LAPORAN TUGAS AKHIR
PENENTUAN KELAYAKAN KREDIT BANK
MENGGUNAKAN NAÏVE BAYES CLASSIFIER BERBASIS
PARTICLE SWARM OPTIMIZATION
Disusun Oleh :
Nama
: Suamanda Ika Novichasari
NIM
: A11.2009.04671
Program Studi
: Teknik Informatika
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2013
LAPORAN TUGAS AKHIR
PENENTUAN KELAYAKAN KREDIT BANK
MENGGUNAKAN NAÏVE BAYES CLASSIFIER BERBASIS
PARTICLE SWARM OPTIMIZATION
Laporan ini disusun guna memenuhi salah satu syarat untuk menyelesaikan program studi Teknik Informatika S-1 pada Fakultas Ilmu Komputer
Universitas Dian Nuswantoro
Disusun Oleh :
Nama
: Suamanda Ika Novichasari
NIM
: A11.2009.04671
Program Studi
: Teknik Informatika
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2013
ii
PERSETUJUAN LAPORAN TUGAS AKHIR
Nama Pelaksana : Suamanda Ika Novichasari NIM : A11.2009.04671
Program Studi : Teknik Informatika Fakultas : Ilmu Komputer
Judul Tugas Akhir : Penentuan Kelayakan Kredit Bank Menggunakan Naïve Bayes Classifier Berbasis Particle Swarm Optimization
Tugas Akhir ini telah diperiksa dan disetujui, Semarang, 5 Juli 2013
Menyetujui : Pembimbing
Noor Ageng Setiyanto, M.Kom.
Mengetahui :
Dekan Fakultas Ilmu Komputer
iii
PENGESAHAN DEWAN PENGUJI
Nama Pelaksana : Suamanda Ika Novichasari NIM : A11.2009.04671
Program Studi : Teknik Informatika Fakultas : Ilmu Komputer
Judul Tugas Akhir : Penentuan Kelayakan Kredit Bank Menggunakan Naïve Bayes Classifier Berbasis Particle Swarm Optimization Tugas akhir ini telah diujikan dan dipertahankan dihadapan Dewan Penguji pada Sidang tugas akhir tanggal 5 Juli 2013. Menurut pandangan kami, tugas akhir ini memadai dari segi kualitas maupun kuantitas untuk tujuan penganugrahan gelar
Sarjana Komputer (S.Kom.)
Semarang, 5 Juli 2013 Dewan Penguji:
Heru Lestiawan, M.Kom
Anggota I
Desi Purwanti K., M.Kom
Anggota II
Etika Kartikadarma, M.Kom
Ketua Penguji
iv
PERNYATAAN KEASLIAN TUGAS AKHIR
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan di bawah ini, saya:
Nama : Suamanda Ika Novichasari NIM : A11.2009.04671
Menyatakan bahwa karya ilmiah saya yang berjudul:
PENENTUAN KELAYAKAN KREDIT BANK MENGGUNAKAN NAÏVE BAYES CLASSIFIER BERBASIS PARTICLE SWARM OPTIMIZATION
merupakan karya asli saya (kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya dan perangkat pendukung seperti web cam dll). Apabila di kemudian hari, karya saya disinyalir bukan merupakan karya asli saya, yang disertai dengan bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak dan kewajiban yang melekat pada gelar tersebut. Demikian surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Semarang Pada tanggal : 5 Juli 2013
Yang menyatakan
v
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan di bawah ini, saya:
Nama : Suamanda Ika Novichasari NIM : A11.2009.04671
demi mengembangkan Ilmu Pengetahuan, menyetujui untuk memberikan kepada Universitas Dian Nuswantoro Hak Bebas Royalti Non-Ekskusif (Non-exclusive Royalty-Free Right) atas karya ilmiah saya yang berjudul:
PENENTUAN KELAYAKAN KREDIT BANK MENGGUNAKAN NAÏVE BAYES CLASSIFIER BERBASIS PARTICLE SWARM OPTIMIZATION
beserta perangkat yang diperlukan (bila ada). Dengan Hak Bebas Royalti Non-Eksklusif ini Universitas Dian Nuswantoro berhak untuk menyimpan, mengcopy ulang (memperbanyak), menggunakan, mengelolanya dalam bentuk pangkalan data (database), mendistribusikannya dan menampilkan/mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya selama tetap mencantumkan nama saya sebagai penulis/pencipta.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak Universitas Dian Nuswantoro, segala bentuk tuntutan hukum yang timbul atas pelanggaran Hak Cipta dalam karya ilmiah saya ini.
Demikian surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Semarang Pada tanggal : 5 Juli 2013
Yang menyatakan
vi
UCAPAN TERIMAKASIH
Alhamdulilah, puji syukur kehadirat Allah SWT atas kekuatan, rahmat dan hidayah-Nya sehingga laporan tugas akhir dengan judul “PENENTUAN KELAYAKAN KREDIT BANK MENGGUNAKAN NAÏVE BAYES CLASSIFIER BERBASIS PARTICLE SWARM OPTIMIZATION” dapat terselesaikan tepat waktu. Terimakasih kepada :
1. Dr.Ir. Edi Noersasongko,M.Kom, selaku Rektor Universitas Dian Nuswantoro Semarang.
2. Dr. Abdul Syukur selaku Dekan Fasilkom.
3. Dr. Heru Agus Santoso,M.Kom, selaku Ka.Progdi Teknik Informatika. 4. Noor Ageng S., M.Kom, selaku pembimbing tugas akhir yang
memberikan bimbingan yang berkaitan dengan penelitian penulis.
5. Ardhyta Luthfiarta, M.Kom.,M.Cs, yang memberikan masukan dan saran kepada penulis.
6. Dosen-dosen Fasilkom Universitas Dian Nuswantoro Semarang yang telah memberikan ilmu sehingga penulis dapat mengimplementasikan ilmu yang telah disampaikan.
7. Keluarga dan rekan-rekan mahasiswa Fasilkom Universitas Dian Nuswantoro yang telah memberikan dukungan material dan moral kepada penulis.
Semoga Tuhan yang Maha Esa memberikan balasan yang lebih besar kepada beliau-beliau, dan pada akhirnya penulis berharap bahwa penulisan laporan tugas akhir ini dapat bermanfaat dan berguna sebagaimana fungsinya.
Semarang, 5 Juli 2013
vii
ABSTRAK
Keberhasilan kredit pada sebuah bank sangat berperan dalam menjaga kelangsungan hidup sebuah bank. Oleh karena itu sangat diperlukan pengukuran kelayakan kredit yang akurat untuk mengelompokkan nasabah dengan kredit baik dan kredit buruk. Berdasarkan kondisi tersebut teknik data mining yang tepat digunakan adalah klasifikasi. Salah satu teknik klasifikasi data mining adalah Naïve Bayes Classifier (NBC) , namun hasil akurasinya masih kurang dibanding algoritma C4.5 dan neural network. NBC unggul jika diterapkan pada data ukuran besar, namun lemah pada seleksi atribut. Laporan tugas akhir ini menguraikan langkah-langkah penelitian yang menggunakan algoritma Particle Swarm Optimizatin (PSO) untuk membobot atribut guna meningkatkan nilai akurasi NBC. Desain penelitian menggunakan model proses CRISP-DM karena penyelesaian masalah dalam penelitian ini mengarah pada masalah strategi bisnis. Penelitian ini menggunakan data set publik German Credit Data. Proses validasi menggunakan tenfold-cross validation, sedangkan pengujian modelnya menggunakan confusion matrix dan kurva ROC. Hasilnya menunjukan akurasi NBC meningkat dari 73,70% menjadi 78,00% setelah dikombinasikan dengan PSO.
Kata kunci : Kelayakan kredit, data mining, teknik klasifikasi data mining, NBC, NBC-PSO.
xv + 54 halaman; 26 gambar; 11 tabel; 4 lampiran Daftar acuan: 25 (1995 – 2012)
viii
ABSTRACT
The success of a bank credit plays an important role in maintaining the viability of a bank. Therefore, it is necessary that an accurate measurement of credit worthiness to classify the customers with good credit and bad credit. Under these conditions the exact data mining techniques used are classification. One of the classification techniques of data mining is the Naïve Bayes Classifier (NBC), but the result is still less accuracy than C4.5 and neural network algorithms. NBC superior when applied to the data large size, but weak on the selection attribute. This final report outlines the steps that research using Particle Swarm Optimization algorithm (PSO) for attribute weighting in order to improve the accuracy NBC. Research design using the CRISP-DM process model because problem solving in this study lead to the business strategy issues. This study uses a data set of public German Credit Data. Validation process using tenfold cross-validation, while testing the model using confusion matrix and ROC curves. The result shows NBC increased accuracy of 73.70% to 78.00% after combined with PSO.
