i
PROPOSAL
PENELITIAN UNGGULAN ITS DANA ITS TAHUN 2020
AUDIOVISUAL SINTESIS UCAPAN BAHASA INDONESIA (VIBIO) SEBAGAI ALAT BANTU PEMBELAJARAN INTERAKTIF BAGI KOMUNITAS ANAK BERKEBUTUHAN KHUSUS TERLAMBAT BICARA
(DELAYED SPEECH)
Tim Peneliti:
Ketua : Dr. Dhany Arifianto, ST., M.Eng. (Teknik Fisika/FTIRS/ITS) Anggota 1 : Ir. Wiratno Argo Asmoro, M.Sc. (Teknik Fisika/FTIRS/ITS)
Anggota 2 : Dr. Nyilo Purnami, dr. Sp. THT-KL (K) FICS (Fakultas Kedokteran/UNAIR) Anggota 3 : Irwansyah ST., M.T., M.Phil., PhD (Computer Science/Kumamoto University)
DIREKTORAT PENELITIAN DAN PENGABDIAN KEPADA MASYARAKAT INSTITUT TEKNOLOGI SEPULUH NOPEMBER
SURABAYA 2020
ii
HALAMAN PENGESAHAN
PROPOSAL PROGRAM PENELITIAN UNGGULAN DANA ITS TAHUN 2020
1. Judul Pengabdian : Audiovisual Sintesis Ucapan Bahasa Indonesia (VIBIO) sebagai Alat Bantu Pembelajaran Interaktif Bagi Komunitas Anak Berkebutuhan Khusus
Terlambat Bicara (Delayed Speech)
2. Bidang Unggulan PT : Kecerdasan Artifisial dan Teknologi Kesehatan 3. Topik Penelitian : Assistive Technology and Medical Rehabilitation
(Device for Mobility, Visual, and hearing Impairments) 4. Ketua Tim
a. Nama : Dr. Dhany Arifianto, ST., M.Eng.
b. NIP/NIDN : 197310071998021001 / 0007107302 c. Pangkat/Golongan : Penata Tk. 1 / IIIc
d. Jabatan Fungsional : Lektor
e. Departemen : Teknik Fisika
f. Fakultas : Fakultas Teknologi Industri dan Rekayasa Sistem g. Alamat Kantor : Gedung E-101, Laboratorium Vibrasi dan Akustik,
Teknik Fisika, Kampus ITS, Surabaya (60111) h. Telp/HP/Fax : - / 0857-0403-6336
5. Jumlah anggota : 3 orang 6. Jumlah mahasiswa yang terlibat : 4 orang 7. Mitra penelitian
a. Nama instansi mitra : Poli Audiologi, RSUD Dr. Soetomo Surabaya b. Contact Person : Dr. Nyilo Purnami, dr. Sp. THT-KL (K) FICS c. Jabatan : Koordinator Penelitian, Pengembangan, dan
Pendidikan, Divisi THT – KL
d. Alamat : Jalan Mayjen Prof. Dr. Moestopo No 6-8, Surabaya e. Telp/HP/Fax : - / 0815-5100-081
8. Lama Penelitian Keseluruhan :3 (tiga) tahun 9. Biaya penelitian
a. Diusulkan Dana ITS Tahun 2020 : Rp.330.000.000,00 b. Sumber lain (RSUD Dr. Soetomo) : Rp. 25.000.000,00 Jumlah : Rp.355.000.000,00
Mengetahui,
Ketua Pusat Penelitian Kecerdasan Artifisial Dan Teknologi Kesehatan
Prof. Dr. Agus Zainal Arifin, M. Kom.
NIP. 197208091995121001
Surabaya, 5 Maret 2020 Ketua tim penneliti
Dr. Eng. Dhany Arifianto, ST., M.Eng NIP. 197310071998021001
iii RINGKASAN
World Health Organization (WHO) pada Hari Pendengaran Dunia (World Hearing Day) menyatakan bahwa pada tahun 2019 terdapat 466 juta penduduk dunia yang mengalami gangguan pendengaran. Gangguan pendengaran berada pada lebih dari 5% populasi dunia dan 34 juta diantaranya adalah anak-anak (WHO, 2019). Bila tidak dilakukan tindakan pencegahan dan penatalaksanaan masalah tersebut, maka pada tahun 2030 diperkirakan akan terdapat 630 juta penderita gangguan dengar dan menjadi 900 juta penduduk dunia pada tahun 2050. Di Indonesia, pada tahun 1994-1996, survei nasional menunjukkan, morbiditas penyakit telinga 40,5 juta jiwa (18.5%), prevalensi gangguan pendengaran 35,28 juta jiwa (16.8%) dan ketulian mencapai 840000 jiwa (0.4). Gangguan pendengaran ini biasanya mempengaruhi perkembangan kemampuan berbicara pada anak sehingga menjadi terlambat.
(Zengin-Akkuş et al., 2018). Gangguan pendengaran anak ini akan diikuti dengan gangguan berbicara akibat tidak menerima rangsang (stimulus) suara yang dapat ditiru oleh balita tersebut. Tenaga speech therapist untuk membantu terapi pasien terlambat bicara (delay speech) hanya dimiliki oleh kota-kota besar. Saat ini untuk Indonesia bagian timur baru dimiliki oleh RSUD Dr. Soetomo, Surabaya.
Berdasarkan keputusan direktur Rumah Sakit Umum Daerah Dr. Soetomo Nomor:
188.4 / 9621 / 301 / 2011, Rumah Sakit Umum Daerah Dr. Soetomo Surabaya merupakan Rumah Sakit Kelas A, yang berarti merupakan rumah sakit pendidikan dan rumah sakit rujukan tertinggi untuk wilayah Indonesia Bagian Timur. Sehingga RSUD Dr. Soetomo dipandang perlu untuk meningkatkan mutu pelayanan kesehatan sesuai dengan tuntutan pelayanan kesehatan kepada masyarakat (Suyoso, dkk., 2012). Melalui Program penelitian ini diharapkan dapat membantu untuk meningkatkan pelayanan kepada pasien. Selain itu, penelitian ini bertujuan untuk menghasilkan alat bantu audiovisual (visual dan auditory stimuli) untuk pembelajaran pengucapan komunitas anak berkebutuhan khusus terlambat bicara (delayed speech) dalam bentuk perangkat lunak. Dampak lain adalah alternatif perangkat keras secara portabel dan murah bagi rumah sakit atau tempat terapi pasien anak terlambat bicara yang belum memiliki tenaga speech therapist. Secara prinsip penelitian yang diusulkan adalah meniru bagaimana manusia normal dapat mereproduksi bunyi ujaran dan kemudian merangkai bunyi ujaran tersebut sehingga memiliki makna. Dengan teknik Hidden Markov Model (HMM) dipakai untuk pemodelan fitur akustik untuk menghasilkan bunyi ujaran sekaligus memodelkan perangkaian fitur akustik tersebut hingga menjadi bunyi ujaran yang memiliki makna utuh sebagai kalimat.
Pola penelitian ini adalah joint-supervision dimana PI dan co-PI membimbing satu mahasiswa Teknik Fisika ITS dan satu mahasiswa program pendidikan dokter spesialis (PPDS) THT-KL. Perekrutan naracoba anak yang berkebutuhan khusus serta speech therapists dilakukan di ruang pemeriksaan poli Audiologi, THT-KL, RSUD Dr. Soetomo, Surabaya. Kolaborasi dalam penelitian ini diperlukan sebagai kontinuitas ketersediaan naracoba berkebutuhan khusus yang sesuai dengan kriteria klinik. Hasil kegiatan penelitian unggulan ini akan digunakan untuk mengevaluasi perangkat lunak dan keras sebagai media pembelajaran interaktif komunitas anak berkebutuhan khusus terlambat bicara di Indonesia.
Hasil penelitian ini akan diseminasikan melalui makalah seminar dan jurnal internasional serta akan dipatenkan.
Kata kunci: Audiovisual sintesis ucapan, Bahasa Indonesia, delayed speech
iv DAFTAR ISI
HALAMAN PENGESAHAN ... ii
RINGKASAN ... iii
DAFTAR ISI ... iv
BAB 1 PENDAHULUAN ... 5
BAB II SOLUSI PERMASALAHAN ... 7
BAB III METODE PELAKSANAAN ... 18
BAB IV LUARAN DAN TARGET CAPAIAN ... 28
BAB V USULAN ANGGARAN BIAYA ... 29
DAFTAR PUSTAKA ... 34
GAMBARAN IPTEK ... 38 PETA LOKASI ... Error! Bookmark not defined.
v
BAB 1 PENDAHULUAN
1.1 Latar Belakang
World Health Organization (WHO) pada Hari Pendengaran Dunia (World Hearing Day) menyatakan bahwa pada tahun 2019 terdapat 466 juta penduduk dunia yang mengalami gangguan pendengaran. Gangguan pendengaran berada pada lebih dari 5% populasi dunia dan 34 juta diantaranya adalah anak-anak (WHO, 2019). Bila tidak dilakukan tindakan pencegahan dan penatalaksanaan masalah tersebut, maka pada tahun 2030 diperkirakan akan terdapat 630 juta penderita gangguan dengar dan menjadi 900 juta penduduk dunia pada tahun 2050. Di Indonesia, pada tahun 1994-1996, survei nasional menunjukkan, morbiditas penyakit telinga 40,5 juta jiwa (18.5%), prevalensi gangguan pendengaran 35,28 juta jiwa (16.8%) dan ketulian mencapai 840000 jiwa (0.4). Gangguan pendengaran ini biasanya mempengaruhi perkembangan kemampuan berbicara pada anak sehingga menjadi terlambat.
Keterlambatan bicara anak dapat menjadi gejala awal yang tidak disadari dari beberapa penyakit, autism spectrum disease, global development delay, atau gangguan pendengaran (Zengin-Akkuş et al., 2018). Pada 91 anak dengan keterlambatan bicara, ditemukan 25 (27.4%) anak mengalami gangguan pendengaran (Douniadakis et al., 2002). Pada anak yang sulit mendengar, perkembangan kemampuan bicara dan kemampuan dengar mengalami keterlambatan dibandingkan dengan anak normal (McCreery et al., 2015). Gangguan pendengaran anak ini akan diikuti dengan gangguan berbicara akibat tidak menerima rangsang (stimulus) suara yang dapat ditiru oleh balita tersebut. Tenaga speech therapist untuk membantu terapi pasien terlambat bicara (delay speech) hanya dimiliki oleh kota-kota besar. Saat ini untuk Indonesia bagian timur baru dimiliki oleh RSUD Dr. Soetomo, Surabaya.
