6
4LANDASAN TEORI
4.1. Pelacak Objek
(Yang, Shao, Zheng, Wang, & Song, 2011) Pelacak objek (Object
Tracking) telah banyak digunakan dalam aplikasi computer vision.
Perkembangan teknologi komputer, ketersediaan kamera yang berkualitas tinggi dan harga yang terjangkau, meningkatkan kebutuhan-kebutuhan akan analisis video yang dimana menimbulkan ketertarikan akan algoritma pelacakan visual. Berbagai penelitian tentang pelacakan atau pengenalan visual telah banyak dilakukan. Seperti pengenalan berdasarkan pergerakan, pengawasan otomatis, pengindeksan dan perolehan kembali video, interaksi manusia dan komputer, pemantauan lalu lintas, dll. (Jacob & J, 2012) pelacak objek merupakan proses memisahkan objek pada suatu frame video dan memantau pergerakan, orientasi, dan keadaan lainnya pada objek untuk mengekstrak informasi yang berguna.
4.1.1. Representasi Objek
(Yilmaz, Javed, & Shah, 2006) Pada proses pelacakan, suatu objek dapat di definisikan sebagai sesuatu yang diinginkan oleh pengguna untuk dilacak. Misalnya seekor ikan yang berada didalam akuarium, kendaraan dijalan, orang yang berjalan dijalan, dan sebagainya. Objek dapat direpresentasikan oleh bentuk atau tampilannya. Representasi bentuk objek yang umum digunakan untuk pelacakan adalah sebagai berikut:
8
- Titik: objek direpresentasikan oleh sebuah titik, yaitu suatu titik pusat massa (Gambar 2.1 (a)) atau merupakan kumpulan dari titik-titik (Gambar 2.1 (b)). Umumnya representasi titik cocok untuk melacak benda-benda yang menempati daerah kecil dalam suatu citra.
- Bentuk geometris primitif: bentuk objek direpresentasikan oleh suatu persegi, elips (Gambar 2.1 (c), (d)). Pergerakan objek untuk representasi tersebut biasanya dimodelkan oleh translasi atau transformasi proyektif.
- Objek Siluet dan kontur: representasi kontur mendefinisikan batas dari suatu objek (Gambar 2.1 (g), (h)). Daerah didalam kontur disebut dengan siluet objek. bentuk yang kompleks dapat dilacak dengan menggunakan representasi siluet atau kontur.
- Model bentuk artikulasi: objek yang diartikulasi terdiri dari bagian-bagian tubuh yang disatukan bersama-sama dengan sambungan seperti pada Gambar 2.1 (e).
- Model rangka: kerangka objek dapat diekstrak dengan menerapkan perubahan sumbu medial ke objek siluet. Model ini biasanya digunakan sebagai representasi bentuk untuk mengenali objek. Representasi rangka dapat digunakan untuk objek yang diartikulasi atau objek yang kaku (Gambar 2.1 (f)).
Gambar 4.1 Representasi Objek
4.1.2. Kategori Pelacak Objek
(Yilmaz, Javed, & Shah, 2006) Menuliskan survey terhadap metode pelacak objek dan melakukan kategorisasi pelacak objek dengan metode-metode yang merepresentasikan setiap kategori. Penulis menambahkan CAMSHIFT pada kategori Kernel Tracking untuk Template and density based
appearance models.
Tabel 4.1 Kategori Pelacak (Yilmaz, Javed, & Shah, 2006)
Categories Representative Work
Point Tracking
Deterministic methods MGE tracker [Salari and Sethi 1990], GOA tracker [Veenman et al. 2001]. Statistical methods Kalman filter [Broida and Chellappa 1986],
JPDAF [Bar-Shalom and Foreman 1988], PMHT [Streit and Luginbuhl 1994]. Kernel Tracking
Template and density based appearance models
Mean-shift [Comaniciu et al. 2003], KLT [Shi and Tomasi 1994], Layering [Tao et al. 2002], CAMSHIFT [Bradski 1998]
10
SVM tracker [Avidan 2001] Silhouette Tracking
Contour evolution State space models [Isard and Blake 1998], Variational methods [Bertalmio et al. 2000], Heuristic methods [Ronfard 1994].
Matching shapes Hausdorff [Huttenlocker et al. 1993], Hough transform [Sato and Aggarwal 2004], Histogram [Kang et al. 2004].
4.1. OpenCV
Berdasarkan (Bradski & Kaehler, 2008) OpenCV merupakan open source
computer vision library yang saat ini banyak digunakan untuk pengembangan
aplikasi computer vision. Library dari OpenCV ditulis dalam C dan C++ dan berjalan dibawah Linux, Windows, dan Mac OS X. OpenCV dirancang untuk efisiensi komputasi dan fokus yang kuat pada aplikasi real-time. Salah satu tujuan dari OpenCV adalah menyediakan infrastruktur visi komputer (computer
vision) yang mudah digunakan yang membantu orang membangun aplikasi yang
cukup canggih secara cepat. Library OpenCV berisi lebih dari 500 fungsi yang menjangkau area permasalahan computer vision seperti, termasuk inspeksi produk pabrik, pencitraan medis, kalibrasi kamera, antarmuka pengguna, stereo
vision, dan robotika.
4.2. Kecerdasan Buatan (Artificial Intelligence)
Menurut (Rich & Knight, 1991) kecerdasan buatan atau artificial
intelligence merupakan studi bagian dari ilmu komputer yang mempelajari
bagaimana membuat komputer melakukan berbagai tindakan pekerjaan dapat seperti dan sebaik yang dilakukan manusia. Kecerdasan buatan dibuat pada suatu mesin dengan tujuan untuk membantu manusia dalam mengerjakan pekerjaan
sehari-hari atau menemukan solusi dari suatu masalah yang kompleks yang dihadapi.
Manusia dianugrahkan memiliki pemikiran, akal, kemampuan untuk belajar dari pengalaman, yang membuatnya bertambah pintar untuk menyelesaikan berbagai masalah yang dihadapi.Demikian pula pada suatu mesin, agar dapat melakukan seperti dan sebaik manusia, maka mesin tersebut diberikan pengetahuan, kemampuan untuk menalar seperti manusia.
Berdasarkan (Russel & Norvig, 1995) definisi tentang kecerdasan buatan dapat dikelompokan menjadi empat kategori:
- Sistem yang dapat berpikir seperti manusia. - Sistem yang dapat berperilaku seperti manusia - Sistem yang berpikir secara rasional
- Sistem yang dapat berperilaku secara rasional
Pengertian kecerdasan buatan dapat dipandang dari berbagai sudut pandang (Kusumadewi, 2003):
1. Sudut pandang kecerdasan
Kecerdasan buatan akan membuat mesin menjadi “cerdas”, mampu berbuat seperti apa yang dilakukan oleh manusia.
