commit to user
CLUSTERING SUMBER-SUMBER EMISI DI SURAKARTA MENGGUNAKAN SINGLE LINKAGE
Hartono, Isnandar Slamet, dan Yuliana Susanti
Program Studi Matematika Fakultas Matematika dan Ilmu pengetahuan Alam Universitas Sebelas Maret Surakarta
Abstrak. Diantara penyebab polusi udara adalah adanya emisi gas buang, yaitu jumlah polutan yang dikeluarkan ke udara dalam satuan waktu. Emisi gas buang terjadi akibat pembakaran yang tidak sempurna, yaitu lepasnya partikel-partikel karena kurang tercu-kupi oksigen dalam proses pembakaran. Perkembangan kota Surakarta yang cukup pesat berpotensi untuk menghasilkan emisi gas buang. Clustering adalah metode untuk klasi-fikasi objek-objek tertentu menjadi kelompok yang lebih kecil berdasarkan karakteristik yang dimilikinya. Tujuan dari penelitian ini, melakukan clustering kategori sumber emisi di Surakarta menggunakan metode hirarki single linkage. Hasil penelitian menunjukkan terdapat tiga cluster penghasil emisi gas buang yaitu cluster pertama adalah bank, seko-lah, restoran, SPBU, perguruan tinggi, perkantoran, mart & sejenisnya, pasar, bengkel, konstruksi, pergudangan, zonasi parkir, menara pemancar, dan parkir dalam area yang digolongkan menjadi kelompok dengan nilai emisi rendah. Cluster kedua yaitu pedagang kaki lima sebagai kelompok dengan nilai emisi yang sedang. Cluster ketiga yaitu peru-mahan yang merupakan kelompok dengan nilai emisi tinggi.
Kata kunci: clustering, emisi gas buang, single linkage
1. Pendahuluan
Udara merupakan unsur penting yang mendukung kehidupan manusia (Ismiya-ti dkk. [4]). Udara dibutuhkan manusia dalam pernapasan terutama oksigen (O2).
Polusi udara yang beredar tinggi di lingkungan sekitar dapat mengurangi kesehatan dan daya tahan tubuh. Jika tubuh rentan terhadap penyakit, lama-kelamaan po-lusi udara tersebut dapat menimbulkan penyakit atau gangguan pernapasan. Oleh karena itu, polusi udara perlu diwaspadai.
Polusi udara di beberapa kota di Indonesia semakin meningkat, terutama di daerah dengan kepadatan lalu lintas yang tinggi. Salah satu sumber polusi udara adalah adanya emisi gas buang. Udara di kota telah tersebar gas-gas yang berbaha-ya bagi kesehatan manusia seperti carbon dioxide (CO2). Menurut laporan World
Resources Institute (W RI) sebagaimana dilansir Daily Mail [6], Indonesia menjadi
negara penghasil emisi CO2 terbesar keenam di dunia dengan total emisi CO2
se-besar 2,05 miliar ton. Hal ini menunjukkan bahwa ada indikasi tingkat polusi udara di Indonesia cukup tinggi dan perlu penanganan lebih lanjut.
Kota Surakarta berpotensi untuk menghasilkan emisi gas buang. Emisi gas bu-ang ini akan semakin meningkat seiring perkembbu-angan transportasi (Ismiyati dkk. [4]). Hasil tes emisi yang dilakukan tim gabungan dari BLH Provinsi, BLH Sura-karta, Dishubkom-info SuraSura-karta, Polresta Surakarta dan DKP Surakarta diperoleh
commit to user
informasi bahwa banyak jenis mobil produksi baru yang memiliki gas emisi buang melebihi ambang batas yang ditentukan oleh pemerintah (Dishubkominfo Surakarta [3]). Terdapat beberapa kategori sumber yang berpotensi sebagai penghasil emisi gas buang. Berdasarkan Billionet et al. [2] dan Ismiyati dkk. [4], berbagai jenis gas buang antara lain CO2, carbon monoxide (CO), non-methane volatile organic
com-pounds (N M V OC), particulate matter (P M 10), nitrogen oxide (N Ox), dan sulfur
oxide (SOx). Setiap gas tersebut merupakan gas beracun yang dapat membuat
sistem pernapasan manusia terganggu.
