PREDIKSI KELAYAKAN KREDIT SEPEDA MOTOR DENGAN MENGGUNAKAN ALGORITMA K-NEAREST NEIGHBOR
1
Hernalom Sitorus, 2RizwanAndreansyah Fakultas Teknik Informatika
1)
Dosen Fakultas Teknik
2)
Lulusan Teknik Informatika Fakultas Teknik Universitas Satya Negara Indonesia
Universitas Satya Negara Indonesia
Jl. Sultan Iskandar Muda No. 11, Jakarta Selaan 12240
ABSTRAK
Pada bidang usaha kredit, faktor kegagalan dan kerugian sangatlah mempengaruhi kinerja suatu suatu usaha, salah satu faktor kegagalannya adalah kurang akuratnya informasi dalam penilaian konsumen dan tidak adanya sistem untuk memprediksi kelayakan pemberian kredit terhadap konsumen baru, diperlukan suatu sitem yang dapat membantu memprediksi kelayakan pemberian kredit kepada calon konsumen. Metode yang akan digunakan dalam penelitian ini adalah metode fuzzy knn, dalam penelitian ini dibutuhkan data sampel atau kasus lama untuk mencari kedekatan dari kasus baru, dan hasil prediksinya adalah layak atau tidak layak.
Kata Kunci : Algoritma k-Nearest Neighbor, Prediksi, Kredit
ABSTRACT
In the field of credit business, the factors of failure and loss are very affect the performance of a business, one of the factors failure is the lack of accurate information in consumer ratings and the absence of a system to predict the creditworthiness of new customers, a system that can help predict the feasibility of lending to potential customers. The method that will be used in this research is fuzzy knn method, in this research we need sample data or old case to look for closeness of new case, and the prediction result is feasible or not feasible.
Keywords: algorithm k-Nearest Neighbor, Predict, Credit
PENDAHULUAN
Data kendaraan sepeda motor didaerah Toboali Bangka mengalami peningkatan dari tahun ke tahun, salah satu pemicu peningkatan kendaraan sepeda motor didaerah Toboali Bangka yang setiap tahun meningkat adalah banyaknya perusahaan-perusahaan pembiayaan kredit sepeda motor yang memberikan kemudahaan kredit kepada masyarakat. Adapun kemudahan yang diberikan pihak perusahaan pembiayaan kredit itu seperti DP (Down Payment) rendah dan persyaratan yang hanya menggunakan Kartu Tanda Penduduk (KTP) dan Kartu Keluarga (KK) masyarakat langsung bisa mendapatkan kendaraan sepeda motor, tanpa ada proses untuk memprediksi kelayakan konsumen di perusahaan tersebut. Dengan adanya kemudahan yang ditawarkan oleh pihak perusahaan pembiayaan ini banyak masyarakat yang tidak lagi memikirkan kondisi keuangan keluarganya.
Dalam proses persetujuan kredit yang diterapkan oleh pihak perusahaan adalah konsumen harus menyerahkan persyaratan kepada pihak perusahaan, adapun persyaratan yang harus diserahkan kepada perusahaan adalah foto copy Kartu Tanda Penduduk (KTP) dan Kartu Keluarga (KK) kepada pihak perusahaan, dan konsumen memilih sepeda motor yang diinginkan, menentukan DP (Down Payment) dan jangka waktu kredit. Setelah persyaratan semuanya sudah dinyatakan lengkap, dari pihakperusahaan melakukan survey dilingkungan sekitar rumah konsumen, setelah proses survey selesai dari pihak karyawan perusahaan langsung memberikan informasi yang didapatkan di lingkunngan rumah konsumen kepada kredit analis, dan kredit analis langsung memberikan keputusan diterima atau ditolaknya konsumen tersebut kepada pihak dealer motor.
