Fakultas Ilmu Komputer
Universitas Brawijaya
10516
Prediksi Keputusan Pelanggan Menggunakan Extreme Learning Machine
Pada Data Telco Customer Churn
Daris Hadyan Tisantri1, Randy Cahya Wihandika2, Sigit Adinugroho3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Pada zaman sekarang, banyak sekali perusahaan dan instansi yang berkompetisi menawarkan jasa seperti internet dan telekomunikasi yang menggunakan sistem berlangganan untuk menjual jasanya sehingga perusahaan tersebut harus berkompetisi melalui strategi pemasaran. Faktor penting dalam pengulangan pembelian pada pelanggan yaitu loyalitas. Loyalitas mempunyai hubungan berbanding lurus dengan performa bisnis. Faktor pemasaran dan loyalitas pelanggan inilah yang mengakibatkan banyaknya pelanggan yang berpindah/berhenti dari perusahaan satu dengan yang lain sejenis sehingga beberapa perusahaan kehilanngan pelanggan (Churn) yang mengakibatkan turunnya revenue
.
Jika perusahaan atau instansi dapat memprediksi churn,perusahaan atau instansi dapat mengantisipasi agar pelanggan tersebut tidak berhenti berlangganan. Pada penelitian ini, data yang digunakan pada penelitian berasal dari Kaggle yang bersumber dari IBM Sample Data Sets. Data ini terdiri dari 7043 data yang terdiri dari 20 fitur dengan dua kelas yaitu yes jika pelanggan churn dan no jika pelanggan tidak churn. Kemudian data akan dieliminasi fitur yang tidak digunakan menggunakan korelasi Pearson.
Kemudian data akan dilatih menggunakanExtreme Learning Machine untuk memprediksi pelanggan akan churn atau tidak. Hasil dari penelitian adalah mendapatkan akurasi sebesar 76,96%, precision churn sebesar 65,45%, precision non churn sebesar 78,65%, recall churn sebesar 29,38%, recall non churn sebesar 94,19%Kata kunci: Prediksi churn, Extreme Learning Machine, Loyalitas Abstract
In this modern era many company and institution compete to sell their services like internet and telecommunication that use subscription system to sell their services. Because of that, company must compete via marketing strategy. Main factor for customer to continuously extend their subscription is loyalty. Loyalty have directly proportional with business performance. Because of marketing factor and customer loyalty, many customers changed or stopped their subscription from one and another similar company and makes some company lost their customer and revenue. If company or institution can predict churn, they can anticipate so that customer didn’t churn. In this research, the dataset that used for this research is from Kaggle sourced from IBM Sample Data Sets. This dataset consists of 7043 data that have 20 features with two classes yes if the customer churn and no if the customer is not churn. After that, the feature on the dataset that not used will be eliminated with Pearson correlation. After that the data will be trained on Extreme Learning Machine to predict customer will churn or not. Result of this research is the system can get accuracy 76,96%, precision churn 65,45%, precision non churn 78,65%, recall churn 29,38%, recall non churn 94,19%
Keywords: Churn Prediction, Extreme Learning Machine, Loyalty
1. PENDAHULUAN
Pada zaman sekarang ini, banyak perusahaan-perusahaan dan instansi yang menawarkan jasa seperti internet dan telekomunikasi yang menggunakan sistem
berlangganan untuk menjual jasanya. Semakin banyaknya perusahaan kompetitor sejenis yang muncul, mengakibatkan adanya kompetisi diantara perusaan tersebut yang mengakibatkan perusahaan tersebut berkompetisi melalui strategi pemasaran. Loyalitas merupakan faktor
