PENDEKATAN ANALISIS FUZZY CLUSTERING PADA PENGELOMPOKKAN STASIUN POS HUJAN UNTUK MEMBUAT ZONA PRAKIRAAN IKLIM (ZPI)
(Studi Kasus Pengelompokkan Zona Prakiraan Iklim (ZPI) dengan Data Curah Hujan di Kabupaten Karawang, Kabupaten Subang dan Kabupaten Indramayu)
Nama Mahasiswa : Azwar Habibi
NRP : 1308201003
Pembimbing : 1. Dr. Sutikno, S.Si, M.Si Co-Pembimbing : 2. Dr. Ir. Setiawan, M.S
ABSTRAK
Analisis kelompok (cluster analysis) telah digunakan diberbagai bidang ilmu pengetahuan, dengan tujuan mengelompokkan objek/observasi. Hal penting dalam analisis kelompok adalah memperoleh nilai simpangan baku dalam kelompok (SW) yang minimum dan nilai
simpangan baku antar kelompok (SB) yang maksimum. Pada penelitian ini dilakukan
pengelompokkan stasiun pos hujan untuk membentuk zona prakiraan iklim (ZPI) di Kabupaten Karawang, Subang dan Indramayu dengan menggunakan analisis Fuzzy clustering, yaitu metode fuzzy c-means cluster, fuzzy c-shell cluster. Berdasarkan nilai rataan rasio SW/SB menunjukkan hasil kelompok yang optimal untuk kedua metode fuzzy
c-means cluster dan fuzzy c-shell cluster diperoleh sama yaitu sebanyak 10 kelompok. Metode fuzzy c-means cluster diperoleh nilai yang paling minimum yaitu 0,483 dari pada metode fuzzy c-shell cluster yaitu 0,798. Metode fuzzy c-means cluster mempunyai hasil yang lebih baik sehingga berpotensi untuk menghasilkan zona prakiraan iklim yang homogen. Sehingga, hasil dari evaluasi kinerja pengelompokkan dengan analisis Fuzzy clustering yaitu metode Fuzzy c-means cluster yang digunakan sebagai acuan akan dibandingkan dengan pengelompokkan zona prakiraan iklim yang pernah dilakukan oleh BMKG. Diperoleh homogenitas iklim hasil zona revisi menggunakan Metode fuzzy c-means cluster (ZPI revisi) mempunyai kinerja lebih bagus dari pada hasil pengelompokkan yang diperoleh dari hasil ZPI BMKG. Hasil pengelompokkan menggunakan metode fuzzy c-means cluster setelah mengalami revisi (pengelompokkan ulang) diperoleh 9 kelompok (zona).
Kata kunci: Analisis kelompok, Fuzzy clustering, fuzzy c-means cluster, fuzzy c-shell cluster, Zona Prakiraan Iklim (ZPI).
PENDAHULUAN
Analisis Cluster merupakan analisis statistika yang bertujuan untuk mengelompokkan objek-objek amatan menjadi beberapa kelompok berdasarkan peubah-peubah yang diamati. Proses penglompokkan objek-objek tersebut berdasarkan kesamaan karakteristik di antara objek-objek tersebut. Dalam analisis cluster ada dua metode pengelompokkan, yaitu metode berhirarki dan metode tidak berhirarki (Johnson dan Wichern, 2002). Pada proses pengelompokkan (clustering) berhirarki atau nonhirarki, pembentukan partisi dilakukan sedemikian rupa sehingga setiap objek berada tepat pada satu partisi. Akan tetapi, pada suatu saat, hal itu tidak dapat dilakukan untuk menempatkan suatu objek tepat pada suatu partisi, karena sebenarnya objek tersebut terletak diantara dua
atau lebih partisi yang lain. Sehingga perlu dilakukan pengelompokkan dengan menggunakan fuzzy clustering dimana dalam melakukan pengelompokan mempertimbangkan tingkat keanggotaan himpunan fuzzy sebagai dasar pembobotan (Abonyi dan Szeifert, 2002).
Ada beberapa metode (algoritma) yang telah dikembangkan dalam analisis Fuzzy clustering, antara lain metode fuzzy c-means cluster (FCM), fuzzy c-shell cluster (FCS), fuzzy Subtractive cluster dan lain sebagainya. Penelitian terdahulu dilakukan oleh Sutikno (2008) membahas tentang evaluasi ZPI BMKG dengan pendekatan analisis kelompok khususnya yang berhirarki yaitu membandingkan metode complete linkage, average linkage, dan Ward’s. Untuk itu dalam penelitian ini akan dikaji perbandingan metode FCS dan FCM dalam mengevaluasi hasil ZPI BMKG untuk melihat seberapa efisien kinerja kedua metode tersebut dalam pembentukan ZPI khusus untuk wilayah Kabupaten Karawang, Subang dan Indramayu. Analisis kuantitatif untuk menentukan efektifitas metode ini akan digunakan nilai simpangan baku dalam kelompok (Sw) dan antar kelompok
(SB).
