MODEL ADITIF TERAMPAT VEKTOR DENGAN KOMPONEN
UTAMA UNTUK PENDUGAAN CURAH HUJAN EKSTRIM
(STUDI KASUS: INDRAMAYU)
EKA PUTRI NUR UTAMI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul “Model Aditif Terampat Vektor dengan Komponen Utama untuk Pendugaan Curah Hujan Ekstrim (Studi Kasus: Indramayu)” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2016
Eka Putri Nur Utami
NIM G151130091
* Pelimpahan hak cipta atas karya tulis dari penelitian kerjasama dengan pihak luar IPB harus didasarkan pada perjanjian kerjasama yang terkait
RINGKASAN
EKA PUTRI NUR UTAMI. Model Aditif Terampat Vektor dengan Komponen
Utama untuk Pendugaan Curah Hujan Ekstrim (Studi Kasus: Indramayu).
Dibimbing oleh AJI HAMIM WIGENA dan ANIK DJURAIDAH.
Perubahan iklim yang terjadi beberapa tahun terakhir ini mengakibatkan terjadinya curah hujan ekstrim. Curah hujan ekstrim ini berpotensi menimbulkan banjir yang akhirnya dapat mengakibatkan gagal panen. Oleh karena itu pemodelan curah hujan diperlukan untuk meminimumkan dampak yang terjadi.
Statistical downscaling (SD) merupakan model statistik yang digunakan
untuk menduga curah hujan (berskala lokal) dengan memanfaatkan informasi dari data luaran global circulation model (GCM). Data GCM adalah data hasil simulasi komputer yang memanfaatkan kaidah fisika, kondisi lautan, dan perubahan iklim pada atmosfer bumi yang dapat digunakan untuk menduga unsur-unsur iklim saat ini ataupun di masa yang akan datang. Permasalahan yang muncul dalam metode SD adalah penentuan teknik statistika yang tepat untuk memodelkan curah hujan ekstrim.
Sebaran nilai ekstrim yang biasa digunakan dalam teori nilai ekstrim adalah
generalized extreme value (GEV) dan generalized pareto distribution (GPD).
Penggunaan sebaran GEV memiliki kelemahan yaitu akan menghilangkan banyak data amatan. Oleh karena itu diusulkan untuk menggunakan GPD.
Pemodelan yang dapat digunakan dalam SD antara lain model aditif terampat (generalized additive model/GAM) yang dapat mengatasi pengaruh nonlinier masing-masing peubah penjelas terhadap peubah respon dengan teknik pemulusan. Kekurangan dari metode ini adalah GAM hanya terbatas pada sebaran-sebaran yang termasuk ke dalam sebaran keluarga eksponensial, sedangkan GPD tidak termasuk ke dalam sebaran keluarga eksponensial. Selain itu, metode GAM hanya dapat membuat satu fungsi hubung dari parameter sebarannya. Permasalahan tersebut, diatasi dengan vector generalized additive
model (VGAM). Teknik ini merupakan perluasan dari model aditif terampat
karena VGAM yang tidak terbatas pada sebaran keluarga eksponensial. Tujuan dari penelitian ini adalah menduga curah hujan ekstrim menggunakan VGAM berdasarkan sebaran GPD di Kabupaten Indramayu.
Data curah hujan di Indramayu digunakan sebagai peubah respon dan data presipitasi GCM sebagai peubah penjelas. Data penelitian dibagi menjadi dua yaitu data tahun 1979-2007 untuk pemodelan dan data tahun 2008 sebagai validasi model. Ukuran grid data GCM yang digunakan yaitu ukuran 6 × 6 dan 8 × 8. Sifat dari data GCM yang berdimensi tinggi dan terdapat multikolinearitas diatasi dengan menggunakan analisis komponen utama.
Pemodelan VGAM dilakukan terhadap data yang lebih besar dari nilai ambang dengan menggunakan metode backfitting vector. Pemilihan nilai ambang ini dilakukan dengan menggunakan mean residual life plot (MRLP). Pemulusan data menggunakan pemulusan spline dan pemilihan derajat bebas optimum dilakukan dengan memilih nilai Akaike Information Criterion (AIC) terkecil. Pemodelan dilakukan dengan memodelkan keseluruhan bulan, dan membagi bulan dalam empat kelompok. Kelompok tersebut adalah bulan hujan, peralihan
hujan-kering, kering, dan peralihan kering-hujan. Model yang dibuat adalah model keseluruhan dan model setiap kelompok.
Hasil analisis komponen utama menghasilkan dua komponen utama untuk data grid 6 × 6 dan empat komponen utama untuk data grid 8 × 8 . Proporsi keragaman kumulatif yang dihasilkan adalah 96% untuk data ukuran grid 6 × 6 dan 95% untuk grid 8 × 8. Berdasarkan hasil MRLP diperoleh nilai ambang secara keseluruhan adalah 145. Nilai ambang untuk kelompok bulan hujan, peralihan hujan-kering, kering, dan peralihan kering-hujan berturut-turut adalah 145, 100,10 dan 45.
Hasil pemodelan VGAM pada tahap awal menunjukkan data grid 6 × 6 menghasilkan nilai root mean square error prediction (RMSEP) yang lebih rendah dibandingkan dengan data grid 8 × 8 . Oleh karena itu pada tahap selanjutnya pemodelan dilakukan dengan menggunakan data grid 6 × 6 . Secara keseluruhan hasil pendugaan curah hujan dengan metode VGAM yang berbasis GPD mampu menghasilkan pola dugaan yang mirip dengan data aktual. Penggunaaan kuantil yang berbeda untuk setiap kelompok bulan menghasilkan dugaan yang lebih baik. Kelompok bulan kering memiliki nilai dugaan yang mendekati aktual pada kuantil rendah yaitu kuantil 5 dan 10, kelompok bulan hujan pada kuantil 75, kelompok bulan peralihan hujan-kering pada kuantil 50, sedangkan pada kelompok bulan peralihan kering-hujan dugaan terbaik yaitu pada kuntil 25. Kebaikan model menunjukkan bahwa model VGAM dengan GPD menghasilkan dugaan yang konsisten meskipun panjang data dugaan ditambah, nilai RMSEP yang dihasilkan tidak jauh berbeda jika dibandingkan dengan melakukan dugaan pada satu tahun.
Kata kunci : generalized pareto distributions, model aditif terampat vektor,
SUMMARY
EKA PUTRI NUR UTAMI. Vector Generalized Additive Model with Principal
Components to Estimate Extreme Rainfall (Case Study: Indramayu). Supervised
by AJI HAMIM WIGENA and ANIK DJURAIDAH.
In the last few years, climate change happened and caused extreme rainfall. A high extreme rainfall potentially cause flooded and then impact on agricultural. Therefore modeling rainfall data needed to minimize the impact.
Statistical downscaling (SD) is a statistical model to predict rainfall data (local-scale) by using the information of global circulation model (GCM). The GCM data is a computer simulation result of a large number interaction of physics, chemistry, and dynamics of the earth’s atmosphere. GCM can be used to predict climate elements in the future. The problems for SD are to choose the methods for modeling the extreme events.
There are two distributions in extreme value theory. They are generalized extreme value (GEV) and generalized pareto distributions (GPD). Modeling based on GEV will elliminate some data, than proposed modeling with generalized pareto distributions (GPD).
One of the models used in SD is generalized additive models (GAM). The advantage of GAM is it can be solved the non-linear effects of predictor variables to responses variable by using a smoothing technique. Unfortunately, GAM are restricted to one-parameter distributions within the classical exponential family, whereas GPD is not included of exponential family. So, there are a new method to solve this problems. The methods known as vector generalized models (VGAM). The method of VGAM is claimed to be a larger framework of distribution. VGAM was an extension from generalized additive models which is not restricted for exponential family. The purpose of this research is to predict the rainfall data in Indramayu based on extreme value distribution (GPD) with VGAM technique.
This research used monthly rainfall data in Indramayu from1979 to 2008 as independent variable and precipitation from GCM as dependent variables. The data divided into two parts, first is 1979-2007 as data modeling and then 2008 as data validation. There are two size of grid for GCM data, that is 6 × 6 and 8 × 8. Principal compenent analysis used to reduce the dimention of the data and solved the multicollinearity.
Data for modeling are the rainfall data that is greater than the threshold value. The threshold values choosed by using the mean residual life plot (MRLP). The method of VGAM are estimated by vector backfitting algorithm with vector smoothing. The optimum degree of freedom from smoothing is choosed by the minimum Akaike Information Criterion (AIC). For the first step, modeling the data for all month and then modeling data for group of month. The groups are rainfall, rainfall-dry transition, dry and transition dry-rainfall.
The result of principal component analysis show that there are two components choosed for grid data 6 × 6 and four components for 8 × 8. The cumulative proportion of data variety is 96% for grid data 6 × 6 and 95% for grid data 8 × 8. Based on MRLP, the threshold value for all months is 145 and
the threshold value for group rainy, rainy-dry transition, dry and dry-rainy transition are 145, 100, 10 and 45 respectively.
For the model of all month, VGAM result shows that the model from grid data 6 × 6 have the lowest value of RMSEP than the model from grid data 8 × 8. So for the next step, modeling is use with the data from grid 6 × 6. Overall, the result show that predicted value have the same pattern with the actual data. By using different quantile for each group of month can give a better estimation than using a same quantile. Dry group have a good predicted value at quantile 5 and 10, but for the rainy group is at quantile 75. Goodness of fit model showed that VGAM based on GPD can give consistent result for different length data.
Keywords : extreme value theory, generalized pareto distribution, statistical downscaling, vector generalized additive model.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah, dan pengutipan tersebut tidak merugikan kepentingan IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini dalam bentuk apapun tanpa izin IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika
MODEL ADITIF TERAMPAT VEKTOR DENGAN
KOMPONEN UTAMA UNTUK PENDUGAAN
CURAH HUJAN EKSTRIM
(STUDI KASUS: INDRAMAYU)
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
Judul Tesis : Model Aditif Terampat Vektor dengan Komponen Utama untuk Pendugaan Curah Hujan Ekstrim (Studi Kasus: Indramayu)
Nama : Eka Putri Nur Utami NIM : G151130091
Disetujui oleh Komisi Pembimbing
Dr Ir Aji Hamim Wigena, MSc Ketua
Dr Ir Anik Djuraidah, MS Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr Ir Kusman Sadik, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji syukur penulis panjatkan kepada Allah SWT atas limpahan rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tesis yang berjudul “Model Aditif Terampat Vektor dengan Komponen Utama untuk Pendugaan Curah Hujan Ekstrim (Studi Kasus: Indramayu)”. Sesungguhnya penyelesaian tugas akhir ini semuanya adalah berkat kemudahan dan pertolongan dari-Nya.
Terima kasih penulis ucapkan kepada Bapak Dr.Ir.Aji Hamim Wigena, MSc dan Ibu Dr.Ir.Anik Djuraidah,MS selaku pembimbing, yang telah sabar membimbing penulis dalam penyusunan tesis ini. Penulis juga mengucapkan ucapan terima kasih kepada Bapak Dr.Ir.Kusman Sadik MSi sebagai dosen penguji dan Ibu Dr. Ir. Indahwati,MSi selaku dosen perwakilan prodi statistika yang telah meluangkan waktunya hadir pada sidang tesis saya.
