Measuring the Performance of Ontological Based Information Retrieval from a
Social Media
Eko Sediyono
Satyawacana Christian University, Jl. Diponegoro 52-60 Salatiga,
Indonesia [email protected]
Suhartono
Diponegoro State University Jl. Imam Bardjo, SH. No. 3
Semarang, Indonesia [email protected]
Christian Nivak STMIK Provisi Semarang Jl. Pattimura 32 - 34 Semarang,
Indonesia [email protected]
Abstract— Users of social media website now can search, share, or just browse for information with ease. In the field of travel and tourism, it can easily find and share information about travel activities, travel destination, and travel accommodation due to plentiful source of information, but there is also a drawback related to the quality of the information. Traditional search engine that uses keyword to search for information about the meaning of a word or a sentence often produce biased and irrelevant search results. Ontology has been developed to overcome this problem. In this paper an ontology framework is presented, which was specifically developed for travel and tourism field using data set from twitter. A crawler application also presented to get the data needed for analysis. Finally a performance measurement is done by using Average Precision and Mean Average Precision. A search result is calculated using the ontology data and crawler data. The goal of this research is to develop ontology for travel & tourism domain and to analyze the quality of the search result on all environments. The result of this research is ontology for travel & tourism domain from twitter with MAP of 91.5%.
Keywords- Ontology; Semantic; Social Media; Searching; Indexing.
I. INTRODUCTION
The rise of social networking websites offer convenience to anyone to share information easily. One of the area that is affected by this development is the field of travel & tourism. The users of the website share information regarding travel, read a review about tourism sites, and use such information as a reference for planning a trip. One of the popular social networking websites is twitter. A lot of information about the tour can be found on this website.
On the other hand these developments pose a problem when someone is searching for information. Existing information retrieval systems generally rely on the search-based keywords. Shortcomings of this model is not paying attention to the sense or meaning of the searched information, but it only provides the ability to search for a word by word or phrases without regarding to the meaning of these words or phrases which is used as keyword [11].
As a solution of this limitation, the ontology can be used as a representation of the data and information. Ontology is an explicit formal specification of how to represent the
objects, concepts and other domain entities and relationships among them [1]. In other words, the ontology provides a representation of knowledge to enable the existence of the same understanding about a domain. In computer science, an ontology is used in the new technology, that is semantic web, that presents the information in a semantic structure.
On our research, ontology framework for information retrieval will be developed using data from the social networking website twitter. The advantages of twitter among other social networking websites such as facebook and linkedin is the availability of a large amount of data that can be accessed freely, whereas on facebook and linkedin information can only be accessed by users who already have a “relationship” with the information source. Fields of travel & tourism was chosen as the subject because there is much information about travel & tourism on twitter, although the information is limited due to restrictions on the number of characters for a single tweet. Information about travel & tourism is taken from the accounts @bbc_travel and @lonelyplanet. Tweets from both accounts is interesting as research object, for most of the tweets contain information about the tourism objects and there is a url link that leads to a Web page with a more complete article about the subject of the tweet. If we use the regular search model, it will cause limitations, because the search results that we get are not necessarily relevant to what we want. By developing ontology for travel & tourism, information from a tweet will be expanded to get more relevant search results.
II. REVIEWOFLITERATURE
Framework Schema) and OWL (Ontology Web Language), etc. 4. Construction of the interface that is easy to understand. From the four aspects, the third aspect is the most crucial stage for achieving semantic search [1].
Reference [6] presents a framework for semantic information retrieval by integrating several techniques of natural language processing (NLP), each of which explains a text with different types of information that has been extracted from the text.
The advantage of the framework presented in this publication is that it can be applied to documents from any domain. But there are some drawbacks of this framework. One of which being a function of scoring in relation to the structural relationships. The scoring method used is not entirely suitable for framework designed due to duplication of annotations on scoring query [6].