penting dalam pengulangan pembelian pada pelanggan. Loyalitas mempunyai hubungan berbanding lurus dengan performa bisnis yang dimana dapat menarik pelanggan baru (Dwi and Rosnita, 2010). Karena faktor marketing dan loyalitas pelanggan maka dapat mengakibatkan banyak pelanggan yang berhenti/berpindah dari perusahaan satu dengan yang lain sejenis sehingga beberapa perusahaan dapat kehilanngan pelanggan (Churn). Dengan hilangnya pelanggan, dapat mengakibatkan turunnya revenue perusahaan. Ketika perusahaan dapat memprediksi pelanggan akan melakukan churn, maka perusahaan atau instansi dapat mengantisipasi hal tersebut, perusahaan atau instansi dapat mencegah agar pelanggan tersebut tidak berhenti berlangganan. Salah satu penelitian sebelumnya dilakukan oleh Nurzahputra, Safitri dan Muslim (2016) yaitu menciptakan decision tree atau pohon keputusan tersebut menggunakan algoritme C4.5. Algoritme ini membentuk pohon kebutuhan dari atas ke bawah yang dimana bagian atas adalah akar dan bagian bawah merupakan daun. Metode ini memiliki kelebihan yaitu dapat dengan mudah menganalisis sejumlah besar atribut dari data yang tersedia serta dapat dipahami dengan mudah oleh end-user. Hasil dari prediksi sistem ini dapat memprediksi kira kira 61 pelanggan loyal dan 35 pelanggan churn (Nurzahputra, Safitri and Muslim, 2016)
Penelitian sebelumnya yang selanjutnya dilakukan oleh Arifin (2015) yaitu membandingkan berapa jauh peningkatan akurasi jika peneliti memprediksi customer churn dengan menggunakan pemilihan fitur Information gain dengan menggunakan klasifikasi KNN biasa. Pengujian dilakukan sepuluh kali dan akan diambil rata ratanya. Dan hasil dari penelitian tersebut yaitu dengan menggunakan information gain pada KNN penambahan akurasinya tidak signifikan yaitu hanya sebesar 1.7%.
Metode ELM ini mempunyai kelebihan pada waktu pelatihan yang lebih cepat dan dapat menghasilkan akurasi yang tinggi walaupun menggunakan data yang berjumlah besar (Rahma, Wijaya and Prawito, 2016). Metode ini bersifat single hidden layer feed-forward neural network bertipe maju dan hanya mempunyai satu hidden layer. ELM sendiri memiliki beberapa kelebihan yang diantaranya kecepatan training yang cepat dan mempunyai
generalisasi yang baik (Pangaribuan et al., 2016). Pada penelitian ini saya gunakan Extreme Learning Machine agar dapat mendeteksi apakah pelanggan akan churn menggunakan Extreme Learning Machine pada dataset Telco Customer Churn.
2. DASAR TEORI 2.1 Churn
Churn adalah keadaan yang cenderung untuk memberhentikan langganan dari produk atau jasa tertentu dalam suatu perusahaan. Kemudian pelanggan tersebut berpindah ke perusahaan lain (Alamsyah dan Salma, 2018). Penyebab pelanggan melakukan churn dikarenakan pelanggan ingin menggurangi atau memberhentikan penggunaan jasa yang pengguna pakai. Faktor yang menyebabkan pelanggan melakukan churn antara lain yaitu ingin berpindah ke perusahaan lain dengan jasa yang serupa, pelanggan yang ingin menurunkan atau menaikan paketnya (Chen, Li and Ge, 2011). Efek dari Customer churn dapat menyebabkan turunya revenue perusahaan. Sedangkan untuk mendapkan pelanggan baru di butuhkan dana yang tidak sedikit (Aditsania, Adiwijaya dan Saonard, 2017)
2.2 Extreme Learning Machine (ELM) ELM merupakan klasifikasi berbasis
neural network bersifat Neural Network
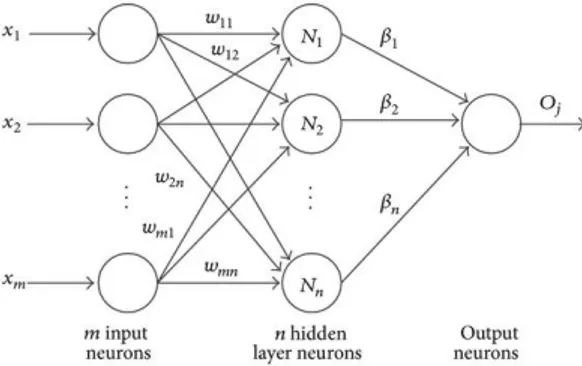
feed-forward dan mempunyai 1 hidden layer atau disebut sebagai single hidden layer feedforward (Huang, Zhu and Siew, 2006). ELM di bentuk agar dapat mengatasi masalah pada metode feed-forward Neural Network yang telah ada sebelumnya terutama pada kecepatan proses pelatihan (Huang, Zhu and Siew, 2006). Desain metode ini bisa dilihat pada Gambar 1.Gambar 1. Desain dari Extreme Learning Machine (ELM) (Zhu-Hong You, dkk., 2014)
Algoritme pelatihan Extreme Learning Machine yaitu:
1. Menginisialisasi weight 𝑊𝑗𝑘 menggunakan
angka acak.