2. Sudut pandang penelitian
Kecerdasan buatan adalah suatu studi bagaimana membuat agar computer dapat melakukan sesuatu sebaik yang dikerjakan oleh manusia.
12
Domain yang sering dibahas oleh para peneliti:
- Mundane Task
• Persepsi (Vision & Speech)
• Bahasa alami (understanding, generation & translation) • Pemikiran yang bersifat commonsense
• Robot control - Formal Task
• Permainan/games
• Matematika (geometri, logika, kalkulus integral, pembuktian) - Expert Task
• Analisis financial • Analisis medical
• Analisis ilmu pengetahuan
• Rekayasa (desain, pencarian kegagalan, perencanaan manufaktur) 3. Sudut pandang bisnis
Kecerdasan buatan adalah kumpulan peralatan yang sangat powerful dan metodologis dalam menyelesaikan masalah-masalah bisnis.
4. Sudut pandang pemrograman
Kecerdasan buatan meliputi studi tentang pemrograman simbolik, penyelesaian masalah (problem solving) dan pencarian(searching). Didalam membangun aplikasi kecerdasan buatan ada 2 bagian utama yang sangat dibutuhkan, yaitu:
- Knowledge Base, berisi fakta-fakta, teori, pemikiran dan hubungan antara satu dengan lainnya.
- Inference Engine, yaitu kemampuan menarik kesimpulan berdasarkan pengalaman.
Gambar 4.2 Penerapan konsep kecerdasan buatan pada suatu sistem
4.2.1. Kecerdasan Buatan dan Kecerdasan Alami
Kecerdasan buatan yang merupakan kecerdasan yang dimiliki oleh suatu mesin dan kecerdasan alami yang dimiliki oleh manusia memiliki keuntungan dan kerugian. Beberapa keuntungan secara komersial dari kecerdasan buatan (Kusumadewi, 2003):
- Kecerdasan buatan bersifat permanen. Tidak akan berubah sepanjang komputer dan program tidak mengubahnya. Sedangkan kecerdasan alami kapan saja dapat hilang dikarenakan sifat manusia yang pelupa. - Kecerdasan buatan lebih mudah diduplikasi & disebarkan.
Pengetahuan yang terletak pada suatu sistem komputer dapat disalin dari komputer yang satu ke komputer lain dengan usaha dan biaya yang murah. Sedangkan mentransfer pengetahuan manusia dari satu orang ke orang lainnya membutuhkan proses yang lebih lama dan suatu keahlian atau kemampuan yang dimiliki tidak akan pernah dapat diduplikasi dengan lengkap.
14
- Kecerdasan buatan bersifat konsisten. Karena kecerdasan buatan adalah bagian dari teknologi komputer. Sedangkan kecerdasan alami akan senantiasa berubah-ubah.
- Kecerdasan buatan dapat didokumentasi. Keputusan yang dibuah oleh komputer dapat didokumentasi dengan mudah dengan cara melacak setiap aktivitas dari sistem tersebut. Kecerdasan alami sangat sulit untuk direproduksi.
- Kecerdasan buatan dapat mengerjakan pekerjaan lebih cepat dibanding dengan kecerdasan alami.
- Kecerdasan buatan dapat mengerjakan pekerjaan lebih baik dibanding dengan kecerdasan alami.
Beberapa keuntungan dari kecerdasan alami adalah :
- Kreatif. Kemampuan untuk menambah ataupun memenuhi pengetahuan itu sangat melekat pada jiwa manusia. Pada kecerdasan buatan, untuk menambah pengetahuan harus dilakukan melalui sistem yang dibangun.
- Kecerdasan alami memungkinkan orang untuk menggunakan pengalaman secara langsung. Sedangkan pada kecerdasan buatan harus bekerja dengan input-input simbolik.
- Pemikiran manusia dapat digunakan secara luas, sedangkan kecerdasan buatan sangat terbatas.
4.3. Computer vision
Definisi Computer Vision menurut (Shapiro & Stockman, 2001) merupakan salah satu cabang ilmu pengetahuan yang mempelajari bagaimana komputer dapat mengenali objek yang diamati, misalnya mempelajari bagaimana suatu sensor dapat memperoleh citra pada dunia nyata, bagaimana mengekstrak informasi yang terkandung didalam suatu citra untuk diproses dan menghasilkan suatu keputusan, mempelajari representasi apakah yang harus digunakan untuk menyimpan deskripsi akan suatu objek yang diamati, dan algoritma apa yang digunakan untuk membangun semua itu.
Tujuan utama dari computer vision adalah untuk membuat keputusan yang berguna mengenai objek fisik yang nyata dan berdasarkan peristiwa atau kejadian pada citra yang diamati. Untuk membuat keputusan-keputusan akan objek yang nyata, hampir selalu memerlukan pembuatan beberapa deskripsi atau model dari suatu citra. Karena hal ini, banyak pakar yang mengatakan bahwa tujuan utama dari computer vision adalah membangun deskripsi akan peristiwa atau kejadian dari suatu citra.
4.4. Citra
Menurut (Sutoyo, Mulyano, Suhartono, Nurhayati, & Wijanarto, 2009) Citra adalah suatu representasi, kemiripan, atau imitasi dari suatu objek. Citra sebagai keluaran suatu sistem perekaman data dapat bersifat optik berupa foto, bersifat analog berupa sinyal-sinyal video seperti gambar pada monitor televisi, atau bersifat digital yang dapat langsung disimpan pada suatu media penyimpanan.
16
- Citra Analog
Citra analog adalah citra yang bersifat kontinu, seperti gambar pada monitor televisi, foto sinar-x, foto yang tercetak di kertas foto, lukisan, pemandangan alam, hasil CT scan, gambar-gambar yang terekam pada pita kaset, dan lain sebagainya. Citra analog tidak dapat direpresentasikan dalam komputer sehingga tidak bisa diproses di komputer secara langsung. Citra analog harus melewati proses konversi analog ke digital untuk dapat diproses di komputer.
- Citra Digital
Menurut (Putra, 2010) Citra digital merupakan sebuah array yang berisi nilai-nilai real maupun kompleks yang direpresentasikan dengan deretan bit tertentu. Suatu citra dapat didefinisikan sebagai fungsi f(x,y) berukuran M baris dan N kolom, dengan x dan y adalah koordinat spasial, dan amplitudo f di titik koordinat (x,y) dinamakan intensitas atau tingkat keabuan dari citra pada titik tersebut. Apabila nilai x,y, dan nilai amplitudo f secara keseluruhan berhingga (finite) dan bernilai diskrit maka dapat dikatakan bahwa citra terebut adalah citra digital.
