ANALISA PREDIKSI LAJU KENDARAAN
MENGGUNAKAN METODE LINEAR REGRESION SEBAGAI
INDIKATOR TINGKAT KEMACETAN
1
Givy Devira Ramady 2
Rolty Glendy Wowiling
Program Studi Teknik Elektro, Sekolah Tinggi Teknologi Mandala Jl.Soekarno Hatta No.597 Bandung
Telp. (022) 7301738, 70791003 Fax. (022) 7304854
Abstract
The growth of population is directly proportional to the growth of motor vehicle users both two-wheeled vehicles and four-two-wheeled vehicles. The thing that is certain is the emergence of congestion problems because the growth rate of vehicles is not matched by the growth of the road lane, so it takes a solution to handle it. Our analysis is to take a sample of one of the crossroads in the city of Bandung which is relatively solid and prone to congestion. The criteria for hazard-prone roads are known by many vehicles passing within a certain time frame. In this research we use linear regression algorithm commonly used to predict things based on previously collected data. So with someone already know the density pattern of a road segment, it will provide information for a person to take a decision whether to avoid the road and look for alternative ways or keep using the path because the travel time has been calculated before.
Keywords: Vehicles, Data, Solids, Congestion, Solutions.
Abstrak
Pertumbuhan jumlah penduduk berbanding lurus dengan pertumbuhan pengguna kendaraan bermotor baik kendaraan roda dua maupun kendaraan roda empat. Hal yang sudah pasti adalah timbulnya permasalahan kemacetan karena laju pertumbuhan kendaraan tidak diimbangi dengan pertumbuhan lajur jalan , sehingga diperlukan suatu solusi untuk menanganinya. Analisa yang kami lakukan adalah dengan mengambil sample salah satu perempatan jalan di kota Bandung yang memang relative padat dan rawan kemacetan. Kriteria jalan rawan macet diketahui berdasarkan banyak kendaraan yang melintas dalam rentang waktu tertentu. Pada penelitian ini kami menggunakan Algoritma linear regression yang biasa digunakan untuk memprediksi sesuatu hal berdasarkan data yang sebelumnya sudah dihimpun. Sehingga dengan seseorang telah mengetahui pola kepadatan suatu ruas jalan , maka akan memberikan informasi bagi seseorang untuk mengambil sebuah keputusan apakah menghindari jalan tersebut dan mencari jalan alternative atau tetap menngunakan jalur tersebut karena waktu tempuh sudah diperhitungkan sebelumnya.
Kata Kunci: Kendaraan, Data, Padat, Kemacetan, Solusi.
I. PENDAHULUAN
Berdasarkan statistic dari data kepolisian tercatat bahwa rata-rata kenaikan jumlah kendaraan di Indonesia adalah sebesar 10% pertahun. Agar dapat menentukan jalan yang rawan kemacetan , jumlah kendaraan yang melintas pada suatu jalan dalam rentang waktu tertentu harus diketahui terlebih dahulu
[1]. Pemanfaatan algoritma komputasi cerdas telah banyak digunakan untuk menyelesaikan permasalahan termasuk peramalan jumlah kendaraan [2] [3].
ISU TEKNOLOGI STT MANDALA VOL.12 NO.2 DESEMBER 2017 – ISSN 1979-4818 23 perjalanan menggunakan lajur umum yang
biasa digunakan namun berpotensi terjebak dalam kemacetan atau mencari jalur alternatif lain sebagai jalan pintas untuk mempersingkat waktu berkendara serta menghindari kemacetan.
Tingkat akurasi pola kepadatan jalur lalu-lintas bergantung kepada periode waktu data yang diinputkan untuk diproses. Semakin banyak data yang diinputkan untuk diproses semakin presisi dan akurat data yang diperoleh.
II. LANDASAN PUSTAKA
Sistem Cerdas
Sistem cerdas adalah sistem yang dapat mengadopsi sebagaian kecil dari tingkat kecerdasan manusia untuk berinteraksi dengan keadaan eksternal suatu sistem. Sebagian kecil dari tingkat kecerdasan itu antara lain: kemampuan untuk dilatih, mengingat kembali kondisi yang pernah dialami, mengolah data-data untuk memberikan aksi yang tepat sesuai yang telah diajarkan, dan kemampuan menyerap kepakaran seorang ahli melalui perintah yang dituliskan dalam sebuah bahasa pemrograman tertentu
Data Minning
Data Mining adalah Serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis data dengan melakukan penggalian pola-pola dari data dengan tujuan untuk memanipulasi data menjadi informasi yang lebih berharga yang diperoleh dengan cara mengekstraksi dan mengenali pola yang penting atau menarik dari data yang terdapat dalam basis data. Data mining biasa juga dikenal nama lain seperti : Knowledge discovery (mining) in databases (KDD), ekstraksi pengetahuan (knowledge extraction) Analisa data/pola dan kecerdasan bisnis (business intelligence) dan merupakan alat yang penting untuk memanipulasi data untuk penyajian informasi sesuai kebutuhan user dengan tujuan untuk membantu dalam analisis koleksi pengamatan perilaku, secara umum definisi data-mining dapat diartikan sebagai berikut :
• Proses penemuan pola yang menarik dari data yang tersimpan dalam jumlah besar.
