SEGMENTASI PRODUK MENGGUNAKAN TEKNIK
DATA MINING CLUSTERING
Langgeng Listiyoko
1)Joko Dewanto
2)Henderi
3) 1)Business Intelligence STMIK Raharja
2)3)Magister Teknik Informatika STMIK Raharja
email : [email protected], 2) [email protected], 3) [email protected]
ABSTRACT
Market /segmentation of product should be define clearly in order to achieve optimum selling. The activity may refer to the market survey in conventional. The research is developed regarding to build an automation in mining knowledge based on data history so the candidate product will be placed into suitable segment correctly. The Methodology use in Knowledge Discovering in Database (KDD) by clustering method with k-means algorithm, the research expected to resulting 3group/ market segmentation and thus will reported as optimum selling achievement.
Key words
Product segmentation, clustering, KDD, k-means, mining knowledge
1. Pendahuluan
Pencapaian penjualan merupakan parameter kinerja utama pada sebuah perusahaan. Laporan ini berasosiasi dengan kesuksesan pemasaran produk yang berdampak luas pada kelangsungan hidup perusahaan. Evaluasi tentang segmentasi/ mapping produk penting untuk mengetahui apakah kebutuhan pasar benar-benar telah dipenuhi.
Secara konvensional kegiatan menentukan segmentasi produk dilakukan secara GDSS (Group Decision Support System) yaitu menggali informasi dari beberapa pihak yang berkepentingan menurut sudut pandang dan kepentingan masing-masing. Dengan demikian sangat mungkin keputusan yang diambil bersifat subyektif sehingga kurang dapat dipertanggungjawabkan.
Teknik data mining clustering membantu menyelesaikan masalah penentuan segmentasi pasar dengan tingkat kepercayaan yang cukup tinggi. Data mining melakukan perhitungan matematis sedemikian hingga data history yang ada dapat dikelompokkan menurut keekatan sifat-sifat atau nilai variablenya.
2. Data Mining
Data mining merupakan sub sistem penting
dalam KDD (Knowledge Discovering in Database)
seperti dijelaskan Maimon et.al [11] seperti gambar
1 di bawah ini:
Gambar 1 Langkah KDD (Sumber: Maimon&Rokah)
Terdapat 9 langkah dalam KDD yang dapat dibagi ke dalam 3 bagian utama yaitu persiapan, proses, dan laporan. Langkah 1-4 (Domain understanding, selection & addition, preprocessing, transformation) dipandang sebagai bagian persiapan yang berperan menyiapkan data input. Data history diolah dengan melewati bagian utama hingga dapat diproses dengan baik pada proses data mining.
Proses data mining sendiri diawali dengan menentukan tipe data mining, menentukan algoritma dan implementasi (langkah 5,6,7 dalam KDD). Clustering adalah tipe data mining yang dipilih dalam penelitian ini dengan algoritma XK-Means [5].
Bagian laporan meliputi evaluasi terhadap kinerja data mining termasuk feasibility, akurasi, dan presisi. Interpretasi terhadap hasil yang tepat selanjutnya disajikan dalam bentuk laporan yang representatif kepada user (langkah 8 dan 9)
2.1 Data history
Data mining bekerja berdasarkan pola yang didapat dari sekumpulan data history. Data dimaksud adalah data latih yang secara spesifik telah diketahui keanggotaan kelompok/ segmen. Sistem akan mempelajari nilai yang dimiliki masing-masing item data atas variable yang melekat. Variable tersebut adalah segala hal yang dapat mempengaruhi pengambilan keputusan.
Ada 2 pendekatan karakteristik data mining kaitannya dengan data history, yaitu [4]:
Otomatisasi pencarian pola menggunakan teknik komputasi dari statistik, machine learning, dan pattern recognition.
Otomatisasi dalam kegiatan pengamatan terhadap informasi, yaitu identifikasi pola dan hubungannya yang tersembunyi.
Gambar 2 Relasi Data history, data test dan aplikasi data mining (Sumber:Gorunescu)
Gambar 2 menjelaskan peranan data history dalam kerangka data mining. Data history (training data set) adalah data yang dimilliki pada saat sistem dibangun. Kemudian dengan algoritma penyelesaian data mining yang dibangun sebagai aplikasi didapatkan pola relasi antar item set. Pola ini kemudian digunakan sebagai referensi penyelesaian masalah terhadap data test yang dimiliki kemudian.
