ANALISIS STATISTIK tentang
PENGERTIAN STATISTIK, PENGERTIAN STATISTIKA,
MACAM-MACAM DATA, DISTRIBUSI FREKUENSI DAN GRAFIKNYA, UKURAN PEMUSATAN, UKURAN PENYEBARAN (FRAKTIL) DAN
UKURAN DISPERSI
DISUSUN OLEH :
1. Trilius Septaliana KR (20102512011) 2. Aisyah (20102512023)
DOSEN PENGASUH : Dr. Ratu Ilma I.P.,M.Si
PROGRAM PASCASARJANA UNIVERSITAS SRIWIJAYA PALEMBANG TAHUN AJARAN 2011/2012
BAB 1
PENGERTIAN STATISTIK, STATISTIKA DAN MACAM-MACAM DATA
1.1. Pengertian Statistik dan Statistika
Statistik adalah kumpulan data, bilangan maupun non-bilangan yang disusun dalam tabel dan atau diagram yang melukiskan suatu persoalan
Statistika adalah pengetahuan yang berhubungan dengan cara-cara pengumpulan data, pengolahan atau penganalisaannya dan penarikan kesimpulan berdasarkan kumpulan data dan penganalisaan yang dilakukan.
1.2. Pembagian Statistik Berdasarkan Cara Pengolahan Datanya
Didasarkan atas cara pengolahan datanya, statistik dapat dibagi dua, yaitu statistik deskriptif dan statistik inferensi.
a. Statistika deskriptif adalah metode yang berkaitan dengan pengumpulan dan penyajian suatu gugus data sehingga memberikan informasi yang berguna.
b. Statistika inferensia adalah metode yang berhubungan dengan analisis sebagian data untuk kemudian sampai pada peramalan atau penarikan kesimpulan tentang seluruh gugus data induknya.
1.3. Pembagian Statistik Berdasarkan Ruang Lingkup Penggunaannya a. Statistik sosial
adalah statistik yang diterapkan atau digunakan dalam ilmu-ilmu sosial. b. Statistik pendidikan
adalah statistik yang diterapkan atau digunakan dalam ilmu dan bidang pendidikan.
c. Statistik ekonomi
adalah statistik yang diterapkan atau digunakan dalam ilmu-ilmu ekonomi. d. Statistik perusahaan
adalah statistik yang diterapkan atau digunakan dalam bidang perusahaan. e. Statistik pertanian
f. Statistik kesehatan
adalah statistik yang diterapkan atau digunakan dalam bidang kesehatan.
1.4. Pembagian Statistik Berdasarkan Bentuk Parameternya a. Statistik parametrik
adalah bagian statistik yang parameter dari populasinya mengikuti suatu distribusi tertentu, seperti distribusi normal dan memiliki varians yang homogen.
b. Statistik nonparametrik
adalah bagian statistik yang parameter dari populasinya tidak mengikuti suatu distribusi tertentu atau memiliki distribusi yang bebas dari persyaratan, dan variansnya tidak perlu homogen.
1.5. Data Statistik
Menurut Kamus Besar Bahasa Indonesia data adalah keterangan yang benar dan nyata. Data adalah bentuk jamak dari datum. Datum adalah keterangan atau ilustrasi itu mengenai sesuatu hal yang bisa berbentuk kategori (misalnya rusak, baik, senang, cerah, berhasil, gagal dan sebagainya) atau bilangan. Jadi, data dapat diartikan sebagai sesuatu yang diketahui atau yang dianggap atau anggapan.
1.6. Pembagian Data
A. Jenis Data Menurut Cara Memperolehnya
1. Data Primer, adalah secara langsung diambil dari objek, atau objek penelitian oleh peneliti perorangan maupun organisasi. Data primer disebut juga data asli atau data baru. Contoh: Mewawancarai langsung penonton bioskop 21 untuk meneliti preferensi konsumen bioskop.
2. Data Sekunder, adalah data yang didapat tidak secara langsung dari objek penelitian. Peneliti mendapatkan data yang sudah jadi yang dikumpulkan oleh pihak lain dengan berbagai cara atau metode baik secara komersial maupun non komersial. Data sekunder disebut juga data tersedia. Contohnya adalah pada peneliti yang menggunakan data statistik hasil riset dari surat kabar atau majalah.
B. Macam-Macam Data Berdasarkan Sumber Data
1. Data Internal, adalah data yang menggambarkan situasi dan kondisi pada suatu organisasi secara internal. Misal : data keuangan, data pegawai, data produksi, dsb. 2. Data Eksternal, adalah data yang menggambarkan situasi serta kondisi yang ada di
luar organisasi. Contohnya adalah data jumlah penggunaan suatu produk pada konsumen, tingkat preferensi pelanggan, persebaran penduduk, dan lain sebagainya.
C. Klasifikasi Data Berdasarkan Jenis Datanya
1. Data Kuantitatif, adalah data yang dipaparkan dalam bentuk angka-angka. Misalnya adalah jumlah pembeli saat hari raya idul adha, tinggi badan siswa kelas 3 ips 2, dan lain-lain.
2. Data Kualitatif, adalah data yang disajikan dalam bentuk kata-kata yang mengandung makna. Contohnya seperti persepsi konsumen terhadap botol air minum dalam kemasan, anggapan para ahli terhadap psikopat dan lain-lain.
D. Pembagian Jenis Data Berdasarkan Sifat Data
1. Data Diskrit, adalah data yang nilainya adalah bilangan asli. Contohnya adalah berat badan ibu-ibu pkk sumber ayu, nilai rupiah dari waktu ke waktu, dan lain-sebagainya.
2. Data Kontinu, adalah data yang nilainya ada pada suatu interval tertentu atau berada pada nilai yang satu ke nilai yang lainnya. Contohnya penggunaan kata sekitar, kurang lebih, kira-kira, dan sebagainya.
E. Jenis-jenis Data Menurut Waktu Pengumpulannya
1. Data Cross Section, adalah data yang menunjukkan titik waktu tertentu. Contohnya laporan keuangan per 31 desember 2006, data pelanggan PT. angin ribut bulan mei 2004, dan lain sebagainya.
2. Data Time Series/ Berkala, adalah data yang datanya menggambarkan sesuatu dari waktu ke waktu atau periode secara historis. Contoh data time series adalah data perkembangan nilai tukar dollar amerika terhadap euro eropa dari tahun 2004 sampai 2006, jumlah pengikut jamaah nurdin m. top dan doktor azahari dari bulan ke bulan, dll.
1.7. Penyajian Data
Fungsi penyajian data yaitu :
1. Menunjukkan perkembangan suatu keadaan, 2. Mengadakan perbandingan pada suatu waktu.
Secara garis besar penyajian data dapat dilakukan melalui tabel dan grafik. a. Tabel
Tabel adalah penyajian data dalam bentuk kumpulan angka yang disusun menurut kategori-kategori tertentu, dalam suatu daftar. Dalam tabel, disusun dengan cara alfabetis, geografis, menurut besarnya angka, historis, atau menurut kelas-kelas yang lazim.
Berdasarkan pengaturan datanya, tabel dibedakan atas beberapa jenis, yaitu : 1. Tabel frekuensi, adalah tabel yang menunjukkan atau memuat banyaknya kejadian
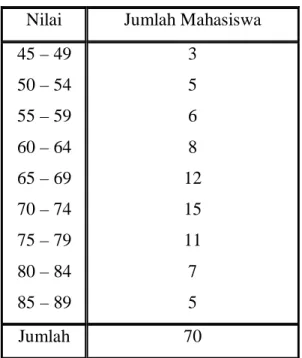
atau frekuensi dari suatu kejadian. Contoh :
TABEL HASIL UJIAN STATISTIK Nilai Jumlah Mahasiswa 45 – 49 50 – 54 55 – 59 60 – 64 65 – 69 70 – 74 75 – 79 80 – 84 85 – 89 3 5 6 8 12 15 11 7 5 Jumlah 70
2. Tabel klasifikasi,
Tabel klasifikasi adalah tabel yang menunjukkan atau memuat pengelompokkan data. Tabel klasifikasi dapat berupa tabel klasifikasi tunggal dan ganda.