2. Mencari output dari hidden layer dengan rumus 𝐻 = 1 (1 + exp (−𝐻𝑖𝑛𝑖𝑡)) (1) Dengan 𝐻𝑖𝑛𝑖𝑡= 𝑋𝑡𝑟𝑎𝑖𝑛 × (𝑊𝑗𝑘)𝑇 (2) Keterangan:
- 𝐻 = Output hidden layer
- 𝐻𝑖𝑛𝑖𝑡 = Inisialisasi output hidden
layer
- 𝑋𝑡𝑟𝑎𝑖𝑛 = Data Latih
- 𝑊𝑗𝑘 = Bobot Awal
3. Menghitung keluaran bobot menggunakan rumus 𝛽̂ = 𝐻+× 𝑌 𝑡𝑟𝑎𝑖𝑛 (3) Dengan 𝐻+= (𝐻𝑡 × 𝐻)−1× 𝐻𝑡 (4) Keterangan:
- 𝐻 = Keluaran dari hidden layer - 𝑌𝑡𝑟𝑎𝑖𝑛 = Kelas data latih
- 𝐻+ = matriks Moore-Penrose
Pseudoinverse
Algoritme pengujian Extreme Learning Machine yaitu:
1. Diketahui data bobot awal (𝑊𝑗𝑘)dan bobot
akhir (𝛽̂) dari hasil pelatihan
2. Menghitung output dari hidden layer menggunakan rumus 𝐻 = 1 (1 + exp (−𝐻𝑖𝑛𝑖𝑡)) (5) Yang dimana 𝐻𝑖𝑛𝑖𝑡= 𝑋𝑡𝑟𝑎𝑖𝑛 × (𝑊𝑗𝑘)𝑇 (6) Keterangan:
- 𝐻 = Keluaran hidden layer
- 𝐻𝑖𝑛𝑖𝑡 = Inisialisasi keluaran hidden
layer
- 𝑋𝑡𝑒𝑠𝑡 = Data uji
- 𝑊𝑗𝑘 = Bobot Awal
3. Kemudian menghtung prediksi dengan rumus
𝑌̂= 𝐻 × 𝛽̂ (7)
Keterangan:
- H = Output hidden layer - 𝑌̂= Kelas prediksi
- 𝛽̂ = Bobot baru
4. Mencari nilai yang akan di jadikan evaluasi seperti akurasi, precision dan recall
2.3 Confusion Matrix
Tabel ini, merupakan tabel untuk mengklasifikasikan jumlah data kelas uji yang benar dan dalah (Indriani, 2014). Dalam matriks ini, kelas aktual ditampilkan pada bagian atas matriks dan kelas hasil prediksi ditampilkan di sisi kiri. Setiap sel pada matriks, terdiri dari angka yang menunjukan berapa banyak kasus yang diambil untuk dirediksi(Hastuti, 2012). Bentuk dari tabel Confusion matrix bisa dilihat pada Tabel 1.
Tabel 1. Bentuk Tabel confusion matrix
Aktual Total
A B Prediksi
A TP(A) FN(B)/FP(A) nP(A)
Prediksi B FN(A)/FP(B) TP(B) nP(B)
Total Aktual
nA(A) nA(B) N
Keterangan:
- N = Jumah banyaknya data
- nA = Jumlah data aktual untuk suatu kategori
- nP = Jumlah data prediksi untuk suatu kategori
- TP (True Positive) = Kondisi yang menyatakan nilai prediksi sesuai dengan nilai aktualnya
- FN (False Negative) = Kondisi yang menyatakan suatu prediksi bernilai negatif tetapi aktualnya justru bernilai positif
- FP (False Positive) = Kondisi yang menyatakan suatu prediksi bernilai positif tetapi aktualnya justru bernilai negative Dari Tabel 1 kita dapat menghitung nilai akurasi yang didapat dari menghitung jumlah prediksi yang tepat pada semua kelas dibagi
dengan jumlah keseluruhan data, rumusnya dapat dilihat pada Persamaan 8.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =𝑇𝑃(𝐴) + 𝑇𝑃(𝐵) 𝑁
(8)
Nilai precision didapat dari menghitung nilai prediksi yang tepat dalam suatu kelas, kemudian dibagi dengan jumlah total dari nilai prediksi yang ada pada kelas tersebut, rumusnya dapat dilihat pada Persamaan 9.