METODE PENELITIAN Analisis Faktor
Johnson dan Wichern (2002), menjelaskan analisis faktor bertujuan untuk mendapatkan sejumlah kecil faktor (komponen utama) yang mampu menerangkan semaksimal mungkin keragaman data. Analisis faktor menggambarkan hubungan kovariansi dari beberapa variabel dalam sejumlah kecil faktor. Variabel-variabel ini dapat dikelompokkan menjadi beberapa faktor, dimana variabel-variabel dalam satu faktor mempunyai korelasi yang tinggi sedangkan korelasi dengan variabel-variabel pada faktor lain relatif kecil. Faktor-faktor tersebut saling independen dan tiap-tiap faktor dapat diinterpretasikan. Vektor variabel random X yang diamati dengan p komponen mempunyai vektor mean μ dan matriks variansi kovariansi ∑, secara linier bergantung pada sejumlah variabel random yang bisa teramati F1, F2,...Fm yang disebut faktor umum (common factor)
dan ε1,ε2,...,εpyang disebut error atau faktor spesifik (specific faktor). Fuzzy c-means cluster (FCM)
FCM adalah suatu teknik penggelompokkan data yang mana keberadaan tiap-tiap data dalam suatu cluster ditentukan oleh nilai keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981. konsep dasar FCM, pertama kali adalah menentukan pusat cluster yang akan menandai rata-rata untuk tiap-tiap cluster. Pada
kondisi awal, pusat cluster ini masih belum akurat. Tiap-tiap data memiliki derajat keanggotaan untuk tiap-tiap cluster. Dengan cara memperbaiki pusat cluster dan nilai keanggotaan tiap-tiap data secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimalisasi fungsi objektif (Pi, Qin dan Wang, 2006).
Fungsi objektif yang digunakan pada fuzzy c-means (FCM) adalah sebagai berikut (Pedrycz, 2006): 2 1 1 (U,V,X) ( ) ( ) c n m W ik ik i k J μ d = = =
∑∑
(1)Dengan w∈ ∞[1, ),dik2 adalah jarak observasi yang dapat dirumuskan sebagai berikut: 2( , ) 2 ( ) (T )
ik k i k i k i k i
d x v = x −v = x −v x −v (2)
Algoritma FCM adalah sebagai berikut :
a.Input data yang akan dicluster X, berupa matriks berukuran n x m (n = jumlah sampel data, m = atribut setiap data). Xij = data sampel ke-i (i = 1,2,…,c), atribut ke-j (j =
1,2,…,m). b.Menentukan :
• Jumlah cluster yang akan dibentuk = k (k ≥2);
• Pangkat (pembobot) = m (m>1), berdasarkan penelitian Klawonn dan Keller (1997), nilai dari m yang paling optimal dan sering dipakai adalah m = 2;
• Maximum Iterasi;
• Error terkecil yang diharapkan (nilai positif yang sangat kecil) sebagai kriteria penghentian = ξ;
• Fungsi objektif awal = P0 = 0;
• Iterasi awal, t = 1, dan Δ= 1;
c.Bentuk matriks partisi awal, U0, adalah sebagai berikut :
11 1 1n 1 1 cn ( ) ( ) U= ( ) ( ) n c n x x x x μ μ μ μ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ L M O M L (3)
Matriks partisi awal biasanya dipilih secara acak;
(
)
1 1 ( ) ( ) n m ik k k i n m ik k x V μ μ = = ⋅ =∑
∑
(4)e.menghitung fungsi objektif pada iterasi ke-t, Pt :
(
)
2( )
1 1 1 c n m m t ij kj ik i k j P X V μ = = = ⎛⎡ ⎤ ⎞ = ⎜⎜⎢ − ⎥ ⎟⎟ ⎣ ⎦ ⎝ ⎠∑∑ ∑
(5) f. menghitung perubahan matriks partisi :1 ( 1) 2 2 1 1 ik m m ik j jk d d μ − = = ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠
∑
(6) dengan : i = 1,2,…,c; dan k = 1,2,…,n.g.menentukan kriteria berhenti, yaitu perubahan matriks partisi pada iterasi sekarang dengan iterasi sebelumnya, sebagai berikut :
Δ = Pt−Pt−1 <ξ (7) Apabila Δ ≤
ξ
, maka iterasi dihentikan, namun apabila Δ >ξ
, maka naikkan iterasi (t = t + 1) dan kembali ke langkah d.Fuzzy c-shell cluster (FCS)
Dave (1992) menjelaskan, dalam algoritma FCS bentuk dasar dari cluster adalah p-dimensi hyper-spherical shell yang dapat dikarakteristikan oleh pusat dan jari-jari. Misal
ℜadalah himpunan riil, ℜpadalah himpunan riil dari p-tuples. Misal
1 2
X {x , x , , x } p n
= L ⊂ ℜ menjadi suatu himpunan data yang infinite sedemikian sehingga xk∈X adalah feature vector ke-k. Misal U∈Mfcadalah fuzzy c-partisi dari X (Mfcdinotasikan sebuah himpunan dari fuzzy c-partisi dari X); dan misal V adalah c-tuple
1 2
{v , v ,L,v }c , vi∈ℜp. Misal R adalah c-tuple { , ,r r1 2 L, },rc ri∈ℜ+.