Keyword : Credit worthiness, data mining, data mining classification techniques, NBC, NBC-PSO
ix
DAFTAR ISI
Halaman
Halaman Sampul Dalam ... i
Halaman Persetujuan Laporan Tugas Akhir ... ii
Halaman Pengesahan Dewan Penguji ... iii
Halaman Pernyataan Keaslian Tugas Akhir ... iv
Halaman Pernyataan Persetujuan Publikasi Karya Ilmiah ... v
Halaman Ucapan Terimakasih ... vi
Halaman Abstrak ... vii
Halaman Daftar Isi ... ix
Halaman Daftar Tabel ... xi
Halaman Daftar Gambar ... xii
Halaman Daftar Lampiran... xiv
Halaman Daftar Singkatan ... xv
BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 3 1.3 Batasan Masalah ... 3 1.4 Tujuan Penelitian ... 3 1.5 Manfaat Penelitian ... 3
BAB II TINJAUAN PUSTAKA ... 5
2.1 Tinjauan studi ... 5 2.2 Landasan teori... 8 2.2.1 Kredit bank ... 8 2.2.2 Data Mining ... 10 2.2.3 CRIPS-DM ... 10 2.2.4 Pembobotan atribut ... 12 2.2.5 Discretize By Frequency ... 12
x
2.2.7 Particle Swarm Optimization (PSO) ... 14
2.2.8 Cross validation ... 15
2.2.9 Confusion matrix ... 16
2.2.10 Kurva ROC ... 17
2.2.11 Kerangka pemikiran ... 18
BAB III METODE PENELITIAN ... 20
3.1 Desain penelitian ... 20
3.1.1 Pengumpulan data ... 20
3.1.2 Pengolahan Data (Data preparation) ... 22
3.1.3 Pemodelan (Modelling) ... 28
3.1.4 Validasi dan evaluasi ... 35
3.1.5 Penyebaran (Deployment) ... 36
3.2 Alat penelitian ... 36
BAB IV HASIL DAN PEMBAHASAN ... 37
4.1 Validasi dan Evaluasi ... 37
4.2 Hasil percobaan dan pengujian metode ... 39
4.2.1 NBC ... 39 4.2.2 NBC-PSO ... 40 BAB V PENUTUP ... 48 5.1 Kesimpulan ... 48 5.2 Saran ... 48 DAFTAR PUSTAKA ... 50 LAMPIRAN ... 53
xi
DAFTAR TABEL
Halaman Tabel 2.1 State of the art……….. 7 Tabel 2.2 Contoh confusion matrix……….. 17 Tabel 3.1 Data set German kredit data setelah diubah ke bentuk Sheet
bertipe xlsx……… 27 Tabel 3.2 Confusion matrik NBC……… 35 Tabel 3.3 Spesifikasi hardware……… 36 Tabel 4.1 Contoh hasil transformasi numerik ke nominal dari German
Data……….. 39 Tabel 4.2 Hasil akurasi dan AUC dari NBC……… 40 Tabel 4.3 Percobaan 1 menggunakan population size 10-600 maximum
number of generation 100……… 41 Tabel 4.4 Percobaan 2 menggunakan population size 350 dan maximum
number of generation 100-1500……….. 42 Tabel 4.5 Hasil komparasi NBC dan NBC-PSO……….. 43 Tabel 4.6 Hasil pembobotan atribut………. 45
xii
DAFTAR GAMBAR
Halaman
Gambar 2.1 Siklus CRISP-DM ... 11
Gambar 2.2 Ilustrasi tenfold cross validation... 16
Gambar 2.3 Confusion matrix untuk 2 model kelas... 17
Gambar 2.4 Kerangka pemikiran ... 19
Gambar 3.1 Link public data set German data kredit ... 21
Gambar 3.2 Data set dalam bentuk txt ... 21
Gambar 3.3 Import data dari file txt kedalam excel ... 22
Gambar 3.4 Jendela import file text ... 23
Gambar 3.5 Langkah 1 dari import file text ... 23
Gambar 3.6 Langkah 2 dari import file txt ... 24
Gambar 3.7 Langkah 3 dari import file txt ... 24
Gambar 3.8 Jendela import data... 25
Gambar 3.9 Tampilan data set pada excel sheets ... 25
Gambar 3.10 Tampilan akhir data set pada excel sheets ... 26
Gambar 3.11 Model yang di usulkan ... 28
Gambar 3.12 Model NBC-PSO yang diusulkan ... 29
Gambar 3.13 Penjelasan data training dan data testing ... 30
Gambar 3.14 Contoh mencari P(A=”A14”|U=”1”) ... 31
Gambar 4.1 Desain model validasi NBC ... 37
Gambar 4.2 Desain model validasi NBC berbasis PSO ... 38
Gambar 4.3 Grafik hasil akurasi confusion matrix pada percobaan 1 dengan maximum number of generation 100 dan population size 10-600 ... 41
Gambar 4.4 Grafik hasil akurasi percobaan 2 dengan population size 350 dan maximum number of generation 100-1500 ... 43
Gambar 4.5 Grafik hasil perbandingan akurasi dari NBC dan NBC-PSO ... 44
Gambar 4.6 Grafik hasil perbandingan AUC dari NBC dan NBC-PSO ... 44
Gambar 4.7 Grafik perbandingan waktu eksekusi dari NBC dan NBC- PSO ... 45
xiii
xiv
DAFTAR LAMPIRAN
Halaman
Lampiran 1 Akurasi confusion matrix dari NBC ... 54
Lampiran 2 Kurva ROC dari NBC ... 54
Lampiran 3 Akurasi confusion matrik dari NBC-PSO ... 55
xv
DAFTAR SINGKATAN
UU = Undang-undang NBC = Naïve Bayes Classifier PSO = Particle Swarm Optimization TA = Tugas akhir
DPSO = Diskrit Particle Swarm Optimization ROC = Receiver Operating Characteristic
AUC = Area Under Curve SVM = Support Vector Machine
CRIPS-DM = Cross-Industry Standart Proses for Data Mining TP = True Positives
TN = True Negatives FP = False Positives FN = False Negatives
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Bank didefinisikan oleh Undang-undang Nomor 10 Tahun 1998 tentang Perubahan Atas UU Nomor 7 Tahun 1992 tentang Perbankan sebagai “badan usaha yang menghimpun dana dari masyarakat dalam bentuk simpanan dan menyalurkannya kepada masyarakat dalam bentuk kredit dan atau bentuk-bentuk lainnya dalam rangka meningkatkan taraf hidup rakyat banyak”.
Kredit menurut UU Perbankan No. 10 tahun 1998 adalah penyediaan uang berdasarkan kesepakatan antara peminjam dan pemberi pinjaman yang mengharuskan peminjam melunasinya beserta bunganya dalam jangka waktu tertentu.
Kredit dalam perbankan sangat mempengaruhi pembiayaan perekonomian nasional dan berfungsi sebagai penggerak pertumbuhan ekonomi [1]. Proses penilaian kredit bagi bank tidak dapat diremehkan, karena bagi bank sangat penting untuk membedakan antara UKM baik dan buruk dalam hal kredit melalui proses penilaian kredit tersebut [2]. Dalam kondisi keuangan yang sangat lemah dengan jumlah kredit bermasalah yang semakin besar, serta likuiditas yang semakin rendah dapat menyebabkan bank kesulitan untuk membiayai kegiatan usahanya [3]. Seperti yang tercantum pada harian suara merdeka yang terbit pada tanggal 18 Maret 2013 bahwa Lembaga Penjamin Simpanan (LPS) telah melakukan pencabutan izin usaha perbankan kepada 47 Bank Perkreditan Rakyat (BPR) dan 1 bank umum sejak tahun 2006 hingga 31 Desember 2012 [4]. Oleh karena itu analisa kelayakan kredit sangat penting dilakukan untuk mencegah jumlah kredit
bermasalah yang semakin besar guna menjaga kelangsungan hidup sebuah bank.
Beberapa peneliti mengembangkan berbagai teknik untuk permasalahan kredit, diantaranya dengan analisa statistik (konvensional) [22], soft computing [23] dan data mining [8][11][12]. Dewasa ini pendekatan data mining lebih berkembang untuk mengatasi berbagai permasalahan termasuk permasalah kredit bank.
Data mining adalah suatu proses yang bertujuan untuk menemukan pola secara otomatis atau semi otomatis dari data yang sudah ada di dalam basis data yang dimanfaatkan untuk menyelesaikan suatu masalah [5]. Data mining memiliki beberapa teknik, diantaranya klasifikasi dan clustering. Teknik klasifikasi adalah teknik pembelajaran yang digunakan untuk memprediksi nilai dari atribut kategori target [16]. Klasifikasi bertujuan untuk membagi objek yang ditugaskan hanya ke salah satu nomor kategori yang disebut kelas [15]. Clustering mengelompokkan objek atau data berdasarkan kemiripan antar data, sehingga anggota dalam satu kelompok memiliki banyak kemiripan dibandingkan dengan kelompok lain [6]. Untuk menyelesaikan masalah analisa resiko kredit data akan diklasifikasikan menjadi dua kelas, yaitu kredit baik dan kredit buruk. Sehingga tepat menggunakan teknik klasifikasi data mining. Metode yang paling populer digunakan untuk teknik klasifikasi adalah Decision Trees, Naïve Bayes Classifiers (NBC), Statistical analysis, dan lain lain [6].
Beberapa peneliti telah menganalisa kelayakan kredit dengan metode klasifikasi data mining, diantaranya adalah yang dilakukan oleh Scott A. Z, Kevin B. K dan Ann E. N menggunakan Bayesian Network dan NBC [8]. Henny Leidiyana pada tahun 2011 menggunakan algoritma C4.5, naïve bayes, dan neural network [11]. Dan Siti Marsipah pada tahun 2011 menggunakan algoritma C4.5 dan C4.5 berbasis Particle Swarm Optimization (PSO).
3
Dari hasil penelitian Henny Leidiyana [11] algoritma NBC untuk kelayakan kredit hasil akurasinya masih kurang dibanding menggunakan algoritma C4.5. Dalam C4.5 seluruh atribut diseleksi untuk kemudian dibagi menjadi himpunan bagian yang lebih kecil, namun jika data berukuran besar dengan banyak atribut maka model yang terbentuk menjadi rumit dan sulit dipahami, sehingga perlu dilakukan pemangkasan (pruning) yang dapat mengurangi akurasi. Sedangkan NBC lebih tepat diterapkan pada data yang besar [7]. Dapat menangani data yang tidak lengkap (missing value) serta kuat terhadap atribut yang tidak relevan dan noise pada data [6]. NBC akan bekerja lebih efektif jika dikombinasikan dengan beberapa prosedur pemilihan atribut [5]
1.2 Rumusan Masalah
Dari latar belakang di atas, masalah pokok yang akan dicari pemecahannya adalah bagaimana PSO dapat meningkatkan akurasi NBC pada kasus kelayakan kredit bank.