Penulis juga mengucapkan ucapan terimakasih yang sebesar-besarnya kepada seluruh dosen departemen Statistika IPB yang telah mendidik dan memberikan ilmunya kepada penulis selama di bangku kuliah hingga berhasil menyelesaikan studi, serta seluruh staf departemen Statistika IPB atas bantuan, pelayanan, dan kerjasamanya selama ini.
Terimakasih juga kepada rekan-rekan satu grup riset downscaling, Bapak Agus M Soleh serta Shynde Limar Kinanti dan Dewi Santri atas kerjasamanya selama ini dalam penelitian downscaling sehingga penyusunan tesis ini dapat selesai dengan baik.
Ucapan terima kasih yang tulus dan penghargaan yang tak terhingga juga penulis ucapkan kepada kedua orangtua, Bapak Isman dan Ibu Nuriyah yang telah memberikan kasih sayangnya kepada penulis dan mendidik penulis dengan penuh kasih sayang. Selain itu kepada kedua adikku tersayang Lena Dwi Prestiyani dan Widiya Tri Astuti atas doa dan semangatnya.
Terakhir tak lupa penulis juga mengucapkan terima kasih kepada seluruh mahasiswa Pascasarjana departemen Statistika atas kerjasama dan kebersamaannya selama menghadapi masa-masa perkuliahan baik itu senang ataupun susah. Terimakasih karena telah menciptakan kenangan yang takkan terlupakan. Semoga tesis ini dapat bermanfaat bagi semua pihak yang membutuhkan.
Bogor, Januari 2016
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi 1 PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 2 2 TINJAUAN PUSTAKA 3 Statistical Downscaling (SD) 3Teori Nilai Ekstrim 4
Model Aditif Terampat Vektor (VGAM) 6
Model Aditif Terampat Vektor untuk Nilai Ekstrim 10
3 METODE PENELITIAN 11
Data 11
Analisis Data 11
4 HASIL DAN PEMBAHASAN 13
Eksplorasi Data 13
Penentuan Nilai Ambang 13
Pemodelan GCM 15
5 SIMPULAN DAN SARAN 25
Simpulan 25
Saran 25
DAFTAR PUSTAKA 26
LAMPIRAN 27
DAFTAR TABEL
1. Nilai akar ciri dan proporsi keragaman dari kumulatif analisis
komponen utama 15
2. Nilai AIC dari model VGAM pada beberapa derajat bebas 16
3. Nilai RMSEP untuk model awal 18
4. Hasil uji sebaran GPD dengan uji Kolmogorov-Smirnov 19 5. Nilai AIC dari model VGAM pada beberapa derajat bebas pemulus
setiap komponen utama 19
6. Penduga parameter VGAM masing-masing kelompok bulan 21 7. Nilai RMSEP data dugaan pada berbagai kuantil 23 8. Nilai RMSEP pada panjang data dugaan yang berbeda 23 9. Nilai korelasi data dugaan dengan data aktual pada pada panjang data
dugaan yang berbeda 24
DAFTAR GAMBAR
1 . Ilustrasi proses statistical downscaling 3
2 . Pola curah hujan Kabupaten Indramayu tahun 1979-2008 13
3. Grafik MRLP data curah hujan 14
4. Grafik hubungan pendugaan parameter GPD dengan
nilai ambang data curah hujan rata-rata 14
5. Pengepasan model VGAM pada data berukuran 6 × 6 17 6. Pengepasan model VGAM pada data berukuran 8 × 8 17 7. MRLP curah hujan masing-masing kelompok bulan 18 8. Pengepasan model VGAM pada model kelompok curah hujan 20 9. Grafik hasil validasi silang model terhadap data curah
hujan tahun 2008 pada kuantil atas 22
10. Grafik hasil validasi silang model terhadap data curah hujan tahun 2008
pada kuantil bawah sampai atas 22
DAFTAR LAMPIRAN
1. Plot diagnostik kecocokan data curah hujan dengan GPD 27 2. Plot curah hujan ekstrim dengan skor komponen utama terpilih 28 3. Nilai dugaan curah hujan tahun 2008 pada model awal 29 4. Grafik hubungan pendugaan parameter dengan nilai ambang pada data
curah hujan setiap kelompok bulan 32
5. Plot diagnostik untuk nilai ambang terpilih setiap kelomok bulan 33 6. Plot pemulusan pada data curah hujan rata-rata berdasarkan kelompok
bulan 35
7. Nilai aktual dan dugaan curah hujan pada model setiap kelompok bulan
1 PENDAHULUAN
Latar Belakang
Indonesia merupakan negara kepulauan yang beriklim tropis. Perubahan iklim yang terjadi beberapa tahun terakhir ini mengakibatkan terjadinya curah hujan ekstrim. Curah hujan ekstrim merupakan kondisi curah hujan yang sangat tinggi atau sangat rendah. Curah hujan ekstrim tinggi berpotensi menimbulkan banjir yang akhirnya mengakibatkan gagal panen. Oleh karena itu diperlukan pendugaan melalui suatu pemodelan untuk mengantisipasi dampak yang akan terjadi.
Penelitian mengenai pemodelan curah hujan menjadi salah satu hal penting untuk memprediksi curah hujan. Salah satu metode pemodelan curah hujan adalah dengan memanfaatan data Global Circulation Model (GCM). Menurut Wigena (2006) GCM merupakan sumber informasi primer dan dapat digunakan untuk memprediksi iklim dan cuaca secara numerik. GCM merupakan model peramalan curah hujan pada skala lokal dengan mempertimbangkan berbagai informasi atmosfer global yang disimulasikan.
Teknik statistika yang menyatakan hubungan fungsional antara peubah-peubah luaran GCM dengan peubah-peubah respon lokal dikenal dengan statistical
downscaling (SD). Peubah respon lokal yang digunakan untuk pemodelan curah
hujan adalah curah hujan daerah setempat dan data GCM sebagai peubah skala global. Pemodelan SD dengan menggunakan data GCM menyertakan peubah berdimensi besar yang saling berkorelasi, sehingga untuk mengatasi hal ini pereduksian dimensi umumnya dilakukan dengan menggunakan analisis komponen utama.
Permasalahan yang muncul dalam metode SD adalah menentukan teknik statistika yang tepat. Berbagai penelitian mengenai metode SD sudah dikaji dan menunjukkan gambaran perkembangan pemodelan SD banyak mengarah ke teknik statistika berbasis regresi parametrik, semi parametrik atau statistika nonparametrik. Penelitian mengenai pemodelan semi parametrik dilakukan oleh Rizki (2014) dan memperoleh kesimpulan bahwa pola hubungan fungsional curah hujan dengan komponen utama memiliki hubungan yang berupa gabungan parametrik dan nonparametrik yaitu semiparametrik kubik.
Penelitian mengenai curah hujan yang berbasis nilai ekstrim telah dilakukan sebelumnya. Secara umum data curah hujan tidak mengikuti sebaran normal, sehingga pemodelan baku tidak dapat dilakukan. Beberapa penelitian menyatakan bahwa curah hujan memiliki sebaran gamma. Sedangkan untuk curah hujan ekstrim, banyak pendekatan dilakukan dari teori nilai ekstrim.
Penelitian curah hujan ekstrim sudah dilakukan antara lain oleh Mondiana (2012) yang menggunakan regresi kuantil, dan Handayani (2014) yang melakukan penelitian mengenai SD untuk curah hujan berdasarkan sebaran nilai ekstrim
Generalized Extreme Value (GEV). Menurut Mallor (2009) pemilihan nilai
ekstrim dengan metode block maxima yang mengikuti sebaran GEV akan mengakibatkan hilangnya banyak data, sehingga baik digunakan jika data yang dimiliki sangat banyak. Alternatif lain dalam pemilihan nilai ekstrim adalah dengan metode peaks over threshold (POT). Nilai ekstrim yang diperoleh dari metode ini akan mengikuti sebaran generalized pareto distribution (GPD).
2
Contoh penelitian curah hujan yang berdasarkan sebaran GPD adalah Li et
al. (2005) yang mengidentifikasi curah hujan ekstrim di wilayah Australia.
Penelitian tersebut tidak menggunakan peubah penjelas dalam pemodelan curah hujan ekstrim, hanya menduga parameter-parameter GPD. Oleh karena itu penelitian kali ini akan melakukan pemodelan curah hujan ekstrim yang mengikuti sebaran GPD dengan mengikutsertakan pengaruh peubah luaran GCM. Model aditif terampat (generalized additive model/GAM) adalah suatu metode nonparametrik yang dapat digunakan untuk memodelkan data GCM. GAM merupakan generalisasi dari model linier terampat (generalized linear
model /GLM). Metode GAM mengganti bentuk linier hubungan Y dan X sebagai
suatu hubungan fungsional yang diharapkan mampu mengatasi pengaruh nonlinier terhadap peubah y (Hastie dan Tibshirani, 1986)
Kelemahan dari metode GLM dan GAM adalah peubah respon terbatas pada sebaran keluarga eksponensial, sedangkan GPD tidak termasuk kedalam keluarga eksponensial. Yee dan Wild (1996) memperkenalkan teknik model aditif terampat vektor (vector generalized aditif model/VGAM) yang merupakan perluasan dari teknik GAM, teknik ini memperluas teknik GAM ataupun GLM dalam tiga cara utama:
1. Sebaran y tidak terbatas hanya untuk keluarga eksponensial
2. Mampu mengatasi multi respon y dengan prediktor linear atau prediktor aditif
3. ηj tidak harus merupakan fungsi dari mean μ, akan tetapidapat sebagai fungsi dari parameter lainnya, yaitu ηj = gj(θj) untuk setiap parameter θj
Sehingga VGAM dapat mengatasi banyak sebaran dan model yang memungkinkan. Yee dan Wild (1996) telah mengembangkan metode VGLM/VGAM yang menjadi dasar berkembangnya metode tersebut. Salah satunya dilakukan oleh Yee dan Stephenson (2007) mengenai VGLM/VGAM untuk nilai ekstrim. Penelitian tersebut menggunakan sebaran dari teori nilai ekstrim yaitu GEV dan GPD sebagai dasar dalam pemodelanVGAM. Sehingga dalam penelitian kali ini metode tersebut akan dikaji dan diikuti namun dengan menggunakan data presipitasi dari data luaran GCM sebagai bagian dari statistical
downscaling. Teknik VGAM diharapkan mampu menduga curah hujan ekstrim
yang terjadi di wilayah Indramayu.
Tujuan Penelitian
Tujuan penelitian ini adalah menduga curah hujan ekstrim menggunakan model aditif terampat vektor berdasarkan sebaran GPD di Kabupaten Indramayu.
3
2 TINJAUAN PUSTAKA
Statistical Downscalling
Data GCM adalah data hasil simulasi komputer yang memanfaatkan kaidah fisika, kondisi lautan, dan perubahan iklim pada atmosfer bumi yang dapat digunakan untuk menduga unsur-unsur iklim saat ini ataupun di masa yang akan datang. Data yang dihasilkan GCM berupa unsur-unsur iklim dalam bentuk grid (persegi) . Setiap grid berukuran 2.5° × 2.5° dan memiliki nilai unsur-unsur iklim masing-masing. Namun, data GCM masih berskala global dan tidak cocok digunakan untuk menduga unsur-unsur iklim pada skala yang lebih kecil. Resolusi data GCM yang rendah tidak cocok digunakan sebagai penduga data berskala lokal, tetapi masih memungkinkan sebagai penduga jika menggunakan teknik downscaling.
