Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 15
SISTEM ADAPTIF PREDIKSI PENGENALAN ISYARAT
VOKAL SUARA KARAKTER
Oleh : Pandapotan Siagia, ST, M.Eng (Dosen tetap STIKOM Dinamika Bangsa Jambi)
Abstrak
Sistem pengenal pola suara atau yang lebih dikenal dengan speech recognition merupakan proses pengubahan sinyal akustik menjadi data-data digital yang kemudian diolah dengan isyarat sistem adaktif, agar dapat di proses dan dikenali oleh komputer sebagai suatu fonem maupun kata. Sistem yang banyak di olah dan dikembangkan untuk membuat suatu sistem yang dapat mengenali dan melakukan respon terhadap sinyal suara manusia.
Proses pengolahan dan pengolahan isyarat suara dengan sistem adaktif dengan menggunakan proses LMS. Proses adaktif terhadap sinyal suara secara digital yang bertujuan untuk membentuk suatu sistem yang dapat memudahkan pengguna berinteraksi dengan perangkat elektronis dengan hanya melakukan respon dan identifikasi yang lebih singkat.
Metode untuk sistem pengenalan suara dalam hal ini hanya membahas tentang skema prediksi menggunakan pendekatan adaptif. Metode adaktif suatu ciri sebuah sinyal suara di-ekstraksi melalui nilai-nilai bobot suara dan Suara yang sudah hasil dari pembobotan akan dikelompokkan pada kelas-kelas yang spesifik sesuai skema prediksi dari sistem adaktif.
Adapun hasil dari keluaran sistem ini mampu memberikan hasil respon yang cukup baik untuk pengenalan beberapa suku kata dalam bahasa Indonesia. Hasil yang di proses sesuai dengan metode LMS sistem adaktif ddan suku kata yang di coba menghasilkan suaru respon yang lebih baik, dimana hasil prediksi dan uji coba klasifikasi dan pembobotan kata suara mendapatkan tingkat keberhasilan pengenalan berkisar antara 70% hingga 95%.
Kata kunci : SiatemAdaktif , Isyarat Ucapan, prediksi suku kata 1. Pendahuluan
Pengenal suara atau yang lebih dikenal dengan speech recognition merupakan proses pengubahan sinyal akustik menjadi data-data digital yang kemudian diolah sedemikian rupa sehingga dikenali oleh komputer sebagai suatu fonem maupun kata.
Proses pengenalan ini dibagi dalam dua tahapan yaitu tahap pelatihan model dan tahap pengenalan suku kata. Tahap pelatihan terdiri dari ekstraksi corak, dan pengumpulan data. Pada tahap pengenalan sistem akan mencoba mengenali suara dengan mencari kelompok yang tepat, dan mengenali suara yang diberikan.
Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 16 Metode untuk membentuk sistem pengenal suara yang digunakan dalam percobaan ini yaitu dengan menggunakan metode prediksi sinyal secara adaptif. Dengan metode adakktif yang mempunyai ciri sebuah sinyal suara di-ekstraksi melalui nilai-nilai bobot dan kemudian dikelompokkan pada kelas yang sesuai dengan ciri kata suara. Adapun pemilihan metoda ini dilakukan karena metode adaktif suatu model yang sederhana serta kemudahan dalam mengaplikasikannya.
2. Sistem Prediksi Adaftif
Sinyal ucapan merupakan sinyal yang stabil pada rentang waktu yang sangat singkat yaitu selama pengucapan sebuah fonem, dan kemudian berpindah ke keadaan stabil berikutnya saat ada perubahan ucapan. Untuk fonem vokal suara, sinyal suara dianggap bersifat periodis dan untuk fonem konsonan sinyal suara dianggap bersifat sama seperti derau putih (white noise)
3. Prediksi least mean square (LMS)
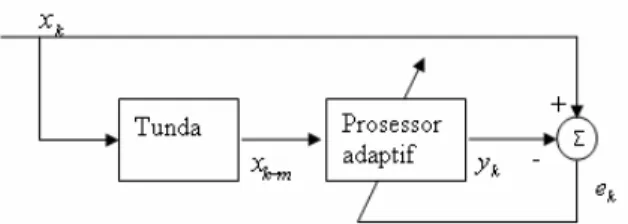
Prediksi adaptif merupakan suatu skema sistem adaptif yang mana tanggapan yang dikehendaki-nya (desired response) merupakan sinyal masukan saat ini sedangkan masukannya merupakan masukan yang di tunda. Selisih dari masukan dengan desired
response ini menghasilkan galat yang oleh prosessor adaptif dikendalikan menjadi seminimal mungkin.