1.3
Batasan MasalahPenelitian ini dibatasi pada peningkatan akurasi metode klasifikasi data mining yaitu algoritma NBC dikombinasikan dengan algoritma PSO untuk pembobotan atribut dalam penentuan kelayakan kredit. Kemudian mengevaluasi hasil akurasi.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan algoritma PSO yang digunakan untuk membobot atribut pada algoritma NBC, sehingga dapat meningkatan akurasi analisa kredit.
1.5 Manfaat Penelitian
Manfaat dari hasil penelitian ini dapat digunakan sebagai Decission Suport System (DSS) oleh analis kredit dan lembaga keuangan dalam
penentuan kelayakan kredit. Juga memberikan kontribusi pada metode data mining dalam membandingkan atau mengkomparasikan beberapa algoritma klasifikasi data mining untuk kasus yang berbeda atau pada kasus yang sama namun dengan menggunakan algoritma yang berbeda.
5
BAB II
TINJAUAN PUSTAKA
Penelitian TA ini menggunakan beberapa referensi media sebagai landasan teori diantaranya buku, jurnal baik jurnal nasional maupun internasional serta prosiding sebagai referensi.
2.1 Tinjauan studi
Beberapa jurnal dan artikel penelitian yang berhubungan dengan teknik klasifikasi algoritma data mining yang memiliki keterkaitan dalam topik penelitian yaitu :
a. Particle Swarm for Attribute Selection in Bayesian Classification: An Application to Protein Function Prediction
Penelitian ini mengukur kinerja Diskrit Particle Swarm Optimization (DPSO) dan PSO dalam seleksi atribut yang diterapkan pada Bayesian network dan Naïve Bayes. Hasil dari penelitian yang dilakukan oleh Elon S. Correa, Alex A. Freitas, dan Colin G. Johnson (2008) adalah dalam hal seleksi atribut pada satu data set DPSO lebih baik dari PSO dan pada 6 data set DPSO terbukti lebih efektif dan meningkatkan efisiensi komputasi dari classifier. Hasil lainnya adalah bahwa pendekatan Bayesian Network melebihi pendekatan dari Naïve Bayes pada semua percobaan [9].
b. Knowledge Discovery from Bio-medical Data Using a Hybrid PSO/Bayesian Classifier
Pada penelitian yang dilakukan oleh S.Devi, A.K. Jagadev, S.Dehuri, R.Mall (2009) ini menggunakan kombinasi antara Bayesian classifier dan PSO untuk menghilangkan atribut yang palsu dan yang tidak relevan dari data set bio-medis. Penelitian ini membuktikan bahwa fungsi diskriminan non-linier yang dikombinasikan dengan seleksi fitur PSO terbukti menjadi seleksi atribut terbaik tanpa menurunkan tingkat akurasinya [10].
c. Komparasi Algoritma Klasifikasi Data mining Dalam Penentuan Resiko Kredit Kepemilikan Kendaraan Bermotor
Dilakukan oleh Henny Leidiyana pada tahun 2011. Dalam penelitian ini menggunakan algoritma C4.5, Naïve Bayes, dan Neural Network untuk penentuan kelayakan kredit motor. Kemudian dibandingkan untuk mengetahui metode mana yang paling akurat. Hasilnya dengan metode pengujian Cross Validation, Confusion Matrix dan Kurva ROC terbukti C4.5 memiliki akurasi tertinggi [11].
d. Algoritma Klasifikasi C4.5 Berbasis PSO Untuk Evaluasi Penentuan Kelayakan Pemberian Kredit Koperasi Syariah
Banyak penelitian tentang penentuan kelayakan kredit yang menggunakan metode C4.5, namun akurasinya masih kurang akurat. Dalam penelitian yang dilakukan oleh Siti Masripah pada tahun 2011 membandingkan dua metode yaitu metode C4.5 dan metode C4.5 berbasis PSO. Hasilnya, terbukti metode C4.5 berbasis PSO lebih akurat dengan akurasi 94% dan Area Under Curve (AUC) sebesar 0,955 [12]. e. Penerapan PSO Untuk Seleksi Atribut Pada Metode Support Vector
Machine Untuk Prediksi Penyakit Diabetes.
Atribut dalam Metode SVM memiliki pengaruh penting dalam akurasi klasifikasi. Penelitian ini menerapkan metode PSO untuk seleksi atribut pada metode SVM. Hasil penelitian yang dilakukan oleh Frisma
7
Handayanna pada tahun 2012 yaitu terbukti PSO yang dterapkan untuk seleksi atribut pada metode SVM untuk prediksi penyakit dengan data set Pima Diabetes, dapat meningkatkan nilai akurasi dan AUC dibanding prediksi hanya dengan menggunakan metode SVM saja [13].
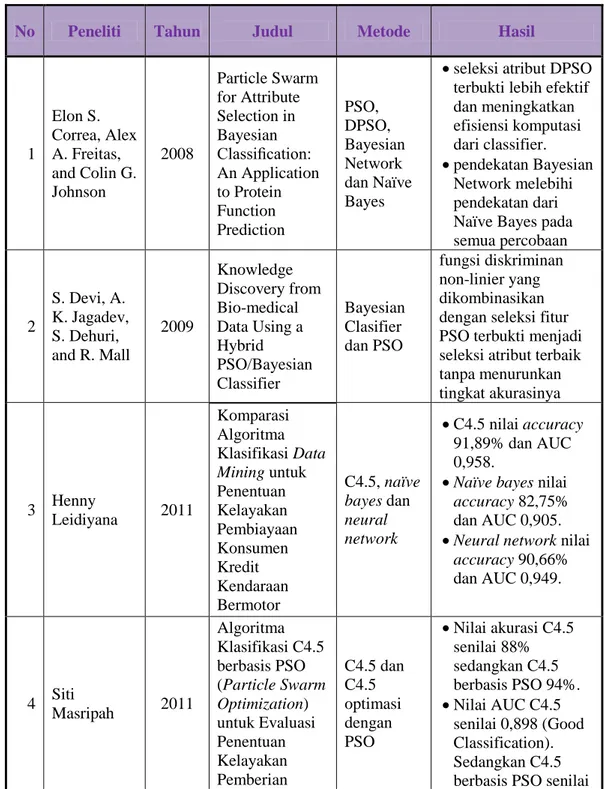
Tabel 2.1 State of the art
No Peneliti Tahun Judul Metode Hasil
1 Elon S. Correa, Alex A. Freitas, and Colin G. Johnson 2008 Particle Swarm for Attribute Selection in Bayesian Classification: An Application to Protein Function Prediction PSO, DPSO, Bayesian Network dan Naïve Bayes
seleksi atribut DPSO terbukti lebih efektif dan meningkatkan efisiensi komputasi dari classifier. pendekatan Bayesian Network melebihi pendekatan dari Naïve Bayes pada semua percobaan 2 S. Devi, A. K. Jagadev, S. Dehuri, and R. Mall 2009 Knowledge Discovery from Bio-medical Data Using a Hybrid PSO/Bayesian Classifier Bayesian Clasifier dan PSO fungsi diskriminan non-linier yang dikombinasikan dengan seleksi fitur PSO terbukti menjadi seleksi atribut terbaik tanpa menurunkan tingkat akurasinya 3 Henny Leidiyana 2011 Komparasi Algoritma Klasifikasi Data Mining untuk Penentuan Kelayakan Pembiayaan Konsumen Kredit Kendaraan Bermotor C4.5, naïve bayes dan neural network C4.5 nilai accuracy 91,89% dan AUC 0,958.
Naïve bayes nilai accuracy 82,75% dan AUC 0,905. Neural network nilai
accuracy 90,66% dan AUC 0,949. 4 Siti Masripah 2011 Algoritma Klasifikasi C4.5 berbasis PSO (Particle Swarm Optimization) untuk Evaluasi Penentuan Kelayakan Pemberian C4.5 dan C4.5 optimasi dengan PSO Nilai akurasi C4.5 senilai 88% sedangkan C4.5 berbasis PSO 94%. Nilai AUC C4.5 senilai 0,898 (Good Classification). Sedangkan C4.5 berbasis PSO senilai
Kredit Koperasi Syariah
0.955 (Excellent Classification).
No Peneliti Tahun Judul Metode Hasil
5 Frisma Handayanna 2012 Penerapan Particle Swarm Optimization Untuk Seleksi Atribut Pada Metode Support Vector Machine Untuk Prediksi Penyakit Diabetes SVM dan SVM berbasis PSO Nilai accuracy SVM adalah 74.21 % dan nilai AUC adalah 0.753.
Nilai accuracy SVM berbasis PSO 77.36% dengan nilai AUC adalah 0.775.
Berdasarkan tinjauan studi diatas ada beberapa peneliti yang sudah menggunakan NBC dan PSO dalam berbagai kasus. Performa NBC terbukti menjadi lebih baik jika dikombinasikan dengan algoritma lain pada seleksi atribut. PSO yang diterapkan pada seleksi atribut terbukti berhasil meningkatkan akurasi pada SVM dan C4.5. Penelitian ini menggunakan PSO untuk menentukan fitur terbaik pada bobot atribut yang sesuai dan optimal pada NBC sehingga hasil prediksi lebih akurat.
