Preliminary Study of Spam Profile Detection for
Social Media using Markov Clustering: Case Study
on Javanese People
Esther Irawati Setiawan1,2, Candra Putra Susanto2,Joan Santoso1,2, Surya Sumpeno1, Mauridhi H. Purnomo1 1Department of Electrical Engineering, Institut Teknologi Sepuluh Nopember, Surabaya, Indonesia
2Department of Computer Science, Sekolah Tinggi Teknik Surabaya, Surabaya, Indonesia
[email protected], [email protected], [email protected], [email protected], [email protected]
Abstract—In this paper, we report our primary findings in detecting spam profiles on Facebook social media. As we already know, spam profiles on social media especially Facebook is often used as a place to spread spam. Spammers generally use wall post feature on Facebook to spread spam. In addition spammers are also targeting page on Facebook which is a community of many people. In this community, spammers can spread spam as desired. Based on that background, this paper aims is to provide solutions in order to reduce the impact from spammers by using Markov Clustering algorithm to detect spam profile. We used B-Cubed Metrics and F-Measure method to test how the clustering process performs. We obtained 220 profiles in Facebook which contains both normal profile and spam profile of Indonesian Facebook users at Javanese island. B-cubed metrics show accuracy 70% and 74% after applying majority voting to merge cluster into two cluster. F-Measure show accuracy 87% and 88% after applying majority voting. This indicates that algorithm has performed well.
Keywords—Social Network Analysis; Markov Clustering; Graph Clustering; Social Media Facebook; Spam Profile Detection
I. INTRODUCTION
Social media has now become a digital media that can be used by all of the people around the world for different purposes. The simplicity and popularity of social media especially Facebook, provide means for spammers to spread spam. They also use this network to circulate spam. Spam can be defined as poor information on social network, mainly unasked or unimportant bulk messages that the user didn’t even subscribed [1]. A spam usually contains advertisement and promotion of a personal website. There are two types of spammers: content based and graph based. Social networks can be modelled as a graph. [2]. The most critical matter is actually not the spam itself, but the spam profiles that spread those spam.
Facebook has more than 1.65 billion active monthly users all over the world until today [3]. Thus Facebook has become a target of spammers for spam spreading, compared to other social media. Spam profiles usually spread spam by using Facebook features such as Wall Posts and Page Likes. They share advertisements or malicious links on their own wall or their friend’s wall by mentioning multiple friends. They also like a great number of pages in order to spread spam in those pages, or collect user ids from those pages. [4]
Social Network Analysis creates a social graph, which is a network structure and shows the role of individuals in a network. In Facebook, the high degree nodes only has some associations [5]. In [6], clustering is applied to social network to identify groups of nodes with little connections in groups. We can also detect connections between these groups. In 2016, a research is conducted on profiling online social behaviors. It is concluded that usually an account that is compromised usually posts spam [7].
Fighting spam is a worldwide effort. But in Indonesia, spam is already a challenging problem. It is reported that Indonesia ranks second in the list of countries with most spammers [10]. As a case study, we implemented the spam filtering on Facebook users that live in Javanese Island, which is the main island in Indonesia with the most population as shown in Figure 1 [11]. There are also some research conducted on Javanese people in this island. In [12], a research is done to classify anger of Javanese Woman.
This paper focuses on how to detect spam profile with Markov Clustering algorithm [8] [9]. We use Markov Clustering instead of supervised learning algorithm like Naïve Bayes and Support Vector Machine because we want to cluster different type of spam profile and also detecting new modus for each spam profile. New modus of spam profile indicates a “new” way to spread spam. This will be useful for detecting more new spam profile in order to overcome the spread.
The experiments were conducted on Indonesian people who lives in Javanese Island. We selected people in this island to give an insight on spam profiles at the main population in Indonesia. We analyzed how spamming Javanese people act on the most popular social network in Indonesia which is Facebook.
II. RELATEDWORK
Social network analysis become more popular nowadays. Many researchers have conducted analysis on the social network for different purposes. In [9], the authors explained how to detect spam profile by using MCL approach in social networks. The authors gave explanation from many different social networks such as Twitter, MySpace, and Facebook but the focus is on Facebook. The authors used three features identification for each profile relation from wall posts, tags, and page likes. The features is divided into three categories such as Active Friends, Page Likes, and URL shared.
In [13], the authors explained how to detect spammers on social networks. The research is focused on Facebook, Twitter, and MySpace. The main feature is Friend Request Ratio, URL Ratio, Message Similarity, Friend Choice, Message Sent, and Friend Number. In [14], the authors reported their study about characteristic of spammers in Chinese social networks. They conducted their research on Chinese Microblogging Networks. The features are social information, activity, account age, and spamming strategy.
