LANDASAN TEORI
2.1. Algoritma
Algoritma adalah urutan langkah-langkah penyelesaian masalah yang disusun secara matematis dan logis. Tanpa kita sadari, kebanyakan dari kegiatan yang kita lakukan setiap harinya selalu berlandaskan algoritma.
Dalam beberapa konteks, algoritma adalah spesifikasi urutan langkah untuk melakukan pekerjaan tertentu. Pertimbangan dalam pemilihan algoritma adalah, pertama, algoritma haruslah benar. Artinya algoritma akan memberikan keluaran yang dikehendaki dari sejumlah masukan yang diberikan. Tidak peduli sebagus apapun algoritma, kalau memberikan keluaran yang salah, pastilah algoritma tersebut bukanlah algoritma yang baik. (Zarlis & Handrizal, 2008).
2.1.1 Algoritma String Matching (pencocokan string)
Pengertian string menurut Dictionary of Algorithms and Data Structures, National Institute of Standards and Technology (NIST) adalah susunan dari
karakter-karakter(angka,alfabet atau karakter yang lain) dan biasanya direpresentasikan sebagai struktur dan array. Pencocokan string (string matching) menurut Dictionary of Algorithms and Data Structures, National
Institute of Standards and Technology (NIST), diartikan sebagai sebuah
Pencocokan string (string matching) secara garis besar dapat dibedakan menjadi dua yaitu :
1) Exact string matching, merupakan pencocokan 2 string secara tepat dengan susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama. Contoh : kata step akan menunjukkan kecocokan hanya dengan kata step.
2) Inexact string matching atau Fuzzy string matching, merupakan pencocokan string secara samar, maksudnya pencocokan string dimana string yang
dicocokkan memiliki kemiripan dimana keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya) tetapi string-string tersebut memiliki kemiripan baik kemiripan tekstual/penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching). Inexact string
matching masih dapat dibagi lagi menjadi dua yaitu :
a. Pencocokan string berdasarkan kemiripan penulisan (approximate string matching) merupakan pencocokan string dengan dasar kemiripan dari segi
penulisannya (jumlah karakter, susunan karakter dalam dokumen). Tingkat kemiripan ditentukan dengan jauh tidaknya beda penulisan dua buah string yang dibandingkan tersebut dan nilai tingkat kemiripan ini ditentukan oleh pemrogram (programmer). Contoh : c mpuler dengan compiler, memiliki jumlah karakter yang sama tetapi ada dua karakter yang berbeda. Jika perbedaan dua karakter ini dapat ditoleransi sebagai sebuah kesalahan penulisan maka dua string tersebut dikatakan cocok.
b. Pencocokan string berdasarkan kemiripan ucapan (phonetic string matching) merupakan pencocokan string dengan dasar kemiripan dari segi
2.1.1.1 Algoritma Not So Naive
Algoritma Not So Naive pertama kali dipublikasikan oleh Christophe Hancart tahun 1992. Algoritma Not So Naive merupakan variasi turunan dari algoritma Naive atau yang sering disebut algoritma Brute Force. Cara kerja algoritma ini adalah dengan memiliki fase pencarian mengecek teks dan pola dari kiri ke kanan. Lalu, algoritma Not So Naive akan mengidentifikasi terlebih dahulu dua kasus yang dimana di setiap akhir fase pencocokan pergeseran dapat dilakukan sebanyak 2 posisi ke kanan, tidak seperti algoritma Naive yang dimana pergeseran tetaplah sebanyak 1 posisi ke kanan.
Kita asumsikan bahwa P[0] P[1]. Jika P[0] = T[s] dan P[1] = T[s+1], maka di akhir fase pencocokan pergeseran s bisa dilakukan sebanyak 2 posisi, karena P[0] P[1] = T[s+1]. Dan jika P[0] = P[1]. Jika P[0] = T[s] tapi P[1] T[s+1], maka sekali lagi pergesaran s dapat dilakukan sebanyak 2 posisi (Cantone & Faro, 2004) dimana P adalah Pattern, T adalah Teks dan s adalah nilai posisi.
2.1.1.1.1 Pencarian Algoritma Not So Naive
Saat fase pencarian dari Algoritma Not So Naive perbandingan karakter dilakukan dengan posisi pola mengikuti urutan 1, 2, ..., m-2, m-1, 0 dimana m adalah panjang pattern.