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =𝑇𝑃(𝑐𝑙𝑎𝑠𝑠) 𝑛𝑃(𝑐𝑙𝑎𝑠𝑠)
(9)
Nilai recall didapat dari menghitung nilai prediksi yang tepat dalam suatu kelas, kemudian dibagi dengan jumlah total dari nilai aktual yang ada pada kelas tersebut, rumusnya dapat dilihat pada Persamaan 10
𝑅𝑒𝑐𝑎𝑙𝑙 =𝑇𝑃(𝑐𝑙𝑎𝑠𝑠) 𝑛𝐴(𝑐𝑙𝑎𝑠𝑠)
(10)
2.4 Korelasi Pearson
Korelasi berfungsi mencari kuat tidaknya
derajat
keeratan
hubungan
dari
dua
variabel
. Koefisien korelasi adalah nilai indeks yang berguna untuk mengukur hubungan antar 2 variabel (Nugroho, Akbar and Vusvitasari, 2008). Korelasi yang diunakan di penelitian ini yaitu Korelasi Pearson. Teknik Korelasi Pearson ini dalam implementasinya menggunakan skala interval atau rasio sebagai parameter korelasi. Parameter disebut dengann nilai koefisien korelasi yang dilambangkan dengan (𝑟) (Nugroho, Akbar and Vusvitasari, 2008). Nilai Kofisien Korelasi Pearson ini dapat dilihat pada Persamaan 11−1 ≤ 𝑟 ≤ 1 (11)
Keterangan
- 𝑟 = 1, memiliki hubungan antara data x dan y sempurna dan positif
- 𝑟 = -1, memiliki hubungan antara data x dan y sempurna dan negativ
-
r = 0, memiliki hubungan antara data x dan y sangat rendah atau tidakRumus Korelasi Pearson dapat di lihat pada Persamaan 12
𝑟 = ∑( 𝑥 − 𝑥̅)(𝑦 − 𝑦̅) √∑(𝑥 − 𝑥̅)2∑(𝑦 − 𝑦̅)2
(12)
Dengan:
- 𝑟 = Nilai koefisien korelasi - 𝑥 = data 1
- 𝑦 = data 2
- 𝑥̅ = Average dari data 1
- 𝑦̅ = Average dari data 2
3. METODOLOGI PENELITIAN 3.1 Gambaran Umum Penelitian
Sistem yang digunakan pada penelitian ini dibagi menjadi 2 yaitu preprocessing prosess ELM. Pertama, proses preprocessing yaitu proses dimana dataset akan diubah menjadi numerikal, kategorikal dan fitur akan di eliminasi menggunakan korelasi pearson. Untuk sistem preprocessing bisa dilihat pada Gambar 2
Sesudah data dipreprocessing, maka data akan masuk ke process ELM. Pada proses ELM data akan dilatih, diuji serta divalidasi dengan parameter precision, recall dan akurasi. Untuk Sistem ELM bisa dilihat pada Gambar 3.
Gambar 3. Proses ELM
3.2 Pengumpulan Data
Pada pengumpulan data, data didapatkan dari website Kaggle. Dataset Kaggle ini, bersumber dari IBM Sample Data Sets. Dataset Telco Customer Churn adalah dataset yang berbentuk .csv. Dataset ini terdiri dari 7043 data
,
dengan dua kelas yaitu yes jika pelanggan churn dan no jika pelanggan tidak churn. Setiap rekaman dataset ini terdiri dari dua puluh satu fitur dan satu kelas.4. PENGUJIAN DAN ANALISIS 4.1 Hasil Dari Pengujian Threshold
Pengujian
Threshold akan menguji pengaruh Threshold pada korelasi pearson terhadap hasil akurasi prediksi sistem. Besar threshold yang di gunakan pada pengujian ini yaitu 0; 0,05; 0,1; 0,15; 0,175; 0,2 dan 0,3 dengan banyak hidden neuron yaitu sebanyak jumlah fitur dari dataset yang sudah dieliminasi fiturnya. Hasil pengujian bisa dilihat pada tabel 2.Tabel 2.Akurasi ELM Dengan Threshold Tertentu
Dari Tabel 2 diketahui bahwa menggunakan threshold 0,175 menghasilan rata-rata akurasi yang terbaik dibandingkan menggunakan threshold-threshold yang lain sebesar 76,1 persen.