Contoh tabel klasifikasi tunggal
TABEL JUMLAH MURID XII IPA SMA X PALEMBANG YANG LULUS UJIAN MATEMATIKA TAHUN 2009
Jenis Jumlah Laki-laki Perempuan 81 88 Jumlah 169
Contoh : tabel klasifikasi ganda
TABEL JUMLAH MURID XII IPA SMA X PALEMBANG YANG LULUS UJIAN MATEMATIKA TAHUN 2009
Jenis Kelamin
Jumlah Murid
Kelas
XII IPA 1 XII IPA 2 XII IPA 3 XII IPA 4 Laki-laki Perempuan 81 88 17 22 20 23 25 18 19 25 Jumlah 169 39 43 43 44 3. Tabel kontingensi,
Tabel kontingensi adalah tabel yang menunjukkan atau memuat data sesuai dengan rinciannya. Apabila bagian baris tabel berisikan m baris dan bagian kolom tabel berisikan n kolom maka didapatkan tabel kontingensi berukuran m x n.
Contoh :
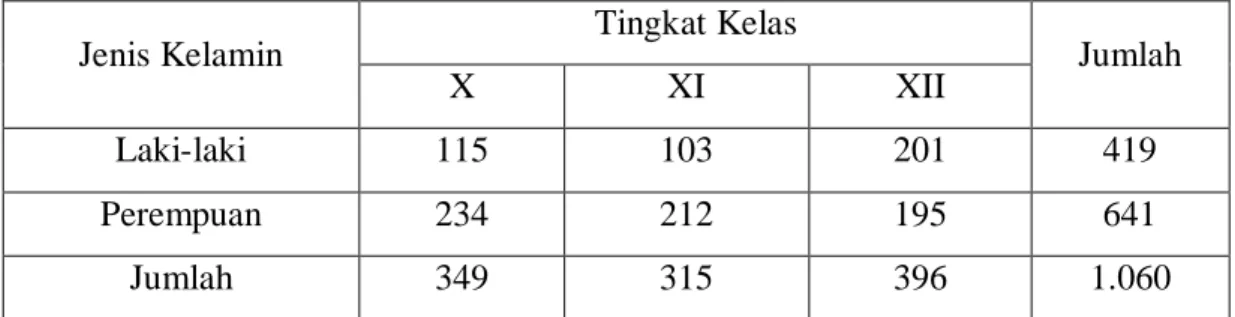
TABEL BANYAK MURID MENYUKAI BELAJAR MATEMATIKA DI SEKOLAH DAERAH T MENURUT TINGKAT KELAS DAN JENIS KELAMIN TAHUN 2009
Jenis Kelamin Tingkat Kelas Jumlah
X XI XII
Laki-laki 115 103 201 419
Perempuan 234 212 195 641
4. Tabel korelasi
Tabel korelasi adalah tabel yang menunjukkan atau memuat adanya korelasi (hubungan) antara data yang disajikan.
Contoh :
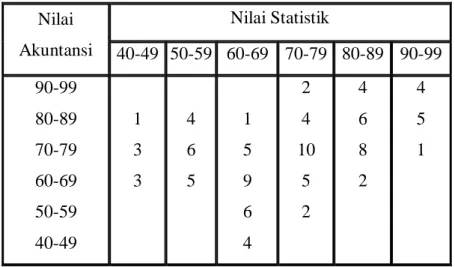
TABEL HASIL UJIAN STATISTIK DAN AKUNTANSI 100 MAHASISWA DI SUATU AKADEMI Nilai Akuntansi Nilai Statistik 40-49 50-59 60-69 70-79 80-89 90-99 90-99 80-89 70-79 60-69 50-59 40-49 1 3 3 4 6 5 1 5 9 6 4 2 4 10 5 2 4 6 8 2 4 5 1 b. Diagram Data
Diagram data disebut juga grafik data, adalah penyajian data dalam bentuk gambar-gambar. Grafik data biasanya berasal dari tabel dan grafik biasanya dibuat bersama-sama, yaitu tabel dilengkapi dengan grafik. Grafik data sebenarnya merupakan penyajian data secara visual dari data bersangkutan. Grafik data dibedakan atas beberapa jenis, yaitu :
1. Piktogram
Piktogram adalah grafik data yang menggunakan gambar atau lambang dari data itu sendiri dengan skala tertentu.
Contoh
Penduduk dunia pada akhir abad ke-20 diperkirakan : 1) Afrika : 350 juta jiwa
2) Amerika : 500 juta jiwa 3) Asia : 2.000 juta jiwa 4) Eropa : 600 juta jiwa 5) Jerman : 50 juta jiwa 6) Uni Soviet : 250 juta jiwa
2. Diagram batang atau balok
Diagram batang atau balok adalah diagram data berbentuk persegi panjang yang lebarnya sama dan dilengkapi dengan skala atau ukuran sesuai dengan data yang bersangkutan. Setiap batang tidak boleh saling menempel atau melekat antara satu dengan lainnya dan jarak antara setiap batang yang berdekatan harus sama.
Contoh :
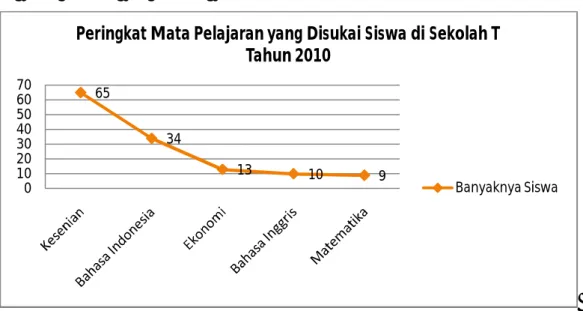
Peringkat Mata Pelajaran yang Disukai Siswa di Sekolah T Tahun 2010 Jenis Mata Pelajaran Banyaknya Siswa
Kesenian Bahasa Indonesia Ekonomi Bahasa Inggris Matematika 65 34 13 10 9 0 20 40 60 80 Kesenian Bahasa Indonesia
Ekonomi Bahasa Inggris Matematika
Peringkat Mata Pelajaran yang Disukai
Siswa di Sekolah T Tahun 2010
3. Diagram garis
Diagram Garis adalah diagram berupa garis, diperoleh dari beberapa ruas garis yang menghubungkan titik-titik pada bidang bilangan. Pada diagram garis digunakan dua garis yang saling berpotongan. Pada garis horizontal (sumbu-X) ditempatkan bilangan-bilangan yang sifatnya tetap, seperti tahun dan ukuran-ukuran. Pada garis tegak (sumbu-Y) ditempatkan bilangan-bilangan yang sifatnya berubah-ubah, seperti harga, biaya jumlah, dan jumlah.
4. Diagram lingkaran
Diagram lingkaran adalah diagram data berupa lingkaran yang telah dibagi menjadi juring-juring sesuai dengan data tersebut. Bagian-bagian dari keseluruhan data tersebut dinyatakan dalam persen.