Untuk FCS, meminimalkan bobot jumlah dari jarak poin dari seperti bentuk dasar (prototipe). Jadi fungsi FCS J :s Mfc×ℜ ×ℜ → ℜcp c +didefinisikan sebagai :
2 1 1 J ( , , ) ( ) ( ) c n m s ik ik i k U V R u D = = =
∑∑
(8) Dengan m∈ ∞[1, ). Jarak Dikadalah jarak antara feature vektor ke-k yaitu xk dan prototype(Dik)2 =( xk−vi −ri)2 (9) Dalam persamaan diatas, ⋅ adalah norm jarak euclid, pusat vi dan jari-jari ri dari
bentuk dasar shell cluster. Definisi di atas didasarkan pada mengukur kuadrat jarak, jadi (Dik)2 adalah nilai determinan untuk sebuah titik xk, dan prototipe (vi, ri). Algoritma
pengelompokan FCS diberikan sebagai berikut:
a. Menentukan k banyak cluster yang ingin dibuat, 2≤ <k n, dengan n adalah jumlah dari data. Menentukan eksponen m, antara 1< < ∞m .
b. Menentukan counter iterasi j = 0. inisialisasi fuzzy c-partisi U0.
c. Menghitung cluster center vi, dan jari-jari cluster ri dengan menggunakan
persamaan 1 1 ( ) x v ( ) n m ik k k i n m ik k u u = = =
∑
∑
dan persamaan 1 1 ( ) x v ( ) n m ik k i k i n m ik k u r u = = − =∑
∑
. menggunakanmetode pengganda lagrange dengan perkiraan inisial untuk iterasi pertama dari persamaan tersebut.
d. Menghitung jarak, (Dik)2 menggunakan persamaan (9).
e. Update anggota iterasi ke-j, Uj dengan persamaan 1 ( 1) 2 2 1 1 ik m n ik j jk u D D − = = ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦
∑
).Periksa nilai kekonvergenan dengan membandingkan Uj dan Uj-1 dalam nilai norm yang sesuai. Jika Uj−Uj−1 <ε , maka berhenti. Jika Uj−Uj−1 >ε, maka naikkan iterasi (j = j + 1) dan kembali kelangkah c.
Evaluasi Hasil Pengelompokkan
Untuk melihat kinerja kedua metode tersebut digunakan kriteria nilai simpangan baku, yaitu: dalam kelompok (Sw) dan antar kelompok (SB). 1
1 K w k k S K− S = =
∑
dengan: K adalah banyaknya kelompok yang terbentuk dan Sk merupakan simpangan baku kelompok(
)
1(
)
2 1/ 2 1 1 K B k k S K − X X = ⎡ ⎤ =⎢ − − ⎥⎣
∑
⎦ dengan: Xk adalah rataan kelompok ke-k dan X rataankeseluruhan kelompok. Semakin kecil nilai Sw dan semakin besar nilai SB, maka metode
tersebut memiliki kinerja yang baik, artinya mempunyai homogenitas yang tinggi. Dengan kata lain metode yang dipilih adalah metode yang mempunyai nilai Sw yang minimum dan
antara nilai Sw dan nilai SB karena terdapat kemungkinan dalam hasil pengelompokkan
diperoleh nilai kriteria Sw yang minimum ternyata nilai SB yang minimum sedangkan
harapanya adalah maksimum, sehingga akan digunakan nilai rasio Sw / SB, dengan kata lain
metode yang dipilih adalah nilai rasio Sw / SB yang terkecil (Bunkers et al. 1996).
Ilustrasi Data
Data yang digunakan dalam penelitian ini merupakan data sekunder yaitu data curah hujan bulanan yang diperoleh dari stasiun-stasiun di wilayah Kabupaten Karawang, Subang dan Indramayu dengan 104 stasiun. Periode data curah hujan antar stasiun cukup beragam mulai tahun 1951-2000. Variabel yang digunakan adalah tingkat curah hujan bulanan, terdiri dari 12 variabel curah hujan bulanan kemudian direduksi menjadi 4 variabel.
Tahapan Analisis Data
Terdapat tiga tahapan dalam melakukan analisis data, yaitu : 1. Pengelompokan ZPI di kabupaten Karawang, Subang dan Indramayu.
a. Mendeskripsikan data curah hujan yang merupakan hasil rataan dari masing-masing stasiun di kabupaten Karawang, Subang dan Indramayu.
b. Mereduksi data curah hujan dengan Analisis Faktor sebagai pra-pemrosesan data c. Membentuk kelompok dengan metode FCM dan FCS.
d. Dilakukan evaluasi kelompok yang didapat dengan kriteria nilai simpangan baku, yaitu: dalam kelompok (Sw) dan antar kelompok (SB) dari dua metode diatas yaitu
FCM dan FCS.
2. Modifikasi hasil pengelompokan melalui koreksi elevasi dan kontur curah hujan. a. Digunakan peta evaluasi kabupaten Karawang, Subang dan Indramayu. sebagai
acuan untuk memodifikasi hasil pengelompokan yang didapat.
b. Memodifikasi hasil pengelompokan berdasarkan elevasi dan kontur curah hujan. c. Mendapatkan ZPI baru dengan mengidentifikasi anggota ZPI.
