Fakultas Ilmu Komputer
Universitas Brawijaya
341
Prediksi Jumlah Pengangguran Terbuka di Indonesia menggunakan
Metode Genetic-Based Backpropagation
Dyva Pandhu Adwandha1, Dian Eka Ratnawati2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1dyvapandhu989@gmail.com, 2dian_ilkom@ub.ac.id, 3adikara.putra@gmail.com
Abstrak
Setiap tahunnya jumlah pengangguran terbuka di Indonesia mengalami peningkatan dan penurunan. Faktor yang mempengaruhi hal tersebut adalah jumlah angkatan kerja tidak sebanding dengan lapangan pekerjaan yang tersedia. Selain itu melemahnya daya serap tenaga kerja di beberapa sektor industri juga menjadi penyebab meningkatnya jumlah pengangguran terbuka di Indonesia. Dengan adanya prediksi jumlah pengangguran terbuka, diharapkan dapat membantu pemerintah dan pihak terkait untuk mengambil kebijakan yang tepat untuk mengurangi jumlah pengangguran terbuka di Indonesia. Metode genetic-based backpropagation adalah salah satu metode yang dapat diimplementasikan untuk melakukan prediksi. Metode ini melakukan proses optimasi bobot dan bias menggunakan algoritma genetika sebagai parameter untuk proses training pada metode backpropagation. Dalam penelitian ini diperoleh rata-rata nilai Average Forecast Error Rate (AFER) untuk metode backpropagation sebesar 4.715198444% dan metode genetic-based backpropagation sebesar 3.877514478%. Dari nilai AFER yang diperoleh metode genetic-based backpropagation dapat digunakan untuk memprediksi jumlah pengangguran terbuka di Indonesia dengan tingkat akurasi yang lebih baik.
Kata kunci: Algoritma genetika, backpropagation, genetic-based backpropagation, prediksi, time
series.
Abstract
The number of open unemployment in Indonesia has increased and decreased every year. The factors that can make unemployment happens is the number of the labor force is not balanced to the available jobs. In addition, the weakening of labor absorption in some industrial sectors has also the cause of the increasing number of open unemployment in Indonesia. Predict the number of open unemployment, expected can help the government and related parties to take the appropriate policy to reduce the number of open unemployment in Indonesia. Genetic-based backpropagation is one of the methods that can be implemented to perform predictions. This method performs weight and biases optimization process as parameters in backpropagation training. In this research the result value of Average Forecast Error Rate (AFER) of backpropagation method is 4.715198444% and genetic-based backpropagation method is 3.877514478%. Based on the result value of AFER, genetic-based backpropagation method can be used to predict the number of open unemployment in Indonesia with a better accuracy.
Keywords: Genetic algorithm, backpropagation, genetic-based backpropagation, predict, time series.
1. PENDAHULUAN
Indonesia adalah salah satu yang termasuk ke dalam kategori negara berkembang. Berdasarkan taraf kesejahteraan masyarakatnya, salah satu permasalahan yang tengah dihadapinya adalah masalah pengangguran.
Pada umumnya hal tersebut disebabkan karena lapangan pekerjaan yang tersedia tidak sebanding dengan jumlah angkatan kerja yang ada. Selain itu daya serap tenaga kerja di Indonesia yang melemah di beberapa sektor industri mengakibatkan jumlah pengangguran semakin bertambah. Pada tahun 2014 lalu Badan Pusat Statistik (BPS) mencatat bahwa jumlah
pengangguran terbuka mencapai 7,24 juta jiwa. Dan pada bulan Agustus tahun 2015 pengangguran terbuka tercatat sebanyak 7,56 juta jiwa. Hal tersebut menandakan bahwa telah terjadi peningkatan jumlah pengangguran sebanyak 320 ribu jiwa. Pada bulan Agustus tahun 2015, tercatat jumlah angkatan kerja meningkat menjadi 122,38 juta jiwa dari tahun 2014 (Badan Pusat Statistik, 2015).
Informasi terkait dengan jumlah pengangguran terbuka yang berubah dari tahun ke tahun, tentunya sangat diperlukan oleh pemerintah dan pihak terkait untuk menentukan sebuah kebijakan. Dengan adanya prediksi jumlah pengangguran, diharapkan dapat membantu pemerintah dan pihak terkait untuk mengambil kebijakan yang tepat serta tindakan preventif dalam menanggulangi permasalahan tersebut. Data hasil prediksi dapat digunakan untuk mengevaluasi program yang telah dijalankan oleh pemerintah pada tahun-tahun sebelumnya, serta mengukur persentase peningkatan atau penurunan jumlah pengangguran terbuka.
Metode yang dapat diimplementasikan untuk melakukan prediksi salah satunya adalah jaringan saraf tiruan backpropagation, karena metode tersebut mampu mempelajari pola dalam
dataset time-series. Penelitian yang telah
menerapkan metode backpropagation dalam kaitannya untuk prediksi seperti, prediksi banjir dengan memperoleh nilai MSE sebesar 0,1139 (Soomlek, Kaewchainam, Simano, & So-In, 2016), prediksi nilai ujian sekolah dengan memperoleh hasil nilai MSE sebesar 0,1405143 (Kosasi, 2014), dan prediksi penyakit asma dengan memperoleh nilai MSE sebesar 0,00100139 (Tanjung, 2015). Banyak peneliti yang mengembangkan metode tersebut agar hasilnya dapat dioptimalkan, salah satunya menggunakan algortima genetika.
Algoritma genetika merupakan jenis dari algoritma evolusi yang paling populer (Mahmudy, 2015). Kombinasi metode
backpropagation dengan algoritma genetika
dikenal dengan metode genetic-based backpropagation. Salah satu penelitian yang
menerapkan metode ini adalah prediksi tentang aktifitas lalu lintas jaringan (Haviluddin & Alfred, 2015). Dalam penelitian tersebut, algoritma genetika dipakai untuk mengoptimasi bobot dan thresholds. Peneliti membandingkan metode backpropagation dengan genetic-based
backpropagation dalam memprediksi aktifitas
lalu lintas jaringan. Kemampuan metode
tersebut diukur menggunakan analisis statistik yang dinamakan Mean of Square Error (MSE). Hasil nilai MSE terbaik yang didapatkan dari kedua metode tersebut berturut-turut adalah 0,009636 dan 0,000565. Dari hasil MSE yang diperoleh, dapat diketahui bahwa metode tersebut memiliki hasil yang baik dalam kasus prediksi.