Sistem prediksi adaptif dapat digambarkan seperti pada gambar 1.
Gambar 1 :Sistem Prediksi Adaptif
Nilai pembobotan yang diberikan dan galat yang dihasilkan dihitung mengunakan algoritma least mean square (LMS). Formula yang digunakan system adaktif menggunakan persamaan LMS , yaitu :
k T k k k d X W e = − (1)
dW
d
W
W
k+1=
k−
µ
ξ
(2)Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 17 k k k k
W
X
W
+1=
+
2
ϕε
(3)Prediksi adaktif sesuai dengan formula pada persamaan diatas, Nilai bobot yang dihasilkan kemudian diklasifikasi menggunakan algoritma k-nearest neighbor, yaitu jika
{
ω1,ω2,...,ωv}
=Ω merupakan set kelas dengan v merupakan jumlah kelas yang digunakan, dan setiap kelas direpresentasikan oleh vektor anggotanya
v
k
pr ,ω , dengan k = 0,1,…,(
v
kω -1), dan jika xr merupakan vektor target yang ingin diklasifikasi, dan jarak antara vektor target dengan anggota suatu kelas dinotasikan sebagai d(x,pk,ωv)
r r
, maka jarak antara xr dan ωv dapat difenisikan sebagai:
)} , ( { min ) ( , v v k k w x d x p d r = r r ω ; k = 0,1,…,( v kω -1) (4)
Dengan menggunakan jarak kelas ini, tugas klasifikasi dapat ditulis sebagai berikut:
xr∈ωv⇔ v = argmin{d (x)} v
v
r
ω (5)
3.1. Klasifikasi Dengan Matlab
Sistem blok prediksi adaptif ini dilakukan dengan lebih dahulu merancang algoritma pengklasifikasian dengan menggunakan aplikasi perangkat lunak Matlab® 7.0, kemudian dilakukan percobaan untuk mengenali sinyal suara masukan.
Sinyal suara direkam dengan menggunakan aplikasi perangkat lunak cool edit pro dengan frekuensi cuplikan 44100 sampel per detik. Masing-masing suku kata direkam sebanyak 40 kali untuk pelatihan dan 20 kali untuk pengujian. Studi literatur dilakukan dengan mempelajari literatur-literatur mengenai proses penghasilan suara, skema adaptif, algoritma LMS dan algoritma klasifikasi.
4. Analisa Dan Peta Nilai Pembobotan 4.1 Proses Pemetaan Bobot
Pemetaan bobot menggunakan prinsip yang digunakan untuk pengenalan suara pada sistem ini adalah memetakan bobot yang dihasilkan sebagai sebuah titik pada sistem koordinat n-dimensi. Dengan n merupakan orde sistem atau jumlah bobot yang digunakan. Dalam memperoleh gambar, dimana hasil pembobotan akan menggambarkan posisi koordinat dari bobot yang dihasilkan oleh sistem prediksi tersebut, nilai bobot dipetakan secara terpisah. Hal ini dilakukan karena pemetaan koordinat berdimensi lebih dari tiga tidak dapat dilakukan. Untuk skema prediksi orde lima, pemetaan bobot ditunjukkan pada gambar 2 dan 3 dengan menggunakan data pengujian suku kata “ba” sebagai contoh.