Analisis multivariat merupakan salah satu metode statistika yang cocok untuk mengolah data dengan banyak variabel (Rencher [9]). Analisis cluster merupakan metode dalam analisis multivariat, yaitu clustering terhadap objek-objek tertentu menjadi kelompok yang lebih kecil berdasarkan karakteristik diantara objek-objek tersebut (Johnson dan Wichern [5]). Warsito dkk. [10] telah melakukan penelitian terkait clustering data pencemaran udara di sektor industri Jawa Tengah dengan
ne-ural network. Austin et al. [1] mengidentifikasi beberapa polutan dalam pencemaran
udara. Plaisance et al. [8] menerapkan analisis cluster untuk mengelompokkan pro-fil emisi carbonyl compounds dari material-material bangunan dan perkakas rumah tangga. Mubtadai dkk. [7] melakukan perbandingan clustering metode manual dan
single linkage untuk menentukan kinerja agen pada call centre. Sejalan dengan
pe-nelitian Warsito dkk. [10], Austin et al. [1], Plaisance et al. [8] dan Mubtadai dkk. [7], digunakan single linkage untuk clustering kategori sumber emisi dan identifikasi hasil cluster terhadap polusi udara di Surakarta.
2. Landasan Teori
2.1. Clustering . Clustering merupakan metode untuk klasifikasi objek-objek ke dalam kelompok-kelompok yang lebih kecil berdasarkan karakteristik tertentu (John-son dan Wichern [5]). Jika terdapat n objek dan p variabel, maka observasi xij
de-ngan i = 1, 2, 3, ..., n dan j = 1, 2, 3, ..., p dapat digambarkan seperti dalam Tabel 1. Analisis cluster memiliki tujuan sebagai konfirmasi dalam pengelompokkan, penye-derhanaan data, dan identifikasi suatu hubungan antar observasi. Ciri-ciri cluster yang baik adalah
(1) homogenitas atau kesamaan yang tinggi antar anggota dalam satu cluster (within-cluster ), dan
(2) heterogenitas atau perbedaan yang tinggi antar cluster (between cluster ). 2.2. Istilah-Istilah Clustering . Beberapa istilah analisis cluster sebagai berikut.
commit to user Tabel 1. Struktur Data
Objek Var 1 Var 2 . . . Var j . . . Var p 1 x11 x12 . . . x1j . . . x1p 2 x21 x22 . . . x2j . . . x2p .. . ... ... ... ... ... ... i xi1 xi2 ... xij ... xip .. . ... ... ... ... ... ... n xn1 xn2 ... xnj ... xnp
(1) Agglomeration schedule ialah jadwal yang memberikan informasi tentang ob-jek atau kasus yang akan dikelompokkan pada setiap tahap.
(2) Cluster memberships adalah keanggotaan yang menunjukkan cluster untuk setiap objek yang menjadi anggotanya.
(3) Dendogram merupakan grafik pohon yang menggambarkan hasil analisis
cluster yang dilakukan peneliti.
2.3. Proses Clustering . Proses pengelompokan cluster dimulai dengan standar-disasi satuan melalui transformasi data, sehingga diperoleh data yang mengikuti distribusi normal standar N (0, 1). Hal ini dilakukan dengan transformasi berikut.
z = xi− ¯x
s , (2.1)
dengan
z : nilai transformasi distribusi normal, xi : nilai objek ke-i,
¯
x : nilai rata-rata objek, s : standar deviasi.