Gambar 4.3 Koordinat citra digital (Gonzalez & Woods, 2002)
Citra digital dapat ditulis dalam bentuk metriks sebagai berikut:
f (x,y) = f 0,0 f 1,0 f M 1,0 f 0,1 f 1,1 f M 1,1 f 0, N 1 f 1, N 1 f M 1, N 1
Nilai pada suatu irisan antara baris dan kolom (pada posisi x,y) disebut dengan picture elements, image elements, pels, atau pixels.
Gambar 4.4 Contoh citra pada area tertentu beserta nilai intensitasnya (Putra, 2010)
18
4.4.1. Pembentukan Citra Digital
Pembentukan citra digital melalui beberapa tahapan, yaitu akuisisi citra, sampling, dan kuantisasi. (Sutoyo, Mulyano, Suhartono, Nurhayati, & Wijanarto, 2009)
1. Akuisisi citra
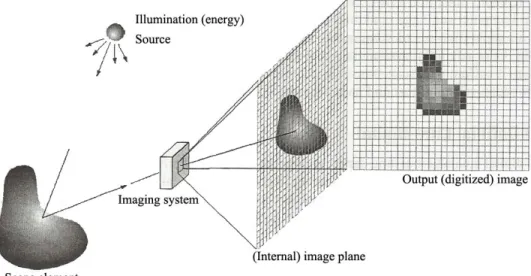
Proses akuisisi citra adalah pemetaan suatu pandangan (scene) menjadi citra kontinu dengan menggunakan sensor.
Gambar 4.5 Pemanfaatan sensor array (larik) (Gonzalez & Woods, 2002)
Gambar diatas menampilkan contoh proses akuisisi citra digital. Dimana ada sebuah objek yang akan di ambil gambarnya (scene element) untuk dijadikan citra digital. Sumber cahaya diperlukan untuk menerangi objek, yang berarti ada intensitas cahaya (brightness) yang diterima oleh objek. Intensitas cahaya ini sebagian diserap oleh oleh objek, dan sebagian lagi dipantulkan ke lingkungan sekitar objek secara radial. Sistem pencitraan (imaging system) menerima
sebagian dari intensitas cahaya yang dipantulkan oleh objek tadi. Didalam sistem pencitraan terdapat sensor optik yang digunakan untuk mendeteksi intensitas cahaya yang masuk ke dalam sistem. Keluaran dari sensor ini berupa arus yang besarnya sebanding dengan intensitas cahaya yang mengenainya. Arus tersebut kemudian dikonversi menjadi data digital yang kemudian dikirimkan ke unit penampil atau unit pengolah lainnya. Secara keseluruhan hasil keluaran sistem pencitraan berupa citra digital.
2. Sampling
Sampling adalah transformasi citra kontinu menjadi citra digital dengan cara membagi citra analog (kontinu) menjadi M kolom dan N baris sehingga menjadi citra diskrit. Semakin besar nilai M dan N, semakin halus citra digital yang dihasilkan dan artinya resolusi citra semakin tinggi.
Pada kamera digital biasanya menggunakan sensor optik jenis CCD (Charge Coupled Device) yang membentuk sebuah array (larik) berukuran M kolom dan N baris. Sensor jenis CCD digunakan untuk mendeteksi intensitas cahaya yang masuk ke dalam kamera. Jumlah seluruh pantulan cahaya yang masuk ke sensor CCD sebenarnya adalah citra analog 2 dimensi. Oleh sensor optik dari seluruh pantulan cahaya ini yang diterima hanya sebagian saja, yaitu sebesar ukuran array tadi (MxN). Akibatnya ada beberapa informasi citra yang hilang (tidak tertangkap oleh sensor). Inilah yang dimaksud dengan sampling, yaitu pengambilan sebagian cahaya dari seluruh cajaya yang diterima oleh sensor. Oleh karena cahaya yang diterima sensor hanya array berukuran M kolom
dan N baris dimensi ber Gambar 4 3. Warn penyusunny ditangkap o intensitas a yang tak te mampu me mengharusk Transforma disebut den misalnya sc digunakan u s maka citra rukuran M k 4.6 (a) Citra 12 kolom, . Kuantisa na sebuah ci ya. Warna i oleh sensor. analog) tidak erhingga. Say enangkap se kan kita m asi intensitas ngan kuantis canner, foto untuk menyi analog 2 dim kolom dan N analog, (b) (c) Citra dig (Gon si itra digital d ini diperoleh Sedangkan k terbatas, y yangnya, sam eluruh grada membuat g s analog yan sasi. Proses digital, dan impan warna
mensi ini dip N baris.
Citra analog gital hasil sam
nzalez & W ditentukan o h dari besar n skala inten yang bisa me mpai saat in asi warna te gradasi wa ng bersifat k s kuantisasi n kamera dig a adalah 3 b proyeksikan g disampling mpling beruk oods, 2002) oleh besar i r kecilnya i nsitas cahay enghasilkan ni belum ada ersebut. Ket arna sesuai kontinu ke d dihasilkan gital. Misal b bit maka grad
n menjadi cit g menjadi 14 kuran 12x14 intensitas pi intensitas ca ya di alam in warna deng a satu sensor terbatasan in dengan daerah intens oleh peralat besarnya me dasi warna c 20 tra digital 2 4 baris dan 4 pixel iksel-piksel ahaya yang ni (gradasi gan jumlah r pun yang nilah yang kebutuhan. sitas diskrit tan digital, emori yang citra analog
pada gambar diatas (yang seharusnya mempunyai jumlah gradasi warna yang tak terhingga) hanya diwakili oleh gradasi warna 3 bit atau memiliki 23 = 8 warna.
Kemudian dilakukan kuantisasi untuk setiap piksel. Warna tiap-tiap piksel disesuaikan dengan gradasi warna yang disediakan oleh memori.