Contoh: Peringkat Mata Pelajaran yang Disukai Siswa di Sekolah T Tahun 2010 Jenis Mata Pelajaran Banyaknya Siswa
Kesenian Bahasa Indonesia Ekonomi Bahasa Inggris Matematika 65 34 12 10 9 65 34 13 10 9 0 10 20 30 40 50 60 70
Peringkat Mata Pelajaran yang Disukai Siswa di Sekolah T Tahun 2010
Untuk mencari besar sudut tiap-tiap juring atau %, caranya sebagai beikut. 1. sudut untuk pelajaran kesenian
0 0 180 360 130 65 = 100% 50% 130 65
2. sudut untuk pelajaran bahasa indonesia 0 0 154 , 94 360 130 34 = 100% 26,154% 130 34
3. sudut untuk pelajaran ekonomi 0 0 231 , 33 360 130 12 = 100% 9,231% 130 12
4. sudut untuk pelajaran bahasa inggris 0 0 692 , 27 360 130 10 = 100% 7,692% 130 10
5. sudut untuk pelajaran matematika 0 0 923 , 24 360 130 9 = 100% 6,923% 130 9 50% 26% 9% 8% 7%
Peringkat Mata Pelajaran yang Disukai
Siswa di Sekolah T tahun 2010
Kesenian
Bahasa Indonesia Ekonomi
Bahasa Inggris Matematika
5. Kartogram
Kartogram atau peta statistik adalah diagram data berupa peta yang menunjukkan kepadatan penduduk, curah hujan, hasil pertanian, hasil pertambangan dsb. Contoh :
TABEL PEMASARAN TELEVISI PERUSAHAAN “X”, SEMESTER I, 1990 Daerah Pemasaran Jumlah
Semarang Yogyakarta Purwokerto Tegal Pati Surakarta 500.000 400.000 300.000 300.000 200.000 350.000
Dalam bentuk kartogram peta statistik tersebut digambarkan sebagai berikut. PETA PEMASARAN TELEVISI PERUSAHAAN “X”, SEMESTER I, 1990
6. Diagram Pencar
Diagram pencar untuk kumpulan data yang terdiri atas dua variable dengan nilai kuantitatif, diagramnya dapat dibuat dalam system sumbu koordinat dan gambarnya akan merupakan kumpulan titik-titik yang terpencar.
0 20 40 60 80 0 1 2 3 4 5 6
Peringkat Mata Pelajaran yang Disukai Siswa di Sekolah T Tahun 2010
BAB 2
DISTRIBUSI FREKUENSI DAN GRAFIKNYA
1. Pengertian Distribusi Frekuensi
Distribusi Frekuensi adalah susunan data menurut kelas-kelas interval tertentu atau menurut kategori tertentu dalam sebuah daftar. Jadi, distribusi frekuensi dapat diartikan pengelompokan data ke dalam beberapa kategori/ kelas yang menunjukkan banyaknya data dalam setiap kategori/ kelas, dan setiap data tidak dapat dimasukkan ke dalam dua atau lebih kategori/ kelas.
Tujuan pengelompokan data ke dalam distribusi frekuensi adalah :
1. untuk memudahkan dalam penyajian data, mudah dipahami dan dibaca sebagai bahan informasi,
2. memudahkan dalam menganalisa/menghitung data, membuat tabel, dan grafik.
2. Langkah-langkah Distribusi Frekuensi: a. Mengumpulkan data,
b. Mengurutkan data dari terkecil ke terbesar atau sebaliknya, c. Membuat kategori kelas
Jumlah kelas k = 1 + 3,3 log n, k bulat
di mana 2k > n; di mana k = jumlah kelas; n = jumlah data, d. Membuat interval kelas,
Interval kelas = (nilai tertinggi – nilai terendah)/ jumlah kelas e. Melakukan penghitungan atau penturuskan setiap kelasnya.
Contoh:
Dari hasil nilai ujian matematika 40 siswa, diperoleh data sebagai berikut.
78 72 74 79 74 71 75 74 72 68
72 73 72 74 75 74 73 74 65 72
66 75 80 69 82 73 74 72 79 71
Penyelesaian: a. Urutan data 65 66 67 68 69 70 70 70 70 71 71 71 72 72 72 72 72 72 73 73 73 74 74 74 74 74 74 74 75 75 75 75 75 76 77 78 79 79 80 82
b. Membuat kategori kelas (k) adalah = 1 + 3,3 log 40 = 1 + 5,3 = 6,3 = 6 c. Membuat interval kelas
( ) = − ℎ ℎ = 82 − 65 6 = = 2,8 = 3 d. Tabelnya
Nilai Turus Frekuensi
65 – 67 68 – 70 71 – 73 74 – 76 77 – 79 80 – 82 III IIII I IIII IIII II IIII IIII III
IIII II 3 6 12 13 4 2 Jumlah 40
3. Histogram, Poligon Frekuensi dan Kurva 3.1. Histogram dan Poligon Frekuensi
Histogram dan poligon frekuensi adalah dua grafik yang sering digunakan untuk menggambarkan distribusi frekuensi. Histogram merupakan grafik batang dari distribusi frekuensi dan poligon frekuensi merupakan grafik garisnya.
Contoh:
Distribusi Frekuensi Hasil Pengukuran Tinggi Badan 50 Siswa Interval Kelas
(Tinggi (cm))
Frekuensi
(Banyak Murid) Tepi Interval Kelas Titik Tengah 140 – 144 145 – 149 150 – 154 155 – 159 160 – 164 165 – 169 170 - 174 3 6 12 15 12 7 5 139,5 – 144,5 144,5 – 149,5 149,5 – 154,5 154,5 – 159,5 159,5 – 164,5 164,5 – 169,5 169,5 – 174,5 142 147 152 157 162 167 172 Σ = 60 a. Histogram b. Poligon Frekuensi 0 5 10 15 139,5 144,5 149,5 154,5 159,5 164,5 169,5 b an ya k si sw a (f re ku e n si ) tinggi badan
Histogram tinggi badan 60 siswa
0 2 4 6 8 10 12 14 16 137 142 147 152 157 162 167 172 177 fr e ku e n si tinggi badan Frekuensi
3.2. Kurva Frekuensi
Kurva distribusi frekuensi, disingkat kurva frekuensi yang telah dihaluskan mempunyai berbagai bentuk dengan ciri-ciri tertentu. Bentuk-bentuk kurva frekuensi adalah sebagai berikut.
1. Simetris atau berbentuk lonceng, ciri-cirinya adalah nilai variabel di sampingkiri dan kanan yang berjarak sama terhadap titik tengah (yang frekuensinya terbesar) mempunyai frekuensi yang sama. Bentuk kurva simetris sering dijumpai dalam distribusi bermacam-macam variabel, karena itu dinamakan distribusi normal. 2. Tidak simetris atau condong, ciri-cirinya ialah ekor kurva yang satu lebih panjang
daripada ekor kurva lainnya. Jika ekor kurva lebih panjang berada di sebelah kanan, kurva disebut kurva condong ke kanan (mempunyai condong positif), sebaliknya disebut kurva condong ke kiri (mempunyai condong negatif).
3. Bentuk J atau J terbalik, ciri-cirinya ialah salah satu nilai ujung kurva memiliki frekuensi maksimum.
4. Bentuk U, dengan ciri kedua ujung kurva memiliki frekuensi maksimum. 5. Bimodal, dengan ciri mempunyai dua maksimal.
6. Multimodal, dengan ciri mempunyai lebih dari dua maksimal.
7. Uniform, terjadi bila nilai-nilai variabel dalam suatu interval mempunyai frekuensi yang sama.
4. Jenis-Jenis Distribusi Frekuensi
Distribusi frekuensi dapat dibedakan atas tiga jenis, yaitu distribusi frekuensi biasa, distribusi frekuensi relatif, dan distribusi frekuensi kumulatif.
a. Distribusi Frekuensi Biasa, adalah distribusi frekuensi yang hanya berisikan jumlah frekuensi dari setiap kelompok data atau kelas.
b. Distribusi Frekuensi Relatif, adalah distribusi frekuensi yang berisikan nilai-nilai hasil bagi antara frekuensi kelas dan jumlah pengamatan yang terkandung dalam kumpulan data yang berdistribusi tertentu. Rumusnya:
= × , = , , , …
Misalkan distribusi frekuensi memiliki k buah interval kelas dengan frekuensi masing-masing: , , … , maka distribusi yang terbentuk adalah sebagai berikut.
Interval Kelas Frekuensi Frekuensi Relatif Interval kelas ke-1
Interval kelas ke-2
Interval kelas ke-k
f1 f2 fk Jumlah Σ = Σ = 1
Frekuensi relatif kadang-kadang dinyatakan dalam bentuk perbandingan, desimal atatupun persen.
c. Distribusi Frekuensi Kumulatif
Distribusi frekuensi kumulatif adalah distribusi yang berisikan frekuensi kumulatif. Frekuensi kumulatif adalah frekuensi yang dijumlahkan. Distribusi frekuensi komulatif memiliki grafik atau kurva yang disebut ogif.