Adapun data history dalam penelitian ini kaitannya dengan peningkatan penjualan mempertimbangkan dimensi-dimensi yang cukup menyulitkan user untuk menetapkan kelompok/segmentasi dengan cara manual. Dimensi-dimensi dimaksud adalah volume produksi, batch volume, margin, sell out, jumlah kompetitor, dan market size.
Tabel 1 Data history Prod uct ID Vol. Produksi Batch
Volume GM Sell Out Jml Kompetit
or
Market Size
Dim 1 Dim 2 Dim 3 Dim 8 Dim 9 Dim 10
1 1519.78 64.465 22.22 567.343 4 12000 2 2.5 2.5 33.54 136.195 3 3000 3 1512.703 23.274 45.01 7.78 6 15000 4 206 51.5 21.32 274.055 2 2500 5 368.73 46.091 41.07 3.085 2 6000 6 483.85 85.335 42.14 216.51 3 3000 7 683.07 93.188 46.56 119.973 5 6000 8 197.5 39.5 35.1 103.548 2 2000 9 93.6 35.056 42.3 15.185 1 1000 10 11914.38 413.708 33.92 2854.16 1 4000
Data yang ditunjukkan dalam Tabel 1 di atas diperoleh dari sebuah data warehouse dalam sebuah perusahaan. Nilai dari masing-masing dimensi berada dalam range yang cukup lebar. Kondisi ini yang selanjutnya menuntut adanya langkah preprocessing.
2.2 Clustering
Teknik clustering adalah salah satu algoritma data mining yang cukup membantu dalam usaha pengelompokan [5]. Secara umum clustering akan mengelompokkan sekumpulan data history sejumlah n kelompok yang dikehendaki user.
Semua nilai variable yang ada diusahakan sedemikian hingga berupa nilai numerik. Nilai numerik dibutuhkan mengingat clustering melakukan perhitungan matematis untuk mendapatkan pola pada data history untuk selanjutnya membuat kelompok berdasarkan kedekatan nilainya.
Beberapa usaha yang dapat dilakukan dalam preprocessing untuk mendapatkan nilai numerik pada algritma clustering misalnya[16] :
1. Agregasi 2. Diskretisasi
Pada Tabel 2 berikut ini dilakukan preprocessing terhadap dimensi 1, yaitu volume produksi.
Tabel 2 Distribusi nilai dimensi ke dalam range
Range Volume Rating
0 – 200,00 1 200,01 – 400,00 2 400,01 – 600,00 3 600,01 – 800,00 4 800,01 – 1000,00 5 >1000,00 6
Dengan demikian maka hasil preprocessing terhadap dimensi volume produksi ditunjukkan pada Tabel 3 sebagai berikut :
Tabel 3 Hasil preprocessing dimensi 1 Product ID Vol. Produksi Dim 1 1 6 2 1 3 1 4 2 5 2 6 3 7 4 8 1 9 1 10 6
Dengan teknik yang sama dilakukan pula terhadap dimensi 2-5. Penentuan range yang sesuai dengan data yang dimiliki menjadi teknik yang penting dalam menunjang keberhasilan clustering. Sebagai catatan pada dimensi market size tidak diberlakukan teknik deskritisasi seperti dimensi lainnya. Dimensi market size cukup dilakukan penyederhanaan bilangan mengingat rentang nilainya yang cukup jauh.
Secara lengkap hasil preprocessing adalah seperti pada Tabel 4 berikut :
Tabel 4 Hasil preprocessing final
Product ID
Vol. Produksi
Batch
Volume GM Sell Out
Jml Kompetit
or
Market Size
Dim 1 Dim 2 Dim 3 Dim 4 Dim 5 Dim 6
1 6 4 3 6 4 12 2 1 1 5 1 3 3 3 1 2 5 2 6 15 4 2 3 5 1 2 2.5 5 2 3 4 3 2 6 6 3 5 4 2 3 3 7 4 5 2 3 5 6 8 1 6 4 1 2 2 9 1 2 5 1 1 1 10 6 6 5 6 1 4
2.3 K-means
K-means merupakan algoritma yang populer untuk menyelesaikan tugas clustering. Sesuai namanya, prinsip pengelompokan k-means adalah berdasar kesamaan nilai rata-rata pada satu cluster. Adapun pada prakteknya, pencarian kemiripan ini merujuk pada kedekatan nilai obyek terhadap pusat cluster (centroid) yang tak lain adalah nilai rata-rata value anggota cluster.