• Ekstraksi dari suatu informasi yang berguna atau menarik (non-trivial, implisit, sebefumnya belum diketahui potensial kegunaannya) pola atau pengetahuan dari data yang disimpan dalam jumfah besar.
Ekplorasi dari analisa secara otomatis atau semiotomatis terhadap data-data dalam jumlah besar untuk mencari pola dan aturan yang berarti.
• Proses penemuan pola yang menarik dari data yang tersimpan dalam jumlah besar.
• Ekstraksi dari suatu informasi yang berguna atau menarik (non-trivial, implisit, sebefumnya belum diketahui potensial kegunaannya) pola atau pengetahuan dari data yang disimpan dalam jumfah besar.
Ekplorasi dari analisa secara otomatis atau semiotomatis terhadap data-data dalam jumlah besar untuk mencari pola dan aturan yang berarti.
Alasan utama mengapa data mining sangat menarik perhatian industri informasi dalam beberapa tahun belakangan ini adalah karena tersedianya data dalam jumlah yang besar dan semakin besarnya kebutuhan untuk mengubah data tersebut menjadi informasi dan pengetahuan yang berguna karena sesuai fokus bidang ilmu ini yaitu melakukan kegiatan mengekstraksi atau menambang pengetahuan dari data yang berukuran/berjumlah besar[4], informasi inilah yang nantinya sangat berguna untuk pengembangan. berikut langkah-langkahnya :
• Data cleaning (untuk menghilangkan noise data yang tidak konsisten) Data integration (di mana sumber data yang terpecah dapat disatukan) • Data selection(di mana data yang
• Data transformation (d berubah atau bersatu yang tepat untuk mena ringkasan performa agresi)
• Knowledge Disco esensial di mana intelejen digunak mengekstrak pola data • Pattern evolutio mengidentifikasi pola benar menarik ya pengetahuan berda beberapa tindakan yan • Knowledge presentat gambaran teknik v pengetahuan digun memberikan pengetah ditambang kepada use
Gbr 2.1 Tahap-tahap da Ada banyak jenis teknik anal digolongkan dalam data minin tiga teknik data mining yang po 1.Association Rule Mining
Association rule mining mining untuk menemukan a antara suatu kombinasi atribu aturan asosiatif dari analisa suatu pasar swalayan diketahu kemungkinan seorang pelan roti bersamaan dengan su pengetahuan tersebut p swalayan dapat mengatur barangnya atau meranca
n (di mana data tu menjadi bentuk nambang dengan nalisa yang dapat
ining. Namun ada popular, yaitu: g
ing adalah teknik aturan asosiatif ribut. Contoh dari isa pembelian di
pemasaran dengan untuk kombinasi bara 2.Klasifikasi
Klasifikasi a menemukan model menjelaskan atau me kelas data, dengan memperkirakan kelas labelnya tidak diketa bisa berupa aturan pohon keputusan, fo neural network. Prose dibagi menjadi dua f Pada fase learning, se diketahui kelas data membentuk model pada fase test mode diuji dengan sebagi mengetahui akurasi akurasinya mencuk dipakai untuk prediksi diketahui.
3.Clustering
Berbeda den mining dan klasifika telah ditentukan se melakukan pengelo berdasarkan kelas clustering dapat dipa label pada kelas data Karena itu clusterin sebagai metode u umum digunakan ad Metode pohon kepu yang sangat besar m yang merepresentasi pohon keputusan a menjadi pohon keput keputusan.
n memakai kupon diskon rang tertentu.