Ada dua macam distribusi frekuensi kumulatif, yaitu distribusi frekuensi kumulatif kurang dari dan lebih dari.
a. Distribusi Frekuensi Kumulatif kurang dari, adalah distribusi frekuensi yang memuat jumlah frekuensi yang memiliki nilai kurang dari nilai batas kelas suatu interval tertentu.
b. Distribusi Frekuensi Kumulatif lebih dari, adalah distribusi frekuensi yang memuat jumlah frekuensi yang memiliki nilai lebih dari nilai batas kelas suatu interval tertentu.
Contoh:
Berikut ini adalah data 50 mahasiswa dalam perolehan nilai statistik pada Pendidikan Matematika Universitas “T” semester II tahun 2010!
70 91 93 82 78 70 71 92 38 56
79 49 48 74 81 95 87 80 80 84
35 83 73 74 43 86 68 92 93 76
81 70 74 97 95 80 53 71 77 63
74 73 68 72 85 57 65 93 83 86
a. berapa orang yang mendapat nilai antara 44 – 52 dan 80 – 88 ? b. berapa % orang yang mendapat nilai antara 53 – 61 dan 89 – 97 ? c. berapa banyak orang yang nilainya kurang dari 44 ?
d. berapa banyak orang yang nilainya lebih dari 71 ? Penyelesaian:
Untuk menjawab pernyataan a diperlukan distribusi frekuensi, untuk menjawab pertanyaan b diperlukan distribusi relatif, untuk menjawab pertanyaan c diperlukan distribusi kumulatif kurang dari, dan untuk pertanyaan d diperlukan distribusi kumulatif lebih dari.
a. Tabel Distribusi Frekuensinya adalah sebagai berikut.
Nilai Statistik 50 Mahasiswa pada Pendidikan Matematika Universitas “T” Semester II tahun 2010 Nilai Frekuensi (f) 35 – 43 44 – 52 53 – 61 62 – 70 71 – 79 80 – 88 89 - 97 3 2 3 7 13 13 9 Jumlah 50
b. Tabel distribusi frekuensi relatinya adalah:
Nilai Frekuensi (f) Frekuensi Relatif
Perbandingan Desimal Persen 35 – 43 44 – 52 53 – 61 62 – 70 71 – 79 80 – 88 89 - 97 3 2 3 7 13 13 9 3 50 2 50 3 50 7 50 13 50 13 50 9 50 0,06 0,04 0,06 0,14 0,26 0,26 0,18 6 4 6 14 26 26 18 Jumlah 50 1 1 100
Jadi, mahasiswa yang mendapat nilai antara 53 – 61 adalah 6% dan yang mendapat nilai antara 89 – 97 adalah 18%, cara mencarinya:
53 − 61 = × 100% = 6%. 89 − 97 = × 100% = 18%.
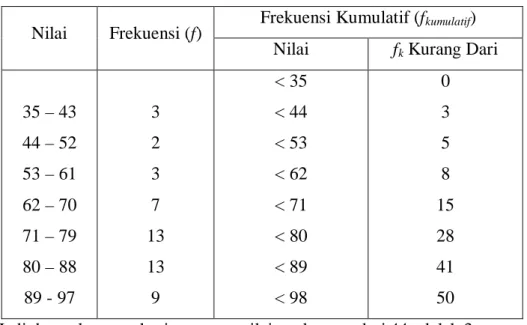
c. Tabel data frekuensi kumulatif untuk data tersebut adalah
Tabel distribusi frekuensi kumulatif Kurang Dari Nilai Frekuensi (f) Frekuensi Kumulatif (fkumulatif)
Nilai fk Kurang Dari
35 – 43 44 – 52 53 – 61 62 – 70 71 – 79 80 – 88 89 - 97 3 2 3 7 13 13 9 < 35 < 44 < 53 < 62 < 71 < 80 < 89 < 98 0 3 5 8 15 28 41 50
Jadi, banyaknya mahasiswa yang nilainya kurang dari 44 adalah 3 orang.
d. Tabel data frekuensi kumulatif untuk data tersebut adalah Tabel distribusi frekuensi kumulatif lebih dari Nilai Frekuensi (f) Frekuensi Kumulatif (fkumulatif)
Nilai fk Lebih Dari
35 – 43 44 – 52 53 – 61 62 – 70 71 – 79 80 – 88 89 - 97 3 2 3 7 13 13 9 > 35 > 44 > 53 > 62 > 71 > 80 > 89 > 98 50 47 44 42 33 20 9 0
e. Ogifnya adalah
Nilai Frekuensi (f)
Frekuensi Kumulatif (fkumulatif)
Nilai fk Kurang Dari Nilai fk Lebih Dari
35 – 43 44 – 52 53 – 61 62 – 70 71 – 79 80 – 88 89 - 97 3 2 3 7 13 13 9 < 35 < 44 < 53 < 62 < 71 < 80 < 89 < 98 0 3 5 8 15 28 41 50 > 35 > 44 > 53 > 62 > 71 > 80 > 89 > 98 50 47 44 42 33 20 9 0 0 10 20 30 40 50 60 0 20 40 60 80 100 120 fk Kurang Dari fk Lebih Dari
BAB 3
UKURAN PEMUSATAN
A. Pengertian Nilai Pusat
Ukuran pemusatan atau nilai pusat adalah ukuran yang dapat mewakili data secara keseluruhan.
B. Jenis-Jenis Ukuran Nilai Pusat 1. Rata-Rata Hitung (Mean)
Mean adalah nilai rata-rata dari data-data yang ada. Rata-rata hitung dari populasi diberi simbol µ dan rata hitung dari sampel diberi simbol . Mencari rata-rata hitung secara umum dapat ditentukan dengan rumus :
a. Untuk data tunggal
Cara menghitung mean untuk data tunggal ialah sebagai berikut.
1. Jika X1, X2, ..., Xn merupakan n buah nilai dari variabel X, maka rata-rata
hitungnya sebagai berikut.
n X X X n X X
1 2 ... nX = rata-rata hitung (mean) X = wakil data
n = jumlah data Contoh :
Hitunglah rata-rata hitung dari nilai-nilai 7, 6, 3, 4, 8, 8? Penyelesaian :
X = 7,6,3,4,8,8; n = 6; ΣX = 7 + 6 + 3 + 4 + 8 + 8 = 36 Sehingga mean adalah : 6
6 36
X
2. Jika nilai X1, X2, ..., Xn masing-masing memiliki frekuensi f1, f2, ..., fn maka mean
adalah, n n n f f f X f X f X f f fX X
... ... 2 1 2 2 1 1Contoh soal :
Hitunglah rata-rata hitung dari nilai-nilai 3, 4, 3, 2, 5, 1, 4, 5, 1, 2, 6, 4, 3, 6, 1? Penyelesaian : X1 = 3 maka f1 = 3; X2 = 4 maka f2 = 3 X3 = 2 maka f3 = 2; X4 = 5 maka f4 = 2 X5 = 1 maka f5 = 3; X6 = 6 maka f6 = 2 ΣfX = (3 x 3) + (4 x 3) + (2 x 2) + (5 x 2) + (1 x 3) + (6 x 2) = 50 Σf = 3 + 3 + 2 + 2 + 3 + 2 = 15
Sehingga mean adalah : 3,3 15 50
X
3. Jika f1 nilai yang memiliki mean m1, f2 nilai yang memiliki mean m2, ... danfk nilai
yang memiliki mean mk. Maka mean dapat dihitung sebagai berikut.
k k k f f f m f m f m f f fm x
... ... 2 1 2 2 1 1b. Untuk data berkelompok
Untuk data berkelompok, mean dihitung dengan menggunakan 3 metode yaitu metode biasa, metode simpangan rata-rata dan metode coding.