Dari mulai berdirinya PT.FIFGROUP Cabang Toboali Bangka dari Tahun 2004 sampai dengan sekarang, perusahaan hanya menggunakan sistem persetujuan yang penulis uraikan diatas. Dengan
Jurnal Ilmiah Fakultas Teknik LIMIT’S Vol.13 No 1 September 2017
sistem persetujuan diatas maka besar resiko angsuran macet yang akan dialami oleh PT.FIFGROUP Cabang Toboali Bangka dikarenakan tidak adanya sistem untuk memprediksi kelayakan konsumen tersebut. Maka saya selaku penulis dalam penelitian ini akan menerapkan Algoritma k-Nearest Neighbor guna memprediksi kelayakan kredit sepeda motor di PT.FIFGROUP Cabang Toboali Bangka.
TUJUAN PENELITIAN
Tujuan dari penelitian ini adalah untuk menerapkan Algoritma k-Nearest Neighbor guna memprediksi kelayakan kredit di PT.FIFGROUP Cabang Toboali Bangka.
LANDASAN TEORI
Kredit
Istilah kredit berasal dari perkataan latin credo, yang berarti I believe, I trust, saya percaya atau saya menaruh kepercayaan (Rivai, 2006). Kredit adalah penyerahan barang, jasa, atau uang dari satu pihak (kreditor/pemberi pinjaman) atas dasar kepercayaan kepada pihak lain (nasalah, konsumen atau pengutang/borrower) dengan janji membayar dari penerima kredit kepada pemberi kredit pada tanggal yang telah disepakati kedua belah pihak.
Memperoleh kredit berarti memperoleh kepercayaan atas dasar kepercayaan kepada seseorang yang memerlukannya maka diberikan uang, barang atau jasa dengan syarat membayar kembali atau memberikan penggantiannya dalam satu jangka waktu yang telah diperjanjikan (Linof,2011).
Pengertian Data Mining
Data Mining adalah suatu istilah yang digunkan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistic, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005).
Menurut Gartner Group data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecendrungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti teknik statistic dan matematika (Larose, 2005).
Data mining bukanlah suatu bidang yang sama sekali baru. Salah satu kesulitan untuk mendefiniskan data mining adalah kenyataan bahwa data mining mewarisi banyak aspek dan teknik dari bidang-bidang ilmu yang sudah mapan terlebih dahulu. Gambar 2.1 menunjukan bahwa data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistic, database, dan juga information retrieval (Pramudiono, 2006).
Algoritma K-Nearest Neighbor
K-Nearest Neighbor adalah pendekatan untuk mencari kasus dengan menghitung kedekatan antara kasus baru dengan kasus lama, yaitu berdasarkan pada pencocokan bobot dari sejumlah fitur yang ada. Misalkan diinginkan untuk mencari solusi terhadap seorang pasien baru dengan menggunkan solusi dari pasien terdahulu. Untuk mencari kasus pasien mana yang akan digunakan, maka dihitung kedekatan kasus pasien baru dengan semua kasus pasien lama. Kasus pasien lama dengan kedekatan terbesarlah yang akan diambil solusinya untuk digunakan pada kasus pasien baru.
Metodelogi Analisa K-Nearest Neighbor
Ada banyak cara untk mengukur jarak kedekatan antara data baru dan data lama (data training), diantaranya Euclidean distance dan manhattan distance (city block distance), yang paling sering digunakan adalah Euclidean distance (Bramer,2007), yaitu :
Dimana a = a1,a2, …, an, dan b = b1, b2, …, bn mewakili n nilai atribut dari dua record. Untuk atribut dengan nilai kategori, pengukuran dengan euclidean distance tidak cocok. Sebagai penggantinya, digunakan fungsi sebagai berikut (Larose, 2006):
Different (ai,bi) = { 0 jika ai = bi = 1 selainnya dimana ai dan bi adalah nilai kategori. Jika nilai atribut antara dua record yang dibandingkan sama maka nilai jaraknya 0, artinya mirip, sebaliknya, jika berbeda maka nilai kedekatannya 1, artinya tidak mirip sama sekali. misalkan atribut warna dengan nilai merah dan merah, maka nilai kedekatannya 0, jika merah dan biru maka nilai kedekatannya 1.
