ANALISA POLA DATA PENYAKIT RUMAH SAKIT DENGAN
MENERAPKAN METODE ASSOCIATION RULE MENGGUNAKAN
ALGORITMA APRIORI
Harris Kurniawan1, Fujiati2, Alfa Saleh3
STMIK Potensi Utama
Jl. K.L. Yos Sudarso Km. 6.5 No.3-A, Tanjung Mulia, Medan, Indonesia [email protected], [email protected], [email protected]
Abstrak
Rumah Sakit adalah tempat untuk menangani pasien dari berbagai daerah dan jenis penyakit pasien tersebut berbeda-beda, karena cara hidup dan lingkungan berperan dalam perjalanan penyakit. Berdasarkan hal tersebut untuk meningkatkan upaya menurunkan angka kesakitan dan prevalensi timbulnya komplikasi pada penyakit maka perlu dilakukan penelitian-penelitian yang mengarah pada pembuatan sistem yang dapat mendeteksi timbulnya penyakit sehingga dapat dilakukan upaya prefentif serta upaya rehabilitatif bagi penderita penyakit dengan pendekatan yang menyeluruh, sehingga dampak terjadinya berbagai penyakit menahun, seperti penyakit jantung koroner, penyakit pada mata, ginjal dan syaraf dapat dikurangi. Dalam usaha peningkatan kesehatan, penguasaan teknologi perlu ditingkatkan. Selain itu, juga perlu diimbangi dengan sistem informasi dan data yang akurat bagi kepentingan dinas kesehatan maupun instansi terkait untuk pengambilan kebijakan. Salah satu alternatif sebagai solusi dari masalah tersebut adalah membuat suatu pencarian pola atau hubungan Association rule (aturan asosiatif) dari data yang berskala besar dan kaitannya sangat erat dengan data mining yang dapat digunakan untuk menemukan aturan-aturan tertentu yang mengasosiasikan data yang satu dengan data yang lainnya dengan Metode algoritma apriori bisa melakukan penelusuran pada data historis untuk mengidentifikasi pola data yang didasarkan pada sifat-sifat yang teridentifikasi sebelumnya. Informasi yang dihasilkan untuk selanjutnya bisa digunakan oleh Dinas Kesehatan setempat maupun dokter sebagai dasar untuk melakukan tindakan-tindakan yang diperlukan. Kata Kunci : Data Mining, Association rule dan algoritma apriori
1. Pendahuluan
Dengan bertambahnya angka harapan hidup bangsa Indonesia perhatian masalah kesehatan beralih dari penyakit infeksi ke penyakit degenerative. Pada umumnya penyakit tidak mengenal usia, karena penyakit bisa menyerang siapapun. karena itu perlu di waspadai serangan dari penyakit tersebut. Penyakit manusia banyak jenisnya seperti, anemia, diabetes, jantung, kulit, kanker, demam berdarah, typus, ginjal dan sebagainya.
Rumah Sakit adalah tempat untuk menangani pasien dari berbagai daerah dan jenis penyakit pasien tersebut berbeda-beda, karena cara hidup dan lingkungan berperan dalam perjalanan penyakit. Berdasarkan hal tersebut untuk meningkatkan upaya menurunkan angka kesakitan dan prevalensi timbulnya komplikasi pada penyakit maka perlu dilakukan penelitian-penelitian yang mengarah pada pembuatan sistem yang dapat mendeteksi timbulnya penyakit sehingga dapat dilakukan upaya prefentif serta upaya rehabilitatif bagi penderita penyakit dengan pendekatan yang menyeluruh, sehingga dampak terjadinya berbagai penyakit menahun, seperti penyakit jantung koroner, penyakit pada mata, ginjal dan
syaraf dapat dikurangi.