1. Metode Biasa
f fX X f = frekuensi X = titik tengah2. Metode simpangan rata-rata
f fd M XM = Rata-rata hitung sementara (titik tengah frekuensi terbesar) f = frekuensi
d = X - M X = titik tengah
3. Metode coding
f fu C M XM = Rata-rata hitung sementara (titik tengah frekuensi terbesar) C = Lebar kelas
u = 0, +1, +2, ….
= , = −
Contoh :
Tentukan rata-rata hitung dari tabel dibawah ini Nilai Ujian Statistik dari 80 mahasiswa universitas Borobudur Tahun 1997
Metode Biasa Metode Simpangan Rata-Rata Metode Coding Nilai Ujian Frekuensi (f) Titik Tengah (X) fX d = X - M fd u = d/C fu 31 - 40 1 35.5 35.5 -40 -40 -4 -4 41 - 50 2 45.5 91 -30 -60 -3 -6 51 - 60 5 55.5 277.5 -20 -100 -2 -10 61 - 70 15 65.5 982.5 -10 -150 -1 -15 71 - 80 25 75.5 1887.5 0 0 0 0 81 - 90 20 85.5 1710 10 200 1 20 91 - 100 12 95.5 1146 20 240 2 24 80 6130 90 9
a. Mean dengan metode biasa 625 , 76 80 6130
f fX Xb. Metode Simpangan Rata-Rata M = 75,5 625 , 76 80 90 5 , 75
f fd M Xc. Metode Coding M = 75,5; C = 10 625 , 76 80 9 10 5 , 75
x f fu x C M X 2. MEDIANMedian adalah nilai tengah dari data yang ada setelah data diurutkan. Median disimbolkan dengan Me atau Md. Untuk Mencari Median dibedakan data tunggal dan data kelompok.
a. Untuk data tunggal - Jika n ganjil maka,
2 1 Xn Me
- Jika n genap maka,
2 2 2 2 n n X X Me Contoh :
Tentukan Median dari data berikut : a. 4, 3, 2, 6, 7, 5, 8 Jawab : Urutan data : 2, 3, 4, 5, 6, 7, 8 n = 7 (ganjil) maka 4 5 2 1 7 X X Me b. 11, 5, 7, 4, 8, 14, 9, 15 Urutkan data : 4, 5, 7, 8, 9, 11, 12, 14 n = 8 (genap) maka 8,5 2 9 8 2 2 5 4 2 2 8 2 8 X X X X Me
b. Untuk data berkelompok f F n p b Me 2 1 Me = Median
b = batas bawah kelas median, ialah kelas dimana median akan terletak. p = panjang interval kelas
n = banyak data
F = Jumlah frekuensi sebelum kelas-kelas median f = frekuensi kelas median
Contoh :
Tentukan median dari Tabel Nilai Ujian Statistik dari 80 mahasiswa universitas Borobudur Tahun 1997 Nilai Ujian Frekuensi (f) Titik Tengah (X) 31 - 40 1 35.5 41 - 50 2 45.5 51 - 60 5 55.5 61 - 70 15 65.5 71 - 80 25 75.5 81 - 90 20 85.5 91 - 100 12 95.5 80 Penyelesaian : n = 80 maka (80) 40 2 1 2 1
n berarti terletak di kelas ke-5
b = 70,5; F = 1 + 2 + 5 + 15 = 23; f = 25
sehingga median dari data diatas adalah 77,3
25 23 ) 80 ( 2 1 10 5 , 70 Me
3. MODUS
Modus adalah nilai yang paling sering muncul. Modus sering disimbolkan dengan Mo. Sejumlah data bisa tidak mempunyai modus, mempunyai satu modus (unimodal), mempunyai dua modus (bimodal), atau mempunyai lebih dari dua modus (multimodal). Untuk Mencari modus dibedakan data tunggal dan data kelompok.
a. Untuk data tunggal
Modus dari data tunggal adalah data yang frekuensi terbanyak. b. Untuk data berkelompok
2 1 1 b b b p b Mo Dimana : Mo = modus
b = tepi bawah kelas modus
b1 = selisih frekuensi kelas modus dengan kelas sebelumnya
b2 = selisih frekuensi kelas modus dengan kelas sesudahnya
p = panjang interval kelas Contoh :
Tentukan modus dari Tabel Nilai Ujian Statistik dari 80 mahasiswa universitas Borobudur Tahun 1997
Nilai Ujian Frekuensi (f) Titik Tengah (X)
31 - 40 1 35.5 41 - 50 2 45.5 51 - 60 5 55.5 61 - 70 15 65.5 71 - 80 25 75.5 81 - 90 20 85.5 91 - 100 12 95.5 80 Penyelesaian :
Dari tabel diketahui bahwa kelas modus adalah kelas ke-5
b = 70,5; P = 10; b1 = 25-15 = 10; b2 = 25-20 = 5 sehingga, 77,17 5 10 10 10 5 , 70 2 1 1 b b b p b Mo
C. RATA-RATA UKUR (RATA-RATA GEOMETRIS)
Jika perbandingan setiap dua data berurut adalah tetap atau hampir tetap maka rata-rata ukur lebih baik digunakan daripada rata-rata hitung. Rata-rata ukur ada 2 yaitu untuk data tunggal dan data kelompok.
a. Untuk data tunggal
Jika seperangkat data adalah X1, X2, X3, ..., Xn maka rata-rata ukurnya dirumuskan.
n n X X X X G 1. 2. 3.... atau
X X X Xn
nG 1 log log log ... log
log 1 2 3
Contoh :
Tentukan rata-rata ukur dari 2, 4, 8, 16, 32 Penyelesaian : n = 5 8 32768 32 16 8 4 2 5 5 x x x x G Atau
8 903 , 0 log 32 log 16 log 8 log 4 log 2 log 5 1 log G G Gb. Untuk data berkelompok
Untuk data berkelompok maka rata-rata ukur dapat dihitung dengan :
f X f G .log log Contoh :Tentukan rata-rata ukur dari Tabel Nilai Ujian Statistik dari 80 mahasiswa universitas Borobudur Tahun 1997
Nilai Ujian Frekuensi (f) Titik Tengah (X) Log X f.Log X 31 - 40 1 35.5 1.5502 1.5502 41 - 50 2 45.5 1.6580 3.3160 51 - 60 5 55.5 1.7443 8.7215 61 - 70 15 65.5 1.8162 27.2436 71 - 80 25 75.5 1.8779 46.9487 81 - 90 20 85.5 1.9320 38.6393 91 - 100 12 95.5 1.9800 23.7600 80 150.1794
37 , 75 8772 , 1 80 1794 , 150 log . log
G f X f GSehingga rata-rata ukur adalah 75,37
c. Rata-rata ukur untuk gejala pertumbuhan atau kenaikan
Rata-rata ukur untuk gejala pertumbuhan atau kenaikan dengan syarat-syarat tertentu, seperti pertumbuhan bakteri, pertumbuhan penduduk, kenaikan bunga dapat dihitung dengan rumus :
t o t X P P 100 1 Keterangan :
Pt = keadaan akhir pertumbuhan
Po = keadaan awal atau permulaan pertumbuhan
X = Rata-rata pertumbuhan setiap waktu t = satuan waktu yang digunakan Contoh Soal :
Tentukan laju pertumbuhan rata-rata penduduk Indonesia jika pada akhir tahun 1946 dan akhir tahun 1956 jumlah penduduk masing-masing 60 juta dan 78 juta ? Penyelesaian :
Pt = 78 Juta
t = 10 tahun
66 , 2 0266 , 1 100 1 3 , 1 100 1 3 , 1 100 1 100 1 60 78 100 1 10 1 10 10 X X X X X X P P t o t D. RATA-RATA HARMONISa. Rata-rata harmonis untuk data tunggal
Rata-rata harmonis dari seperangkat data X1, X2, X3, ..., Xn dirumuskan :
n X X X X n X n RH 1 ... 1 1 1 1 3 2 1
Contoh soal :Si B berepgian pergi-pulang ke kampus dengan kendaraan mobil. Waktu pergi ia menggunakan waktu 40 km/jam, sedang waktu kembali menggunakan waktu 30 km/jam. Berapa kecepatan rata-rata pergi pulang si B?