Angka kejadian pada anak terlambat bicara, yaitu antara 1% hingga 32%, karena kriteria diagnosis yang berbeda-beda dan terminologi yang belum pasti sehingga belum dapat dipastikan secara tepat (Soetjiningsih, 2014). Keterlambatan bicara dapat ditemukan sebagai manifestasi dari penyakit lain. Pada 110 anak dengan keluhan tidak dapat berbicara, tidak dapat membentuk kalimat dan terlambat bicara, ditemukan berdasarkan klinis terdapat 28.18% anak dengan perkembangan bicara terlambat dan lainnya ditemukan mental retardation, pervasive developmental disorder, dan phonological disorder (Yasin et al., 2017).
2
Intervensi dini merupakan hal yang sangat penting setelah diagnosis gangguan dengar ditegakkan. Intervensi yang dilakukan adalah penggunaan alat bantu dengar, yang bertujuan agar ambang dengar pasien meningkat sehingga sama dengan ambang dengar normal, disertai dengan terapi/habilitasi wicara.
Gambar 1.1 memperlihatkan data gangguan dengar berdasarkan provinsi yang terjadi di Indonesia pada RISKESDAS 2013 [1] dimana jumlah populasi penduduk Indonesia pada 2013 adalah 254 juta penduduk. DKI Jakarta dan Banten menduduki provinsi terendah dalam gangguan dengar. Secara keseluruhan terdapat 2.6% (sekitar 6.6 juta orang) menderita gangguan dengar pada tahun 2013.
%
Provinsi
Gambar 1.1 Gangguan Dengar Berdasarkan Provinsi untuk Umur >= 5 Tahun (RISKESDAS, 2013)
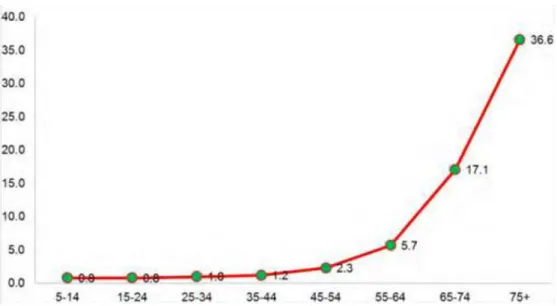
Gambar 1.2 memperlihatkan data gangguan dengar berdasarkan kelompok umur yang terjadi di Indonesia pada RISKESDAS 2013 [1]. Terjadi penurunan kualitas penurunan secara drastis pada umur di atas 64 tahun. Terlihat pada data, terdapat lebih dari 36% dari orang dengan umur diatas 75 tahun, menderita gangguan dengar. Dengan terjadinya gangguan dengar pada seseorang, produktifitasnya di dalam menjalani kegiatan sehari-sehari dapat menurun secara drastis seperti; tidak dapat berkomunikasi dengan lancar sehingga tidak dapat berinteraksi dengan orang lain maupun bekerja dengan baik.
3
%
Kelompok Umur
Gambar 1.2 Gangguan Dengar Berdasarkan Kelompok Umur (RISKESDAS, 2013)
%
Karakteristik (Biru: Pendidikan, Hijau: Pekerjaan, Merah: Status Ekonomi) Gambar 1.3 Gangguan Dengar Berdasarkan Karakteristik (RISKESDAS, 2013)
Gambar 1.3 menunjukkan data gangguan dengar berdasarkan karakteristiknya yang terjadi di Indonesia menurut RISKESDAS 2013. Terlihat pada data, bahwa tingkat pendidikan sangat mempengaruhi pemahaman seseorang di dalam menangani gangguan dengar. Pada kelompok masyarakat yang tidak sekolah, gangguan dengar terjadi dengan persentase yang tinggi hingga 8%. Hal ini sejalan dengan pemahaman seseorang tentang kesehatan telinga yang juga dipengaruhi oleh sanitas, lingkungan dan inveksi penyakit. Dari
4
data tersebut perlu diadakan penyuluhan kepada masyarakat yang lebih intensif, agar kesehatan telinga dapat lebih dijaga yang dengannya produktifitas dari masyarakat dapat meningkat lebih drastis.
Sesuai dengan program ke-5 Nawa Cita Presiden Republik Indonesia, yaitu meningkatkan kualitas hidup manusia Indonesia, yang dituangkan pada Rencana Strategis Kementerian Kesehatan 2015-2019 yaitu peningkatan pelayanan kesehatan. Terapi untuk mengatasi permasalahan gangguan berbicara tersebut masih terbatas pada ketersediaan perawat ahli dan fasilitas terapi yang saat ini hanya tersedia di poli audiologi di beberapa kota besar. Pada tanggal 3 Maret 2017, WHO mencanangkan sebagai hari World Hearing Day, yaitu kampanye upaya intensif dan masif untuk mencegah, mengidentifikasi, rehabilitasi dan edukasi untuk menurunkan angka penderita gangguan pendengaran. Upaya yang dilakukan diberbagai negara telah banyak seperti pemeriksaan mutasi genetik penyebab gangguan pendengaran (Wu, 2017) hingga studi pemetaan (Marcoux, 2012) mulai dari bayi (Wroblewska-Seniuk, 2017) hingga dewasa (Kiessling, 2015).
Berdasarkan keputusan direktur Rumah Sakit Umum Daerah Dr. Soetomo Nomor:
188.4 / 9621 / 301 / 2011, Rumah Sakit Umum Daerah Dr. Soetomo Surabaya merupakan Rumah Sakit Kelas A, yang berarti merupakan rumah sakit pendidikan dan rumah sakit rujukan tertinggi untuk wilayah Indonesia Bagian Timur. Sehingga, sebagai RSU kelas A, RSUD Dr. Soetomo dipandang perlu untuk meningkatkan mutu pelayanan kesehatan sesuai dengan tuntutan pelayanan kesehatan kepada masyarakat (Suyoso, dkk., 2012). Melalui Program penelitian unggulan ITS ini diharapkan dapat membantu untuk meningkatkan pelayanan kepada pasien. Selain itu, penelitian ini bertujuan untuk menghasilkan alat bantu audiovisual (visual dan auditory stimuli) untuk pembelajaran pengucapan komunitas anak berkebutuhan khusus terlambat bicara (delayed speech) dalam bentuk perangkat lunak.
Dampak lain adalah alternatif perangkat keras secara portabel dan murah bagi rumah sakit atau tempat terapi pasien anak terlambat bicara yang belum memiliki tenaga speech therapist.
Secara prinsip penelitian yang diusulkan adalah meniru bagaimana manusia normal dapat mereproduksi bunyi ujaran dan kemudian merangkai bunyi ujaran tersebut sehingga memiliki makna. Dengan teknik Hidden Markov Model (HMM) dipakai untuk pemodelan fitur akustik untuk menghasilkan bunyi ujaran sekaligus memodelkan perangkaian fitur akustik tersebut hingga menjadi bunyi ujaran yang memiliki makna utuh sebagai kalimat.
Setiap negara memiliki bahasa yang beragam seperti bahasa Indonesia, Arab, Mandarin, Jepang, Inggris, dan lain-lain. Pada prinsipnya perkembangan teknologi speech processing dipengaruhi oleh jenis bahasa yang digunakan di negara tersebut. Hal itu
5
menyebabkan setiap negara memiliki teknologi speech processing yang berbeda-beda (Dessi, 2010). Teknologi pemrosesan suara terdiri dari dua komponen utama yaitu automatic speech recognition (ASR) dan speech synthesis. Sistem ASR mengkonversikan input suara menjadi output dalam bentuk teks. Sedangkan speech synthesis menkonversikan input yang berupa teks menjadi output dalam bentuk suara. Meskipun beberapa sistem sintesis suara mampu menghasilkan suara yang berkualitas tinggi, namun masih belum dapat menghasilkan suara sintesis yang memiliki bermacam-macam karakteristik suara seperti, speaking style, emotions, speaker individuallities, dan lainnya. Karakteristik pada suara sintesis maka dibutuhkan data suara dalam jumlah yang besar. Oleh karena itu, diusulkan sistem sintesis suara berbasis hidden markov models (HMM).
Dalam penelitian lintas disiplin ini diharapkan mendapatkan hasil evaluasi untuk perangkat lunak dan keras sebagai media pembelajaran interaktif komunitas anak berkebutuhan khusus terlambat bicara di Indonesia. Dengan demikian dapat dihasilkan perangkat audiometri lunak dan keras sebagai alat bantu pembelajaran interaktif komunitas anak berkebutuhan khusus terlambat bicara sehingga memudahkan dokter, perawat dan pasien melakukan pengawalan dalam proses terapi wicara. Dalam penelitian ini prosedur diawali dengan pembuatan basis data suara bahasa Indonesia melalui proses perekaman untuk keperluan training dan testing algoritma komputasi dari program yang telah dibuat dengan basis Hidden Markove Model (HMM). Kalimat yang digunakan untuk membangun basis data suara bahasa Indonesia dibuat berdasarkan kaidah keseimbangan fonetik (phonetically balanced). Keseimbangan fonetik akan tercapai jika dalam basis data kalimat yang digunakan telah mencakup seluruh fonem yang terdapat dalam bahasa Indonesia. Jumlah fonem yang terdapat dalam bahasa Indonesia adalah sebanyak 33 fonem (Suyanto, 2007). Selanjutnya dalam penelitian ini akan dibangun perangkat lunak dan perangkat keras berbasis audiovisual sistem speech synthesis netral (tidak berintonasi) dan ekspresif berbahasa Indonesia berbasis Hidden Markove Model (HMM).
