BAB 2
LANDASAN TEORI
2.1 Basis Data
Basis data merupakan sekumpulan data yang besar dan saling terhubung yang dapat digunakan secara bersamaan oleh banyak departemen dan pengguna. Basis data berisi data operasional dan mengandung deskripsi data. Basis data disebut sebagai gabungan data yang merupakan kumpulan penjelasan tentang dirinya sendiri. Deskripsi dari data merupakan system catalog (kamus data atau meta-data, yaitu informasi data mengenai data itu sendiri) (Connolly, 2002, p14).
Basis data adalah sekumpulan dari data yang tetap yang digunakan oleh sistem aplikasi dari perusahaan. Perusahaan mungkin berupa individu tunggal (dengan basis data perseorangan yang kecil), atau perusahaan besar (dengan basis data besar yang bersifat sharing), atau di antara keduanya (Date, 2000, p10).
Dalam arsitektur sistem basis data terdiri dari tiga level, yaitu level external, level conceptual, dan level internal. Level external mempunyai beberapa skema eksternal atau user view. Tiap skema menggambarkan bagian dari basis data yang dapat menampilkan dan menyembunyikan sebagian data dari pengguna. Level conceptual mempunyai skema konseptual, yang menggambarkan keseluruhan basis data untuk komunitas pengguna. Skema konseptual menyembunyikan detil dari struktur penyimpanan physical dan berpusat dalam menggambarkan entitas, tipe data, hubungan, operasi dan batasan. Level internal mempunyai skema internal, yang menggambarkan struktur penyimpanan physical
dalam basis data. Skema internal menggambarkan secara lengkap detil penyimpanan data dan akses ke basis data. (Elmasri , 2000, p27). Internal view, yang digambarkan oleh skema internal, mendefinisikan bermacam-macam tipe baris dan juga indeks yang tersedia, bagaimana menampilkan data yang disimpan, urutan baris disimpan dalam physical storage (Date, 2000, p40).
2.2 Relational Database
Relational database berdasarkan dari relational model dan menggunakan kumpulan tabel untuk menggambarkan baik data maupun hubungan yang ada di antara data (Silbreschatz, 2006, p11). Dalam buku Elmasri dituliskan bahwa relational model pertama kali diperkenalkan oleh Ted Codd dari IBM Research tahun 1970 dalam sebuah karya ilmiah, dan menarik perhatian karena kesederhanaan dan landasan matematikanya. Model ini menggunakan konsep dari sebuah relasi matematika yang melihat nilai dari sebuah tabel sebagai dasar dari kumpulan data dan mempunyai dasar teori dalam set dan logika pengurutan.
Relational model merepresentasikan sebuah basis data sebagai kumpulan relasi. Setiap relasi merupakan tabel atau sebuah “flat” file dari baris-baris yang ada. Ketika sebuah relasi dibayangkan seperti sebuah tabel, tiap baris dalam tabel merepresentasikan sebuah kumpulan data yang terhubung. Dalam terminologi formal relational model, sebuah baris disebut tuple, sebuah header kolom disebut atribut, dan tabel disebut sebuah relasi. Tipe data yang menjelaskan nilai yang dapat dimunculkan pada tiap kolom disebut domain (Elmasri , 2000, p196).
2.2.1 Struktur Data Relational
Dalam Connolly (2002, p72-74) ditulis bahwa struktur data relational terdiri dari:
• Relasi
Suatu relasi adalah sebuah tabel dengan kolom-kolom dan baris-baris. • Atribut
Suatu atribut adalah sebuah nama kolom dari suatu relasi. • Domain
Sebuah domain merupakan sekumpulan nilai-nilai yang diperbolehkan bagi satu atau lebih atribut.
• Tuple
Tuple merupakan sebuah baris dari sebuah relasi. • Derajat (degree)
Derajat dari suatu relasi adalah sejumlah atribut yang terkandung di dalamnya.
• Kardinalitas (cardinality)
Kardinalitas dari sebuah relasi adalah sejumlah tuple yang terkandung di dalamnya.
• Relasi Basis Data
Suatu koleksi dari sejumlah relasi normalisasi dengan nama-nama relasi yang jelas.
2.2.2 Domain, Atribut, Tuple dan Relasi
Sebuah domain adalah sebuah set dari nilai yang atomik. Atomik berarti tidak dapat dipisahkan sejauh yang dibutuhkan oleh relational model. Salah satu metode untuk menjelaskan sebuah domain adalah dengan menjelaskan tipe data dari data yang membentuk domain tersebut. Selain itu, memberikan nama sebuah domain juga berguna untuk membantu menjelaskan nilai yang ada didalamnya.
Contoh:
¾ Nama : sebuah set nama-nama orang
¾ No_Telp : sebuah set nomor telepon yang panjangnya 10 digit angka dimana terkandung kode area di dalamnya
Bentuk ini disebut definisi logikal dari domain. Tipe data atau format juga dijelaskan untuk setiap domain. Sebuah skema relasi, yang digambarkan dengan R (A1, A2, ... , An), terdiri dari sebuah nama relasi R
dan sebuah daftar atribut A1, A2, ... , An yang berguna untuk menjelaskan
sebuah relasi. Setiap atribut Ai merupakan nama dari sebuah aturan untuk
beberapa domain D dalam skema relasi R. D disebut domain dari Ai dan
digambarkan dengan dom (Ai). Sebuah skema relasi digunakan untuk
menggambarkan sebuah relasi. Degree dari sebuah relasi adalah jumlah atribut yang dimiliki skema relasi .
Sebuah relasi r dari skema relasi R (A1, A2, ... , An), juga
digambarkan dengan r(R), yang merupakan sebuah bentuk dari n-tuples r = {t1, t2, ... tm}. Setiap n-tupleadalah daftar yang terurut dari n nilai r = < v1,
dom (Ai) atau merupakan nilai null. Nilai yang ke-i, yang berhubungan
dengan atribut Ai digambarkan dengan t[Ai] (Elmasri , 2000, p197-p198).
2.2.3 Karakteristik Relasi
Definisi awal relasi adalah karakteristik tertentu yang membuat sebuah relasi menjadi berbeda dengan sebuah file maupun sebuah tabel. Karakteristik relasi sebagai berikut:
• Tuple-tuple dalam sebuah relasi tidak diurutkan
• Pengurutan atribut dalam sebuah skema relasi dan juga pengurutan nilai dalam sebuah tuple
• Sebuah alternatif definisi relasi yang diberikan tidak membutuhkan dua kali pengurutan, tapi dengan menggunakan definisi pertama yang membutuhkan atribut dan nilai tuple terurut saat dibutuhkan (Elmasri, 2000, p199).
2.2.4 Entity Integrity, Referential Integrity dan Foreign Key
Nilai yang unik yang digunakan untuk mengenali tuple-tuple dalam sebuah relasi disebut primary key. Entity Integrity Constraint menyatakan bahwa nilai primary key tidak boleh null karena primary key digunakan untuk mengenali tuple individual dalam relasi sehingga apabila primary key bernilai null maka akibatnya akan ada beberapa tuple yang tidak dapat dikenali.
Key constraint dan entity integrity constraint dikhususkan pada relasi individual sedangkan referential integrity constraint dikhususkan antara 2 relasi untuk menjaga konsistensi di antara tuple-tuple pada 2 relasi tersebut. Secara tidak langsung, referential integrity constraint mengatur agar sebuah tuple dalam sebuah relasi yang terhubung ke relasi lain juga harus terhubung pada sebuah tuple yang terdapat dalam relasi lain tersebut.