Smart Web Query (SWQ) is a method for collecting data. It was mentioned in the publication entitled “Smart web query method for semantic retrieval of web data”. SWQ method uses semantic domain represented by the ontological context to define and formulate a suitable web query for information retrieval. This method also relies on semantic search filters to identify and sort the websites semi-automatically. The Domain that is used as an example for testing in this publication is stock trading domain. SWQ architecture consists of the engine and components like SWQ query parser and engine component context ontology. SWQ interface can be found in [2].
An extraction system and ontology-based search in [4] has been applied on the domain of football. This system applies semantic search-based keywords.
The performance of the system being built was compared to the traditional search systems. The result obtained from the experiment shows that the system is able to respond to the complex semantic query that cannot be done by traditional search engines. The experiment also shows the flexibility of the system in responding to data modification and data updates [4]. The next paragraphs discuss the theoretical background of semantic web and ontology.
A. Semantic
According to [9] the semantic is the science of words and sentences; knowledge of the shifting meaning of the word; the structure of the language as it relates to the meaning of the phrase or the structure of the meaning of a speech. Semantic forms a network that describes the relationships between concepts as a form of knowledge representation.
B. Semantic Web
Reference [3] defines semantic web as data networks, with the aim of creating a database of inter-connected globally on the whole web. The semantic web is not intended to replace the existing standard, but is an extension of the World Wide Web. It has some capabilities and new technologies for modeling, annotation, search and data integration. By using Semantic web user can easily do a search on the World Wide Web by following a hyperlink that will direct them to the information they want.
Reference [12] said that the retrieval is not based on the similarity of string, but similarity in meaning. He gives an example, the pair cat:meow is analogous to the pair dog:bark. Regular web pages are made up of html code, php, java script and other syntax that does not provide clues about the sense or meaning of the existing content, so that users sometimes have difficulties in finding relevant information. Semantic web is capable of giving meaning to the document and the entity by means of modeling, annotation and integration of data. Two different entities or documents can be coupled each other through a property that allows data integration and automation.
C. Ontology
In its general meaning, ontology is the theory or study of being as such as a basic characteristic of all reality. Though the term was first introduced in the 17th century, ontology is synonymous with meta physics of “first philosophy” as defined by Aristotle in the 4th century BC [5].
Since the beginning of the nineties the usage of the term “ontology” has become more frequent in artificial intelligence community, i.e., in knowledge sharing, agent interoperation, common sense knowledge representation, natural language processing, and other fields. In general the idea behind ontology is exposing knowledge explicitly by way of expressing the concepts and the relationships between concepts. In other words the ontology defines a term or concept that will be used to represent an area of knowledge or information about the collection of data and how the data is interrelated. Thus the ontology provides the means for creating semantic structure. In terms of communication theory, ontology represents the context of a term. In the semantic web, ontology is a semi structural form and represents an open model, which means that the model can thrive with the ontology data and ontology does not have to include any entity from the real world.
In the process of designing ontology there are a few things to note [7] :
1. There is not the most appropriate way in designing ontology; there are always other alternatives. The best solution is always looking toward the ultimate goal of the application to be accomplished.
2. The ontology development process is iterative. 3. The concept of ontology must represent real-world
object concepts both physically and logically. It is also represent the relationship of domains those are taken as an ontological subject.
Thus, the goal of ontology development and its detail or general is depending on the design of ontological modeling.
D. Semantic Knowledge Representation
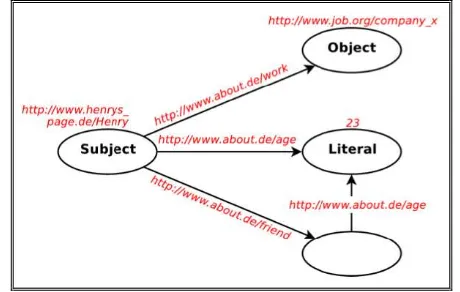
The basis of semantic knowledge representation is RDF (Resource Description Framework). RDF is a simple data model that describes the objects or resource and the relationship between these objects with triple syntax subject-predicate-object as in the structure of a sentence [10].
empty. The object node could be the literal and the property could also be a URI.
Figure 1. Relationships in RDF Triples among Resource, literals, and empty Node.