Dalam usaha peningkatan kesehatan, penguasaan teknologi perlu ditingkatkan. Selain itu, juga perlu diimbangi dengan sistem informasi dan data yang akurat bagi kepentingan dinas kesehatan maupun instansi terkait untuk pengambilan kebijakan. Misalnya informasi mengenai daerah pemberantasan penyakit dan potensi adanya penyakit dalam suatu daerah tertentu sehingga informasi-informasi ini dapat mengarahkan paramedis melakukan usaha pemberantasan penyakit tersebut. Untuk mengatasi masalah dalam pemberantasan penyakit ini, diperlukan analisa terhadap data penyakit yang terlah didapat dari setiap daerah yang pernah dirawat pada rumah sakit, sehingga dapat diketahui penyakit apa yang paling banyak dalam masing-masing daerah dan daerah mana yang jenis penyakitnya paling berbahaya. Dengan demikian, daerah yang utama untuk pemberantasan penyakit tersebut dapat di tentukan.
tertentu yang mengasosiasikan data yang satu dengan data yang lainnya dengan suatu metode algoritma. Metode algoritma apriori bisa melakukan penelusuran pada data historis untuk mengidentifikasi pola data yang didasarkan pada sifat-sifat yang teridentifikasi sebelumnya. Kemudian dapat diberikan alternatif pengobatan atau pencegahan bila ditemukan indikasi yang mengarah pada timbulnya penyakit. Informasi yang dihasilkan untuk selanjutnya bisa digunakan oleh Dinas Kesehatan setempat maupun dokter sebagai dasar untuk melakukan tindakan-tindakan yang diperlukan.
2. Tinjauan Pustaka
Data Mining (DM)
Data mining adalah proses pengolahan informasi dari sebuah database yang besar, meliputi proses ekstraksi, pengenalan, komprehensif, dan penyajian informasi sehingga dapat digunakan dalam pengambilan keputusan
bisnis yang krusial”.[1][3] Metodologi Data Mining
Langkah-langkah yang dibutuhkan untuk mengerjakan implementasi Data Mining :
1. Problem Analysis, langkah ini untuk menganalisa permasalahan dalam bisnis yang hendak diatasi dengan menggunakan Data Mining. Dari sini harus dibuat penilaian pada ketersediaan data, teknologi yang dipakai dan hasil yang diinginkan sebagai bagian dari keseluruhan solusi.
2. Data Preparation, langkah ini untuk mengekstrasi data dan mentransformasikannya ke dalam format yang dibutuhkan oleh algoritma Data Mining, termasuk di dalamnya join tabel, menambah field baru, membersihkan data dan sebagainya.
3. Data Exploration, langkah ini mendahului langkah pencarian pola yang sesungguhnya. Didalamnya terdapat proses eksplorasi secara visual dan memberikan pengguna kemudahan untuk menemukan kesalahan yang terjadi dalam proses data preparation.
4. Pattern Generation, langkah ini menggunakan cara induksi dan mengumpulkan algoritma penelusuran untuk membuat pola-pola tertentu.
5. Pattern Deployment, langkah ini pengembangan pola-pola yang ditemukan yang didesain dalam langkah problem analysis. Pola-pola ini khusus digunakan dalam Decision Support System (DSS), untuk membuat laporan-laporan atau buku petunjuk, atau memfilter data untuk tujuan pemrosesan. 6. Pattern Monitoring, kesimpulan utama dari
hasil pengembangan Data Mining adalah kesamaan pola-pola di waktu yang lalu dapat
diaplikasikan untuk kondisi-kondisi yang terjadi di masa depan. [1]
Association Rule
Association rule merupakan salah satu teknik data mining yang paling banyak digunakan dalam penelusuran pola pada sistem pembelajaran unsupervised . Metodologi ini akan mengambil seluruh kemungkinan pola -pola yang diamati dalam basis data. Association rule menjelaskan kejadian–kejadian yang sering muncul dalam suatu kelompok. Bentuk umum aturan
B1,B2,…,Bm, yang berarti jika item Ai muncul, item Bj juga muncul dengan peluang tertentu. Misalkan X adalah itemset. transaksi T dikatakan mengandung X jika dan hanya
transaksi dengan tingkat kepercayaan (confidence ) C, jika C % dari transaksi dalam D yang mengandung X juga mengandung Y. transaksi set D jika S% dari transaksi dalam basis