Downscaling adalah suatu teknik transformasi hasil simulasi GCM pada
skala besar ke dalam skala yang lebih kecil. Statistical downscaling (SD) adalah proses downscaling yang memanfaatkan ilmu statistika untuk menduga data berskala lokal. SD didasarkan pada pandangan bahwa iklim regional dikondisikan oleh dua faktor yaitu iklim skala global dan kondisi fisiografi lokal yaitu curah hujan di daratan (Wilby et al. 2004). Gambar 1 menunjukkan ilustrasi dari SD.
Output dari data GCM adalah memberikan masukan untuk pemodelan statistik terhadap data daerah lokal yang berhubungan. SD dapat dimulai denganmenghubungkan variabel iklim skala global (X) dengan variabel-variabel lokal (Y). Luaran skala besar dari simulasi GCM dimasukkan sebagai input bagi model statistik tersebut untuk memperkirakan karakteristik iklim lokal atau regional yang bersangkutan. Bentuk umum dari model SD adalah:
𝐲 = f(𝐗) dengan , 𝐲 : peubah iklim lokal (curah hujan)
𝐗 : peubah GCM (presipitasi) t : banyaknya waktu (bulanan) g : banyaknya grid domain GCM
Gambar 1 Ilustrasi proses statistical downscaling
4
Teori Nilai Ekstrim
Teori nilai ekstrim (extreme value theory, EVT) merupakan salah satu cara yang dapat digunakan untuk memodelkan kejadian-kejadian ekstrim. Hal yang membedakan antara EVT dengan teknik statisktika lain adalah EVT bertujuan untuk menghitung pola stokastik dari amatan yang sangat besar atau sangat kecil dibandingkan dengan amatan lain. Analisis nilai ekstrim biasanya memerlukan pendugaan dari sebaran amatan yang lebih ekstrim dari yang sudah diamati (Coles 2001).
Model EVT didasarkan pada kejadian-kejadian ekstrim. Misalkan peubah acak Y1, Y2… , Yn yang bebas stokastik identik dengan sebaran F maka EVT didasarkan pada nilai Mn yaitu
Mn = maks{Y1, … , Yn}
Sebaran Mn pada teori dapat diturunkan dengan mudah jika sebaran Yi diketahui. Pemilihan kejadian ekstrim terdiri dari dua cara, pertama memilih kejadian ekstrim dalam suatu blok atau yang dikenal dengan block maxima sehingga data mengikuti sebaran generalized extreme value distribution (GEV). Fungsi sebaran GEV adalah sebagai berikut :
F(y) = exp {− [1 + ξ (y − μ σ )]
−1ξ
} dengan x ∶ 1 + ξ (y−µ
σ ) > 0, -∞ < µ < ∞, σ > 0 dan -∞ < ξ < ∞, dalam model ini ξ, σ, dan µ berturut-turut adalah parameter bentuk, skala, dan lokasi.
Kelemahan dari metode blok maxima adalah keharusan membagi data ke dalam ukuran blok yang sama. Selain itu pemilihan nilai maksimum dari setiap blok akan mengakibatkan hilangnya banyak data amatan. Oleh karena itu metode kedua yang digunakan untuk menentukan kejadian ekstrim adalah dengan menentukan nilai ambang u dan dikenal dengan metode pemilihan nilai ambang (peaks over threshold/POT) . Metode POT ini akan mengakibatkan data mengikuti sebaran generalized pareto distribution (GPD). Kejadian-kejadian ekstrim didefinisikan sebagai data Y yang lebih besar dari u. Dalam terminologi kejadian ekstrim Y − u disebut excesses (Yee 2007).
Fungsi sebaran (Y − u) untuk Y > u didekati dengan fungsi berikut yang dikenal dengan sebaran pareto terampat (generalized pareto distribution/GPD).
G(y) = {1 − (1 + ξy σ) − 1ξ , ξ ≠ 0 1 σ− exp ( −y σ) , ξ = 0
dan fungsi kepekatan GPD:
g (y) = { 1 σ(1 + ξy σ) − 1ξ−1 , ξ ≠ 0 1 σexp ( −y σ) , ξ = 0 (1)
5 dalam model ini ξ adalah parameter bentuk, dan σ adalah parameter skala. Sebaran GPD akan menjadi bentuk pareto jika nilai ξ > 0 . Hubungan antara sebaran GPD dengan pareto dapat diturunkan sebagai berikut:
jika ξ > 0 maka 𝜇 = 𝜎 𝜉 g (y) = 1 𝜎 (1 + 𝜉(𝑋−𝜇) 𝜎 ) −1 𝜉 −1 = 1 𝜎 (1 + 𝜉(𝑋−𝜎 𝜉) 𝜎 ) −1 𝜉 −1 = 1 𝜎 (1 + 𝜉𝑋 𝜎 − 1) −1 𝜉 −1 = 1 𝜎 ( 𝜉 𝜎) −1 𝜉 −1 𝑋 −1 𝜉 −1 = 1 𝜉 ( 𝜎 𝜉) 1 𝜉 𝑋( 1 𝑝+1) = 1 𝜉 ( 𝜎 𝜉) 1 𝜉 𝑋( 1 𝑝+1)
Sehingga fungsi kepekatan pareto adalah: h (y) = 𝛼𝛽 𝛼 𝑋(𝛼+1) dengan 1 𝜉= 𝛼 dan 𝜎
𝜉 merupakan parameter dari sebaran pareto.
Penentuan nilai ambang u pada GPD dapat ditentukan dengan berbagai cara salah satunya adalah dengan menggunakan mean residual life plot (MRLP). Pemilihan nilai ambang dengan menggunakan MRLP dianalogikan seperti menentukan ukuran blok yang akan dipilih sehingga ada keseimbangan antara bias dan keragaman. Nilai ambang yang terlalu rendah mengakibatkan pendekatan dari model yang gagal atau parameter yang diduga bias meskipun ragamnya kecil sedangkan nilai ambang yang terlalu tinggi akan mengakibatkan jumlah nilai
excesses yang diamati sedikit sehingga mengakibatkan keragaman yang tinggi.
Prosedur untuk menentukan nilai ambang ini dapat dilakukan dengan cara membentuk MRLP. Titik plot (X, Y) dalam MRLP ditentukan berdasarkan:
{(u , 1
nu∑ (y(i)− u)
nu
i=1 ) ∶ u < ymaks}
dengan y(1), … . , y(nu) adalah observasi sebanyak nu yang melebihi nilai u dan ymaks adalah nilai terbesar dari Yi. Interpretasi dari MRLP tidak selalu mudah dan sedikit subjektif. Nilai ambang batas yang dipilih adalah nilai yang berada diatas nilai dimana plot mendekati linear terhadap u ( Mallor et al. 2009).
Pendugaan parameter dari sebaran GPD dapat dilakukan dengan menggunakan metode kemungkinan maksimum. Jika terdapat y1, … , yk adalah k
6
banyaknya pengamatan yang melebihi nilai ambang u. Untuk ξ ≠ 0 fungsi log-kemungkinan didapatkan dari persamaan (1) menjadi
ℓ ( σ, ξ ) = −k log σ − ( 1 + 1 ξ ) ∑ log( 1 + ξyi σ k i=1 ) dengan syarat ( 1 + 𝜉𝑦𝑖
𝜎 ) > 0 untuk i= 1, ...,k . Maksimisasi dari fungsi log-kemungkinan tersebut dibutuhkan teknik analisis numerik, dan salah satu analisis numerik yang digunakan adalah metode Newton Raphson.
Model Aditif Terampat Vektor
Regresi linear klasik memerlukan asumsi bahwa peubah respon mengikuti sebaran Normal. Kenyataannya, banyak ditemukan peubah respon yang tidak mengikuti sebaran Normal. Oleh karena itu dikembangkan suatu metode yang dapat mengatasi peubah respon yang tidak menyebar normal yaitu model linier terampat (generalized linear model/GLM). Regresi linear, regresi Poisson, regresi logistik, analisis probit dan beberapa model lainnya dapat diperlakukan sebagai kasus dari GLM. Peningkatan yang utama dari GLM dibandingkan regresi linear adalah kemampuan untuk mengatasi kelas sebaran peubah respon yang lebih besar tetapi masih termasuk ke dalam keluarga eksponensial.
Terdapat tiga komponen utama dalam GLM yaitu (McCullagh dan Nelder 1983):
1. Komponen acak: komponen acak adalah peubah respon Y. Dalam model linier terampat peubah respon diasumsikan mengikuti sebaran keluarga eksponensial.
2. Komponen sistematik: komponen sistematik adalah kombinasi linier dari x1, x2, … , xp. Sehingga dapat dituliskan sebagai berikut:
η = ∑pi=1βiXi
η disebut juga sebagai penduga linier atau linear predictor dan βi adalah konstanta.
3. Fungsi hubung: yaitu fungsi yang menghubungkan antara komponen acak dengan komponen sistematik. Misalkan E (y) = μ selanjutnya dapat dibuat hubungan
g(μ) = η = ∑pi=1βiXi
Fungsi hubung η yang berpola linier memiliki keterbatasan yaitu tidak mampu mengatasi hubungan nonlinier antara peubah respon dengan peubah bebas. Oleh karena itu dikembangkan model aditif terampat atau generalized
additive models (GAM) sebagai model semi-parametrik yang dapat mengatasi
pengaruh tidak linier peubah respon. GAM merupakan bentuk aditif dari model GLM dengan mengubah bentuk linier dari ∑(βixi) menjadi penjumlahan hubungan fungsional fj(. ) antara peubah bebas dengan peubah respon yang dimodelkan secara nonparametrik dengan suatu fungsi pemulus (Hastie dan Tibshirani 1987). Bentuk umum model GAM adalah sebagai berikut:
η = β0+ ∑mj=1fj(Xk)
Batasan dalam metode GLM/GAM yaitu metode ini hanya dapat memodelkan satu parameter dari sebarannya. Contohnya pada model linier, peubah respon Y diasumsikan mengikuti sebaran Normal (𝜇, 𝜎2) dengan fungs
7 hubung η1 = μ = 𝛃i T𝑥. Teori standar GLM/GAM memperlakukan parameter σ sebagai skala.
Yee dan Wild (1996) mengusulkan suatu metode yang lebih luas yang mampu memodelkan lebih dari satu parameter dan tidak terbatas hanya pada keluarga eksponensial. Metode ini dikenal dengan vector generalized linear model (VGLM) dan vector generalized additive model (VGAM). VGLM/VGAM merupakan perluasan dari model GLM/GAM dengan mengikutsertakan lebih dari satu prediktor aditif ( η ) (Mackenzie dan Yee 2002). Banykanya prediktor aditif ( η ) yang dapat diikutseratkan maksimal sebanyak jumlah parameter dari sebaran yang digunakan. Sehingga VGLM/VGAM diklaim berpotensial untuk menangani berbagai model dari bermacam-macam sebaran.
