BAB 2
TINJAUAN PUSTAKA
Pada bab ini akan diuraikan konsep-konsep dasar yang berhubungan dengan algoritma QUEST dan algoritma CART yaitu: skala pengukuran data, metode klasifikasi berstruktur pohon, konsep-konsep dasar pada algoritma QUEST dan algoritma CART, uji Chi-kuadrat, uji ANOVA F, uji Levene F, analisis diskriminan kuadratik, algoritma QUEST dan algoritma CART.
2.1 Skala Pengukuran Data
Skala pengukuran adalah penempatan angka atau lambang untuk menyatakan suatu hasil pengamatan/pengukuran terhadap objek. Secara umum terdapat 4 skala pengukuran dalam penelitian, yaitu:
1. Skala Nominal
Skala nominal adalah skala pengukuran data yang digunakan untuk mengklasifikasi objek-objek dalam kategori (kelompok) yang terpisah untuk menunjukkan kesamaan atau perbedaan ciri-ciri tertentu dari objek yang diamati. Kategori (kelompok) yang ada sudah didefinisikan sebelumnya dan dilambangkan dengan kata-kata, huruf symbol atau angka. Contoh skala nominal adalah agama, jenis kelamin, suku bangsa, golongan darah, pekerjaan, area geografis dan sebagainya.
2. Skala Ordinal
3. Skala Interval
Skala interval memiliki semua karakteristik skala ordinal. Perbedaanya dengan skala ordinal adalah bahwa skala ini mempunyai satuan skala. Antar angka kategori memilikim jarak yang sama. Skala ini tidak mempunyai titik nol yang sesungguhnya, yang artinya titik nol merupakan sesuatu yang bermakna ada dengan nilai nol. Contoh skala interval adalah suhu (C).
4. Skala Rasio
Skala rasio sama dengan skala interval, tetapi skala rasio mempunyai titik nol yang sesunguhnya, yang artinya titik nol merupakan nilai yang bermakna tidak ada. Contoh skala rasio adalah berat badan, panjang, usia, lama waktu dan sebagainya.
Data dengan skala nominal dan ordinal seringkali disebut sebagai data kategorik sedangkan data dengan skala interval dan rasio biasa disebut data numerik.
2.2 Metode Klasifikasi Berstruktur Pohon
Dalam statistika, terdapat berbagai metode yang dapat digunakan dalam menarik kesimpulan mengenai hubungan antara suatu peubah respon dengan beberapa peubah bebas. Jika peubah respon berupa data kuantitatif maka analisa mengenai hubungan peubah bebas dan respon biasanya dilakukan melalui analisis regresi biasa. Namun, bila peubah respon merupakan data kualitatif maka analisa mengenai hubungan peubah bebas dan respon salah satunya dapat dilakukan melalui teknik klasifikasi.
diketahui. Setiap himpunan data dinyatakan sebagai simpul dalam pohon yang terbentuk.
Pohon klasifikasi dapat disajikan dalam gambar berikut:
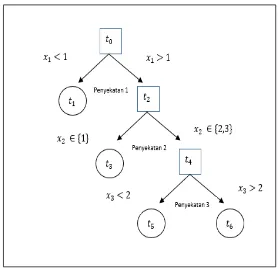
Gambar 2.1 Pohon Klasifikasi
Dalam pohon klasifikasi seperti pada Gambar 2.1, himpunan data dari awal disebut simpul induk, dinotasikan sebagai . Pada simpul , dilakukan penyekatan sehingga terbentuk simpul dan . Penyekatan dilakukan secara berulang sampai diperoleh sebuah simpul yang tidak dapat disekat lagi, yang disebut dengan simpul akhir. Simpul yang tidak termasuk pada simpul induk dan simpul akhir disebut simpul dalam. Dapat dilihat bahwa , adalah simpul dalam sedangkan , , dan adalah simpul akhir. Pada simpul akhir ini dilakukan pendugaan respon.
simpul bila > . Simpul disekat lagi berdasarkan peubah menjadi simpul bila ∈ { } dan simpul bila ∈ { , }. Simpul disekat lagi berdasarkan peubah menjadi simpul bila < dan simpul bila > . Dalam menyekat suatu simpul, setiap peubah bebas memiliki kesempatan untuk terpilih sebagai peubah penyekat, meskipun peubah tersebut telah terpilih sebelumnya sebagai peubah penyekat simpul lain.