Berdasarkan dari latar belakang demikian dan tingkat akurasi yang baik, maka dalam penelitian ini akan menggunakan metode
genetic-based backpropagation untuk
memprediksi jumlah pengangguran terbuka di Indonesia.
2. DASAR TEORI 2.1 Backpropagation
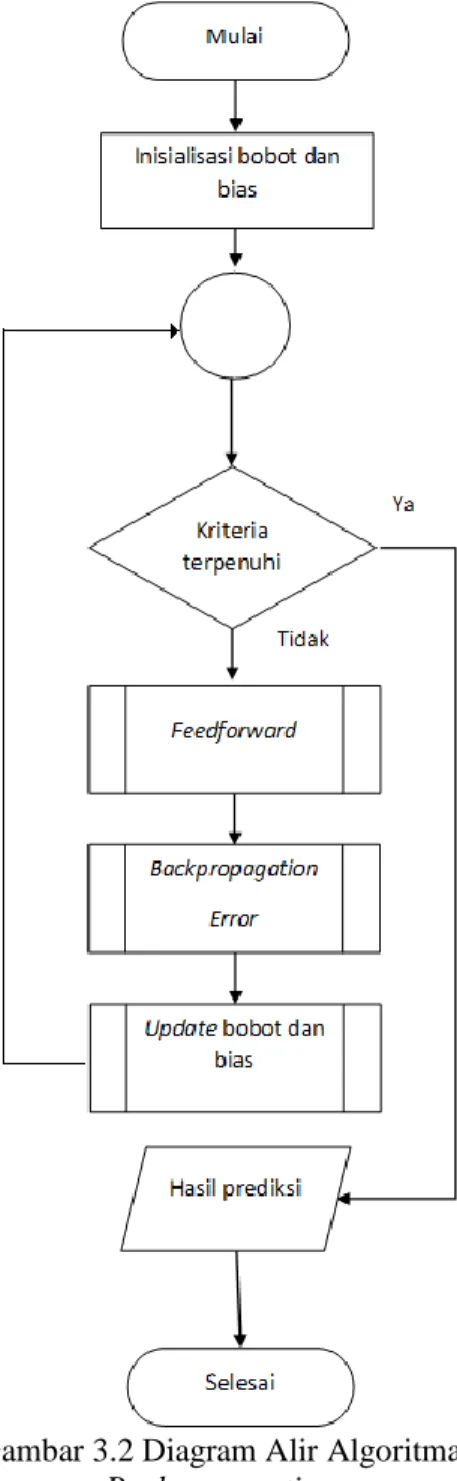
Backpropagation merupakan salah satu
algoritma yang terdapat pada jaringan saraf tiruan dengan karakteristik meminimalkan error pada output yang dihasilkan oleh jaringan. Algoritma ini memiliki tiga tahapan yaitu memasukkan pola training (feedforward), propagasi balik dari nilai error
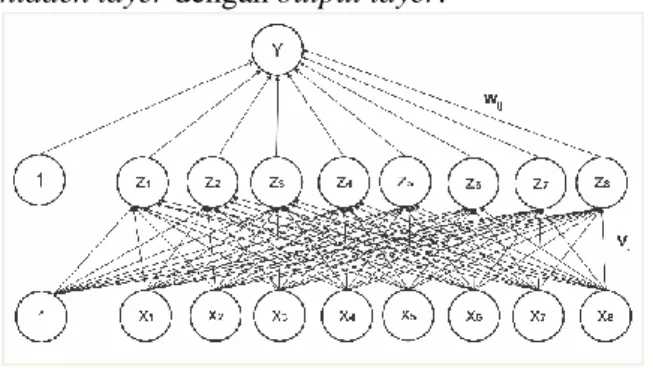
(backpropagation error), dan penyesuaian bobot dan bias (update) (Fausett, 1994). Gambar 2.1 menunjukkan arsitektur jaringan saraf tiruan
backpropagation dengan 1 hidden layer. Dari
gambar tersebut terdapat 2 buah bobot dan bias yaitu wij dan vij. Bobot dan bias w menghubungkan input layer dan hidden layer, sedangkan bobot dan bias v menghubungkan
hidden layer dengan output layer.
Gambar 2.1 Arsitektur Jaringan Saraf Tiruan
Backpropagation dengan 1 Hidden Layer
2.1.1 Normalisasi Data
Data dilakukan normalisasi sebelum diolah dengan tujuan untuk mempermudah perhitungan. Data dinormalisasi pada interval 0,1-0,9 karena fungsi sigmoid hampir tidak pernah mencapai nilai 0 atau 1 (Jauhari, Himawan, & Dewi, 2016).
𝑥′ = 0.8(𝑥−𝑎) 𝑏−𝑎 + 0.1 (2.1) Keterangan: a: nilai minimum b: nilai maksimum 2.1.2 Langkah-langkah Algoritma Backpropagation
Berikut merupakan langkah-langkah dari algoritma backpropagation (Fausett, 1994): 1. Menginisialisasi bobot dan bias.
2. Ketika kondisi berhenti belum terpenuhi, tahap 3-10 dilakukan.
3. Untuk setiap pasangan training, tahap 4-9 dilakukan.
Tahap Feedforward
4. Menghitung nilai pada hidden unit (zj). Nilai dari zj kemudian dimasukkan ke dalam fungsi aktivasi dengan sigmoid biner.
𝒛_𝒊𝒏𝒋= 𝒗𝟎𝒋+ ∑ 𝒙𝒊 𝒊𝒗𝒊𝒋 (2.2)
𝒛𝒋= 𝟏
𝟏+𝐞𝐱𝐩 (−𝒛_𝒊𝒏𝒋) (2.3)
5. Menghitung nilai pada output unit (yk). Nilai dari yk kemudian dimasukkan ke dalam fungsi aktivasi dengan sigmoid biner. 𝑦_𝑖𝑛𝑘 = 𝑤0𝑗+ ∑ 𝑧𝑖 𝑖𝑤𝑖𝑗 (2.4)
𝑦𝑘 = 𝟏
𝟏+𝐞𝐱𝐩 (−𝒚_𝒊𝒏𝒌) (2.5) Tahap Backpropagation Error
6. Menghitung nilai δ pada output unit untuk
mengetahui tingkat error.