Bentuk umum dari VGLM adalah sebagai berikut:
f(𝐲|𝐱; 𝐁) = h(𝐲, η1, … , ηm) (2)
m adalah banyaknya parameter dalam sebaran yang digunakan. dengan 𝐁 = (𝛃1,T… , 𝛃m,T )T dan 𝛃
i T = ( β
(1)1… β(1)p) dan
η(j)= η(j)(x) = β0j+ β1(j) x1+ ⋯ + βj(p) xp = β0j+ ∑pk=1βk(j)xk (3) Persamaan (3) dalam bentuk umum VGAM berubah menjadi
ηj(𝐱) = β(j)0+ f(j)1 x1+ ⋯ + f(j)p xp= β(j)0+ ∑pk=1f(j)k(xk) (4) Model dalam persamaan (2) , dapat dibuat menjadi bentuk log-kemungkinan
ℓ(𝛃) = ∑ni=1𝓵i{η1(𝐱1), … , ηm(𝐱i)}
dengan η(j) = η(j)(𝐱) = 𝛃jT𝐱k. Nilai 𝐔(β) = ϑℓ ϑβ⁄ menunjukkan skor vektor untuk model dan ℐ(𝛃) = −ϑ2ℓ(𝛃)⁄ϑ𝛃 ϑ𝛃T adalah matriks informasi. Algoritma Newton-Raphson untuk memaksimalkan log-kemungkinan adalah
𝛃(a) = 𝛃(a−1)+ ℐ(𝛃(a−1))−1 𝐔 (𝛃(a−1))
Untuk setiap iterasi a. dapat dituliskan dalam bentuk iterasi kuadrat terkecil terboboti yang pertama kali diperkenalkan oleh Green (1984):
𝛃(a) = (∑ni=1𝐗iT𝐖𝑖(𝑎−1)𝐗i) −1
(∑𝐧𝐢=𝟏𝐗𝐢𝐓𝐖𝑖(𝑎−1)𝐳i)
dengan 𝐖i adalah matriks berukuran m × m dengan element (j, k) (𝐖i)jk = −
ϑ2ℓi ϑηjϑηk
Persamaan (4) merupakan penjumlahan fungsi pemulusan dari peubah bebas yang diduga secara simultan. Proses pemulusan dalam model aditif terampat merupakah langkah penting dalam proses pendugaan. Pada metode GAM, pemulusan dilakukan dengan pemulusan spline. Oleh karena itu pada metode VGAM pemulusan dilakukan dengan menggunakan pemulusan vektor spline. Fungsi pemulusan vektor f(x) yang dituliskan (f1(x), … , fM(x) )T dapat diduga dengan meminimumkan jumlah kuadrat terpenalti, yaitu:
8
∑ni=1{𝐲i− 𝐟 (xi) }T∑ {𝐲i−1 i− 𝐟 (𝐱i)}+ ∑mj=1λj∫ fj′′(t)2 dt (5)
Pada persamaan (5), Σi adalah matriks ragam peragam galat yang bersifat definit positif. Setiap komponen dari fungsi fj memiliki parameter non-negatif pemulusan λj. Seperti halnya pada spline, persamaan (5) dapat diubah ke dalam suatu nilai dari vektor fungsi f pada observasi nilai x. Jika 𝑥1 < 𝑥2 < ⋯ < 𝑥𝑛 , 𝐲 = (𝐲1T, … , 𝐲nT )T , 𝐟 = (f
1(x1), … , fm(x1), … , f1(xn), … , fm(xn)) T
dan 𝚺 = diag (𝚺1, … , 𝚺n). Maka kriteria jumlah kuadrat terpenalti pada persamaan (5)
sama dengan
(𝐲 − 𝐟)T𝚺−1 (𝐲 − 𝐟) + 𝐟T𝐊𝐟
dan 𝐊 = (𝐐𝐓−1𝐐T) ⨂ diag (λ1, … , λM) . Elemen-elemen dari matriks T dan Q adalah sebagai berikut:
(𝐐)𝑖𝑖= hi−1 (𝐐)𝑖+1,𝑖= −(hi−1+ hi+1−1 (𝐐)i+2,i= −(hi+1−1) (𝐓)𝑖𝑖= ( hi+ hi+1) 3⁄ (𝐓)𝑖,𝑖−1 = (𝐓)𝑖,𝑖+1 = hi⁄ 6 hi= xi+1− xi untuk i= 1,…., n-1
Pendugaan VGLM dan VGAM
Pendugaan VGLM dilakukan dengan menggunakan metode iteratively
reweighted least square dengan algoritma sebagai berikut:
1. Bentuk matriks 𝐗VLM dari 𝐗LM dan 𝐇1, … , 𝐇p 𝐗LM ≡ 𝐗 = (𝒙𝟏, … , 𝒙𝒏)𝑻
𝐗VLM= 𝐗LM ⊗ 𝐈M
Sedangkan 𝐇p adalah matriks kendala dengan elemen 0 dan 1. Penentuan nilai ini berdasarkan fungsi hubung yang ditetapkan.
2. Inisialisasi : a = 1 dan tentukan 𝛈i(0)dari 𝛃(0) atau 𝛍(0) 3. Jika diperlukan hitung 𝛍i(0), ℓ(0), definisikan 𝛃(0)
ℓ(𝛃) = ∑ni=1𝓵i{η1(𝐱1), … , ηM(𝐱i)}
4. Hitung turunan pertama dan kedua 𝒖𝑖(0) dan 𝐖i(0) (𝐮𝐢)𝐣= ϑℓ ϑη j ⁄ (𝐖i)jk = − ϑ 2ℓ i ϑηjϑηk 5. Hitung 𝐳(0)= (𝐳 1(0)T, … , 𝐳n(0)T) T dengan fungsi: 𝐳i(0)= 𝛈i(0)+ (𝐖i(0))−1𝐮i(0) 6. Setelah itu
(a). Regresikan 𝐳(a−1) terhadap 𝐗
9
W(a−1) = diag (w
1W1
(a−1)
, … , wnWn(a−1)) untuk menghasilkan 𝛃(a)
𝐳∗∗(a−1)= 𝐗VLM∗∗(a−1) 𝛃(a)+ ε∗∗(a−1)
𝐗VLM ≡ 𝐗LM⊗ 𝐈M = (𝐗1T, … , 𝐗nT)T (b) Tentukan η(a) = 𝐗VLM 𝛃(a)
(c). Hitung 𝛍i(a), 𝓵(a) dari 𝛈(a)
(d). Uji kekonvergenan, konvergen jika 𝓵(a)− 𝓵(a−1) < ε
(e). Jika tidak konvergen dan a < iterasi maksimum , maka: a = a + 1 kemudian hitung 𝐮i(a−1), 𝐖i(a−1) dan
𝐳i(a−1) = 𝛈i(a−1)+ (𝐖i(a−1)) −1 𝐮i(a−1)
7. Simpan a, 𝛈(a) , 𝛍(a), 𝛃(a) sebagai penduga akhir
Seperti halnya GAM, metode VGAM dilakukan dengan menggunakan algoritma backfitting. Pada prosedur lebih dari satu kovariate, algoritma
backfitting dapat diaplikasikan terhadap peubah bebas terkoreksi zi dengan
menggunakan vektor pemulus. Istilah ini disebut sebagai algoritma backfitting vektor (Yee & Wild 1996).
Metode pendugaan VGAM menggunakan algoritma vektor backfitting yang diaplikasikan terhadap zi dapat dituliskan sebagai berikut:
Inisialisasi:
𝛃0 = rata − rata {𝐳1, . . . , 𝐳n} dan 𝐟k(0)= 0 , k= 1, . . .,p 𝐳i adalah peubah bebas terkoreksi, 𝐳i = 𝐗i𝛃(a+1)+ 𝐖
i−1𝐝i
di adalah elemen ke j dari (𝐝i)j = ϑℓi⁄ϑηj dan (𝐖i)jk = −
ϑ2ℓi
ϑηjϑηk
Iterasi untuk β=1,2…
(a) Iterasikan untuk k=1,….p
(i) Hitunglah fungsi vektor 𝐟k∗ sebagai fungsi vektor bobot penghalus dari observasi (xik, 𝐳i(k)) dan (bobot Wi), i=1, . . ., n
∑ {𝐳i− 𝐟k(xik)}T𝐖 i {𝐳i− 𝐟k(xik)} + n i=1 ∑mj=1λ(j)k ∫ f(j)k′′ (t)2 dt dengan 𝐟k(xik) = (𝐟(1)k(xik) … … . , 𝐟M(xik)) T .
(ii) Duga intersep β0 = β0+ rata − rata {𝐟k∗(𝐱ik), … . 𝐟k∗(𝐱
nk)}
(iii) Duga 𝐟k(b)(xik) = 𝐟k∗(xik) − rata − rata {𝐟k∗(xik), … . 𝐟k∗(xnk)} (b) Berhenti jika perbedaan antara 𝐟(b−1) dengan 𝐟(b) kecil.
Pada iterasi diatas 𝐳i(k) adalah penyesuaian dari zi sehingga efek dari semua peragam kecuali ke-k dihilangkan. Penyesuaian β0 dibutuhkan untuk memudahkan identifikasi.
10
Proses pemulusan dalam model aditif terampat merupakah langkah penting dalam proses pendugaan. Derajat bebas dari fungsi pemulus mengukur banyaknya pemulusan yang dilakukan. Berdasarkan Yee (2015), derajat bebas didefinisikan sebagai teras dari matriks A, df = teras (𝐀) dan A didefinisikan sebagai berikut:
𝐀(λ) = (𝐈nM+ ∑𝐊)−1
Matriks K adalah matriks penalti yang sudah didefinisikan sebelumnya dan ∑ merupakan matriks ragam peragam galat. Besarnya pemulusan yang dapat dilakukan adalah 2 sampai n. Semakin besar derajat bebas artinya semakin banyak pemulusan yang dilakukan.
VGAM untuk Nilai Ekstrim
Analisis VGAM dengan sebaran GPD akan memiliki dua penduga sesuai dengan jumlah parameter dalam fungsi sebaran. Model VGAM GPD dapat dituliskan sebagai berikut (Yee & Stephenson, 2007)
log σ ( x) = η1 = β(1)+ f1(x1) + f2(x2) + ⋯ + fk(xk) (6) log (ξ + 1
2 ) = η2 = β2 (7)
Nilai dugaan dari VGAM GPD pada persentil-p adalah sebagai berikut: yp = μ + σ
ξ [(1 − p)
−ξ− 1]
dengan nilai σ dan ξ yang diperoleh dari persamaan (6) dan (7), sedangkan p adalah besarnya persentil.
11
3 METODE PENELITIAN
Data
Data yang digunakan adalah data curah hujan bulanan Kabupaten Indramayu dari tahun 1979 sampai dengan 2008 sebagai peubah respon dan data GCM presipitasi sebagai peubah bebas. Data luaran GCM yang digunakan berasal dari Climate Model Intercomparison Project (CIMP5) dan diperoleh dari http://climexp.knmi.nl.