Gambar 4.7 Gradasi warna 3 bit yang hanya memiliki 8 warna (Putra, 2010)
Setelah tiap-tiap piksel dikuantisasi, nilai-nilai intensitas diperoleh sebagai berikut:
Gambar 4.8 Citra digital yang disimpan oleh memori hanyalah nilai-nilai
intensitas tersebut, yang berbentuk metriks berukuran 12 kolom x 14 baris
22
Bila citra digital tersebut ditulis dalam bentuk matematis sebagai fungsi
f(x,y), maka:
Gambar 4.9 Citra digital yang ditulis dalam bentuk matematis. Pada f(3,10) = 7,
artinya piksel di titik (3,10) mempunyai nilai intensitas sebesar 7 (Putra,
2010)
4.4.2. Jenis Citra
Nilai suatu pixel memiliki nilai dalam rentang tertentu, dari nilai minimum sampai nilai maksimum. Jangkauan yang digunakan berbeda-beda tergantung dari jenis warnanya. Namun secara umum jangkauannya adalah 0-255. Citra dengan penggambaran seperti ini digolongkan kedalam citra integer. Berikut adalah jenis-jenis citra berdasarkan nilai pixelnya (Sutoyo, Mulyano, Suhartono, Nurhayati, & Wijanarto, 2009):
Citra putih. Sehin putih. Untu Grada -Banya untuk mena Gamb -biner adala ngga, citra b uk menyimpa asi warna: Citra Gra aknya warna ampung kebu bar 4.11 Perb Citra Wa ah citra yan biner hanya an kedua wa Gamba ayscale (Ska a tergantung utuhan warn bandingan g arna(True C 0 1 ng hanya me a tampak den arna ini dibut
ar 4.10 Citra ala Keabuan g pada juml na ini. gradasi warna Color) emiliki 2 w ngan kombi tuhkan 1 bit a biner n) ah bit yang a mulai dari warna, yaitu nasi warna di memori. disediakan 1 bit sampa hitam dan hitam atau di memori ai 8 bit
24
Setiap piksel pada citra warna mewakili warna yang merupakan kombinasi dari tiga warna dasar atau primer yaitu RGB (Red, Green, Blue). Warna dasar tersebut dapat menghasilkan warna-warna lain dengan perpaduan antara warna dan intensitasnya. Misalnya perpaduan dari warna primer, dapat menghasilkan warna sekunder, yaitu:
1. Magenta = merah + biru 2. Cyan = hijau + biru 3. Kuning = merah + hijau
Gambar 4.12 Perpaduan warna pada RGB.
Setiap warna primer menggunakan penyimpanan 8 bit = 1 byte, yang berarti setiap warna mempunyai gradasi sebanyak 256 warna. Berarti setiap piksel mempunyai kombinasi warna sebanyak 2 · 2 · 2 16.777.216 warna (24 bit).
4.4.3. Model Warna
Pada warna premier, karakteristik umum yang digunakan untuk membedakan satu warna dengan warna lainnya adalah:
2. Hue, ukuran panjang gelombang yang dominan dalam campuran gelombang cahaya. Hue menunjukan warna dominan yang diterima oleh pengamat.
3. Saturation, ukuran sedikit/banyaknya cahaya putih yang tercampur dengan hue (kemurnian warna).
Hue dan saturation jika digabung disebut sebagai chromaticity.
Jumlah warna merah, hijau, dan biru yang dibutuhkan untuk membentuk warna tertentu disebut nilai tristimulus yang dinotasikan dengan X(merah), Y(hijau), Z(biru). Dengan demikian setiap warna bisa dinotasikan sebagai berikut:
, , , 1
Model warna adalah sebuah sistem koordinat yang bisa memetakan semua warna dalam sistem tersebut dengan sebuah titik.Berikut beberapa model warna yang ada:
- Model Warna RGB (Red, Green, Blue)
Model warna RGB berorientasi hardware, terutama untuk warna monitor dan warna pada kamera video. Dalam model ini tiap warna ditunjukan dengan kombinasi tiga warna primer. Ketiga warna primer tersebut membentuk sistem koordinat cartesian tiga dimensi. Subruang pada diagram tersebut menunjukan posisi tiap warna. Nilai RGB terletak pada satu sudut dan nilai cyan, magenta, dan yellow berada di sudut lainnya. Warna hitam berada pada titik asal,
26
sedangkan warna putih terletak pada titik terjauh dari titik asal. Grayscale membentuk garis lurus dan terletak diantara dua titik tersebut.
Gambar 4.13 Skema warna kubus RGB (Gonzalez & Woods, 2002)
- Model Warna HSV (Hue Saturation Value)
(Putra, 2010) Model HSV menunjukan ruang warna dalam bentuk tiga komponen utama yaitu hue, saturation, dan value (atau disebut juga brightness).
Hue adalah sudut dari 0 sampai 360 derajat. Biasanya 0 adalah merah, 60 adalah
kuning, 120 adalah hijau, 180 adalah cyan, 240 adalah biru, dan 300 adalah magenta. Hue menunjukan jenis warna atau corak warna, yaitu tempat warna tersebut ditemukan dalam spektrum warna. Saturation dari suatu warna adalah ukuran seberapa besar kemurnian dari warna tersebut. Sebagai contoh suatu warna yang semuanya merah tanpa putih adalah saturation penuh. Jika ditambahkan putih pada warna merah, hasilnya akan menjadi warna merah muda, dimana hue masih tetap merah tetapi nilai saturation-nya berkurang. Saturation biasanya bernilai dari 0 sampai 1 (atau 0 sampai 100%) dan menunjukan nilai keabu-abuan warna dimana 0 menunjukan abu-abu dan 1 menunjukan warna
primer murni. Komponen yang ketiga dari HSV adalah value atau disebut juga intensitas (intensity) yaitu ukuran seberapa besar kecerahan dari suatu warna atau seberapa besar cahaya datang dari suatu warna. Value dapat bernilai dari 0 sampai 100%.
Gambar 4.14 Sistem warna HSV. (Bradski & Clara, 1998)
Suatu warna dengan nilai value 100% akan tampak secerah mungkin dan suatu warna dengan nilai value 0 akan tampak segelap mungkin. Sebagai contoh jika hue adalah merah dan value bernilai tinggi maka warna akan kelihatan cerah tetapi ketika nilai value rendah maka warna tersebut akan kelihatan gelap.
4.4.4. Elemen Citra Digital
Berikut merupakan elemen-elemen yang terdapat pada citra digital (Sutoyo, Mulyano, Suhartono, Nurhayati, & Wijanarto, 2009):
28
Kecerahan merupakan intensitas cahaya yang dipancarkan piksel dari citra yang ditangkap oleh sistem penglihatan. Kecerahan pada sebuah titik (piksel) didalam citra merupakan intensitas rata-rata dari suatu area yang melingkupinya.
- Kontras (Contrast)
Kontras menyatakan sebaran terang dan gelap dalam sebuah citra. Pada citra yang baik, komposisi gelap dan terang tersebar secara merata.