Untuk mengukur jarak dari atribut yang mempunyai nilai besar, seperti atribut pendapatan,
maka dilakukan normalisasi bisa dilakukan dengan min-max normalization atau Z-score
standardization (Larose, 2006). Jika data training terdiri dari atribut campuran antara numeric dan kategori, lebih baik gunakan min-max normalization (Larose, 2006).
Untuk menghitung kemiripan kasus, digunakan rumus (Kusrini, 2009):
similarity(T,S) = ∑ ( )
Keterangan : T = Kasus baru
S = Kasus yang ada dalam penyimpanan N = Jumlah atribut dalam tiap kasus
i = Atribut individu antara 1 sampai dengan n
f = Fungsi similarity atribut I antara kasus p dan kasus q w = Bobot yang diberikan pada atribut ke-i
METODE PENELITIAN Data Primer
Data Primer adalah data yang dikumpulkan sendiri oleh perorangan/suatu organisasi secara langsung dari objek yang diteliti dan untuk kepentingan studi yang bersangkutan yang dapat berupa interview, observasi. Di dalam pengambilan data sampel dan menentukan bobot yang tertera di tabel 3.2 atribut dan bobot, tabel 4.4 data sampel, itu semua penulis dapatkan atas kerja sama dengan pihak perusahaan, serta bobot-bobot di dalam nilai-nilai atribut, sehingga dalam penentuan nilai bobot tersebut semuanya dari pihak perusahaan. Dibawah ini adalah atribut dan nilai atribut yang digunakan untuk memprediksi kelayakan konsumen.
Tabel1 Data Atribut
Atribut Status Perkawinan Jumlah Tanggun gan Status Rumah Kondisi Rumah Pekerjaan Status Kepegawaian Usia Status Perusahaan DP Nilai Atribut -Belum Menikah - Menikah - Duda / Janda -Tidak Ada - < 3 - > 3 - Sewa / Kontrak - Pribadi - Orang Tua -Permanen - Semi Permanen - Non Permanen -Pegawai Pemerintahan - Polisi / TNI - Guru -Karyawan Swasta -Wiraswasta Kecil -Wiraswasta Menengah -Wiraswasta Besar - Nelayan -Petani / Berkebun - Pedagang -PNS/ASN - Tetap - Kontrak - Honorer - Pemilik -Buruh Harian -21– 55 Tahun -56– 60 Tahun -Aparatur Negara -Lembaga Negara - BUMD -Lembaga Pendidikan - Perusahaan Swasta -Swasta Besar -Swasta Menengah -Swasta Kecil - > 50% - 40 – 50 % - 30 – 40 % - 20 – 30 % - 10 – 20 % - < 10 %
Tabel 2 Atribut Dan Bobot
Atribut Status Perkawinan Jumlah Tanggungan Status Rumah Kondisi Rumah Pekerjaan Status Kepegawaian Usia Status Perusahaan DP (Down Payment) Bobot 0,8 1,4 1,2 1,1 1,2 1,2 0,8 0,8 1,5 PEMBAHASAN
1. Perhitungan Algoritma K-Nearest Negihbor
Algoritma k-Nearest Neighbor adalah pendekatan untuk mencari kasus dengan menghitung kedekatan antara kasus baru dengan kasus lama, yaitu berdasarkan pada pencocokan bobot dari
Jurnal Ilmiah Fakultas Teknik LIMIT’S Vol.13 No 1 September 2017
sejumlah fitur yang ada. Misalkan diinginkan mencari solusi terhadap seorang konsumen yang ingin kredit sepeda motor dengan menggunakan solusi dari konsumen terdahulu. Untuk mencari kasus konsumen mana yang akan digunakan, maka di hitung kedekatan kasus konsumen yang baru dengan semua kasus konsumen lama. Kasus konsumen lama dengan kedekatan terbesarlah yang akan diambil solusinya untuk digunakan pada kasus konsumen yang baru.