Proses penyekatan terhadap simpul dilakukan secara berulang sampai ditemukan salah satu dari tiga hal berikut:
1. Respon di semua simpul sudah homogen nilainya. 2. Tidak ada lagi peubah bebas yang bisa digunakan.
3. Jumlah objek di dalam simpul sudah terlalu sedikit untuk menghasilkan pemisahan yang memuaskan.
Proses penyekatan terhadap suatu simpul dapat bersifat biner atau non biner. Penyekatan biner, setiap simpul hanya boleh disekat menjadi dua simpul baru, sedangkan penyekatan non biner setiap simpul dapat menghasilkan lebih dari dua simpul baru. Gambar 2.1 merupakan pohon klasifikasi dengan penyekatan biner.
2.3 Konsep-Konsep Dasar pada Algoritma QUEST dan Algoritma CART Konsep-konsep statistika yang menjadi dasar pada algoritma QUEST dan algoritma CART yaitu uji khi-kuadrat, uji ANOVA F, uji Levene, dan analisis diskriminan kuadtratik.
2.3.1 Uji Khi-kuadrat (� )
Uji khi-kuadrat (� ) pada dasarnya menyangkut pembuatan tabulasi silang yang digunakan untuk mengetahui hubungan antara dua variabel kategorik. Hubungan yang didapatkan tersebut digunakan untuk mengontrol susunan dari pohon klasifikasi.
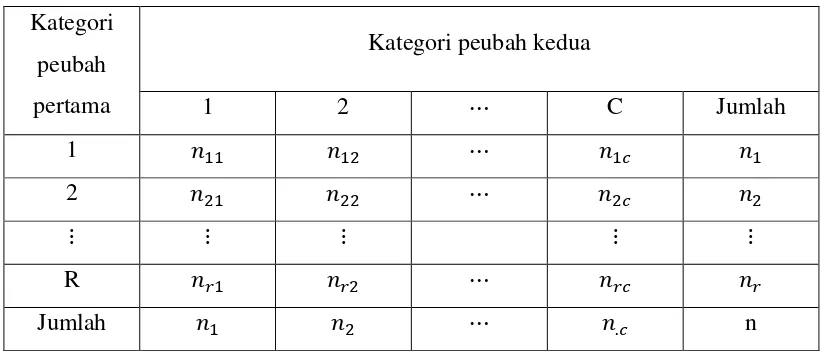
kategorik, data disajikan dalam tabel kontingensi dua arah seperti pada table
Tabel disusun dari r baris dan c kolom masing- masing adalah banyaknya kategori dari peubah kategorik pertama dan kedua. Isi sel pada baris-i = peubah tidak saling bebas. Uji khi-kuadrat ini dilakukan dengan membandingkan frekuensi teramati dengan frekuensi yang diharapkan jika benar.
Hipotesis pada pengujian khi-kuadrat adalah: : Kedua variabel saling bebas
: Kedua variabel tidak saling bebas Sedangkan statistik ujinya adalah:
� = ∑
=∑
= �−� dengan=
� ��
(2.1)
dengan menyatakan nilai harapan pengamatan pada baris ke- dan kolom ke- ,
banyaknya pengamatan pada baris ke- , dan � menyatakan total banyaknya responden.
Keputusan yang diambil dari uji khi-kuadrat ini adalah ditolak jika nilai
�� �� > �� � atau � − < �.
2.3.2Uji ANOVA F
Uji ANOVA F biasa digunakan untuk membandingkan nilai tengah dari dua atau lebih kelompok contoh yang saling bebas. Ukuran contoh antara masing-masing kelompok contoh tidak harus sama, tetapi perbedaan yang besar dalam ukuran contoh dapat mempengaruhi hasil uji perbandingan nilai tengah.