2.2 Landasan teori
Penulis meninjau beberapa buku dan jurnal sebagai landasan untuk menjelaskan berbagai hal yang berhubungan dengan topik penelitian.
2.2.1 Kredit bank
Bank didefinisikan oleh Undang-undang Nomor 10 Tahun 1998 tentang Perubahan Atas UU Nomor 7 Tahun 1992 tentang Perbankan sebagai “Bank adalah badan usaha yang menghimpun dana dari masyarakat dalam bentuk simpanan dan menyalurkannya kepada masyarakat dalam bentuk kredit dan atau bentuk-bentuk lainnya dalam rangka meningkatkan taraf hidup rakyat banyak”.
9
Bank akan rugi jika tidak memanfaatkan dana yang sudah terhimpun dari masyarakat. Karena bank harus memberikan bunga kepada masyarakat. Pendapatan utama bank diharapkan berasal dari penyaluran kredit [3].
Kredit adalah penyediaan uang berdasarkan kesepakatan antara peminjam dan pemberi pinjaman yang mengharuskan peminjam melunasinya beserta bunganya dalam jangka waktu tertentu (UU Perbankan No. 10 tahun 1998).
Hal-hal yang perlu diketahui oleh bank sebagai bahan pertimbangan sebelum menyalurkan dananya dalam bentuk kredit yaitu [3]:
a. Perijinan dan legalitas, usaha dari calon nasabah harus sah secara yuridis.
b. Karakter, meliputi : profesi, penampilan, lingkungan sosial, pengalaman dan perilaku masa lalu yang dapat mempengaruhi kemampuan nasabah untuk membayar kewajibannya.
c. Pengalaman dan manajemen, pengalaman dan managemen usaha yang baik menjadikan nasabah mampu mengelola usahanya dengan baik sehingga berdampak memudahkan nasabah menyelesaikan kewajibannya kepada bank.
d. Kemampuan teknis, meliputi hal-hal yang mendukung kelancaran usaha nasabah secara teknis.
e. Pemasaran, keberhasilan nasabah dalam memasarkan produknya akan mengalami kesulitan untuk memenuhi kewajibannya kepada bank.
f. Sosial, pendapat masyarakat yang negatif terhadap keberadaan kegiatan yang dibiayai oleh bank dapat mengganggu jalannya usaha nasabah yang juga dapat mengganggu kemampuan nasabah untuk membayar tagihan kepada bank.
g. Keuangan, laporan keuangan digunakan untuk mengetahui kesehatan usaha nasabah.
h. Agunan, nasabah wajib menyerahkan berbagai bentuk anggunan sebagai jaminan.
2.2.2 Data Mining
Data mining adalah suatu proses untuk menemukan hubungan baru dengan cara memilah-milah data yang sudah ada di dalam database menggunakan teknologi pengenalan pola dan statistik [14]. Data mining adalah proses menggali informasi atau pola dalam data berukuran besar yang sudah ada dalam database untuk keperluan tertentu. Salah satu teknik dari data mining adalah klasifikasi yang tujuannya membagi objek untuk ditugaskan hanya ke salah satu nomor kategori yang dsebut kelas [15]. Variable target dari klasifikasi adalah variable kategori [14]. Klasifikasi adalah suatu proses pencarian untuk memprediksi kelas dari suatu obyek yang belum diketahui kelasnya.
2.2.3 CRIPS-DM
Cross-Industry Standart Proses for Data Mining (CRIPS-DM) dikembangkan pada tahun 1996 oleh analis dari beberapa industri. CRIPS-DM menyediakan standart proses data mining sebagai pemecahan masalah secara umum dari bisnis atau unit penelitian. CRIPS-DM memiliki siklus hidup yang terbagi dalam enam fase, yaitu [14] :
11
Gambar 2.1 Siklus CRISP-DM [14]. a. Pemahaman Bisnis(Business Understanding)
Merupakan tahap awal yaitu pemahaman penelitian, penentuan tujuan dan rumusan masalah data mining.
b. Pemahaman Data(Data Understanding)
Dalam tahap ini dilakukan pengumpulan data, mengenali lebih lanjut data yang akan digunakan.
c. Pengolahan Data(Data Preparation)
Tahap ini adalah pekerjaan berat yang perlu dilaksanakan secara intensif. Memilih kasus atau variable yang ingin dianalisis,
Bussines Understanding
Deployment Data Preparation
Modeling Evaluation
Data Understanding
melakukan perubahan pada beberapa variable jika diperlukan sehingga data siap untuk dimodelkan.
d. Pemodelan(Modeling)
Memilih teknik pemodelan yang sesuai dan sesuaikan aturan model untuk hasil yang maksimal. Dapat kembali ke tahap pengolahan untuk menjadikan data ke dalam bentuk yang sesuai dengan model tertentu.
e. Evaluasi (Evaluation)
Mengevaluasi satu atau model yang digunakan dan menetapkan apakah terdapat model yang memenuhi tujuan pada tahap awal. Kemudian menentukan apakah ada permasalahan yang tidak dapat tertangani dengan baik serta mengambil keputusan hasil penelitian.
f. Penyebaran (Deployment)
Menggunakan model yang dihasilkan seperti pembuatan laporan atau penerapan proses data mining pada departemen lain. 2.2.4 Pembobotan atribut
Tidak semua atribut memiliki peranan penting dalam akurasi. Pembobotan atribut adalah proses pemberian nilai pada setiap atribut dengan metode tertentu berdasarkan tingkat pengaruhnya terhadap nilai akurasi [5]. Pembobotan atribut pada penelitian ini menggunakan metode Particle Swarm Optimization (PSO).
2.2.5 Discretize By Frequency
Discretize adalah proses transformasi nilai pada atribut numerik menjadi nominal [15]. Terdapat 5 macam discretize dalam RapidMiner 5.3.008 yaitu discretize by frequency, discretize by size,
13
discretize by binning, discretize by user specification, discretize by entropy. Penelitian ini menggunakan discretize by frequency yaitu transformasi atribut numerik menjadi atribut nominal oleh operator frekuensi yang menciptakan kelompok rentang terbaik sehingga jumlah nilai yang unik dalam kelompok rentang hampir sama.
2.2.6 Naïve Bayes Classifier (NBC)
Disebut juga dengan Bayesian Classification adalah pengklasifikasian statistik yang didasarkan pada teorema bayes yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu kelas. Bayesian Classification terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database yang besar [17].
Bentuk umum teorema bayes sebagai berikut :
Dimana :
X = data dengan kelas yang belum diketahui
H = Hipotesa data X merupakan suatu kelas spesifik
P(H|X) = Probabilitas hipotesis H berdasarkan kondisi X (posterior probability)
P(H) = probabilitas hipotesis H (prior probability)
Naive bayes classifier mengestimasi peluang kelas bersyarat dengan mengasumsikan bahwa atribut adalah independen secara bersyarat yang diberikan dengan label kelas . Asumsi independen bersyarat dapat dinyatakan dalam bentuk berikut [18]:
……..2.2 y
d i iY y X P y Y X P 1dengan tiap set atribut terdiri dari atribut. Peluang bersyarat atribut kategorikal dinyatakan dalam bentuk [6]:
Dimana |Aij| adalah jumlah contoh training dari kelas Ai yang
menerima nilai Cj. Jika hasilnya adalah nol, maka menggunakan
pendekatan yang dinyatakan dalam bentuk [24]:
Dimana n adalah total dari jumlah record dari kelas Cj. nc adalah
jumlah contoh training dari kelas Ai yang menerima nilai Cj. nequiv
adalah nilai konstan dari ukuran sampel yang equivalen. P adalah peluang estimasi prior, P=1/k dimana k adalah jumlah kelas dalam variable target.
Peluang bersyarat atribut kontinu dinyatakan dalam bentuk [6]:
Parameter ij dapat diestimasi berdasarkan sampel mean A
i untuk
seluruh training record yang dimiliki kelas Cj. Dengan cara sama, ij
2
dapat diestimasi dari sampel varian
2s training record tersebut. 2.2.7 Particle Swarm Optimization (PSO)
PSO adalah algoritma pencarian berbasis populasi yang diinisialisasi dengan populasi solusi acak dan digunakan untuk memecahkan masalah optimasi [20]. PSO adalah metode optimasi
X X Xd
15
heuristic global yang diperkenalkan oleh Dokter Kennedy dan Eberhart pada tahun 1995 berdasarkan penelitian terhadap perilaku kawanan burung dan ikan [19].
Setiap partikel dalam PSO juga dikaitkan dengan kecepatan partikel terbang melalui ruang pencarian dengan kecepatan yang dinamis disesuaikan untuk perilaku historis mereka. Oleh karena itu, partikel memiliki kecenderungan untuk terbang menuju daerah pencarian yang lebih baik dan lebih baik selama proses pencarian [20].