4.2 Hasil Dari Pengujian Hidden Neuron Pengujian mencari Hidden Neuron akan menguji pengaruh banyaknya Hidden Neuron terhadap hasil akurasi prediksi sistem. Banyaknya hidden neuron yang digunakan untuk pengujian yaitu sebanyak 1 sampai 7 dan menggunakan data dengan threshold 0,175 yang didapat dari pengujian sebelumnya. Hasil pengujian bisa dilihat pada Tabel 3.
Tabel 3.Akurasi ELM Dengan Variasi Banyaknya Hidden Neuron
Dari Tabel 3 dapat diketahui bahwa menggunakan banyaknya hidden neuron sebanyak 6 dapat menghasilkan akurasi yang terbaik daripada menggunakan banyak hidden neuron sebesar 1,2,3,4,5, atau 7.
4.3 Hasil Pengujian Keseluruhan
Pengujian yang terakhir yaitu pengujian keseluruhan yang berguna untuk mengukur performa ELM dalam memprediksi churn. Untuk pengujian ini, penulis akan mengkombinasikan banyaknya hidden neuron dan threshold untuk mengevaluasi performa system. Pengukuran performa yang digunakan yaitu akurasi, recall, precicion dan juga confusion matrix. Hasil evaluasi dapat dilihat pada Tabel 3.
Keterangan: - C = Churn
-
NC = Not ChurnDari Tabel 3 dapat diketahui hasil dari pengujian sebanyak lima kali perulangan adalah:
- Precision terbaik dihasilkan dari kelas non Churn sebesar 78,65%
- Recall terbaik dihasilkan dari kelas non Churn : 94,19%
- Akurasi sebesar 76,96%
Recall dan precision kelas churn rendah dikarenakan jumlah data dengan kelas churn dan non churn pada dataset tidak seimbang. Yaitu sebesar 5177 (73,5%) data berkelas non churn dan 1866 (26,5%) data berkelas churn. 4.4 Analisis
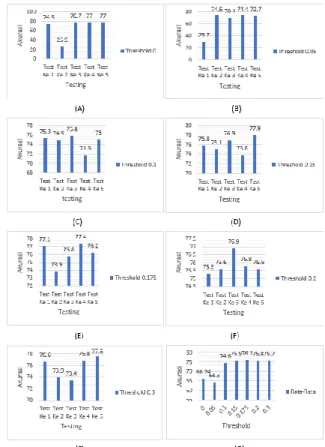
Sebelum evaluasi sistem dengan mencari akurasi,precision dan recall, pertama-tama kita harus mengeliminasi fitur dan menentukan banyaknya hidden neuron yang digunakan. Pertama, yaitu mengeliminasi fitur dengan korelasi pearson. Fungsi dari mengeliminasi fitur yaitu untuk membuang fitur yang tidak penting (noise) agar dapat menghasilkan hasil yang maksimal. Threshold yang di gunakan yaitu 0; 0,05; 0,1; 0,15; 0,175; 0,2 dan 0,3 Kemudian data akan diuji akurasi sebanyak 5 kali untuk melihat berapa threshold yang dapat menghasilkan rata-rata akurasi yang paing baik. Untuk hasil analisis bisa dilihat pada Gambar 4 dan 5
Gambar 4 Jumlah fitur dari hasil korelasi dengan
threshold tertentu
Gambar 5 Hasil Akurasi Dengan (A)Threshold 0, (B)Threshold 0,05,(C) Threshold 0,1, (D)Threshold
0,15, (E)Threshold 0,175, (F)Threshold 0,2, (G)Threshold 0,3, (H)Rata-rata Akurasi berdasarkan
Threshold
Dari Gambar 5 dapat disimpulkan bahwa dengan menggunakan threshold sebesar −0,175 ≤ 𝑥 ≤ 0,175 menghasilan rata-rata akurasi terbaik dibandingkan dengan menggunakan threshold lang lain. Hal ini disebabkan oleh curse of dimensionality atau kutukan dimensi. Kutukan dimensi ini terjadi jika ketika fitur ditambah atau di kurangi maka hasilnya akan semangkin bagus sampai dengan titik tertentu. Ketika sudah di titik tertentu tetapi fitur masih ditambah atau dikurang maka hasil perhitungan dari sistem tersebut akan menurun.