δ𝑘= (𝑡𝑘− 𝑦𝑘)𝑓′(𝑦_𝑖𝑛𝑘) (2.6)
7. Menghitung kebenaran bobot untuk memperbaiki (update) nilai dari bobot dan bias wjk.
𝛥𝑤𝑗𝑘 = 𝛼δ𝑘𝑧𝑗 (2.7)
𝛥𝑤0𝑘= 𝛼δ𝑘 (2.8)
8. Menghitung nilai δj pada hidden unit untuk mengetahui tingkat error.
δ_𝑖𝑛𝑗= ∑𝑚𝑘 = 1δ𝑘𝑤𝑗𝑘 (2.9)
δ𝑗= δ_𝑖𝑛𝑗 𝑓′(z_𝑖𝑛𝑗) (2.10)
9. Menghitung kebenaran bobot untuk memperbaiki (update) nilai dari bobot dan bias vij.
𝛥𝑣𝑖𝑗 = 𝛼δ𝑗𝑥𝑖 (2.11)
𝛥𝑣0𝑗= 𝛼δ𝑗 (2.12) Tahap Update Bobot dan Bias
10. Menghitung bobot dan bias wjk baru. 𝑤𝑗𝑘(𝑏𝑎𝑟𝑢) = 𝑤𝑗𝑘(𝑙𝑎𝑚𝑎) + 𝛥𝑤𝑗𝑘(2.13)
11. Menghitung bobot dan bias vij baru. 𝑣𝑖𝑗(𝑏𝑎𝑟𝑢) = 𝑣𝑖𝑗(𝑙𝑎𝑚𝑎) + 𝛥𝑣𝑖𝑗 (2.14) 2.2 Perhitungan Error
2.2.1 MSE
Mean Square Error (MSE) merupakan
salah satu dari beberapa fungsi untuk mengukur perbedaan diantara sebuah estimator dan nilai aktual. Semakin kecil nilai MSE, maka tingkat kesalahan yang diberikan semakin kecil (M.Deborah & Prathap, 2014).
𝑀𝑆𝐸 = 1 𝑛∑ (𝑌′𝑖− 𝑌𝑖) 2 𝑛 𝑖=1 (2.15) 2.2.2 AFER
Selain menggunakan MSE, dalam penelitian ini juga menggunakan perhitungan AFER untuk menghitung tingkat kesalahan.
Average Forecasting Error Rate (AFER)
merupakan salah satu perhitungan tingkat error yang dilakukan dengan cara menyatakan persentase selisih antara data aktual dengan data hasil prediksi (Syukriyawati, 2015). Semakin kecil nilai AFER, maka tingkat akurasi yang diberikan untuk prediksi semakin baik.
𝐴𝐹𝐸𝑅 =∑ |
𝐴𝑖−𝐹𝑖 𝐴𝑖 |
𝑛 ∗ 100% (2.16) 2.3 Algoritma Genetika
Algoritma genetika atau biasa disebut
genetic algorithms (GAs) adalah jenis dari
Seiring dengan perkembangan teknologi informasi yang sangat pesat, GA juga turut berkembang. Algoritma ini banyak diimplementasikan dalam bidang biologi, fisika, ekonomi, sosiologi, dan lainnya karena kemampuannya untuk menangani masalah yang kompleks terkait dengan masalah optimasi (Mahmudy, 2015).
Ada 4 tahapan dalam algoritma genetika yaitu inisialisasi, reproduksi, evaluasi, dan seleksi.
2.3.1 Inisialisasi
Inisialisasi merupakan proses membangkitkan individu secara acak yang memiliki susunan gen tertentu dan diletakkan pada penampungan atau wadah yang disebut
popSize. PopSize menyatakan jumlah
individu/chromosome yang ditampung dalam satu populasi. Panjang dari setiap chromosome disebut dengan stringLen (Mahmudy, 2015).
Chromosome dapat direpresentasikan
dalam bentuk biner dan pengkodean real. Representasi chromosome dalam bentuk biner memiliki kelemahan yaitu tidak dapat menjangkau beberapa titik solusi jika range solusi berada dalam daerah kontinyu, selain itu untuk mentransformasikan biner ke dalam bilangan desimal ataupun sebaliknya dapat menambah waktu perhitungan (Mahmudy, 2015). Maka dari itu dalam penelitian ini digunakan representasi chromosome dengan pengkodean bilangan real yang ditunjukkan pada Gambar 2.2.
Panjang chromosome yang digunakan dalam penelitian ini adalah 9, dimana posisi 1-8 merepresentasikan bobot w, sedangkan untuk posisi 9 merepresentasikan bias w. Batas (constraints) untuk nilai bobot dan bias wi adalah -0,1 ≤ wi ≤ 0,9.
Gambar 2.2 Representasi Chromosome
2.3.2 Reproduksi
Reproduksi merupakan proses untuk mendapatkan keturunan (offspring) baru dari individu yang terdapat pada populasi. Proses reproduksi dibagi menjadi 2 bagian yaitu tukar silang (crossover) dan mutasi (mutation) (Mahmudy, 2015). Pada tahap crossover,
crossover rate (cr) harus ditentukan terlebih
dahulu. Crossover rate berfungsi untuk menunjukkan rasio offspring yang diperoleh dari proses crossover terhadap popSize, sehingga dihasilkan offspring sebanyak (cr x popSize). Selain cr, pada tahap ini juga dicari nilai
mutation rate (mr). Mutation rate berfungsi
untuk menunjukkan rasio offspring yang diperoleh dari proses mutasi terhadap popSize sehingga dihasilkan offspring sebanyak (mr x
popSize).
Metode crossover yang digunakan adalah
one-cut point. Contoh jika ditentukan cr=0,2 dan popSize=10, maka terdapat 0,2 x 10 = 2 offspring. Jika ditentukan setiap crossover
menghasilkan 2 buah child, maka terdapat satu kali proses crossover. Contoh jika P1 dan P4 induk terpilih, dan cut point adalah 3, maka diperoleh offspring C1 dan C2.
Gambar 2.3 Proses Crossover Menggunakan
One-Cut Point
Dalam proses mutasi terdapat beberapa metode yang dapat diterapkan, salah satunya adalah metode reciprocal exchange. Metode ini memilih dua posisi secara acak lalu menukarnya. Misal P5 merupakan induk terpilih dan ditentukan mr=0,1 dan popSize=10, maka terdapat 0,1 x 10 = 1 offspring.