Rumus untuk menghitung perpindahan posisi dan kecepatan partikel yaitu [25]:
Dimana :
Vi(t) = kecepatan partikel i saat iterasi t
Xi (t) = posisi partikel i saat iterasi t
c1 dan c2 = learning rates untuk kemampuan individu (cognitive)
dan pengaruh sosial (group)
r1 dan r2 = bilangan random yang berdistribusi uniformal dalam
interval 0 dan 1
XPbesti = posisi terbaik partikel i
XGbest = posisi terbaik global
2.2.8 Cross validation
Cross validation adalah teknik pengambilan sampel secara random yang menjamin setiap jumlah kemunculan data yang diamati dama dengan jumlah data training dan hanya sekali pada data testing
[16]. Dalam cross validation kita harus menetapkan jumlah partisi atau fold, standar yang biasa digunakan untuk memperoleh estimasi kesalahan terbaik adalah 10 kali partisi atau tenfold cross-validation [6]. Data dibagi secara random menjadi 10 bagian dengan perbandingan yang sama kemudian error rate dihitung bagian demi bagian, selanjutnya error rate secara keseluruhan diperoleh dari menghitung rata-rata error rate dari 10 bagian
. Gambar 2.2 Ilustrasi tenfold cross validation
2.2.9 Confusion matrix
Untuk melakukan evaluasi terhadap model klasifikasi berdasarkan perhitungan objek testing mana yang diprediksi benar dan tidak benar. Perhitungan ini ditabulasikan kedalam tabel yang disebut confusion matrix [6]. Confusion matrix merupakan data set hanya memiliki dua kelas, kelas yang satu sebagai positif dan kelas yang lain sebagai negatif. Terdiri dari empat sel yaitu True Positives (TP), False Positives (FP), True Negatives (TN) dan False Negatives (FN) [15].
17
Gambar 2.3 Confusion matrix untuk 2 model kelas [6] Untuk menghitung akurasi menggunakan rumus [6]:
Tabel.2.2 Contoh confusion matrix
Model NBC Kelas yang prediksi Kelas yang di amati
250 45
5 200
Dari table di atas dapat dilakukan pengukuran akurasi model NBC sebagai berikut : 2.2.10 Kurva ROC
Kurva ROC menunjukan visualisasi dari akurasi model dan perbandingkan perbedaan antar model klasifikasi. ROC mengekspresikan confusion matrix [16]. ROC adalah grafik dua dimensi dengan false positives sebagai garis horizontal dan true positives untuk mengukur perbedaaan performasi metode yang digunakan. Kurva ROC adalah teknik untuk memvisualisasi dan menguji kinerja pengklasifikasian berdasarkan performanya [6]. Model klasifikasi yang lebih baik adalah yang mempunyai kurva ROC
lebih besar [16]. Performa keakurasian AUC dapat diklasifikasikan menjadi lima kelompok yaitu [6]:
a. 0.90 – 1.00 = Sempurna b. 0.80 – 0.90 = Bagus c. 0.70 – 0.80 = Cukup d. 0.60 – 0.70 = Kurang e. 0.50 – 0.60 = Gagal 2.2.11 Kerangka pemikiran
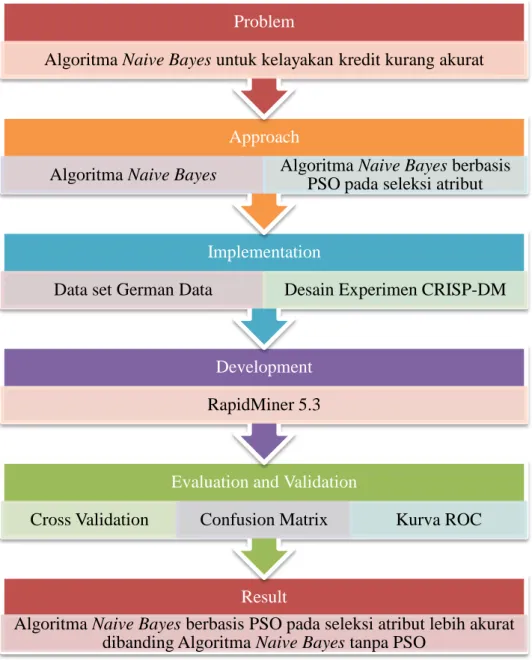
Masalah (problem) dalam penelitian ini adalah algoritma NBC untuk kelayakan kredit kurang akurat. Untuk itu digunakan model (approach) algoritma PSO dalam seleksi atribut pada algoritma Naïve Bayes untuk meningkatkan akurasi. Desain penelitian menggunakan CRISP-DM dan RapidMiner digunakan untuk mengembangkan aplikasi model. Kemudian dilakukan pengujian terhadap kinerja dari algoritma NBC dan algoritma NBC berbasis PSO dengan menggunakan metode Cross Validation. Akurasi algoritma dukur dengan Confusion Matrix dan AUC diukur dengan kurva ROC. Dari hasil perbandingan nilai akurasi diketahui algoritma yang paling akurat.
19
Gambar 2.4 Kerangka pemikiran
Result
Algoritma Naive Bayes berbasis PSO pada seleksi atribut lebih akurat dibanding Algoritma Naive Bayes tanpa PSO
Evaluation and Validation
Cross Validation Confusion Matrix Kurva ROC
Development
RapidMiner 5.3
Implementation
Data set German Data Desain Experimen CRISP-DM
Approach
Algoritma Naive Bayes Algoritma Naive Bayes berbasis PSO pada seleksi atribut
Problem
20
BAB III
METODE PENELITIAN
3.1 Desain penelitian
Metode yang digunakan dalam penelitian ini adalah model CRISP-DM, dengan langkah-langkah sebagai berikut :
3.1.1 Pengumpulan data
3.1.1.1 Pemahaman bisnis (Bussiness understanding)
Keberhasilan kredit pada sebuah bank sangat berperan dalam menjaga kelangsungan hidup sebuah bank. Bank akan rugi jika tidak memanfaatkan dana yang sudah terhimpun dari masyarakat. Karena bank harus memberikan bunga kepada masyarakat. Pendapatan utama bank diharapkan berasal dari penyaluran kredit. Dalam kondisi keuangan yang sangat lemah dengan jumlah kredit bermasalah yang semakin besar, serta likuiditas yang semakin rendah dapat menyebabkan bank kesulitan untuk membiayai kegiatan usahanya [3].
Seperti yang tercantum pada harian suara merdeka yang terbit pada tanggal 18 Maret 2013 bahwa Lembaga Penjamin Simpanan (LPS) telah melakukan pencabutan izin usaha perbankan kepada 47 Bank Perkreditan Rakyat (BPR) dan 1 bank umum sejak tahun 2006 hingga 31 Desember 2012 [4]. Oleh karena itu analisa kelayakan kredit sangat penting dilakukan untuk mencegah jumlah kredit bermasalah yang semakin besar guna menjaga kelangsungan hidup sebuah bank.
21
3.1.1.2 Pemahaman data (Data understanding)
Data yang digunakan pada penelitian ini berasal dari University of California, Irvine (UCI) Machine Learning dengan judul German Credit data. Data yang disediakan oleh Professor Dr. Hans Hofmann ini berjumlah 1000 record dan terdiri dari 20 atribut, dengan 7 atribut bertipe numerik dan 13 bertipe kategorikal. Data ini juga pernah digunakan sebagai data set penelitian oleh beberapa peneliti diantaranya adalah Jeroen Eggermont, Joost N. Kok dan Walter A. Kosters pada tahun 2004 dan Ke Wang, Shiyu Zhou, Ada Wai-Chee Fu dan Jeffrey Xu Yu pada tahun 2003 [21].
Gambar 3.1 Link public data set German data kredit
3.1.2 Pengolahan Data (Data preparation)
Dalam tahap ini, data yang diperoleh dari UCI dalam bentuk text bertipe txt. untuk dapat digunakan pada RapidMiner, data tersebut harus diubah dalam bentuk sheet bertipe csv atau xls. Karena NBC tidak dapat menangani atribut numerik, maka dilakukan proses discretize by frequency sebelum melakukan pemodelan. Proses validasi menggunakan cross-validation, dengan sendirinya data akan dbagi menjadi dua, yaitu 1/10 digunakan sebagai data testing dan 9/10 untuk data training.
Berikut langkah-langkah mengubah data set yang bertipe txt menjadi data set yang bertipe xlsx :
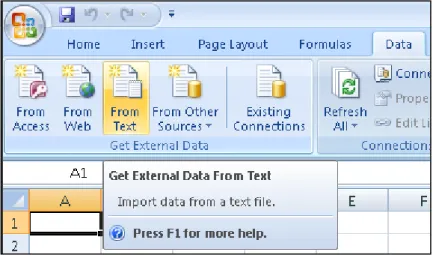
1. Buka Ms.Excel, pilih menu from text pada menu get external data seperti gambar 3.3 dibawah ini.
Gambar 3.3 Import data dari file txt kedalam excel.
2. Pilih file data set yang akan dimasukkan kedalam Ms.Excel, kemudian klik Import.
23
Gambar 3.4 Jendela import file text 3. Klik tombol next.
4. Klik space pada kolom delimiters, kemudian klik next.
Gambar 3.6 Langkah 2 dari import file txt 5. Klik finish.
25
6. Klik OK.
Gambar 3.8 Jendela import data.
Gambar 3.9 Tampilan data set pada excel sheets.
7. Kemudian sisipkan 1 baris untuk memasukkan nama dari masing-masing atribut.
27
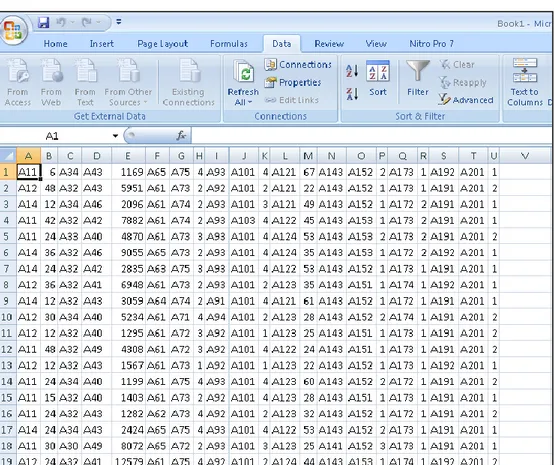
Tabel 3.1 Data set German Kredit Data setelah diubah ke bentuk Sheet bertipe xlsx.