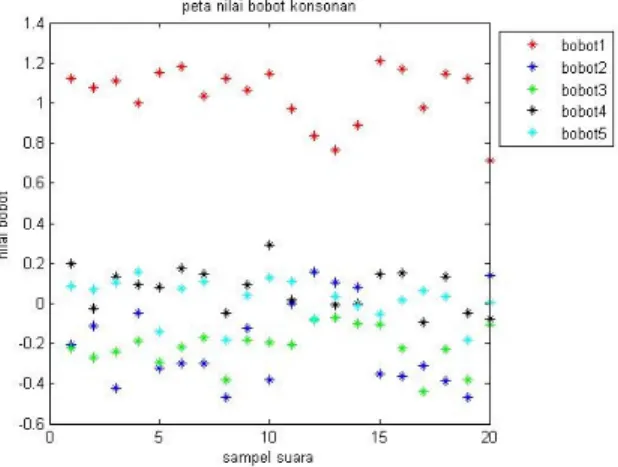
Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 18 Sebaran lima bobot konsonan untuk 20 kali pengujian Gambar 2 merupakan gambar. Proses pada matlab mendapatkan titik-titik sebpada satu garis vertikal merupakan nilai-nilai sebaran dominan sesuai dengan nilai-nilai bobot dari satu buah sampel suara dan merupakan sebuah titik koordinat pada bidang lima dimensi. Dari gambar tersebut terlihat sebaran nilai dari lima bobot konsonan relatif konstan, hanya terdapat beberapa nilai pada bobot pertama yang mengalami penyimpangan. Pada tabel pengenalan suku kata ba, diketahui bahwa pada pengenalan konsonan /b/ terjadi kesalahan pengenalan sebanyak lima kali. Hal ini menunjukkan bahwa nilai bobot yang menyimpang menyebabkan suku kata berada pada daerah yang salah sehingga menyebabkan kesalahan klasifikasi.
Gambar 2: Peta nilai bobot konsonan suku kata “ba”
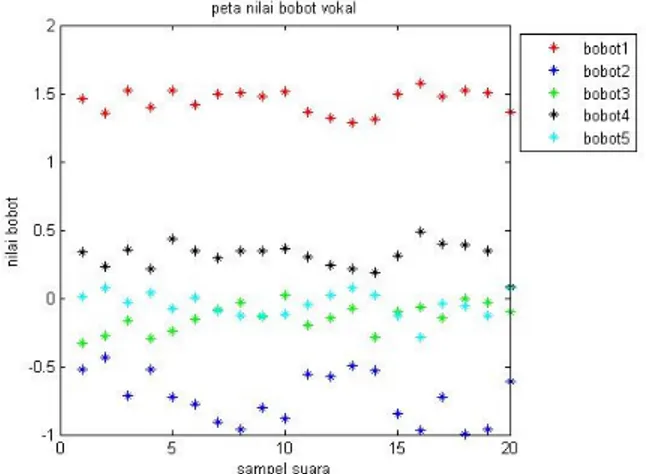
Peta pembobotan yang terdapat pada gambar 2, merupakan gambaran sebaran lima bobot pada pengenalan komponen vokal pada suku kata ba. Sama dengan ucapan kata dengan komponen konsonan, sebaran bobot pada komponen vokal ini relatif konstan pada suatu rentang daerah tertentu, bahkan jika dibandingkan dengan sebaran bobot konsonan, sebaran bobot vokal cenderung lebih konstan di banding dengan sebaran bobot pada komponen konsonan. Nilai konstan bobot-bobot vokal ini menghasilkan tingkat keberhasilan 100% dari pengenalan komponen vokal pada pengujian suku kata ba.
4.2 Tingkat Keberhasilan Pengenalan Suku Kata
Pada pengujian menggunakan 5 buah bobot, didapat tingkat keberhasilan pengenalan suku kata yang disajikan pada 4 buah tabel berikut:
Tabel 1: Tingkat pengenalan suku kata kelompok /b/ Suku kata ba be bi bo bu Total Kesalahan 5 5 1 6 3 20 Persen
keberhasilan (%)
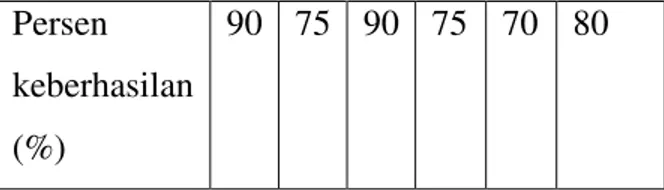
Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 19 Tingkat pengenalan suku kata yang tercatat pada tabel 1. Tabel 1 menunjukkan tingkat keberhasilan pengenalan suku kata berawalan konsonan /b/. Hasil persentase yang di peroleh pada tabel 1, tersebut terlihat bahwa suku kata bo memiliki tingkat keberhasilan terendah yaitu 70%, sedangkan suku kata bi memiliki tingkat keberhasilan tertinggi yaitu 95%. Perolehan data dan persentase keberhasilan, juga di peroleh data rata-rata tingkat keberhasilan yang mencapai 80%.
