Fakultas Ilmu Komputer
177
Query Expansion
Pada LINE TODAY Dengan Algoritme
Extended Rocchio
Relevance Feedback
Chandra Ayu Anindya Putri1, Indriati2, Ahmad Afif Supianto3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
LINE TODAY memberikan akses informasi berupa konten-konten berita up to date. Data pada LINE TODAY dimanfaatkan untuk dapat dilakukan fitur pencarian berita. Teknik Query Expansion akan sangat berguna jika dikombinasikan dengan sistem pencarian, sebab query yang diinputkan pengguna akan dikombinasi dengan query tambahan yang diberikan oleh sistem. Query tambahan akan membuat
query yang pengguna hasilkan lebih spesifik. Selain itu, hadirnya feedback pengguna (user judgement/explicit relevance feedback) yang melakukan penilaian pada tiap berita akan meminimalisir
query yang ambigu. Proses yang dilakukan diawali dengan teknik preprocessing, yang terdiri dari beberapa tahapan, yaitu cleansing, case folding, tokenization, filtering, hingga stemming. Kemudian dilakukan pembobotan term (term weighting) dan cosine similarity. Setelah itu, proses yang dilakukan ialah perhitungan dengan metode Extended Rocchio Relevance Feedback yang merupakan metode turunan dari Rocchio Relevance Feedback, untuk menghasilkan query tambahan. Hasil yang diperoleh berdasarkan dari implementasi maupun pengujian pada penelitian Query Expansion pada LINE TODAY dengan Algoritme Extended Rocchio Relevance Feedback menghasilkan rata-rata nilai Precision
sebesar 0.53308, Recall sebesar 0.81708, F-Measure sebesar 0.59553, dan Akurasi sebesar 0.9574. Nilai akurasi yang didapat dengan metode Extended Rocchio Relevance Feedback berdasar user judgement
cenderung meningkat hingga 2% dibandingkan pencarian otomatis dengan metode Rocchio Relevance Feedback.
Kata kunci: Text Mining, Query Expansion, LINE TODAY, Extended Rocchio Relevance Feedback.
Abstract
LINE TODAY provides access to up-to-date news contents. Data on LINE TODAY are used to be able to do search engine feature. Query Expansion technique will be very useful if it is to be combined with search engine system where the queries inputted by users are combined with additional queries from the system. These additional queries will make queries generated by users more specific. In addition, users feedback (user judgement/explicit relevance feedback) assessing on each news can minimize ambiguous queries. The process begins with preprocessing technique consisting of several stages which are cleansing, case folding, tokenization, filtering, and stemming. And then, term weighting and cosine similarity. The next process is calculated using the Extended Rocchio Relevance Feedback method which is a traditional method from Rocchio Relevance Feedback to generate an additional queries. The results are obtained from implementation and testing process of Query Expansion on LINE TODAY with Extended Rocchio Relevance Feedback Algorithm resulted an average Precision value of 0.53308, Recall value of 0.81708, F-Measure value of 0.59553, and Accuracy value of 0.9574. The accuracy value obtained with Extended Rocchio Relevance Feedback method based on user judgement increase by 2% compared to automated search by the method of Rocchio Relevance Feedback.
Keywords: Text Mining, Query Expansion, LINE TODAY, Extended Rocchio Relevance Feedback.
1. PENDAHULUAN
Informasi merupakan salah satu kebutuhan utama masyarakat untuk bertahan hidup, karena dengan melalui informasi kita dapat mengambil
kebenarannya. Informasi dapat diakses melalui media apapun, salah satunya media elektronik, yaitu dengan memanfaatkan teknologi informasi berbasis internet. Informasi yang didapat melalui internet cenderung lebih cepat, mudah, dan efektif. Informasi yang didapatkan biasanya dalam bentuk berita artikel yang di sebarluaskan melalui situs website berita, misalnya seperti LINE TODAY, yang merupakan salah satu fitur yang berisi kumpulan artikel berita dari aplikasi pengiriman pesan LINE.