Langkah-langkah dalam algoritma clustering dalam penelitian ini adalah sebagai berikut[5] :
1. Menentukan jumlah cluster 2. Inisialisasi
3. Menghitung pusat cluster/ centroid 4. Alokasi item set
5. Iterasi
2.3.1 Menentukan jumlah cluster
Pada mulanya user menentukan jumlah cluster, yang pada penelitian ini ditetapkan 3 cluster. Hal ini akan mewakili keadaan pasar sesungguhnya yakni segment bawah, menengah, dan atas.
2.3.2 Inisialisasi
Selanjutnya yang dilakukan adalah inisialisasi, yaitu menetapkan secara acak keanggotaan item set ke dalam cluster yang telah dibentuk. Umumnya inisialisasi dikerjakan atas dasar hasil keputusan melalui GDSS, baik itu yang sedang berlangsung maupun berupa ekspektasi. Tujuan dari tahap inisialisasi adalah memberikan ruang pada sistem untuk menentukan centroid yang merupakan tahapan algoritma selanjutnya.
Mengingat data history yang digunakan dalam penelitian adalah kondisi sesungguhnya yang sedang berlaku (existing) maka model inisialisasi yang dianut algoritma clustering sangat membantu menyelesaikan masalah segmentasi pasar. Nantinya akan dilihat komparasi hasil segmentasi yang terbentuk oleh GDSS dan Data Mining.
Tabel 5 Inisialisasi cluster Product
ID Vol. Produksi
Batch
Volume GM Sell Out Jml Kompetit
or
Market Size Cluster Dim 1 Dim 2 Dim 3 Dim 4 Dim 5 Dim 6
1 6 4 3 6 4 12 C3 2 1 1 5 1 3 3 C3 3 1 2 5 2 6 15 C1 4 2 3 5 1 2 2.5 C2 5 2 3 4 3 2 6 C1 6 3 5 4 2 3 3 C3 7 4 5 2 3 5 6 C1 8 1 6 4 1 2 2 C2 9 1 2 5 1 1 1 C3 10 6 6 5 6 1 4 C2 2.3.3 Menghitung centroid
Pusat cluster atau centroid dapat dibayangkan sebagai pusat magnet yang akan memiliki kemampuan menarik item set data history yang berada dalam range jarak. Item set yang dimiliki secara tepat hanya akan tertarik kepada satu centroid saja. Keadaan seperti ini sangat sesuai dengan tujuan penelitian ini yaitu menghilangkan keraguan/ ambiguitas. Dalam kenyataannya diharapkan item set akan berada pada segmen yang tepat.
Rumus (1) di bawah ini digunakan untuk menghitung centroid pada masing-masing dimensi. Dapat dijelaskan bahwa Ci adalah centroid dimensi ke-i, M merupakan jumlah anggota cluster, dan x adalah nilai/value dari dimensi ke-i masing-masing anggota cluster.