Keterbatasan penelitian ini adalah data curah hujan lokal yang digunakan hanya sampai tahun 2008. Hal ini dikarenakan adanya program dari BMKG pada tahun tersebut sehingga data sampai tahun 2008 dapat dipertanggungjawabkan. Selain itu alasan lainnya adalah dikarenakan agar dapat membandingkan dengan penelitian-penelitian yang sudah dilakukan sebelumnya.
Berdasarkan Wigena (2006) ukuran grid yang digunakan adalah 8 × 8. Penelitian kali ini akan mencoba ukuran lain yaitu 6 × 6 , dengan alasan korelasi antar grid pada ukuran grid tersebut lebih tinggi. Posisi wilayah untuk data grid 8 × 8 adalah 1.25 – 18.75 LS sampai 98.75 – 118.75 BT. Sedangkan posisi wilayah untuk data grid 6 × 6 adalah 1.25 – 11.25 LS sampai 101.25 – 113.75. Data yang dihasilkan GCM berupa grid-grid berdasarkan garis lintang dan garis bujur dengan ukuran 2.5°(±300 km).
Analisis Data
1. Eksplorasi Data
a. Deskripsi data curah hujan dengan membuat diagram kotak garis data curah hujan berdasarkan bulan amatan untuk melihat pola curah hujan yang terjadi.
b. Mengidentifikasi data curah hujan ekstrim dengan menentukan nilai ambang melalui MRLP.
c. Melakukan uji kesesuaian sebaran dengan menggunakan uji Kolmogorov-Smirnov. Pengujian ini dilakukan dengan menyesuaikan fungsi sebaran empirik curah hujan lokal yang diatas nilai ambang Fn(y) dengan sebaran teoritis tertentu F0(y) dengan hipotesis:
H0 : Fn(y) = F0(y) ( data mengikuti sebaran GPD )
H1 : Fn(y) ≠ F0(y) ( data tidak mengikuti sebaran GPD ) Fn(y) adalah fungsi sebaran kumulatif tertentu.
Statistik uji Kolmogorov-Smirnov ini adalah D-hitung = sup | Fn(y) - F0(y)|
Untuk mendapatkan kesimpulan maka D-hitung dibandingkan dengan tabel ( D1-α ) pada tabel Kolmogorov Smirnov.
2. Data GCM
a. Mereduksi data GCM yang bersesuaian dengan analisis komponen utama (AKU), dengan langkah-langkah sebagai berikut:
i. Sekumpulan data GCM berukuran p × p, dengan p = 6 dan 8 ii. Menghitung matriks ragam peragam atau matriks korelasi A
iii. Menghitung nilai akar ciri dengan menggunakan persamaan |𝐀 − λ𝐈| iv. Menghitung skor komponen utama (KU) dari setiap akar ciri, yaitu
𝐲i = a′i𝐗 , dengan ai′ adalah vektor ciri.
12
b. Melihat pola sebaran skor KU sebagai peubah penjelas (x) dengan peubah respon curah hujan (y)
3. Pemodelan
Pemodelan dilakukan dengan membagi dua data menjadi data untuk pemodelan sampai tahun 2007 dan data tahun 2008 untuk validasi model. Selanjutnya menghitung rata-rata curah hujan bulanan dari 15 stasiun. Nilai rata-rata inilah yang menjadi peubah respon dalam pemodelan. Tahap pemodelan adalah sebagai berikut:
a. Menentukan derajat bebas pemulus pada peubah yang mempunyai hubungan nonlinear dengan pemulusan vektor spline dan nilai
akaike information criterion (AIC)
AIC = 2k − 2 ln 𝐿
b. Menduga fungsi fj pada model ηj dengan menggunakan algoritma
backfitting vector.
c. Melakukan prediksi dengan menggunakan data validasi dan model yang sudah dibentuk. Nilai dugaan curah hujan dapat dirumuskan: yp = μ + σ
ξ [(1 − p)
−ξ− 1]
dengan p adalah besarnya kuantil. Penelitian kali ini menggunakan kuantil yang berbeda untuk setiap kelompok bulan, yaitu;
i. Bulan hujan: 75, 90,95
ii. Bulan peralihan hujan-kering: 25, 70, 75 iii. Bulan kering: 5, 10, 25
iv. Bulan peralihan kering-hujan: 10, 25, 50 4. Validasi dan Kebaikan model
Validasi dan kebaikan model dilakukan untuk memilih model terbaik yang sudah dibuat. Validasi ini dilakukan dengan cara menghitung korelasi dan nilai root mean square error of prediction (RMSEP). Korelasi antara nilai dugaan dan nilai aktul digunakan untuk melihat kesamaan pola dugaan. Semakin mendekati satu artinya data dugaan dan data aktual memiliki hubungan yang kuat dan memiliki pola yang sama. Rumus korelasi adalah sebagai berikut:
2 1 1 2 2 1 1 2 1 1 1 ˆ ˆ ˆ ˆ n i i n i i n i i n i i n i i n i i n i i i y y n y y n y y y y n rSelain itu nilai RMSEP digunakan untuk melihat rata-rata eror antara data dugaan dengan data aktual. Semakin kecil nilai RMSEP artinya semakin kecil selisih antara nilai dugaan dengan nilai aktual artinya, model yang dibangun semakin baik. Rumus dari RMSEP adalah:
RMSEP = √1 n ∑ (yi− ŷ )i n i=1 2
13
4 HASIL DAN PEMBAHASAN
Eksplorasi Data
Eksplorasi data dilakukan sebagai informasi awal untuk mengetahui karakteristik curah hujan di Indramayu. Deskriptif statistik menunjukkan bahwa rata-rata curah hujan di Kabupaten Indramayu pada tahun 1979 sampai 2008 adalah 123 mm dengan curah hujan minimum yaitu 0 dan curah hujan maksimum mencapai 583 mm. Nilai simpangan baku sebesar 110 mm menggambarkan keragaman data curah hujan yang cukup besar.
Gambar 2 menunjukkan gambaran curah hujan di Kabupaten Indramayu yang berpola monsun. Pola monsun adalah pola curah hujan yang membentuk huruf U atau dapat dikatakan memiliki satu puncak musim hujan. Pola curah hujan pada Kabupaten Indramayu memiliki puncak curah hujan pada bulan Januari dan berada pada nilai terendah sekitar bulan Agustus. Rata-rata curah hujan bulan Januari yaitu sebesar 308 mm, sedangkan rata-rata curah hujan bulan Agustus adalah 16 mm. Berdasarkan Gambar 2 dapat dilihat bahwa terjadi kejadian ekstrim pada beberapa bulan yaitu Februari, Juli, Agustus, September, November dan Desember.
Gambar 2 Pola Curah hujan Kabupaten Indramayu tahun 1979 – 2008
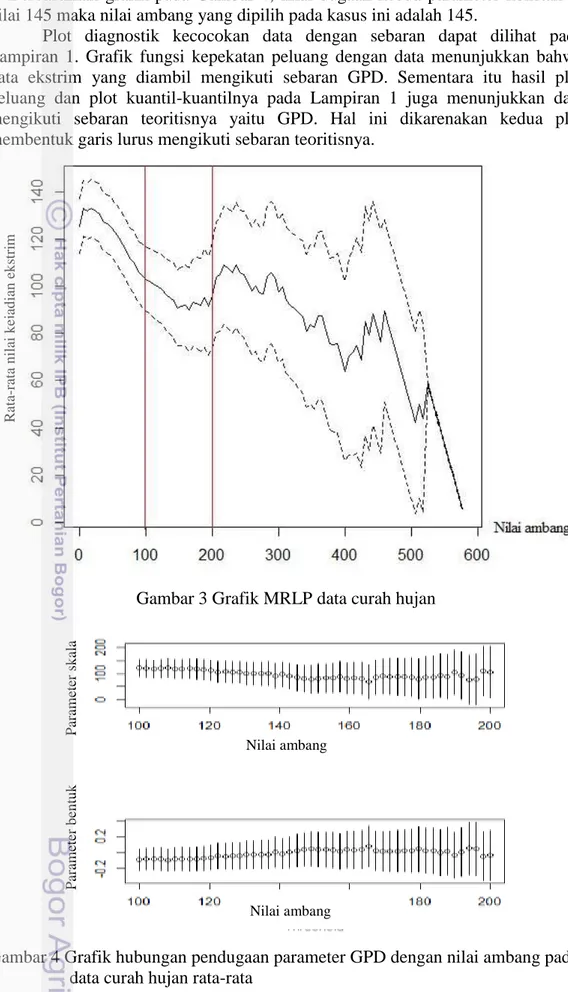
Penentuan Nilai Ambang
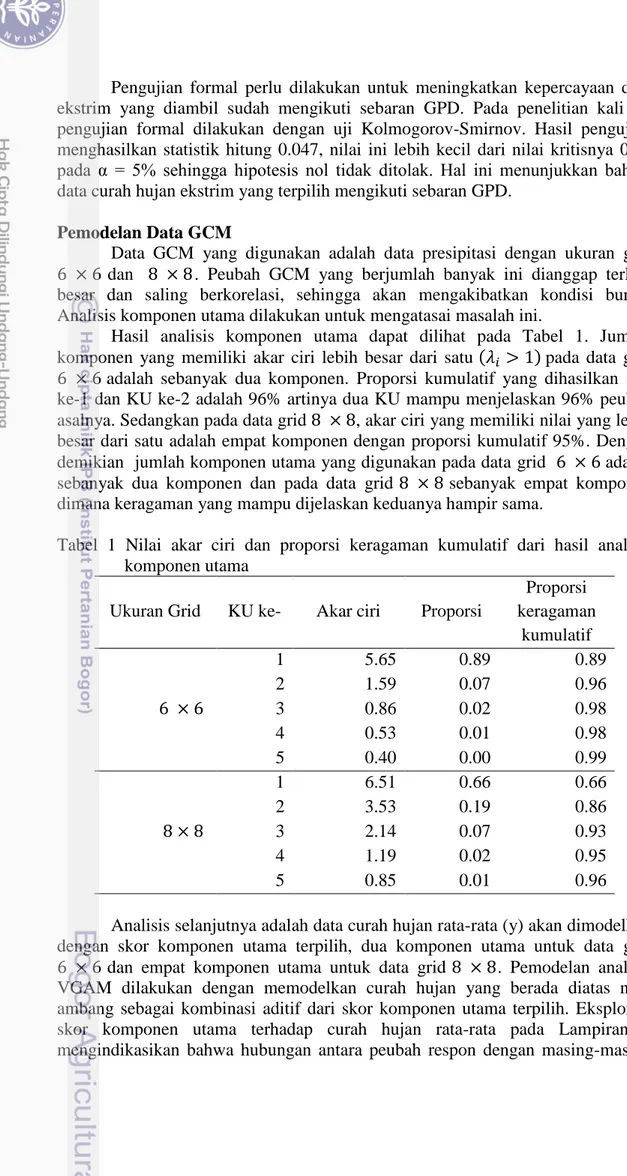
Identifikasi curah hujan ekstrim dilakukan dengan menentukan nilai ambang (u) dengan menggunakan MRLP. Gambar 3 adalah hasil MRLP untuk curah hujan rata-rata di Kabupaten Indramayu. Nilai ambang dipilih dengan cara melihat pola grafik yang membentuk garis lurus atau linier terhadap u. Ketika pola grafik sudah tidak beraturan maka nilai ambang dipilih pada titik awal terjadinya perubahan pola tersebut. Pada Gambar 3 terlihat pola mulai konstan di titik 100 dan mulai terjadi perubahan di titik antara 100 dan 200 seperti yang ditunjukkan pada garis putus-putus. Selanjutnya untuk menentukan titik nilai ambang digunakan grafik range pendugaan parameter dengan nilai ambang pada Gambar
14
4. Berdasarkan grafik pada Gambar 4, nilai dugaan kedua parameter konstan di nilai 145 maka nilai ambang yang dipilih pada kasus ini adalah 145.
