BAB III
TINJAUAN PUSTAKA
3.1. Penjadwalan
Penjadwalan adalah pengurutan pembuatan atau pengerjaan produk secara menyeluruh yang dikerjakan pada beberapa buah mesin. Dengan demikian masalah sequencing senantiasa melibatkan pengerjaan sejumlah komponen yang sering disebut dengan istilah job. Job sendiri masih merupakan komposisi dari sejumlah elemen-elemen dasar yang disebut aktivitas atau operasi. Tiap aktivitas atau operasi ini membutuhkan alokasi sumber daya tertentu selama periode waktu tertentu yang sering disebut dengan waktu proses.
Penjadwalan merupakan alat ukur yang baik bagi perencanaan agregat. Pesanan-pesanan aktual pada tahap ini akan ditugaskan pertama kalinya pada sumberdaya tertentu (fasilitas, pekerja, dan peralatan), kemudian dilakukan pengurutan kerja pada tiap-tiap pusat pemrosesan sehingga dicapai optimalitas utilisasi kapasitas yang ada. Pada penjadwalan ini, permintaan akan produk-produk yang tertentu (jenis dan jumlah) dari MPS akan ditugaskan pada pusat-pusat pemrosesan tertentu untuk periode harian.
Penjadwalan proses produksi yang baik dapat mengurangi waktu menganggur (idle time) pada unit-unit produksi dan meminimumkan barang yang sedang dalam proses (work in process).
Penjadwalan (scheduling) menurut Conway adalah pengurutan pembuatan produk secara menyeluruh yang dikerjakan pada beberapa buah mesin. Sedangkan menurut Kenneth R. Baker, penjadwalan didefinisikan sebagai proses pengalokasian sumber daya untuk memilih sekumpulan tugas dalam jangka waktu tertentu. Dari defenisi di atas, maka terdapat dua elemen penting dalam proses penjadwalan, yakni urutan (sequence) job yang memberikan solusi optimal dan pengalokasian sumber daya (resources). Karakteristik sumber daya yang dibicarakan adalah kapasitas kualitatif dan kuantitatif, yakni jenis apa dan jumlah berapa sumber daya yang dimiliki. Pekerjaan (job order) yang diterima diuraikan dalam bentuk kebutuhan akan sumber daya, waktu proses, waktu dimulai dan waktu berakhirnya proses.
terbaik misalnya waktu pemrosesan tersingkat, utilitas mesin/peralatan tertinggi, idle time minimum dan lain-lain.
3.1.1.Tujuan Penjadwalan
Bedwort (1987), mengidentifikasikan beberapa tujuan dari aktivitas penjadwalan adalah sebagai berikut:
1. Meningkatkan penggunaan sumber daya atau mengurangi waktu tunggunya, sehingga total waktu proses dapat berkurang dan produktivitas dapat meningkat.
2. Mengurangi persediaan barang setengah jadi atau mengurangi sejumlah pekerjaan yang menunggu dalam antrian ketika sumberdaya yang ada masih mengerjakan tugas yang lain. Teori Baker mengatakan, jika aliran kerja suatu jadwal konstan maka antrian yang mengurangi rata-rata waktu alir akan mengurangi rata-rata persediaan setengah jadi.
3. Mengurangi beberapa keterlambatan pada pekerjaan yang mempunyai batas waktu penyelesaian sehingga akan meminimasi penalty cost (biaya keterlambatan).
3.1.2. Terminologi Penjadwalan
Beberapa defenisi yang digunakan dalam penjadwalan adalah sebagai berikut:
1. Processing Time (ti)
Processing Time adalah waktu yang dibutuhkan untuk mengerjakan suatu pekerjaan. Dalam waktu proses ini sudah termasuk waktu yang dibutuhkan untuk persiapan dan pengaturan (setup) selama proses berlangsung.
2. Due-date (di)
Due-date adalah batas waktu dimana operasi terakhir dari suatu pekerjaan harus selesai.
3. Slack time (SLi)
Slack time adalah waktu tersisa yang muncul akibat dari waktu prosesnya lebih kecil dari due- datenya.
SLi = di - ti 4. Flow time (Fi)
Flow time adalah rentang waktu antara saat pekerjaan dapat dimulai (tersedia) dan saat pekerjaan selesai. Jadi flow time sama dengan processing time dijumlahkan dengan waktu tunggu sebelum pekerjaan diproses.
5. Completion time (Ci)
6. Lateness (Li)
Lateness adalah selisih antara completion time(Ci) dengan due-date-nya (di). Suatu pekerjaan memiliki lateness yang bernilai positif apabila pekerjaan tersebut diselesaikan setelah due-date-nya.
7. Tardiness (Ti)
Tardiness adalah lateness positif dimanapekerjaan diselesaikan lebih lambat dari due date yang telah ditetapkan. Tardiness disimbolkan dengan Ti.
8. Makespan (M)
Makespanadalah total waktu penyelesaian pekerjaan mulai dari urutan pertama yang dikerjakan pada mesin atau work center pertama sampai kepada urutan-urutan pekerjaan terakhir pada mesin atau work center terakhir.
3.1.3. Klasifikasi Penjadwalan
Penjadwalan produksi dapat diklasifikasi berdasarkan beberapa kriteria sebagai berikut(Nahmias, 2000):
1. Penjadwalan produksi secara umum, yaitu: a. Penjadwalan maju (forward scheduling)
b. Penjadwalan mundur (backward scheduling)
Teknik penjadwalan dimulai dari waktu penyelesaian operasi terakhir. Keuntungannya adalah mengurangi persediaan barang setengah jadi (work in process).
2. Penjadwalan produksi berdasarkan mesin yang digunakan, yaitu: a. Model Single-Machine
Model ini hanya berisi sejumlah m mesin yang sejenis, yang harus memproses sejumlah job yang terdiri dari satu operasi. Setiap job dapat dikerjakan pada salah satu mesin yang ada tersebut. Model ini banyak digunakan pada penjadwalan yang menggunakan metode dekomposisi, yaitu suatu model penjadwalan yang memecahkan permasalahan penjadwalan yang kompleks ke dalam sejumlah permasalahan yang lebih sederhana dalam bentuk single-machine.
b. Model Paralle-Machine
c. Model Flow shop
Suatu proses manufaktur seringkali harus melewati banyak operasi yang membutuhkan jenis mesin yang berbeda pada tiap operasinya. Jika rute yang harus dilewati untuk setiap job adalah sama, maka bentuk konfigurasi ini disebut juga model flow shop. Mesin-mesin pada model ini disusun secara seri dan pada saat sebuah job selesai diproses pada sebuah mesin, maka job tersebut akan meninggalkan mesin tersebut untuk kemudian mengisi antrian pada mesin berikutnya untuk diproses.
d. Model Job Shop
Dalam suatu proses manufaktur yang memerlukan banyak operasi, seringkali rute yang harus dilalui setiap job adalah tidak sama. Model seperti ini disebut juga model job shop. Bentuk sederhana dari model ini mengasumsikan bahwa setiap job hanya melewati satu jenis mesin sebanyak satu kali dalam rutenya pada proses tersebut. Namun ada juga model lainnya di mana setiap job diperbolehkan untuk melewati mesin sejenis lebih dari satu kali pada rutenya. Model ini disebut juga job shop dengan recirculation (pengulangan).
3. Penjadwalan produksi berdasarkan pola kedatangan pekerjaan, yaitu: a. Penjadwalan statis
b. Penjadwalan dinamis
Pekerjaan datang terus-menerus pada waktu yang berbeda-beda. Pendekatan yang sering digunakan pada penjadwalan ini adalah penggunaan aturan dispatching yang berbeda untuk setiap stasiun kerja. 4. Penjadwalan produksi berdasarkan sifat informasi yang diterima, yaitu:
a. Penjadwalan deterministic
Informasi yang diperoleh bersifat pasti seperti waktu kedatangan job, waktu setup, dan waktu proses.
b. Penjadwalan stokastik
Informasi yang diperoleh tidak pasti tetapi memiliki keCEnderungan yang jelas atau menyangkut adanya distribusi probabilitas tertentu, misalnya kedatangan pekerjaan bersifat acak.
3.1.4. Penjadwalan Flow shop
Menurut Baker (1974) model penjadwalan dapat dibedakan menjadi 4 jenis keadaan, yaitu:
1. Mesin yang digunakan, dapat berupa proses dengan mesin tunggal atau proses dengan mesin majemuk.
2. Pola aliran proses, dapat berupa aliran identik atau sembarang. 3. Pola kedatangan pekerjaan, statis atau dinamis.
biasanya dapat diterapkan dalam kasus mesin majemuk. Pada model kedua, pola aliran dapat dibedakan atas flow shop dan job shop. Pada flow shop dijumpai pola aliran pemrosesan dari suatu mesin ke mesin lainnya dalam urutan (routing) tertentu. Semua pekerjaan yang mengalir pada alat produksi yang sama tanpa boleh melewatinya disebut dengan pureflow shop. Tetapi jika pekerjaan yang datang kedalam flow shop tidak harus dikerjakan pada semua mesin, jenis flow shop ini disebut dengan generalflow shop.
3.2. Makespan
Makespan untuk flow shop dan job shopmerupakankriteria sederhana yan
secara jangka panjang dapat digunakan secara maksimal, hal ini dikarenakan
makespan merupakan satu-satunya fungsi tujuan yang sederhana namun memiliki
hasil yang analitik untuk permasalahan mesin tunggal ataupun paralel. Masalah
makespanmemang akan lebih sulit pada permasalah mesin paralel.
Pendekatan minimasi makespan pada penjadwalan flow shoppada m mesin dapat digunakan formulasi sebagai berikut:
B = max {b1, b2, b3, … , bk, … , bm} dimana
bm = qm + Tm
bm-1 = qm-1 + Tm-1 + min {pjm}
jЄσ’
bm-2 = qm-2 + Tm-2 + min {pj.m-1 + pj.m }
jЄσ’
. .
