Jurusa n Te knik Ele ktro UNRA M – Ma ta ra m , 17 Juli 2012 257
Otomatisasi Klasifikasi Buku Perpustakaan dengan Metode K-NN
Ni Nyomang Emang Smrti1, I. K.G Darma Putra2
1
Program Studi Magister Teknik Elektro Bidang Keahlian Manajemen Informasi dan Komputer, Universitas Udayana
2
Jurusan Teknologi Informasi, Fakultas Teknik, Universitas Udayana
1
2
Abstrak
Klasifikasi buku perpustakaan sangatlah penting untuk memudahkan pengunjung dalam pencarian buku. Dengan memanfaatkan metode yang ada pada data mining khususnya text mining, maka dalam penelitian ini akan dibangun program aplikasi untuk otomatisasi klasifikasi buku perpustakaan. Metode yang akan digunakan untuk mengklasifikasi buku perpustaan adalah metode K-Nearest neighborhood (K-NN). Program aplikasi otomatisasi klasifikasi buku perpustakaan ini dibangun dengan data latih dari buku perpustakaan STMIK Bandung Bali dan data uji berasal dari beberapa toko buku online yang menyediakan judul buku dan synopsis buku. Aplikasi yang dibuat mampu mengklasifikasi buku perpustakaan dengan prosentase keberhasilan 55% dengan jumlah data latih 538 dan 20 data uji.
Kata kunci : klasifikasi, text mining, K-NN
1. Pendahuluan
Jumlah koleksi buku dalam sebuah perpustakaan selalu mengalami penambahan buku-buku baru, seperti yang terjadi di STMIK Bandung Bali. Setiap tahun masing-masing program studi memiliki anggaran pengadaan buku. Klasifikasi buku secara manual akan menyulitkan petugas perpustakaan khususnya yang kurang berpengalaman. Keterbatasan pengetahuan petugas memungkinkan terjadinya kesalahan dalam mengklasifikasi buku serta membutuhkan waktu yang lama, karena petugas tersebut minimal harus membaca resensi dan daftar isinya. Untuk itu perlu ada mekanisme yang cepat dan objektif untuk klasifikasi koleksi buku perpustakaan.
Permasalahan klasifikasi koleksi buku yang lebih objektif, akan diselesaikan dalam penelitian ini dengan memanfaatkan text mining. Definisi dari
text mining adalah menambang data yang berupa
teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen (Milkha Harlian Ch, 2006).
Banyak metode yang mendukung text mining salah satunya adalah algoritma K-Nearest Neighbor (K-NN). Berdasarkan survey paper tahun 2008 algoritma K-NN termasuk dalam 10 algoritma terpopuler dalam data mining. Hal ini dapat dilihat dari penelitian yang menyelesaikan masalah klasifikasi teks, banyak yang memanfaatkan metode
K-NN, antara lain: (1) Pengelompokan Dokumen
Berbahasa Indonesia Menggunakan Metode K-NN oleh Achmad Ridok dan Muhammad Tanzil Furqon (2009). (2) Rancang Bangun Sistem Pengelolaan Dokumen-dokumen Penting Menggunakan Text
Mining oleh Ahmad Hatta Nana Ramadijanti dan
Afrida Helen (2010). (3) Using K-NN Model-based
Approach for Automatic Text Categorization oleh
Gongde Guo dkk (2003). Kesimpulan secara umum dari penelitian di atas adalah dengan menggunakan metode K-NN memberikan hasil yang cukup akurat dengan prosentase keberhasilan sebesar 71,58 % sampai dengan 83,2 %.
2. Preprosesing Dokumen
Sebelum proses klasifikasi dilakukan dengan menggunakan metode K-NN, maka data latih maupun data uji yang berupa judul buku diolah terlebih dahulu menjadi data numerik. Tahapan preposesing ini merupakan tahapan dari text mining yang harus dilakukan, bila akan menambang informasi berupa teks.
Menurut Milkha Harlian Ch, (2006) text mining merupakan menambang data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen dan tujuannya adalah mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen.