Untuk menjelaskan referential integrity secara formal, kita harus mendefinisikan terlebih dahulu konsep dari foreign key. Foreign Key adalah primary key yang mejadi atribut pada relasi lain sehingga relasi-relasi tersebut saling terhubung (Elmasri , 2000, p206-p207).
2.2.5 Operasi Insert, Update, Delete • Operasi Insert
Operasi insert digunakan untuk memasukkan tuple baru dalam sebuah relasi. Operasi insert mendukung sebuah daftar nilai atribut pada sebuah tuple baru sehingga dapat masuk ke dalam relasi. Insert dapat gagal karena:
- nilai sebuah key pada tuple baru sudah pernah ada dalam tuple yang lain dalam sebuah relasi yang sama.
- Primary key pada tuple baru tersebut bernilai null.
- Nilai referential integrity yang menjadi foreign key pada tuple baru tersebut tidak terdapat pada relasi yang terhubung tersebut. • Operasi Update
Operasi update digunakan untuk mengubah nilai dari beberapa atribut pada tuple yang terdapat dalam sebuah relasi. Dibutuhkan penjelasan untuk beberapa kondisi operasi update. Contohnya: saat mengubah sebuah primary key pada sebuah tuple yang menjadi foreign key untuk relasi yang lain. Selain itu perlu dicocokkan tipe data dan domainnya apakah sudah benar.
• Operasi Delete
Operasi delete digunakan untuk menghapus tuple dari sebuah relasi. Operasi delete dapat mengalami kegagalan karena tuple yang ingin dihapus mempengaruhi tuple pada relasi yang lain. Ada 3 cara penanganan kegagalan tersebut antara lain:
o Menolak operasi delete tersebut
o Ikut menghapus tuple yang berhubungan dengan tuple yang ingin dihapus
o Mengabaikannya walaupun hasilnya akan mengganggu entity integrity relasi lain yang terpengaruh (Elmasri , 2000, p209-p211).
2.2.6 Dasar Operasi untuk Relational Aljabar
Dalam Elmasri ditulis bahwa operasi yang sederhana terdiri dari operasi select dan project.
¾ Operasi Select
Operasi select digunakan untuk memilih sebagian baris dari sebuah tabel sesuai dengan kondisi seleksi. Hal ini menyebabkan operasi select
melakukan pemilihan baris dan yang ditampilkan hanya baris yang memenuhi kondisi.
σ <selecttion condition> (R)
untuk σ (sigma) menggambarkan operasi select dan hasilnya akan memiliki atribut yang sama dengan R. Ekspresi dalam <selection condition> dengan format <nama atribut> <operator pembanding> <nilai konstan> atau <nama atribut> <operator pembanding> <nama atribut> dimana <nama atribut> adalah nama dari atribut R, <operator pembanding> biasa terdiri dari {=,<,≤,>,≥,≠}.
¾ Operasi Project
Operasi project digunakan untuk memilih sebagian kolom sehingga kolom yang lain tidak ditampilkan. Penggunaannya juga dapat digabungkan dengan operasi select.
Π<daftar atribut> (R)
untuk Π (pi) adalah simbol yang digunakan untuk menampilkan operasi project dan <daftar atribut> merupakan daftar atribut dari atribut dalam R (Elmasri , 2000, p211-p215).
2.3 Database Management System (DBMS)
Database management system (DBMS) merupakan sebuah perangkat lunak yang memungkinkan pengguna untuk mengenali, membuat, memelihara dan mengkontrol akses ke basis data (Connolly, 2002, p4). DBMS merupakan perangkat lunak yang dirancang untuk membantu dalam memelihara dan menggunakan koleksi data yang besar (Gehrke, 2003, p4),.
DBMS adalah perangkat lunak yang menghubungkan antara program aplikasi yang digunakan pengguna dengan basis data. DBMS menyediakan beberapa fasilitas, yaitu:
• DBMS memungkinkan pengguna untuk mendefinisikan basis data melalui Data Definition Language (DDL).
• DBMS memungkinkan pengguna untuk menambah, mengubah, mengambil maupun menghapus data dari basis data melalui Data Manipulation Language (DML).
• Menyediakan kontrol pengaksesan terhadap basis data, yaitu:
Security system yang berfungsi untuk mencegah pengguna yang tidak berhak mengakses basis data.
Integrity system yang berfungsi untuk memelihara konsistensi data yang disimpan.
Concurrency control system yang berfungsi untuk mengijinkan pemberian hak akses pada basis data.
Recovery control system yang berfungsi untuk melakukan mengambalikan data ke kondisi sebelumnya jika terjadi kegagalan perangkat keras atau perangkat lunak.
User accessible catalog yang berisi deskripsi-deskripsi dari data dalam basis data.
Dalam Connolly (2002, p18) ditulis bahwa komponen utama dari DBMS yaitu : o Perangkat keras (Hardware)
Untuk menjalankan DBMS dan aplikasi, dibutuhkan perangkat keras. Perangkat keras yang digunakan dapat berupa komputer pribadi (PC), mainframe tunggal, sampai komputer jaringan.
o Perangkat lunak (Software)
Komponen perangkat lunak terdiri dari perangkat lunak DBMS itu sendiri dan program aplikasi, bersama-sama dengan sistem operasi, termasuk perangkat lunak jaringan jika DBMS digunakan melalui jaringan. Biasanya program aplikasi ditulis dengan bahasa pemrograman generasi ketiga (3GL) seperti C, C++, Java, VB, atau menggunakan generasi keempat (4GL) seperti SQL digabungkan di 3GL.
o Data
Komponen paling penting dari lingkungan DBMS adalah data. Data berperan sebagai jembatan antara komponen mesin dan manusia. Basis data terdiri dari data operasional dan meta-data (informasi data tentang data itu sendiri). o Prosedur
Prosedur mengacu pada instruksi dan aturan-aturan yang menentukan desain dan penggunaan basis data. Pengguna sistem dan staff yang mengatur basis data membutuhkan dokumen berisi aturan bagaimana menjalankan sistem. o Pengguna
Komponen terakhir dari DBMS adalah orang yang terkait dengan sistem.
2.4 Relational Database Management System (RDBMS)
Dalam Webopedia (2002) ditulis bahwa RDBMS adalah sebuah tipe sistem manajemen basis data yang menyimpan data dalam bentuk tabel-tabel yang saling
berhubungan. RDBMS sangat bagus karena hanya membutuhkan sedikit asumsi tentang bagaimana data berhubungan atau bagaimana data akan diambil dari sistem basis data. Hasilnya, basis data yang sama dapat ditampilkan dalam berbagai cara.
Dalam Wikipedia (2006) ditulis bahwa RDBMS berdasar pada relational model yang dikenalkan oleh T.Codd. Dalam RDBMS, hal yang paling utama adalah :
• Menampilkan data kepada pengguna sebagai relasi (tampilan dalam bentuk kumpulan tabel dimana setiap tabel terdiri dari baris dan kolom).
• Menyediakan operasional relasi yang memanipulasi data.
2.5 Hierarki Memori dan Alat Penyimpanan
Kumpulan data yang akan dibuat menjadi sebuah basis data yang terkomputerisasi disimpan secara fisik dalam beberapa media penyimpanan komputer (computer storage medium). Media penyimpanan komputer membentuk sebuah hierarki penyimpanan yang secara umum terbagi menjadi :
• Primary Storage. Yang termasuk dalam kategori ini adalah media yang dapat langsung dioperasikan oleh central processing unit (CPU), seperti main memory pada komputer dan cache memory. Media yang termasuk dalam kategori ini biasanya menyediakan akses yang cepat ke data namun ukuran yang terbatas (sedikit).