Plot diagnostik kecocokan data dengan sebaran dapat dilihat pada Lampiran 1. Grafik fungsi kepekatan peluang dengan data menunjukkan bahwa data ekstrim yang diambil mengikuti sebaran GPD. Sementara itu hasil plot peluang dan plot kuantil-kuantilnya pada Lampiran 1 juga menunjukkan data mengikuti sebaran teoritisnya yaitu GPD. Hal ini dikarenakan kedua plot membentuk garis lurus mengikuti sebaran teoritisnya.
Gambar 3 Grafik MRLP data curah hujan
Gambar 4 Grafik hubungan pendugaan parameter GPD dengan nilai ambang pada data curah hujan rata-rata
R ata -r ata n ilai k ejad ian ek str im Par am eter s k ala Par am eter b en tu k Nilai ambang Nilai ambang
15 Pengujian formal perlu dilakukan untuk meningkatkan kepercayaan data ekstrim yang diambil sudah mengikuti sebaran GPD. Pada penelitian kali ini pengujian formal dilakukan dengan uji Kolmogorov-Smirnov. Hasil pengujian menghasilkan statistik hitung 0.047, nilai ini lebih kecil dari nilai kritisnya 0.11 pada α = 5% sehingga hipotesis nol tidak ditolak. Hal ini menunjukkan bahwa data curah hujan ekstrim yang terpilih mengikuti sebaran GPD.
Pemodelan Data GCM
Data GCM yang digunakan adalah data presipitasi dengan ukuran grid 6 × 6 dan 8 × 8. Peubah GCM yang berjumlah banyak ini dianggap terlalu besar dan saling berkorelasi, sehingga akan mengakibatkan kondisi buruk. Analisis komponen utama dilakukan untuk mengatasai masalah ini.
Hasil analisis komponen utama dapat dilihat pada Tabel 1. Jumlah komponen yang memiliki akar ciri lebih besar dari satu (𝜆𝑖 > 1) pada data grid 6 × 6 adalah sebanyak dua komponen. Proporsi kumulatif yang dihasilkan KU ke-1 dan KU ke-2 adalah 96% artinya dua KU mampu menjelaskan 96% peubah asalnya. Sedangkan pada data grid 8 × 8, akar ciri yang memiliki nilai yang lebih besar dari satu adalah empat komponen dengan proporsi kumulatif 95%. Dengan demikian jumlah komponen utama yang digunakan pada data grid 6 × 6 adalah sebanyak dua komponen dan pada data grid 8 × 8 sebanyak empat komponen dimana keragaman yang mampu dijelaskan keduanya hampir sama.
Tabel 1 Nilai akar ciri dan proporsi keragaman kumulatif dari hasil analisis komponen utama
Ukuran Grid KU ke- Akar ciri Proporsi
Proporsi keragaman kumulatif 6 × 6 1 5.65 0.89 0.89 2 1.59 0.07 0.96 3 0.86 0.02 0.98 4 0.53 0.01 0.98 5 0.40 0.00 0.99 8 × 8 1 6.51 0.66 0.66 2 3.53 0.19 0.86 3 2.14 0.07 0.93 4 1.19 0.02 0.95 5 0.85 0.01 0.96
Analisis selanjutnya adalah data curah hujan rata-rata (y) akan dimodelkan dengan skor komponen utama terpilih, dua komponen utama untuk data grid 6 × 6 dan empat komponen utama untuk data grid 8 × 8. Pemodelan analisis VGAM dilakukan dengan memodelkan curah hujan yang berada diatas nilai ambang sebagai kombinasi aditif dari skor komponen utama terpilih. Eksplorasi skor komponen utama terhadap curah hujan rata-rata pada Lampiran 2 mengindikasikan bahwa hubungan antara peubah respon dengan masing-masing
16
peubah penjelas ada yang tidak linear, hal ini terlihat dari sebaran data yang membentuk pola tidak linear.
Penelitian kali ini terdiri dari beberapa alternatif model untuk memperoleh model yang paling baik. Model pertama adalah model dasar tanpa dummy, model kedua adalah model dengan menambahkan satu peubah dummy (1 untuk bulan hujan dan 0 untuk bulan kering), dan model ketiga adalah model dengan empat kategori (hujan, peralihan hujan-kering, kering dan peralihan kering-hujan).
Model aditif terampat menggunakan pemulusan dan teknik pemulusan yang digunakan dalam model ini adalah pemulusan vektor spline. Banyaknya pemulusan yang dilakukan ditunjukkan dengan besarnya derajat bebas. Semakin besar derajat bebas maka pemulusan yang dilakukan semakin banyak.
Penentuan derajat bebas dilakukan dengan membuat model semua kemungkinan derajat bebas pada setiap komponen dari 2 sampai banyaknya observasi. Derajat bebas terbaik adalah model yang memiliki nilai AIC paling kecil dibandingkan dengan derajat bebas yang lain. Nilai AIC setiap model dapat dilihat pada Tabel 2. Berdasarkan hasil tersebut pada data grid 6 × 6, derajat bebas yang dipilih untuk KU1 adalah 9 dan 7 untuk KU2, sedangkan untuk data grid 8 × 8 derajat bebas yang dipilih untuk KU1, KU2, KU3, dan KU4 berturut-turut adalah 9, 3, 2 dan 4.
Tabel 2 Nilai AIC dari model VGAM pada beberapa derajat bebas derajat
bebas
Grid 6 × 6 Grid 8 × 8
KU1 KU2 KU1 KU2 KU3 KU4
2 1410.91 1405.08 1416.89 1405.95 1398.11 1414.23 3 1410.40 1403.45 1417.17 1405.11 1398.73 1411.60 4 1408.92 1402.81 1416.67 1405.68 1398.81 1410.36 5 1407.50 1402.20 1416.14 1406.03 1398.80 1410.38 6 1406.65 1401.76 1415.78 1406.24 1398.86 1410.72 7 1406.26 1401.66 1415.44 1406.32 1399.10 1410.96 8 1406.16 1401.89 1415.18 1406.33 1399.56 1411.05 9 1406.15 1402.32 1415.12 1406.33 1400.19 1411.08 10 1406.16 1402.83 1415.33 1406.42 1400.92 1411.17
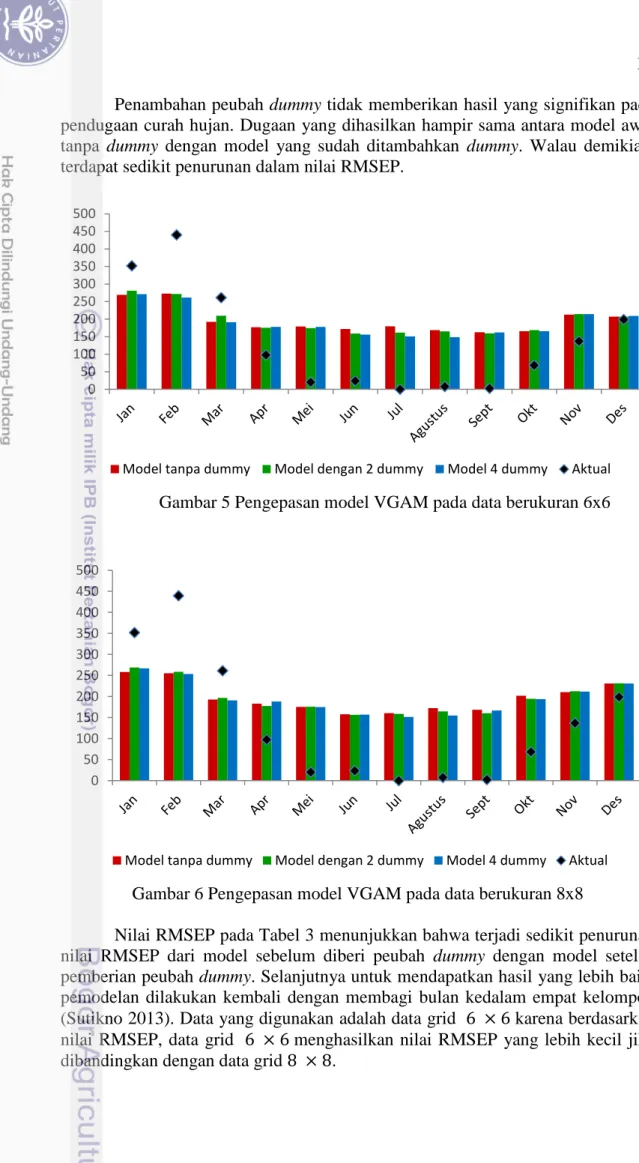
Pengepasan model terhadap data 2008 dilakukan dengan menggunakan kuantil ke 50. Hasil pengepasan untuk masing-masing grid 6 × 6 dan 8 × 8 ditampilkan pada Gambar 5 dan Gambar 6. Berdasarkan kedua gambar tersebut, terlihat bahwa pola dugaan curah hujan data grid 6 × 6 dan 8 × 8 hampir sama. Pada kedua data terlihat bahwa hasil nilai dugaan curah hujan belum membentuk pola monsun seperti pola curah hujan aktual.
Berdasarkan Gambar 5 dan Gambar 6, kedua model menduga curah hujan pada musim kering jauh diatas nilai aktualnya dan menduga curah hujan ekstrim pada musim hujan dibawah nilai aktual. Terdapat beberapa bulan yang memiliki nilai dugaan mendekati nilai aktual yaitu bulan November dan Desember. Nilai dugaan curah hujan tahun 2008 masing-masing model secara lengkap dapat dilihat pada Lampiran 4.
17 Penambahan peubah dummy tidak memberikan hasil yang signifikan pada pendugaan curah hujan. Dugaan yang dihasilkan hampir sama antara model awal tanpa dummy dengan model yang sudah ditambahkan dummy. Walau demikian, terdapat sedikit penurunan dalam nilai RMSEP.