...(1) Dengan demikian maka centroid untuk cluster 1 sesuai inisialisasi adalah seperti pada Tabel 6 berikut:
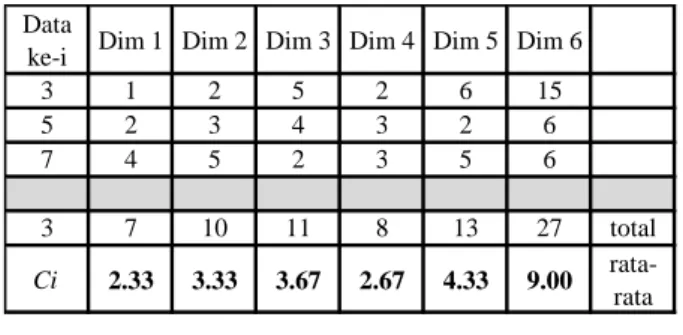
Tabel 6 Perhitungan centroid C1 Data
ke-i Dim 1 Dim 2 Dim 3 Dim 4 Dim 5 Dim 6
3 1 2 5 2 6 15 5 2 3 4 3 2 6 7 4 5 2 3 5 6 3 7 10 11 8 13 27 total Ci 2.33 3.33 3.67 2.67 4.33 9.00 rata-rata Sedangkan secara lengkap seluruh centroid yang terbentuk dari inisialisasi ditunjukkan dalam Tabel 7 berikut :
Tabel 7 Centroid untuk masing-masing cluster Centroid- Dim 1 Dim 2 Dim 3 Dim 4 Dim 5 Dim 6
1 2.33 3.33 3.67 2.67 4.33 9.00
2 3.00 5.00 4.67 2.67 1.67 2.83
3 2.75 3.00 4.25 2.50 2.75 4.75
2.3.4 Alokasi item set
Setelah centroid dapat ditentukan, maka selanjutnya adalah menetapkan anggota cluster dengan cara menghitung jarak Euclidean item set ke masing-masing centroid. Jarak terdekat menandakan keanggotaan item terhadap cluster. Keadaan selanjutnya bisa jadi anggota masing-masing cluster berubah dari kondisi inisialisasi.
...(2) Rumus (2) merupakan perhitungan Euclidean, di mana D(x2-x1) menyatakan jarak masing-masing item set terhadap sebuah centroid, P adalah populasi atau jumlah dimensi, x2j adalah nilai dimensi ke-j item set, x1j adalah centroid dimensi ke-j pada sebuah cluster. Untuk masing-masing item set dilakukan perhitungan jarak Euclidean terhadap centroid yang ada untuk mengetahui jarak terdekat (minimal) sehingga dapat ditentukan keanggotaan cluster selanjutnya.
Tabel 8 Alokasi cluster baru
Data ke-i C1 C2 C3 Cluster
1 5.878397 10.64712 8.916277 C1 2 7.039571 4.969351 3.605551 C3 3 6.674995 13.42986 10.97725 C1 4 7.243771 2.848001 3 C2 5 3.858612 3.961621 1.732051 C3 6 6.44636 1.641476 2.738613 C2 7 4.229526 5.418589 4.1833 C3 8 8.137704 3.004626 4.743416 C2 9 9.122621 4.437842 4.898979 C2 10 8.339997 4.798727 6 C2
Tabel 8 di atas adalah hasil lengkap perhitungan jarak Euclidean yang dengannya diketahui kondisi terbaru mengenai keanggotaan cluster.
2.3.5 Iterasi
Jika terjadi perubahan anggota cluster maka langkah selanjutnya adalah iterasi. Iterasi dilakukan terhadap langkah perhitungan ulang centroid berdasar kondisi terbaru, dan selanjutnya kembali mengalokasikan anggota cluster. Iterasi ini dilanjutkan sehingga dicapai kondisi di mana anggota cluster tidak berubah dari iterasi sebelumnya.
3. Hasil Percobaan
Dari data history yang dimiliki diperoleh pola yang dapat divisualisasikan dalam segmentasi produk sebagai berikut :
Tabel 9 Hasil clustering (DM vs GDSS)
ID Cluster Awal Cluster Akhir 1 3 1 2 3 3 3 1 1 4 2 2 5 1 1 6 3 2 7 1 3 8 2 2 9 3 2 10 2 2
Dengan dihasilkannya tabel 9 hasil di atas maka dapat dikatakan bahwa sistem telah menemukan knowledge yang berguna untuk melakukan pekerjaan yang sama terhadap beberapa data lain yang diberikan. Pengujian terhadap knowledge pada penelitian ini dilakukan dengan cara sebagai berikut :
Gambar 3 Metode pengujian
Dijelaskan pada gambar 3 di atas bahwa hasil clustering terhadap data test beserta data history akan dievaluasi mengenai konsistensi membership. Presisi direfleksikan oleh kesamaan hasil clustering item data
history sebelum dan sesudah ditambahkan data test. Untuk melakukan testing ini dapat dibantu oleh engine data mining Rapid Miner 5.3.