Di setiap percobaan dimana “jendela” diposisikan di teks faktory[i..j +
m-1]. Jika x[0] = x[1] dan x[1] y[j+1] atau jika x[0] x[1] dan x[1] = y[j+1]
polanya akan digeser sebanyak 2 posisi di setiap akhir percobaan dan sebanyak 1 posisi jika kondisi di atas tidak terpenuhi (Alapati & Mannava, 2011) dimana y adalah teks dan x adalah pattern.
Tabel 2.1 Proses Pencocokan Algoritma Not So Naive di Percobaan Pertama
Pada Tabel 2.1, perbandingan karakter pertama (x[1] == y[j+1]) mengalami kecocokan namun di perbandingan kedua mengalami ketidakcocokan, karena saat perbandingan pertama telah terjadi kecocokan, namun di urutan selanjutnya tidak terjadi kecocokan maka posisi pola akan digeser sebanyak 2 posisi sesuai dengan nilai variabel ell.
Tabel 2.2 Proses Pencocokan Algoritma Not So Naive di Percobaan Kedua
Pada Tabel 2.2, perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 2.3 Proses Pencocokan Algoritma Not So Naive di Percobaan Ketiga
Pada Tabel 2.3, perbandingan karakter pertama (x[1] != y[j+1]) masih mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
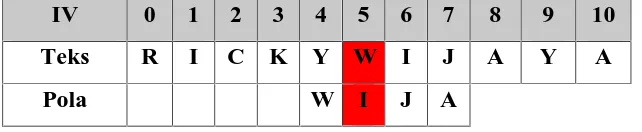
Tabel 2.4 Proses Pencocokan Algoritma Not So Naive di Percobaan Keempat
I 0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Pola W I J A
II 0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Pola W I J A
III 0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Pola W I J A
IV 0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Pada Tabel 2.4, perbandingan karakter pertama (x[1] != y[j+1]) masih mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 2.5 Proses Pencocokan Algoritma Not So Naive di Percobaan Kelima
Pada Tabel 2.5, perbandingan karakter mengalami kecocokan (x[1] == y[j+1]) dimulai dari perbandingan karakter W, I, J, dan A semua mengalami kecocokan, oleh sebab itu teks akan dikeluarkan. Namun, algoritma Not So Naive tidak berhenti sampai disini. Algoritma Not So Naive akan melakukan percobaan terus sampai sisa teks lebih kecil daripada pola. Untuk percoabaan selanjutnya, posisi pola akan digeser sebanyak 2 posisi sesuai dengan nilai variabel ell.
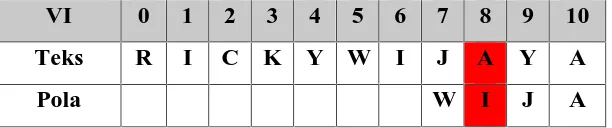
Tabel 2.6 Proses Pencocokan algoritma Not So Naive di Percobaan Keenam
Pada Tabel 2.6, perbandingan karakter pertama mengalami ketidakcocokan (x[1] != y[j+1]). Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k. Namun dikarenakan sisa teks telah lebih kecil daripada pola maka fase pencarian berhenti disini.
2.1.1.2 Algoritma Skip Search
Algoritma Skip Search merupakan salah satu algoritma pencocokan string, yang dipublikasikan secara luas oleh Charas, C et al., (1998). Cara kerja algoritma Skip Search seperti algoritma Knuth Morris Pratt dengan mendeteksi jendela dari
karakter yang ada dari kiri ke kanan dan menyimpannya ke dalam sebuah wadah untuk menentukan titik awal dari jendela karakter tersebut (Charas et al., Naser et al., 2012, 1998).
V 0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Pola W I J A
VI 0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Jadi, terdapat suatu pola yang ingin kita cari dan kita inisialkan x dan memiliki panjang yang kita inisialkan dengan m. Teks yang ingin kita cari kita inisialkan y dan memiliki panjang yang kita inisialkan dengan n. Untuk setiap simbol alfabet, sebuah wadah akan menyimpan semua posisi simbol dari x. Saat sebuah simbol berulang sebanyak k di dalam teks, maka akan ada sebanyak k posisi yang sesuai dalam wadah simbol. Saat pola lebih pendek daripada alfabet yang ada dalam teks, maka akan ada banyak tempat kosong dalam wadah.