Untuk mengelompokkan objek yang memiliki kemiripan, perlu diukur seberapa ja-uh ada kesamaan antar objek. Dalam mengukur kemiripan antar objek tersebut dapat digunakan metode ukuran jarak. Ukuran jarak yang biasa dipakai adalah jarak Euclidean. Johnson dan Wichern [5] mendefinisikan jarak Euclidean sebagai besarnya jarak suatu garis lurus yang menghubungkan antar objek. Ukuran jarak nilai emisi antar objek ke-i dengan objek ke-j, disimbolkan dij dengan i, j = 1, . . . , n
dan k = 1, . . . , p. Nilai dij diperoleh melalui perhitungan jarak kuadrat Euclidean
yaitu
dij =
√
Σpk=1(zik− zjk)2, (2.2)
dengan
n : banyaknya objek, p : banyaknya variabel cluster, dij : jarak kuadrat Euclidean antar objek ke-i dengan objek ke-j,
commit to user
zik / zjk : nilai transformasi dari objek ke-i/j pada variabel ke-k,
2.4. Metode Single Linkage. Single linkage merupakan metode hirarki kategori
agglomeration atau penggabungan objek. Dimulai dengan dua objek yang
dipi-sahkan dengan jarak paling pendek, maka keduanya akan ditempatkan pada cluster pertama, dan seterusnya. Pada setiap tahapan, banyaknya cluster berkurang satu. Menurut Johnson dan Wichern [5], jarak dua buah cluster antara dij dan sembarang
cluster lain yang belum digabung misal dh didefinisikan sebagai
d(ij)h = min{d(dih, djh)}. (2.3)
Clustering dengan algoritme single linkage dilakukan dengan beberapa langkah yaitu
(1) dimulai dengan n cluster, setiap cluster mengandung entiti tunggal dan se-buah matriks simetrik dari jarak dik,
(2) dihitung matriks jarak untuk pasangan cluster yang terdekat. Misal jarak antara cluster U dan V yang terdekat adalah duv,
(3) digabungkan cluster U dan V dan label cluster baru dibentuk dengan U V . diperbarui nilai masukan pada matriks jarak dengan cara
(a) dihapus baris dan kolom yang bersesuaian cluster U dan V ,
(b) ditambahkan baris dan kolom yang memberikan jarak-jarak antara
clus-ter (U V ) dan clusclus-ter-clusclus-ter yang clus-tersisa.
(4) diulangi langkah (2) dan (3) sebanyak n− 1 kali,
(5) dicatat identitas dari cluster yang digabungkan dan jarak similaritas dimana penggabungan terjadi.
setelah terbentuk cluster, diberikan ciri atau karakteristik berdasarkan nilai rata-rata dari emisi pada masing-masing cluster dan pertimbangan besar polutan udara.
3. Metode Penelitian
Pada penelitian ini, metode yang digunakan adalah penerapan kasus. Adapun langkah-langkah yang dilakukan sebagai berikut.
(1) Mendeskripsikan data kategori sumber emisi.
(2) Pengolahan data penelitian dengan langkah-langkah sebagai berikut. (a) Melakukan standardisasi satuan dengan persamaan (2.1).
(b) Membentuk matriks ketakmiripan antar objek dengan persamaan (2.2). (c) Membandingkan jarak ketakmiripan antar objek melalui persamaan (2.3). (d) Menentukan jumlah cluster berdasarkan dendogram.
commit to user
(e) Memberikan karakteristik pada tiap cluster. (3) Memberikan kesimpulan.
4. Hasil dan Pembahasan
4.1. Deskripsi Data Emisi. Terdapat 16 kategori sumber dan 6 variabel polutan udara sebagai nilai masukan dalam proses clustering. Data yang digunakan adalah nilai emisi gas buang di Surakarta tahun 2011. Sumber data tersebut diberikan oleh Prabang Setyono, yang merupakan peneliti di progam studi Biologi FMIPA Univer-sitas Sebelas Maret. Tabel ?? menunjukkan nilai emisi dari setiap kategori sumber berdasarkan polutan masing-masing. Perhitungan emisi dilakukan dengan sampling beberapa peralatan pada kategori sumber seperti genset, kompor gas, tungku, boiler, las, oven, kompresor, kendaraan, cooking set dan cooking machine.