Gambar 2.4 Proses Mutasi Menggunakan
Reciprocal Exchange
2.3.3 Evaluasi
Evaluasi merupakan proses yang berfungsi untuk menghitung nilai fitness pada setiap
chromosome. Semakin tinggi nilai fitness dari chromosome, maka semakin baik chromosome
tersebut untuk dijadikan sebagai sebuah calon solusi (Mahmudy, 2015).
Sebuah fungsi fitness merepresentasikan sebuah solusi dari masalah yang akan diselesaikan. Fungsi fitness digunakan untuk
mengukur seberapa baik kualitas dari sebuah individu. Semakin tinggi nilai fitness, maka menandakan individu tersebut semakin baik untuk dijadikan sebagai sebuah solusi (Mahmudy, 2015).
𝒇𝒊𝒕𝒏𝒆𝒔𝒔 = 𝟏
𝑴𝑺𝑬 (2.17) 2.3.4 Seleksi
Proses seleksi bertujuan untuk menyaring individu dari populasi serta offspring yang akan dipertahankan pada generasi selanjutnya. Terdapat beberapa metode yang dapat diimplementasikan untuk proses seleksi, salah satunya adalah metode elitism selection. Cara kerja metode ini adalah dengan menghimpun semua individu dalam populasi dan offspring dalam satu wadah. Selanjutnya metode ini akan mengambil individu terbaik sebanyak popSize untuk diloloskan pada generasi selanjutnya (Mahmudy, 2015).
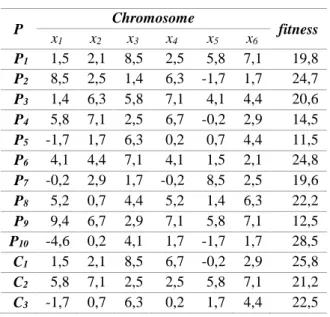
Contoh terdapat himpunan individu dan
offspring pada Tabel 2.1. Jika popSize awal
adalah 10, maka setelah dilakukan proses seleksi akan diperoleh individu baru pada Tabel 2.2.
Tabel 2.1 Himpunan Individu
P Chromosome fitness x1 x2 x3 x4 x5 x6 P1 1,5 2,1 8,5 2,5 5,8 7,1 19,8 P2 8,5 2,5 1,4 6,3 -1,7 1,7 24,7 P3 1,4 6,3 5,8 7,1 4,1 4,4 20,6 P4 5,8 7,1 2,5 6,7 -0,2 2,9 14,5 P5 -1,7 1,7 6,3 0,2 0,7 4,4 11,5 P6 4,1 4,4 7,1 4,1 1,5 2,1 24,8 P7 -0,2 2,9 1,7 -0,2 8,5 2,5 19,6 P8 5,2 0,7 4,4 5,2 1,4 6,3 22,2 P9 9,4 6,7 2,9 7,1 5,8 7,1 12,5 P10 -4,6 0,2 4,1 1,7 -1,7 1,7 28,5 C1 1,5 2,1 8,5 6,7 -0,2 2,9 25,8 C2 5,8 7,1 2,5 2,5 5,8 7,1 21,2 C3 -1,7 0,7 6,3 0,2 1,7 4,4 22,5
Tabel 2.2 Individu Baru
asal P(t) Chromosome fitness x1 x2 x3 x4 x5 x6 P10 -4,6 0,2 4,1 1,7 -1,7 1,7 28,5 C1 1,5 2,1 8,5 6,7 -0,2 2,9 25,8 P6 4,1 4,4 7,1 4,1 1,5 2,1 24,8 P2 8,5 2,5 1,4 6,3 -1,7 1,7 24,7 C3 -1,7 0,7 6,3 0,2 1,7 4,4 22,5 P8 5,2 0,7 4,4 5,2 1,4 6,3 22,2 C2 5,8 7,1 2,5 2,5 5,8 7,1 21,2 P3 1,4 6,3 5,8 7,1 4,1 4,4 20,6 P1 1,5 2,1 8,5 2,5 5,8 7,1 19,8 P7 -0,2 2,9 1,7 -0,2 8,5 2,5 19,6 3. PERANCANGAN DAN IMPLEMENTASI
3.1. Perancangan Alur Proses Algoritma
Tahapan algoritma genetic-based backpropagation untuk memprediksi jumlah
pengangguran terbuka di Indonesia dibagi menjadi 2 tahap, yang pertama yaitu algoritma genetika untuk mengoptimasi bobot dan bias w yang ditunjukkan pada Gambar 3.1. Tahap kedua yaitu backpropagation untuk melakukan prediksi yang ditunjukkan pada Gambar 3.2.
Gambar 3.1 Diagram Alir Diagram Alir Algoritma Genetika untuk Optimasi Bobot dan
Gambar 3.2 Diagram Alir Algoritma
Backpropagation
Berikut merupakan langkah-langkah pada metode genetic-based backpropagation untuk prediksi:
1. Membangkitkan populasi awal (bobot dan bias w) yang akan dihitung menggunakan algoritma genetika. Hasil individu terbaik pada proses ini akan digunakan sebagai
input untuk proses training pada metode backpropagation.
2. Melakukan proses reproduksi (crossover dan mutasi). Crossover menggunakan
one-cut point dan mutasi menggunakan reciprocal exchange
3. Melakukan evaluasi pada hasil reproduksi. 4. Melakukan seleksi menggunakan metode
elitism selection untuk mendapatkan individu terbaik.
5. Jika sudah memenuhi kriteria yang telah ditentukan, maka sistem akan menghentikan proses training
menggunakan algoritma genetika. Kriteria yang dimaksud adalah jumlah iterasi atau generasi.
6. Selanjutnya sistem akan memulai proses
training menggunakan metode
backpropagation menggunakan individu
terbaik yang diperoleh, dalam hal ini bobot dan bias w. Prediksi dilakukan pada tahap ini.
4. PENGUJIAN DAN ANALISIS
4.1 Pengujian Pengaruh Ukuran Populasi Terhadap Nilai Fitness
Ukuran populasi yang diuji adalah kelipatan 50 dari 50 sampai 700, sedangkan ukuran generasi yang dipakai adalah 10. Nilai cr dan mr yang digunakan berturut-turut adalah 0,5 dan 0,5. Pengujian dilakukan sebanyak 10 kali dan dicari rata-rata nilai fitness yang diperoleh.