In [15], spam detection in done on various social networks, by detecting similar spam within a social network and utilize it in different social networks. Compared to the existing related work, we try to implement Markov Clustering Algorithm to detect spam profile and identify the different type of spam profile in order to develop a method to overcome the spam profile problem. In this research, we use dataset in Facebook because of its popularity and we collected user profiles from Indonesian Facebook Profiles in Java Island.
To obtain our goal, we collected information from existing paper that explained how to detect spammers in social media and its approach. We try to implement Markov Clustering for spam profile detection by using related features from Facebook Wall Posts and Page Likes. The existing paper explained how to detect spammers in social networks not just in Facebook but the other popular social media. We then try to compare between existing paper and then choose the best approach for detect spam profile. This needed because every paper has different method and different feature.
III. PROPOSEDWORK A. Data Collection
We obtained 220 profiles from Facebook which contains both 110 normal profile and 110 spam profile. There are approximately 4000 relation available. For each profile we used 100 newest posts and 100 newest page likes. From that Wall post and Page Likes then we can calculate the features and use it as value for weighted graph each relation of user profile. Before applying Markov Clustering, we have to create association matrix first. Association matrix can be obtained by compare every profile from existing dataset. For example, if we have 220 profiles then we have to create matrix association with size 220 x 220 dimension. After matrix created then we can continue with the next stages which are normalization,
expansion, and inflation. We collected it about three months from different profile and different regions in Java Island. We used three main features from existing paper [9] such as Active Friends, Page Likes, and URL shared. These features are obtained from Wall Posts and Page Likes from each profile. Every value from each feature will be combined in order to get weighted graph for each profile relation.
B. Clustering Facebook Profile
The social networks usually defined as a weighted graph and the notation is G = (V,E,W) where G is graph, V is set of profile, and E is set of edge and W is set of weight. In order to get cluster profile, first step we have to do is create association matrix from each profile. We used three main features such as Active Friends, Page Likes, and URL and then combine it to get the weight of every relation between each profile. Below is the pattern explanation of three main features for creating association matrix.
• Active Friends
This feature will get the interaction frequency of a profile with each profile in dataset. For each profile Vi,
the set of active friends is the set of friends from dataset who have interactions each other through wall posts. For every interaction or edge = (Vi,Vj), the value
between both profile is calculated from intersection between it.
= (1)
In Equation (1), we calculate the frequency of active friends between each profile in dataset. This will show the closeness between each profile. This feature then will be combined with other 2 features in the following.
• Page Likes
This feature will get the similarity page likes between each profile in dataset. For each profile Vi, the set of page likes is the set of page likes of profile Vi. Then for every interaction or edge = (Vi,Vj), the value between both profile is calculated from intersection between it.
= (2)
Equation (2) shows how to calculate the same page likes between each profile in dataset. Then it will show how close each profile is. This feature then will be combined with another feature in the following.
• URL
This feature will get the similarity URL shared between each profile in dataset. For each profile Vi, the set of
URL shared is the set of URL shared by profile Vi.
Then for every interaction or edge = (Vi,Vj), the
value of URL is calculated from intersection divided by union between it.
= (3)
Equation (3) shows how to calculate the URL shared between each profile in dataset. After all feature obtained, then combined it to get the weighted edge for every user profile relation by using the following equation. Division by union is done to know the common url shared.
= + + (4)
After we obtained weight for every relation then we can create the association matrix N x N where N is the amount of dataset. In this paper, we used 220 profile so the value of N is 220. Below is the detailed steps of Markov Clustering algorithm:
1. Input is weighted graph, parameter power e, and parameter inflation r.
2. Create association matrix between each profile.
3. Normalize association matrix that already obtained in step 2.
4. Expand the matrix by using parameter power e (Expansion). 5. Inflate the matrix by using parameter r (Inflation).
6. Repeat step 4 and 5 until convergence is reached. 7. Use resultant matrix to find cluster.
After we created the association matrix, then we normalize the matrix by using probability concept. Each value in a single column of matrix is divided by sum of all value in that column. Then we will get matrix probability of each profile and do the expansion and inflation process until cluster obtained.
Expansion is the process to expand the cluster region. Before the expansion, we need parameter e for input. Expansion will multiply the normalized matrix by itself in e times. Expansion in Markov Clustering will do random walk to explore the graph and find the cluster. The goal of expansion is to find another cluster in weighted graph and then the cluster will be eliminated by inflation process to get appropriate cluster.
Inflation is the process to reduce the cluster region. Before do inflation, we need parameter r for input. Inflation will multiply each value in matrix by itself r times and then normalize it once again.