Data yang dimanfaatkan pada penelitian ini memanfaatkan artikel berita LINE TODAY,. Karena berita yang dihadirkan berasal dari sumber terpercaya dan up-to-date. Selain itu, permasalahan yang sering kita hadapi, ialah saat melakukan pencarian, query yang ingin kita inputkan tidak sesuai atau kurang spesifik dengan hasil dokumen yang ingin kita dapatkan. Oleh sebab itu, adanya query expansion sangat membantu dalam perluasan query pengguna. Perluasan query yang ditampilkan oleh sistem akan membantu menyempurnakan query
pengguna yang ambigu dan agar lebih terstruktur. Pada penelitian sebelumnya yang dilakukan oleh, Zanwar Yoga Pamungkas pada tahun 2015, penelitian pada query expansion terbukti berhasil memberikan query tambahan kata dengan hasil pencarian yang lebih spesifik dan relevan.
Penelitian sebelumnya telah dilakukan eksplorasi metode dari metode tradisional
Rocchio Relevance Feedback, yaitu Extended Rocchio Relevance Feedback. Seperti yang telah diteliti sebelumnya oleh, Chris Jordan pada tahun 2004, modifikasi query akan menjadi lebih spesifik, karena adanya kombinasi antara query
tambahan dengan query pengguna, selain itu juga memanfaatkan pendekatan user judgement
atau penilaian relevansi dokumen dari pengguna. Pencarian yang efektif pada sistem IR akan dilakukan dengan model Relevance Feedback. (Adisantoso, Ridha, & Agusetyawan, 2006). Salah satunya, ialah model user judgement atau
explicit rocchio relevance feedback. Model tersebut membutuhkan feedback dari pengguna untuk menilai relevansi dokumen-dokumen yang ditampilkan dari query yang diinputkan. Selain penelitian dari Chris Jordan, pendekatan
explicit ini juga dilakukan oleh Hassan Saneifar pada tahun 2014. Dalam penelitian tersebut pendekatan explicit diterapkan dalam file log maupun dokumen dengan mengidentifikasi suatu konteks dalam informasi permintaan.
Berdasarkan uraian-uraian di atas,
penelitian ini membahas tentang Query Expansion pada LINE TODAY dengan Algoritme Extended Rocchio Relevance Feedback. Algoritme tersebut dinilai cukup baik jika diterapkan dalam query expansion, karena hasil pencarian dari queryasli yang dikombinasikan dengan query tambahan akan menghasilkan dokumen relevan yang semakin sedikit, hal ini dikarenakan query yang digunakan semakin spesifik .
2. DASAR TEORI
2.1 LINE TODAY
LINE TODAY, merupakan situs berita online salah satu fitur dari aplikasi pengiriman pesan, LINE. Informasi berita yang dihadirkan berupa berita terkini dan up-to-date, serta diperbarui secara real time. Berita-berita yang dihadirkan berasal dari artikel situs lain yang merupakan mitra media yang terpercaya. Pencarian berita yang dilengkapi dengan query expansion, tentunya akan semakin memudahkan pengguna, karena dengan adanya query expansion atau query tambahan, akan membuat
query pencarian lebih spesifik dan lebih mudah menghasilkan dokumen-dokumen yang relevan.
2.2 Pemrosesan Teks
Pemrosesan teks atau preprocessing ini digunakan untuk mempermudah proses
information retrieval, dengan melalui proses
cleansing dan case folding, tokenization, filtering, dan stemming.
1. Cleansing dan Case Folding
Cleansing digunakan untuk menghapus komponen-komponen yang tidak dibutuhkan, seperti tag URL dan karakter lainnya. Sedangkan
case folsing untuk mengubah semua kata menjadi lowercase atau huruf kecil.
2. Tokenization
Proses ini dilakukan dengan pemecahan teks menjadi kata atau token, dimana pemisahan dilakukan dengan whitespace.
3. Filtering
Proses ini dilakukan dengan cek list kata pada stipword, dimana list tersebut mengandung kata yang tidak penting atau yang seharusnya dihilangkan. Bila dalam teks terdapat kata pada list stopword, maka akan dihilangkan.