E. Indexing
Indexing is an important part in the search system. Indexing can improve query performance and speed up response time on the search process by way of storing the position of text for each occurrence of the keyword being searched for [8].
F. Ranking
In the process of indexing, the documents obtained by the search process are given a score according to the level of match between the query keywords and the document itself. Further the documents are ordered by scores, so that those that are most relevant to the query keywords will be shown at the top. The rank associated with evaluation methods will be discussed in the next section [8].
G. Evaluation Metrics
The performance of the search results can be measured using evaluation metrics [4]. Formerly we count the average precision (AP). From the AP value of each query, we can find Mean Average Precision (MAP). To count the AP, let us see the query result scenario as seen in Figure 2.
Figure 2. Example of query result scenario.
As an example, there are four relevant documents such as in the Figure 2. The first relevant document was found in the first place. The next relevant document was in fourth, fifth, and eighth places. The AP value can be found as equation 1.
AP=1 /1+2 / 4+3 / 5+4 / 8
4 =0.65=65%
(1)
The 1/1 in the equation 1 meant that query precision level 1. The 2/4 meant that the second precision in level 4, and so on. It means that AP value will be 100% if all relevant documents placed in the top level.
Mean Average Precision (MAP) is used as an evaluation metrics. The value of AP for each query is calculated by finding the average value obtained from a set of documents that have top rank k and relevant documents from each of the query process. The AP values are then averaged to get the MAP value.
(2)
where Q is number of query.
III. METHODOLOGY
A. Materials and Research Tools
Research material used is in the form of a social networking website data from twitter.com. From the selected website, two accounts related to travel and tourism domain is used, i.e. @bbc_travel and @lonelyplanet. The data taken as research material is from September 1st, 2013 to September 30th, 2013. Data taken from both of this tweeter account is in the form of Tweets that has the following characteristics:
• Tweet in the form of words, phrases or sentences with the maximum amount of 140 characters per tweet.
• Tweet can contain the hashtag that is usually symbolized with # in front of the word that made a hashtag, for example: #travel
• Tweet can contain a mention. Mention is another account name that is mentioned in a tweet.
• Tweet may contain hyperlinks in the form of a url.
• Tweet contains information in the form of time, date, month and year when the tweet is sent.
An ontology-based search using data from twitter has some restrictions because the information obtained from it —tweets— contains only short information of the subject concerned. This is due to the restriction of the number of characters in a tweet which only amounted to a maximum of 140 characters.
B. Ontology Development
Steps in building ontology are as follows:
1. Determine the domain and scope of the ontology. Ontology that was built on this research is in the travel & tourism domain. This will be applied to ontology for semantic search. In the development of ontology design, data from twitter is used as a reference in determining the class, class hierarchy, and property.
this research there are two references made in an ontological study, they are travel.owl file that was taken from ontology repository from the url http://protege.cim3.net/file/pub/ontologies/travel/, and TravelOntology.owl that was taken from repository http://fivo.cyf-kr.edu/ontologies.
3. Write down the important terms that will be used in the ontology design. On ontology with travel & tourism domain, there are several terms that need to be noted such as tourist activities, tourist destination, type of tourist activity, type of tourist destinations, city, country, etc. This glossary of terms will be used as reference in the next step. It will define the class and the class hierarchy.
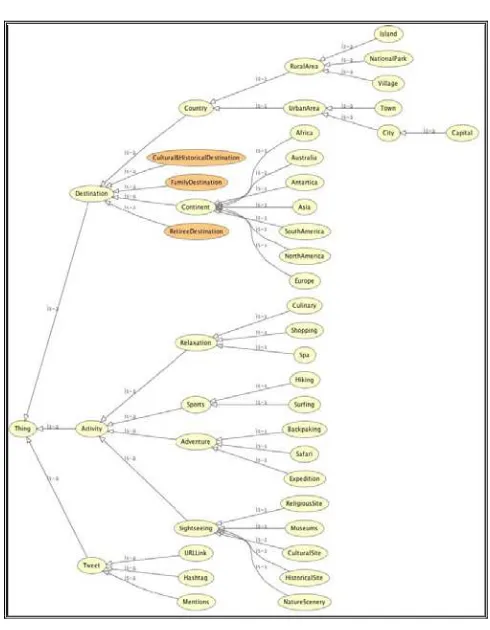
4. Define the class and the class hierarchy. The stage combine the top-down and bottom-up methods to the design of the class and the class hierarchy [13]. The result can be seen in Figure 3.