Dalam penelitian ini dilakukan pengujian terhadap 10 data baru yang secara GDSS telah ditentukan segmentasinya. Data yang diberikan nantinya akan bertindak sebagai intruder yang mungkin saja dapat mempengaruhi knowledge yang telah dimiliki sebelumnya. Data test tersebut adalah seperti Tabel 10 berikut :
Tabel 10 Inisialisasi data test secara GDSS
ID Dim 1 Dim 2 Dim 3 Dim 4 Dim5 Dim6 Cluster
A 4 2 3 6 5 8 C2 B 3 1 3 1 2 4 C3 C 3 2 5 2 6 7 C3 D 2 6 5 1 3 4 C2 E 6 3 2 3 2 6 C1 F 3 5 1 5 3 3 C2 G 4 5 2 3 5 6 C1 H 5 6 4 1 2 2 C1 I 1 4 5 4 4 1 C3
Hasil testing terhadap data test yang melibatkan data history ditunjukkan pada tabel 11 berikut :
Tabel 11 Hasil pengujian data test dengan knowledge data history
No Cluster (Init) Final 1 1 1 2 3 3 3 1 1 4 2 2 5 1 1 6 2 2 7 3 1 8 2 2 9 2 3 10 2 2 A 2 1 B 3 3 C 3 1 D 2 2 E 1 1 F 2 2 G 1 1 H 1 2 I 3 2 J 1 1
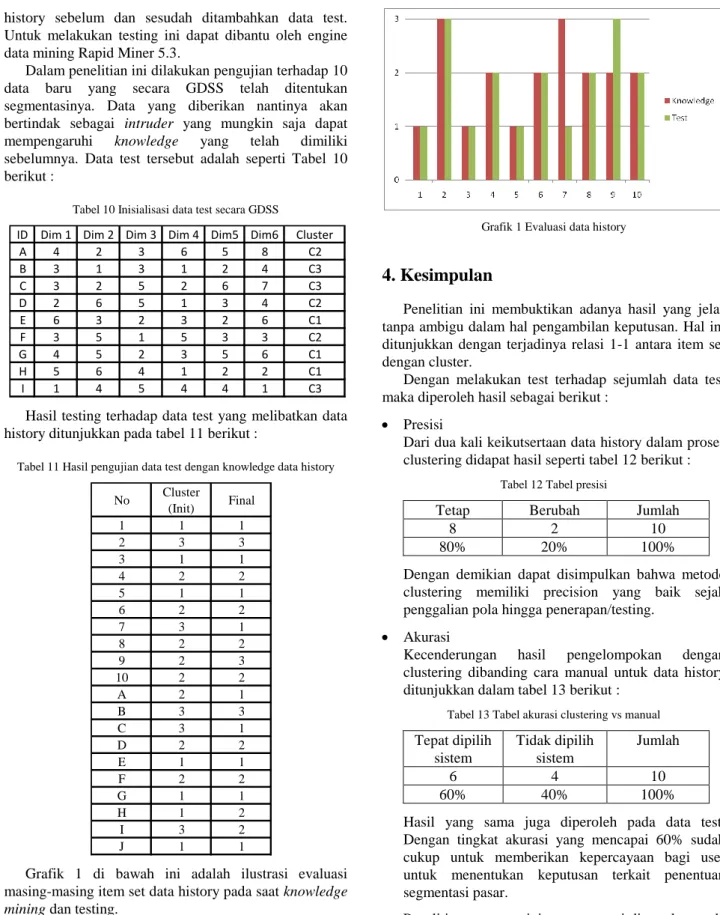
Grafik 1 di bawah ini adalah ilustrasi evaluasi masing-masing item set data history pada saat knowledge mining dan testing.
Grafik 1 Evaluasi data history
4. Kesimpulan
Penelitian ini membuktikan adanya hasil yang jelas tanpa ambigu dalam hal pengambilan keputusan. Hal ini ditunjukkan dengan terjadinya relasi 1-1 antara item set dengan cluster.
Dengan melakukan test terhadap sejumlah data test maka diperoleh hasil sebagai berikut :
Presisi
Dari dua kali keikutsertaan data history dalam proses clustering didapat hasil seperti tabel 12 berikut :
Tabel 12 Tabel presisi
Tetap Berubah Jumlah
8 2 10
80% 20% 100%
Dengan demikian dapat disimpulkan bahwa metode clustering memiliki precision yang baik sejak penggalian pola hingga penerapan/testing.