Gambar 5 Pengepasan model VGAM pada data berukuran 6x6
Gambar 6 Pengepasan model VGAM pada data berukuran 8x8
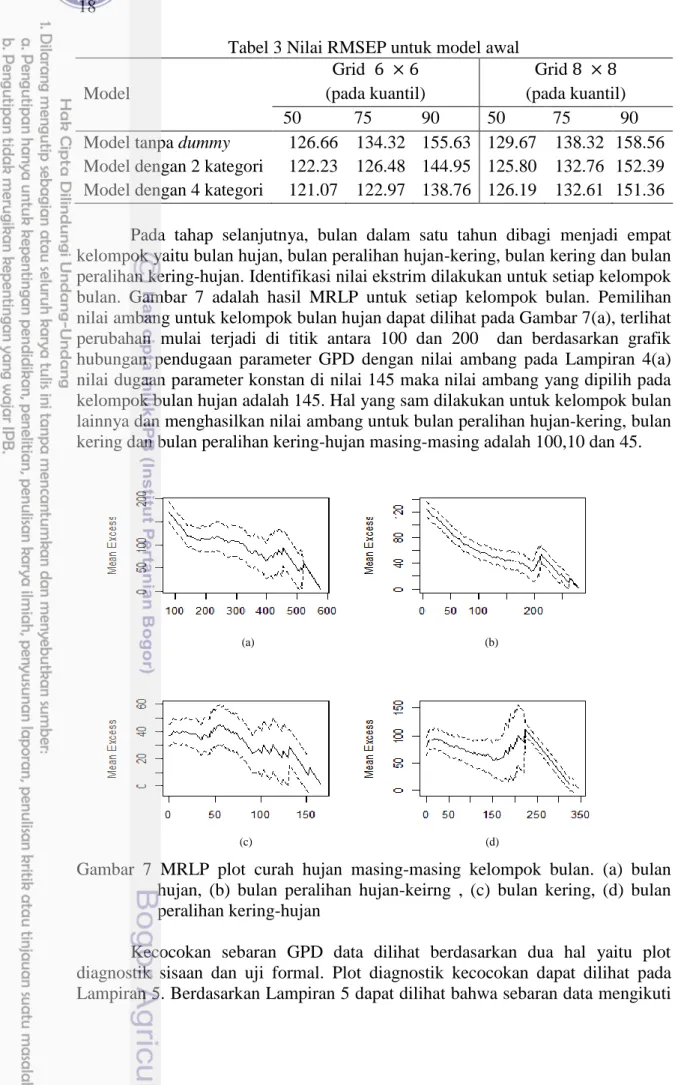
Nilai RMSEP pada Tabel 3 menunjukkan bahwa terjadi sedikit penurunan nilai RMSEP dari model sebelum diberi peubah dummy dengan model setelah pemberian peubah dummy. Selanjutnya untuk mendapatkan hasil yang lebih baik, pemodelan dilakukan kembali dengan membagi bulan kedalam empat kelompok (Sutikno 2013). Data yang digunakan adalah data grid 6 × 6 karena berdasarkan nilai RMSEP, data grid 6 × 6 menghasilkan nilai RMSEP yang lebih kecil jika dibandingkan dengan data grid 8 × 8.
0 50 100 150 200 250 300 350 400 450 500
Model tanpa dummy Model dengan 2 dummy Model 4 dummy Aktual
0 50 100 150 200 250 300 350 400 450 500
18
Tabel 3 Nilai RMSEP untuk model awal Model Grid 6 × 6 (pada kuantil) Grid 8 × 8 (pada kuantil) 50 75 90 50 75 90
Model tanpa dummy 126.66 134.32 155.63 129.67 138.32 158.56 Model dengan 2 kategori 122.23 126.48 144.95 125.80 132.76 152.39 Model dengan 4 kategori 121.07 122.97 138.76 126.19 132.61 151.36 Pada tahap selanjutnya, bulan dalam satu tahun dibagi menjadi empat kelompok yaitu bulan hujan, bulan peralihan hujan-kering, bulan kering dan bulan peralihan kering-hujan. Identifikasi nilai ekstrim dilakukan untuk setiap kelompok bulan. Gambar 7 adalah hasil MRLP untuk setiap kelompok bulan. Pemilihan nilai ambang untuk kelompok bulan hujan dapat dilihat pada Gambar 7(a), terlihat perubahan mulai terjadi di titik antara 100 dan 200 dan berdasarkan grafik hubungan pendugaan parameter GPD dengan nilai ambang pada Lampiran 4(a) nilai dugaan parameter konstan di nilai 145 maka nilai ambang yang dipilih pada kelompok bulan hujan adalah 145. Hal yang sam dilakukan untuk kelompok bulan lainnya dan menghasilkan nilai ambang untuk bulan peralihan hujan-kering, bulan kering dan bulan peralihan kering-hujan masing-masing adalah 100,10 dan 45.
(a) (b)
(c) (d)
Gambar 7 MRLP plot curah hujan masing-masing kelompok bulan. (a) bulan hujan, (b) bulan peralihan hujan-keirng , (c) bulan kering, (d) bulan peralihan kering-hujan
Kecocokan sebaran GPD data dilihat berdasarkan dua hal yaitu plot diagnostik sisaan dan uji formal. Plot diagnostik kecocokan dapat dilihat pada Lampiran 5. Berdasarkan Lampiran 5 dapat dilihat bahwa sebaran data mengikuti
19 sebaran GPD. Plot kuantil-kuantil yang dihasilkan menunjukkan bahwa sebaran data mengikuti sebaran empiriknya.
Tabel 4 Hasil Uji sebaran GPD dengan uji Kolmogorov-Smirnov
Kelompok Statistik hitung Titik daerah kritis (α=5%) Kesimpulan Sebaran
Bulan Hujan 0.05 0.15 menyebar GPD
Bulan peralihan hujan-kering 0.07 0.17 menyebar GPD
Bulan kering 0.07 0.17 menyebar GPD
Bulan peralihan kering-hujan 0.07 0.19 menyebar GPD Hasil pengujian uji Kolmogorov-Smirnov dapat dilihat pada Tabel 4. Berdasarkan Tabel 4 setiap kelompok bulan menghasilkan statistik hitung yang lebih kecil dibandingkan dengan nilai kritisnya pada α = 5% sehingga tidak tolak hipotesis nol. Hal ini menunjukkan bahwa data curah hujan ekstrim setiap kelompok bulan mengikuti sebaran GPD.
Tabel 5 Nilai AIC dari model VGAM pada beberapa derajat bebas pemulus setiap komponen utama GCM
Kelompok Bulan db KU1 KU2
Hujan 2 893.47 891.34 3 893.78 889.32 4 894.69 889.82 5 895.50 890.37 6 896.35 890.83 7 897.40 891.32 Peralihan hujan- kering 2 603.91 603.69 3 605.38 605.02 4 606.89 606.64 5 608.57 608.47 Bulan kering 2 573.11 587.32 3 573.22 588.34 573.24 589.12 4 572.89 589.63 5 573.41 590.11 Peralihan kering-hujan 2 497.13 505.75 3 501.22 506.40 4 Tidak Konvergen 506.76 5 507.65
Tabel 5 menunjukkan nilai AIC yang mungkin untuk setiap komponen utama pada masing-masing kelompok bulan. Tabel 5 memperlihatkan bahwa pada
20
kelompok bulan hujan derajat bebas yang terpilih untuk KU1 sampai KU4 masing-masing adalah 2, 5. Hal ini berarti pada bulan hujan, KU2 memiliki pengaruh nonlinier. Sedangkan untuk kelompok bulan peralihan hujan-kering, bulan kering dan peralihan kering-hujan derajat bebas yang terpilih untuk semua komponen adalah 2 artinya bentuk hubungan cruah hujan dengan komponen utama yang paling optimal adalah bentuk linier.
(a) Bulan hujan
(b) Bulan peralihan hujan-kering
(c) Bulan peralihan kering
(d) Bulan peralihan kering-hujan
Gambar 8 Pengepasan model VGAM pada model kelompok curah hujan
S ( K U 1 , d f = 2 ) S ( K U 2 , d f = 2 ) S (KU2 d f = 2 ) S ( K U 1 , d f = 2 ) S (KU2 d f = 2 ) S ( K U 1 , d f = 2 ) KU1 KU2 KU1 KU2 KU1 KU2 S ( K U 1 , d f = 2 ) S ( K U 2 , d f = 5 ) KU2 KU1
21 Pada analisis VGAM, parameter bentuk (ξ) hanya dimodelkan menjadi intersep. Gambar 8 memperlihatkan hasil pengepasan dengan ±2 simpangan baku. Berdasarkan Gambar 8, skor KU memiliki hubungan yang linear dan nonlinear terhadap curah hujan bulanan. Misalnya pada bulan hujan, skor komponen 1 memiliki hubungan yang linear negatif sedangkan skor komponen 2 memiliki hubungan nonlinear.
Hasil pemodelan dengan VGAM dapat dilihat pada Tabel 6. Berdasarkan Tabel 6 hasil dugaan untuk parameter bentuk (ξ) pada kelompok bulan hujan adalah -0.41, dan pada kelompok peralihan hujan-kering, kering serta peralihan kering-hujan memiliki dugaan parameter ξ masing-masing
-0.47, -0.39, dan -0.49. Hasil ini sejalan dengan hasil yang ditunjukkan pada MRLP bahwa bentuk yang linear menurun mengindikasikan bahwa nilai dari parameter bentuk adalah negatif.
Tabel 6. Penduga parameter VGAM masing-masing kelompok bulan
Kelompok Komponen Derajat Bebas Pemulus Koefisien Bulan Hujan Intersep 1 0 3.84 Intersep 2 0 -2.32 f(KU1) 2 -0.13 f(KU2) 5 0.23
Bulan peralihan hujan-kering
Intersep 1 0 3.82 Intersep 2 0 -3.85 f(KU1) 2 -0.05 f(KU2) 2 -0.22 Bulan kering Intersep 1 0 4.49 Intersep 2 0 -2.21 f(KU1) 2 -0.18 f(KU2) 2 -0.29
Bulan peralihan kering - hujan
Intersep 1 0 7.44
Intersep 2 0 -10.91
f(KU1) 2 0.44
f(KU2) 2 -0.39
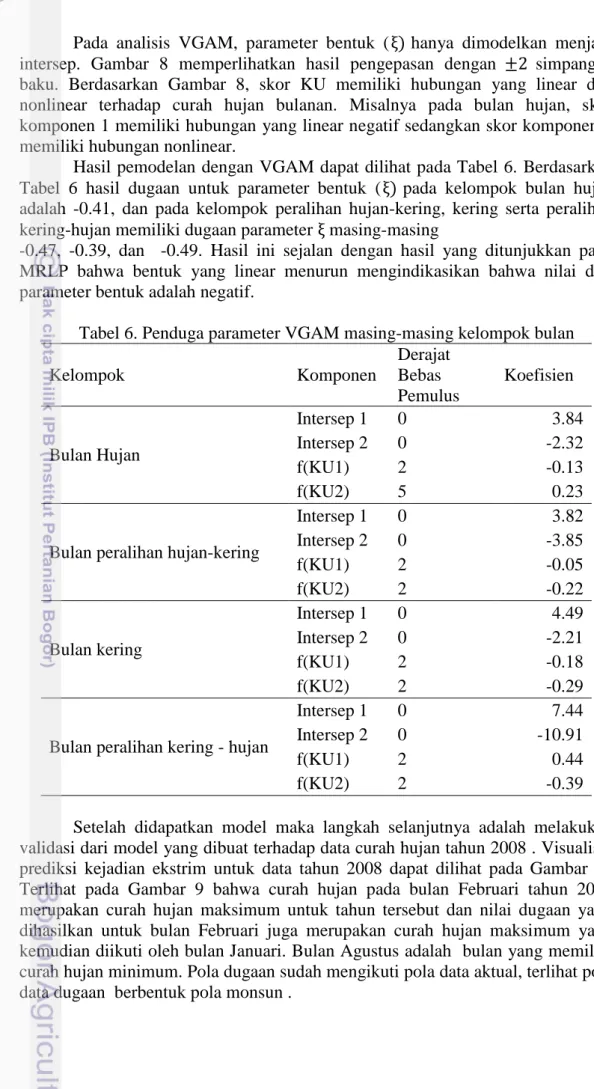
Setelah didapatkan model maka langkah selanjutnya adalah melakukan validasi dari model yang dibuat terhadap data curah hujan tahun 2008 . Visualisai prediksi kejadian ekstrim untuk data tahun 2008 dapat dilihat pada Gambar 9.. Terlihat pada Gambar 9 bahwa curah hujan pada bulan Februari tahun 2008 merupakan curah hujan maksimum untuk tahun tersebut dan nilai dugaan yang dihasilkan untuk bulan Februari juga merupakan curah hujan maksimum yang kemudian diikuti oleh bulan Januari. Bulan Agustus adalah bulan yang memiliki curah hujan minimum. Pola dugaan sudah mengikuti pola data aktual, terlihat pola data dugaan berbentuk pola monsun .