Proses ini mengubah semua kata hasil
filtering menjadi kata dasar. Algoritma Nazief-Adriani digunakan selama proses stemming, karena dapat melakukan pengecekan tiap penerapan pada aturan stemming dapat diidentifikasikan. Berikut merupakan prosesnya (Wahyudi, Susyanto, & Nugroho, 2017), diantaranya:
1 Kata yang belum dilakukan stemming dicari di dalam kamus, jika tersedia, maka kata tersebut akan dianggap sebagai kata dasar yang tepat dan algoritma dihentikan. 2 Menghilangkan imbuhan infeksi atau
inflectional suffixes (“-lah”,”-kah”,”-tah”,
serta “-pun”). Kemudian jika berhasil dan
akhirannya memiliki imbuhan (“-lah” atau
”-kah”), maka akan dilanjutkan ke langkah berikutnya dengan menghilangkan
inflectional posseive pronoun suffixes (“
-ku”,”-mu”, dan “-nya”). Cek apakah kata berada di dalam kamus kata dasar, jika ada, maka algoritma dihentikan, jika tidak, dilanjutkan ke step berikutnya.
3 Menghilangkan derivational suffix, yaitu
(“-i” atau “-an”). Jika langkah tersebut berhasil, kemudian dilanjutkan ke langkah berikutnya, namun jika tidak, maka dilakukan hal berikut ini, diantaranya: a. Jika “-an” dihilangkan dan huruf terakir
dari kata “-k”, maka “-k” juga dihilangkan dan dilanjutkan ke langkah berikutnya.
b. Penghapusan akhiran (“-I”, “-an”, serta
“-kan”) dikembalikan dan lanjut ke step berikutnya.
4 Penghapusan pada derivational prefix (“be
-“,”di-“,”ke-“,”me-“,”pe-“,”se-“, dan ”te-“). Bila kata yang dimiliki tersedia dalam kamus kata dasar, maka proses akan dihentikan dan bila tidak tersedia, maka akan dilakukan recoding. Tahap-tahap proses dihentikan, karena memenuhi beberapa kondisi berikut ini, diantaranya:
a.
Ada kombinasi awalan maupun akhiranyang tidak diijinkan
b.
Awalan yang terdeteksi sama dengan awalan yang dihapuskan sebelumnya.c.
Tiga awalan dihilangkan.5 Jika semua langkah sebelumnya telah dilakukan namun kata dasar belum ditemukan pada kamus, maka algoritma ini akan mengembalikan kata yang asli sebelum dilakukannya proses stemming.
2.3 TF.IDF
Pembobotan yang dilakukan dengan
TF.IDF, merupakan metode untuk pembobotan hubungan kata pada dokumen. Metode ini menggabungkan dua konsep perhitungan bobot, yaitu Term Frequency (TF) dan Document Frequency (DF) (Rosid, Gunawan, & Pramana, 2015). Berikut merupakan beberapa metode yang ada pada pembobotan (Fauzi, Arifin, & Yuniarti, 2014), diantaranya:
1. TF
Metode ini melakukan pembobotan term
yang diasumsi memiliki suatu kepentingan yang proposional terhadap kemunculan term pada dokumen. Bobot term t pada dokumen d, yaitu:
𝑊𝑡𝑓(𝑡, 𝑑) = 1 + 𝑓(𝑡, 𝑑)
= {1 + log100, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒𝑡𝑓𝑡,𝑑 , 𝑖𝑓 𝑡𝑓𝑡,𝑑> 0 (1)
2. IDF
IDF lebih terfokus kemunculan term pada seluruh kumpulan dokumen. Pada pembobotan ini, term yang jarang muncul di kumpulan dokumen memiliki nilai kepentingan.