3. Membandingkan kinerja ZPI antara ZPI BMKG dan ZPI terbaik. a. Membandingkan ZPI baru yang didapat dengan ZPI milik BMKG.
b. Didapat ZPI terbaik dari hasil evaluasi kriteria simpangan baku dalam dan antar kelompok.
HASIL DAN PEMBAHASAN
Deskripsi Umum Curah Hujan Tiap Stasiun Pos Hujan di Kabupaten Karawang, Subang dan Indramayu
Tabel 1 menunjukkan bahwa rata-rata curah hujan pada Bulan Januari adalah tertinggi di Kabupaten Karawang, Subang dan Indramayu, yaitu sebesar 338,3 mm. Hal ini menunjukkan pada Bulan Januari merupakan puncak dari musim penghujan. Rata-rata curah hujan terendah terjadi Bulan Agustus, yaitu sebesar 28,44 mm. Ini berarti pada bulan ini merupakan puncak dari musim kemarau di Kabupaten Karawang, Subang dan Indramayu. Jika dilihat nilai simpangan baku, pada Bulan Januari memiliki simpangan baku tertinggi, artinya pada bulan tersebut terdapat variasi curah hujan diantara stasiun pos hujan di Kabupaten Karawang, Subang dan Indramayu. Menurut nilai range, yaitu selisih nilai minimum dan maksimum yang besar, dapat diartikan tingkat curah hujan setiap stasiun pos hujan di Kabupaten Karawang, Subang dan Indramayu tinggi.
Tabel 1. Deskripsi Tinggi Curah Hujan Bulanan di Kabupaten Karawang, Subang dan Indramayu
Bulan Minimum Maksimum Rata-rata Simpangan baku
Januari 162,3 569,5 338,3 83,31 Februari 123,9 442,5 238,1 65,35 Maret 95,65 491,50 198,82 79,65 April 64,6 427,9 157,7 79,14 Mei 31,70 297,95 92,68 48,42 Juni 19,63 146,40 62,29 27,11 Juli 10,69 119,09 42,71 20,51 Agustus 1,53 94,29 28,44 18,18 September 9,58 124,47 37,11 21,37 Oktober 32,40 246,90 85,65 43,64 November 74,9 410,8 161,6 69,54 Desember 91,88 459,70 203,84 66,60
Gambar 1 menjelaskan bahwa tipe curah hujan di Kabupaten Karawang, Subang dan Indramayu yaitu tipe monsunal yang berarti bersifat monsun karena dari gambar tersebut pola curah hujannya membentuk huruf U. Selanjutnya dari Gambar 1 dapat diidentifikasi bahwa musim penghujan di Kabupaten Karawang, Subang dan Indramayu
mulai Bulan November – April, sedangkan musim kemarau terjadi pada Bulan Mei – Oktober. 0 50 100 150 200 250 300 350 400 mm Bulan
Gambar 1. Rata-rata tinggi curah hujan menurut bulan Interpretasi Analisis Faktor
Analisis faktor yang bertujuan untuk mereduksi variabel-variabel bulan yang ada dalam penelitian ini agar supaya tidak terjadi dependensi antar variabel karena data curah hujan yang digunakan dalam penelitian ini cenderung terdapat kasus multikolinieritas, karena dalam metode metode FCS atau FCM menggunakan jarak euclid yang mengharuskan bebas dari multikolinieritas. Berdasarkan scree plot menunjukkan bahwa terdapat 4 faktor yang terbentuk dengan total keragaman 95,2% yang ditunjukkan pada Gambar 2 Untuk memperjelas dalam menggambarkan karakteristik curah hujan bulanan di Kabupaten Subang, Karawang dan Indramayu dilakukan rotasi Varimax. Hasil loading faktor selengkapnya disajikan pada Tabel 2.
12 11 10 9 8 7 6 5 4 3 2 1 10 8 6 4 2 0 Jumlah Faktor Ei g e nv a lue
Scree Plot of Jan, ..., Des
Gambar 2. Scree-plot (untuk menentukan jumlah Loading faktor yang optimum) Tabel 2 menunjukkan bahwa faktor 1 (F1) menggambarkan bulan-bulan musim transisi baik transisi musim kemarau (Maret, April dan Mei) maupun musim penghujan (Oktober,
November dan Desember), faktor 2 (F2) lebih menggambarkan puncak musim hujan (Januari dan Februari), faktor 3 (F3) lebih menggambarkan awal musim kemarau (Juni, Juli dan Agustus), sementara faktor 4 lebih menunjukkan puncak musim kemarau (September). Total keragaman yang dapat dijelaskan dengan empat faktor tersebut sebesar 95,2%. Keragaman masing-masing faktor adalah secara berututan faktor 1 (F1) sebesar 43,7%, faktor 2 (F2) adalah 23,7%, faktor 3 (F3) sebesar 16,9% dan faktor 4 (F4) yaitu 11%. Data untuk pengelompokkan stasiun curah hujan selanjutnya menggunakan empat score factor.