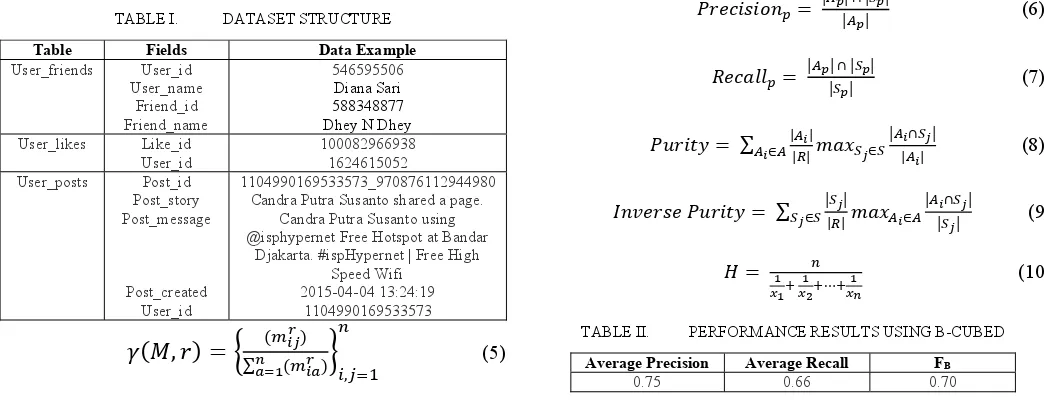
TABLE I. DATASETSTRUCTURE
Table Fields Data Example
User_friends User_id User_name
Friend_id Friend_name
546595506
Diana Sari 588348877 Dhey N Dhey
User_likes Like_id User_id
100082966938 1624615052 User_posts Post_id
Post_story Post_message
Post_created User_id
1104990169533573_970876112944980 Candra Putra Susanto shared a page.
Candra Putra Susanto using @isphypernet Free Hotspot at Bandar
Djakarta. #ispHypernet | Free High Speed Wifi
2015-04-04 13:24:19 1104990169533573
,
=
∑, (5)
Equation (5) is the pattern for calculate the inflation of Matrix M with parameter inflation r. Every value mijin matrix i
x j will be calculated with equation 5. This inflation process will be repeated until convergence is reached.
Matrix will be declared convergence if the condition nearly idempotent matrix. Idempotent matrix means if we multiply the matrix by itself, it will also result the matrix itself. This is the two conditions that show the matrix is nearly reached convergence:
1. Matrix is already in steady state that there is not many different value before and after expansion and inflation process.
2. Every value in a single column has the same value. IV. PERFORMANCEEVALUATION
In order to know the algorithm’s performance, we provide B-cubed metrics and F-measure methods [16] to evaluate the performance of algorithm for detecting spam profile. We used 220 Facebook profiles which contains of 110 normal profiles and 110 spam profiles. Then we labeled each profiles with class of Yes and No. Where class Yes is represented as spam profile and No is represented as normal profile. This label will indicate how good the performance of the algorithm in detecting spam profiles.
B-cubed (FB) is a mixed metrics for graph clustering
invented by Bagga and Baldwin in 1998. B-cubed (FB) is the
harmonic mean from recall and precision. For each profile p, let Spis the set of profiles whose class is the same as p class in
dataset and Apis the set of profiles whose class is the same as p
class in the resultant clusters. After each profiles recall and precision obtained by using equation 6 and 7 then average of recall and precision will be used as harmonic mean using equation 10.
F-measure (FP) is the harmonic mean of purity and inverse
purity. Considering a set S of clusters in the test dataset and a set A of clusters obtained in the resultant clusters. The purity and inverse purity is calculated by using equation 8 and 9. Purity and inverse purity. The harmonic mean of purity and inverse purity is calculated using equation 10.
= (6)
= (7)
= ∑ ∈ | || | ∈ | | (8)
= ∑ ∈ | | ∈ (9)
= ⋯ (10)
TABLE II. PERFORMANCERESULTSUSINGB-CUBED
Average Precision Average Recall FB
TABLE III. PERFORMANCERESULTSUSINGF-MEASURE
Purity Inverse Purity FP
1 0.78 0.87
TABLE IV. PERFORMANCERESULTSAFTERMAJORITYVOTING
Average Precision
Average Recall FB
0.76 0.73 0.74
Purity Inverse Purity FP
1 0.78 0.88
Table II and III show the performance evaluation result using B-Cubed metrics and F-measure. B-Cubed metrics show average precision of 0.75, average recall valued 0.66, and the harmonic mean 0.70 (70%). F-measure show purity 1, inverse purity 0.78, and harmonic mean 0.87 (87%).
Table IV show the performance evaluation after applying majority voting. Majority voting is applied to handle the cases in which a clusters contain both spam and normal profiles. Majority voting is done in order to include outlier clusters into the majority clusters. Majority voting merge the resultant cluster at table I into two cluster as normal profile and spam profile then calculate the B-Cubed metrics and F-measure again. After majority voting B-cubed metrics show average precision 0.76, average recall 0.73, harmonic mean of precision and recall is 0.74 (74%). After majority voting F-measure show purity 1, inverse purity 0.78, and harmonic mean of purity and inverse purity 0.88 (88%).