258 Jurusa n Te knik Ele ktro UNRA M - Ma ta ra m , 17 Juli 201 2 sama dengan proses kerja data mining pada
umumnya hanya saja data yang di mining merupakan text databases.
Di dalam knowladge discovery terdapat tahap
data mining seperti yang telah disebutkan diatas
sebenarnya pada tahap data mining inilah text
mining dijalankan. Jadi pada intinya text mining
adalah istilah yang dipakai oleh data mining yang mengekstrak data berupa teks.
Tahap-tahap text mining secara umum adalah: 1. Tahap tokenizing adalah tahap pemotongan string
input berdasarkan tiap kata yang menyusunnya.
2. Tahap filtering adalah tahap mengambil kata-kata penting dari hasil token. Algoritma yang digunakan adalah algoritma stoplist (membuang kata yang kurang penting) atau wordlist (menyimpan kata penting).
3. Tahap stemming adalah tahap mencari root kata dari tiap kata hasil filtering. Pada tahap ini dilakukan proses pengembalian berbagai bentukan kata ke dalam suatu representasi yang sama. Tahap ini kebanyakan dipakai untuk teks berbahasa Inggris dan lebih sulit diterapkan pada teks berbahasa Indonesia.
4. Tahap tagging adalah tahap mencari bentuk awal/root dari tiap kata hasil stemming.
5. Tahap analizing merupakan tahap penentuan seberapa jauh keterhubungan antara kata-kata antar dokumen yang ada. Tahap ini menggunakan algoritma frekuensi term (TF),
invers document frequency (IDF) dan kombinasi
perkalian antara keduanya (TFxIDF).
(1)
∑
(2)
Dari kelima tahapan diatas dapat digambarkan pada gambar 1.
Gambar 1. Tahapan text mining
Untuk matrik A, jumlah baris berhubungan dengan jumlah kata M dalam koleksi dokumen.
3. Metode K-NN
Algoritma K-nearest neighborhood (K-NN) merupakan algoritma supervised learning yang hasil klasifikasi data baru berdasar kepada kategori mayoritas tetangga terdekat ke-K. Tujuan dari algoritma ini adalah mengklasifikasikan objek baru berdasarkan atribut dan data training. Algoritma
K-NN menggunakan klasifikasi ketetanggaan sebagai
prediksi terhadap data baru.
Pada fase pembelajaran, algoritma ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi dari data pembelajaran. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk data tes (yang klasifikasinya tidak diketahui). Jarak dari vektor yang baru ini terhadap seluruh vektor data pembelajaran dihitung, dan sejumlah k buah yang paling dekat diambil. Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik-titik tersebut.
Nilai k yang terbaik untuk algoritma ini tergantung pada data, pada umumnya nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi lebih kabur. Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation. Kasus khusus di mana klasifikasi diprediksikan berdasarkan data pembelajaran yang paling dekat (dengan kata lain, k = 1) disebut algoritma nearest neighbor. Berikut rumus pencarian jarak menggunakan rumus
Euclidean Distance
(3)
dengan :
x1 = sampel data
x2 = data uji
I = varibel data
d = jarak
p = dimensi data
Jurusa n Te knik Ele ktro UNRA M – Ma ta ra m , 17 Juli 2012 259
Langkah-langkah Algoritma K-nearest neighbors (K-NN) :
1. Tentukan Parameter K = jumlah tetangga terdekat.
2. Hitung jarak antara data yang akan ditentukan klasifikasinya dengan semua sampel pelatihan. 3. Urutkan jarak dan tentukan tetangga terdekat
berdasarkan jarak minimum K. 4. Kumpulkan kategori tetangga terdekat.
Gunakan mayoritas sederhana dari kategori tetangga terdekat sebagai nilai prediksi dari data yang ditentutukan klasifikasinya.