- Kontur (Contour)
Kontur adalah keadaan yang ditimbulkan oleh perubahan intensitas pada piksel yang bertetangga. Karena adanya perubahan intensitas inilah mata mampu mendeteksi tepi-tepi objek didalam citra.
- Warna (Colour)
Warna sebagai persepsi yang ditangkap sistem visual terhadap panjang gelombang cahaya yang dipantulkan oleh objek.
- Bentuk (Shape)
Bentuk adalah properti intrinsik dari objek 3 dimensi, dengan pengertian bahwa bentuk merupakan properti intrinsik utama untuk sistem visual manusia.
- Tekstur (Texture)
Tekstur dicirikan sebagai distribusi spasial dari derajat keabuan di dalam sekumpulan piksel-piksel yang bertetangga atau bersebelahan. Tekstur adalah sifat-sifat atau karakteristik yang dimiliki oleh suatu daerah yang cukup besar sehingga secara alami sifat-sifat tadi dapat berulang dalam daerah tersebut.
Tekstur adalah keteraturan pola-pola tertentu yang terbentuk dari susunan piksel-piksel dalam citra digital. Informasi tekstur dapat digunakan untuk membedakan sifat-sifat permukaan suatu benda dalam citra yang berhubungan dengan kasar dan halus, juga sifat-sifat spesifik dari kekasaran dan kehalusan permukaan tadi yang sama sekali terlepas dari warna permukaan tersebut.
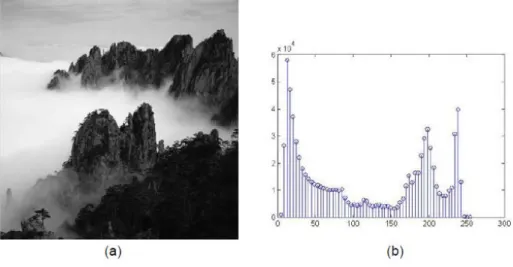
4.4.5. Histogram
Menurut (Zhou, Wu, & Zhang, 2010) Histogram merupakan satu hal yang sangat penting dalam fitur statistik dari suatu citra. Histogram telah banyak digunakan dalam pengolahan citra. Histogram intensitas adalah distribusi dari nilai intensitas warna dari seluruh pixel didalam citra. Setiap bin dalam histogram merepresentasikan jumlah pixel yang ada dalam citra terhadap bin tertentu. Jika digambarkan dalam koordinat kartesian, maka sumbu X menunjukan tingkat warna dan sumbu Y menunjukan frekuensi kemunculan.
30
4.4.6. Back projection
Berdasarkan (Bradski & Kaehler, 2008)back projection merupakan cara untuk mengetahui seberapa baik pixel-pixel dalam suatu citra, cocok dengan distribusi pixel dalam suatu model histogram. Sebagai contoh, terdapat suatu histogram dari warna kulit, kemudian digunakan back projection untuk menemukan warna kulit pada suatu area dalam suatu citra.
Gambar 4.16 Contoh penggunaan back projection.
Pada gambar kiri atas, merupakan histogram dari warna kulit yang akan digunakan untuk mengkonversi citra tangan (kanan atas) menjadi citra distribusi probabilitas warna kulit (kanan bawah). Dan gambar kiri bawah merupakan histogram dari citra tangan.
4.4.7. Perbandingan Histogram
Berdasarkan (Bradski & Kaehler, 2008) perbandingan histogram diperkenalkan oleh Swain dan Ballard dan diteruskan oleh Schiele dan Crowly. Perbandingan histogram dilakukan untuk mendapatkan spesifik kriteria kemiripan.
Beberapa metode yang dapat digunakan untuk perbandingan histogram :
- Chi-square
, ∑ (2.1)
Untuk chi-square, semakin rendah nilai merepresentasikan kecocokan semakin baik, dibanding dengan nilai tinggi. Nilai sempurna adalah 0 dan total ketidakcocokan adalah tak terhingga (tergantung dari besarnya histogram).
- Intersection
, ∑ min , (2.2)
Untuk histogram intersection, semakin tinggi nilai menunjukan semakin tinggi tingkat kecocokan, dan sebaliknya semakin rendah nilai semakin rendah tingkat kecocokan. Jika kedua histogram dinormalisasi menjadi 1, maka nilai sempurna adalah 1, dan total jika tidak ada kecocokan adalah 0.
- Bhattacharyya distance
, 1 ∑ ·
32
Untuk pencocokan Bhattacharyya, semakin rendah skor menunjukan tingkat kecocokan semakin tinggi, dan skor tinggi menunjukan tingkat kecocokan yang rendah.Skor dengan kecocokan sempurna adalah 0, dan skor jika tidak ada kecocokan adalah 1.
4.5. Pengolahan Citra Digital
Pengolahan citra digital adalah sebuah disiplin ilmu yang mempelajari hal-hal yang berkaitan dengan perbaikan kualitas gambar (peningkatan kontras, transformasi warna, restorasi citra), transformasi gambar (rotasi, translasi, skala, transformasi geometrik), melakukan pemilihan citra ciri (feature images) yang optimal untuk tujuan analisis, melakukan proses penarikan informasi atau deskripsi objek atau pengenalan objek yang terkandung pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data, transmisi data, dan waktu proses data. Input dari pengolahan citra adalah citra, sedangkan ouput-nya adalah citra hasil pengolahan.
4.5.1. Hubungan dengan bidang lain
Pengolahan citra digital berkaitan dengan disiplin ilmu grafika komputer dan computer vision, sehingga batasan ketiganya hampir tidak jelas (Sutoyo, Mulyano, Suhartono, Nurhayati, & Wijanarto, 2009).
- Grafika Komputer
Grafika komputer adalah sebuah disiplin ilmu yang mempelajari proses menciptakan suatu gambar berdasarkan deskripsi objek maupun latar belakang yang terkandung pada gambar tersebut. Hal ini tentu meliputi teknik-teknik untuk
membuat gambar objek sesuai dengan objek tersebut di alam nyata. Grafika komputer mencoba memvisualisasikan suatu informasi menjadi citra. Jadi, input dari grafika komputer adalah informasi mengenai citra yang akan digambar, sedangkan output-nya berupa citra.
- Computer Vision
Komputer vision adalah sebuah disiplin ilmu yang mempelajari proses menyusun deskripsi tentang objek yang terkandung pada suatu gambar atau mengenali objek yang ada pada gambar. Komputer vision berusaha menerjemahkan citra menjadi deskripsi atau suatu informasi yang merepresentasikan citra tersebut. Jadi, input-nya berupa citra, sedangkan output-nya berupa informasi.
