15 BAB 3
LANDASAN TEORI
3.1 Konsep Kepuasan Konsumen
Menurut Gerson, kepuasan konsumen merupakan pandangan konsumen bahwa harapannya telah terpenuhi atau terlampaui (Gerson,1999,p3). Sedangkan menurut Kotler, kepuasan konsumen merupakan tingkat perasaan puas ataupun kecewa terhadap perbandingan antara kesan kinerja suatu produk serta jasa yang diberikan dengan harapan dari orang tersebut. Dengan demikian kepuasan konsumen merupakan fungsi dari kesan kinerja dan harapan (Kotler,1995, p458).
Suatu pelayanan dinilai memuaskan bila pelayanan tersebut dapat memenuhi kebutuhan dan harapan konsumen dengan cepat dan tepat. Apabila konsumen merasa tidak puas terhadap suatu pelayanan yang disediakan, maka pelayanan tersebut dapat dipastikan tidak efektif dan tidak efisien. Hal ini terutama sangat penting bagi pelayanan publik. Pada kondisi persaingan sempurna, dimana konsumen mampu untuk memilih diantara beberapa alternatif pelayanan dan memiliki informasi yang memadai, kepuasan konsumen merupakan satu determinan kunci dari tingkat permintaan pelayanan dan fungsi atau operasionalisasi pemasok. Tingkat operasionalisasi dari setiap perusahaan ditekankan untuk mencapai keseimbangan antara pengadaan produk dan kebutuhan pasar. Perencanaan yang kurang baik dapat mengakibatkan ketidakpuasan konsumen, sementara itu pengadaan produk yang berlebihan akan berakibat pada kelebihan stok.
Oleh karena itu, jika kepuasan konsumen dapat dicapai, berarti perusahaan akan memperoleh peluang untuk meraih pangsa pasar pada suatu segmen atau periode tertentu, dan dipastikan akan terjadi sesuatu yang lebih baik untuk bisnis perusahaan tersebut dimasa yang akan datang dan pada akhirnya kepuasan konsumen akan mempengaruhi kinerja keuangan setiap perusahaan (anonim3).
3.2 Pengelolaan Stok
Pengelolaan stok secara efektif merupakan salah satu cara untuk menekan jumlah pengeluaran agar menjadi lebih kecil dan mendapatkan keuntungan yang lebih besar, baik perusahaan kecil maupun besar. Untuk mengatur jumlah pengeluaran dan peningkatan keuntungan penting adanya pengelolaan terhadap setiap stok, serta modal yang dimiliki. kegagalan untuk mengatur stok secara efektif dapat menyebabkan peningkatan pengeluaran untuk pemeliharaan terhadap stok yang berlebihan, kekurangan keuntungan, dan tidak tersedianya stok (Hohenstein,1982,p1).
Salah satu tujuan dari penempatan stok adalah untuk menghindari penurunan penjualan akibat dari kekurangan stok disaat terjadi permintaan berlebih. Selain itu juga, tujuan lainnya adalah untuk menghindari kelebihan inventory dan biasanya hal ini menimbulkan pengeluaran biaya lebih untuk pemeliharaan barang yang telah dipesan tapi belum terjual (Hohenstein,1982,p36).
Dengan semakin meningkatnya pertumbuhan atau pun pengaruh bisnis, maka tingkat penjualan pun semakin meningkat. Dan seiring dengan itu, diperlukan adanya pengaturan stok yang baik. Misalnya jika penjualan menurun untuk alasan tertentu,
maka stok barang juga harus ikut menurun. Jika terlalu banyak melakukan penyimpanan stok maka akan meningkatkan biaya pemeliharaan dalam jumlah yang besar. Oleh karena itu, jumlah penempatan stok harus mengikuti nilai atau turunnya permintaan (Hohenstein, 1982,p153).
Biasanya perkiraan stok penjualan menggunakan laporan dari data masa lalu sebagai informasi. Dengan kata lain barang yang dijual atau tingkat penjualan menjadi sederhana jika didasarkan keputusan dari manager (”kira-kira membutuhkan tiga paket setiap minggu”). Penjualan atau penggunaan sebuah barang akan meningkat karena peningkatan kebutuhan. Bersamaan dengan itu permintaan akan barang lain akan cenderung menurun. Bagaimana pun juga, jika hanya menggunakan data masa lalu dan membuat keputusan, maka penempatan jumlah stok akan salah. Oleh karena banyaknya barang yang memiliki tren naik dan turun, maka pengelolaan stok yang efektif dapat dilakukan dengan melakukan peramalan (forecasting) stok penjualan yang menggunakan metode aritmatik untuk mendapatkan perkiraan penjualan yang lebih tepat pada periode mendatang. Hal ini lebih baik dari pada dilakukan berdasarkan keputusan sepihak seorang manajer (Hohenstein,1982,pp.142-143).
3.3 Peramalan
Pada bagian ini akan diberikan definisi tentang peramalan dan teori-teori mengenai metode peramalan yang digunakan.
3.3.1 Definisi Peramalan
Peramalan menurut Assauri (1984,p1) merupakan, kegiatan untuk memperkirakan apa yang terjadi pada masa yang akan datang. Sedangkan peramalan atau forecasting menurut Levine et. al. (2002,p654) adalah sebuah teknik yang dapat membantu perencanaan untuk kebutuhan masa depan berdasarkan pengalaman atau data masa lalu yang relevan.
3.3.2 Kegunaan dan Peran Peramalan
Menurut Makridakis, Wheelwright, dan McGee (2000,p229) perencanaan sebagai suatu tugas yang dilakukan sebelum mengambil tindakan. Perencanaan biasanya merupakan pengambilan keputusan yang dilakukan lebih awal, walaupun tidak semua bentuk pengambilan keputusan merupakan perencanaan. Assauri (1984,p2) menerangkan bahwa, dalam usaha mengetahui atau melihat perkembangan dimasa depan, peramalan sangat dibutuhkan untuk menentukan kapan suatu peristiwa akan terjadi atau suatu kebutuhan akan timbul apalagi jika perbedaan waktu dalam kegiatan tersebut panjang, sehingga dapat dipersiapkan kebijakan dan tindakan-tindakan yang perlu dilakukan. Dengan demikian dapat dikatakan bahwa peramalan merupakan dasar untuk penyusunan rencana.
Kegunaan dari peramalan terlihat pada saat pengambilan keputusan. Keputusan yang baik adalah keputusan yang didasarkan atas pertimbangan apa yang akan terjadi pada waktu keputusan itu dilaksanakan. Apabila kurang tepat ramalan yang disusun atau yang dibuat, maka makin kurang baiklah keputusan yang diambil. Oleh karena itu, dalam suatu perusahaan, ramalan dibutuhkan untuk memberikan informasi
kepada pimpinan sebagai dasar untuk membuat suatu keputusan dalam berbagai kegiatan, seperti penjualan, permintaan, persediaan keuangan dan sebagainya.
Dengan demikian dapat dilihat bahwa peramalan memiliki peranan yang sangat penting, baik dalam penelitian, perencanaan maupun dalam pengambilan keputusan. Tetapi dapat diperhatikan bahwa peramalan memiliki tujuan untuk memperkecil kemungkinan kesalahan. Baik tidaknya suatu ramalan sangat tergantung pada unsur atau faktor data dan metode yang digunakan.
3.3.3 Jenis-Jenis Peramalan
Menurut Assauri (2002,pp. 3-4), peramalan dapat dibedakan dari berbagai segi tergantung dari cara melihatnya. Apabila dilihat dari cara penyusunannya, maka peramalan dapat dibedakan menjadi dua macam, yaitu :
1. Peramalan yang subjektif, yaitu peramalan yang didasarkan atas perasaan atau intuisi dari orang yang menyusunnya. Dalam hal ini pandangan atau ”judgement” dari orang yang menyusunnya sangat menentukan baik tidaknya hasil ramalan tersebut.
2. Peramalan yang objektif, adalah peramalan yang didasarkan atas data yang relevan pada masa lalu, dengan menggunakan teknik-teknik dan metode-metode dalam penganalisaan data tersebut.
Dilihat dari jangka waktu ramalan yang disusun, maka peramalan dapat dibedakan atas dua macam, yaitu :
1. Peramalan jangka panjang, yaitu peramalan yang dilakukan untuk menyusun hasil ramalan yang jangka waktunya lebih dari satu setengah tahun atau tiga semester.