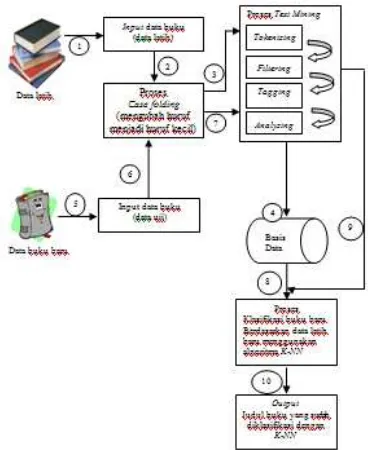
4. Arsitektur Aplikasi Klasifikasi Buku
Gambar 2. Arsitektur Sistem Klasifikasi Buku
Keterangan Gambaran Umum Sistem
1. Masukkan data latih berupa judul buku yang ada di perpustakaan.
2. Mengubah semua huruf besar menjadi huruf kecil di setiap data latih.
3. Semua data latih masuk kedalam proses text
mining.
4. Menyimpan data latih ke dalam database. 5. Memasukkan data buku baru sebagai data uji. 6. Mengubah data buku baru yang menggunakan
huruf besar menjadi huruf kecil.
7. Data buku baru masuk kedalam proses text
mining.
8,9 Data buku perpustakaan (sebagai data latih) yang sudah tersimpan di database digunakan untuk mengklasifikasi data buku baru (data uji) yang telah selesai melalui proses text mining. 10. Hasil yang didapatkan adalah data buku baru yang sudah diklasifikasi dengan metode K-NN.
5. Data
Data latih yang digunakan untuk otomatisasi proses klasifikasi buku perpustakaan sejumlah 538 judul buku dengan jumlah kategori 21 buah, untuk data yang lebih detil dapat dilihat pada tabel berikut ini
Tabel 1. Data Latih
Kode Kategori Jumlah buku
003.3 3 004.019 4 004.028 10 004.5 11 004.2 6 004.3 3 004.67 12 004.678 11 004.68 3 005.12 9
005.13 11
005.268 126
005.3 149 005.43 57 005.74 56 005.8 15
006 14
006.3 10
006.6 4 006.7 19 413 5
Kategori yang digunakan dalam klasifikasi buku perpustakaan mengacu pada aturan Dewey
Decimal Classification (DCC).
Data uji yang digunakan sejumlah 20 judul yang diperoleh dari toko buku online bukukita.com.
6. Hasil Penelitian
Penelitian ini dilakukan melalui dua tahapan pertama tahap menginputkan data latih dan tahap yang kedua adalah melakukan pengujian terhadap data latih yang telah diinputkan.
Tahap pertama memasukkan data latih kedalam program. Dari tabel 1 dapat dilihat untuk kode kategori 413 yaitu kategori kamus. Pada perpustakaan tempat penelitian dilakukan terdapat 5 buah kamus yaitu Kamus Umum Lengkap, Kamus Indonesia Inggris, Kamus Lengkap Inggris-Indonesia & Inggris-Indonesia Inggris, Kamus Besar Bahasa Indonesia dan Kamus Apelatif cara praktis temukan 1100 entri istilah pengetahuan. Dari kelima data tersebut dilakukan proses text mining seperti yang terlihat pada gambar 1. Setelah melalui proses text
mining maka hasilnya yang didapatkan dapat dilihat
260 Jurusa n Te knik Ele ktro UNRA M - Ma ta ra m , 17 Juli 201 2 Tabel 2. Hasil Text Mining
hasil
stemmer D1 D2 D3 D4 D5 DF
Apelatif 0 0 0 0 1 1
Bahasa 0 0 0 1 0 1
Besar 0 0 0 1 0 1
Cara 0 0 0 0 1 1
Entri 0 0 0 0 1 1
Indonesia 0 1 2 1 0 4
Inggris 0 1 2 0 0 3
Istilah 0 0 0 0 1 1
Kamus 1 1 1 1 1 5
Lengkap 1 0 1 0 0 2
Tahu 0 0 0 0 1 1
Praktis 0 0 0 0 1 1
Temu 0 0 0 0 1 1
Umum 1 0 0 0 0 1
Keterangan:
D1 sampai dengan D5 merupakan data 1 sampai dengan data 5 dari data latih yang diinputkan ke dalam program kemudian angka yang ada pada koordinat menunjukkan jumlah kata yang muncul pada setiap data.
DF adalah document frequency.