Bila � adalah rata-rata dari kelompok ke-k (k = 1, 2, …, K), maka hipotesis yang digunakan adalah:
: � = � = = � (tidak ada perbedaan rata-rata antarkelompok)
: Minimal ada satu � yang berbeda
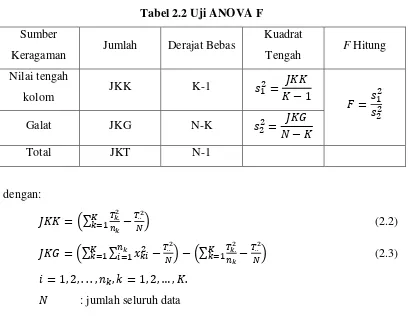
Uji yang digunakan adalah uji F yang diperoleh dengan membentuk tabel ANOVA F seperti tabel di bawah ini:
Tabel 2.2 Uji ANOVA F Sumber
Keragaman Jumlah Derajat Bebas
: jumlah kelompok
� : ukuran contoh kelompok ke-
. : jumlah pengamatan kelompok ke-k .. : jumlah pengamatan data
: pengamatan ke-i dari kelompok ke-k
dalam pengambilan keputusan, ditolak pada taraf nyata � jika nilai statistik uji F hasil perhitungan lebih besar daripada nilai �, − , − .
2.3.3Uji Levene F
Uji Levene F digunakan untuk menguji kesamaan ragam variabel dari beberapa kelompok. Bila � adalah simpangan baku populasi dari kelompok ke-k, maka hipotesis yang digunakan adalah:
∶ � = � = = � , (data homogen)
: Minimal ada satu � yang heterogen
2.3.4Analisis Diskriminan Kuadratik
Analisis diskriminan bertujuan untuk membentuk fungsi diskriminan yang mampu membedakan kelompok. Analisis ini dilakukan berdasarkan suatu perhitungan statistik terhadap objek-objek yang telah diketahui denagn jelas dan mantap pengelompokannya.
Fungsi diskriminan yang dibangun dengan asumsi bahwa kelompok-kelompok memiliki matriks ragam peragam yang sama disebut fungsi diskriminan linear, sedangkan fungsi yang dibangun tanpa asumsi tersebut disebut fungsi diskriminan kuadratik.
Misalkan = , , … , � , maka dapat disajikan struktur data seperti
Tabel 2.3 Struktur Data Analisis Diskriminan Kuadratik
Peubah Kelompok
1 2 ... K
� �̅ �̅ ... �̅
� �̅ �̅ ... �̅
�� �̅� �̅� ... �̅�
Bila adalah fungsi kepekatan peluang bersama dari contoh acak yang berasal dari kelompok ke-k ( = , , … , ). Jika contoh acak pada kelompok tersebut menyebar menurut sebaran normal multivariat, maka
=
� �|∑ | [− − � ∑ − �
− ] (2.5)
dengan:
� adalah vektor nilai tengah dari kelompok ke-k
∑ adalah matriks ragam peragam kelompok ke-k
�adalah banyaknya peubah.
Skor diskriminan kuadratik untuk sebuah pengamatan dengan nilai =
, , … , � terhadap kelompok ke-k dan � menyatakan peluang awal dari
kelompok ke-k:
= �|∑ | − − � ∑− − � + � � (2.6)
dengan:
� adalah peluang awal dari kelompok ke-k ( = , , … , ).
Bila individu yang berasal dari kelompok k dinyatakan sebagai kelompok , maka peluangnya dinotasikan menjadi � | .
Kelompokkan ke-k jika
Apabila � dan ∑ tidak diketahui, maka harus dicari taksiran dari � dan ∑ dengan memanfaatkan data sampel yang telah dikelompokkan dengan benar. Taksiran dari skor diskriminan kuadratik menjadi:
̂ = − �| | − − ̅ − − ̅ + � � (2.8)
Kelompokkan ke-k jika
Skor kuadratik ̂ = max { ̂ , ̂ , … , ̂ } (2.9)
2.4 Metode QUEST
QUEST (Quick, Unbiased, Efficient Statistical Trees) merupakan salah satu metode yang digunakan untuk membentuk pohon klasifikasi. QUEST merupakan algoritma pemisah yang menghasilkan pohon biner yang digunakan untuk klasifikasi. Algoritma pembentukan pohon klasifikasi ini merupakan modifikasi dari analisis diskriminan kuadratik.