2. Peramalan jangka pendek, yaitu peramalan yang dilakukan untuk penyusunan hasil ramalan dengan jangka waktu yang kurang dari satu setengah tahun, atau tiga semester. Umumnya peramalan jangka pendek didasarkan pada analisis deret waktu. Oleh karena itu, peramalan jangka pendek menggunakan teknik analisa hubungan dimana satu-satunya variabel yang mempengaruhi adalah waktu. Dalam peramalan jangka pendek selalu ditemui adanya pola musiman. Jadi pada bulan-bulan atau triwulan yang sama setiap tahun mempunyai nilai variabel cukup tinggi, dan pada bulan-bulan atau triwulan tertentu lainnya mempunyai nilai variabel yang cukup rendah. Oleh karena itu maka dalam peramalan jangka pendek perlu ditinjau dulu apakah deret data yang ada memiliki pola musiman.
Berdasarkan sifat ramalannya, menurut Assauri (2002,pp. 3-4), ada dua pendekatan umum yang dipakai yaitu :
1. Peramalan kuantitatif, yaitu peramalan yang didasarkan atas data kualitatif pada masa lalu atau dengan kata lain peramalan yang didasarkan atas permikiran yang bersifat intuisi, judgement atau pendapat, dan pengetahuan serta pengalaman dari penyusunnya. Metode ini penting saat data historis tidak tersedia.
2. Peramalan kuantitatif, yaitu peramalan yang didasarkan pada data historis. Tujuan metode ini adalah mempelajari apa yang terjadi dimasa lalu untuk prediksi nilai-nilai yang akan datang.
3.3.4 Metode Peramalan Kuantitatif
Menurut Makridakis, Wheelwright, dan McGee (1999,pp.19-20), metode peramalan kualitatif dapat dibagi menjadi :
1. Metode peramalan yang didasarkan atas penggunaan analisa pola hubungan antara variabel yang akan diperkirakan dengan variabel waktu, yang merupakan deret waktu, atau ”time series”.
2. Metode peramalan yang didasarkan atas penggunaan analisa pola hubungan antara variabel yang akan diperkirakan dengan variabel lain yang mempengaruhinya, yang bukan waktu atau sering disebut sebagai motede korelasi atau model regresi (”causal methods”).
3. (Rosadi,2006,p1) Panel atau Pooled data, yakni tipe data yang dikumpulkan menurut urutan waktu dalam suatu rentang waktu tertentu pada sejumlah individu atau kategori.
3.3.5 Deret Waktu (Time Series)
Data time series adalah data yang dikumpulkan, dicatat atau diobservasi berdasarkan urutan waktu yang secara umum bertujuan untuk menemukan bentuk pola variasi dari data dimasa lampau dan menggunakan pengetahuan ini untuk melakukan peramalan terhadap sifat-sifat dari data dimasa yang akan datang (Rosadi,2005, p16).
Peramalan dengan menggunakan analisa deret waktu, mendasarkan hasil ramalan yang disusun atas pola hubungan antara variabel yang dicari atau diramalkan dengan variabel waktu yang merupakan satu-satunya variabel yang mempengaruhi atau bebas. Dalam peramalan dengan analisa deret waktu, dilakukan usaha untuk menemukan pola deret data historis dan kemudian mengekstrapolasikan pola tersebut untuk masa yang akan datang. Suatu langkah yang penting dalam memilih metode analisa deret waktu adalah mempertimbangkan jenis pola yang terdapat dari data observasi (Assauri,1984,p45). Menurut Rosadi (2005,p16), didalam pola deret waktu terdapat komponen-komponen yang membangun pola data dan dikelompokan dalam empat komponen utama yaitu :
1. Trend : bentuk penurunan atau pertambahan data.
2. Musiman (seasonal) : bentuknya berupa fluktuasi berulang (dan beraturan) atau naik turunnya variabel dalam jangka waktu periode yang sama, yang ditemui setiap tahun.
3. Siklikal (cyclical) : berupa pola siklus, umumnya periode waktu relatif lebih panjang dibanding musiman
4. Komponen tak beraturan (irregular atau random) : berupa pola acak.
Sedangkan pola yang dibentuk dari komponen tersebut dapat dikelompokan lagi kedalam empat jenis pola data antara lain (Assauri,1984,p46) :
1. Pola horizontal atau stationary, bila nilai-nilai dari data observasi berfluktuasi disekitar nilai konstan rata-rata. Dengan demikian dapat dikatakan pola ini sebagai stationary pada rata-rata hitungnya (means). Pola jenis ini terdapat
pada suatu produk yang mempunyai jumlah penjualan yang tidak menaik atau menurun selama beberapa waktu atau periode, seperti terlihat pada Gambar 3.1.
Gambar 3.1 Pola Data Horizontal (Assauri,1984,p46)
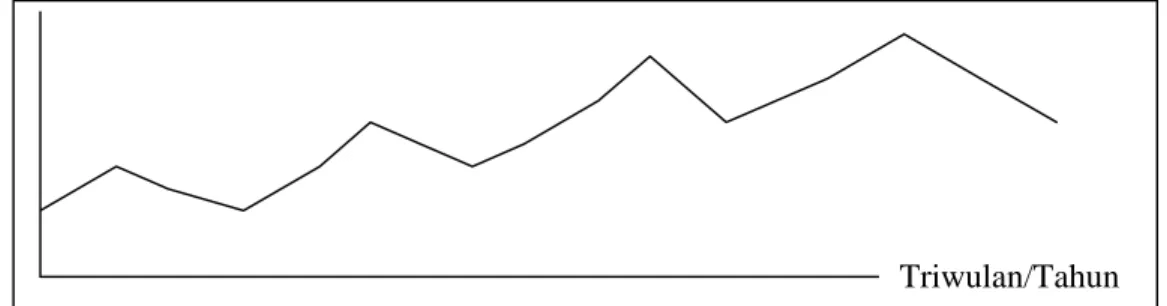
2. Pola Musiman atau seasonal, bila suatu deret waktu dipengaruhi oleh faktor musim (seperti kuartalan, bulanan, mingguan dan harian). Banyak produk yang penjualannya menunjukkan pola musiman, seperti minuman segar, ice cream, jasa angkutan, obat-obatan tertentu, dan ban mobil. Contoh pola musiman kwartalan seperti terlihat pada Gambar 3.2.
Gambar 3.2 Pola Data Musiman (Assauri,1984,p46)
3. Pola siklus atau cyclical bila data observasi dipengaruhi oleh fluktuasi ekonomi jangka panjang yang berkaitan atau tergabung dengan siklus usaha (business cycle). Ada beberapa produk yang penjualannya menunjukkan pola siklus, seperti mobil sedan, besi baja, dan perkakas atau peralatan bengkel. Pola dari jenis ini seperti terdapat pada Gambar 3.3
Waktu/Periode
Gambar 3.3 Pola Data Siklus (Assauri,1984,p47)
4. Pola trend bila ada pertambahan/kenaikan atau penurunan dari data observasi untuk jangka panjang. Pola ini terlihat pada penjualan produk dari banyak perusahaan. Pendapatan Domestik/Nasional Bruto (GDP/GNP) dan indikator ekonomi. Pola trend ini dapat dilihat pada gambar 3.4
Gambar 3.4 Pola Data Trend (Assauri,1984,p47)
Oleh karena itu, harus dilakukan penyaringan adaptasi dengan metode yang dapat menyesuaikan pola data yang ada (Assauri,1984,p169). Menurut Levine et. al. (2002,p655), metode peramalan deret waktu melibatkan proyeksi nilai yang akan datang dari sebuah variabel dengan berdasarkan seluruhnya pada pengamatan masa lalu dan sekarang dari variabel tersebut. Metode peramalan deret waktu dapat dibagi menjadi beberapa metode, antara lain:
1. Metode smoothing.
Metode ini digunakan untuk melakukan pemulusan terhadap suatu deret berkala dengan membuat rata-rata tertimbang dari sederetan data yang lalu.
Waktu/Periode Waktu/Periode
Metode ini sangat efektif untuk peramalan jangka pandek dan tidak membutuhkan banyak data.
2. Metode Box Jenkins.
Metode ini menggunakan dasar deret waktu dengan model matematis dan hanya cocok untuk jangka pendek.
3. Metode Proyeksi Trend.
Metode ini berdasarkan garis trend untuk suatu persamaan matematis. Cocok untuk jangka pendek maupun jangka panjang. Makin banyak data yang tersedia, hasilnya akan makin baik.
4. Metode Dekomposisi.
Metode ini memisahkan tiga komponen yaitu trend, siklis, dan musiman. Metode ini cocok bagi rencana jangka pendek dan semakin banyak data yang tersedia akan semakin baik hasil peramalannya.
