengan mengunakan algoritma Backpropagation dengan dataset yang sama, didapatkan nilai akurasi 85,48 % dan nilai AUC 0,531. Sedangkan pengujian dengan mengunakan algoritma Backpropagation berbasis Particle Swarm Optimization didapatkan nilai akurasi 86,05% dan nilai AUC adalah 0,637.
B.Q. Huang, et.al [5] juga melakukan penelitian tentang prediksi loyalitas pengguna jasa telekomunikasi menggunakan algoritma ANN, Support Vector Machine dan Decision Tree. Data set yang digunakan berbeda, yakni 47.391 pengguna yang dipilih secara acak dari beberapa kantor telekomunikasi di Ireland dan didapatkan 9999 churners dan 18.196 non churners. Total keseluruhan pelanggan dalam proses training sebesar 28.195. Jumlah pelanggan yang didapatkan untuk proses testing sebesar 19.196
http://research. pps. dinus. ac. id , 167 dengan 1000 churners dan 18.196 non churners. Dari penelitian ini diperoleh hasil tingkat akurasi 83.23%.
Berdasarkan pengujian tingkat akurasi dan AUC menggunakan algoritma Naïve Bayes dan pemilihan fitur Particle Swarm Optimization, menunjukkan hasil bahwa akurasi yang dihasilkan sebesar 98,54 %, dan dengan menggunakan kurva ROC menghasilkan nilai AUC sebesar 0,99. Waktu yang digunakan untuk memproses pengujian ini membutuhkan waktu lebih kurang 2 jam 45 menit dengan 3333 record yang digunakan.
Dari 20 variabel dilakukan seleksi atribut sehingga menghasilkan 10 atribut yang digunakan yaitu : State, Account Length, Phone, VMail Plan, Day Mins, Day Charge, Eve Charge, Intl Mins, Int Calls, CustServ Calls. Sedangkan atribut lainnya seperti Area Code, Int Plan, VMail Message, Day Calls, Eve Mins, Eve Calls, Night Mins, Night Calls, Night Charge, Intl Charge tidak terpengaruh terhadap bobot atribut, karena bobot atribut tersebut 0, maka dari itu bobot atribut yang dipakai adalah 1 (satu).
Berikut ini adalah pendapat alasan terpilihnya atribut-atribut dalam Particle Swarm Optimization: a. State (negara bagian Columbia): kemungkin budaya di Columbia yang menjadikan alasan kenapa
banyak pelanggan yang loyal.
b. Account Length (layanan akun aktif): disebabkan karena nomor yang digunakan tidak berganti- ganti
c. Phone (nomor telepon): bisa disebabkan karena nomor layanan yang digunakan biasanya nomor cantik atau sudah banyak disebarkan kepada teman.
d. VMail Plan (perencanaan pesan suara): pendaftaran layanan pesan suara, bila sudah melakukan pendaftaran biasanya penggunaan layanan telekomunikasi masih akan berlanjut untuk menggunakan layanan yang sudah didaftarkan.
e. Day Mins (jumlah layanan permenit dalam sehari di siang hari): semakin sering menggunakan layanan, berarti pengguna nyaman dengan layanan yang diberikan dan biasanya diberikan bonus layanan pada jam- jam tertentu.
f. Day Charger (jumlah biaya dalam sehari di siang hari): semakin banyak biaya yang dikeluarkan untuk menggunakan layanan telekomunikasi, artinya pengguna nyaman dengan layanan yang diberikan dan biasanya diberikan bonus layanan pada jam- jam tertentu.
g. Eve Charge (jumlah biaya dalam sehari di sore hari): semakin banyak biaya yang dikeluarkan untuk menggunakan layanan telekomunikasi di sore hingga malam hari, artinya pengguna terbiasa mengisi waktu mereka menggunakan layanan di sore hingga malam hari.
h. Intl Mins (jumlah layanan permenit pada panggilan internasional): disebabkan pengguna nyaman dengan fasilitas panggilan internasional yang diberikan layanan telekomunikasi serta discount untuk panggilan international.
i. Intl Calls (jumlah panggilan internasional): disebabkan pengguna nyaman dengan fasilitas panggilan internasional yang diberikan layanan telekomunikasi serta discount untuk panggilan international.
j. Custserv Calls (jumlah panggilan ke layanan pelanggan): semakin sering pengguna menghubungi layanan pelanggan berarti semakin banyak hal pula yang ingin diketahui tentang layanan yang bisa digunakan oleh pelanggan.
6. PENUTUP
Dalam penelitian ini dilakukan pengujian model akurasi prediksi dengan menggunakan algoritma Naïve Bayes berbasis Particle Swarm Optimization guna mengetahui loyalitas pelanggan pada perusahaan telekomunikasi di Columbia. Model akurasi yang dihasilkan diuji untuk mendapatkan nilai akurasi dan AUC. Dari hasil pengujian didapat nilai akurasi adalah 98,54 % dan nilai AUC adalah 0,99.
168 http://research. pps. dinus. ac. id DAFTAR PUSTAKA
[1] Jadhav. J and Pawar. T, “Churn Prediction in Telecommunication Using Data Mining Technology,” (IJACSA) International Journal of Advanced Computer Science and Applications,Vol. 2, No.2, February 2011.