4.5.2. Operasi Pengolahan Citra
Pengolahan citra dapat dibagi kedalam tiga kategori yaitu:
1. Kategori rendah
Pada kategori pengolahan citra rendah, operasi yang terlibat seperti peningkatan kualitas citra (Image Enhancement), perbaikan citra (Image
Restoration). Peningkatan kualitas citra dan perbaikan citra bertujuan
meningkatkan kualitas tampilan citra untuk pandangan manusia atau untuk mengkonversi suatu citra agar memiliki kualitas yang lebih baik seperti prapengolahan citra untuk mengurangi derau (noise reduction), pengaturan kontras, dan pengaturan ketajaman citra. Pengolahan kategori rendah ini memiliki input dan outputnya berupa citra.
34
2. Kategori menengah
Pada kategori pengolahan citra menengahmelibatkan operasi-operasi seperti segmentasi citra yang bertujuan untuk membagi wilayah-wilayah yang homogen ataumembagi citra ke dalam daerah intensitasnya masing-masing sehingga bisa membedakan antara objek dan background-nya. Kemudian Operasi klasifikasi citra yang mengelompokan objek berdasarkan pengukuran kuantitatif fitur atau sifat utama dari suatu objek.Proses pengolahan citra menengah ini melibatkan input berupa citra dan output berupa atribut (fitur) citra yang dipisahkan dari citra input.
3. Kategori tinggi
Melibatkan proses pengenalan dan deskripsi citra. Operasi pada pengolahan citra pada kategori ini seperti memberikan label atau deskripsi terhadap suatu objek, pengenlan pola huruf, pengenalan wajah, sidik jari, dan lain sebagainya sehingga objek tersebut dapat dikenali dan diproses lebih lanjut.
4.5.3. Segmentasi
Menurut (Bradski & Kaehler, 2008) segmentasi citra merupakan komponen penting dalam aplikasi computer vision, dan dapat mengatasi masalah pengelompokan suatu wilayah dalam suatu citra. Sebagai contoh pada suatu video keamanan, kamera selalu mengambil latar belakang beserta objeknya. Dalam computer vision terkadang diperlukan suatu proses untuk memisahkan objek dengan latar belakangnya untuk keperluan analisis. Segmentasi citra membagi suatu citra menjadi beberapa wilayah. Setiap wilayah dibagi dengan
mempertimbangkan atribut tertentu (misalnya intensitas, warna, dan tekstur) dari citra sampai bagian-bagian wilayah cukup homogen. Dengan membagi-bagi wilayah dalam suatu citra, dimungkinkan dapat memisahkan objek dengan latar belakangnya.
4.5.4. Segmentasi Mean-shift
Berdasarkan (Bradski & Kaehler, 2008) segmentasi mean-shift merupakan algoritma segmentasi / clustering. Segmentasi mean-shift menggunakan algoritma dari mean-shift dimana tujuan dari algoritma ini adalah untuk menemukan nilai maksimum lokal dari suatu kepadatan probabilitas yang diberikan. Dengan dilakukan segmentasi mean-shift, suatu citra akan memiliki warna-warna yang homogen dalam suatu wilayah.
36
4.5.5. Region growing
Region growing merupakan salah satu teknik segmentasi, dimana
menggunakan suatu titik “seed” dengan tujuan untuk menumbuhkannya, sehingga suatu wilayah tertentu dalam suatu citra akan terpilih. Region growing juga digunakan untuk membuat suatu batas dalam suatu wilayah tertentu,
Salah satu teknik region growing yang sering digunakan adalah flood fill. Berdasarkan (Bradski & Kaehler, 2008) flood fill merupakan fungsi yang sangat berguna dimana sering digunakan untuk menandai atau mengisolasi suatu bagian dalam suatu citra untuk keperluan analisis atau pengolahan citra lebih lanjut.
Flood fill juga bisa digunakan untuk menghasilkan suatu mask yang dapat
digunakan pada proses selanjutnya untuk mempercepat atau membatasi suatu proses pengolahan citra dimana hanya pixel-pixel yang diproses sesuai dengan bagian yang ditunjukan oleh mask.
Penggunaan metode floodfill dalam OpenCV, mirip dengan operasi pada suatu program pengolahan citra pada komputer. Dimana suatu titik “seed” dipilih dalam suatu citra dan semua titik-titik tetangganya yang memiliki kemiripan warna sesuai rentang tertentu akan terpilih dengan ditandai suatu warna yang seragam untuk menandai bagian yang terpilih.
Gambar 4.18 Contoh region growing dengan menggunakan metode flood fill.
4.5.6. Ekstraksi Fitur (Feature Extraction)
(Lu, 1999) Salah satu hal yang paling penting didalam pengolahan citra adalah ekstraksi fitur atau representasi isi (fitur apakah yang paling penting didalam suatu citra). Ekstraksi fitur bisa merupakan proses otomatis atau semi-otomatis. Ekstraksi fitur dapat juga dikatakan sebagai indexing. Fitur dan atribut dari suatu informasi citra di ekstrak, diparameterkan, dan disimpan bersama dengan citra itu sendiri.Fitur dan atribut dari citra yang di query juga diekstrak dengan cara yang sama jika citra tersebut secara eksplisit tidak ditentukan. Sistem akan melakukan pencocokan pada basis data citra yang memiliki kemiripan fitur dan atribut berdasarkan kesamaan metrik tertentu.
Suatu citra yang ada pada basis data citra biasanya diolah untuk diekstrak fitur dan atributnya. Selama proses pencarian, fitur-fitur dan atribut ini di cari dan
38
di bandingkan antara citra query dengan citra yang ada pada basis data citra. Oleh karena itu, kualitas dari fitur dan atribut yang di ekstrak sangat menentukan hasil dari pencarian.
Ekstraksi fitur harus memenuhi persyaratan sebagai berikut (Lu, 1999):
1. Fitur dan atribut yang diekstrak harus selengkap mungkin untuk mewakili isi dari informasi yang terkandung di dalam citra.
2. Fitur-fitur yang diekstrak harus mewakili dan disimpan dengan lengkap. Fitur yang rumit dan kompleks dapat menjauh dari tujuan ekstraksi fitur, karena sangat menentukan kecepatan dan perbandingan pada saat proses pencarian.
3. Perhitungan jarak antara fitur harus efisien, karena jika tidak memperhatikan hal ini, waktu respons sistem dapat memakan waktu.