Tabel 4.1 Hasil Uji Coba Ukuran Populasi
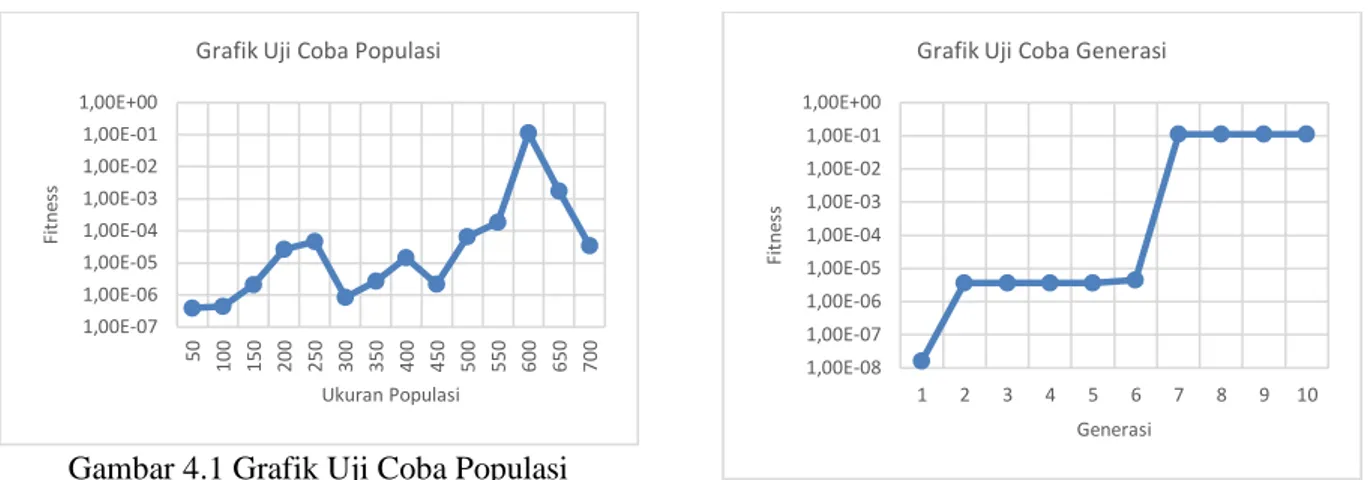
Uji Coba Ukuran Populasi Fitness Terbaik 1 50 3,92 x 10-7 2 100 4,40 x 10-7 3 150 2,11 x 10-6 4 200 2,63 x 10-5 5 250 4,57 x 10-5 6 300 8,54 x 10-7 7 350 2,68 x 10-6 8 400 1,46 x 10-5 9 450 2,18 x 10-6 10 500 6,42 x 10-5 11 550 1,83 x 10-4 12 600 1,11 x 10-1 13 650 1,74 x 10-3 14 700 3,46 x 10-5
Gambar 4.1 Grafik Uji Coba Populasi Nilai fitness terkecil diperoleh pada jumlah populasi 50 dan nilai fitness terbesar diperoleh pada jumlah populasi 600. Dari grafik pada Gambar 4.1 dapat disimpulkan bahwa ukuran populasi sebesar 600 dapat menghasilkan nilai
fitness terbaik, karena selebihnya nilai fitness
yang dihasilkan cenderung menurun. Pada jumlah populasi sebesar 50, diperoleh nilai
fitness terbesar disebabkan karena ukuran
populasi yang digunakan masih sedikit, sehingga daerah yang dieksplorasi masih terbatas dan solusi yang diberikan belum mencapai hasil optimal, namun ukuran populasi yang terlalu besar tidak menjamin bahwa nilai fitness yang dihasilkan juga akan lebih baik.
4.2 Pengujian Pengaruh Jumlah Generasi Terhadap Nilai Fitness
Ukuran populasi yang digunakan adalah sebanyak 600 individu yang berasal dari hasil pengujian pertama. Nilai cr dan mr yang digunakan berturut-turut adalah 0,5 dan 0,5. Jumlah generasi yang akan diuji adalah dari 1 sampai 10 generasi. Pengujian dilakukan sebanyak 10 kali dan dicari rata-rata nilai fitness yang diperoleh.
Tabel 4.2 Hasil Uji Coba Jumlah Generasi
Uji Coba Jumlah Generasi Fitness Terbaik 1 1 1,60 x 10-8 2 2 3,64 x 10-6 3 3 3,64 x 10-6 4 4 3,64 x 10-6 5 5 3,64 x 10-6 6 6 4,51 x 10-6 7 7 1,11 x 10-1 8 8 1,11 x 10-1 9 9 1,11 x 10-1 10 10 1,11 x 10-1
Gambar 4.2 Grafik Uji Coba Generasi Dapat dilihat pada grafik tersebut nilai
fitness terkecil terdapat pada generasi 1. Hal
tersebut disebabkan karena jumlah generasi yang masih sangat kurang sehingga daerah eksplorasi masih sangat sempit. Pada umumnya semakin banyak jumlah generasi, maka dimungkinkan untuk mendapatkan nilai fitness yang lebih baik. Dapat disimpulkan bahwa berdasarkan grafik pada Gambar 4.2 jumlah generasi yang optimal diperoleh ketika jumlah generasi 7, karena selebihnya nilai fitness yang diperoleh bernilai konvergen.
4.3 Pengujian Kombinasi Nilai Crossover Rate (Cr) dan Mutation Rate (Mr)
Ukuran populasi yang digunakan adalah sebanyak 600 individu yang berasal dari hasil pengujian pertama dan jumlah generasi yang digunakan adalah 7 generasi yang berasal dari hasil pengujian kedua. Nilai cr dan mr yang diuji adalah pada range 0 sampai dengan 1. Pengujian dilakukan sebanyak 10 kali dan dicari rata-rata nilai fitness yang diperoleh.