Tabel 2. Nilai Standardisasi Satuan untuk 16 Kategori Sumber Emisi
No. Kategori Z-Score
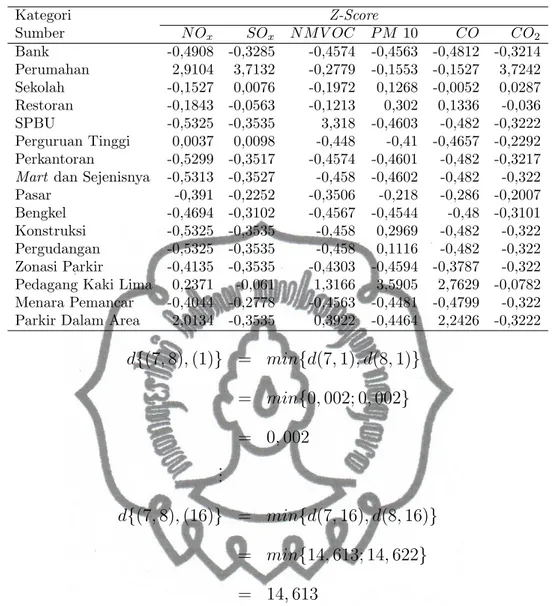
Sumber N Ox SOx N M V OC P M 10 CO CO2 1 Bank -0,4908 -0,3285 -0,4574 -0,4563 -0,4812 -0,3214 2 Perumahan 2,9104 3,7132 -0,2779 -0,1553 -0,1527 3,7242 3 Sekolah -0,1527 0,0076 -0,1972 0,1268 -0,0052 0,0287 4 Restoran -0,1843 -0,0563 -0,1213 0,3020 0,1336 -0,0360 5 SPBU -0,5325 -0,3535 3,3180 -0,4603 -0,4820 -0,3222 6 Perguruan Tinggi 0,0037 0,0098 -0,4480 -0,4100 -0,4657 -0,2292 7 Perkantoran -0,5299 -0,3517 -0,4574 -0,4601 -0,4820 -0,3217 8 Mart dan Sejenisnya -0,5313 -0,3527 -0,4580 -0,4602 -0,4820 -0,3220 9 Pasar -0,3910 -0,2252 -0,3506 -0,2180 -0,2860 -0,2007 10 Bengkel -0,4694 -0,3102 -0,4567 -0,4544 -0,4800 -0,3101 11 Konstruksi -0,5325 -0,3535 -0,4580 0,2969 -0,4820 -0,3220 12 Pergudangan -0,5325 -0,3535 -0,4580 0,1116 -0,4820 -0,3220 13 Zonasi Parkir -0,4135 -0,3535 -0,4303 -0,4594 -0,3787 -0,3220 14 Pedagang Kaki Lima 0,2371 -0,0610 1,3166 3,5905 2,7629 -0,0782 15 Menara Pemancar -0,4044 -0,2778 -0,4563 -0,4481 -0,4799 -0,3220 16 Parkir Dalam Area 2,0134 -0,3535 0,3922 -0,4464 2,2426 -0,3222
4.2. Clustering Data Emisi dengan Single Linkage. Langkah awal yang di-lakukan adalah standardisasi satuan melalui persamaan (2.1) dan diperoleh hasil pada Tabel 3. Langkah kedua, jarak setiap kategori sumber penghasil emisi dihi-tung dengan jarak kuadrat Euclidean yaitu persamaan (2.2). Jarak masing-masing objek ditampilkan dalam matriks jarak yang ada dalam proximitry matrix yaitu Tabel 4 dan Tabel 5. Langkah ketiga, membandingkan jarak ketakmiripan antar objek dalam cluster satu dengan cluster lain melalui persamaan (2.3). Pada awal proses dimiliki 16 cluster, lalu dihitung nilai jarak terdekat dari proximitry matrix. Jarak antara perkantoran dan mart & sejenisnya merupakan jarak terdekat yaitu sebesar 0,000 sebagai satu cluster. Dilakukan perbaikan matriks jarak dari sisa 14
commit to user
Tabel 3. Nilai Standardisasi Satuan untuk 16 Kategori Sumber Emisi
Kategori Z-Score Sumber N Ox SOx N M V OC P M 10 CO CO2 Bank -0,4908 -0,3285 -0,4574 -0,4563 -0,4812 -0,3214 Perumahan 2,9104 3,7132 -0,2779 -0,1553 -0,1527 3,7242 Sekolah -0,1527 0,0076 -0,1972 0,1268 -0,0052 0,0287 Restoran -0,1843 -0,0563 -0,1213 0,302 0,1336 -0,036 SPBU -0,5325 -0,3535 3,318 -0,4603 -0,482 -0,3222 Perguruan Tinggi 0,0037 0,0098 -0,448 -0,41 -0,4657 -0,2292 Perkantoran -0,5299 -0,3517 -0,4574 -0,4601 -0,482 -0,3217 Mart dan Sejenisnya -0,5313 -0,3527 -0,458 -0,4602 -0,482 -0,322 Pasar -0,391 -0,2252 -0,3506 -0,218 -0,286 -0,2007 Bengkel -0,4694 -0,3102 -0,4567 -0,4544 -0,48 -0,3101 Konstruksi -0,5325 -0,3535 -0,458 0,2969 -0,482 -0,322 Pergudangan -0,5325 -0,3535 -0,458 0,1116 -0,482 -0,322 Zonasi Parkir -0,4135 -0,3535 -0,4303 -0,4594 -0,3787 -0,322 Pedagang Kaki Lima 0,2371 -0,061 1,3166 3,5905 2,7629 -0,0782 Menara Pemancar -0,4044 -0,2778 -0,4563 -0,4481 -0,4799 -0,322 Parkir Dalam Area 2,0134 -0,3535 0,3922 -0,4464 2,2426 -0,3222