Dalam perulangan utama dari fase pencarian terdapat proses memeriksa setiap teks simbol ke m, Yj (yang nantinya iterasi utama n/m). Untuk Yj, menggunakan setiap posisi yang ada di wadah z[Yj] untuk mendapatkan titik awal yang memungkinkan (p) dari x di dalam y. Lalu dilakukan proses perbandingan x dengan y dari posisi p, simbol dengan simbol, sampai terjadi ketidakcocokan atau seluruhnya cocok (Charras et al., 1998). Algoritma Skip Search memiliki efisiensi dalam mencari huruf kecil dalam pola yang panjang (Naser et al., 2012).
2.1.1.2.1 Fase Preprocessing Algoritma Skip Search
Tahap preprocessing Algoritma Skip Search terdiri dari tahap komputasi wadah untuk menampung seluruh karakter alfabet untuk c
z[c] = { i; 0 i m-1 and x[i] = c}.
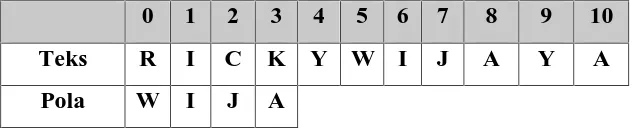
Ruang dan waktu kompleksitas dari fase preprocessing adalah O (m+ ) (Charras & Lecroq, 2004). Berikut diberikan contoh pada Tabel 2.7 untuk menunjukkan proses pencarian Algoritma Skip Search dengan pola WIJA yang akan dicari pada teks RICKYWIJAYA.
Tabel 2.7 Tabel Teks dan Pola yang akan Dijadikan Contoh Kasus
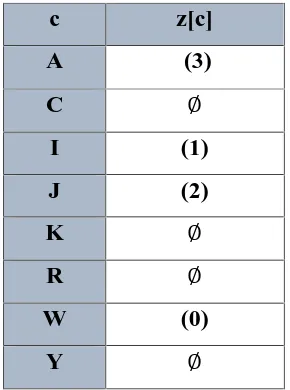
Maka hasil dari fase preprocessing Algoritma Skip Search dapat dilihat di Tabel 2.8
0 1 2 3 4 5 6 7 8 9 10
Teks R I C K Y W I J A Y A
Tabel 2.8 Tabel Hasil preprocessing dari Algoritma Skip Search
2.1.1.2.2 Fase Pencarian Algoritma Skip Search
Dalam Fase Pencarian, algoritma Skip Search menggunakan aturan The Two Window Rule untuk menentukan batas sampai mana pola boleh digeser. Panjang
batas The Two Window Rule menggunakan rumus 2m-1 dimana m adalah panjang dari pola (Bhandari & Kumar, 2013). Lalu panjang dari hasil aturan The Two Window Rule akan bernilai ganjil dan karakter yang terdapat di tengah panjang
teks tersebutlah yang akan dilakukan proses pencocokan.
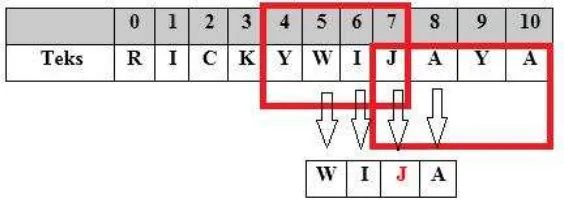
Gambar 2.1 Penentuan Panjang window dan Karakter Tengah yang akan Digunakan dalam Proses Pencocokan 1
Dari Gambar 2.1 didapatkan batas panjang untuk pola digeser adalah dari urutan 0 (huruf R) sampai urutan 6 (huruf I) dan karakter yang akan digunakan dalam proses pencocokan adalah karakter K. Namun, berdasarkan tabel 8 karakter K
c z[c]
A (3)
C
I (1)
J (2)
K R
W (0)
bernilai nol (tidak ada dalam pola) maka percobaan akan dilanjutkan dengan posisi jendela digeser sebanyak 4 posisi sesuai dengan panjang pola (m).
Gambar 2.2 Penentuan Panjang window dan Karakter Tengah yang akan Digunakan dalam Proses Pencocokan 2
Dari Gambar 2.2 didapatkan batas panjang untuk pola digeser adalah dari urutan 4 (huruf W) sampai urutan 10 (huruf A) dan karakter yang akan digunakan dalam proses pencocokan adalah karakter J. Berdasarkan tabel 8 karakter J terdapat di posisi 2 dalam pola, oleh karena itu pola akan langsung diposisikan menurut posisi J, dan dilakukan proses pencocokan dari urutan 5, 6, 7 dan 8. Dalam pencocokan 2 ini, pola yang berisi karakter W, I, J, dan A mengalami kecocokan maka teks akan ditampilkan. Dan fase pencarian berhenti sampai disini. Ini dikarenakan saat pola digeser sebanyak 4 posisi, panjang teks untuk dibandingkan hanya bersisa 3 dimana panjang pola lebih banyak daripada panjang teks yang akan dicocokan.