[2] A. Idris, M. Rizwan, and A. Khan, “Churn Prediction In Telecom Using Random Forest And PSO Based Data Balancing In Combination With Various Feature Selection Strategies,” Computers & Electrical Engineering, vol. 38, no. 6, pp. 1808–1819, Nov. 2012.
[3] C.-S. Lin, G.-H. Tzeng, and Y.-C. Chin, “Combined rough set theory and flow network graph to predict customer Churn in credit card accounts,” Expert Systems with Applications, vol. 38, no. 1, pp. 8–15, Jan. 2011.
[4] G. Nie, W. Rowe, L. Zhang, Y. Tian, and Y. Shi, “Credit card Churn forecasting by logistic regression and decision tree,” Expert Systems with Applications, vol. 38, no. 12, pp. 15273–15285, Nov. 2011.
[5] B. Huang, M. T. Kechadi, and B. Buckley, “Customer Churn prediction in telecommunications,” Expert Systems with Applications, vol. 39, no. 1, pp. 1414–1425, Jan. 2012.
[6] Muzakir Irvan, “Peningkatan Accuracy Algoritma Backpropagation Dengan Seleksi Fitur Particle Swarm Optimization Dalam Prediksi Pelanggan Telekomunikasi Yang Hilang ,” Program Pasca Sarjana Magister Teknik Informatika Universitas Dian Nuswantoro 2013.
[7] S. H. Ling, H. T. Nguyen, and K. Y. Chan, “A New Particle Swarm Optimization Algorithm for ANN Optimization,” 2009 Third International Conference on Network and System Security, pp. 516–521, 2009.
[8] S. H. Ling, H. T. Nguyen, and K. Y. Chan, “A New Particle Swarm Optimization Algorithm for ANN Optimization,” 2009 Third International Conference on Network and System Security, pp. 516–521, 2009.
[9] H. Emilia, “Customer Churn Prediction for the Icelandic Mobile Telephony Market,” 2011 60ECTS thesis submitted in partial fulfillment of a Magister Scientiarum degree in Mechanical Engineering.
[10] Owczarczuk Marcin, “Churn models for prepaid customer in the cellular telecommunication industry using large data marts,” Expert Systems with Applications37 (2010) 4710–4712.
[11] Kaur Manjit, et al, " Data Mining as a tool to Predict the Churn Behaviour among Indian bank customers," International Journal on Recent and Innovation Trends in Computing and
Communication, vol. 1, no. 9, pp.720-725, September 2013
[12] S. H. Ling, H. T. Nguyen, and K. Y. Chan, “A New Particle Swarm Optimization Algorithm for ANN Optimization,” 2009 Third International Conference on Network and System Security, pp. 516–521, 2009.
[13] M. Bramer, Principles of Data Mining. Springer, 2007.
[14] J. Han and M. Kamber, Data Mining: Concepts and Techniques, vol. 12. Morgan Kaufmann, 2011, p. 2006.
[15] F. Gorunescu, Data Mining Concepts, Models and Techniques, vol. 12. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011.
[16] Zhai Tingting and He Zhenfeng, “Instance selection for time series classification based on immune binary Particle Swarm Optimization,”Knowledge-Based Systems 49 (2013) 106–115.
[17] J. Burez and D. Vandenpoel, “Separating financial from commercial customer Churn: A modeling step towards resolving the conflict between the sales and credit department,” Expert Systems with Applications, vol. 35, no. 1–2, pp. 497–514, Jul. 2008.
[18] T.-S. Park, J.-H. Lee, and B. Choi, “Optimization for Artificial ANN with Adaptive inertial weight of Particle Swarm Optimization,” 2009 8th IEEE International Conference on Cognitive Informatics, pp. 481–485, Jun. 2009.
http://research. pps. dinus. ac. id , 169 [19] G. Xia and W. Jin, “Model of Customer Churn Prediction on Support Vector Machine,” Systems
Engineering - Theory & Practice, vol. 28, no. 1, pp. 71–77, Jan. 2008.
[20] W. Verbeke, K. Dejaeger, D. Martens, J. Hur, and B. Baesens, “New Insights Into Churn Prediction In The Telecommunication Sector: A Profit Driven Data Mining Approach,” European Journal of Operational Research, vol. 218, no. 1, pp. 211–229, Apr. 2012.
[21] Bird Steven, Klein Ewan, and Loper Edward “Natural Language PROCessing with Python,” US: Natural Language Tollkit 2009.
![Tabel 1. Model Confusion Matrix [13]](https://thumb-ap.123doks.com/thumbv2/123dok/4327864.2915370/4.918.304.676.791.923/tabel-model-confusion-matrix.webp)
![Gambar 1. Faktor yang Mempengaruhi Customer Churn [10]](https://thumb-ap.123doks.com/thumbv2/123dok/4327864.2915370/6.918.321.736.613.945/gambar-faktor-mempengaruhi-customer-churn.webp)
![Tabel 3. Model Confusion Matrix [13]](https://thumb-ap.123doks.com/thumbv2/123dok/4327864.2915370/9.918.88.752.124.444/tabel-model-confusion-matrix.webp)