𝑖𝑑𝑓𝑡 = 𝑙𝑜𝑔10(𝑁/𝑑𝑓𝑡) (2)
3. TF.IDF
TF.IDF dihasilkan dari penggabungan perkalian dari rumus di atas, yaitu rumus TF dengan IDF sehingga kombinasi bobotnya, ialah:
𝑊𝑡,𝑓(𝑡, 𝑑) × 𝑖𝑑𝑓𝑡 (3)
2.4 Query Expansion
Query Expansion, merupakan teknik untuk menambahkan query baru atau tambahan kata dari yang dikombinasikan dengan query asli. Kinerja pencarian akan meninkat dengan adanya perluasan query pencarian (Saneifar, Bonniol, Poncelet, & Roche, 2014). Berikut ini merupakan teknik dari query expansion
(Pamungkas, 2015),ialah:
1. Manual Query Expansionn (MQE), pengguna sendiri akan melakukan modifikasi query.
2. Autmatic Query Expansion (AQE), teknik ini memodifikasi query tanpa adanya control dari pengguna.
3. Interactive Query Information, teknik ini dibutuhkan adanya interaksi antara pengguna dengan sistem, yaitu dalam proses query expansion.
expansion menurut Ludviani, (2015) yang ditunjukkan pada Gambar 1.
Gambar 1 Diagram Tahapan Query Expansion
2.5 Relevance Feedback
Relevance feedback, teknik ini memodifikasi suatu query yang sering diimplementasikan pada information retrieval. Cara kerjanya ialah dengan memilih term
penting dalam dokumen yang dianggap dokumen relevan oleh pengguna, serta menambahkan term penting ke dalam proses modifikasi query. Berikut ini merupakan metode
relevance feedback (Pamungkas, Indriati, & Ridok, 2015), diantaranya:
1.
User Judgement (Explicit Rocchio Relevance FeedbackPada metode ini membutuhkan penilaian relevansi dokumen pada query tertentu. Penilaian yang diberikan, yaitu dengan penilaian terhadap suatu dokumen dan menentukan mana dokumen relevan maupun tidak.
2.
User Behavior(Implicit Relevance FeebackMetode ini berhubungan dengan perilaku pengguna, yaitu seperti mencatat dokumen terpilih maupun tidak dan durasi waktu untuk melihat dokumen maupun proses selama melakukan pencarian hingga scrolling halaman.
3.
Top K Relevance (Blind/Pseudo Relevance Feedback)Metode ini hanya melibatkan pengguna saat proses keputusan dan dokumen relevan yang ditampilkan secara otomatis, karena tanpa memerlukan feedback dari pengguna.
2.6 User Judgement (Explicit Relevance Feedback)
Relevance feedback jenis ini mendapatkan
feedback secara explicit dari pengguna untuk menunjukkan penilaian. Pengguna secara eksplisit memberikan penilaian pada dokumen, yaitu berupa dokumen relevan maupun tidak relevan dari perangkingan dokumen hasil dari
query yang dimasukkan. Pengguna secara eksplisit memberikan penilaian pada dokumen, yaitu berupa dokumen relevan maupun tidak relevan dari perangkingan dokumen hasil dari
query yang dimasukkan.
2.7 Extended Rocchio Relevance Feedback
Metode ini merupakan turunan dari metode tradisional Rocchio Relevance Feedback. Metode extended rocchio, menunjukkan peningkatan kinerja pada saat pengambilan dokumen VSR atau Vector Spave Retrieval, serta akan mendapatkan hasil yang sebanding
dengan algoritme tradisionalnya. Selain itu,
pada metode ini dinilai memiliki lebih banyak pengujian parameter untuk mengukur baik buruknya query expansion dari metode ini. Berikut merupakan proses perhitungan, diantaranya:1. Query Modification
Pada proses ini memanfaatkan perhitungan nilai dari cosine similarity.
𝑆𝑖𝑚(𝑄, 𝑉) =|𝑄|×|𝑉|𝑄●𝑉 (4)
Dokumen dengan nilai similarity tertinggilah yang akan dijadikan nilai V sebagai penentu penggunaan rumus untuk modifikasi
query yang sebelumnya diset nilai dari σ,
sebagai threshold, dengan kondisi sebagai berikut:
1. Jika nilai V tidak memiliki similarity atau (V<σ), maka tidak perlu dilakukan
modifikasi query.