2.2. Kompleksitas Algoritma
Kebenaran suatu algoritma harus diuji dengan jumlah masukan tertentu untuk melihat kinerja algoritma berupa waktu yang diperlukan untuk menjalankan algoritmanya dan ruang memori yang diperlukan untuk struktur datanya. Algoritma yang bagus adalah algoritma yang mangkus (efisien). Kemangkusan algoritma diukur dari jumlah waktu dan ruang memori yang dibutuhkan untuk menjalankan algoritma tersebut.
suatu masalah dengan menggunakan algoritma. Ukuran yang dimaksud mengacu ke jumlah langkah-langkah perhitungan dan waktu tempuh pemrosesan. Kompleksitas waktu merupakan hal penting untuk mengukur efisiensi suatu algoritma.
Kompleksitas waktu dari suatu algoritma yang terukur sebagai suatu fungsi ukuran masalah. Kompleksitas waktu dari algoritma berisi ekspresi bilangan dan jumlah langkah yang dibutuhkan sebagai fungsi dari ukuran permasalahan. Kompleksitas ruang berkaitan dengan sistem memori yang dibutuhkan dalam eksekusi program.
Untuk mengukur kebutuhan waktu sebuah algoritma yaitu dengan mengeksekusi langsung algoritma tersebut pada sebuah komputer, lalu dihitung berapa lama durasi waktu yang dibutuhkan untuk menyelesaikan sebuah persoalan dengan n yang berbeda-beda. Kemudian dibandingkan hasil komputasi algoritma tersebut dengan notasi kompleksitas waktunya untuk mengetahui efisiensi algoritmanya (Nugraha, D.W. 2012).
Kompleksitas algoritma diukur berdasarkan kinerjanya dengan menghitung waktu eksekusi suatu algoritma. Menurut Cormen et al. (2009) waktu eksekusi algoritma dapat diklasifikasikan menjadi tiga kelompok besar, yaitu best-case (kasus terbaik), average-case (kasus rata-rata) dan worst-case (kasus
terjelek).
Pada pemrograman yang dimaksud dengan kasus terbaik, kasus terjelek dan kasus rata-rata suatu algoritma adalah besar kecilnya atau banyak sedikitnya sumber-sumber yang digunakan oleh suatu algoritma. Makin sedikit makin baik, makin banyak makin jelek (Subandijo. 2011).
2.3. Kamus
2.4. Android
Android adalah sistem operasi berbasis Linux yang dirancang untuk perangkat layar bergerak seperti smartphone atau komputer tablet. Android menyediakan platform terbuka bagi para pengembang untuk menciptakan aplikasi mereka sendiri untuk digunakan oleh bermacam peranti bergerak.
Google Inc. membeli Android Inc., pendatang baru yang membuat peranti lunak untuk ponsel. Kemudian untuk mengembangkan Android, dibentuklah Open Handset alliance, konsorsium dari 34 perusahaan peranti keras, peranti
lunak, dan telekomunikasi, termasuk Google, HTC, Intel, Motorola, Qualcomm, T-Mobile, dan Nvidia. Pada saat perilisan perdana Android, 5 November 2007, Android bersama Open Handset alliance menyatakan mendukung pengembangan standar terbuka pada perangkat seluler. Di lain pihak, Google merilis kode–kode Andorid di bawah lisensi Apache, sebuah lisensi perangkat lunak dan standar terbuka perangkat seluler. Di dunia ini terdapat dua jenis distributor sistem operasi Android. Pertama yang mendapat dukungan penuh dari Google atau Google Mail Services (GMS) dan kedua adalah yang benar–benar bebas distribusinya tanpa dukungan langsung Google atau dikenal sebagai Open Handset Distribution (OHD).