A B C D E F G H I J K L M N O P Q R S T U
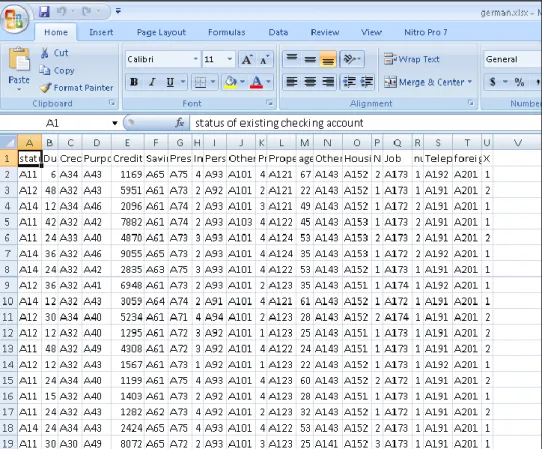
A11 6 A34 A43 1169 A65 A75 4 A93 A101 4 A121 67 A143 A152 2 A173 1 A192 A201 1 A12 48 A32 A43 5951 A61 A73 2 A92 A101 2 A121 22 A143 A152 1 A173 1 A191 A201 2 A12 12 A32 A40 1295 A61 A72 3 A92 A101 1 A123 25 A143 A151 1 A173 1 A191 A201 2 A11 42 A32 A42 7882 A61 A74 2 A93 A103 4 A122 45 A143 A153 1 A173 2 A191 A201 1 A11 24 A33 A40 4870 A61 A73 3 A93 A101 4 A124 53 A143 A153 2 A173 2 A191 A201 2 A14 36 A32 A46 9055 A65 A73 2 A93 A101 4 A124 35 A143 A153 1 A172 2 A192 A201 1 A11 24 A34 A40 1199 A61 A75 4 A93 A101 4 A123 60 A143 A152 2 A172 1 A191 A201 2 A12 36 A32 A41 6948 A61 A73 2 A93 A101 2 A123 35 A143 A151 1 A174 1 A192 A201 1 A14 24 A34 A43 2424 A65 A75 4 A93 A101 4 A122 53 A143 A152 2 A173 1 A191 A201 2 Keterangan : A = status of existing checking account J = other debtors/guarantors S = telephone
B = duration in mounth K = Present residence since T = foreign work C = credit history L = property U = credit status D = purpose M = age
E = credit amount N = Other installment plans F = savings account O = Housing
G = present employment since P = existing credits at this bank H = instalment of disposable income Q = job
3.1.3 Pemodelan (Modelling)
Terdapat dua metode yang digunakan yaitu algoritma NBC dan algoritma NBC yang dikombinasikan dengan algoritma PSO pada seleksi atribut. Untuk membandingkan atau mengkomparasi dalam penelitian ini akan menggunakan framework RapidMiner versi 5.3 sehingga akan ditemukan algoritma mana yang paling akurat.
Gambar 3.11 Model yang di usulkan
Gambar 3.11 merupakan model keseluruhan dari penelitian ini yang terdiri dari model NBC dan model NBC-PSO. Model NBC-PSO yang lebih rinci dapat dilihat pada gambar 3.2 dibawah ini. Trained Model Confusion Matrix Curva ROC Model Naïve bayes Preprocessing Atribut Wieghting PSO German Credit Data (UCI) New Data Set
Training Data Training Data
Testing Data Testing Data
Compare Accuracy
29 PSO NBC yes no yes no yes no yes no yes no
Hitung atribut weight; j=j+1
Pbest = F(xi (t)); Xpbesti = xi (t)
Gbest = F(xi (t)); XGbest = xi (t) Evaluasi nilai fungsi tujuan
setiap partikel; t=t+1 F(xi (t)) > Pbest? F(xi (t)) > Gbest?
Update kecepatan dan posisi partikel
konvergen? Hitung P(X|Ci), i=1,2
untuk setiap kelas
P(X|C1)> P(X|C2)? Kesimpulan C1 Kesimpulan C2 Finish jmax?
Inisialisasi posisi setiap partikel atribut ke-j
Start
Identifikasi populasi sampel Hitung P(Ci) untuk
setiap kelas Transformasi numerik ke
nominal
Gambar 3.12 Model NBC-PSO yang diusulkan
Data dari atribut numerik diubah menjadi nominal, kemudian identifikasi populasi sampel dari data set. Hitung P(Ci) untuk setiap
kelas, dalam kasus data set pada penelitian ini terdiri dari 2 kelas yaitu kredit baik yang dinyatakan dengan “1” dan kredit buruk yang dinyatakan dengan “2”.
Inisialisasi posisi setiap partikel atribut ke-j merupakan awal dari tahap pembobotan atribut dengan PSO. Langkah selanjutnya adalah evaluasi nilai fungsi tujuan dari setiap partikel untuk mendapatkan posisi terbaik (Pbest) dan posisi global terbaik (Gbest), kemudian update kecepatan dan posisi partikel. Ulangi langkah evaluasi nilai fungsi tujuan sampai mencapai konvergen, kemudian Gbest = bobot atribut ke-j. Cek apakah nilai j sudah maksimal, jika belum ulangi langkah-langkah dari inisialisasi posisi setiap partikel atribut ke-j sampai menemukan bobot atribut ke-j. Ulangi langkah tersebut sampai nilai j sudah maksimal atau semua atribut sudah terbobot.
Kemudian hitung P(X|Ci), i=1,2 untuk setiap kelas atau atribut. Setelah itu bandingkan, jika P(X|C1) > P(X|C2) maka
kesimpulannya adalah C1 atau dalah kasus pada penelitian ini bearti
kredit baik. Jika P(X|C1) < P(X|C2) maka kesimpulannya C2 atau
kredit buruk.
3.1.3.1 Model NBC
Berikut perhitungan manual NBC dengan menggunakan data set pada table 3.1 jika data terakhir dijadikan data training:
Gambar 3.13 Penjelasan data training dan data testing.
31
P (U=”1”) = jumlah nilai “1” pada kolom kelas U = 4/8
P (U=”2”) = jumlah nilai “2” pada kolom kelas U = 4/8 b. Menghitung jumlah kasus yang sama dari kelas yang
sama
Gambar 3.14 Contoh mencari P(A=”A14”|U=”1”)
P (A=”A14” | U=”1”) = 1/4
P (A=”A14” | U=”2”) = 0 , karena hasil 0 maka perlu melakukan pendekatan estimasi peluang seperti : ” ” ” ”
P (B=”24” | U=”1”) = 0, karena hasil 0 maka perlu melakukan pendekatan estimasi peluang seperti : ” ” ” ” P (B=”24” | U=”2”) = 1/2 P (C=”A34” | U=”1”) = 1/4 P (C=”A34” | U=”2”) = 1/4 P (D=”A43” | U=”1”) = 1/4 P (D=”A43” | U=”2”) = 1/4
Variable E bersifat kontinu, maka menggunakan prediksi numerik seperti ;
2424 2424 P (F=”A65” | U=”1”) = 1/2,
P (F=”A65” | U=”2”) = 0 , karena hasil 0 maka perlu melakukan pendekatan estimasi peluang seperti : ” ” ” ” P (G=”A75” | U=”1”) = 1/4 P (G=”A75” | U=”2”) = 1/4 P (H=”4” | U=”1”) = 1/4 P (H=”4” | U=”2”) = 1/4 P (I=”A93” | U=”1”) = 1 P (I=”A93” | U=”2”) = 1/2 P (J=”A101” | U=”1”) = 3/4 P (J=”A101” | U=”2”) = 1 P (K=”4” | U=”1”) = 3/4 P (K=”4” | U=”2”) = 1/2 P (L=”A122” | U=”1”) = 1/4
P (L=”A122” | U=”2”) = 0 , karena hasil 0 maka perlu melakukan pendekatan estimasi peluang seperti : ” ” ” ”
Variable M bersifat kontinu, maka menggunakan prediksi numerik seperti ;
33 53 53 P (N=”A143” | U=”1”) = 1 P (N=”A143” | U=”2”) = 1 P (O=”A152” | U=”1”) = 1/4 P (O=”A152” | U=”2”) = 1/2 P (P=”2” | U=”1”) = 1/4 P (P=”2” | U=”2”) = 1/2 P (Q=”A173” | U=”1”) = 1/2 P (Q=”A173” | U=”2”) = 3/4 P (R=”1” | U=”1”) = 1/2 P (R=”1” | U=”2”) = 3/4 P (S=”A191” | U=”1”) = 1/4 P (S=”A191” | U=”2”) = 1 P (T=”A201” | U=”1”) = 1 P (T=”A201” | U=”2”) = 1 c. Kalikan semua hasil variable
P(X | U=”1”) = ¼ x 0,033 x ¼ x ¼ x (2,838 x 10-7 ) x ½ x ¼ x ¼ x 1 x ¾ x ¾ x ¼ x 0,023 x 1 x ¼ x ¼ x ½ x ½ x ¼ x 1 = 5,78 x 10-17 P(X | U=”2”) = 0,067 x ½ x ¼ x ¼ x 0,00014 x 0,1 x ¼ x ¼ x ½ x 1 x ½ x 0,05 x 0,016 x 1 x ½ x ½ x ¾ x ¾ x 1 x 1 = 5,15 x 10-14 P(X | U=”1”) P (U=”1”) = 5,78 x 10-17 x 4/8 = 2,89 x 10-17 P(X | U=”2”) P (U=”2”) = 5,15 x 10-14 x 4/8 = 2,575 x 10-14
d. Bandingkan hasil kelas
P(X | U=”1”) P (U=”1”) < P(X | U=”2”) P (U=”2”) Kesimpulan : U = “2” (Sesuai dengan table 3.1) 3.1.3.2 Model NBC berbasis PSO
Langkah-langkah perhitungan weighting PSO pada NBC seperti dibawah ini, misalnya atribut B pada table 3.1 : a. Diketahui P(C1) = P(U=”1”) = 4/8 ; n = 4;
X1 = 6; X2 = 42; X1 = 36; X1 = 36;
F(Xi (t)) = P(X|Ci) – Ʃ P(X|~Ci);
b. Evaluasi nilai fungsi tujuan setiap partikel
F1(0) = ¼ - 0 = 0,25
F2(0) = ¼ - 0 = 0,25
F3(0) = ½ - 0 = 0, 5
F4(0) = ½ - 0 = 0, 5
c. V1(0) = V2(0) = V3(0) = V4(0) = 0; XPbest1= 6; XPbest2=
42; XPbest3= 36; XPbest4= 36; Gbest= 0,5; XGbest =
36; c1 = c2 = 1; r1 = 0,1 dan r2 = 0,5. Hitung kecepatan
dan perpindahan posisi partikel
V1(1) = 0 + 0,1(6-6) + 0,5(36-6) = 15 V2(1) = 0 + 0,1(42-42) + 0,5(36-42) = -3 V3(1) = 0 + 0,1(6-6) + 0,5(36-36) = 0 V4(1) = 0 + 0,1(6-6) + 0,5(36-36) = 0 X1(1) = 6+15 = 21 X2(1) = 42+(-3) = 39 X3(1) = 36+0 = 36 X4(1) = 36+0 = 36
d. Evaluasi nilai fungsi tujuan sekarang pada partikel xj(1)
35
F2(1) = F(39) = 0;
F3(1) = F(36) = 0,5;
F4(1) = F(36) = 0,5;
Nilai dari F dari iterasi sebelumnya tidak ada yang lebih baik sehingga Pbest untuk masing-masing partikel sama dengan nilai x-nya. Gbest = 0,5 ; XGbest = 36. e. Menghitung P(B=”24”|U=”1”) dengan penambahan
bobot atribut B yaitu dari hasil Gbest = 0,5
f. Ulangi langkah a-e sampai semua atribut terbobot kemudian dilanjutkan langkah NBC dari penghitungan P(X|Ci) sampai akhir.