• Secondary Storage. Kategori ini meliputi magnetic disk, optical disk dan tape. Peralatan ini biasanya mempunyai kapasitas yang lebih besar, harga yang lebih murah dan akses yang lebih lambat dibandingkan dengan alat
yang termasuk primary storage. Data pada secondary storage tidak dapat diakses langsung oleh CPU, melainkan harus di-copy terlebih dahulu ke dalam primary storage.
Dalam primary storage level, yang termasuk dalam level yang paling mahal adalah cache memory, yaitu statik RAM (Random Access Memory). Chace memory biasanya digunakan oleh CPU untuk meningkatkan kecepatan eksekusi program. Level selanjutnya adalah DRAM (Dynamic RAM), yang menyediakan area utama agar CPU dapat menjaga program dan data tetap berjalan dan dikenal juga sebagai main memory. Pada secondary storage level, termasuk magnetic disk, seperti mass storage dalam bentuk CD-ROM (Compact Disk-Read-Only-Memory) dan tape. Kapasitas penyimpanan dihitung dalam satuan kilobytes, megabytes, gigabytes, dan bahkan terabytes.
Di antara DRAM dan magnetic disk, terdapat bentuk memori lain, memori flash, karena isinya dapat diganti-ganti. Flash memiliki performance yang sangat baik karena menggunakan teknologi EEPROM (Electrically Erasable Programmable Read Only Memory). Keuntungan dari flash adalah kecepatan akses, dan kerugiannya adalah semua block data harus dihapus dan ditulis dalam waktu tertentu.
CD-ROM menyimpan data secara optical dan dibaca dengan laser. CD-ROM menyimpan data yang tidak dapat ditulis ulang. WORM (Write-Once-Read-Many) disk adalah bentuk penyimpanan optical yang digunakan untuk penyimpanan data, yang mengizinkan sekali penulisan data dan dapat dibaca berulang kali tanpa terhapus (Elmasri, 2000 ,p114-p115).
2.6 Secondary Storage
2.6.1 Deskripsi Hardware dari Disk Devices
Magnetic disk digunakan untuk menyimpan data dalam jumlah besar. Dasar unit dari data dalam disk adalah informasi tiap bit. Dengan magnetizing sebuah daerah dalam disk dengan cara tertentu, sebuat bit value dapat direpresentasikan dengan 0 atau 1. Untuk menghasilkan informasi, bit dikumpulkan menjadi bytes (atau karakter). Byte berukuran 4 atau 8 bit. Kapasitas dari suatu disk adalah jumlah byte yang dapat disimpan (Elmasri, 2000, p117).
2.6.2 Magnetic Tape Storage Devices
Disk adalah salah satu secondary storage yang mengakses secara acak (random access), karena setiap bit dalam block disk mungkin langsung diakses jika kita bisa menyebutkan alamatnya. Magnetic tape adalah peralatan yang mengakses satu persatu (sequential access), untuk mengakses block ke-n, kita harus membaca semua sampai block n-1. Dengan alasan ini, pengaksesan dapat menjadi lambat dan tidak dapat untuk menyimpan on-line data, kecuali aplikasi khusus.
Namun demikian, tape menyediakan fungsi yang sangat penting, yaitu untuk back-up database. Salah satu alasan back-up adalah untuk menyimpan salinan dari disk file ketika disk mengalami crash, yang dapat terjadi karena kesalahan mekanik. Untuk alasan ini, disk file di-copy dalam periode waktu tertentu ke tape. Tape juga dapat digunakan untuk menyimpan file untuk basis data yang besar. Jadi file basis data yang jarang
diakses tetapi dibutuhkan untuk pencatatan dapat disimpan dalam tape (Elmasri, 2000, p121-p122).
2.7 Menyimpan File Records dalam Disk 2.7.1 Baris dan Tipe Baris
Data biasanya disimpan dalam bentuk baris-baris. Setiap baris terdiri dari kumpulan nilai atau item data yang saling berhubungan dimana setiap nilai dibentuk dari satu atau lebih byte dan saling berhubungan. Baris biasanya menggambarkan entitas dan atribut yang dimiliki. Contohnya, baris EMPLOYEE menampilkan entitas dari seorang karyawan dan setiap nilai kolom dalam baris menggambarkan atribut, seperti NAME, BIRTHDATE, SALARY, atau SUPERVISOR. Kumpulan dari nama kolom dan hubungan tipe data menyusun sebuah definisi untuk format baris atau tipe baris. Sedangkan tipe data, berhubungan dengan tiap kolom, dan menjelaskan tipe dari nilai suatu kolom.
Tipe data dari suatu kolom biasanya merupakan standard yang digunakan dalam pemrograman antara lain seperti numeric (integer, long integer, floating point), string (fixed-length, varying), boolean (0/1, TRUE/FALSE) dan juga date atau time. Jumlah bytes yang diperlukan untuk setiap tipe data tetap sesuai dengan sistem yang diberikan komputer. Sebuah integer memerlukan 4 bytes, real 4 bytes, boolean 1 bytes, date 10 bytes (dengan asumsi format: YYYY-MM-DD), dan string n karakter memerlukan n bytes.
Contoh sebuah format baris untuk EMPLOYEE (dalam bahasa pemrograman C) : struct employee { char name[30]; char ssn[9]; int salary; int jobcode; char department[20]; }; (Elmasri, 2000, p128-p129).
2.7.2 Files, Fixed-Length Records dan Variable Length Records
Sebuah file adalah sebuah urutan dari baris-baris. Dalam banyak hal, semua baris dalam satu file memiliki format baris yang sama. Jika setiap baris dalam file memiliki ukuran yang sama (dalam bytes), file akan disebut fixed-length records. Jika baris yang berbeda memiliki ukuran yang berbeda, maka file disebut variable-length records. Sebuah file mempunyai variable-length records untuk beberapa alasan, yaitu :
• File record dengan tipe baris yang sama, tetapi satu atau lebih kolom memiliki ukuran yang berbeda (variable-length fields). Sebagai contoh, kolom NAME dari EMPLOYEE dapat berupa variable– length field.
• File record dengan tipe baris yang sama, tetapi satu atau lebih kolom mungkin mempunyai beberapa nilai untuk satu baris. Kolom ini disebut dengan repeating field dan kumpulan nilai dari kolom ini disebut repeating group.
• File record dengan tipe baris yang sama, tetapi satu atau lebih kolom merupakan pilihan, jadi beberapa baris memiliki nilai untuk kolom tersebut, tapi yang lain tidak (disebut juga optional fields).
• File yang mengandung tipe baris yang berbeda-beda dan memiliki ukuran yang berbeda (mixed file). Ini akan terjadi jika baris yang berhubungan yang berbeda tipe telah di-clusteres (ditempatkan bersama) dalam blok penyimpanan, contohnya, baris HASIL_NILAI dari murid ditempatkan bersama dengan baris MURID.
Fixed-length records KARYAWAN dalam contoh di atas memiliki ukuran 68 bytes. Setiap baris memiliki kolom yang sama, dan ukuran tiap kolom sama, sehingga sistem dapat menentukan posisi byte awal dari tiap kolom dengan menghitung mulai dari posisi baris paling awal. Ini memungkinkan mengambil nilai dari kolom tertentu dengan program yang mengakses file. Selain itu juga sebuah file yang memiliki variable-length records bisa dianggap sebagai fixed-length records. Contoh, dalam kasus optional fields, semua kolom dalam tiap baris ada tetapi disimpan dalam bentuk nilai NULL jika tidak ada nilai untuk kolom tersebut. Untuk repeating field, dapat menyediakan beberapa tempat dalam setiap baris
sebagai jumlah maksimal. Namun, hal ini akan membuat adanya space yang terbuang.