1.2 Tujuan
Dalam usulan penelitian unggulan ini bertujuan untuk mengatasi permasalahan terbatasnya ketersediaan perawat ahli dan fasilitas terapi pasien terlambat berbicara (delayed speech) akibat tidak menerima rangsang (stimulus) suara. Oleh karena itu, dilaksanakan penelitian guna mengatasi permasalahan tersebut dengan keluaran berupa perangkat lunak dan perangkat keras yang digunakan sebagai media pembelajaran interaktif dalam bahasa Indonesia. Adapun rincian tujuan dari penelitian ini adalah sebagai berikut:
6
a. Diperolehnya basis data dalam bahasa Indonesia untuk pembuatan sintesis ucapan (speech synthesis) netral (tidak berintonasi) dan ekspresif berdasarkan kaidah keseimbangan fonetik (phonetically balanced).
b. Menghasilkan perangkat lunak dan perangkat keras sebagai Alat Bantu Media Interaktif Pembelajaran Komunitas tuna wicara dan tuna rungu dengan basis speech synthesis alamiah bahasa Indonesia.
1.3 Kebaruan dan Terobosan Teknologi
Kerjasama penelitian antara Laboratorium Vibrasi dan Akustik (Vibrastic), Departemen Teknik Fisika FTIRS-ITS dengan SMF THT-KL RSUD Dr. Soetomo/Fakultas Kedokteran Universitas Airlangga telah berlangsung sejak 1998 yang telah mempublikasikan lebih dari 15 artikel ilmiah. Kerjasama ini kemudian diperluas ke sub-bagian telinga (Neuro-Otologi) yang dimulai sejak 2009. Fasilitas yang dimiliki oleh oleh Lab. Vibrastic terkait penelitian ini berupa satu buah ruang semi-kedap (semi-anechoic chamber), satu unit 24bit audio digital-to-analog converter untuk membangkitkan bunyi stimulus. SMF THT-KL RSUD Dr.
Soetomo memiliki 4 ruang kedap (audiology booth) dan peralatan hearing screening seperti timpanometri. Usulan penelitian Unggulan ITS ini akan lebih memperkuat jejaring kolaborasi antar profesi dokter dan perekayasa untuk memudahkan pasien dengan gangguan pendengaran dan terlambat bicara yang pada akhirnya akan membantu pemerintah untuk memperbaiki kualitas hidup bangsa Indonesia.
Tidak meratanya penyebaran fasilitas kesehatan yang memadai antara satu daerah dengan daerah yang lain di Indonesia dapat menyebabkan keterlambatan diagnosa dan penanganan pasien. Fasilitas kesehatan terbaik masih terkonsentrasi pada pulau Jawa dan kota-kota besar saja. Sebaran tenaga dokter spesialis telinga, hidung dan tenggorok juga masih terbatas di daerah ibu kota propinsi. Tahap pertama berupa pemetaan pola gangguan pendengaran sensorineural dengan mengelompokkan menurut akibat, yaitu grup akibat paparan bising berlebih (noise-induced hearing impairment), faktor keturunan, dan faktor usia (age-related hearing impairment). Selanjutnya dilakukan Development Denver Screening Test II, yakni digunakan alat untuk men-screening perkembangan anak mencakup empat hal yaitu motorik kasar, motorik halus, bahasa, dan sosial-personal. Penelitian ini diharapkan mampu mengawal proses terapi wicara dan mempermudah dokter serta tenaga medis terapi wicara untuk memastikan pasien selalu konsisten berlatih bicara di rumah.
7
BAB II TINJAUAN PUSTAKA
Sebelum melakukan perancangan multimedia untuk pasien terlambat bicara, dilakukan beberapa studi literatur dan konsultasi dengan tenaga ahli terapi wicara sebagai berikut:
➢ Skrining Pendengaran
Saat ini baku emas untuk skrining pendengaran digunakan OAE (Otoacoustic Emission) dan ABR (Auditory Brainstem Respons) sebagai pemeriksaan obyektif :
a. Pemeriksaan OAE
Tujuan utama uji emisi otoakustik (OAE) adalah menentukan status koklea, khususnya fungsi sel rambut. Informasi ini dapat digunakan untuk (1) pendengaran layar (terutama pada neonatus, bayi, atau individu dengan cacat perkembangan), (2) memperkirakan sensitivitas pendengaran sebagian dalam rentang terbatas, (3) membedakan antara komponen sensoris dan neural dari pendengaran sensorineural.
Kehilangan, dan (4) tes untuk gangguan pendengaran fungsional (pura-pura).
Informasi tersebut bisa didapat dari pasien yang sedang tidur atau bahkan koma karena tidak ada respon tingkah laku yang diperlukan.
Koklea normal tidak hanya menerima suara, hal ini juga menghasilkan suara dengan intensitas rendah yang disebut OAEs. Suara ini diproduksi secara khusus oleh koklea dan kemungkinan besar, oleh sel rambut luar koklea saat mereka berkembang dan berkontraksi. Kehadiran emisi koklea dihipotesiskan pada tahun 1940an berdasarkan model matematis nonlinier koklea. Namun, OAE tidak dapat diukur sampai akhir 1970-an, ketika teknologi menciptakan mikrofon dengan noise rendah yang sangat sensitif yang diperlukan untuk mencatat respons ini.
Ada 4 jenis emisi otoakustik adalah sebagai berikut: Emisi otoakustik spontan (SOAEs) - Suara yang dipancarkan tanpa stimulus akustik (yaitu, secara spontan).
Emisi otoakustik transien (TOAE) atau emisi otoakustik yang ditimbulkan sementara (TEOAEs) - Kedengarannya dipancarkan sebagai respons terhadap rangsangan akustik dengan durasi yang sangat singkat; Biasanya klik tapi bisa nada-semburan.
Distorsi emisi otoakustik produk (DPOAEs) - Suara yang dipancarkan sebagai respons terhadap 2 nada simultan dari frekuensi yang berbeda. Emisi otoakustik frekuensi tetap (SFOAEs) - Kedengarannya dipancarkan sebagai respons terhadap nada yang terus-menerus
8
Pengukuran audiometri murni di seluruh telinga luar, telinga tengah, koklea, saraf kranial (CN) VIII, dan sistem pendengaran sentral. Namun, OAE hanya mengukur sistem pendengaran periferal, yang meliputi telinga luar, telinga tengah, dan koklea.
Responnya hanya berasal dari koklea, tapi telinga bagian luar dan tengahnya harus bisa mentransmisikan suara yang dipancarkan kembali ke mikrofon rekaman.
Pengujian OAE sering digunakan sebagai alat skrining untuk mengetahui ada tidaknya fungsi koklea, walaupun analisis dapat dilakukan untuk daerah frekuensi koklea individual. OAEs tidak dapat digunakan untuk menggambarkan secara penuh ambang batas pendengaran seseorang, namun dapat membantu mempertanyakan atau memvalidasi langkah-langkah ambang lainnya (misalnya, pada gangguan pendengaran fungsional yang dicurigai fungsional, atau mereka dapat memberikan informasi tentang lokasi lesi tersebut.
Dengan menggunakan teknologi saat ini, kebanyakan peneliti dan dokter menemukan korelasi antara analisis frekuensi spesifik TOAE / DPOAE dan gangguan pendengaran koklea. Namun, pada saat ini, korelasi tersebut tidak dapat sepenuhnya menggambarkan ambang pendengaran. Tentu, korelasi tidak akan diharapkan untuk gangguan pendengaran noncochlear (Campbell, 2016).
b. Pemeriksaan ABR
ABR merupakan suatu metoda pemeriksaan neurologis yaitu mengenai respon fungsi batang otak auditorik terhadap stimulus auditorik (click). ABR mampu memberikan informasi mengenai fungsi auditorik dan sensitivitas pendengaran, meskipun demikian penggunaan ABR tidak berarti dapat menggantikan tindakan evaluasi pendengaran yang formal, pemeriksaan ABR sebaiknya dilanjutkan dengan audiometri behavioral.
ABR menilai fungsi saraf pendengaran, batang otak, dan korteks pendengaran.
ABR audiometri merupakan metodayang baik untuk pemeriksaan keadaan retrokoklea. ABRs dapat digunakan untuk mendeteksi neuropati auditorik atau gangguan konduksi saraf pada bayi baru lahir. ABR audiometri menggunakan stimulus click yang menimbulkan respon dari regio basilar koklea. Sinyal melalui jalur auditorik dari kompleks nuklear proksimal dari kolikulus inferior. Hasil pemeriksaan ABR terdiri dari beberapa komponen gelombang. Gelombang I dan II adalah potensial aksi yang sebenarnya. Gelombang yang lain menggambarkan aktivitas postsinaps di major brainstem auditory centers yang membentuk gambaran
9
peak dan troughs. Peak positif menggambarkan aktivitas dari jalur akson di batang otak auditorik. Automated ABR (AABR) mudah dikerjakan dan memiliki tingkat ketepatan yang baik. AABR tidak memerlukan interprestasi dari audiologis, AABR menginterpretasi respon pada intensitas tertentu sebagai kriteria pass dan refer (HTA Indonesia, 2010).
c. Development Denver Screening Test II (DDST atau Denver II)
Development Denver Screening Test II adalah alat untuk men-screening perkembangan anak mencakup empat hal yaitu motorik kasar, motorik halus, bahasa, dan sosial-personal (Çelikkiran, Bozkurt and Coşkun, 2015). Pada motorik kasar, anak dilakukan penilaian pada kemampuan berjalan, melompat, dan kontrol motorik tubuh. Sedangkan pada motorik halus, anak dilakukan penilaian pada koordinasi visual manual, dan manipulasi objek (Oliveira et al., 2018). Pada penelitian validitas bersama antara DDST, ASQ-3, dan BDI-2 dengan skala kognitif, bahasa, dan motorik halus, DDST dan ASQ-3 ini memerlukan waktu pemeriksaan yang lebih sedikit bila dibandingkan dengan BDI-2, namun, nilai validitas bersama pada ASQ-3 lebih rendah daripada DDST, sehingga dapat disimpulkan bahwa pemeriksaan yang sesuai dengan skala adalah DDST (Rubio-Codina et al., 2016).