Pada algoritma ini, proses penyekatan dapat dilakukan pada peubah tunggal (univariate). Pemilihan peubah penyekatan pada QUEST menerapkan uji kebebasan chi-kuadrat untuk peubah kategorik dan uji F untuk peubah numerik. Suatu peubah dipilih sebagai peubah penyekat jika menghasilkan kelompok dengan tingkat kehomogenan peubah respon yang paling besar. Penentuan titik penyekat pada pohon klasifikasi ini dilakukan dengan menerapkan analisis diskriminan kuadratik. Pemilihan peubah dan penentuan titik penyekat dilakukan secara terpisah. Komponen dasar QUEST adalah beberapa peubah bebas yang merupakan peubah kategorik atau numerik dan peubah respon yang merupakan peubah kategorik.
2.4.1 Algoritma QUEST
kesempatan untuk terpilih sebagai peubah penyekat, meskipun peubah tersebut telah dipilih sebagai peubah penyekat untuk simpul sebelumnya.
1. Algoritma Pemilihan Peubah Penyekat
Dalam Menentukan peubah penyekat pada suatu simpul setiap peubah memiliki kesempatan untuk terpilih sebagai peubah penyekat, meskipun peubah tersebut telah terpilih sebagai peubah penyekat untuk simpul sebelumnya. Langkah-langkah pemilihan peubah penyekatan:
nilai p dari pengujian tersebut. 2. Pilih peubah dengan nilai p terkecil.
3. Bandingkan nilai p terkecil dengan taraf �/ , dengan pilih taraf nyata � =
, dan adalah banyaknya peubah bebas.
Jika nilai p kurang dari �/ , maka pilih peubah yang bersesuaian sebagai
peubah penyekat. Teruskan ke langkah (5).
Jika nilai p lebih dari �/ , teruskan ke langkah (4).
4. Untuk setiap peubah X yang numerik, maka hitung nilai p dari uji Leneve untuk menguji kehomogenan ragam.
Pilih peubah dengan nilai p terkecil.
Bandingkan nilai p terkecil dari uji Leneve dengan taraf �/ + ,
dengan adalah banyaknya peubah bebas numerik.
Jika nilai p kurang dari �/ + , maka pilih peubah yang bersesuaian
sebagai peubah penyekat. Teruskan ke langkah (5).
Jika nilai p lebih dari �/ + , maka peubah tersebut tidak dipilih
menjadi peubah penyekat.
5. Misalkan �∗ adalah peubah penyekat yang diperoleh dari langkah (3) dan (4).
Jika �∗ merupakan peubah kategorik, �∗ ditransformasikan ke dalam
peubah dummy, lalu proyeksikan ke dalam koordinat diskiriminan terbesarnya.
6. Lakukan analisis diskriminan kuadratik untuk menentukan titik penyekat.
2. Algoritma Penentuan Titik Penyekat
Misalkan peubah respon memiliki dua kategori. Misalkan pula bahwa �∗ merupakan peubah yang terpilih untuk menyekat simpul t. Langkah-langkah penentuan titik penyekat:
1. Definisikan ̅ dan adalah nilai tengah dan ragam �∗ dari pengamatan dengan respon 0, sedangkan ̅ dan adalah nilai tengah dan ragam �∗ dari pengamatan respon 1. Misalkan = | = , / merupakan peluang
dari masing-masing kategori peubah respon, dengan , adalah jumlah data pada simpul t untuk respon k dan adalah jumlah data pada simpul awal untuk respon k.