3.3.6 Pemilihan Metode Peramalan Deret Waktu
Pola atau karakteristik data mempengaruhi teknik peramalan yang dipilih. Seringkali, pola data tersebut merupakan karakteristik inherent dari kegiatan yang sedang diteliti. Hubungan antar data dengan jangka waktu semakin jelas dengan mengamati bahwa pola trend merupakan kecenderungan jangka panjang. Sedangkan variasi musiman menunjukkan pola data yang berulang dalam satu tahun. Teknik regresi cocok untuk hampir semua pola yang dapat diidentifikasi. Dalam mengevalusi teknik-teknik yang dikaitkan dengan pola data, bisa saja diterapkan lebih dari satu teknik untuk data yang sama. Misalnya, teknik-teknik tertentu
mungkin lebih akurat dalam memprediksi titik balik, sedangkan lainnya terbukti lebih handal dalam peramalan pola perubahan yang stabil. Bisa juga terjadi beberapa model meramalkan terlalu tinggi (overestimate) atau terlalu rendah (underestimate) dalam situasi tertentu. Selain itu, mungkin juga terjadi bahwa prediksi jangka pendek dari suatu model lebih baik dari model lain yang memiliki prediksi jangka panjang yang lebih akurat.
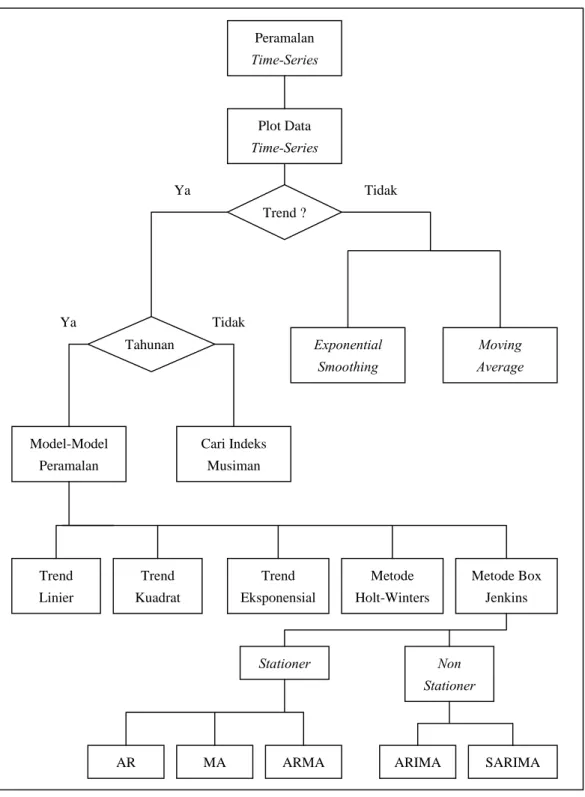
Hakim (2001,p372) dan Rosadi (2005,pp.16-17) menggambarkan sebuah bagan seperti pada Gambar 3.5 yang berisi pemilihan metode peramalan deret berkala yang tepat sesuai dengan situasi dan jenis plot data yang ada.
Gambar 3.5 Pemilihan Metode Peramalan Deret Berkala (Rosadi,2005,pp.16-17)
3.3.7 Teknik Peramalan Data Musiman
Data deret waktu yang berpola musiman didifenisikan sebagai suatu data deret waktu yang bentuknya berupa fluktuasi berulang (dan beraturan) atau naik turunnya
Peramalan Time-Series Plot Data Time-Series Exponential Smoothing Moving Average Trend Linier Trend ? Tahunan Cari Indeks Musiman Model-Model Peramalan Trend Kuadrat Trend Eksponensial Metode Box Jenkins Metode Holt-Winters Stationer Non Stationer
AR MA ARMA ARIMA SARIMA
Ya Tidak
variabel dalam jangka waktu periode yang sama, yang ditemui setiap tahun (Rosadi,2006,p16). Mengembangkan teknik peramalan musiman memerlukan pemilihan metode perkalian dan pertambahan dan kemudian mengestimasi indeks musiman dari data tersebut. Indeks ini kemudian digunakan untuk memasukkan sifat musiman dalam peramalan atau untuk menghilangkan pengaruh seperti musiman dari nilai-nilai yang diobservasi.
Teknik-teknik peramalan untuk data musiman digunakan dalam keadaan berikut ini : 1. Jika cuaca mempengaruhi variabel yang diteliti, seperti penggunaan listrik,
kegiatan musim kemarau, musim hujan, pakaian, dam musim tanam pertanian. 2. Jika kalender tahunan mempengaruhi variabel yang diteliti, seperti penjualan
eceran dipengaruhi oleh musim liburan, kalender sekolah, dan hari-hari besar lainnya.
Teknik-teknik yang diperhatikan ketika meramalkan data deret waktu yang bersifat musiman adalah metode Dekomposi klasik, Census II, pemulusan eksponensial dari winter, regresi berganda deret waktu, dan metode Box-Jenkins. 3.4 Metode Analisis
Menurut Assauri (1984,pp.126-128), metode peramalan Box Jenkins adalah salah satu metode yang sangat tepat untuk menangani atau mengatasi kerumitan deret waktu dan situasi peramalan lainnya. Kerumitan itu terjadi karena terdapatnya variasi dari pola data yang ada. Oleh karena itu diperlukan pendekatan untuk meramalkan data dengan pola yang rumit tersebut dengan menggunakan beberapa aturan yang relatif baik. Metode Box Jenkins atau dikenal dengan nama ARIMA merupakan
singkatan dari Autoregressive Integrated Moving Average. Dimana model ini, dapat diduga bahwa model terdiri atas dua aspek, yaitu aspek autoregresi dan rata-rata bergerak.
Model autoregresi merupakan model yang menggambarkan hubungan antara variabel terikat Y dengan variabel bebas yang merupakan nilai Y pada waktu sebelumnya, sedangkan model moving average merupakan model yang menggambarkan ketergantungan variabel terikat Y terhadap nilai-nilai error pada waktu sebelumnya yang berurutan. Error ini sering juga disebut nilai kesalahan atau deviasi nilai prediksi terhadap nilai sesungguhnya. Secara umum, model ARIMA dituliskan dengan notasi ARIMA (p,d,q). dimana p adalah derajat proses autoregresi (AR), d adalah pembedaan, dan q adalah derajat proses moving average (MA). Adanya nilai pembedaan (d) pada model ARIMA disebabkan karena aspek-aspek AR dan MA hanya dapat diterapkan pada data time series yang stasioner. Pada kenyataannya, sebagian besar time series menunjukkan perubahan dari waktu ke waktu, baik rata-rata maupun variansnya. Data time series yang mempunyai sifat demikian disebut data time series tidak stasioner. Beberapa model non stationer menurut Rosadi (2006,p2), yakni model trend, model ARIMA, model SARIMA, model ARIMAX, model ARC/GARCH.
Untuk dapat menggambarkan metode Box-Jenkins, maka George Box dan Gwilyn Jenkins telah mengembangkan suatu diagram skema yang dapat dilihat pada gambar 3.6 metode ini membagi masalah peramalan dalam tiga tahap yang didasarkan pada postulasi atas kelas yang umum dari model-model peramalan. Pada
tahap pertama, suatu model tertentu dapat dimasukkan secara tentative sebagai suatu metode peramalan yang sangat cocok untuk keadaan yang diidentifikasi. Tahap kedua mencocokkan model tersebut untuk data historis yang tersedia dan melakukan suatu pengecekan untuk menentukan apakah model tersebut sudah cukup tepat. Jika tidak tepat, maka pendekatan ini kembali lagi ke tahap pertama dan suatu model alternative diidentifikasikan. Bila suatu model yang sudah cukup tepat, hendaklah diisolasikan dan tahap ketiga dilakukan, yaitu penyusunan ramalan untuk beberapa periode yang akan datang. Dalam rangka ini perlu diketahui unsur-unsur yang penting untuk dapat mengaplikasikan pendekatan Box-Jenkins.
Gambar 3.6 Diagram Arus Strategi Pembentukan Model Box-Jenkins (Assauri,1984,p128)
3.4.1 Autokorelasi (ACF)
Autokorelasi diantara nilai-nilai yang berturut-turut dari data merupakan suatu alat penentu atau kunci dari identifikasi pola dasar yang menggambarkan data itu.
Postulasi suatu kelas yang umum dari model-model
Identifikasi model yang dapat dimasukkan secara tentatif Pengestimasian paramater dalam model yang dimasukkan secara tentatif
Pengecekan diagnostik: metode itu cukup tepat
Menggunakan model-model untuk peramalan
Tahap 1
Tahap 2
Seperti telah diketahui bahwa konsep korelasi di antara dua variabel menyatakan assosiasi atau hubungan diantara dua variabel. Nilai korelasi menunjukkan apa yang terjadi atas salah satu variabel, terdapat perubahan dalam variabel lainnya.