Tabel 2. Nilai Loading faktor dengan Rotasi Varimax
Variabel/ Bulan F1 F2 F3 F4 Januari 0.138 0.947 0.210 0.131 Februari 0.436 0.749 0.319 0.311 Maret 0.836 0.346 0.251 0.279 April 0.872 0.209 0.272 0.283 Mei 0.675 0.393 0.531 0.229 Juni 0.594 0.483 0.580 0.093 Juli 0.401 0.418 0.668 0.387 Agustus 0.455 0.543 0.593 0.308 September 0.487 0.385 0.314 0.687 Oktober 0.792 0.198 0.282 0.457 November 0.894 0.120 0.288 0.237 Desember 0.856 0.402 0.254 0.051 Analisis Fuzzy Clustering dengan Metode FCM dan Metode FCS
Ada dua pendekatan metode yang dilakukan dalam penelitian ini, yaitu analisis Fuzzy Clustering menggunakan metode FCM dan FCS. Penerapan metode FCM dan FCS pada pengelompokkan ZPI diawali dengan menentuan kelompok yang akan dilakukan dari banyak cluster, k =2,…,10. Menentukan pangkat atau pembobot ke-fuzzy-an dalam penelitian ini nilai m yang digunakan adalah 2 karena berdasarkan penelitian Klawonn dan Keller (1997) nilai dari m yang paling optimal dan sering dipakai adalah 2, menentukan maksimum iterasi sebesar 200, input data yang dilakukan dalam penelitian ini yaitu nilai skor faktor dari data curah hujan yang merupakan hasil rataan bulanan dari masing-masing stasiun yang tersedia series datanya (non-missing) terdiri dari 12 variabel curah hujan (Januari-Desember). Untuk melihat evaluasi kinerja metode FCM dan FCS digunakan nilai rataan dari rasio simpangan baku dalam kelompok (Sw) dan simpangan baku antar
kelompok (SB), data yang digunakan dalam mengevaluasi Sw dan SB merupakan data hasil
yang telah dilakukan terlebih dahulu dalam analisis faktor. Berdasarkan nilai rataan rasio Sw/Sb menunjukkan metode FCM diperoleh nilai yang paling minimum yaitu 0,483 dari
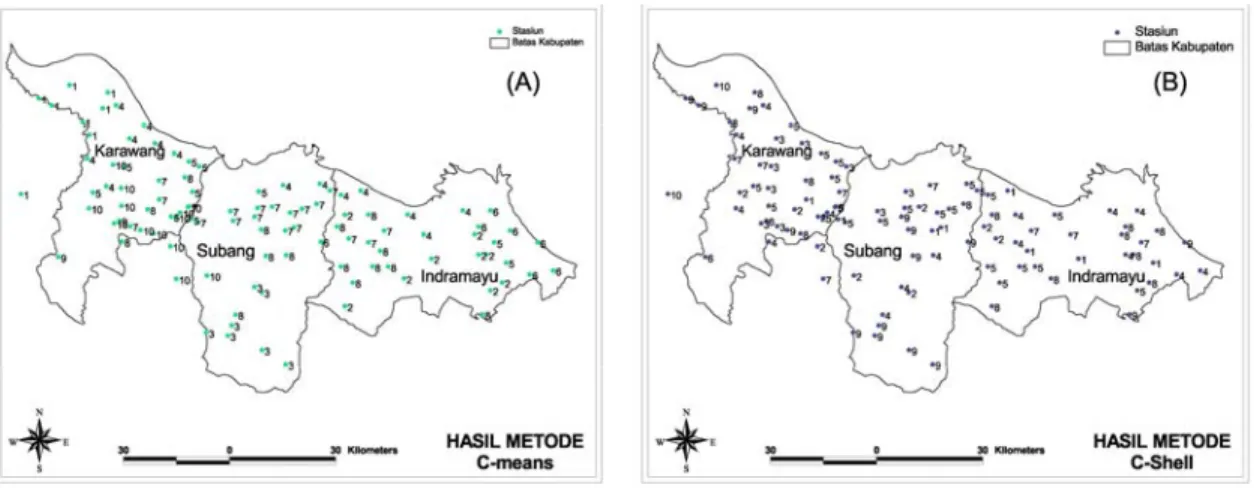
pada metode FCS yaitu 0,798 dengan hasil kelompok yang optimal diperoleh sama yaitu sebanyak 10 kelompok untuk kedua metode tersebut. Dapat dikatakan metode FCM lebih baik dari pada metode FCS. Hasil penggelompokkan menggunakan metode FCM yang akan dievaluasi dan digunakan sebagai acuan untuk pembentukan ZPI. Langkah selanjutnya yaitu mengkonvert hasil pengelompokkan yang optimum berdasarkan hasil yang diperoleh pada metode FCM dan metode FCS kedalam software ArcView GIS 3.3 (salah satu perangkat lunak yang populer dan paling banyak digunakan untuk mengelola data, menganalisa dan membuat peta serta laporan yang berkaitan dengan data spasial bereferensi geografis), bertujuan untuk menetukan luasan ZPI hasil penggelompokkan menggunakan metode FCM dapat diidentifikasi pada gambar 3A. Penyebaran hasil penggelompokkan ZPI dengan metode FCS yang optimum dapat diinterpretasikan dalam bentuk peta yaitu pada gambar 3B.