. .
bk = qk + Tk + min {pj.k+1 + pj.k+2 + … + pj.m}
jЄσ’
. .
. .
. .
b1 = q1 + T1 + min {pj.2 + pj.3 + … + pj.m}
jЄσ’
3.3. Pengukuran Waktu (Time Study)
Pengukuran waktu ditujukan untuk mendapatkan waktu baku penyelesaian pekerjaan yaitu waktu yang dibutuhkan secara wajar oleh seorang pekerja normal untuk menyelesaikan suatu pekerjaan yang dijalankan dalam sistem kerja terbaik. Ini dimaksudkan untuk menunjukkan bahwa waktu baku yang dicari bukanlah waktu penyelesaian yang diselesaikan secara tidak wajar seperti terlalu cepat atau terlalu lambat.
Secara garis besar, metode pengukuran waktu terbagi ke dalam dua bagian, yaitu:
1. Pengukuran secara langsung
Pengukuran yang dilakukan secara langsung di tempat dimana pekerjaan yang bersangkutan dijalankan. Dua cara yang termasuk pengukuran langsung adalah cara jam henti (stopwatch time study) dan sampling kerja (work sampling). 2. Pengukuran secara tidak langsung
elemen gerakan. Yang termasuk pengukuran tidak langsung adalah data waktu baku dan data waktu gerakan.
Dengan salah satu cara ini, waktu penyelesaian pekerjaan yang dikerjakan dengan suatu sistem kerja tertentu dapat ditentukan. Sehingga jika pengukuran dilakukan terhadap beberapa alternatif sistem kerja, kita dapat memilih yang terbaik dari segi waktu yaitu sistem yang membutuhkan waktu penyelesaian yang tersingkat.
3.3.1 Pengukuran Waktu Jam Henti
Pengukuran waktu jam henti adalah pekerjaan mengamati pekerja dan mencatat waktu kerjanya baik setiap elemen ataupun siklus dengan menggunakan alat yang telah disiapkan. Sesuai dengan namanya, maka pengukuran waktu ini menggunakan jam henti (stop watch) sebagai alat utamanya. Cara ini tampaknya merupakan cara yang paling banyak digunakan.
Tahapan dalam melakukan pengukuran waktu adalah sebagai berikut: 1. Penetapan Tujuan Pengukuran
Dalam melakukan pengukuran waktu kerja, tujuan pengukuran harus ditetapkan terlebih dahulu dan untuk apa hasil pengukuran digunakan. Dalam penentuan tujuan tersebut, dibutuhkan adanya tingkat kepercayaan dan tingkat ketelitian yang digunakan dalam pengukuran jam henti.
2. Melakukan Penelitian Pendahuluan
dianalisis hasil pengukuran waktu kerja, apakah masih ada kondisi yang tidak optimal, jika perlu dilakukan perbaikan kondisi kerja dan cara kerja yang baik.
3. Memilih Operator
Operator yang akan melakukan pekerjaan harus dipilih yang memenuhi beberapa persyaratan agar pengukuran dapat berjalan baik, dan dapat diandalkan hasilnya. Syarat tersebut yang dibutuhkan berkemampuan normal dan dapat bekerja sama menjalankan prosedur kerja yang baik.
4. Melatih Operator
Operator harus dilatih terlebih dahulu agar terbiasa dengan kondisi dan cara yang telah ditetapkan dan telah dibakukan untuk menyelesaikan pekerjaan secara wajar.
5. Menguraikan Pekerjaan Atas Beberapa Elemen Pekerjaan
Pekerjaan dibagi menjadi beberapa elemen pekerjaan yang merupakan gerakan bagian dari pekerjaan yang bersangkutan. Pengukuran waktu dilakukan atas elemen pekerjaan. Ada beberapa pedoman yang harus diperhatikan dalam melakukan pemisahan menjadi beberapa elemen pekerjaan yaitu:
a. Uraikan pekerjaan tersebut, tetapi harus dapat diamati oleh alat ukur dan dapat dicatat dengan menggunakan jam henti.
b. Jangan sampai ada elemen yang tertinggal karena jumlah waktu elemen kerja tersebut merupakan siklus penyelesaian suatu pekerjaan.
Hal ini dilakukan agar tidak timbul keraguan dalam menentukan kapan berakhirnya atau mulainya suatu pekerjaan.
6. Menyiapkan Alat Pengukuran
Alat yang digunakan melakukan pengukuran waktu baku tersebut yaitu: a. Jam henti (stopwatch)
b. Lembar pengamatan c. Pena atau pensil d. Papan pengamatan
3.3.2. Tingkat Ketelitian dan Tingkat Keyakinan
Tingkat ketelitian dan tingkat keyakinan adalah pencerminan tingkat kepastian yang diinginkan oleh pengukur setelah memutuskan untuk melakukan sampling dalam pengambilan data.
3.3.3. Pengujian Keseragaman Data
Pengujian keseragaman data adalah suatu pengujian yang berguna untuk memastikan bahwa data yang dikumpulkan berasal dari satu sistem yang sama. Melalui pengujian ini kita dapat mendeteksi adanya perbedaan-perbedaan dan data-data yang di luar batas kendali (out of control) yang dapat kita gambarkan pada peta kontrol. Data-data yang demikian dibuang dan tidak dipergunakan dalam perhitungan selanjutnya. Langkah-langkah pengujian keseragaman data adalah sebagai berikut:
1. Menghitung harga rata-rata pengamatan (N) 2. Menghitung standar deviasi (σ)
Rumus untuk menghitung standar deviasi adalah sebagai berikut:
σx =
�
∑(�−��)2�−1
Keterangan :
σ = Standar deviasi
X = Data yang diperoleh dari pengamatan
�� =Rata-rata dari data pengamatan N = Jumlah pengamatan yang dilakukan
3. Menentukan batas kontrol atas (BKA) dan batas kontrol bawah (BKB)
Untuk menguji keseragaman data, digunakan peta kontrol dengan persamaan berikut :
BKA = X + kσ BKB = X - kσ
3.3.4. Menghitung Jumlah Data Pengamatan yang Diperlukan (N’)
Uji kecukupan data dilakukan untuk mengetahui apakah data yang diambil dari lapangan telah mencukupi untuk digunakan dalam menyelesaikan permasalahan yang ada. Uji kecukupan data dapat dihitung dengan menggunakan rumus umum sebagai berikut:
(
)
2N = Jumlah pengamatan yang dilakukan N’ = Jumlah pengamatan yang harus dilakukan ΣXi = Jumlah seluruh data
ΣXi2 = Jumlah kuadrat data
K = Nilai absis pada tabel distribusi normal untuk luasan sebesar tingkat kepercayaan
s = Tingkat ketelitian
Apabila N’ < N, maka jumlah data pengamatan sudah mencukupi dan apabila N’ > N, maka jumlah data pengamatan belum mencukupi.
3.3.5. Menentukan Waktu Terpilih, Waktu Normal dan Waktu Standar Waktu terpilih yang digunakan adalah harga rata-rata data yang telah seragam dan cukup di tiap stasiun kerja. Harga rata-rata tersebut diperoleh dari data pengamatan waktu siklus operasi yang telah berada pada batas kontrol yang ditentukan seperti yang terlihat pada perhitungan sebelumnya. Untuk menghitung waktu normal (Wn) dilakukan dengan menggunakan rumus:
Untuk menentukan Rf (Rating Factor) digunakan metode Westinghouse system of rating yang terdiri dari empat faktor yang mempengaruhi penentuan ratingyaitu keterampilan, kondisi kerja, usaha dan konsistensi. Penentuan Rf (Rating Factor) adalah sebagai berikut:
Rf = 1 + Westinghousefactor
Waktu baku dihitung setelah mengetahui allowance. Persentase allowancemerupakan kelonggaran untuk istirahat yang diberikan kepada tenaga kerja.
3.3.6. Penyesuaian dan Kelonggaran
Setelah pengukuran berlangsung, pengukur harus mengamati kewajaran kerja yang diitujukkan operator. Ketidakwajaran dapat saja terjadi misalnya bekerja tanpa kesungguhan, sangat cepat seolah-olah diburu waktu, atau karena menjumpai kesulitan-kesulitan seperti kondisi ruangan yang buruk. Penyebab seperti diatas mempengaruhi kecepatan kerja yang berakibat terlalu singkat atau terlalu panjangnya waktu penyelesaian. Hal ini jelas tidak diinginkan karena waktu baku yang dicari adalah waktu yang diperoleh dari kondisi dan cara kerja baku yang diselesaikan secara wajar.
1. Konsep tentang bekerja wajar
melalui pengamatan pengukur dapat melihat cara kerja operator. Dalam kehidupan sehari-hari pun hal ini sering bisa dirasakan, yaitu bila suatu waktu melihat seorang yang sedang bekerja. Dalam waktu yang tidak terlalu lama, dapat menyatakan bahwa orang tersebut bekerja dengan lambat atau sangat cepat. Ketepatan pengukur akan lebih teliti apabila dia telah cukup berpengalaman bagi jenis pekerjaan yang sedang diukur. Semakin berpengalaman seseorang pengukur, indera yang dimiliki akan semakin peka melakukan penyesuaian. Untuk memudahkan pemilihan konsep wajar, seorang pengukur dapat mempelajari cara kerja seorang operator yang dianggap normal yaitu jika seorang operator yang dianggap berpengalaman, bekerja tanpa
usaha-usaha yang berlebihan sepanjang hari kerja, menguasai cara kerja yang ditetapkan
dan menunjukkan kesungguhan dalam menjalankan pekerjaannya. Disamping
konsep-konsep yang dikemukakan oleh InternationalLabour Organization ini, terdapat juga konsep yang lebih terperinci yaitu yangdikemukakan oleh Lawry,
Maynard, dan Stegemarten melalui cara penyesuaianWestinghouse. Ada empat faktor yang menyebabkan kewajaran atauketidakwajaran dalam bekerja, yaitu keterampilan, usaha, kondisi kerja, dan konsistensi. Walaupun usaha-usaha membakukan konsep bekerja wajar telah dilakukan, namun penyesuaian tetap tampak sebagai hal yang subjektif.