Waktu yang diperlukan untuk melakukan screening dengan DDST adalah 20 sampai 30 menit (Rydz et al., 2005). DDST digunakan sebagai screening perkembangan pada anak usia 0-6 tahun (Rydz et al., 2005). Pemeriksaan DDST terdiri dari 125 item, dan tiap item dinilai berdasarkan usia dengan empat kategori skor, yaitu pass, fail, refusal, dan no opportunity. Pada anak yang tidak kooperatif dalam pemeriksaan, dinilai sebagai refusal. Dan pada item yang diniliai yang tidak muncul pada anak tersebut, dinilai sebagai no opportunity. Sedangkan bila anak dapat menunjukkan kemampuan pada item yang dinilai, maka dapat dinilai sebagai pass.
Dan bila anak gagal melakukan atau menunjukkan kemampuan sesuai item yang diperiksa, maka dapat dikategorikan sebagai fail atau caution(Rydz et al., 2005).
10
Gambar 3.2 Lembar Pemeriksaan DDST atau DENVER
11
Terdapat tiga kategori hasil screening ini, yaitu normal, beresiko, dan non testable. Kategori normal berarti tidak ada keterlambatan dan maximal ada satu caution. Pada kategori beresiko, anak mempunyai satu atau lebih keterlambatan dan satu atau lebih caution. Dan pada kategori non testable bila terdapat nilai refuse pada satu atau lebih item yang diperiksa (Rydz et al., 2005). Lembar pemeriksaan DDST ini, terdiri dari usia anak dan percentile anak yang dapat menunjukkan kemampuan di setiap item, seperti pada gambar 3.2. Skor DDST ditemukan normal pada anak dengan skor expressive language yang tinggi (Yılmaz et al., 2016).
➢ Terapi Wicara
Terapi wicara adalah suatu ilmu yang mempelajari tentang gangguan bahasa, wicara dan suara yang bertujuan untuk digunakan sebagai landasan membuat diagnosis dan penanganan. Dalam perkembangannya terapi wicara memiliki cakupan pengertian yang lebih luas dengan mempelajari hal-hal yang terkait dengan proses berbicara, termasuk di dalamnya adalah proses menelan, gangguan irama/kelancaran dan gangguan neuromotor organ artikulasi (articulation) lainnya.
Gambar 3.3 Ruang Terapi Wicara di SMF THT-KL, Poli Audiologi, RSUD Dr.
Soetomo
12
Terapi wicara di gunakan untuk menangani anak dengan gangguan komunikasi hal ini sering dideteksi terlambat bicara. Untuk itu diperlukan terapi wicara dengan melatih wicara anak agar anak dapat berkomunikasi dengan masyarakat. Terapi ini untuk melatih anak terampil mempergunakan sistem encoding berupa kemampuan mempergunakan organ untuk bicara, menggerakkan lengan tangan dan tubuh yang lain, serta ekspresi wajah. Berikut adalah prosedur kerja terapi wicara di SMF THT-KL, Poli Audiologi, RSUD Dr. Soetomo secara lebih terperinci diuraikan sebagai berikut:
1) Asesmen, bertujuan untuk mendapatkan data awal sebagai bahan yang harus dikaji dan dianalisa untuk membuat program selanjutnya. Asesmen ini meliputi tiga cara, yaitu melalui anamnesa, observasi, dan melakukan tes, di samping itu juga diperlukan data penunjang lainnya seperti hasil pemeriksaan dari ahli lain.
2) Diagnosis dan prognosis, setelah terkumpul data, selanjutnya data tersebut digunakan sebagai bahan untuk menetapkan diagnosis dan jenis gangguan/gangguan untuk membuat prognosis tentang sejauh mana kemajuan optimal yang bisa dicapai oleh penderita.
3) Perencanaan terapi wicara, perencanaan terapi wicara ini secara umum terdiri dari: (a) Tujuan dan program (jangka panjang, jangka pendek dan harian), (b) Perencanaan metode, teknik, frekuensi dan durasi, (c) Perencanaan penggunaan alat, (d) Perencanaan rujukan (jika diperlukan), (e) Perencanaan evaluasi.
4) Pelaksanaan terapi wicara, pelaksanaan terapi harus mengacu pada tujuan, teknik/metode yang digunakan serta alat dan fasilitas yang digunakan.
5) Evaluasi, kegiatan ini terapis wicara menilai kembali kondisi pasien dengan membandingkan kondisi, setelah diberikan terapi dengan data sebelum diberikan terapi. Hasilnya kemudian digunakan untuk membuat program selanjutnya.
6) Pelaporan hasil, pelaporan pelaksanaan dari asesmen sampai selesai program terapi dan evaluasi (Sunanik, 2013).
Berdasarkan kebutuhan perangkat lunak dan keras untuk membantu dokter dan perawat melakukan terapi wicara, maka solusi permasalahan ini dibagi menjadi tiga (3) rangkaian kegiatan besar, yaitu perancangan dan validasi perangkat lunak dan keras, serta penyuluhan kepada pasien dan orang tua pasien. Gambar 2.1 berikut ini adalah skema solusi permasalahan yang ditawarkan. VIBIO adalah nama produk perangkat lunak dan peragkat
13
keras sebagai alat bantu media pembelajaran komunitas anak berkebutuhan khusus terlambat bicara.
7) Gambar 2.1 Solusi Permasalahan terapi wicara (delayed speech) menggunakan VIBIO
2.1 Perancangan VIBIO (Software dan Hardware) untuk Terapi Wicara
2.1.1 Perekaman Tenaga Terapi Wicara Melakukan Terapi (Tanpa Pasien) di Poli Audiologi RSUD Dr. Soetomo
Terapi wicara adalah suatu ilmu yang mempelajari tentang gangguan bahasa, wicara dan suara yang bertujuan untuk digunakan sebagai landasan membuat diagnosis dan penanganan. Dalam perkembangannya terapi wicara memiliki cakupan pengertian yang lebih luas dengan mempelajari hal-hal yang terkait dengan proses berbicara, termasuk di dalamnya adalah proses menelan, gangguan irama/kelancaran dan gangguan neuromotor organ artikulasi (articulation) lainnya Terapi wicara di gunakan untuk menangani anak dengan gangguan komunikasi hal ini sering dideteksi terlambat bicara. Untuk itu diperlukan terapi wicara dengan melatih wicara anak agar anak dapat berkomunikasi dengan masyarakat.
Terapi ini untuk melatih anak terampil mempergunakan sistem encoding berupa kemampuan mempergunakan organ untuk bicara, menggerakkan lengan tangan dan tubuh yang lain, serta ekspresi wajah.
14
Gambar 2.2 Proses Perekaman Terapi Wicara di Poli Audiologi, RSUD Dr. Soetomo
Pada tahap ini, peneliti melakukan shoot video tenaga terapi wicara yang sedang melakukan terapi wicara, tetapi tidak menggunakan pasien. Tenaga terapi wicara diminta mempraktikan serangkaian proses terapi yang mengacu pada Deafness Management Quotient (DMQ) yang dikembangkan oleh Marion Downs (1974) dan diterapkan oleh tenaga terapi wicara di Poli Audiologi, RSUD Dr. Soetomo. Hasil rekaman ini akan menjadi basis data tim peneliti dari Institut Teknologi Sepuluh Nopember untuk mengembangkan perangkat lunak alat bantu media interaktif pembelajaran pasien terlambat bicara (delay speech). Basis data ini diharapkan memberikan informasi untuk mendesain perangkat lunak alat bantu media pembelajaran interaktif untuk pasien delay speech yang komunikatif dan merepresentasikan cara perawat/petugas medis selama melakukan terapi wicara.
2.1.2 Validasi Perangkat Lunak dan Keras VIBIO sebagai Alat Bantu Media Interaktif Pembelajaran Komunitas Anak Berkebutuhan Khusus Terlambat Bicara (Delayed Speech)
Pada tahapan ini dilakukan penilaian terhadap perangkat lunak dan Keras VIBIO sebagai alat bantu media interaktif pembelajaran komunitas anak berkebutuhan khusus terlambat bicara (delayed speech). Penilaian dilakukan oleh pasien, orang tua pasien, serta tenaga medis terapi wicara yang bertugas di SMF THT-KL, Poli Audiologi, RSUD Dr.
15
Soetomo, Surabaya. Pada proses validasi ini diberikan media komunikasi berupa presentasi dan media baca berupa buku informasi tentang informasi penggunaan alat bantu dan peralatan apa yang diperlukan untuk menggunakan alat bantu tersebut. Pada tahapan ini, orang tua pasien dan tenaga medis diberikan kuisioner penilaian media informasi.
Kuisioner ini dilakukan dengan tujuan menilai apakah media yang digunakan untuk mengedukasi pasien dapat dipahami dengan baik dan dapat mewakili perawat/petugas medis untuk melakukan terapi wicara. Kuisioner ini terdiri dari beberapa pertanyaan terkait penilaian dengan skala penilaian 1 – 5, dimana 5 merupakan penilaian “Sangat Baik”, 4 merupakan penilaian “Baik”, 3 merupakan penilaian “Cukup”, 2 merupakan penilaian “Kurang”, dan 1 merupakan penilaian “Sangat Kurang”. Kemudian perawat/petugas medis diminta untuk memberikan saran dan kritik terhadap perangkat lunak yang divalidasi.
2.2 Penyuluhan Perangkat Lunak dan Keras VIBIO sebagai Alat Bantu Media Interaktif Pembelajaran Pasien Terlambat Bicara (Delay Speech)
Pada tahapan ini dilakukan penyuluhan/ceramah mengenai perangkat lunakdan keras VIBIO sebagi alat bantu media interaktif pembelajaran pasien terlambat bicara (delayed speech) kepada pasien dan orang tua pasien di SMF THT-KL, Poli Audiologi, RSUD Dr.
Soetomo, Surabaya. Pada proses penyuluhan ini dilakukan dalam dua (2) bentuk kegiatan, yaitu seminar awareness mengenai VIBIO dan sosialisasi secara private. Selain itu, pada tahapan ini juga dilakukan evaluasi yang terdiri dari 2 tahapan, diantaranya:
1. Evaluasi I: Seminar Awareness VIBIO (software dan hardware) kepada pasien dan orang tua pasien secara komunal yang diselenggarakan di SMF THT-KL, Poli Audiologi, RSUD Dr. Soetomo, Surabaya.
Pada saat seminar awareness dilaksanakan, dilakukan presentasi dan peragaan oleh tim untuk mengenalkan VIBIO serta dilakukan pemantauan jumlah peserta yang hadir. Peserta yang hadir akan dipantau keberlanjutannya dengan cara melakukan evaluasi tahap II.