Gambar 2.1 Sebuah fixed-length record dengan 6 kolom dan berukuran 71 bytes.
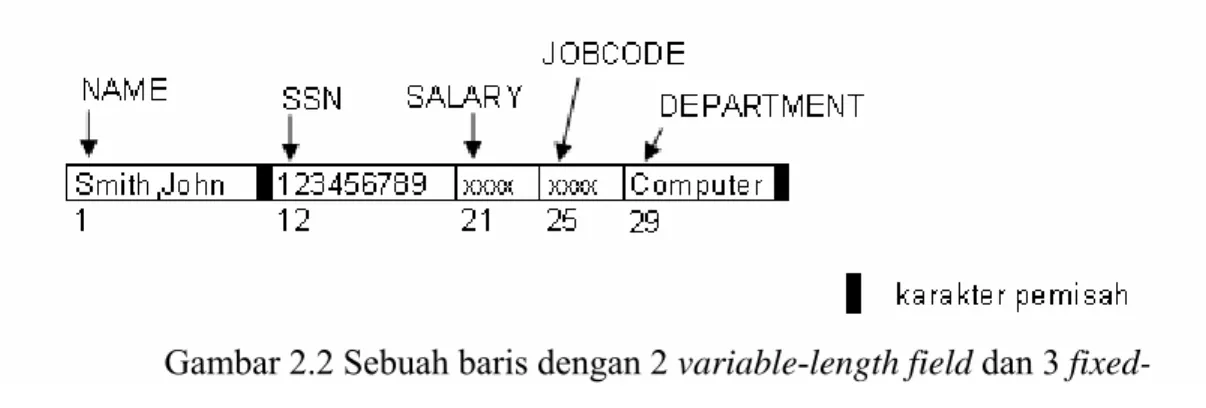
Untuk variable-length field, setiap baris mempunyai nilai untuk tiap kolom, tetapi ukuran tiap kolom tidak dapat diketahui. Untuk menentukan byte dalam tiap kolom di satu baris, kita dapat menggunakan karakter pemisah yang khusus (seeperti karakter ? atau % atau $ atau karakter yang tidak akan muncul sebagai nilai) atau menyediakan panjang sesuai dengan saat deklarasi.
Gambar 2.2 Sebuah baris dengan 2 variable-length field dan 3 fixed-length field
Jika sebuah baris memiliki ukuran yang besar, tetapi jumlah kolom yang dimiliki hanya sedikit, setiap baris dapat disimpan dalam bentuk <field-name, field-value> daripada hanya field-value saja. Ini disebut dengan tiga tipe karakter pemisah. Tujuannya adalah memisahkan kolom name dari kolom value dan memisahkan satu kolom dengan kolom
setelahnya. Untuk pilihan bentuk lain bisa juga digunakan <field-type,field-value>.
Gambar 2.3 Sebuah variable-field record dengan 3 tipe karakter pemisah
Sebuah repeating field memerlukan sebuah karakter untuk memisahkan nilai-nilai dalam kolom tersebut, dan karakter pemisah lain untuk pemisah antar kolom. Jadi untuk file yang memiliki baris dengan tipe yang berbeda-beda, setiap barisnya harus disertai dengan penanda. Oleh sebab itu, program yang mengakses file yang memiliki variable-length record (yang biasanya bagian dari file-system dan disembunyikan dari user) biasanya lebih rumit daripada fixed-length record (Elmasri, 2000, p129-p131).
2.7.3 Block Record dan Spanned VS. Unspanned Records
Baris-baris dari file harus dialokasikan ke block disk karena sebuah block adalah unit dari data transfer antara disk dan memory. Ketika ukuran block lebih besar daripada ukuran baris, tiap block akan terisi bermacam-macam baris, meskipun beberapa file boleh saja mempunyai ukuran baris yang besar sehingga tidak cukup dalam satu block. Misalkan bahwa ukuran
block adalah B bytes. Untuk sebuah file untuk fixed-length records dengan ukuran R bytes, dimana B ≥ R, maka bfr =
⎣
B/R baris tiap block, dimana⎦
⎣ ⎦
x dibulatkan ke bawah sehingga x memiliki nilai integer. Nilai bfr disebut blocking factor untuk file. Pada umumnya, R tidak membagi B dengan tepat, jadi ada unused space (space yang tidak terpakai) dalam tiap block, yaitu B – (bfr * R) bytes.Untuk menggunakan unused space, bagian dari sebuah baris dapat disimpan dalam satu block dan sisanya di block lain. Sebuah pointer pada akhir block pertama menunjuk ke block yang berisi lanjutan baris, dalam kasus block yang ditunjuk bukan block yang selanjutnya dalam disk. Cara pengaturan ini disebut spanned, karena baris dapat terletak lebih dari satu block. Ketika sebuah baris lebih besar dari satu block, maka harus digunakan pengaturan spanned. Jika baris tersebut tidak diizinkan untuk melewati batasan block, maka pengaturan ini disebut unspanned. Ini digunakan untuk fixed-length record dengan B>R karena hal ini akan membuat lokasi tiap baris diketahui dalam block dan menyederhanakan proses menyimpan. Untuk variable-length record, baik pengaturan spanned maupun unspanned dapat digunakan. Jika baris rata-rata berukuran besar, akan lebih menguntungkan jika menggunakan spanned untuk mengurangi hilangnya space dalam tiap block.
Gambar 2.5 Spanned Block
Untuk variable-length record menggunakan pengaturan spanned, setiap block dapat menyimpan beberapa baris. Dalam kasus ini, blocking factor bfr menampilkan jumlah rata-rata baris tiap block untuk sebuah file. bfr dapat digunakan untuk menghitung jumlah block b diperlukan dalam sebuah file untuk r baris:
B= di
⎡
(r / bfr )⎤
block (Elmasri, 2000, p131-p132)2.7.4 Mengalokasikan Block File dalam Disk
Ada beberapa teknik standar untuk mengalokasikan block dari sebuah file dalam disk. Dalam contiguous allocation, block file dialokasikan pada block disk selanjutnya. Ini membuat pembacaan seluruh file sangat cepat menggunakan double buffering, tetapi membuat perluasan file menjadi sulit. Dalam linked allocation setiap block file mengandung pointer ke block file selanjutnya. Ini memudahkan saat perluasan file tetapi lambat saat membaca semua file. Kombinasi dari 2 pengalokasian, cluster dari block disk yang berkelanjutan dan cluster dari link. Cluster juga disebut file segment atau extents. Kemungkinan lain adalah menggunakan pengalokasian indexed, dimana satu atau lebih dari index block
mengandung pointer ke block file yang sebenarnya atau sering juga digunakan kombinasi dari teknik-teknik ini (Elmasri, 2000, p132).
2.7.5 File Header
File header atau file descriptor mengandung informasi tentang sebuah file yang diperlukan oleh program sistem yang mengakses file record. Header mengandung informasi yang menggambarkan alamat disk dalam block file maupun deskripsi format baris, dimana mungkin termasuk panjang kolom dan pengurutan kolom dengan sebuah baris untuk fixed-length unspanned record dan tipe kolom, karakter pemisah, dan tipe baris untuk variable-length record.