2. Tentukan solusi dari persamaan
| − � �−�̅ = | − � �−�̅ (2.10)
solusi tersebut dapat ditentukan dengan menentukan akar persamaan kuadrat
+ + = , dengan:
= + (2.11)
= ̅ − ̅ (2.12)
= ̅ − ̅ + � { ( | )( | ) } (2.13)
3. Simpul disekat pada titik �∗= , di mana d didefinisikan sebagai berikut:
Jika ̅ ≥ ̅ , maka = ̅
= {�̅ −�̅ − ̅ − ̅ − ln { ( | )( | )} , ̅ ≠ ̅
̅ , ̅ = ̅ (2.14)
Jika a≠ , maka
Jika − < , maka = ̅ + _ ̅
Jika − ≥ , maka d adalah akar dari − ±√ − yang lebih
mendekati nilai ̅ , dengan syarat menghasilkan dua simpul tak-kosong.
3. Algorima Transformasi Peubah Kategorik Menjadi Peubah Numerik Misalkan � adalah peubah kategorik, dengan kategori , , … , . Transformasi
� menjadi peubah numerik � untuk tiap kelas � dilakukan dengan langkah-langkah sebagai berikut:
1. Transformasikan masing-masing nilai x ke vektor dummy L dimensi
� = , , … , ′, dengan = { =
≠ , = , , … ,
2. Cari nilai tengah untuk X
�̅ = ∑= � �
�� (2.15)
�̅ =∑= � �
��, (2.16)
dengan :
̅ : rata-rata untuk semua pengamatan pada simpul t
̅ : rata-rata untuk semua pengamatan pada simpul t untuk kelompok ke-k
: jumlah pengamatan pada simpul t untuk
� : jumlah pengamatan pada simpul t kelompok ke-k untuk : jumlah pengamatan pada simpul t
3. Tentukan matriks x berikut:
�̅ =∑= � �
��
�̅ =∑=�� �
�,
� = ∑ = � ,� �̅ − �̅ �̅ − �̅ ′ (2.17)
� = ∑ � � − �̅ � − �̅ ′
= (2.18)
4. Lakukan SDV dari T=QDQ’, dengan :
Q adalah matriks orthogonal yang kolomnya merupakan vektor eigen dari
�′�
D = diag( , … , ) dengan ≥ ≥ ≥ ≥ .
5. Tentukan �− = ∗, … , ∗ , dengan ∗ = {
⁄
�� . >
6. Lakukan SVD dari �− �′���− , tentukan vektor eigen � yang merupakan vektor eigen yang berpadanan dengan nilai eigen terbesar.
7. Tentukan koordinat diskriminan terbesar dari �, yaitu:
� = �′�− �′� (2.19)
2.5 Metode CART
CART merupakan metodologi statistik nonparametrik yang dikembangkan untuk topik analisis klasifikasi, baik untuk variabel respon kategorik maupun kontinu. CART menghasilkan suatu pohon klasifikasi jika variabel responnya kategorik, dan menghasilkan pohon regresi jika variabel responnya kontinu.
besar, variabel yang sangat banyak dan dengan skala variabel campuran melalui prosedur pemilihan biner.
2.5.1 Algoritma CART
Menurut Susanto dan Suryadi (2010), pada klasifikasi algoritma CART (Classification and Regresion Trees), sebuah record akan diklasifikasikan ke dalam salah satu dari sekian klasifikasi yang tersedia pada variabel tujuan berdasarkan nilai-nilai variabel prediktornya.
Langkah-langkah Algoritma CART:
1. Susunlah calon cabang (candidate split) yang dilakukan terhadap seluruh variabel prediktor. Daftar yang berisi calon cabang disebut calon cabang mutakhir.
2. Berikan penilaian keseluruhan calon cabang mutakhir dengan menghitung besaran Φ | .
3. Tentukan cabang yang memiliki kesesuaian Φ | . Setelah noktah keputusan tidak ada lagi, algoritma CART dihentikan.
Kesesuaian (goodness) Φ | dari calon cabang pada noktah keputusan , didefinisikan sebagai persamaan-persaman berikut:
Φ | = | (2.20)
| = ∑ |= | − | | (2.21)
dengan:
JK : jumlah kategori
: cabang kiri dari noktah keputusan : cabang kanan dari noktah keputusan
= L (2.22)
| = L (2.23)
= R (2.24)