2. Jika nilai V memiliki similarity atau (V>σ),
maka perlu dilakukan modifikasi query
𝑄
𝑚𝑜𝑑2. Relevance Feedback
Proses ini dilakukan untuk menunjukkan proses dokumen retrieval. Dokumen yang telah dilakukan perangkingan digunakan untuk memberntuk 3 vector sebagai berikut:
1. Term Vector P : berisi nilai rata-rata pada
term weight dan dikususkan pada dokumen relevan yang tidak termasuk dalam original
query, Q.
2. Term Vector N : berisi nilai rata-rata pada
term weight dan dikususkan pada dokumen tidak relevan yang tidak termasuk dalam original query, Q.
3. Term Vector F, berisi nilai dari term vector,
V, namun tidak berasal dari P, N, dan Q.
1.
Jika pada tahap 1 tidak dilakukan
modifikasi kueri, maka menggunakan
rumus Dengan arti lain jika σ>
V
, maka
menggunakan rumus:
𝑉𝑛𝑒𝑤 = 𝛼 ∗ 𝑄 + 𝛽 ∗ 𝑃 − 𝛾 ∗ 𝑁 (5)
2. Jika pada tahap 1 dilakukan modifikasi
query atau σ<
V
, maka perhitungan yang
dilakukan sebagai berikut:𝑉 = 𝛼 ∗ 𝑄𝑚𝑜𝑑+ 𝛽 ∗ 𝑃 − 𝛾 ∗ 𝑁 + ∆ ∗ 𝐹 (6)
Nilai 𝛼, 𝛽, dan 𝛾, merupakan nilai konstan yang ada pada algoritme Rocchio.
Sedangkan ∆, merupakan nilai konstanta
yang mengatur kerusakan pada term.
2.8 Precision, Recall, F-Measure, dan Akurasi
Evaluasi peforma efektivitas pada sistem klasifikasi teks dengan menggunakan standar
confussion matrix yang berisi informasi klasifikasi yang sebenarnya dan merupakan prediksi klasifikasi oleh sistem (Pamungkas, Indriati, & Ridok, 2015).
Tabel 1. Confussion Matrix
Actual Class (expectation)
+ -
Predicted Class (Observation)
+ TP FP
- FN TN
Keterangan:
TP : True Positive, dimana menunjukkan perangkingan sistem merupakan dokumen yang sesuai dengan query.
FP : False Prositive, dimana menunjukkan dokumen dalam hasil perangkingan sistem tidak sesuai dengan query.
FN : False Negative, dimana menunjukkan dokumen tidak termasuk dalam perangkingan sistem dan harusnya sesuai dengan query.
TN : True Negative, dimana menunjukkan dokumen tidak termasuk perangkingan sistem dan memang seharusnya tidak sesuai query.
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃+𝐹𝑃𝑇𝑃 (7)
(2.10)
𝑟𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃+𝐹𝑁𝑇𝑃 (8)
(2.11)
Semakin tinggi nilai akurasi yang didapatkan, maka akan menunjukkan kesesuaian nilai dari prediksi pengujian pada ground truth atau nilai actual.
𝑎𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃+𝐹𝑃+𝑇𝑁+𝐹𝑁𝑇𝑃+𝑇𝑁 ∗ 100% (9)
(2.12)
𝐹1 = 2×𝑟𝑒𝑐𝑎𝑙𝑙×𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛𝑟𝑒𝑐𝑎𝑙𝑙+𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 (10)
(2.13)
F1 measure, ialah bobot harmonic mean yang ada pada recall dan precision.
3. METODOLOGI PENELITIAN
Pada bagian ini membahas tentang teknik dan proses yang dilakukan selama penelitian pada query expansion pada LINE TODAY dengan algoritme Extended Rocchio Relevance Feedback.
3.1 Rancangan Penelitian
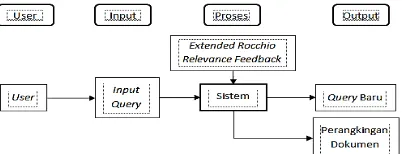
Rancangan ini digunakan untuk memberikan gambaran umum mengenai bagaimana sistem yang dibangun ini berjalan dimulai dari input, proses, hingga output. Berikut rancangan arsitekturnya ditunjukkan pada Gambar 2.