Untuk mencari sebuah baris dalam disk, satu atau beberapa block di-copy ke buffer main memory. Program kemudian mencari baris yang diinginkan dengan menggunakan informasi dari file header. Jika alamat block yang mengandung baris yang diinginkan tidak diketahui, maka program pencari harus melakukan linear search, pencarian data secara satu per-satu dan berurutan, dalam seluruh disk block. Setiap block file di-copy ke buffer dan dicari sampai baris tersebut ditemukan atau semua block file sudah dicari dan baris tersebut tidak ditemukan. Ini menghabiskan banyak waktu untuk file yang besar. Tujuan dari file organization yang baik adalah mengetahui lokasi block yang mengandung baris yang diinginkan dengan jumlah block transfer seminimal mungkin (Elmasri, 2000, p133).
2.8 Operasi pada File
Dalam Elmasri disebutkan bahwa, operasi dalam file yang digunakan dalam program software DBMS meliputi :
• Open
Menyiapkan file untuk dibaca atau ditulis • Reset
Mengatur pointer dari file ke awal file. • Find (atau Locate)
Mencari baris pertama yang sesuai dengan kondisi pencarian. • Read (atau Get)
Menduplikasi baris tertentu dari buffer ke program milik user. • FindNext
Mencari baris untuk urutan selanjutnya dalam file yang sesuai dengan kondisi pencarian.
• Delete
Menghapus baris tertentu. • Modify
Mengubah beberapa nilai kolom dari baris tertentu • Insert
Menambahkan baris baru dalam file. • Close
Menutup akses file dengan melepaskan buffer dan melakukan operasi cleanup yang diperlukan(Elmasri, 2000, p133-p134).
2.9 Teknik – Teknik File Organization
Dalam Connolly dan Begg (Database Systems, 2002, p1147-p1154) disebutkan bahwa file organization adalah pengaturan fisik data dalam sebuah file menjadi baris dan page dalam secondary storage. Ada tiga jenis file organization dasar yaitu heap files, ordered file, dan hash file.
2.9.1 Heap (unordered) files
Heap files adalah tipe yang paling sederhana dalam pengaturan file. Heap file atau pile file atau sequential file adalah suatu metode dimana baris-baris ditempatkan sesuai dengan urutan saat dimasukkan, jadi baris baru akan ditambahkan di bagian paling akhir file. Memasukkan baris baru sangat efisien: disk block terakhir dari file di-copy ke buffer; kemudian baris baru ditambahkan; dan block dituliskan kembali ke disk. Alamat dari file block terakhir disimpan dalam file header. Namun demikian pencarian untuk sebuah baris menggunakan linear search dalam file tiap block merupakan prosedur yang tidak menguntungkan. Jika hanya satu baris yang memenuhi kondisi pencarian, rata-rata program akan membaca memory dan mencari dalam setengah file block sebelum menemukannya. Jadi untuk file b block, maka rata-rata membutuhkan pencarian (b/2) block. Jika tidak ada baris atau beberapa baris yang memenuhi kondisi pencarian, sebuah program harus membaca dan mencari semua b block dalam file.
Untuk menghapus baris, program pertama harus menemukan blocknya, meng-copy block ke buffer kemudian menghapus baris dari buffer dan menulis kembali block ke disk. Ini akan membuat adanya unused
space dalam disk block Menghapus banyak baris dengan cara ini akan membuat banyak tempat penyimpanan yang terbuang. Teknik lain adalah dengan menggunakan sebuah extra byte atau bit, yang disebut deletion
marker, yang disimpan di tiap baris. Sebuah baris yang dihapus, maka deletion marker akan diset untuk nilai tertentu. Nilai yang lain adalah
penanda bahwa baris tersebut belum dihapus. Program pencari hanya berdasar pada baris yang belum dihapus. Kedua teknik penghapusan ini memerlukan periode reorganization dari file untuk menghilangkan tempat yang tidak terpakai dari baris yang dihapus. Selama reorganization, file block diakses berurutan dan baris diatur dengan menghilangkan baris yang sudah dihapus.
Untuk unordered file, baik pengaturan spanned maupun unspanned dapat digunakan dan juga fixed-length record atau variable-length record. Untuk membaca semua baris dengan urutan tertentu, maka sebuah duplikasi dari file dapat dibuat. Pengurutan adalah operasi yang membutuhkan memori yang besar untuk file disk yang besar dan menggunakan teknik untuk external sorting.
Untuk file dengan fixed-length record menggunakan block unspanned dan alokasi contiguous, maka dibutuhkan pencarian sesuai posisinya di file. Jika baris dari file bernomer 0,1,2,...,r-i dan baris-baris di tiap block bernomer 0,1,...,bfr-1, dimana bfr adalah blocking factor, kemudian baris yang ke-i dari file beralokasi di block
⎣
i / bfr⎦
dan baris yang ke-(i mod bfr) dalam block tersebut. File seperti ini disebut filerelative atau direct karena baris tersebut dapat diakses secara langsung sesuai posisinya (Elmasri, 2000, p135).
2.9.2 Sequential (ordered) files
Semua baris dalam file dapat diurutkan berdasarkan nilai dari satu atau lebih kolom. Kolom inilah yang disebut ordering field. Jika ordering field juga merupakan key dari file dan memiliki nilai yang unik dari semua baris yang ada, kolom ini juga disebut ordering key.
Ordered record (terurut) memiliki beberapa keuntungan dibandingkan unordered (tidak terurut). Pertama, saat membaca baris dengan urutan sesuai ordering key, maka proses menjadi efisien. Kedua, menemukan baris selanjutnya sesuai dengan urutan, ordering key tidak memerlukan tambahan akses ke block lain, karena biasa terletak dalam satu block (kecuali baris tersebut adalah yang terakhir dalam block). Ketiga, menggunakan syarat pencarian berdasarkan ordering key akan lebih cepat jika digunakan teknik pencarian binary.
Ordered record tidak memberikan keuntungan untuk akses acak atau terurut jika berdasarkan pada non-ordering field. Dalam kasus ini harus digunakan pencarian linear.
Menambah dan menghapus baris adalah operasi yang membutuhkan banyak waktu dan memori dalam ordered file karena baris-baris tersebut harus diurutkan secara fisik. Untuk menambahkan sebuah baris, posisi dalam file diberi berdasarkan nilai dari ordering field dan memberikan ruang untuk menambahkan baris pada posisi tersebut. Untuk file yang besar
akan menghabiskan cukup banyak waktu karena rata-rata setengah dari file block harus dibaca dan ditulis ulang.
Cara lain adalah dengan menyediakan tempat kosong di tiap block untuk baris baru. Namun demikian, jika tempat itu sudah terisi, masalah yang sama akan terjadi. Metode lain yang sering digunakan adalah membuat unordered file yang bersifat sementara, disebut overflow atau transaction file. Dengan teknik ini, ordered file disebut dengan main atau master file. Baris baru dimasukkan dalam posisi akhir overflow file. Setiap beberapa waktu, overflow diurutkan dan digabungkan dengan master file selama reorganization. Memasukkan data menjadi efisien dengan metode ini, namun akan meningkatkan kompleksitas pencarian. Pencarian dilakukan dari main file dengan pencarian binary, dan jika tidak ditemukan maka dilakukan pencarian linear di overflow file.
Mengubah nilai dari suatu kolom harus melihat dua faktor yaitu kondisi pencarian untuk mengetahui lokasi baris dan kolom yang diubah. Jika pencarian berdasarkan ordering key field, maka dapat digunakan pencarian binary, jika tidak digunakan pencarian linear. Jika yang dibuah adalah non-ordering field maka data baru ditulis kembali ke lokasi yang sama di disk, dengan anggapan digunakan fixed-length record. Pengubahan untuk ordering field berarti dapat mengakibatkan perubahan posisi dalam file, yang berarti harus menghapus baris lama dan menambahkan baris yang sudah diubah.