5. Define the class property. As individual tweets those are categorized by class and class hierarchy. Each individual must have the property that defines a concept. Because of the individual is formed by a tweet, then the result information comes from tweet include hashtag, mention, url, tweet, and activity. 6. Define a data property. The Data property is used to
describe the data type of each property embedded in individuals. For example, property hashtag, mention, url and tweet were given a string type.
7. Create the individual. The sentence from twitter is taken using crawler applications in the form of text. The text is formatted by the crawler into an .xml file and added data id and time. Time is taken from metadata in the tweet. By using Protégé tool, the xml file is taken as part of the text. For example a tweet “A worthy-migration of wildebeests bikes in #Bogota:http://t.co/mozUsjOdvU". In the tweet, the name of the city Bogota was found. The city name was made as an individual.
C. System Design
The system that is designed is a data capture system, the construction of ontology, and semantics search. A diagram of the whole system can be seen in Figure 4.
The description of how the system works is as follows: 1. Simple twitterClient as crawler application retrieves
data from twitter. The data that was taken from twitter was two accounts i.e. @bbc_travel and @lonelyplanet.
2. The Data generated by the crawler is used for the construction of ontology with reference to the design of ontology class hierarchy as described above. 3. When the ontology data is completed, then it is
extracted into XML file. XML documents extracted from the ontology must be adjusted to the correct format using SOLR indexing process.
4. The process of indexing is performed with the SOLR server. This consists of two parts, i.e. for simple data that is output of the crawler and the ontology data.
Both are in the form of XML documents formatted for indexing on SOLR.
5. The final stage is the search with a query that has been prepared; an interface for searching has been provided by SOLR. This search is carried out on two different environments, namely the simple data environment from crawler and data ontology environment.
Figure 3. Class dan Class Hierarchy for Travel and Tourism Domain.
Figure 4. System Diagram.
D. Indexing and Searching with SOLR
search server with servlet container called Jetty. Indexing configuration on SOLR is conducted in schema.xml file as SOLR server indexing configuration. Modifications were made to two different environments: for indexing data crawler and indexing results simple data ontology. The query is done using an existing interface on SOLR server, and the results will be shown in the form and format that can be arranged according to the needs, e.g. XML, Json, PHP, or Ruby format.
IV. RESULTANDDISCUSSION
The data that is taken from the website twitter.com comes from two accounts, i.e. @lonelyplanet and @bbc_travel. The data collected is limited from September 1st, 2013 to September 30th, 2013. By using a crawler applications obtained as many as 315 tweets from the account @lonelyplanet and 268 from the account @bbc_travel, so the total tweets obtained amounted to 581. The crawl results data is in the form of xml documents.
Results from the data crawler are then built into the ontology model of having a hierarchy, and property relations. There are a few tweets which cannot be processed into the individual in ontology because information that is not relevant to the domain of travel & amp; tourism and don't have enough quality information as a condition to be used as an individual in the ontology. In this research the rules used to select whether a tweet can be used as an individual in the ontology with travel and tourism domain among others
• Tweets must contain the name of the city, country or continent.
• Tweet must contain the name tourism place or tourist activity made in that place.
• Tweet should relate to the travel and tourism domain. After collecting an eligible tweet data then built the ontology data by using ontology editor i.e. Protégé. The ontology is built based on a design that has been described in the previous chapter. From the ontology development process resulted in seventy-four individuals were categorized by city, country, continent, or types of tourism activities. When it was discoveredsome tweets that discuss the same city or country, it will be merged into one individual.