Y. Tingkat kepercayaan menunjukkan kekuatan implikasi, dan support menunjukkan seringnya pola terjadi dalam rule.
Mining association rule dilakukan dalam dua tahap yaitu :
1. Mencari semua association rule yang mempunyai minimum support (Smin) dan minimum confidence Cmin. Itemset dikatakan sering muncul (frequent) jika Support(A)
min.
2. Menggunakan itemset yang besar untuk menentukan association rule untuk basis data yang mempunyai tingkat kepercayaan C di atas nilai minimum yang telah ditentukan (Cmin.). [2][3][4][5]
3. Analisa dan Pembahasan
Analisa Association Rule
Penerapan data mining dengan association rule bertujuan menemukan informasi item-item
yang saling berhubungan dalam bentuk rule, dengan demikian association rule di terapkan pada pola data penyakit yang paling sering muncul dengan menggunakan algoritma apriori.
Tabel 1. Association Analysis pada data penyakit pasien
NO ITEM
1 Dyspepsia, Febris, DHF
2 Vertigo, Febris, Dyspepsya
3 Vertigo, Dispepsya
4 CHF, Astmah, Vertigo, Dispepsya
5 DHF, Dispepsya, Febris, Astmah
RULL dditemukan
{Dispepsya } {Vertigo } { Febris, Dispepsia {DHF}
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Aturan assosiatif dari penyakit pasien di rumah sakit adalah dapat diketahuinya berapa besar kemungkinan seorang pasien dapat mengidap penyakit TB. Paru bersamaan dengan Febris. Dengan pengetahuan tersebut Dokter yang merawat dapat mengambil tindakan penolongan pertama pada pasien.
Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frequensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang) yaitu persentase kombinasi item tersebut dalam database dan confidence (nilai kepastian) yaitu kuatnya hubungan antar item dalam aturan assosiatif.
Aturan assosiatif biasanya dinyatakan dalam bentuk :
{Febris, TB.Paru} -> {Dispepsya} (support = 40%, confidence = 50%)
Yang artinya : "50% dari transaksi di database yang memuat item Febris dan TB.Paru juga memuat item Dispepsya. Sedangkan 40% dari seluruh transaksi yang ada di database memuat ketiga item itu." Dapat juga diartikan : "Seorang pasien yang mengidam penyakit Febris dan TB.Paru kemungkinan 50% punya penyakit Dispepsya. Aturan ini cukup signifikan karena mewakili 40% dari catatan transaksi selama ini." Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan assosiatif yang memenuhi syarat minimum untuk support (minimum support) dan syarat
minimum untuk confidence (minimum confidence). Dasar analisis asosiasi terbagi menjadi dua tahap :
Analisa pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dari data penyakit. Nilai support sebuah item diperoleh dengan rumus 1 berikut :