Gambar 2 Model Perancangan Arsitektur
3.2 Partisipan Penelitian
Pada penelitian ini memanfaatkan partisipan sebanyak 3 orang mahasiswa untuk menilai suatu dokumen. Dokumen yang dinilai berupa hasil kesesuaiannya dengan query, apakah tergolong relevan atau tidak.
3.3 Teknik Pengumpulan Data
3.4 Teknik Pengujian
Pengujian dilakukan dengan uji hasil kerja sistem dan dilakukan evaluasi sistem. Proses tersebut dilakukan guna mengetahui hasil sistem yang nantinya akan digunakan sebagai penarikan kesimpulan. Pengujian yang dilakukan dengan menilai dari hasil tingkat akurasi, precision, recall, dan f-measure. Selain itu, perbandingan juga dilakukan pada query sebelum dan sesudah dilakukan perhitungan dengan metode Extended Rocchio Relevance Feedback.
4. PERANCANGAN
Perancangan sistem bertujuan untuk mengetahui langkah apa saha yang harus dilakukan dalam membangun sistem.
4.1 Diagram Alir Sistem
Diagram alir ini menunjukkan jalan proses sistem yang dilakukan secara keseluruhan, yaitu dimulai dari proses preprocessing, pembobotan TF.IDF dan cosine similarity. Selanjutnya dilakukan pemilihan dokumen relevan maupun tidak relevan dan masuk ke proses metode untuk tambahan kata query, yaitu Extended Rocchio Rlelevance Feedback. Berikut diagram alirnya ditunjukkan pada Gambar 3.
Gambar 3. Diagram Alir Sistem
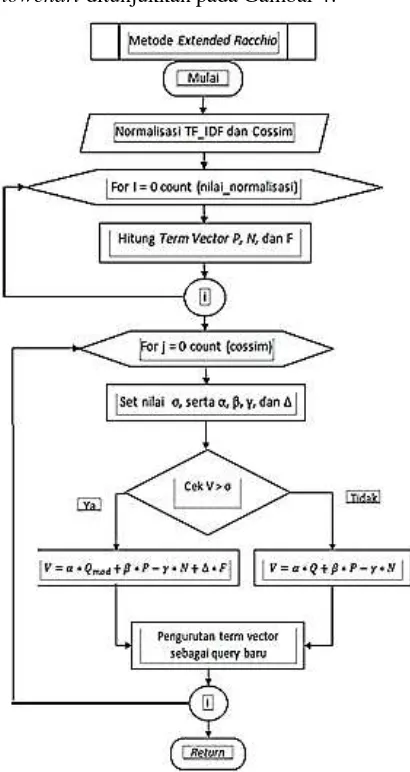
4.2 Diagram Alir Sistem Metode Extended Rocchio Relevance Feedback
Metode ini digunakan untuk perhitungan
query expansion sebagai tambahan kata dari
query asli. Selain itu, metode ini juga dinilai efektif diterapkan dalam query expansion,
karena memanfaatkan pendekatan user judgement. Berikut merupakan rancangan
flowchart ditunjukkan pada Gambar 4.
Gambar 4. Diagram Alir Metode Extended Rocchio Relevance Feedback
5. PENGUJIAN DAN ANALISIS
Pada bagian ini membahas tentang pengujian yang merupakan hasil dari sistem yang kemudian nantinya akan dianalisis.
5.1 Pengujian
query pengujian saja, yaitu “Avenger Infinity
War”. Tiap parameter yang diuji dan mendapatkan nilai kenaikan tertinggi akan menjadi nilai parameter yang digunakan untuk perhitungan pada keseluruhan query. Nilai kenaikan didapat dengan mengukur berapa besar perubahan nilai yang terjadi antara query asli pengguna dengan query tambahan dari sistem. Berikut merupakan parameter terpilih ditunjukkan pada Tabel 1.