Peta pembobotan yang terdapat pada gambar 3, merupakan gambaran sebaran lima bobot pada pengenalan komponen vokal pada suku kata va. Untuk kelompok suku kata berawalan konsonan /V/, data tingkat keberhasilan terdapat pada tabel 2, pembobotan yang terdapat dari konsonan tersebut dapat diketahui bahwa suku kata ve, vi, dan vo memiliki tingkat keberhasilan dikenali tertinggi, yaitu mencapai 90%, sedangkan suku kata ba memiliki tingkat keberhasilan terendah, yaitu 70%.
Gambar 3 : Peta nilai bobot vokal suku kata” va”
Untuk nilai rata-rata tingkat keberhasilan kelompok suku kata v mencapai 83%. Tabel 2 : Tingkat pengenalan suku kata kelompok /v/
Hasil pada table 3, menyajikan data tingkat keberhasilan kelompok suku kata yang berawalan /p/. Dari tabel 3 terlihat bahwa suku kata pa dan pi memiliki tingkat keberhasilan tertinggi, yaitu mencapai 90%, sedangkan tingkat keberhasilan terendah pada kelompok ini adalah suku kata pu, yaitu mencapai 70%. Rata-rata tingkat keberhasilan kelompok suku kata ini mencapai 80%.
Tabel 3 : Tingkat pengenalan suku kata kelompok /p/ Suku kata Pa Pe Pi Po Pu Total Kesalahan 2 5 2 5 6 20 Suku kata Va Ve V i Vo Vu Tota l Kesalahan 6 2 2 2 5 17 Persen keberhasilan (%) 70 90 9 0 90 75 83
Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 20 Persen
keberhasilan (%)
90 75 90 75 70 80
Pada tabel 4 disajikan data tingkat keberhasilan kelompok suku kata berawalan konsonan /s/. Dari tabel tersebut dapat terlihat bahwa suku kata se dan si memiliki tingkat keberhasilan tertinggi, mencapai 95%, dan tingkat keberhasilan terendah terjadi pada suku kata so, yaitu mencapai 75%. Rata-rata tingkat keberhasilan kelompok suku kata ini mencapai 90%.
Tabel 4 : Tingkat pengenalan suku kata kelompok /s/
Suku kata Sa Se Si So Su Total
Kesalahan 2 1 1 5 1 10
Persen Keberhasilan (%)
90 95 95 75 95 90
Pembobotan untuk masing masing vocal kata awalan b, v, p, s yang terdapat pada table masing masing dapat dikelompokkan sesuai persenttasi pembobotan. Terlihat bahwa kelompok suku kata berawalan konsonan /s/ memiliki tingkat keberhasilan rata-rata tertinggi, yaitu mencapai 90%, sedangkan kelompok suku kata berawalan konsonan /b/ dan /p/ memiliki tingkat keberhasilan rata-rata terendah, yaitu mencapai 80%.
5. Tingkat Keberhasilan Pengenalan Fonem
Keberhasilan pengenalan fonem tersebut menggunnakan komponen fonem, tingkat keberhasilan sistem mengenali komponen konsonan maupun vokal disajikan pada dua buah tabel berikut:
Tabel 5 : Tingkat pengenalan komponen konsonan
Konsonan /b/ /v/ /p/ /s/
Kesalahan 18 15 20 6
Persen keberhasilan (%) 82 85 80 94
Tabel 6 : Tingkat pengenalan komponen vokal Vokal /a/ /e/ /i/ /o/ /u/
Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 21 Persen
keberhasilan (%)
97,5 100 100 93,75 96,25
Dari tabel 5 dan 6 di atas, terlihat bahwa kemampuan sistem mengenali fonem vokal jauh lebih baik dibandingkan kemampuan sistem mengenali fonem konsonan. Hal ini dikarenakan pada pengenala konsonan, nilai bobot yang digunakan masih dalam keadaan
transcient. Tingkat keberhasilan yang dicapai berkisar antara 93,75% hingga 100%, dan keberhasilan fonem pengenalan konsonan berkisar antara 82% hingga 94%.
Fonem /k/ dan /p/ merupakan fonem konsonan yang memiliki tingkat keberhasilan terendah, dan fonem konsonan /s/ memiliki tingkat keberhasilan tertinggi. Rata-rata keberhasilan mengenali fonem konsonan mencapai 85,25%.