Support(A)= [rumus 1]
Nilai support dari 2 item diperoleh dari rumus 2 berikut:
Support(A,B) =P(A B)=
..[rumus 2]
Data dari Penyakit pasien seperti ditunjukkan dalam tabel 2 berikut :
Tabel 2. Penyakit Pasien
Pasien Item Penyakit
1 2 3 4 5 6 7 8 9 10 11
Febris, Dispepsya, Anemia Anemia, Febris, DM DM, DHF, Dispepsya Dispepsya, Febris, Anemia Febris, Anemia, Dispepsya Dispepsya, Febris, DHF Febris, Anemia, DM Febris, DM, DHF
Anemia, Dispepsya, Thyphoid Febris, Hypertensi, Dyspepsia Hypertensi, Dispepsya. Febris Data tersebut diatas dalam database Pasien direpresentasikan dalam bentuk seperti tampak pada tabel 3. berikut:
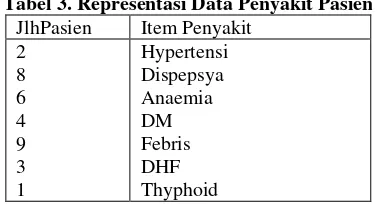
Tabel 3. Representasi Data Penyakit Pasien JlhPasien Item Penyakit
2 8 6 4 9 3 1
Hypertensi Dispepsya Anaemia DM Febris DHF Thyphoid
Tabel 4. Format Tabular Data Penyakit Pasien direperesentasikan dalam tabel 1, dimana masing-masing Pasien T dalam D merepresentasikan himpunan item yang berada dalam I. Himpunan items A (Febris dan Dispepsya) dan himpunan item lain B (Anemia). Kemudian aturan asosiasi akan berbentuk :
Jika Febris dan Dispepsya Maka Febris. Dimana antecedent A dan consequent B merupakan subset dari I, kemudian A dan B merupakan mutually exclusive. Definisi ini tidak berlaku untuk aturan trivial seperti :
Jika A, maka B ( A_B)
Penulis hanya akan mengambil aturan yang memiliki support dan/atau confidence yang tinggi. Aturan yang kuat adalah aturan-aturan yang melebihi kriteria support dan/atau
confidence minimum. Aturan yang memiliki
support lebih dari 20 % dan confidence lebih dari 35 %. Sebuah itemset adalah himpunan item-item yang ada dalam I, dan k-itemset adalah itemset
yang berisi k item. Misalnya {Febris, Dispepsya) adalah sebuah 2-itemset dan {Tb. Paru, Anemia, DM) merupakan 3-itemset. Frequent Itemset
menunjukkan itemset yang memiliki frekuensi kemunculan lebih dari nilai minimum yang telah
ditentukan (ф). Misalkan ф = 3, maka semua itemset yang frekuensi kemunculannya lebih dari 3 kali disebut frequent. Himpunan dari frequent k-itemset dilambangkan dengan Fk .
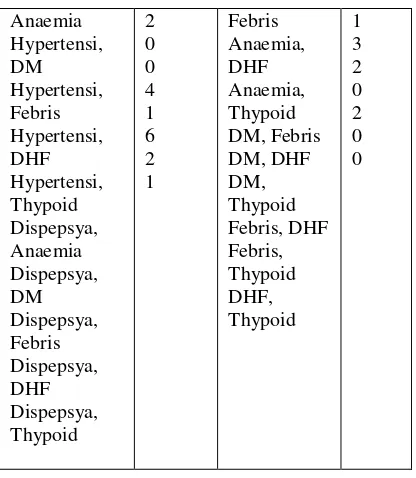
Tabel 5. Calon 2-itemset
Combinasi Count Combinasi Count Hypertensi, itemset dari data Penyakit pada tabel 1. Dari data
tersebut diatas, jika ditetapkan nilai ф = 3 maka
F2 = { { Dispepsya, Anaemia}, { Dispepsya, Febris}, { Anaemia, Febris}{ DM, Febris}}
Tabel 6. Calon 3-Itemset
Combination Count Anemia, Febris}}, karena hanya kombinasi inilah
yang memiliki frekeunsi kemunculan >= ф.