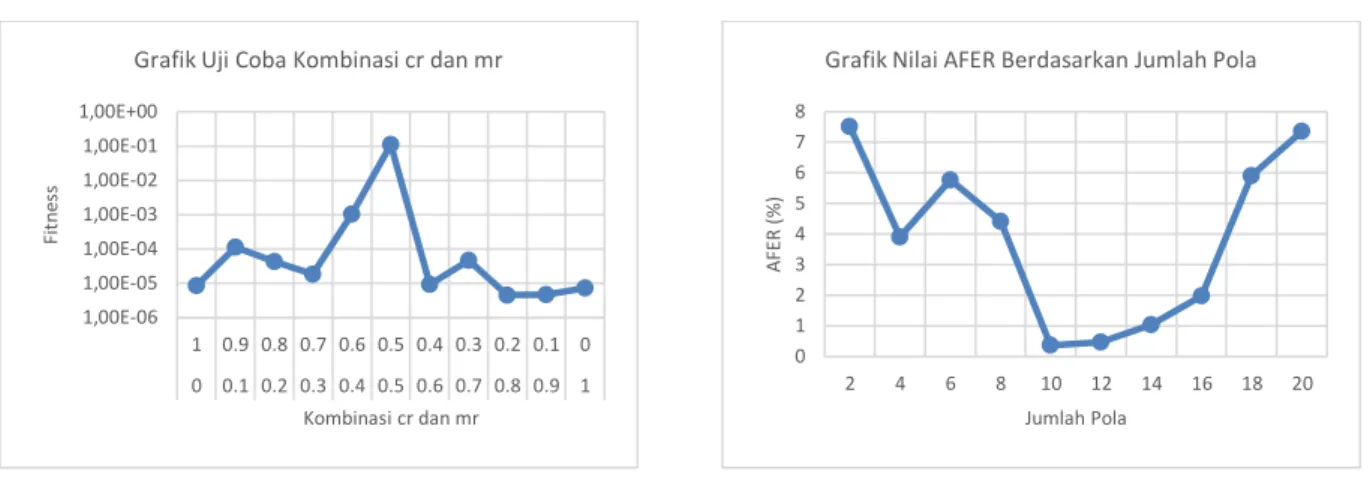
Tabel 4.3 Hasil Uji Coba Kombinasi Cr dan Mr
Uji Coba cr mr Fitness Terbaik 1 0 1 8,55 x 10-6 2 0,1 0,9 1,13 x 10-4 3 0,2 0,8 4,33 x 10-5 4 0,3 0,7 1,84 x 10-5 5 0,4 0,6 1,04 x 10-3 6 0,5 0,5 1,11 x 10-1 7 0,6 0,4 9,13 x 10-6 8 0,7 0,3 4,57 x 10-5 9 0,8 0,2 4,55 x 10-6 10 0,9 0,1 4,62 x 10-6 11 1 0 7,15 x 10-6 1,00E-07 1,00E-06 1,00E-05 1,00E-04 1,00E-03 1,00E-02 1,00E-01 1,00E+00 50 100 150 200 250 300 350 400 450 500 550 600 650 700 Fi tn es s Ukuran Populasi
Grafik Uji Coba Populasi
1,00E-08 1,00E-07 1,00E-06 1,00E-05 1,00E-04 1,00E-03 1,00E-02 1,00E-01 1,00E+00 1 2 3 4 5 6 7 8 9 10 Fi tn es s Generasi
Gambar 4.3 Grafik Uji Coba Kombinasi Cr dan
Mr
Nilai fitness terbaik adalah 1,11 x 10-1 ditemukan pada kombinasi cr 0,5 dan mr 0,5, sedangkan nilai fitness terendah adalah 4,55 x 10-6 diperoleh pada kombinasi cr 0,8 dan mr 0,2. Dapat disimpulkan bahwa kombinasi nilai cr dan
mr terbaik berturut-turut adalah 0,5 dan 0,5.
4.4 Pengujian Pengaruh Jumlah Pola Terhadap Nilai AFER
Pola merupakan data jumlah pengangguran terbuka pada tahun tertentu yang digunakan untuk proses training. Contoh, untuk memprediksi tahun 2016 dibutuhkan data jumlah pengangguran terbuka pada tahun 2010-2015. Pada pengujian ini dilakukan 10 kali uji coba untuk memprediksi jumlah pengangguran terbuka pada tahun 2016A menggunakan jumlah pola yang berbeda. Parameter pada algoritma
backpropagation untuk training yang digunakan
berupa nilai alpha sebesar 0,2 dan jumlah iterasi sebanyak 15000.
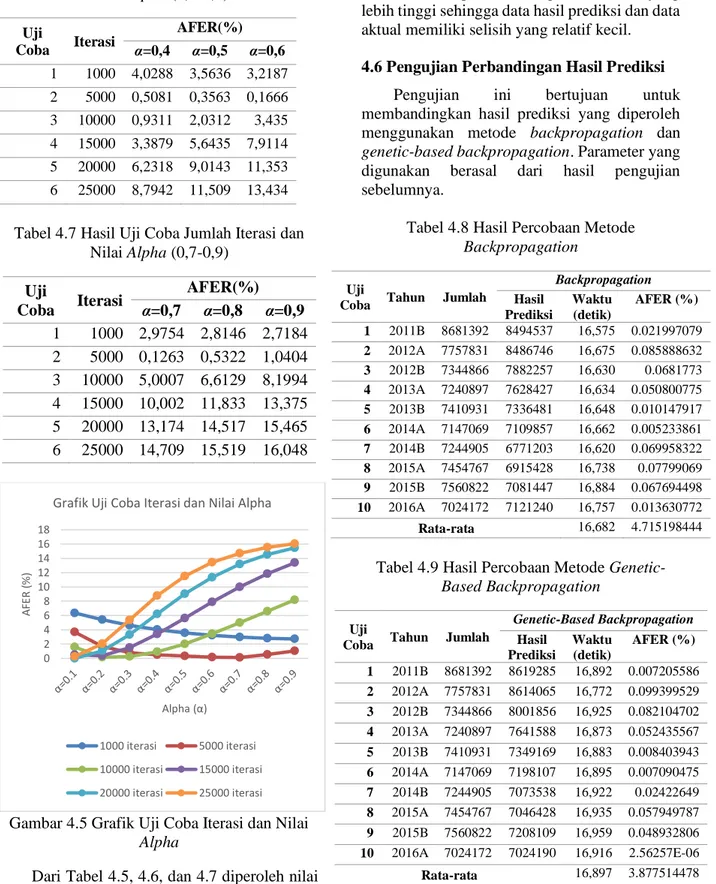
Tabel 4.4 Hasil Uji Coba Jumlah Pola
Uji Coba Jumlah Pola Tahun Awal Tahun Prediksi AFER (%) 1 2 2015A 2016A 7,5227 2 4 2014A 2016A 3,9098 3 6 2013A 2016A 5,7698 4 8 2012A 2016A 4,4232 5 10 2011A 2016A 0,3648 6 12 2010A 2016A 0,4643 7 14 2009A 2016A 1,0393 8 16 2008A 2016A 1,9801 9 18 2007A 2016A 5,9051 10 20 2006A 2016A 7,3563
Gambar 4.4 Grafik Nilai AFER Berdasarkan Jumlah Pola
Pola yang dihasilkan pada Gambar 4.4 mengalami peningkatan dan penurunan, namun cenderung mengalami peningkatan. Dari uji coba 1 sampai 10, nilai AFER terkecil yang diperoleh terdapat pada uji coba ke-5 dengan jumlah pola 10 dan nilai AFER sebesar 0,3648%. Dapat disimpulkan bahwa penggunaan terlalu banyak pola dapat menyebabkan nilai AFER yang dihasilkan semakin tinggi. Hal tersebut dapat terjadi karena
range nilai pada tahun awal dengan data satu
tahun sebelum prediksi (2016A) relatif besar.