adalah proses untuk del atau fungsi yang membedakan konsep atau gan tujuan untuk dapat las dari suatu objek yang etahui. Model itu sendiri ran “jika-maka”, berupa formula matematis atau roses klasifikasi biasanya a fase : learning dan test. , sebagian data yang telah atanya diumpankan untuk el perkiraan. Kemudian del yang sudah terbentuk agian data lainnya untuk si dari model tsb. Bila cukupi model ini dapat iksi kelas data yang belum
dengan association rule fikasi dimana kelas data sebelumnya, clustering elompokan data tanpa s data tertentu. Bahkan ipakai untuk memberikan ata yang belum diketahui. ering sering digolongkan unsupervised learning. clustering adalah esamaan antar anggota eminimumkan kesamaan
n
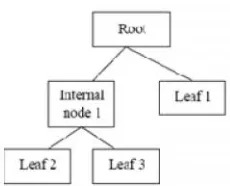
ISU TEKNOLOGI STT MANDALA VOL.12 NO.2 DESEMBER 2017 – ISSN 1979-4818 25 Gbr 2.2 Konsep Dasar Poh
Bagian awal dari pohon adalah titik akar (root), sed cabang dari pohon keputusa pembagian berdasarkan hasi akhir (leaf) merupakan pem yang
Pohon keputusan mempunya yaitu:
• Simpul akar, diman cabang yang masu cabang lebih dari sa tidak memiliki caban Simpul ini biasanya yang paling mem terbesar pada suatu • Simpul internal, d
memiliki 1 cabang dan memiliki lebih akar, jika pada pengujian menghasilkan sesuatu m pengujian juga dilakukan pada berdasarkan hasil dari peng berlaku juga untuk simpul in suatu kondisi pengujian baru a pada simpul daun. Pada um dari sistem pohon kepu mengadopsi strategi penca untuk solusi ruang penca proses mengklasifikasikan sam diketahui, nilai atribut akan di keputusan dengan cara mel titik akar sampai titik akhir, k diprediksikan kelas yang dit baru
Pohon keputusan banyak dig
Gbr.3.1 Gambar Perancangan
ISU TEKNOLOGI STT MANDALA VOL.12 NO.2 DESEMBER 2017 – ISSN 1979-4818 25 ohon Keputusan ri satu, terkadang bang sama sekali. ya berupa atribut emiliki pengaruh an tidak memiliki kali dan menandai l internal dimana u akan diterapkan elacak jalur dari r, kemudian akan ditempati sampel tersebut. digunakan dalam
proses data mining ka kelebihan, yaitu:
1. Tidak memerl saat membang 2. Mudah untuk d 3. Mudah men
sistem basis d 4. Memiliki nilai
baik.
5. Dapat mene terduga dan su
III. PERA Adapun tahap kami lakukan adal volume kendaraan lampu lalu lintas da untuk mendapatkan p kemacetan. Kami me perempatan diwilaya dijadikan acuan. datanya dilakukan langsung pada cctv Polri ) dan melalui pe
Gbr.3.2 Tabel Kendaraan
ISU TEKNOLOGI STT MANDALA VOL.12 NO.2 DESEMBER 2017 – ISSN 1979-4818 25 karena memiliki beberapa
erlukan biaya yang mahal angun algoritma.
k diinterpetasikan.
engintegrasikan dengan s data.
ilai ketelitian yang lebih nemukan hubungan tak
suatu data. ANCANGAN
hapan perancangan yang dalah untuk mengetahui n pada suatu perepatan dan hasil akhirnya akan ipotesa yang merujuk pada n pada jam atau hari – hari
Gbr.3.1 Gambar Perancangan
Data
ercobaan ini kami etode linear regression n prediksi atau peramalan mengambil sample sebuat yah Kota Bandung untuk Adapun pengambilan n melalui pengamatan tv ( aplikasi mobile NTMC
pengamatan langsung.
Clustering yang kami lakukan adalah dengan menjadikan segmentasi waktu pengambilan sample ke dalam empat periode waktu , yaitu :
• Pagi ( 06.00 – 08.00 ) • Siang ( 11.00 – 13.00 ) • Sore ( 16.00 – 18.00 ) • Malam ( 19.00 – 21.00 )
Masing-masing segmen diambil sample setiap per tiga puluh menit sekali , dan lamanya durasi pengambilan sample disesuaikan dengan lamanya waktu yang sudah ditetapkan pada traffictlight.