Pembentukan aturan assosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif yang memenuhi syarat minimum untuk confidence
dengan menghitung confidence aturan assosiatif
confidence
diperoleh dari rumus 3 berikut:
Confidence =P(B | A)=
Tabel 7. Calon Aturan Asosiasi dari F3
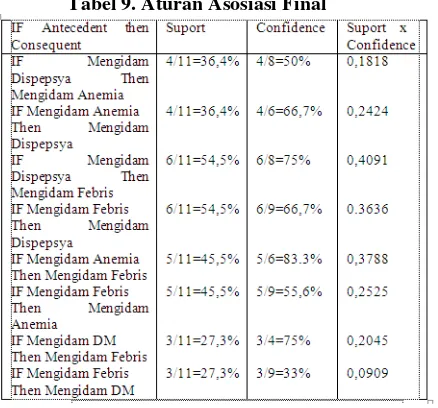
Confidence minimal adalah 75% maka aturan yang bisa terbentuk adalah aturan dengan 1
antecedent berikut:
“IF Mengidam Dispepsya end Anaemia, Then Mengidam Febris”
Sementara itu calon aturan asosiasi dari F2 bisa dilihat pada tabel 8. berikut:
Tabel 8. Calon Aturan Asosiasi dari F2
Aturan asosiasi final terurut berdasarkan
Support x Confidence terbesar dapat dilihat pada table 9. berikut:
Tabel 9. Aturan Asosiasi Final
Analisa Penerapan Algoritma Apriori Apriori adalah suatu algoritma yang sudah sangat dikenal dalam melakukan
pencarian frequent itemset, dengan association rule. Sesuai dengan namanya, algoritma ini menggunakan knowledge mengenai frequent itemset yang telah diketahui sebelumnya, untuk memproses informasi selanjutnya. Algoritma apriori memiliki beberapa prinsip dasar yaitu : 1. Kumpulan jumlah item tunggal, dapatkan
item besar.
2. Dapatkan kandidat pairs, hitung => large pair dari item-item.
3. Dapatkan candidate triplets, hitung => large triplets dari item-item dan seterusnya. 4. Sebagai petunjuk : setiap sumset dari sebuah
frequent itemset harus menjadi frequent. Pada gambar 2 adalah ilustrasi penerepan apriori
Gambar 2. ilustrasi penerapan apriori
Bila dilihat pada Gambar 2 dimana dari 5 candidat dari 1-itemset yang memenuhi
support ≥ 2 hanya 4 candidat atau calon dari 1-itemset ini memenuhi support yaitu 1, 2, 3, dan 5 sedangkan item 4 tidak memenuhi syarat minimum support karena memiliki jumlah 1. Selanjutnya dari ke 4 item yang memenuhi syarat minimum support di gunakan untuk mencari atau menemukan 2-itemset maka di peroleh 6 pasang item yang menjadi candidat dari 2-itemset, setelah itu dicari kembali item yang memenuhi syarat minimum support. selanjutnya 2-itemset digunakan untuk mencari 3-itemset begitu seterusnya sehingga algortitma tidak dapat menemukan lagi frequent dan algoritma berhenti setelah menemukan semua frequent itemset.
Berikut table penerapan cara kerja Apriori :
Table 10. Data pasien Code
Pasien
Item Penyakit 1 Febris, Dispepsya, Anemia 2 Anemia, Febris, DM 3 DM, DHF, Dispepsya 4 Dispepsya, Febris, Anemia 5 Febris, Anemia, Dispepsya 6 Dispepsya, Febris, DHF 7 Febris, Anemia, DM 8 Febris, DM, DHF
1. Pada iterasi pertama dari algoritama , setiap item adalah anggota dari set calon 1-itemset, C1. Algoritma akan secara langsung memeriksa semua penyakit yang ada untuk dapat menghitung kejadian munculnya setiap item. Jika diasumsikan bahwa minimum support yang dibutuhkan adalah 2 ( misalnya min_sup = 3/11=27,3%. Set dari 1-itemset, L1, dapat ditentukan yaitu semua calon 1-itemset yang memenuhi minimum support.