Akurasi
Kecenderungan hasil pengelompokan dengan clustering dibanding cara manual untuk data history ditunjukkan dalam tabel 13 berikut :
Tabel 13 Tabel akurasi clustering vs manual Tepat dipilih sistem Tidak dipilih sistem Jumlah 6 4 10 60% 40% 100%
Hasil yang sama juga diperoleh pada data test. Dengan tingkat akurasi yang mencapai 60% sudah cukup untuk memberikan kepercayaan bagi user untuk menentukan keputusan terkait penentuan segmentasi pasar.
Penelitian semacam ini sangat sesuai diterapkan pada model simplifikasi produk atau proses akuisisi yang berguna untuk meminimalisir duplikasi. Lebih jauh hasil yang dapat diperoleh adalah peningkatan penjualan seiring dengan turunnya tingkat kompetisi dalam satu segmen pasar.
Penelitian ini dapat dikembangkan lagi untuk mendapatkan nilai akurasi dan presisi dengan banyak variasi pada skenario inisialisasi.
REFERENSI
[1] Bishop, C. M., 2006, “Pattern Recognition and Machine Learning”, Springer, New York.
[2] Bramer, M., 2007, “Principles of Data Mining”, Springer, London.
[3] Ediyanto, Mara, M. N., & Satyahade, N., 2013, “Pengklasifikasian Karakter Dengan Metode K-Means Cluster Analysis”, Buletin Ilmiah Mat. Stat. dan Terapannya (Bimaster) , 133-136.
[4] Gorunescu, F., 2011, “Data Mining Concepts, Models and Techniques”, Springer, Berlin.
[5] Han, J., & Kamber, M., 2006, “Data Mining : Concepts and Techniques”, Elsevier, San Fransisco.
[6] Hand, D., Mannila, H., & Smyth, P., 2001, “Principles of Data mining”, MIT Press, London.
[7] Hermawati, F. A., 2013, “Data Mining”, Andi Publisher, Yogyakarta.
[8] Irdiansyah, E., 2010, “Penerapan Data Mining Pada Penjualan Produk minuman Di PT. Pepsi Cola Indobeverages Menggunakan Metode Clustering”, Jurnal TA/SKRIPSI Unikom .
[9] Larose, D. T., 2005, “Discovering Knowledge in Data : An Introduction to Data Mining”, John Wiley & Sons, Inc., New jersey.
[10] Lindawati, 2008, “Data Mining Dengan Teknik Clustering Dalam Pengklasifikasian Data Mahasiswa”, Seminar Nasional Informatika , 174-180.
[11] Maimon, O., & Rokach, L., 2010, “Data Mining And Knowledge Discovery Handbook (Second Edition)”, Springer, New York.
[12] Muningsih, E., & Kiswati, S., 2015, “Penerapan Metode K-Means Untuk Clustering Produk Online Shop Dalam Penentuan Stok Barang”, Jurnal Bianglala Informatika , 10-17.
[13] Ong, J. O., 2013, “Implementasi Algoritma K-Means Clustering Untuk Menentukan Strategi Marketing President University”, Jurnal Ilmiah Teknik Industri , 10-20.
[14] Riswawan, T., & Kusumadewi, S., 2008, “Aplikasi K-Means Untuk Pengelompokan Mahasiswa Berdasarkan Nilai Body Mass Index (BMI) & Ukuran Kerangka”, Seminar Nasional Aplikasi Teknologi Informasi , E43-E48.
[15] Susanto, S., & Suryadi, D., 2010, “Pengantar Data Mining Menggali Pengetahuan Dari Bongkahan Data”, Andi Publisher, Yogyakarta.
[16] Vercellis, C., 2009, “Business Intelligence : Data Mining And Optimization For Decision Making”, John Wiley & Son Ltd, Padstow.
Langgeng Listiyoko, memperoleh gelar S.Kom tahun2008 di
STMIK Muhammadiyah Jakarta. Saat ini sedang
menyelesaikan study pada jurusan Business Intelligence STMIK Raharja Tangerang.