d{(7, 8), (1)} = min{d(7, 1), d(8, 1)} = min{0, 002; 0, 002} = 0, 002 .. . d{(7, 8), (16)} = min{d(7, 16), d(8, 16)} = min{14, 613; 14, 622} = 14, 613
Nilai jarak 0,002 adalah bank sebagai jarak terdekat selanjutnya dan dijadikan satu
cluster dengan sisa 13 cluster. Proses perbaikan matriks jarak kembali berulang
de-ngan cara yang sama hingga semua sumber objek telah dibandingkan dan terbentuk satu cluster keseluruhan. Langkah keempat adalah menentukan banyaknya
clus-Tabel 4. Proximitry Matrix untuk Kategori Sumber Emisi 1-8
1 2 3 4 5 6 7 8 1 0 44,501 0,984 1,315 14,256 0,370 0,002 0,002 2 0 36,879 38,241 57,896 37,985 44,962 44,984 3 0 0,065 13,326 0,654 1,034 1,036 4 0 13,08 1,049 1,361 1,363 5 0 14,612 14,253 14,257 6 0 0,427 0,429 7 0 0 8 0 .. . 16
ter berdasarkan dendogram yaitu Gambar 1. Pembentukan tiga cluster diperoleh cluster memberships yaitu
commit to user
Tabel 5. Proximitry Matrix untuk Kategori Sumber Emisi 9-16
9 10 11 12 13 14 15 16 1 0,142 0,001 0,570 0,325 0,018 30,709 0,010 14,412 2 41,841 44,115 45,110 44,977 44,127 60,923 43,514 39,987 3 0,384 0,947 0,722 0,693 0,859 22,119 0,891 10,674 4 0,597 1,282 0,784 0,82 1,16 19,975 1,231 10,272 5 13,607 14,254 14,831 14,585 14,074 31,681 14,267 22,465 6 0,291 0,335 0,928 0,7 0,325 29,622 0,26 12,221 7 0159 0,006 0,573 0,327 0,025 30,815 0,021 14,613 8 0,16 0,006 0,573 0,327 0,025 30,822 0,022 14,622 9 0 0,13 0,366 0,21 0,105 27,011 0,120 12,808 10 0 0,57 0,326 0,016 30,638 0,005 14,3 11 0 0,034 0,598 25,264 0,577 15,18 12 0 352 26,519 0,335 14,939 13 0 29,892 0,017 13,437 14 0 30,488 20,722 15 0 13,983 16 0
(1) anggota cluster 1 adalah bank, sekolah, restoran, SPBU, perguruan tinggi, perkantoran, mart & sejenisnya, pasar, bengkel, konstruksi, pergudangan, zona parkir, menara pemancar dan parkir dalam area.
(2) anggota cluster 2 adalah pedagang kaki lima, dan (3) anggota cluster 3 adalah perumahan.
Gambar 1. Dendogram dengan Single Linkage
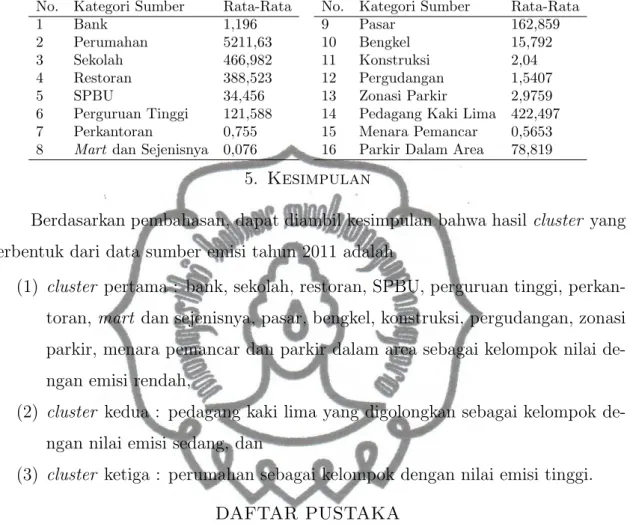
Langkah terakhir adalah memberi ciri spesifik untuk menggambarkan isi cluster ter-sebut melalui rata-rata emisi pada Tabel 6. Cluster pertama merupakan 14 kategori sumber yang memiliki nilai rata-rata emisi dan beban polutan yang lebih rendah
commit to user
dari kategori sumber cluster lainnya. Pada cluster kedua memiliki nilai rata-rata emisi kurang dari cluster ketiga, yang memiliki nilai rata-rata emisi tertinggi.