Berdasarkan minat peserta dalam mengikuti program ini, maka bila jumlah peserta yang ikut > 90 % (program sangat berhasil) dari jumlah pasien yang melakukan terapi di Poli Audiologi, RSUD Dr. Soetomo, bila peserta yang ikut 60 – 89 % (program cukup berhasil), dan bila peserta yang ikut < 59 % (program tidak berhasil).
2. Evaluasi II: Sosialisasi Private yang dilakukan setelah seminar awareness dilaksanakan.
Tim dibantu dengan mahasiswa ITS yang melakukan kegiatan KKN melakukan penyuluhan secara private pada saat pasien dan orang tua pasien melakukan terapi wicara
16
di SMF THT-KL, Poli Audiologi, RSUD Dr. Soetomo, Surabaya. Apabila terdapat kendala pasien tidak dapat hadir, tim akan berkunjung door to door ke rumah pasien dengan seizin dan berkoordinasi dengan orang tua pasien serta tenaga medis terapi wicara di Poli Audiologi. Sosialisasi private ini bertujuan untuk melakukan pengawalan pasca seminar awareness agar orang tua pasien semakin memahami bagaimana cara menggunakan VIBIO secara mandiri di rumah.
2.3 Keberlanjutan
Pengetahuan pasien dan orang tua tentang media terapi wicara untuk anak-anak berkebutuhan khusus terlambat bicara masih
rendah
Penelitian Unggulan ITS VIBIO
Pengetahuan pasien dan orang tua tentang media terapi wicara untuk anak-anak berkebutuhan khusus terlambat
bicara meningkat
Pasien dan orang tua mengetahui pentingnya peran dokter, tenaga medis terapi wicara, dan teknologi tepat guna sebagai
media terapi wicara untuk anak-anak berkebutuhan khusus terlambat bicara
VIBIO (software dan Hardware) dapat menjadi solusi teknologi tepat guna sebagai media terapi wicara untuk anak-anak berkebutuhan khusus terlambat bicara di Poli Audiologi, RSUD Dr. Soetomo pada
khususnya, dan klinik kesehatan di Indonesia pada Umumnya
17
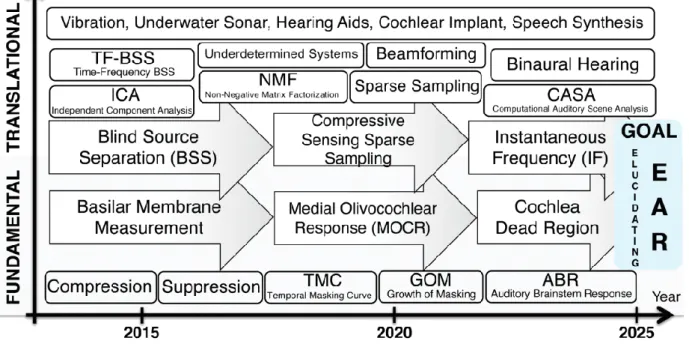
Selain itu, peta jalan penelitian Institut Teknologi Sepuluh Nopember mengenai Hearing Science ditunjukkan pada Gambar 2.3 yang kemudian dikerucutkan menjadi peta jalan penelitian speech synthesis yang mendukung hearing impairment.
Gambar 2.3 Peta Jalan Penelitian Bersama Speech Synthesis di ITS
18
BAB III METODE PELAKSANAAN
3.1 Prosedur Pelaksanaan
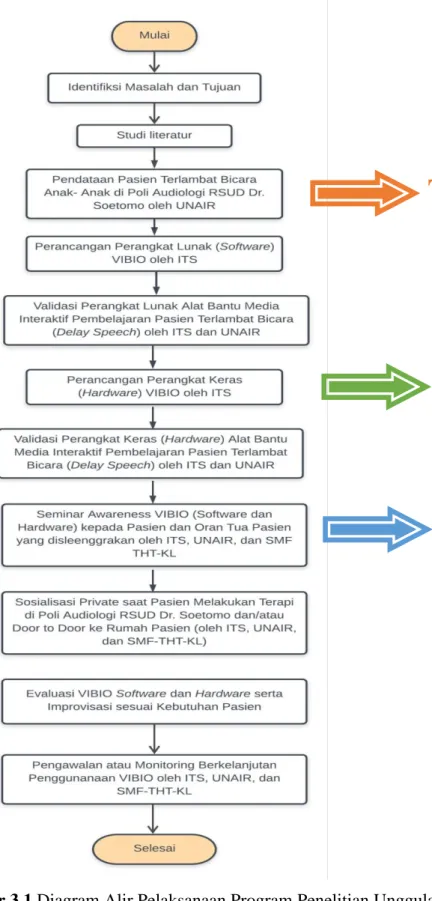
Prosedur pelaksanaan secara garis besar digambarkan dalam diagram alir di bawah ini :
Gambar 3.1 Diagram Alir Pelaksanaan Program Penelitian Unggulan VIBIO
TAHUN 1
TAHUN 2
TAHUN 3
19
Prosedur penelitian dibagi menjadi beberapa tahapan yang akan dijelaskan sebagai berikut:
3.1.1 Pembuatan Bahasa Indonesia Speech Corpus
Speech corpus merupakan suatu kumpulan basisdata suara dalam bentuk file suara/audio dan berupa transkripsi teksnya. Basisdata yang digunakan dalam penelitian ini merupakan basisdata dalam Bahasa Indonesia. Langkah yang dilakukan dalam pembuatan speech corpus ini adalah (a) pengumpulan kalimat basis data natural dan ekspresif dalam Bahasa Indonesia, (b) perekaman kalimat basis data natural dan ekspresif dalam Bahasa Indonesia, (c) pengolahan sinyal suara.
a. Pengumpulan kalimat basis data natural dan ekspresif dalam Bahasa Indonesia
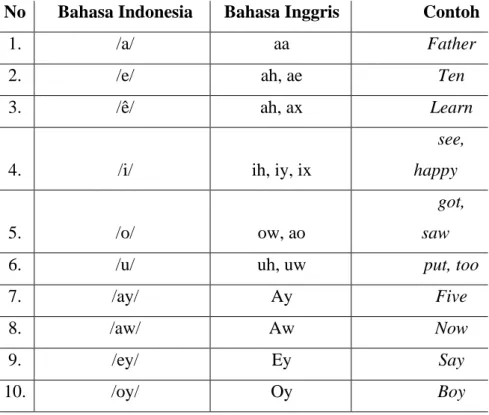
Kalimat Bahasa Indonesia yang dikumpulkan dipilih dari beberapa sumber literatur, yaitu buku pelajaran, majalah, novel, koran dan website. Pemilihan kalimat didasarkan pada kaidah fonem Bahasa Indonesia yang sesuai dengan standard International Phonetic Alphabet (IPA). Bahasa Indonesia memiliki total 32 fonem yang terdiri dari enam fonem vokal, tiga fonem diftong, dan 23 fonem konsonan. Pada tabel 3.1 menunjukkan fonem dalam Bahasa Indonesia sesuai dengan standar International Phonetic Alphabet (IPA) yang juga mencakup karakter silence.
Tabel 3.1 Fonem Bahasa Indonesia sesuai dengan standar International Phonetic Alphabet (IPA)
No Bahasa Indonesia Bahasa Inggris Contoh
1. /a/ aa Father
2. /e/ ah, ae Ten
3. /ê/ ah, ax Learn
4. /i/ ih, iy, ix
see, happy
5. /o/ ow, ao
got, saw
6. /u/ uh, uw put, too
7. /ay/ Ay Five
8. /aw/ Aw Now
9. /ey/ Ey Say
10. /oy/ Oy Boy
20
11. /b/ B Bad
12. /c/ Ch Chain
13. /d/ d, dx, dh Did
14. /f/ f, v fall, van
15. /g/ G Got
16. /h/ Hh Hat
23. /R/ r red
24. /S/ s so
25. /T/ t¸th tea
26. /W/ w wet
27. /Y/ y yes
28. /Z/ z, zh zoo
29. /Kh/ - -
30. /Ng/ ng sing
31. /Ny/ - -
32. /Sy/ - share
Kalimat basis data natural mempunyai pencampuran kata, suku kata, dan fonem yang sesuai dalam kaidah Bahasa Indonesia. Kalimat yang dipilih adalah kalimat yang biasa digunakan dalam kehidupan sehari-hari. Jumlah kata pada kalimat basis data natural bervariasi dari 5-10 kata pada satu kalimat untuk kalimat yang pendek dan dari 11-20 kata pada satu kalimat untuk kalimat panjang. Jumlah total kalimat basis data yang dibangun, yaitu sebanyak 1529 kalimat dengan rincian 1029 kalimat berupa kalimat berita dan 500 kalimat berupa kalimat tanya. Berikut adalah beberapa kalimat basis data natural yang harus naracoba ucapkan:
kalimat basis data ekspresif bahasa Indonesia diucapkan dengan gaya emosional marah, sedih, dan senang. Basis data kalimat ini sebanyak 600 kalimat yang mencakup tiga ekspresi dengan variasi kalimat pendek (1 atau 2 kata), kalimat sedang (2 sampai 5 kata), dan kalimat panjang (lebih dari 5 kata). Kalimat basis data suara ujaran bahasa Indonesia ini disusun dengan mengambil sampel kalimat yang diperoleh dari beberapa sumber, yaitu majalah, novel, film, dan website. Kalimat yang dipilih adalah kalimat yang biasa digunakan dalam kehidupan sehari-hari. Berikut adalah contoh kalimat ekspresif:
21 b. Perekaman basis data suara bahasa Indonesia
Kalimat basis data yang telah dikumpulkan selanjutnya dilakukan perekaman suaranya. Perekaman basis data ini dilakukan dengan cara membaca kalimat basisd ata yang tersedia oleh narasuara yang telah ditentukan. Untuk basis data natural narasuara yang dipilih pada penelitian ini adalah narasuara yang berprofesi sebagai pembawa berita profesional, baik di radio maupun televisi. Hal tersebut ditujukan agar pembacaan kalimat basis data yang direkam tidak terdapat logat dari daerah tertentu. Sedangkan untuk kalimat basis data ekspresif, narasuara dipilih yang berprofesi sebagai pemain teater professional yang tergabung dalam Dewan Kesenian Surabaya, Jawa Timur serta Dewan Kesenian Bandung, Jawa Barat dan telah diseleksi sebelum melakukan perekaman dengan ketentuan diperbolehkan memiliki logat daerah asal.