Setelah didapatkan nilai DF maka dilanjutkan perhitungan IDF (Invers document frequency) dan TF (frekuensi term) dikalikan dengan IDF yang terlihat pada tabel 3 berikut ini:
Tabel 3. Hasil perhitungan TF-IDF
Tahap kedua menginputkan 20 data uji kedalam program. Seperti terlihat pada gambar 1, data uji ini juga melalui proses text mining sebelum dilakukan klasifikasi dengan menggunakan metode
K-NN.
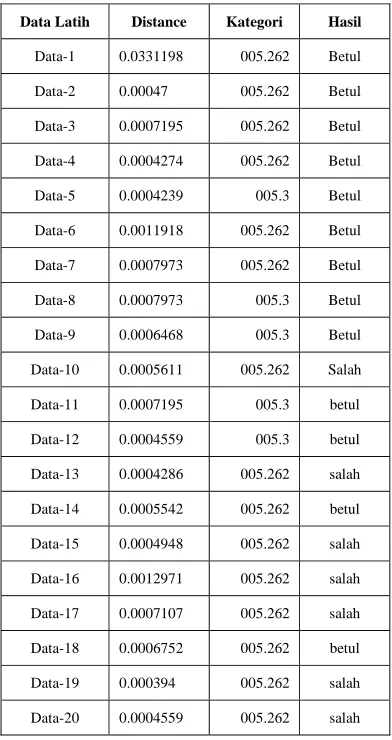
Hasil klasifikasi buku yang didapatkan setelah data uji diinputkan dapat terlihat pada tabel 4 berikut ini:
Tabel 4. Hasil Klasifikasi
Data Latih Distance Kategori Hasil
Data-1 0.0331198 005.262 Betul
Data-2 0.00047 005.262 Betul
Data-3 0.0007195 005.262 Betul
Data-4 0.0004274 005.262 Betul
Data-5 0.0004239 005.3 Betul
Data-6 0.0011918 005.262 Betul
Data-7 0.0007973 005.262 Betul
Data-8 0.0007973 005.3 Betul
Data-9 0.0006468 005.3 Betul
Data-10 0.0005611 005.262 Salah
Data-11 0.0007195 005.3 betul
Data-12 0.0004559 005.3 betul
Data-13 0.0004286 005.262 salah
Data-14 0.0005542 005.262 betul
Data-15 0.0004948 005.262 salah
Data-16 0.0012971 005.262 salah
Data-17 0.0007107 005.262 salah
Data-18 0.0006752 005.262 betul
Data-19 0.000394 005.262 salah
Data-20 0.0004559 005.262 salah
Dari 20 data uji 11 data buku diklasifikasi dengan benar dan 9 data buku salah. Jadi tingkat akurasi yang didapat dari penelitian ini adalah 55%.
7. Kesimpulan
Setelah dilakukan pengujian terhadap data buku baru, maka kesimpulan yang dapat ditarik adalah metode K-NN ini memiliki (1) presentase keberhasilan 55%. (2) Keberhasilan klasifikasi buku dipengaruhi proses text mining. (3) Banyaknya judul buku yang memiliki kata yang sama, menyumbang penurunan tingkat akurasi pada proses klasifikasi.
Daftar Pustaka:
Jurusa n Te knik Ele ktro UNRA M – Ma ta ra m , 17 Juli 2012 261
Dokumen-dokumen Penting Menggunakan Text
Mining, Proyek Akhir, Institut Teknologi
Sepuluh Nopember. [Online]
http://digilib.its.ac.id/public/ITS-Undergraduate-14856-cover-idpdf.pdf, 2010. [di unduh tanggal 1 Desember 2011]
Ahmad Ridok dan Muhammad Tanzil Furqon. 2009. Pengelompokan Dokumen Berbahasa Indonesia
Menggunakan Metode K-NN.. [Online]
http://matematika.ub.ac.id/web/cms/index2.php? option=com_docman&task=doc_view&gid=319 &Itemid=76. [di unduh tanggal 1 Desember 2011]
Ari Fadli, Konsep Data Mining. 2011. [Online]
ilmukomputer.org/wp-content/uploads/2011/03/Ari_Fadli_Konsep_Dat a_Mining.pdf [di unduh tgl 22 Nopember 2011]. Atri Nurani, Budi Susanto, Umi Proboyekti. 2007.