Ordered file jarang digunakan untuk aplikasi basis data jika tidak ada akses path tambahan, yang disebut primary index dan akan menghasilkan indexed-sequential file (Elmasri, 2000, p136-p139).
2.9.3 Hash files
Dalam sebuah file hashing, baris tidak harus ditulis secara berurutan dalam file, melainkan sebuah hash function akan menghitung alamat page dimana sebuah baris akan disimpan berdasarkan satu atau lebih kolom. Hash function adalah suatu fungsi yang dibuat untuk menentukan alamat sehingga baris yang ada dapat dibagi ke dalam seluruh bagian file. Jenis-jenis hashing:
• Static hashing
Static hashing adalah suatu keadaan dimana besar alamat hash yang disediakan sudah tidak akan diubah lagi sejak file dibuat.
• Dynamic hashing
Dynamic hashing adalah suatu metode dimana ukuran file untuk hash akan berubah sesuai dengan pertumbuhan basis data.
2.10 Teknik – Teknik Metode Akses
Dalam Connolly dan Begg (Database Systems, 2002, p1155-p1163) disebutkan bahwa metode akses adalah langkah-langkah untuk meningkatkan dalam menyimpan dan mengambil baris dari suatu file. Metode yang ada antara lain Indeks dan Cluster.
2.10.1 Indeks
Indeks adalah sebuah struktur data yang mengizinkan DBMS untuk menempatkan bagian dari baris dalam sebuah file dengan lebih cepat dan peningkatan response time terhadap query dari user.
• Primary Index
Data dalam file diurutkan berdasarkan sebuah ordering field key, dan indeks dibuat berdasarkan ordering field key tersebut, yang memiliki nilai yang unik untuk tiap baris.
• Clustering Index
Dimana data dalam file diurutkan berdasarkan sebuah non-key field, dan indeks dibuat berdasakan kolom ini, sehingga memungkinkan ada lebih dari satu baris yang berhubungan dengan nilai dari indeks. Non-key field inilah yang disebut dengan clustering index.
• Secondary Index
Secondary index juga sebuah cara untuk mengurutkan file mirip dengan primary index. Perbedaannya adalah, dimana data yang berhubungan dengan primary index diurutkan berdasakan index key, dan data yang berhubungan dengan secondary index tidak dirutukan berdasakan index key. Jadi, secondary index key tidak perlu mengandung nilai yang unik. • Multilevel Indexes
Ketika sebuah file indeks menjadi besar dan terbagi menjadi banyak page, waktu pencarian akan meningkat. Multilevel index mengatasi masalah ini dengan mengurangi jarak pencarian. Ini dapat dilakukan
dengan membagi indeks yang ada ke beberapa file, untuk membagi ke ukuran yang lebih kecil dan mengatur indeks dengan indeks.
• B-Tree
B-Tree adalah sebuah tree yang seimbang dan biasanya dirancang untuk media penyimpanan sekunder serta banyak dipakai oleh sistem basis data. Sebuah B-Tree T mempunyai root T dan ciri-ciri sebagai berikut :
1. Setiap node x mempuyai penjelasan sebagai berikut : a. n[x], sejumlah key yang disimpan di node x,
b. key dari n[x] itu sendiri, yang disimpan terurut sehingga key1[x]
≤ key2[x] ≤ . . . ≤ keyn[x][x],
c. leaf[x], sebuah nilai yang bernilai benar jika x adalah leaf, dan salah jika x adalah node internal.
2. Setiap node internal x selalu mempunyai pointer sebanyak n[x]+1 buah ke node anaknya, sedangkan node leaf tidak mempunyai node anak.
3. Semua leaf mempunyai ketinggian yang sama (h).
4. Sebuah node mempunyai batas bawah dan atas di sejumlah key dan batasan ini dapat dinyatakan dalam bilangan bulat t ≥ 2 disebut derajat minimum dari B-Tree :
a. Setiap node selain root harus mempunyai sedikitnya key t-1 buah. Setiap node internal selain root mempunyai sedikitnya t node anak. Jika tree tidak kosong, maka root minimal mempunyai 1 key.
b. Setiap node dapat berisi maksimal 2t-1 key disebut keadaan penuh. Dengan demikian, sebuah node internal dapat mempunyai maksimal 2t node anak.
Tinggi untuk sebuah B-Tree dengan jumlah data n dalam keadaan terburuk adalah :
2
1
log
+
≤
n
h
t Keterangan: h = tinggi t = derajat minimumn = banyak data (Cormen, 2001, p447) Operasi dasar pada B-Tree terdiri dari :
a. Operasi Searching
Prosedur pencarian B-Tree hampir sama dengan pencarian pada tree umumnya, namum pada setiap node internal, terdapat (n[x] + 1) cara penentuan percabangan. Pencarian B-Tree menggunakan inputan sebagai pointer dari root x dan key k untuk dicari dalam subtreenya. Jika terdapat key k yang dicari, maka akan dikembalikan pasangan nilai (y, i) dengan node y dan indeks i sehingga keyi[y] = k, sedangkan jika tidak ditemukan, akan
dikembalikan nilai NIL.
B-TREE-SEARCH (x, k) i Å 1
while i ≤ n[x] and k > keyi[x]
do i Å i + 1 if i ≤ n[x] dan k = keyi[x]
then return (x, i) if leaf[x]
then return NIL else DISK-READ (ci[x])
return B-TREE-SEARCH (ci[x], k)
Jumlah akses ke disk dalam pencarian B-Tree adalah O(h) = O(logt n) dengan h adalah tinggi dari tree, n adalah jumlah data,
dan t adalah derajat minimum.
b. Operasi Insert
Menambahkan nilai pada B-Tree harus memperhatikan beberapa hal berikut :
• Tidak langsung membuat node baru dalam memasukkan key baru.
• Tidak dapat memasukkan key untuk node yang sudah penuh. • Jika operasi terdapat pada node yang penuh (2t-1), maka
node harus dipecah dengan mengambil nilai tengahnya dengan masing-masing node memiliki t-1 buah key, nilai
tengah akan naik ke node induknya sebagai nilai pembagi bagi dua node yang baru.
• Hal ini berlaku apabila node induknya penuh, maka juga menggunakan langkah di atas.
B-TREE-SPLIT-CHILD (x, i, y) z Å ALLOCATE-NODE() leaf[z] Å leaf[y]
n[z] Å t – 1 for j Å to t – 1
do keyj[z] Å keyj+t[y]
if not leaf[y] then for j Å 1 to t do cj[z] Å cj+t[y] n[y] Å t -1 for j Å n[x] + 1 downto i + 1 do cj+1[x] Å cj[x] ci+1[x] Å z for j Å n[x] downto i do keyj+1[x] Å keyj[x]
keyi[x] Å keyt[y]
n[x] Å n[x] + 1 DISK-WRITE (y) DISK-WRITE (z)
DISK-WRITE (x) B-TREE-INSERT (T, k) r Å root[T] if n[r] = 2t – 1 then s Å ALLOCATE-NODE() root[T] Å s leaf[s] Å FALSE n[s] Å 0 c1[s] Å r B-TREE-SPLIT-CHILD (s, 1, r) B-TREE-INSERT-NONFULL (s, k) else B-TREE-INSERT-NONFULL (r, k) B-TREE-INSERT-NONFULL (x, k) i Å n[x] if leaf[x]
then while i ≥ and k < keyi[x]
do keyi+1 Å keyi[x]
i Å i – 1 keyi+1[x] Å k
n[x] Å n[x] + 1 DISK-WRITE(x) else while i ≥ 1 and k < keyi[x]
do i Å i – 1 i Å i + 1 DISK-READ (ci[x]) if n[ci[x]] = 2t – 1 then B-TREE-SPLIT-CHILD (x, i, ci[x]) if k > keyi[x] then i Å i + 1 B-TREE-INSERT-NONFULL (ci[x], k)
Ilustrasi dari memasukkan beberapa key pada B-Tree (dengan degree 3 yang dapat menampung maksimum 5 buah key dan 6 node anak dalam 1 node internal) (Cormen, 2001, p448)
G M P X B ditambahkan
A B C D E J K N O R S T U V Y Z G M P X
Struktur tree mula-mula
c. Operasi Delete
Di bawah ini beberapa aturan kerja dalam menghapus sebuah key :