Tingkat korelasi ini diukur dengan koefisien korelasi yang besarnya bervariasi di antara +1 dan -1. Suatu nilai koefisien yang mendekati +1 menunjukkan kuatnya hubungan positif diantara dua variabel itu. Ini berarti bahwa bila nilai dari salah satu variabel meningkat atau bertambah, maka nilai daripada variabel lainnya juga cenderung bertambah. Demikian pula halnya dengan nilai koefisien korelasi yang mendekati -1, menunjukkan bertambahnya nilai salah satu variabel akan mengakibatkan turunnya atau kurangnya nilai dari variabel lainnya. Suatu nilai koefisien korelasi nol menunjukkan bahwa kedua variabel secara statistik adalah bebas, tidak tergantung satu dengan lainnya, sehingga tidak ada perubahan dalam satu variabel, bila variabel lainnya berubah.
Suatu koefisien autokorelasi adalah sama dengan suatu koefisien korelasi hanya bedanya bahwa koefisien ini menggambarkan assosiasi atau hubungan antara nilai-nilai dari variabel yang sama, tetapi pada periode waktu yang berbeda.
Autokorelasi memberikan informasi yang penting tentang susunan atau struktur data dan polanya. Dalam suatu kumpulan data acak yang lengkap, autokorelasi di antara nilai-nilai data dari ciri yang musiman dan siklus akan mempunyai autokorelasi yang kuat. Sebagai contoh, informasi yang menunjukkan suatu hubungan yang positif di antara temperatur setiap dua belas bulan berturut-turut, merupakan informasi yang diperoleh dengan perhitungan autokorelasi yang dapat
dipergunakan dalam pendekatan Box-Jenkins untuk mengidentifikasikan model peramalan yang optimal. Dengan mengetahui nilai koefisien autokorelasi dapat diketahui pula ciri, pola dan jenis data, sehingga dapat memenuhi maksud untuk mengidentifikasikan suatu model tentatif atau percobaan yang dapat disesuaikan dengan data.
Menurut Makridarkis (Makridarkis,2000,pp.399-402), autokorelasi untuk time-lag 1,2,3,4,..,k dapat dicarikan dan dinotasikan rk, sebagai berikut:
∑
∑
= − = + − − − = n t t t k n t k t t k Y Y Y Y Y Y r 1 2 1 ) ( ) )( ( Persamaan (3.1)Dengan koefisien autokorelasi dari data acak mempunyai sebaran penarikan contoh yang mendekati kurva normal dengan nilai tengah nol dan galat standar ±2/ n.
3.4.2 Autokorelasi Parsial (PACF)
Didalam analisis regresi, apabila variabel tidak bebas Y diregresikan kepada variabel-variabel bebas X1 dan X2 maka akan timbul pertanyaan sejauh mana
variabel X1 mampu menerangkan keadaan Y apabila mula-mula X2 dipisahkan
(partialled out). Ini berarti meregresikan Y kepada X2 dan menghitung galat nilai
sisa (residual errors), kemudian meregresikan lagi nilai sisa tersebut kepada X1. di
dalam analisis deret waktu konsep yang sama.
Autokorelasi parsial digunakan untuk mengukur tingkat keeratan (association) antara X1 dan X1-k, apabila pengaruh dari time lag 1,2,3,.., dan seterusnya sampai k-1
membantu menetapkan model ARIMA yang tepat untuk peramalan, kenyataannya, ACF dan PACF memang dibentuk hanya untuk tujuan ini.
Koefisien autokorelasi parsial berorde m didefinisikan sebagai koefisien autoregresi terakhir dari model AR(m). Sebagai contoh, persamaan-persamaan 3.2 sampai 3.6 masing-masing digunakan untuk menetapkan AR(1), AR(2), AR(3),..AR(m). Koefisien X yang terakhir pada masing-masing persamaan merupakan koefisien autokorelasi parsial. Ini berarti notasi Φ1,Φ2,Φ3,…Φm−1, dan
m
Φ adalah m buah koefisien autokorelasi parsial yang pertama untuk deret waktu tersebut. , 1 1 t t t X e X =Φ − + Persamaan (3.2) , 2 2 1 1 t t t t X X e X =Φ − +Φ − + Persamaan (3.3) , 3 3 2 2 1 1 t t t t t X X X e X =Φ − +Φ − +Φ − + Persamaan (3.4) : , ... 1 1 2 2 1 1 t t m t m t t X X X e X =Φ − +Φ − + +Φ − − + + Persamaan (3.5) t m t m m t m t t t X X X X e X =Φ1 −1+Φ2 −2+...+Φ −1 − +1+Φ − + Persamaan (3.6) Dari persamaan-persamaan ini dapat dicari nilai Φ1,Φ2,Φ3,…Φm−1, dan Φm perhitungan yang diperlukan akan memakan banyak waktu. Oleh karena itu lebih memuaskan untuk memperoleh taksiran Φ1,Φ2,Φ3,…Φm−1,Φm berdasarkan pada koefisien autokorelasi. Penaksiran tersebut dapat dilakukan dengan metode di bawah ini.
Apabila ruas kiri dan kanan persamaan 3.2 dikalikan dengan Xt-1, hasilnya adalah
t t t t t t X X X X e X −1 =Φ1 −1 −1+ −1 Persamaan (3.7)
Dengan mengambil nilai harapan pada persamaan 3.7 akan menghasilkan: ) ( ) ( ) (Xt 1Xt 1E Xt 1Xt 1 E Xt 1et E − =Φ − − + − Persamaan (3.8)
Yang dapat ditulis ulang sebagai: 0
1
1 γ
γ =Φ Persamaan (3.9)
Karena berdasarkan definisi E(Xt−1Xt)=γ1,E(Xt−1Xt−1)=γ0, dan E(Xt−1et)=0. Apabila kedua ruas persamaan 3.9 dibagi γ0, hasilnya adalah
1 1=Φ
ρ Persamaan (3.10)
Karena ρ1=(γ1/γ0) merupakan cara untuk menetapkan autokorelasi pertama jadi
1 1= ρ
Φ ini berarti bahwa autokorelasi parsial yang pertama adalah sama dengan autokorelasi pertama dan kedua-duanya ditaksir didalam sampel dengan r1. secara umum, karena ρk =(γ1/γ0), maka operasi yang terlihat pada persamaan 3.7 sampai 3.10 dapat diperluas sebagai berikut. Kalikan kedua ruas persamaan 3.2 dengan Xt-1,
hitung nilai harapan dan bagilah dengan γ0, sehingga menghasilkan sekumpulan persamaan simultan (disebut persamaan Yule-Walker), yang dapat dipakai untuk mencari nilai Φ1,Φ2,Φ3,…Φm−1,Φm. nilai-nilai ini dapat digunakan sebagai penduga nilai-nilai autokorelasi parsial sampai m time lag. Untuk mendapatkan jawaban persamaan-persamaan tersebut, terdapat prosedur-prosedur penaksiran rekursif. Secara umum persamaan autokorelasi parsial dapat dituliskan sebagai berikut ini (anonim 2):
1 11 =r ∧ φ Persamaan (3.11)
(
)
(
2)
1 2 1 2 22 1 r r r − − = ∧ φ Persamaan (3.12)1 ,..., 2 , 1 ,..., 2 , 1 , 1 − = = − = ∧ − ∧ ∧ − − ∧ k j k j k k kk j k kj φ φ φ φ Persamaan (3.13) ,.... 3 , 1 1 1 , 1 1 1 , 1 ⎟⎟ = ⎠ ⎞ ⎜⎜ ⎝ ⎛ − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − =
∑
∑
− = − − − = − ∧ k r r r k j j j k j k k j j k k kk φ φ φ Persamaan (3.14)Selanjutnya autokorelasi parsial akan digunakan untuk menetapkan model ARIMA yang tepat. Apabila proses yang mendasari diperolehnya rangkaian (series) adalah model AR(1), maka harus dimengerti bahwa hanya Φ1 yang secara nyata akan berbeda dari nol, sedangkan Φ2,Φ3,…Φm−1,Φm tidak akan berbeda nyata secara statistika. Apabila proses pembangkit yang sebenarnya adalah AR(2), maka hanya
1
Φ dan Φ2 yang akan berbeda nyata, sedangkan nilai-nilai taksiran lainnya tidak akan signifikan. Hal ini berlaku untuk proses-proses AR yang berorde lebih tinggi.