2. Cara Menentukan Faktor Penyesuaian
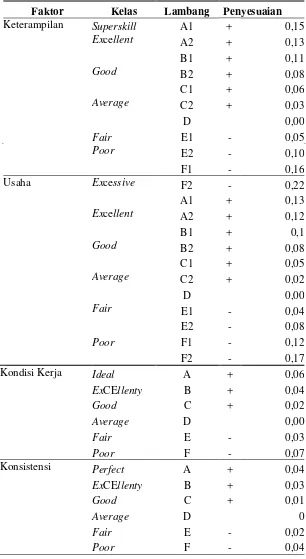
skill didefenisikan sebagai kemampuan mengikuti cara kerja yang ditetapkan.Latihan dapat meningkatkan keterampilan, tetapi hanya sampai ke tingkat tertentu saja, tingkat yang merupakan kemampuan maksimal yang dapat diberikan pekerja yang bersangkutan. Keterampilan juga dapat menurun, yaitu bila terlampau lama tidak menangani pekerjaan tersebut. Atau karena sebab-sebab lain seperti karena kesehatan yang terganggu, rasa fatigue yang berlebihan, pengaruh lingkungan sosial dan sebagainya. Faktor lain yang harus diperhatikan adalah konsistensi atau consistency. Faktor ini perlu diperhatikan karena pada setiap pengukuran waktu angka-angka yang dicatat tidak pernah semuanya sama, waktu penyelesaian yang ditunjukkan pekerja selalu berubah-ubah dari siklus ke siklus lainnya, dari jam ke jam, bahkan dari hari ke hari. Selama ini masih dalam batas kewajaran, masalah tidak timbul tetapi jika variabilitisnya tinggi maka hal tersebut harus diperhatikan. Sebagaimana halnya faktor-faktor lain, konsistensi juga dibagi enam kelas yaitu perfect,exCEllent, good, average, fair dan poor. Westinghouse factors dilihat padaTabel 3.1.(Iftikar Z Sutalaksana,2005)
3. Kelonggaran (Allowance)
Kelonggaran (allowance) diberikan kepada tiga hal yaitu untuk kebutuhan pribadi, menghilangkan kelelahan dan hambatan yang tidak dapat dihindarkan. Ketiganya merupakan hal yang secara nyata dibutuhkan oleh pekerja selama pengamatan karenanya setelah mendapatkan waktu normal perlu ditambahkan kelonggaran. Dalam menghitung besarnya allowance, keadaan yang dianggap wajar diambil harga allowance=100 %. Sedangkan bila terjadi penyimpangan dari keadaan ini, allowance harus ditambah dengan faktor-faktor berpengaruh terhadap kegiatan kerja yang dilakukan. Kelonggaran diberikan untuk tiga hal, yaitu:
a. Kelonggaran untuk kebutuhan pribadi (personal)
Yang termasuk didalam kebutuhan pribadi adalah hal-hal sepeti minum sekedarnya untuk menghilangkan rasa haus, ke kamar kecil, berbicara dengan teman untuk menghilangkan ketegangan ataupun kejenuhan dalam bekerja.
b. Kelonggaran untuk menghilangkan rasa fatique
Fatique merupakan hal yang akan terjadi pada diri seseorang sebagai akibatdari melakukan suatu pekerjaan.
3.4. Cross Entropy
Metode Cross Entropy termasuk teknik yang cukup baru. Awalnya diterapkan untuk simulasi kejadian langka (rare event). Lalu dikembangkan untuk beberapa kasus seperti optimasi kombinatorial, optimasi berlanjut, machine learning dan beberapa kelas masalah lain. Metoda CE termasuk dalam keluarga teknik Monte Carlo yang bisa digunakan untuk menyelesaikan kasus estimasi maupun optimasi. Dalam hal estimasi, CE memberikan cara yang adaptif untuk menemukan distribusi sampling yang optimal untuk beberapa problem yang cukup luas cakupannya. Jika masalah optimasi bisa kita formulasikan sebagai masalah estimasi maka metoda CE menjadi sangat handal dan berlaku umum sebagai algoritma search stokhastik.
Metoda CE melibatkan prosedur iterasi, dimana tiap iterasi dapat dipecah menjadi dua fase yaitu:
1. Melakukan pembangkitan sampel random(x) dengan menggunakan mekanisme atau distribusi tertentu.
2. Memperbaharui parameter (ν) dari mekanisme random berdasarkan data sampel elit untuk menghasilkan sampel yang lebih baik pada iterasi berikutnya.
Sampel elit adalah berapa persen dari sampel yang kita pilih untuk memperbaiki atau mengupdate parameter ν yang digunakan. Proses tersebut secara matematis dapat ditulis sebagai berikut
1. Tentukan nilai N, yaitu banyaknya sampel, ν0, ρ dan α.
2. Bangkitkan sampel sebanyak N dengan mekanisme tertentu, memanfaatkan parameter ν0.
mencari nilai x mana yang memberikan f terkecil. Sejumlah nilai x terbaik ini gunakan untuk memperbaharui parameter ν.
4. Memperbaharui γt secara adaptif. Untuk ν yang sudah diperbaharui, gunakan untuk membangkitkan nilai x yang baru. Kemudian masukkan ke dalam γt dan νt−1 yang telah ditetapkan.
Algoritma utama CE untuk optimasi adalah sebagai berikut: 1. Tentukan parameter awal ν = u, α,dan ρ.Tetapkaniterasi it =1.
2. Bangkitkan sampel random X1, XN dari fungsi probabilitas distribusi tertentu f(−; u) dan pilih sampel (1−ρ) quantile dari performansi setelah diurutkan. 3. Gunakan sampel yang sama untuk memperbarui nilai parameter.
4. Aplikasikan persamaan untuk memuluskan vektor ν = u.Kembali ke langkah 2 dengan nilai parameter yang baru, tetapkan it = it +1.
5. Jika stopping criteria sudah dipenuhi, berhenti.
Perlu dicatat bahwa stopping criteria, vektor solusi awal, ukuran sampel N dan nilai ρ harus dinyatakan secara spesifik dari awal iterasi. Parameter ν diperbaharui hanya berdasarkan sejumlah (1 − ρ) sampel terbaik. Sampel yang digunakan untuk memperbaharui parameter ini dinamakan sampel elit.
3.4.1. Ide Dasar Cross Entropy
KonsepCross Entropy dikembangkan untuk mengukur distribusi referensi
ideal dan pendistribusian yang sebenarnya. Metode ini umumnya memiliki dua
langkah dasar, menghasilkan sampel dengan mekanisme parameter dan
diusulkan oleh Reuven Rubinstein dengan menggabungkan konsep Kullback-
Leibler dan teknik simulasi Monte Carlo.
Cross Entropy (CE) telah diterapkan di berbagai macam masalah. Salah
satunya untuk memecahkan masalah optimasi. Aplikasi CE telah diadopsi secara
luas dalam kasus kombinasi yang sulit seperti masalah maksimisasi, Traveling
Salesman Problem (TSP), masalah penugasan kuadrat dan berbagai macam
masalah penjadwalan dan Buffer Allocation Problem (BAP).
Untuk memecahkan masalah optimasi, cross entropydilibatkan dalam dua
fase berulang berikut:
1. Generasi sampel data acak (lintasan dan vektor) sesuai dengan mekanisme
acak probabilitas dengan fungsi kepadatan.
2. Memperbarui parameter dari mekanisme random, biasanya parameter atas
dasar data untuk menghasilkan sampel yang lebih baikpada iterasi berikutnya.
Misalkan ingin meminimalkan beberapa fungsi biaya S(z) atas semua z di
beberapa set Z. Maka minimum oleh γ * akan ditunjukkan sebagai berikut: γ * = min S(z)
xeZ
Masalah deterministik tersebut diacak dengan mendefinisikan {f(;v),v⋅∈ V}
dan persamaan masalah estimasi di atas untuk skalar γ dapat diberikan:
Pu(S(Z)≤γ) = Eu [Is(z)≤γ] yang disebut masalah stokastik.
Di sini, Z adalah vektor acak dengan (;.u), untuk beberapa u ∈ V (misalnya Z
menjadi vektor acak Bernoulli). Untuk memperkirakan, metode CE menghasilkan
optimal (γ*){v*}, di mana γ* adalah solusi dari permasalahan, dan v* yang
menekankan nilai-nilai di Z dengan solusi optimal.
Fraksi sampel ditunjukkan oleh ρyang digunakan untuk mencari batasan γ.
Proses didasarkan pada sampel data stochastic. Jumlah sampel dalam setiap tahap
stochastic dilambangkan dengan N, yang merupakan parameter yang telah
ditetapkan.
3.4.2. Cross Entropy Sebagai Kombinasi Optimisasi
Dalam kasus penjadwalan diperlukan parameter P di tempat v. P adalah
matriks transisi di mana setiap entri pi,jmenunjukkan probabilitas ke-j, untuk i = 1,
2 , .. , n , j = 1 , 2 , ... , n , di mana n adalah jumlah pekerjaan. Untuk P awal dapat ditempatkan nilai-nilai yang sama dengan semua entri yang berarti bahwa
probabilitas dari pekerjaan ke tempat j didistribusikan merata.