4.5 Pengujian Pengaruh Iterasi dan Nilai Alpha Terhadap Nilai AFER
Parameter yang digunakan berupa jumlah iterasi mulai dari 1000, 5000, 10000, 15000, 20000, dan 25000. Nilai alpha yang akan diuji berada pada range 0,1 sampai 0,9.
Tabel 4.5 Hasil Uji Coba Jumlah Iterasi dan Nilai Alpha (0,1-0,3) Uji Coba Iterasi AFER(%) α=0,1 α=0,2 α=0,3 1 1000 6,3592 5,3987 4,6333 2 5000 3,6921 1,6792 0,8141 3 10000 1,5908 0,1669 0,2382 4 15000 0,4967 0,3648 1,4986 5 20000 0,0003 1,0639 3,3297 6 25000 0,2585 2,0489 5,3895 1,00E-06 1,00E-05 1,00E-04 1,00E-03 1,00E-02 1,00E-01 1,00E+00 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Fi tn es s Kombinasi cr dan mr
Grafik Uji Coba Kombinasi cr dan mr
0 1 2 3 4 5 6 7 8 2 4 6 8 10 12 14 16 18 20 A FE R ( %) Jumlah Pola
Tabel 4.6 Hasil Uji Coba Jumlah Iterasi dan Nilai Alpha (0,4-0,6) Uji Coba Iterasi AFER(%) α=0,4 α=0,5 α=0,6 1 1000 4,0288 3,5636 3,2187 2 5000 0,5081 0,3563 0,1666 3 10000 0,9311 2,0312 3,435 4 15000 3,3879 5,6435 7,9114 5 20000 6,2318 9,0143 11,353 6 25000 8,7942 11,509 13,434 Tabel 4.7 Hasil Uji Coba Jumlah Iterasi dan
Nilai Alpha (0,7-0,9) Uji Coba Iterasi AFER(%) α=0,7 α=0,8 α=0,9 1 1000 2,9754 2,8146 2,7184 2 5000 0,1263 0,5322 1,0404 3 10000 5,0007 6,6129 8,1994 4 15000 10,002 11,833 13,375 5 20000 13,174 14,517 15,465 6 25000 14,709 15,519 16,048
Gambar 4.5 Grafik Uji Coba Iterasi dan Nilai
Alpha
Dari Tabel 4.5, 4.6, dan 4.7 diperoleh nilai AFER terkecil yaitu 0,0003% ketika jumlah iterasi 20000 dan alpha 0,1. Pada umumnya nilai
alpha yang semakin kecil, kemungkinan
mendekati hasil prediksi semakin tinggi namun iterasi yang diperlukan juga semakin besar. Hal
tersebut dapat terjadi karena dengan menggunakan nilai alpha 0,1 sistem mampu mencari hasil prediksi dengan ketelitian yang lebih tinggi sehingga data hasil prediksi dan data aktual memiliki selisih yang relatif kecil.
4.6 Pengujian Perbandingan Hasil Prediksi
Pengujian ini bertujuan untuk membandingkan hasil prediksi yang diperoleh menggunakan metode backpropagation dan
genetic-based backpropagation. Parameter yang
digunakan berasal dari hasil pengujian sebelumnya.
Tabel 4.8 Hasil Percobaan Metode
Backpropagation Uji
Coba Tahun Jumlah
Backpropagation Hasil Prediksi Waktu (detik) AFER (%) 1 2011B 8681392 8494537 16,575 0.021997079 2 2012A 7757831 8486746 16,675 0.085888632 3 2012B 7344866 7882257 16,630 0.0681773 4 2013A 7240897 7628427 16,634 0.050800775 5 2013B 7410931 7336481 16,648 0.010147917 6 2014A 7147069 7109857 16,662 0.005233861 7 2014B 7244905 6771203 16,620 0.069958322 8 2015A 7454767 6915428 16,738 0.07799069 9 2015B 7560822 7081447 16,884 0.067694498 10 2016A 7024172 7121240 16,757 0.013630772 Rata-rata 16,682 4.715198444
Tabel 4.9 Hasil Percobaan Metode
Genetic-Based Backpropagation Uji
Coba Tahun Jumlah
Genetic-Based Backpropagation Hasil Prediksi Waktu (detik) AFER (%) 1 2011B 8681392 8619285 16,892 0.007205586 2 2012A 7757831 8614065 16,772 0.099399529 3 2012B 7344866 8001856 16,925 0.082104702 4 2013A 7240897 7641588 16,873 0.052435567 5 2013B 7410931 7349169 16,883 0.008403943 6 2014A 7147069 7198107 16,895 0.007090475 7 2014B 7244905 7073538 16,922 0.02422649 8 2015A 7454767 7046428 16,935 0.057949787 9 2015B 7560822 7208109 16,959 0.048932806 10 2016A 7024172 7024190 16,916 2.56257E-06 Rata-rata 16,897 3.877514478 0 2 4 6 8 10 12 14 16 18 A FE R ( % ) Alpha (α)
Grafik Uji Coba Iterasi dan Nilai Alpha
1000 iterasi 5000 iterasi
10000 iterasi 15000 iterasi
Gambar 4.6 Grafik Perbandingan Hasil Prediksi Dari Tabel 4.8 dan 4.9 diketahui bahwa metode genetic-based backpropagation
memperoleh rata-rata nilai AFER yang lebih kecil dari metode backpropagation yaitu sebesar 3.877514478%. Hal tersebut dapat disebabkan karena dalam penentuan bobot dan bias w pada metode backpropagation dilakukan secara acak, sedangkan pada metode genetic-based backpropagation bobot dan bias w akan dicari
yang paling optimal sebelum diproses. Sehingga hasil dari metode genetic-based backpropagation memperoleh nilai AFER yang
lebih kecil daripada metode backpropagation. Namun waktu yang dibutuhkan metode
genetic-based backpropagation untuk proses training
sedikit lebih lama karena adanya proses optimasi bobot dan bias.