2. Rancangan Input dan Output
Gambar1. Contoh Rancangan Input Gambar2 Contoh Rancangan Output
3. Rancangan Proses
a. Kriteria Kelayakan
Dalam sistem yang akan penulis rancang ini, ada beberapa contoh kriteria-kriteria yang dinyatakan layak dari perusahaan. Adapun contoh adalah sebagai berikut:
Tabel 3. Kriteria Kelayakan
No Atribut Nilai Atribut
1. Status Perkawinan -Belum Menikah 2. Jumlah Tanggungan -Tidak Ada
3. Status Rumah -Pribadi
4. Kondisi Rumah -Permanen 5. Pekerjaan -Pegawai Pemerintahan 6. Status Kepegawaian -PNS/ASN 7. Usia -21 – 55 Tahun 8. Status Perusahaan -Lembaga Negara 9. DP (Down Payment) -40 – 50 % 10. Status Layak
Tabel 4. Kriteria Kelayakan
No Atribut Nilai Atribut
1. Status Perkawinan -Menikah 2. Jumlah Tanggungan -< 3
3. Status Rumah -Pribadi
4. Kondisi Rumah -Permanen 5. Pekerjaan -Polisi/TNI 6. Status Kepegawaian -PNS/ASN 7. Usia -21 – 55 Tahun 8. Status Perusahaan -Aparatur Negara 9. DP (Down Payment) ->50 % 10. Status Layak
b. Data Bobot
Untuk proses perhitungan menggunakan algoritma k-nearest neighbor, setiap atribut dan nilainilai atribut itu akan diberikan bobot. Total semua bobot dari atribut ini 10, dan dari angka 10 dibagikan kesemua atribut. Untuk nilai bobot yang lebih besar itu diartikan atribut tersebut sangat berpengaruh untuk prediksi dan sebaliknya, jika untuk nilai bobot rendah itu diartikan atribut tersebut tidak berpengaruh untuk memprediksi.
Tabel 5. Atribut Dan Bobot
No Atribut Bobot 1. Status Perkawinan 0,8 2. Jumlah Tanggungan 1,4 3. Status Rumah 1,2 4. Kondisi Rumah 1,1 5. Pekerjaan 1,2 6. Status Kepegawaian 1,2 7. Usia 0,8 8. Status Perusahaan 0,8 9. DP (Down Payment) 1,5 c. Data Sampel
Adapun data sampel yang penulis gunakan didalam penelitian ini adalah data yang didapatkan dari perusahaan, yaitu PT.FIFGROUP Cabang Toboali Bangka.
Tabel 6. Data Sampel
Status Perkawinan Juml Tanggungan Status Rumah Kondisi Rumah Pekerjaan Status Kepegawaian Usia Status Perusahaan DP (Down Payment) Status Belum Menikah
Tidak Ada Pribadi Permanen Pegawai Pemerintah PNS/ASN 21-55 Lembaga Negara 20 – 30 % Layak Menikah >3 Orang tua Non Permanen Pegawai Pemerintah Honorer 21-55 Lembaga Negara <10 % Tidak Layak d. Data Uji
Data uji adalah data kasus konsumen baru yang ingin melakukan kredit sepeda motor di PT.FIFGROUP Cabang Toboali Bangka.