Berdasarkan matriks P, akan menghasilkan N urutan pekerjaan. Setiap
urutan (Zi) akan dievaluasi berdasarkan S(zi) di mana S = nilai Cmax untuk setiap
urutan. Dari urutan N dapat diambilρN sampel elit persen dengan S terbaik (bukan
menggunakan γ sebagai batas untuk memilih sampel elit). Rumus ES = ρN,
diberikan olehPt(i,j)sebagai berikut:
�(��,�) =
∑���=��{��=�}
��
Algoritma utama Cross Entropy (CE) yang digunakan dalam penjadwalan adalah sebagai berikut: (R.Y. Rubinstein dan D. P. Kroese ,2014)
2. Dihasilkan sampel Z1, … , ZN urutan pekerjaan melalui algoritmadengan P =
t - 1 dan pilih ρN sampel elit dengan kinerja terbaik dari S(z).
3. Gunakan sampel elit untuk memperbarui Pt
4. Terapkan untuk menghasilkan matriks Pt
5. Jika untuk beberapat ≥ d, misalkan d = 5 , γt = γt-1 = … = γt-d kemudian
berhenti, jika tidak diatur t = t + 1 dan ulangi dari langkah 2.
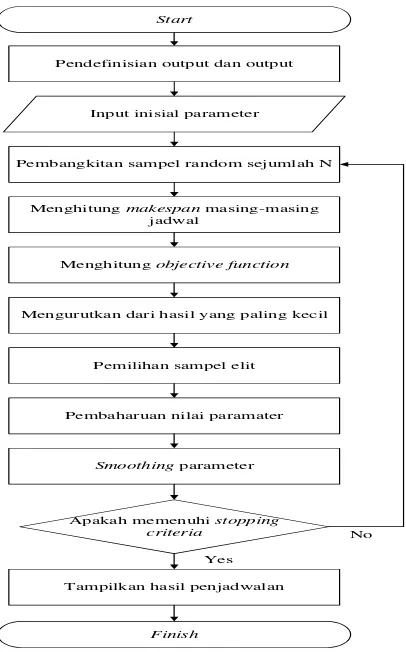
Langkah-langkah algoritma cross entropy secara umum ditunjukkan pada Gambar 3.1.(Sayid Basori,2011)
Start
Pendefinisian output dan output
Pembangkitan sampel random sejumlah N Input inisial parameter
Menghitung makespan masing-masing jadwal
Menghitung objective function
Mengurutkan dari hasil yang paling kecil
Pemilihan sampel elit
Pembaharuan nilai paramater
Smoothing parameter
Tampilkan hasil penjadwalan Apakah memenuhi stopping
criteria
Finish
No Yes
3.5. Algoritma Genetika
Algoritma genetika adalah algoritma pencarian heuristik yang didasarkan atas mekanisme biologis. Keberagaman pada evolusi biologis adalah variasi dari kromosom antar individu organisme untuk tetap hidup. Pada dasarnya ada 4 kondisi yang sangat memengaruhi proses evaluasi yakni sebagai berikut:
1. Kemampuan organisme untuk melakukan reproduksi.
2. Keberadaan populasi organisme yang bisa melakukan reproduksi. 3. Keberagaman organisme dalam suatu populasi.
4. Perbedaan kemampuan untuk survive.
Individu yang lebih kuat akan memiliki tingkat survival dan tingkat reproduksi yang lebih tinggi jika dibandingkan dengan individu yang kurang fit. Pada kurun waktu tertentu (sering dikenal dengan istilah generasi), populasi secara keseluruhan akan lebih banyak memuat organisme yang fit. Algoritma genetika pertama kali dikembangkan oleh John Hollan mengatakan bahwa setiap masalah yang berbentuk adaptasi (alami maupun buatan) dapat diformulasikan dalam terminologi genetika. Algoritma genetika adalah simulasi dari proses evolusi Darwin dan operasi genetika atas kromosom.
sehingga memungkinkan untuk menyelesaikan permasalahan-permasalahan optimisasi yang kompleks secara lebih mudah dan akurat. Algoritma genetik merupakan teknik search stochastic yang berdasarkan mekanisme seleksi alam dan genetika natural. Yang membedakan algoritma genetik dengan berbagai algoritma konvensional lainnya adalah bahwa algoritma genetik memulai dengan suatu himpunan penyelesaian acak awal yang disebut populasi.
3.5.1. Struktur Umum Algoritma Genetika
Pada algoritma ini, teknik pencarian dilakukan sekaligus atas sejumlah solusi yang mungkin dikenal dengan istilah populasi. Individu yang terdapat dalam satu populasi disebut dengan istilah kromosom. Kromosom ini merupakan suatu solusi yang masih berbentuk simbol. Populasi awal dibangun secara acak, sedangkan populasi berikutnya merupakan hasil evolusi kromosom-kromosom melalui iterasi yang disebut dengan istilah generasi. Pada setiap generasi, kromosom akan melalui proses evaluasi dengan menggunakan alat ukur yang disebut dengan fungsi fitness. Nilai fitness dari suatu kromosom akan menunjukkan kualitas kromosom dalam populasi tersebut.
(offspring), serta menolak kromosom-kromosom yang lainnya sehingga ukuran populasi (jumlah kromosom dalam suatu populasi) konstan. Setelah melalui beberapa generasi, maka algoritma ini akan konvergen ke kromosom terbaik.
3.5.2. Istilah dalam Genetic Algorithm
Beberapa istilah yang sering digunakan dalam Genetic Algorithm adalah sebagai berikut:
1. Individu, salah satu solusi yang mungkin dilakukan pada metode genetic algorithm. Sama seperti dalam kehidupan sehari-hari, individu terdiri dari sekumpulan gen.
2. Genotype (gen), sebuah nilai yang menyatakan satuan dasar yang membentuk satu kesatuan yang disebut kromoson. Dalam genetic algorithm gen ini dapat berbentuk nilai biner, float, integer maupun karakter, atau kombinational. 3. Alel, nilai dari gen.
4. Kromosom, gabungan dari beberapa gen yang membentuk nilai-nilai tertentu. 5. Populasi, sekumpulan individu yang akan diproses dalam satu siklus evolusi. 6. Generasi, satu siklus proses evolusi atau dalam genetic algorithm disebut satu
proses iterasi.
3.5.3. Komponen Utama Dalam Genetic Algorithm
Algoritma genetik memiliki lima buah komponen utama dalam proses penyelesaiannya, yaitu:
1. Teknik Pengkodean
Teknik pengkodean adalah bagaimana proses mengkodekan gen dari kromoson, dimana gen merupakan bagian dari kromoson. Satu gen biasanya akan mewakili satu variabel. Gen dapat direpresentasikan dalam bentuk bit, bilangan real, daftar aturan, elemen permutasi, elemen program atau representasi lainnya yang dapat diimplementasikan untuk operator genetika. 2. Membangkitkan Populasi Awal
Membangkitkan populasi awal adalah proses membangkitkan sejumlah individu secara acak atau melalui prosedur tertentu. Ukuran untuk populasi tergantung pada masalah yang akan diselesaikan dan jenis operator genetika yang akan diimplementasikan. Setelah ukuran populasi ditentukan, kemudian dilakukan pembangkitan populasi awal. Syarat-syarat yang harus dipenuhi untuk menunjukkan suatu solusi harus benar-benar diperhatikan dalam setiap pembangkitan individunya.
Teknik dalam pembangkitan awal ini ada beberapa cara, diantaranya adalah: a. Random generator
generator adalah penggunaan rumus berikut untuk pembangkitan populasi awal.
IPOP = round{random[Nipop, Nbits]}
Dimana ipop adalah gen yang nantinya berisi pembulatan dari bilangan random yang dibangkitkan sebanyak Nipop (jumlah populasi) x Nbits (jumlah gen tiap kromoson).
b. Pendekatan tertentu (memasukan nilai tertentu ke dalam gen)
Cara ini adalah dengan memasukan nilai tertentu ke dalam gen populasi awal yang dibentuk.
c. Permutasi Gen
Permutasi gen dalam pembangkitan awal adalah penggunaan permutasi Josephus dalam permasalahan kombinatorial seperti TSP.
3. Seleksi
Seleksi digunakan untuk memilih individu-individu mana saja yang akan dipilih untuk proses kawin silang dan mutasi. Seleksi digunakan untuk mendapatkan calon yang baik. Induk yang baik akan menghasilkan keturunan yang baik. Semakin tinggi nilai fitness suatu individu semakin besar kemungkinannya untuk terpilih.
sendiri terhadap nilai objektif dari semua individu dalam wadah seleksi tersebut.
a. Seleksi dengan Mesin Roulette
Metode seleksi dengan mesin roulette ini merupakan metode yang paling sederhana dan sering dikenal dengan nama stochastic sampling with replaCEment. Cara kerja metode ini adalah sebagai berikut:
1). Dihitung nilai fitness dari masing-masing individu (fi dimana i adalah individu ke-1 sampai ke-n).
2). Dihitung total fitness semua individu.
3). Dihitung probabilitas masing-masing individu.
4). Dari probabilitas tersebut, dihitung jatah masing-masing individu pada angka 1 sampai 100.
5). Dibangkitkan bilangan random antara 1 sampai 100.
6). Dari bilangan random yang dihasilkan, ditentukan individu mana yang terpilih dalam proses seleksi.
b. Seleksi dengan Turnamen
Pada seleksi dengan turnamen, ditetapkan nilai suatu tour untuk individu-individu yang dipilih secara random dari suatu populasi. Individu-individu-individu yang terbaik dalam kelompok ini akan diseleksi sebagai induk. Parameter yang digunakan pada metode ini adalah ukuran tour yang bernilai antara 2 sampai N (jumlah individu dalam suatu populasi).