3.1.4 Validasi dan evaluasi
Dalam tahap ini dilakukan validasi dan pengukuran keakuratan hasil yang dicapai oleh model menggunakan beberapa teknik yang terdapat dalam framework RapidMiner versi 5.3 yaitu confusion matrix dan kurva ROC untuk pengukuran akurasi model, dan cross-validation untuk validasi.
Tabel 3.2 Confusion matrik NBC
NBC True range1 (-∞ - 1.500) True range2 (1.500 - ∞)
pred range1 (-∞ - 1.500) 585 148
pred range2 (1.500 - ∞) 115 152
Dari table tersebut dapat dihitung akurasinya sebagai berikut :
3.1.5 Penyebaran (Deployment)
Hasil penelitian ini adalah analisa yang mengarah ke Decission Suport System (DSS) untuk dapat digunakan oleh bank pada saat menentukan apakah nasabah yang mengajukan kredit disetujui atau tidak.
3.2 Alat penelitian
Dalam penelitian ini penulis menggunakan spesifikasi software dan hardware sebagai alat bantu dalam penelitian yang tercantum pada table 3.3 dibawah ini.
Tabel 3.3 Spesifikasi hardware
Software Hardware
Sistem operasi : Windows 7 Ultimate
Prosesor : Intel(R) Core(TM)2Duo CPU P7570 @2.26Ghz 2.26Ghz
Data mining : RapidMiner versi 5.3.008
37
BAB IV
HASIL DAN PEMBAHASAN
4.1 Validasi dan Evaluasi
Tujuan utama penelitian ini adalah untuk mengetahui nilai akurasi dari algoritma NBC dan NBC berbasis PSO pada pembobotan atribut yang digunakan untuk menangani kelayakan kredit bank. Kemudian membandingkan kedua algoritma tersebut sehingga dapat diperoleh salah satu algoritma yang terbaik.
Untuk menentukan akurasi dari setiap algoritma, penelitian ini menggunakan metode validasi tenfold cross-validation. Desain model NBC yang terdapat pada RapidMiner seperti gambar 4.1.
Gambar 4.1 Desain model validasi NBC
Retrieve berfungsi untuk memasukan data set ke dalam RapidMiner. Discretize untuk mengubah isi dari atribut numerik menjadi nominal, karena
NBC tidak dapat menangani atribut numerik. Model ini menggunakan Dizcretize by frequency yaitu transformasi atribut numerik menjadi atribut nominal oleh operator frekuensi yang menciptakan kelompok rentang terbaik sehingga jumlah nilai yang unik dalam kelompok rentang hampir sama. Validation menggunakan tenfold cross-validation. Didalam validation terdapat dua kolom, training dan testing. Didalam kolom training terdapat algoritma klasifikasi yang diterapkan yaitu Naive Bayes, sedangkan di dalam kolom testing terdapat Apply Model untuk menjalankan algoritma/model Naive Bayes dan Performance untuk mengukur performa dari model Naive Bayes tersebut.
Sedangkan desain model NBC berbasis PSO pada pembobotan atribut pada Rapidminer dapat dilihat pada gambar 4.2
39
Optimize Weights (PSO) untuk menerapkan algoritma PSO pada pembobotan atribut. Didalam Optimize Weights (PSO) terdapat Validation yang menggunakan tenfold cross-validation. Didalam validation terdapat dua kolom, training dan testing. Didalam kolom training terdapat algoritma klasifikasi yang diterapkan yaitu Naive Bayes, sedangkan di dalam kolom testing terdapat Apply Model untuk menjalankan algoritma/model Naive Bayes dan Performance untuk mengukur performa dari model Naive Bayes tersebut.
4.2 Hasil percobaan dan pengujian metode
4.2.1 NBC
NBC tidak dapat menangani atribut numerik, sehingga data atribut numerik di transformasi ke nominal dengan proses yang disebut discretize. Hasil dari discretize by frequency terlihat pada tabel 4.1. Kemudian hasil percobaan dengan algoritma NBC dapat dilihat pada table 4.2.
Tabel 4.1 Contoh hasil transformasi numerik ke nominal dari German data. B E H K M P R U range1 [-∞ - 19] range1 [-∞ - 2319.500] range2 [3.500 - ∞] range2 [3.500 - ∞] range2 [33.500 - ∞] range2 [1.500 - ∞] range1 [-∞ - 1.500] range1 [-∞ - 1.500] range2 [19 - ∞] range2 [2319.500 - ∞] range1 [-∞ - 3.500] range1 [-∞ - 3.500] range1 [-∞ - 33.500] range1 [-∞ - 1.500] range1 [-∞ - 1.500] range2 [1.500 - ∞] range1 [-∞ - 19] range1 [-∞ - 2319.500] range1 [-∞ - 3.500] range1 [-∞ - 3.500] range2 [33.500 - ∞] range1 [-∞ - 1.500] range2 [1.500 - ∞] range1 [-∞ - 1.500] range2 [19 - ∞] range2 [2319.500 - ∞] range1 [-∞ - 3.500] range2 [3.500 - ∞] range2 [33.500 - ∞] range1 [-∞ - 1.500] range2 [1.500 - ∞] range1 [-∞ - 1.500] range2 [19 - ∞] range2 [2319.500 - ∞] range1 [-∞ - 3.500] range2 [3.500 - ∞] range2 [33.500 - ∞] range1 [-∞ - 1.500] range2 [1.500 - ∞] range1 [-∞ - 1.500] Keterangan : B = duration in mounth
E = credit amount
H = instalment of disposable income K = Present residence since
M = Age
P = existing credits at this bank
R= number of people being liable to provide maintenance for
U = credit status
Masing-masing atribut dikelompokan menjadi 2 rentang. Atribut B terdiri dari range1 [-∞ - 19] dan range2 [19 - ∞]. Atribut E terdiri dari range1 [-∞ - 2319.500] dan range2 [2319.500 - ∞], dan seterusnya.
Tabel 4.2 Hasil akurasi dan AUC dari NBC.
NBC
Accuracy Confusion matrix (%) 73,70
Accuracy AUC 0,774
Time (s) 1
Hasil di atas menunjukan algoritma NBC yang diterapkan pada data set german kredit data menghasilkan nilai akurasi confusion matrix sebesar 73,70% dan akurasi AUC 0,774 dalam selang waktu 1 detik.
4.2.2 NBC-PSO
Pertama, dilakukan uji coba dengan memberi nilai pada parameter population size antara 10-600 dan maximum number of generation 100 bernilai konstan. Population size adalah jumlah individual pada tiap generasi, sedangkan maximum number of generation adalah jumlah generasi maksimum untuk menghentikan jalannya algoritma. Terdapat 13 hasil dari percobaan tersebut seperti yang tercantum pada table 4.3 dibawah ini.
41
Table 4.3 Percobaan 1 menggunakan population size 10-600 maximum number of generation 100.