Gambar 3. Pola Sebaran kelompok stasiun pos hujan hasil metode FCM (A) dan FCS (B) Untuk menentukan luasan ZPI yaitu dengan cara mengidentifikasi awal yaitu dilakukan dengan menggunakan banyaknya kelompok yang ideal yang dihasilkan dari metode FCM, yaitu 10 kelompok, lihat Gambar 3(A) diatas. Berdasarkan Gambar 3(B) tampak bahwa hasil pengelompokkan dengan metode FCS sangat tidak teratur sehingga sulit untuk melakukan identifikasi guna untuk melakukan pengelompokkan ulang, sedangkan hasil pengelompokkan dengan metode FCM sangat teratur sehingga mudah untuk melakukan identifikasi guna untuk melakukan pengelompokkan ulang jadi Metode FCM mempunyai hasil yang baik sehingga berpotensi untuk menghasilkan ZPI yang homogen. Hal ini didukung juga dengan hasil perhitungan indeks kualitas kelompok yang
digunakan yaitu nilai rataan rasio Sw/Sb menunjukkan metode FCM diperoleh nilai yang
paling minimum.
Tabel 3. Hasil Rataan Rasio Simpangan Baku Dalam Kelompok (Sw) dan Simpangan Baku
Antar Kelompok (SB) untuk FCM dan FCS
Kelompok SF1 SF2 SF3 SF4 Average
--- Fuzzy C-Means Cluster ---
2 1,213 11,271 1,991 3,971 4,612 3 1,033 0,844 1,559 2,302 1,434 4 0,712 0,797 1,794 1,163 1,117 5 0,386 0,624 1,579 1,075 0,916 6 0,295 0,525 1,386 1,006 0,803 7 0,609 0,601 1,118 0,831 0,789 8 0,328 0,565 0,909 0,804 0,652 9 0,344 0,582 0,799 0,759 0,621 10 0,344 0,565 0,516 0,507 0,483
--- Fuzzy C-Shell Cluster ---
2 21,704 2,142 444,999 19,479 122,081 3 3,224 5,667 2,923 4,057 3,968 4 2,576 2,399 4,538 7,136 4,162 5 4,833 3,318 1,993 4,991 3,784 6 3,105 2,261 3,210 4,674 3,313 7 4,908 1,144 1,578 2,307 2,484 8 0,738 0,967 2,433 1,859 1,499 9 2,116 2,258 1,901 1,581 1,964 10 1,072 0,674 0,779 0,667 0,798
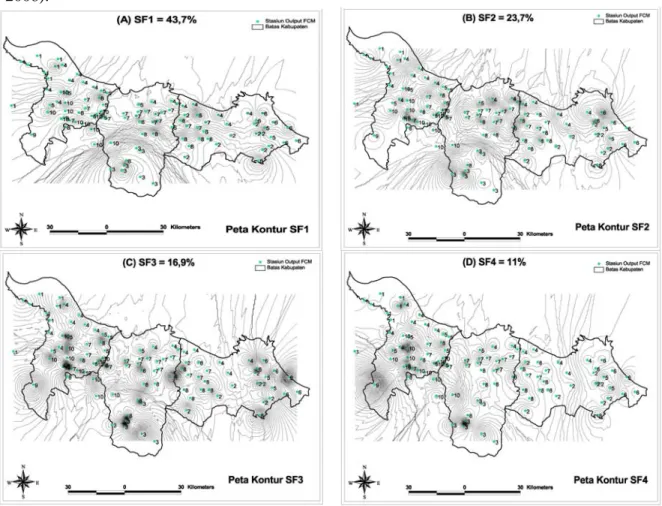
Pengelompokkan ulang dapat dilakukan pada stasiun pos hujan yang memiliki kode hasil pengelompokkan sama dalam satu kelompok yang menjadi outlier atau memencil pola sebaranya. Untuk membantu pengelompokkan ulang digunakan peta kontur elevasi yaitu peta kontur masing-masing skor faktor (Gambar 4). Dalam hasil pengelompokkan pembagian zona tidak dibatasi oleh wilayah administrasi kabupaten atau kota, sehingga dalam satu zona tertentu bisa mencakup beberapa kabupaten/kota. Dalam penelitian ini selanjutnya akan dilakukan revisi atau pengelompokkan ulang agar diperoleh ZPI yang baik yaitu dengan mengidentifikasi plot peta kontur elevasi yang ditunjukkan pada Gambar 4. Berdasarkan Gambar 4 menunjukkan bahwa beberapa kode stasiun dapat dilakukan pengelompokan ulang atau tidak perlu mengalami pengelompokkan ulang karena satu kelompok sudah homogen semua. Seperti pada zona 1 tidak perlu dilakukan pengelompokkan ulang karena anggota kelompoknya sudah sama semua (Gambar 4). Zona 1 meliputi Karawang bagian Barat laut yang berhadapan langsung dengan Laut Jawa. Zona 2 yang tidak mengalami pengelompokkan ulang (Tabel 4). Zona 2 mempunyai ciri
yang agak khusus, yaitu tidak terdapat perbedaan yang nyata tinggi hujan antara musim hujan dan kemarau. Rataan tinggi hujan puncak musim kemarau sebesar 125 mm. Menurut BMKG zona ini dikatakan sebagai wilayah yang tidak mempunyai ZPI (non-ZPI) (Sutikno, 2008).