3.1.2 Instalasi dan Identifikasi HMM-based Speech Synthesis System (HTS)
HMM-based Speech Synthesis System (HTS) pertama kali diusulkan oleh Yoshimura, Tokuda dan Kobayashi, (1999), kemudian dipublikasikan sebagai open-source software pada tahun 2002 oleh kelompok kerja HTS sebagai perluasan dari HMM toolkit (HTK). Pada HTS terdapat dua proses utama yaitu proses training dan proses sintesis.
a. Persiapan data
Data yang diperlukan sebagai input untuk menjalankan sistem sintesis suara bahasa Indonesia berbasis HMM diantaranya adalah sebagai berikut :
• File .raw (~/data/raw/*.raw): merupakan format audio tanpa kompresi yang dihasilkan dari konversi file .wav hasil rekaman kalimat basis data ucapan bahasa Indonesia.
• File .utt (~/data/utts/*.utt): merupakan file informasi teks dari kalimat basis data ucapan bahasa Indonesia yang digunakan untuk proses training.
• File .lab (~/data/labels/gen/*.lab): merupakan file informasi label kalimat yang digunakan sebagai input proses training dan sintesis.
• File question (~/data/question/*.hed): merupakan file informasi pohon keputusan yang digunakan untuk membangun sistem sintesa suara bahasa Indonesia sesuai dengan kaidah fonem yang berlaku.
• File teks (~/data/teks/*.txt) : berisi kalimat prompt basis data dalam tiap kalimat pada setiap file .txt.
b. HMM-based Speech Synthesis System (HTS)
22
➢ Proses Training HTS
Proses training bertujuan untuk mendapatkan model akustik suara dari suara basis data. Bahasa Indonesia speech corpus yang telah dibuat, akan digunakan sebagai input pada sistem HTS. Tahapan pada proses training adalah sebagai berikut,
1. Input basis data terdapat dua macam, yaitu sinyal suara dan teks label. Input teks label berupa informasi rangkaian teks dalam bentuk file utterance (*.utt) dan label (*.lab). File utterance dan label ini kemudian diekstraksi sesuai dengan Persamaan 3.1. Proses ekstraksi ini untuk mengestimasi label mono dan full context, master label file (MLF), serta untuk pembuatan list data training.
(3. 1)
dimana terdapat dua variable acak A dan B, dengan P(A|B) merupakan probabilitas bersyarat dari kejadian A. merupakan peluang kejadian B yang telah terjadi dan merupakan peluang kejadian A.
2. Input sinyal suara berupa file raw (*.raw) yang kemudian diekstrak menjadi parameter eksitasi dan parameter spektral sesuai dengan Persamaan 3.2 yang menunjukkan estimasi likelihood dari input yang digunakan pada sistem HTS.
Hasil estimasi dari persamaan 2.2 ini akan menghasilkan fitur akustik suara seperti
cepstrum, LPC, F0, dan aperiodisitas. (3.
2)
dimana merupakan estimasi kumpulan teks basis data, adalah label yang dihasilkan dari kumpulan set basisdata ( ).
3. Hasil ekstraksi input basis data pada tahap 1 dan 2 kemudian dilakukan estimasi pembentukan model HMM. Model HMM ini diestimasi dengan Persamaan 3.3, dimana pada setiap model HMM akan terbentuk distribusi Gaussian sehingga menghasilkan distribusi multivariate Gaussian sesuai pada Persamaan 3.4. Output pdf dari masing-masing distribusi Gaussian memiliki nilai mean dan variansi masing-masing. Nilai mean dan varian ini diestimasi dengan maximum likelihood estimation (Persamaan 2.5) untuk mendapatkan nilai maksimumnya.
(3. 3)
23
dimana merupakan model estimasi ucapan dan o adalah parameter ucapan.
(3. 4)
dimana terdapat dua variable acak A dan B, dengan P(A|B) merupakan probabilitas bersyarat dari kejadian A. merupakan peluang kejadian B yang telah terjadi dan merupakan peluang kejadian A.
➢ Proses Sintesis HTS
Proses sintesis bertujuan untuk membangkitkan kembali model akustik suara yang telah dihasilkan pada proses training sesuai dengan input yang teks yang akan disintesis sesuai Gambar 2.8. Tahapan sintesis ini menggunakan tools HMGens dari HTK yang menghasilkan 39-order cepstrum (*.mgc), logF0 (*.lf0) dan aperiodisitas (*.ap1-5), kemudian melalui SPTK akan dibangkitkan sinyal suara sintesis yang diinginkan. Proses pembangkitan suara ini terdapat tahapan untuk pembuatan model tersembunyi (Persamaan 3.5), dimana model ini belum dideteksi pada saat proses training basis data. Pohon keputusan yang telah terbentuk pada proses training digunakan untuk memetakan model tersembunyi pada cluster yang memiliki informasi linguistik yang serupa.
(3.5)
adalah pembobot, -dimensi vektor mean dan matriks kovarian dari komponen pada state , secara berurutan. Persamaan (3.5) merupakan distribusi Gaussian pada masing-masing komponen, dimana merupakan dimensi dari data observasi .
Gambar 3.4 Tahapan Proses Sintesis, (Sumber: Krebs, 2010)
3.1.3 HTS Speaker Dependent
24
Bahasa Indonesia memiliki sistem bunyi yang mirip dengan bahasa Inggris, dimana keduanya memiliki diftong, similitude (kemiripan bunyi pada suatu fonem dalam satu kata), assimilation (proses historis dimana bunyi dipengaruhi oleh bunyi disebelahnya), dan elision (peleburan bunyi), oleh karena itu digunakan HTS-demo_CMU-ARCTIC-SLT untuk diterapkan dalam bahasa Indonesia. Penerapannya yaitu dengan menyesuaikan format labeling kalimat dan decision tree kalimat sesuai dengan kaidah fonologi bahasa Indonesia.
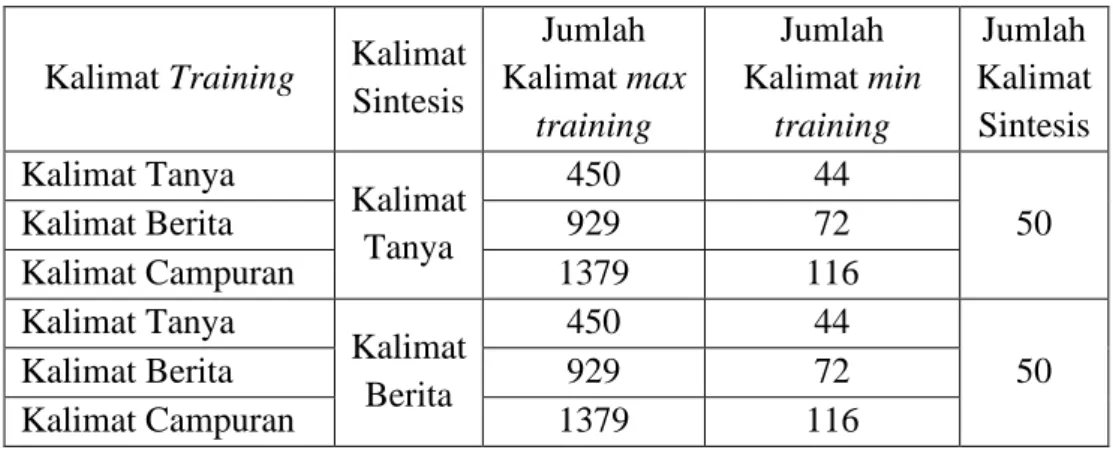
Tabel 3.2 Variasi Jumlah Basis Data Training Kalimat Training Kalimat
Sintesis
Jumlah Kalimat max
training
Jumlah Kalimat min
training
Jumlah Kalimat Sintesis Kalimat Tanya
Kalimat Tanya
450 44
50
Kalimat Berita 929 72
Kalimat Campuran 1379 116
Kalimat Tanya
Kalimat Berita
450 44
50
Kalimat Berita 929 72
Kalimat Campuran 1379 116
Pembuatan speaker dependent sintesis suara bahasa Indonesia digunakan basis data suara satu narasuara laki-laki dan satu narasuara perempuan pada kalimat berita dan kalimat tanya. Variasi dilakukan pada jumlah basis data yang digunakan, yaitu menggunakan minimal dan maksimal training (Cahyaningtyas, 2015). Jumlah variasi yang dilakukan terdapat pada Tabel 3.2. Pengaturan untuk proses eksperimen ditunjukkan pada Tabel 3.3, dimana menggunakan kalimat basis data Bahasa Indonesia dengan dua pembicara yaitu pembicara mmht dan fena.
Tabel 3.3 Experimental Set-Up Speaker Dependent
Demo HTS-demo_CMU-ARCTIC-SLT
Basis data Bahasa Indonesia
Jenis kalimat Kalimat berita dan kalimat tanya Jumlah kalimat Kalimat tanya : 44 kalimat, 450 kalimat
Kalimat berita : 72 kalimat, 929 kalimat Kalimat campuran : 116 kalimat, 1379 kalimat Test data 50 kalimat
Sampling rate 16 kHz
25 Frame length 25 ms
Frame shift 5 ms
HMM topology 5-state, left to right HMM[21], MSD F0[22], MDL[23]
Acoustic feature 0-39th mel-cepstrum, log F0, 5-band aperiodicity dengan dan 2
3.2 Peralatan Penelitian
Peralatan pada kegiatan penelitian bersama naracoba pasien yang digunakan meliputi:
a. Komputer
Komputer digunakan sebagai perangkat komputasi untuk menjalan program HTS.