Kawin silang (crossover) adalah operator dari algoritma genetika yang melibatkan dua induk untuk membentuk kromoson baru. Crossover menghasilkan titik baru dalam ruang pencarian yang siap diuji. Operasi ini tidak selalu dilakukan pada semua individu yang ada. Individu dipilih secara acak untuk dilakukan crossing dengan Pc antara 06 sampai dengan 0,95. Jika crossover tidak dilakukan, maka nilai dari induk akan diturunkan kepada keturunan. Prinsip dari crossover ini adalah melakukan operasi (pertukaran, aritmatika) pada gen-gen yang bersesuaian dari dua induk untuk menghasilkan individu baru. Proses crossover dilakukan pada setiap individu dengan probabilitas crossover yang ditentukan.
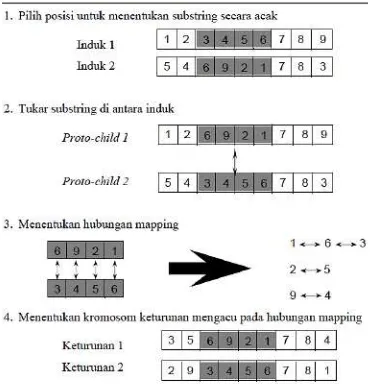
Untuk proses crossover dengan gen berbentuk permutasi metode yang digunakan adalah Partial-Mapped Crossover (PMX) seperti pada Gambar 3.2. PMX diciptakan oleh Goldberg dan Lingle. PMX merupakan rumusan modifikasi dari kawin silang 2 point. Hal yang penting dalam PMX adalah kawin silang 2 point ditambah dengan beberapa prosedur tambahan. PMX mempunyai langkah kerja sebagai berikut:(Entin, 2010)
a. Langkah 1: tentukan 2 posisi pada kromoson dengan aturan acak. Substring yang berada dalam dua posisi ini dinamakan daerah pemetaan. b. Langkah 2: tukar kedua substring antar induk untuk menghasilkan
protochild.
c. Langkah 3: tentukan hubungan pemetaan diantara 2 daerah pemetaan. d. Langkah 4: tentukan kromoson keturunan dengan mengacu pada
Gambar 3.2. Ilustrasi Prosedur PMX
5. Mutasi
BAB IV
METODOLOGI PENELITIAN
4.1. Tempat dan Waktu Penelitian
Penelitian dilakukan di PT. Florindo Makmur yang berada di Jl. Besar Desa Pergulaan Dusun V, Kecamatan Sei Rampah, Kabupaten Serdang Bedagai, Provinsi Sumatera Utara. Waktu penelitian dilakukan pada Oktober 2016 hingga Juni 2017.
4.2. Jenis Penelitian
Jenis penelitian inia dalah action research yang merupakan penelitian yang dilakukan untuk mendapatkan temuan-temuan praktis atau untuk keperluan pengambilan keputusan operasional. Karena tujuannya untuk pengambilan keputusan operasional guna mengembangkan keterampilan baru atau pendekatan baru maka penelitian ini kurang memberikan kontribusi terhadap ilmu pengetahuan(Sinulingga, 2015).
4.3. Objek Penelitian
4.4. Variabel Penelitian
Variabel adalah sesuatu yang memiliki nilai yang berbeda-beda atau bervariasi. Nilai dari variable dapat bersifat kuantitatif atau kualitatif (Sinulinggga, 2015). Variabel-variabel yang terdapat dalam penelitian inia dalah: 1. Variabel Independen
a. Permintaan tiap jenis produk pada periode bulanan.
b. Kapasitas stasiun kerja yang tersedia yang dinyatakan dalam batch. c. Waktu proses produksi pada masing-masing stasiun.
Variabel-variabel ini adalah factor-faktor yang mempengaruhi penjadwalan produksi pada lantai produksi.
2. Variabel Dependen
Variabel dependen merupakan variabel yang dipengaruhi. Variabel tersebut yaitu penjadwalan produksi yang dilaksanakan pada lantai pabrik.
4.5. Kerangka Berpikir
Kerangka berpikir menunjukan hubungan logis antara faktor / variabel yang telah diidentifikasi penting untuk menganalisis masalah penelitian (Sinulingga, 2015).
Nilai Makespan Jumlah permintaan produk
Waktu proses tiap stasiun kerja
Kapasitas stasiun kerja tersedia
Gambar 4.1. Kerangka Berpikir
4.6. Metode Pengumpulan Data
Metode pengumpulan data yang dilakukan pada penelitian adalah dengan melakukan observasi, yaitu dengan melakukan pengamatan secara langsung terhadap objek yang akan dipelajari baik dalam lingkungan kerja alamiahnya ataupun dalam laboratorium setting (Sinulingga,2015). Observasi yang dilakukan dengan cara melakukan pengamatan langsung dilantai produksi.
Terdapat dua jenis data yang dikumpulkan berdasarkan sumber dalam penelitian ini yaitu data primer dan data sekunder.
1. Data primer adalah data yang diperoleh dengan cara mencari/menggali secara langsung dari sumbernya oleh peneliti bersangkutan. Data primer yang digunakan adalah data waktu proses mesin yang dilakukan oleh operator melalui pengukuran pada lantai pabrik menggunakan stopwatch time study. 2. Data sekunder adalah data yang sudah tersedia oleh pihak lain sehingga tidak
perlu lagi dikumpulkan secara langsung dari sumbernya oleh peneliti. Data sekunder yang digunakan untuk penelitian ini diperoleh langsung dari perusahaan, data sekunder yang digunakanyaitudata permintaanproduk, data produksi, dan data kapasitas produksi.
4.7. Metode Pengolahan Data
Langkah-langkah pengolahan data dalam penelitian ini terdiri atas beberapa tahapan yaitu:
a. Penentuan waktu standar setiap proses pada stasiun kerja dengan menggunakan metode stopwatch time study.
1) Melakukan pengukuran waktu proses pada setiap stasiun kerja dengan menggunakan stopwatch.
2) Melakukan perhitungan uji keseragaman dan kecukupan data 3) Melakukan perhitungan rating factor dengan metodeWestinghouse
4) Melakukan perhitungan waktu normal berdasarkan waktu siklus dan rating factor
5) Menentukan allowanced engan menggunakan Tabel Industrial Labour Organization (ILO)
6) Melakukan perhitungan waktu standar berdasarkan waktu normal dan allowance.
b. Penjadwalan dengan metode Cross Entropy – Genetic Algorithm
Penjadwalan dengan metode gabungan Cross Entropy dan Genetic Algorithm terdiri atas beberapa tahap yaitu:
1) Inisialisasi parameter, paramenter yang digunakan yaitu jumlah sampel yang dibangkitkan, parameter kejarangan, koefisien penghalusan, parameter pindah silang, dan parameter pemberhentian.
3) Perhitungan fungsi tujuan, dihitung berdasarkan nilai makespan.
4) Penentuan sampel elit, maka nilai makespan dari semua sampel diurutkan dari terkecil hingga terbesar.
5) Pembobotan sampel elit, diperoleh dari evaluasi terhadap nilai terbaik pada iterasi sebelumnya.
6) Perhitungan Linear Fitness Rangking (LFR), digunakan untuk pemilihan induk pada proses pindah silang.
7) Update parameter pindah silang, diperlukan untuk mendapatkan nilai parameter yang update untuk evaluasi criteria pemberhentian.
8) Elitisme, bertujuan menyimpan sampel dengan nilai fungsi tujuan terbaik pada setiap iterasi.
9) Pemilihan induk pindah silang, yakni pemilihan dua buah kromosom sebaga iinduk yang akan dipindah silangkan secara proposional sesuai nilai fitness -nya.
10) Cross over (pindah silang), menyilangkan 2 induk untuk membentuk kromosom baru untuk menghasilkan individu baru yang lebih baik.
11) Mutasi, dimaksudkan untuk memunculkan individu baru yang berbeda dengan individu yang sudah ada.
12) Perhitungan nilai fungsi tujuan dari populasi baru.
Rancangan jadwal hasil metode Cross Entropy – Genetic Algorithm adalah makespan minimum dan urutan job yang optimal.
nilai nilai makespan paling kecil. Perhitungan performansi terdiri dari 2 tahap, yaitu :
1) Menghitung nilai Efficiency Index (EI) 2) Menghitung nilai Relative Error (RE)
Uji Keseragaman data
Uji kecukupan data
Menetapkan waktu baku berdasarkan allowance dan rating factor
Penjadwalan produksi
Metode FCFS Pendekatan Algoritma Cross Entropy-Genetic
Algorithm
Performansi penjadwalan
Gambar 3.2. Blog DiagramPengolahan Data
4.8. Metode Analisis
Analisis pemecahan masalah menguraikan jawaban dari pertanyaan yang berkaitan dengan masalah dalam penelitian ini. Analisis yang dilakukana dalah: 1. Analisis perbandingan performansi metode perusahaan dengan metode Cross
Entropy-Genetic Algorithm.
4.9. Blok Diagram Prosedur Penelitian
BAB V
PENGUMPULAN DAN PENGOLAHAN DATA
5.1. Pengumpulan Data
Dalam menyelesaian masalah pada penelitian di PT. Florindo Makmur dibutuhkan sejumlah data yang relevan. Pengumpulan data ini dilakukan dengan cara pengamatan langsung terhadap objek penelitian. Terdapat dua jenis merk produk yang dihasilkan yaitu Rose Brand (Tipe A) dan Gunung Agung (Tipe B).
5.1.1. Data Mesin
Data mesin yang diambil merupakan jumlah mesin yang terdapat pada masing-masing stasiun kerja di lantai produksi seperti ditunjukkan pada Tabel 5.1.