Dengan kata lain, karena cara pembentukan Φ1,Φ2,Φ3,…Φm−1,Φm , maka koefisien yang akan berbeda nyata dari nol hanya sampai pada orde proses AR yang digunakan untuk membangkitkan data. Di dalam identifikasi model, kemudian diasumsikan bahwa apabila hanya terdapat dua autokorelasi parsial yang berbeda nyata dari nol, maka generating prosesnya berorde dua dan orde dari model peramalannya adalah AR(2). Apabila ada p autokorelasi parsial yang signifikan, maka orde yang diambil AR(p).
Apabila proses pembentukan datanya adalah MA bukannya AR, maka autokorelasi parsial tidak akan menunjukkan orde proses MA tersebut, karena nilai tersebut dibentuk untuk mencocokkan proses AR. Kenyataannya, nilai tersebut menunjukkan suatu ketergantungan dari satu lag ke lag berikutnya yang membuatnya menyerupai cara autokorelasi untuk proses AR. Autokorelasi parsial
akan menurun mendekati nol secara eksponensial. Untuk tujuan identifikasi, apabila autokorelasi parsial tidak memperlihatkan penurunan nilai secara acak sesudah p time-lag, melainkan menurun sampai nol secara eksponensial, hal ini dapat diasumsikan bahwa generating proses yang sebenarnya adalah MA.
Sebagai ringkasan, apabila hanya terdapat p autokorelasi parsial yang signifikansinya berbeda dari nol, maka diasumsikan bahwa proses tersebut adalah AR(p). Jika autokorelasi parsial menurun mendekati nol secara eksponensial, proses tersebut diasumsikan sebagai proses MA. Angka dari autoregresi dan rata-rata bergerak (ordo p dan q) pada model ARMA ditentukan dari pola sampel autokorelasi dan autokorelasi parsial dan nilai dari kriteria seleksi model. Pada prakteknya, nilai p dan q masing-masing jarang melebihi dua (Hanke,2005,p328).
3.4.3 Metode Autoregresi (AR)
Model autoregresi merupakan suatu persamaan dengan bentuk umum:
t p t p t t t t Y Y Y Y Y =ϕ0+ϕ1 −1+ϕ2 −2+ϕ3 −3 +...+ϕ − +ε Persamaan (3.15) Dimana
Yt = variabel respon (terikat) pada waktu t. 1
−
t
Y ,Yt−2,..., Yt−p = variabel respon pada masing-masing selang waktu t-1, t-2,..., t-p. Nilai Y berperan sebagai variabel bebas.
0
ϕ ,ϕ1,ϕ2,...,ϕp = koefisien yang diestimasikan.
t
ε = galat pada saat t yang mewakili dampak variabel-variabel yang tidak dijelaskan oleh model. Asumsi mengenai galat adalah sama dengan asumsi model regresi standar.
Dimana Yt adalah variabel yang diramalkan atau variabel terikat, misalnya
volume penjualan dan Yt−1,Yt−2,..., Yt−p adalah variabel yang menentukan atau
variabel bebas. Dalam kasus ini variabel bebasnya adalah varibel yang sama (auto variable), yaitu volume penjualan tetapi pada periode-periode sebelumnya (t-1,t-2,t-3,...,t-p). Sedangkan εt adalah unsur kesalahan atau residual yang menunjukkan peristiwa acakan atau random events yang tidak dapat diuraikan atau dijelaskan oleh model.
Model autoregresi (AR) pada persamaan 3.15 adalah sama dengan persamaan regresi (y=a+b1X1+b2X2+b3X3+...+bpXp+ εt ). perbedaan antara persamaan
autoregresi (AR) model dengan persamaan regresi adalah bahwa pada model autoregresi, variabel bebas atau yang menentukan adalah nilai yang lalu dari variabel yang diramalkan (dependent variable). Perbedaan-perbedaan tersebut terletak pada X1=Yt-1, X2=Yt-2, X3=Yt-3,...,Xp=Yt-p, sehingga variabel bebas yang menentukan
adalah nilai-nilai lag dari variabel yang diramalkan dengan lag waktu 1,2,3,..., p periode. Perbedaan yang lain adalah parameter regresi, diestimasikan dengan menggunakan metode least square yang linear, sedangkan parameter autoregresi diperoleh dengan menggunakan metode least squares yang nonlinear.
Metode autoregresi (AR) yang umum dari persamaan 3.15 terdapat dalam beberapa bentuk, tergantung pada derajat susunan (order) dari p. Bila p=1, bentuknya menjadi model autoregresi dengan susunan (order) pertama atau AR(1) atau ARIMA(1,0,0). Dalam bentuk umum, model ini dituliskan sebagai AR(p). Seharusnya sebelum suatu model AR dapat dipergunakan untuk susunan (order) p
tersebut harus dispesifikasikan. Nilai yang berlaku untuk p yang mespesifikasikan jumlah unsur yang terkandung, dapat diperoleh dengan menyelidiki nilai koefisien autokorelasi.
3.4.4 Metode Moving Average (MA)
Pada metode autoregresi diketahui mempunyai kesamaan dengan bentuk multiple regresi. Model autoregresi pada dasarnya tidak dapat menangani seluruh deretan data. Oleh karena itu pendekatan Box-Jenkins mempertimbangkan dua kelas yang lain untuk mengatasi masalah tersebut. Salah satu dari model tersebut adalah model moving average (MA). Bentuk umum dari model moving average (MA) adalah: ARIMA (0,0,q) atau MA (q) q t q t t t t e e e e Y =μ+ −θ1 −1−θ2 −2 −θ − Persamaan (3.16) Dimana t
Y = Variabel respon (terikat) pada saat t. 1
θ sampai θq = parameter moving average (yang menjadi sasaran pembatas-pembatas nilai).
k t
e− = nilai galat pada t-k dan μ adalah suatu konstanta.
Dalam prakteknya, dua kasus yang kemungkinan besar akan dihadapi adalah q=1 dan q=2 yaitu berturut-turut proses MA(1) dan MA(2). Dua kasus ini dapat ditulis sebagai ARIMA(0,0,1) atau MA(1) dituliskan Yt =et −θ1et−1 atau
t
t B e
Y =(1−θ1 ) mempunyai daerah terbatas antara -1 dan +1. Nilai pengamatan Yt bergantung pada nilai kesalahan et dan juga kesalahan sebelumnya et-1, dengan
koefisien θ1. ARIMA(0,0,2) atau MA(2) dituliskan: Yt =et −θ1et−1−θ2et−2 atau t t B B e Y (1 2) 2 1 θ θ − −
= dimana et adalah kesalahan (error) atau residual dan
1
−
t
e ,et−2,... et−q adalah nilai terdahulu dari kesalahan (error).
Persamaan umum dari AR dan MA merupakan persamaan yang hampir sama, sedangkan perbedaannya adalah bahwa persamaan MA mencantumkan variabel tidak bebas yang diramalkan Y tergantung pada nilai-nilai sebelumnya dari unsur kesalahan (error term), yaitu et−1,et−2,... et−q, dan bukan dipengaruhi oleh variabel
itu sendiri.
Dengan perkataan lain, dalam model ini harus diperhatikan autokorelasi diantara nilai berturut-turut dari residual atau kesalahan (error). Sebagai contoh, penjualan pada masa yang akan datang dapat diramalkan dengan menggunakan pertimbangan kesalahan dari masing-masing variabel pada beberapa periode yang lalu.
Model MA dalam pendekatan Box-Jenkins penting karena beberapa pola data tidak dapat diisolasikan dengan menggunakan model AR dengan susunan p atau AR(p), dimana p sangat kecil. Model MA memberikan hasil ramalan Yt berdasarkan
atas kombinasi linear dari kesalahan-kesalahan yang lalu. Hal ini berbeda dengan model AR yang menyatakan bahwa Yt pada masa-masa sebelumnya.