A. Indexing on SOLR Server
Indexing by using SOLR server was started by modifying the document schema.xml in SOLR configuration. This document shall be responsible for the indexing process that is carried out in two neighborhoods of simple data crawler results environment in the form of xml document named bbc_travel.xml and lonelyplanet.xml. The second environment is data ontology. The Data ontology obtained from the owl Protégé, and extracted into the xml document. This document should be modified in accordance with the format of the xml document that is able to read by the indexer of SOLR.
B. Measuring the Performance
Performance evaluation is carried out by preparing query components as shown in table 1.
TABLE I. COMPONENT QUERY TO MEASURE THE PERFORMANCE.
Q1 Find all traveling info in Paris (query:
travel+Paris)
Q2 Find all traveling info in Europe (query: travel+Europe)
Q3 Find all destination in Asia (query:
destination+Asia)
Q4 Find backpacking destination all over the world (query: Backpacking+destination)
Q5 Find a Cultural & Historical destination (query: Cultural+Historical+destination)
Q6 Find expedition destination in South America (query: expedition+South+America)
Q7 Find all traveling info in a capital city all over Europe (query: travel+capital+city+europe)
Q8 Find safari destination in Africa (query:
destination+Safari+Africa)
Q9 Find all Retiree Destination (query:
Retiree+Destination)
Q10 Find a relaxation destination in an island (query: Relaxation+Island)
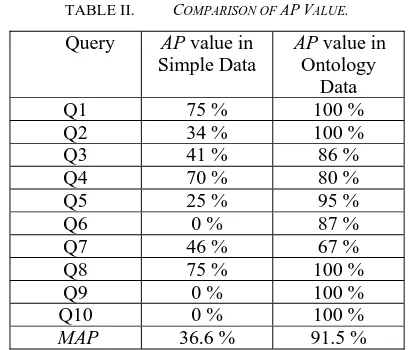
C. Average Precission (AP) as a Performance Metric By applying Equation 1 and 2 we found AP and MAP of Simple data and ontology, as shown in Table 2.
TABLE II. COMPARISON OF APVALUE. Query AP value in
Simple Data
AP value in Ontology
Data
Q1 75 % 100 %
Q2 34 % 100 %
Q3 41 % 86 %
Q4 70 % 80 %
Q5 25 % 95 %
Q6 0 % 87 %
Q7 46 % 67 %
Q8 75 % 100 %
Q9 0 % 100 %
Q10 0 % 100 %
MAP 36.6 % 91.5 %
Table 2 shows a comparison of the value of the AP for each query in the simple data environment and the ontology data environment. From the results of each query search then it is calculated the MAP value. From the calculation found that the value of simple data is 36.60% and 91.50% for ontology data.
D. Discussion
the effect of data that has been built into the ontology data in the search process.
The effect of the information extraction from tweeter show that, each tweet generally has a property hashtag with the value prefixed to the symbol “#”. On twitter, hashtag is used as the marker to facilitate the search. This brings the influence in the search results on this research, e.g. on a query Q1 and Q2 are using keyword travel+Paris travel+Europe. It was found that most of the Tweets coming from @lonelyplanet using the hashtag #travel. So when we see the results of query Q1 and Q2 are found quite a lot of search results i.e. 270 documents for Q1 and Q2 on document 268. This of course affects the calculation of the AP value since the number of the document that are not necessarily relevant to the query.
Query on Q6, Q9, Q10 has zero result. It can be explained that query in Q6 use query text expedition+south+America. This query is quite difficult to do, because of the need to find a tourist destination with the type of expedition and the location in South America. Extracted data that was yield does not explicitly mention a tourist activity that has the type of expedition and maybe just mentioned the name of a country like Brazil, with tours in the Amazon River but do not explicitly mention that Amazon that is in South America.
The effect of ontology data is better. An ontology that is built successfully expanded the knowledgebase of every tweet that is processed. While constructing the ontology, some properties and relation is added into the respective data. Construction of ontology by adding properties and relationships such as these, have proven very good effects in the process of querying that produce relevant documents. Even when it is seen from the table, the value of All the AP calculation resulted for each query is fairly low. It means that the document search results relevance quality is good enough. For a fairly difficult to query such as the query Q9 and Q10, it produced 100% relevance value due to the effects on some inference of some tweet that categorized to the retiree and tourist sites in an island.