Tabel 2. Hasil Pengujian Parameter
σ α β γ ∆
0.1 1.25 0.79 0.28 0.54
5.1.1 Pengujian Query Asli dengan Query
Expansion
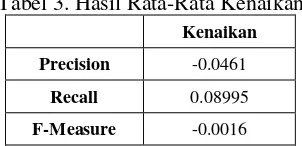
Pengujian ini dilakukan dengan membandingkan nilai kenaikan precision, recall, dan f-measure antara query asli atau awal (query pengguna) dengan query dengan tambahan kata. Nilai kenaikan didapat dengan mengukur berapa besar perubahan nilai yang terjadi. Kemudian, kenaikan dihitung rata-ratanya di tiap indikator pengujiannya. Berikut ditunjukkan pada Tabel 2.
Tabel 3. Hasil Rata-Rata Kenaikan
Kenaikan
Precision -0.0461
Recall 0.08995
F-Measure -0.0016
5.1.2 Pengujian Tambahan 1 dan 2 Kata
Pengujian ini dilakukan dengan membandingkan nilai precision, recall,
f-measure, dan akurasi antara query tambahan 1 kata dengan tambahan 2 kata. Berikut Tabel 3 menunjukkan hasil rata-rata perbandingan antara
query dengan 1 tambahan kata dan dengan 2 tambahan kata.
Tabel 4. Hasil Perbandingan Pengujian Tambahan 1 dan 2 Kata
Jumlah
Kata Precision Recall
F-Measure Akurasi
1 kata 0.53308 0.81708 0.59553 0.9574 2 kata 0.45273 0.81971 0.52469 0.9478
5.1.3 Pengujian Precision@K
Pengujian ini digunakan untuk menguji nilai threshold K pada precision. Dokumen yang dianalisis ialah dokumen teratas sejumlah
K dan mengabaikan dokumen yang berada di
batas bawah K. Berikut merupakan pengujian pada P@K yang ditunjukkan pada Tabel 4 dengan tambahan hingga 5 kata..
Tabel 5. Pengujian P@K
5.1.4 Pengujian Perbandingan Metode
Pengujian ini dilakukan dengan membandingkan metode tradisional, Rocchio Relevance Feedback dengan metode turunannya, yaitu Extended Rocchio Relevance Feedback.
Perbandingan dilakukan dengan mengukur nilai dari Precision, Recall, F-Measure, dan Akurasi. Berikut Tabel 5 menunjukkan hasil perbandingannya.
Tabel 6. Hasil Perbandingan Pengujian Metode
Metode Precision Recall
F-Measure Akurasi
Extended
Rocchio 0.53308 0.81708 0.59553 0.9574
Rocchio 0.25951 0.89867 0.35478 0.9372
5.2 Analisis
Pada pengujian Tabel 2, menunjukkan adanya penurunan pada nilai precision, hal ini disebabkan karena nilai FP mengalami kenaikan, dimana FP merupakan banyak dokumen yang tidak sesuai dengan query. Sedangkan recall
cenderung naik, karena FN menurun. FN menunjukkan banyaknya dokumen relevan yang tidak masuk dalam perangkingan.
Pengujian Tabel 3. Dilakukan pengujian perbandingan pada tambahan kata 1 dan 2 kata. Pada nilai precision tambahan 2 kata cenderung menurun, karena banyak dokumen tidak sesuai muncul dalam perangkingan. Nilai recall
Pengujian Tabel 4 dilakukan dengan menguji nilai precision pada P@K., dimana nilai
K adalah threshold dengan nilai perangkingan di atas K=10. Tambahan kata cenderung meningkatkan nilai precisionnya.
Pada pengujian Tabel 5. Perbandingan dilakukan antar metode, dimana metode
Extended Rocchio memiliki nilai kenaikan lebih tinggi hingga 2 %.
6. KESIMPULAN
Pada bagian ini akan membahas tentang kesimpulan yang didapatkan dari hasil penelitian
Query Expansion Pada LINE TODAY Dengan Algoritme Extended Rocchio Relevance Feedback, berikut diantaranya:
1. Metode Extended Rocchio Relevance Feedback dapat diterapkan dalam melakukan pencarian pada situs berita online LINE TODAY. Dokumen yang tersedia akan melalui tahapan preprocessing, kemudian dilakukan perhitungan pada term weighting dan cosine similarity, selanjutnya dilakukan pencarian Term Vector P, N, dan
F, hingga set parameter untuk dapat digunakan dalam perhitungan untuk pencarian query tambahan baru. Semakin banyak query yang ditambahkan dari query
aslinya, maka pencarian akan semakin spesifik dan dokumen yang relevanpun akan semakin sedikit sebaliknya dokumen tidak relevan akan semakin banyak.