3.4.5 Metode ARIMA
(Assauri,1984,pp.158-168) Dalam melakukan peramalan, terlebih dahulu dilakukan penganalisaan trend dan musiman dari deret waktu, dengan penyusunan tabel dua arah. Walaupun tabel yang demikian membutuhkan estimasi koefisien
(rata-rata bulanan dan tahunan), yang banyak informasinya tidak dapat dipergunakan secara efektif untuk peramalan nilai-nilai yang akan datang. Dalam hal ini model regresi memberikan suatu peralatan dari model linear yang tepat, dimana fungsi waktu merupakan variabel bebas yang menentukan (independent variable), yang tepat untuk jangkauan atau jarak yang tidak terbatas. Meskipun demikian model ini sangat lemah atau kurang baik untuk diextrapolasikan. Hal ini terlebih lagi, apabila model regresi tersebut menggunakan variabel-variabel bebas, sehingga untuk penyusunan ramalan, harus ditambahkan atau dilengkapi secara menyeluruh, agar nilai peramalan yang terakhir dapat mencapai atau memperoleh peramalan yang efektif dari nilai-nilai yang akan datang. Model ARIMA memberikan cara untuk mengatasi kesulitan-kesulitan tersebut. Keuntungan nyata dari model-model ARIMA adalah bahwa ramalan-ramalan yang dilakukan dapat dikembangkan untuk periode-periode yang sangat pendek. Lebih banyak waktu yang dipergunakan untuk memperoleh atau mendapatkan data yang berlaku, dari pada waktu untuk penyusunan modelnya.
Model ARIMA berhubungan dengan variabel yang ditentukan (dependent) untuk unsur lag itu sendiri dan unsur-unsur kesalahan lag. Ada alat notasi yang mudah digunakan untuk menyatakan operasi suatu variabel yaitu lag atau shift, yang dikenal sebagai ”backshift operatif”. Notasi ini membuat pernyataan atau manipulasi dari suatu model, sehingga lebih sederhana dan lebih mudah bila dikerjakan secara aljabar.
Backshift operator B adalah suatu alat notasi yang mudah untuk menyatakan model ARIMA dalam bentuk yang kompak (compact form). Bentuk ini dirumuskan untuk operasi B dalam indek Y, sehingga BY menghasilkan Yt-1 yang nilai Yt
dirubah kembali dalam waktu satu unit, misalnya satu bulan. Oleh karena itu diperoleh
B2Y = B(BYt) = BYt-1 = Yt-2
Operasi B2 merubah tanda dari t dari Yt dengan unit waktu. Demikian pula halnya
untuk:
BkYt = Yt-k Persamaan (3.17)
Dalam notasi B, suatu selisih atau pengurangan nilai yang pertama adalah:
Yt-Yt-1 = Yt-BYt = (1-B)Yt. Persamaan (3.18)
Hasilnya berupa suatu model polynomial dalam B ”operating” pada Yt. Dimana
model AR(1) menjadi:
(
1−θ1B)
Yt =α+εt Persamaan (3.19)Dimana εt merupakan kesalahan yang sangat kecil dan tidak berarti.
Didalam model ARIMA, dirumuskan Yt dengan memasukkan α, sehingga menjadi (Yt -α ). Dalam kenyataannya proses ini dapat diselesaikan dengan menggunakan model Yt-Y, dimana Y adalah rata-rata dari deret waktu (time series).
Model AR (1) dapat dituliskan sebagai
(
1−θ1B)
Yt =εt, yang bila dibagi dengan(
1−θ1B)
, menghasilkan Yt dalam bentuk:(
B)
Yt =εt/1−θ1 Persamaan (3.20)
Bila dilanjutkan dengan
(
−)
= + + 2 + 2 11 1
1 /
t t B B Y (1 θ θ 2 ...)ε 1 1 + + + = ... 2 1 1 1 + + + =εt θεt− θεt− Persamaan (3.21)
Oleh karena itu, maka sebenarnya model AR(1) adalah sama dengan model MA dengan susunan (order) yang tidak terbatas. Susunan (order) yang tertinggi dari model AR, MA dan ARMA dapat dituliskan sebagai hal khusus dari
(
) (
)
t q q t p pB Y B B B B θ θ ε θ − − − = −∂ − −∂ − .. 1 .. 1 1 2 2 2 2 Persamaan (3.22)Deret Yt dianggap perlu disesuaikan dengan rata-rata, sehingga unsur α.. ditekan
atau dihilangkan dalam penguraian diatas. Jadi persamaannya dapat dinyatakan sebagai
(
)
(
p)
t p q q B B B B B B Yt ε θ θ θ − − − − ∂ − − ∂ − ∂ − = .. 1 .. 1 2 2 1 2 2 1 t B H( )ε = Persamaan (3.23)Maksud dari penyusunan model-model linear dari kelas ARMA adalah untuk mengidentifkasikan dan mengestimasikan H(B) dengan beberapa parameter yang mungkin diperoleh. Sekali estimasi ini diperoleh, selanjutnya akan dipergunakan untuk peramalan.
Misalkan Wt = (1-B)Yt, maka Wt, menunjukkan perbedaan pertama dari Yt.
Suatu model ARMA untuk Wt adalah suatu model ARIMA untuk Yt. Anggaplah
bahwa suatu deret dapat dikurangi atau disederhanakan untuk ”stationarity” yakni dengan membedakan deret untuk beberapa angka yang terbatas dari waktu (yang mungkin setelah perubahan suatu trend tertentu).
Susunan pembedaan ini dinyatakan sebagai d. Selanjutnya diasumsikan
Adalah ”stationary”.
Untuk suatu model ARIMA(p,d,q) teratur, bentuk umum diasumsikan sebagai :
(
− − − − p)
(
−)
d t = pB B Y B B ... 1 1 θ1 θ2 2 θ(
1−∂1B−∂2B2 −...−∂qBq)
εt Persamaan (3.25) Di mana εt adalah bilangan yang dapat diabaikan atau sangat kecil, yang merupakan suatu urutan dari kesalahan yang tidak berkorelasi dan didistribusikan secara identik. Untuk pemecahannya maka perlu dicari hasil-hasil akar dari kedua persamaan polynomial dalam B , dan katakanlah akar-akar tersebut adalahθ( )
B =0 dan ∂( )
B =0, Kondisi pertama menjamin ”stationary” dari Wt, yaitu keseimbanganstatistik disekitar rata-rata yang tetap. Kondisi yang kedua diketahui sebagai ”invertability” untuk menjamin keunikan dari penggambaran bobot timbangan yang dipergunakan untuk data historis yang lalu dari Wt, guna dapat
menghasilkan suatu ramalan.
Notasi tersebut sering disederhanakan menjadi
( )(
)
t( )
td
p B B Y Bε
θ 1− =∂ Persamaan (3.26)
Dimana unsur AR(p) dinyatakan dalam bentuk polynomial.
( )
(
p)
p p B φB φ B φ B φ = 1− − 2 −...− 2 1 Persamaan (3.27)Dan unsur MA(q) adalah
( )
(
q)
q q B = −∂ B−∂ B − −∂ B ∂ 1 2 ... 2 1 Persamaan (3.28)Sehingga model ARIMA(1,1,1) adalah menjadi bentuk
3.4.6 Metode Seasonal ARIMA (SARIMA)
Menurut Rosadi (2006,p1), model dengan komponen trend (tetapi tidak seasonal) dapat dimodelkan dengan ARIMA sedangkan model musiman dapat dianalisa dengan model SARIMA. SARIMA merupakan salah satu model deret waktu non stationer yang dikembangkan oleh Box-Jenkins pada tahun 1970. Pada umumnya, model ARIMA yang memiliki unsur seasonal disebut sebagai seasonal ARIMA (SARIMA) model, karena didalam data, dapat terjadi pola seasonal dan non seasonal.
Model SARIMA dapat terdiri dari dua komponen model yaitu seasonal dan non seasonal. Model seasonal menggambarkan hubungan antara data pengamatan setiap tahun dan model non seasonal menggambarkan hubungan antara data pengamatan yang bukan seasonal atau dengan kata lain, data sisa yang tidak mengandung seasonal. Dan modelnya dapat disusun seperti cara menyusun ARIMA. (anonim1) Bentuk umum dari model SARIMA adalah:
( )
( )
(
)
(
)
( )
( )
t s Q q t D s d s P p B Φ B −B −B X =θ B Θ B w φ 1 1 Persamaan (3.30) Dimana :( )
Ps P s s s B B B B = −Φ −Φ − −ΦΦ 1 1 2 2 ... merupakan AR polynomial untuk model seasonal.
( )
Qs Q s s s B B B B = −Θ −Θ − −Θ Θ 1 2 .. 21 merupakan MA polynomial untuk model
seasonal.
( )
( )
( )
( )
p p p B φ B φ B φ B φ =1− − 2 −...− 2( )
( )
( )
( )
q qq B θ B θ B θ B
θ =1− 1 − 2 2 −...− merupakan MA non seasonal yang sama
seperti model ARIMA.
Notasi untuk model Seasonal ARIMA adalah :
SARIMA(p,d,q)x(P,D,Q)s Persamaan (3.31)
Dimana:
p,d,q masing-masing merupakan orde AR, pembeda, dan MA seperti pada ARIMA. P merupakan jumlah lag pada seasonal AR.