Gambar 4. Peta Kontur Masing-masing Skor Faktor dan nilai Keragamannya Pada zona 3, kode stasiun 4, 5, 7, 8, dan 9 dilakukan pengelompokkan dengan kode 10. Pada zona ini meliputi Karawang bagian tengah, sebagian Subang bagian utara. Zona 4 meliputi pesisir pantai utara Karawang, Subang, Indramayu. Kode stasiun yang masuk pada zona ini adalah 5 dan 7, dilakukan pengelompokkan ulang dominan ke kode 4. Zona 5 meliputi Sebagian Subang bagian tengah sebelah timur, sebagian Indramayu bagian tengah sebelah barat. Kode stasiun yang termasuk dalam zona ini adalah 2, 5, 6, dan 8. Zona 6 adalah sebagian wilayah subang bagian tenggara, sebagian indramayu bagian barat daya. Kode stasiun zona ini adalah 8 pada zona ini tidak perlu mengalami pengelompokkan ulang (revisi). Zona 7 adalah sebagian wilayah subang bagian tenggara, sebagian indramayu bagian barat daya (Subang bagian selatan), yang mempunyai tinggi hujan yang relatif tinggi baik terutama pada musim hujan dan musim transisi. Yang membedakan zona ini dengan zona lain adalah topografinya, pada zona ini banyak pegunungan (Sutikno,
2008). Kode stasiun yang masuk dalam zona ini adalah 3 dan 8 yang dominan ke kode 3. Zona 8 meliputi Indramayu bagian selatan dan barat daya. Kode stasiun yang termasuk dalam zona ini adalah 2 dan 8. Zona 9 meliputi Indramayu bagian timur dan tenggara yang berbatasan dengan Cirebon. Kode stasiun yang masuk pada zona ini adalah 5 dan 6. Zona 9 ini mengalami pengelompokkan ulang yaitu kode 5 dominan ke stasiun kode 6. Hasil pengelompokkan ulang menghasilkan 9 kelompok yang selanjutnya dinamakan ZPI hasil revisi (Gambar 5).
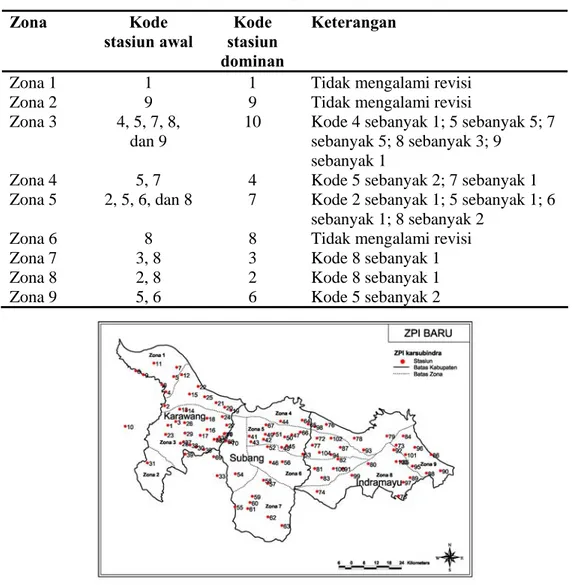
Tabel 4. Kode stasiun yang dilakukan pengelompokkan ulang menurut zona Zona Kode stasiun awal Kode stasiun dominan Keterangan
Zona 1 1 1 Tidak mengalami revisi
Zona 2 9 9 Tidak mengalami revisi
Zona 3 4, 5, 7, 8, dan 9
10 Kode 4 sebanyak 1; 5 sebanyak 5; 7 sebanyak 5; 8 sebanyak 3; 9
sebanyak 1
Zona 4 5, 7 4 Kode 5 sebanyak 2; 7 sebanyak 1 Zona 5 2, 5, 6, dan 8 7 Kode 2 sebanyak 1; 5 sebanyak 1; 6
sebanyak 1; 8 sebanyak 2
Zona 6 8 8 Tidak mengalami revisi
Zona 7 3, 8 3 Kode 8 sebanyak 1
Zona 8 2, 8 2 Kode 8 sebanyak 1
Zona 9 5, 6 6 Kode 5 sebanyak 2
Gambar 5. ZPI Baru Berdasarkan Stasiun Pos Hujan. Perbandingan Hasil Pengelompokkan FCM dan FCS dengan ZPI BMKG
Hasil dari penelitian terdahulu yang pernah dilakukan oleh BMKG (Sutikno, 2008) yang memakai metode complete linkage khusus Kabupaten Karawang, Subang, dan Indramayu terbagi atas 10 ZPI, pada dasarnya hasil penggelompokkan yang dilakukan dalam penelitian ini yaitu menggunakan analisis Fuzzy clustering memperoleh 10
kelompok yang ideal akan tetapi setelah dilakukan pengelompokkan ulang guna untuk mendeteksi kelompok yang menjadi outlier diperoleh 9 kelompok jadi diperoleh 9 ZPI. Dalam penelitian ini hasil dari evaluasi kinerja pengelompokkan dengan analisis Fuzzy clustering yaitu FCM yang digunakan sebagai acuan akan dibandingkan dengan pengelompokkan ZPI yang pernah dilakukan oleh BMKG menggunakan kriteria nilai simpangan baku dalam kelompok (Sw) dan simpangan baku antar kelompok (SB).