Implementasi Naive Bayes Classifier Pada Program Bantu Penentuan Buku Referensi
Matakuliah. [Online]
ti.ukdw.ac.id/ojs/index.php/informatika/article/d ownload/60/12. [diunduh 19 Pebruari 2011].
Efraim Turban, Jay E. Aronson, Ting-Peng Liang. 2005. Decision Support Systems and Intelligent Systems. Yogyakarta: Andi.
Fadillah Z. Tala, A Study of Stemming Effect on Information Retrieval in Bahasa Indonesia, Netherland, Universiteit van Amsterdam, http://ucrel.lancs.ac.uk/acl/P/P00/P00-1075.pdf, diakses terakhir tanggal 25 Juli 2009.
Gongde Guo, Hui Wang, David Bell, Yaxin Bi and Kieran Greer. 2003. Using K-NN Model-based Approch for Automatic Text Categorization, School of Computing and Mathematics, University of Ulster Newtownabbey. [Online].
officeobjects.info/publications/%5BGuo2003a% 5D.pdf. [diunduh tanggal 20 Pebruari 2011]. Heri Kurniawan, Rizal Fathoni Aji. 2006.
Otomatisasi Pengelompokkan Koleksi Perpustakaan Dengan Pengukuran Cosine Similarity Dan Euclidean Distance, [Online]
Journal.uii.ac.id/index.php/Snati/article/view/15 99/1374. [diunduh: tanggal 15 April 2011].
Hearst, M. 2004. What is text mining. [online].
sims.berkeley.edu/~hearst/ textmining.html,
[diunduh: 30 Nopember 2011].
Helmi Harniawati. 2007. “Image Clustering Berdasarkan Warna untuk Identifikasi Buah dengan Metode Valley Tracing” (Proyek akhir). Surabaya: Institut Teknologi Sepuluh Nopember. Iko Pramudiono. 2003. Pengantar Data Mining:
Menambang Permata Pengetahuan di Gunung Data. [online], http://ikc.depsos.go.id/umum/iko-datamining.php. [diunduh: tanggal 15 April 2011]
Kusrini, Emha Taufiq Luthfi. 2009. Algoritma Data Mining. Yogyakarta: Andi.
Michael J. A. Berry and Gordon S. Linoff. 2004. Data Mining Techniques For Marketing, Sales, and Customer Relationship Management. United States of America.
Milkha Harlian Ch. 2006. Text Mining. [online] kesehatankerja.depkes.go.id/downloads/6Text%2 0Mining.pdf [diunduh: tanggal 30 Nopember 2011].
Sheni Wahyuni. 2010. Penerapan Text Mining Untuk Automatic Book Classification Dengan Metode Naive Bayes. [Online].
http://elib.unikom.ac.id/gdl.php?mod=browse&o p=read&id=jbptunikompp-gdl-sheniwahyu-18589. [diunduh: tanggal 15 April 2011].
Thorsten Joachims. 2002. Classify Text Using Support Vector Machines. America.
Tawa P. Hamakonda, Mls & J. N. B Tairas. 2008. Pengantar Klasifikasi Persepuluhan Dewey. Cetakan ke – 18. Jakarta.
Turban, E., dkk, 2005, Decision Support System and
Intelligent System, Yogyakarta: Andi.
Wahyu Supriyanto, Ahmad Muhsin. 2008. Informasi Perpustakaan. Yogyakarta: Kansius (Anggota IKAPI).
Yudho Giri Sucahyo. 2003. Data Mining Menggali Informasi Terpendam. [online].
ikc.dinus.ac.id/populer/yudho-datamining.php. [diunduh: 20 Pebruari 2011].
Zhou Yong. 2009. An Improved KNN Text Classification Algorithm Based on Clustering,. [Online] academypublisher.com/jcp/vol04/no03/ jcp0403230237.pdf. [diunduh: tanggal 5 Mei