Tabel 7. Data Uji
No Status Perkawinan Jumlah Tanggungan Status Rumah Kondisi Rumah Pekerjaan Status Kepegawaian Usia Status Perusahaan DP (Down Paymen) 1 Menikah >3 Orang Tua Non Permanen Karyawan Swasta Kontrak 21-55 Perusahaan Swasta <10 % 2 Belum Menikah
Tidak Ada Orang Tua Semi Permanen Polisi/TNI PNS/ASN 21 – 55 Aparatur Negara 10 – 20 %
Jurnal Ilmiah Fakultas Teknik LIMIT’S Vol.13 No 1 September 2017
4. Proses Perhitungan Algoritma K-Nearest Neighbor
Dalam perhitungan kedekatan antara kasus baru pada data uji (tabel 4.5 dan tabel 4.6) dengan kasus lama sebagai data sampel (tabel 4.3 dan tabel 4.4), yaitu :
Contoh Data Uji 1
Dibawah ini adalah perhitungan Kedekatan kasus baru data uji 1 dengan kasus lama data sampel nomor 1
A : Kedekatan bobot atribut status perkawinan (belum menikah dengan belum)=1 B : Untuk bobot atribut status perkawinan = 0,8
C : Kedekatan bobot atribut jumlah tanggungan (> 3 dengan tidak ada)= 0,5 D : Untuk bobot atribut jumlah tanggungan=1,4
E : Kedekatan bobot atribut status rumah (orang tua dengan pribadi)=0,5 F : Untuk bobot atribut status rumah=1,2
G : Kedekatan bobot atribut kondisi rumah (non permanen dengan permanen)=0,5 H : Untuk bobot atribut kondisi rumah=1,1
I : Kedekatan bobot atribut pekerjaan (karyawan swasta dengan pegawai pemerintah)=0,2 J : Untuk bobot atribut pekerjaan=1,2
K : Kedekatan bobot atribut status kepegawaian (kontrak dengan PNS/ASN)=0,4 L : Untuk bobot atribut status kepegawaian=1,2
M : Kedekatan bobot atribut usia (21-55 dengan 21-55)=0 N : Untuk bobot atribut usia=0,8
O : Kedekatan bobot atribut status perusahaan (perusahaan swasta dengan lembaga negara)=0,4 P : Untuk bobot atribut status perusahaan=0,8
Q : Kedekatan bobot atribut DP (<10% dengan < 20 - 30%)=0,2 R : Untuk bobot atribut DP (Down Payment)=1,5
Similarity = [(A*B)+(C*D)+(E*F)+(G*H)+(I*J)+(K*L)+(M*N)+(O*P)+(Q*R)] / (B+D+F+H+J+L+N+P+R) =[(1*0,8)+(0,5*1,4)+(0,5*1,2)+(0,5*1,1)+(0,2*1,2)+(0,4*1,2)+(0*0,8)+(0,4*0,8)+ (0,2*1,5)] /(0,8+1,4+1,2+1,1+1,2+1,2+0,8+0,8+1,5) =(0,8+0,7+0,6+0,55+0,24+0,48+0+0,32+0,3) / 10 =3,99 / 10 =0,399
Hasil perhitungan dari kedekatan data sampel nomor 1 dengan kasus baru 1 adalah 0,399 - Kedekatan kasus baru data uji 1 dengan kasus lama data sampel nomor 2
A : Kedekatan bobot atribut status perkawinan (menikah dengan menikah)=0 B : Untuk bobot atribut status perkawinan = 0,8
C : Kedekatan bobot atribut jumlah tanggungan (<3 dengan >3)= 0 D : Untuk bobot atribut jumlah tanggungan=1,4
E : Kedekatan bobot atribut status rumah (orang tua dengan orang tua)=0 F : Untuk bobot atribut status rumah=1,2
G : Kedekatan bobot atribut kondisi rumah (non permanen dengan non permanen)=0 H : Untuk bobot atribut kondisi rumah=1,1
I : Kedekatan bobot atribut pekerjaan (karyawan swasta dengan pegawai pemerintah)=0,2 J : Untuk bobot atribut pekerjaan=1,2
K : Kedekatan bobot atribut status kepegawaian (kontrak dengan honorer)=0,1 L : Untuk bobot atribut status kepegawaian=1,2
M : Kedekatan bobot atribut usia (21-55 dengan 21-55)=0 N : Untuk bobot atribut usia=0,8
O : Kedekatan bobot atribut status perusahaan (perusahaan swasta dengan lembaga negara)=0,4 P : Untuk bobot atribut status perusahaan=0,8
Q : Kedekatan bobot atribut DP (10 % dengan <10 %)=0 R : Untuk bobot atribut DP (Down Payment)=1,5
Similarity = [(A*B)+(C*D)+(E*F)+(G*H)+(I*J)+(K*L)+(M*N)+(O*P)+(Q*R)] / (B+D+F+H+J+L+N+P+R) =[(0*0,8)+(0*1,4)+(0*1,2)+(0*1,1)+(0,2*1,2)+(0,1*1,2)+(0*0,8)+(0,4*0,8)+ (0*1,5)] /(0,8+1,4+1,2+1,1+1,2+1,2+0,8+0,8+1,5) =(0+0+0+0+0,24+0,12+0+0,32+0) / 10 =0,68 / 10 =0,068 .