4.7 Pengujian Hasil Prediksi Beberapa Jangka Waktu
Pengujian ini bertujuan untuk mengetahui hasil prediksi mengunakan metode
genetic-based backpropagation untuk jangka 10 tahun
ke depan. Pengujian dilakukan untuk memprediksi tahun 2016A menggunakan data aktual pada tahun 2006B sampai tahun 2011A.
Tabel 4.10 Hasil Prediksi 10 Tahun
Tahun Jumlah Hasil
Prediksi AFER (%) 2011B 8681392 8619285 0,007205586 2012A 7757831 8794679 0,117894923 2012B 7344866 8808483 0,166159939 2013A 7240897 8862957 0,183015668 2013B 7410931 9002970 0,176834867 2014A 7147069 9200855 0,223216864 2014B 7244905 9371199 0,226896686 2015A 7454767 9417629 0,208424222 2015B 7560822 9395702 0,195289293 2016A 7024172 9379307 0,251099042 17,5603709
Gambar 4.7 Grafik Data Aktual dan Hasil Prediksi
Dari grafik pada Gambar 4.7, hasil prediksi yang paling mendekati data aktual adalah pada tahun 2011B sejumlah 8619285 jiwa. Hal tersebut dapat terjadi karena prediksi yang dilakukan untuk jangka waktu 10 tahun ke depan menggunakan pola yang dilatih untuk tahun 2011B, sehingga hasil prediksi yang mendekati data aktual terdapat pada tahun 2011B. Dari hasil pengujian ini dapat dikatakan bahwa metode genetic-based backpropagation tidak cocok untuk memprediksi jumlah pengangguran terbuka untuk jangka waktu lebih dari 1 tahun ke depan.
5. KESIMPULAN
Prediksi jumlah pengangguran terbuka di Indonesia dapat diimplementasikan menggunakan metode genetic-based backpropagation melalui 2 tahap. Tahap yang
pertama adalah optimasi bobot dan bias w menggunakan algoritma genetika dan tahap kedua adalah proses prediksi menggunakan
backpropagation. Algoritma genetika yang 0 2000000 4000000 6000000 8000000 10000000 2 0 1 1 B 2 0 1 2 A 2 0 1 2 B 2 0 1 3 A 2 0 1 3 B 2 0 1 4 A 2 0 1 4 B 2 0 1 5 A 2 0 1 5 B 2 0 1 6 A Juml ah P eng ang guran Ter buk a Tahun
Grafik Perbandingan Kedua Metode
Data Aktual Backpropagation Genetic-Based Backpropagation 0 2000000 4000000 6000000 8000000 10000000 2 0 1 1 B 2 0 1 2 A 2 0 1 2 B 2 0 1 3 A 2 0 1 3 B 2 0 1 4 A 2 0 1 4 B 2 0 1 5 A 2 0 1 5 B 2 0 1 6 A Juml ah P eng ang guran Ter buk a Tahun
Grafik Data Aktual dan Hasil Prediksi
digunakan pada penelitian ini memiliki beberapa kriteria yaitu menggunakan pengkodean bilangan real, chromosome dengan panjang 9 yang merepresentasikan bobot dan bias w. Proses crossover menggunakan metode one-cut
point dan untuk mutasi menggunakan reciprocal exchange, sedangkan pada proses seleksi
menggunakan elitism selection. Dan nilai fitness yang digunakan adalah 1/MSE.
Dari hasil pengujian yang telah dilakukan, parameter optimal yang digunakan pada metode
genetic-based backpropagation yaitu ukuran
populasi sebesar 600, jumlah generasi 7, nilai cr dan mr 0,5 untuk parameter algoritma genetika. Dan untuk parameter backpropagation yaitu pola untuk training sebesar 10 pola, jumlah iterasi 20000, dan nilai alpha sebesar 0,1. Dari parameter tersebut metode genetic-based backpropagation memperoleh nilai AFER yaitu
3.877514478%. Namun metode ini tidak cocok untuk memprediksi dalam jangka waktu lebih dari 1 tahun.
6. DAFTAR PUSTAKA
Badan Pusat Statistik. (2015). Keadaan
Ketenagakerjaan Agustus 2015.
Fausett, L. (1994). Fundamentals of Neural
Networks (Prentice-H). Prentice-Hall.
Haviluddin, & Alfred, R. (2015). A Genetic-Based Backpropagation Neural Network for Forecasting in Time-Series Data (p. 6). IEEE.
https://doi.org/10.1109/ICSITech.2015.74 07796
Jauhari, D., Himawan, A., & Dewi, C. (2016). PREDIKSI DISTRIBUSI AIR PDAM MENGGUNAKAN METODE JARINGAN, 3(2).
Kosasi, S. (2014). Penerapan metode jaringan saraf tiruan backpropagation untuk memprediksi nilai ujian sekolah. Jurnal
Teknologi, 7, 20–28.
M.Deborah, & Prathap, C. S. (2014). Detection of Fake currency using Image Processing.
IJISET, 1(10), 151–157.
Mahmudy, W. F. (2015). Dasar-Dasar
Algoritma Evolusi. Malang: Program
Teknologi Informasi dan Ilmu Komputer (PTIIK) Universitas Brawijaya.
Soomlek, C., Kaewchainam, N., Simano, T., & So-In, C. (2016). Using backpropagation neural networks for flood forecasting in PhraNakhon Si Ayutthaya, Thailand.
ICSEC 2015 - 19th International
Computer Science and Engineering Conference: Hybrid Cloud Computing: A New Approach for Big Data Era.
https://doi.org/10.1109/ICSEC.2015.7401 424
Syukriyawati, G. (2015). Implementasi Metode
Average-Based Fuzzy Time Series Models pada Prediksi Jumlah Penduduk Provinsi DKI Jakarta. Brawijaya University.
Tanjung, D. H. (2015). Jaringan Saraf Tiruan dengan Backpropagation untuk
![[PS4RK] Tafsir Ayat Alquran Tentang Aqad](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)