2.4.1 Versi Android
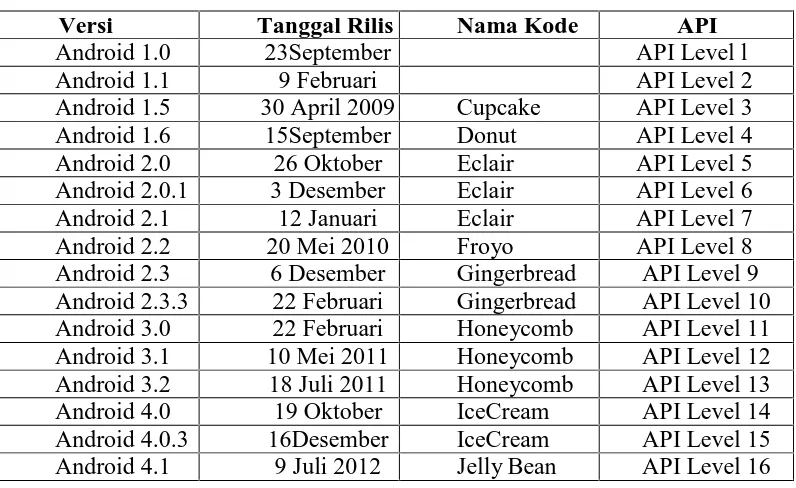
Tabel 2.9 Versi-versi Android
Versi Tanggal Rilis Nama Kode API
Android 1.0 23September Android 1.5 30 April 2009 Cupcake API Level 3 Android 1.6 15September
Versi Tanggal Rilis Nama Kode API Android 4.2 13November
2012
Jelly Bean API Level 17 Android 4.3 24 Juli 2013 Jelly Bean API Level 18 Android 4.4 31 Oktober
2013
Kitkat API Level 19 Android 5.0 25 Juni 2014 Lolipop API Level 21 Android 6.0 28 Mei 2015 Marshmallow API Level 23
Tabel 2.9 menjelaskan versi android beserta nama, tanggal rilis dan API nya.
Gambar 2.3 Logo-logo android dari versi 1.0 – 6.0 (sumber : https://indoberita.com)
Gambar 2.3 menunjukkan logo – logo android dimulai dari android versi 1.0 yang diwakili gambar Alpha, android versi 1.1 yang diwakili gambar Beta, android versi 1.2 – 1.5 yang diwakili gambar Cupcake, android versi 1.6 yang diwakili gambar Donut, android versi 2.0 – 2.1 yang diwakili gambar Eclair, android versi 2.2–2.2.3 yang diwakili gambar Froyo, android versi 2.3–2.4 yang diwakili gambar Gingerbread, android versi 3.0 – 3.2 yang diwakili gambar Honeycomb, android versi 4.0 yang diwakili gambar Ice Cream Sandwich,
2.5. Penelitian yang Relevan
Berikut ini beberapa penelitian yang terkait dengan Algoritma Not So Naive dan Algoritma Skip Search :
1. Bhandari, J. & Kumar, A. (2013) Menjelaskan tentang korelasi antara Suffix to Prefix rule, Two Window Rule dan Non-Tandem Rule dari Exact
String Matching. Yang dimana cara kerja dari Two Window Rule adalah
dengan membuat dua jendela terlebih dahulu, yang panjang tiap jendelanya sesuai dengan panjang pattern/pola dan diletakan di teks yang akan dicocokan, dimana posisi salah satu huruf dari teks diapit oleh dua jendela. Sehingga panjang jendela di teks sebesar 2m-1. Algoritma yang mengunakan Two Window Rule dalam fase pencariannya adalah Algoritma Skip Search, Algoritma Alpa Skip Search dan Algoritma Wide-Window.
2. Naser et al., (2012) Menyatakan bahwa Algoritma Skip Search bertingkah seperti Algoritma Knuth Morris Pratt dimana pemindaian jendela karakter dimulai dari kiri ke kanan sementara algoritma menggunakan wadah yang bisa kita sebut sebagai ember untuk menentukan posisi awal dari jendela di dalam teks saat melakukan pengecekan. Wadah yang digunakan dalam Algoritma Skip Search berisi lokasi paling kiri dari semua alphabet yang terdapat dalam pattern/pola. Proses pre-processing yang dilakukan algortima Skip Search berguna untuk mengurangi komparasi karakter yang akan dilakukan di proses pencarian.
3. Cantone, D. & Faro, S. (2004) Menjelaskan bahwa Algoritma Not So Naive merupakan variasi simpel dari Algoritma Naive yang ternyata
cukup efisien dalam beberapa kasus. Proses searching dari Algoritma Not So Naive dilakukan dengan mencocokan teks dan pola dari kiri ke