Tabel 5.1. Jumlah Mesin di Setiap Stasiun Kerja
5.1.2. Uraian Proses Produksi
Proses produksi pembuatan tepung tapioka pada PT. Florindo Makmur adalah sebagai berikut:
1. Stasiun Kerja Pengupasan (WC I)
Satu siklus pada stasiun kerja ini dimulai dari proses memasukkan bahan baku singkong ke dalam mesin root peeler. Setelah itu mesin dihidupkan dan proses pengupasan singkong dilakukan. Setelah selesai diproses mesin dimatikan.
2. Stasiun Kerja Pencucian (WC II)
Satu siklus pada stasiun kerja ini dimulai dari proses memasukkan singkong yang telah dikupas ke dalam mesin root washer. Setelah itu mesin dihidupkan dan proses pencucian singkong dilakukan. Setelah selesai diproses mesin dimatikan.
3. Stasiun Kerja Pemarutan (WC III)
Satu siklus pada stasiun kerja ini dimulai dari proses memasukkan singkong yang telah dicuci ke dalam mesin root rashper. Setelah itu mesin dihidupkan dan proses pemarutan singkong dilakukan hingga menjadi bubur singkong. Setelah selesai diprosees mesin dimatikan.
4. Stasiun Kerja Ekstraksi (WC IV)
5. Stasiun Kerja Separasi (WC V)
Satu siklus pada stasiun kerja ini dimulai dari pengakutan air kandungan pati ke dalam mesin separator. Setelah itu mesin dihidupkan dan proses pengolahan dilakukan hingga menjadi stratch milk. Setelah selesai mesin dimatikan..
6. Stasiun Kerja Filter (WC VI)
Satu siklus pada stasiun kerja ini dimulai dari pengakutan stratch milkke dalam mesin center view. Setelah itu mesin dihidupkan dan proses penyaringan dilakukan hingga tepung dalam kondisi 40% kering. Setelah selesai mesin dimatikan.
7. Stasiun Kerja Pengeringan (WC VII)
Satu siklus pada stasiun kerja ini dimulai dari pengangkutan stratch milk ke dalam mesin drying cyclone. Setelah itu mesin dihidupkan dan proses pengeringan dilakukan hingga tepung menjadi kering utuh. Setelah selesai mesin dimatikan.
8. Stasiun Kerja Pendinginan (WC VIII)
9. Stasiun Kerja Pengepakan (WC IX)
Satu siklus pada stasiun kerja ini dimulai dari penghidupan mesin pengayakan tepung yang telah didinginkan. Setelah selesai diayak, tepung dijatuhkan kedalam karung yang telah disiapkan dan dilakukan penjahitan pada karung. Karung yang telah selesai dijahit disusun diatas lantai.
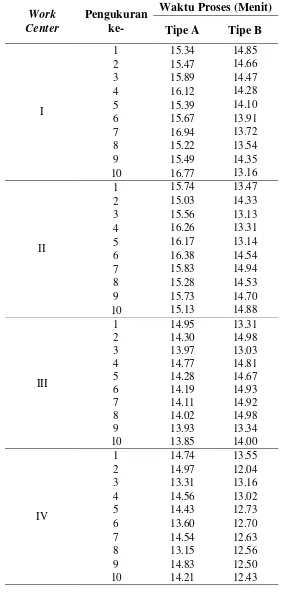
5.1.3. Data Pengukuran Waktu Proses Tiap Produk
Waktu proses setiap pengerjaan produk untuk setiap mesin diperoleh dari pengukuran waktu dengan menggunakan metode jam henti (stopwatch time study). Data waktu siklus diambil sebanyak 10 kali pengukuran, karena waktu siklus lebih dari 2 menit (Barnes, 1972). Bila tidak memenuhi kecukupaan data, maka dilakukan pengukuran tambahan sehingga data dinyatakan cukup.
IX
Sumber : Pengukuran Waktu pada PT. Florindo Makmur
Tabel 5.3. Data Pengukuran Waktu Proses Operator pada WC IX
Work
Sumber : Pengukuran Waktu pada PT. Florindo Makmur
5.1.4. Rating Factor dan Allowance
poor. Faktor kondisi kerja terdiri dari ideal, excellent, good, average, fair dan poor. Faktor konsistensi terdiri dari perfect, excellent, good, average, fair dan poor.
Rating Factor untuk stasiun kerja I diperoleh dari perhitungan sebagai berikut:
Keterampilan : Average (D) : 0,00 Usaha : Good (C2) : 0,02 Kondisi Kerja : Good (C) : 0,02 Konsistensi : Good (C) : 0,01 Total : 0,05
Allowance (kelonggaran) dapat dilihat dari tiga faktor yaitu untuk kebutuhan pribadi, menghilangkan rasa lelah dan hambatan-hambatan yang tidak terhindarkan. Allowance untuk stasiun kerja I adalah sebagai berikut:
Kebutuhan pribadi : pria : 1
Tenaga yang dikeluarkan : dapat diabaikan : 1
Sikap kerja : berdiri di atas dua kaki : 1
Gerakan kerja : agak terbatas : 0
Kelelahan mata : pandangan yang terputus-putus : 0
Keadaan temperatur : tinggi : 5
Keadaan lingkungan : sangat bising : 1
Hambatan yang terhindarkan : : 2
Jumlah 11%
Rating factor dan Allowance untuk tiap operator pada setiap stasiun kerja dapat dilihat pada Tabel 5.10.
Tabel 5.10. Rating Factor dan Allowance Tiap Stasiun Kerja
Stasiun Kerja Rating Factor Allowance
WC I 0,05 11
WC II 0,07 13
WC III 0,09 12
WC IV 0,05 10
WC V 0,08 13
WC VI 0,09 11
WC VII 0,09 10
WC VIII 0,08 13
5.1.5. Waktu Set Up
Waktu set up masing-masing stasiun kerja dapat dilihat pada Tabel 5.3. Tabel 5.3. Waktu Set Up Mesin Pada Setiap Stasiun Kerja Stasiun
Kerja Nama Proses
Waktu Set Up (Menit) I Memuat Bahan Baku Singkong dan Setup Mesin 2
II Setup Mesin Pencucian Singkong 2
III Memuat Parutan Singkong dan Setup Mesin 3 IV
Pengaturan Control Mesin Pengeringan Pengisian Tepung Kering
Sumber : Pengukuran Waktu Set Up PT. Florindo Makmur
5.2. Pengolahan Data
5.2.1. Peramalan Permintaan Bulan Januari 2017 dengan Menggunakan Metode Time Series
Data permintaan produk yang digunakan adalah data penjualan pada bulan Januari 2017. Untuk memperoleh data penjualan bulan Januari 2017 dilakukan peramalan berdasarkan data historis yang ada diperusahaan.
5.2.1.1. Peramalan Besarnya Permintaan Tipe A
Tabel 5.4. Data Permintaan Tipe A Periode Januari 2016 - Desember 2016
No. Bulan Permintaan (Ton)
1 Januari 1,325
2 Februari 1,573
3 Maret 1,273
4 April 1,367
5 Mei 1,596
6 Juni 1,256
7 Juli 1,436
8 Agustus 1,502
9 September 1,316
10 Oktober 1,650
11 November 1,340 12 Desember 1,634
Sumber: PT. Florindo Makmur
Langkah-langkah peramalan yang dilakukan terdiri atas : 1. Mendefinisikan tujuan peramalan
Tujuan peramalan adalah untuk meramalkan besarnya permintaan Tipe A pada bulan Januari 2017 hingga Desember 2017.
2. Pembuatan Scatter diagram
Gambar 5.1.Scatter DiagramPermintaan Tipe A
Sumber: Hasil Pengolahan Data
3. Pemilihan Metode Peramalan
Metode peramalan yang digunakan adalah : a. Metode Dekomposisi
b. Metode Siklis
4. Menghitung parameter peramalan
Untuk memudahkan perhitungan, maka dimisalkan X sebagai variabel bulan (periode) dan Y sebagai variabel jumlah produksi.
a. Metode Dekomposisi
Langkah – langkah yang dilakukan peramalan dekomposisi yaitu : membagi pola data menjadi bagian-bagian yang memiliki pola yang mirip dan berulang pada periode tertentu. Berdasarkan pola data yang dapat dilihat pada Gambar 5.1. maka data dibagi menjadi 3 pola berulang,
0 200 400 600 800 1.000 1.200 1.400 1.600 1.800
1 2 3 4 5 6 7 8 9 10 11 12
Scatter Diagram
selanjutnya dihitung nilai rata- rata bergerak dalam kurun waktu per 4 periode selama 12 periode.
1). Menghitung nilai rata – rata dari 12 periode
Nilai rata- rata bergerak yang dihitung adalah rata- rata dalam kurun waktu per 4 periode selama 12 periode yakni dari periode Januari 2016 – Desember 2016. Contoh perhitungan untuk periode Januari 2016 – Desember 2016 :
Nilai Rata – Rata = 1.325+1.573+1.273+1.367 4
= 1.385
Rekapitulasi perhitungan nilai rata- rata per 4 periode selama periode Januari 2016 – Desember 2016. Dapat dilihat pada Tabel 5.8.
2). Menghitung nilai indeks musim
Nilai indeks musim dihitung dengan menggunakan nilai indeks rata- rata bergerak yang telah dihitung sebelumnya. Hal yang pertama dilakukan adalah menghitung faktor musim dengan cara membagi hasil rata – rata per 4 periode dengan permintaan pada setiap periodenya kemudian menghitung nilai indeks musim dengan cara merata- ratakan nilai dari faktor musim yang ada. Contoh perhitungan nilai faktor musim yaitu :
Nilai faktor musim = 1.325 1.385 = 0,9570
= 0,9819
Perhitungan nilai indeks musim periode selanjutnya dilakukan dengan cara yang sama. Hasil rekapitulasi perhitungan nilai indeks musim dapat dilihat pada Tabel 5.5.