Spesifikasi komputer yang digunakan adalah Intel Core i7-3930K, 3,20 GHz x8 32- bit, 916.7 GB, 62.8 GiB.
b. Operating Sistem Linux Ubuntu 14.04-32 bit
Perangkat lunak ini digunakan untuk mengoperasikan sistem sintesa suara dikarenakan beberapa software pendukung seperti Festival, Speech Tools hanya digunakan pada sistem operasi linux 32-bit.
c. Software HMM-based Speech Synthesis System (HTS)
Untuk menjalankan software HTS dibutuhkan beberapa software pendukung yaitu SPTK-3.8, HTK, HDcode, HTS-2.2, hts_engine API-1.05, Festival, ActiveTcl 8.4.19, Speech Tools. Selain itu juga digunakan demo speech synthesis HTS- demo_CMU-ARCTIC-SLT dan HTS-demo_CMU-ARCTIC-SLT-ADAPT yang dikembangkan secara open source oleh kelompok kerja HTS (http://hts.sp.nitech.ac.jp/).
d. Headphone Seinnheiser HD 650
Headphone ini memiliki impedansi 300 Ω dan THD ≤ 0.05%, yang berarti dapat menyampaikan suara yang detail. Selain itu juga memiliki frekuensi respon 16-30.000 Hz (-30 dB) sesuai dengan frekuensi pendengaran manusia.
e. Digital Sound Card M-Audio FastTrack Ultra
Alat ini merupakan alat penghubung antara headphone dengan komputer yang memilik fungsi sebagai Digital Converter to Analog Converter.
26 3.3 Waktu dan Tempat Penelitian
Penelitian ini dimulai setelah proposal disetujui dengan jumlah sampel terpenuhi dan direncanakan berlangsung selama 8 bulan. Pengabdian masyarakat ini dilaksanakan di:
1. SMF THT-KL, Poli Audiologi, RSUD Dr. Soetomo untuk terapi wicara dan kegiatan sosialisasi.
3. Institut Teknologi Sepuluh Nopember untuk melakukan pengolahan dan analisis data.
3.4 Organisasi Tim Penelitian Unggulan
Penelitian ini terdiri dari seorang ketua dan tiga anggota peneliti serta empat mahasiswa yang mengambil tugas akhir, tesis, dan disertasi. Ketua tim (Dr. Eng. Dhany Arifianto, ST., M.Eng.) bertugas mengkoordinir serta melakukan sebagian besar aktivitas penelitian.
Anggota tim (Ir. Wiratno Argo Asmoro, M.Sc. dan Irwansyah, ST., MT., M.Phil., PhD) bertugas untuk mensupervisi, membantu menyediakan algoritma dan perangkat lunak serta beberapa database yang diperlukan untuk menunjang penelitian. Perekrutan naracoba anak yang berkebutuhan khusus serta speech therapists dilakukan di ruang pemeriksaan poli Audiologi, THT-KL, RSUD Dr. Soetomo, Surabaya oleh Dr. Nyilo Purnami, dr. Sp. THT-KL (K) FICS. Empat mahasiswa yang mengambil tugas akhir/tesis/disertasi bertugas untuk membantu dalam perancangan dan pembangunan perangkat keras dan lunak VIBIO yang berunjuk kerja sesuai standarisasi yang ada.
No Nama / NIDN / NIP Instansi Asal
Bidang Ilmu
Alokasi Waktu (jam
/ minggu)
Uraian Tugas 1 Dr. Dhany Arifianto, S.T, M.Eng
/NIDN. 19731007 199802 1 001
Teknik Fisika ITS
Pemrosesan Sinyal (Signal Processing )
10 Mengkoordinir serta melakukan sebagian besar aktivitas penelitian
2 Ir. Wiratno Argo Asmoro,M.Sc. / NIDN.19600229 198701 1 001
Teknik Fisika ITS
Akustik Ruang
10 Mensupervisi,
membantu menyediakan algoritma dan perangkat lunak serta basis data speech dan pasien 3 Irwansyah, ST., MT., M.Phil., PhD
Computer Science Kumamoto
University
Bone- conduction hearing aids
10
4. Dr. Nyilo Purnami, dr. Sp. THT-KL (K) FICS / NIP.
Kedokteran UNAIR
Audiologi Klinik
5 1. Perancangan informed consent
2. Perekrutan naracoba
27
196407241989102001 anak yang berkebutuhan
khusus serta speech therapists
3. Pengukuran evaluasi subjektif kepada dokter dan pasien
5. Roudhotul Jannah Rouf NRP. 02311650010006
Mahasiswa S1 Teknik Fisika ITS
Speech Recognition
5 Membantu perancangan
& pembangunan perangkat keras VIBIO portable yang berunjuk kerja sesuai standarisasi ISO
6. Farahiyah Aisah Sidik NRP. 02311640000055
Mahasiswa S1 Teknik Fisika ITS
Speech Synthesis
5 Membantu simulasi average voice HTS untuk mendukung perancangan perangkat lunak dan keras VIBIO 7. Sangsaka Wira
NRP. 02311850010005
Mahasiswa S2 Teknik Fisika ITS
Sistem Audio dan
Akustik
5 Membantu perancangan
& pembangunan perangkat lunak VIBIO 8. Elok Anggrayni
NRP. 02311960010001
Mahasiswa S3 Teknik Fisika ITS
Signal Procsssing
5 Membantu simulasi desain, serta pengujian unjuk kerja dari purwarupa
28
BAB IV LUARAN DAN TARGET CAPAIAN
Indikator keberhasilan atau target capaian yang diharapkan dari penelitian unggulan dasar ini adalah produk potensial (purwarupa), yaitu berupa purwarupa perangkat lunak dan keras VIBIO sebagai alat bantu media interaktif pembelajaran komunitas anak berkebutuhan khusus terlambat bicara (delayed speech) dengan basis audiovisual speech synthesis alamiah bahasa Indonesia. Peralatan ini akan diuji coba kemudahan penggunaannya dari speech therapists di SMF THT-KL, RSUD Dr. Soetomo dan juga naracoba pasien dan keluarganya. Dari hasil penelitian ini diseminasikan berupa paper di seminar internasional ASA (Acoustical Society of America) Meeting dan artikel jurnal di Speech Communication Journal. Target luaran dapat dilihat pada Tabel 4.1 Target Capaian.
Tabel 4.1 Target Capaian
No. Jenis Luaran Luaran
1. Publikasi Ilmiah Internasional/ bereputasi Internasional (1 artikel per tahun)
Nasional terakreditasi
2. Sistem Perangkat Lunak
3. Sistem Perangkat Keras
4. Video Kegiatan
5. Produk yang Dipatenkan
29
BAB V RANCANGAN ANGGARAN BIAYA
Biaya penelitian Unggulan ITS yang diusulkan selama tiga (3) tahun, dapat dilihat sebagai berikut:
1. Biaya Bahan Habis Pakai
No. Nama Bahan Volume Biaya Satuan Biaya
1. Sewa ruang Audiologi (300 jam x
Rp.100.000/jam) 1 unit Rp 30.000.000 Rp 30.000.000 2. Sewa Sound Booth (750 jam x
Rp.30.000/jam) 1 unit Rp 22.500.000 Rp 22.500.000 3. Mini Sirin Whistle (Alat Terapis
Wicara) 50 Rp 20.000 Rp 1.000.000
4. Mini Train Whistle (Alat Terapis
Wicara) 50 Rp 20.000 Rp 1.000.000
5. Echo Mic (Alat Terapis Wicara) 10 Rp 200.000 Rp 2.000.000 6. Horn Kit / Horn Hierarki Talktools
(Alat Terapis Wicara) 5 Rp 1.500.000 Rp 7.500.000 7. Melody Flutes (Alat Terapis
Wicara) 10 Rp 100,000 Rp 1.000,000
8. Cloud Server (3 Tahun) 36 Rp 300.000 Rp 10.800,000 Pengembangan Perangkat Keras
9. Audio Fully Integrated Processor 2
Channel PowerSSO-36 EPD 30 Rp 100.000 Rp 3.000.000 10. STM32F4291 DISCO Core Signal
Generator 3 Rp 1.800.000 Rp 5.400.000
11. EMS WiFi Shield 1 Rp 1.000.000 Rp 1.000.000
12. 24-bit HD audio interface 1 Rp 22.000.000 Rp 22.000.000 13. Digital Audio Amplifier 1 Rp 15.000.000 Rp 15.000.000
14. CUDA GPU GTX 1080 2 Rp 15.000.000 Rp 15.000.000
15. Komponen elektronik audio + casing
1 Rp 25.800.000 Rp 25.800.000
JUMLAH BIAYA Rp163.000.000
30 2. Biaya Peralatan Penunjang
No. Nama Bahan Volume Biaya Satuan Biaya
1. Sennheiser HD 820 2 unit Rp 35.000.000 Rp 70.000.000 JUMLAH BIAYA Rp 70.000.000
3. Biaya Naracoba
No. Uraian Kegiatan Volume Biaya Satuan Biaya
1. Uji Software VIBIO 50 kali Rp 80.000 Rp 4.000.000 2. Uji Hardware VIBIO 50 kali Rp 80.000 Rp 4.000.000
3.
Pengujian Software VIBIO pada
Naracoba Normal 50 kali Rp 80.000 Rp 4.000.000
4.
Pengujian Software VIBIO pada
Naracoba Delayed Speech 50 kali Rp 80.000 Rp 4.000.000
5.
Pengujian Hardware VIBIO pada
Naracoba Normal 50 kali Rp 80.000 Rp 4.000.000
6.
Pengujian Hardware VIBIO pada
Naracoba Delayed Speech 50 kali Rp 80.000 Rp 4.000.000 7. Terapis dan Asisten 6 orang Rp 2.000.000 Rp 12.000.000 JUMLAH BIAYA Rp 36.000.000
4. Biaya Perjalanan
No. Uraian Kegiatan Volume Biaya Satuan Biaya
1. Pertemuan (dokter THT-KL) 10 kali Rp 1.000.000 Rp 10.000.000 JUMLAH BIAYA Rp 10.000.000
5. Publikasi
No. Uraian Kegiatan Volume Biaya Satuan Biaya
1. Seminar Internasional 3 kali Rp 12.000.000 Rp 36.000.000 2. Diseminasi Jurnal Internasional 1 kali Rp 15.000.000 Rp 15.000.000 JUMLAH BIAYA Rp. 51.000.000
31 Total Pengeluaran
No. Uraian Kegiatan Biaya
1. Bahan Habis Pakai Rp 163.000.000
2. Peralatan Penunjang Rp 70.000.000
3. Naracoba Rp 36.000.000
4. Perjalanan Rp 10.000.000
5. Publikasi Rp 51.000.000
JUMLAH BIAYA Rp 330.000.000
32
JADWAL PELAKSANAAN
Program Penelitian Unggulan Dasar Dana ITS 2020 ini akan berlangsung selama tiga (3) tahun, dan berikut adalah jadwal penelitian yang akan diusulkan.