22
Gambar 9. Grafik hasil validasi silang antara nilai dugaan dengan nilai aktual terhadap data curah hujan tahun 2008 pada quantil atas
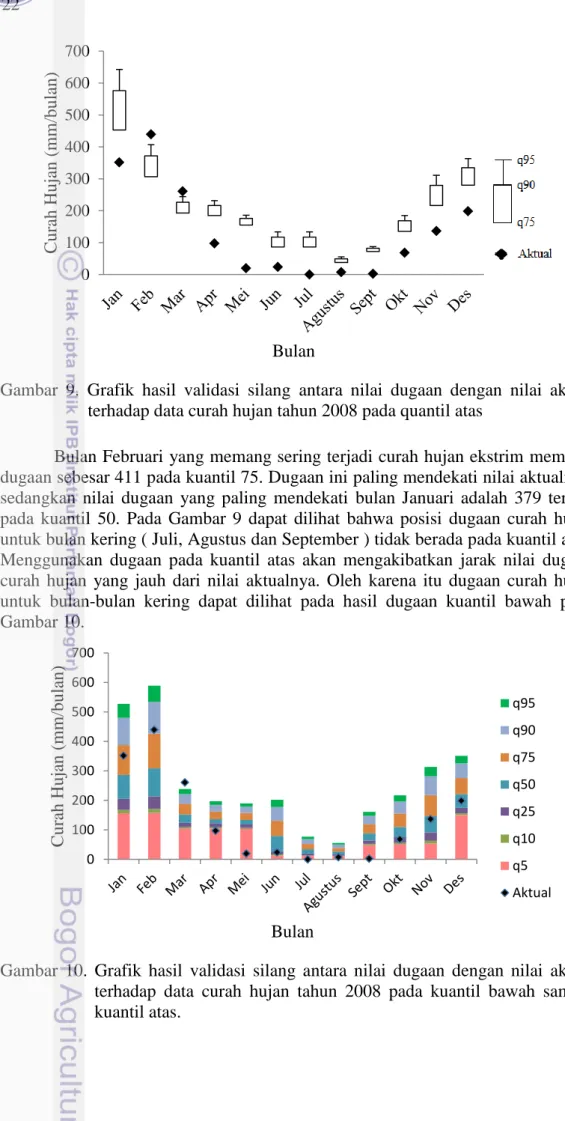
Bulan Februari yang memang sering terjadi curah hujan ekstrim memiliki dugaan sebesar 411 pada kuantil 75. Dugaan ini paling mendekati nilai aktualnya, sedangkan nilai dugaan yang paling mendekati bulan Januari adalah 379 terjadi pada kuantil 50. Pada Gambar 9 dapat dilihat bahwa posisi dugaan curah hujan untuk bulan kering ( Juli, Agustus dan September ) tidak berada pada kuantil atas. Menggunakan dugaan pada kuantil atas akan mengakibatkan jarak nilai dugaan curah hujan yang jauh dari nilai aktualnya. Oleh karena itu dugaan curah hujan untuk bulan-bulan kering dapat dilihat pada hasil dugaan kuantil bawah pada Gambar 10.
Gambar 10. Grafik hasil validasi silang antara nilai dugaan dengan nilai aktual terhadap data curah hujan tahun 2008 pada kuantil bawah sampai kuantil atas. 0 100 200 300 400 500 600 700 C ur ah Huja n (mm/ bulan) Bulan q95 q90 q75 aktual 0 100 200 300 400 500 600 700 C ur ah Huja n (mm/ bulan) Bulan q95 q90 q75 q50 q25 q10 q5 Aktual
23 Gambar 10 menyajikan dugaan curah hujan dari kuantil bawah sampai dengan kuantil atas. Berdasarkan gambar tersebut, dpaat dilihat bahwa untuk bulan-bulan kering, dugaan curah hujan yang tepat terjadi pada kuantil ke-5. Dugaan curah hujan pada kuantil ke-5 untuk bulan Juli, Agustus dan September masing-masing adalah 11.8, 11.6 dan 48.6. Nilai ini sudah mendekati nilai aktualnya untuk bulan Juli dan Agustus tetapi tidak untuk bulan September. Hal ini kemungkinan dapat disebabkan karena bulan September berbatasan dengan kelompok bulan peralihan. Dibandingkan dengan Gambar 5 dan Gambar 6, pola dugaan curah hujan bulan kering pada Gambar 10 jauh lebih mendekati aktualnya. Pembagian dugaan pada kuantil yang berbeda menghasilkan RMSEP yang lebih kecil dibandingkan degan menggunakan kuantil yang sama untuk setiap kelompok bulan. Hal ini dapat dilihat pada Tabel 7. Berdasarkan Tabel 7 terlihat bahwa nilai RMSEP untuk bulan kering pada kuantil 5 dan 10 kecil yaitu 9.2 dan 9.3. Hal serupa juga terjadi untuk bulan hujan dan bulan peralihan kering hujan, yaitu memiliki nilai RMSEP yang kecil pada kuantil 75 untuk bulan hujan , kuantil 25 untuk bulan peralihan kering-hujan. Hasil nilai RMSEP ini dapat dibandingkan dengan hasil RMSEP keseluruhan pada Tabel 8, yaitu rata-rata nilai RMSEP yang dihasilkan lebih besar.
Tabel 7. Nilai RMSEP data dugaan pada berbagai kuantil
Kategori Kuantil RMSEP
Bulan Hujan
75 49.84
90 117.62
95 159.85
Bulan peralihan hujan-kering
25 98.55 50 93.76 75 97.26 Bulan kering 5 9.28 10 9.32 25 13.02
Bulan peralihan kering-hujan
10 51.85
25 44.41
50 55.89
Tabel 8. Nilai RMSEP pada panjang data dugaan yang berbeda Data Historis Data Dugaan RMSEP pada kuantil
50 75 90 95 1979-2007 2008 74.17 79.17 113.19 136.44 1979-2006 2007-2008 72.04 80.44 113.29 136.27 1979-2005 2006-2008 68.14 82.60 117.92 141.03 1979-2004 2005-2008 63.14 85.45 123.81 147.11 1979-2003 2004-2008 73.17 92.25 127.14 148.92 Simpangan baku 4.53 5.19 6.26 5.89
Validasi dilakukan untuk mengetahui seberapa valid model yang dibangun. Hasil ini dapat dilihat pada Tabel 8. Nilai RMSEP yang dihasilkan pada
24
kuantil 50 lebih kecil dibandingkan dengan RMSEP pada kuantil yang lain. Berdasarkan Tabel 8, RMSEP yang dihasilkan tidak terlalu berbeda jauh meskipun panjang data dugaan bertambah. Hal ini terlihat dari nilai simpangan baku pada setiap kuantil. Secara keseluruhan kuantil 75 menghasilkan simpangan baku RMSEP 5.1, kuantil 90 menghasilkan 6.2 dan kuantil 95 menghasilkan 5.8. Sehingga dapat disimpulkan bahwa model yang dibangun dengan VGAM GPD sudah valid.
Nilai korelasi dihitung untuk mengetahui kesamaan pola dugaan dengan aktual. Semakin tinggi nilai korelasi berarti dugaan memiliki pola yang mirip dengan curah hujan aktual. Hasil korelasi pada beberapa tahun dugaan dapat dilihat pada Tabel 9. Berdasarkan Tabel 9, nilai korelasi yang dihasilkan semuanya diatas 0.8 dengan simpangan baku 0.03. Hal ini berarti ada korelasi yang cukup kuat antara dugaan dengan data aktual. Korelasi yang positif menunjukkan pola yang sama antara dugaan dengan data aktual. Simpangan baku yang kecil untuk RMSEP dan korelasi menunjukkan bahwa meskipun panjang data dugaan ditambah sampai ke lima tahun ke depan, nilai dugaan tidak memili eror yang semakin besar dan tetap memiliki pola yang sama.
Tabel 9. Nilai korelasi data dugaan dengan data aktual pada panjang data dugaan yang berbeda
Data Historis Data Dugaan Korelasi pada kuantil
50 75 90 95 1979-2007 2008 0.91 0.92 0.93 0.93 1979-2006 2007-2008 0.86 0.85 0.85 0.84 1979-2005 2006-2008 0.87 0.88 0.87 0.87 1979-2004 2005-2008 0.86 0.86 0.85 0.85 1979-2003 2004-2008 0.82 0.82 0.82 0.81 Simpangan baku 0.03 0.04 0.04 0.04
25
5 SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian ini dapat disimpulkan bahwa penggunaan ukuran grid 6 × 6 menghasilkan nilai dugaan yang lebih baik dibandingkan dengan menggunakan ukuran 8 × 8. Pemodelan curah hujan dengan menggunakan VGAM yang mengikuti sebaran teori nilai ekstrim GPD di Kabupaten Indramayu memberikan pola dugaan yang mendekati data aktual. Penggunaaan kuantil yang berbeda untuk setiap kelompok bulan menghasilkan dugaan yang lebih baik. Kelompok bulan kering memiliki nilai dugaan yang mendekati aktual pada kuantil rendah yaitu kuantil 5 dan 10, kelompok bulan hujan pada kuantil 75, kelompok bulan peralihan hujan-kering pada kuantil 50, sedangkan pada kelompok bulan peralihan kering-hujan dugaan terbaik yaitu pada kuntil 25. Kebaikan model menunjukkan bahwa model VGAM dengan GPD menghasilkan dugaan yang konsisten meskipun panjang data dugaan ditambah, nilai RMSEP yang dihasilkan tidak jauh berbeda jika dibandingkan dengan melakukan dugaan pada satu tahun.
Saran
Pemilihan nilai ambang yang menggunakan MRLP sedikit subjektif, oleh karena itu perlu dilakukan kajian mengenai penentuan nilai MRLP secara teoritik dan tidak subjektif. Selain itu, erlu dilakukan kajian lebih lanjut juga mengenai pemilihan derajat pemulusan yang optimum untuk metode VGAM yang mengikuti sebaran GPD sehingga menghasilkan model yang konvergen.