1. Jika key k berada di dalam node x dan x adalah leaf, hapus key k dari x.
2. Jika key k berada di dalam node x dan x adalan node internal, maka lakukan hal berikut :
a. Jika node anak y yang mendahului k mempunyai t buah key, kemudian cari predecessor k’ dari k dalam
C G M T X P F ditambahkan A B D E F J K L N O Q R S U V Y Z T X G M P L ditambahkan A B C D E J K L N O Q R S U V Y Z G M P T X Q ditambahkan A B C D E J K N O Q R S U V Y Z
subtree dengan y sebagai root. Secara rekursif hapus k’ dan ganti k dengan k’ pada x. (Pencarian dan penghapusan k’ diikut langkah (b))
b. Bersamaan setelah langkah (a), jika node anak z yang mengikuti k mempunyai t buah key, cari pengganti k’ dengan z sebagai root. Secara rekursif hapus k’ dan ganti k dengan k’ pada x. (Pencarian dan penghapusan k’ diikut langkah (c))
c. Selain itu, jika y dan z hanya mempunyai t-1 buah key, gabungkan key k dengan semua data dari z ke dalam y, sehingga x tidak akan lagi memiliki key k dan pointer ke z, dan y sekarang mempunyai 2t-1 buah key. Kemudian hapus z dan hapus k dari y.
3. Jika key k tidak terdapat pada node internal x, tentukan root ci[x] dari subtree yang memiliki key k. Jika ci[x]
hanya mempunyai t-1 buah key, lakukan langkah (3a) dan (3b) untuk menjamin bahwa sebuah node memiliki minimal t buah key.
a. Jika ci[x] hanya memiliki t-1 buah key tetapi memiliki
node di sebelahnya dengan minimal t buah key, berikan ci[x] sebuah key baru dengan memindahkan
key dari x turun ke ci[x], pindahkan key dari ci[x] dari
kiri atau kanan node sebelahnya ke x, dan pindahkan pointer node anak dari node sebelahnya ke ci[x].
b. Jika ci[x] dan node sebelah kiri dan kanan ci[x]
memiliki t-1 buah key, gabungkan ci[x] dengan satu
node sebelahnya, dengan memindahkan key turun ke node gabungan baru untuk menjadi nilai tengah bagi node tersebut.
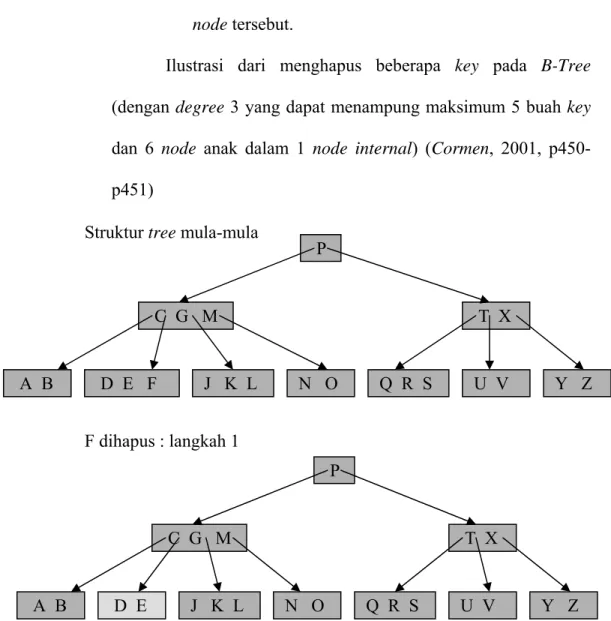
Ilustrasi dari menghapus beberapa key pada B-Tree (dengan degree 3 yang dapat menampung maksimum 5 buah key dan 6 node anak dalam 1 node internal) (Cormen, 2001, p450-p451) C G M T X P F dihapus : langkah 1 A B D E J K L N O Q R S U V Y Z C G M T X P Struktur tree mula-mula
E L P T X B dihapus : langkah 3a
A C J K N O Q R S U V Y Z C L P T X
tinggi tree disusutkan
A B E J K N O Q R S U V Y Z C G L T X P M dihapus : langkah 2a A B D E J K N O Q R S U V Y Z C L P T X D dihapus : langkah 3b A B E J K N O Q R S U V Y Z C L T X P G dihapus : langkah 2c A B D E J K N O Q R S U V Y Z
2.10.2 Cluster
Cluster adalah mengelompokkan satu atau lebih tabel secara fisik untuk disimpan bersama karena mereka membagi kolom yang umum dan sering digunakan. Dengan baris yang berhubungan disimpan bersama-sama, dapat meningkatkan waktu akses (waktu akses lebih singkat).
• Indexed Cluster
Dalam sebuah clustering index, baris dengan cluster key yang sama disimpan bersama. Oracle menyarankan penggunaan indexed cluster ketika:
9 Query penarikan data melebihi batasan nilai cluster key 9 Clustered table mungkin bertambah di luar perkiraan • Hash Cluster
Baris yang disimpan pada hash cluster berdasarkan pada hasil untuk menerapkan sebuah hash function pada baris yang mengandung nilai cluster key. Semua baris dengan hash key yang sama akan disimpan bersama. Oracle menyarankan penggunaan hash cluster ketika:
9 Query penarikan data berdasakan kondisi yang mengandung semua kolom cluster key.
9 Clustered table tetap atau dapat ditentukan jumlah maksimal baris dan jumlah maksimum space yang diperlukan ketika membuat clustered table.
2.11 Penggunaan XML dalam penyimpanan dan pengaksesan data
Extensible Markup Language (XML) merupakan format bahasa yang sederhana dan fleksibel yang dikembangkan dari Standard Generalized Markup Language (SGML), yang dapat mendukung perancang untuk membuat bahasa atau tag sendiri sesuai fungsinya. XML dikembangkan oleh World Wide Web Consortium (W3C) yang didukung sekitar 150 orang anggotanya dan versi 1.0 pertama kali dirilis pada tahun 1998 (Wikipedia, 2006).
XML adalah sebuah meta-language (bahasa yang digunakan untuk menjelaskan bahasa lain) yang memungkinkan seorang desainer membuat sendiri tag yang menyediakan fungsi yang tidak tersedia dalam HTML (Connolly, 2002, p1006).
Dalam Webopedia (2005) ditulis bahwa XML merupakan sebuah versi yang diturunkan dari SGML, didesain khusus untuk dokumen web. Desainer diperbolehkan untuk menciptakan tag sendiri, yang memiliki kemampuan untuk mendefinisikan, transmisi, validasi dan interpretasi data antara aplikasi dan organisasi.