Tabel 5.5. Rekapitulasi Nilai Faktor Musim dan Nilai Indeks Musim
X
Sumber: Hasil Pengolahan Data
3). Trend Linier
Fungsi peramalan : Y = a + bx
Tabel 5.6. Persamaan Garis Trend
No. X Y XY X2
1 1 1,325 1,325 1
2 2 1,573 3,146 4
3 3 1,273 3,819 9
4 4 1,367 5,468 16
5 5 1,596 7,980 25
6 6 1,256 7,536 36
7 7 1,436 10,052 49
8 8 1,502 12,016 64
9 9 1,316 11,844 81
10 10 1,650 16,500 100
11 11 1,340 14,740 121
12 12 1,634 19,608 144
Jumlah 78 17,268 114,034 650
Rata-Rata 6,5 1,439 9,503 54.17
Sumber: Hasil Pengolahan Data
b = n Σ XY- ΣX ΣY
���2–(�)2
= 12 x 114.034-(78 x 17.268 ) 12 x 650-(782) = 12,53
a = x Y – (b) ( x )
= 1.439 – (12,53 ) (6,5) = 1.357,55
b. Metode Siklis
Fungsi peramalan : Y = Y = a + b sin 2 π x
n + c cos 2 π x
n
Tabel 5.7. Perhitungan Parameter Peramalan Tipe A dengan Metode Siklis
x Y Sin(2πx/n) Cos(2πx/n) Y.sin(2πx/n) Y.cos(2πx/n) sin 2(2π
Sumber: Hasil Pengolahan Data
3368.2572 = a (0) + b (6,2505) + c (0)
Maka fungsi peramalannya adalah :
Y’ = 1596,67+ 538,878sin 2 π x
n + 363,1368cos 2 π x
n
5. Menghitung setiap kesalahan setiap metode
Perhitungan kesalahan menggunakan metode MSE (Mean Square Error) dengan menggunakan rumus sebagai berikut:
MSE = ∑ �Xt–Ft
a. Metode Dekomposisi
Perhitungan MSE untuk metode Dekomposisi, yaitu :
Tabel 5.8. Perhitungan MSE untuk Metode Dekomposisi
1 1 1,325 1,370 -45 2,032
2 2 1,573 1,383 190 36,249
3 3 1,273 1,395 -122 14,918
4 4 1,367 1,408 -41 1,654
5 5 1,596 1,420 176 30,905
6 6 1,256 1,433 -177 31,235
7 7 1,436 1,445 -9 86
8 8 1,502 1,458 44 1,954
9 9 1,316 1,470 -154 23,817
10 10 1,650 1,483 167 27,936
11 11 1,340 1,495 -155 24,147
12 12 1,634 1,508 126 15,895
Jumlah 78 17,268 17,268 6.821E-13 210,828
Sumber: Hasil Pengolahan Data
MSE = ∑ �Xt–Ft n �
2
= �17.268−17.268
12 �
2
= 0
b. Metode Siklis ( f = 3 )
Tabel 5.9. Perhitungan MSE untuk Metode Siklis
Sumber: Hasil Pengolahan Data
MSE = ∑ �Xt–Ft
Terlihat bahwa MSE Dekomposisi< MSE Metode Siklis maka peramalan yang digunakan adalah peramalan dengan dekomposisi.
6. Menghitung nilai ramalan
Nilai ramalan akhir didapatkan dengan cara mengalikan nilai persamaan garis trend dengan nilai indeks musim fungsi peramalannya adalah :
Hasil rekapitulasi nilai ramalan akhir dapat dilihata pada Tabel 5.10.
Tabel 5.10.Nilai Ramalan dengan Menggunakan Metode Dekomposisi
No. Periode a b Pers.
Garis
Indeks
Musim Y' 1 13 1,357.55 12.53 1520.45 0.9819 1,493 2 14 1,357.55 12.53 1532.99 1.0383 1,592 3 15 1,357.55 12.53 1545.52 0.9380 1,450 4 16 1,357.55 12.53 1558.05 1.0418 1,623 5 17 1,357.55 12.53 1570.58 0.9819 1,542 6 18 1,357.55 12.53 1583.11 1.0383 1,644 7 19 1,357.55 12.53 1595.64 0.9380 1,497 8 20 1,357.55 12.53 1608.17 1.0418 1,675 9 21 1,357.55 12.53 1620.71 0.9819 1,591 10 22 1,357.55 12.53 1633.24 1.0383 1,696 11 23 1,357.55 12.53 1645.77 0.9380 1,544 12 24 1,357.55 12.53 1658.3 1.0418 1,728
Sumber: Hasil Pengolahan Data
Tabel 5.11. Hasil Peramalan untuk Periode Januari 2017 – Desember
Gambar 5.2. Scatter Diagram Hasil Peramalan Tipe A
5.2.1.2. Peramalan Besarnya Permintaan Tipe B
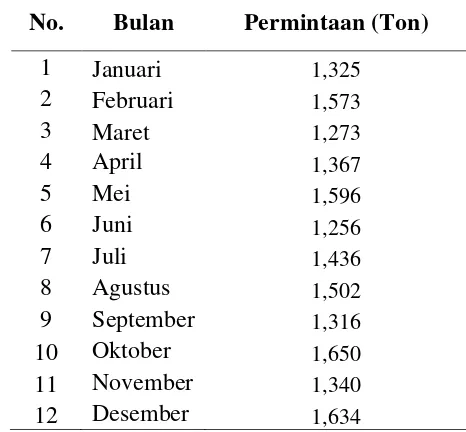
Data besarnya permintaan Tipe B dari bulan Januari 2016 hingga Desember 2016 dapat dilihat pada Tabel 5.12.
Tabel 5.12. Data Permintaan Tipe B
No. Bulan Produksi Tipe B
1 Januari 1,325
2 Februari 1,287
3 Maret 1,380
4 April 1,213
5 Mei 1,204
6 Juni 1,535
7 Juli 1,755
8 Agustus 1,229
9 September 1,264
10 Oktober 1,100
11 November 1,340 12 Desember 1,337
Sumber: PT. Florindo Makmur
Langkah-langkah peramalan yang dilakukan terdiri atas : 1. Mendefinisikan tujuan peramalan
2. Pembuatan Scatter diagram
Dari Tabel 5.14. maka akan dibuat scatter diagram untuk melihat pola data yang dapat dilihat pada Gambar 5.3.
Gambar 5.3. Scatter DiagramPermintaan Tipe B
Sumber: Hasil Pengolahan Data
3. Pemilihan Metode Peramalan
Metode peramalan yang digunakan adalah : c. Metode Dekomposisi
d. Metode Siklis
4. Menghitung parameter peramalan
Untuk memudahkan perhitungan, maka dimisalkan X sebagai variabel bulan (periode) dan Y sebagai variabel jumlah produksi.
a. Metode Dekomposisi
Langkah – langkah yang dilakukan peramalan dekomposisi yaitu : membagi pola data menjadi bagian-bagian yang memiliki pola yang mirip dan berulang pada periode tertentu. Berdasarkan pola data yang dapat
dilihat pada Gambar 5.3. maka data dibagi menjadi 4 pola berulang, selanjutnya dihitung nilai rata- rata bergerak dalam kurun waktu per 3 periode selama 12 periode.
1). Menghitung nilai rata – rata dari 12 periode
Nilai rata- rata bergerak yang dihitung adalah rata- rata dalam kurun waktu per 3 periode selama 12 periode yakni dari periode Januari 2016 hingga Desember 2016. Contoh perhitungan untuk periode Januari 2016 hingga Desember 2016 :
Nilai Rata – Rata = 1.325+1.287+1.380 3
= 1.331
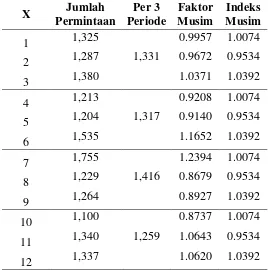
Rekapitulasi perhitungan nilai rata- rata per 3 periode selama periode Januari 2016 hingga Desember 2016. Dapat dilihat pada Tabel 5.16. 2). Menghitung nilai indeks musim
Nilai indeks musim dihitung dengan menggunakan nilai indeks rata- rata bergerak yang telah dihitung sebelumnya. Hal yang pertama dilakukan adalah menghitung faktor musim dengan cara membagi hasil rata – rata per 3 periode dengan permintaan pada setiap periodenya kemudian menghitung nilai indeks musim dengan cara merata- ratakan nilai dari faktor musim yang ada. Contoh perhitungan nilai faktor musim yaitu :
Maka nilai indeks musim dapat dihitung dengan : Nilai indeks musim = 0,9957+0,9208+1,2394+0,8737
4 = 1,0074
Perhitungan nilai indeks musim periode selanjutnya dilakukan dengan cara yang sama. Hasil rekapitulasi perhitungan nilai indeks musim dapat dilihat pada Tabel 5.13.
Tabel 5.13. Rekapitulasi Nilai Faktor Musim dan Nilai Indeks Musim
X Jumlah
Sumber: Hasil Pengolahan Data
3). Trend Linier
Fungsi peramalan : Y = a + bx
perhitungan parameter dengan trend linear peramalan Tipe B dapat dilihat pada Tabel 5.14.