Item Penyakit Juml Pasien
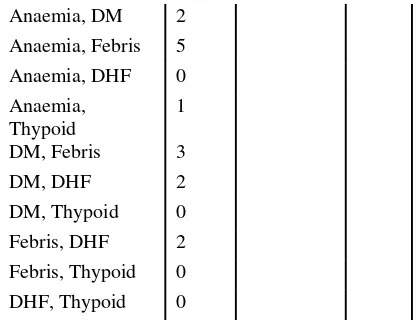
2. Untuk menemukan 2-itemset, L2, algorima ini menggunakan pengkombinasian C1 dengan L1 untuk menghasilkan candidate set dari 2-itemset, C2. C2 merupakan hasil kombinasi dari L1. Penyakit yang ada dalam database D diperiksa dan support count dari setiap calon itemset yang ada di C2 ditambahkan, seperti yang diajukkan pada table.
Tabel 12. C2 dan L2, Untuk mencari 2- itemset
C2 L2
Combinasi Count Combinasi count Hypertensi, yaitu semua candidate 2-itemset yang memenuhi minimum support. Proses untuk menghasilakan suatu set candidate dari 3-itemset, C2, dijelaskan secara lebih detail pada table 10, 11, 12 Pertama dapatkan C3, yaitu dengan cara mengkombinasikan L2 dengan C2, maka menhasilkan { Dispepsya, Anemia, Febris}berdasarkan pada algoritma apriori, maka semua sumset dari frequent itemset diatas, harus juga frequent, dapat dipastikan kemudian ke-empat candidate terakhit tidak mungkin akan frequent. Oleh karena itu harus disingkirkan dari C3, dengan demikian dapat menghemat usaha yang tidak diperlukan untuk melakukan perhitungan terhadap database, ketika akan menentukan L3. Penyakit yang ada di D di periksa untuk menentukan L3, yaitu terdiri dari candidate 3-Itemset di C3 yang memenuhi minimum support yang sudah ditentukan.
4. Algoritma akan melakukan kombinasi antara C3 dengan L3 untuk menghasilkan candidate dari 4-itemset, C4. Dengan demikian , C4 ?, dan algoritma berhenti karena telah menemukan semua frequent itemset.
Table 13. final proses 3-itemset
Combination Count dengan menerapkan Metode Association Rule
Menggunakan Algoritma Apriori, maka dapat diambil kesimpulan sebagai berikut:
1. Metode Association Rule Menggunakan
data yang didasarkan pada sifat-sifat yang teridentifikasi sebelumnya.
2. Penggunaan Metode Association Rule
Menggunakan Algoritma Apriori sangat membantu dalam memperkirakan Penyakit Pasien yang harus ditangani oleh Rumah Sakit dalam periode yang akan datang.
3. Penggunaan aplikasi Data Mining dapat membantu dalam pengambilan keputusan untuk pengklasifikasian untuk banyak data. 4. Penggunaan Metode Association Rule
Menggunakan Algoritma Apriori dalam menemukan penyakit telah menemukan semua frequent itemset untuk penyakit Dispepsya, Anemia, Febris sebanyak 3.
5. Metode ini dapat diterapkan pada permasalahan yang berkaitan dalam pencarian informasi dimasa yang akan datang.
Daftar Pustaka
[1] Abdallah Alashqur, “Mining Association
Rule: A Database Perspective”,
International Journal of Computer Science and Network Security, Vol 8 No. 12, December 2008, Page 69 – 74, HTTP:// paper.ijcsns.org/07_book/200812/20081211. pdf
[2] D,Suryadi, (2001) Pengantar Data Mining, Andi, Yogyakarta
[3] Kusrini (2007), “Penerapan Algoritma Apriori pada Data Mining untuk Mengelompokkan Barang Berdasarkan Kecenderungan Kemunculan Bersama
dalam Satu Transaksi”, Page 1 – 16, HTTP://dosen.amikom.ac.id/.../Publikasi%2 0Apriori-Kusrini_Feb-07_.pdf
[4] Susanto. (2010). Pengantar Data Mining. Informatika. Jakarta
[5] Therling K. (2006).“ An Introduction to DataMining: Discovering hidden value in
your data warehouse”, www.thearling.com,