Berdasarkan nilai simpangan baku dalam kelompok (Sw) nampak bahwa ZPI revisi lebih
konsisten kecil jika dibandingkan dengan ZPI BMKG (Tabel 5). Namun simpangan baku antar kelompok (SB) belum menunjukkan perbedaan yang nyata.
Tabel 5. Nilai simpangan baku dalam kelompok (Sw) dan antar kelompok (SB)
masing-masing score faktor menurut ZPI BMKG dan ZPI Revisi
Simpangan
baku SF1 SF2 SF3 SF4 SF1 SF2 SF3 SF4
--- ZPI BMKG --- --- ZPI Baru ---
Sw 0,40 0,52 0,68 0,41 0.30 0.48 0,60 0.40
SB 1,11 1,23 0,88 1,66 1.07 0,87 0,70 0,66
KESIMPULAN
Kesimpulan yang didapat dari penelitian ini adalah sebagai berikut:
1. Berdasarkan nilai rataan rasio Sw/Sb menunjukkan hasil kelompok yang optimal untuk
kedua metode FCM dan FCS diperoleh sama yaitu sebanyak 10 kelompok. Metode FCM diperoleh nilai yang paling minimum yaitu 0,483 dari pada metode FCSyaitu 0,798. Metode FCM mempunyai hasil yang lebih baik sehingga berpotensi untuk menghasilkan ZPI yang homogen jika dibandingkan dengan metode FCS Hasil pengelompokkan menggunakan metode FCM setelah mengalami revisi (pengelompokkan ulang) diperoleh 9 kelompok atau 9 zona. Anggota kelompok masing-masing zona adalah sebagai berikut:
a) Zona 1 : Karawang bagian barat laut b) Zona 2 : Karawang bagian barat daya
c) Zona 3 : Karawang bagian tengah, sebagian Subang bagian utara d) Zona 4 : Pantai utara Karawang/Subang/Indramayu
e) Zona 5 : Sebagian Subang bagian tengah sebelah timur, sebagian Indramayu bagian tengah sebelah barat
f) Zona 6 : Sebagian subang bagian tenggara, sebagian indramayu bagian barat daya g) Zona 7 : Subang bagian selatan
i) Zona 9 : sebagian Indramayu bagian timut dan tenggara.
2. Homogenitas iklim hasil zona revisi menggunakan Metode FCM (ZPI revisi) mempunyai kinerja lebih bagus dari pada hasil pengelompokkan yang diperoleh dari hasil ZPI BMKG.
DAFTAR PUSTAKA
Abonyi, J. dan Szeifert, F. 2003. Supervised Fuzzy Clustering for the Identification of Fuzzy Classifiers. Journal Elsevier. 24:2195-2207
Bunkers, M.J. dan Miller, J. R. 1996. Definition of Climate Regions in the Northern Plains Using an Objective Cluster Modification Technique. Journal of Climate. 9: 130-146
Dave,R.N. 1992. Generalized Fuzzy C-Shell Clustering and Detection of Circular And Elliptical Boundaries. Journal Pergamon Pattern Regognition 25(7):713-721 Johnson, R.A dan Wichern, D.W. 2002. Applied Multivariate Statistical Analysis. 5th
edition, Prentice Hall, Upper Sandle River, New Jerse
Klawonn, F. dan Keller, A. 1997. Fuzzy Clustering and Fuzzy Rules. Science Journal Pedrycz, W., 2006. Collaborate and Knowledge-Based Fuzzy Clustering. International
Journal of Innovative Computing, information and Control 3(1):1-12
Pi, D., Qin, X., Wang, Q., 2006. Fuzzy Clustering Algoritma Based on Tree For Association Rules. International Journal of Information Tecnology. 12(3): 43-52 Sutikno, Boer R, Bey A, Notodiputro KA, dan Las I. 2008. Evaluasi Zona Prakiraan Iklim
(ZPI) untuk Kabupaten Karawang, Subang, dan Indramayu dengan Pendekatan Analisis Kelompok. Buletin Meteorologi dan Geofisika. 3(4): 365-379
RIWAYAT HIDUP PENULIS
Azwar Habibi, S.Si. dilahirkan di Jember, Jawa Timur pada tanggal 24 April 1985. Pendidikan Sarjana (S1) ditempuh di Jurusan Matematika FMIPA-UNEJ antara tahun 2003 sampai 2007. Saat ini penulis adalah mahasiswa Program Pascasarjana (S2) pada Jurusan Statistika FMIPA-ITS.