2. Pengujan query expansion dengan Metode
Extended Rocchio Relevance Feedback
menghasilkan nilai rata-rata precision
sebesar 0.53 untuk 1 kata tambahan dan 0.45 untuk 2 tambahan kata. Untuk nilai
recall pada 1 tambahan kata sebesar 0.817 dan 0.819 untuk 2 tambahan kata. Kemudian pada f-measure memiliki nilai rata-rata sebesar 0.596 untuk 1 kata tambahan dan 0.525 untuk 2 tambahan kata. Sedangkan rata-rata akurasinya pada 1 kata tambahan sebesar 0.96 dan 0.95 untuk 2 tambahan kata. Penambahan jumlah kata pada query expansion dapat mempengaruhi nilai precision, recall, f-measure, dan akurasinya. Selain itu dilakukan perbandingan dengan metode tradisional, yaitu Rocchio dan hasilnya terbukti lebih baik dengan menggunakan Extended Rocchio dengan kenaikan hingga 2%.
7. DAFTAR PUSTAKA
Adisantoso, J., Ridha, A., & Agusetyawan, W. (2006). RELEVANCE FEEDBACK
PADA TEMU-KEMBALI TEKS
BERBAHASA INDONESIA
DENGAN METODE IDE-DEC-HI DAN IDE-REGULAR. Jurnal Ilmiah Ilmu Komputer, 1-8.
Alam, M., & Sadaf, K. (2015). Relevance Feedback versus Web Search Document Clustering. IEEE Conference (pp. 4294-4298).India: BharatiVidyapeeth's Institute of Computer Applications and Management (BVICAM).
Blair, David C. (2003). Information retrieval and the philosophy of language. New York: Elseiver North-Holland, Inc. New York, NY, USA.
Fauzi, M. A., Arifin, A. Z., & Yuniarti, A. (2014). Term Weighting Berbasis Indeks Buku dan Kelas untuk Perangkingan Dokumen Berbahasa Arab. LONTAR KOMPUTER VOL. 5, NO.2, 435-442.
Hamzah, Amir. (2006). Pengaruh Stemming Kata Dalam Peningkatan Unjuk Kerja Document Clustering Untuk Dokumen Berbahasa Indonesia. Seminar Nasional Riset Teknologi Informasi-SRITI 2006
(pp. 253-263). Yogyakarta: Sekolah Tinggi Manajemen Informatika dan Komputer AKAKDM Yogyakarta.
Hazimeh, H., & Zhai, C. (2015). AxiomatiAnalysis of Smoothing Methods in Language Models for Pseudo-Relevance Feedback. ICTIR '15 Proceedings of the 2015 International Conference on The Theory of Information Retrieval (pp. 141-150). Northampton, Massachusetts, USA: ACM New York, NY, USA.
Herlambang, Y. R., Putri, R. R., & Wihandika, R. C. (2017). IMPLEMENTASI METODE K-NEAREST NEIGHBOUR
DENGAN PEMBOBOTAN
TF.IDF.ICF UNTUK KATEGORISASI
IDE KREATIF PADA
PERUSAHAAN. JTIIK, 97-103.
Advances in Web Intelligence (pp. 135-144). Berlin, Heidelberg: Springer.
Kurniawan, B., Effendi, S., & Sitompul, O. S. (2012). Klasifikasi Konten Berita Dengan Metode Text Mining. Jurnal Dunia Teknologi Informasi Vol.1, No.1, 14-19.
Ludviani, R., Hayati, K. F., Arifin, A. Z., & Purwitasari, D. (2015). Optimasi Pembobotan pada Query Expansion dengan Term Relatedness to Query-Entropy based (TRQE). Jurnal Buana Informatika, Volume 6, Nomor 3, 203-212.