Tabel 6. Rata-Rata Emisi untuk 16 Kategori Sumber Emisi
No. Kategori Sumber Rata-Rata No. Kategori Sumber Rata-Rata
1 Bank 1,196 9 Pasar 162,859
2 Perumahan 5211,63 10 Bengkel 15,792
3 Sekolah 466,982 11 Konstruksi 2,04
4 Restoran 388,523 12 Pergudangan 1,5407
5 SPBU 34,456 13 Zonasi Parkir 2,9759
6 Perguruan Tinggi 121,588 14 Pedagang Kaki Lima 422,497
7 Perkantoran 0,755 15 Menara Pemancar 0,5653
8 Mart dan Sejenisnya 0,076 16 Parkir Dalam Area 78,819 5. Kesimpulan
Berdasarkan pembahasan, dapat diambil kesimpulan bahwa hasil cluster yang terbentuk dari data sumber emisi tahun 2011 adalah
(1) cluster pertama : bank, sekolah, restoran, SPBU, perguruan tinggi, perkan-toran, mart dan sejenisnya, pasar, bengkel, konstruksi, pergudangan, zonasi parkir, menara pemancar dan parkir dalam area sebagai kelompok nilai de-ngan emisi rendah,
(2) cluster kedua : pedagang kaki lima yang digolongkan sebagai kelompok de-ngan nilai emisi sedang, dan
(3) cluster ketiga : perumahan sebagai kelompok dengan nilai emisi tinggi. DAFTAR PUSTAKA
1. Austin, E., B. Coull, D. Thomas, and P. Koutakris, A Framework for Identifying Distinct Multipollutant Profiles in Air Pollution Data, Environment International Journal 45 (2012). 2. Billionnet, C., D. Sherrill, and I. A. Maesano, Estimating the Health Effects of Exposure to
Multi-Pollutant Mixture, AEP 22 (2012), 126–141.
3. Dinas Perhubungan Komunikasi dan Informatika Kota Surakarta, Uji Gas Emisi, Banyak Mobil Melebihi Ambang Batas Gas Emisi, (2014).
4. Ismiyati, D. Marlita, dan D. Saidah, Pencemaran Udara Akibat Emisi Gas Buang Kendaraan Bermotor, Jurnal Manajemen Transportasi dan Logistik 01 (2014), no. 03, 241–248.
5. Johnson, R.A., and D.W. Wichern, Applied Multivariate Statistical Analysis, fourth ed., Pren-tice Hall Inc., United States of America, 1998.
6. Daily Mail, Now that’s Global Warming: Interactive Maps Reveal which Countries have Emit-ted The Most CO2 Over The Last 160 Years, (2014).
7. Mubtada’i, N.R., M. Yuliana, dan B.I. Priyambodo, Analisa Perbandingan Clustering Metode Manual dan Metode Single Linkage untuk Menentukan Kinerja Agent di Call Centre Berba-sis Asterisk for Java, The 13th Industrial Electronics Seminar 2011 Electronic Engineering Polytechnic Institute Of Surabaya (2011).
8. Plaisance, H., A. Blondel, V. Desauziers, and P. Mocho, Hierarchical Cluster Analysis of Carbonyl Compounds Emission Profiles from Building And Furniture Materials, Building And Environment Journal 75 (2014), 40–45.
9. Rencher, A.C., Methods of Multivariate Analysis, second ed., John Wiley and Sons Inc., United States of America, 2002.
10. Warsito, B., D. Ispriyanti dan H. Widayanti, Clustering Data Pencemaran Udara Sektor In-dustri di Jawa Tengah dengan Kohonen Neural Network, Jurnal Presipitasi 4 (2008).