Q merupakan jumlah lag pada seasonal MA. D merupakan jumlah perbedaan seasonal.
s merupakan seasonal (misalnya untuk data bulanan maka s=12, kwartil maka s=4). Jika s bernilai 1 maka model akan menjadi model ARIMA non seasonal.
Proses pemilihan model SARIMA yang tepat terdiri atas tiga tahap seperti yang telah di uraikan sebelumnya pada model Box-Jenkins, yaitu identifikasi model, estimasi parameter, dan pengecekan diagnostik.
1. Tahap Identifikasi :
(Makridakis,1999,p469) Pada tahap identifikasi, perlu mengenali adanya faktor musiman yaitu antara lain dengan memeriksa koefisien autokorelasi pada lag time 12 yang memiliki nilai positif. Setelah itu perlu ditentukan pula apakah deret tersebut stasioner, yaitu apakah deret waktu muncul beragam disekitar tingkat tertentu. Teknik yang paling mudah untuk melihat kestasioneran data adalah membuat plot antara waktu dan nilai.
Menurut Makridakis (1999,p469) bila fluktuasi data berada disekitar nilai rata-rata dengan besaran yang relative tidak berbeda, tidak terdapat pertumbuhan atau penurunan data, data kasarnya horizontal sepanjang sumbu waktu, maka data tersebut dapat disebut stasioner. Bila data tidak stasioner maka dibutuhkan nilai pembeda seasonal dan non seasonal untuk mendapatkan kondisi deret data yang stasioner dari nilai masa lampau deret waktu yang diamati. Seandainya dari data hasil pembedaan terhadap data seasonal diplot dan tidak lagi menunjukkan keadaan yang tidak stasioner, maka data tersebut dapat langsung digunakan untuk membuat model SARIMA. Akan tetapi, bila masih menunjukkan tidak stasioner, maka perlu dilakukan pembedaan terhadap data non seasonal dan berulang hingga orde kedua, ketiga, dan seterusnya, sampai didapat data stasioner. Selain itu juga, setelah didapat data stasioner, analisis harus mengidentifikasi bentuk dari model yang akan digunakan.
Tahapan ini diselesaikan melalui pembandingan antara autokorelasi dengan autokorelasi parsial yang dihitung dari data ke autokorelasi teoritis dan autokorelasi parsial dari beragam model SARIMA. Kemudian dapat dilihat nilai dari AR dan MA baik seasonal maupun non seasonal berdasarkan fungsi autokorelasi dan autokorelasi parsial. Jika autokorelasi sampel menghilang kearah nol secara eksponensial dan autokorelasi parsial sampel terpotong, modelnya akan memerlukan bentuk autoregresi. Jika autokorelasi sampel terpotong dan autokorelasi parsial sampel menghilang, modelnya akan membutuhkan bentuk rata-rata bergerak. Sedangkan jika autokorelasi sampel dan autorelasi parsial sample menghilang, bentuk autoregresi
dan rata-rata bergerak terindikasi. Sedangkan untuk model seasonal, dapat diidentifikasi dengan cara yang sama tetapi dengan melihat pola potongan yang berulang setiap tahunnya.
Jika dalam satu model terdapat bentuk autoregresi dan rata-rata, maka terdapat beberapa alat bantu statistik seperti Akaike Information Criterion (Akaike, 1974) dan Schwartz’s Bayesian Criterion (Schwartz, 1987), yang dapat digunakan untuk memilih model yang terbaik dari beberapa model yang mungkin dari kombinasi model seasonal dan non seasonal. Model AIC dan BIC dapat dituliskan sebagai berikut: AIC = ln n r 2 2 + σ Persamaan (3.32) Dimana Ln = logaritma natural. 2
σ = jumlah kuadrat residu dibagi jumlah pengamatan. n = jumlah pengamatan (residual).
r = jumlah total parameter (termasuk bentuk konstanta) dalam model SARIMA. BIC = ln n r n. . ln 2+ σ Persamaan (3.33)
Penggunaan AIC dan BIC untuk pemilihan model akan menghasilkan hasil model yang jumlah parameternya hampir sama. AIC dan BIC hendaknya dilihat sebagai tambahan prosedur dalam membantu pemilihan model. Kriteria tersebut hendaknya tidak digunakan sebagai pengganti penelaahan cermat dari autokorelasi sample dan autokorelasi parsial.
Kemudian untuk menilai signifikansinya, kedua autokorelasi sampel dan autokorelasi parsial sampel biasanya dibandingkan dengan ± 2/ n ,dimana n adalah jumlah pengamatan deret waktu. Limit ini akan bekerja baik apabila n besar. 2. Tahap estimasi:
Setelah berhasil menetapkan model sementara, selanjutnya digunakan estimasi maksimum likelihood atau metode kuadrat terkecil untuk mendapatkan parameter dari model. Menurut Montgomery et. al. (1990,p264), tidak ada bentuk penyelesaian yang pasti dalam estimasi parameter menggunakan metode kuadarat terkecil pada model persamaan nonlinear. Pendekatan umum yang dilakukan dalam melakukan estimasi adalah menggunakan pencarian iterasi langsung pada fungsi jumlah sisa kuadrat. Oleh karena itu dapat digunakan pendekatan-pendekatan pencarian melalui iterasi dengan metode Gauss Newton.
Menurut Neter et. al. (1996), metode Gauss Newton sering disebut sebagai linearization method, serta menggunakan deret Taylor untuk menjabarkan model nonlinear ke dalam bentuk linear dan kemudian menggunakan metode umum kuadrat terkecil untuk melakukan estimasi parameter.
Metode Gauss Newton didasarkan pada perkiraan model linear yang didapat dari penjabaran Taylor sebagai berikut:
(
(0))
1 0 ) 0 ( ) 0 ( ) , ( ) , ( ) , ( k k g p k k i i i g x f g x f x f ⎥ − ⎦ ⎤ ⎢ ⎣ ⎡ ∂ ∂ + ≅ = − =∑
γ γ γ γ γ Persamaan (3.34) Dimana: ) 0 ((
(0))
k k −g
γ = βk(0) merupakan koefisien regresi yang menyatakan selisih perbedaan koefisien. ) , (x g(0) f i = ) 0 ( i
f merupakan peramalan dengan xi dan parameter iterasi ke-0.
) 0 ( 1 0 ) , ( g p k k i x f = − =
∑
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ∂ ∂ γ γ γ atau ) 0 ( ) , ( ) 0 ( g k i ik X f D = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ∂ ∂ = γ γ γmerupakan turunan pertama
terhadap parameter ke-k.
Penjabaran Taylor persamaan 3.34 untuk respon rata-rata untuk xi menjadi :
≅ ) , (xi γ f (0) i f + (0) 1 0 ik p k D
∑
− = .βk(0) Persamaan (3.35)Dan sebuah perkiraan untuk model nonlinear adalah :
i i i f X
Y = ( ,γ)+ε Persamaan (3.36)
Maka dengan subsitusi persamaan 3.35 pada persamaan 3.36 menjadi : = i Y (0) i f + (0) 1 0 ik p k D
∑
− = .βk(0) + εi Persamaan (3.37) Menjadi : = ) 0 ( i Y Yi -) 0 ( i f = (0) 1 0 ik p k D∑
− = .βk(0) + εi untuk I = 1,2,...,n Persamaan (3.38)Dari model diatas Yi(0)merupakan residual, di daerah persamaan nonlinear dengan memakai parameter pada perkiraan awal.
Pendekatan model linear dapat dituliskan dalam model matrik sebagai berikut : ε β + ≅ (0) (0) ) 0 ( D Y Persamaan (3.39)
Dan untuk itu dapat diestimasi parameter β(0) dengan menggunakan persamaan umum metode kuadrat terkecil sebagai berikut:
) 0 ( )' 0 ( 1 ) 0 ( )' 0 ( ) 0 ( ) (D D D Y b = − Persamaan (3.40)
Dimana b(0) merupakan vektor koefiesien hasil perkiraan kuadrat terkecil. Untuk mendapatkan perubahan nilai koefisien setiap iterasi maka digunakan:
) 0 ( ) 0 ( ) 1 ( k k k g b g = + Persamaan (3.41)
Kemudian hasil koefisien dari perubahan tersebut dibanding dengan koefisien sebelumnya. Jika hasil dari iterasi sekarang dan sebelumnya telah sama (tidak berubah lagi dengan ketepatan beberapa angka dibelakang koma) maka, iterasi dapat dihentikan dan pencarian koefisien telah selesai. Pembandingan iterasi selain membandingkan parameter, juga dapat dilakukan pada iterasi nilai jumlah kuadrat kesalahan.