Untuk bagian vokal fonem /e/ dan /i/ merupakan fonem dengan tingkat keberhasilan tertinggi, sedangkan vokal /a/ memiliki tingkat keberhasilan terendah untuk dikenali. Rata-rata keberhasilan mengenali fonem konsonan mencapai 97,5%.
6. Pengujian dengan berbagai jumlah bobot
Jumlah bobot (orde) yang digunakan untuk sistem prediksi merupakan jumlah dimensi dalam klasifikasi k-nearest neighbor. Penentuan jumlah bobot mempengaruhi keakuratan posisi sehingga mempengaruhi tingkat keberhasilan pengenalan.
Untuk mengetahui pengaruh jumlah bobot yang digunakan terhadap tingkat keberhasilan pengenalan suku kata, dilakukan pengujian pengenalan suku kata dari kelompok fonem /k/ dengan nilai orde yang berbeda-beda. Dari pengujian yang dilakukan tersebut didapat hasil yang disajikan pada tabel 7 berikut:
Tabel 7 : Pengujian dengan berbagai nilai orde Persen Keberhasilan Pengenalan
Orde Ka Ke Ki Ko Ku 2 75% 55% 30% 70% 80% 4 60% 75% 85% 65% 85% 5 75% 75% 95% 70% 85% 6 80% 75% 50% 60% 80% 9 75% 65% 65% 60% 50%
Dari data tabel 7 di atas, diketahui bahwa peningkatan orde tidak berkorelasi positif terhadap peningkatan keberhasilan pengenalan. Orde yang terlalu besar justru menurunkan tingkat keberhasilan pengenalan. Hal ini dapat terlihat pada pengujian orde enam, sebagian besar mengalami penurunan tingkat keberhasilan dan ketika jumlah nilai orde ditingkatkan menjadi sembilan, sebagian besar tingkat keberhasilan pengenalan
Jurnal Processor Vol. 5, No. 2, Nopember 2010 – STIKOM Dinamika Bangsa - Jambi 22 tetap mengalami penurunan. Hal ini disebabkan karena penggunaan nilai orde yang terlalu besar menimbulkan beberapa bobot yang bernilai sangat kecil, sehingga dapat dianggap sebagai derau dan mengganggu ketepatan posisi dari suku kata tersebut.
Namun demikian, penggunaan nilai orde yang terlalu kecil juga menyebabkan tingkat keberhasilan pengenalan yang rendah. Hal ini dapat terlihat pada pengujian orde dua, yang mana tingkat keberhasilan pengenalan beberapa suku kata masih rendah. Hal ini disebabkan karena jumlah dimensi yang terlalu kecil, sehingga pemetaan posisi suku kata menjadi kurang akurat dan tingkat keberhasilan pengenalan beberapa suku kata menjadi kecil.
7. Kesimpulan
1. Proses pembobotan suku kata dari keseluruhan proses yang telah dilaksanakan bahwa sistem prediksi adaptif dapat digunakan sebagai algoritma untuk identifikasi suara terutama untuk pengenalan suku kata dalam bahasa Indonesia. Tingkat keberhasilan sistem dalam mengenali fonem-fonem baik konsonan maupun vokal sudah cukup baik, walaupun masih perlu beberapa peningkatan terutama pada kemampuan pengenalan komponen konsonan. Sistem prediksi mengalami kesulitan dalam mengenali beberapa jenis konsonan karena rentang waktu pengucapan yang sangat singkat sehingga perubahan bobot masih dalam keadaan transient.
2. Pemilihan nilai orde juga berpengaruh pada tingkat keberhasilan pengenalan. Jumlah
orde tidak boleh terlalu sedikit ataupun terlalu banyak. Hasil proses yang dilakukan bahwa orde lima memberikan hasil pengenalan yang paling baik.
5. Daftar Pustaka
1. A. James and W. Wiliams.P. , “ Adactif System Recogniton Theory and Implementation”, Prentice-Hall, 1999.
2. B. Widrow dan S. D. Stearns, “Adaptive Signal Processing”, Prentice-Hall, New Jersey, 1985.
3. B. Palnnerer, “An Introduction to Speech Recognition”, [email protected], 2005. 4. C. Beccheti dan L.P. Riccoti, “Speech Recogniton Theory and C++
Implementation”, John Wiley & Sons Ltd, Chichester,1999. 5. ---, Software Matlab ver 7.0