No Kegiatan
Tahun I Bulan
1 2 3 4 5 6 7 8 9 10
1 Observasi Klinik THT-KL RSUD dr.
Soetomo (FK Unair)
2 Pembuatan dan porting perangkat lunak (ITS)
3
Validasi hardware dan software VIBIO kepada tenaga medis, pasien, dan orang tua pasien
4 Uji coba pemakaian pasien (FK Unair & ITS)
No Kegiatan
Tahun II Bulan
1 2 3 4 5 6 7 8 9 10 1 Pembuatan perangkat keras ( ITS)
2
Integrasi & Evaluasi perangkat lunak &
perangkat keras (ITS)
3 Validasi dengan Gold Standard (FK Unair & ITS)
33
Ditargetkan pengiriman manuskrip ke ASA (Acoustical Society of America) Meeting dan Journal of Speech Communication (Q1).
No Kegiatan
Tahun III Bulan
1 2 3 4 5 6 7 8 9 10 1 Validasi dengan Gold Standard
(FK Unair, ITB & ITS)
2
Uji coba hardware dan software VIBIO kepada tenaga medis, pasien, dan orang tua pasien
(FK Unair & ITS)
3 Diseminasi (Unair dan ITS)
34
DAFTAR PUSTAKA
Anastasakos, McDonough, Schwartz, and Makhoul. A compact model for speaker-adaptive training. InProc. ICSLP-96, pages 1137–1140, October 1996
Anne, S., Lieu, J. E. C. and Cohen, M. S., 2017, ‘Speech and Language Consequences of Unilateral Hearing Loss: A Systematic Review’, Otolaryngology - Head and Neck Surgery (United States), 157(4),pp.572–579. doi:10.1177/0194599817726326.
Anggrayni, 2013, “Pembuatan Perangkat Basis Data Untuk Sintesis Ucapan (Natural Speech Synthesis) Berbahasa Indonesia Berbasis Hidden Markov Model (HMM)”. Jurnal Teknik POMITS Vol. 2, No. 2, (2013) ISSN: 2337-3539, hal. A 443-A 447.
American Speech Language Hearing Association (ASHA), 2015, 'Audiology Information Series', AUDIOLOGY Information Series TYPES OF HEARING LOSS CONFIGURATION OF HEARING LOSS. Available at: www.asha.org (Accessed: 26 June 2019).
Black, Alan W., Heiga Zen, and Keiichi Tokuda. "Statistical parametric speech synthesis." Acoustics, Speech and Signal Processing, 2007. ICASSP 2007. IEEE International Conference on. Vol. 4. IEEE, 2007.
Carruth, B. R. and Skinner, J. D., 2002, ‘Feeding Behaviors and Other Motor Development in Healthy Children (2–24 Months)’, Journal of the American College of Nutrition.
Routledge, 21(2),pp.88–96.doi:10.1080/07315724.2002.10719199.
Çelikkiran, S., Bozkurt, H. and Coşkun, M., 2015, ‘Denver Developmental Test Findings and their Relationship with Sociodemographic Variables in a Large Community Sample of 0-4-Year-Old Children.’, Noro psikiyatri arsivi. Turkish Neuropsychiatric Society, 52(2), pp. 180–184. doi: 10.5152/npa.2015.7230.
Collisson, B. A. et al., 2016, ‘Risk and protective factors for late talking: An epidemiologic investigation’, Journal of Pediatrics. Elsevier Inc., 172, pp. 168-174.e1. doi:
10.1016/j.jpeds.2016.02.020.
Cushing, S. L. and Papsin, B. C., 2015, ‘Taking the History and Performing the Physical Examination in a Child with Hearing Loss’, Otolaryngologic Clinics of North America.
Elsevier Inc, 48(6), pp. 903–912. doi: 10.1016/j.otc.2015.07.010.
Esmeir dan S. Markovitch, 2007, “Anytime learning of decision trees,” J. Mach. Learn. Res., vol. 8, hal. 891–933.
ITU-T, “Methods for Objective and Subjective Assessment of Quality”, http://www.itu.int/rec/T-REC-P.800-199608-I/en.
35
J. Yamagishi et al., "Robust Speaker-Adaptive HMM-Based Text-to-Speech Synthesis,"
in IEEE Transactions on Audio, Speech, and Language Processing, vol. 17, no. 6, pp.
1208-1230, Aug. 2009. doi: 10.1109/TASL.2009.2016394
J. Yamagishi, K. Ogata, Y. Nakano, J. Isogai and T. Kobayashi, "HSMM-Based Model Adaptation Algorithms for Average-Voice-Based Speech Synthesis," 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, 2006, pp. I-I. doi: 10.1109/ICASSP.2006.1659961
Junichi Yamagishi, Takashi Nose, Heiga Zen, Tomoki Toda and Keiichi Tokuda,
"Performance evaluation of the speaker-independent HMM-based speech synthesis system “HTS 2007” for the Blizzard Challenge 2007," 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, 2008, pp.
3957-3960. doi: 10.1109/ICASSP.2008.4518520
K. Tokuda, Y. Nankaku, T. Toda, H. Zen, J. Yamagishi and K. Oura, "Speech Synthesis Based on Hidden Markov Models," in Proceedings of the IEEE, vol. 101, no. 5, pp.
1234-1252, May 2013. doi: 10.1109/JPROC.2013.2251852
K. Oura, K. Tokuda, J. Yamagishi, S. King and M. Wester, "Unsupervised cross-lingual speaker adaptation for HMM-based speech synthesis," 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, 2010, pp. 4594- 4597. doi: 10.1109/ICASSP.2010.5495558
Kawahara, 1997. ”Speech representation and transformation using adaptive interpolation of weighted spectrum : vocoder revisited”, IEEE ICASSP-97, vol. 22, hal. 1303-1306.
Kawahara. 2006. ”STRAIGHT, exploitation of the other aspect of VOCODER: Perceptually isomorphic decomposition of speech sounds”, Acoustical Science and Technology 27, 6, hal. 349–353.
Kondo. 2012. “Subjective Quality Measurement of Speech, its Evaluation, Estimation and Applications”. XIV, 154p, ISBN: 978-3-642- 27505-0
Lestari, Dessi Puji, Nonmember and Sadaoki FURUI, and Fellow, Honorary Member. IEICE TRANS. INF & SYST., VOL.E93-D, NO.9 SEPTEMBER 2010.
McCreery, R. W. et al., 2015, ‘Speech Recognition and Parent Ratings From Auditory Development Questionnaires in Children Who Are Hard of Hearing.’, Ear and hearing.
NIH Public Access, 36 Suppl 1(0 1), pp. 60S-75S. doi:
10.1097/AUD.0000000000000213.
Muslich, Masnur, “Fonologi Bahasa Indonesia Tinjauan Deskriptif Sistem Bunyi Bahasa Indonesia”, Jakarta: PT Bumi Aksara, 2009.
36
Nakano, Yuji, Makoto Tachibana, Junichi Yamagishi, and Takao Kobayashi. "Constrained structural maximum a posteriori linear regression for average-voice-based speech synthesis." In Ninth International Conference on Spoken Language Processing. 2006.
RISKESDAS 2013 (diakses 6 April 2019)
Rydz, D. et al., 2005, ‘Developmental Screening’, Journal of Child Neurology, pp. 4–21.
Available at: https://www.medscape.com/viewarticle/504722_6 (Accessed: 19 June 2019).
Saeed, HT, Abdulaziz, B, dan Al-Daboon, SJ, 2018, 'Prevalence and Risk Factors of Primary Speech and Language Delay in Children Less Than Seven Years of Age', Journal of Community Medicine & Health Education, vol 8, doi: 10.4172/2161-0711.1000608 Sahli, A. S., 2019, ‘Developments of children with hearing loss according to the age of
diagnosis, amplification, and training in the early childhood period’, European Archives of Oto-Rhino-Laryngology. Springer Berlin Heidelberg, (0123456789). doi:
10.1007/s00405-019-05501-w.
Suyanto. 2007. “An Indonesian Phonetically Balanced Sentence Set for Collecting Speech Database”. JurnalTeknologi Industri Vol. XI No. 1 Januari 2007: 59-68.
Tamura, Masuko, Tokuda, and Kobayashi. Speaker adaptation for HMM-based speech synthesis system using MLLR. In The Third ESCA/COCOSDA Workshop on Speech Synthesis, pages 273–276, November, 1998.
Tokuda, Keiichi, Heiga Zen, and Alan W. Black. "An HMM-based speech synthesis system applied to English." In IEEE Speech Synthesis Workshop, pp. 227-230. 2002.
Tokuda, H. Zen, J. Yamagishi, T. Masuko, S. Sako, T. Nose, and K. Oura, “HMM-based speech synthesis system (HTS),” http://hts.sp.nitech.ac.jp.
World Health Organization (WHO), 2017, ‘WHO | Grades of hearing impairment’, WHO.
World Health Organization. Available at:
https://www.who.int/pbd/deafness/hearing_impairment_grades/en/ (Accessed: 14 June 2019).
World Health Organization (WHO), 2019, 'Deafness and hearing loss', World Health Organization. Available at:
https://www.who.int/newsroom/factsheets/detail/deafness-and-hearing-loss (Accessed:
14 June 2019).
37
![Gambar 1.1 memperlihatkan data gangguan dengar berdasarkan provinsi yang terjadi di Indonesia pada RISKESDAS 2013 [1] dimana jumlah populasi penduduk Indonesia pada 2013 adalah 254 juta penduduk](https://thumb-ap.123doks.com/thumbv2/123dok/3853937.3961947/6.892.183.735.391.685/memperlihatkan-gangguan-berdasarkan-provinsi-indonesia-riskesdas-populasi-indonesia.webp)




![Trend kutipan zakat perniagaan di negeri Sabah / Nor Alhana Abd Malik … [et al.]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)