3. Tahap pengecekan diagnostik:
Sebelum menggunakan model untuk peramalan, perlu adanya pengecekan terhadap model yang telah diidentifikasi. Secara mendasar, model sudah memadai apabila nilai residual dari model yang dipilih tidak dapat dipergunakan untuk memperbaiki ramalan. Dengan kata lain, residual hendaknya bersifat acak. Jika hasil estimasi autokorelasi dari model residual pada lag yang berbeda menunjukkan tidak ada autokorelasi yang signifikan pada setiap lagnya, maka model itu dapat dianggap cukup baik. Namun jika terdapat satu atau lebih lag autokorelasi yang signifikan, maka dapat dilakukan pengecekan dengan metode yang telah disediakan yaitu uji chi-square (X2
) yang berbasis pada statistik Ljung-Box-Pierce-Q (Ljung dan Box, 1978). Uji ini mencari ukuran residual autokorelasi sebagai suatu kelompok. (anonim 6) Uji statistik Q untuk model SARIMA adalah:
( )
∑
= − = m k k m N U r e Q 1 2 ) ( Persamaan (3.42)Dimana : ) (e
rk = residual autokorelasi pada selang k N = jumlah residual
U = sD + d
D = pembedaan seasonal d = pembedaan non seasonal
m = jumlah selang waktu yang disertakan dalam pengujian. Apabila nilai chi-square (X2
) dengan derajat bebas M-p-q-P-Q terkait dengan statistik Qm kecil maka model dipertimbangkan tidak memadai. Analisis model baru
dipertimbangkan dan melanjutkan analisis sampai model yang memuaskan didapat. 3.5 Ketepatan Metode Peramalan
Makridakis, Wheelwright, dan McGee (1999, pp.57-58) menyatakan bahwa dalam banyak hal, kata ”ketepatan (accuracy)”, menunjuk ke ”kebaikan suai”, yang pada akhirnya penunjukkan seberapa jauh model peramalan tersebut mampu mereproduksi data yang telah diketahui. Dalam pemodelan deret berkala, sebagian data yang diketahui dapat digunakan untuk meramalkan sisa data berikutnya sehingga memungkinkan orang untuk mempelajari ketepatan ramalan secara lebih langsung. Bagi pemakai ramalan, ketepatan ramalan yang akan datang adalah yang paling penting. Bagi pembuat model, kebaikan suai model untuk fakta yang diketahui harus diperhatikan. Berikut akan dijelaskan mengenai beberapa metode yang digunakan untuk mengetahui ketepatan sebuah metode peramalan.
3.5.1 Mean Squared Error (MSE)
Makridakis, Wheelwright, dan McGee (1999, p58) mempunyai beberapa ukuran statistik standar untuk mengukur ketepatan hasil peramalan. Ukuran berikut menunjukkan pencocokan suatu model terhadap data historis. Perbandingan nilai MSE yang terjadi selama tahap pencocokan peramalan mungkin memberikan sedikit indikasi ketepatan model dalam peramalan.
i i
i X F
e = − Persamaan (3.43)
Dimana :
ei = kesalahan untuk periode ke-i.
Xi = data aktual untuk periode ke-i. Fi = ramalan untuk periode ke-i.
Jika terdapat nilai pengamatan dan ramalan untuk n periode waktu, maka akan terdapat n buah galat dan ukuran statistik standar berikut yang dapat didefinisikan : Nilai Tengah Galat Kuadrat (Mean Squared Error)
n e MSE n i i
∑
= = 1 2 Persamaan (3.44)3.6 State Transition Diagram (STD)
Menurut Pressman (2002,p354), State Transision Diagram (STD) menunjukkan bagaimana sistem bertingkah laku sebagai akibat dari kejadian eksternal. Untuk melakukannya, STD menunjukkan berbagai model tingkah laku (disebut state) sistem dan cara dimana transisi dibuat dari state satu ke state lainnya. STD berfungsi sebagai dasar bagi pemodelan tingkah laku. Informasi tambahan
mengenai aspek kontrol dari perangkat lunak diisikan dalam control specification (CSPEC).
3.7 Microsoft .Net
Microsoft .NET ialah istilah umum yang mencakup sejumlah teknologi yang baru dikeluarkan oleh Microsoft (Duthie, 2003, p3). Sebagai suatu kesatuan, teknologi ini ialah perubahan paling penting pada platform pengembangan Microsoft sejak pergeseran dari 16 bit ke 32 bit. Microsoft .NET mencakup teknologi berikut ini:
1. .NET Framework 2. .NET Enterprise Servers
3. Bahasa-Bahasa dan tool-tool bahasa. .NET 3.7.1 .Net Framework
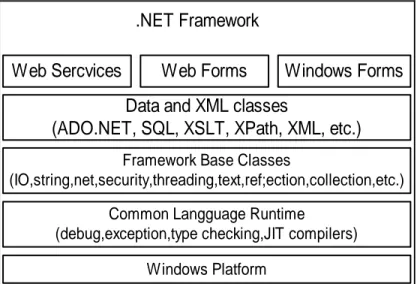
.NET Framework adalah dasar dari pengembangan beberapa bahasa yang digunakan untuk building, deploying, dan running XML Web services serta aplikasi. .NET Framework terdiri dari 3 bagian antara lain (Duthie., 2002, p3):
1. Common Language Runtime
Runtime melakukan pengaturan terhadap component runtime dan waktu pengerjaannya. Sewaktu component bekerja, runtime mengatur alokasi memory, starting up dan stopping threads dan proses, dan menjalankan security policy.
2. Unified Programming Classes
.Net Framework menyediakan developers dengan unified, object-oriented, hierarchical, dan extensible set of class libraries (APIs). Dengan menggunakan fasilitas dari framework ini dapat menggunakan bahasa yang berbeda dalam pengambilan library.
3. ASP.NET
ASP.NET merupakan bahasa pemograman yang berdiri dari classes dari .NET Framework. Pada ASP.NET terdapat beberapa tools yang mempermudah dalam membuat web applications. ASP.NET juga menyediakan infrastructure services, seperti session dan process recycling.
.NET Framework
Web Sercvices
Web Forms
Windows Forms
Data and XML classes
(ADO.NET, SQL, XSLT, XPath, XML, etc.)
Framework Base Classes
(IO,string,net,security,threading,text,ref;ection,collection,etc.) Common Langguage Runtime
(debug,exception,type checking,JIT compilers) Windows Platform
3.7.2 ASP.Net
ASP.NET tidak sekedar upgrade dari ASP. ASP.NET menyediakan platform pengembangan Web terdepan yang diciptakan dewasa ini. Yang membuat ASP.NET menjadi sebuah revolusi ialah pembuatannya yang didasarkan pada platform baru Microsoft .NET, atau lebih tepatnya .NET Framework.
ASP.NET memiliki beberapa kelebihan dibandingkan teknologi terdahulu, antara lain :
1. Kemudahan mengakses berbagai library .NET Framework secara konsisten dan powerfull, yang mempercepat pengembangan aplikasi. 2. Penggunaan berbagai macam bahasa pemrograman secara penuh
misalnya VB.NET, C#, J# dan visual C++. Selain itu tersedia berbagai Web Control yang dapat digunakan membangun aplikasi secara cepat. Code Behind, artinya kode-kode pemrograman yang menjadi logic aplikasi ditempatkan terpisah dengan kode user interface yang berbentuk HTML. Ini sangat memudahkan dalam debugging, karena kode untuk presentation layer tidak tercampur dengan kode application logic.
3.7.3 Sistem Basis Data
Menurut Subekti (1997, p1), sistem basis data adalah sistem penyimpanan record secara komputer (elektronis) sedangkan pengertian basis data sendiri menurut Subekti (1997, p8), adalah tempat penyimpanan sekumpulan data yang telah diorganisasi, yang dapat diakses, diatur dan diupdate dengan mudah. Basis data yang paling lazim adalah relational database, sebuah basis data yang berupa tabel dimana
data didefinisikan sehingga dapat diorganisasikan kembali dan diakses dengan beberapa cara (Subekti, 1997, p27). Sedangkan sebuah distributif database adalah basis data yang terintegrasi, aplikasi yang dapat secara transparan beroperasi pada data yang penyimpanannya berada pada beberapa lokasi, bekerja pada komputer yang berbeda, sistem operasi yang berbeda, serta dihubungkan satu sama lain melalui berbagai media jaringan komunikasi (Subekti, 1997, p106).