In Javanese population, it could also be identified that the between users in Facebook, usually mutual friends are very rare between spam and non-spam users. In this research, we also found that page likes become the most useful feature for spam profile because they can spread spam to all of page member for just one published post. More page member more useful for spam profile.
V. CONCLUSIONANDFUTUREWORK
In this paper, we used three main features from authors to detect spam profile on Facebook [9]. Performance evaluation using B-cubed show accuracy 70% and after applying majority voting 74%. F-measure show accuracy 87% and 88% after majority voting. This indicates that algorithm running well. In this research, we found that usually normal profile has similar page likes, communicate by using tag feature on wall post from each users, and shared URL relatively common and spam profile has a habit to exchange page likes, share URL address with the same domain but different page, tagging on wall post for each profiles, and has a lot of common page likes.
In future work, we hope that this research will be the foundation of another method to support analysis on social networks not just in Facebook, but other social networks such as Twitter, Instagram, and Path. We could also personalize this research to handle personal spam, where the spam criteria is different from one person to another.
ACKNOWLEDGMENT
The research for this paper was financially supported by Indonesia Endowment Fund for Education (Lembaga
Pengelola Dana Pendidikan (LPDP)), Ministry of Finance, Indonesia.
REFERENCES
[1] D. Wang, D. Irani, and C. Pu, “A social-spam detection framework,” Proc. 8th Annu. Collab. Electron. Messag. Anti-Abuse Spam Conf. - CEAS ’11, no. January, pp. 46–54, 2011.
[2] M. Jalali and M. H. Moattar, “Spam Detection In Social Networks : A Review,” no. Ictck, pp. 11–12, 2015.
[3] Emil Protalinkski, “Facebook passes 1.65 billion monthly active users, 54% access the service only on mobile | VentureBeat | Social | by Emil
Protalinski,” 2016. [Online]. Available:
http://venturebeat.com/2016/04/27/facebook-passes-1-65-billion-monthly-active-users-54-access-the-service-only-on-mobile/.
[4] U. Brandes, “Social Network Analysis and Visualization,” IEEE Signal Process. Mag., vol. 25, no. 6, pp. 147–151, 2008.
[5] N. Akhtar, H. Javed, and G. Sengar, “Analysis of facebook social network,” Proc. - 5th Int. Conf. Comput. Intell. Commun. Networks, CICN 2013, pp. 451–454, 2013.
[6] D. Combe, C. Largeron, E. Egyed-Zsigmond, and M. Géry, “A comparative study of social network analysis tools,” Soc. Networks, vol. 2, no. 2010, pp. 1–12, 2010.
[7] H. Wang, “Exploiting Online Social Behaviors for Compromised Account Detection,” vol. 11, no. 1, p. 1, 2016.
[8] S. van Dongen, “Graph clustering by flow simulation,” Graph Stimul. by flow Clust., vol. PhD thesis, p. University of Utrecht, 2000.
[9] F. Ahmed and M. Abulaish, “An MCL-based approach for spam profile detection in online social networks,” Proc. 11th IEEE Int. Conf. Trust. Secur. Priv. Comput. Commun. Trust. - 11th IEEE Int. Conf. Ubiquitous Comput. Commun. IUCC-2012, pp. 602–608, 2012.
[10] Amir Karimuddin, “Kapersky: Indonesia Is The World’s 2nd Biggest Spammers | Dailysocial.” [Online]. Available: https://dailysocial.id/post/kapersky-indonesia-is-the-worlds-2nd-biggest-spammers.
[11] “Indonesia Population (2016) - World Population Review.” [Online]. Available: http://worldpopulationreview.com/countries/indonesia-population/.
[12] N. Z. Fanani, “Multi Attribute Decision Making Model Using Multi Rough Set : Case Study Classification of Anger Intensity of Javanese Woman,” pp. 0–4, 2016.
[13] X. Zheng, Z. Zeng, Z. Chen, Y. Yu, and C. Rong, “Detecting spammers on social networks,” Neurocomputing, vol. 159, pp. 27–34, 2015. [14] Y. Zhou, K. Chen, L. Song, X. Yang, and J. He, “Feature analysis of
spammers in social networks with active honeypots: A case study of chinese microblogging networks,” Proc. 2012 IEEE/ACM Int. Conf. Adv. Soc. Networks Anal. Mining, ASONAM 2012, pp. 728–729, 2012. [15] H. Xu and A. Javaid, “Efficient Spam Detection across Online Social
Networks.”