Tahap selanjutnya yaitu mencari banyaknya hidden neuron yang di gunakan untuk menghasilkan akurasi terbaik. Proses ini bertujuan agar menghindari underfitting dan overfitting sehingga bisa mendapatkan hasil yang maksimal
.
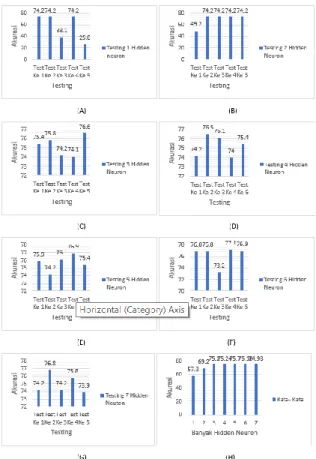
Banyaknya hidden neuron sebanyak 1 sampai 7 dengan menggunakan treshold −0,175 ≤ 𝑥 ≤ 0,175 yang di dapat dari pengujian sebelumnya. Kemudian data akan di uji akurasi sebanyak 5 kali untuk melihat berapa banyak hidden neuron yang bisa mendapatkan rata-rata akurasi terbaik. Hasilanalisis dapat dilihat pada Gambar 6
Gambar 4 Hasil Akurasi menggunakan 1
Hidden Neuron (A), 2 Hidden Neuron (B), 3 Hidden Neuron (C), 4 Hidden Neuron (D), 5 Hidden Neuron
(E), 6 Hidden Neuron (F), 7 Hidden Neuron (G) dan Rata-rata Akurasi berdasarkan banyaknya Hidden
Neuron (H),
Dari Tabel 4 dapat dilihat dengan menggunakan banyak hidden neuron sebanyak 6 menghasilan rata-rata akurasi terbaik dibandingkan menggunakan banyak hidden neuron sebesar 1,2,3,4,5 atau 7. Dapat disimpulkan jika menggunakan hidden neuron kurang dari 6 maka akan mengakibatkan underfitting yang dapat menyebabkan model yang terbentuk tidak dapat mengenai pola data. Sedangkan jika menggunakan hidden neuron kurang dari 6 maka akan mengakibatkan overfitting yang menyebabkan model yang terbentuk sangat mengenali data latih sehingga tidak dapat mengenali data testing dengan bailk 5. PENUTUP
5.1 Kesimpulan
Berdasarkan hasil percobaan dan pembahasan yang ada pada bab-bab sebelumnya. Disimpulkan bahwa Semakin
banyak hidden neuron maka akurasi bertambah tinggi, tapi akurasi terbaik di dapat di hidden neuron berjumlah 6 dengan rata rata akurasi sebesar 76,16%.
Performa terbaik di yang dapatkan adalah rata-rata akurasi sistem sebesar 76,96%, precision churn sebesar 65,45%, precision non churn sebesar 78,6%, recall churn sebesar 29,3%, recall non churn sebesar 94,19% yang diperoleh dari pengujian threshold yaitu sebesar -0,175≤x≤0,175 dan banyaknya neuron yang didapatkan dari pengujian pencarian hidden neuron terbaik yaitu sebanyak 6 hidden neuron..