Hasil perhitungan dari kedekatan data sampel nomor 2 dengan kasus baru 1 adalah 0,068
Dari data sampel 1 dan 2 dapat diketahui bahwa nilai yang terkeciladalah kasus nomor 2. Bearti kasus yang terdekat dengan kasus baru 1 adalah kasus nomor 2, dengan demikian hasil uji data kasus baru di prediksikan Tidak Layak.
Contoh Data Uji 2
Dibawah ini adalah perhitungan Kedekatan kasus baru data uji 2 dengan kasus lama data sampel nomor 1
A : Kedekatan bobot atribut status perkawinan (belum menikah dengan belum menikah)=0 B : Untuk bobot atribut status perkawinan = 0,8
C : Kedekatan bobot atribut jumlah tanggungan (tidak ada dengan tidak ada)= 0 D : Untuk bobot atribut jumlah tanggungan=1,4
E : Kedekatan bobot atribut status rumah (orang tua dengan pribadi)=1 F : Untuk bobot atribut status rumah=1,2
G : Kedekatan bobot atribut kondisi rumah (semi permanen dengan permanen)=1 H : Untuk bobot atribut kondisi rumah=1,1
I : Kedekatan bobot atribut pekerjaan (Polisi/TNI dengan pegawai pemerintah)=0,1 J : Untuk bobot atribut pekerjaan=1,2
K : Kedekatan bobot atribut status kepegawaian (PNS/ASN dengan PNS/ASN)=0 L : Untuk bobot atribut status kepegawaian=1,2
M : Kedekatan bobot atribut usia (21-55 dengan 21-55)=0 N : Untuk bobot atribut usia=0,8
O : Kedekatan bobot atribut status perusahaan (aparatur negara dengan lembaga negara)=0,1 P : Untuk bobot atribut status perusahaan=0,8
Q : Kedekatan bobot atribut DP (<10 – 20 % dengan < 20 – 30 %)=0,1 R : Untuk bobot atribut DP (Down Payment)=1,5
Similarity = [(A*B)+(C*D)+(E*F)+(G*H)+(I*J)+(K*L)+(M*N)+(O*P)+(Q*R)] / (B+D+F+H+J+L+N+P+R) =[(0*0,8)+(0*1,4)+(1*1,2)+(1*1,1)+(0,1*1,2)+(0*1,2)+(0*0,8)+(0,1*0,8)+(0,1*1,5)] / (0,8+1,4+1,2+1,1+1,2+1,2+0,8+0,8+1,5) =(0+0+1,2+1,1+0,12+0+0+0,08+0,15) / 10 =2,65 / 10 =0,265
Hasil perhitungan dari kedekatan data sampel nomor 1 dengan kasus baru nomor 2 adalah 0,265 - Dibawah ini adalah perhitungan Kedekatan kasus baru data uji 2 dengan kasus lama data sampel nomor 2
A : Kedekatan bobot atribut status perkawinan (belum menikah dengan menikah)=1 B : Untuk bobot atribut status perkawinan = 0,8
C : Kedekatan bobot atribut jumlah tanggungan (tidak ada dengan> 3)= 0,5 D : Untuk bobot atribut jumlah tanggungan=1,4