Gbr 3.3 Tabel Skala Jumlah kendaraan Per detik
Tabel diatas dipereroleh dengan cara membagi jumlah kendaraan per cluster dengan periode waktu traffictlight yang dalam kasus ini ( t=120s ). Adapun hasil pengkategorian berdasarkan skala rata-rata kendaraan perdetik berdasarkan tabel parameter tingkat kemacetan sebagai berikut:
IV. PENGUJIAN
Regresi Linear Sederhana adalah Metode Statistik yang berfungsi untuk menguji sejauh mana hubungan sebab akibat [5] antara Variabel Faktor Penyebab (X) terhadap Variabel Akibatnya. Faktor Penyebab pada umumnya dilambangkan dengan X atau disebut juga dengan Predictor sedangkan Variabel Akibat dilambangkan dengan Y atau disebut juga dengan Response. Regresi Linear Sederhana atau sering disingkat dengan SLR (Simple Linear Regression) juga merupakan salah satu Metode Statistik yang dipergunakan dalam produksi untuk melakukan peramalan ataupun prediksi tentang karakteristik kualitas maupun
Kuantitas[6]. Adapun persamaan sederhana dari simple linear regression ini adalah :
Y = a + bX
Dimana: :
Y = Variabel Response atau Variabel akibat X = Variabel Predictor atau Variabel penyebab
a = Konstanta
b = Koefisien Regresi
Program regresi linear pada matlab: clear;clc;
xi=[X1X2X3X4…..Xn-1]; yi=[Y1Y2Y3Y4…….Yn-1]; Xi2=xi*xi’;
XiYi=xi*yi’; Sx=sum(xi); Sy=sum(yi); N=7;
a = (Xi2*Sy-Sx*XiYi)/(N*Xi2-Sx^2); b = (N*XiYi-Sx*Sy) / (N*Xi2-Sx^2); a
b
xx=0:25; yy=a+b*xx; plot(xi,yi,’o’,xx,yy) axis([0 25 0 15])
title(’data pengamatan’) xlabel(’x’)
ylabel(’y’)
fprintf(’Persamaan Regresi Linear Y=[%2.4f]+[%2.4f]x\n’,a,b)
Dengan menerapkan persamaan rumus diatas , kemudian kita memasukan inputan data yang bersumber dari table data pengamatan jumlah kendaraan yang sebelumnya kita record. Inputan data
ISU TEKNOLOGI STT MANDALA VOL.12 NO.2 DESEMBER 2017 – ISSN 1979-4818 27 Gambar 4.1 Grafik pengamatan segmen pagi
Dari data diatas dapat dilihat bahwa terjadi pola kepadatan dengan pola yang rapat setiap harinya pada segmen ke-1 (06.00-08.00) yaitu skala 2 ( kategori C ) , yang mana pada jam tersebut mayoritas pengguna adalah siswa/siswi sekolah dan pekerja kantoran.
Gambar 4.2 Grafik pengamatan cluster siang Berdasarkan data diatas dapat dilihat bahwa terjadi pola kepadatan dengan pola yang rapat setiap harinya yaitu pada segmen ke-2 ( 11.00-13.00 ) skala 2 (C) dan 3(D)) yang mana pada jam tersebut kendaraan pengangkut dan pribadi yang menuju arah luar kota mendominasi lajur jalan.
Gambar 4.3 Grafik pengamatan cluster sore Berdasarkan data diatas dapat dilihat bahwa terjadi pola kepadatan dengan pola yang rapat setiap harinya yaitu skala 3 (D) dan 4 (E) yang mana pada cluster inilah terjadi puncak kepadatan kendaraan.
Gambar 4.4 Grafik pengamatan cluster malam
V. KESIMPULAN
Dari pengujian sample yang kami lakukan diperoleh suatu pola segmentasi kemacetan diperempatan kiaracondong-buahbatu . Pada segmen I ( pagi ) , tingkat kepadatan kendaraan relative tinggi karenakan banyak siswa/siswi yang hendak berangkat sekolah ditambah para pekerja yang menuju lokasi kerjanya. Pada segmen II ( siang ) , tingkat kepadatan kendaraan masih cukup tinggi namun cenderung lancer. Pada segmen III ( Sore ) , kepadatan kendaraan mencapai puncaknya. Pada segmen IV ( malam ) kendaraan relative padat namun lancer. Data tersebut memberikan informasi kepada pengguna jalan untuk mengambil keputusan mengenai jalur yang akan dipilih apakah terus melalui jalan tersebut dengan estimasi waktu kemacetan yang sudah diperkirakan atau mencari solusi alternatif jalur lain.
Daftar Pustaka
Purwitasari, Edwadr, Mukhtar, Buliali — Algoritma Komputasi Cerdas untuk Prediksi Jumlah Pengguna Kendaraan sebagai Indikator Rawan Macet , ITS
Y. Kao and S.-Y. Lee, 2009,"Combining K-means and particle swarm optimization for dynamic data clustering problems," in IEEE International Conference on Intelligent Computing and Intelligent Systems, Shanghai.
V. Topuz, 2010, "Hourly Traffic Flow Prediction Using Different ANN Models," in Urban Transport and Hybrid Vehicles, InTech.
Han, J.K., 2001, Data Mining: Concept and
Technique. San
Fransisco: Morgan Kaufmann Publisher.
PREDA, C. and SAPORTA, G. (2004). PLS approach for clusterwise linear regression on functional data. In Classification, Clustering, and Data Mining Applications (D. Banks, L. House, F. R. McMorris, P. Arabie and W.
Gaul, eds.) 167–176. Springer, Berlin. MR2113607