Penyelesaian : jam km RH 32,3 / 30 1 40 1 2
b. Rata-rata harmonis untuk data berkelompok
Untuk data berkelompok, rata-rata harmonis dapat dihitung dengan rumus :
X f f RHAntara ketiga rata-rata dalam ukuran nilai pusat, yaitu rata-rata hitung, rata-rata ukur dan rata-rata harmonis terdapat hubungan : RH G X
Contoh :
Tentukan rata-rata harmonis dari Tabel Nilai Ujian Statistik dari 80 mahasiswa universitas Borobudur! Nilai Ujian Frekuensi (f) Titik Tengah (X) 31 - 40 1 35.5 0.0282 41 - 50 2 45.5 0.0440 51 - 60 5 55.5 0.0901 61 - 70 15 65.5 0.2290 71 - 80 25 75.5 0.3311 81 - 90 20 85.5 0.2339 91 - 100 12 95.5 0.1257 80 1.0819 Penyelesaian : 94 , 73 0819 , 1 80
X f f RHBAB 4
UKURAN PENYEBARAN (FRAKTIL)
1. Pengertian Fraktil
Fraktil adalah nilai-nilai yang membagi seperangkat data yang telah terurut menjadi beberapa bagian yang sama. Fraktil dapat berupa kuartil, desil dan persentil. a. Kuartil
Kuartil adalah nilai-nilai yang membagi seperangkat data yang telah terurut menjadi empat bagian yang sama. Ada 3 kuartil yaitu kuartil bawah (Q1), kuartil tengah
(Q2), dan kuartil atas (Q3).
a. Untuk data tunggal
Q = nilai yang kei(n + 1)
4 , i = 1, 2, 3
Contoh :
Tentukan kuartil dari data : 2, 6, 8, 5, 4, 9, 12 Penyelesaian : Data diurutkan : 2, 4, 5, 6, 8, 9, 12 n = 7
4 , 2 4 1 7 1 1 yaitu Q
4, 6 4 1 7 2 2 yaitu Q
9 , 6 4 1 7 3 3 yaitu Q b. Untuk data berkelompok
= + 4 − (Σ ) ∙ C Keterangan:
Bi = tepi bawah kelas kuartil n = jumlah semua frekuensi
i = 1, 2, 3 = frekuensi kelas kuartil (Σ ) = jumlah frekuensi semua kelas sebelum kelas kuartil
Contoh :
Tentukan kuartil ke-3 dari Tabel Nilai Ujian Statistik dari 80 mahasiswa Universitas T Tahun 2010 Nilai Ujian Frekuensi (f) Titik Tengah (X) 31 - 40 1 35.5 41 - 50 2 45.5 51 - 60 5 55.5 61 - 70 15 65.5 71 - 80 25 75.5 81 - 90 20 85.5 91 - 100 12 95.5 Penyelesaian : n = 80; i = 3, maka
60 4 80 3 4 interletak di kelas ke-6
Bi = 80,5; C = 10; = 20; (Σ ) = 1+2+5+15+25 = 48
= + 4 − (Σ ) ∙ C
= + 4 − (Σ ) ∙ C = 80,5 +60 − 48
20 ∙ 10 = 80,5 + 6 = 86,5
b. DESIL
Desil adalah nilai-nilai yang membagi seperangkat data yang telah terurut menjadi sepuluh bagian yang sama.
1. Untuk data tunggal
9 ,..., 3 , 2 , 1 ; 10 1 i n i Di2. Untuk data berkelompok
Contoh:
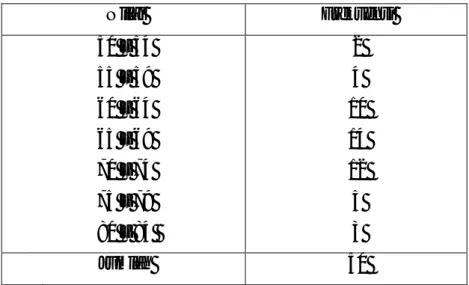
Tentukan desil ke-4 (D4) dan desil ke-8 (D8) dari distribusi frekuensi berikut.
Nilai Matematika 40 Mahasiswa Universitas T Tahun 2010 Nilai Frekuensi (f) 30 – 39 40 – 49 50 – 59 60 – 69 70 – 79 80 – 89 90 – 99 5 3 6 7 8 7 4 Jumlah 40 Penyelesaian:
Untuk desil ke-4 (D4)
n = 40; i = 4, maka
16 10 40 4 10 interletak di kelas ke-4 B4 = 59,5; C = 10; = 7; (Σ ) = 5 + 3 + 6 = 14
= + 10− (Σ ) ∙ C = 59,5 +16 − 14
7 ∙ 10 = 59,5 + 2,86 = 62,36 Untuk desil ke-8 (D8)
n = 40; i = 8, maka
32 10 40 8 10 interletak di kelas ke-6
B8 = 79,5; C = 10; = 7; (Σ ) = 5 + 3 + 6 + 7 + 8 = 29
= + 10− (Σ ) ∙ C = 79,5 +32 − 29
7 ∙ 10 = 79,5 + 4,29 = 83,79
c. PERSENTIL
Persentil adalah nilai-nilai yang membagi seperangkat data yang telah terurut menjadi seratus bagian yang sama.
1. Untuk data tunggal
99 ,..., 3 , 2 , 1 ; 100 1 i n i Pi2. Untuk data berkelompok
= + 100− (Σ ) ∙ C Contoh:
Dari distribusi frekuensi di bawah ini, tentukan P88!
Tinggi 100 Mahasiswa Universitas Borobudur Tinggi (cm) Frekuensi (f) 150 – 154 155 – 159 160 – 164 165 – 169 170 – 174 175 - 179 4 8 14 35 27 12 Jumlah 100 Penyelesaian: n = 100; i = 88, maka
88 100 100 88 100 interletak di kelas ke-5 B88 = 169,5; C = 5; = 27; (Σ ) = 4 + 8 + 14 + 35 = 61
= + 100− (Σ ) ∙ C = 169,5 +88 − 61
BAB 5
UKURAN DISPERSI A. PENGERTIAN DISPERSI
Ukuran dispersi atau ukuran variasi atau ukuran penyimpangan adalah ukuran yang menyatakan seberapa jauh penyimpangan nilai-nilai data dari nilai-nilai pusatnya atau ukuran yang menyatakan seberapa banyak nilai-nilai data yang berbeda dengan nilai-nilai pusatnya.
B. JENIS-JENIS UKURAN DISPERSI 1. Jangkauan (Range, R)
Jangkauan atau ukuran jarak adalah selisih nilai terbesar data dengan nilai terkecil data. Cara mencari jangkauan dibedakan antara data tunggal dan data berkelompok.
a. Jangkauan Data Tunggal
Bila ada sekumpulan data tunggal, X1, X2, ..., Xn maka jangkauannya adalah:
Jangkauan = Xn – X1
Contoh:
Tentukan jangkauan data: 2, 6, 8, 5, 4, 12, 9 Penyelesaian:
Data diurutkan: 2, 4, 5, 6, 8, 9, 12 X7 = 12 dan X1 = 2
Jangkauan = X7 – X1 = 12 – 2 = 10
b. Jangkauan Data Berkelompok
Dapat ditentukan dengan dua cara:
1) Jangkauan adalah selisih titik tengah kelas tertinggi dengan titik tengah kelas terendah.