E : Kedekatan bobot atribut status rumah (orang tua dengan orang tua)=0 F : Untuk bobot atribut status rumah=1,2
G : Kedekatan bobot atribut kondisi rumah (semi permanen dengan non permanen)=0,5 H : Untuk bobot atribut kondisi rumah=1,1
I : Kedekatan bobot atribut pekerjaan (polisi/TNI dengan pegawai pemerintah)=0,1 J : Untuk bobot atribut pekerjaan=1,2
Jurnal Ilmiah Fakultas Teknik LIMIT’S Vol.13 No 1 September 2017 L : Untuk bobot atribut status kepegawaian=1,2
M : Kedekatan bobot atribut usia (21-55 dengan 21-55)=0 N : Untuk bobot atribut usia=0,8
O : Kedekatan bobot atribut status perusahaan (aparatur negara dengan lembaga negara)=0,1 P : Untuk bobot atribut status perusahaan=0,8
Q : Kedekatan bobot atribut DP (<10 – 20 % dengan <10%)=0,1 R : Untuk bobot atribut DP (Down Payment)=1,5
Similarity = [(A*B)+(C*D)+(E*F)+(G*H)+(I*J)+(K*L)+(M*N)+(O*P)+(Q*R)] / (B+D+F+H+J+L+N+P+R) =[(1*0,8)+(0,5*1,4)+(0*1,2)+(0,5*1,1)+(0,1*1,2)+(0,5*1,2)+(0*0,8)+(0,1*0,8)+(0,1*1,5)]/ (0,8+1,4+1,2+1,1+1,2+1,2+0,8+0,8+1,5) =(0,8+0,7+0+0,55+0,12+0,6+0+0,08+0,15) / 10 =3 / 10 =0,3
Hasil perhitungan dari kedekatan data sampel nomor 2 dengan kasus baru 2 adalah 0,3. Dari data sampel 1 dan 2 dapat diketahui bahwa nilai yang terkecil adalah kasus nomor 1. Dengan demikian kasus yang terdekat dengan kasus baru 2 adalah kasus lama atau data sampel nomor 1, dengan demikian hasil uji data kasus baru di prediksikan Layak.
HASIL
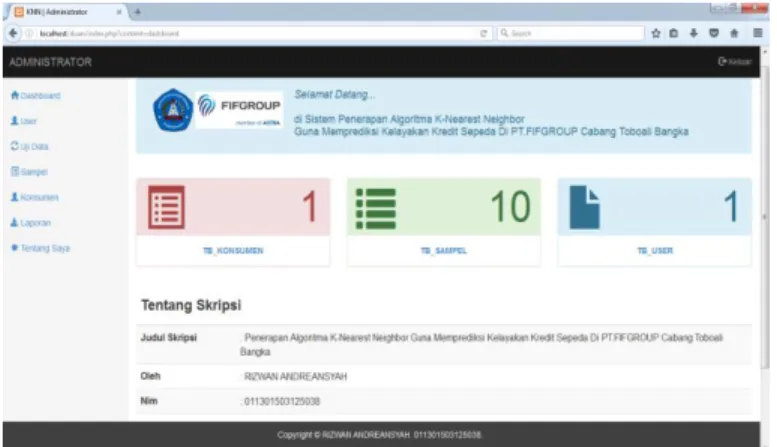
1. Tampilan Utama
Gambar 3. Tampilan Utama
Gambar diatas merupakan tampilan awal setelah admin melakukan login. Ditampilan Utama ini menampilkan beberapa menu yang bisa digunakan. TB_Konsumen Adalah data konsumen baru yang disimpan oleh admin, TB_SAMPEL Adalah kumpulan data atau kasus lama yang akan digunakan untuk mencari kedekatan dengan data atau kasus baru, sedangkan TB_User adalah data username dan password admin.
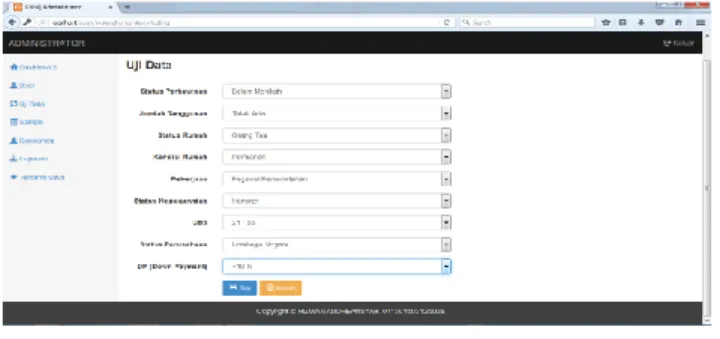
2. Form Data Uji
Gambar 4.Form Data Uji
Form data uji digunakan admin untuk melakukan input data konsumen baru, untuk mencari kedekatan antara kasus baru dengan kasus lama. Setelah admin melakukan input data konsumen baru dan mengklik tombol yang berwarna biru yang bertuliskan TES, maka program akan melakukan perhitungan K-NN.