Population size Accuracy Time Confusion Matrix AUC 10 77,30% 0,778 0:00:36 50 76,60% 0,774 0:03:32 100 77,50% 0,776 0:06:30 150 76,70% 0,782 0:11:28 200 77,30% 0,782 0:14:17 250 77,60% 0,771 0:17:03 300 77,70% 0,773 0:21:34 350 77,80% 0,771 0:26:05 400 77,80% 0,772 0:26:38 500 77,70% 0,777 0:36:19 550 77,80% 0,772 0:39:13 600 76,90% 0,776 0:46:36
Gambar 4.3 Grafik hasil akurasi confusion matrix pada percobaan 1 dengan maximum number of generation 100 dan population size 10-600
77.30% 76.60% 77.50% 76.70% 77.30% 77.60% 77.70% 77.80% 77.80% 77.00% 77.70% 77.80% 76.90% 76.50% 76.60% 76.70% 76.80% 76.90% 77.00% 77.10% 77.20% 77.30% 77.40% 77.50% 77.60% 77.70% 77.80% 77.90% 10 50 100 150 200 250 300 350 400 450 500 550 600 Pe rc en tage of A cc u racy Population size
Hasil nilai akurasi tertinggi pada percobaan dengan maximum number of generation bernilai 100 adalah 77,80 % yaitu pada saat population size bernilai 350, 400, dan 550. Pada table 4.3 terlihat bahwa dari 3 nilai population size yang menghasilkan nilai akurasi tertinggi, waktu eksekusi terendah terjadi pada saat population size bernilai 350. Maka terpilih nilai population size terbaik adalah 350 dengan hasil akurasi 77,80 % dan AUC 0,771. Selanjutnya dilakukan percobaan dengan population size bernilai tetap 350 dan maximum number of generation bernilai 100-1500.
Table 4.4 Percobaan 2 menggunakan population size 350 dan maximum number of generation 100-1500.
Maximum number of generation
Accuracy AUC Time 100 77,80% 0,771 0:26:05 200 77,80% 0,771 0:53:37 400 77,80% 0,770 1: 39:32 500 78,00% 0,778 2:06:49 600 78,00% 0,778 2:32:36 700 77,80% 0,771 2:58:29 800 78,00% 0,778 3:21:59 900 78,00% 0,778 3:46:36 1000 78,00% 0,778 4:01:23 1100 78,00% 0,778 4:24:47 1200 78,00% 0,778 5:10:57 1300 77,90% 0,774 5:38:55 1400 77,90% 0,774 5:54:18 1500 78,00% 0,778 6:34:36
Hasil akurasi tertinggi dengan population size bernilai 350 adalah 78,00 % yaitu terjadi pada saat maximum number of generation bernilai 500, 600, 800, 900, 1000, 1100, 1200, dan 1500. Pada tabel 4.4 terlihat bahwa dari beberapa nilai maximum number of generation yang menghasilkan akurasi tertinggi, waktu eksekusi
43
terendah terjadi pada saat maximum number of generation bernilai 500.
Gambar 4.4 Grafik hasil akurasi percobaan 2 dengan population size 350 dan maximum number of generation 100-1500.
Gambar 4.4 menunjukkan hasil akurasi dari maximum number of generation 500 sampai 1500 sudah konvergen. Artinya hasil akurasi sudah maksimal, jika dilakukan percobaan lagi dengan maximum number of generation lebih dari 1500 maka akan terjadi overfiting (kelebihan iterasi) yang berdampak pada meningkatnya waktu eksekusi sedangkan hasil akurasi tidak meningkat. Dengan demikian diketahui bahwa algoritma NBC-PSO menghasilkan nilai akurasi terbaik pada saat population size bernilai 350 dan maximum number of generation bernilai 500 yaitu akurasi bernilai 78,00 % dan AUC 0,778 dengan waktu eksekusi 2 jam 6 menit 49 detik.
Tabel 4.5 Hasil komparasi NBC dan NBC-PSO
Perbandingan NBC NBC-PSO
Akurasi confusion matrix (%) 73,70 78,00 Akurasi AUC 0,774 0,778 Waktu eksekusi 1 s 2 h. 6 m. 49 s 77.80% 77.80% 77.80% 77.80% 78.00% 78.00% 77.80% 78.00% 78.00% 78.00% 78.00% 78.00% 77.90% 77.90% 78.00% 77.00% 77.20% 77.40% 77.60% 77.80% 78.00% 78.20% Pe rc en tage of A cc u racy
Maximum number of generation
Table 4.5 merupakan hasil akhir percobaan. Memperlihatkan perbandingan akurasi dan AUC antara algoritma NBC dan algoritma NBC-PSO.
Gambar 4.5 Grafik hasil perbandingan akurasi dari NBC dan NBC-PSO
Grafik diatas menunjukan akurasi NBC-PSO 78,00%, angka tersebut lebih tinggi 4,30% dari NBC yang hanya 73,70%. Hal ini membuktikan PSO dapat meningkatkan akurasi NBC.
Gambar 4.6 Grafik hasil perbandingan AUC dari NBC dan NBC-PSO NBC, 73.70% NBC-PSO, 78.00% 71.00% 72.00% 73.00% 74.00% 75.00% 76.00% 77.00% 78.00% 79.00% Akurasi (%) T in gk at Aku rasi
Perbandingan Akurasi
NBC, 0.774 NBC-PSO, 0.778 0.772 0.774 0.776 0.778 0.78 AUC T in gk at Aku rasiPerbandingan Area Under
Curve (AUC)
45
Grafik diatas menunjukkan AUC dari NBC 0,774. Sedangkan AUC dari NBC-PSO 0,004 lebih tinggi yaitu 0,778.
Gambar 4.7 Grafik perbandingan waktu eksekusi dari NBC dan NBC-PSO
Dalam grafik tersebut perbedaan waktu eksekusi sangat jelas terlihat. NBC hanya memerlukan waktu eksekusi 1 detik sedangkan NBC-PSO membutuhkan waktu 7609 detik.
Pembobotan atribut diperlukan karena tidak semua atribut mempunyai pengaruh terhadap hasil akurasi. Hasil dari pembobotan atribut oleh PSO pada saat hasil akurasi terbaik dapat dilihat pada tabel 4.5.
Table 4.6 Hasil pembobotan atribut
Atribut Bobot
status of existing checking account 0.519
duration in mounth 1
credit history 1
Purpose 0
credit amount 0
savings account 1
present employment since 1 instalment of disposable income 1
NBC, 1 NBC-PSO, 7609 -1000 1000 3000 5000 7000 9000 W ak tu E k se k u si (s)
Atribut Bobot personal status n sex 0 other debtors/guarantors 1 Present residence since 0
Property 1
Age 1
Other installment plans 0
Housing 0
existing credits at this bank 1
Job 0
number of people being liable to provide maintenance for 1
Telephone 1
foreign work 1
Terdapat 7 atribut yang bobotnya bernilai 0 atau tidak berpengaruh terhadap akurasi yaitu tujuan dari pengajuan kredit (purpose), jumlah kredit yang diajukan (credit amount), jenis kelamin (personal status of sec), lama waktu bertempat tinggal (present residence since), rencana angsuran lain (Other installment plans), status tempat tinggal (housing), dan pekerjaan (job). Beberapa atribut tersebut jika dihilangkan tidak mempengarui hasil akurasi.
Bobot dari atribut yang bernilai 1 dangat mempengaruhi hasil akurasi. Terdapat 12 atribut yang bobotnya 1 yaitu jangka waktu kredit (Duration in mounth), sejarah kredit pribadi (credit history), uang yang disimpan (saving amount), lama menjadi karyawan (present employment since) , pengasilan tambahan tak terduga (instalment of disposable income), pinjaman lain (other debtor); property, umur (age), masih ada tidaknya kredit dalam bank (existing credit at this bank), jumlah orang yang menjadi tanggungan (number of people being liable to provide maintenance for), telephone, status kepegawaian luar negeri atau domestik (foreign work).
47
Gambar 4.8 Grafik hasil pembobotan atribut NBC-PSO
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.519 1 1 0 0 1 1 1 0 1 0 1 1 0 0 1 0 1 1 1 W eigh t Atribut
48
BAB V
PENUTUP
5.1 Kesimpulan
Pada penelitian ini dilakukan pemodelan menggunakan algoritma NBC dan NBC-PSO dengan menggunakan data nasabah bank yang akan mengajukan kredit. Fokus penelitian ini adalah penerapan algoritma PSO pada pembobotan atribut teknik klasifikasi data mining NBC. Validasi model menggunakan 10fold cross-validation dan evaluasi model menggunakan confusion matrix dan kurva ROC.
Hasil penelitian menunjukan bahwa model NBC-PSO memiliki akurasi yang lebih baik dengan 78,00 % dibandingkan model NBC dengan akurasi 77,80 %. Namun waktu eksekusi NBC-PSO lebih lama dengan 2 jam 6 menit 49 detik, sedangkan NBC hanya 1 detik. Dari 20 atribut terdapat 7 atribut mempunyai bobot 0, 12 atribut mempunyai bobot 1 dan 1 atribut mempunyai bobot 0,519. Sehingga atribut yang berbobot 0 dapat dihilangkan karena tidak mempunyai pengaruh pada akurasi kelayakan kredit bank.
Dengan demikian terbukti bahwa PSO yang diterapkan pada pembobotan atribut NBC meningkatkan nilai akurasi. Hal ini menjadikan NBC-PSO memberikan pemecahan untuk permasalahan kelayakan kredit bank lebih akurat.
5.2 Saran
Proses penelitian ini mendapatkan banyak hambatan seperti terbatasnya data penelitian dan perangkat keras yang digunakan, untuk penelitian selanjutnya terdapat beberapa saran sebagai berikut :
![Gambar 2.1 Siklus CRISP-DM [14].](https://thumb-ap.123doks.com/thumbv2/123dok/4161523.3081603/27.892.178.758.190.697/gambar-siklus-crisp-dm.webp)
![Gambar 2.3 Confusion matrix untuk 2 model kelas [6]](https://thumb-ap.123doks.com/thumbv2/123dok/4161523.3081603/33.892.264.765.170.316/gambar-confusion-matrix-untuk-model-kelas.webp)