Contoh:
Tentukan jangkauan dari distribusi frekuensi berikut! Tabel Nilai Matematika 50 Siswa
Nilai Frekuensi 50 – 54 55 – 59 60 – 64 65 – 69 70 – 74 75 – 79 80 – 84 2 4 10 14 12 5 3 Jumlah 50 Penyelesaian:
Titik tengah kelas terendah = 52 Titik tengah kelas tertinggi = 82 Tepi bawah kelas terendah = 49,5 Tepi atas kelas tertinggi = 84,5 1. Jangkauan = 82 – 52 = 30
2. Jangkauan = 84,5 – 49,5 = 35
2. Jangkauan Antarkuartil dan Jangkauan Semi Interkuartil
Jangkauan antarkuartil adalah selisih antar kuartil atas (Q3) dan kuatil bawah
(Q1). Dirumuskan: JK = Q3 – Q1
Jangkauan semi interkuartil adalah setengah dari selisih kuartil atas (Q3) dan
kuatil bawah (Q1). Dirumuskan: = ( − )
Rumus-rumus di atas berlaku untuk data tunggal dan data berkelompok. Contoh Soal:
1. Tentukan jangkauan antarkuartil dan jangkauan semi interkuartil dari data berikut! 2, 4, 6, 8, 10, 12, 14
Penyelesaian:
Q1 = 4 dan Q3 = 12, JK = Q3 – Q1 = 12 – 4 = 8
2. Tentukan jangkauan antarkuartil dan jangkauan semi interkuatil distribusi frekuensi berikut. NILAI UJIAN STATISTIK 80 MAHASISWA
Nilai Ujian Frekuensi (f) 30 – 39 40 – 49 50 – 59 60 – 69 70 – 79 80 – 89 90 – 99 2 3 5 14 24 20 12 Jumlah 80 Penyelesaian: JK = 85,5 – 66,64 = 18,86 dan
85,5 66,64
9,43 2 1 Qd .Jangkauan antarkuartil (JK) dapat digunakan untuk menemukan data pencilan, yaitu data yang dianggap salah atau salah ukur atau berasal dari kasus yang menyimpang, karena itu perlu diteliti ulang. Data pencilan adalah data yang kurang dari pagar luar. L = 1,5 x JK PD = Q1 – L PL = Q3 + L Keterangan: L = satu langkah PD = pagar dalam PL = pagar luar C fQ f n B Q
1 1 1 1 ) ( 4 10 14 10 4 80 5 , 59 1 Q 64 , 66 14 , 7 5 , 59 1 Q C fQ f n B Q
3 3 3 3 ) ( 4 3 10 20 48 4 ) 80 ( 3 5 , 79 3 Q 5 , 85 6 5 , 79 3 QContoh soal:
Selidikilah apakah terdapat data pencilan dari data dibawah ini! 15, 33, 42, 50, 51, 51, 53, 55, 62, 64, 65, 68, 79, 85, 97. Penyelesaian: Q1 = 50 dan Q3 = 68 JK = 68 – 50 = 18 L = 1,5 x 18 = 27 PD = 50 – 27 = 23 PL = 68 + 27 = 95
Pada data di atas terdapat nilai 15 dan 97 yang berarti kurang dari pagar dalam (23) atau lebih dari pagar luar (95). Dengan demikian, nilai 15 dan 97 termasuk data pencilan, karena itu perlu diteliti ulang. Adanya nilai 15 dan 97 mungkin disebabkan salah dalam mencatat, salah dalam mengukur, atau data dari kasus menyimpang.
3. Deviasi Rata-Rata (Simpangan Rata-Rata)
Deviasi rata-rata adalah nilai rata-rata hitung dari harga mutlak simpangan-simpangannya.
a. Deviasi rata-rata data tunggal
Contoh soal : Tentukan deviasi rata-rata data 2, 3, 6, 8, 11! Penyelesaian: Rata-rata hitung = 6 5 11 8 6 3 2 X 14 6 11 6 8 6 6 6 3 6 2
Xi X 8 , 2 5 14
n X X DR ib. Deviasi rata-rata untuk data berkelompok
n X X f X X f n DR
1 n X X X X n DR
14. Varians
Varians adalah nilai tengah kuadrat simpangan dari nilai simpangan rata-rata kuadrat. Varians sampel disimbolkan dengan s2. Varians populasi disimbolkan dengan σ2(sigma).
a. Varians data tunggal
Dapat digunakan dengan dua metode, yaitu metode biasa dan metode angka kasar.
1. Metode Biasa
a. Untuk sampel besar (n > 30) :
b. Untuk sampel kecil (n 30):
2. Metode Angka Kasar
a. Untuk sampel besar (n > 30) :
b. Untuk sampel kecil (n 30):
Contoh Soal:
Tentukan varians dari data 2, 3, 6, 8, 11 ? Penyelesaian: n = 5
n 2 s2
1 2 s2 n 2 2 s2 n X n X
) 1 ( 2 1 2 s2 n n n X 6 5 11 8 6 3 2 XX X X
X X
2 X2 2 3 6 8 11 -4 -3 0 2 5 16 9 0 4 25 4 9 36 64 121 30 54 234b. Varians data berkelompok
Untuk data berkelompok, dapat digunakan dengan tiga metode, yaitu : 1) Metode biasa,
a. Untuk sampel besar (n > 30) :
b. Untuk sampel kecil (n 30):
2) Metode angka kasar, dan
a. Untuk sampel besar (n > 30) :
b. Untuk sampel kecil (n 30):
3) Metode coding.
a. Untuk sampel besar (n > 30) : 2 2 2 2
n fu n fu C sb. Untuk sampel kecil (n 30):
n f 2 s2
1 2 s2 n f 2 2 2 s n fX n fX
1
2 2 2 s n n fX n fX
5 , 13 1 5 54 1 2 s2 n
5 1
13,5 5 2 30 1 5 234 ) 1 ( 2 1 2 s2 n n n
1
1 2 2 2 2
n n fu n fu C s Keterangan:C = panjang interval kelas
u = C M X C d
M = rata-rata hitung sementara Contoh:
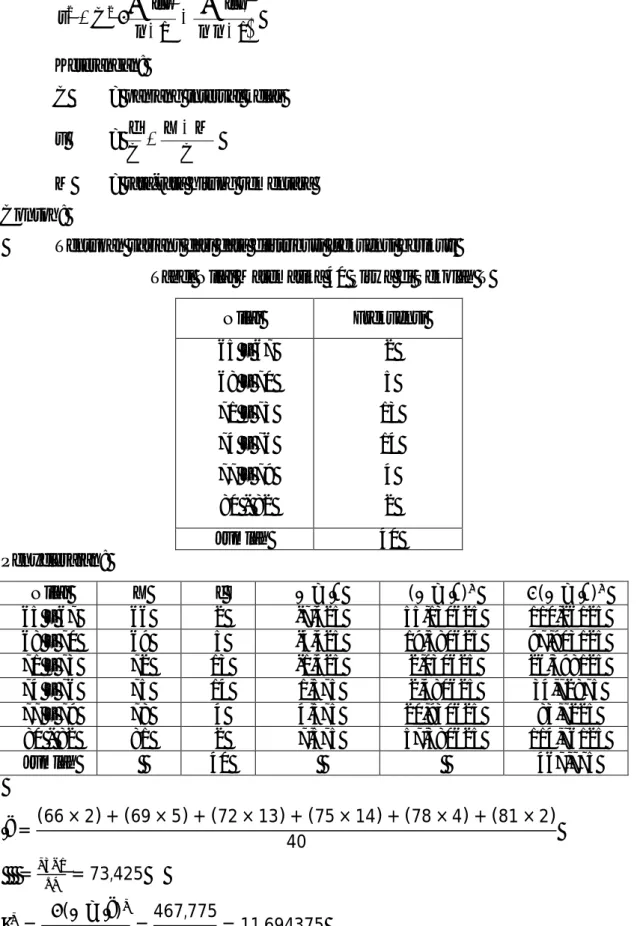
Tentukan varians dari data diistribusi frekuensi berikut! Tabel Nilai Matematika 40 Siswa di Sekolah T
Nilai Frekuensi 65 – 67 68 – 70 71 – 73 74 – 76 77 – 79 80 - 82 2 5 13 14 4 2 Jumlah 40 Penyelesaian: Nilai X f − ( − ) ( − ) 65 – 67 66 2 -7,425 55,130625 110,26125 68 – 70 69 5 -4,425 19,580625 97,903125 71 – 73 72 13 -1,425 2,030625 26,398125 74 – 76 75 14 1,575 2,480625 34,72875 77 – 79 78 4 4,575 20,930625 83,7225 80 - 82 81 2 7,575 57,380625 114,76125 Jumlah 40 467,775 = (66 × 2) + (69 × 5) + (72 × 13) + (75 × 14) + (78 × 4) + (81 × 2) 40 = = 73,425 =Σ ( − ) =467,775 40 = 11,694375
5. Simpangan Baku (Standar Deviasi)
Simpangan baku adalah akar dari tengah kuadrat. Simpangan Baku sampel disimbolkan dengan s. Simpangan Baku populasi disimbolkan dengan σ.