5.2 Saran
Dari hasil penelitian yang sudah dilaksanakan, saran yang dapat di gunakan untuk referensi penelitian selanjutnya yaitu menggunakan optimasi bobot seperti Particle Swarm Optimation, algortime genetika, dan sebagainya. Dikarenakan pada penelitian ini bobot di inisialisasi secara acak, optimasi bobot ini digunakan ketika menginisialisasi bobot acak pada Extreme Learning Machine. Fungsi dari optimasi bobot agar dapat meningkatkan performa sistem dalam memprediksi churn. 6. DAFTAR PUSTAKA
Aditsania, A., Adiwijaya and Saonard, A.L., 2017. Handling imbalanced data in churn prediction using ADASYN and backpropagation algorithm. Proceeding - 2017 3rd International Conference on Science in Information Technology: Theory and Application of IT for Education, Industry and Society in Big Data Era, ICSITech 2017, [online] pp.533–536. Available at: <https://ieeexplore.ieee.org/document/8 257170>.
Alamsyah, A. and Salma, N., 2018. A Comparative Study of Employee Churn Prediction Model. 2018 4th International Conference on Science and Technology (ICST), [online] 1(2),
pp.1–4. Available at:
<https://ieeexplore.ieee.org/document/8 528586>.
Chen, Y.B., Li, B.S. and Ge, X.Q., 2011. Study on predictive model of customer churn
of mobile telecommunication company. Proceedings - 2011 4th International Conference on Business Intelligence and Financial Engineering, BIFE 2011, [online] pp.114–117. Available at: <https://ieeexplore.ieee.org/document/6 121101>.
Dwi, A. and Rosnita, F., 2010. Pengaruh Kualitas Layanan terhadap Kepuasan Pelanggan dalam Membentuk Loyalitas Pelanggan. Bisnis & Birokrasi: Jurnal Ilmu Administrasi dan Organisasi Print, [online] 17(2), pp.114–126.
Available at:
<http://journal.ui.ac.id/index.php/jbb/ar ticle/view/632>.
Hastuti, K., 2012. Komparasi Algoritma Klasifikasi untuk Mahasiswa Non Aktif. Seminar Nasional Teknologi Informasi & Komunikasi Terapan 2012, [online] 2012(Semantik), pp.241–249. Available at: <http://publikasi.dinus.ac.id/index.php/ semantik/article/view/132>.
Huang, G.-B., Zhu, Q.-Y. and Siew, C.-K., 2006. Extreme learning machine: algorithm, theory and applications. In: Neurocomputing. [online] pp.489–501.
Available at:
<https://www.sciencedirect.com/scienc e/article/pii/S0925231206000385>. Indriani, A., 2014. Klasifikasi Data Forum
dengan menggunakan Metode Naive Bayes Classifier. Seminar Nasional Aplikasi Teknologi Informasi (SNATI), [online] pp.5–10. Available at: <http://journal.uii.ac.id/Snati/article/vie w/3284>.
Nugroho, S., Akbar, S. and Vusvitasari, R.,
2008. Kajian Hubungan Koefisien Korelasi Pearson (r), Spearman-rho (?), Kendall-Tau (?), Gamma (G), dan Somers. Gradien, [online] 4(2), pp.372–381. Available at: <https://ejournal.unib.ac.id/index.php/g radien/article/view/279>.
Nurzahputra, A., Safitri, A.R. and Muslim, M.A., 2016. Klasifikasi Pelanggan pada Customer Churn Prediction Menggunakan Decision Tree. Prosiding Seminar Nasional Matematika X 2016, [online] pp.717–722. Available at: <https://journal.unnes.ac.id/sju/index.p hp/prisma/article/download/21528/1028 8/>.
Pangaribuan, J.J., Komputer, F.I., Pelita, U. and Medan, H., 2016. Mendiagnosis Penyakit Diabetes Melitus Dengan Menggunakan Metode Extreme Learning Machine. Journal Information System Development (ISD), [online]
1(2). Available at:
<https://ejournal.medan.uph.edu/index. php/isd/article/view/24>.
Rahma, O.N., Wijaya, S.K. and Prawito, 2016. Implementasi Extreme Learning Machine Sebagai Alat Bantu Identifikasi Stroke Iskemik Akut dan Normal dengan Metode Brain Symmetry Index. Jurnal Teknik Biomedis Indonesia, [online] 2(1),
pp.1–7. Available at: <https://www.researchgate.net/publicati on/301727087_Implementasi_Extreme _Learning_Machine_Sebagai_Alat_Ba ntu_Klasifikasi_Stroke_Iskemik_Akut_ dan_Normal_dengan_Metode_Brain_S ymmetry_Index>.