V. CONCLUDING REMARK
Based on the results of the study and the discussion on ontology-based search using semantic indexing on domain tour & travel can be concluded that the ontology for the domain travel & tourism has been developed using data sets from twitter. Ontology framework developed with a combination approach of top-down and bottom up.
At the time of development, the ontology elements such as class, class hierarchy, property, and data type customized with data obtained from twitter. Search results on environment ontology data shows better results than the simple set of results with the data crawler. This is due to the expansion of knowledge resulting from the construction of the ontology.
In this research the ontology framework for travel and tourism domain has been successfully developed. But the wide variety of information on the social networking website needs the ontology with a wider coverage. In this research,
the ontology being developed based solely on data from one source only; future development is building the ontology from several data sources, because on other social networking websites are also found information about the travel & tourism. This can be done by building a crawler to retrieve data, such as html, pdf, doc, or sourced from other social media websites that are public such as flickr, pinterest, stumbleupon, etc.
ACKNOWLEDGMENT
We would like to thank the research consortium of Satyawacana Christian University and Diponegoro State University who supported our research technically and financially.
A special note to thanks to Tunjung Mahatma, Sciences and Mathematics Lecturer of Satyawacana Christian University who reviewed the language structure of this paper.
REFERENCES
[1] Chen, L., Nugent, C.D., Mulvenna, M., Finlay, D. and Hong, X., “Semantic Smart Homes: Towards Knowledge Rich Assisted Living Environments”, Studies in Computational Intelligence, Vol.189, pp.279-296, 2009.
[2] Chiang, Roger H.L and Cecil Eng Huang Chua, “A smart web query method for semantic retrieval of web data”, Data & Knowledge Engineering vol 38(1), pp. 63-84, 2001.
[3] Köhler, Jacob, Stephan Philippi, Michael Specht, and Alexander Rüegg. Ontology based text indexing and querying for semantic web. Knowledge-Based Systems 19(8), pp. 744 – 754, 2006.
[4] Kara, Soner, “An Ontology-Based Retrieval System Using Semantic Indexing”, Thesis, Middle East Technical University, 2010.
[5] Maskeliunas, Saulus, “Ontological Engineering : Common Approaches and Visualisation Capabilities”, Informatica vol. 11, No. 1, pp. 41-48, 2000.
[6] Masuda, Katsuya; Matsuzaki, Takuya, Tsujii, Jun’ichi, “Semantic Search based on the Online Integration of NLP Techniques”, Procedia – Social and Behaviour Sciences vol 27, pp. 281 - 290 , 2011. [7] Noy, Natalya F; McGuiness, Deborah L, “Ontology Development
101:A Guide to Creating Your First Ontology”, Standford University, 2003.
[8] Ogynyanoff, Damyan; Manov, Dimitar; Terziev, Ivan; Popov, Borislav; Kiryakov, Atanas. “Semantic annotation, indexing, and retrieval”, Web Semantics: Semantics and Agents on the World Wide Web 2, pp. 49 – 79, 2004.
[9] Sarno, Riyanto; Anistyasari, Yeni; Fitri, Rahimi. Semantic Search Based on Content, ANDI Publisher, Yogyakarta, 2012.
[10] Stroka, Stephanie, “Knowledge Representation Technologies in the Semantic Web”, Paper, Information Technology and System Management, Salzburg University of Applied Science, 2005.
[11] Tang, Lijun and Chen, Xu, “The Study of Semantic Retrieval Based on the Ontology of Teaching Management”, Advanced in Control Engineering and Information Science, Procedia Engineering, pp. 1555 -1559, May 2011.
[12] Turney. Peter D., “Measuring Semantic by Latent Relational Analysis”, Proceeding of International Joint Conference on Artificial Intelligence, pp. 1136, 2005.