Menentukan simpangan baku : s varians a. Simpangan Baku Data Tunggal
1. Metode biasa
a. Untuk sampel besar (n > 30) :
b. Untuk sampel kecil (n 30):
3. Metode angka kasar
a. Untuk sampel besar (n > 30) : 2 2
n X n X sb. Untuk sampel kecil (n 30):
1
1 2 2
n n X n X s Contoh Soal:1. Tentukan simpangan baku (standar deviasi) dari data 2, 3, 6, 8, 11 ? Penyelesaian:
Dari perhitungan sebelumnya, diperoleh s2 = 13,5 Simpangan bakunya adalah:
67 , 3 5 , 13 var ians s .
2. Berikut ini adalah sampel nilai mid test statistik I dari sekelompok mahasisiwa di sebuah universitas.
30 35 42 50 58 66 74 82 90 98
Tentukan simpangan bakunya! Penyelesaian: n = 10
n 2 s
1 2 s nX X X
2 X X X 2 30 35 42 50 58 66 74 82 90 98 -32,5 -27,5 -20,5 -12,5 -4,5 3,5 11,5 19,5 27,5 35,5 1056,25 756,25 420,25 156,25 20,25 12,25 132,25 380,25 756,25 1260,25 900 1225 1764 2500 3364 4356 5476 6724 8100 9604 625
X 62,5 4950,5 44013
10 1
4890,33 4340,28 23,45 10 625 1 10 44013 1 1 2 2 2
n n X n X sb. Simpangan baku Data Berkelompok 1. Metode biasa
a. Untuk sampel besar (n > 30) :
b. Untuk sampel kecil (n 30):
2. Metode angka kasar
a. Untuk sampel besar (n > 30) :
n f 2 s
1 2 s n f 2 2 s n fX n fX
45 , 23 056 , 550 1 10 5 , 4905 1 2 s nb. Untuk sampel kecil (n 30):
3. Metode coding
a. Untuk sampel besar (n > 30) : 2 2
n fu n fu C sb. Untuk sampel kecil (n 30):
1
1 2 2
n n fu n fu C s Contoh:Tentukan simpangan baku dari distribusi frekuensi berikut (gunakan ketiga rumuusnya)! Penyelesaian:
Berat Badan 100 Mahasiswa Universitas T tahun 2010 Berat Badan (kg) Frekuensi (f)
40 – 44 45 – 49 50 – 54 55 – 59 60 – 64 65 – 69 70 - 74 8 12 19 31 20 6 4 Jumlah 100 Penyelesaian:
a. Dengan metode Biasa
Nilai X f fX − ( − ) ( − ) 40 – 44 42 8 336 -13,85 191,8225 1534,58
1
2 1 2 s n n fX n fX45 – 49 47 12 564 -8,85 78,3225 939,87 50 – 54 52 19 988 -3,85 14,8225 281,6275 55 – 59 57 31 1767 1,15 1,3225 40,9975 60 – 64 62 20 1240 6,15 37,8225 756,45 65 – 69 67 6 402 11,15 124,3225 745,935 70 - 74 72 4 288 16,15 260,8225 1043,29 Jumlah 100 5585 5342,75 = Σ Σ = 5585 100 = 55,85 = Σ ( − ) = 5342,75 100 = 7,31
b. Metode Angka Kasar
Nilai X f fX X2 fX2 40 – 44 42 8 336 1.764 14.112 45 – 49 47 12 564 2.209 26.508 50 – 54 52 19 988 2.704 51.376 55 – 59 57 31 1.767 3.249 100.719 60 – 64 62 20 1.240 3.844 76.880 65 – 69 67 6 402 4.489 26.934 70 - 74 72 4 288 5.184 20.736 Jumlah 100 5.585 317.265 = Σ − Σ = 317.265 100 − 5.585 100 = 7,31 c. Metode Coding Nilai X f u u2 fu fu2 40 – 44 42 8 -3 9 -24 72 45 – 49 47 12 -2 4 -24 48
50 – 54 52 19 -1 1 -19 19 55 – 59 57 31 0 0 0 0 60 – 64 62 20 1 1 20 20 65 – 69 67 6 2 4 12 24 70 - 74 72 4 3 9 12 36 Jumlah 100 -23 219 c = 5; = c ∙ Σ − Σ = 5 ∙ 219 100− −23 100 = 7,31 C. KOEFISIEN VARIASI
Koefisien dispersi atau variasi yang telah dibahas sebelumnya merupakan dispersi absolut, seperti jangkauan, simpangan rata-rata, simpangan kuartil dan simpangan baku. Untuk membandingkan dispersi atau variasi dari beberapa kumpulan data, digunakan istilah dispersi relatif, yaitu perbandingan antara dispersi absolut dan rata-ratanya.
Dispersi relatif digunakan untuk membandingkan tingkat variabilitas nilai-nilai observasi suatu data dengan tingkat variabilitas nilai-nilai observasi data lainnya. Koefisien variasi adalah contoh dispersi relatif.
Ada empat macam dispersi relatif, yaitu : 1. Koefisien Variasi (KV)
Jika dispersi absolut digantikan dengan simpangan bakunya maka dispersi relatifnya disebut koefisien variasi (KV).
% 100 X s KV Keterangan: KV = koefisien variasi s = simpangan baku X = rata-rata Contoh Soal:
Dari hasil penelitian 2 sekolah, diketahui jumlah siswa yang menyukai belajar matematika, datanya sebagai berikut.
Sekolah B = XB 785anak, sB 5
Tentukan Koefisien variasi masing-masing! Penyelesaian: % 53 , 1 % 100 980 15 % 100 A A A X s KV % 636 , 0 % 100 785 5 % 100 B B B X s KV 2. Variasi Jangkauan (VR)
Variasi jangkauan adalah dispersi relatif yang dispersi absolutnya digantikan dengan jangkauan. % 100 X R VR 3. Variasi Simpangan Rata-Rata (VSR)
Variasi Simpangan Rata-Rata adalah dispersi relatif yang dispersi absolutnya digantikan dengan simpangan rata-rata.
% 100 X SR VR 4. Variasi Kuartil (VQ)
Variasi Kuartil adalah dispersi relatif yang dispersi absolutnya digantikan dengan kuartil. % 100 % 100 1 3 1 3 Q Q Q Q VQ Me Qd VQ
DISPERSI ABSOLUT digunakan untuk mengetahui tingkat variabilitas nilai-nilai observasi pada suatu data, sedangkan DISPERSI RELATIF digunakan untuk membandingkan tingkat variabilitas nilai-nilai observasi suatu data dengan tingkat variabilitas nilai-nilai observasi data lainnya.
DAFTAR PUSTAKA
Hasan, Iqbal. 2006. Analisis Data Penelitian dengan Statistik. Jakarta: Bumi Aksara. Irianto, Agus. 2008. Statistik Konsep Dasar dan Aplikasinya. Jakarta: Kencana.
Pusat Pembina dan Pengembangan Bahasa. 1998. Kamus Besar Bahasa Indonesia Edisi ke 2. Jakarta: Balai Pustaka.