METODE PENELITIAN 3.1 Desain Penelitian
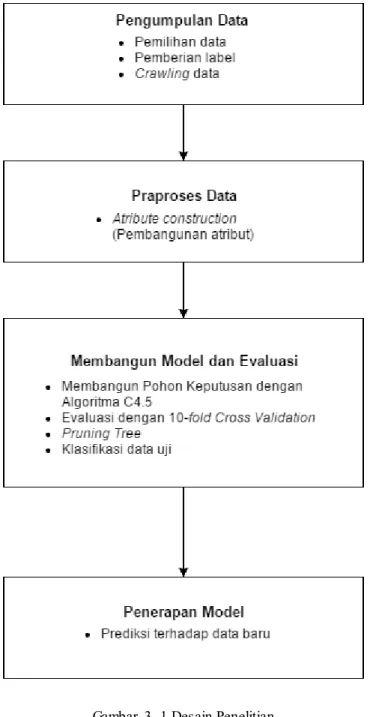
Desain penelitian adalah tahapan atau gambaran yang akan dilakukan dalam penelitian. Berikut merupakan langkah langkah yang akan dilakukan dalam melakukan penelitian:
1. Pengumpulan Data
Dalam pengumpulan data, hal pertama yang dilakukan adalah pemilihan akun-akun yang akan dijadikan dataset. Akun-akun tersebut akan diberi label sesuai kategori masing-masing. Setelah pemberian label, maka akun akan dibagi menjadi 2 bagian, yaitu data pelatihan dan data uji. Selanjutnya dilakukan proses
crawling pada masing-masing data dengan melakukan permintaan (request)
menggunakan Twitter REST API. Berikut request yang dikirimkan.
No Jenis Request Contoh request
1 GET statuses/user_timeline https://api.twitter.com/1.1/statu
ses/user_timeline.json?screen_nam e=dionajie&count=200
2 GET users/lookup https://api.twitter.com/1.1/users
/lookup.json?screen_name=dionajie
Tabel 3. 1 Jenis request
Berikut adalah atribut yang diambil:
No Atribut Keterangan
1 Username Nama pengguna
2 followers_count Jumlah pengikut/follower pengguna 3 friends_count Jumlah teman/following pengguna 4 verified Status verifikasi akun
5 description Deskripsi biodata pengguna 6 url Deskripsi tautan website pengguna 7 location Deskripsi lokasi pengguna
9 status_count Jumlah tweet pengguna
10 last_update_date Tanggal status terakhir pengguna 11 taken_tweet Jumlah tweet yang diambil
12 taken_tweet_date Tanggal diambilnya data pengguna
13 start_taken_tweet_data Tanggal tweet pertama yang diambil dari
pengguna
14 last_taken_tweet_date Tanggal tweet terakhir yang diambil dari pengguna
15 mention_number Jumlah mention tweet yang terdapat dalam tweet yang diambil dari pengguna
16 retweet_number Jumlah retweet yang terdapat dalam tweet yang diambil dari pengguna
17 hashtag_number Jumlah hashtag yang terdapat dalam tweet yang diambil dari pengguna
18 url_number Jumlah url yang terdapat dalam tweet yang diambil dari pengguna
Tabel 3. 2 Features hasil crawling
2. Praproses Data
Pada tahap ini dilakukan transformasi data dengan metode attribute
construction (pembuatan atribut). Setelah melakukan tahap praproses maka
atribut yang didapat adalah sebagai berikut.
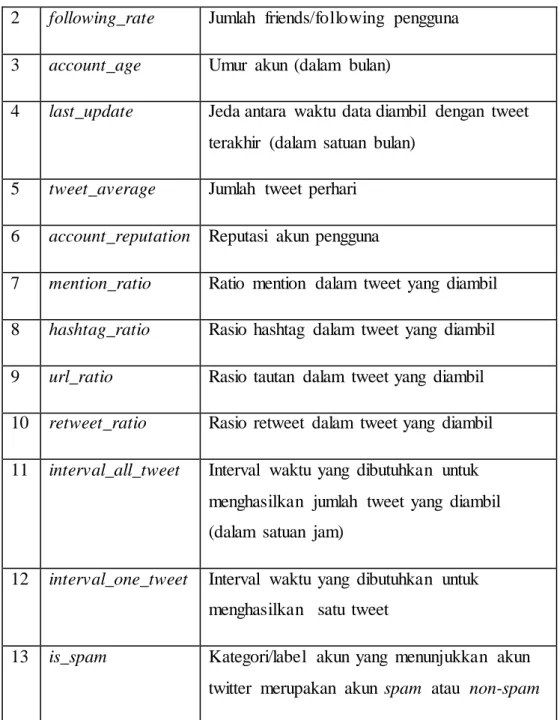
No Atribut Keterangan
2 following_rate Jumlah friends/following pengguna 3 account_age Umur akun (dalam bulan)
4 last_update Jeda antara waktu data diambil dengan tweet terakhir (dalam satuan bulan)
5 tweet_average Jumlah tweet perhari 6 account_reputation Reputasi akun pengguna
7 mention_ratio Ratio mention dalam tweet yang diambil 8 hashtag_ratio Rasio hashtag dalam tweet yang diambil 9 url_ratio Rasio tautan dalam tweet yang diambil 10 retweet_ratio Rasio retweet dalam tweet yang diambil 11 interval_all_tweet Interval waktu yang dibutuhkan untuk
menghasilkan jumlah tweet yang diambil (dalam satuan jam)
12 interval_one_tweet Interval waktu yang dibutuhkan untuk menghasilkan satu tweet
13 is_spam Kategori/label akun yang menunjukkan akun twitter merupakan akun spam atau non-spam
Tabel 3. 3 Features hasil praproses data
3. Membangun model dan evaluasi
Pada tahap ini dilakukan pembuatan model pohon keputusan dengan menggunakan algoritma C4.5. Setelah pembuatan model, akurasi model akan dievaluasi. Evaluasi menggunakan metode 10-fold cross validation untuk menentukan akurasi dari sebuah model menggunakan data pelatihan. Setelah melakukan evaluasi langkah selanjutnya yaitu melakukan pruning tree (pemangkasan pohon). Pada tahap pruning, model yang telah dibuat akan
dengan hasil maksimal.