4.6. CAMSHIFT
CAMSHIFT (Continuously Adaptive Mean-shift) adalah algoritma pelacakan pergerakan yang merupakan perluasan dari algoritma Mean-shift yang diusulkan oleh (Bradski & Clara, 1998). (Chouhan, Mishra, & Nitnawwre, 2012)
Mean-shift merupakan teknik non-parametric yang mendaki suatu kepadatan
pada distribusi probabilitas untuk menemukan puncak dari suatu distribusi.
Algoritma mean-shift diusulkan oleh (Fukunaga & Hostetler, 1975) dan diterapkan untuk pencocokan pola. Pada tahun 1995, (Cheng, 1995) mengenalkan penggunaan mean-shift untuk bidang computer vision. Algoritma
diperoleh dari urutan citra video selalu berubah. Sehingga algoritma mean-shift harus dimodifikasi untuk beradaptasi secara dinamis terhadap perubahan distribusi pada citra.
Untuk memenuhi kebutuhan tersebut, (Bradski & Clara, 1998) mengusulkan metode pelacakan yang disebut dengan CAMSHIFT. Ide utamanya adalah dengan melakukan operasi mean-shift terhadap semua frame dalam urutan video, menggunakan pusat massa dan ukuran dari search window yang diperoleh dari frame sebelumnya sebagai nilai inisial untuk search window pada frame selanjutnya, dan mencapai pelacakan objek dengan proses secara iterasi.
(Li, Zhang, Zhou, Guo, Wang, & Zhao, 2011) CAMSHIFT menggunakan fitur warna berupa histogram warna sebagai model objek. Karena histogram dari citra objek merupakan probabilitas warna dari objek, algoritma ini tidak akan mudah dipengaruhi oleh perubahan bentuk dari objek. Dengan demikin dapat mengatasi masalah sewaktu objek berpindah lokasi atau objek hanya tampil sebagian. Selain itu, algoritma CAMSHIFT memiliki waktu komputasi yang cepat, sehingga dapat melakukan pelacakan secara real-time.
40
Gambar 4.19 Blok diagram dari pelacakan objek dengan CAMSHIFT. (Bradski & Clara, 1998)
4.6.1. Algoritma Mean-shift
(Bradski & Clara, 1998) Prosedur dari penggunaan algoritma mean-shift adalah sebagai berikut :
1. Tentukan ukuran dari search window. 2. Tentukan inisial lokasi dari search window. 3. Hitung lokasi mean didalam search window
4. Pusatkan search window pada lokasi mean yang dihitung pada langkah 3.
5. Ulangi langkah 3 dan 4 sampai konvergen (atau dapat dikatakan, sampai lokasi mean berpindah dibawah nilai threshold yang telah ditentukan)
Perbedaan utama antara algoritma mean-shift dan CAMSHIFT adalah algoritma mean-shift dirancang untuk distribusi yang statis, sedangkan CAMSHIFT dirancang untuk dapat mengubah distribusi secara dinamis. Hal ini terjadi ketika objek yang dilacak pada urutan video dimana objek selalu berpindah (bergerak maju dan mundur mendekati kamera) sehingga ukuran dan lokasi dari distribusi probabilitas berubah setiap waktu. Algoritma CAMSHIFT melakukan penyesuaian terhadap ukuran dari search window.
4.6.2. Algoritma CAMSHIFT
(Bradski & Clara, 1998) Prosedur dari penggunaan algoritma CAMSHIFT:
1. Tentukan ukuran dan lokasi search window untuk menentukan daerah kalkulasi (calculation region) yang berisikan objek yang ingin dilacak. Kemudian hitung histogram warna pada daerah tersebut sebagai model objek.
2. Membuat distribusi probabilitas dari frame saat ini menggunakan histogram warna dari model objek dengan menggunakan metode
histogram back projectionuntuk menghasilkan citra back projection
(citra distribusi probabilitas).
3. Berdasarkan citra distribusi probabilitas, hitung lokasi pusat massa(centroid) didalamsearch window, pusatkan search window pada pusat massa tersebut, dan hitung area tersebut.
4. Jika search window konvergen (sampai lokasi window tersebut berpindah dengan jarak dibawah threshold yang ditentukan), maka
42
kembali ke langkah 2, selain itu kembali ke langkah 3 sampai konvergen.
Untuk menghitung pusat massa menggunakan persamaan berikut, dimana , adalah tiap-tiap nilai pixel pada citra distribusi probabilitas:
0-order moment:
∑ ∑ , (2.4)
1-order moment:
∑ ∑ , (2.5)
∑ ∑ , (2.6)
Maka koordinat pusat dari search window adalah:
, (2.7)
Untuk menentukan orientasi dari distribusi probabilitas menggunakan persamaan:
2-order moment:
∑ ∑ , (2.8)
∑ ∑ , (2.9)
∑ ∑ , (2.10)
Search window dari CAMSHIFT merupakan elips, untuk menghitung
panjang l dan lebar w:
(2.12)
(2.13)
Dimana :
, 2 ,
4.7. SURF (Speeded Up Robust Feature)
(Bay, Ess, Tuytelaars, & Gool, 2007) SIFT (Scale Invariant Feature
Transform) merupakan fitur citra yang diusulkan oleh Lowe yang invarian
terhadap rotasi dan skala. SIFT sering digunakan dalam pencocokan citra, namun kompleksitas dan data yang digunakan sangat besar sehingga membutuhkan waktu komputasi yang lebih lama. SURF menawarkan kinerja yang lebih baik dari pada SIFT.
(Du, Su, & Cai, 2009) Sama seperti SIFT, detektor dari SURF ditugaskan untuk menemukan keypoint dalam suatu citra, dan kemudian deskriptor digunakan untuk mengekstrak vektor fitur pada setiap keypoint. Perbedaan yang mendasar antara SIFT dan SURF adalah SIFT menggunakan difference of
gaussian untuk mendeteksi keypoint, sedangkan SURF menggunakan pendekatan
44
dimana dengan pendekatan metriks hessian ini menurunkan waktu komputasi dengan drastis.
(Li, Hu, Shen, Zhang, Dick, & Hengel, 2013) Melakukan perbandingan secara kualitatif terhadap metode-metode yang umumnya digunakan untuk membangun pendeskripsi objek yang digunakan untuk sistem pelacak objek:
Tabel 4.2 Berda SURF meru memiliki k 2 Perbandin asarkan perb upakan met kecepatan ya gan kualitati Di bandingan se tode yang d ang sedang, if representa
ick, & Heng
ecara kualita dapat dianda
namun dap
asi visual (Li
gel, 2013)
atif dari met alkan. Dari s pat mengata i, Hu, Shen, tode-metode segi kecepa asi gangguan , Zhang, e yang ada, atan, SURF n terhadap
46
objek yang tampil hanya sebagian, mengalami perubahan iluminasi, dan perubahan bentuk dari objek.