Keunggulan yang dimiliki XML antara lain :
1. Bahasa XML sederhana, dirancang sesuai bahasa manusia dan jelas. 2. Mendukung pembacaan data Unicode.
3. Standar terbuka dan tidak bergantung pada platform tertentu.
4. Dapat dikembangkan sesuai dengan keinginan users untuk membuat tags sendiri.
5. XML memisahkan antara isi dan tampilan dari suatu data sesuai dengan pengaturan yang diinginkan.
6. Meningkatkan pengambilan data sehingga data dapat ditampilkan pada browser lebih cepat.
7. Mendukung integritas data untuk berbagai proses sumber. 8. Dapat menjelaskan data dari berbagai jenis aplikasi.
9. Lebih baik digunakan untuk pencarian data (search engine).
XML menggunakan teknologi Document Type Definitions (DTDs) yang dapat mendefinisikan sintaks yang valid dari dokumen XML.
Contoh bahasa XML :
<?xml version=”1.0” encoding=”UTP-8” standalone=”yes?> <?xml:stlesheet tupe=”text/xsl” href=”staff_list.xsl”?> <!DOCTYPE STAFFLIST SYSTEM “staff_list.dtd”> <STAFFLIST> <STAFF branchNo=”B005”> <STAFFNO>SL21</ STAFFNO> <NAME> <FNAME>John</FNAME> <LNAME>White</LNAME> </NAME> <POSITION>Manager</POSITION> <DOB>1-Oct-45</DOB> <SALARY>30000</SALARY> </STAFF> </STAFFLIST>
Keterangan :
9 Deklarasi XML
Sebuah file XML diawali dengan pilihan deklarasi XML, yang menunjukkan versi XML yang digunakan oleh penulis dalam sebuah dokumen, sistem encoding yang digunakan dan akan menentukan apakah ada deklarasi external markup yang perlu dimasukkan.
9 Elemen
Elemen atau tag, adalah bentuk umum dalam markup. Elemen pertama pastilah root element, yang mengandung banyak elemen lain. Sebuah dokumen XML harus mempunyai satu root element. Untuk contoh diatas adalah <STAFFLIST>. Setiap elemen diawali dengan tag awal (<STAFF>) dan diakhiri dengan tag akhir (</STAFF>). Sebuah elemen yang kosong dapat ditunjukan dengan tag: <EMPTYELEMENT/>
9 Atribut
Atribut adalah nilai pasangan yang mengandung informasi untuk mendeskripsikan informasi tentang suatu elemen. Atibut diletakkan dalam tag awal setelah nama elemen dan nilai atribut ada dalam tanda petik.
Contoh : <STAFF brachNo=”B005”>. Jika sudah diberikan atribut maka dapat ditunjukkan elemen itu adalah elemen yang kosong, contoh: <SEX gender=”M”/>
9 Entity references
Setiap entity harus mempunyai nama yang unik dan penggunaan dalam sebuah dokumen XML disebut dengan entity reference. Sebuah entity
<NAME FNAME=”John” LNAME=”White”/>
reference diawali dengan tanda dan (&) dan diakhiri dengan titik koma (;), contoh: <.
9 Komentar
Komentar dapat diletakkan dalam tag <!-- dan --> dan dapat mengandung semua string kecuali ‘–‘.
9 CDATA section dan instruksi proses
CDATA section memberitahu prosesor XML untuk melewati karakter markup dan memberikan teks langsung ke aplikasi tanpa interpretasi. Instruksi proses dapat digunakan untuk menyediakan informasi ke aplikasi. 9 Urutan
Dalam XML urutan elemen akan berpengaruh, Jadi jika urutan elemen berbeda maka akan dianggap data yang berbeda. Contoh :
akan berbeda dengan
Sedangkan atribut tidak terpengaruh dengan urutan. Contoh : <NAME> <FNAME>John</FNAME> <LNAME>White</LNAME> </NAMA> <NAME> <LNAME>White</LNAME> <FNAME>John</FNAME> </NAMA>
merupakan elemen yang sama dengan
2.12 Pemodelan Fungsi Sistem Menggunakan Use Case
Dalam Britton (2001, p97-p98) disebutkan bahwa sebuah sistem pasti dikembangkan dengan satu tujuan, yaitu menyediakan fungsi atau aktivitas yang akan memenuhi kebutuhan dan sesuai dengan permintaan user atau client. Untuk itu digunakan diagram yang dapat menjadi dasar untuk penulisan program yang menggambarkan permintaan yaitu dengan menggunakan use case.
Use case berpusat dengan fungsi dari sistem yang tampak, dengan tujuan untuk menampilkan apa saja yang sistem dapat lakukan dari sisi user, hal ini supaya diagram dapat juga dipahami oleh user. Meskipun biasanya dihubungkan dengan pengembangan berdasarkan objek, tetapi use case dapat digunakan sebagai bagian dari pendekatan pengembangan sistem yang lain.
Use case biasanya memperjelas fungsi dari sistem yang disediakan untuk user. Sebuah use case memperjelas interaksi antara user dan sistem untuk memperoleh tujuan tertentu.
Use Case Diagram adalah diagram yang menggambarkan interaksi antara sistem dengan sistem luar dan user. Dengan kata lain, secara grafik menggambarkan siapa yang akan menggunakan sistem dan dengan cara bagaimana user bisa berinteraksi dengan sistem. Diagram ini secara grafik menggambarkan sistem sebagai kumpulan use case, actor (user) dan hubungan yang terjadi (Whitten, 2004, p271). Notasi-notasi yang digunakan dalam use case diagram :
1. Use case
Use case adalah alat untuk menggambarkan fungsi-fungsi sistem dari perspektif pengguna luar dan dalam cara dan istilah yang mereka mengerti (Whitten, 2004, p272).
Use case digambarkan secara grafik oleh sebuah elips horizontal dengan nama yang muncul di atas, di bawah atau di dalam elips. Sebuah use case menggambarkan tujuan sistem dan rangkaian kegiatan dan interaksi yang dilakukan user dalam mencapai tujuan tersebut.
Use case merupakan hasil penguraian batasan-batasan fungsionalitas sistem ke dalam pernyataan – pernyataan yang lebih pendek.
Gambar 2.6 Notasi Use Case 2. Actor
Actor adalah segala sesuatu yang perlu berinteraksi dengan sistem untuk pertukaran informasi (Whitten, 2004, p273)..
Gambar 2.7 Notasi Actor 3. Relationship
Relationship digambarkan dengan garis di antara dua simbol di dalam diagram use case. Arti hubungan yang terjadi bisa bervariasi tergantung
bagaimana garis digambarkan dan tipe simbol apa yang mereka hubungkan (Whitten, 2004, p273). Jenis – jenis hubungan yang terjadi ada lima, yaitu • Association
Sebuah hubungan antara sebuah actor dengan sebuah use case dimana interaksi terjadi di antara mereka (Whitten, 2004, p274).
• Extend
Sebuah use case yang terdiri dari langkah-langkah yang dikutip dari use case yang lebih kompleks untuk menyederhanakan use case asli dan memperluas fungsionalitasnya. Biasanya ditandai dengan label “<<extend>>” (Whitten, 2004, p274).
• Include
Sebuah use case yang mengurangi redundansi di antara dua atau lebih use case dengan menggabungkan langkah-langkah yang sering ditemukan. Hubungannya digambarkan dengan “<<uses>>” (Whitten, 2004, p274). • Depends on
Hubungan yang menggambarkan ketergantungan antar use case. Jenis hubungan ini digambarkan dengan garis yang berpanah dimulai dari satu use case menunjuk ke use case tempat ia bergantung. Garis hubungan ditandai dengan label “<<depends on>>” (Whitten, 2004, p275). • Inheritance
Hubungan yang terjadi jika terdapat dua atau lebih actor yang memiliki sifat yang sama (Whitten, 2004, p275).