Proses terakhir dari membangun model dan evaluasi adalah klasifikasi data uji. Klasifikasi dengan data uji untuk mengukur akurasi model terhadap data diluar data pengujian.Tingkat akurasi model yang dihasilkan sebelum dan setelah melakukan pruning akan dibandingkan hasil akurasinya. Model dengan akurasi paling baik akan menjadi model yang digunakan dalam penerapan.
4. Penerapan model
Membuat sistem yang dapat melakukan prediksi kategori akun yang belum diketahui kategorinya berdasarkan model yang telah dibuat sebelumnya.
1.2 Metode Penelitian
Metode penelitian ini dibagi menjadi dua, yaitu metode pengumpulan data dan metode pengembangan perangkat lunak.
1.2.1 Metode Pengumpulan Data
Data yang diambil dalam penelitian ini merupakan data akun yang diambil dari Twitter. Pemberian label pada akun-akun tersebut ditentukan berdasarkan karakteristik spam account yang telah dijelaskan oleh Twitter sebelumnya. Selanjutnya pengambilan data akun akan dilakukan dengan memanfaatkan REST API Twitter. Data inilah yang akan dijadikan dataset untuk penelitian.
1.2.2 Metode Pengembangan Perangkat Lunak
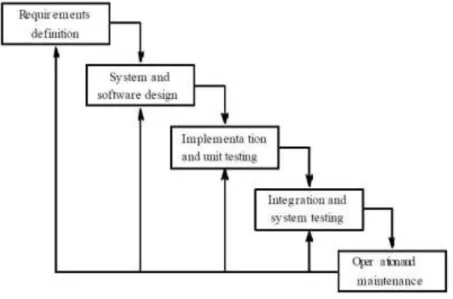
Proses dalam pengembangan perangkat lunak dalam penelitian ini menggunakan model waterfall. Model waterfall adalah sebuah contoh dari proses perencanaan, dimana semua proses kegiatan harus terlebih dahulu direncanakan dan dijadwalkan sebelum dikerjakan (Sommerville, 2011). Berikut adalah tahapan-tahapannya :
Gambar 3. 2 Model Waterfall (Sommerville,2011)
1. Requirements definition (Definisi kebutuhan)
Mengumpulkan kebutuhan, penetapan fitur, kendala dan tujuan sistem melalui konsultasi dengan pengguna sistem. Semua hal tersebut akan ditetapkan secara rinci dan berfungsi sebagai spesifikasi sistem.
2. System and software design (Desain sistem dan perangkat lunak)
Dalam tahapan ini akan dibentuk suatu arsitektur sistem berdasarkan persyaratan yang telah ditetapkan. Dan juga mengidentifikasi dan menggambarkan abstraksi dasar sistem perangkat lunak dan hubungan-hubungannya.
3. Implementation and unit tesing (Tes implementasi dan unit)
Hasil dari desain perangkat lunak akan direalisasikan sebagai satu set program atau unit program. Setiap unit akan diuji apakah sudah memenuhi spesifikasinya.
4. Integration and unit tesing (Tes integrasi dan unit)
Setiap unit program akan diintegrasikan satu sama lain dan diuji sebagai satu sistem yang utuh untuk memastikan sistem sudah memenuhi persyaratan yang ada. Setelah itu sistem akan dikirim ke pengguna sistem.
Dalam Operation and maintenance, sistem diinstal dan mulai digunakan. Selain itu juga memperbaiki error yang tidak ditemukan pada tahap pembuatan. Dalam tahap ini juga dilakukan pemeliharaan software serta pengembangan sistem seperti penambahan fitur dan fungsi baru.
1.3 Alat dan Bahan Penelitian
Berdasarkan kebutuhan-kebutuhan di atas, maka ditentukan bahwa alat dan bahan yang digunakan pada penelitian ini adalah sebagai berikut:
1.3.1 Alat Penelitian
Dalam penelitian ini, peneliti menggunakan bebagai alat bantu penunjang baik berupa perangkat keras maupun perangkat lunak. Adapun perangkat keras yang digunakan adalah seperangkat komputer yang mempunyai spesifikasi sebagai berikut:
1. Processor Intel Core i5 2.4Ghz 2. RAM 4 GB
3. Hardisk 500GB 4. Monitor 14 inch 5. Mouse dan Keyboard
Sedangkan perangkat lunak yang digunakan yaitu : 1. Sistem operasi Ubuntu 14.04
2. Sublime text 3.0 3. Python 2.7.0 4. XAMPP 1.8.3 5. Google Chrome
1.3.2 Bahan Penelitian
Bahan Penelitian dilakukan dengan menggunakan dataset yang dibagi menjadi dua bagian:
Jumlah akun yang dijadikan data pelatihan adalah 1391 akun dengan 442 akun kategori akun spam account dan 949 akun kategori
non-spam account. Data pelatihan akan digunakan untuk membangun model
dan validasi menggunakan k-fold cross validation. 2. Data uji
Jumlah akun pada data uji adalah sebanyak 100 akun dengan 50 akun kategori spam account dan 50 akun kategori kategori non-spam
account. Data uji akan digunakan untuk menghitung akurasi sebenarnya