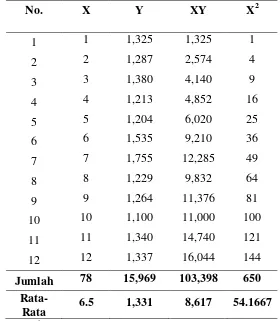
Tabel 5.14. Persamaan Garis Trend
No. X Y XY X2
1 1 1,325 1,325 1
2 2 1,287 2,574 4
3 3 1,380 4,140 9
4 4 1,213 4,852 16
5 5 1,204 6,020 25
6 6 1,535 9,210 36
7 7 1,755 12,285 49
8 8 1,229 9,832 64
9 9 1,264 11,376 81
10 10 1,100 11,000 100
11 11 1,340 14,740 121
12 12 1,337 16,044 144
Jumlah 78 15,969 103,398 650
Rata-Rata 6.5 1,331 8,617 54.1667
Sumber: Hasil Pengolahan Data
b = n Σ XY- ΣX ΣY
���2–(�)2
= 12 x 103.398 -(78 x 15.969 ) 12 x 650-(782) = -2,8
Maka persamaan garis trend yang didapat adalah :
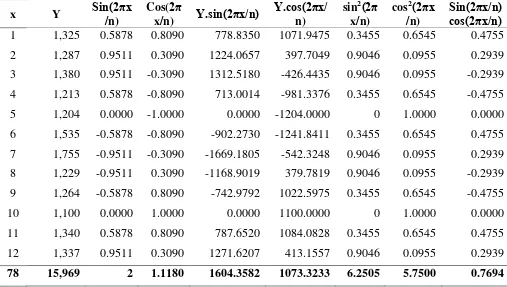
Tabel 5.15. Perhitungan Parameter Peramalan Tipe B dengan Metode Siklis
x Y Sin(2πx
Sumber: Hasil Pengolahan Data
1604,3582 = a (0) + b (6,2505) + c (0) Maka fungsi peramalannya adalah :
Y’ = 1330,75+ 256,6768sin 2 π x
n + 186,6649cos 2 π x
n
5. Menghitung setiap kesalahan setiap metode
Perhitungan kesalahan menggunakan metode MSE (Mean Square Error) dengan menggunakan rumus sebagai berikut:
MSE = ∑ �Xt–Ft
a. Metode Dekomposisi
Tabel 5.16. Perhitungan MSE untuk Metode Dekomposisi
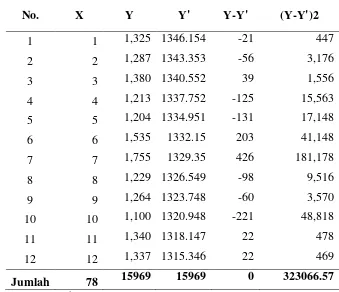
No. X Y Y' Y-Y' (Y-Y')2
1 1 1,325 1346.154 -21 447
2 2 1,287 1343.353 -56 3,176
3 3 1,380 1340.552 39 1,556
4 4 1,213 1337.752 -125 15,563
5 5 1,204 1334.951 -131 17,148
6 6 1,535 1332.15 203 41,148
7 7 1,755 1329.35 426 181,178
8 8 1,229 1326.549 -98 9,516
9 9 1,264 1323.748 -60 3,570
10 10 1,100 1320.948 -221 48,818
11 11 1,340 1318.147 22 478
12 12 1,337 1315.346 22 469
Jumlah 78 15969 15969 0 323066.57
Sumber: Hasil Pengolahan Data
MSE = ∑ �Xt–Ft n �
2
= �15969−15969
12 �
2
= 0
b. Metode Siklis ( f = 3 )
Tabel 5.17. Perhitungan PE dan SEE untuk Metode Siklis
Sumber: Hasil Pengolahan Data
MSE = ∑ �Xt–Ft
Terlihat bahwa MSE Dekomposisi< MSE Metode Siklis maka peramalan yang digunakan adalah peramalan dengan dekomposisi.
6. Menghitung nilai ramalan
Nilai ramalan akhir didapatkan dengan cara mengalikan nilai persamaan garis trend dengan nilai indeks musim fungsi peramalannya adalah :
YX =1.349 + -2,8 X
Tabel 5.18.Nilai Ramalan dengan Menggunakan Metode Dekomposisi
No. Periode a b Persamaan
Garis
Indeks
Musim Y' 1 13 1348.955 -2.8 1,312.5 1.0074 1,322 2 14 1348.955 -2.8 1,309.7 0.9534 1,249 3 15 1348.955 -2.8 1,306.9 1.0392 1,358 4 16 1348.955 -2.8 1,304.1 1.0074 1,314 5 17 1348.955 -2.8 1,301.3 0.9534 1,241 6 18 1348.955 -2.8 1,298.5 1.0392 1,349 7 19 1348.955 -2.8 1,295.7 1.0074 1,305 8 20 1348.955 -2.8 1,292.9 0.9534 1,233 9 21 1348.955 -2.8 1,290.1 1.0392 1,341 10 22 1348.955 -2.8 1,287.3 1.0074 1,297 11 23 1348.955 -2.8 1,284.5 0.9534 1,225 12 24 1348.955 -2.8 1,281.7 1.0392 1,332
Sumber: Hasil Pengolahan Data
Tabel 5.19. Hasil Peramalan Tipe B untuk Periode Januari 2017 –
Gambar 5.4. Scatter Diagram Hasil Peramalan Tipe B
Sehingga diperoleh data permintaan untuk bulan Januari 2017 adalah sebagai berikut :
Tabel 5.20. Data Permintaan Produk Bulan Januari 2017 PT. Florindo Makmur
Job Jenis Produk Jumlah (Ton)
A Tipe A 1.493
B Tipe B 1.322
5.2.2. Perhitungan Waktu Standar
Data waktu penyelesaian satu proses dari operasi yang telah diperoleh sebelumnya kemudian dihitung waktu standarnya. Ada beberapa tahapan yang harus dilakukan untuk menentukan waktu standar, yaitu pengujian keseragaman data, perhitungan jumlah data yang diperlukan, perhitungan waktu proses (siklus), perhitungan waktu normal, kemudian dilanjutkan dengan perhitungan waktu standar.
5.2.2.1.Uji Keseragaman Data
Uji keseragaman data ini dilakukan untuk menentukan apakah data waktu penyelesaian yang diperoleh berada dalam batas-batas kontrol yang telah ditetapkan. Berikut ini akan dijabarkan contoh perhitungan keseragaman data waktu proses untuk Work Center I pada pembuatan produk Tipe A. Waktu proses (siklus) rata-ratanya adalah sebagai berikut:
��= ∑ ��
∑ �
∑ � = jumlah pengamatan
�� =(15,34+15,47+15,89+16,12+15,39+15,67+16,94+15,22+15,49+16,77)
10 = 15,83 menit
Standar deviasi dari pengukuran waktu siklus pada Work Center I pembuatan produk Tipe A adalah:
�= �∑(�� − ��)
2 � −1
= �(15,34–15,83)
2 +…+ (16,77-15,83)2
10-1 = 0,573menit
Pengujian keseragaman data yang dihasilkan dari pengukuran tersebut dilakukan dengan peta kontrol, dibuat berdasarkan tingkat ketelitian sebesar 5% dan tingkat keyakinan sebesar 95%, maka dapat diperoleh batas kontrolnya adalah:
Batas Kontrol Atas (BKA) = ��+ 1,96�
= 15,83 + 1,96 (0,573) = 16,951 menit Batas Kontrol Bawah (BKB) = �� −1,96�
= 15,83 – 1,96 (0,573) = 14,707 menit
Tabel 5.21. Hasil Uji Keseragaman Waktu Proses Pada Setiap Work Center
Pengukuran Work
Center
Jenis Produk Rata-Rata Standar Deviasi BKA BKB
Tabel 5.21. Hasil Uji Keseragaman Waktu Proses Pada Setiap Work Center(Lanjutan)
Pengukuran Work
Center
Jenis Produk Rata-Rata Standar Deviasi BKA BKB
Tabel 5.21. Hasil Uji Keseragaman Waktu Proses Pada Setiap Work Center(Lanjutan)
Pengukuran Work
Center
Jenis Produk Rata-Rata Standar Deviasi BKA BKB
Tabel 5.21. Hasil Uji Keseragaman Waktu Proses Pada Setiap Work Center(Lanjutan)
Pengukuran Work
Center
Jenis Produk Rata-Rata Standar Deviasi BKA BKB
Tabel 5.21. Hasil Uji Keseragaman Waktu Proses Pada Setiap Work Center(Lanjutan)
Pengukuran Work
Center
Jenis
Produk Rata-Rata Standar Deviasi BKA BKB Keterangan
Tipe A
(Opt) Tipe B
(Opt)
Tipe A Tipe B Tipe A Tipe B Tipe A Tipe B Tipe A Tipe B
1
IX
4.94 1.02 3.32 1.23
5,31 4,19 0,457 0,091 6,203 4,366 4,413 4,010
Seragam
2 4.03 1.10 3.30 1.21 Seragam
3 3.99 1.32 3.26 1.11 Seragam
4 4.40 1.12 3.23 1.45 Seragam
5 4.37 1.24 3.20 1.10 Seragam
6 \4.94 1.21 3.17 1.03 Seragam
7 4.30 1.11 3.14 1.04 Seragam
8 4.38 1.17 3.11 1.24 Seragam
9 3.94 1.31 3.08 1.71 Seragam
5.2.2.2.Uji Kecukupan Data
Dengan menggunakan data pengamatan yang diperlukan di atas, selanjutnya dihitung jumlah data pengamatan yang diperlukan (N’). Jumlah data pengamatan yang diperlukan untuk tingkat kepercayaan 95% dimana nilai k = 1,96dan ketelitian 5% dimana nilai s = 0,05 adalah:
N’ =
�
�/��� ∑ ��Hasil perhitungan N’ dapat dilihat pada Tabel 5.22. dan Tabel 5.23. berikut ini.
Tabel 5.22. Uji Kecukupan Data untuk produk Tipe A pada Setiap Work
Tabel 5.22. Uji Kecukupan Data untuk produk Tipe A pada Setiap Work