4.7.1. Keypoints Detection
Berdasarkan (Bay, Ess, Tuytelaars, & Gool, 2007) untuk membuat suatu fitur yang invarian(memiliki ketahanan) terhadap perubahan skala, maka tahap pertama yang dilakukan adalah membuat ruang skala. Ruang skala citra disebut juga dengan Gaussian Pyramid yang digunakan untuk menemukan keypoint pada skala yang berbeda. Ruang skala terbagi kedalam beberapa tingkatan yang disebut dengan octave. Setiap octave merepresentasikan respon filter yang diperoleh dengan melakukan proses konvolusi box filter terhadap citra yang diinputkan dengan ukuran filter yang semakin besar sesuai dengan ukuran citra untuk membentuk piramid citra.
(Li, Zhang, Zhou, Guo, Wang, & Zhao, 2011) Pada SIFT, citra secara berulang dikonvolusi dengan menggunakan Gaussian Kernel dan berulang kali di sub sampel, dimana hasil metode ini dalam setiap lapisan bergantung pada proses sebelumnya, dengan demikian kompleksitasnya sangat besar. Untuk pyramid citra, SURF menggunakan box filter sebagai aproksimasi dari turunan parsial kedua dari Gaussian.
Gambar 4.20 Dari kiri ke kanan: Turunan parsial kedua dari Gaussian pada arah
sumbu y dan sumbu xy; pendekatan yang digunakan dengan box filter. Daerah abu-abu sama dengan 0.
Untuk mendeteksi keypoint yang invarian terhadap perubahan skala, SURF menggunakan determinant of Hessian matrix yang digunakan pada lokalisasi
keypoint untuk menentukan apakah suatu titik merupakan nilai ekstrim.
Diberikan suatu titik x = (x,y) pada suatu citra I, metriks Hessian , pada
xpada skala σ, didefinisikan sebagai berikut:
, ,, ,,
Dimana , , , , dan , adalah konvolusi dari penurunan orde kedua dari Gaussian dengan citra I pada titik xberturut-turut.
Untuk mengurangi waktu komputasi, suatu box filter berukuran 9x9 digunakan sebagai tafsiran dari Gaussian dengan σ = 1.2 dan merepresentasikan skala terendah untuk menghitung blob response maps, yang dinotasikan dengan
, , dan . Persamaannya adalah sebagai berikut:
48
Pembobotan diterapkan pada wilayah persegi untuk menjaga efisiensi komputasi. Pada persamaan diatas, adalah bobot untuk menyeimbangkan determinan Hessian yang dibutuhkan untuk menyeimbangkan bobot relatif:
1.2 9
1.2 9 0.912 … 0.9
Untuk melokalisasi keypoint pada citra dan keseluruhan skala ditentukan dengan non-maximum suppresion pada 3 x 3 x 3 dari tetangganya. Nilai ekstrim dari determinan metriks hessian diinterpolasikan pada skala ruang dengan metode yang diusulkan oleh (Brown & Lowe, 2002).
4.7.2. Keypoint Descriptor
Berdasarkan (Bay, Ess, Tuytelaars, & Gool, 2007) pendeskripsian keypoint menjadi deskriptor vektor dilakukan agar keypoint invarian terhadap perubahan rotasi, iluminasi, dan perubahan sudut pandang. Untuk membuat keypoint yang invarian terhadap perubahan rotasi, maka setiap keypoint yang terdeteksi akan diberikan orientasi. Deskriptor keypoint SURF mengandalkan orientasi dominan dari seluruh keypoint, kemudian komponen deskriptor dibangun. Perhitungan orientasi dominan berdasarkan respon Haar wavelet, dimana menghitung respon
Haar pada koordinat X dan Y pada suatu wilayah lingkaran dimana pusatnya
adalah keypoint dengan radius 6s. Dengan melakukan sampling pada tiap-tiap skala s, begitu juga perhitungan respon haar wavelet sesuai dengan skalanya. Sehingga pada skala yang besar, ukuran wavelet juga akan besar. Pada tahap ini penggunaan citra integral kembali digunakan untuk melakukan filter yang cepat. Dengan demikian hanya dibutuhkan enam operasi untuk menghitung respon pada
sumbu x dan sumbu y pada tiap skala. Ukuran dari haar wavelet adalah 4s dan jumlah dari vektor dihitung setiap 60 derajat pada lingkaran. Dan pada akhirnya orientasi dengan jumlah terbesar dari vektor adalah orientasi yang dominan. Proses dari penentuan orientasi dapat dilihat pada gambar berikut:
Gambar 4.21 Penentuan orientasi. (Li, Zhang, Zhou, Guo, Wang, & Zhao, 2011)
Setelah orientasi dominan telah ditentukan, untuk mengekstrak deskriptor, langkah pertama yang diambil adalah membuat daerah persegi yang berpusat disekitar keypoint, dan orientasinya mengarah ke orientasi yang sudah ditentukan sebelumnya. Ukuran dari jendela persegi tersebut adalah 20σ.
Daerah tersebut kemudian dibagi lagi menjadi 4x4 sub daerah. Daerah ini tetap berisi informasi spasial sesuai dengan aslinya. Untuk masing-masing sub daerah ini, akan dihitung beberapa respon haar wavelet pada 5x5 titik sampel ruang. Untuk kesederhanaan, respon haar wavelet pada arah horizontal akan disebut dengan dan respon haar wavelet pada arah vertikal akan disebut dengan . Untuk meningkatkan ketahanan terhadap deformasi geometrik dan kesalahan lokalisasi, maka respon dan akan dibobot dengan sebuah Gaussian (σ = 3.3s) yang berpusat pada keypoint.
50
Kemudian respon wavelet dan dijumlahkan untuk setiap sub wilayah. Hal ini akan memberikan informasi tentang polar dari perubahan intensitas, dan juga akan dihasilkan jumlah nilai absolut dari respon | |dan . Masing-masing sub wilayah mempunyati 4 dimensi vektor deskriptor v, yaitu , , | |, dan . Untuk 4x4 sub daerah, akan dihasilkan vektor deskriptor dengan panjang 64. Terakhir dilakukan normalisasi, dan didapatkanlah komponen vektor deskriptor. Deskriptor SURF invarian terhadap skala, rotasi, dan translasi citra.