3 Form Data Sampel
Gambar 5. Form Data Sampel
Gambar diatas adalah form data sampel yang didalamnya terdapat data atau kasus lama. Jika admin ingin melakukan input data sampel yang baru, maka admin mengklik tombol Tambah yang berada di atas sebelah kanan layar dan jika ingin menghapus atau merubah data, admin mengklik tombol biru untuk merubah dan tombol merah untuk menghapus data.
4 Form Hasil Prediksi
Gambar 6. Form Hasil Prediksi
Setelah melakukan pengujian data di Gambar 4 dan mencari kedekatan dari data sampel di Gambar 5, maka didapatkan hasil prediksi untuk konsumen baru Seperti Gambar diatas. Setelah hasil prediksi tampil, di tampilan ini juga akan menampilkan tombol yang berwarna biru untuk menambahkan data konsumen kedalam database perusahaan dan tombol berwarnah kuning untuk batal menambahkan data konsumen tersebut.
Jurnal Ilmiah Fakultas Teknik LIMIT’S Vol.13 No 1 September 2017
KESIMPULAN DAN SARAN
1. Kesimpulan
Proses untuk memprediksi kelayakan kredit sepeda motor dapat dilakukan dengan menerapkan algoritma k-nearest neighbor. Algoritma k-nearest neighbor dapat memprediksi konsumen baru yang ingin melakukan kredit dengan cara mencari kedekatan antara kasus konsumen baru yang ingin melakukan kredit dengan kasus lama sebagai data sampel, berdasarkan nilai-nilai atribut yang telah ditentukan oleh perusahaan dan kriteria-kriteria konsumen yang dinyatakan layak atau tidak layaknya konsumen baru tersebut. Adapun kesimpulan yang dapat diambil adalah algoritma k-nearest neighbor dalam kasus memprediksi konsumen baru yang ingin melakukan kredit sepeda motor ini sangatlah sesuai. Dalam tujuan penelitian ini adalah untuk menerapkan algoritma k-nearest neighbor guna memprediksi kelayakan kredit sepeda motor di PT. FIFGROUP Cabang Toboali Bangka.
DAFTAR PUSTAKA
Kusrini, Amha Taufiq Lutfhi. (2009). Algoritma Data Mining, 93-99.
Larose, D. T. (2005). Discovering Knowledge in Data: An Introduction to Data. John Willey & Sons, Inc.
Leidiyana, H. (2013). PENERAPAN ALGORITMA K-NEAREST NEIGHBOR UNTUK PENENTUAN RESIKO KREDIT KEPEMILIKAN KENDARAAN BEMOTOR. Jurnal Penelitian Ilmu Komputer, System Embedded & Logic, 65-76.
Muliadinata, Saban. (2014). Algoritma K-Nearest Neighbor (KNN). http://sharewy .blogspot.com/2013 /04/algoritma-k-nearest-neighbor-knn_16.html., 54-67. Pramudiono, I. (16 januari 2007). Apa Itu Data Mining?
"http:/datamining.japati.net/cgi-bin/indodm.cgi?bacaarsip&115552761&artikel".
Purwanti, E. (2015). Klasifikasi Dokumen Temu Kembali Informasi dengan K-Nearest Neighbor. 129-138.
Rivai, V. A. (2006). Credit Management Handbook. jakarta: Raja GrafindoPersada.
Rumbaugh, James, Jacobson, Ivan and Booch, Grady. (2005). The Unified Modeling Language User Guide.
Sumarlin. (2015). Implementasi Algoritma K-Nearest Neighbor Sebagai Pendukung Keputusan Klasifikasi Penerima Beasiswa PPA dan BBM. http://ejournal.undip.ac.id/index.php/jsinbis, 52-62.
Sunarfrihantono, B. (2002). PHP dan MySQL Untuk Web.